【数据结构与算法】从完全二叉树到堆再到优先队列
完全二叉树 CBT
设二叉树的深度为 h , 若非最底层的其他各层的节点数都达到最大个数 , 最底层 h 的所有节点都连续集中在左侧的二叉树叫做 完全二叉树 .
特点
- 对任意节点 , 其右分支下的叶子节点的最底层为 L , 则其左分支下的叶子节点的最低层一定是 L 或 L + 1 .
- 完全二叉树度为 1 的点只有 1 个或 0 个 .
- 按层序遍历的顺序访问 , 度为 1 或 0 的节点的后续节点的度均为 0 .
二叉树的层序遍历
层序遍历是一种广度优先搜索 , 要借助 队列 数据结构实现 , 核心逻辑如下 :
- 初始化队列 , 把根节点加入队列 .
- 从队列取出一个节点 , 将该节点的左右节点加入队列 , 重复处理至队列为空 .
class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(int val){this.val = val;}public static List<Integer> levelOrderTraversal(TreeNode root){Queue<TreeNode> queue = new LinkedList<>();List<Integer> list = new ArrayList<>();if (root == null) {return list;}queue.offer(root);while(!queue.isEmpty()){TreeNode node = queue.poll();list.add(node.val);if (node.left != null) {queue.offer(node.left);}if (node.right != null) {queue.offer(node.right);}}return list;}
}
Queue 的 offer 方法会将 null 加入队列 , 因此我们要加入条件语句避免产生空指针异常 .
判断二叉树是否为完全二叉树
因为完全二叉树最底层 h 的所有节点都连续集中在左侧 , 且按层序遍历的顺序访问 , 度为 1 或 0 的节点的后续节点的度均为 0 ( 特点 3 ) , 判断是否为完全二叉树较常用的方法要借助 二叉树的层序遍历 , 核心逻辑如下 :
- 对二叉树进行层序遍历 , 使用队列保存节点 .
- 遍历过程中维护标识符 end , 其表示是否遇到过度为 1 或 0 的节点 .
- end 标识符翻转后如果再次遇到有左右任一子节点的节点 , 直接返回 .
class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(int val){this.val = val;}public static Boolean isCBTorNot(TreeNode root){Queue<TreeNode> queue = new LinkedList<>();if (root == null) {return true;}queue.offer(root);boolean end = false;while(!queue.isEmpty()){TreeNode node = queue.poll();if(node.left != null){if(end) return false;queue.offer(node.left);}else end = true;if(node.right != null){if(end) return false;queue.offer(node.right);}else end = true;}return true;}
}
完全二叉树的数组表示
为什么可以使用数组表示 ?
完全二叉树非最底层的其他各层的节点数都达到最大个数 , 最底层 h 的所有节点都连续集中在左侧 , 使得使用数组存储时能够紧密排列 , 避免空间浪费 .
父子节点的索引关系
推导过程如图 , 结论 :
- 父节点的数组索引为 n , 则左子节点的数组索引为 2 * n + 1 , 右子节点的数组索引为 2 * n + 2 , 祖父节点的数组索引为 ( n - 1 ) / 2 .

值得注意的是 , 叶子节点在数组表示的堆中分布在 (n / 2) - 1 到 n - 1 中 ( n 是堆的节点数量 ) , 证明如下 :
- 对于任意节点 i , 若存在左子节点 , 则左子节点索引 left = 2 * i + 1 .
- 当 left >= n 时 , 意味着该节点没有左子节点 . 由于完全二叉树的节点是靠左排列的 , 没有左子节点也就意味着没有右子节点 , 所以该节点一定是叶子节点 .
- 2 * i + 1 >= n 得到 i >= (n / 2) - 1 , 得证 .
堆 Heap
堆是满足特定条件的完全二叉树 , 主要分为 大顶堆 和 小顶堆 两种类型 , 大顶堆指 任意节点值 >= 其子节点值 , 小顶堆指 任意节点值 <= 其子节点值 .
堆化
堆化是将无序数组转化为堆的过程 . 添加元素入堆时执行上浮操作 :
- 给定元素 val , 我们首先将该元素添加到堆底 .
- val 可能大于堆中其他元素 , 此时堆被暂时破坏 , 我们要从堆底至顶进行堆化 .
- 比较 val 节点与其节点的值 , 若插入节点更大则交换二者 , 重复执行操作直到节点上升到根节点或其父节点更大时结束 .
初始化无序数组为堆时执行下沉操作 :
- 自下而上对每个非叶子节点执行下沉操作 : 比较该节点与左右子节点 , 若该节点值小于子节点最大值 , 则交换该节点与最大值子节点 .
- 重复操作直到节点下沉到叶子节点或该节点值大于或等于左右子节点值的最大值 .
上浮操作常用于向堆中添加元素 , 下沉操作常用于初始化无序数组为堆和删除堆中元素等场景 .
堆的节点总数为 n , 树的层数为 log n , 堆化操作的迭代次数至多为 log n , 知初始化无序数组为堆的时间复杂度是 O(n log n) .
class Heap {public static void heapify(int[] arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && arr[left] > arr[largest]) largest = left;if (right < n && arr[right] > arr[largest]) largest = right;if (largest != i) {int swap = arr[i];arr[i] = arr[largest];arr[largest] = swap;heapify(arr, n, largest);}}public static void buildMaxHeap(int[] arr) {int n = arr.length;for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}} // 我们不需要对叶子节点进行下沉操作.
堆排序
堆排序基于顶堆的特性 , 重复将堆顶元素与堆尾元素交换 , 堆化非队尾元素的剩余元素 直至数组有序 . 堆的节点数为 n , 堆化操作的时间复杂度为 log n , 因此堆排序的时间复杂度是 O(n log n) , 堆排序基于原地交换 , 空间复杂度为常数级 , 是性能良好的排序方法 .
class Heap{public static void heapSort(int[] arr) {int n = arr.length;for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}for (int i = n - 1; i > 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;heapify(arr, i, 0);}}
}
优先队列 PriorityQueue
优先队列是特殊的队列数据结构 , 在 Java PriorityQueue 类中 , 默认优先级为从小到大的自然排序 , 可以通过 lambda 表达式自定义比较器 Comparator 函数类型 .
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(); // 默认为自然顺序
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Comparator.reverseOrder()); // 更改比较器为降序
如果要储存自定义引用数据类型时 , 有两种方式定义元素优先级 :
- 引用类实现
Comparable接口 : 在类中实现compareTo()方法 . - 在初始化 PriorityQueue 时传入比较器对象 .
class Person{private String name;private int age;Person(String name, int age){this.name = name;this.age = age;}@Overridepublic int compareTo(Person person){retutn Integer.compare(this.age, person.age);}
}
public class Main{public static void main(String[] args){PriorityQueue<Person> pq = new PriorityQueue<>();// 或PriorityQueue<Person> pq = new PriorityQueue<>((p1, p2) -> Integer.compare(p2.getAge(), p1.getAge()));}
}
底层实现
Java 使用小顶堆实现优先队列 .
- 初始化 : 对无序集合对应的非子叶节点逐个进行下沉操作 .
- 插入元素
offer(): 在优先队列中插入元素通常插入到堆底 , 对堆底元素进行堆化的上浮操作 . - 删除元素
poll(): 在优先队列中删除元素通常删除的是堆顶元素 , 先保存堆顶元素 , 再将堆底元素推到堆顶 , 对更新后的堆顶元素进行堆化的下沉操作 .
堆是一种具体的数据结构 , 优先队列是基于堆实现的抽象数据类型 , 堆除了实现优先队列外还可以应用到堆排序等场景 .
23. 合并 K 个升序链表

我们维护一个按节点值自然排序的优先队列 , 将链表数组内的所有非空数组加入队列 , 每次出堆堆顶节点 , 定义返回节点指向出堆节点 , 入堆出堆节点的后继节点 , 返回节点指针后移 , 重复操作直到堆为空即可 .
class Solution {public ListNode mergeKLists(ListNode[] lists) {PriorityQueue<ListNode> pq = new PriorityQueue<>((a, b) -> a.val - b.val);for (ListNode head : lists) {if (head != null) {pq.offer(head);}}ListNode dummy = new ListNode();ListNode cur = dummy;while (!pq.isEmpty()) {ListNode node = pq.poll();if (node.next != null) {pq.offer(node.next);}cur.next = node;cur = cur.next;}return dummy.next;}
}
相关文章:
【数据结构与算法】从完全二叉树到堆再到优先队列
完全二叉树 CBT 设二叉树的深度为 h , 若非最底层的其他各层的节点数都达到最大个数 , 最底层 h 的所有节点都连续集中在左侧的二叉树叫做 完全二叉树 . 特点 对任意节点 , 其右分支下的叶子节点的最底层为 L , 则其左分支下的叶子节点的最低层一定是 L 或 L 1 .完全二叉树…...

【linux】SSH 连接 WSL2 本地环境的完整步骤
SSH 连接 WSL2 本地环境的完整步骤 要在 Windows 的 WSL2 环境中启用 SSH 服务,并允许本地或局域网设备连接,需完成以下步骤: 1. 安装 openssh-server sudo apt update sudo apt install openssh-server -y2. 配置 sshd 修改配置文件 sud…...

vue项目前后端分离设计
在Vue前端架构中,通过分层结构和模块化设计实现高效的前后端分离,需要系统性规划各层职责、接口管理和数据流控制。以下是结合业界最佳实践的完整方案: 一、分层架构设计 1. 分层结构(自上而下) 层级职责示例技术实现…...
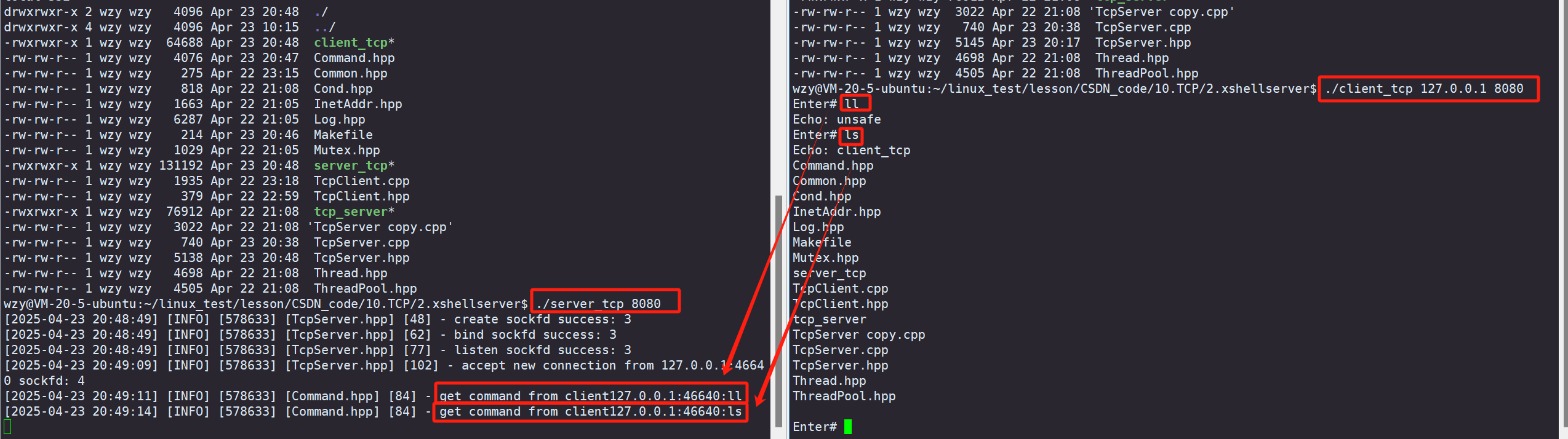
【Linux网络】构建类似XShell功能的TCP服务器
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

Spring Boot 配置源详解(完整版)
Spring Boot 配置源详解(完整版) 一、配置源加载顺序与优先级 配置源类型优先级顺序(从高到低)对应配置类/接口是否可覆盖典型文件/来源命令行参数(--keyvalue)1(最高)SimpleComman…...

JDK 17 与 Spring Cloud Gateway 新特性实践指南
一、环境要求与版本选择 1. JDK 17 的必要性 最低版本要求:Spring Boot 3.x 及更高版本(如 3.4)强制要求 JDK 17,以支持 Java 新特性(如密封类、模式匹配)和性能优化。JDK 17 核心特性: 密封类…...
)
异构迁移学习(无创脑机接口中的跨脑电帽迁移学习)
本文介绍BCI中的跨脑电帽的迁移学习最新算法。 (发表于2025 arxiv,应该属于投稿阶段,这个场景具有非常不错的研究意义和前景) 最新跨脑电帽异构算法github开源代码 SDDA算法原文 一、脑机接口绪论 脑机接口(BCI)指在人或动物大脑与外部设备之间创建的直接连接,通过脑…...
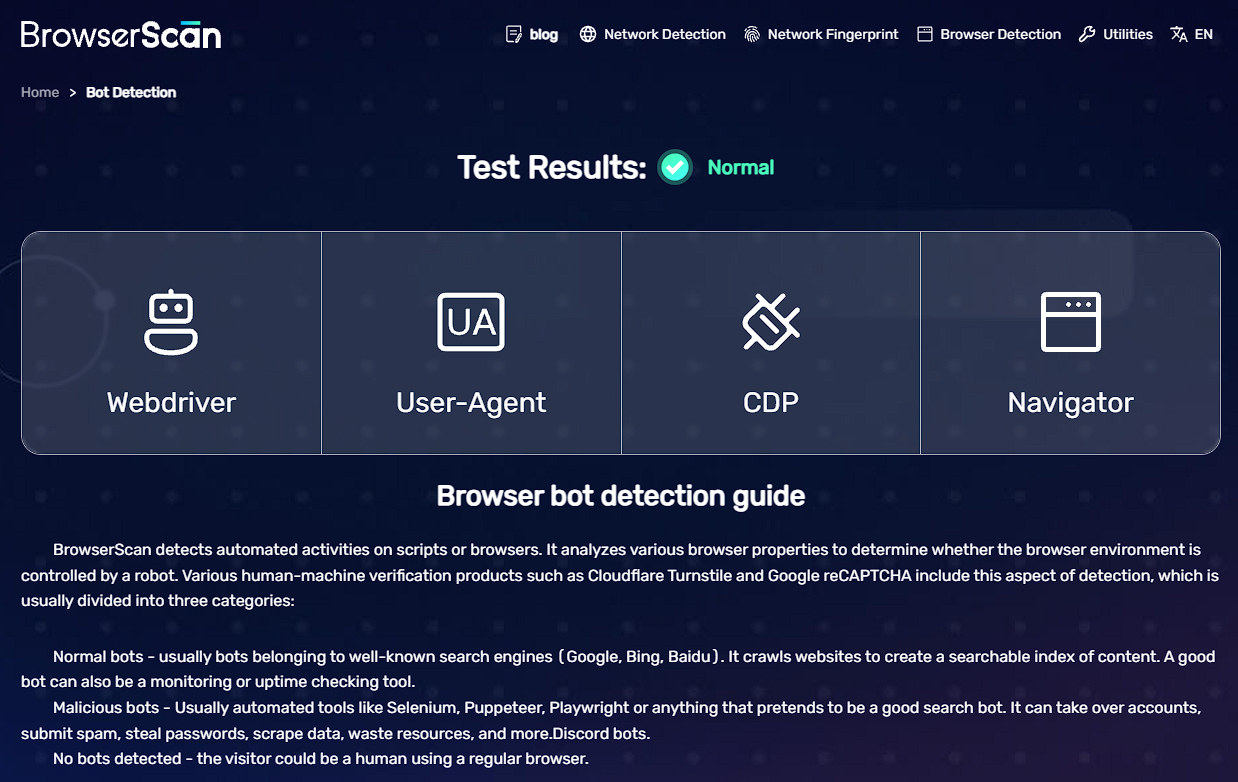
puppeteer注入浏览器指纹过CDP
一、背景 通过puppeteer爬取目标网站时,经常会被对方网站检测到,比如原生puppeteerCDP特征非常明显,另外指纹如果一直不变,也会引发风控 二、实现 通过以下几行代码即可轻松过大部分检测点,并且能够切换指纹&#x…...

1.8软考系统架构设计师:系统架构设计师概述 - 练习题附答案及超详细解析
系统架构设计师概述综合知识单选题 每道题均附有答案解析: 架构设计师的定义、职责和任务 1、系统架构设计师的核心职责是: A. 编写具体功能模块的代码 B. 制定系统整体架构和技术选型 C. 管理项目预算和进度 D. 直接对接客户进行销售支持 答案&#x…...
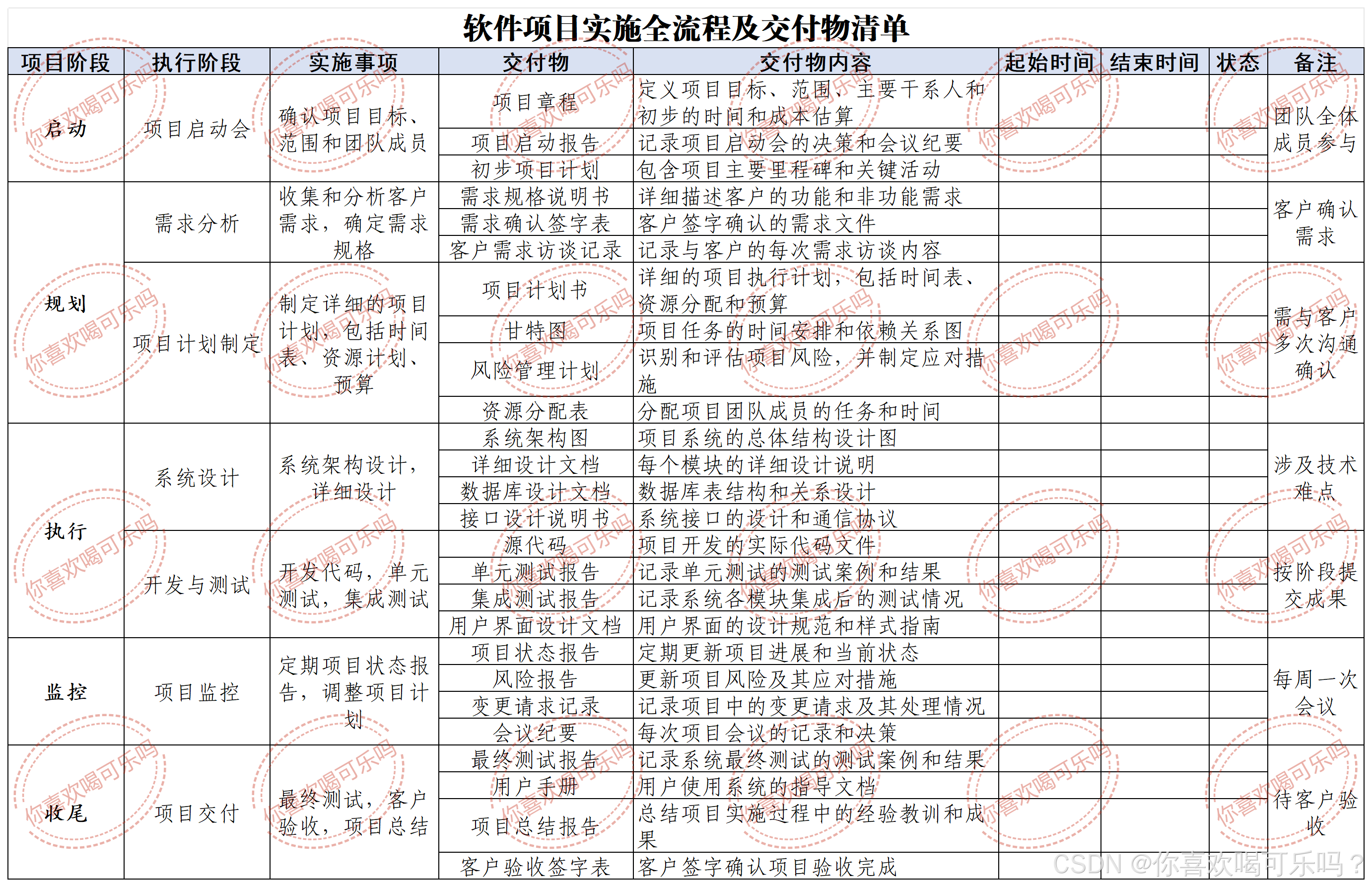
软件项目实施全流程及交付物清单
需求分析 -> 概要设计 -> 详细设计 -> 开发实现 -> 测试 -> 部署 -> 运维 一、确认项目目标、范围和团队成员 二、收集和分析客户需求,确定需求规格 三、制定详细的项目计划,包括时间表、资源计划、预算 四、系统架构设计…...
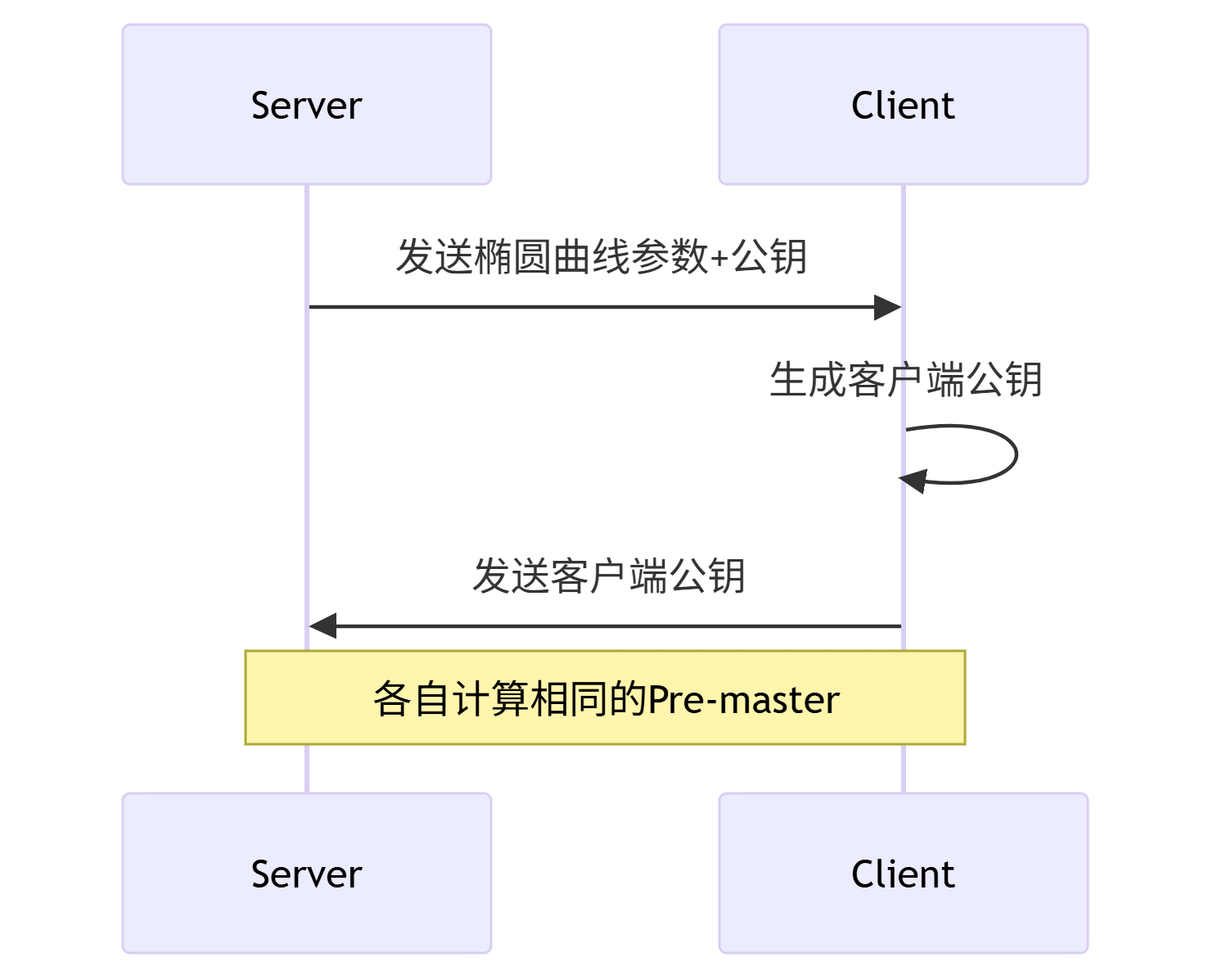
【2025计算机网络-面试常问】http和https区别是什么,http的内容有哪些,https用的是对称加密还是非对称加密,流程是怎么样的
HTTP与HTTPS全面对比及HTTPS加密流程详解 一、HTTP与HTTPS核心区别 特性HTTPHTTPS协议基础明文传输HTTP SSL/TLS加密层默认端口80443加密方式无加密混合加密(非对称对称)证书要求不需要需要CA颁发的数字证书安全性易被窃听、篡改、冒充防窃听、防篡改…...

从梯度消失到百层网络:ResNet 是如何改变深度学习成为经典的?
自AlexNet赢得2012年ImageNet竞赛以来,每个新的获胜架构通常都会增加更多层数以降低错误率。一段时间内,增加层数确实有效,但随着网络深度的增加,深度学习中一个常见的问题——梯度消失或梯度爆炸开始出现。 梯度消失问题会导致梯…...

2025.4.26总结
今天把马良老师的《职场十二法则》看完后,感触极大,这们课程就是一场职场启蒙课。 虽然看过不少关于职场的书籍,但大多数是关于职场进阶,方法方面的。并没有解答“面对未来二三十年的职场生涯,我该怎么去看待自己的工…...
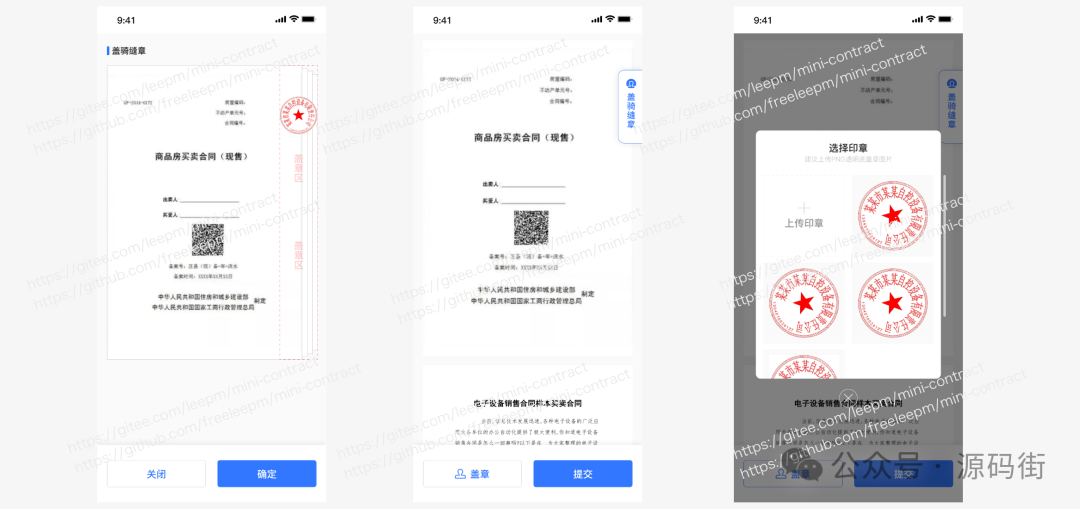
Uni-App 多端电子合同开源项目介绍
项目概述 本项目是一款基于 uni-app框架开发的多端电子合同管理平台,旨在为企业及个人用户提供高效、安全、便捷的电子合同签署与管理服务。项目创新性地引入了 “证据链”与“非证据链”两种签署模式,满足不同场景下的签署需求,支持多种签署…...

多语言笔记系列:共享数据
在笔记中共享数据(变量) 使用 .NET 交互式内核,可以在单个笔记本中以多种语言编写代码。为了利用每种语言的不同优势,您会发现在它们之间共享数据很有用。即一种语言的变量,可以在其它语言中使用。 默认情况下,.NET Interactive …...
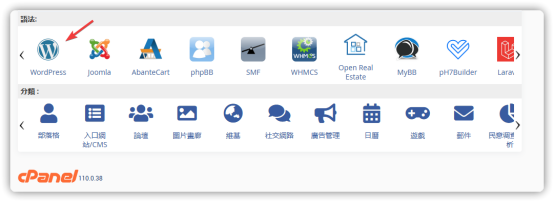
如何使用SeedProd创建无缝的WordPress维护页面
不管您刚接触 WordPress ,还是经验丰富的站长,SeedProd 都是创建网站维护页面的得力助手。通过SeedProd,您可以轻松创建一个与网站风格一致、功能齐全的维护页面,让您的用户在网站维护期间也能感受到您的专业与关怀。本文将为您提…...
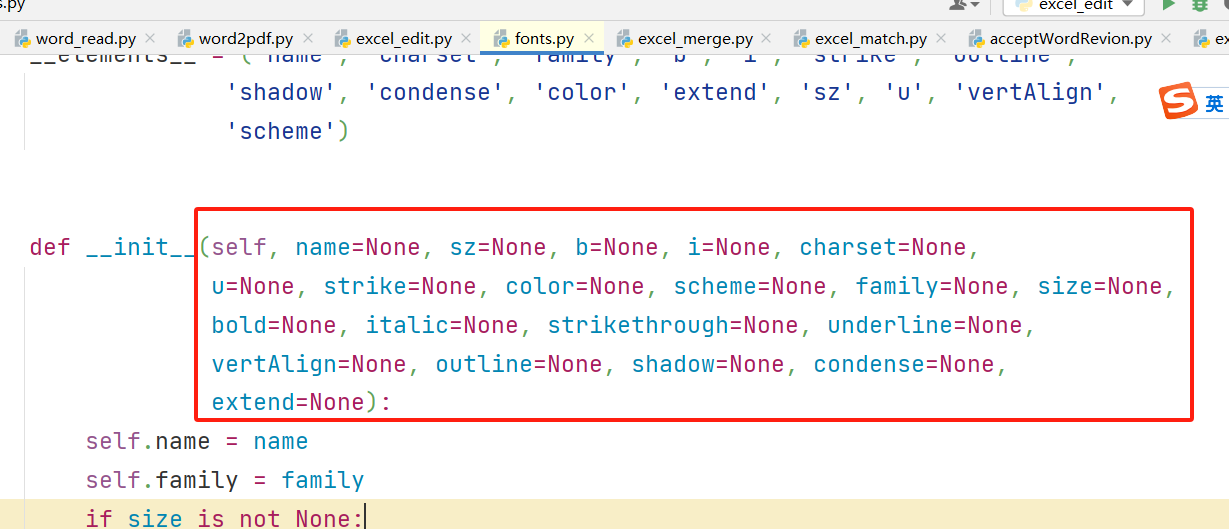
使用Python设置excel单元格的字体(font值)
一、前言 通过使用Python的openpyxl库,来操作excel单元格,设置单元格的字体,也就是font值。 把学习的过程分享给大家。大佬勿喷! 二、程序展示 1、新建excel import openpyxl from openpyxl.styles import Font wb openpyxl.…...

【PCB工艺】推挽电路及交越失真
推挽电路(Push-Pull Circuit) 推挽电路(Push-Pull Circuit) 是一种常用于功率放大、电机驱动、音频放大等场合的电路结构,具有输出对称、效率高、失真小等优点。 什么是推挽电路? 推挽是指:由两种极性相反的器件(如 NPN 和 PNP、NMOS 和 PMOS)交替导通,一个“推”电…...

告别手动映射:在 Spring Boot 3 中优雅集成 MapStruct
在日常的后端开发中,我们经常需要在不同的对象之间进行数据转换,例如将数据库实体(Entity)转换为数据传输对象(DTO)发送给前端,或者将接收到的 DTO 转换为实体进行业务处理或持久化。手动进行这…...

uv run 都做了什么?
uv run 都做了什么? uv run <命令> [参数...] 的主要作用是:在一个由 uv 管理或发现的 Python 虚拟环境中,执行你指定的 <命令>。它会临时配置一个子进程的环境,使其表现得如同该虚拟环境已经被激活一样。这意味着&am…...
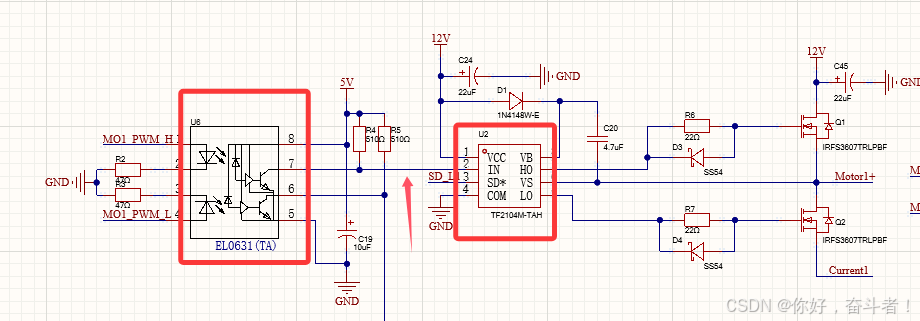
求解,如何控制三相无刷电机?欢迎到访评论
问题:通过一个集成的TF2104芯片控制H桥上桥臂和下桥臂,如何控制?还是说得需要PWM_UH和PWM_UL分开控制?...

Java ThreadLocal与内存泄漏
当我们利用 ThreadLocal 来管理数据时,我们不可避免地会面临内存泄漏的风险。 原因在于 ThreadLocal 的工作方式。当我们在当前线程的 ThreadLocalMap 中存储一个值时,一旦这个值不再需要,释放它就变得至关重要。如果不这样做,那么…...
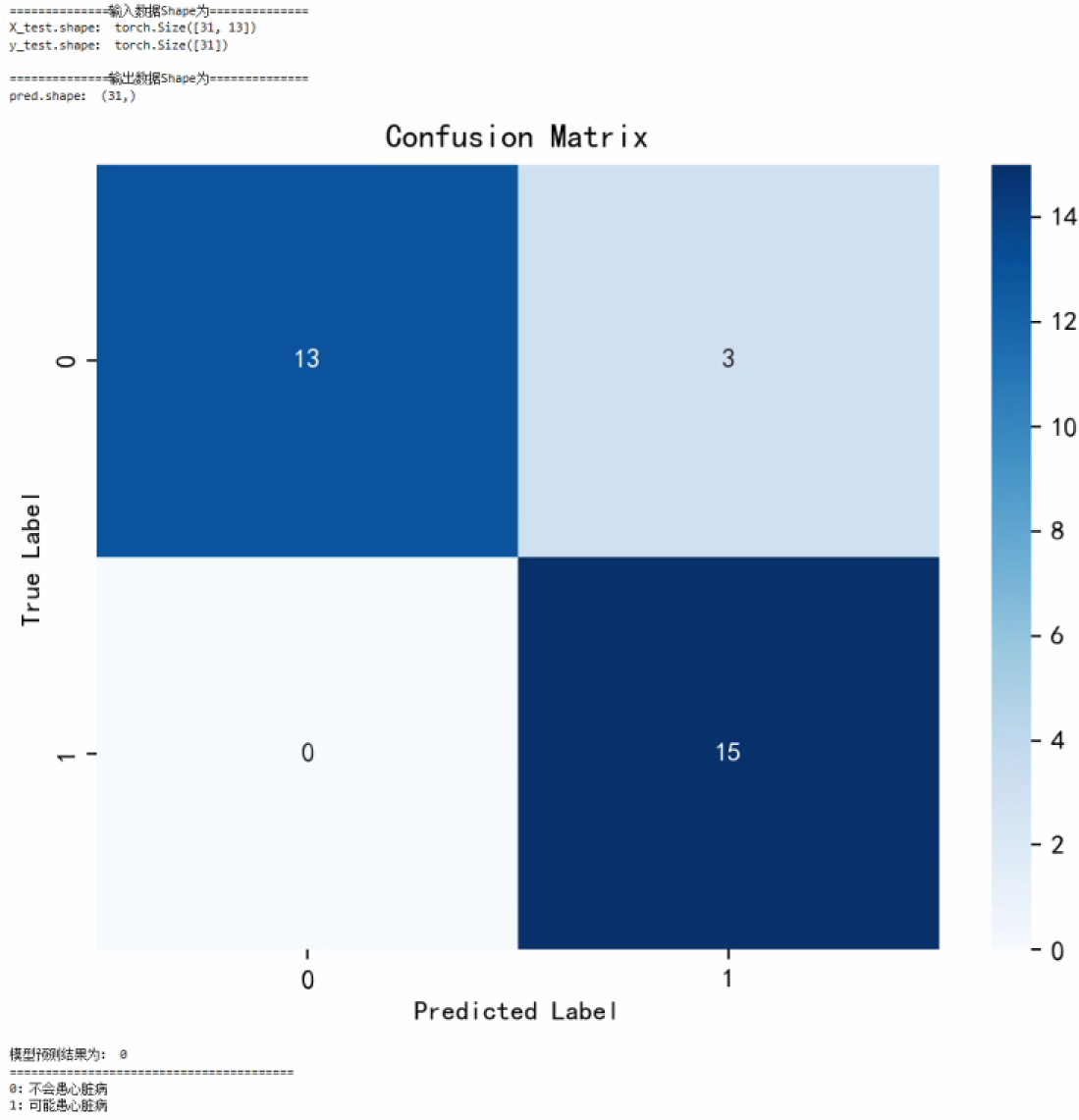
365打卡第R3周: RNN-心脏病预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 🏡 我的环境: 语言环境:Python3.10 编译器:Jupyter Lab 深度学习环境:torch2.5.1 torchvision0…...

1.1.1 用于排序规则的IComparable接口使用介绍
在C#中,IComparable 是一个核心接口,用于定义对象的自然排序规则。实现该接口的类可以指定其实例如何与其他实例比较大小,从而支持排序操作(如 Array.Sort()、List.Sort()). 1. 该接口CompareTo返回值含义:…...
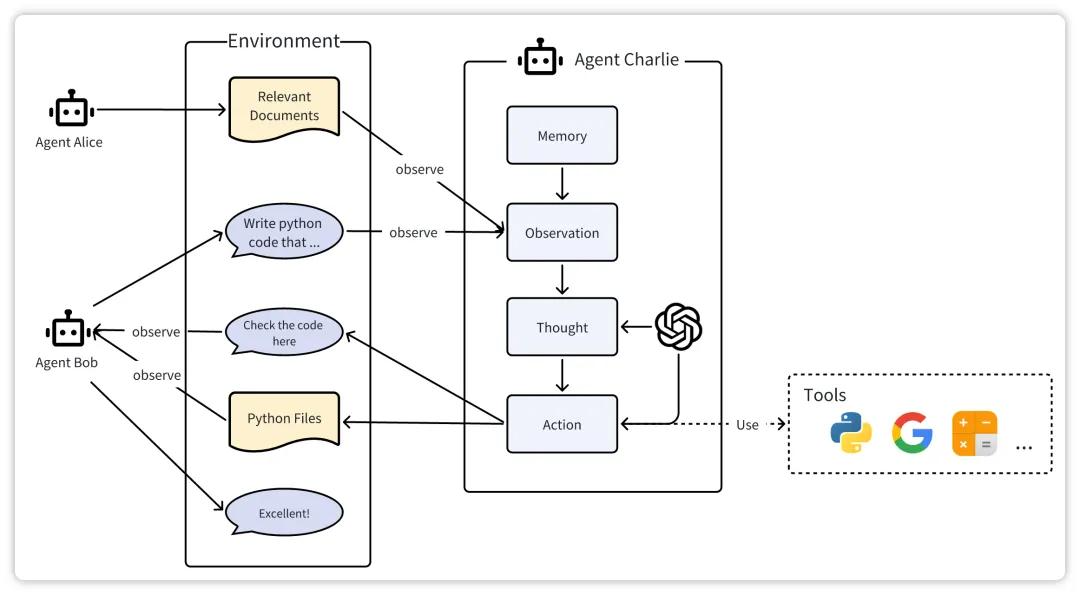
【实战】基于强化学习的 Agent 训练框架全流程拆解
一、引言 在人工智能蓬勃发展的今天,强化学习(Reinforcement Learning, RL)作为让智能体(Agent)在复杂环境中自主学习并做出最优决策的核心技术,正日益受到关注。从游戏领域中击败人类顶尖选手的 AlphaGo&a…...

【音视频】⾳频处理基本概念及⾳频重采样
一、重采样 1.1 什么是重采样 所谓的重采样,就是改变⾳频的采样率、sample format、声道数等参数,使之按照我们期望的参数输出。 1.2 为什么要重采样 为什么要重采样? 当然是原有的⾳频参数不满⾜我们的需求,⽐如在FFmpeg解码⾳频的时候…...

Prompt 结构化提示工程
Prompt 结构化提示工程 目前ai开发工具都大同小异,随着deepseek的流行,ai工具的能力都差不太多,功能基本都覆盖到了。而prompt能力反而是需要更加关注的(说白了就是能不能把需求清晰的输出成文档)。因此大家可能需要加…...

设计心得——数据结构的意义
一、数据结构 在老一些的程序员中,可能都听说过,程序其实就是数据结构算法这种说法。它是由尼克劳斯维特在其著作《算法数据结构程序》中提出的,然后在一段时期内这种说法非常流行。这里不谈论其是否正确,只是通过这种提法&#…...

【Pandas】pandas DataFrame rdiv
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

Pycharm 代理配置
Pycharm 代理配置 文章目录 Pycharm 代理配置1. 设置系统代理1.1 作用范围1.2 使用场景1.3 设置步骤 2. 设置 python 运行/调试代理2.1 作用范围2.2 使用场景2.3 设置步骤 Pycharm 工具作为一款强大的 IDE,其代理配置在实际开发中也是必不可少的,下面介绍…...