【python】使用Python和BERT进行文本摘要:从数据预处理到模型训练与生成
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门!
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界
随着信息爆炸时代的到来,海量文本数据的高效处理与理解成为亟待解决的问题。文本摘要作为自然语言处理(NLP)中的关键任务,旨在自动生成简明扼要的文本摘要,帮助用户快速获取关键信息。近年来,基于深度学习的预训练语言模型,尤其是BERT(Bidirectional Encoder Representations from Transformers),在文本理解和生成任务中取得了显著进展。本文深入探讨了如何利用Python和BERT模型进行文本摘要,包括数据预处理、模型构建与训练、摘要生成及结果评估等环节。首先,介绍了文本摘要的基本概念及其在实际应用中的重要性。随后,详细阐述了BERT模型的架构及其在文本摘要任务中的应用原理。接着,通过实际案例,展示了如何使用Python进行数据清洗与预处理,并利用Hugging Face的Transformers库构建和训练基于BERT的文本摘要模型。文章还涵盖了生成摘要的具体方法,包括抽取式和生成式摘要技术,并结合代码示例进行详细说明。最后,探讨了模型评估指标及优化策略,旨在为研究人员和开发者提供一套完整的基于BERT的文本摘要解决方案,助力其在信息提取与内容生成领域的创新与实践。
引言
在当今信息爆炸的时代,海量的文本数据如新闻报道、学术论文、社交媒体内容等以惊人的速度涌现。如何高效地从这些海量数据中提取关键信息,成为了自然语言处理(NLP)领域的重要研究方向之一。文本摘要作为NLP中的核心任务,旨在自动生成简明扼要的文本摘要,帮助用户快速获取所需信息,提升信息处理的效率和效果。
传统的文本摘要方法主要分为抽取式摘要和生成式摘要两类。抽取式摘要通过从原文中直接提取关键句子或片段来构建摘要,而生成式摘要则尝试理解原文内容,生成新的句子来表达核心信息。随着深度学习技术的迅猛发展,基于神经网络的文本摘要方法逐渐成为研究热点,尤其是预训练语言模型的应用,为文本摘要任务带来了革命性的突破。
BERT(Bidirectional Encoder Representations from Transformers)作为一种基于Transformer架构的双向编码器表示模型,自推出以来在多个NLP任务中表现出色。其强大的语义理解能力使其在文本摘要任务中具备巨大的潜力。然而,如何有效地利用BERT进行文本摘要,包括数据预处理、模型构建与训练、摘要生成及结果评估,仍然是一个值得深入探讨的问题。
本文旨在系统地介绍如何使用Python和BERT模型进行文本摘要任务。通过详细的理论解析与丰富的代码示例,展示从数据预处理到模型训练,再到摘要生成的完整流程。同时,探讨模型评估与优化策略,帮助读者全面掌握基于BERT的文本摘要技术,推动其在实际应用中的落地与创新。
BERT模型概述
Transformer架构
Transformer架构由Vaswani等人于2017年提出,是一种完全基于注意力机制(Attention Mechanism)的神经网络模型,广泛应用于各种NLP任务。与传统的循环神经网络(RNN)相比,Transformer具有更高的并行化能力和更好的长距离依赖建模能力。Transformer主要由编码器(Encoder)和解码器(Decoder)两部分组成,每部分由多个相同的层(Layer)堆叠而成。
每个编码器层包含两个子层:多头自注意力机制(Multi-Head Self-Attention)和前馈全连接网络(Feed-Forward Neural Network)。每个解码器层则在此基础上增加了一个编码器-解码器注意力机制(Encoder-Decoder Attention)。这种设计使得Transformer在处理序列到序列(Sequence-to-Sequence)任务时表现尤为出色。
BERT模型
BERT(Bidirectional Encoder Representations from Transformers)是Google于2018年提出的预训练语言模型,基于Transformer的编码器部分。BERT的核心创新在于其双向性,即在进行词表示学习时同时考虑左右上下文信息,这一特性显著提升了模型的语义理解能力。
BERT通过两个主要任务进行预训练:掩蔽语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。MLM任务随机掩蔽输入句子中的一些词汇,模型需根据上下文预测被掩蔽的词;NSP任务则要求模型判断两句话是否在原文中相邻。这两种任务共同训练出具有深厚语义理解能力的语言表示。
BERT在文本摘要中的应用
在文本摘要任务中,BERT可以作为编码器,用于理解输入文本的语义信息。结合解码器部分,BERT可以被扩展为生成式摘要模型。此外,基于BERT的预训练模型,如BERTSUM,通过调整模型结构和训练目标,专门用于摘要生成,取得了良好的效果。
然而,直接使用BERT进行文本摘要存在一些挑战,包括生成的摘要质量、模型的训练效率以及对大规模数据的适应能力。本文将探讨如何通过数据预处理、模型构建与训练、摘要生成等步骤,充分发挥BERT在文本摘要任务中的潜力。
数据预处理
数据集选择
文本摘要任务需要大量的带有摘要的文本对作为训练数据。常用的数据集包括:
- CNN/Daily Mail:包含新闻文章及其摘要,广泛用于文本摘要任务。
- DUC:由美国国家标准与技术研究院(NIST)组织的文档理解评估会议提供的数据集。
- Gigaword:包含大量的新闻摘要数据,适用于训练大规模摘要模型。
本文以CNN/Daily Mail数据集为例,展示数据预处理的具体步骤。
数据清洗与格式化
数据预处理的主要目的是将原始数据转化为模型可以接受的格式,包括去除噪声、统一文本格式、分割训练与测试集等。以下是具体的代码实现:
import os
import re
import json
import pandas as pd
from tqdm import tqdm# 定义数据集路径
DATA_DIR = 'cnn_dm_dataset'
TRAIN_FILE = os.path.join(DATA_DIR, 'train.json')
VALID_FILE = os.path.join(DATA_DIR, 'valid.json')
TEST_FILE = os.path.join(DATA_DIR, 'test.json')# 检查数据文件是否存在
for file in [TRAIN_FILE, VALID_FILE, TEST_FILE]:if not os.path.exists(file):raise FileNotFoundError(f'文件 {file} 不存在,请检查数据集路径。')# 加载数据
def load_data(file_path):"""加载JSON格式的数据参数:file_path -- 数据文件路径返回:texts -- 原文列表summaries -- 摘要列表"""texts = []summaries = []with open(file_path, 'r', encoding='utf-8') as f:for line in tqdm(f, desc=f'加载 {file_path}'):data = json.loads(line)text = data['article']summary = data['highlights']texts.append(text)summaries.append(summary)return texts, summaries# 加载训练、验证和测试集
train_texts, train_summaries = load_data(TRAIN_FILE)
valid_texts, valid_summaries = load_data(VALID_FILE)
test_texts, test_summaries = load_data(TEST_FILE)# 数据示例
print(f'训练集样本数: {len(train_texts)}')
print(f'验证集样本数: {len(valid_texts)}')
print(f'测试集样本数: {len(test_texts)}')# 数据清洗函数
def clean_text(text):"""清洗文本数据,去除特殊字符和多余空格参数:text -- 输入文本返回:清洗后的文本"""# 去除特殊字符text = re.sub(r'[^A-Za-z0-9\s,.!?\'\"-]', '', text)# 替换多个空格为一个空格text = re.sub(r'\s+', ' ', text)return text.strip()# 清洗所有数据
train_texts = [clean_text(text) for text in tqdm(train_texts, desc='清洗训练集')]
valid_texts = [clean_text(text) for text in tqdm(valid_texts, desc='清洗验证集')]
test_texts = [clean_text(text) for text in tqdm(test_texts, desc='清洗测试集')]train_summaries = [clean_text(summary) for summary in tqdm(train_summaries, desc='清洗训练集摘要')]
valid_summaries = [clean_text(summary) for summary in tqdm(valid_summaries, desc='清洗验证集摘要')]
test_summaries = [clean_text(summary) for summary in tqdm(test_summaries, desc='清洗测试集摘要')]# 将清洗后的数据保存为CSV文件,便于后续处理
def save_to_csv(texts, summaries, file_name):"""将文本和摘要保存为CSV文件参数:texts -- 原文列表summaries -- 摘要列表file_name -- 输出文件名"""df = pd.DataFrame({'text': texts, 'summary': summaries})df.to_csv(file_name, index=False, encoding='utf-8')print(f'已保存到 {file_name}')# 保存数据
save_to_csv(train_texts, train_summaries, 'train_clean.csv')
save_to_csv(valid_texts, valid_summaries, 'valid_clean.csv')
save_to_csv(test_texts, test_summaries, 'test_clean.csv')
数据分词与编码
在使用BERT进行文本摘要任务之前,需要对文本进行分词和编码。BERT使用WordPiece分词器,将词汇拆分为更小的子词单元,以处理未登录词和多样化的词汇形式。以下是具体的实现代码:
from transformers import BertTokenizer# 加载预训练的BERT分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 定义最大序列长度
MAX_INPUT_LENGTH = 512
MAX_SUMMARY_LENGTH = 128# 分词和编码函数
def tokenize_and_encode(texts, summaries, tokenizer, max_input_len=MAX_INPUT_LENGTH, max_summary_len=MAX_SUMMARY_LENGTH):"""对文本和摘要进行分词和编码参数:texts -- 原文列表summaries -- 摘要列表tokenizer -- BERT分词器max_input_len -- 原文最大长度max_summary_len -- 摘要最大长度返回:input_ids -- 原文的编码attention_masks -- 原文的注意力掩码summary_ids -- 摘要的编码summary_attention_masks -- 摘要的注意力掩码"""input_ids = []attention_masks = []summary_ids = []summary_attention_masks = []for text, summary in tqdm(zip(texts, summaries), total=len(texts), desc='分词和编码'):# 编码原文encoded_dict = tokenizer.encode_plus(text,add_special_tokens=True,max_length=max_input_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_ids.append(encoded_dict['input_ids'])attention_masks.append(encoded_dict['attention_mask'])# 编码摘要summary_encoded = tokenizer.encode_plus(summary,add_special_tokens=True,max_length=max_summary_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')summary_ids.append(summary_encoded['input_ids'])summary_attention_masks.append(summary_encoded['attention_mask'])# 将列表转换为张量input_ids = torch.cat(input_ids, dim=0)attention_masks = torch.cat(attention_masks, dim=0)summary_ids = torch.cat(summary_ids, dim=0)summary_attention_masks = torch.cat(summary_attention_masks, dim=0)return input_ids, attention_masks, summary_ids, summary_attention_masksimport torch# 进行分词和编码
train_inputs, train_masks, train_summaries_ids, train_summaries_masks = tokenize_and_encode(train_texts, train_summaries, tokenizer
)
valid_inputs, valid_masks, valid_summaries_ids, valid_summaries_masks = tokenize_and_encode(valid_texts, valid_summaries, tokenizer
)
test_inputs, test_masks, test_summaries_ids, test_summaries_masks = tokenize_and_encode(test_texts, test_summaries, tokenizer
)# 查看编码结果
print('原文编码示例:', train_inputs[0])
print('摘要编码示例:', train_summaries_ids[0])
构建数据加载器
为了高效地将数据输入模型进行训练,需要构建适当的数据加载器。以下代码展示了如何使用PyTorch的Dataset和DataLoader类进行数据封装:
from torch.utils.data import Dataset, DataLoaderclass SummarizationDataset(Dataset):"""自定义数据集类,用于文本摘要任务"""def __init__(self, input_ids, attention_masks, summary_ids, summary_attention_masks):self.input_ids = input_idsself.attention_masks = attention_masksself.summary_ids = summary_idsself.summary_attention_masks = summary_attention_masksdef __len__(self):return len(self.input_ids)def __getitem__(self, idx):return {'input_ids': self.input_ids[idx],'attention_mask': self.attention_masks[idx],'summary_ids': self.summary_ids[idx],'summary_attention_mask': self.summary_attention_masks[idx]}# 创建数据集对象
train_dataset = SummarizationDataset(train_inputs, train_masks, train_summaries_ids, train_summaries相关文章:

【python】使用Python和BERT进行文本摘要:从数据预处理到模型训练与生成
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着信息爆炸时代的到来,海量文本数据的高效处理与理解成为亟待解决的问题。文本摘要作为自然语言处理(NLP)中的关键任务,旨在自动生成…...
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】5.3 相关性分析(PEARSON/SPEARMAN相关系数)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 5.3 相关性分析(PEARSON/SPEARMAN相关系数)5.3.1 相关性分析理论基础5.3.1.1 相关系数定义与分类5.3.1.2 Pearson相关系数( Pearson Corr…...

Redis面试 实战贴 后面持续更新链接
redis是使用C语言写的。 面试问题列表: Redis支持哪些数据类型?各适用于什么场景? Redis为什么采用单线程模型?优势与瓶颈是什么? RDB和AOF持久化的区别?如何选择?混合持久化如何实现&#x…...
)
小程序滚动条隐藏(uniapp版本)
单独指定页面隐藏(找到对应的scroll-view) <style> /* 全局隐藏滚动条样式 */ ::-webkit-scrollbar { display: none; width: 0; height: 0; color: transparent; background: transparent; } /* 确保scroll-view组件也隐藏滚动条 */ …...
python基础:序列和索引-->Python的特殊属性
一.序列和索引 1.1 用索引检索字符串中的元素 # 正向递增 shelloworld for i in range (0,len(s)):# i是索引print(i,s[i],end\t\t) print(\n--------------------------) # 反向递减 for i in range (-10,0):print(i,s[i],end\t\t)print(\n--------------------------) print(…...

java反射(2)
package 反射;import java.lang.reflect.Constructor; import java.lang.reflect.Field; import java.lang.reflect.Method; import java.util.Arrays;public class demo {public static void main(String[] args) throws Exception {// 通过类的全限定名获取对应的 Class 对象…...

C++核心概念全解析:从析构函数到运算符重载的深度指南
目录 前言一、构析函数1.1 概念1.2 语法格式 1.3 核心特性1.4 调用时机1.5 构造函数 vs 析构函数1.6 代码示例 二、this关键字2.1 基本概念2.2 核心特性2.3 使用场景2.3.1 区分成员与局部变量2.3.2 返回对象自身(链式调用)2.3.3 成员函数间传递当前对象2…...

如何巧妙解决 Too many connections 报错?
1. 背景 在日常的 MySQL 运维中,难免会出现参数设置不合理,导致 MySQL 在使用过程中出现各种各样的问题。 今天,我们就来讲解一下 MySQL 运维中一种常见的问题:最大连接数设置不合理,一旦到了业务高峰期就会出现连接…...

自由学习记录(58)
Why you were able to complete the SpringBoot MyBatisPlus task smoothly: Clear logic flow: Database → Entity → Service → Controller → API → JSON response. Errors are explicit, results are verifiable — you know what’s broken and what’s fixed. Sta…...

ES6 知识点整理
一、变量声明:var、let、const 的区别 作用域 var:函数作用域(函数内有效)。let/const:块级作用域({} 内有效,如 if、for)。 变量提升 var 会提升变量到作用域顶部(值为…...
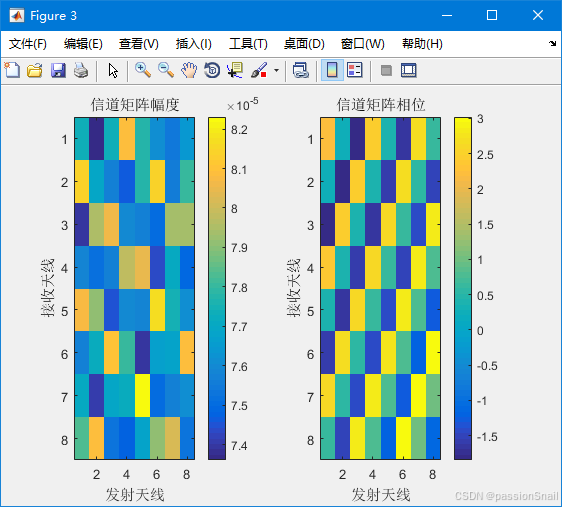
《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-《5G通信速成:MATLAB毫米波信道建模仿真指南》
《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-5G通信速成:MATLAB毫米波信道建模仿真指南 🚀📡 大家好!今天我将带大家进入5G通信的奇妙世界,我们一起探索5G通信中最激动人心的部分之一——毫米波信…...

工程师 - 汽车分类
欧洲和中国按字母对汽车分类: **轴距**:简单来说,就是前轮中心点到后轮中心点之间的距离,也就是前轮轴和后轮轴之间的长度。根据轴距的大小,国际上通常把轿车分为以下几类(德国大众汽车习惯用A\B\C\D分类&a…...

57.[前端开发-前端工程化]Day04-webpack插件模式-搭建本地服务器
Webpack常见的插件和模式 1 认识插件Plugin 认识Plugin 2 CleanWebpackPlugin CleanWebpackPlugin 3 HtmlWebpackPlugin HtmlWebpackPlugin 生成index.html分析 自定义HTML模板 自定义模板数据填充 4 DefinePlugin DefinePlugin的介绍 DefinePlugin的使用 5 mode模式配置…...

K8S - 金丝雀发布实战 - Argo Rollouts 流量控制解析
一、金丝雀发布概述 1.1 什么是金丝雀发布? 金丝雀发布(Canary Release)是一种渐进式部署策略,通过逐步将生产流量从旧版本迁移至新版本,结合实时指标验证,在最小化风险的前提下完成版本迭代。其核心逻辑…...

Qt中数据结构使用自定义类————附带详细示例
文章目录 C对数据结构使用自定义类1 QMap使用自定义类1.1 使用自定义类做key1.2 使用自定义类做value 2 QSet使用自定义类 参考 C对数据结构使用自定义类 1 QMap使用自定义类 1.1 使用自定义类做key QMap<key,value>中数据存入时会对存入key值的数据进行比较ÿ…...
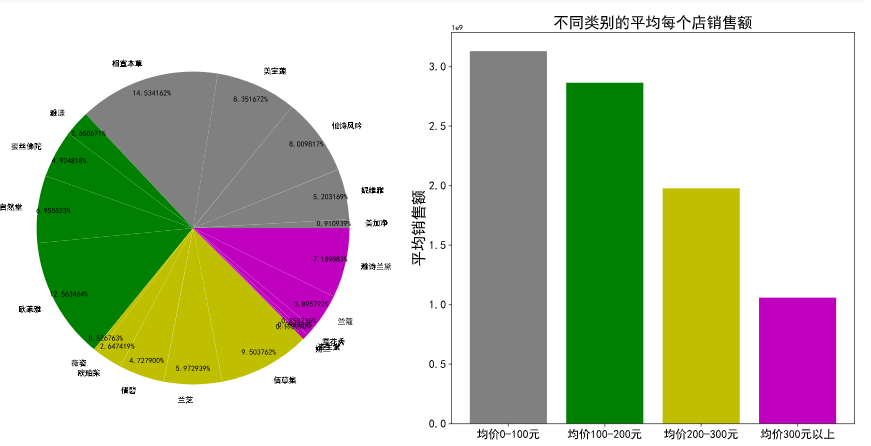
数据可视化与分析
数据可视化的目的是为了数据分析,而非仅仅是数据的图形化展示。 项目介绍 项目案例为电商双11美妆数据分析,分析品牌销售量、性价比等。 数据集包括更新日期、ID、title、品牌名、克数容量、价格、销售数量、评论数量、店名等信息。 1、数据初步了解…...

基于大模型预测的产钳助产分娩全方位研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与方法 二、产钳助产分娩概述 2.1 产钳助产定义与历史 2.2 适用情况与临床意义 三、大模型预测原理与数据基础 3.1 大模型技术原理 3.2 数据收集与处理 3.3 模型训练与验证 四、术前预测与准备 4.1 大模型术前风险预…...

通过混合机器学习和 TOPSIS 实现智能手机身份验证的稳健行为生物识别框架
1. 简介 随着日常工作、个人生活和金融操作对智能手机的依赖性不断增强,对弹性安全身份验证系统的需求也日益增长。尽管 PIN 码、密码和静态生物识别等传统身份验证方法仍可为系统提供一定的安全级别,但事实证明,它们容易受到多种威胁,包括敏感数据泄露、网络钓鱼、盗窃和…...

旅游设备生产企业的痛点 质检系统在旅游设备生产企业的应用
在旅游设备制造行业,产品质量直接关系到用户体验与企业口碑。从景区缆车、观光车到水上娱乐设施,每一件设备的安全性与可靠性都需经过严苛检测。然而,传统质检模式常面临数据分散、流程不透明、合规风险高等痛点,难以满足旅游设备…...

使用ESPHome烧录固件到ESP32-C3并接入HomeAssistant
文章目录 一、安装ESPHome二、配置ESP32-C3控制灯1.主配置文件esp32c3-luat.yaml2.基础通用配置base.yaml3.密码文件secret.yaml4.围栏灯four_light.yaml5.彩灯rgb_light.yaml6.左右柱灯left_right_light.yaml 三、安装固件四、HomeAssistant配置ESPHome1.直接访问2.配置ESPHom…...
【漫话机器学习系列】237. TSS总平方和
深度理解 TSS(总平方和):公式、意义与应用 在机器学习与统计建模领域,评价模型好坏的重要指标之一就是方差与误差分析。其中,TSS(Total Sum of Squares,总平方和)扮演着非常关键的角…...

DeepSeek多尺度数据:无监督与原则性诊断方案全解析
DeepSeek 多尺度数据诊断方案的重要性 在当今的 IT 领域,数据如同石油,是驱动各类智能应用发展的核心资源。随着技术的飞速发展,数据的规模和复杂性呈爆炸式增长,多尺度数据处理成为了众多领域面临的关键挑战。以计算机视觉为例,在目标检测任务中,小目标可能只有几个像素…...

Spring Framework 6:虚拟线程支持与性能增强
文章目录 引言一、虚拟线程支持:并发模型的革命二、AOT编译与原生镜像优化三、响应式编程与可观测性增强四、HTTP接口客户端与声明式HTTP五、性能比较与实际应用总结 引言 Spring Framework 6作为Spring生态系统的基础框架,随着Java 21的正式发布&#…...

用Redisson实现库存扣减的方法
Redisson是一个在Redis基础上实现的Java客户端,提供了许多高级功能,包括分布式锁、计数器、集合等。使用Redisson实现库存扣减可以保证操作的原子性和高效性。本文将详细介绍如何使用Redisson实现一个简单的库存扣减功能。 一、初始化Redisson客户端 首…...

视频转GIF
视频转GIF 以下是一个使用 Python 将视频转换为 GIF 的脚本,使用了 imageio 和 opencv-python 库: import cv2 import imageio import numpy as np """将视频转换为GIF图参数:video_path -- 输入视频的路径gif_path -- 输出GIF的路径fp…...

一场静悄悄的革命:AI大模型如何重构中国产业版图?
一场静悄悄的革命:AI大模型如何重构中国产业版图? 当ChatGPT在2022年掀起全球AI热潮时,很少有人意识到,这场技术变革正在中国产业界掀起更深层次的革命。在浙江宁波,一个纺织企业老板打开"产业链智能创新平台",30秒内就获得了原料采购、设备升级、海外拓客的全…...

kotlin 02flow-sharedFlow 完整教程
一 sharedFlow是什么 SharedFlow 是 Kotlin 协程中 Flow 的一种 热流(Hot Flow),用于在多个订阅者之间 共享事件或数据流。它适合处理 一次性事件(如导航、弹窗、Toast、刷新通知等),而不是持续状态。 ✅ …...
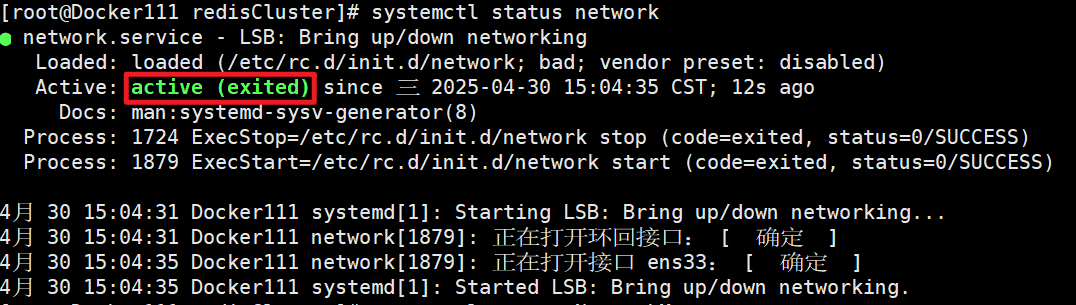
CentOS网络之network和NetworkManager深度解析
文章目录 CentOS网络之network和NetworkManager深度解析1. CentOS网络服务发展历史1.1 传统network阶段(CentOS 5-6)1.2 过渡期(CentOS 7)1.3 新时代(CentOS 8) 2. network和NetworkManager的核心区别3. ne…...

【AI】模型与权重的基本概念
在 ModelScope 平台上,「模型」和「权重」的定义与工程实践紧密结合,理解它们的区别需要从实际的文件结构和加载逻辑入手。以下是一个典型 ModelScope 模型仓库的组成及其概念解析: 1. ModelScope 模型仓库的典型结构 以 deepseek-ai/deepse…...
)
设计模式-基础概念学习总结(继承、多态、虚方法、方法重写)
概念使用例子的方式介绍(继承,多态,虚方法,方法重写),实现代码python 1. 继承(Inheritance) 概念:子类继承父类的属性和方法,可以直接复用父类的代码&#…...