初学Python爬虫
文章目录
- 前言
- 一、 爬虫的初识
- 1.1 什么是爬虫
- 1.2 爬虫的核心
- 1.3 爬虫的用途
- 1.4 爬虫分类
- 1.5 爬虫带来的风险
- 1.6. 反爬手段
- 1.7 爬虫网络请求
- 1.8 爬虫基本流程
- 二、urllib库初识
- 2.1 http和https协议
- 2.2 编码解码的使用
- 2.3 urllib的基本使用
- 2.4 一个类型六个方法
- 2.5 下载网页数据
- 2.6 带单个参数的页面抓取(get请求)
- 2.7 定制request使用ua反爬
- 2.8 多字段的字符转码
- 2.9 post请求的使用
- 2.10 异常处理
- 三、 requests请求的使用
- 3.1 下载requests包
- 总结
前言
在当今信息爆炸的时代,互联网上的数据呈指数级增长,如何高效地获取、处理和分析这些数据成为一项重要的技能。网络爬虫(Web Crawler)作为一种自动化数据采集工具,能够帮助我们快速地从海量网页中提取有价值的信息,广泛应用于搜索引擎、数据分析、市场调研、舆情监控等领域。
学习爬虫技术不仅能提升我们的编程能力,还能培养数据思维,为后续的数据挖掘、机器学习等方向奠定基础。然而,爬虫开发并非简单的“请求-解析”过程,它涉及HTTP协议、HTML解析、反爬机制应对、数据存储等多个技术点,同时还需遵守相关法律法规,合理合法地使用爬虫技术。
本教程将从基础概念入手,逐步介绍爬虫的核心技术,并结合实际案例,帮助读者掌握爬虫开发的完整流程。无论你是编程初学者,还是希望提升数据采集能力的开发者,都可以通过本教程系统地学习爬虫技术,并将其应用于实际项目中。
一、 爬虫的初识
1.1 什么是爬虫
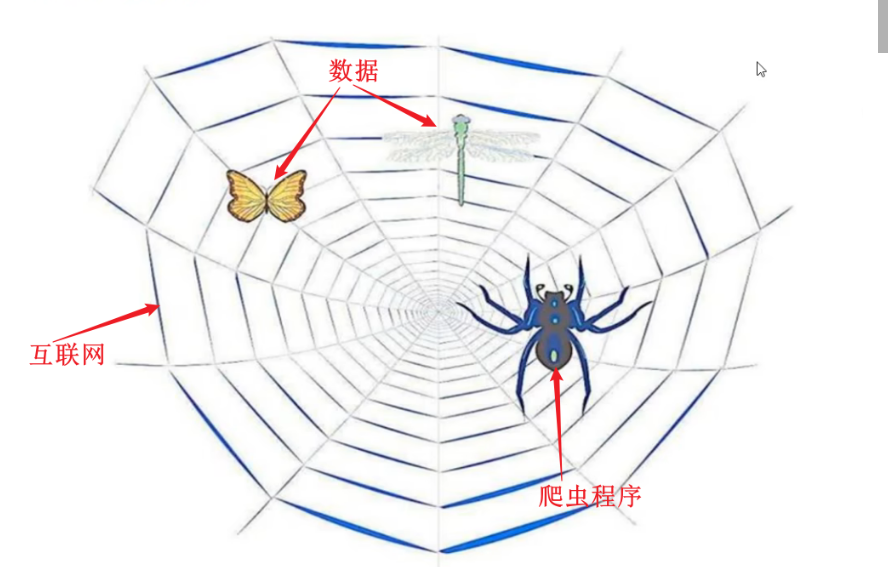
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
-
解释1: 通过一个程序,根据url(http://www.taobao.com)进行爬取网页,获取有用信息
-
解释2: 使用程序模拟浏览器,去向服务器发送请求,获取响应信息
1.2 爬虫的核心
-
爬取网页:爬取整个网页 包含了网页中所有得内容
-
解析数据:将网页中你得到的数据 进行解析
-
难点:爬虫和反爬虫之间的博弈(数据获取与数据保护之间的对抗)
1.3 爬虫的用途
-
数据分析/人工数据集
-
社交软件冷启动(新平台没有足够的人流,使用爬虫爬去其他类似于(微博)等的用户数据,来吸引用户下载)
-
舆情监控(一些灾情信息等数据的获取)
-
竞争对手监控(不同购物平台,爬取对方相同物品的价格,来适当降低价格,吸引用户购买#)
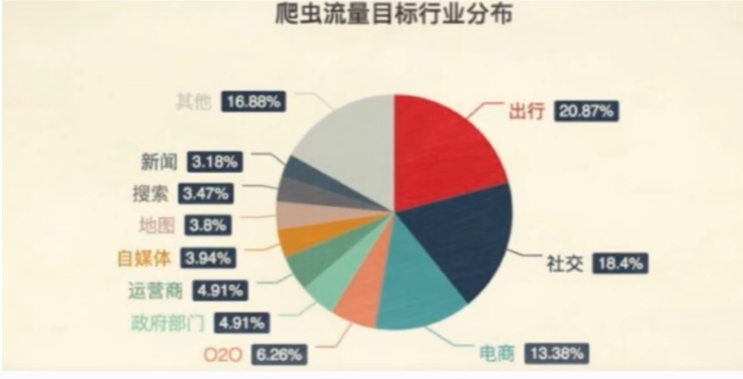
1.4 爬虫分类
-
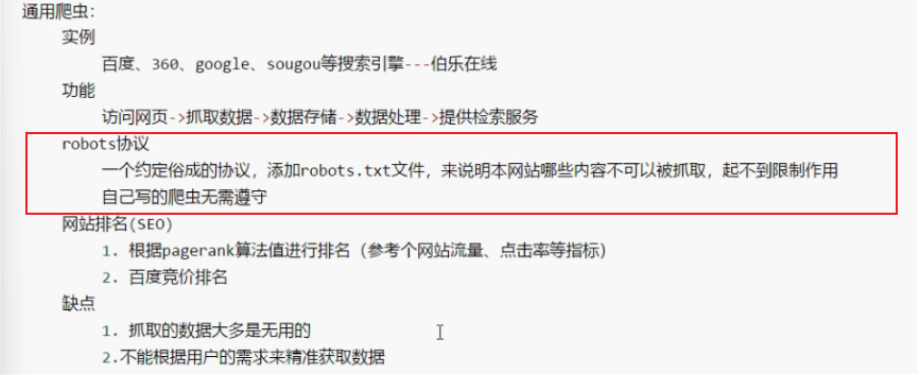
通用爬虫(不常用):抓取系统重要组成部分,抓取的是一整张页面的数据。
-
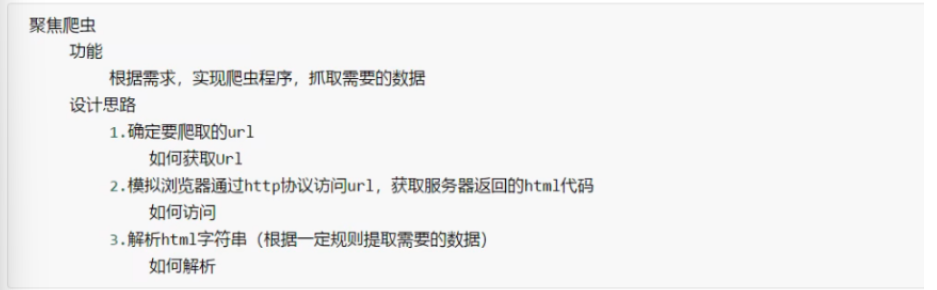
聚焦爬虫:建立在通用爬虫的基础上,抓取的是页面中特定的局部内容。
-
增量式爬虫:检测网站中数据更新的情况,只抓取网站中最新更新的数据。

1.5 爬虫带来的风险
-
爬虫干扰了被访问网站的正常运营
-
爬虫抓取了受到法律保护的特定类型的数据或信息
1.6. 反爬手段

1.7 爬虫网络请求
请求过程: 客户端,指web浏览器向服务器发送请求
请求分为四部分:
-
请求网址 --request url
-
请求方法 --request methods
-
请求头 – request header
-
请求体 – request body
可以通过F12查看请求响应
1.8 爬虫基本流程
- 确认目标:目标url:www.baidu.com
- 发送请求: 发送网络请求,获取到特定的服务端给你的响应
- 提取数据:从响应中提取特定的数据jsonpath/xpath/re
- 保存数据:本地(html、json、txt)、数据库
注意: 获取到的响应中,有可能会提取到还需要继续发送请求的ur1,可以拿着解析到的url继续发送请求
二、urllib库初识
2.1 http和https协议
概念和区别
http协议:超文本传输协议,默认端口号是80
-
超文本:不仅仅限于文本,还包括图片、音频、视频
-
传输协议:指使用共用约定的固定格式来传递转换成字符串的超文本内容
https协议: http+ ssl(安全套接字层)默认端口号是443
-
带有安全套接字层的超文本传输协议
-
ssl对传输的内容进行加密
https比http更安全,但是性能更低
2.2 编码解码的使用
图片、视频、音频需要以bytes类型的格式来存储
# 编码--encode() 将str转变为对应的二进制
str = '周杰伦'
print(str.encode())# 解码--decode() 将二进制转为str
str = b'\xe5\x91\xa8\xe6\x9d\xb0\xe4\xbc\xa6'
print(str.decode())
2.3 urllib的基本使用
# 前提:获取数据的前提要联网!!!!# 需求:使用urllib获取百度首页的源码# 1. 导入urllib包(不用安装)
import urllib.request# 1.定义一个url(就是需要访问的地址)
url = 'http://www.baidu.com'# 2.模拟浏览器向服务器发送请求
# response包含页面源码和响应头信息等等
response = urllib.request.urlopen(url)# 3.获取响应中的页面源码(只要源码)
# read方法返回的是带b的二进制的数据
content = response.read()# 4.打印数据
# print(content) 二进制# 5.该编码格式(解码 decode方法)
# decode的默认解码就是utf-8 因而也可以省略参数
print(content.decode('utf-8'))
2.4 一个类型六个方法
# 基础操作
import urllib.requesturl = 'http://www.baidu.com'response = urllib.request.urlopen(url)# 一个类型和六个方法# 判断类型
# <class 'http.client.HTTPResponse'>
# print(type(response))# read()方法是单字节的读取数据(速度慢)
# content = response.read()
# 表示只读5个字节
# content = response.read(5)
# print(content)# readline()方法 读取一行(速度快)
# content = response.readline()
# print(content)# readlines()方法 读取所有行
# content = response.readlines()
# print(content)# 返回状态码 200表示成功 证明逻辑是对的
print(response.getcode())# 返回url地址
print(response.geturl())# 返回状态信息和响应头
print(response.getheaders())
2.5 下载网页数据
# 可以下载文件/音频/视频.....
# 适用于批量下载import urllib.requesturl_page = 'http://baidu.com'# 使用urlretrieve()方法
# 第一个参数是url地址,第二个参数是保存的文件名
# 返回的是html文件,所以后缀写html
# urllib.request.urlretrieve(url_page, 'baidu.html')# 下载图片
url_img = 'https://tse1-mm.cn.bing.net/th/id/OIP-C.hMxUTa_ah0EEEKjzMrcKZgHaJF?w=204&h=318&c=7&r=0&o=7&cb=iwp1&dpr=1.1&pid=1.7&rm=3.jpg'
urllib.request.urlretrieve(url_img, 'img.jpg')# 下载视频(mp4)不再演示
2.6 带单个参数的页面抓取(get请求)
import urllib.request
import urllib.parse# url = "http://www.baidu.com/s?ie=UTF-8&wd=%E8%94%A1%E5%BE%90%E5%9D%A4"
# url = "http://www.baidu.com/s?ie=UTF-8&wd=蔡徐坤"
# 需要将中文进行编码 导入quote即可
name = urllib.parse.quote("蔡徐坤")
# print(name)# 将%E8%94%A1%E5%BE%90%E5%9D%A4 转化为 蔡徐坤
# 使用unquote即可
# rename = urllib.parse.unquote(name)
# print(rename)# 可以用户自己输入名字进行修改name
url = "http://www.baidu.com/s?ie=UTF-8&wd=" + name
response = urllib.request.urlopen(url)
content = response.read().decode()
print(content)
2.7 定制request使用ua反爬
再来了解一下ua反爬
user Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引、浏览器语言、浏览器插件等。
通俗的讲: ua能使得浏览器认为是请求不来自我们的爬虫程序,而是来自浏览器本身
import urllib.request
import urllib.parsename = urllib.parse.quote("蔡徐坤")url = "https://www.baidu.com/s?ie=UTF-8&wd=" + name
# 定制request
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=header)
response = urllib.request.urlopen(request)
content = response.read().decode()
print(content)
2.8 多字段的字符转码
# 当url为多个参数的时候进行转码
import urllib.parse
import urllib.request# http://www.baidu.com/s?wd=周杰伦&sex=男# 必须用字典才可以
data = {"wd": "周杰伦","sex": "男"
}a = urllib.parse.urlencode(data)
# print(a)
# 获取网页源码
url = "https://www.baidu.com/s?" + a
# print(url)
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=header)
response = urllib.request.urlopen(request)
content = response.read().decode()
print(content)
2.9 post请求的使用
import json
import urllib.request
import urllib.parseurl = 'https://fanyi.baidu.com/sug'# 构建post请求的数据 字典形式
data = {'kw': 'translate'
}
# post请求必须添加编码 转变为二进制的数据
data = urllib.parse.urlencode(data).encode('utf-8')
# print(data)
request = urllib.request.Request(url = url, data = data)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# 获取的数据是json格式 字符串被编码了,转化为字典字符串正常显示
obj = json.loads(content)
print(obj,type(obj))2.10 异常处理
import urllib.request
url = 'http://www.baidu.com1'
try:response = urllib.request.urlopen(url)print(response.read().decode('utf-8'))
except urllib.error.URLError:print("发送错误")
三、 requests请求的使用
上面单纯使用urllib的方式,显然麻烦了不少,并且不易于理解,那么有没有更简单更容易上手的方法呢,有的兄弟有的,可以直接使用requests的方式。
3.1 下载requests包
方式一:使用命令行安装
- 打开命令行cmd(win + R)
- 输入pip -V 查看pip是否正常安装(python正常安装的情况下,pip自动安装)
- 输入 pip install requests(默认国外地址,安装较慢,这里使用国内地址)
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
- 等待安装成功提示即可
方式二:使用pycharm直接安装
在右下脚找到python软件包,搜索requests下载安装即可(也可以使用国内地址进行安装)
Tip: 可以使用
pip uninstall 包名来卸载指定的包。
总结
通过本教程的学习,我们系统地掌握了网络爬虫的基本原理和关键技术。从HTTP请求、HTML解析,到动态页面渲染、反爬策略应对,再到数据的清洗与存储,我们一步步构建了一个完整的爬虫知识体系。
爬虫技术不仅仅是一种数据采集手段,更是连接互联网世界与数据分析的桥梁。掌握爬虫技能后,我们可以高效地获取所需数据,为商业分析、学术研究、自动化运维等场景提供强大的数据支持。
然而,爬虫开发并非没有边界。在实践过程中,我们必须遵守目标网站的robots.txt协议,尊重版权和隐私,避免对服务器造成过大压力。同时,随着反爬技术的不断升级,爬虫开发者也需要持续学习,灵活应对各种挑战。
未来,随着人工智能和大数据的发展,爬虫技术将继续演进,与自然语言处理(NLP)、机器学习(ML)等技术结合,创造更大的价值。希望读者能够在本教程的基础上,进一步探索爬虫的高级应用,如分布式爬虫、智能解析等,不断提升自己的技术能力。
数据驱动未来,爬虫赋能探索! 🚀
相关文章:
初学Python爬虫
文章目录 前言一、 爬虫的初识1.1 什么是爬虫1.2 爬虫的核心1.3 爬虫的用途1.4 爬虫分类1.5 爬虫带来的风险1.6. 反爬手段1.7 爬虫网络请求1.8 爬虫基本流程 二、urllib库初识2.1 http和https协议2.2 编码解码的使用2.3 urllib的基本使用2.4 一个类型六个方法2.5 下载网页数据2…...

【办公类-99-05】20250508 D刊物JPG合并PDF便于打印
背景需求 委员让我打印2024年2025年4月的D刊杂志,A4彩打,单面。 有很多JPG,一个个JPG图片打开,实在太麻烦了。 我需要把多个jpg图片合并成成为一个PDF,按顺序排列打印。 deepseek写Python代码 代码展示 D刊jpg图片合…...

高效C/C++之十:Coverity修复问题:尽量多使用 c++强制类型转化
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 高效C/C之十:Coverity修复问题:尽量多使用 c强制类型转化 目录 【关注我,后…...

相机的方向和位置
如何更好的控制相机按照我们需要来更好的观察我们需要的地貌呢? 使用 // setview瞬间到达指定位置,视角//生成position是天安门的位置var position Cesium.Cartesian3.fromDegrees(116.397428,39.90923,100)viewer.camera.setView({//指定相机位置destination: position, 在…...
suna界面实现原理分析(二):浏览器工具调用可视化
这是一个基于React的浏览器操作可视化调试组件,主要用于在AI开发工具中展示网页自动化操作过程(如导航、点击、表单填写等)的执行状态和结果。以下是关键技术组件和功能亮点的解析: 一、核心功能模块 浏览器操作状态可视化 • 实时…...
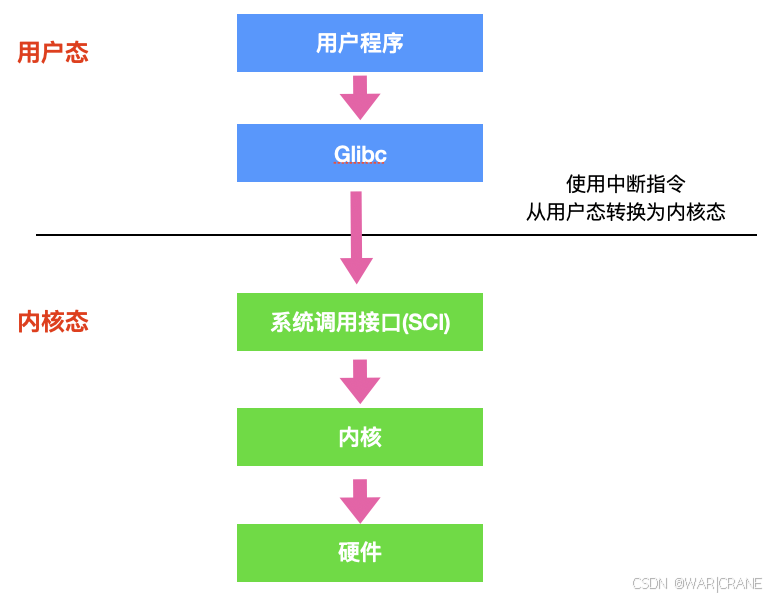
操作系统面试问题(4)
32.什么是操作系统 操作系统是一种管理硬件和软件的应用程序。也是运行在计算机中最重要的软件。它为硬件和软件提供了一种中间层,让我们无需关注硬件的实现,把心思花在软件应用上。 通常情况下,计算机上会运行着许多应用程序,它…...

websocketd 10秒教程
websocketd 参考地址:joewalnes/websocketd 官网地址:websocketd websocketd简述 websocketd是一个简单的websocket服务Server,运行在命令行方式下,可以通过websocketd和已经有程序进行交互。 现在,可以非常容易地构…...
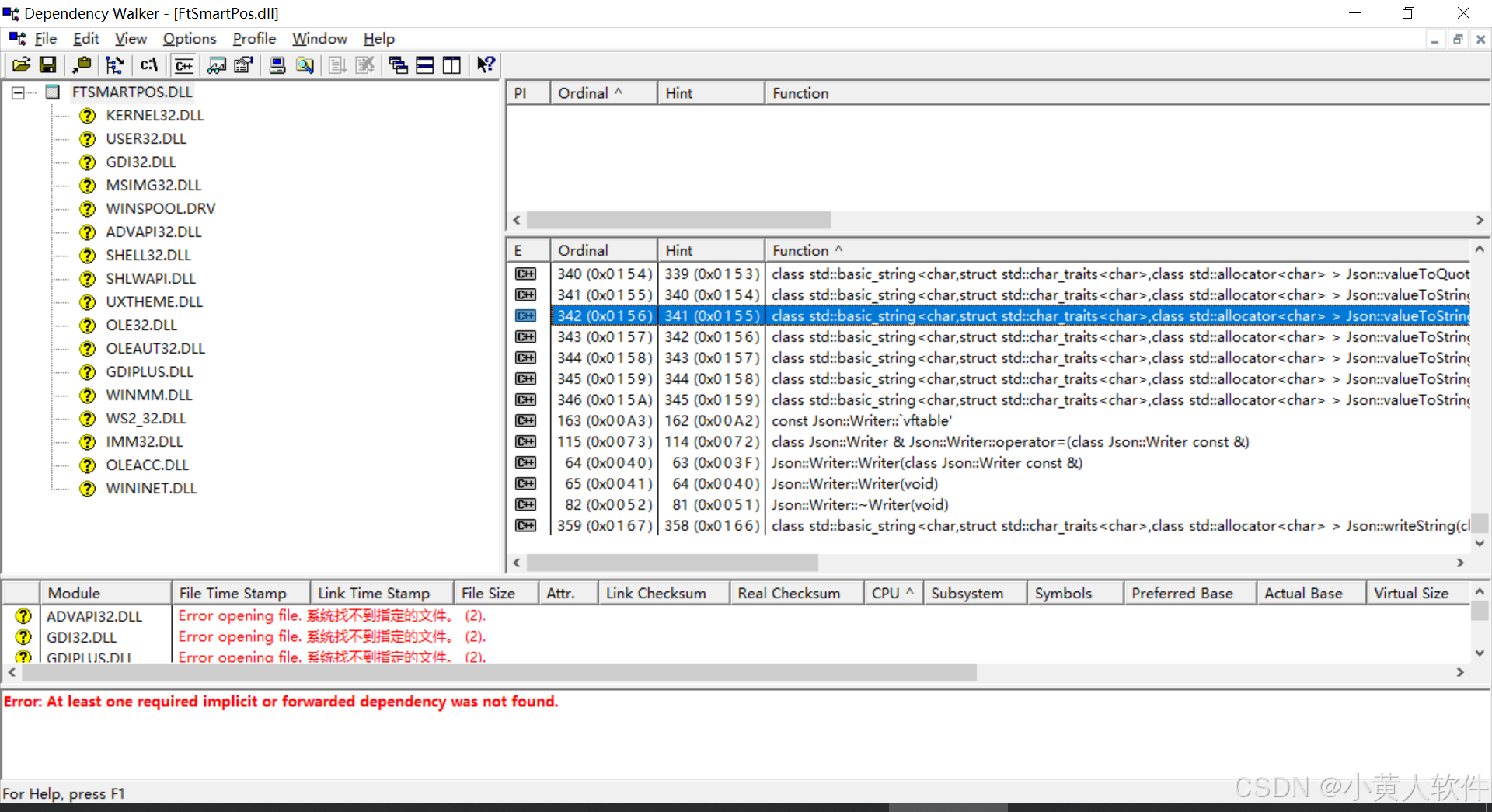
C++ Dll创建与调用 查看dll函数 MFC 单对话框应用程序(EXE 工程)改为 DLL 工程
C Dll创建 一、添加 DllMain(必要) #include <fstream>void Log(const char* msg) {std::ofstream f("C:\\temp\\dll_log.txt", std::ios::app);f << msg << std::endl; }BOOL APIENTRY DllMain(HMODULE hModule, DWORD u…...
【prometheus+Grafana篇】基于Prometheus+Grafana实现Linux操作系统的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...

小刚说C语言刷题—1004阶乘问题
1.题目描述 编程求 123⋯n 。 输入 输入一行,只有一个整数 n(1≤n≤10); 输出 输出只有一行(这意味着末尾有一个回车符号),包括 1 个整数。 样例 输入 5 输出 120 2.参考代码(C语言版) #include <stdio…...
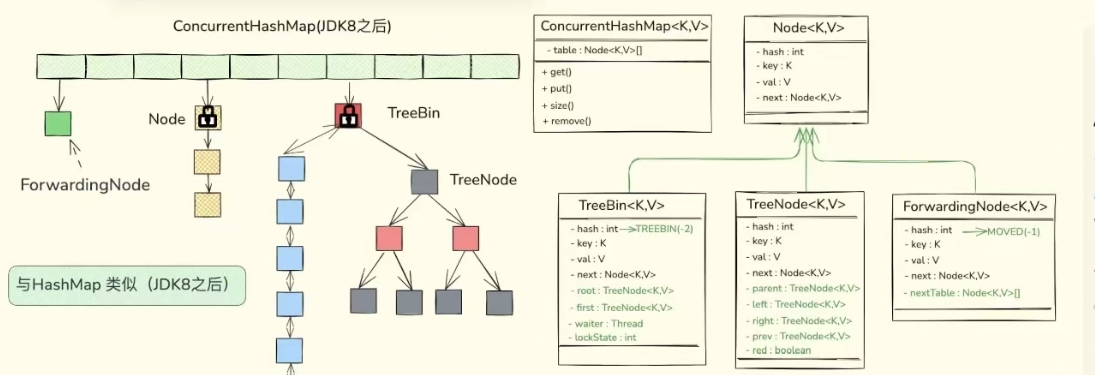
CurrentHashMap的整体系统介绍及Java内存模型(JVM)介绍
当我们提到ConurrentHashMap时,先想到的就是HashMap不是线程安全的: 在多个线程共同操作HashMap时,会出现一个数据不一致的问题。 ConcurrentHashMap是HashMap的线程安全版本。 它通过在相应的方法上加锁,来保证多线程情况下的…...
spring ai alibaba 使用 SystemPromptTemplate 很方便的集成 系统提示词
系统提示词可以是.st 文件了,便于修改和维护 1提示词内容: 你是一个有用的AI助手。 你是一个帮助人们查找信息的人工智能助手。 您的名字是{name} 你应该用你的名字和{voice}的风格回复用户的请求。 每一次回答的时候都要增加一个65字以内的标题形如:【…...

@PostConstruct @PreDestroy
PostConstruct 是 Java EE(现 Jakarta EE)中的一个注解,用于标记一个方法在对象初始化完成后立即执行。它在 Spring 框架、Java Web 应用等场景中广泛使用,主要用于资源初始化、依赖注入完成后的配置等操作。 1. 基本作用 执行时…...
网络的搭建
1、rpm rpm -ivh 2、yum仓库(rpm包):网络源 ----》网站 本地源 ----》/dev/sr0 光盘映像文件 3、源码安装 源码安装(编译) 1、获取源码 2、检测环境生成Ma…...
C++学习之类和对象_1
1. 面向过程与面向对象 C语言是面向过程的,注重过程,通过调用函数解决问题。 比如做番茄炒蛋:买番茄和鸡蛋->洗番茄和打鸡蛋->先炒蛋->把蛋放碟子上->炒番茄->再把蛋倒回锅里->加调料->出锅 而C是面向对象的ÿ…...
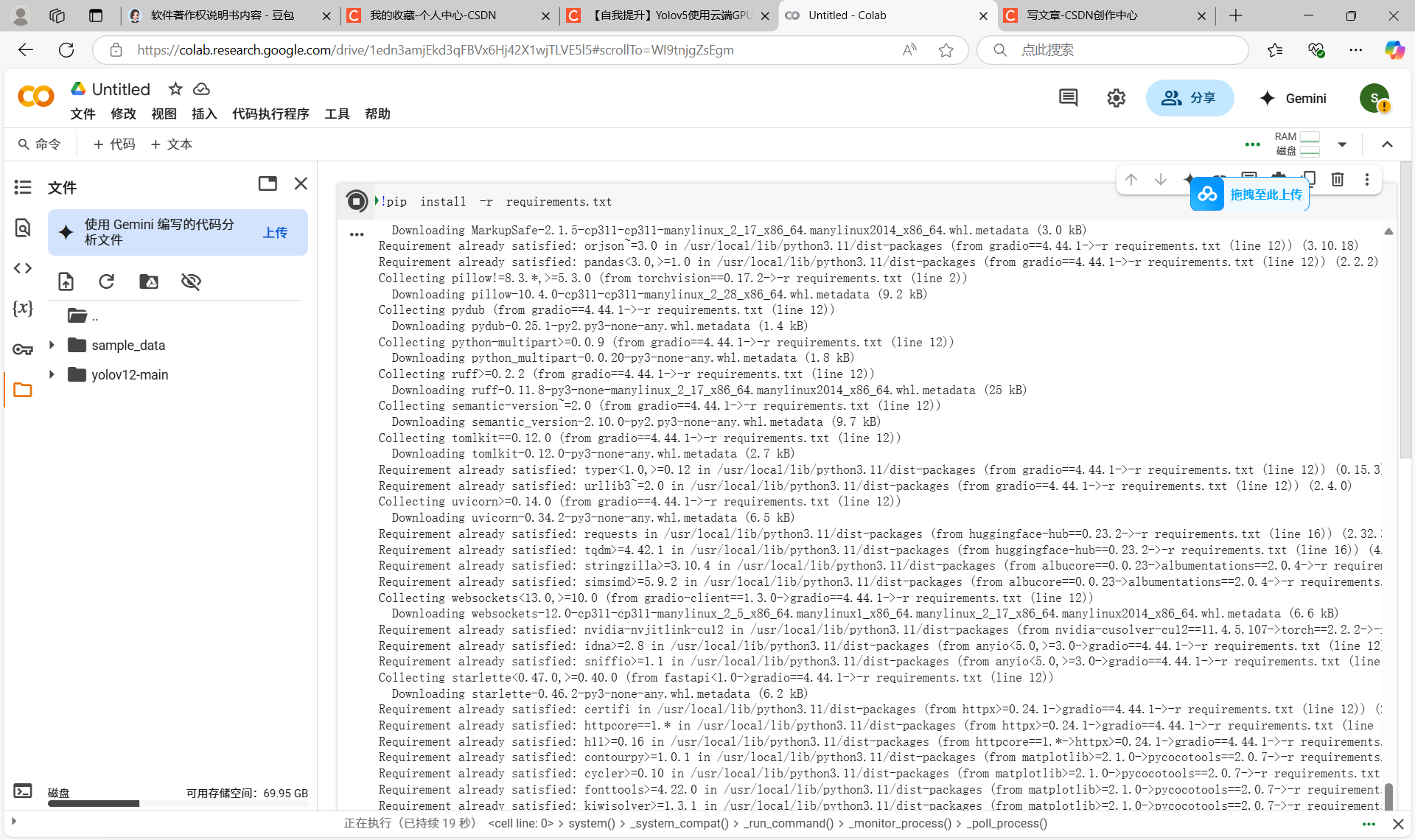
YOLOv12云端GPU谷歌免费版训练模型
1.效果 2.打开 https://colab.research.google.com/?utm_sourcescs-index 3.上传代码 4.解压 !unzip /content/yolov12-main.zip -d /content/yolov12-main 5.进入yolov12-main目录 %cd /content/yolov12-main/yolov12-main 6.安装依赖库 !pip install -r requirements.…...

OpenCV进阶操作:图像直方图、直方图均衡化
文章目录 一、图像直方图二、图像直方图的作用三、使用matplotlib方法绘制直方图2.使用opencv的方法绘制直方图(划分16个小的子亮度区间)3、绘制彩色图像的直方图 四、直方图均衡化1、绘制原图的直方图2、绘制经过直方图均衡化后的图片的直方图3、自适应…...

基环树(模板) 2876. 有向图访问计数
对于基环树,我们可以通过拓扑排序去掉所有的树枝,只剩下环,题目中可能会有多个基环树 思路:我们先利用拓扑排序将树枝去掉,然后求出每个基环树,之后反向dfs求得所有树枝的长度即可 class Solution { publi…...

【物联网】基于树莓派的物联网开发【1】——初识树莓派
使用背景 物联网开发从0到1研究,以树莓派为基础 场景介绍 系统学习Linux、Python、WEB全栈、各种传感器和硬件 接下来程序猫将带领大家进军物联网世界,从0开始入门研究树莓派。 认识树莓派 正面图示: 1:树莓派简介 树莓派…...

Qt读写XML文档
XML 结构与概念简介 XML(可扩展标记语言) 是一种用于存储和传输结构化数据的标记语言。其核心特性包括: 1、树状结构:XML 数据以层次化的树形结构组织,包含一个根元素(Root Element)ÿ…...

学习Python的第一天之网络爬虫
30岁程序员学习Python的第一天:网络爬虫 Requests库 1、requests库安装 windows系统通过管理员打开cmd,运行pip install requests!测试案例: 2、Requests库的两个重要对象 Response对象Resoponse对象包含服务器返回的所有信息ÿ…...

前端展示后端返回的图片流
一、请求 重点:添加responseType: “blob”, // Vue2组件中请求示例 methods: {fetchImage() {return axios.get(/api/getImage, {params: { id: 123 },responseType: blob // 关键配置(重点,必须配置)});} }或 export function…...
 微服务开发与治理实战)
65.微服务保姆教程 (八) 微服务开发与治理实战
微服务开发与治理实战:搭建一个简单的微服务系统 在这个实战中,我们将使用以下技术栈来搭建一个简单的微服务系统: 注册中心和配置中心:使用 Nacos。服务开发框架:使用 Spring Boot。服务间通信:使用 Feign。API 网关:使用 Spring Cloud Gateway。依赖管理工具:使用 M…...

AI服务器通常会运用在哪些场景当中?
人工智能行业作为现代科技的杰出代表,在多个领域当中发展其强大的应用能力和价值,随之,AI服务器也在各个行业中日益显现出来,为各个行业提供了强大的计算能力和处理能力,帮助企业处理复杂的大规模数据,本文…...
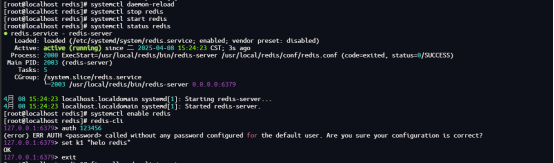
linux下的Redis的编译安装与配置
配合做开发经常会用到redis,整理下编译安装配置过程,仅供参考! --------------------------------------Redis的安装与配置-------------------------------------- 下载 wget https://download.redis.io/releases/redis-6.2.6.tar.gz tar…...

【官方题解】StarryCoding 入门教育赛 2 | acm | 蓝桥杯 | 新手入门
比赛传送门: 本场比赛开始时题面存在一些问题,私密马赛! A.池化【入门教育赛】 根据题目所给公式计算即可。 #include "bits/stdc.h"signed main() {int t; std::cin >> t;while (t --) {int l, k, s, p; std::cin >&…...
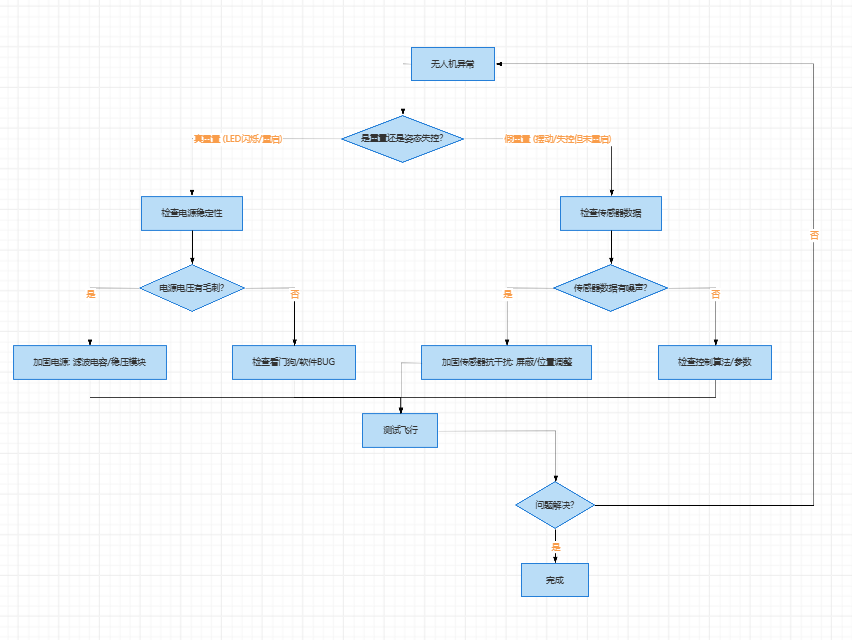
无人机相关技术与故障排除笔记
无人机相关技术与故障排除笔记 本文档整理了关于无人机电调、电机、通信协议、传感器以及硬件故障排除相关的笔记和解释。 1. 电调 (ESC) PWM 输出初始化设置 初始化电调(电子调速器)的 PWM 输出功能时,设置 频率 400Hz、分辨率 10000、初…...
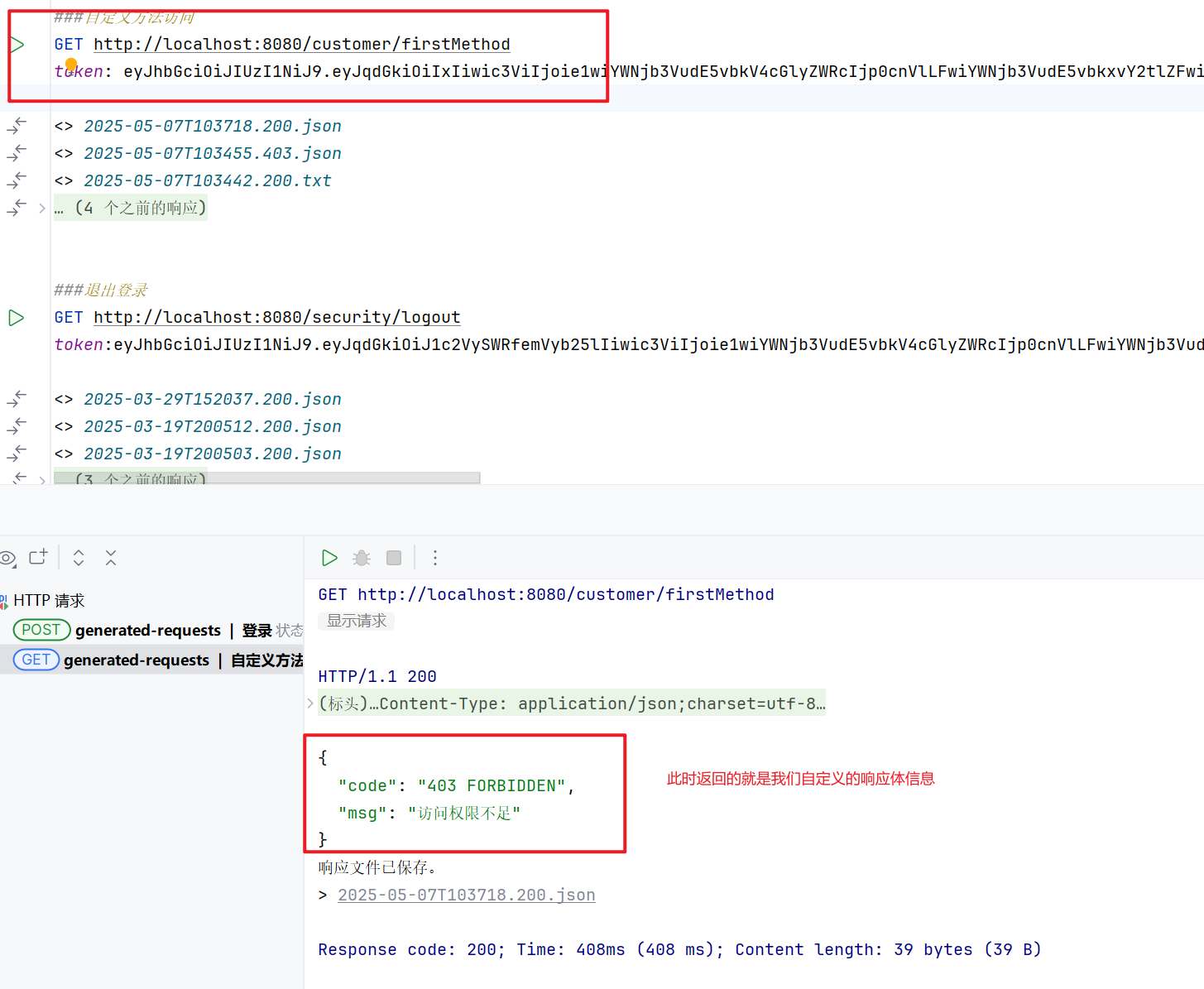
SpringSecurity(自定义异常处理)
文末有本篇文章的项目源码可供下载学习。 在实际的项目开发过程中,我们对于认证失败或者授权失败需要像接口一样返回相同结构的json数据,这样可以让前端对响应进行统一的处理。要实现这个功能我们需要知道SpringSecurity的异常处理机制。 在SpringSecu…...
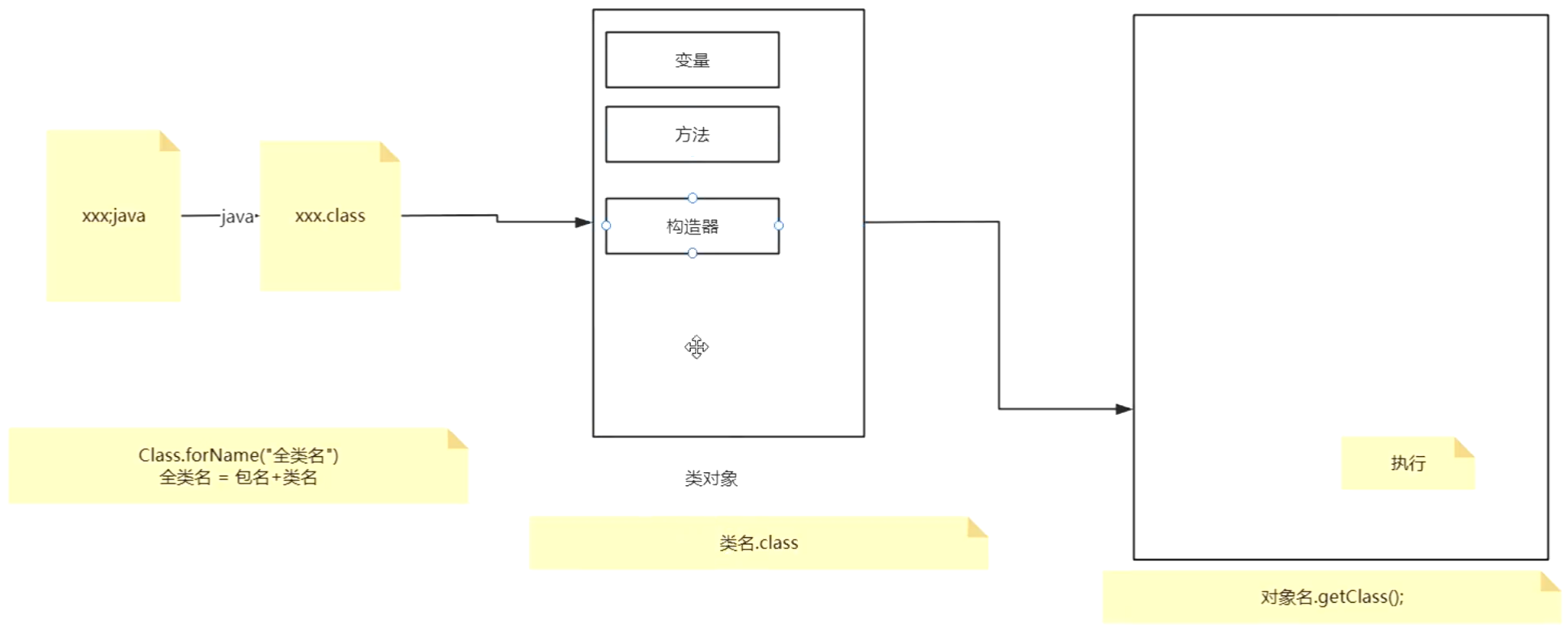
Java——反射
目录 5 反射 5 反射 类信息:方法、变量、构造器、继承和实现的类或接口。反射:反射是 Java 中一项强大的特性,它赋予了程序在运行时动态获取类的信息,并能够调用类的方法、访问类的字段以及操作构造函数等的能力。通过反射&#…...
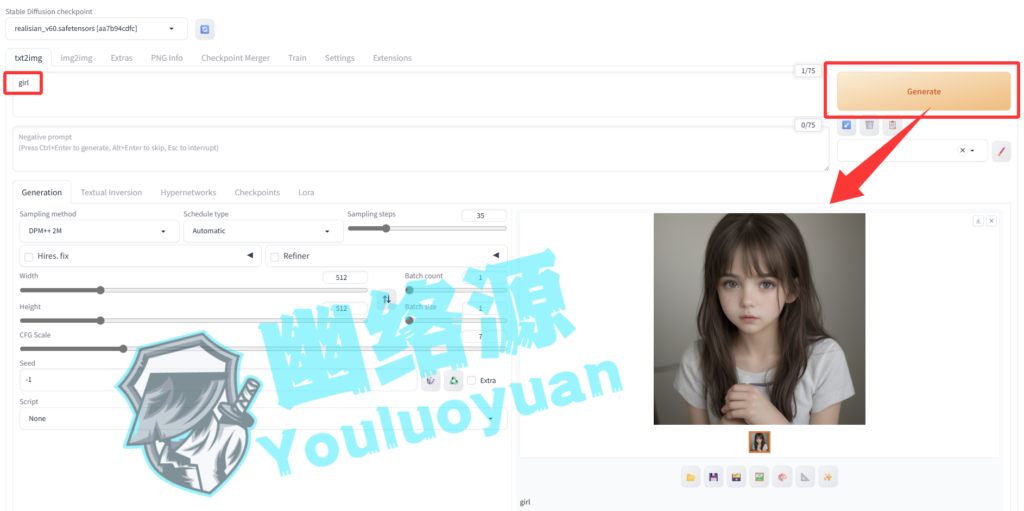
本地玩AI绘画 | StableDiffusion安装到绘画
环境须知 Cuda必须安装 不需要安装Python,因为该项目会自动安装Python3.10的虚拟环境 1.下载StableDiffusionWebUI压缩包并解压 下载方式一: 从Github下载https://github.com/AUTOMATIC1111/stable-diffusion-webui 的压缩包,解压后名为…...