从零开始:用PyTorch构建CIFAR-10图像分类模型达到接近1的准确率
为了增强代码可读性,代码均使用Chatgpt给每一行代码都加入了注释,方便大家在本文代码的基础上进行改进优化。
本文是搭建了一个稍微优化了一下的模型,训练200个epoch,准确率达到了99.74%,简单完成了一下CIFAR-10数据集的实验,再调调参可能就到100%了吧,算是一个入门学习吧 ~
完整代码链接: MachineLearningCourseWork
数据: data5 - CIFAR10
完整代码ipynb格式文件: work5-CIFAR10.ipynb
【本文参考资料】
- CIFAR-10 官方网站:由数据集创建者 Alex Krizhevsky 维护,提供了数据集的下载链接、格式说明等详细信息。
- Deep Learning with Python:由 Francois Chollet 撰写的深度学习书籍,其中使用 CIFAR-10 数据集作为案例讲解图像分类模型的构建和训练方法。
- CS231n: Convolutional Neural Networks for Visual Recognition:斯坦福大学的CV课。
文章目录
- 1. 数据集介绍
- 1.1 数据集概述
- 1.2 数据集结构
- 1.3 数据集格式
- 1.4 数据集应用场景
- 1.5 数据集特点
- 2. 实验流程
- 2.1 导包
- 2.2 数据获取与加载
- 2.3 定义网络
- 2.4 增强的数据预处理
- 2.5 模型训练
- 2.6 测试准确率
- 2.7 收集所有样本的预测概率
- 2.8 评价一下
- 2.8.1 混淆矩阵
- 2.8.2 精确 - 召回
- 2.8.3 ROC曲线
1. 数据集介绍
1.1 数据集概述
数据集名称:CIFAR-10
官方链接:https://www.cs.toronto.edu/~kriz/cifar.html
数据集简介:
CIFAR-10 数据集是一个广泛用于图像分类任务的基准数据集,由 Alex Krizhevsky 在 2009 年创建,是计算机视觉领域最常用的数据集之一。它包含 60000 张 32x32 彩色图像,分为 10 个不同的类别,每个类别有 6000 张图片,其中 50000 张用于训练模型,10000 张用于测试模型性能。
1.2 数据集结构
- 训练集:包含 5 个批次,每个批次有 10000 张图像。虽然训练批次内图像顺序是随机的,但各批次间图像分布可能存在不均衡,即某些批次可能包含某一类别更多的图片,但总体来说所有训练批次合起来每个类别有 5000 张图片。
- 测试集:包含 1 个批次,有 10000 张图像,每个类别在测试集中正好有 1000 张随机选择的图片。
数据集示例:
CIFAR-10 的图像涵盖了多种常见的物体类别,具体类别包括: - plane(飞机):例如各种型号的飞机在不同场景下的图片,如在天空飞行、停在机场等。
- car(汽车):涵盖不同品牌、款式和颜色的汽车,可能在道路上行驶或停在停车场。
- bird(鸟):包含多种鸟类的图片,如麻雀、鸽子等,可能处在飞翔或栖息状态。
- cat(猫):有不同品种、毛色和姿态的猫的图像,比如家猫、波斯猫等。
- deer(鹿):展示在野外环境中的鹿,如梅花鹿等。
- dog(狗):包含各种品种的狗,如金毛犬、哈士奇等在不同场景下的图片。
- frog(蛙类):有不同种类青蛙的图片,可能在水中、岸边等环境。
- horse(马):展示不同品种马的图片,如在草原上奔跑或被饲养的场景。
- ship(船):包含各种船只,如货船、游轮等在水中的图片。
- truck(卡车):有不同类型的卡车,如货运卡车、油罐车等的图片。
1.3 数据集格式
- 图像像素:每个图像都是 32x32 像素的彩色图像,具有 RGB 三个通道(数据集中本身是 BGR 通道,但在使用时通常会转换为 RGB 通道)。
- 存储格式:数据以 Python 拾取(pickle)文件的形式存储,包含字典对象,其中包含图像数据和标签等信息。在使用时,通常需要通过 Python 的 pickle 库加载数据,并将其转换为 NumPy 数组等常用数据格式以便进行处理和训练模型。
1.4 数据集应用场景
- 图像分类:CIFAR-10 最常见的应用场景是作为图像分类任务的数据集,用于训练和测试各种卷积神经网络(CNN)模型,如 LeNet、AlexNet、ResNet 等,评估模型对不同类别图像的识别准确率。
- 模型评估与比较:作为标准数据集,方便研究者和开发者对比不同模型的性能,推动图像识别技术的发展。
- 迁移学习:可以作为预训练模型的基础数据集,通过在 CIFAR-10 上训练得到的模型参数,迁移到其他类似的图像分类任务中,减少新任务的数据量需求和计算资源消耗。
- 深度学习研究:为深度学习算法的研究提供实验平台,例如研究新的网络架构、优化算法、正则化方法等在 CIFAR-10 数据集上的效果。
1.5 数据集特点
优势:
- 典型性和代表性:涵盖了多种常见的物体类别,能够反映日常生活中的一些基本图像分类场景,适用于研究和测试基础的图像识别模型。
- 规模适中:60000 张图像的数量对于现代计算资源来说既足够大以提供有代表性的数据集,又不至于过于庞大而难以处理,适合在个人计算机或小型服务器上进行实验和研究。
- 数据多样性:虽然图像尺寸较小,但包含不同类别、颜色、姿态和背景的图片,具有一定的数据多样性,有助于模型学习到更通用的特征。
局限性:
- 图像尺寸较小:32x32 像素的图像尺寸可能限制了模型对图像细节的捕捉能力,对于一些需要精细识别的任务来说,可能不够精确,例如对于图像中一些微小特征或复杂纹理的识别。
- 类别相对简单:相较于一些更复杂的图像数据集(如 ImageNet),CIFAR-10 的类别较为基础,可能无法充分测试模型在面对高度复杂、多样化的图像内容时的性能。
- 背景简单:图像中的物体通常具有相对简单的背景,这可能使模型在处理更复杂背景或具有遮挡的图像时表现不佳。
2. 实验流程
2.1 导包
import torch # 导入 PyTorch 框架,用于构建和训练深度学习模型
import torch.nn as nn # 导入 PyTorch 的神经网络模块,用于定义神经网络结构
import torch.optim as optim # 导入 PyTorch 的优化器模块,用于定义优化算法(如 SGD、Adam 等)
import torchvision # 导入 torchvision 库,提供图像处理和预训练模型等功能
import torchvision.transforms as transforms # 导入 torchvision 的数据预处理模块,用于对图像数据进行变换(如归一化、裁剪等)
from torch.utils.data import DataLoader # 导入 PyTorch 的数据加载器模块,用于批量加载和管理数据集
from datetime import datetime
import time
# 画图相关
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np # 数据计算
from torch.nn.functional import softmax #softmax函数
2.2 数据获取与加载
# 定义一个数据预处理的组合操作
transform = transforms.Compose([transforms.ToTensor(), # 将图像数据从 PIL 图像格式转换为 PyTorch 张量(Tensor),并将其值归一化到 [0, 1] 范围transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像的每个通道进行标准化处理,均值为 0.5,标准差为 0.5
])# 加载 CIFAR-10 训练数据集
trainset = torchvision.datasets.CIFAR10(root='./data4', # 数据集存储的根目录路径train=True, # 指定加载训练集download=False, # 不从网络下载数据集(假设数据已经下载到本地)transform=transform # 应用上面定义的预处理操作
)# 加载 CIFAR-10 测试数据集
testset = torchvision.datasets.CIFAR10(root='./data4', # 数据集存储的根目录路径train=False, # 指定加载测试集download=False, # 不从网络下载数据集(假设数据已经下载到本地)transform=transform # 应用上面定义的预处理操作
)
# 定义每个批次的大小
batch_size = 64 # 每个批次包含 64 张图像# 创建训练数据的 DataLoader
trainloader = DataLoader(trainset, # 指定加载的训练数据集batch_size=batch_size, # 每个批次的大小shuffle=True, # 在每个 epoch 开始时随机打乱数据顺序num_workers=2 # 使用 2 个子进程加载数据,加速数据读取
)# 创建测试数据的 DataLoader
testloader = DataLoader(testset, # 指定加载的测试数据集batch_size=batch_size, # 每个批次的大小shuffle=False, # 测试时不需要打乱数据顺序num_workers=2 # 使用 2 个子进程加载数据,加速数据读取
)
2.3 定义网络
这里我定义的是一个比较简单的卷积神经网络模型,包含特征提取层和分类器层,但是整体的效果也还行了,可以改成ResNet18或ResNet34
# 定义一个简单的卷积神经网络模型
class TestNet(nn.Module):def __init__(self, dropout_rate=0.5):super(TestNet, self).__init__() # 调用父类的初始化方法# 特征提取部分self.features = nn.Sequential( # 定义特征提取层的序列nn.Conv2d(3, 64, kernel_size=3, padding=1), # 第一层卷积,输入通道数为3,输出通道数为64,卷积核大小为3x3,边缘填充为1nn.BatchNorm2d(64), # 对64个通道进行批量归一化nn.ReLU(inplace=True), # ReLU激活函数,inplace=True表示直接在原变量上操作,节省内存nn.Conv2d(64, 64, kernel_size=3, padding=1), # 第二层卷积,输入输出通道数均为64nn.BatchNorm2d(64), # 批量归一化nn.ReLU(inplace=True), # ReLU激活nn.MaxPool2d(2, 2), # 最大池化,池化窗口大小为2x2,步长为2nn.Dropout2d(p=dropout_rate/2), # 二维Dropout,随机丢弃一半的特征图,防止过拟合nn.Conv2d(64, 128, kernel_size=3, padding=1), # 第三层卷积,输入通道数为64,输出通道数为128nn.BatchNorm2d(128), # 批量归一化nn.ReLU(inplace=True), # ReLU激活nn.Conv2d(128, 128, kernel_size=3, padding=1), # 第四层卷积,输入输出通道数均为128nn.BatchNorm2d(128), # 批量归一化nn.ReLU(inplace=True), # ReLU激活nn.MaxPool2d(2, 2), # 最大池化nn.Dropout2d(p=dropout_rate), # Dropoutnn.Conv2d(128, 256, kernel_size=3, padding=1), # 第五层卷积,输入通道数为128,输出通道数为256nn.BatchNorm2d(256), # 批量归一化nn.ReLU(inplace=True), # ReLU激活nn.Conv2d(256, 256, kernel_size=3, padding=1), # 第六层卷积,输入输出通道数均为256nn.BatchNorm2d(256), # 批量归一化nn.ReLU(inplace=True), # ReLU激活nn.MaxPool2d(2, 2), # 最大池化)# 分类器部分self.classifier = nn.Sequential( # 定义分类器层的序列nn.Linear(256 * 4 * 4, 512), # 全连接层,输入特征数为256*4*4,输出特征数为512nn.BatchNorm1d(512), # 一维批量归一化nn.ReLU(inplace=True), # ReLU激活nn.Dropout(p=dropout_rate), # Dropoutnn.Linear(512, 256), # 全连接层,输入特征数为512,输出特征数为256nn.BatchNorm1d(256), # 批量归一化nn.ReLU(inplace=True), # ReLU激活nn.Dropout(p=dropout_rate/2), # Dropoutnn.Linear(256, 10) # 最后一层全连接层,输出10个类别)def forward(self, x):x = self.features(x) # 将输入数据通过特征提取层x = torch.flatten(x, 1) # 将特征图展平为一维向量,从第1维开始展平x = self.classifier(x) # 将展平后的特征通过分类器层return x # 返回最终的输出
2.4 增强的数据预处理
# 定义训练集的数据预处理操作
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), # 随机裁剪,裁剪大小为32x32,边缘填充为4transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # 随机调整亮度、对比度和饱和度transforms.ToTensor(), # 将图像转换为张量transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # 标准化,均值和标准差分别为CIFAR-10数据集的均值和标准差
])# 定义测试集的数据预处理操作
transform_test = transforms.Compose([transforms.ToTensor(), # 将图像转换为张量transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # 标准化
])
net = TestNet() # 初始化
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # GPU
net.to(device)
2.5 模型训练
# 开始训练模型
start_time = time.time() # 记录训练开始时间
for epoch in range(10): # 训练 10 个 epochrunning_loss = 0.0 # 初始化每轮的累计损失for i, data in enumerate(trainloader, 0): # 遍历训练数据加载器inputs, labels = data[0].to(device), data[1].to(device) # 将输入数据和标签移动到指定设备(如 GPU)optimizer.zero_grad() # 清零梯度,避免梯度累积outputs = net(inputs) # 前向传播,计算模型输出loss = criterion(outputs, labels) # 计算损失值loss.backward() # 反向传播,计算梯度optimizer.step() # 更新模型参数running_loss += loss.item() # 累加损失值# 每 100 批次打印一次详细信息if i % 100 == 99: avg_loss = running_loss / 100 # 计算平均损失print(f'[Epoch {epoch + 1}/{10}, Batch {i + 1}/{len(trainloader)}] 'f'Average Loss: {avg_loss:.4f} | 'f'Current Batch Loss: {loss.item():.4f} | 'f'Running Loss: {running_loss:.4f}')running_loss = 0.0 # 重置累计损失scheduler.step() # 更新学习率end_time = time.time() # 记录训练结束时间
elapsed_time = end_time - start_time # 计算总耗时
print(f'Finished Training. Total time taken: {elapsed_time:.2f} seconds')# 保存模型
timestamp = datetime.now().strftime("%y-%m-%d-%H-%M-%S") # 获取当前时间戳
model_name = f"CIFAR10Net-{timestamp}.pth"
torch.save(net.state_dict(), model_name)
print(f"Model saved successfully as {model_name}")
2.6 测试准确率
# 初始化正确预测的数量和测试数据的总数
correct_predictions = 0
total_samples = 0# 禁用梯度计算,节省内存和计算资源
with torch.no_grad():for data in testloader: # 遍历测试数据加载器images, labels = data[0].to(device), data[1].to(device) # 将图像和标签移动到指定设备outputs = net(images) # 前向传播,获取模型的输出_, predicted_labels = torch.max(outputs.data, 1) # 获取预测的类别(概率最高的类别)total_samples += labels.size(0) # 累加测试数据的总数correct_predictions += (predicted_labels == labels).sum().item() # 累加正确预测的数量# 计算准确率
accuracy = 100 * correct_predictions / total_samples
print(f'Accuracy: {accuracy:.2f}%') # 打印准确率
2.7 收集所有样本的预测概率
import numpy as np
from torch.nn.functional import softmax# 初始化两个列表,用于保存所有样本的预测概率和真实标签
all_preds = [] # 保存所有样本的预测概率
all_labels = [] # 保存所有真实标签# 使用torch.no_grad()上下文管理器,这可以暂时禁用计算图中的梯度计算,节省内存和计算资源
with torch.no_grad():for data in testloader: # 遍历测试数据加载器testloaderimages, labels = data[0].to(device), data[1].to(device) # 将图像和标签数据移动到指定的设备(如GPU)outputs = net(images) # 通过神经网络模型net获取预测输出probabilities = softmax(outputs, dim=1) # 将输出转换为概率分布,dim=1表示在类别维度上进行softmax操作all_preds.append(probabilities.cpu().numpy()) # 将概率分布转移到CPU并转换为numpy数组,然后添加到all_preds列表中all_labels.append(labels.cpu().numpy()) # 将标签数据转移到CPU并转换为numpy数组,然后添加到all_labels列表中# 合并所有批次的结果,使用numpy的concatenate函数沿着第一个轴(axis=0)合并数组
all_preds = np.concatenate(all_preds, axis=0) # 形状 [N, 10],其中N是样本总数,10是类别数
all_labels = np.concatenate(all_labels, axis=0) # 形状 [N, ],其中N是样本总数
2.8 评价一下
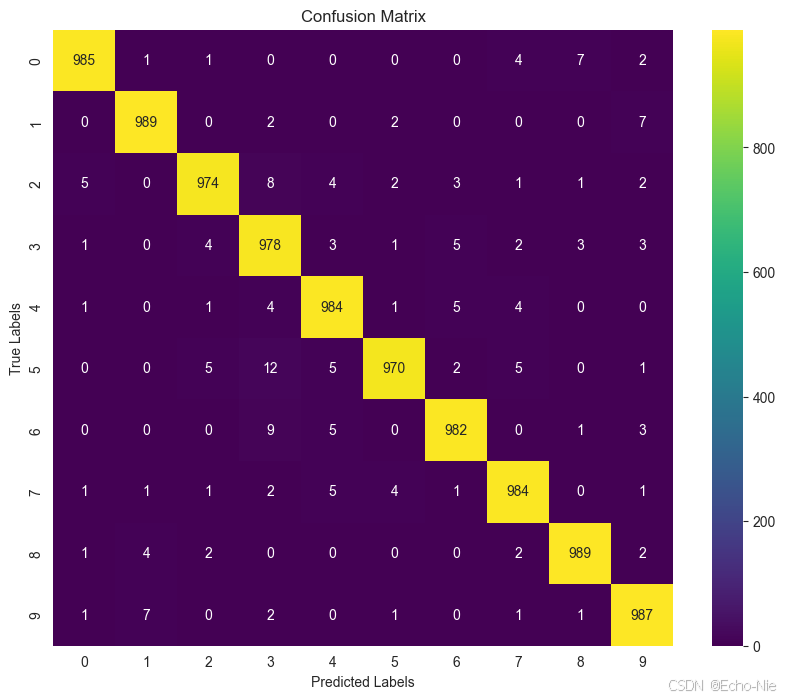
2.8.1 混淆矩阵
from sklearn.metrics import confusion_matrix # 导入混淆矩阵计算函数
import seaborn as sns # 导入seaborn库,用于绘制热图
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘图# 初始化两个列表,用于存储模型预测的标签和真实标签
all_preds, all_labels = [], []# 使用torch.no_grad()来禁用梯度计算,因为在测试阶段不需要计算梯度
with torch.no_grad():# 遍历测试数据加载器for data in testloader:# 将图像数据和标签数据移动到设备上(如GPU)images, labels = data[0].to(device), data[1].to(device)# 将图像数据输入模型进行预测outputs = net(images)# 获取模型输出中概率最大的索引,即预测的类别_, predicted = torch.max(outputs, 1)# 将预测的类别和真实类别添加到列表中all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_preds)# 设置图形的大小
plt.figure(figsize=(10, 8))
# 使用seaborn库绘制热图,显示混淆矩阵
# annot=True表示在每个单元格中显示数值,fmt='d'表示数值格式为整数
# cmap='viridis'指定使用viridis配色方案
sns.heatmap(cm, annot=True, fmt='d', cmap='viridis')
plt.title('Confusion Matrix')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.show()
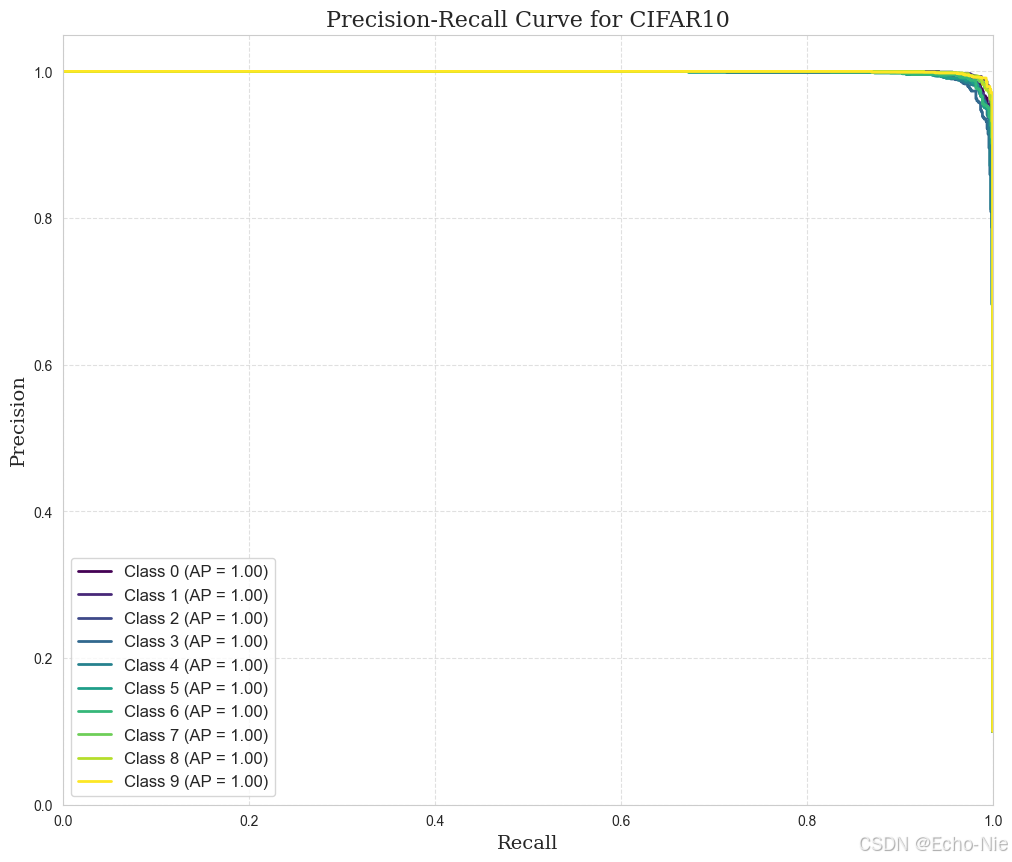
2.8.2 精确 - 召回
from sklearn.metrics import precision_recall_curve, auc
import matplotlib.pyplot as plt
import numpy as npn_classes = 10 # CIFAR10数据集有10个类别# 初始化字典来存储每个类别的精确度、召回率和平均精确度
precision = dict()
recall = dict()
average_precision = dict()# 遍历所有类别
for i in range(n_classes):# 提取第i类的概率作为预测分数,并生成对应的二分类标签precision[i], recall[i], _ = precision_recall_curve((all_labels == i).astype(int), all_preds[:, i])average_precision[i] = auc(recall[i], precision[i])plt.figure(figsize=(12, 10), dpi=100)
colors = plt.cm.viridis(np.linspace(0, 1, n_classes))for i in range(n_classes):plt.plot(recall[i], precision[i], color=colors[i], lw=2, label=f'Class {i} (AP = {average_precision[i]:.2f})')
plt.xlabel('Recall', fontsize=14, fontfamily='serif')
plt.ylabel('Precision', fontsize=14, fontfamily='serif')
plt.title('Precision-Recall Curve for CIFAR10', fontsize=16, fontfamily='serif')
plt.legend(loc='best', fontsize=12, frameon=True)
plt.grid(True, linestyle='--', alpha=0.6)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.savefig('precision_recall_curve.png', bbox_inches='tight')
plt.show()
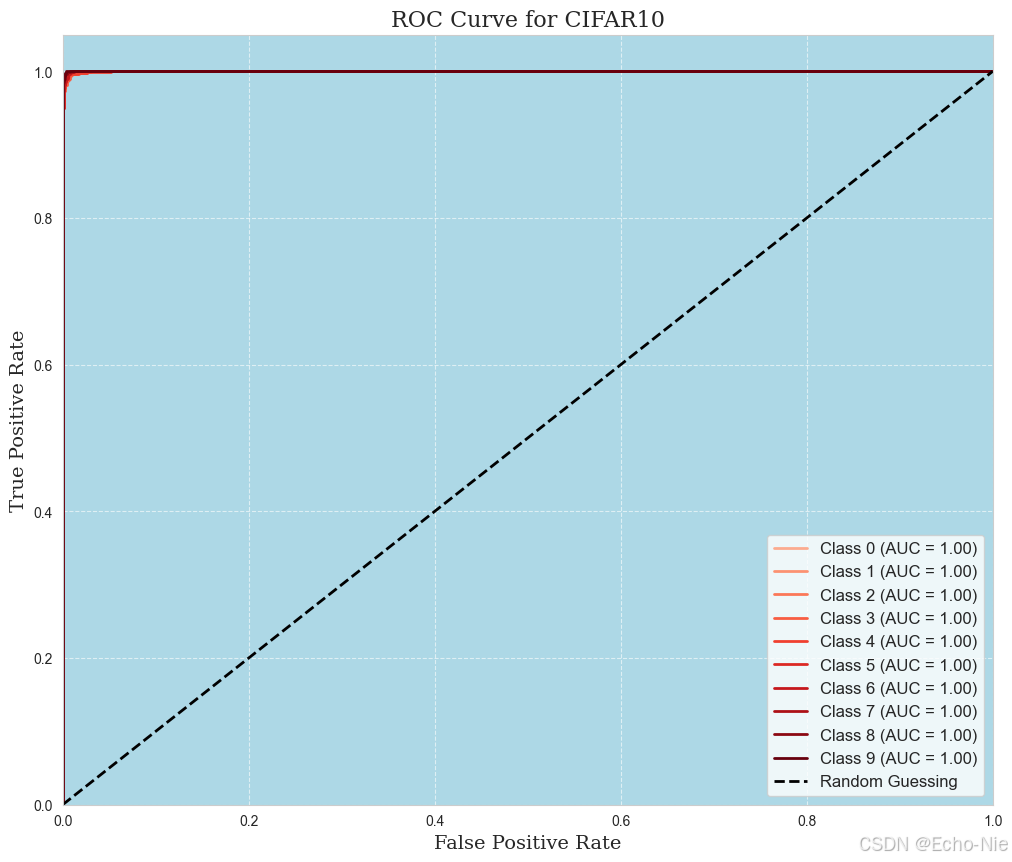
2.8.3 ROC曲线
from sklearn.preprocessing import label_binarize
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
import numpy as np# ROC曲线
all_labels_binarized = label_binarize(all_labels, classes=np.arange(n_classes))
all_preds_binarized = all_preds
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):fpr[i], tpr[i], _ = roc_curve(all_labels_binarized[:, i], all_preds_binarized[:, i])roc_auc[i] = auc(fpr[i], tpr[i])plt.figure(figsize=(12, 10), dpi=100)plt.gca().set_facecolor('#ADD8E6')
colors = plt.cm.Reds(np.linspace(0.3, 1, n_classes))for i in range(n_classes):plt.plot(fpr[i], tpr[i], color=colors[i], lw=2, label=f'Class {i} (AUC = {roc_auc[i]:.2f})')plt.plot([0, 1], [0, 1], 'k--', lw=2, label='Random Guessing')plt.xlabel('False Positive Rate', fontsize=14, fontfamily='serif')
plt.ylabel('True Positive Rate', fontsize=14, fontfamily='serif')plt.title('ROC Curve for CIFAR10', fontsize=16, fontfamily='serif')plt.legend(loc='best', fontsize=12, frameon=True)plt.grid(True, linestyle='--', alpha=0.6, color='white')plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])plt.savefig('roc_curve_red.png', bbox_inches='tight')plt.show()

相关文章:
从零开始:用PyTorch构建CIFAR-10图像分类模型达到接近1的准确率
为了增强代码可读性,代码均使用Chatgpt给每一行代码都加入了注释,方便大家在本文代码的基础上进行改进优化。 本文是搭建了一个稍微优化了一下的模型,训练200个epoch,准确率达到了99.74%,简单完成了一下CIFAR-10数据集…...

uni-app使用web-view组件APP实现返回上一页
一、功能概述 本案例实现了在Uniapp中内嵌H5网页并深度控制的三项核心功能: 隐藏指定特征的内链元素自定义导航栏返回逻辑Webview原生特性保留 二、代码解析 2.1 基础结构 <template><view><web-view :webview-styles"webviewStyles"…...

Apache Velocity代码生成简要介绍
Apache Velocity 概述 Apache Velocity 是一个基于 Java 的模板引擎,它允许将 Java 代码与 HTML、XML 或其他文本格式分离,实现视图与数据的解耦。在 Web 开发中,Velocity 常用于生成动态网页内容;在其他场景下,也可用…...

初学Python爬虫
文章目录 前言一、 爬虫的初识1.1 什么是爬虫1.2 爬虫的核心1.3 爬虫的用途1.4 爬虫分类1.5 爬虫带来的风险1.6. 反爬手段1.7 爬虫网络请求1.8 爬虫基本流程 二、urllib库初识2.1 http和https协议2.2 编码解码的使用2.3 urllib的基本使用2.4 一个类型六个方法2.5 下载网页数据2…...

【办公类-99-05】20250508 D刊物JPG合并PDF便于打印
背景需求 委员让我打印2024年2025年4月的D刊杂志,A4彩打,单面。 有很多JPG,一个个JPG图片打开,实在太麻烦了。 我需要把多个jpg图片合并成成为一个PDF,按顺序排列打印。 deepseek写Python代码 代码展示 D刊jpg图片合…...

高效C/C++之十:Coverity修复问题:尽量多使用 c++强制类型转化
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 高效C/C之十:Coverity修复问题:尽量多使用 c强制类型转化 目录 【关注我,后…...

相机的方向和位置
如何更好的控制相机按照我们需要来更好的观察我们需要的地貌呢? 使用 // setview瞬间到达指定位置,视角//生成position是天安门的位置var position Cesium.Cartesian3.fromDegrees(116.397428,39.90923,100)viewer.camera.setView({//指定相机位置destination: position, 在…...
suna界面实现原理分析(二):浏览器工具调用可视化
这是一个基于React的浏览器操作可视化调试组件,主要用于在AI开发工具中展示网页自动化操作过程(如导航、点击、表单填写等)的执行状态和结果。以下是关键技术组件和功能亮点的解析: 一、核心功能模块 浏览器操作状态可视化 • 实时…...
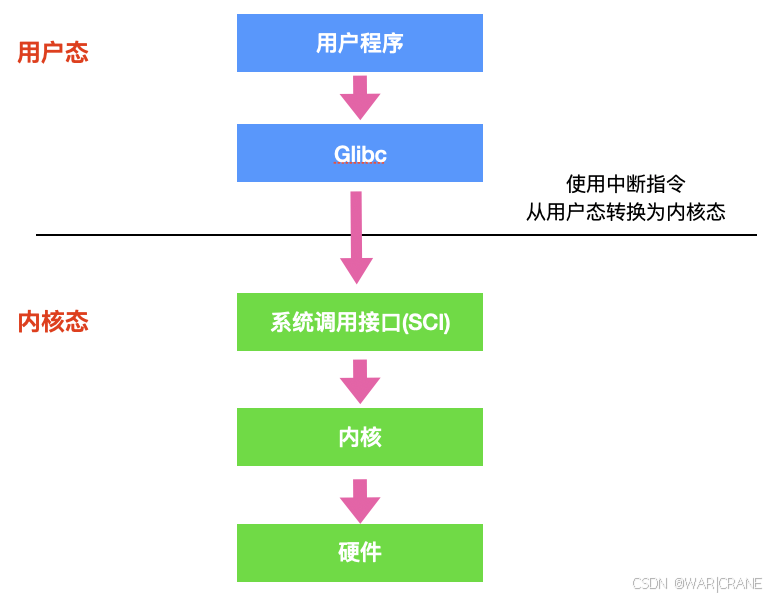
操作系统面试问题(4)
32.什么是操作系统 操作系统是一种管理硬件和软件的应用程序。也是运行在计算机中最重要的软件。它为硬件和软件提供了一种中间层,让我们无需关注硬件的实现,把心思花在软件应用上。 通常情况下,计算机上会运行着许多应用程序,它…...

websocketd 10秒教程
websocketd 参考地址:joewalnes/websocketd 官网地址:websocketd websocketd简述 websocketd是一个简单的websocket服务Server,运行在命令行方式下,可以通过websocketd和已经有程序进行交互。 现在,可以非常容易地构…...
C++ Dll创建与调用 查看dll函数 MFC 单对话框应用程序(EXE 工程)改为 DLL 工程
C Dll创建 一、添加 DllMain(必要) #include <fstream>void Log(const char* msg) {std::ofstream f("C:\\temp\\dll_log.txt", std::ios::app);f << msg << std::endl; }BOOL APIENTRY DllMain(HMODULE hModule, DWORD u…...
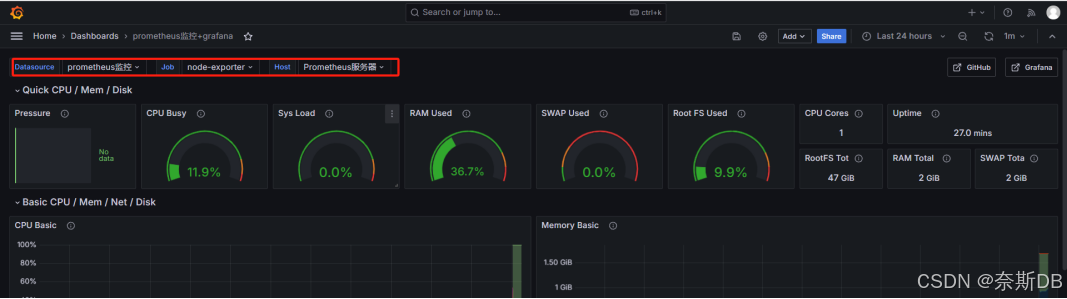
【prometheus+Grafana篇】基于Prometheus+Grafana实现Linux操作系统的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...

小刚说C语言刷题—1004阶乘问题
1.题目描述 编程求 123⋯n 。 输入 输入一行,只有一个整数 n(1≤n≤10); 输出 输出只有一行(这意味着末尾有一个回车符号),包括 1 个整数。 样例 输入 5 输出 120 2.参考代码(C语言版) #include <stdio…...
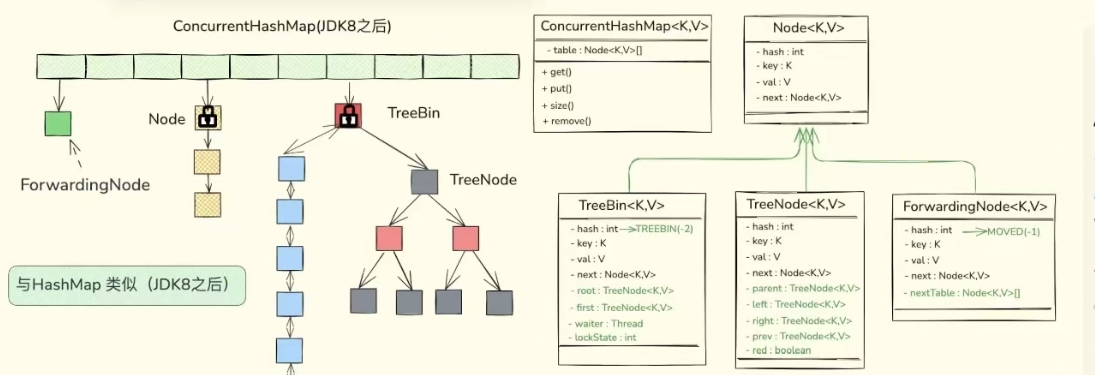
CurrentHashMap的整体系统介绍及Java内存模型(JVM)介绍
当我们提到ConurrentHashMap时,先想到的就是HashMap不是线程安全的: 在多个线程共同操作HashMap时,会出现一个数据不一致的问题。 ConcurrentHashMap是HashMap的线程安全版本。 它通过在相应的方法上加锁,来保证多线程情况下的…...
spring ai alibaba 使用 SystemPromptTemplate 很方便的集成 系统提示词
系统提示词可以是.st 文件了,便于修改和维护 1提示词内容: 你是一个有用的AI助手。 你是一个帮助人们查找信息的人工智能助手。 您的名字是{name} 你应该用你的名字和{voice}的风格回复用户的请求。 每一次回答的时候都要增加一个65字以内的标题形如:【…...

@PostConstruct @PreDestroy
PostConstruct 是 Java EE(现 Jakarta EE)中的一个注解,用于标记一个方法在对象初始化完成后立即执行。它在 Spring 框架、Java Web 应用等场景中广泛使用,主要用于资源初始化、依赖注入完成后的配置等操作。 1. 基本作用 执行时…...
网络的搭建
1、rpm rpm -ivh 2、yum仓库(rpm包):网络源 ----》网站 本地源 ----》/dev/sr0 光盘映像文件 3、源码安装 源码安装(编译) 1、获取源码 2、检测环境生成Ma…...
C++学习之类和对象_1
1. 面向过程与面向对象 C语言是面向过程的,注重过程,通过调用函数解决问题。 比如做番茄炒蛋:买番茄和鸡蛋->洗番茄和打鸡蛋->先炒蛋->把蛋放碟子上->炒番茄->再把蛋倒回锅里->加调料->出锅 而C是面向对象的ÿ…...
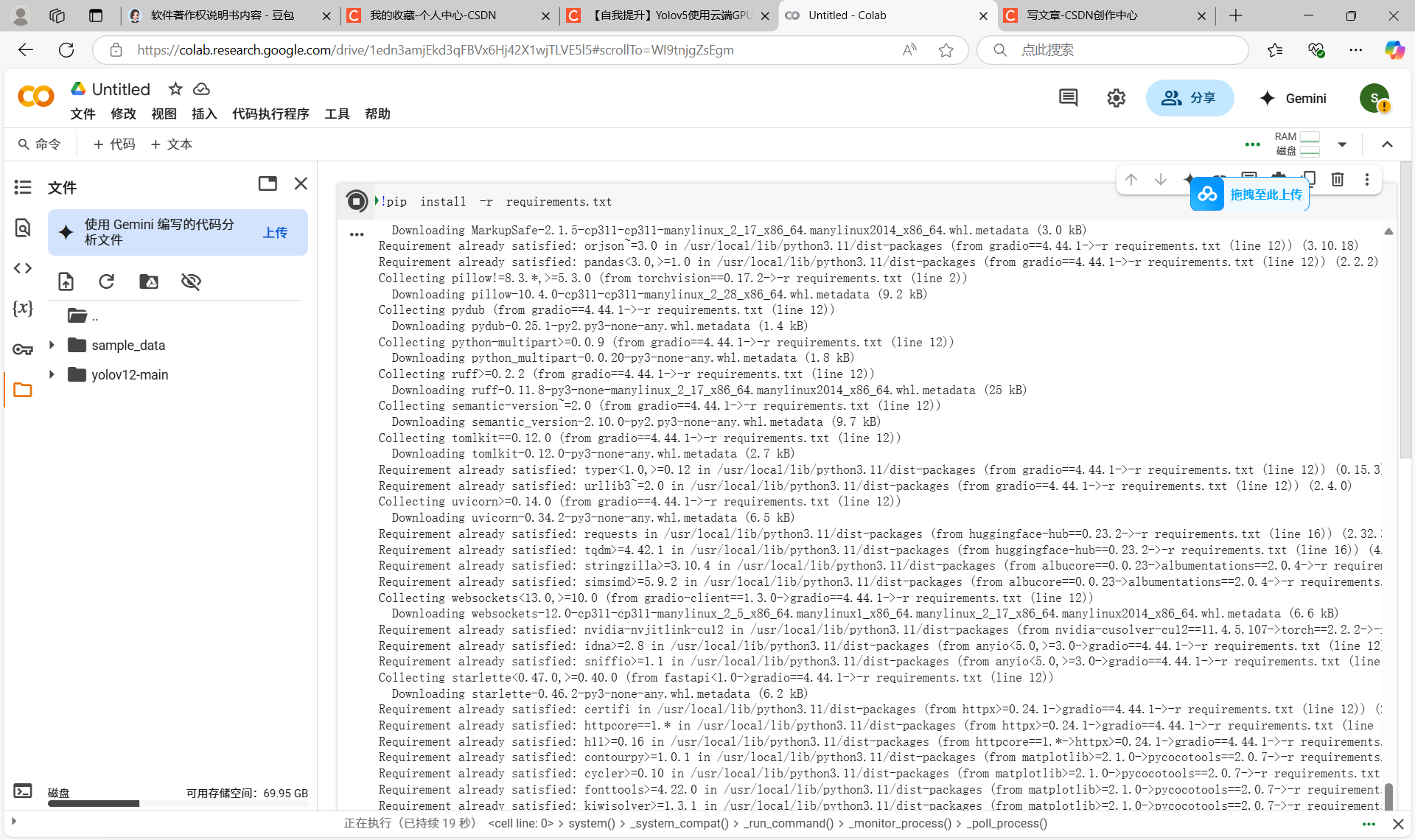
YOLOv12云端GPU谷歌免费版训练模型
1.效果 2.打开 https://colab.research.google.com/?utm_sourcescs-index 3.上传代码 4.解压 !unzip /content/yolov12-main.zip -d /content/yolov12-main 5.进入yolov12-main目录 %cd /content/yolov12-main/yolov12-main 6.安装依赖库 !pip install -r requirements.…...

OpenCV进阶操作:图像直方图、直方图均衡化
文章目录 一、图像直方图二、图像直方图的作用三、使用matplotlib方法绘制直方图2.使用opencv的方法绘制直方图(划分16个小的子亮度区间)3、绘制彩色图像的直方图 四、直方图均衡化1、绘制原图的直方图2、绘制经过直方图均衡化后的图片的直方图3、自适应…...

基环树(模板) 2876. 有向图访问计数
对于基环树,我们可以通过拓扑排序去掉所有的树枝,只剩下环,题目中可能会有多个基环树 思路:我们先利用拓扑排序将树枝去掉,然后求出每个基环树,之后反向dfs求得所有树枝的长度即可 class Solution { publi…...

【物联网】基于树莓派的物联网开发【1】——初识树莓派
使用背景 物联网开发从0到1研究,以树莓派为基础 场景介绍 系统学习Linux、Python、WEB全栈、各种传感器和硬件 接下来程序猫将带领大家进军物联网世界,从0开始入门研究树莓派。 认识树莓派 正面图示: 1:树莓派简介 树莓派…...

Qt读写XML文档
XML 结构与概念简介 XML(可扩展标记语言) 是一种用于存储和传输结构化数据的标记语言。其核心特性包括: 1、树状结构:XML 数据以层次化的树形结构组织,包含一个根元素(Root Element)ÿ…...

学习Python的第一天之网络爬虫
30岁程序员学习Python的第一天:网络爬虫 Requests库 1、requests库安装 windows系统通过管理员打开cmd,运行pip install requests!测试案例: 2、Requests库的两个重要对象 Response对象Resoponse对象包含服务器返回的所有信息ÿ…...

前端展示后端返回的图片流
一、请求 重点:添加responseType: “blob”, // Vue2组件中请求示例 methods: {fetchImage() {return axios.get(/api/getImage, {params: { id: 123 },responseType: blob // 关键配置(重点,必须配置)});} }或 export function…...
 微服务开发与治理实战)
65.微服务保姆教程 (八) 微服务开发与治理实战
微服务开发与治理实战:搭建一个简单的微服务系统 在这个实战中,我们将使用以下技术栈来搭建一个简单的微服务系统: 注册中心和配置中心:使用 Nacos。服务开发框架:使用 Spring Boot。服务间通信:使用 Feign。API 网关:使用 Spring Cloud Gateway。依赖管理工具:使用 M…...

AI服务器通常会运用在哪些场景当中?
人工智能行业作为现代科技的杰出代表,在多个领域当中发展其强大的应用能力和价值,随之,AI服务器也在各个行业中日益显现出来,为各个行业提供了强大的计算能力和处理能力,帮助企业处理复杂的大规模数据,本文…...
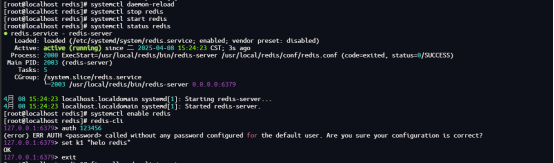
linux下的Redis的编译安装与配置
配合做开发经常会用到redis,整理下编译安装配置过程,仅供参考! --------------------------------------Redis的安装与配置-------------------------------------- 下载 wget https://download.redis.io/releases/redis-6.2.6.tar.gz tar…...

【官方题解】StarryCoding 入门教育赛 2 | acm | 蓝桥杯 | 新手入门
比赛传送门: 本场比赛开始时题面存在一些问题,私密马赛! A.池化【入门教育赛】 根据题目所给公式计算即可。 #include "bits/stdc.h"signed main() {int t; std::cin >> t;while (t --) {int l, k, s, p; std::cin >&…...
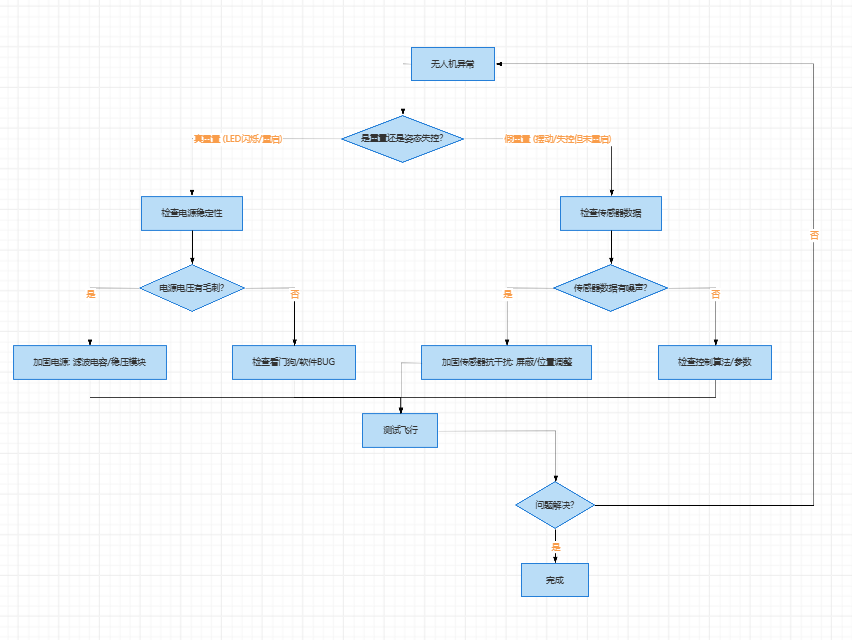
无人机相关技术与故障排除笔记
无人机相关技术与故障排除笔记 本文档整理了关于无人机电调、电机、通信协议、传感器以及硬件故障排除相关的笔记和解释。 1. 电调 (ESC) PWM 输出初始化设置 初始化电调(电子调速器)的 PWM 输出功能时,设置 频率 400Hz、分辨率 10000、初…...