C++修炼:stack和queue
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路!
我的博客:<但凡.
我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C++修炼之路》
欢迎点赞,关注!

目录
1、stack和queue的使用
1.1、stack
1.2、queue
2、stack和queue的模拟实现
2.1、容器适配器
2.2、模拟实现
3、list,vector,deque的对比
3.1、list和vector对比
3.2、缓存命中率
3.3、deque
1、stack和queue的使用
1.1、stack
栈这个数据结构相信大家都不陌生了,在这我就不过多介绍了,我们直接使用stl中的栈进行一些基础操作。
#include<iostream>
#include<stack>
using namespace std;
int main()
{stack<int> st;st.push(1);//插入操作st.push(2);st.push(3);st.push(4);st.push(5);st.push(6);st.push(7);while (st.size()){cout << st.top() <<" ";//取栈顶操作st.pop();}
}stack的接口很少,并且stack不支持迭代器。以上操作输出结果为7 6 5 4 3 2 1。
1.2、queue
队列这个结构我们也很熟悉了,这里的queue和stack一样也不支持迭代器访问,并且接口也很少。我们拿和上面一样的方法来使用一下。
#include<iostream>
#include<queue>
using namespace std;
int main()
{queue<int> q;q.push(1);//插入操作q.push(2);q.push(3);q.push(4);q.push(5);q.push(6);q.push(7);while (q.size()){cout << q.front() << " ";//输出队头q.pop();}cout << endl;q.push(1);cout << q.back() << endl;//支持输出队尾
}输出结果:

2、stack和queue的模拟实现
2.1、容器适配器
现在我们进入第二个阶段模拟实现。我们前两篇list和vector都用了很大的篇幅去模拟实现,但是stack和queue就很简单了。因为我们可以用到一个叫 容器适配器 的东西来帮助我们。
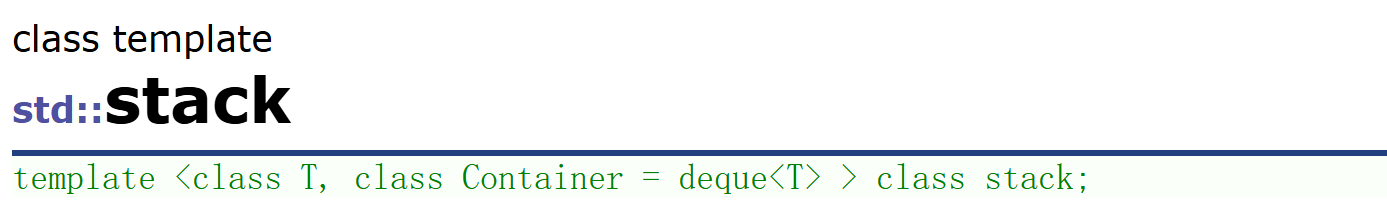
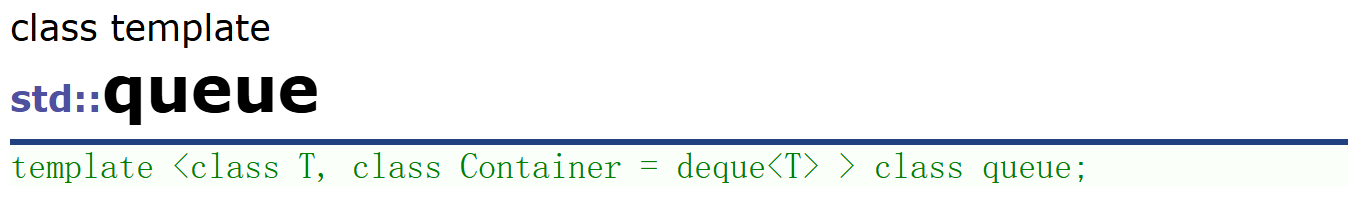
我们注意到STL底层在实现这两个数据结构的时候用了一个叫Container(容器适配器)的东西。
在 C++ 标准模板库(STL)中,容器适配器(Container Adaptor) 是一种特殊的容器,它们基于现有的 STL 容器(如 std::deque、std::list 或 std::vector)进行封装,所以本质上是一种复用,就像我们之前在模拟实现string里面部分接口是复用了memcpy,memset这种库里已经写好的函数。只不过这回我们复用的不是函数了而是一个容器,一个写好的数据结构。
使用容器适配器的结构不能通过迭代器访问,因为这样可能会破坏这个容器的使用规则,比如栈要求后进先出,而queue要求先进先出。虽然不能用迭代器但是我们可以更换底层容器(deque,vector,list等)。
现在我们来模拟实现以下stack和queue。
2.2、模拟实现
模拟实现stack:
template<class T,class con=deque<T>>
class stack
{
public:stack(){}void push(const T& x){_c.push_back(x);}void pop(){_c.pop_back();}T& top(){return _c.back();}const T& top() const{return _c.back();}size_t size() const{return _c.size();}bool empty() const{return _c.empty();}
private:con _c;//默认调用deque的构造
};模拟实现queue:
template<class T,class con=deque<T>>
class queue
{
public:queue(){}void push(const T& x) {_c.push_back(x);}void pop() {_c.pop_front();}T& back() { return _c.back(); }const T& back() const { return _c.back(); }T& front() { return _c.front(); }const T& front() const { return _c.front(); }size_t size() {return _c.size();}bool empty() const{return _c.empty;}
private:con _c;
};我们可以用刚开始写的代码测试一下他们的逻辑发现没有问题,符合栈和队列的使用规范。
我们同样可以把适配器换成vector和list,其他不用改变。在这里我就不再演示了。
那现在就有一个问题,list,deque,vector这三种容器作为适配器有什么区别呢?到底哪个更好呢?
3、list,vector,deque的对比
3.1、list和vector对比
我们先来看list和vector,这两个容器的特点可以说是两个极端或者说是两个对立。
list的优点是插入,删除效率高,任意位置插入删除时间复杂度都是O(1)级别。
并且空间利用率高,节点都是按需申请,按需释放的。
而vector的与list相比在这两方面都是劣势,缺点。vector头插和头删需要挪动数据,效率低下。并且存在扩容浪费空间的问题。比如说我们申请二十个空间,但实际上我们只插入一个元素。
那vector有什么优点呢?首先它支持迭代器随机访问,而list是不支持迭代器随机访问的。当然了这一点也不是那么重要因为做适配器根本就不能用迭代器访问。
第二点非常重要也是大家以前可能从来没听说过的,vector的cpu高速缓冲命中率高,而list的cpu高速缓存命中率低。
什么是cpu高速缓存命中率呢?我们展开解释一下。
3.2、缓存命中率
我们先来补充一点作为程序员,应该知道的有关cpu的“常识”。
我们的cpu现在基本都有三级缓存(L3,L2,L1),当然较老的cpu只有两级缓存(L2,L1),他们的访问速度L3>L2>L1,在这之后还有内存,硬盘。当然了硬盘的访问速度就很慢了。我们的数据从内存,先到L3,再到L2,再到L1,然后到寄存器中进行cpu计算。
数据的距离cpu核心越来越近、因为L1,L2分布在cpu的每一个核中,而L3是所有cpu核共有的内存。
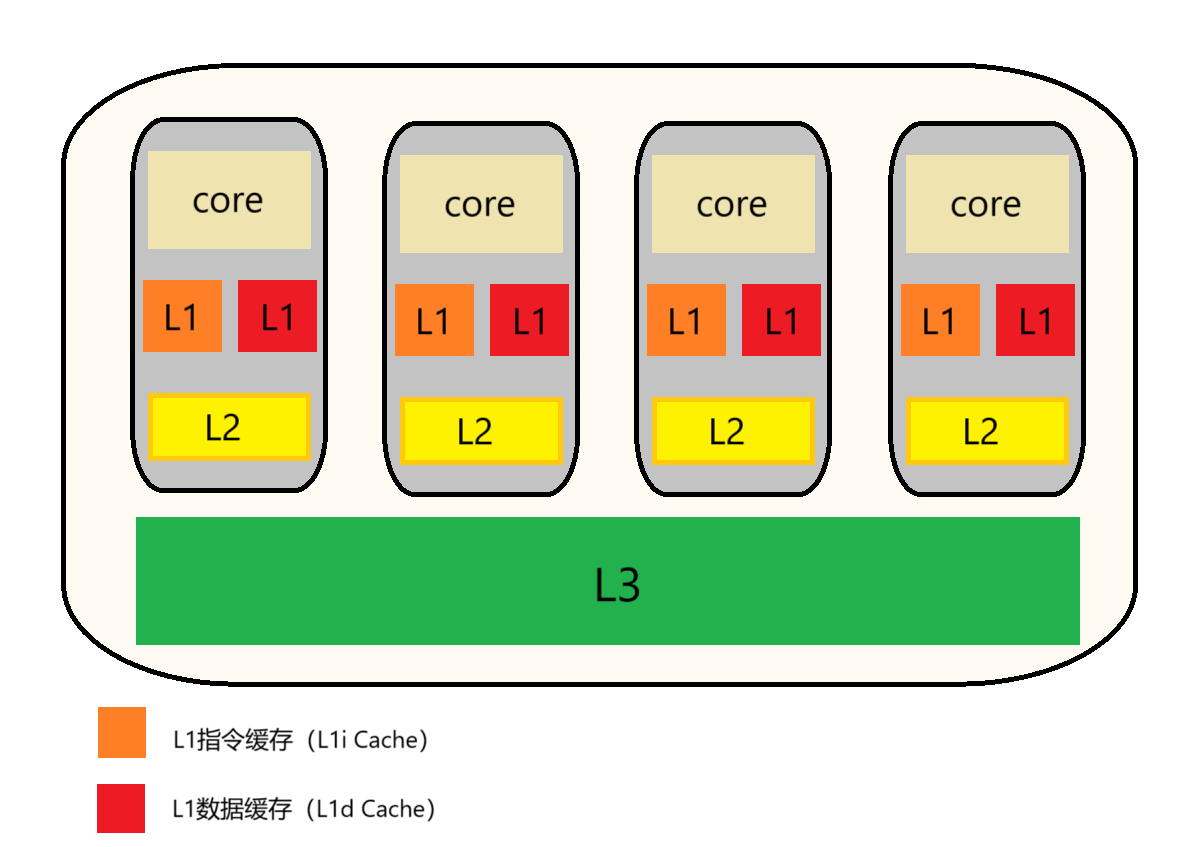
注:上图展示的是一个4核CPU的缓存结构示例,而现代主流CPU通常配备6-16个物理核心,服务器级CPU甚至可达128核。随着核心数量增加,实际缓存架构会存在些许差异。
那我们数据是通过什么一层一层的往上走的呢?首先明确一点他不是一个字节一个字节加载向上走的,而是一块一块的向上走的。什么意思?我们打个比方。我们在写文章的时候,如果想引用什么名人名言可以去百度上搜索,比如我搜索出了一段鲁迅说过的话,想把他复制到我的文章中,我肯定不是一个字一个字的复制的吧?那样也太累了。我们肯定是把一段话都复制下来然后放到文章中。
cpu也是,如果傻傻的一个字节一个字节的挪动数据那也太慢了,他是一块一块的挪动,那么这一块数据单位就叫一个“Cache Line”。
那为什么vector缓存命中率高呢?比方说我们就挪动64字节(目前主流cpu的Cache Line是64字节),恰巧我们64个字节是存储的连续的16个int类型数据,那好了我一次性都加载走了。
但如果是list呢?他的内存分布是不连续的,是这一块内存一个数据,那一块内存一个数据,倘若我对于某一块内存扫描64字节的话,可能只能挪走一个数据,甚至一个也挪不到。那命中率就低了。进而效率也就低了。
介绍完vector和list以及缓存命中率,我们再来看一下deque。
3.3、deque
deque(双端队列)是一种支持高效头尾插入/删除的序列容器,它结合了vector和list的优缺点,既支持随机访问,又能高效的插入和删除。
deque可以说是把两者融合了一下,但是由于他的底层逻辑设计起来比较复杂,他的头插尾插效率高,但是高不过list,他的cpu缓存命中率比list优秀,但是也优秀不过vector。我们在这里不模拟实现他,但是我们说一下他的底层是什么样子的。
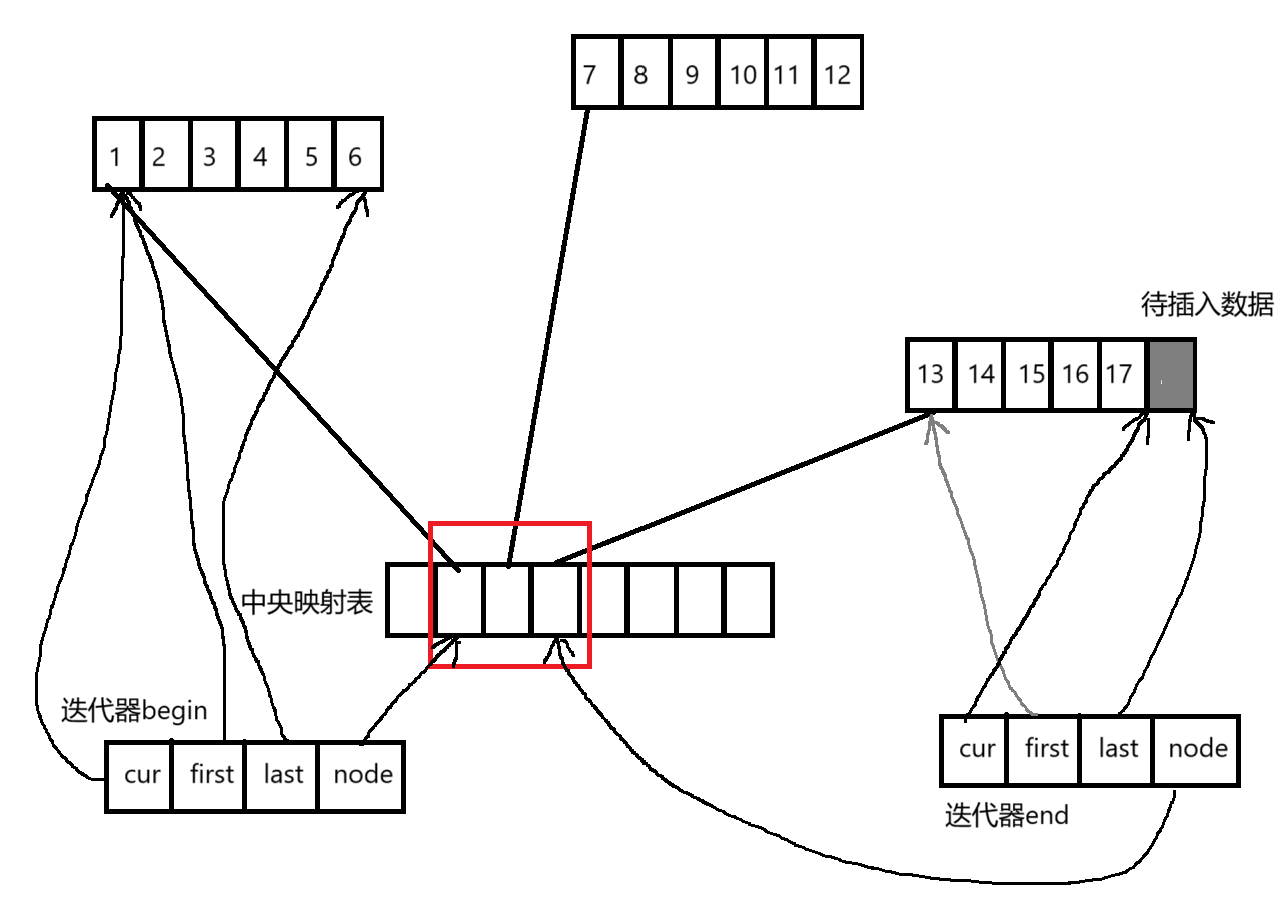
deque通常由多个固定大小的连续内存块(分块数组)通过中央控制器(如指针数组)链接而成,具体结构如下:
(1)分块储存
每个内存块存储若干元素,独立分配,插入新元素无需整体挪动,只需要分配新的内存块
(2)中央映射表
通过一个存储着每块内存地址的数组来快速找到这块内存。
STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。 结合了deque的优点,而完美的避开了其缺陷。
好了,今天的内容就分享到这,我们下期再见!
相关文章:
C++修炼:stack和queue
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...

【软件工程】基于频谱的缺陷定位
基于频谱的缺陷定位(Spectrum-Based Fault Localization, SBFL)是一种通过分析程序执行覆盖信息(频谱数据)来定位代码中缺陷的方法。其核心思想是:通过测试用例的执行结果(成功/失败)和代码覆盖…...

【计算机视觉】优化MVSNet可微分代价体以提高深度估计精度的关键技术
优化MVSNet可微分代价体以提高深度估计精度的关键技术 1. 代价体基础理论与分析1.1 标准代价体构建1.2 关键问题诊断 2. 特征表示优化2.1 多尺度特征融合2.2 注意力增强匹配 3. 代价体构建优化3.1 自适应深度假设采样3.2 可微分聚合操作改进 4. 正则化与优化策略4.1 多尺度代价…...

为什么tcp不能两次握手
TCP **不能用“两次握手”**的根本原因是:两次握手无法确保双方“都知道”连接是可靠建立的,容易引发“旧连接请求”造成错误连接。 🔁 先看标准的 三次握手(3-Way Handshake)流程 客户端 服务器| …...

常见音频主控芯片以及相关厂家总结
音频主控芯片是音频设备(如蓝牙耳机、音箱、功放等)的核心组件,负责音频信号的解码、编码、处理和传输。以下是常见的音频主控芯片及其相关厂家,按应用领域分类: 蓝牙音频芯片 主要用于无线耳机、音箱等设备࿰…...

掌握 Kubernetes 和 AKS:热门面试问题和专家解答
1. 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序是什么? 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序如下: 集群&#…...

【MyBatis-7】深入理解MyBatis二级缓存:提升应用性能的利器
在现代应用开发中,数据库访问往往是性能瓶颈之一。作为Java生态中广泛使用的ORM框架,MyBatis提供了一级缓存和二级缓存机制来优化数据库访问性能。本文将深入探讨MyBatis二级缓存的工作原理、配置方式、使用场景以及最佳实践,帮助开发者充分利…...

5.9-selcct_poll_epoll 和 reactor 的模拟实现
5.9-select_poll_epoll 本文演示 select 等 io 多路复用函数的应用方法,函数具体介绍可以参考我过去写的博客。 先绑定监听的文件描述符 int sockfd socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in serveraddr; memset(&serveraddr, 0, sizeof(struc…...
》阅读笔记:p17-p27)
《算法导论(第4版)》阅读笔记:p17-p27
《算法导论(第4版)》学习第 10 天,p17-p27 总结,总计 11 页。 一、技术总结 1. insertion sort (1)keys The numbers to be sorted are also known as the keys(要排序的数称为key)。 第 n 次看插入排序,这次有两个地方感触比较深&#…...
软考错题集
一个有向图具有拓扑排序序列,则该图的邻接矩阵必定为()矩阵。 A.三角 B.一般 C.对称 D.稀疏矩阵的下三角或上三角部分包含非零元素,而其余部分为零。一般矩阵这个术语太过宽泛,不具体指向任何特定性 质的矩阵。对称矩阵…...

T2I-R1:通过语义级与图像 token 级协同链式思维强化图像生成
文章目录 速览摘要1 引言2 相关工作统一生成与理解的 LMM(Unified Generation and Understanding LMM.)用于大型推理模型的强化学习(Reinforcement Learning for Large Reasoning Models.)3 方法3.1 预备知识3.2 语义级与令牌级 CoT语义级 CoT(Semantic-level CoT)令牌级…...

Dockers部署oscarfonts/geoserver镜像的Geoserver
Dockers部署oscarfonts/geoserver镜像的Geoserver 说实话,最后发现要选择合适的Geoserver镜像才是关键,所以所以所以…🐷 推荐oscarfonts/geoserver的镜像! 一开始用kartoza/geoserver镜像一直提示内存不足,不过还好…...

【脑机接口临床】脑机接口手术的风险?脑机接口手术的应用场景?脑机接口手术如何实现偏瘫康复?
脑机接口的应用 通常对脑机接口感兴趣的两类人群,一类是适应症患者 ,另一类是科技爱好者。 1 意念控制外部设备 常见的外部设备有:外骨骼、机械手、辅助康复设备、电刺激设备、电脑光标、轮椅。 2 辅助偏瘫康复或辅助脊髓损伤患者意念控制…...

扩增子分析|微生物生态网络稳定性评估之鲁棒性(Robustness)和易损性(Vulnerability)在R中实现
一、引言 周集中老师团队于2021年在Nature climate change发表的文章,阐述了网络稳定性评估的原理算法,并提供了完整的代码。自此对微生物生态网络的评估具有更全面的指标,自此网络稳定性的评估广受大家欢迎。本系列将介绍网络稳定性之鲁棒性…...

Client 和 Server 的关系理解
client.py 和 server.py 是基于 MCP(Multi-Component Protocol)协议的客户端-服务端架构,二者的关系如下: 1. 角色分工 server.py:服务端,负责注册和实现各种“工具函数”(如新闻检索、情感分…...
【含文档+PPT+源码】基于微信小程序的社区便民防诈宣传系统设计与实现
项目介绍 本课程演示的是一款基于微信小程序的社区便民防诈宣传系统设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套…...
)
Kafka的核心组件有哪些?简要说明其作用。 (Producer、Consumer、Broker、Topic、Partition、ZooKeeper)
Kafka 核心组件解析 1. 基础架构图解 ┌─────────┐ ┌─────────┐ ┌─────────┐ │Producer │───▶ │ Broker │ ◀─── │Consumer │ └─────────┘ └─────────┘ └────────…...

Java中对象集合转换的优雅实现【实体属性范围缩小为vo】:ListUtil.convert方法详解
1.业务场景 在开发电商系统时,我们经常需要处理订单信息的展示需求。例如:订单详情页需要显示退款信息列表,而数据库中存储的RefundInfo实体类包含敏感字段,直接返回给前端存在安全风险。此时就需要将RefundInfo对象集合转换为Or…...

【MySQL】存储引擎 - ARCHIVE、BLACKHOLE、MERGE详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

代码随想录第41天:图论2(岛屿系列)
一、岛屿数量(Kamacoder 99) 深度优先搜索: # 定义四个方向:右、下、左、上,用于 DFS 中四向遍历 direction [[0, 1], [1, 0], [0, -1], [-1, 0]]def dfs(grid, visited, x, y):"""对一块陆地进行深度…...
详解)
Vue插槽(Slots)详解
文章目录 1. 插槽简介1.1 什么是插槽?1.2 为什么需要插槽?1.3 插槽的基本语法 2. 默认插槽2.1 什么是默认插槽?2.2 默认插槽语法2.3 插槽默认内容2.4 默认插槽实例:创建一个卡片组件2.5 Vue 3中的默认插槽2.6 默认插槽的应用场景 …...

中国古代史1
朝代歌 三皇五帝始,尧舜禹相传。 夏商与西周,东周分两段。 春秋和战国,一统秦两汉。 三分魏蜀吴,二晋前后延。 南北朝并立,隋唐五代传。 宋元明清后,皇朝至此完。 原始社会 元谋人,170万年前…...

vue +xlsx+exceljs 导出excel文档
实现功能:分标题行导出数据过多,一个sheet表里表格条数有限制,需要分sheet显示。 步骤1:安装插件包 npm install exceljs npm install xlsx 步骤2:引用包 import XLSX from xlsx; import ExcelJS from exceljs; 步骤3&am…...

nginx之proxy_redirect应用
一、功能说明 proxy_redirect 是 Nginx 反向代理中用于修改后端返回的响应头中 Location 和 Refresh 字段的核心指令,主要解决以下问题:协议/地址透传错误:当后端返回的 Location 包含内部 IP、HTTP 协议或非标准端口时,需修正为…...

在 Flink + Kafka 实时数仓中,如何确保端到端的 Exactly-Once
在 Flink Kafka 构建实时数仓时,确保端到端的 Exactly-Once(精确一次) 需要从 数据消费(Source)、处理(Processing)、写入(Sink) 三个阶段协同设计,结合 Fli…...

Qt 中基于 spdlog 的高效日志管理方案
在开发 Qt 应用程序时,日志记录是一项至关重要的功能,它能帮助我们追踪程序的运行状态、定位错误和分析性能。本文将介绍如何在 Qt 项目中集成 spdlog 库,并封装一个简单易用的日志管理类 QtLogger,实现高效的日志记录和管理。 为什么选择 spdlog? spdlog 是一个快速、头…...

VUE CLI - 使用VUE脚手架创建前端项目工程
前言 前端从这里开始,本文将介绍如何使用VUE脚手架创建前端工程项目 1.预准备(编辑器和管理器) 编辑器:推荐使用Vscode,WebStorm,或者Hbuilder(适合刚开始练手使用),个…...

Linux 学习笔记2
Linux 学习笔记2 一、定时任务调度操作流程注意事项 二、磁盘分区与管理添加新硬盘流程磁盘管理命令 三、进程管理进程操作命令服务管理(Ubuntu) 四、注意事项 一、定时任务调度 操作流程 创建脚本 vim /path/to/script.sh # 编写脚本内容设置可执行权…...

JS DOM操作与事件处理从入门到实践
对于前端开发者来说,让静态的 HTML 页面变得生动、可交互是核心技能之一。实现这一切的关键在于理解和运用文档对象模型 (DOM) 以及 JavaScript 的事件处理机制。本文将带你深入浅出地探索 DOM 操作的奥秘,并掌握JavaScript 事件处理的方方面面。 目录 …...
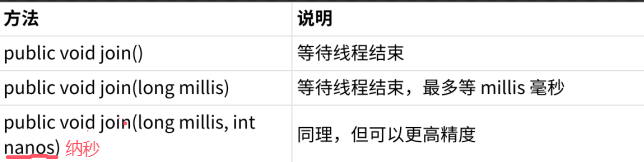
Java EE初阶——初识多线程
1. 认识线程 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。 基本概念:一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间、文件描述符等,但每个线程都有自己独…...