AI安全之对抗样本攻击---FGSM实战脚本解析
一、对抗样本与FGSM的背景
在深度学习安全领域,对抗样本(Adversarial Examples)因其特殊的生成机制备受关注。2015年ICLR会议收录的里程碑式论文《Explaining and Harnessing Adversarial Examples》中,Goodfellow等学者首次系统阐述了快速梯度符号方法(FGSM)的生成原理,这一发现揭示了深度神经网络在鲁棒性方面存在的重大缺陷。
二、FGSM的核心工作原理
不同于常规训练中的梯度下降优化,FGSM采用逆向梯度操作实现对抗样本生成。其本质是通过梯度符号方向的参数扰动,构造出使模型产生错误判断的输入样本。具体而言:
- 梯度方向逆转:传统网络训练通过损失函数梯度反方向(-∇)更新参数,而FGSM则沿梯度正方向(+∇)施加扰动
- 扰动控制机制:通过ε参数约束扰动幅度,确保对抗样本在人类视觉感知中与原始样本无明显差异
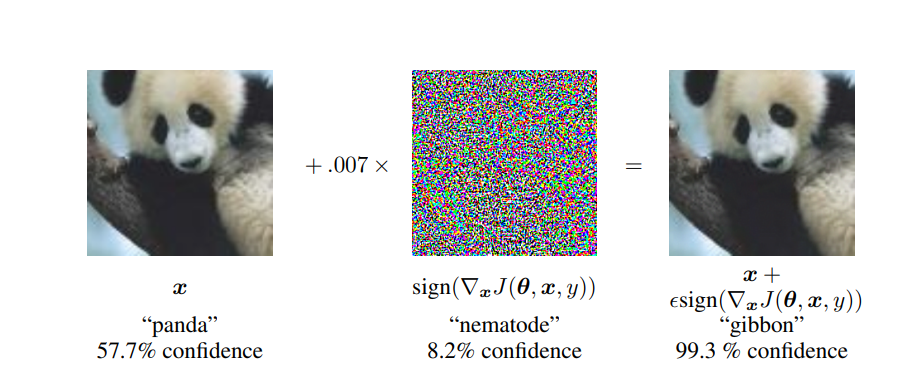
- 损失函数最大化:数学表达为x_adv = x + ε·sign(∇_xJ(θ,x,y)),其中J为损失函数,θ为模型参数
实战代码解析:
# -*- coding: utf-8 -*-
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt# 下载MNIST数据集时,解决"用户代理"限制的问题
# 详情参考: https://github.com/pytorch/vision/issues/3497
from six.moves import urllib
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)"""代码实现
--------------本节将详细阐述本教程的输入参数定义、受攻击模型配置,以及攻击算法的具体实现与验证测试。输入参数配置
~~~~~~本实现包含三个关键输入参数,其定义如下:- **扰动系数(epsilons)** 用于实验的ε值列表,需注意:- 必须包含0值用于基准测试(原始样本准确率)- 根据数据归一化范围$[0,1]$,ε最大值不应超过1- 经验规律:ε值与扰动可见性、模型准确率下降程度呈正相关- **预训练模型(pretrained_model)** 基于PyTorch官方MNIST示例训练的模型路径:``` https://github.com/pytorch/examples/tree/master/mnist``` 为方便使用,可直接下载预训练模型:```https://drive.google.com/drive/folders/1fn83DF14tWmit0RTKWRhPq5uVXt73e0h?usp=sharing``` - **GPU加速(use_cuda)** 布尔型标志位,启用条件:- CUDA环境可用时自动启用GPU加速- 注:本实验CPU计算耗时可控,非必须使用GPU"""
#新建扰动强度列表,从0开始到0.3,步长为0.05 ,epsilon = 0 表示无扰动(原始图像),值越大表示添加的扰动越强。这些值将用于测试模型在不同扰动强度下的表现。
epsilons = [0, .05, .1, .15, .2, .25, .3]
#指定预训练模型的路径
pretrained_model = "data/lenet_mnist_model.pth"
#是否使用GPU加速,True 表示如果有 GPU 可用就使用 GPU,使用 GPU 可以加快模型的计算速度,如果没有 GPU,代码会自动回退到 CPU
use_cuda=True"""受攻击模型配置
~~~~~~~~~~~~~~~~~~本实验的攻击对象为PyTorch官方MNIST示例项目实现的分类模型
(代码库见:<https://github.com/pytorch/examples/tree/master/mnist>)。使用者可选择以下任一方式获取模型:
1. **自主训练模式** 基于官方代码库重新训练并保存MNIST分类模型2. **预训练模型调用** 直接加载本文提供的已训练模型文件本模块完整复用了原始项目的以下核心组件:
- 网络结构定义(*Net* 类)
- 测试集数据加载器(Test Dataloader)"""# LeNet 模型定义 先定义与图像识别模型相同的模型结构 Net类定义了模型的"骨架"(网络结构),
# lenet_mnist_model.pth 文件提供了这个骨架上的"肌肉"(具体参数)
# 这个 Net 类实现的是 LeNet 卷积神经网络,
# 包含:
#- 2个卷积层(用于提取图像特征)
#- Dropout层(防止过拟合)
#- 2个全连接层(进行最终的分类)
#- 输出10个类别(对应0-9这10个数字)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)# 前向传播函数 定义数据在网络中的流动路径def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2)) # 第一层:卷积->池化->ReLU激活x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) # 第二层:卷积->Dropout->池化->ReLU激活x = x.view(-1, 320) # 将特征图展平x = F.relu(self.fc1(x)) # 第一个全连接层,接ReLU激活x = F.dropout(x, training=self.training) # Dropout层x = self.fc2(x) # 第二个全连接层return F.log_softmax(x, dim=1) # 输出层,使用log_softmax激活
"""
上面这个方法定义了数据从输入到输出的完整处理流程:1. 输入的手写数字图像先经过两层卷积层提取特征
2. 然后将特征图展平成一维向量
3. 接着通过两个全连接层进行分类
4. 最后用 log_softmax 输出每个数字类别的概率
当我们调用 model(data) 时,实际上就是在调用这个 forward 方法。这是 PyTorch 的一个特性,它会自动调用 forward ,使代码更简洁。"""# MNIST数据集加载器,检查本地 ./data 目录是否已有数据集,如果没有,则从官方地址下载
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=False, download=True, transform=transforms.Compose([transforms.ToTensor(),])), batch_size=1, shuffle=True)# 定义我们使用的设备
print("CUDA Available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")# 初始化网络
model = Net().to(device)# 加载预训练模型
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))# 将模型设置为评估模式
model.eval()"""FGSM 攻击算法实现本模块定义通过梯度扰动生成对抗样本的核心函数"""# FGSM 攻击代码
def fgsm_attack(image, epsilon, data_grad):# 收集数据梯度的元素符号sign_data_grad = data_grad.sign()# 通过调整输入图像的每个像素来创建扰动的图像perturbed_image = image + epsilon*sign_data_grad# 添加剪辑以维护[0,1]范围perturbed_image = torch.clamp(perturbed_image, 0, 1)# 返回扰动后的图像return perturbed_image"""测试函数
~~~~~~~~~~~~~~~~最后,本教程的核心结果来自于test函数。每次调用此测试函数都会在MNIST测试集上执行完整的测试步骤并报告最终准确率。
然而,请注意该函数还接受epsilon输入参数。这是因为test函数报告的是在强度为epsilon的攻击下模型的准确率。
具体来说,对于测试集中的每个样本,该函数计算损失相对于输入数据的梯度($data\_grad$),使用fgsm_attack创建扰动图像($perturbed\_data$),
然后检查扰动后的样本是否成为对抗样本。除了测试模型的准确率外,该函数还保存并返回一些成功的对抗样本,以便后续可视化。"""def test( model, device, test_loader, epsilon ):# 准确度计数器correct = 0adv_examples = []# 循环遍历测试集中所有案例for data, target in test_loader:# 向设备发送数据和标签data, target = data.to(device), target.to(device)# 设置张量的requires_grad属性,这对攻击非常重要data.requires_grad = True# 数据通过模型前向传播output = model(data)init_pred = output.max(1, keepdim=True)[1] # 获取最大对数概率的索引# 如果初始预测报错,无需攻击,直接跳过if init_pred.item() != target.item():continue# 计算损失loss = F.nll_loss(output, target)# 清零所有现有梯度model.zero_grad()# 在反向传播中计算模型的梯度loss.backward()# 收集数据梯度data_grad = data.grad.data# 调用FGSM攻击perturbed_data = fgsm_attack(data, epsilon, data_grad)# 重新分类扰动图像output = model(perturbed_data)# 检查攻击是否成功final_pred = output.max(1, keepdim=True)[1] # 获取最大对数概率的索引if final_pred.item() == target.item():correct += 1# 保存0扰动样本的特殊情况if (epsilon == 0) and (len(adv_examples) < 5):adv_ex = perturbed_data.squeeze().detach().cpu().numpy()adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )else:# 保存一些对抗样本用于后续可视化if len(adv_examples) < 5:adv_ex = perturbed_data.squeeze().detach().cpu().numpy()adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )# 计算此epsilon值的最终准确率final_acc = correct/float(len(test_loader))print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))# 返回准确率和对抗样本return final_acc, adv_examples"""执行攻击
~~~~~~~~~~代码实现的最后一部分是执行攻击。在这里,我们对*epsilons*输入中的每个epsilon值运行完整的测试步骤。
对于每个epsilon值,我们还保存最终的准确率和一些成功的对抗样本,以便在后续章节中进行绘图。
注意观察随着epsilon值的增加,打印的准确率如何下降。另外,请注意$\epsilon=0$的情况代表原始测试准确率,即无攻击状态。"""accuracies = []
examples = []# 对每个epsilon运行测试
for eps in epsilons:acc, ex = test(model, device, test_loader, eps)accuracies.append(acc)examples.append(ex)"""结果
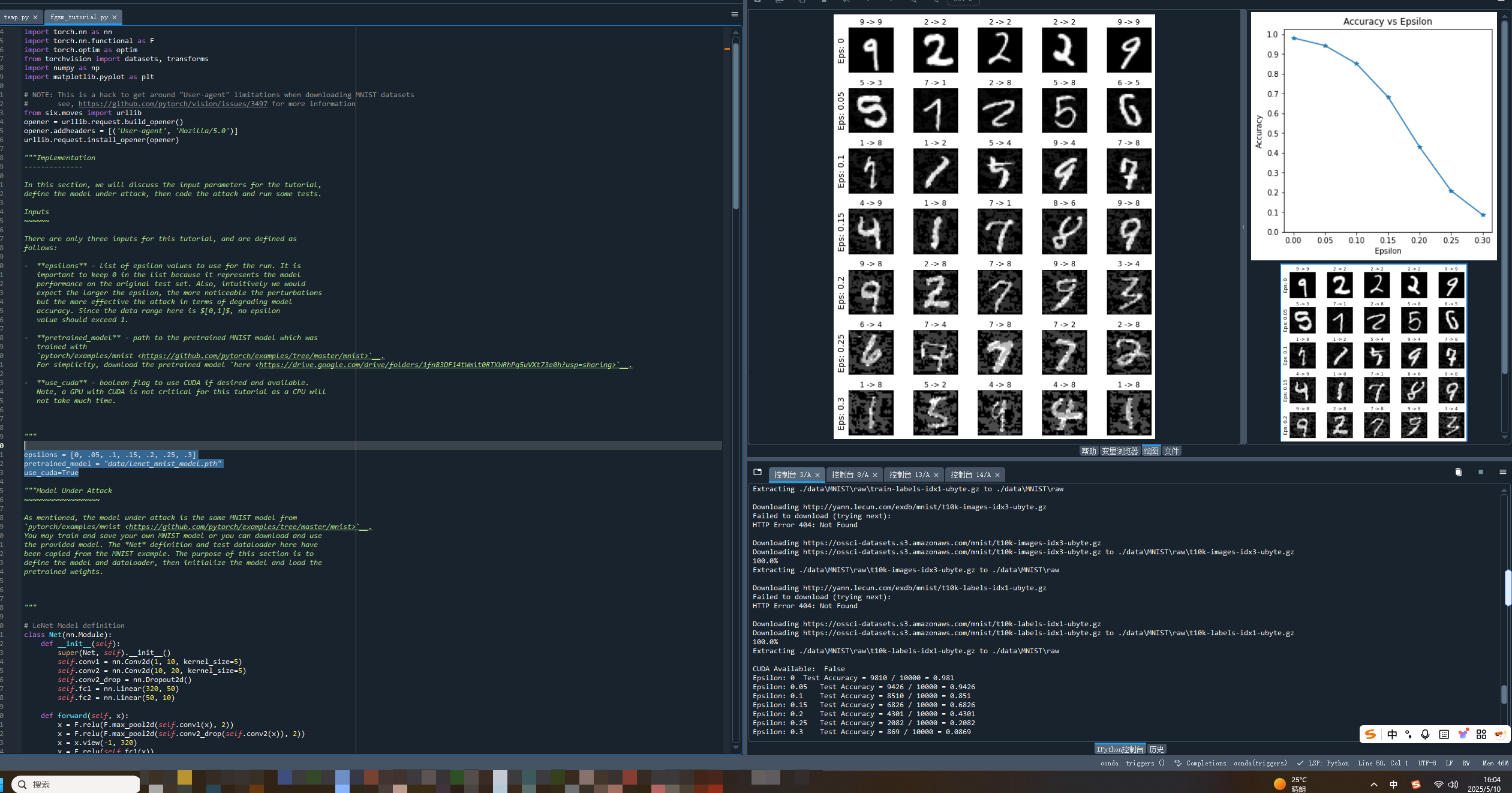
-------准确率 VS 扰动系数
~~~~~~~~~~~~~~~~~~~第一个结果是准确率与epsilon(扰动系数)的关系图。如前所述,随着epsilon的增加,我们预期测试准确率会下降。
这是因为较大的epsilon意味着我们在最大化损失的方向上迈出更大的步伐。注意曲线趋势并非线性,尽管epsilon值是线性间隔的。
例如,epsilon=0.05时的准确率仅比epsilon=0低约4%,但epsilon=0.2时的准确率比epsilon=0.15低25%。
此外,注意模型的准确率在epsilon=0.25和epsilon=0.3之间达到了10类分类器的随机准确率水平。"""plt.figure(figsize=(5,5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()"""对抗样本示例
~~~~~~~~~~~~~~~~~~~~~~~~~~~世上没有免费的午餐。在本例中,随着epsilon的增加,测试准确率下降,但扰动变得更容易被感知。
实际上,攻击者必须考虑准确率下降与可感知性之间的权衡。在这里,我们展示了每个epsilon值下成功对抗样本的一些示例。
图的每一行显示不同的epsilon值。第一行是epsilon=0的示例,代表无扰动的原始"干净"图像。
每个图像的标题显示了"原始分类 -> 对抗分类"。注意,在epsilon=0.15时扰动开始变得明显,在epsilon=0.3时非常明显。
然而,在所有情况下,尽管有噪声添加,人类仍然能够识别正确的类别。"""# 绘制几个在epsilon值下对抗样本示例
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):for j in range(len(examples[i])):cnt += 1plt.subplot(len(epsilons),len(examples[0]),cnt)plt.xticks([], [])plt.yticks([], [])if j == 0:plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)orig,adv,ex = examples[i][j]plt.title("{} -> {}".format(orig, adv))plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()实战案例效果
说明:
代码来自于https://pytorch.org/tutorials/beginner/fgsm_tutorial.html,
应在github:https://github.com/pytorch/tutorials/blob/master/beginner_source/fgsm_tutorial.py
基本使用说明:
1. 安装依赖项。
pip3 install numpy torch torchvision matplotlib
2. 执行FGSM算法对图像识别进行攻击,请保证您的电脑可以联网,代码会自动下载mnist数据集。
python fgsm_tutorial.py
相关文章:
AI安全之对抗样本攻击---FGSM实战脚本解析
一、对抗样本与FGSM的背景 在深度学习安全领域,对抗样本(Adversarial Examples)因其特殊的生成机制备受关注。2015年ICLR会议收录的里程碑式论文《Explaining and Harnessing Adversarial Examples》中,Goodfellow等学者首次系统…...
《Python星球日记》 第50天:深度学习概述与环境搭建
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、什么是深度学习?它与传统机器学习的区别1. 深度学习的定义2. 深…...

Android开发-图像显示
在Android应用开发中,图像显示是提升用户体验的重要元素之一。无论是展示产品图片、用户头像还是应用程序图标,合理地使用图像资源可以显著增强界面的吸引力和功能性。本文将详细介绍如何在Android应用中有效地显示图像,包括加载本地与网络图…...

linux搭建hadoop学习
linux搭建hadoop学习 下载安装包: 海外资源可能需要翻墙或者找国内资源 cd /opt wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz tar -zxvf hadoop-2.10.2.tar.gz mv hadoop-2.10.2 hadoop配置环境变量 # 在/etc/profile文件中添加下面内…...
PyTorch API 8 - 工具集、onnx、option、复数、DDP、量化、分布式 RPC、NeMo
文章目录 torch.nn.inittorch.nn.attention工具集子模块 torch.onnx概述基于 TorchDynamo 的 ONNX 导出器基于TorchScript的ONNX导出器贡献与开发 torch.optim如何使用优化器构建优化器每个参数的选项执行优化步骤optimizer.step()optimizer.step(closure) 基类算法如何调整学习…...

0基础 | STM32 | TB6612电机驱动使用
TB6612介绍及使用 单片机通过驱动板连接至电机 原因:单品机I/O口输出电流I小 驱动板:从外部引入高电压,控制电机驱动 电源部分 VM:电机驱动电源输入,输入电压范围建议为3.7~12V GND:逻辑电…...
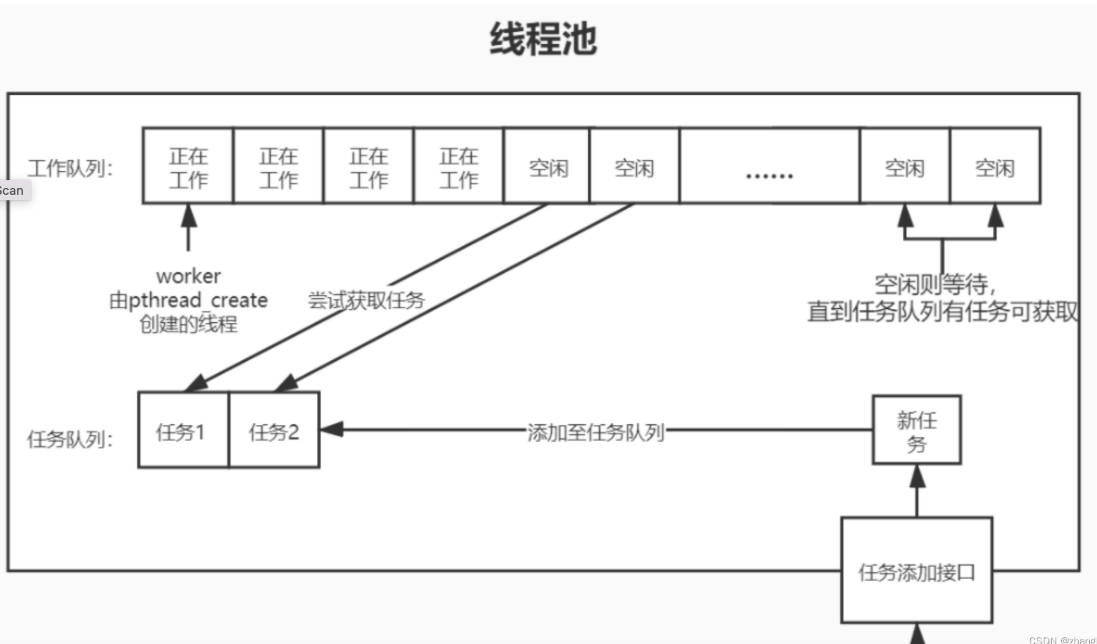
【Linux】POSIX 线程信号量与互斥锁▲
代码要求:高内聚,低耦合 高内聚:元素之间具有很强的关联性,模块的功能单一且集中 低耦合:代码之间的依赖关系尽可能简单,相互之间的影响和交互尽可能少 线程安全问题:多线程访问共享数据&…...

轻松制作高质量视频,实时生成神器LTX-Video重磅登场!
探索LTX-Video:实时视频生成跨越新高度 在如今这个视觉内容主导的数字时代,视频生成成为推动创意表达的关键。而今天,我们将带您深入探索LTX-Video,一个强大的开源项目,致力于通过尖端技术将视频生成提升到一个全新的…...
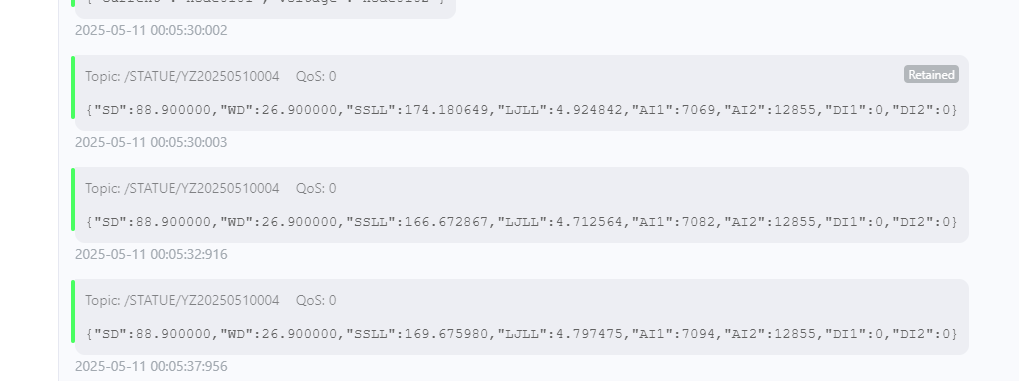
USR-M100采集数据并提交MQTT服务器
本文为记录备忘,不做过多解释。 模块自身带有2路数字量输入,2路模拟量输入,2路485接口 数字量接报警输入,模拟量接压力传感器,液位传感器,485接口分别接流量计,温湿度传感器。 正确接线&…...
内网穿透系列三:开源本地服务公网映射工具 tunnelmole
以下是对 tunnelmole 简要介绍: tunnelmole 是一款开源的内网穿透工具,一行命令就能把本地http服务映射成公网可访问的链接提供公共免费的网络服务,直接下载运行命令即可使用,也支持自行配置搭建私有客户端、服务端参考开源地址&…...

数据集-目标检测系列- 冥想 检测数据集 close_eye>> DataBall
数据集-目标检测系列- 冥想 检测数据集 close * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitHub - XIAN-HHappy/ultralytics-yolo-…...

计算机网络:家庭路由器WiFi信号的发射和手机终端接收信号原理?
WiFi路由器与手机之间的信号传输涉及多个技术层面的协作,以下是其工作原理的详细步骤: 一、数据封装与协议处理 应用层数据生成 用户操作(如浏览网页、视频播放)产生数据包,经TCP/IP协议栈逐层封装,添加IP地址(网络层)和MAC地址(数据链路层)。协议封装 数据包被封装…...

用 NGINX 打造高性能 FastCGI 加速 `ngx_http_fastcgi_module`
一、安装与启用 # 在编译 NGINX 源码时加上: ./configure --with-http_fastcgi_module make && sudo make install# 或确保你使用的二进制已内置(大多数发行版都默认包含) nginx -V | grep fastcgi二、基础转发配置 http {server {…...

深度学习 ———— 迁移学习
迁移学习原理 什么是迁移学习? 迁移学习利用在大规模数据集(如ImageNet)上预训练的模型,改装小数据集(如CIFAR-10)。优势: 减少训练时间:预训练模型已学习通用特征(如边…...

论文精读:YOLOE: Real-Time Seeing Anything
文章目录 前言1、背景2、方法2.1.重参Region-Text对齐模块2.2.VisualPrompt模块2.3.PromptFree 2.4.损失函数3、实验3.1.训练集3.2.实验结果 总结 前言 本文介绍一篇来自清华的开放词汇检测论文:YOLOE;源码链接。 1、背景 本文在yolo-world基础上&#x…...

以影像为笔,劳润智在世界舞台上书写艺术之路
在光影交织中,摄影师劳润智的镜头仿佛能穿透喧嚣,捕捉人类情感最细腻的脉动。从疫情下洛杉矶裁缝日常的温馨瞬间,到象征自由与解脱的飞鸟影像,再到探索时间与空间交错的抽象作品,每一幅作品都展现了他对艺术的深度追求与对生活的温柔洞察。 劳润智的作品为他赢得了多个国际奖项…...

vue3 computed方法传参数
我们对computed的基础用法不陌生,比如前端项目中经常会遇到数据处理的情况,我们就会选择computed方法来实现。但大家在碰到某些特殊场景,比如在template模板中for循环遍历时想给自己的计算属性传参,这个该怎么实现呢,很…...

【ES】Elasticsearch字段映射冲突问题分析与解决
在使用Elasticsearch作为搜索引擎时,经常会遇到一些映射(Mapping)相关的问题。本文将深入分析字段映射冲突问题,并通过原生的Elasticsearch API请求来复现和解决这个问题。 问题描述 在实际项目中,我们遇到以下错误: Transport…...

昇腾NPU容器内 apt 换源
环境 昊算NPU云910b 问题 缺少vim等,同时无法apt安装新的依赖 解决办法 使用vi修改/etc/apt/sources.list.d/debian.sources Types: deb URIs: http://deb.debian.org/debian Suites: bookworm bookworm-updates bookworm-backports Components: main contrib…...
:索引深度解析 —— 性能优化的核心武器)
MySQL 从入门到精通(五):索引深度解析 —— 性能优化的核心武器
目录 一、索引概述:数据库的 “目录” 1.1 什么是索引? 1.2 索引的性能验证:用事实说话 实验环境准备 无索引查询耗时 有索引查询耗时 索引的 “空间换时间” 特性 二、索引的创建:三种核心方式 2.1 方式 1:C…...

spark-Join Key 的基数/rand函数
在数据处理中,Join Key 的基数 是指 Join Key 的唯一值的数量(也称为 Distinct Key Count)。它表示某个字段(即 Join Key)在数据集中有多少个不同的值。 1. Join Key 基数的意义 高基数:Join Key 的唯一值…...
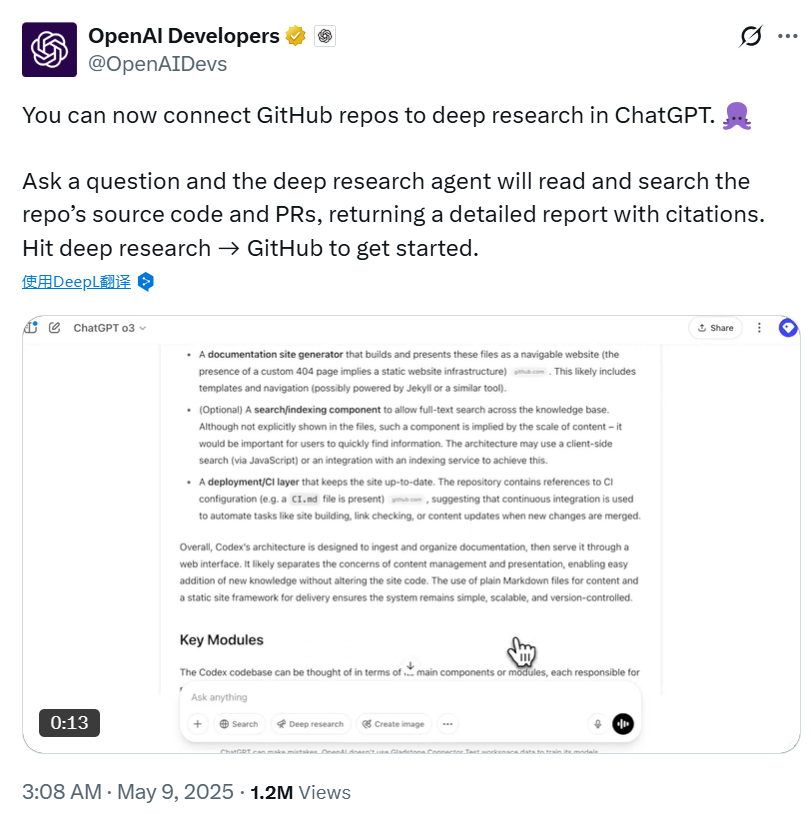
LLMs之ChatGPT:《Connecting GitHub to ChatGPT deep research》翻译与解读
LLMs之ChatGPT:《Connecting GitHub to ChatGPT deep research》翻译与解读 导读:这篇OpenAI帮助文档全面介绍了将GitHub连接到ChatGPT进行深度代码研究的方法、优势和注意事项。通过连接GitHub,用户可以充分利用ChatGPT强大的代码理解和生成…...

【桌面】【输入法】常见问题汇总
目录 一、麒麟桌面系统输入法概述 1、输入法介绍 2、输入法相关组件与服务 3、输入法调试相关命令 3.1、输入法诊断命令 3.2、输入法配置重新加载命令 3.3、启动fcitx输入法 3.4、查看输入法有哪些版本,并安装指定版本 3.5、重启输入法 3.6、查看fcitx进程…...

R语言学习--Day01--数据清洗初了解andR的经典筛选语法
当我们在拿到一份数据时,是否遇到过想要分析数据却无从下手?通过编程语言去利用它时发现有很多报错不是来源于代码而是因为数据里有很多脏数据;在这个时候,如果你会用R语言来对数据进行清洗,这会让你的效率提升很多。 …...
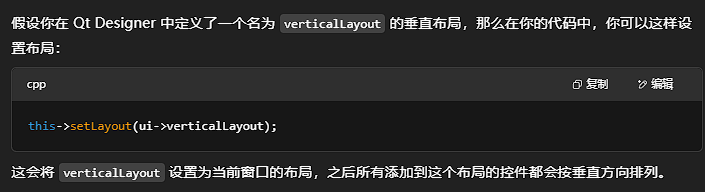
QT的初始代码解读及其布局和弹簧
this指的是真正的当前正在显示的窗口 main函数: Widget w是生成了一个主窗口,QT Designer是在这个主窗口里塞组件 w.show()用来展示这个主窗口 头文件: namespace Ui{class Widget;}中的class Widget和下面的class Widget不是一个东西 Ui…...

Profinet转CanOpen网关,打破协议壁垒的关键技术
在石油化工行业的生产现场,各类自动化设备如同精密运转的神经系统,而通信协议则是传递信号的"语言"。当不同厂商的设备采用Canopen与Profinet这两种主流工业协议时,就像两个使用不同方言的专家需要实时协作,此时开疆智能…...
引用第三方自定义组件——微信小程序学习笔记
1. 使用 npm 安装第三方包 1.1 下载安装Node.js 工具 下载地址:Node.js — Download Node.js 1.2 安装 npm 包 在项目空白处右键弹出菜单,选择“在外部终端窗口打开”,打开命令行工具,输入以下指令: 1> 初始化:…...

Docker、Docker-compose、K8s、Docker swarm之间的区别
1.Docker docker是一个运行于主流linux/windows系统上的应用容器引擎,通过docker中的镜像(image)可以在docker中构建一个独立的容器(container)来运行镜像对应的服务; 例如可以通过mysql镜像构建一个运行mysql的容器,既可以直接进入该容器命…...
SpringAI实现AI应用-使用redis持久化聊天记忆
SpringAI实战链接 1.SpringAl实现AI应用-快速搭建-CSDN博客 2.SpringAI实现AI应用-搭建知识库-CSDN博客 3.SpringAI实现AI应用-内置顾问-CSDN博客 4.SpringAI实现AI应用-使用redis持久化聊天记忆-CSDN博客 5.SpringAI实现AI应用-自定义顾问(Advisor)…...
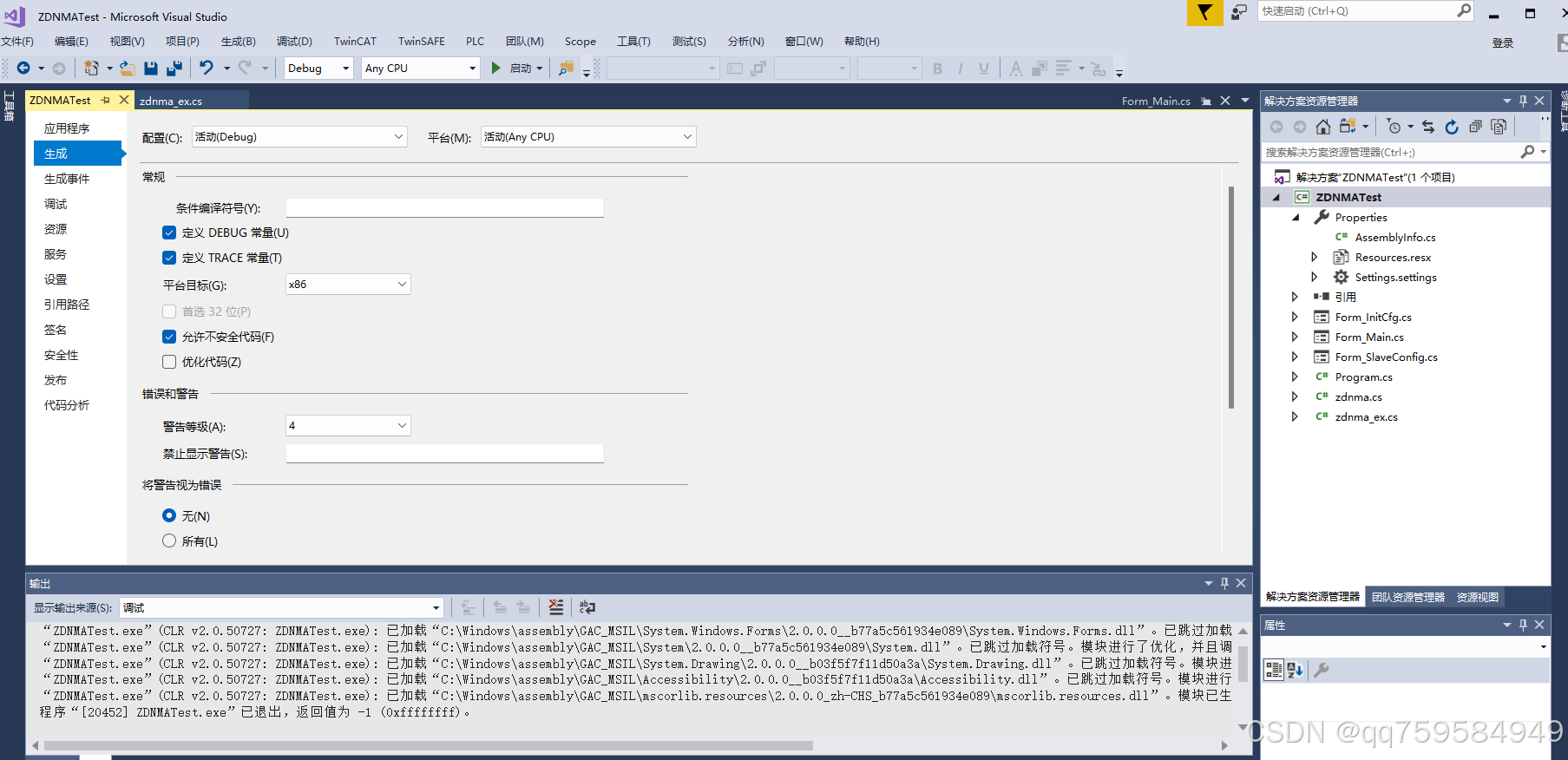
C#问题 加载格式不正确解决方法
出现上面问题 解决办法:C#问题 改成x86 不要选择anycpu...