并发笔记-锁(一)
文章目录
- 1. 基本问题与锁的概念 (The Basic Idea)
- 2. 锁的API与Pthreads (Lock API and Pthreads)
- 3. 构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)
- 4. 早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)
- 4.1 控制中断 (Controlling Interrupts)
- 4.2 仅使用加载/存储指令 (Figure 28.1 - A Failed Attempt)
- 5. 基于硬件原子指令的自旋锁 (Hardware Primitives & Spin Locks)
- 5.1 测试并设置 (Test-and-Set / Atomic Exchange) (Figure 28.3)
- 5.2 其他原子指令
- 5.3 票据锁 (Ticket Lock) (使用 Fetch-and-Add 实现公平性) (Figure 28.7)
- 6. 避免过度自旋:操作系统支持 (Avoiding Excessive Spinning: OS Support)
- 6.1 简单方法:让步 (Yield) (Figure 28.8)
- 6.2 使用队列:休眠代替自旋 (Using Queues: Sleeping Instead Of Spinning) (Figure 28.9)
- 7. 高级主题与实际考量 (Advanced Topics & Real-World Considerations)
- 7.1 Linux Futex (Fast Userspace muTEX) (Figure 28.10 概念)
- 7.2 优先级反转 (Priority Inversion)
- 8. Peterson算法
- 8.1 核心思想
- 8.2 算法组件(共享变量)
- 8.3 算法流程(以进程P_i为例,另一个进程为P_j)
- 8.4 为什么Peterson算法能工作?(满足互斥的三个条件)
- 8.5 优点
- 8.6 缺点和局限性
- 9. 锁改进机制的演进流程
- 9.1 最原始尝试 - 控制中断
- 9.2 简单软件尝试 - 仅使用加载/存储指令(失败)
- 9.3 硬件原子指令支持 - 自旋锁(第一次重大改进)
- Test-and-Set 自旋锁
- 票据锁(改进公平性)
- 9.4 操作系统支持 - 避免过度自旋(第二次重大改进)
- 简单让步(Yield)
- 使用队列:休眠代替自旋
- 9.5 混合策略 - Linux Futex(最优化方案)
- 9.6 总结改进流程
- 10. 简要总结
1. 基本问题与锁的概念 (The Basic Idea)
- 核心问题: 在并发环境中,如何确保一系列指令(临界区, critical section)能够原子地 (atomically) 执行,以防止因中断或多线程/多处理器并发访问共享资源而导致的竞争条件。
- 锁 (Lock): 一种同步机制,程序员用它来"标记"临界区。其目标是确保在任何时刻,只有一个线程能够进入该临界区执行,使得这段代码如同一个不可分割的原子指令。
- 锁的状态: 锁变量自身通常有两种状态:
- 可用 (available / unlocked / free): 没有线程持有该锁。
- 已被获取 (acquired / locked / held): 某个线程正持有该锁。
2. 锁的API与Pthreads (Lock API and Pthreads)
- 基本操作:
lock(): 尝试获取锁。如果锁已被其他线程持有,则调用线程通常会等待(阻塞或自旋)。unlock(): 释放当前线程持有的锁,这可能唤醒一个正在等待该锁的线程。
- Pthreads: POSIX线程库提供了互斥量 (mutex) 作为锁的实现,类型为
pthread_mutex_t。pthread_mutex_lock(&mutex): 获取互斥锁。pthread_mutex_unlock(&mutex): 释放互斥锁。
- 锁的粒度:
- 粗粒度锁 (Coarse-grained locking): 用一个锁保护大块数据或多个数据结构。简单但可能限制并发性。
- 细粒度锁 (Fine-grained locking): 用多个锁分别保护不同的数据或数据结构的不同部分。复杂但能提高并发性。
3. 构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)
构建一个高效且正确的锁通常需要硬件原子指令和操作系统支持。
评估锁的主要标准:
- 互斥性 (Mutual Exclusion): 这是最基本的要求。锁必须能阻止多个线程同时进入临界区。
- 公平性 (Fairness): 等待锁的线程是否都有机会获取锁?是否存在某些线程会饿死 (starvation)(即永远无法获得锁)的情况?
- 性能 (Performance): 锁操作本身带来的开销。
- 无竞争情况下的开销(单个线程获取和释放锁)。
- 高竞争情况下的开销(多个线程争抢同一个锁),需考虑单CPU和多CPU场景。
4. 早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)
4.1 控制中断 (Controlling Interrupts)
(主要用于早期单处理器系统内核)
- 原理: 在进入临界区前禁用中断,退出后启用中断。
- 缺点: 需要特权指令;滥用风险高;不适用于多处理器系统;长时间禁用中断会导致系统响应问题和中断丢失。
4.2 仅使用加载/存储指令 (Figure 28.1 - A Failed Attempt)
// lock_t结构定义
typedef struct __lock_t {int flag; // 0: lock is available, 1: lock is held
} lock_t;void init(lock_t *mutex) {mutex->flag = 0; // 初始化锁为可用
}void lock(lock_t *mutex) {while (mutex->flag == 1) // 检查锁是否被持有 (TEST); // 自旋等待 (spin-waiting)mutex->flag = 1; // 获取锁 (SET it!)
}void unlock(lock_t *mutex) {mutex->flag = 0; // 释放锁
}
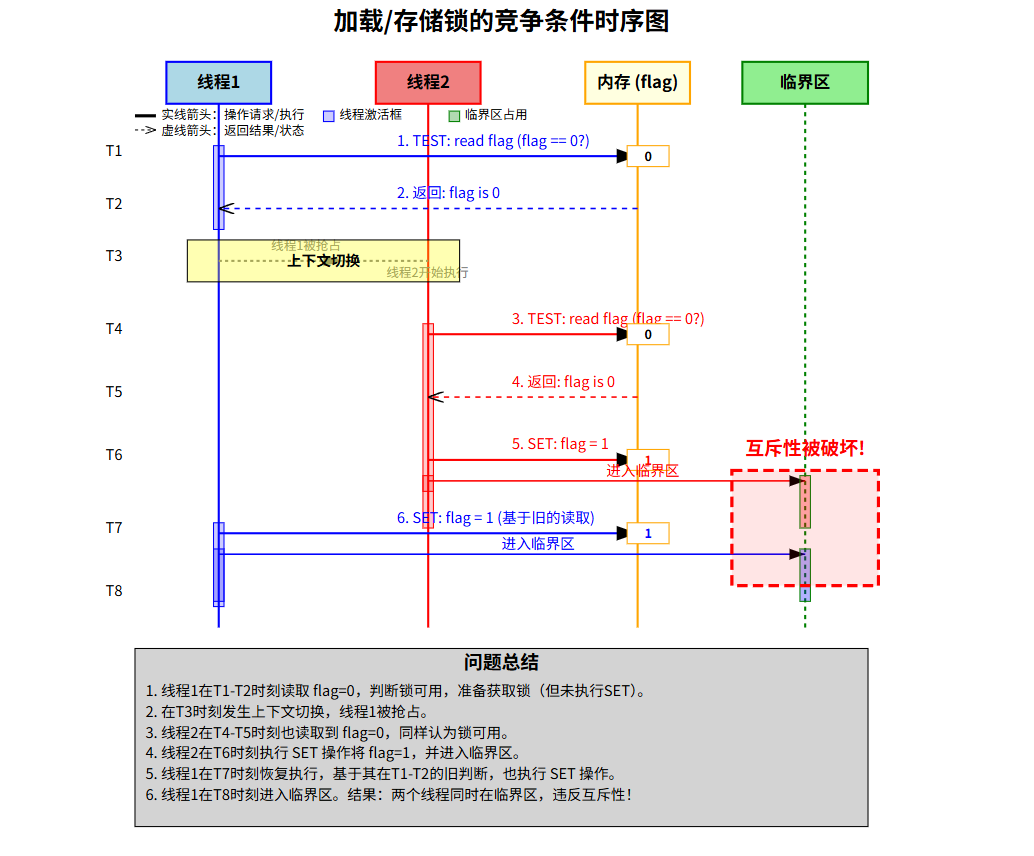
笔记:
- 原理: 尝试用一个共享
flag变量表示锁状态。 - 关键问题: 不正确! 在
while (mutex->flag == 1)(TEST) 和mutex->flag = 1(SET) 之间存在竞争条件。如果一个线程在TEST之后、SET之前被中断,另一个线程可能也通过TEST并进入临界区,破坏互斥性。 - 缺点: 不保证互斥性;引入了自旋等待 (spin-waiting),即使在单CPU上也可能浪费CPU。
- 目的: 此例说明了构建锁为何需要原子操作。
5. 基于硬件原子指令的自旋锁 (Hardware Primitives & Spin Locks)
现代CPU提供特殊的原子指令来构建锁。自旋锁是指当线程尝试获取一个已被持有的锁时,它会持续地循环检查(“自旋”)锁的状态,直到锁变为可用。
5.1 测试并设置 (Test-and-Set / Atomic Exchange) (Figure 28.3)
- 原子指令
TestAndSet(int *old_ptr, int new_val): 原子地读取*old_ptr的旧值,将*old_ptr设置为new_val,并返回旧值。
// lock_t结构定义同上
void init(lock_t *lock) { lock->flag = 0; }void lock(lock_t *lock) {// TestAndSet返回flag的旧值,并原子地将其设置为1// 若旧值为1 (锁已被持有),继续自旋// 若旧值为0 (锁可用),循环终止,锁已被当前线程获取 (flag已被原子设为1)while (TestAndSet(&lock->flag, 1) == 1); // 自旋等待
}void unlock(lock_t *lock) { lock->flag = 0; }
笔记:
- 关键:
TestAndSet的原子性保证了测试和设置操作之间不会被打断,从而确保互斥。 - 优点: 简单、保证互斥。
- 缺点: 仍是自旋等待;不保证公平性,可能导致线程饿死。
- 适用: 临界区非常短的多处理器系统。
5.2 其他原子指令
- 比较并交换 (Compare-and-Swap - CAS):
CAS(ptr, expected, new)原子地比较*ptr与expected,若相等则将*ptr更新为new,并返回操作是否成功(或旧值)。功能比Test-and-Set更强大。 - 加载链接/条件存储 (Load-Linked / Store-Conditional - LL/SC):
LL加载一个值,SC只有在该内存位置自LL以来未被其他操作修改过的情况下,才会将新值存储成功。 - 读取并加 (Fetch-and-Add):
FetchAndAdd(ptr, val)原子地读取*ptr的旧值,然后将*ptr增加val,并返回旧值。
5.3 票据锁 (Ticket Lock) (使用 Fetch-and-Add 实现公平性) (Figure 28.7)
typedef struct __lock_t {int ticket; // 下一个可用的票号int turn; // 当前轮到哪个票号
} lock_t;void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; }void lock(lock_t *lock) {int myturn = FetchAndAdd(&lock->ticket); // 原子地获取票号while (lock->turn != myturn); // 自旋等待轮到自己的号
}void unlock(lock_t *lock) {// FetchAndAdd(&lock->turn, 1); // 更安全的做法是也用原子操作lock->turn = lock->turn + 1; // 书中简化
}
笔记:
- 原理: 模拟排队。
FetchAndAdd原子地分配唯一的、递增的ticket号。线程等待全局turn号轮到自己。 - 优点: 保证互斥性;保证公平性 (FIFO),避免饿死。
- 缺点: 仍然是自旋等待。
6. 避免过度自旋:操作系统支持 (Avoiding Excessive Spinning: OS Support)
自旋锁在某些情况(如单CPU高竞争、持有锁的线程被长时间阻塞)下效率低下。
6.1 简单方法:让步 (Yield) (Figure 28.8)
- 原理: 获取锁失败时,调用
yield()主动放弃CPU。
// lock_t结构定义同上,使用TestAndSet
void lock(lock_t *lock) {while (TestAndSet(&lock->flag, 1) == 1)yield(); // 如果锁被占用,则让出CPU
}
笔记:
- 优点: 在单CPU高竞争时,比纯自旋好,可能让持有锁的线程有机会运行。
- 缺点: 频繁
yield导致上下文切换开销大;不解决饿死问题。
6.2 使用队列:休眠代替自旋 (Using Queues: Sleeping Instead Of Spinning) (Figure 28.9)
JAVA的AQS引入了阻塞队列
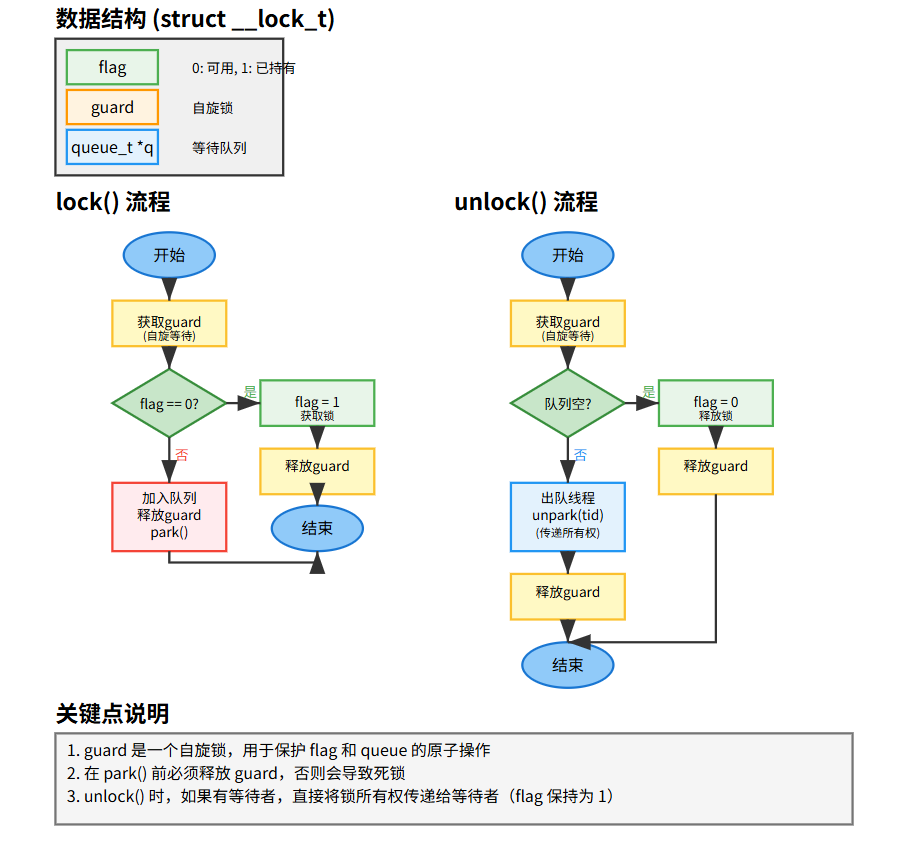
- 引入OS原语如 Solaris 的
park()(使线程休眠) 和unpark(threadID)(唤醒特定线程)。
typedef struct __lock_t {int flag; // 主锁状态 (0:可用, 1:已持有)int guard; // 保护flag和队列的自旋锁queue_t *q; // 等待线程队列
} lock_t;void lock_init(lock_t *m) { /* ... */ }void lock(lock_t *m) {while (TestAndSet(&m->guard, 1) == 1); // 获取guardif (m->flag == 0) { // 锁可用m->flag = 1;m->guard = 0; // 释放guard} else { // 锁被占用queue_add(m->q, gettid());m->guard = 0; // 在park前释放guard!park(); // 休眠}
}void unlock(lock_t *m) {while (TestAndSet(&m->guard, 1) == 1); // 获取guardif (queue_empty(m->q)) {m->flag = 0;} else {int tid = queue_remove(m->q);unpark(tid); // 唤醒等待者 (锁所有权直接传递)}m->guard = 0; // 释放guard
}
笔记:
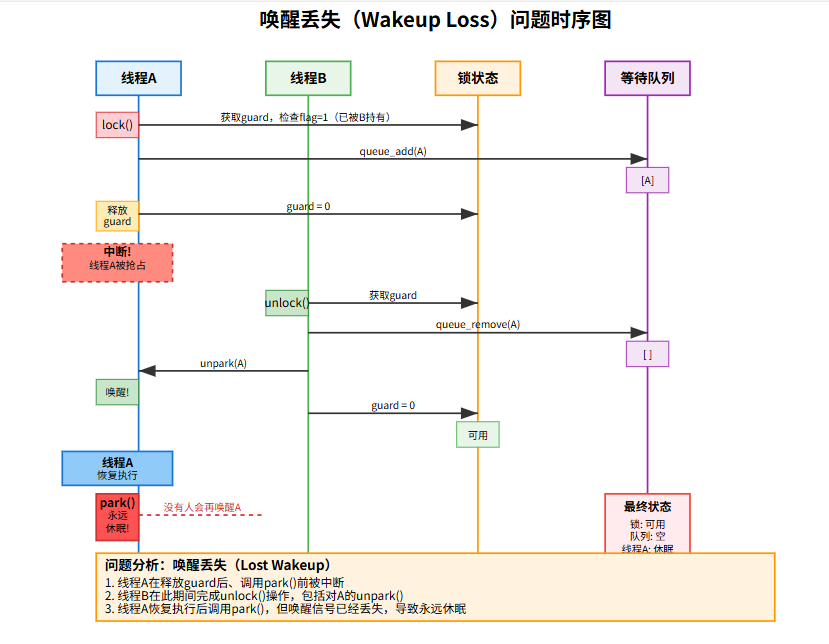
“唤醒丢失”(Lost Wakeup)问题的发生过程:
- 线程A尝试获取锁:发现锁被B持有,将自己加入等待队列
- 关键时刻:线程A释放guard后,在调用park()之前被中断/抢占
- 线程B释放锁:
- 获取guard
- 从队列中移除线程A
- 调用unpark(A)尝试唤醒A
- 释放guard
- 问题发生:线程A恢复执行后才调用park(),但唤醒信号已经在之前发送过了
- 结果:线程A永远休眠,因为没有人会再次唤醒它
这个问题的根源在于:
- park()和unpark()的语义不是对称的
- unpark()只是设置一个标志,如果线程还没有park(),这个标志会被"消费"掉
- 当线程A最终调用park()时,之前的唤醒信号已经丢失
解决方案通常包括:
- 使用条件变量等更高级的同步原语
- 确保park()和unpark()的调用顺序正确
- 在关键路径上使用原子操作或其他保护机制
- 原理: 用
guard自旋锁保护主锁状态flag和等待队列q。获取锁失败则入队休眠;释放锁时若队列不空则唤醒队首线程。 - 优点: 线程等待时不消耗CPU;通过队列可实现公平。
- 缺点: 实现复杂;有上下文切换开销;需要处理唤醒/等待竞争 (wakeup/waiting race)。
- 竞争问题: 线程A在释放
guard后、调用park()前被中断,此时锁被释放且线程A被unpark,之后A再执行park()就可能永远休眠。 - 解决: Solaris的
setpark()或Linuxfutex的机制。
- 竞争问题: 线程A在释放
7. 高级主题与实际考量 (Advanced Topics & Real-World Considerations)
7.1 Linux Futex (Fast Userspace muTEX) (Figure 28.10 概念)
- 原理: 一种混合策略,也是两阶段锁 (Two-Phase Lock) 的一种。
- 快速路径: 在用户空间通过原子操作尝试获取/释放锁。无竞争时非常快,不陷入内核。
- 慢速路径: 当检测到竞争,才陷入内核调用
futex_wait()休眠或futex_wake()唤醒。
// 极简伪代码概念
void mutex_lock(int *mutex_word) {if (atomic_try_acquire(mutex_word)) return; // 快速路径// 慢速路径:atomic_increment_waiters(mutex_word);while (1) {if (atomic_try_acquire(mutex_word)) { /* ... */ return; }futex_wait(mutex_word, EXPECTED_STATE_WHEN_HELD);}
}
void mutex_unlock(int *mutex_word) {atomic_release(mutex_word);if (has_waiters(mutex_word)) {futex_wake(mutex_word, 1);}
}
笔记:
- 优点: 无竞争时开销极低;竞争时休眠。
- 关键: 使用一个整数同时编码锁状态和等待者信息;依赖原子操作和内核
futex调用。
7.2 优先级反转 (Priority Inversion)
高优先级线程等待一个被低优先级线程持有的锁,而该低优先级线程可能因优先级更低而无法运行,导致高优先级线程也无法执行。
8. Peterson算法
8.1 核心思想
- 每个进程都有一个
flag,表示它是否想要进入临界区。 - 有一个共享的
turn变量,表示当前轮到哪个进程进入(如果双方都想进入)。
一个进程要进入临界区,必须满足以下两个条件之一:
- 另一个进程不想进入临界区。
- 或者,另一个进程想进入,但当前轮到自己。
8.2 算法组件(共享变量)
假设有两个进程P0和P1。
-
volatile boolean flag[2];flag[0]:如果P0想进入临界区,则为true;否则为false。flag[1]:如果P1想进入临界区,则为true;否则为false。- 初始化为
{false, false}。 volatile关键字提示编译器不要对这些变量的读写进行过度优化(例如缓存到寄存器中),因为它们可能被其他进程并发修改。但在现代多核处理器中,volatile不足以保证内存可见性和顺序性,需要内存屏障。
-
volatile int turn;- 表示如果两个进程都想进入临界区,轮到哪个进程。
- 如果
turn == 0,轮到P0;如果turn == 1,轮到P1。 - 初始化可以是0或1。
8.3 算法流程(以进程P_i为例,另一个进程为P_j)
进程P_i (其中 i 是0或1, j = 1 - i):
// 共享变量 (在进程/线程间共享)
volatile boolean flag[2] = {false, false};
volatile int turn; // 可以初始化为 0 或 1// 进程 P_i 的代码
// i = 0 或 1
// j = 1 - i (代表另一个进程的索引)// Entry Protocol (进入临界区前的代码)
flag[i] = true; // 1. 表达意愿:我想进入临界区
turn = j; // 2. 谦让:把机会让给另一个进程 j// 3. 检查条件并等待:
// - 如果进程 j 也想进入 (flag[j] == true)
// - 并且 当前确实轮到进程 j (turn == j)
// 那么,进程 i 就在这里自旋等待。
while (flag[j] && turn == j) {// busy wait (自旋等待)
}// ---- 临界区 (Critical Section) ----
// ... 执行需要互斥访问的代码 ...
// ---- 临界区结束 ----// Exit Protocol (离开临界区后的代码)
flag[i] = false; // 4. 取消意愿:我不再想进入临界区 (或已离开)// 这会允许另一个等待的进程进入// ---- 剩余区 (Remainder Section) ----
代码解释:
flag[i] = true;: 进程i设置自己的标志,表明它有兴趣进入临界区。turn = j;: 这是算法的关键一步。即使进程i想进入,它也"礼貌地"将turn设置为另一个进程j的。这表示:“如果你(进程j)也想进入,那么你先请。”while (flag[j] && turn == j): 这是等待条件。进程i会一直等待,只要满足以下两个条件:- 另一个进程
j也想进入 (flag[j] == true)。 - 并且,当前确实是进程
j的回合 (turn == j)。 - 如果
flag[j]为false(进程j不想进入),进程i可以直接进入。 - 如果
flag[j]为true但turn == i(轮到进程i了,因为进程j之前可能把turn设成了i),进程i也可以进入。
- 另一个进程
flag[i] = false;: 当进程i离开临界区后,它将自己的flag设为false,表明它不再占用临界区,其他进程可以尝试进入了。
8.4 为什么Peterson算法能工作?(满足互斥的三个条件)
-
互斥 (Mutual Exclusion): 不可能有两个进程同时在临界区。
- 假设P0和P1都想进入。它们都设置自己的
flag为true。 turn变量最终会被设置为0或1(取决于哪个进程最后执行turn = j;)。- 假设
turn最后被设置为0(P1执行了turn = 0;)。- P1的等待条件是
flag[0] && turn == 0。因为flag[0]是true,turn == 0也是true,所以P1会等待。 - P0的等待条件是
flag[1] && turn == 1。因为turn是0,所以turn == 1是false。因此P0的等待条件不满足,P0会进入临界区。
- P1的等待条件是
- 对称地,如果
turn最后被设置为1,则P1进入,P0等待。 - 因此,只有一个进程能通过
while循环。
- 假设P0和P1都想进入。它们都设置自己的
-
前进 (Progress / No Deadlock): 如果没有进程在临界区中,并且有进程想要进入临界区,那么这些想进入的进程中必须有一个能够最终进入。
- 如果P0想进入,P1不想进入 (
flag[1] == false)。P0设置flag[0] = true,turn = 1。P0的等待条件flag[1] && turn == 1因为flag[1]为false而不成立,P0进入。 - 如果两个进程都想进入,如上所述,
turn变量会确保其中一个进程最终会进入。
- 如果P0想进入,P1不想进入 (
-
有限等待 (Bounded Waiting / No Starvation): 一个请求进入临界区的进程不能无限期地等待。
- 当一个进程P_i想进入临界区时,它设置
flag[i] = true。它最多只会等待另一个进程P_j完成一次临界区操作。 - 因为一旦P_j退出临界区,它会设置
flag[j] = false,这将使P_i的while循环条件(flag[j] && turn == j)中的flag[j]为false,从而允许P_i进入。 - 即使P_j立即又想进入临界区,它会执行
turn = i,把优先权交给了P_i。
- 当一个进程P_i想进入临界区时,它设置
8.5 优点
- 纯软件方案:不需要特殊的硬件原子指令(如Test-and-Set, Compare-and-Swap),只需要原子性的读写共享变量。
- 简单优雅:对于两个进程的情况,逻辑相对清晰。
- 保证了互斥、前进和有限等待。
8.6 缺点和局限性
- 仅适用于两个进程/线程:这是其最大的局限性。不能直接推广到N个进程。对于N个进程,需要更复杂的算法,如Lamport面包店算法。
- 忙等待 (Busy Waiting):当进程在
while循环中等待时,它会持续消耗CPU周期,效率低下。 - 现代多核处理器上的问题 (Memory Model Issues):
- Peterson算法依赖于对共享变量
flag和turn的写操作对其他处理器立即可见,并且操作的顺序得到保证(例如,flag[i] = true;必须在turn = j;之前对其他处理器可见,并且while循环中的读操作能读到最新的值)。 - 现代CPU为了性能会进行指令重排和使用缓存,这可能导致一个CPU上的写操作不能立即被另一个CPU看到,或者执行顺序与代码顺序不一致。
volatile关键字在C/C++中主要用于防止编译器优化,不足以解决多核处理器上的内存可见性和指令重排问题。- 要在现代多核系统上正确实现Peterson算法(或其他类似的软件同步算法),需要使用内存屏障 (Memory Barriers/Fences) 指令来强制内存操作的顺序和可见性。这使得它不再是"纯"软件方案,并且增加了复杂性。
- 由于这些原因,在实际系统中,通常会使用基于硬件原子指令(如互斥锁
mutex的实现)或操作系统提供的同步原语,而不是直接使用Peterson算法。
- Peterson算法依赖于对共享变量
9. 锁改进机制的演进流程
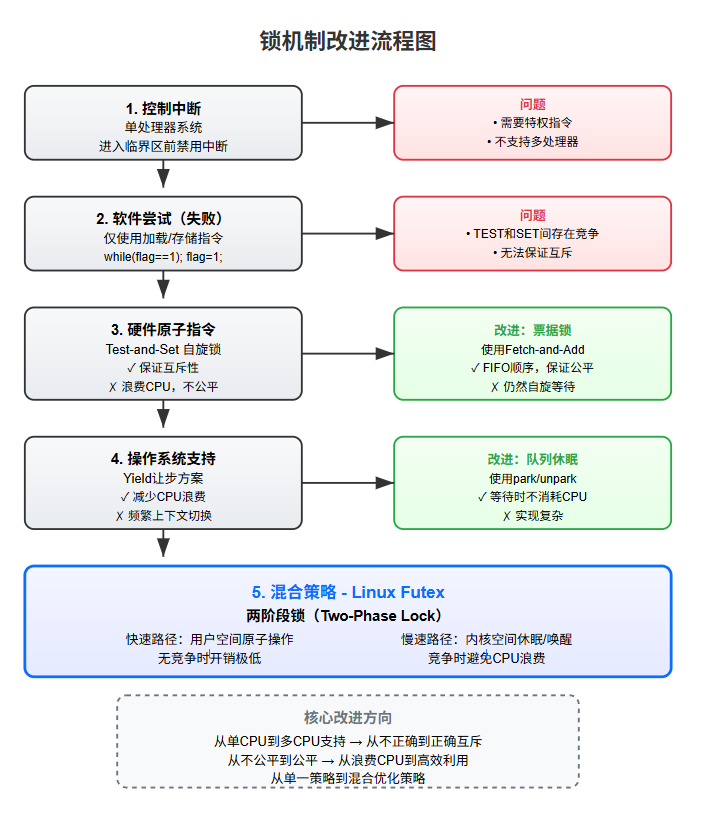
9.1 最原始尝试 - 控制中断
- 原理:在单处理器系统中,进入临界区前禁用中断,退出后启用中断
- 问题:需要特权指令、不适用于多处理器、长时间禁用中断会导致系统响应问题
9.2 简单软件尝试 - 仅使用加载/存储指令(失败)
void lock(lock_t *mutex) {while (mutex->flag == 1) ; // TESTmutex->flag = 1; // SET
}
- 问题:TEST和SET之间存在竞争条件,无法保证互斥性
9.3 硬件原子指令支持 - 自旋锁(第一次重大改进)
Test-and-Set 自旋锁
void lock(lock_t *lock) {while (TestAndSet(&lock->flag, 1) == 1); // 自旋等待
}
- 优点:通过原子操作保证了互斥性
- 缺点:持续占用CPU、不保证公平性
票据锁(改进公平性)
void lock(lock_t *lock) {int myturn = FetchAndAdd(&lock->ticket);while (lock->turn != myturn); // 自旋等待
}
- 优点:FIFO顺序,保证公平性,避免饿死
- 缺点:仍然是自旋等待,浪费CPU
9.4 操作系统支持 - 避免过度自旋(第二次重大改进)
简单让步(Yield)
void lock(lock_t *lock) {while (TestAndSet(&lock->flag, 1) == 1)yield(); // 主动放弃CPU
}
- 优点:在单CPU高竞争时比纯自旋好
- 缺点:频繁上下文切换开销大,不解决饿死问题
使用队列:休眠代替自旋
void lock(lock_t *m) {while (TestAndSet(&m->guard, 1) == 1);if (m->flag == 0) {m->flag = 1;m->guard = 0;} else {queue_add(m->q, gettid());m->guard = 0;park(); // 休眠}
}
- 优点:线程等待时不消耗CPU,通过队列实现公平
- 缺点:实现复杂,需要处理唤醒/等待竞争
9.5 混合策略 - Linux Futex(最优化方案)
- 两阶段锁策略:
- 快速路径:在用户空间通过原子操作尝试获取锁(无竞争时开销极低)
- 慢速路径:检测到竞争时,才陷入内核进行休眠/唤醒
void mutex_lock(int *mutex_word) {if (atomic_try_acquire(mutex_word)) return; // 快速路径// 慢速路径:陷入内核futex_wait(mutex_word, EXPECTED_STATE_WHEN_HELD);
}
9.6 总结改进流程
1. 控制中断 → 软件尝试 → 硬件原子指令 → OS支持 → 混合策略
-
每次改进都在解决前一版本的问题:
- 从单CPU到多CPU支持
- 从无法保证互斥到实现正确互斥
- 从不公平到公平(FIFO)
- 从浪费CPU到高效利用CPU
- 从单一策略到混合优化策略
-
最终的Futex实现结合了:
- 用户空间快速路径(无竞争时性能最优)
- 内核空间慢速路径(竞争时避免CPU浪费)
- 原子操作保证正确性
- 队列机制保证公平性
针对常见情况(无竞争)优化,同时正确处理特殊情况(高竞争)。
10. 简要总结
-
基本问题与锁的概念 (The Basic Idea)
- 并发编程的核心问题之一是如何原子地 (atomically) 执行一系列指令(即临界区,critical section),防止因中断或多线程/多处理器并发执行导致的竞争条件。
- 锁是一种机制,程序员用它来“标记”临界区,确保任何时候只有一个线程能进入该临界区执行,如同这段代码是一个不可分割的原子指令。
- 一个锁变量自身有状态:可用 (available/unlocked/free) 或 已被获取 (acquired/locked/held)。
-
锁的API与Pthreads (Lock API and Pthreads)
- 基本操作是
lock()(尝试获取锁,若锁被占用则等待) 和unlock()(释放锁,可能唤醒等待者)。 - POSIX 线程库 (Pthreads) 中对应的锁是 互斥量 (mutex),如
pthread_mutex_t,通过pthread_mutex_lock()和pthread_mutex_unlock()操作。 - 提到了粗粒度锁 (coarse-grained locking) 和 细粒度锁 (fine-grained locking) 的概念,后者通过使用多个锁保护不同数据以提高并发性。
- 基本操作是
-
构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)
- 构建一个高效且正确的锁需要硬件和操作系统的支持。
- 评估锁的三个主要标准:
- 互斥性 (Mutual Exclusion):是否能正确阻止多个线程同时进入临界区。
- 公平性 (Fairness):等待锁的线程是否都有机会获取锁,是否存在饿死 (starvation) 现象。
- 性能 (Performance):锁操作带来的开销,包括无竞争情况下的开销和高竞争情况下的开销(单CPU和多CPU场景)。
-
早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)
- 控制中断 (Controlling Interrupts):
- 单处理器系统上的早期方法,通过在临界区前后开关中断实现原子性。
- 缺点:需要特权指令,滥用会导致系统问题;不适用于多处理器;长时间关中断会导致中断丢失。
- 仅使用加载/存储指令 (Just Using Loads/Stores - A Failed Attempt):
- 尝试用一个简单标志位 (flag) 来实现锁。
- 问题:
TEST标志位和SET标志位这两个操作之间可能发生中断或并发,导致多个线程同时进入临界区,无法保证互斥。 - 这种等待方式引入了自旋等待 (spin-waiting) 的概念。
- 控制中断 (Controlling Interrupts):
-
基于硬件原子指令的自旋锁 (Hardware Primitives & Spin Locks)
- 现代CPU提供了特殊的原子指令来构建锁:
- 测试并设置 (Test-and-Set / Atomic Exchange):原子地读取旧值并写入新值。
- 比较并交换 (Compare-and-Swap - CAS):原子地比较内存值与期望值,若相等则写入新值。
- 加载链接/条件存储 (Load-Linked / Store-Conditional - LL/SC):
LL加载一个值,SC只有在该值未被改变时才存储成功。 - 读取并加 (Fetch-and-Add):原子地读取一个值并将其增加。
- 使用这些原子指令可以构建自旋锁 (Spin Locks)。线程在获取锁失败时会循环检查锁状态。
- 评估自旋锁:
- 互斥性:正确。
- 公平性:基本自旋锁不保证公平,可能导致饿死。票据锁 (Ticket Lock) (使用 Fetch-and-Add) 可以实现公平性,按到达顺序获取锁。
- 性能:在单CPU上,如果持有锁的线程被抢占,其他线程自旋会浪费大量CPU时间。在多CPU上,如果临界区很短,自旋锁开销小,效率尚可。
- 现代CPU提供了特殊的原子指令来构建锁:
-
避免过度自旋:操作系统支持 (Avoiding Excessive Spinning: OS Support)
- 问题:自旋锁在某些情况下(如单CPU高竞争、持有锁的线程被长时间阻塞)效率低下。
- 简单方法:让步 (Yield):线程获取锁失败时调用
yield()主动放弃CPU。- 比纯自旋好,但若等待线程很多,仍有大量上下文切换开销,且不解决饿死问题。
- 使用队列:休眠代替自旋 (Using Queues: Sleeping Instead Of Spinning):
- 引入操作系统原语如 Solaris 的
park()(使线程休眠) 和unpark(threadID)(唤醒特定线程),或 Linux 的futex。 - 当线程获取锁失败时,将其加入等待队列并休眠。当锁被释放时,从队列中唤醒一个线程。
- 这种方法需要一个额外的保护锁 (guard lock) (通常是自旋锁) 来保护队列和锁状态本身的操作。
- 需要处理唤醒/等待竞争 (wakeup/waiting race) 问题,例如 Solaris 的
setpark()可以在park()前声明意图。
- 引入操作系统原语如 Solaris 的
-
高级主题与实际考量 (Advanced Topics & Real-World Considerations)
- 优先级反转 (Priority Inversion):高优先级线程等待一个被低优先级线程持有的锁(该低优先级线程可能无法运行),导致高优先级线程无法执行。
- 两阶段锁 (Two-Phase Locks):一种混合策略。第一阶段尝试自旋一小段时间,如果获取不到锁,则进入第二阶段,将线程休眠。Linux Futex锁实现有此特性。
参考:
ostep 28章
相关文章:
并发笔记-锁(一)
文章目录 1. 基本问题与锁的概念 (The Basic Idea)2. 锁的API与Pthreads (Lock API and Pthreads)3. 构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)4. 早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)4.1 控制中断 (Controlling Interrupts)4.2 仅…...

【Bootstrap V4系列】学习入门教程之 组件-媒体对象(Media object)
Bootstrap V4系列 学习入门教程之 组件-媒体对象(Media object) 媒体对象(Media object)一、Example二、Nesting 嵌套三、Alignment 对齐四、Order 顺序五、Media list 媒体列表 媒体对象(Media object) B…...

ALSTOM D-984-0721 自动化组件
ALSTOM D-984-0721是一款高性能自动化组件,专为电力行业、石化行业和一般自动化应用的苛刻环境而设计。该型号旨在提供卓越的可靠性和精度,因其强大的输入/输出能力、耐用性和无缝集成能力而脱颖而出,成为现代工业自动化系统不可或缺的工具。…...

2025数字中国创新大赛-数字安全赛道数据安全产业积分争夺赛决赛Writeup
文章目录 综合场景赛-模型环境安全-3综合场景赛-数据识别与审计-1综合场景赛-数据识别与审计-2综合场景赛-数据识别与审计-3 有需要题目附件的师傅,可以联系我发送 综合场景赛-模型环境安全-3 upload文件嵌套了多个png图片字节数据,使用foremost直接分离…...
无法更新Google Chrome的解决问题
解决问题:原文链接:【百分百成功】Window 10 Google Chrome无法启动更新检查(错误代码为1:0x80004005) google谷歌chrome浏览器无法更新Chrome无法更新至最新版本? 下载了 就是更新Google Chrome了...

数字孪生市场格局生变:中国2025年规模214亿,工业制造领域占比超40%
一、技术深度解析:数字孪生的核心技术栈与演进 1. 从镜像到自治:数字孪生技术架构跃迁 三维重建突破:LiDAR点云精度达2cm,无人机测深刷新频率5Hz,支撑杭州城市大脑内涝预警模型提前6小时预测。AI算法融合:…...
 详解)
ES6 (ECMAScript 2015) 详解
文章目录 一、ES6简介1.1 什么是ES6?1.2 为什么要学习ES6?1.3 浏览器支持情况 二、let和const关键字2.1 let关键字2.2 const关键字2.3 var、let和const的选择 三、箭头函数3.1 基本语法3.2 箭头函数的特点3.3 何时使用箭头函数 四、模板字符串4.1 基本语…...
全球首款无限时长电影生成模型SkyReels-V2本地部署教程:视频时长无限制!
一、简介 SkyReels-V2 模型集成了多模态大语言模型(MLLM)、多阶段预训练、强化学习以及创新的扩散强迫(Diffusion-forcing)框架,实现了在提示词遵循、视觉质量、运动动态以及视频时长等方面的全面突破。通过扩散强迫框…...

SQL 数据库监控:SQL语句监控工具与实践案例
SQL 数据库监控:SQL语句监控工具与实践案例 SQL语句监控的主要方法 SQL监控主要通过以下几种方式实现: 数据库内置监控功能:大多数数据库系统提供内置的SQL监控工具数据库性能视图/系统表:通过查询特定的系统视图获取SQL执行信…...

AB测试面试题
AB测试面试题 常考AB测试问答题(1)AB测试的优缺点是什么?(2)AB测试的一般流程/介绍一下日常工作中你是如何做A/B实验的?(3)第一类错误 vs 第二类错误 vs 你怎么理解AB测试中的第一、二类错误?(4)统计显著=实际显著?(5)AB测试效果统计上不显著?(6)实验组优于对…...

颠覆性技术革命:CAD DWG图形瓦片化实战指南
摘要 CAD DWG图形瓦片化技术通过金字塔模型构建多分辨率地图体系,实现海量工程图纸的Web高效可视化。本文系统解析栅格瓦片与矢量瓦片的技术原理,详细对比两者在生成效率、样式自由度和客户端性能等维度的差异,并结合工程建设、工业设计和智…...
不换设备秒通信,PROFINET转Ethercat网关混合生产线集成配置详解
在汽车制造中,连接Profinet控制的PLC(如西门子S7)与EtherCAT伺服驱动器(如倍福AX5000),实现运动控制同步。 在汽车制造的混合生产线集成中,实现西门子S7 PLC与倍福AX5000 EtherCAT伺服驱动器的…...
c++STL-string的使用
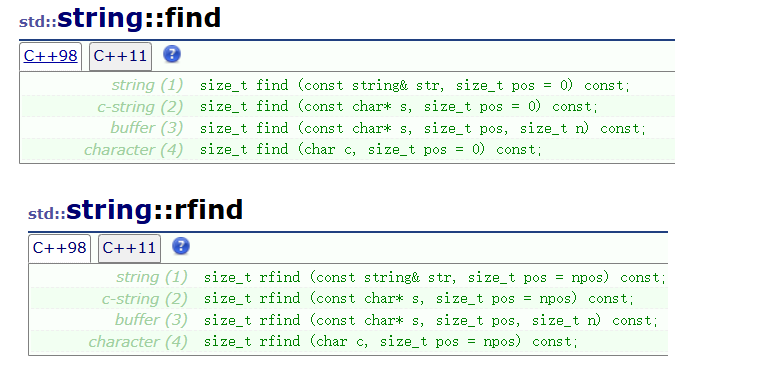
这里写自定义目录标题 string的使用string写成类模板的原因string的版本举例构造、析构函数和赋值重载构造函数和析构函数operator Iterators迭代器begin和endrbegin和rendcbegin和cend,crbegin和crend(c11) capacity容量有关函数不同编译器下…...

UNet网络 图像分割模型学习
UNet 由Ronneberger等人于2015年提出,专门针对医学图像分割任务,解决了早期卷积网络在小样本数据下的效率问题和细节丢失难题。 一 核心创新 1.1对称编码器-解码器结构 实现上下文信息与高分辨率细节的双向融合 如图所示:编码器进行了4步&…...

使用 SHAP 进行特征交互检测:揭示变量之间的复杂依赖关系
我们将探讨如何使用 SHAP(SHapley 加法解释)来检测和可视化机器学习模型中的特征交互。了解特征组合如何影响模型预测对于构建更透明、更准确的模型至关重要。SHAP 有助于揭示这些复杂的依赖关系,并使从业者能够以更有意义的方式解释模型决策…...
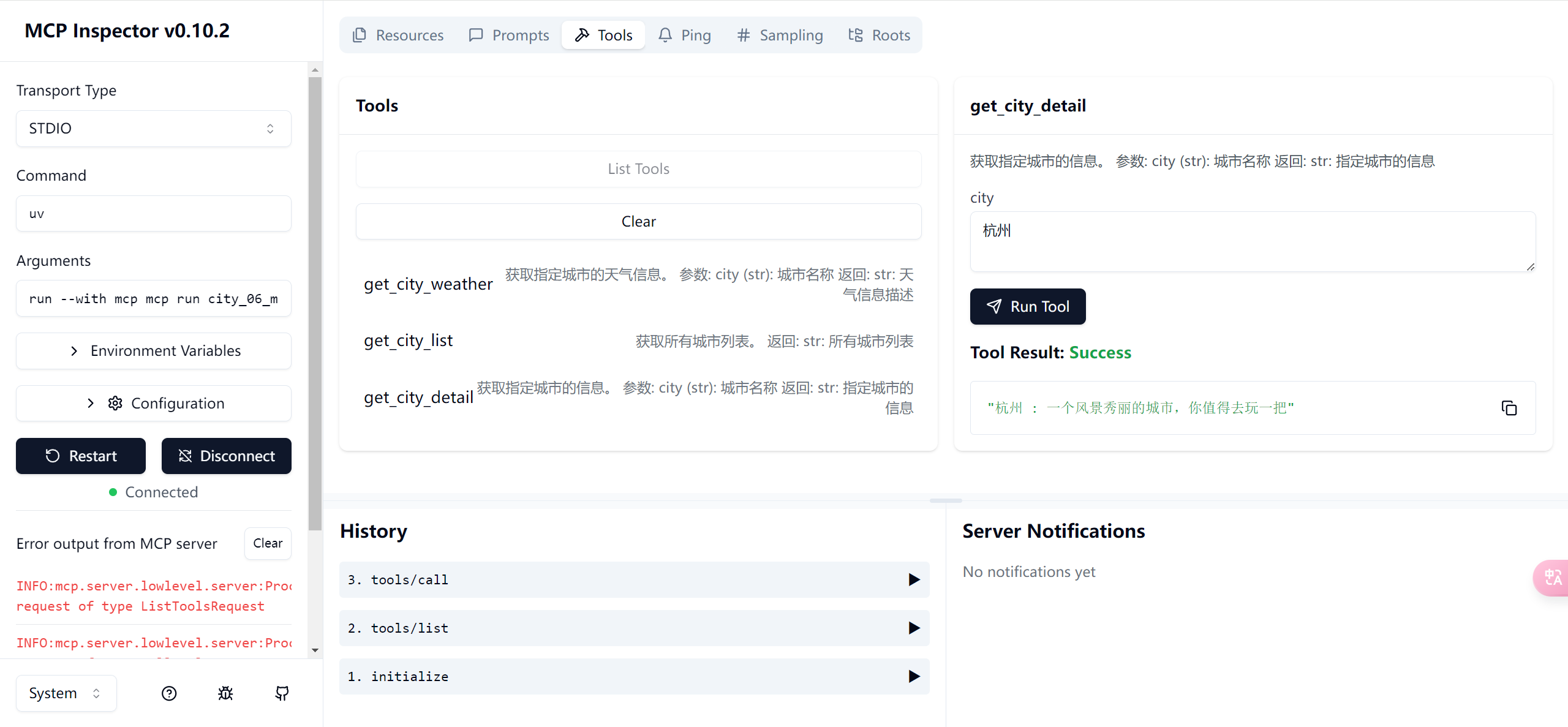
Python-MCPInspector调试
Python-MCPInspector调试 使用FastMCP开发MCPServer,熟悉【McpServer编码过程】【MCPInspector调试方法】-> 可以这样理解:只编写一个McpServer,然后使用MCPInspector作为McpClient进行McpServer的调试 1-核心知识点 1-熟悉【McpServer编…...
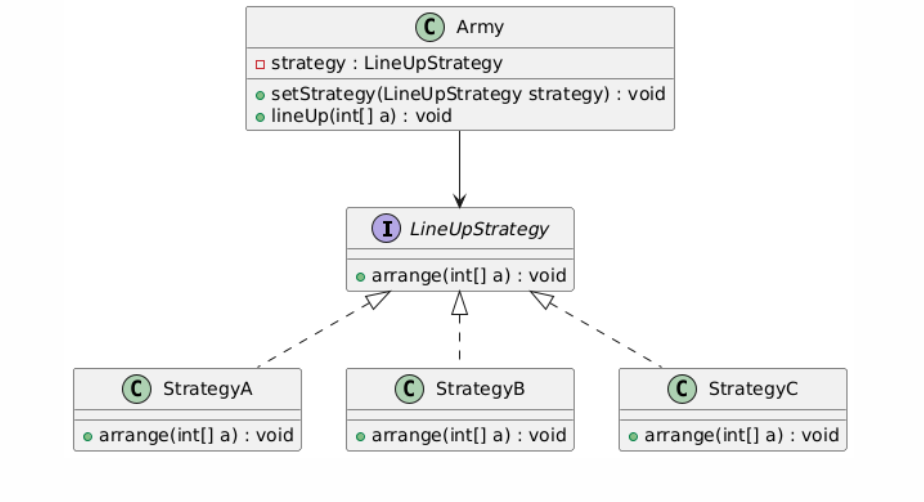
Java设计模式-策略模式(行为型)
策略模式详解 一、策略模式概述 1.1 基本概念 策略模式是一种行为型设计模式,它主要用于处理算法的不同变体。其核心思想是将算法的定义与使用分离开来,把一系列具体的算法封装成独立的策略类,这些策略类实现相同的策略接口。客户端可以在…...
html body 设置heigth 100%,body内元素设置margin-top出滚动条(margin 重叠问题)
今天在用移动端的时候发现个问题,html,body 设置 height:100% 会出现纵向滚动条 <!DOCTYPE html> <html> <head> <title>html5</title> <style> html, body {height: 100%; } * {margin: 0;padding: 0; } </sty…...
C语言模糊不清的知识
1、malloc、calloc、realloc的区别和用法 malloc实在堆上申请一段连续指定大小的内存区域,并以void*进行返回,不会初始化内存。calloc与malloc作用一致,只是calloc会初始化内存,自动将内存清零。realloc用于重新分配之前通过mallo…...

如何配置光猫+路由器实现外网IP访问内部网络?
文章目录 前言一、网络拓扑理解二、准备工作三、光猫配置3.1 光猫工作模式3.2 光猫端口转发配置(路由模式时) 四、路由器配置4.1 路由器WAN口配置4.2 端口转发配置4.3 动态DNS配置(可选) 五、防火墙设置六、测试配置七、安全注意事…...

springboot3+vue3融合项目实战-大事件文章管理系统获取用户详细信息-ThreadLocal优化
一句话本质 为每个线程创建独立的变量副本,实现多线程环境下数据的安全隔离(线程操作自己的副本,互不影响)。 关键解读: 核心机制 • 同一个 ThreadLocal 对象(如示意图中的红色区域 tl)被多个线…...

【高数上册笔记篇02】:数列与函数极限
【参考资料】 同济大学《高等数学》教材樊顺厚老师B站《高等数学精讲》系列课程 (注:本笔记为个人数学复习资料,旨在通过系统化整理替代厚重教材,便于随时查阅与巩固知识要点) 仅用于个人数学复习,因为课…...
c++STL-string的模拟实现
cSTL-string的模拟实现 string的模拟实现string的模拟线性表的实现构造函数析构函数获取长度(size)和获取容量(capacity)访问 [] 和c_str迭代器(iterator)交换swap拷贝构造函数赋值重载(&#x…...

YashanDB(崖山数据库)V23.4 LTS 正式发布
2024年回顾 2024年11月我们受邀去深圳参与了2024国产数据库创新生态大会。在大会上崖山官方发布了23.3。这个也是和Oracle一样采用的事编年体命名。 那次大会官方希望我们这些在一直从事在一线的KOL帮助产品提一些改进建议。对于这样的想法,我们都是非常乐于合作…...

python 写一个工作 简单 番茄钟
1、图 2、需求 番茄钟(Pomodoro Technique)是一种时间管理方法,由弗朗西斯科西里洛(Francesco Cirillo)在 20 世纪 80 年代创立。“Pomodoro”在意大利语中意为“番茄”,这个名字来源于西里洛最初使用的一个…...

C++.IP协议通信
C++IP协议通信 1. TCP协议通信1.1 服务端实现创建套接字绑定地址监听连接接受连接数据传输关闭连接1.2 客户端实现创建套接字连接服务器数据传输关闭连接1.3 示例代码服务端代码示例客户端代码示例绑定地址接收数据发送数据关闭套接字2.2 客户端实现创建套接字发送数据接收数据…...

css背景相关
背景书写 background: url(src); // 注意:在写动态样式时,backgournd赋值格式错误,是不会在浏览器dom的style上显示的 // 但是可以创建不可见的img,预加载来提高性能背景也会加载图片资源 同img的src一样,background也…...
PyCharm 加载不了 conda 虚拟环境,不存在的
#工作记录 前言 在开发过程中,PyCharm 无法加载 Conda 虚拟环境是常见问题。 在不同情况下,“Conda 可执行文件路径”的指定可能会发生变化,不会一尘不变,需要灵活处置。 以下是一系列解决此问题的经验参考。 检查 Conda 安装…...
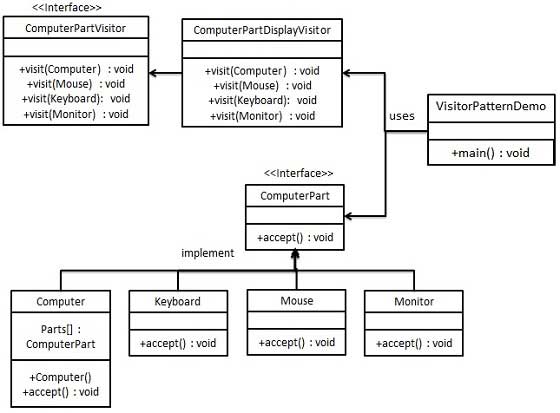
设计模式学习整理
目录 UML类图 设计模式六大原则 1.单一职责原则 2.里氏替换原则 3.依赖倒置原则 4.接口隔离原则 5.迪米特法则(最少知道原则) 6.开(放封)闭原则 设计模式分类 1.创建型模式 2.结构型模式 4.行为型模式 一、工厂模式(factory——简单工厂模式和抽象工厂模式) 1.1、…...
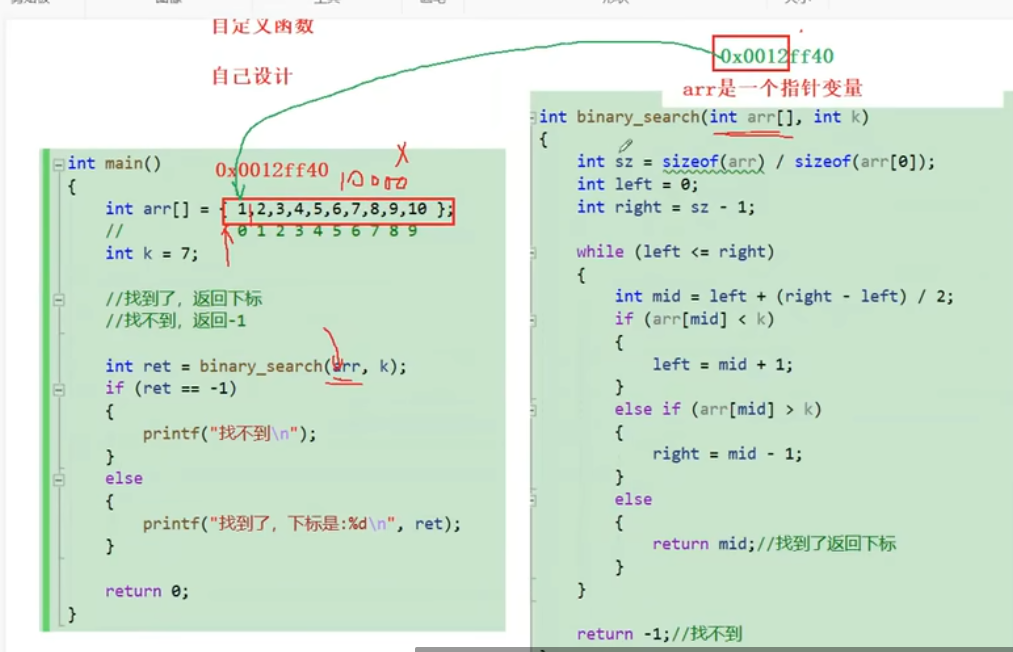
二分查找的理解
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h>int binary_search(int arr[], int k, int sz) {int left 0;int right sz - 1;//这个是下标,减一是因为在0开始的,怕越界(访问无效)while (left < right){int mid…...