菜鸟之路Day30一一MySQL之DMLDQL
菜鸟之路Day30一一MySQL之DML&DQL
作者:blue
时间:2025.5.8
文章目录
- 菜鸟之路Day30一一MySQL之DML&DQL
- 一.DML
- 0.概述
- 1.插入语句(insert)
- 2.更新语句(update)
- 3.删除语句(delete)
- 二.DQL
- 1.基本查询
- 2.条件查询
- 3.聚合函数
- 4.分组查询
- 5.排序查询
- 6.分页查询
一.DML
0.概述
DML(数据操作语言),用来对数据库中表的数据记录进行增,删,改操作
1.插入语句(insert)
指定字段添加数据:insert into 表名(字段名1,字段名2)values(值1,值2);全部字段添加数据:insert into 表名 values (值1,值2,..);批量添加数据(指定字段):insert into 表名(字段名1,字段名2)values(值1,值2),(值1,值2)批量添加数据(全部字段):insert into 表名 values (值1,值2,….),(值1,值2,….);
练习:
-- 1.为tb_emp表,字段(username,name,gender)插入一条数据
insert into tb_emp(username,name,gender,create_time,update_time)values ('xiaomu','木',2,now(),now());-- 2.为tb_emp表,全部字段插入一条数据
insert into tb_empvalues (null,'xiaolan','12345','蓝',1,null,null,null,now(),now());-- 3.为tb_emp表,字段(username,name,gender)批量插入数据
insert into tb_emp(username,name,gender,create_time,update_time)
values ('ning','宁',2,now(),now()),('lan','岚',1,now(),now());
2.更新语句(update)
修改数据:update 表名 set 字段名1=值1,字段名2=值2,…[where 条件];
练习:
-- 1.将tb_emp表,id为2的用户,用户名改成zhangsan
update tb_emp set username='zhangsan',update_time=now() where id=2;-- 2.将tb_emp表,所有用户的入职时间改为2010-01-01
update tb_emp set entry_time='2010-01-01',update_time=now();
注意:在更新语句中如果没有加条件就会更新整张表的数据
3.删除语句(delete)
删除数据:delete from 表名 [where 条件];
练习:
-- 1.将tb_emp表中,id为1的用户删除
delete from tb_emp where id=1;-- 2.将tb_emp表中,所有用户都删除
delete from tb_emp;
DELETE语句不能删除某一个字段的值(如果要操作,可以使用UPDATE,将该字段的值置为NULL)
先插入十五条数据,做为数据库中可被查询的数据
-- 插入数据 1
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (1,'john_doe','password123','John Doe', 1, 'john.jpg', 1, '2012-05-15', now(), now());-- 插入数据 2
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (2,'jane_smith','securepass','Jane Smith', 2, 'jane.jpg', 2, '2015-09-20', now(), now());-- 插入数据 3
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (3,'mike_johnson','mypassword','Mike Johnson', 1, 'mike.jpg', 3, '2018-03-10', now(), now());-- 插入数据 4
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (4,'lisa_brown','pass1234','Lisa Brown', 2, 'lisa.jpg', 1, '2019-11-25', now(), now());-- 插入数据 5
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (5,'david_wilson','secretpass','David Wilson', 1, 'david.jpg', 2, '2020-07-08', now(), now());-- 插入数据 6
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (6,'susan_lee','susanpass','Susan Lee', 2, 'susan.jpg', 3, '2013-06-12', now(), now());-- 插入数据 7
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (7,'tom_wang','tom1234','Tom Wang', 1, 'tom.jpg', 4, '2016-08-18', now(), now());-- 插入数据 8
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (8,'amy_zhang','amysecure','Amy Zhang', 2, 'amy.jpg', 1, '2017-10-22', now(), now());-- 插入数据 9
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (9,'peter_liu','peterpass','Peter Liu', 1, 'peter.jpg', 2, '2021-02-03', now(), now());-- 插入数据 10
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (10,'emily_zhou','emily123','Emily Zhou', 2, 'emily.jpg', 3, '2022-04-16', now(), now());-- 插入数据 11
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (11,'jack_chen','jackpass','Jack Chen', 1, 'jack.jpg', 4, '2014-07-28', now(), now());-- 插入数据 12
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (12,'linda_wu','lindasecure','Linda Wu', 2, 'linda.jpg', 1, '2019-01-09', now(), now());-- 插入数据 13
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (13,'brian_huang','brianpass','Brian Huang', 1, 'brian.jpg', 2, '2020-05-21', now(), now());-- 插入数据 14
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (14,'grace_he','grace123','Grace He', 2, 'grace.jpg', 3, '2023-03-14', now(), now());-- 插入数据 15
insert into tb_emp (id, username, password, name, gender, image, job, entry_time, create_time, update_time)
values (15,'kevin_zhang','kevinpass','Kevin Zhang', 1, 'kevin.jpg', 4, '2011-09-06', now(), now());
二.DQL
DQL用来查询数据库中的数据
1.基本查询
查询多个字段:select 字段1,字段2,字段3 from 表名;查询所有字段(通配符):select * from 表名;设置别名:select 字段1 [as 别名1],字段2 [as 别名2]from 表名;去除重复记录:select distinct 字段列表 from 表名;
练习:
-- 1.查询指定字段name,entry_time 并返回
select name,entry_time from tb_emp;-- 2.查询表所有内容
select * from tb_emp;-- 3.查询指定字段name,entry_time 并取别名 姓名,入职日期
select name as '姓名',entry_time as '入职日期' from tb_emp;-- 4.查询员工关联了哪几种职业(不要重复)
select distinct job from tb_emp
2.条件查询
select 字段 from 表名 where 条件

部分练习:
-- 5.查询id为6的员工
select * from tb_emp where id=6;-- 6.查询id小于6的员工信息
select * from tb_emp where id<6;-- 7.查询id在6-10之间的员工信息
select * from tb_emp where id>=6 and id<=10;select * from tb_emp where id between 6 and 10;
3.聚合函数
介绍:将一列数据作为一个整体,进行纵向计算
select 聚合函数(字段列表) from 表名;
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
练习:
-- 8.统计员工数量
select count(*) from tb_emp;-- 9.查询最早入职员工
select min(entry_time) from tb_emp;-- 10.查询最晚入职员工
select max(entry_time) from tb_emp;-- 11.求所有员工id总和
select sum(id) from tb_emp;-- 12.求所有员工id平均数
select avg(id) from tb_emp;
注意:null值不参与所有聚合函数运算
统计数量可以使用:count(*) count(字段) count(常量),推荐使用第一种
4.分组查询
分组查询:select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
练习:
-- 13.根据性别分组,统计男性和女性员工的数量 - count(*)
select gender,count(*) from tb_emp group by gender;-- 14.先查询入职时间在‘2020-01-01’(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*) from tb_emp where entry_time <= '2020-01-01' group by job having count(*) >= 2;
Q:where与having的区别
A:1.执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
2.判断条件不同:where不能对聚合函数进行判断,而having可以
注意事项
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
执行顺序:where>聚合函数>having
5.排序查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1,字段2 排序方式2;-- 排序方式:ASC:升序(默认值) DESC:降序
练习:
-- 15.根据入职时间对员工进行,升序排序
select * from tb_emp order by entry_time ASC;-- 16.根据入职时间对员工进行,降序排序
select * from tb_emp order by entry_time DESC;-- 17.根据入职时间对员工进行升序排序,若入职时间相同,根据更新时间降序排序
select * from tb_emp order by entry_time ASC,update_time DESC;
注意事项:如果是多字段排序,当第一个字段值相同时,才会对第二个字段进行排序
6.分页查询
select 字段列表 from 表名 limit 起始索引,查询记录数-- 起始索引 = (页码-1)* 每页记录数
练习:
-- 18.查询第一页,展示5条记录
select * from tb_emp limit 0,5;-- 19.查询第二页,展示5条记录
select * from tb_emp limit 5,5;-- 20.查询第三页,展示5条记录
select * from tb_emp limit 10,5;
注意:如果查询的是第一页的数据
相关文章:
菜鸟之路Day30一一MySQL之DMLDQL
菜鸟之路Day30一一MySQL之DML&DQL 作者:blue 时间:2025.5.8 文章目录 菜鸟之路Day30一一MySQL之DML&DQL一.DML0.概述1.插入语句(insert)2.更新语句(update)3.删除语句(delete…...

集团云解决方案:集团企业IT基础架构的降本增效利器
在当今数字化飞速发展的时代,集团企业面临着诸多挑战,尤其是IT基础架构的管理和运营成本居高不下,效率却难以提升。别担心,集团云解决方案的出现为集团企业带来了全新的曙光,真正实现了降本增效! 一、集团…...
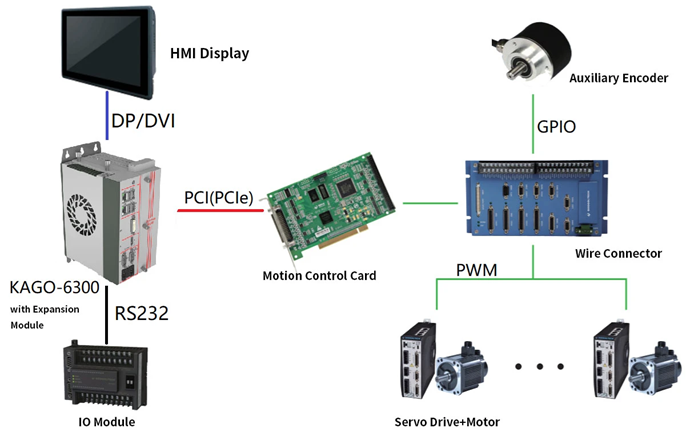
基 LabVIEW 的多轴电机控制系统
在工业自动化蓬勃发展的当下,多轴伺服电机控制系统的重要性与日俱增,广泛应用于众多领域。下面围绕基于 LabVIEW 开发的多轴伺服电机控制系统展开,详细阐述其应用情况。 一、应用领域与场景 在 3D 打印领域,该系统精确操控打印头…...
)
SD06_前后端分离项目部署流程(采用Nginx)
本文档详细描述了如何在Ubuntu 20.04服务器上从零开始部署Tlias前后端分离系统。Tlias系统由Spring Boot后端(tlias-web-management)和Vue前端(vue-tlias-management)组成。 目录 环境准备安装MySQL数据库部署后端项目部署前端项…...

【kubernetes】通过Sealos 命令行工具一键部署k8s集群
一、前言 1、sealos安装k8s集群官网:K8s > Quick-start > Deploy-kubernetes | Sealos Docs 2、本文安装的k8s版本为v1.28.9 3、以下是一些基本的安装要求: 每个集群节点应该有不同的主机名。主机名不要带下划线。所有节点的时间需要同步。需要…...
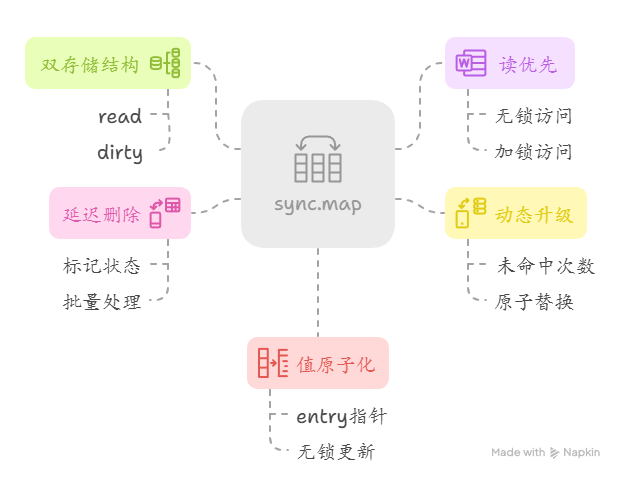
《Go小技巧易错点100例》第三十二篇
本期分享: 1.sync.Map的原理和使用方式 2.实现有序的Map sync.Map的原理和使用方式 sync.Map的底层结构是通过读写分离和无锁读设计实现高并发安全: 1)双存储结构: 包含原子化的 read(只读缓存,无锁快…...

怎么判断是不是公网IP?如何查看自己本地路由器是内网ip还是公网?
在网络世界中,IP 地址如同每台设备的 “门牌号”,起着至关重要的标识作用。而 IP 地址又分为公网 IP 和私网 IP,准确判断一个 IP 属于哪一类,对于网络管理、网络应用开发以及理解网络架构等都有着重要意义。接下来,我们…...

【上位机——MFC】单文档和多文档视图架构
单文档视图架构 特点:只能管理一个文档(只有一个文档类对象) #include <afxwin.h> #include "resource.h"//文档类 class CMyDoc :public CDocument {DECLARE_DYNCREATE(CMyDoc) //支持动态创建机制 }; IMPLEMENT_DYNCREATE(CMyDoc,CDocument) //…...

需求分析阶段测试工程师主要做哪些事情
在软件测试需求分析阶段,主要围绕确定测试范围、明确测试目标、细化测试内容等方面开展工作,为后续测试计划的制定、测试用例的设计以及测试执行提供清晰、准确的依据。以下是该阶段具体要做的事情: 1. 需求收集与整理 收集需求文档&#x…...
 深入解析)
Web 实时通信技术:WebSocket 与 Server-Sent Events (SSE) 深入解析
一、WebSocket: (一)WebSocket 是什么? WebSocket 是一种网络通信协议,它提供了一种在单个 TCP 连接上进行全双工通信的方式。与传统的 HTTP 请求 - 响应模型不同,WebSocket 允许服务器和客户端在连接建立…...
项目模拟实现消息队列第二天
消息应答的模式 1.自动应答: 消费者把这个消息取走了,就算是应答了(相当于没有应答) 2.手动应答: basicAck方法属于手动应答(消费者需要主动调用这个api进行应答) 小结 1.需要实现生产者,broker server,消费者这三个部分的 2.针对生产者和消费…...
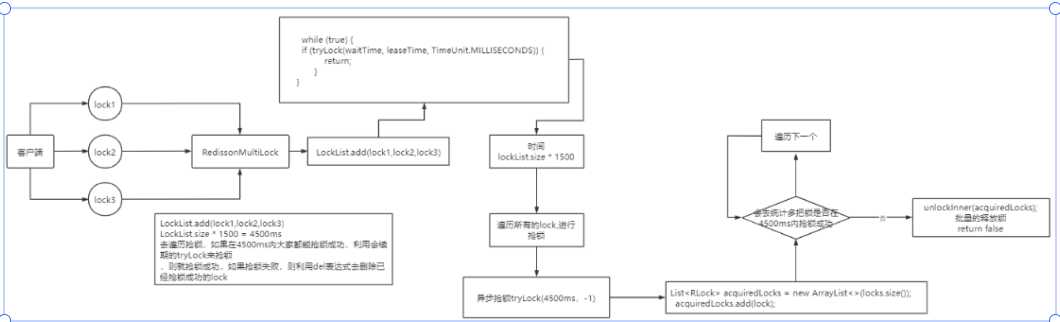
5.Redission
5.1 前文锁问题 基于 setnx 实现的分布式锁存在下面的问题: 重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如 HashTable 这样的代码中,他的方法都是使用 sync…...

c#数据结构 线性表篇 非常用线性集合总结
本人能力有限,使用了一些Ai的结论,如有不足还请斧正 目录 1.HashSet <> Dictionary 2.SortedSet <>提供升序方法的List 3.ArrayList<>List 4.BitArray <> Bit[] array 5.StringCollection <>List 6.StringDictionary<>Dictionary 1…...
dify 部署后docker 配置文件修改
1:修改 复制 ./dify/docker/.env.example ./dify/docker/.env 添加一下内容 # 启用自定义模型 CUSTOM_MODEL_ENABLEDtrue# 将OLLAMA_API_BASE_URL 改为宿主机的物理ip OLLAMA_API_BASE_URLhttp://192.168.72.8:11434# vllm 的 OPENAI的兼容 API 地址 CUSTOM_MODE…...
数据结构——排序(万字解说)初阶数据结构完
目录 1.排序 2.实现常见的排序算法 2.1 直接插入排序 编辑 2.2 希尔排序 2.3 直接选择排序 2.4 堆排序 2.5 冒泡排序 2.6 快速排序 2.6.1 递归版本 2.6.1.1 hoare版本 2.6.1.2 挖坑法 2.6.1.3 lomuto前后指针 2.6.1.4 时间复杂度 2.6.2 非递归版本 2.7 归并排序…...

SQLite3介绍与常用语句汇总
SQLite3简介 SQLite3是一款轻量级的、基于文件的开源关系型数据库引擎,由 D. Richard Hipp 于 2000 年首次发布。它遵循 SQL 标准,但与传统的数据库系统不同,SQLite 并不运行在独立的服务器进程中,而是作为一个嵌入式数据库引擎直…...
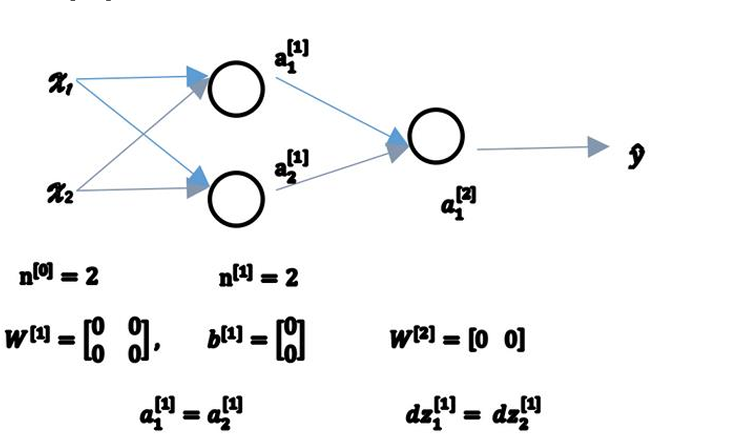
快速入门深度学习系列(3)----神经网络
本文只针对图进行解释重要内容 这就是入门所需要掌握的大部分内容 对于不懂的名词或概念 你可以及时去查 对于层数 标在上面 对于该层的第几个元素 标在下面 输入层算作第0层 对于第一层的w b 参数 维度如下w:4*3 b:4*1 这个叫做神经元 比如对于第一层的神经元 这里说的很…...
在线工具源码_字典查询_汉语词典_成语查询_择吉黄历等255个工具数百万数据 养站神器,安装教程
在线工具源码_字典查询_汉语词典_成语查询_择吉黄历等255个工具数百万数据 养站神器,安装教程 资源宝分享:https://www.httple.net/154301.html 一次性打包涵盖200个常用工具!无论是日常的图片处理、文件格式转换,还是实用的时间…...

ORB-SLAM3和VINS-MONO的对比
直接给总结,整体上orbslam3(仅考虑带imu)在初始化阶段是松耦合,localmap和全局地图优化是紧耦合。而vins mono则是全程紧耦合。然后两者最大的区别就在于vins mono其实没有对地图点进行优化,为了轻量化,它一…...

大数据处理利器:Hadoop 入门指南
一、Hadoop 是什么?—— 分布式计算的基石 在大数据时代,处理海量数据需要强大的技术支撑,Hadoop 应运而生。Apache Hadoop 是一个开源的分布式计算框架,致力于为大规模数据集提供可靠、可扩展的分布式处理能力。其核心设计理念是…...

Docker容器网络架构深度解析与技术实践指南——基于Linux内核特性的企业级容器网络实现
第1章 容器网络基础架构 1 Linux网络命名空间实现原理 1.1内核级隔离机制深度解析 1.1.1进程隔离的底层实现 通过clone()系统调用创建新进程时,设置CLONE_NEWNET标志位将触发内核执行以下操作: 内核源码示例(linux-6.8.0/kernel/fork.c&a…...
)
基于Kubernetes的Apache Pulsar云原生架构解析与集群部署指南(下)
文章目录 k8s安装部署Pulsar集群前期准备版本要求 安装 Pulsar Helm chart管理pulsarClustersBrokersTopic k8s安装部署Pulsar集群 前期准备 版本要求 Kubernetes 集群,版本 1.14 或更高版本Helm v3(3.0.2 或更高版本)数据持久化ÿ…...

IoTDB端边云同步技术的五大常见场景及简便使用方式
IoTDB端边云同步技术提供了一种高效、可靠的数据同步解决方案,通过简洁灵活的SQL操作和直观的配置方式,实现了数据在端、边、云之间的无缝流动。以下是IoTDB端边云同步的五大常见场景及其简便的使用方式。 一、基础数据同步 基础数据同步包括全量数据同…...
Linux 阻塞和非阻塞 I/O 简明指南
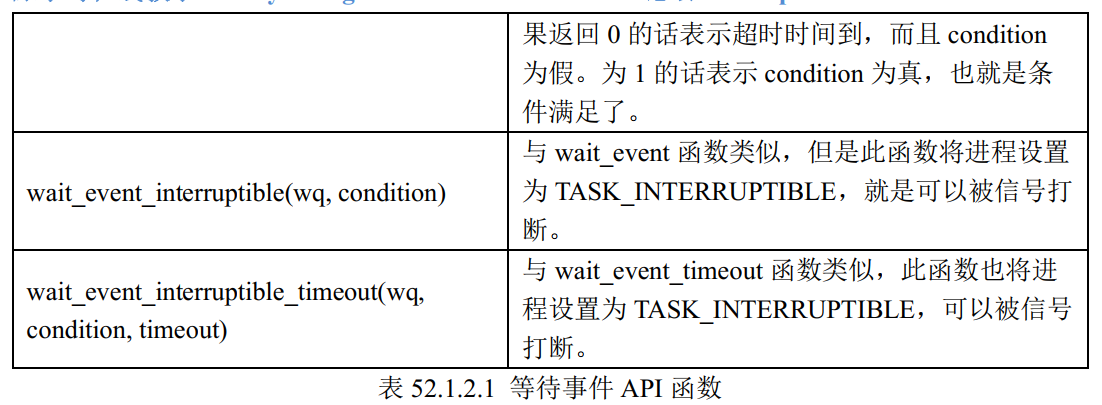
目录 声明 1. 阻塞和非阻塞简介 2. 等待队列 2.1 等待队列头 2.2 等待队列项 2.3 将队列项添加/移除等待队列头 2.4 等待唤醒 2.5 等待事件 3. 轮询 3.1 select函数 3.2 poll函数 3.3 epoll函数 4. Linux 驱动下的 poll 操作函数 声明 本博客所记录的关于正点原子…...
)
libtorch配置指南(包含Windows和Linux)
libtorch libtorch是pytorch的c库,提供了用于深度学习和张量计算的功能,允许开发者在c环境中使用pytorch的核心功能。特别是当一些pt模型无法转换到ncnn、mnn等模型时(ncnn、mnn可能还不支持某些层),可以在libtorch直…...
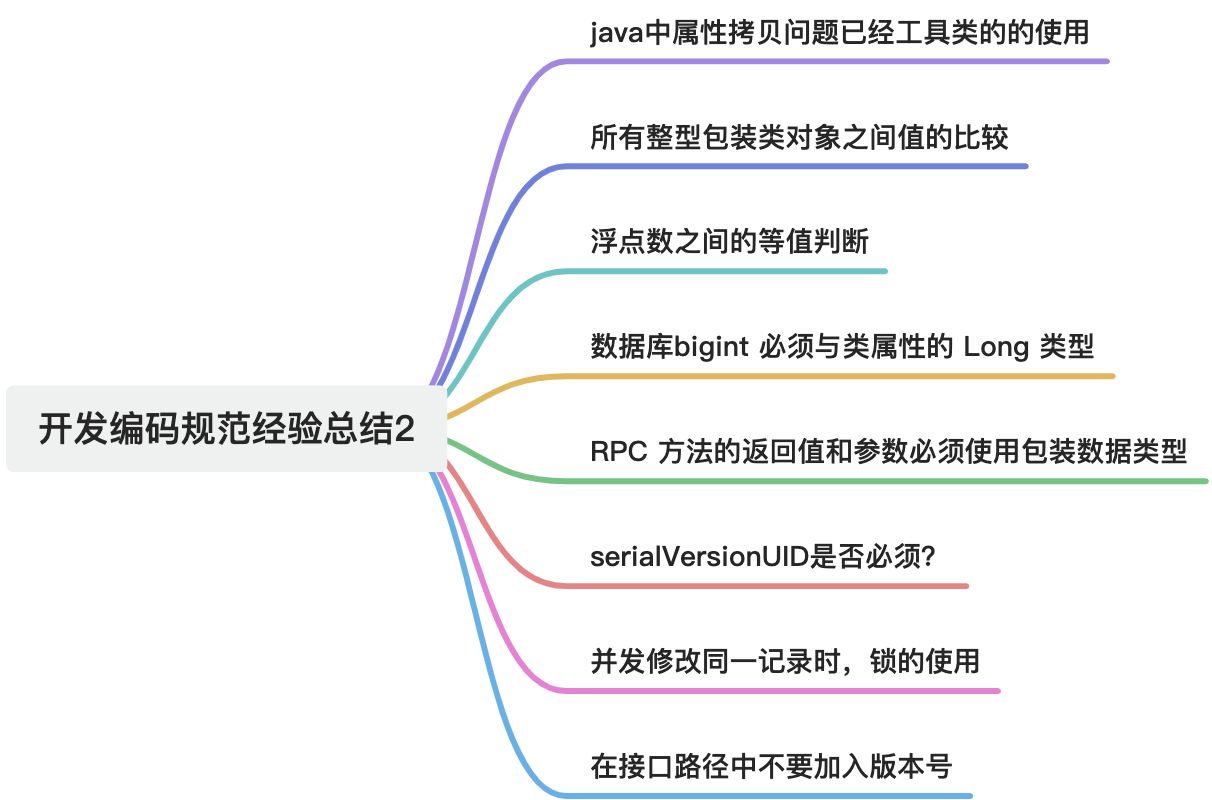
Java开发经验——阿里巴巴编码规范经验总结2
摘要 这篇文章是关于Java开发中阿里巴巴编码规范的经验总结。它强调了避免使用Apache BeanUtils进行属性复制,因为它效率低下且类型转换不安全。推荐使用Spring BeanUtils、Hutool BeanUtil、MapStruct或手动赋值等替代方案。文章还指出不应在视图模板中加入复杂逻…...
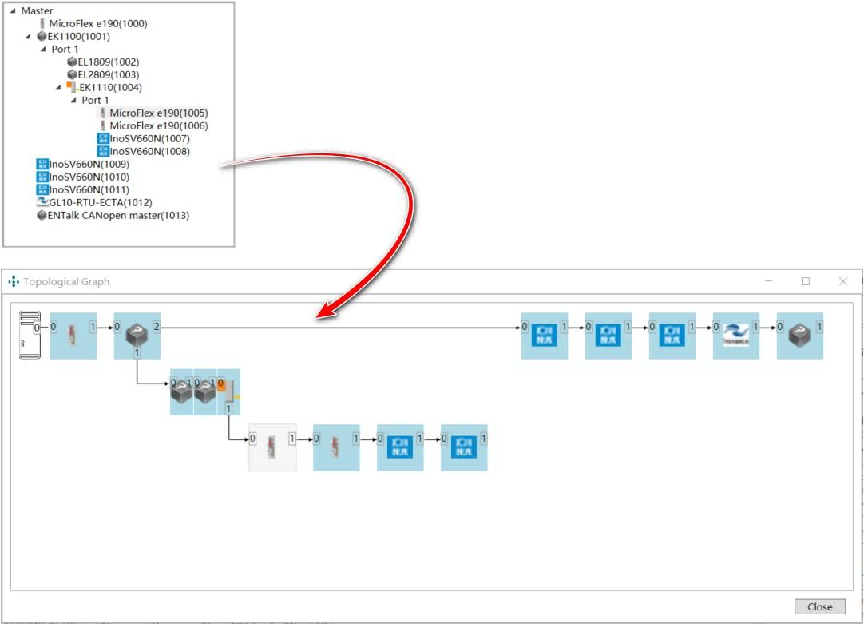
机器人手臂“听不懂“指令?Ethercat转PROFINET网关妙解通信僵局
机器人手臂"听不懂"指令?Ethercat转PROFINET网关妙解产线通信僵局 协作机器人(如KUKA iiWA)使用EtherCAT控制,与Profinet主站(如西门子840D CNC)同步动作。 客户反馈:基于Profinet…...
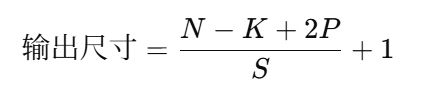
深度学习 CNN
CNN 简介 什么是 CNN? 卷积神经网络(Convolutional Neural Network)是专为处理网格数据(如图像)设计的神经网络。核心组件: 卷积层 :提取局部特征(如边缘、纹理)通过卷…...

GrassRoot备份项目
Windows服务项目 Grass.cs using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Http.Headers; using System.Net.Http; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Time…...

iOS开发架构——MVC、MVP和MVVM对比
文章目录 前言MVC(Model - View - Controller)MVP(Model - View - Presenter)MVVM(Model - View - ViewModel) 前言 在 iOS 开发中,MVC、MVVM、和 MVP 是常见的三种架构模式,它们主…...