Python爬虫第20节-使用 Selenium 爬取小米商城空调商品
目录
前言
一、 本文目标
二、环境准备
2.1 安装依赖
2.2 配置 ChromeDriver
三、小米商城页面结构分析
3.1 商品列表结构
3.2 分页结构
四、Selenium 自动化爬虫实现
4.1 脚本整体结构
4.2 代码实现
五、关键技术详解
5.1 Selenium 启动与配置
5.2 页面等待与异步加载
5.3 商品数据解析
5.4 分页处理
5.5 异常处理
5.6 可选:保存到 MongoDB
六、Headless 模式与浏览器兼容
七、常见问题与优化建议
7.1 反爬机制
7.2 页面结构变动
7.3 数据完整性
7.4 性能优化
八、总结

🎬 攻城狮7号:个人主页
🔥 个人专栏: 《python爬虫教程》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Selenium 的实战
📚 本期文章收录在《python爬虫教程》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在实际数据采集和电商分析中,很多网站采用了前端渲染和复杂的 Ajax 请求,直接分析接口变得困难。小米商城就是这样一个典型案例。与淘宝类似,小米商城的商品列表和分页都依赖于前端 JavaScript 动态渲染,Ajax 接口参数复杂且可能包含加密校验。对于这种页面,最直接、最稳定的抓取方式就是使用 Selenium 模拟真实用户操作。
本篇文章将以"空调"为例,详细讲解如何用 Selenium 自动化爬取小米商城的空调商品信息,包括商品名称、价格、图片链接、商品详情链接等,并实现自动翻页抓取。文章内容涵盖环境准备、页面结构分析、Selenium 脚本编写、数据解析、翻页处理、异常处理、可选的 MongoDB 存储、Headless 模式、常见问题与优化建议等,帮助你系统掌握电商前端动态页面的爬取方法。
一、 本文目标
- 利用 Selenium 自动化爬取小米商城空调商品信息
- 用 PyQuery 解析商品名称、价格、图片、链接等数据
- 实现自动翻页抓取多页商品
- 可选:将数据保存到 MongoDB
- 兼容 Headless(无界面)模式
- 具备异常处理和反爬优化思路
二、环境准备
2.1 安装依赖
- Chrome 浏览器(建议最新版)
- ChromeDriver(版本需与 Chrome 主版本一致)
- Python 3.7+
- Selenium
- PyQuery
- (可选)MongoDB
安装 Python 依赖:
pip install selenium pyquery# 可选:pip install pymongoChromeDriver 下载地址:( https://googlechromelabs.github.io/chrome-for-testing/ )
注意: ChromeDriver 版本必须和 Chrome 浏览器主版本号一致,否则 Selenium 启动会报错。
2.2 配置 ChromeDriver
- 将 chromedriver.exe 放到 PATH 路径下,或在代码中指定其绝对路径。
- 建议用 ChromeDriver 的"可分离"模式,便于调试。
三、小米商城页面结构分析
以( https://www.mi.com/shop/search?keyword=空调 ) 为例,打开开发者工具,分析商品列表和分页结构。
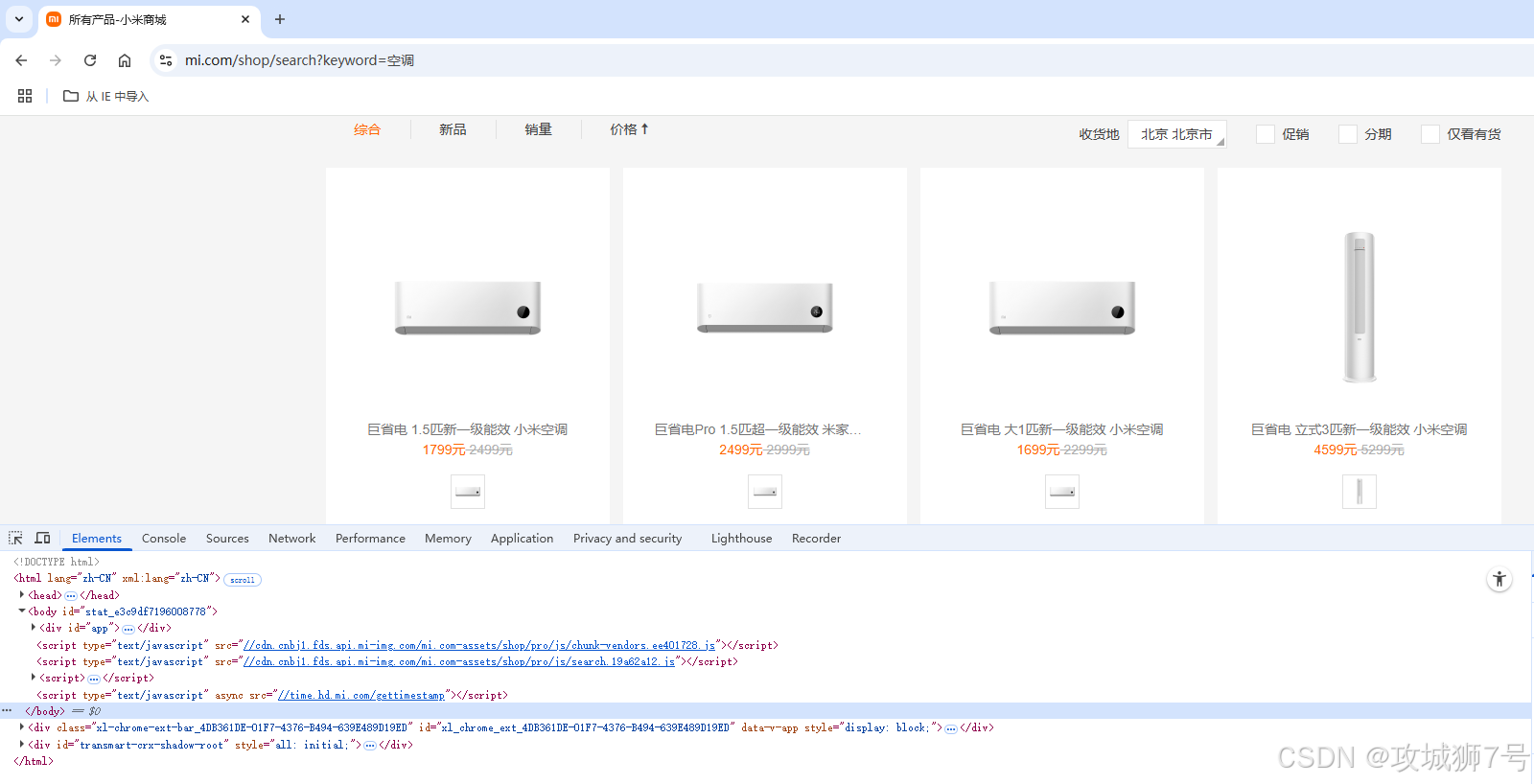
3.1 商品列表结构
点击网页元素,按鼠标右键的检查项,快速定位
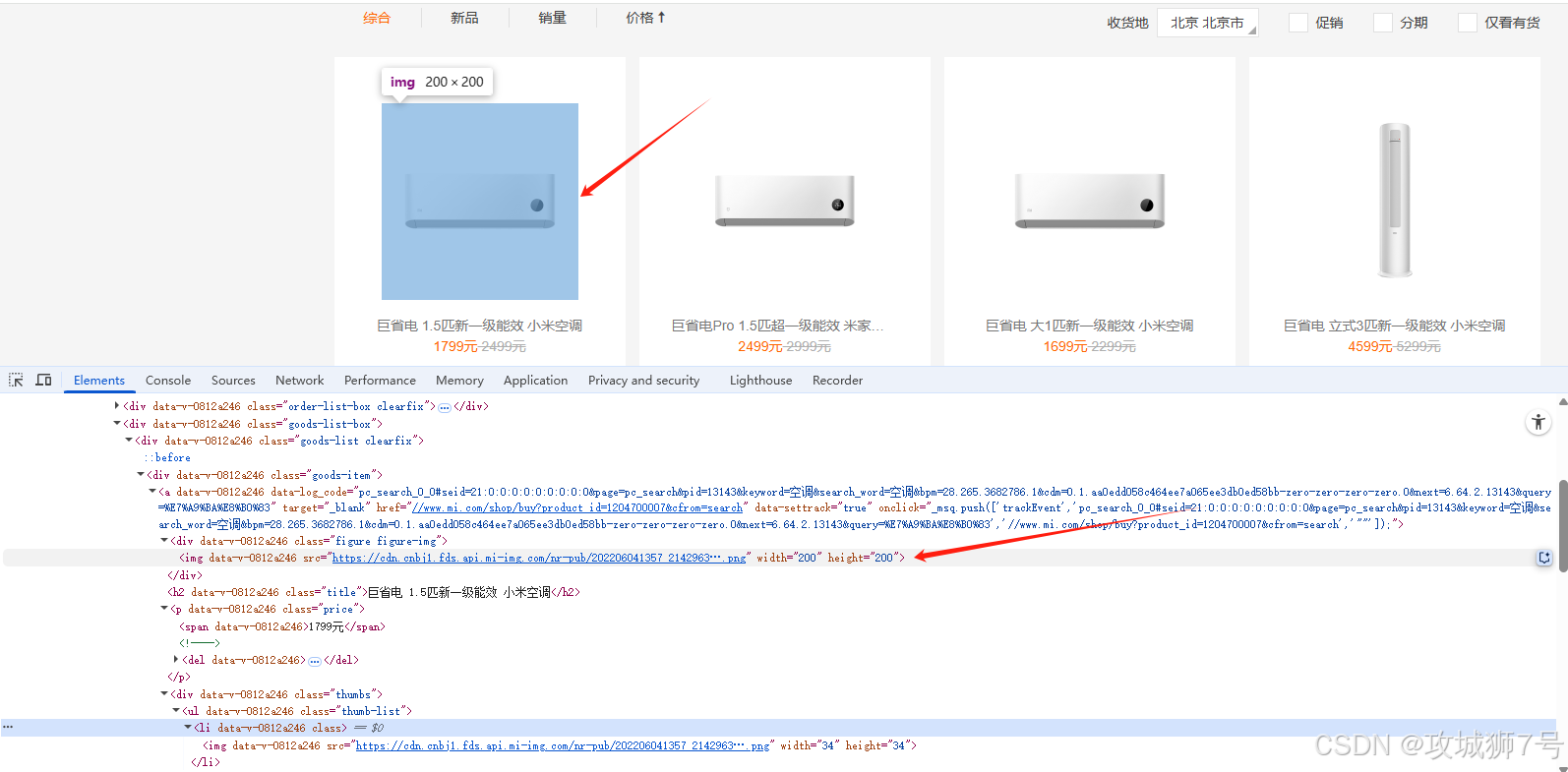
商品列表在如下结构下:
<ul class="goods-list"><li><a href="商品详情链接"><img src="图片链接" ...><div class="title">商品名称</div><div class="price">价格</div>...</a></li>...</ul>实际页面可能有多种 class,如 `.goods-list li`、`.product-list li`、`.goods-item` 等。需根据实际页面调整选择器。
3.2 分页结构
同样点击网页分页标签元素,按鼠标右键的检查项,快速定位分析
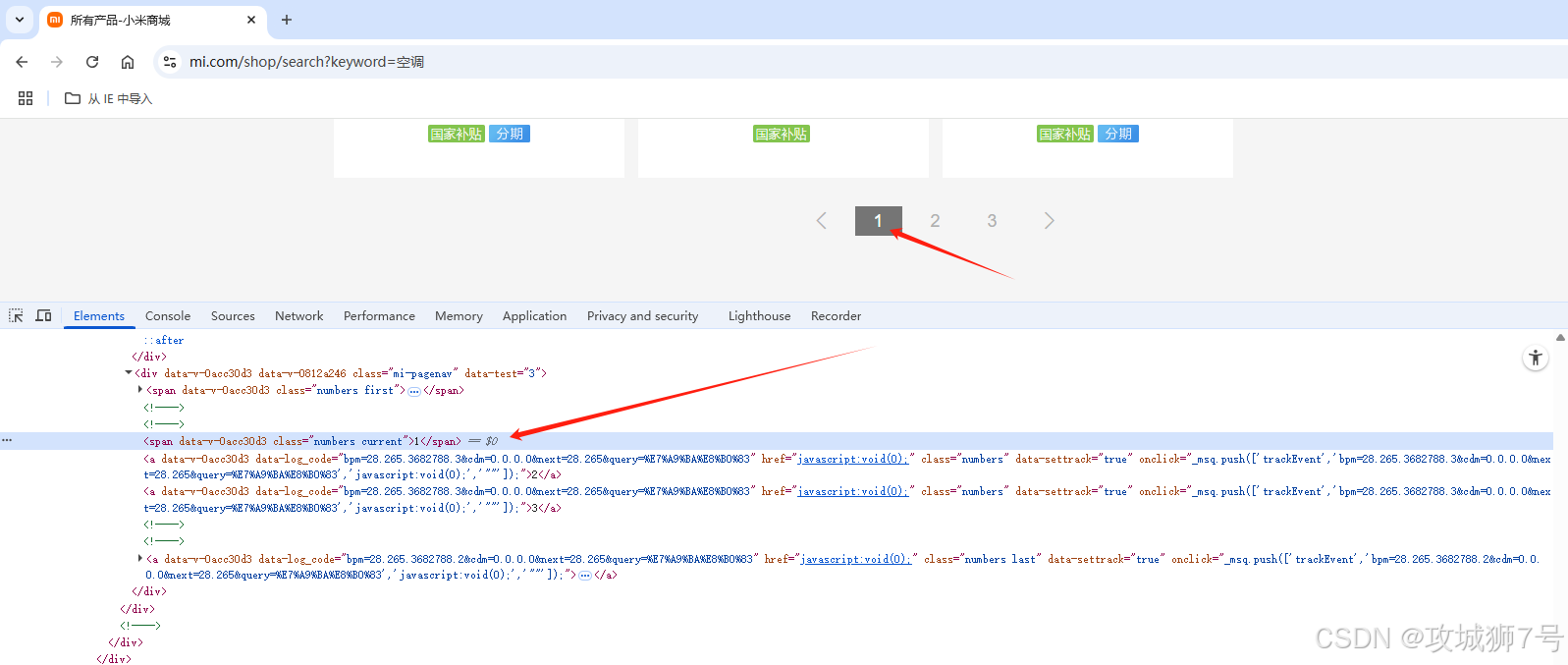
分页栏如下:
<div class="mi-pagenav"><span class="numbers current">1</span><a class="numbers">2</a><a class="numbers">3</a>...</div>- 当前页为 `<span class="numbers current">1</span>`
- 其它页为 `<a class="numbers">2</a>`
- 需用 Selenium 模拟点击 `<a class="numbers">2</a>` 实现翻页
四、Selenium 自动化爬虫实现
4.1 脚本整体结构
核心流程:
1. 启动 Selenium,打开小米商城空调搜索页
2. 解析当前页商品数据
3. 模拟点击分页按钮,依次抓取多页
4. 解析每页数据并输出
5. 关闭浏览器
4.2 代码实现
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.chrome.options import Optionsfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom pyquery import PyQuery as pqimport timeKEYWORD = '空调'MAX_PAGE = 3chrome_options = Options()# chrome_options.add_argument('--headless') # 如需无头模式可取消注释chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_experimental_option("detach", True)service = Service()browser = webdriver.Chrome(service=service, options=chrome_options)wait = WebDriverWait(browser, 20)def get_products(page):html = browser.page_sourcedoc = pq(html)products = []for item in doc('.goods-list li, .product-list li, .list li, .goods-item, .product-item').items():title = item.find('.title, .name, .pro-title, .text').text()price = item.find('.price, .pro-price, .num').text()img = item.find('img').attr('src') or item.find('img').attr('data-src')link = item.find('a').attr('href')if title and ('空调' in title or '空调' in item.text()):products.append({'title': title,'price': price,'img': img,'link': link})if not products:for a in doc('a').items():text = a.text()if '空调' in text:img = a.find('img').attr('src') or a.find('img').attr('data-src')price = ''parent = a.parent()for p in parent.parents():price = p.find('.price, .pro-price, .num').text()if price:breakproducts.append({'title': text,'price': price,'img': img,'link': a.attr('href')})print(f'第{page}页空调商品:')for p in products:print(p)return productsdef main():browser.get(f'https://www.mi.com/shop/search?keyword={KEYWORD}')for page in range(1, MAX_PAGE + 1):wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'body')))time.sleep(2)get_products(page)if page < MAX_PAGE:try:page_btn = browser.find_element(By.XPATH, f'//div[contains(@class,"mi-pagenav")]//a[@class="numbers" and text()="{page+1}"]')browser.execute_script("arguments[0].click();", page_btn)time.sleep(2)except Exception as e:print(f'点击第{page+1}页失败:', e)breakbrowser.quit()if __name__ == '__main__':main()运行爬取截图:

五、关键技术详解
5.1 Selenium 启动与配置
- 推荐用 Chrome 浏览器,需保证 ChromeDriver 版本匹配
- 可选用 Headless 模式,适合服务器环境
- `detach` 选项可让浏览器调试时不自动关闭
5.2 页面等待与异步加载
- 小米商城商品列表为异步渲染,需用 WebDriverWait 等待元素加载
- `time.sleep()` 可适当延迟,确保页面渲染完成
5.3 商品数据解析
- 用 PyQuery 解析 HTML,支持 jQuery 风格选择器
- 兼容多种商品卡片结构,适应页面变动
- 兜底方案:遍历所有 a 标签,抓取带"空调"字样的商品
5.4 分页处理
- 不能直接拼接 URL 翻页,需模拟点击分页按钮
- 用 XPath 精确定位 `<a class="numbers">`,并用 JS 执行点击,兼容前端事件绑定
- 每次翻页后需等待页面刷新再抓取数据
5.5 异常处理
- 分页点击失败时自动中断,避免死循环
- 可根据实际需求增加重试机制
5.6 可选:保存到 MongoDB
如需将数据保存到 MongoDB,可参考如下代码:
import pymongoMONGO_URL = 'localhost'MONGO_DB = 'xiaomi'MONGO_COLLECTION = 'ac_products'client = pymongo.MongoClient(MONGO_URL)db = client[MONGO_DB]def save_to_mongo(result):try:if db[MONGO_COLLECTION].insert_one(result):print('存储到 MongoDB 成功')except Exception:print('存储到 MongoDB 失败')在 `get_products` 中调用 `save_to_mongo(product)` 即可。
六、Headless 模式与浏览器兼容
- Headless 模式适合服务器、云主机等无桌面环境
- 启用方式:
chrome_options.add_argument('--headless')- 也可用 Firefox、Edge 等浏览器,Selenium 语法基本一致
七、常见问题与优化建议
7.1 反爬机制
- 有些网站如频繁访问可能弹出验证码
- 有些网站需要登录才能进行下一步数据获取,如果有登录步骤,就需要自己通过Selenium自行实现
- 建议适当延迟、降低抓取频率
- 可用代理池、账号池等方式进一步优化
7.2 页面结构变动
- 商品卡片 class 可能变动,需定期检查并调整选择器
- 建议用多种选择器兜底,提升健壮性
7.3 数据完整性
- 某些商品可能缺少价格、图片等字段,需容错处理
- 可用 try/except 或默认值兜底
7.4 性能优化
- Headless 模式+禁用图片加载可提升速度
- 可用多进程/多线程并发抓取不同关键词
八、总结
本文系统讲解了如何用 Selenium 自动化爬取小米商城空调商品信息,涵盖了环境准备、页面结构分析、自动化脚本实现、数据解析、翻页处理、异常处理、可选的 MongoDB 存储、Headless 模式、常见问题与优化建议等内容。通过这种"可见即可爬"的方式,可以高效应对前端动态渲染和复杂 Ajax 的电商页面,极大提升数据采集的灵活性和稳定性。
你可以根据实际需求,扩展脚本支持更多商品类型、更多字段、并发抓取、数据存储等功能,打造属于自己的电商数据采集工具。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!
相关文章:
Python爬虫第20节-使用 Selenium 爬取小米商城空调商品
目录 前言 一、 本文目标 二、环境准备 2.1 安装依赖 2.2 配置 ChromeDriver 三、小米商城页面结构分析 3.1 商品列表结构 3.2 分页结构 四、Selenium 自动化爬虫实现 4.1 脚本整体结构 4.2 代码实现 五、关键技术详解 5.1 Selenium 启动与配置 5.2 页面等待与异…...

无线定位之 三 SX1302 网关源码 thread_gps 线程详解
前言 笔者计划通过无线定位系列文章、系统的描述 TDOA 无线定位和混合定位相关技术知识点, 并以实践来验证此定位系统精度。 笔者从实践出发、本篇直接走读无线定位系统关键节点、网关 SX1302 源码框架,并在源码走读过程 中、着重分析与无线定位相关的PPS时间的来龙去脉、并在…...

Aware和InitializingBean接口以及@Autowired注解失效分析
Aware 接口用于注入一些与容器相关信息,例如: a. BeanNameAware 注入 Bean 的名字 b. BeanFactoryAware 注入 BeanFactory 容器 c. ApplicationContextAware 注入 ApplicationContext 容器 d. EmbeddedValueResolverAware 注入 解析器&a…...
Unity3D仿星露谷物语开发41之创建池管理器
1、目标 在PersistentScene中创建池管理器(Pool Manager)。这将允许一个预制对象池被创建和重用。 在游戏中当鼠标点击地面时,便会启用某一个对象。比如点击地面,就创建了一棵树,而这棵树是从预制体对象池中获取的&a…...

Modbus协议介绍
Modbus是一种串行通信协议,由Modicon公司(现为施耐德电气)在1979年为可编程逻辑控制器(PLC)通信而开发。它是工业自动化领域最常用的通信协议之一,具有开放性、简单性和跨平台兼容性,广泛应用于…...

深度学习遇到的问题处理
小土堆课程学习 1.tensorboard远程到本地无法显示 1.检查本地与远程端口是否被占用 2.一定要在远程服务器的项目下创建对应的存储文件夹 且 远程服务器一定要有需要处理的数据 ## 此时远程项目路径下有logs文件夹 存放上传的图像与数据 writerSummaryWriter("logs"…...
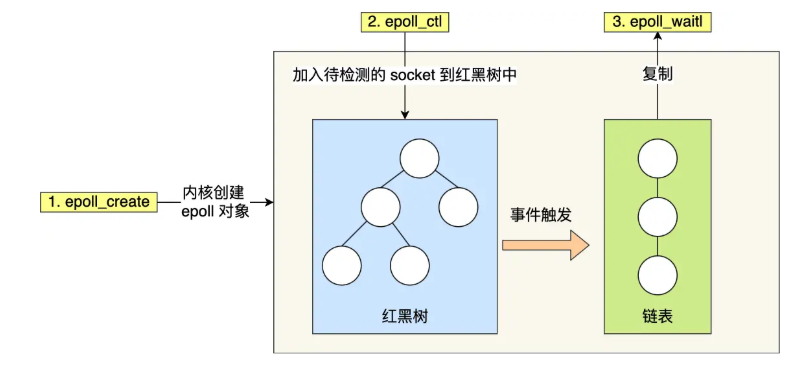
I/O多路复用(select/poll/epoll)
通过一个进程来维护多个Socket,也就是I/O多路复用,是一种常见的并发编程技术,它允许单个线程或进程同时监视多个输入/输出(I/O)流(例如网络连接、文件描述符)。当任何一个I/O流准备好进行读写操…...
Westlake-Omni 情感端音频生成式输出模型
简述 github地址在 GitHub - xinchen-ai/Westlake-OmniContribute to xinchen-ai/Westlake-Omni development by creating an account on GitHub.https://github.com/xinchen-ai/Westlake-Omni Westlake-Omni 是由西湖心辰(xinchen-ai)开发的一个开源…...

Egg.js知识框架
一、Egg.js 核心概念 1. Egg.js 简介 基于 Koa 的企业级 Node.js 框架(阿里开源) 约定优于配置(Convention over Configuration) 插件化架构,内置多进程管理、日志、安全等能力 适合中大型企业应用,提供…...
随手记录5
一些顶级思维: 顶级思维 1、永远不要自卑。 也永远不要感觉自己比别人差,这个人有没有钱,有多少钱,其实跟你都没有关系。有很多人就是那个奴性太强,看到比自己优秀的人,甚至一些装逼的人,这…...
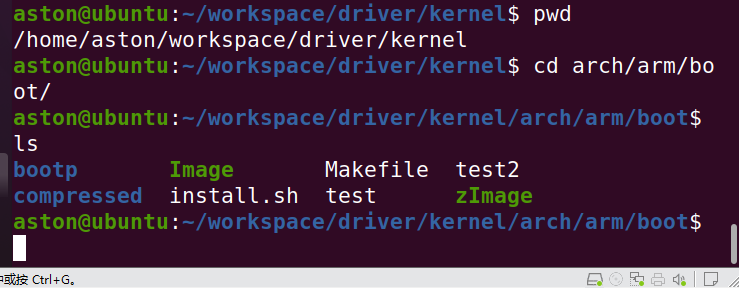
Linux驱动:驱动编译流程了解
要求 1、开发板中的linux的zImage必须是自己编译的 2、内核源码树,其实就是一个经过了配置编译之后的内核源码。 3、nfs挂载的rootfs,主机ubuntu中必须搭建一个nfs服务器。 内核源码树 解压 tar -jxvf x210kernel.tar.bz2 编译 make x210ii_qt_defconfigmakeCan’t use ‘…...
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程)
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程) 在构建 AI 客服时,常见的需求是让机器人基于企业自身的知识文档,提供准确可靠的答案。本文将手把手教你如何使用 Flowise + 向量数据库(如 Pinecone),构建一个结合 RAG(Retrieval-Augmented Generation)检…...

RabbitMQ ③-Spring使用RabbitMQ
Spring使用RabbitMQ 创建 Spring 项目后,引入依赖: <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp --> <dependency><groupId>org.springframework.boot</groupId><artifac…...

测试文章标题01
模型上下文协议(Model Context Protocol, MCP)深度解析 一、MCP的核心概念 模型上下文协议(Model Context Protocol, MCP)是一种用于规范机器学习模型与外部环境交互的标准化框架。其核心目标是通过定义统一的接口和数据格式&am…...
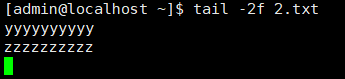
linux中常用的命令(四)
目录 1-cat查看文件内容 2-more命令 3-less命令 4-head命令 5-tail命令 1-cat查看文件内容 cat中的一些操作 -b : 列出行号(不含空白行)-E : 将结尾的断行以 $ 的形式展示出来-n : 列出行号(含空白行)-T : 将 tab 键 以 ^I 显示…...
)
2025年阿里云大数据ACP高级工程师认证模拟试题(附答案解析)
这篇文章的内容是阿里云大数据ACP高级工程师认证考试的模拟试题。 所有模拟试题由AI自动生成,主要为了练习和巩固知识,并非所谓的 “题库”,考试中如果出现同样试题那真是纯属巧合。 1、下列关于MaxCompute的描述中,错误的是&am…...

【FAQ】HarmonyOS SDK 闭源开放能力 — PDF Kit
1.问题描述: 预览PDF文件,文档上所描述的loadDocument接口,可以返回文件的状态,并无法实现PDF的预览,是否有能预览PDF相关接口? 解决方案: 1、执行loadDocument进行加载PDF文件后,…...
的翻转概率)
二元随机响应(Binary Randomized Response, RR)的翻转概率
随机响应(Randomized Response)机制 ✅ 回答核心: p 1 1 e ε 才是「翻转概率」 \boxed{p \frac{1}{1 e^{\varepsilon}}} \quad \text{才是「翻转概率」} p1eε1才是「翻转概率」 而: q e ε 1 e ε 是「保留真实值」…...

hive两个表不同数据类型字段关联引发的数据倾斜
不同数据类型引发的Hive数据倾斜解决方案 #### 一、原因分析 当两个表的关联字段存在数据类型不一致时(如int vs string、bigint vs decimal),Hive会触发隐式类型转换引发以下问题: Key值的精度损失:若关联字…...
利用SSRF击穿内网!kali靶机实验
目录 1. 靶场拓扑图 2. 判断SSRF的存在 3. SSRF获取本地信息 3.1. SSRF常用协议 3.2. 使用file协议 4. 172.150.23.1/24探测端口 5. 172.150.23.22 - 代码注入 6. 172.150.23.23 SQL注入 7. 172.150.23.24 命令执行 7.1. 实验步骤 8. 172.150.23.27:6379 Redis未授权…...
DVWA在线靶场-xss部分
目录 1. xxs(dom) 1.1 low 1.2 medium 1.3 high 1.4 impossible 2. xss(reflected) 反射型 2.1 low 2.2 medium 2.3 high 2.4 impossible 3. xss(stored)存储型 --留言板 3.1 low 3.2 medium 3.3 high 3.…...
Go 语言 slice(切片) 的使用
序言 在许多开发语言中,动态数组是必不可少的一个组成部分。在实际的开发中很少会使用到数组,因为对于数组的大小大多数情况下我们是不能事先就确定好的,所以他不够灵活。动态数组通过提供自动扩容的机制,极大地提升了开发效率。这…...

Android Exoplayer 实现多个音视频文件混合播放以及音轨切换
在之前的文章ExoPlayer中常见MediaSource子类的区别和使用场景中介绍了Exoplayer中各种子MediaSource的使用场景,这篇我们着重详细介绍下实现多路流混合播放的用法。常见的使用场景有:视频文件电影字幕、正片视频广告视频、背景视频背景音乐等。 初始化…...

深入浅出:Java 中的动态类加载与编译技术
1. 引言 Java 的动态性是其强大功能之一,允许开发者在运行时加载和编译类,从而构建灵活、可扩展的应用程序。动态类加载和编译在许多高级场景中至关重要,例如插件系统、动态代理、框架开发(如 Spring)和代码生成工具。Java 提供了两大核心机制来实现这一目标: 自定义 Cl…...

js常用的数组遍历方式
以下是一个完整的示例,将包含图片、文字和数字的数组渲染到 HTML 页面,使用 多种遍历方式 实现不同的渲染效果: 1. 准备数据(数组) const items [{ id: 1, name: "苹果", price: 5.99, image: "h…...

【网络编程】五、三次握手 四次挥手
文章目录 Ⅰ. 三次握手Ⅱ. 建立连接后的通信Ⅲ. 四次挥手 Ⅰ. 三次握手 1、首先双方都是处于未通信的状态,也就是关闭状态 CLOSE。 2、因为服务端是为了服务客户端的,所以它会提前调用 listen() 函数进行对客户端请求的监听。 3、接着客户端就…...

【类拷贝文件的运用】
常用示例 当我们面临将文本文件分成最大大小块的时,我们可能会尝试编写如下代码: public class TestSplit {private static final long maxFileSizeBytes 10 * 1024 * 1024; // 默认10MBpublic void split(Path inputFile, Path outputDir) throws IOException {…...

从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景20250509
🤖 从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景 作者:AI 应用实践者 在过去的几年中,AI 领域飞速发展,从简单的文本生成模型演进为今天具备复杂推理、感知能力的“智能体”系统。本文将从核心概念出发&#x…...
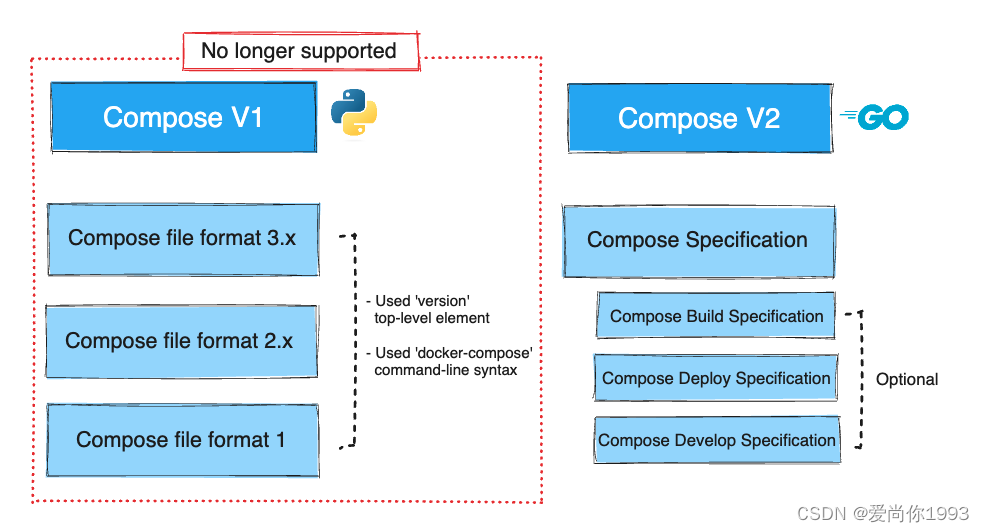
Docker Compose 的历史和发展
这张图表展示了Docker Compose从V1到V2的演变过程,并解释了不同版本的Compose文件格式及其支持情况。以下是对图表的详细讲解: Compose V1 No longer supported: Compose V1已经不再支持。Compose file format 3.x: 使用了版本3.x的Compose文件格式。 …...

ARMV8 RK3399 u-boot TPL启动流程分析 --crt0.S
上一篇介绍到start.S 最后一个指令是跳转到_main, 接下来分析 __main 都做了什么 arch/arm/lib/crt0.S __main 注释写的很详细,主要分为5步 1. 准备board_init_f的运行环境 2. 跳转到board_init_f 3. 设置broad_init_f 申请的stack 和 GD 4. 完整u-boot 执行re…...