浅谈大语言模型原理
1.反向传播算法
-
背景

反向传播算法是当前深度学习的核心技术。 -
神经网络

- x是输入,o是输出,w是需要训练的参数(w有初始值)
- 三层全连接的神经网络:输入层、隐藏层、输出层
-
激活函数
f ( x ) = 1 1 + x − 1 f(x)=\frac{1}{1+x^{-1}} f(x)=1+x−11 (sigmod函数)
激活函数必须是非线性的
-
前向传播
z 1 = x 1 ∗ w 1 + x 2 ∗ w 3 + b 1 z_1=x_1*w_1+x_2*w_3+b_1 z1=x1∗w1+x2∗w3+b1
f ( z 1 ) = 1 1 + z 1 − 1 f(z_1)=\frac{1}{1+z_1^{-1}} f(z1)=1+z1−11
i 1 = f ( z 1 ) ∗ w 5 + f ( z 2 ) ∗ w 7 + b 2 i_1=f(z_1)*w_5+f(z_2)*w_7+b_2 i1=f(z1)∗w5+f(z2)∗w7+b2
o 1 = f ( i 1 ) = 1 1 + i 1 − 1 o_1=f(i_1)=\frac{1}{1+i_1^{-1}} o1=f(i1)=1+i1−11
注:b为常数
-
损失函数
E = 1 / 2 ∗ ( o 1 − t a r g e t 1 ) 2 + 1 / 2 ∗ ( o 2 − t a r g e t 2 ) 2 E=1/2*(o_1-target_1)^2+1/2*(o_2-target_2)^2 E=1/2∗(o1−target1)2+1/2∗(o2−target2)2
-
梯度计算
链式求导法则: ∂ ( E ) ∂ ( w 5 ) = ∂ ( E ) ∂ ( o 1 ) ∗ ∂ ( o 1 ) ∂ ( i 1 ) ∗ ∂ ( i 1 ) ∂ ( w 5 ) \frac{\partial(E)}{\partial(w_5)} = \frac{\partial(E)}{\partial(o_1)}*\frac{\partial(o_1)}{\partial(i_1)}* \frac{\partial(i_1)}{\partial(w_5)} ∂(w5)∂(E)=∂(o1)∂(E)∗∂(i1)∂(o1)∗∂(w5)∂(i1)
∂ ( E ) ∂ ( o 1 ) = − ( o 1 − t a r g e t 1 ) \frac{\partial(E)}{\partial(o_1)}= -(o_1-target_1) ∂(o1)∂(E)=−(o1−target1)
∂ ( o 1 ) ∂ ( i 1 ) = f ( z 1 ) ∗ ( 1 − f ( z 1 ) ) \frac{\partial(o_1)}{\partial(i_1)}=f(z_1)*(1-f(z_1)) ∂(i1)∂(o1)=f(z1)∗(1−f(z1))
∂ ( i 1 ) ∂ ( w 5 ) = f ( z 1 ) \frac{\partial(i_1)}{\partial(w_5)}=f(z_1) ∂(w5)∂(i1)=f(z1)
-
反向传播
沿着梯度相反的方向更新参数:
w 5 + = w 5 − η ∗ ∂ ( E ) ∂ ( w 5 ) w_5^+=w_5-\eta * \frac{\partial(E)}{\partial(w_5)} w5+=w5−η∗∂(w5)∂(E)
学习率 η \eta η不可太大也不可太小,太大会导致震荡,太小会导致收敛速度慢,太大错过最优点。
-
反复迭代上述过程,直至E值达到全局最小(大)值。

-
常见的神经网络层
- 全连接层
- 卷积层
- 池化层
- 循环层
- dropout层
- 归一化
每个模型的参数量,层数,神经元连接方式,激活函数,损失函数,参数更新方式都可能不同。
-
大模型
-
通过训练模型来学习从输入到输出的映射关系。
-
这种映射关系通常由一组权重和偏置参数来定义,这些参数是通过优化损失函数来获得的。
-
通过调整这些参数,模型可以逐渐改进其预测和生成结果的能力。
-
大模型和传统神经网络最本质区别是什么?
规模效应带来的涌现能力是最本质区别。传统模型依赖专门设计的架构解决特定任务,大模型通过海量参数和数据习得通用能力,并能迁移到未见过的任务。
-
2.训练深度神经网络
深度神经网络由多层神经元组成,每层神经元都可以学习到输入数据的不同特征。
图像识别,语音识别、自然语言处理、自动驾驶、推荐系统、游戏等都广泛应用。
-
算法+算力+数据
深度学习能成功的三大马车。
- 合适的的数据:
- 数据标注、数据清洗、数据增强、数据裁剪
- 合适的网络:
- 参数量大小,网络层数
- 参数初始化:随机、平均、归一化
- 激活函数、损失函数、学习率、优化器
- 参数与GPU显存使用直接相关
- 合适的神经元连接方式:
-
卷积神经网络

-
循环神经网络

-
- 合适的训练方式:
-
预训练、迁移学习、微调,生成对抗;
-
深度学习四大范式 :深度监督、无监督、半监督、强化学习;
- https://developer.baidu.com/article/details/3034262
-
强化学习:
- 智能体与环境的不断交互(即在给定状态采取动作),进而获得奖励,此时环境从一个状态转移到下一个状态。
- 智能体通过不断优化自身动作策略,以期待最大化其长期回报或收益(奖励之和)。

-
- 合适的的数据:
-
常见的问题:
- 过拟合是指模型过于拟合训练数据,而欠拟合是指模型拟合不足
- 梯度消失是指在反向传播过程中,梯度值随着层的深度而减小,导致深层神经元的梯度值接近于零
- 梯度爆炸是指在反向传播过程中,梯度值随着层的深度而增大,导致深层神经元的梯度值变得非常大
-
常见的深度学习框架
- TensorFlow:谷歌
- PyTorch:Facebook
- MXNet:亚马逊
- Caffe:伯克利大学
- Horovod:优化分布式训练的框架
这些框架提供了丰富的API和工具用于构建、训练、验证、评价模型。
3.大语言模型构建
-
NLP模型发展:统计模型(马尔可夫假设)-> 神经网络(循环神经网络) -> 预训练语言模型 -> 大语言模型(超大参数量,千、万亿级别)
-
大语言模型:在海量无标注文本数据上预训练的得到的大型预训练语言模型 —>强大的语言理解能力和复杂任务求解能力。
- 扩展法则:小算力去预估大算力后性能,早期性能去预估后期性能。–>减少试验成本
- 涌现能力:模型扩展到一定规模时,模型的特定的任务性能突然出现显著跃升的趋势(无法解释!)。
- 上下文学习
- 指令遵循:听人的话执行任务
- 逐步推理:思维连–>引入中间推理步骤做数学应用题
-
相关资源:
- 模型检查点
- 公共API:可以采用自己的数据来微调,以便更好地适用于个性化应用场景
- 数据集
- 预训练数据集:网页、书籍、代码数据集
- 指令微调数据集
- 人类对齐数据集
3.1大规模预训练
编码世界,知识注入(几T数据,清洗、词元化–>算力消耗)
3.1.1数据准备
- 数据:文本、百科、代码
- 数据预处理:质量过滤,敏感内容过滤,去重
- 词元化:将原始文本分割成模型可识别和建模的词元序列,用于模型输入。把文本拆转成更小的单元,再转成数字。
- 数据调度:各种数据的混合比例和用与训练的顺序
3.1.2模型架构
当前的大语言模型都是基于Tansformer模型设计的。
-
Transformer:由多层的多头自注意力模块堆叠而成的神经网络模型。
-
循环神经网络的劣势
- 输出取决于先前的隐藏状态和当前的输入,要等上一个步骤完成后,才能进行当前的计算。
- RNN不擅长处理长序列,因为难以捕捉到长距离依赖性的语义关系。
-
transformoer架构
- 编解码器,Transformer通常包括一个编码器用于处理输入序列和一个解码器用于生成输出序列,这使其适用于序列到序列的任务,如机器翻译。
- 输入编码:转化成具有位置信息的词向量,因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
- 多个编码器串联,多个解码器串联

-
tansformer实现

- 前馈网络层:引入非线性映射变换,提升模型表达能力,更好捕获复杂交互关系。
- ADD & Nomral层:解决网络训练中的一些问题。
- softmax层:输出预测词的概率
- 自注意力机制:自注意力机制允许模型根据输入序列中的不同部分来赋予不同的注意权重,从而更好地捕捉语义关系。
-
Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V是输入和矩阵的乘积。
-
$Q_1 = W_Q * X_1; K_1 = W_KX_1; V_1 = W_KX_1 $ (可并行计算 GPU,TPU)
-
Z 1 = A ( Q , K , V ) Z_1 = A(Q,K,V) Z1=A(Q,K,V) (需要拿输入句子中的每个单词对本单词打分,帮助模型对本单词更好地进行编码)
-
卷积神经网络代替循环神经网络:卷积层多次层叠后,可以获取更大的上下文信息。
-
- 多头自注意力机制:多个Self-Attention并列,对输入X 生成多个Z,多个Z拼接再乘一个权重矩阵,得到输出。
核心创新,建模任意词元的交互关系,进而有效捕获长程依赖关系,具有更强的序列建模能力。
每个单元关注不同的地方。 - Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作。
因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可 以翻译第 i+1 个单词。
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。 - outputs 是之前预测的输出结果。(根据之前的输出求解此次的输出)
-
-
大模型:使用了更长的向量维度,更深的层数,更多参数的解码器架构。
- 大语言模型是Transformer架构的规模化扩展,通过量变引发质变,获得了更强大的语言理解和生成能
- GPT1为例,它有1.17亿个参数,到了GPT2,参数有15亿个参数。而GPT3参数有1750亿个参数,96层和96个头数,GPT4有1.8万亿参数。
- 编解码器可以单独使用
- BERT为编码器架构
- GPT为解码器架构
3.1.3 模型预训练方法
- 语言建模:预测下一个单词的能力
- 参数优化设置:
- 大批次, 逐渐增大批次大小(尽快收敛->稳定收敛)
- 学习率从一个非常小的值现行增加到一个较大阈值,再逐步衰减
- 优化器:梯度修正
- 其他:模型存档,dropout等
- 其他训练技术(3D并行)
- 数据并行:将模型参数和优化器分到多个GPU,在每个GPU上获取梯度,使用梯度平均值更新所有GPU上的参数。
- 流水线并行:不同层的参数分配到不同GPU,累积前向传播多个批次后,再更新参数。
- 张量并行:矩阵运算 I W = [ I W 1 , I W 2 ] IW=[IW1,IW2] IW=[IW1,IW2],将矩阵W分解成W1,W2两个矩阵,将W1,W2放置到两个GPU上,并行执行两个矩阵运算,通过GPU通信,合并结果。
3.2指令微调
- 有监督训练,使用任务输入与输出的配对数据(模仿学习,激发作用)–>通过问答进行任务求解。
- 让模型听懂人的指令。
- 数据集仅预训练过程万分之一的大小。
- 指令数据集
- 输入:数据(language)+任务描述(翻译成中文);输出:语言
- NLP数据集:从公开NLP数据集中构建(人工标注任务描述)
- 日常对话数据集:从用户给模型的指令(对话)中,构建数据集
- 合成数据集:半自动化构建:提示模型,让模型帮忙生成数据集,再过滤
- 引入思维链数据:算数推理等
- 输入:数据(language)+任务描述(翻译成中文);输出:语言
- 指令微调的作用
- 小训练模型能力大提升
- 解决未见过的任务:如补全英文句子->补全日文句子
- 面向特定领域指令微调
- 指令微调训练
- 较小的学习率和批次小幅度调整
- 数据组织:
- 样本比例混合(NLP、日常对话、合成数据集三个数据集混合)
- 多阶段:三个数据集先后训练
- 指令微调阶段引入预训练数据->模型更加稳定
3.3人类对齐
- 对齐标注难以通过形式化的目标来优化,引入人类反馈指导。
- 基于人类反馈的强化学习,训练符合人类价值观的模型,防止产生冒犯偏见和事实错误文本。
- 标准
- 有用性:简洁高效完成任务,了解用户真实意图
- 诚实性:客观,准确,适当表达不确定性避免误导
- 无害性:消除冒犯性和歧视性,查询敏感主图时,应拒绝
- 步骤
- 奖励模型训练
- 使用模型生成多个候选输出,人为标注排序
- 训练模型来预测这个排序,有效的拟合人类偏好
- 强化学习训练
- 强化学习算法:策略梯度,PPO
- 奖励模型训练
3.4 评测
- 建模能力:反映模型对语言的基本理解和建模能力(可根据前文预测后文的能力)。困惑度
- 分类任务和问答:真正例,真负例,假正例,假负例。精确率,召回率,F1分数。
- 文本生成:衡量文本生成的质量,连贯性逻辑性等。BLEU(生成文本和参考范文之间的相似度)
- 执行任务能力:成功率(比如代码生成后能通过编译的成功率)
- 每一种能力的测评,都有相关的公开数据集。
3.5 提示学习
经过预训练、指令微调和人类对齐后,提示学习方法可有效地使用大语言模型解决实际任务。
- 人工提示
任务描述:清晰具体
输入数据:明确的数字
上下文信息:提供参考文档
提示策略:如“让我们一步步思考” - 自动提示:将提示词作为可训练参数
- 上下文学习:将示例样本格式化的输入到大模型
3.5 AI agent

参考文献
- 词元化:https://zhuanlan.zhihu.com/p/17845281626
- 反向传播算法:https://blog.csdn.net/ft_sunshine/article/details/90221691
- 大模型概述:https://llmbook-zh.github.io/
- transformer:
- https://zhuanlan.zhihu.com/p/163909808
- https://blog.csdn.net/weixin_42475060/article/details/121101749
- https://blog.csdn.net/weixin_42475060/article/details/121101749
- https://blog.51cto.com/u_16213711/13024654
- https://blog.csdn.net/weixin_42475060/article/details/121101749
相关文章:
浅谈大语言模型原理
1.反向传播算法 背景 反向传播算法是当前深度学习的核心技术。 神经网络 x是输入,o是输出,w是需要训练的参数(w有初始值)三层全连接的神经网络:输入层、隐藏层、输出层 激活函数 f ( x ) 1 1 x − 1 f(x)\frac…...

Clickhouse 迁移到 Doris 的最佳实践
一、引言 在将数据从 Clickhouse 迁移到 Apache Doris / SelectDB Cloud 的过程中,涉及表结构迁移、查询语句迁移以及数据迁移等多个关键环节。每个环节都有其复杂性和需要注意的细节,本文将详细介绍这些内容及对应的最佳实践方法。 二、表结构迁移 &…...
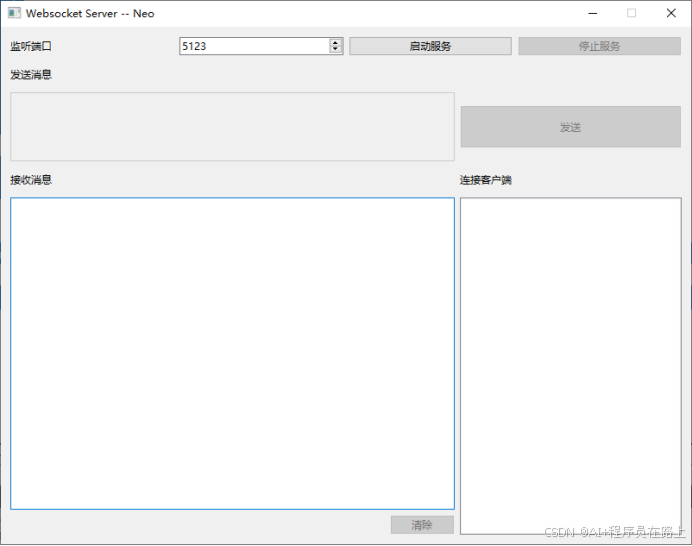
WebSocket的原理及QT示例
一.WebSocket 介绍 1.概述 WebSocket 是一种在单个 TCP 连接上进行全双工通讯的协议,它在 2011 年被 IETF 定为标准 RFC 6455,并由 RFC7936 补充规范。与传统的 HTTP 协议不同,WebSocket 允许服务器和客户端之间进行实时、双向的数据传输&a…...

数据库故障排查指南以及各类常用数据库基础用法
数据库故障排查指南大纲 数据库故障排查的基本概念 数据库故障的定义与分类常见数据库故障的表现形式故障排查的重要性与目标 数据库故障通常指数据库系统在运行过程中出现的异常情况,导致数据无法正常访问或操作。故障可以分为硬件故障、软件故障、网络故障、配…...

Spring Boot动态配置修改全攻略
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 无需重启应用,实时更新配置的终极指南 在微服务架构中,动态配置管理是提高系统灵活性的关键技术。本文将通过4种主流方案,…...
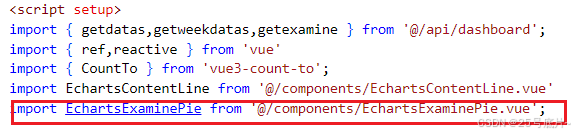
vue3:十二、图形看板- echart图表-柱状图、饼图
一、效果 如图展示增加了饼图和柱状图,并且优化了浏览器窗口大小更改,图表随着改变 二、 饼图 1、新建组件文件 新增组件EchartsExaminePie.vue,用于存储审核饼图的图表 2、写入组件信息 (1)视图层 写入一个div,写入变量chart和图表宽高 <template><div ref…...

2025年best好用的3dsmax插件和脚本
copitor 可以从一个3dsmax场景里将物体直接复制到另一个场景中 Move to surface 这个插件可以将一些物体放到一个平面上 instancer 实体器,举例:场景中有若干独立的光源,不是实体对象,我们可以使用instancer将他变成实体。 paste …...

趣谈Ai各种模型算法及应用
机器学习与深度学习模型选型终极指南:告别选择困难症! 大家好!今天,我们来聊一个让很多初学者甚至有经验的开发者都头疼的问题:面对琳琅满目的机器学习和深度学习模型,到底该如何选择?就像走进…...
HAProxy + Keepalived + Nginx 高可用负载均衡系统
1. 项目背景 在现代Web应用中,高可用性和负载均衡是两个至关重要的需求。本项目旨在通过HAProxy实现流量分发,通过Keepalived实现高可用性,通过Nginx提供后端服务。该架构能够确保在单点故障的情况下,系统仍然能够正常运行&#…...

vue2升级vue3
vue2升级vue3 父子自定义事件插槽差异 父子自定义事件 父组件的传给子组件的自定义事件以短横形式命名,例如:my-click 子组件声明该自定义事件时为 myClick 事件可以正常触发 插槽差异 vue2: <el-table-column:label"$t(hcp_devrs…...
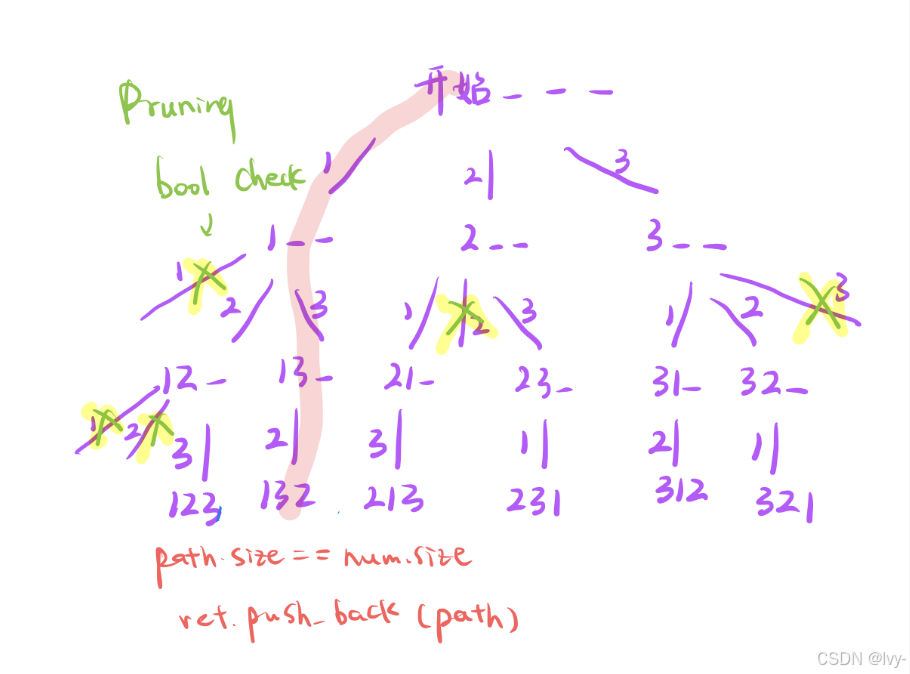
5.12 note
Leetcode 图 邻接矩阵的dfs遍历 class Solution { private: vector<vector<int>> paths; vector<int> path; void dfs(vector<vector<int>>& graph, int node) { // 到n - 1结点了保存 if (node graph.size() - 1)…...
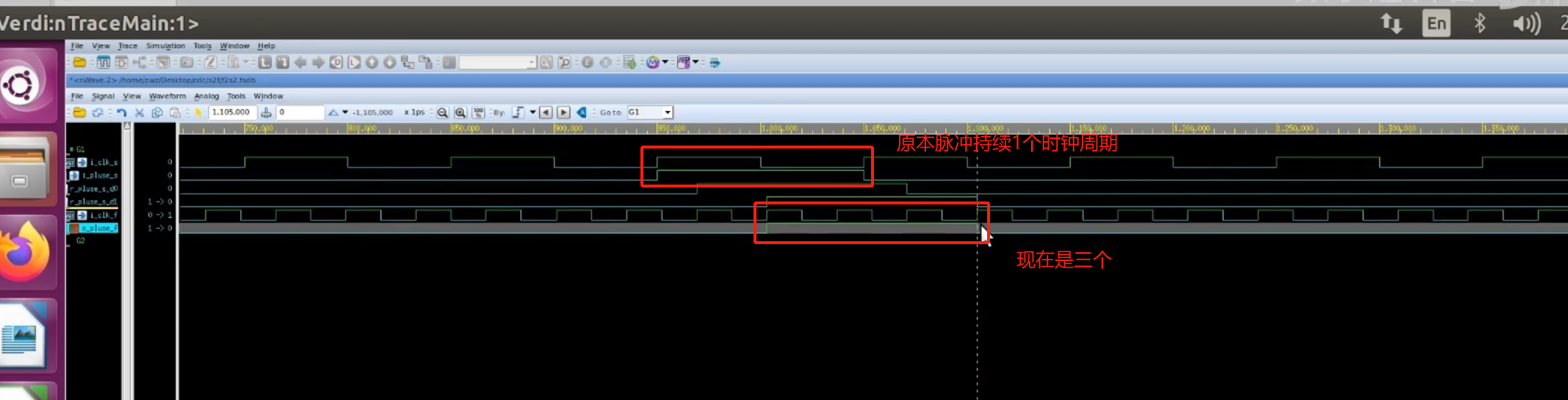
跨时钟域(CDC,clock domain crossing)信号处理
参考视频: 数字IC,FPGA秋招【单bit信号的CDC跨时钟域处理手撕代码合集】_哔哩哔哩_bilibili 一、亚稳态 原因是:建立时间和保持时间没有保持住。然后在下图的红框里面,产生亚稳态。因为电路反馈机制,最后大概率会恢复…...

鸿蒙HarmonyOS list优化一: list 结合 lazyforeach用法
list列表是开发中不可获取的,非常常用的组件,使用过程中会需要不断的优化,接下来我会用几篇文章进行list在纯原生的纯血鸿蒙的不断优化。我想进大厂,希望某位大厂的看到后能给次机会。 首先了解一下lazyforeach: Laz…...
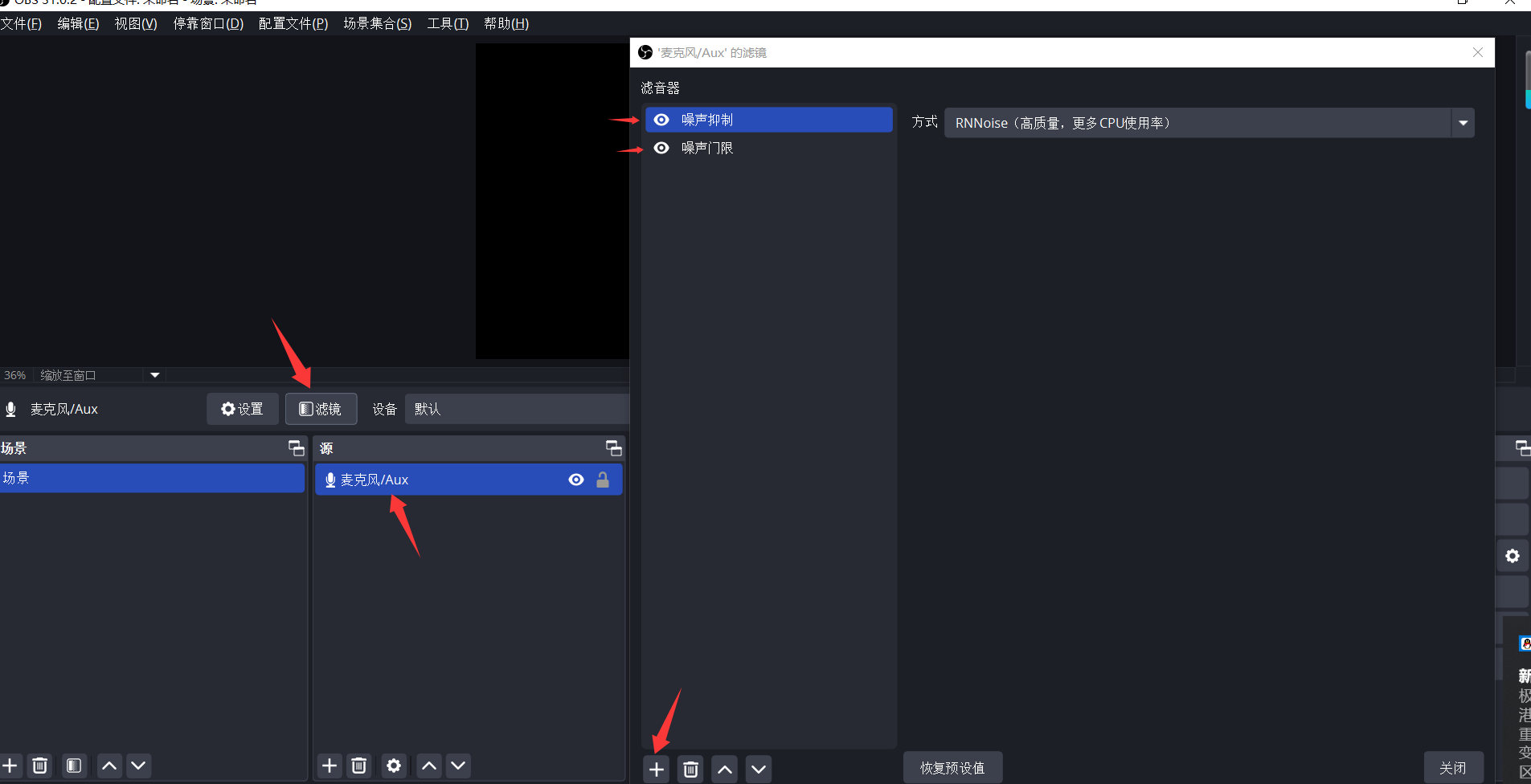
OBS studio 减少音频中的杂音(噪音)
1. 在混音器中关闭除 麦克风 之外的所有的音频输入设备 2.在滤镜中增加“噪声抑制”和“噪声门限”...

基于神经网络的 YOLOv8、MobileNet、HigherHRNet 姿态检测比较研究
摘要 随着人工智能技术的飞速发展,基于神经网络的姿态检测技术在计算机视觉领域取得了显著进展。本文旨在深入比较分析当前主流的姿态检测模型,即 YOLOv8、MobileNet 和 HigherHRNet,从模型架构、性能表现、应用场景等多维度展开研究。通过详…...

智能手表 MCU 任务调度图
智能手表 MCU 任务调度图 处理器平台:ARM Cortex-M33 系统架构:事件驱动 多任务 RTOS RTOS:FreeRTOS(或同类实时内核) 一、任务调度概览 任务名称优先级周期性功能描述App_MainTask中否主循环调度器,系统…...

青少年编程与数学 02-019 Rust 编程基础 03课题、变量与可变性
青少年编程与数学 02-019 Rust 编程基础 03课题、变量与可变性 一、使用多个文件(模块)1. 创建包结构2. 在 main.rs 中引入模块示例:main.rs 3. 定义模块文件示例:module1.rs示例:module2.rs 4. 定义子模块示例&#x…...

S7-1500——零基础入门2、PLC的硬件架构
PLC的硬件架构 一,西门子PLC概述二,CPU介绍三,数字量模块介绍四,模拟量模块介绍五,其他模块介绍一,西门子PLC概述 本节主要内容 西门子PLC硬件架构,主要内容包括PLC概述、组成、功能及S7-1500 demo的组成与安装演示。 介绍了PLC的定义、功能、应用场合,以及与继电器控…...

前端面试宝典---webpack面试题
webpack 的 tree shaking 的原理 Webpack 的 Tree Shaking 过程主要包含以下步骤: 模块依赖分析:Webpack 首先构建一个完整的模块依赖图,确定每个模块之间的依赖关系。导出值分析:通过分析模块之间的 import 和 exportÿ…...

【PmHub后端篇】Skywalking:性能监控与分布式追踪的利器
在微服务架构日益普及的当下,对系统的性能监控和分布式追踪显得尤为重要。本文将详细介绍在 PmHub 项目中,如何使用 Skywalking 实现对系统的性能监控和分布式追踪,以及在这过程中的一些关键技术点和实践经验。 1 分布式链路追踪概述 在微服…...

Grafana v12.0 引入了多项新功能和改进
Grafana v12.0 引入了多项新功能和改进,旨在提升可观测性、仪表板管理和用户体验。以下是主要更新内容的总结: 🚀 主要新功能与改进 1. Git 同步仪表板(Git Sync) Grafana v12.0 支持将仪表板直接同步到 GitHub 仓库…...
利用“Flower”实现联邦机器学习的实战指南
一个很尴尬的现状就是我们用于训练 AI 模型的数据快要用完了。所以我们在大量的使用合成数据! 据估计,目前公开可用的高质量训练标记大约有 40 万亿到 90 万亿个,其中流行的 FineWeb 数据集包含 15 万亿个标记,仅限于英语。 作为…...

MongoDB使用x.509证书认证
文章目录 自定义证书生成CA证书生成服务器之间的证书生成集群证书生成用户证书 MongoDB配置java使用x.509证书连接MongoDBMongoShell使用证书连接 8.0版本的mongodb开启复制集,配置证书认证 自定义证书 生成CA证书 生成ca私钥: openssl genrsa -out ca…...

创始人 IP 的破局之道:从技术突围到生态重构的时代启示|创客匠人评述
在 2025 年的商业版图上,创始人 IP 正以前所未有的深度介入产业变革。当奥雅股份联合创始人李方悦在 “中国上市公司品牌价值榜” 发布会上,将 IP 赋能与城市更新大模型结合时,当马斯克在特斯拉财报电话会议上宣称 “未来属于自动驾驶和人形机…...

Gin 框架入门
Gin 框架入门 一、响应数据 JSON 响应 在 Web 开发中,JSON 是一种常用的数据交换格式。Gin 提供了简便的方法来响应 JSON 数据。 package mainimport ("github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/json", func(c *…...
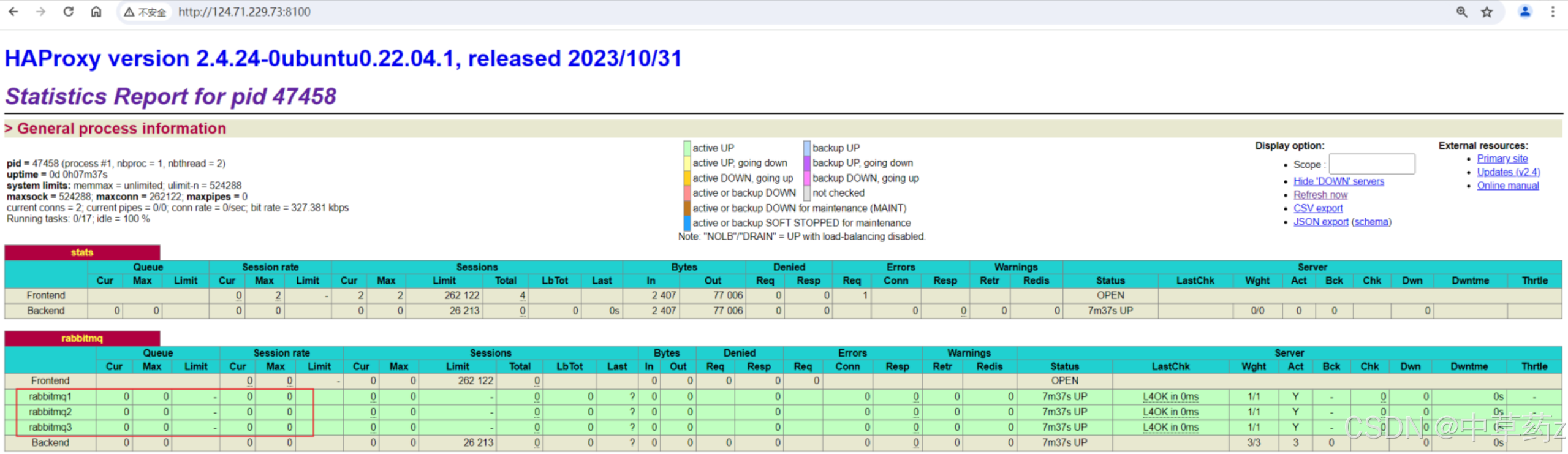
【RabbitMQ】应用问题、仲裁队列(Raft算法)和HAProxy负载均衡
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、幂等性保障 什么是幂等性? 幂等性是指对一个系统进行重复调用(相同参数),无论同一操作执行多少次,这些请求…...

软件设计师-错题笔记-系统开发与运行
1. 解析: A:模块是结构图的基本成分之一,用矩形表示 B:调用表示模块之间的调用关系,通过箭头等符号在结构图中体现 C:数据用于表示模块之间的传递的信息,在结构图中会涉及数据的流向等表示 …...

硬件设备基础
一、ARM9 内核中有多少个通用寄存器?其中 sp、lr、pc、cpsr、spsr 的作用是什么? 在 ARM9 内核中,寄存器组织包含 37 个 通用寄存器,其中,有 13 个通用目的寄存器(R0 - R12)。 S3C2440 是 ARM 架…...

[编程基础] PHP · 学习手册
🔥 《PHP 工程师修炼之路:从零构建系统化知识体系》 🔥 🛠️ 专栏简介: 这是一个以工业级开发标准打造的 PHP 全栈技术专栏,涵盖语法精粹、异步编程、Zend引擎原理、框架源码、高并发架构等全维度知识体系…...
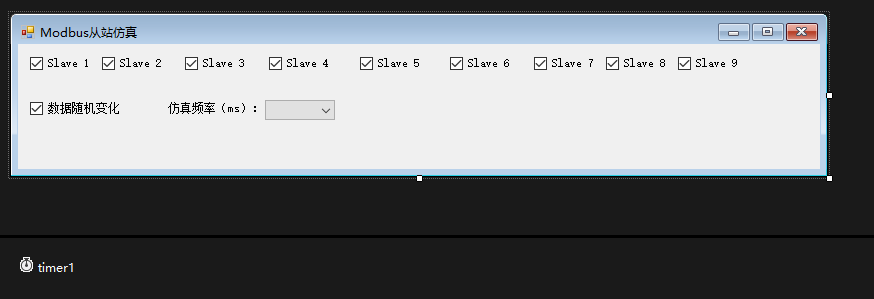
C#简易Modbus从站仿真器
C#使用NModbus库,编写从站仿真器,支持Modbus TCP访问,支持多个从站地址和动态启用/停用从站(模拟离线),支持数据变化,可以很方便实现,最终效果如图所示。 项目采用.net framework 4.…...