深入 MySQL 查询优化器:Optimizer Trace 分析
目录
一、前言
二、参数详解
optimizer_trace
optimizer_trace_features
optimizer_trace_max_mem_size
optimizer_trace_limit
optimizer_trace_offset
三、Optimizer Trace
join_preparation
join_optimization
condition_processing
substitute_generated_columns
table_dependencies
ref_optimizer_key_uses
rows_estimation
potential_range_indexes
setup_range_conditions
group_index_range
skip_scan_range
analyzing_range_alternatives
considered_execution_plans
attaching_conditions_to_tables
finalizing_table_conditions
refine_plan
join_execution
附件
一、前言
我们在日常维护数据库的时候,如果遇到慢语句查询的时候,我们一般会怎么做?执行EXPLAIN去查看它的执行计划?
是的。我们经常会这么做,然后看到执行计划展示给我们的一些信息,告诉我们MySQL是如何执行语句的。
但是执行计划往往只给我们带来了最基础的分析信息,比如是否有使用索引,还有一些其他供我们分析的信息,比如使用了临时表、排序等等。我们能从这些信息里面找一些优化点,这样就足够了吗?

看看这张图里的执行计划,我们可以提很多问题:为什么t1表上明明使用了索引在Extra列中还是能看到filesort?如果possible_keys列中有多个索引的话,优化器是基于什么选定使用的索引?这些问题,并不能非常直观地从执行计划中看出来更多的信息,这个时候,我们可以开启OPTIMIZER_TRACE,基于OPTIMIZER_TRACE捕获的信息,去做更细致的追踪分析。一起来看看吧~
二、参数详解

optimizer_trace
- enabled:启用/禁用optimizer_trace功能
- one_line:决定了跟踪信息的存储方式,为on表示使用单行存储,否则以json树的标准展示形式存储
optimizer_trace_features
该变量中存储了跟踪信息中可控的打印项,可以通过调整该变量,控制在INFORMATION_SCHEMA.OPTIMIZER_TRACE表中的trace列需要打印的JSON项和不需要打印的JSON项。默认打开该参数下的所有项。
- greedy_search: 对于有N个表的join操作,可能产生N的阶乘的查询计划路径。如果禁用,则不跟踪贪婪搜索
- range_optimizer: range优化,如果禁用,则不会跟踪范围优化器
- dynamic_range: dynamic range optimizer,如果关闭该选项的话,只有第一次调用JOIN_TAB::SQL_SELECT才被跟踪
- repeated_subselect :子查询,如果关闭的话,只有第一次调用Item_subselect才被跟踪
optimizer_trace_max_mem_size
- optimizer_trace内存的大小,如果跟踪信息超过这个大小,信息将会被截断
optimizer_trace_limit
- optimizer_trace_limit,约束跟踪信息存储的个数
optimizer_trace_offset
- optimizer_trace_offset,约束偏移量
三、Optimizer Trace
在Optimizer Trace的输出中,主要分为三个部分:
- join_preparation SQL的准备阶段
- join_optimization SQL优化阶段
- join_execution SQL执行阶段
join_preparation
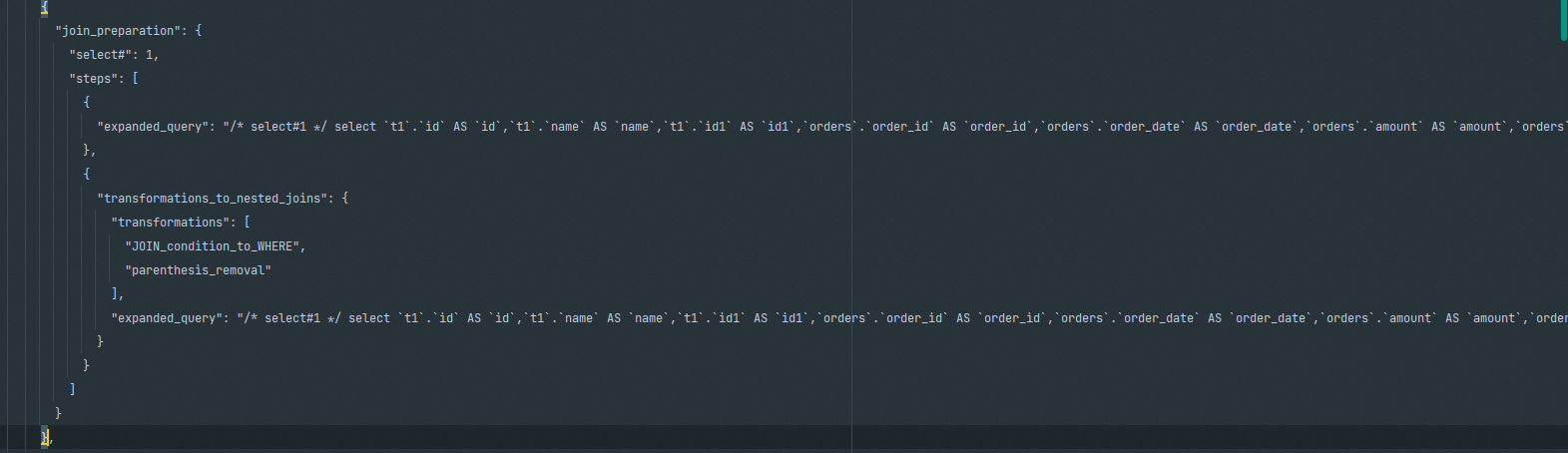
第一部分是完成SQL的准备工作。在这个阶段,SQL语句会被格式化输出,通配符*会被具体字段代替,但不会进行等价改写动作。如上图中传入的SQL语句是”select * from dept”的结果。在完成了语句的补充、格式化后,准备阶段结束并进入下一阶段。
join_optimization
第二部分,是完成SQL语句的逻辑与物理优化的过程,这其中的优化步骤比较多
在展开具体内容之前,先解释下”select #”的问题。在输出中经常会看到有”select#:N”的字样,它表示当前跟踪的结构体是属于第几个SELECT。
如果语句中使用多个SELECT语句拼接(如UNION)或者有嵌套子查询中有SELECT,会产生多个序号。
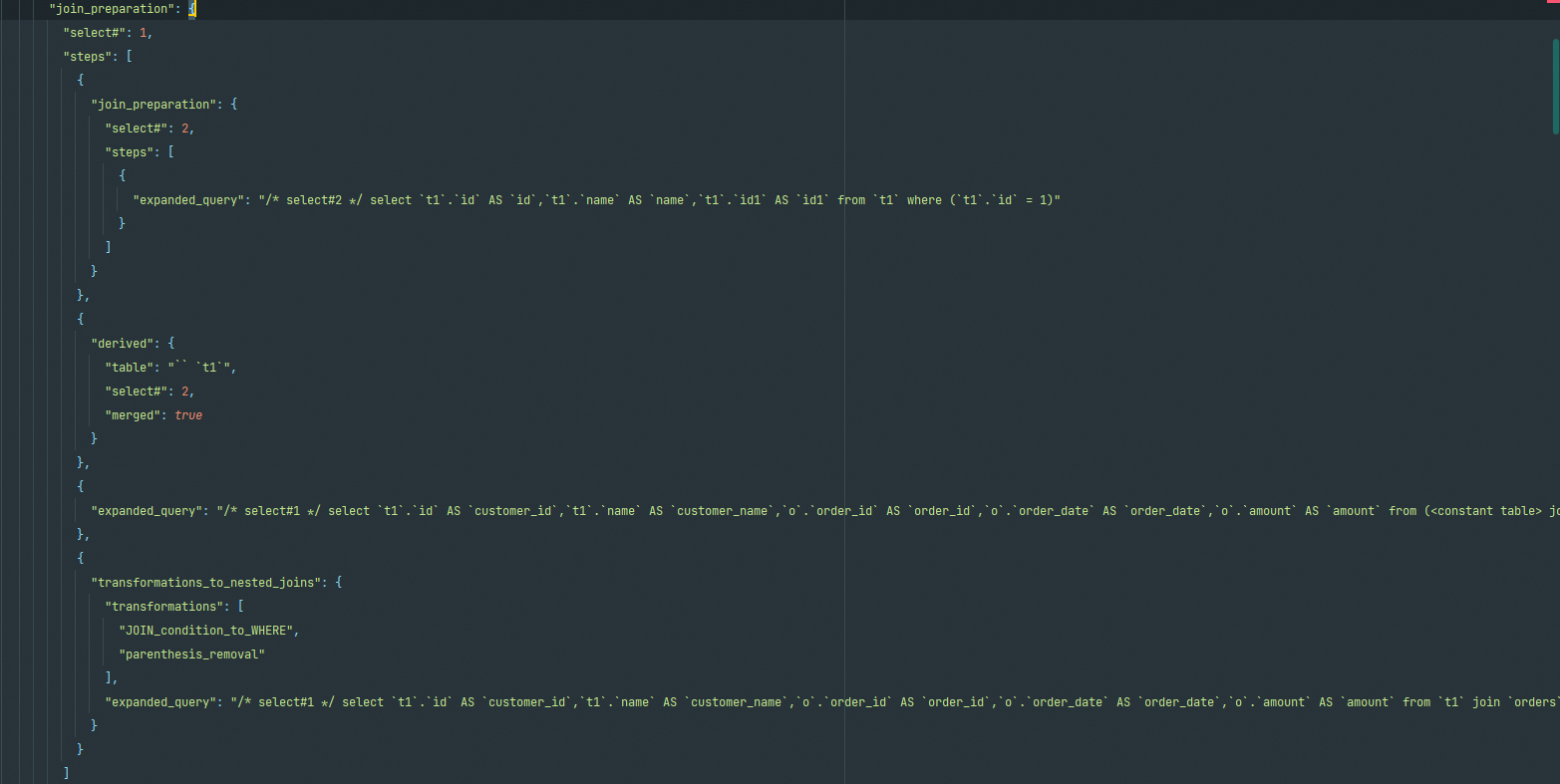
condition_processing
这一部分是完成对条件语句的优化,包括对WHERE子句或HAVING子句的优化。在后面的”condition”部分就标识出是对哪类子句的优化,如下图就是对WHERE子句的优化。

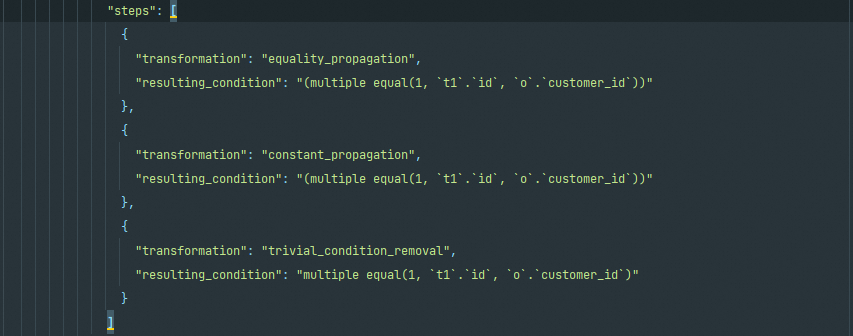
在后面是三个优化过程,每步都写明了转换类型(transformation),明确转换做的事情,以及转换之后的结果语句(resulting_condition)。这三个转换分别是:
- equality_propagation(等值条件句转换)
- constant_propagation(常量条件句转换
- trivial_condition_removal(无效条件移除的转换)
substitute_generated_columns
用于替换虚拟生成列
![]()
table_dependencies
这部分是要找出表之间的相互依赖关系。如查询中存在多个表且之间是有依赖关系,会影响优化行为。这部分信息更多是提示作用,没有实质优化动作。
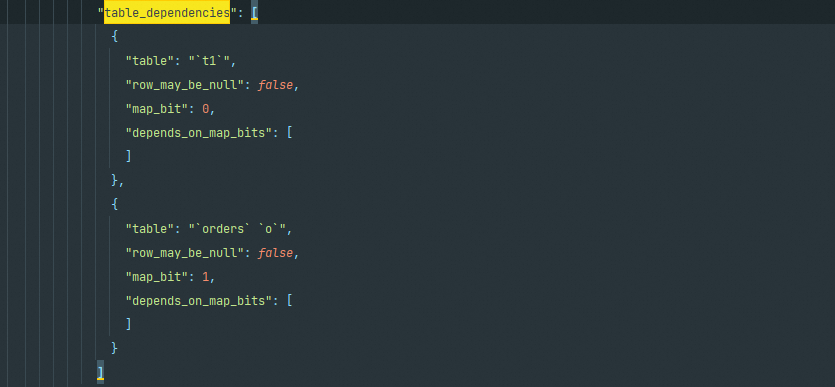
在具体字段含义上:
- table:涉及的表名(如果有别名,也会显示出来)
- row_may_be_null:列是否允许为NULL,这里并不是指表中的列属性是否允许为NULL,而是指JOIN操作之后的列是否为NULL。比如说原始语句中如果使用了LEFT JOIN,那么后一张表的row_may_be_null则会显示为true。
- map_bit:表的映射编号,从0开始递增。
- depends_on_map_bits:依赖的映射表,这里主要是在使用STRAIGHT_JOIN进行强制连接顺序或者是LEFT JOIN/RIGHT JOIN有顺序差别时,会在depends_on_map_bits中列出前置表的map_bit。
ref_optimizer_key_uses
列出了所有可用的ref类型的索引,在图中显示可过滤的字段
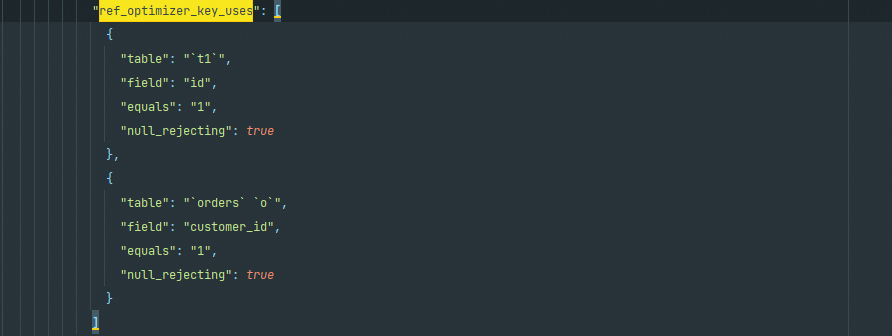
rows_estimation
在这一阶段会评估各种扫描方式的成本,包括全表扫描机索引扫描的代价估算。这一段以表对象作为结构体进行展开

potential_range_indexes
该阶段会列出表中所有的索引并分析其是否可用,并且还会列出索引中可用的列字段;如果不可用,则列出不可用的原因
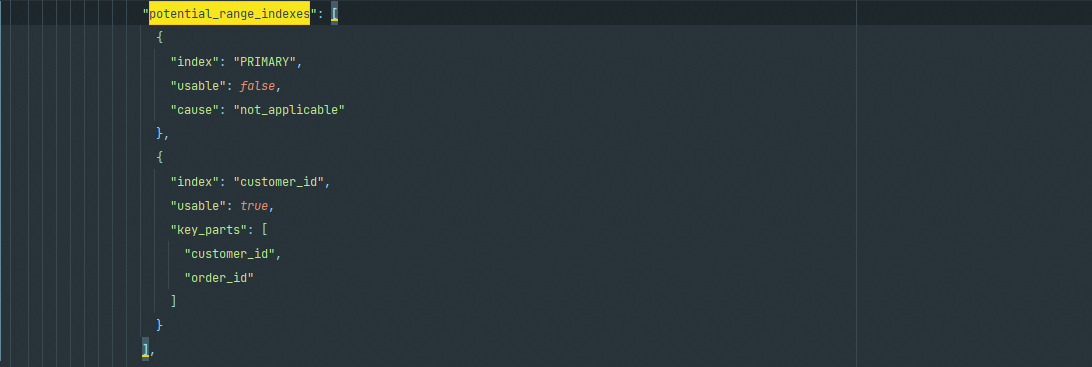
setup_range_conditions
如果有可下推的条件,则带条件考虑范围查询
![]()
group_index_range
评估在使用了GROUP BY或者是DISTINCT的时候是否有适合的索引可用

skip_scan_range
8.0新增,是否使用了skip scan

在 MySQL 中,skip_scan_range 是优化器跟踪输出中的一个元素,它表示优化器使用了跳过扫描(Skip Scan)访问方法。跳过扫描是一种范围访问方法,它在查询过程中跳过不满足条件的行,从而减少需要扫描的行数,提高查询效率
analyzing_range_alternatives
分析各索引使用成本,包括range_scan_alternatives(range扫描分析)、analyzing_roworder_intersect(index merge分析)两个阶段,分别针对不同的情况进行执行代价的分析,从中选择出更优的执行计划
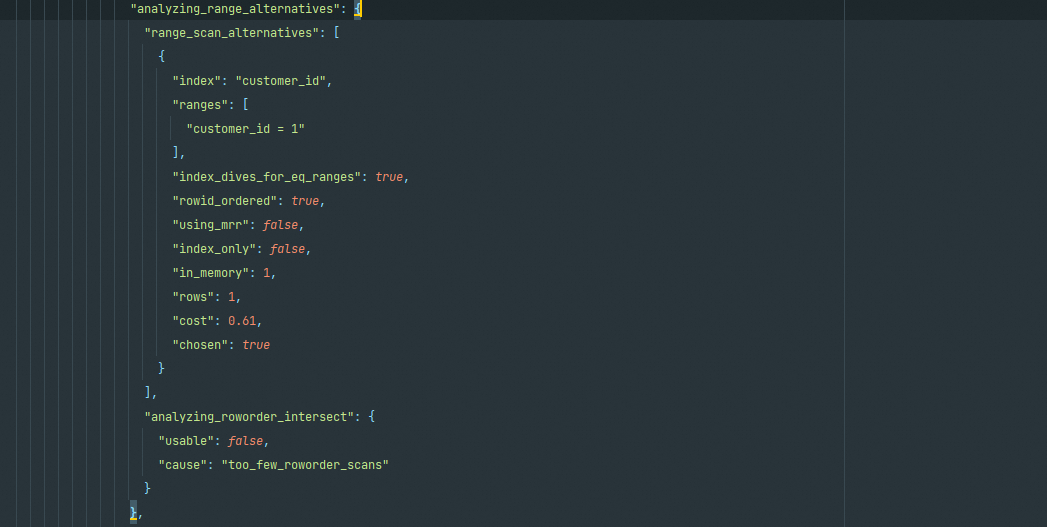
在有了上述对比之后,在下面chosen_range_access_summary给出这部分的最终结论,使用了"index": "customer_id"
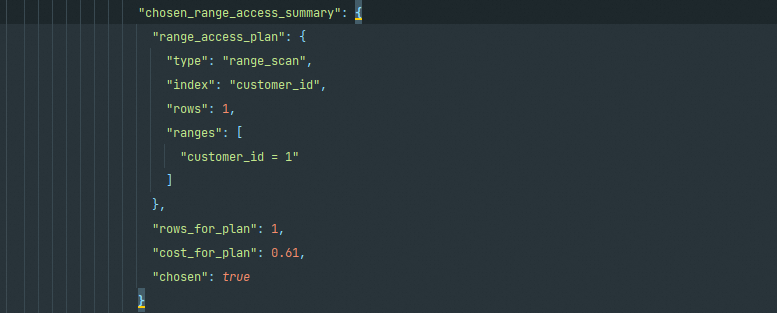
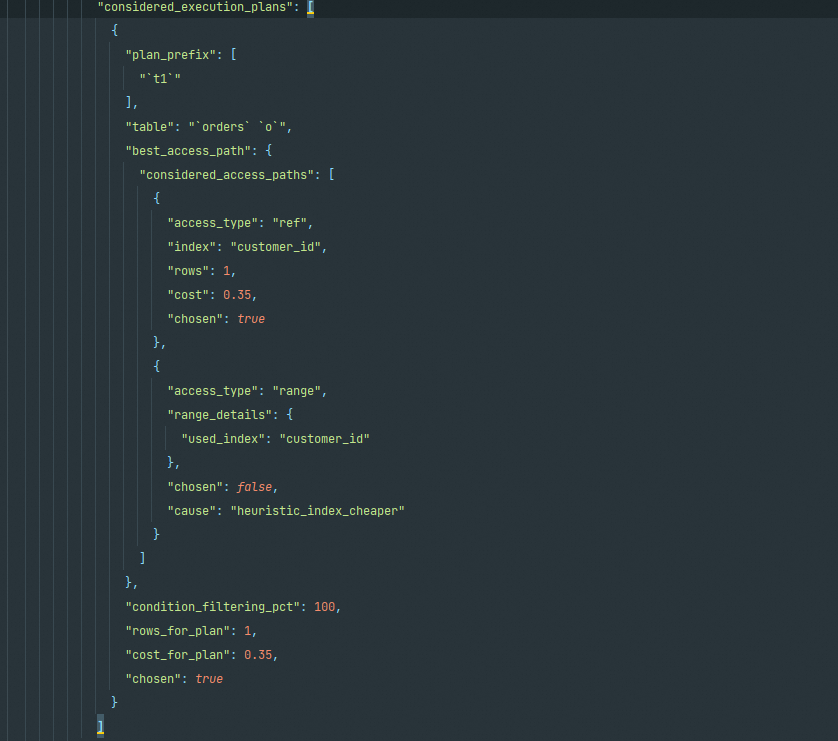
considered_execution_plans
对比实际的不同路径的成本。如果是多表关联,且有存在执行顺序(如left/right join或straight_join来强制指定顺序),则在plan_prefix部分会有前置条件;否则,就按照所有可能性评估
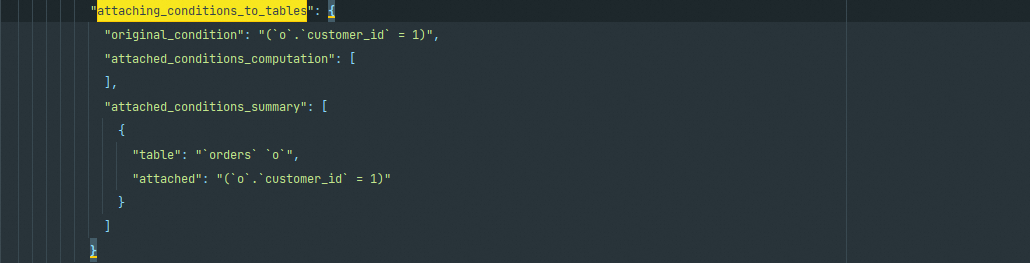
attaching_conditions_to_tables
这一步是在上面的基础上,尽量通过绑定条件到对应表上来获取更好的数据筛选。如果能做ICP(索引条件推入)则更佳
finalizing_table_conditions

refine_plan
最后的优化后的结果,如果只是展示对应的表对象没有其他字段,则说明之前已经确定的执行计划已经是最优的结果

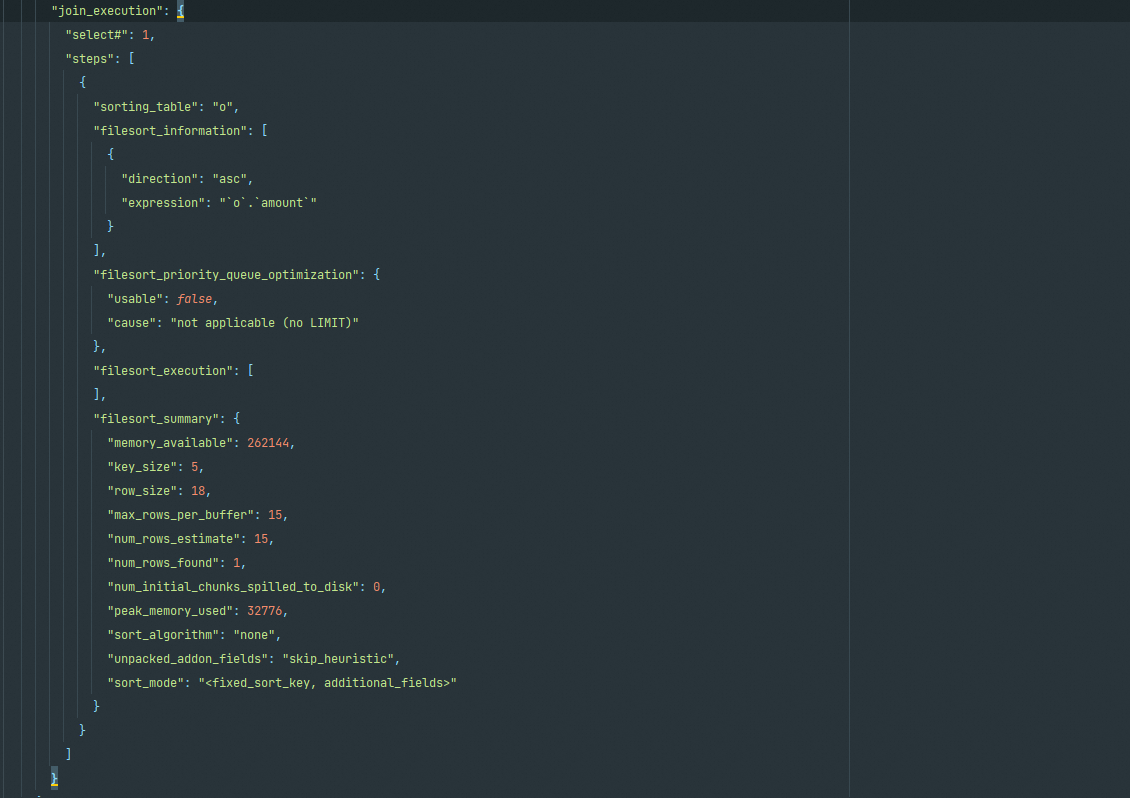
join_execution
在SQL在阶段,大部分都是空白的

只有当语句中包含有排序等操作时,才会在此部分显示
附件
CREATE TABLE `t1` (`id` INT NOT NULL AUTO_INCREMENT,`name` VARCHAR(20) DEFAULT NULL,`id1` INT DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO t1 (name, id1) VALUES
('Alice', 101),
('Bob', 102),
('Charlie', 103),
('David', 104),
('Eve', 105),
('Frank', 106),
('George', 107),
('Hannah', 108),
('Ivan', 109),
('Jack', 110),
('Kevin', 111);INSERT INTO orders (order_date, amount, customer_id) VALUES
('2023-01-01', 100.00, 1),
('2023-01-02', 200.50, 2),
('2023-01-03', 300.75, 3),
('2023-01-04', 400.00, 4),
('2023-01-05', 500.00, 5),
('2023-01-06', 600.25, 6),
('2023-01-07', 700.50, 7),
('2023-01-08', 800.00, 8),
('2023-01-09', 900.75, 9),
('2023-01-10', 1000.00, 10);SELECT t1.id AS customer_id,t1.name AS customer_name,GROUP_CONCAT(o.amount ORDER BY o.amount SEPARATOR ',') AS grouped_amount, -- 使用 GROUP_CONCAT() 函数并确保它在 SELECT 列表中COUNT(o.order_id) AS order_count
FROM (SELECT * FROM t1 WHERE id = 1) AS t1
JOIN orders AS o ON t1.id = o.customer_id
GROUP BY amount; SELECT t1.id AS customer_id,t1.name AS customer_name,GROUP_CONCAT(DISTINCT o.amount ORDER BY o.amount SEPARATOR ',') AS grouped_amount, -- 使用 GROUP_CONCAT() 函数并确保它在 SELECT 列表中,添加 DISTINCT 以去重COUNT(o.order_id) AS order_count
FROM (SELECT * FROM t1 WHERE id = 1) AS t1
JOIN orders AS o ON t1.id = o.customer_id
GROUP BY amount;QUERY | SELECTt1.id AS customer_id,t1.name AS customer_name,GROUP_CONCAT(DISTINCT o.amount ORDER BY o.amount SEPARATOR ',') AS grouped_amount, -- 使用 GROUP_CONCAT() 函数并确保它在 SELECT 列表中,添加 DISTINCT 以去重COUNT(o.order_id) AS order_count
FROM(SELECT * FROM t1 WHERE id = 1) AS t1 -- 子查询,先从 t1 表中选出 id 为 1 的记录
JOINorders AS o ON t1.id = o.customer_id -- 将子查询的结果与 orders 表进行连接
GROUP BYamount
TRACE | {"steps": [{"join_preparation": {"select#": 1,"steps": [{"join_preparation": {"select#": 2,"steps": [{"expanded_query": "/* select#2 */ select `t1`.`id` AS `id`,`t1`.`name` AS `name`,`t1`.`id1` AS `id1` from `t1` where (`t1`.`id` = 1)"}]}},{"derived": {"table": "`` `t1`","select#": 2,"merged": true}},{"expanded_query": "/* select#1 */ select `t1`.`id` AS `customer_id`,`t1`.`name` AS `customer_name`,group_concat(distinct `o`.`amount` order by `o`.`amount` ASC separator ',') AS `grouped_amount`,count(`o`.`order_id`) AS `order_count` from (<constant table> join (`t1`) on((`t1`.`id` = 1)) join `orders` `o` on((`t1`.`id` = `o`.`customer_id`))) group by `o`.`amount`"},{"transformations_to_nested_joins": {"transformations": ["JOIN_condition_to_WHERE","parenthesis_removal"],"expanded_query": "/* select#1 */ select `t1`.`id` AS `customer_id`,`t1`.`name` AS `customer_name`,group_concat(distinct `o`.`amount` order by `o`.`amount` ASC separator ',') AS `grouped_amount`,count(`o`.`order_id`) AS `order_count` from `t1` join `orders` `o` where ((`t1`.`id` = `o`.`customer_id`) and (`t1`.`id` = 1)) group by `o`.`amount`"}},{"functional_dependencies_of_GROUP_columns": {"all_columns_of_table_map_bits": [0],"columns": ["demo3.o.amount","demo3.t1.id"]}}]}},{"join_optimization": {"select#": 1,"steps": [{"condition_processing": {"condition": "WHERE","original_condition": "((`t1`.`id` = `o`.`customer_id`) and (`t1`.`id` = 1))","steps": [{"transformation": "equality_propagation","resulting_condition": "(multiple equal(1, `t1`.`id`, `o`.`customer_id`))"},{"transformation": "constant_propagation","resulting_condition": "(multiple equal(1, `t1`.`id`, `o`.`customer_id`))"},{"transformation": "trivial_condition_removal","resulting_condition": "multiple equal(1, `t1`.`id`, `o`.`customer_id`)"}]}},{"substitute_generated_columns": {}},{"table_dependencies": [{"table": "`t1`","row_may_be_null": false,"map_bit": 0,"depends_on_map_bits": []},{"table": "`orders` `o`","row_may_be_null": false,"map_bit": 1,"depends_on_map_bits": []}]},{"ref_optimizer_key_uses": [{"table": "`t1`","field": "id","equals": "1","null_rejecting": true},{"table": "`orders` `o`","field": "customer_id","equals": "1","null_rejecting": true}]},{"rows_estimation": [{"table": "`t1`","rows": 1,"cost": 1,"table_type": "const","empty": false},{"table": "`orders` `o`","range_analysis": {"table_scan": {"rows": 2,"cost": 2.55},"potential_range_indexes": [{"index": "PRIMARY","usable": false,"cause": "not_applicable"},{"index": "customer_id","usable": true,"key_parts": ["customer_id","order_id"]}],"setup_range_conditions": [],"group_index_range": {"chosen": false,"cause": "not_single_table"},"skip_scan_range": {"chosen": false,"cause": "not_single_table"},"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "customer_id","ranges": ["customer_id = 1"],"index_dives_for_eq_ranges": true,"rowid_ordered": true,"using_mrr": false,"index_only": false,"in_memory": 1,"rows": 1,"cost": 0.61,"chosen": true}],"analyzing_roworder_intersect": {"usable": false,"cause": "too_few_roworder_scans"}},"chosen_range_access_summary": {"range_access_plan": {"type": "range_scan","index": "customer_id","rows": 1,"ranges": ["customer_id = 1"]},"rows_for_plan": 1,"cost_for_plan": 0.61,"chosen": true}}}]},{"considered_execution_plans": [{"plan_prefix": ["`t1`"],"table": "`orders` `o`","best_access_path": {"considered_access_paths": [{"access_type": "ref","index": "customer_id","rows": 1,"cost": 0.35,"chosen": true},{"access_type": "range","range_details": {"used_index": "customer_id"},"chosen": false,"cause": "heuristic_index_cheaper"}]},"condition_filtering_pct": 100,"rows_for_plan": 1,"cost_for_plan": 0.35,"chosen": true}]},{"attaching_conditions_to_tables": {"original_condition": "(`o`.`customer_id` = 1)","attached_conditions_computation": [],"attached_conditions_summary": [{"table": "`orders` `o`","attached": "(`o`.`customer_id` = 1)"}]}},{"optimizing_distinct_group_by_order_by": {"simplifying_group_by": {"original_clause": "`o`.`amount`","items": [{"item": "`o`.`amount`"}],"resulting_clause_is_simple": true,"resulting_clause": "`o`.`amount`"}}},{"finalizing_table_conditions": [{"table": "`orders` `o`","original_table_condition": "(`o`.`customer_id` = 1)","final_table_condition ": null}]},{"refine_plan": [{"table": "`orders` `o`"}]},{"considering_tmp_tables": [{"creating_tmp_table": {"tmp_table_info": {"table": "intermediate_tmp_table","columns": 1,"row_length": 6,"key_length": 0,"unique_constraint": false,"makes_grouped_rows": false,"cannot_insert_duplicates": false,"location": "TempTable"}}},{"adding_sort_to_table": "o"}]}]}},{"join_execution": {"select#": 1,"steps": [{"sorting_table": "o","filesort_information": [{"direction": "asc","expression": "`o`.`amount`"}],"filesort_priority_queue_optimization": {"usable": false,"cause": "not applicable (no LIMIT)"},"filesort_execution": [],"filesort_summary": {"memory_available": 262144,"key_size": 5,"row_size": 18,"max_rows_per_buffer": 15,"num_rows_estimate": 15,"num_rows_found": 1,"num_initial_chunks_spilled_to_disk": 0,"peak_memory_used": 32776,"sort_algorithm": "none","unpacked_addon_fields": "skip_heuristic","sort_mode": "<fixed_sort_key, additional_fields>"}}]}}]
}
MISSING_BYTES_BEYOND_MAX_MEM_SIZE | 0
INSUFFICIENT_PRIVILEGES | 0
相关文章:
深入 MySQL 查询优化器:Optimizer Trace 分析
目录 一、前言 二、参数详解 optimizer_trace optimizer_trace_features optimizer_trace_max_mem_size optimizer_trace_limit optimizer_trace_offset 三、Optimizer Trace join_preparation join_optimization condition_processing substitute_generated_column…...

每日一道leetcode
790. 多米诺和托米诺平铺 - 力扣(LeetCode) 题目 有两种形状的瓷砖:一种是 2 x 1 的多米诺形,另一种是形如 "L" 的托米诺形。两种形状都可以旋转。 给定整数 n ,返回可以平铺 2 x n 的面板的方法的数量。返…...

FFmpeg在Android开发中的核心价值是什么?
FFmpeg 在 Android 开发中的核心价值主要体现在其强大的多媒体处理能力和灵活性上,尤其在音视频编解码、流媒体处理及跨平台兼容性方面具有不可替代的作用。以下是具体分析: --- 1. 强大的音视频编解码能力 - 支持广泛格式:FFmpeg 支持几乎所…...
 ArrayList)
C#进阶(1) ArrayList
前言 在我们进行了入门,基础,核心的学习后,我们已经学了相当多的知识了,不知道你现在对比打开入门时候的你,进步了多少。是否也能自己写一点简单的程序来作为小成就炫耀一下呢? 博主给你留的小项目你是否都有认真去复刻或者改进呢? 这些问题的答案只有你自己清楚。 …...

竞业禁止协议中AI技能限制的深度剖析
首席数据官高鹏律师团队 在当今科技飞速发展的时代,人工智能(AI)领域成为了商业竞争的关键战场。随着AI技术在各行业的广泛渗透,竞业禁止协议中涉及AI技能的限制条款愈发受到关注,其背后蕴含着复杂而关键的法律与商业…...
)
动态查找滚动容器(通用方案)
需求:点击置顶按钮返回页面的顶部,涉及产生滚动条的元素不唯一的情况,如果确定滚动元素的情况,直接元素.scrollTop 0 就实现置顶了 也是查了一段时间,这个方法很赞,递归寻找滚动元素 步骤 1:判…...

CD3MN 双相钢 2205 材质保温 V 型球阀:恒温工况下复杂介质控制的高性能之选-耀圣
CD3MN 双相钢 2205 材质保温 V 型球阀:恒温工况下复杂介质控制的高性能之选 在石油化工、沥青储运、食品加工等行业中,带颗粒高粘度介质与料浆的恒温输送面临着腐蚀、磨损、堵塞等多重挑战。普通阀门难以兼顾耐高温、强密封与耐腐蚀性,导致设…...

SpringBoot整合MyBatis-Plus:零XML实现高效CRUD
前言 作为一名开发者,数据库操作是我们日常工作中不可或缺的部分。传统的MyBatis虽然强大,但需要编写大量XML映射文件,这在快速开发的今天显得效率不足。MyBatis-Plus(简称MP)作为MyBatis的增强工具,在保留…...

python酒店健身俱乐部管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...
嵌入式开发学习(第二阶段 C语言基础)
综合案例《猜拳游戏》 需求: 本游戏是一款单机游戏,人机交互 规则: 需要双方出拳:石头、剪刀、布赢: 石头→剪刀剪刀→ 布布 →石头 两边出拳相等输: … 实现: 选择对手玩家出拳对手出拳判断胜…...

Easysearch 时序数据的基于时间范围的合并策略
如果你正在使用 Easysearch 处理日志、监控指标、事件流或其他任何具有时间顺序的数据,那么你一定知道索引的性能和效率至关重要。Easysearch 底层的 Lucene Segment 合并是保持搜索和索引性能的关键后台任务。然而,你是否意识到,默认的合并策…...

【C++】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希
【C】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希 在日常开发中,无论是数据结构优化、缓存设计,还是分布式架构搭建,unordered_map、布隆过滤器和一致性哈希都是绕不开的关键工具。它们高效、轻量,在性能与扩展性方面…...
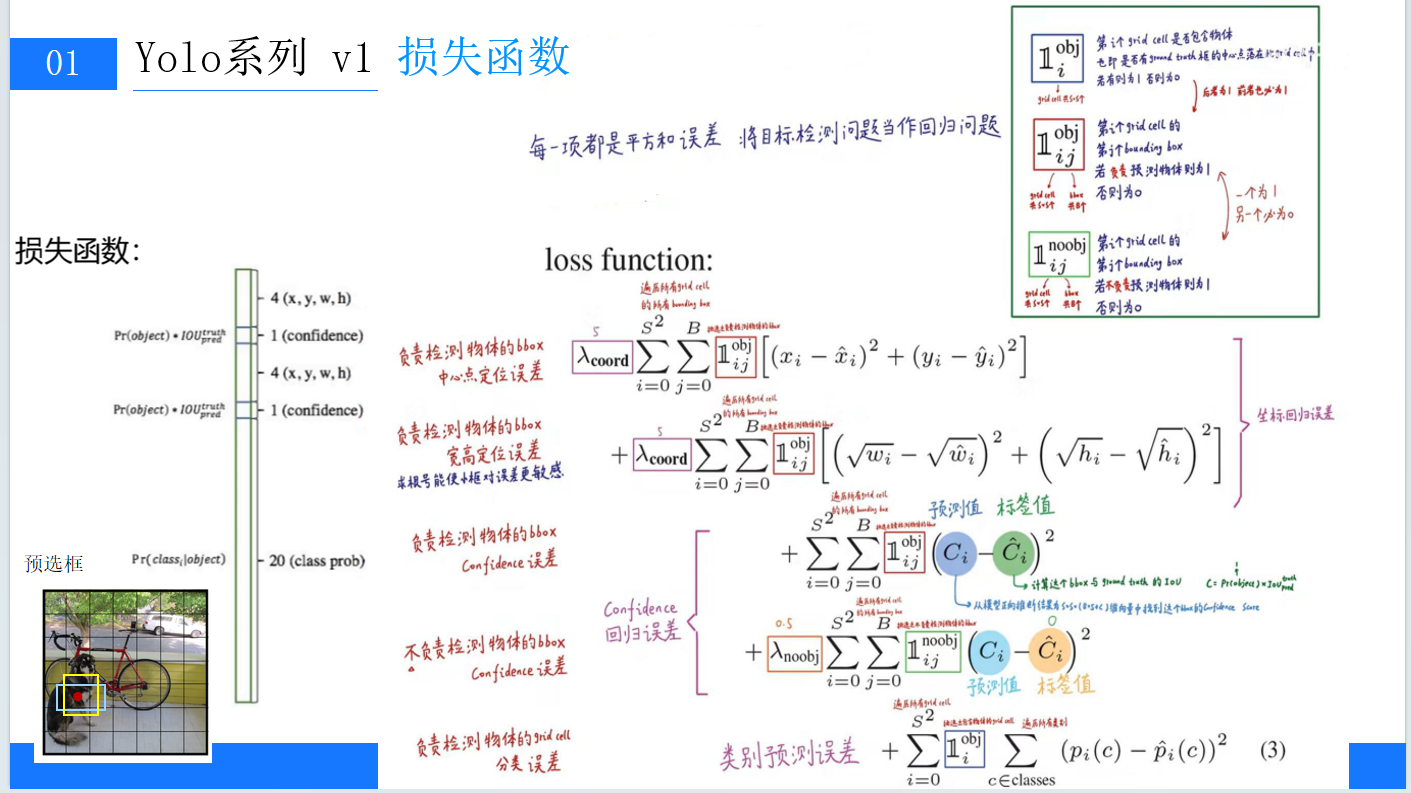
YOLOv1:开启实时目标检测的新篇章
YOLOv1:开启实时目标检测的新篇章 在深度学习目标检测领域,YOLO(You Only Look Once)系列算法无疑占据着重要地位。其中,YOLOv1作为开山之作,以其独特的设计理念和高效的检测速度,为后续的目标…...

Spring Boot 整合 Redis 实战
一、整合准备:环境与依赖 1. 技术栈说明 Spring Boot 版本:3.1.2(兼容 Java 17) Redis 服务器:Redis 7.0(本地部署或 Docker 容器) Maven 依赖: <dependency><…...

Spring事务失效的全面剖析
文章目录 1. Spring事务基础1.1 什么是Spring事务1.2 Spring事务的实现原理1.3 `@Transactional`注解的主要属性1.4 使用Spring事务的简单示例2. Spring事务失效的常见场景及解决方案2.1 方法不是public的问题描述问题示例解决方案技术原理解释2.2 自调用问题(同一个类中的方法…...

Pytorch张量和损失函数
文章目录 张量张量类型张量例子使用概率分布创建张量正态分布创建张量 (torch.normal)正态分布创建张量示例标准正态分布创建张量标准正态分布创建张量示例均匀分布创建张量均匀分布创建张量示例 激活函数常见激活函数 损失函数(Pytorch API)L1范数损失函数均方误差损失函数交叉…...
ConcurrentHashMap发送)
消息~组件(群聊类型)ConcurrentHashMap发送
为什么选择ConcurrentHashMap? 在开发聊天应用时,我们需要存储和管理大量的聊天消息数据,这些数据会被多个线程频繁访问和修改。比如,当多个用户同时发送消息时,服务端需要同时处理这些消息的存储和查询。如果用普通的…...
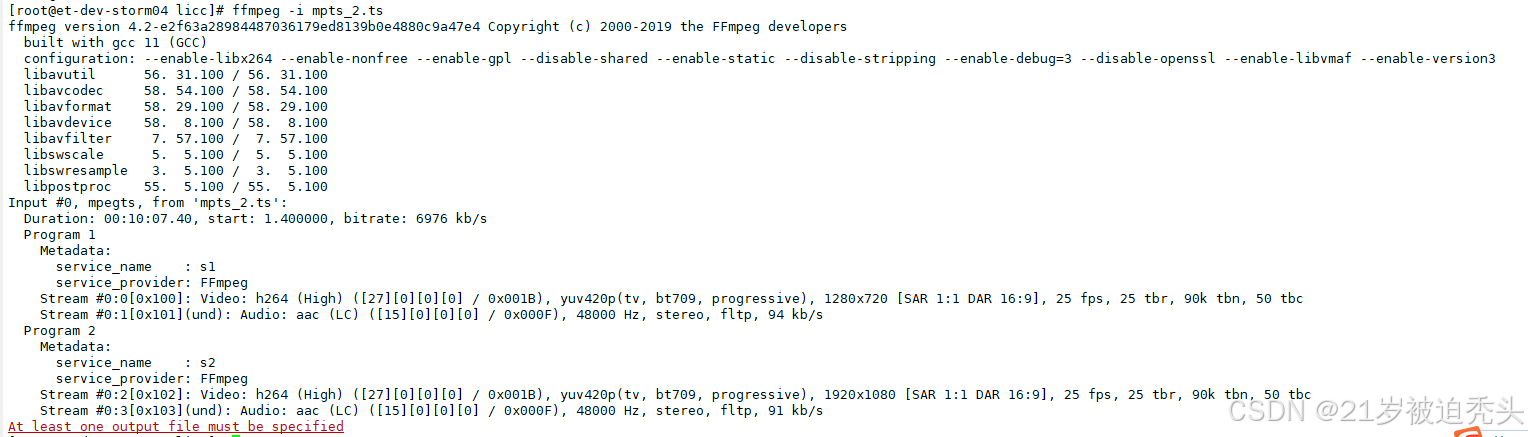
FFmpeg多路节目流复用为一路包含多个节目的输出流
在音视频处理领域,将多个独立的节目流(如不同频道的音视频内容)合并为一个包含多个节目的输出流是常见需求。FFmpeg 作为功能强大的多媒体处理工具,提供了灵活的流复用能力,本文将通过具体案例解析如何使用 FFmpeg 实现…...
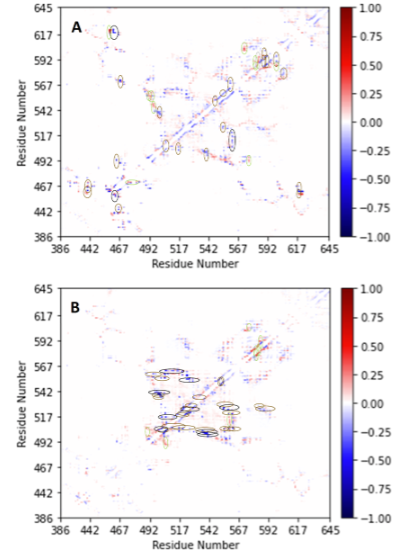
分子动力学模拟揭示点突变对 hCFTR NBD1结构域热稳定性的影响
囊性纤维化(CF) 作为一种严重的常染色体隐性遗传疾病,全球约有 10 万名患者深受其害。它会累及人体多个器官,如肺部、胰腺等,严重影响患者的生活质量和寿命。CF 的 “罪魁祸首” 是 CFTR 氯离子通道的突变,…...

关于SIS/DCS点检周期
在中国化工行业,近几年在设备维护上有个挺有意思的现象,即SIS和DCS这两个系统的点检周期问题,隔三差五就被管理层会议讨论,可以说是企业管理层关注的重要方向与关心要素。 与一般工业行业中设备运维不同,SIS与DCS的点…...

python-pyqt6框架工具开发总结
菜单栏 工具栏 状态栏 QTreeView 用于展示树形结构数据(模-视图框架),文件系统,组织结构 通常与QAbstractItemModel的子类(如QStandardItemModel或自动义模型) 展开/折叠 控制节点的显示状态,展开时显示子节点,折叠时隐藏子节点 s…...

Docker Volumes
Docker Volumes 是 Docker 提供的一种机制,用于持久化存储容器数据。与容器的生命周期不同,Volumes 可以独立存在,即使容器被删除,数据仍然保留。以下是关于 Docker Volumes 的详细说明: 1. 为什么需要 Volumes&#…...
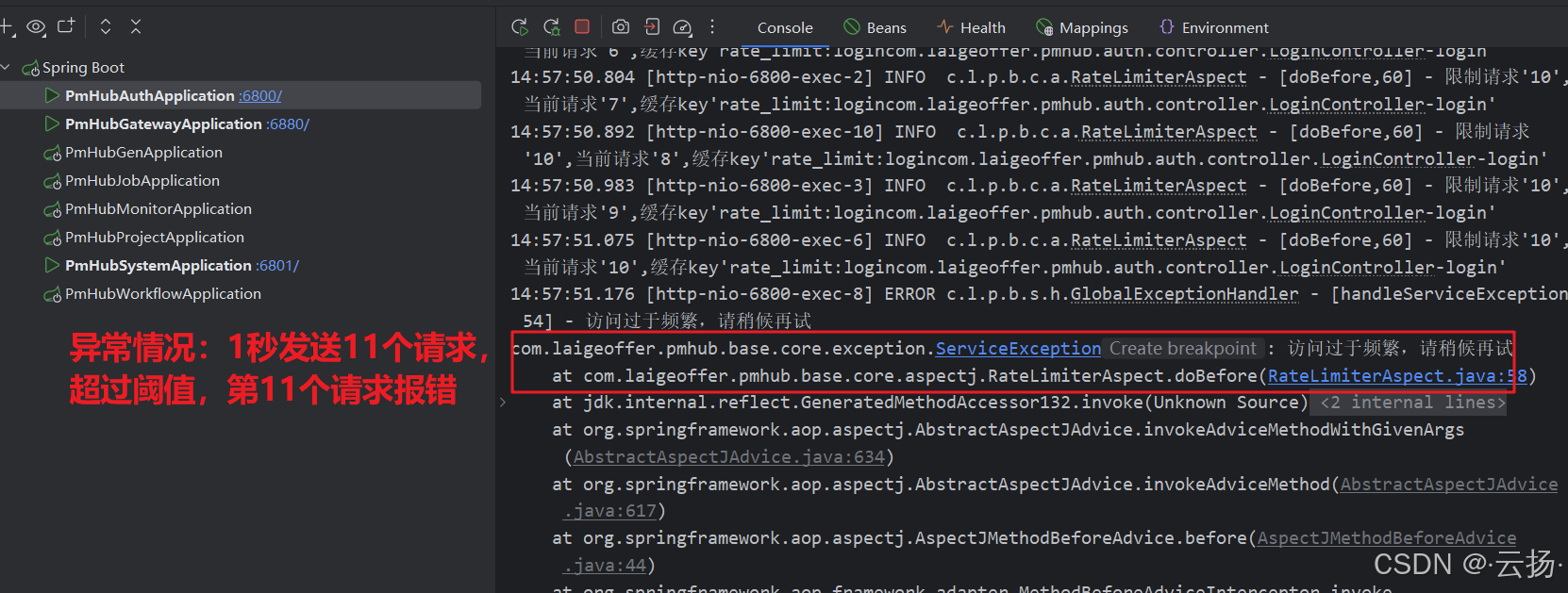
【PmHub后端篇】PmHub中基于Redis加Lua脚本的计数器算法限流实现
1 限流的重要性 在高并发系统中,保护系统稳定运行的关键技术有缓存、降级和限流。 缓存通过在内存中存储常用数据,减少对数据库的访问,提升系统响应速度,如浏览器缓存、CDN缓存等多种应用层面。降级则是在系统压力过大或部分服务…...

FPGA实战项目2———多协议通信控制器
1. 多协议通信控制器模块 (multi_protocol_controller) 简要介绍 这是整个设计的顶层模块,承担着整合各个子模块的重要任务,是整个系统的核心枢纽。它负责协调 UART、SPI、I2C 等不同通信协议模块以及 DMA 模块的工作,同时处理不同时钟域之间的信号交互,确保各个模块能够…...
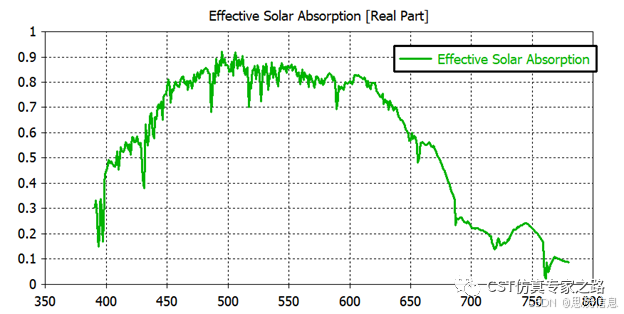
CST软件仿真案例——太阳能薄膜频谱吸收率
CST软件中的太阳能薄膜的功率吸收可用光频电磁波在介质材料中的损耗来计算。本案例计算非晶硅的功率吸收,然后考虑真实太阳频谱,计算有效吸收频谱。 用太阳能单元模板,时域求解器: 材料库提取四个材料,非晶硅…...
)
多线程进阶核心知识详解(通俗版)
Java多线程进阶详解 一、锁策略:如何高效管理资源竞争 在多线程环境中,锁是协调资源访问的核心机制。不同的锁策略适用于不同的场景,理解它们的差异能帮助优化程序性能。 1. 乐观锁 vs 悲观锁 悲观锁: 核心思想:假设…...

大模型中的KV Cache
1. KV Cache的定义与核心原理 KV Cache(Key-Value Cache)是一种在Transformer架构的大模型推理阶段使用的优化技术,通过缓存自注意力机制中的键(Key)和值(Value)矩阵,避免重复计算&…...

FHQ平衡树
FHQ平衡树 大致是这样的题目: 您需要动态地维护一个可重集合 M M M,并且提供以下操作: 向 M M M 中插入一个数 x x x。从 M M M 中删除一个数 x x x(若有多个相同的数,应只删除一个)。查询 M M M 中…...

力扣算法---总结篇
5.13 数组总结 数组是存放在连续内存空间上的相同类型数据的集合。 数组可以方便的通过下标索引的方式获取到下标对应的数据。 正是因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。 数组的元素是不…...
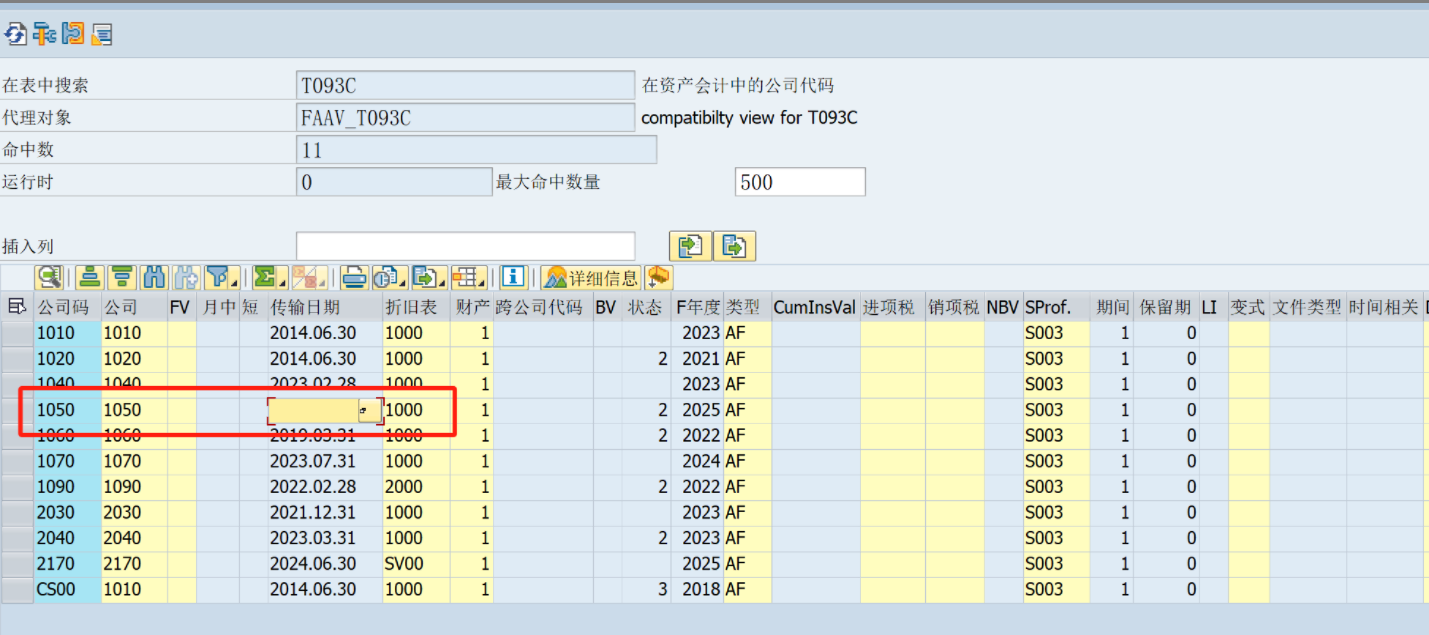
ABAP+旧数据接管的会计年度未确定
导资产主数据时,报错旧数据接管的会计年度未确定 是因为程序里面使用了下列函数AISCO_CALCULATE_FIRST_DAY,输入公司代码,获取会计年度,这个数据是在后台表T093C表中取数的,通过SE16N可以看到后台表数据没有数…...