使用聊天模型和提示模板构建一个简单的 LLM 应用程序
官方教程
官方案例
在上面的链接注册后,请确保设置您的环境变量以开始记录追踪
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
或者,如果在笔记本中,您可以使用以下命令设置它们
import getpass
import osos.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = getpass.getpass()
使用语言模型
pip install -qU "langchain[openai]"
import getpass
import osif not os.environ.get("OPENAI_API_KEY"):os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")from langchain.chat_models import init_chat_modelmodel = init_chat_model("gpt-4o-mini", model_provider="openai")
让我们首先直接使用模型。ChatModels 是 LangChain Runnables 的实例,这意味着它们公开了一个用于与它们交互的标准接口。要简单地调用模型,我们可以将 消息 列表传递给 .invoke 方法。
from langchain_core.messages import HumanMessage, SystemMessagemessages = [SystemMessage("Translate the following from English into Italian"),HumanMessage("hi!"),
]model.invoke(messages)
AIMessage(content='Ciao!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 3, 'prompt_tokens': 20, 'total_tokens': 23, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0705bf87c0', 'finish_reason': 'stop', 'logprobs': None}, id='run-32654a56-627c-40e1-a141-ad9350bbfd3e-0', usage_metadata={'input_tokens': 20, 'output_tokens': 3, 'total_tokens': 23, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})huggingface 模型
因为gpt要花钱,所以换了一个模型
记得获取token
!pip install langchain
!pip install -U langchain-openai
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "hf_rxxxxxxxxxxxxxx"import os
from langchain_huggingface import HuggingFaceEndpoint
# from langchain_community.chat_models import ChatHuggingFace
from langchain_core.messages import HumanMessage, SystemMessage# 设置 Token
os.environ["HF_TOKEN"] = "hf_Xxxxxxxxxxxx"# 模型 ID(使用 HuggingFace 上公开的模型)
repo_id = "HuggingFaceH4/zephyr-7b-beta"# 初始化 LLM
llm = HuggingFaceEndpoint(repo_id=repo_id,max_new_tokens=512,top_k=10,top_p=0.95,typical_p=0.95,temperature=0.01,repetition_penalty=1.03,huggingfacehub_api_token=os.environ["HF_TOKEN"]
)# 封装成聊天模型
# chat_model = ChatHuggingFace(llm=llm)# 构造消息
messages = [SystemMessage(content="Translate the following from English into Chinese"),HumanMessage(content="hi!")
]# 调用模型
response = llm.invoke(messages)
print(response)选择一个公开可访问的替代模型,例如:
HuggingFaceH4/zephyr-7b-beta ✅ 公开
mistralai/Mistral-7B-v0.1 ❌ 受限
tiiuae/falcon-7b ✅ 公开
google/gemma-7b ✅ 公开

# 1. 导入必要的模块
from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint
# HuggingFaceEndpoint是一个 LangChain 封装的类,用于连接 Hugging Face 的推理 API(也就是调用远程模型)。
# ChatHuggingFace:将 LLM 包装成“聊天模型”的适配器。它支持像 messages = [SystemMessage(), HumanMessage()] 这样的对话格式。
from langchain_core.messages import HumanMessage, SystemMessage
# SystemMessage:系统提示词,告诉模型应该做什么(如翻译、写诗等)。
# HumanMessage:用户输入的内容。
# 还有 AIMessage 是模型输出)# 2. 创建 LLM 实例,创建了一个指向 Hugging Face 模型的客户端对象
llm = HuggingFaceEndpoint(endpoint_url="https://api-inference.huggingface.co/models/HuggingFaceH4/zephyr-7b-beta", # 要调用的模型地址(即 API 地址)huggingfacehub_api_token="hf_Xopuxxxxxxxxxxxxxxx", # 替换为你的 tokentemperature=0.7, # 控制生成文本的随机性(越高越随机)max_new_tokens=512, # 最多生成多少个新 token(控制输出长度)top_k=50,top_p=0.95,repetition_penalty=1.03 # 防止重复输出相同内容
)# 3. 用 ChatHuggingFace 封装成聊天模型
chat_model = ChatHuggingFace(llm=llm) # 这一步把原始的 LLM 封装成一个“聊天模型”,这样就可以使用类似 GPT 的接口(例如传入多个角色消息)。# 4. 构造对话消息
messages = [SystemMessage(content="Translate the following from English into Italian"),HumanMessage(content="hi!")
]# 调用模型
response = chat_model.invoke(messages)
print(response.content)

有的时候,import错误、不兼容,也会报错,例如
import os
from langchain_huggingface import HuggingFaceEndpoint
from langchain_community.llms import HuggingFaceEndpoint # 这里重复引用,会引发错误
from langchain_community.chat_models import ChatHuggingFace # 这里新旧版本不兼容
# from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint 正确的
from langchain_core.messages import HumanMessage, SystemMessage# 设置 Token
os.environ["HF_TOKEN"] = "hf_XXXXXXXXXXXXXXXX"# 使用公开可访问的模型
repo_id = "HuggingFaceH4/zephyr-7b-beta" # 替换为你想用的公开模型llm = HuggingFaceEndpoint(repo_id=repo_id,max_new_tokens=512,top_k=10,top_p=0.95,typical_p=0.95,temperature=0.01,repetition_penalty=1.03,huggingfacehub_api_token=os.environ["HF_TOKEN"]
)# 封装成聊天模型
chat_model = ChatHuggingFace(llm=llm)# 构造消息
messages = [SystemMessage(content="Translate the following from English into Italian"),HumanMessage(content="hi!")
]# 调用模型
response = chat_model.invoke(messages)
print(response.content)
你使用了 langchain_community.chat_models.ChatHuggingFace,但是它只接受 langchain_community.llms 中的 LLM 实例(比如旧的 HuggingFaceEndpoint),而你现在用的是新的 langchain_huggingface 中的 HuggingFaceEndpoint,所以 类型不兼容。
其他token方法:
from huggingface_hub import login
login(token="hf_XXXXXXXXXXXXXXXX") #这里替换为自己的API Token
或者:
!huggingface-cli login
其他参数
- repo_id: 这是模型在 Hugging Face Hub 上的唯一标识符。它通常由用户名(或组织名)和模型名组成,例如 “microsoft/Phi-3-mini-4k-instruct”。这种方式更适合于本地运行或者通过 Hugging Face Inference API 直接访问公开模型。
- task: 指定你想要执行的任务类型,比如 “text-generation”、“translation” 等等。
- endpoint_url: 这是指向 Hugging Face Inference API 的具体URL,用于直接调用远程部署的模型服务。例如 “https://api-inference.huggingface.co/models/HuggingFaceH4/zephyr-7b-beta”。
| 场景 | 是否需要 API Token |
|---|---|
使用 repo_id 加载公开模型 | 不需要 |
使用 repo_id 加载私有或受限模型 | 需要 |
使用 endpoint_url 访问 Hugging Face Inference API | 大多数情况下需要 |
你可以从 Hugging Face 设置页面 获取或生成新的API token。
如何扩展
✅ 1. 换一个模型(只需修改 endpoint_url)
你可以访问 Hugging Face 上任意公开模型页面,复制它的推理地址。
🔁 示例:换成 TinyLlama/TinyLlama-1.1B-Chat-v1.0
这个模型很小,速度快,适合测试。
llm = HuggingFaceEndpoint(endpoint_url="https://api-inference.huggingface.co/models/TinyLlama/TinyLlama-1.1B-Chat-v1.0",huggingfacehub_api_token="你的token",temperature=0.7,max_new_tokens=512
)
🔁 示例:换成中文模型 Qwen/Qwen2-0.5B-Instruct
如果你想要中文模型:
llm = HuggingFaceEndpoint(endpoint_url="https://api-inference.huggingface.co/models/Qwen/Qwen2-0.5B-Instruct",huggingfacehub_api_token="你的token",temperature=0.7,max_new_tokens=512
)
⚠️ 注意:有些模型需要申请权限才能使用(会报错
GatedRepoError),请前往对应模型页面点击 “Request Access”。
✅ 2. 改变任务(只需修改 SystemMessage)
比如你想让模型写一首诗:
messages = [SystemMessage(content="You are a poet. Write a short poem about the moon in Chinese."),HumanMessage(content="Please write a poem.")
]
或者你想让它做 QA:
messages = [SystemMessage(content="Answer the question briefly and accurately."),HumanMessage(content="What is the capital of France?")
]
📌 三、推荐常用公开模型(可直接替换)
| 模型名称 | 描述 | 是否需要申请 |
|---|---|---|
HuggingFaceH4/zephyr-7b-beta | 英文聊天模型 | ❌ 不需要 |
TinyLlama/TinyLlama-1.1B-Chat-v1.0 | 很小的英文聊天模型 | ❌ 不需要 |
Qwen/Qwen2-0.5B-Instruct | 阿里通义千问系列,中文友好 | ❌ 不需要 |
google/gemma-7b-it | Google 推出的指令微调模型 | ❌ 不需要 |
mistralai/Mistral-7B-Instruct-v0.2 | Mistral 系列指令模型 | ✅ 需要申请 |
📝 总结
| 功能 | 修改位置 | 示例 |
|---|---|---|
| 换模型 | 修改 endpoint_url | https://api-inference.huggingface.co/models/用户名/模型名 |
| 控制输出 | 修改参数 | temperature=0.1, max_new_tokens=256 |
| 更换任务 | 修改 SystemMessage 和 HumanMessage 内容 | “你是谁?”、“帮我翻译”、“写一篇作文”等 |
| 使用中文模型 | 选择支持中文的模型 | 如 Qwen2-0.5B-Instruct |
相关文章:
使用聊天模型和提示模板构建一个简单的 LLM 应用程序
官方教程 官方案例 在上面的链接注册后,请确保设置您的环境变量以开始记录追踪 export LANGSMITH_TRACING"true" export LANGSMITH_API_KEY"..."或者,如果在笔记本中,您可以使用以下命令设置它们 import getpass imp…...

探索 C++23 的 views::cartesian_product
文章目录 一、背景与动机二、基本概念与语法三、使用示例四、特点与优势五、性能与优化六、与 P2374R4 的关系七、编译器支持八、总结 C23 为我们带来了一系列令人兴奋的新特性,其中 views::cartesian_product 是一个非常实用且强大的功能,它允许我们轻…...
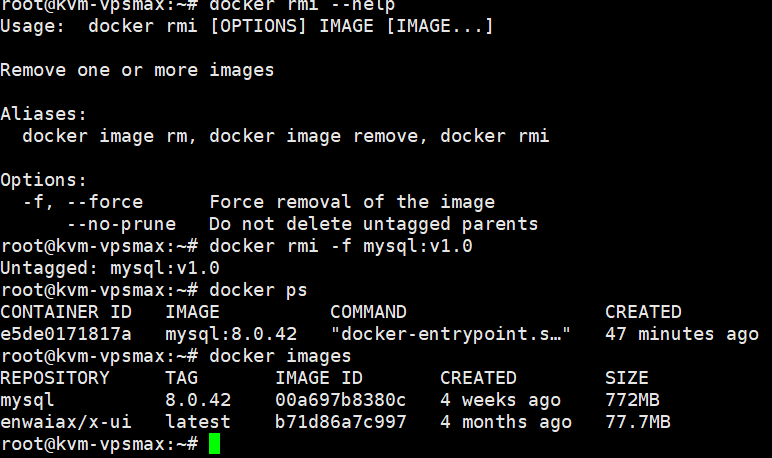
【docker】--镜像管理
文章目录 拉取镜像启动镜像为容器连接容器法一法二 保存镜像加载镜像镜像打标签移除镜像 拉取镜像 docker pull mysql:8.0.42启动镜像为容器 docker run -dp 8080:8080 --name container_mysql8.0.42 -e MYSQL_ROOT_PASSWORD123123123 mysql:8.0.42 连接容器 法一 docker e…...

Stapi知识框架
一、Stapi 基础认知 1. 框架定位 自动化API开发框架:专注于快速生成RESTful API 约定优于配置:通过标准化约定减少样板代码 企业级应用支持:适合构建中大型API服务 代码生成导向:显著提升开发效率 2. 核心特性 自动CRUD端点…...

Hapi.js知识框架
一、Hapi.js 基础 1. 核心概念 企业级Node.js框架:由Walmart团队创建,现由社区维护 配置驱动:强调声明式配置而非中间件 插件架构:高度模块化设计 安全优先:内置安全最佳实践 丰富的生态系统:官方维护…...

Node.js 中的 URL 模块
一、URL 模块基础 1. 模块导入方式 // Node.js 方式 const url require(url);// ES 模块方式 (Node.js 14 或启用 ESM) import * as url from url; 2. 核心功能 解析 URL 字符串 格式化 URL 对象 URL 处理工具方法 WHATWG URL 标准实现 二、URL 解析与构建 1. 传统解…...

Java集合框架详解与使用场景示例
Java集合框架是Java标准库中一组用于存储和操作数据的接口和类。它提供了多种数据结构,每种数据结构都有其特定的用途和性能特点。在本文中,我们将详细介绍Java集合框架的主要组成部分:List、Set和Queue,并通过代码示例展示它们的…...
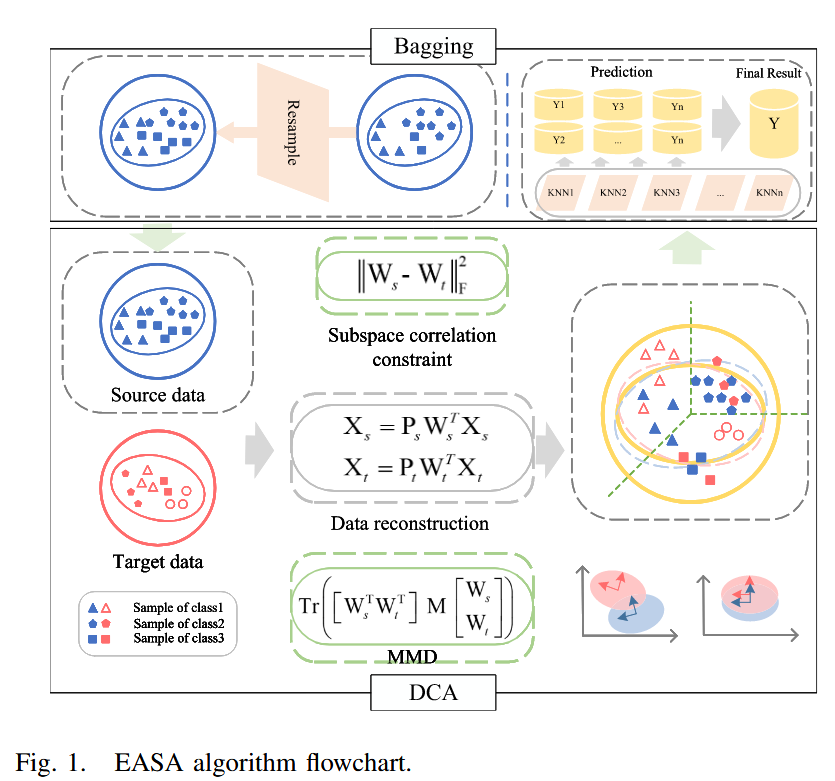
Ensemble Alignment Subspace Adaptation Method for Cross-Scene Classification
用于跨场景分类的集成对齐子空间自适应方法 摘要:本文提出了一种用于跨场景分类的集成对齐子空间自适应(EASA)方法,它可以解决同谱异物和异谱同物的问题。该算法将集成学习的思想与域自适应(DA)算法相结合…...
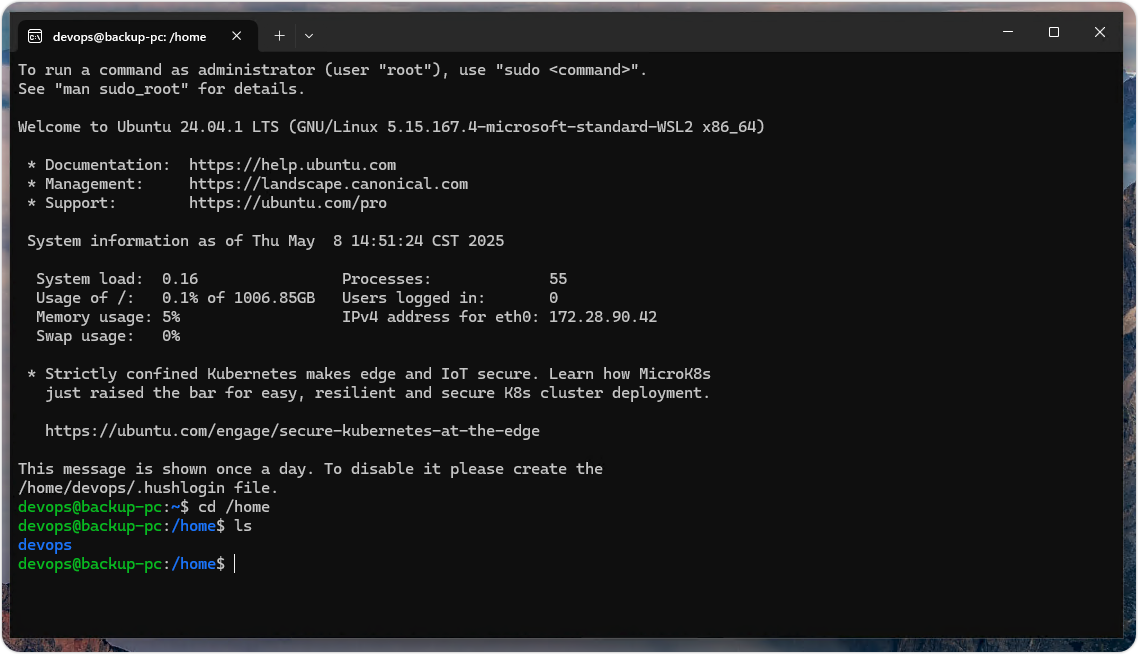
如何通过 Windows 图形界面找到 WSL 主目录
WSL(Windows Subsystem for Linux)是微软开发的一个软件层,用于在 Windows 11 或 10 上原生运行 Linux 二进制可执行文件。当你在 WSL 上安装一个 Linux 发行版时,它会在 Windows 内创建一个 Linux 环境,包括自己的文件系统和主目录。但是,如何通过 Windows 的图形文件资…...
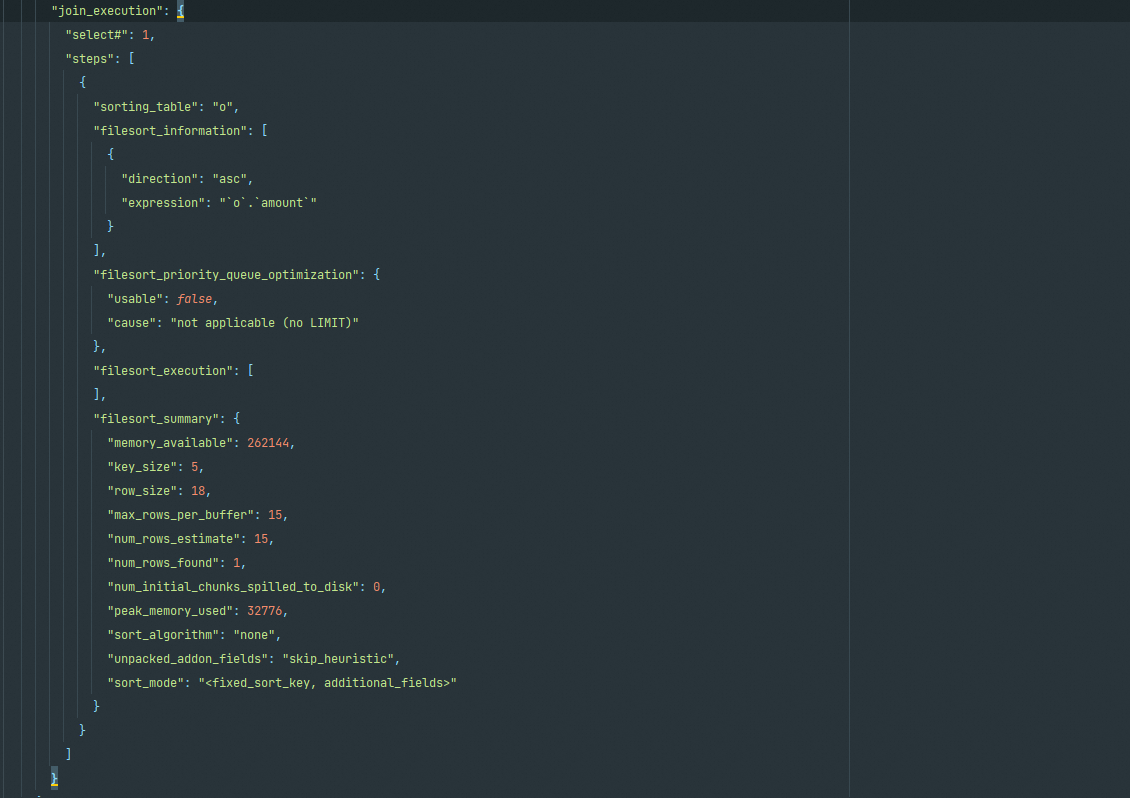
深入 MySQL 查询优化器:Optimizer Trace 分析
目录 一、前言 二、参数详解 optimizer_trace optimizer_trace_features optimizer_trace_max_mem_size optimizer_trace_limit optimizer_trace_offset 三、Optimizer Trace join_preparation join_optimization condition_processing substitute_generated_column…...

每日一道leetcode
790. 多米诺和托米诺平铺 - 力扣(LeetCode) 题目 有两种形状的瓷砖:一种是 2 x 1 的多米诺形,另一种是形如 "L" 的托米诺形。两种形状都可以旋转。 给定整数 n ,返回可以平铺 2 x n 的面板的方法的数量。返…...

FFmpeg在Android开发中的核心价值是什么?
FFmpeg 在 Android 开发中的核心价值主要体现在其强大的多媒体处理能力和灵活性上,尤其在音视频编解码、流媒体处理及跨平台兼容性方面具有不可替代的作用。以下是具体分析: --- 1. 强大的音视频编解码能力 - 支持广泛格式:FFmpeg 支持几乎所…...
 ArrayList)
C#进阶(1) ArrayList
前言 在我们进行了入门,基础,核心的学习后,我们已经学了相当多的知识了,不知道你现在对比打开入门时候的你,进步了多少。是否也能自己写一点简单的程序来作为小成就炫耀一下呢? 博主给你留的小项目你是否都有认真去复刻或者改进呢? 这些问题的答案只有你自己清楚。 …...

竞业禁止协议中AI技能限制的深度剖析
首席数据官高鹏律师团队 在当今科技飞速发展的时代,人工智能(AI)领域成为了商业竞争的关键战场。随着AI技术在各行业的广泛渗透,竞业禁止协议中涉及AI技能的限制条款愈发受到关注,其背后蕴含着复杂而关键的法律与商业…...
)
动态查找滚动容器(通用方案)
需求:点击置顶按钮返回页面的顶部,涉及产生滚动条的元素不唯一的情况,如果确定滚动元素的情况,直接元素.scrollTop 0 就实现置顶了 也是查了一段时间,这个方法很赞,递归寻找滚动元素 步骤 1:判…...

CD3MN 双相钢 2205 材质保温 V 型球阀:恒温工况下复杂介质控制的高性能之选-耀圣
CD3MN 双相钢 2205 材质保温 V 型球阀:恒温工况下复杂介质控制的高性能之选 在石油化工、沥青储运、食品加工等行业中,带颗粒高粘度介质与料浆的恒温输送面临着腐蚀、磨损、堵塞等多重挑战。普通阀门难以兼顾耐高温、强密封与耐腐蚀性,导致设…...

SpringBoot整合MyBatis-Plus:零XML实现高效CRUD
前言 作为一名开发者,数据库操作是我们日常工作中不可或缺的部分。传统的MyBatis虽然强大,但需要编写大量XML映射文件,这在快速开发的今天显得效率不足。MyBatis-Plus(简称MP)作为MyBatis的增强工具,在保留…...

python酒店健身俱乐部管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...
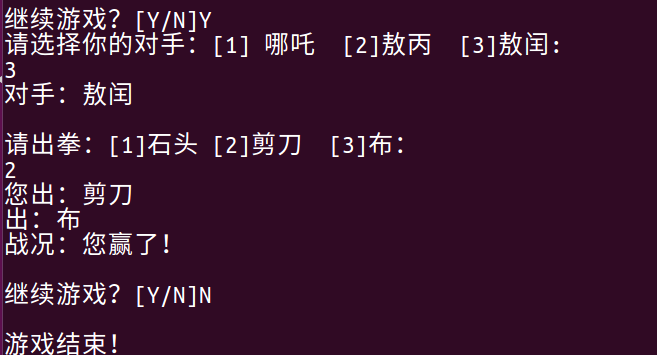
嵌入式开发学习(第二阶段 C语言基础)
综合案例《猜拳游戏》 需求: 本游戏是一款单机游戏,人机交互 规则: 需要双方出拳:石头、剪刀、布赢: 石头→剪刀剪刀→ 布布 →石头 两边出拳相等输: … 实现: 选择对手玩家出拳对手出拳判断胜…...

Easysearch 时序数据的基于时间范围的合并策略
如果你正在使用 Easysearch 处理日志、监控指标、事件流或其他任何具有时间顺序的数据,那么你一定知道索引的性能和效率至关重要。Easysearch 底层的 Lucene Segment 合并是保持搜索和索引性能的关键后台任务。然而,你是否意识到,默认的合并策…...

【C++】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希
【C】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希 在日常开发中,无论是数据结构优化、缓存设计,还是分布式架构搭建,unordered_map、布隆过滤器和一致性哈希都是绕不开的关键工具。它们高效、轻量,在性能与扩展性方面…...
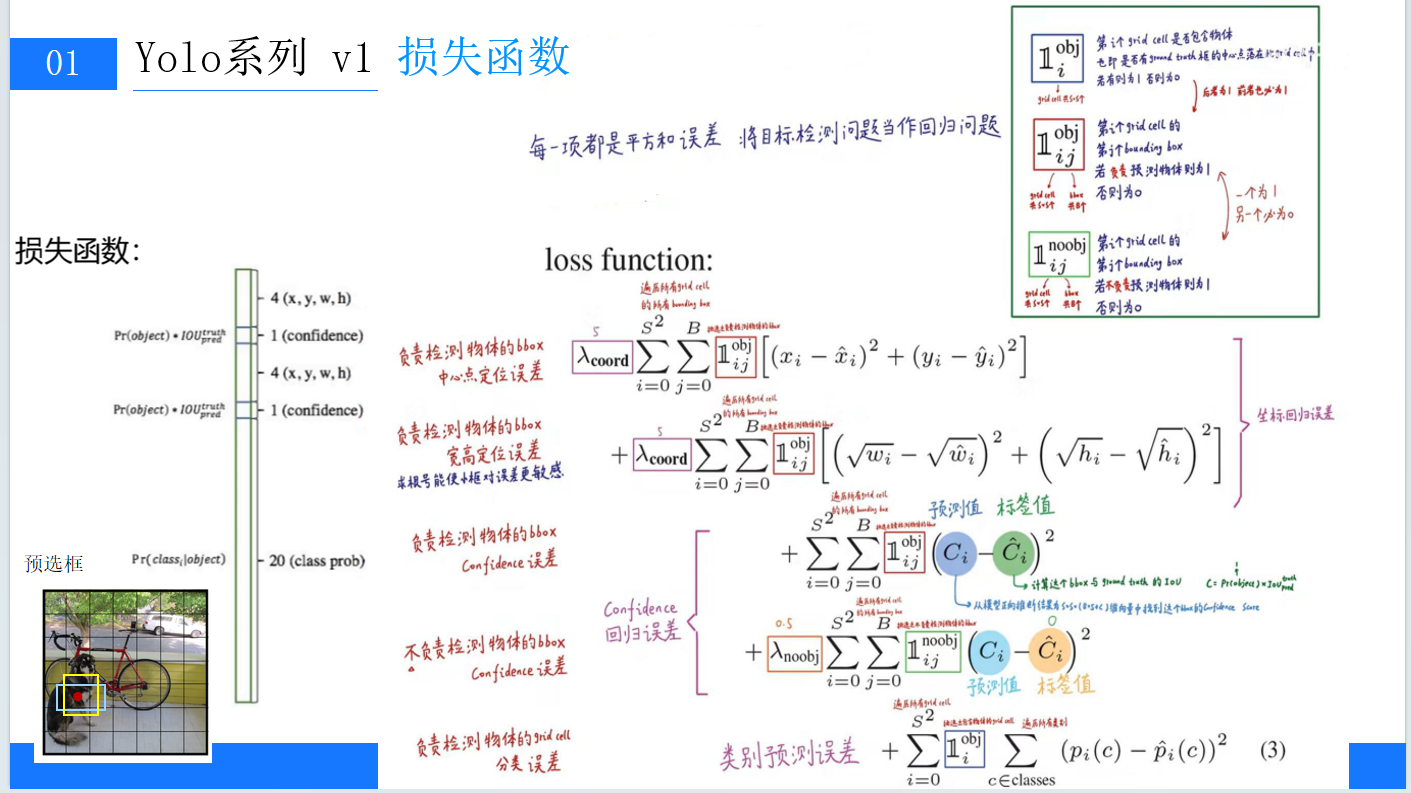
YOLOv1:开启实时目标检测的新篇章
YOLOv1:开启实时目标检测的新篇章 在深度学习目标检测领域,YOLO(You Only Look Once)系列算法无疑占据着重要地位。其中,YOLOv1作为开山之作,以其独特的设计理念和高效的检测速度,为后续的目标…...

Spring Boot 整合 Redis 实战
一、整合准备:环境与依赖 1. 技术栈说明 Spring Boot 版本:3.1.2(兼容 Java 17) Redis 服务器:Redis 7.0(本地部署或 Docker 容器) Maven 依赖: <dependency><…...

Spring事务失效的全面剖析
文章目录 1. Spring事务基础1.1 什么是Spring事务1.2 Spring事务的实现原理1.3 `@Transactional`注解的主要属性1.4 使用Spring事务的简单示例2. Spring事务失效的常见场景及解决方案2.1 方法不是public的问题描述问题示例解决方案技术原理解释2.2 自调用问题(同一个类中的方法…...

Pytorch张量和损失函数
文章目录 张量张量类型张量例子使用概率分布创建张量正态分布创建张量 (torch.normal)正态分布创建张量示例标准正态分布创建张量标准正态分布创建张量示例均匀分布创建张量均匀分布创建张量示例 激活函数常见激活函数 损失函数(Pytorch API)L1范数损失函数均方误差损失函数交叉…...
ConcurrentHashMap发送)
消息~组件(群聊类型)ConcurrentHashMap发送
为什么选择ConcurrentHashMap? 在开发聊天应用时,我们需要存储和管理大量的聊天消息数据,这些数据会被多个线程频繁访问和修改。比如,当多个用户同时发送消息时,服务端需要同时处理这些消息的存储和查询。如果用普通的…...
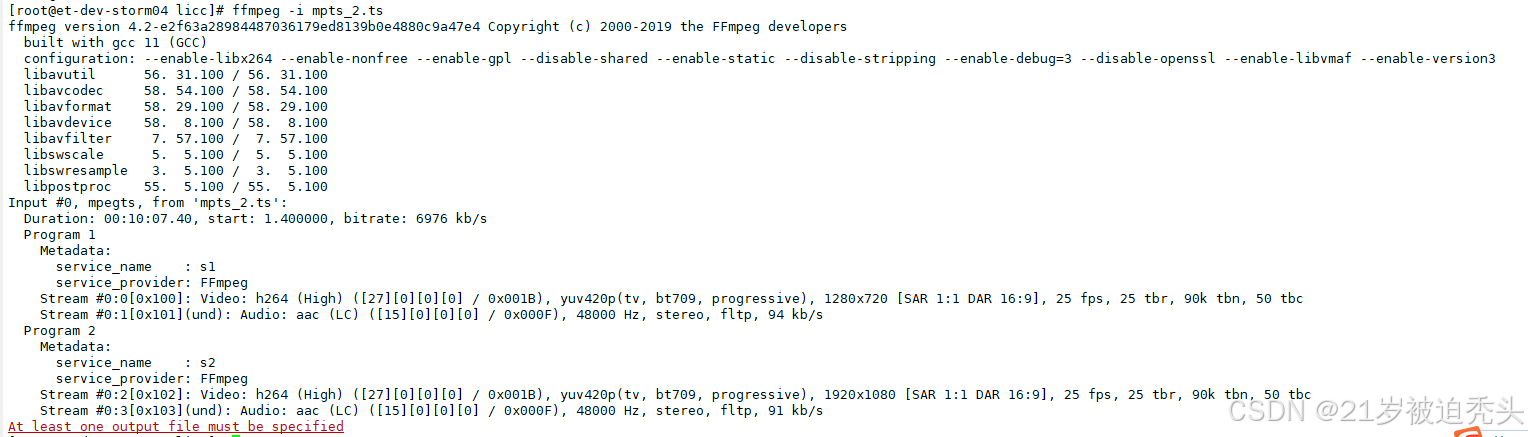
FFmpeg多路节目流复用为一路包含多个节目的输出流
在音视频处理领域,将多个独立的节目流(如不同频道的音视频内容)合并为一个包含多个节目的输出流是常见需求。FFmpeg 作为功能强大的多媒体处理工具,提供了灵活的流复用能力,本文将通过具体案例解析如何使用 FFmpeg 实现…...
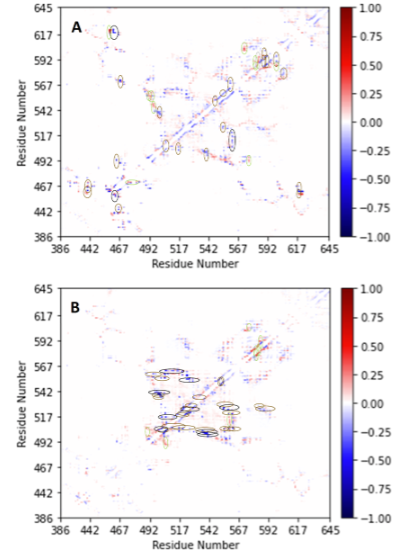
分子动力学模拟揭示点突变对 hCFTR NBD1结构域热稳定性的影响
囊性纤维化(CF) 作为一种严重的常染色体隐性遗传疾病,全球约有 10 万名患者深受其害。它会累及人体多个器官,如肺部、胰腺等,严重影响患者的生活质量和寿命。CF 的 “罪魁祸首” 是 CFTR 氯离子通道的突变,…...

关于SIS/DCS点检周期
在中国化工行业,近几年在设备维护上有个挺有意思的现象,即SIS和DCS这两个系统的点检周期问题,隔三差五就被管理层会议讨论,可以说是企业管理层关注的重要方向与关心要素。 与一般工业行业中设备运维不同,SIS与DCS的点…...

python-pyqt6框架工具开发总结
菜单栏 工具栏 状态栏 QTreeView 用于展示树形结构数据(模-视图框架),文件系统,组织结构 通常与QAbstractItemModel的子类(如QStandardItemModel或自动义模型) 展开/折叠 控制节点的显示状态,展开时显示子节点,折叠时隐藏子节点 s…...