deepseek梳理java高级开发工程师算法面试题
Java高级工程师算法面试题与答案
一、数据结构与算法基础
1. 红黑树与AVL树比较
题目:详细说明红黑树和AVL树的区别及各自的适用场景,并用Java实现红黑树的插入操作。
答案:
区别对比:
┌──────────────────┬──────────────────────────────┬──────────────────────────────┐
│ 特性 │ 红黑树 │ AVL树 │
├──────────────────┼──────────────────────────────┼──────────────────────────────┤
│ 平衡标准 │ 松散平衡(最长路径≤2倍最短路径)│ 严格平衡(左右子树高度差≤1) │
│ 插入/删除效率 │ O(1)旋转次数 │ O(log n)旋转次数 │
│ 查找效率 │ 稍慢(因不够严格平衡) │ 更快 │
│ 存储开销 │ 1bit颜色信息 │ 平衡因子(int) │
│ 适用场景 │ 频繁插入删除(如Java HashMap)│ 查找密集型(如数据库索引) │
└──────────────────┴──────────────────────────────┴──────────────────────────────┘
红黑树Java实现:
class RedBlackTree {private static final boolean RED = true;private static final boolean BLACK = false;class Node {int key;Node left, right;boolean color;Node(int key) {this.key = key;this.color = RED; // 新节点总是红色}}private Node root;private boolean isRed(Node x) {return x != null && x.color == RED;}public void insert(int key) {root = insert(root, key);root.color = BLACK; // 根节点始终黑色}private Node insert(Node h, int key) {if (h == null) return new Node(key);if (key < h.key) h.left = insert(h.left, key);else if (key > h.key) h.right = insert(h.right, key);// 平衡化操作if (isRed(h.right) && !isRed(h.left)) h = rotateLeft(h);if (isRed(h.left) && isRed(h.left.left)) h = rotateRight(h);if (isRed(h.left) && isRed(h.right)) flipColors(h);return h;}private Node rotateLeft(Node h) {Node x = h.right;h.right = x.left;x.left = h;x.color = h.color;h.color = RED;return x;}// rotateRight和flipColors实现类似...
}
二、高级算法设计
2. 分布式ID生成算法
题目:设计一个分布式环境下高性能ID生成服务,要求满足:
- 全局唯一
- 趋势递增
- 高可用
- 每秒至少10万ID生成
答案:
Snowflake算法改进版:
public class DistributedIdGenerator {private final long twepoch = 1288834974657L; // 起始时间戳private final long workerIdBits = 10L; // 工作机器ID位数private final long maxWorkerId = ~(-1L << workerIdBits);private final long sequenceBits = 12L; // 序列号位数private final long workerIdShift = sequenceBits;private final long timestampShift = sequenceBits + workerIdBits;private final long sequenceMask = ~(-1L << sequenceBits);private long workerId;private long sequence = 0L;private long lastTimestamp = -1L;public DistributedIdGenerator(long workerId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException("workerId不合法");}this.workerId = workerId;}public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException("时钟回拨异常");}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - twepoch) << timestampShift) | (workerId << workerIdShift) | sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}
}
优化点:
- 时钟回拨处理:抛出异常或等待
- 性能优化:无锁CAS(如用AtomicLong)
- 分段缓冲:预生成ID减少实时计算压力
- 监控报警:ID生成速率监控
三、并发算法
3. 高效缓存淘汰算法
题目:实现一个线程安全的LFU(Least Frequently Used)缓存,要求所有操作时间复杂度O(1)。
答案:
class LFUCache {class Node {int key, value, freq;Node prev, next;Node(int key, int value) {this.key = key;this.value = value;this.freq = 1;}}class FreqList {int freq;Node head, tail;FreqList prev, next;FreqList(int freq) {this.freq = freq;head = new Node(0, 0);tail = new Node(0, 0);head.next = tail;tail.prev = head;}void addNode(Node node) {node.next = head.next;head.next.prev = node;head.next = node;node.prev = head;}void removeNode(Node node) {node.prev.next = node.next;node.next.prev = node.prev;}boolean isEmpty() {return head.next == tail;}}private int capacity;private Map<Integer, Node> cache;private Map<Integer, FreqList> freqMap;private FreqList minFreqList;public LFUCache(int capacity) {this.capacity = capacity;cache = new HashMap<>();freqMap = new HashMap<>();minFreqList = new FreqList(0);freqMap.put(0, minFreqList);}public int get(int key) {if (!cache.containsKey(key)) return -1;Node node = cache.get(key);updateFreq(node);return node.value;}public void put(int key, int value) {if (capacity == 0) return;if (cache.containsKey(key)) {Node node = cache.get(key);node.value = value;updateFreq(node);return;}if (cache.size() == capacity) {Node toRemove = minFreqList.tail.prev;minFreqList.removeNode(toRemove);cache.remove(toRemove.key);if (minFreqList.isEmpty()) {freqMap.remove(minFreqList.freq);}}Node newNode = new Node(key, value);cache.put(key, newNode);FreqList freqList = freqMap.getOrDefault(1, new FreqList(1));freqList.addNode(newNode);freqMap.put(1, freqList);minFreqList = freqList;}private void updateFreq(Node node) {FreqList oldList = freqMap.get(node.freq);oldList.removeNode(node);if (oldList.isEmpty() && node.freq == minFreqList.freq) {minFreqList = oldList.next != null ? oldList.next : oldList;}node.freq++;FreqList newList = freqMap.getOrDefault(node.freq, new FreqList(node.freq));newList.addNode(node);freqMap.put(node.freq, newList);}
}
时间复杂度分析:
- get操作:HashMap查询O(1) + 链表操作O(1) = O(1)
- put操作:HashMap查询O(1) + 链表操作O(1) = O(1)
- 空间复杂度:O(capacity)
四、分布式算法
4. 一致性哈希算法
题目:实现带虚拟节点的一致性哈希算法,解决分布式缓存数据倾斜问题。
答案:
public class ConsistentHash<T> {private final HashFunction hashFunction;private final int numberOfReplicas; // 虚拟节点数private final SortedMap<Long, T> circle = new TreeMap<>();public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,Collection<T> nodes) {this.hashFunction = hashFunction;this.numberOfReplicas = numberOfReplicas;for (T node : nodes) {add(node);}}public void add(T node) {for (int i = 0; i < numberOfReplicas; i++) {long hash = hashFunction.hash(node.toString() + i);circle.put(hash, node);}}public void remove(T node) {for (int i = 0; i < numberOfReplicas; i++) {long hash = hashFunction.hash(node.toString() + i);circle.remove(hash);}}public T get(Object key) {if (circle.isEmpty()) return null;long hash = hashFunction.hash(key.toString());if (!circle.containsKey(hash)) {SortedMap<Long, T> tailMap = circle.tailMap(hash);hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();}return circle.get(hash);}interface HashFunction {long hash(String key);}// 测试用例public static void main(String[] args) {Set<String> nodes = new HashSet<>(Arrays.asList("Node1", "Node2", "Node3"));ConsistentHash<String> ch = new ConsistentHash<>(key -> {// 使用MD5哈希try {MessageDigest md = MessageDigest.getInstance("MD5");byte[] digest = md.digest(key.getBytes());return ((long)(digest[3] & 0xFF) << 24) | ((long)(digest[2] & 0xFF) << 16)| ((long)(digest[1] & 0xFF) << 8) | (digest[0] & 0xFF);} catch (NoSuchAlgorithmException e) {return key.hashCode();}}, 1000, nodes);System.out.println(ch.get("user123")); // 返回对应的节点}
}
优化点:
- 虚拟节点数量:通常设置100-200个
- 哈希函数选择:MD5、MurmurHash等
- 数据迁移:节点增减时只影响相邻节点
- 监控统计:节点负载均衡监控
五、机器学习算法
5. 推荐系统相似度算法
题目:实现基于用户的协同过滤推荐算法,包含余弦相似度计算和推荐生成。
答案:
public class UserCFRecommender {private Map<Integer, Map<Integer, Double>> userItemMatrix; // 用户-物品评分矩阵public UserCFRecommender(Map<Integer, Map<Integer, Double>> userItemMatrix) {this.userItemMatrix = userItemMatrix;}// 计算用户相似度矩阵public Map<Integer, Map<Integer, Double>> calculateUserSimilarities() {Map<Integer, Map<Integer, Double>> simMatrix = new HashMap<>();List<Integer> users = new ArrayList<>(userItemMatrix.keySet());for (int i = 0; i < users.size(); i++) {int u1 = users.get(i);simMatrix.putIfAbsent(u1, new HashMap<>());for (int j = i + 1; j < users.size(); j++) {int u2 = users.get(j);double similarity = cosineSimilarity(userItemMatrix.get(u1),userItemMatrix.get(u2));simMatrix.get(u1).put(u2, similarity);simMatrix.putIfAbsent(u2, new HashMap<>());simMatrix.get(u2).put(u1, similarity);}}return simMatrix;}// 余弦相似度计算private double cosineSimilarity(Map<Integer, Double> v1, Map<Integer, Double> v2) {Set<Integer> commonItems = new HashSet<>(v1.keySet());commonItems.retainAll(v2.keySet());double dotProduct = 0.0;double norm1 = 0.0;double norm2 = 0.0;for (int item : commonItems) {dotProduct += v1.get(item) * v2.get(item);}for (double rating : v1.values()) {norm1 += Math.pow(rating, 2);}for (double rating : v2.values()) {norm2 += Math.pow(rating, 2);}return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));}// 生成推荐public List<Integer> recommendItems(int userId, int topN) {Map<Integer, Double> scores = new HashMap<>();Map<Integer, Double> userRatings = userItemMatrix.get(userId);Map<Integer, Map<Integer, Double>> simMatrix = calculateUserSimilarities();for (Map.Entry<Integer, Map<Integer, Double>> entry : userItemMatrix.entrySet()) {int otherUserId = entry.getKey();if (otherUserId == userId) continue;double similarity = simMatrix.get(userId).getOrDefault(otherUserId, 0.0);if (similarity <= 0) continue;for (Map.Entry<Integer, Double> itemEntry : entry.getValue().entrySet()) {int itemId = itemEntry.getKey();if (userRatings.containsKey(itemId)) continue;scores.merge(itemId, itemEntry.getValue() * similarity, Double::sum);}}return scores.entrySet().stream().sorted(Map.Entry.<Integer, Double>comparingByValue().reversed()).limit(topN).map(Map.Entry::getKey).collect(Collectors.toList());}
}
优化方向:
- 相似度计算:改用皮尔逊相关系数
- 矩阵稀疏性:使用稀疏矩阵存储
- 实时更新:增量计算相似度
- 并行计算:MapReduce实现
相关文章:

deepseek梳理java高级开发工程师算法面试题
Java高级工程师算法面试题与答案 一、数据结构与算法基础 1. 红黑树与AVL树比较 题目:详细说明红黑树和AVL树的区别及各自的适用场景,并用Java实现红黑树的插入操作。 答案: 区别对比: ┌─────────────────…...

leetcode - 滑动窗口问题集
目录 前言 题1 长度最小的子数组: 思考: 参考代码1: 参考代码2: 题2 无重复字符的最长子串: 思考: 参考代码1: 参考代码2: 题3 最大连续1的个数 III: 思考&am…...
一分钟在Cherry Studio和VSCode集成火山引擎veimagex-mcp
MCP的出现打通了AI模型和外部数据库、网页API等资源,成倍提升工作效率。近期火山引擎团队推出了 MCP Server SDK: veimagex-mcp。本文介绍如何在Cherry Studio 和VSCode平台集成 veimagex-mcp。 什么是MCP MCP(Model Context Protocol&…...

Tomcat与纯 Java Socket 实现远程通信的区别
Servlet 容器(如 Tomcat) 是一个管理 Servlet 生命周期的运行环境,主要功能包括: 协议解析:自动处理 HTTP 请求/响应的底层协议(如报文头解析、状态码生成); 线程…...

为什么企业建站或独立站选用WordPress
与大多数组织相比,企业业务更需要保持可扩展和可靠的网络存在,以保持竞争力。为此,许多大型企业的 IT 领导者历来寻求昂贵的网络解决方案,这些方案需要签订专有支持合同来保证质量。不过,还有另一种方法。WordPress问世…...

镜头内常见的马达类型(私人笔记)
① 螺杆式马达 驱动来源:机身内马达。镜头尾部有一个接收“螺杆”的接口,通过机械传动带动镜头对焦组。缺点:慢、吵、不能用于无机身马达的相机。✅ 典型镜头:尼康 AF、AF-D 系列;美能达老镜头。尼康传统的AF镜头通过…...

docker-compose——安装mysql8
一、编写Dockerfile FROM mysql:8.0.39 ENV TZAsia/Shanghai RUN ln -sf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone二、编写docker-compose.yml version : 3.8services:zaomeng-mysql:build:context: ./mysqlimage: mysql:8.0.39conta…...

从代码学习深度学习 - 语义分割和数据集 PyTorch版
文章目录 前言什么是语义分割?图像分割和实例分割Pascal VOC2012 语义分割数据集Pascal VOC2012 语义分割数据集介绍基本信息语义分割部分特点数据格式评价指标应用价值数据集获取使用提示辅助工具代码 (`utils_for_huitu.py`)读取数据预处理数据自定义语义分割数据集类读取数…...

4G物联网模块实现废气处理全流程数据可视化监控配置
一、项目背景 随着工业化进程的加速,工业废气的排放对环境造成了严重影响,废气处理厂应运而生。然而,废气处理厂中的设备众多且分散,传统的人工巡检和数据记录方式效率低下,难以及时发现问题。为了实现对废气处理设备…...

深圳SMT贴片加工厂制造流程解析
内容概要 作为大湾区电子制造产业链的重要节点,深圳SMT贴片加工厂凭借精密的生产体系与技术创新,构建了涵盖12道核心工序的标准化流程。从PCB基板的来料检验开始,通过全自动贴片机的高精度元件定位、SPI三维锡膏检测、智能温控回流焊接等关键…...

电商平台如何做好DDoS 攻防战?
一、新型 DDoS 攻击技术演进分析 1.1 电商平台面临的四类攻击范式 graph LR A[DDoS攻击] --> B{网络层} A --> C{应用层} B --> D[CLDAP反射攻击<br>峰值达3.5Tbps] B --> E[QUIC协议洪水攻击] C --> F[API CC攻击<br>精准打击抢购接口] C -->…...

Spark处理过程-转换算子
大家前面的课程,我们学习了Spark RDD的基础知识,知道了如何去创建RDD,那spark中具体有哪些rdd,它们有什么特点呢? 我们这节课来学习。 (一)RDD的处理过程 Spark使用Scala语言实现了RDD的API,程…...

【计算机视觉】OpenCV实战项目:Athlete-Pose-Detection 运动员姿态检测系统:基于OpenCV的实时运动分析技术
运动员姿态检测系统:基于OpenCV的实时运动分析技术 1. 项目概述1.1 技术背景1.2 项目特点 2. 技术架构与算法原理2.1 系统架构2.2 核心算法2.3 模型选择 3. 项目部署与运行指南3.1 环境准备硬件要求软件依赖 3.2 项目配置3.3 运行项目基本运行模式高级参数 4. 常见问…...

Java 性能调优全解析:从设计模式到 JVM 的 7 大核心方向实践
引言 在高并发、低延迟的技术场景中,Java 性能优化需要系统化的方法论支撑。本文基于7 大核心优化方向(复用优化、计算优化、结果集优化、资源冲突优化、算法优化、高效实现、JVM 优化),结合权威框架与真实案例,构建从…...

为什么要选择七彩喜数字康养平台?加盟后有何优势?
一.七彩喜数字康养平台 1.技术领先性 七彩喜依托“端-网-云-脑”四层技术架构,整合毫米波雷达、AI算法引擎、区块链等前沿技术,解决传统养老的隐私泄露、设备孤岛等痛点。 比如非接触式健康监测系统通过毫米波雷达实现跌倒检测准确率&#…...

【计算机视觉】OpenCV实战项目:基于OpenCV的车牌识别系统深度解析
基于OpenCV的车牌识别系统深度解析 1. 项目概述2. 技术原理与算法设计2.1 图像预处理1) 自适应光照补偿2) 边缘增强 2.2 车牌定位1) 颜色空间筛选2) 形态学操作3) 轮廓分析 2.3 字符分割1) 投影分析2) 连通域筛选 2.4 字符识别 3. 实战部署指南3.1 环境配置3.2 项目代码解析 4.…...
鸿蒙接入flutter环境变量配置windows-命令行或者手动配置-到项目的创建-运行demo项目
鸿蒙接入flutter环境变量配置 参考官网 下载flutter git clone https://gitcode.com/openharmony-sig/flutter_flutter.git git checkout -b dev origin/dev # 国内镜像 export PUB_HOSTED_URLhttps://pub.flutter-io.cn export FLUTTER_STORAGE_BASE_URLhttps://storage.fl…...
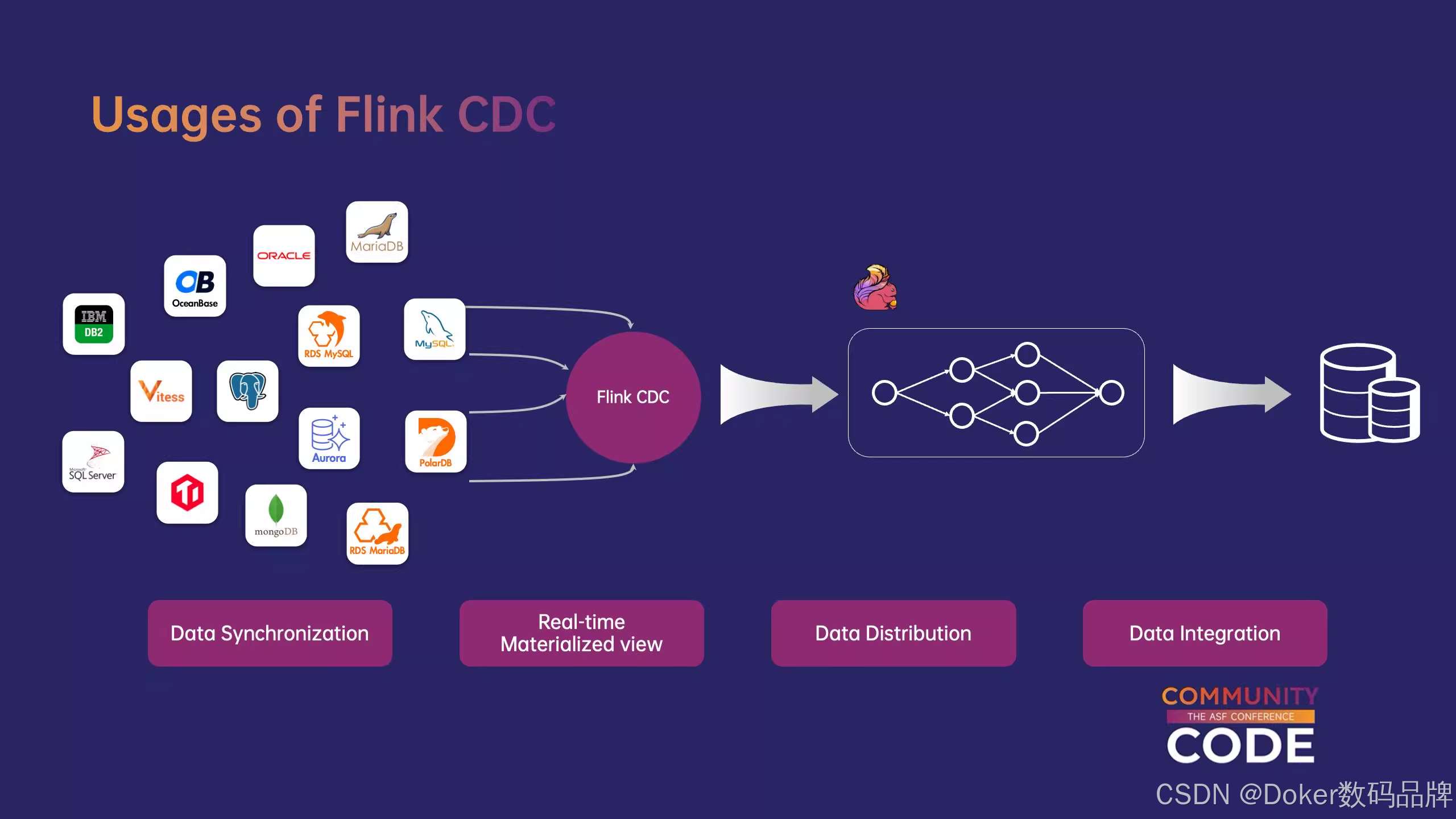
Flink CDC—实时数据集成框架
Flink CDC 是一个基于流的数据集成工具,旨在为用户提供一套功能更加全面的编程接口(API),它基于数据库日志的 CDC(变更数据捕获)技术实现了统一的增量和全量数据读取。 该工具使得用户能够以 YAML 配置文件…...

Redis的持久化:RDB和AOF机制
概述 Redis 提供 RDB 和 AOF 两种持久化机制,它们在数据安全性、性能、恢复速度等方面有显著差异。 为什么要进行持久化?如果是大数据量的恢复,会有下述的影响 会对数据库带来巨大的压力,数据库的性能不如Redis。导致程序响应慢…...
微调ModernBERT为大型语言模型打造高效“过滤器”
ModernBERT(2024 年 12 月)是最近发布的小型语言模型,由 Answer.AI、LightOn 和 HuggingFace 共同开发。它利用了现代优化技术,如用于 8,192 token 上下文窗口的 RoPE 和 GeGLU layers,在保持效率的同时提升性能。jina…...

数据库查询中的分页实现:Page对象与Pageable接口详解
文章目录 前言1. 分页查询的核心概念1.1 Page对象1.2 Pageable接口2. 实现代码详解2.1 实体类定义2.2 Repository接口定义2.3 服务层实现2.4 控制器层实现3. 关键点解析3.1 Pageable对象的创建3.2 Page对象的常用方法3.4 错误用法示例4.完整示例输出4.1 基本分页查询输出4.2 条…...
各大编程语言基本语法区别
1:语言特点 函数式语言和面向对象语言的区别:函数式用函数直接进行操作,面向对象用object.method()进行操作;如:len() <=> object.length() C 语言:1)C 语言可以像汇编语言一样对位、字节和地址进行操作;2)有函数原型;3)具有大量的数值类型;4)函数是C语言…...

云计算中的虚拟化:成本节省、可扩展性与灾难恢复的完美结合
云计算中虚拟化的 4 大优势 1. 成本效益 从本质上讲,虚拟化最大限度地减少了硬件蔓延。团队可以将多个虚拟机整合到单个物理主机上,而不是为每个工作负载部署单独的服务器。这大大减少了前期硬件投资和持续维护。 结果如何?更低的功耗、更低…...
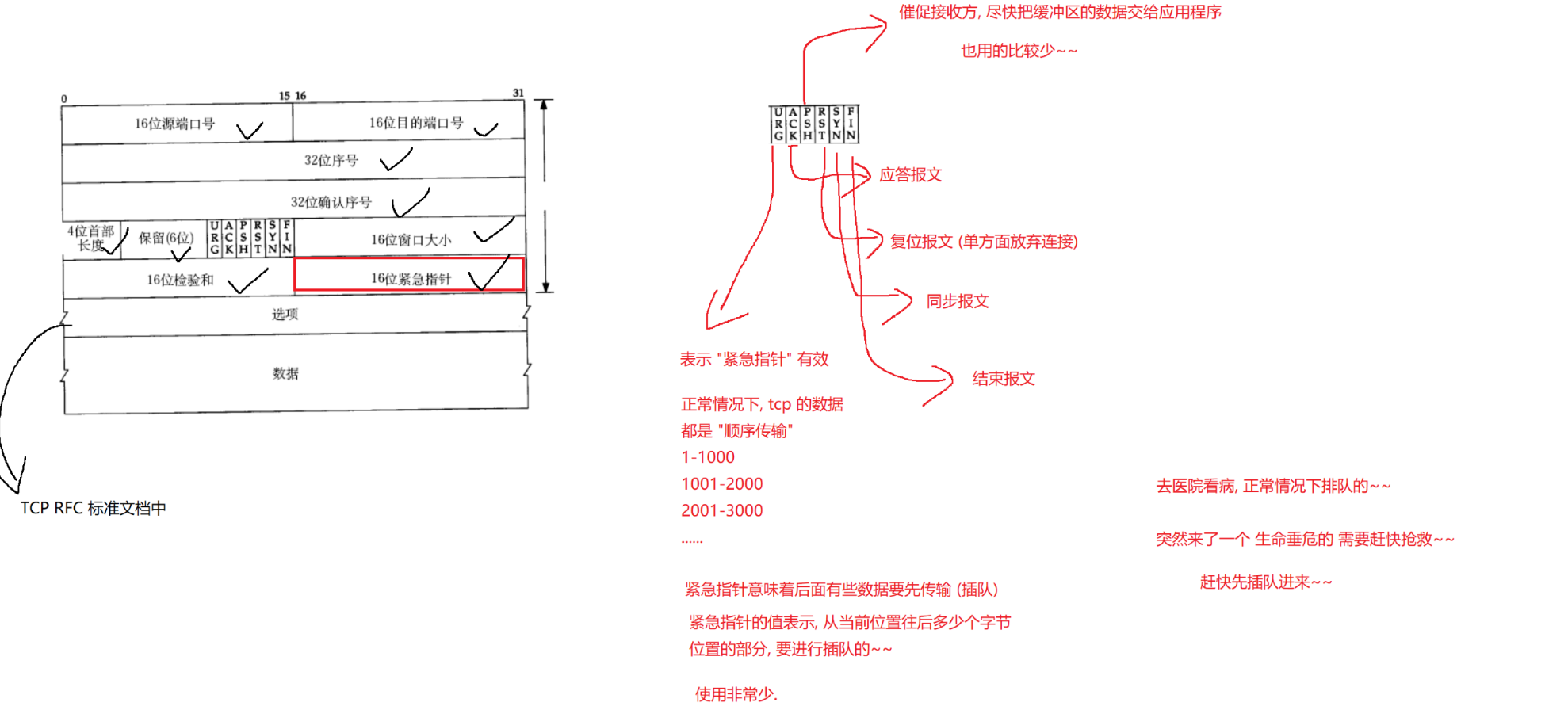
【Java ee初阶】网络原理
TCP协议 1.确认应答 实现可靠传输的核心机制 2.超时重传 实现可靠传输的核心机制 3.连接管理 网络部分最高频的面试题 4.滑动窗口 提高传输效率的机制 5.流量控制 依据接收方的处理能力,限制发送方的发送速度。 6.拥塞控制 依据传输链路的处理能力,…...
是什么?)
MongoDB 的核心概念(文档、集合、数据库、BSON)是什么?
MongoDB 是一个面向文档的数据库,它的核心概念与传统的关系型数据库(RDBMS)有所不同。以下是它的四个主要核心概念: 文档 (Document) 定义: 文档是 MongoDB 中的基本数据单元。它类似于关系型数据库中的一行记录&#…...

Spring 事件监听机制的使用
文章目录 1. 创建自定义事件2. 发布事件3. 监听事件4. 异步事件 1. 创建自定义事件 事件可以是任意对象(Spring 4.2支持POJO),或继承ApplicationEvent(旧版)。 // 自定义事件(POJO形式,无需继…...
awesome-digital-human本地部署及配置:打造高情绪价值互动指南
在数字化交互的浪潮中,awesome-digital-human-live2d项目为我们打开了本地数字人互动的大门。结合 dify 聊天 api,并借鉴 coze 夸夸机器人的设计思路,能为用户带来充满情绪价值的交互体验。本文将详细介绍其本地部署步骤、dify 配置方法及情绪…...

WebSocket与Socket.IO实现简易客服聊天系统全解析
WebSocket结合Socket.IO实现简易客服聊天系统全解析 一、技术选型对比 技术优点缺点适用场景原生WebSocket浏览器原生支持,性能好API较底层,需手动处理断线重连等逻辑简单实时应用Socket.IO自动重连,房间管理,兼容性好体积较大&…...
:[macOS 64bit App开发]: 获取macOS App的Bundle路径信息.)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: 获取macOS App的Bundle路径信息.
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

C++取时间戳窗口
应用场景 防止接口在指定的时间内重复调用,比如 10 秒内不能重复调用。 函数实现 #include <chrono>/// brief 计算当前时间戳所属时间窗口的起始点(对齐到 Window 秒的整数倍) /// param Window 时间窗口长度(单位&…...