从代码学习深度学习 - 实战 Kaggle 比赛:图像分类 (CIFAR-10 PyTorch版)
文章目录
- 前言
- 1. 读取并整理数据集
- 1.1 读取标签文件
- 1.2 划分训练集和验证集
- 1.3 整理测试集
- 1.4 执行数据整理
- 2. 图像增广
- 2.1 训练集图像变换
- 2.2 测试集(和验证集)图像变换
- 3. 读取数据集
- 3.1 创建 Dataset 对象
- 3.2 创建 DataLoader 对象
- 4. 定义模型
- 4.1 获取 ResNet-18 模型
- 4.2 损失函数
- 5. 定义训练函数
- 6. 训练和验证模型
- 7. 在完整训练集上训练并预测测试集
- 8. 辅助工具代码 (`utils_for_train.py` 和 `utils_for_huitu.py`)
- 8.1 `utils_for_train.py`
- 8.2 `utils_for_huitu.py`
- 总结
前言
欢迎来到我们的深度学习实战系列!在本文中,我们将深入探讨一个经典的图像分类问题——CIFAR-10挑战,并通过一个实际的 Kaggle 比赛流程来学习。我们将从原始图像文件开始,一步步进行数据整理、图像增广、模型构建、训练、评估,并最终生成提交结果。本教程将全程使用 PyTorch 框架,并详细解释每一段代码的功能和背后的原理。
在以往的教程中,我们可能更多地依赖深度学习框架的高级API直接获取处理好的张量格式数据集。但在真实的比赛和项目中,我们往往需要从更原始的数据形态(如.jpg, .png 文件和标签列表)入手。本篇博客旨在弥补这一差距,带你体验一个相对完整的小型 Kaggle 比赛pipeline。
我们将使用一个名为 kaggle_cifar10_tiny 的数据集,它是 CIFAR-10 的一个小型子集,方便我们快速迭代和学习。让我们开始吧!
完整代码:下载链接
1. 读取并整理数据集
在任何机器学习项目中,数据准备都是至关重要的一步。对于图像分类任务,这通常意味着读取图像文件,将其与对应的标签关联起来,并组织成适合模型训练的结构。
1.1 读取标签文件
我们的原始数据包含一个 trainLabels.csv 文件,其中记录了训练集中每张图像的文件名及其类别标签。下面的代码定义了一个函数 read_csv_labels 来读取这个 CSV 文件,并将其内容转换为一个字典,方便后续查找。
import os# 定义数据目录路径
data_dir = 'kaggle_cifar10_tiny'def read_csv_labels(fname):"""读取CSV文件并返回文件名到标签的映射字典参数:fname (str): CSV文件路径返回:dict: 包含文件名到标签的映射字典- 键 (str): 图像文件名 (不含扩展名)- 值 (str): 对应的类别标签"""with open(fname, 'r') as f:# 跳过CSV文件的第一行(列名)lines = f.readlines()[1:]# 将每行按逗号分割成tokens# tokens是一个列表,每个元素是[文件名, 标签]形式的列表# 维度: tokens - list[list[str, str]], 长度为样本数量tokens = [l.rstrip().split(',') for l in lines]# 构建字典,将文件名映射到对应的标签# 维度: 返回的字典 - dict{str: str}, 键为文件名,值为标签return dict(((name, label) for name, label in tokens))# 读取训练标签文件
# 维度: labels - dict{str: str}, 键为文件名,值为标签
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))# 打印训练样本数量(即字典中键值对的数量)
# len(labels) - int, 表示训练样本的数量
print('# 训练样本:', len(labels))# 打印类别数量(即标签种类的数量)
# len(set(labels.values())) - int, 表示不同类别的数量
print('# 类别:', len(set(labels.values())))
运行上述代码,我们会得到训练样本的总数和类别的总数。例如:
# 训练样本: 1000
# 类别: 10
这表明我们的微型数据集中有1000个训练样本,分布在10个类别中。
1.2 划分训练集和验证集
为了评估模型的泛化能力并进行超参数调整,我们需要从原始训练数据中划分出一部分作为验证集。下面的 reorg_train_valid 函数实现了这个功能。它会根据指定的验证集比例 valid_ratio,从每个类别中抽取一定数量的样本放入验证集,其余的放入新的训练集。同时,它会将所有原始训练图像(未划分前)也复制到一个单独的目录,以便后续在完整训练数据上训练模型。
copyfile 是一个辅助函数,用于将单个文件复制到目标目录,并在目标目录不存在时创建它。
import shutil
import collections
import mathdef copyfile(filename, target_dir):"""将文件复制到目标目录参数:filename (str): 源文件路径target_dir (str): 目标目录路径"""# 创建目标目录(如果不存在)# target_dir - str, 目标目录路径os.makedirs(target_dir, exist_ok=True)# 复制文件到目标目录# filename - str, 源文件路径# target_dir - str, 目标目录路径shutil.copy(filename, target_dir)def reorg_train_valid(data_dir, labels, valid_ratio):"""将验证集从原始的训练集中拆分出来参数:data_dir (str): 数据集目录路径labels (dict): 文件名到标签的映射字典valid_ratio (float): 验证集比例,取值范围[0, 1]返回:int: 每个类别中分配给验证集的样本数量"""# 获取样本数最少的类别中的样本数# collections.Counter(labels.values()) - Counter{str: int}, 统计每个标签出现的次数# most_common() - list[(str, int)], 按出现次数降序排列的(标签, 出现次数)列表# most_common()[-1] - tuple(str, int), 出现次数最少的(标签, 出现次数)对# most_common()[-1][1] - int, 出现次数最少的标签的出现次数# n - int, 样本数最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 计算验证集中每个类别应有的样本数# math.floor(n * valid_ratio) - int, 向下取整的验证集样本数# max(1, math.floor(n * valid_ratio)) - int, 确保每个类别至少有1个样本# n_valid_per_label - int, 每个类别分配给验证集的样本数n_valid_per_label = max(1, math.floor(n * valid_ratio))# 用于跟踪每个类别已分配到验证集的样本数# label_count - dict{str: int}, 键为标签,值为该标签在验证集中的样本数label_count = {}# 遍历训练目录中的所有文件# train_file - str, 训练集中的文件名for train_file in os.listdir(os.path.join(data_dir, 'train')):# 获取文件对应的标签# train_file.split('.')[0] - str, 去除文件扩展名的文件名# label - str, 文件对应的类别标签label = labels[train_file.split('.')[0]]# 构建完整的源文件路径# fname - str, 训练文件的完整路径fname = os.path.join(data_dir, 'train', train_file)# 将所有文件复制到train_valid目录下对应类别目录中# os.path.join(data_dir, 'train_valid_test', 'train_valid', label) - str, 目标目录路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','train_valid', label))# 如果该类别在验证集中的样本数未达到目标数量,则将文件添加到验证集if label not in label_count or label_count[label] < n_valid_per_label:# 复制文件到验证集目录对应类别文件夹下# os.path.join(data_dir, 'train_valid_test', 'valid', label) - str, 验证集目标目录路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','valid', label))# 更新该类别在验证集中的样本计数# label_count.get(label, 0) - int, 当前类别已有的验证集样本数,如果不存在则为0# label_count[label] - int, 更新后该类别在验证集中的样本数label_count[label] = label_count.get(label, 0) + 1else:# 如果该类别在验证集中的样本数已达到目标数量,则将文件添加到训练集# os.path.join(data_dir, 'train_valid_test', 'train', label) - str, 训练集目标目录路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','train', label))# 返回每个类别中分配给验证集的样本数量# n_valid_per_label - intreturn n_valid_per_label
1.3 整理测试集
测试集图像最初也存放在一个扁平的目录 test 中。为了方便后续使用 PyTorch 的 ImageFolder 类进行读取,我们需要将它们也组织到一个特定的目录结构下。reorg_test 函数将所有测试图像复制到 train_valid_test/test/unknown 目录下。这里将它们归类为 “unknown” 是因为在预测阶段,我们并不知道它们的真实标签。
import os
import shutildef reorg_test(data_dir):"""在预测期间整理测试集,以方便读取该函数将测试集图像文件复制到组织化的目录结构中,所有测试图像都归为"unknown"类别参数:data_dir (str): 数据集根目录路径"""# 遍历测试目录中的所有文件# data_dir - str, 数据集根目录路径# os.path.join(data_dir, 'test') - str, 测试集目录的完整路径# os.listdir(...) - list[str], 测试集目录中的所有文件名列表# test_file - str, 当前处理的测试文件名for test_file in os.listdir(os.path.join(data_dir, 'test')):# 构建源文件路径# os.path.join(data_dir, 'test', test_file) - str, 测试文件的完整源路径# 构建目标目录路径,所有测试文件都放在'unknown'类别文件夹下# os.path.join(data_dir, 'train_valid_test', 'test', 'unknown') - str, 目标目录的完整路径# 将测试文件复制到组织化的目录结构中# 源文件: 原始测试集目录下的测试文件# 目标位置: train_valid_test/test/unknown/文件名copyfile(os.path.join(data_dir, 'test', test_file),os.path.join(data_dir, 'train_valid_test', 'test','unknown'))
1.4 执行数据整理
现在,我们将上述函数整合到 reorg_cifar10_data 中,并执行它来完成整个数据集的重新组织。
import os
import shutil
import collections
import mathdef reorg_cifar10_data(data_dir, valid_ratio):"""重新组织CIFAR-10数据集,划分为训练集、验证集和测试集该函数完成CIFAR-10数据集的整体重组,包含三个主要步骤:1. 读取训练标签文件获取图像标签2. 重组训练集和验证集(从原始训练集中划分出验证集)3. 重组测试集(将所有测试图像归类为"unknown"类别)参数:data_dir (str): CIFAR-10数据集根目录路径valid_ratio (float): 验证集比例,取值范围[0, 1],表示从训练集中划分多少比例作为验证集"""# 步骤1: 读取训练标签文件,获取文件名到标签的映射# data_dir - str, 数据集根目录路径# os.path.join(data_dir, 'trainLabels.csv') - str, 训练标签文件的完整路径# read_csv_labels(...) - 函数调用,读取CSV文件并返回字典# labels - dict{str: str}, 键为图像文件名,值为对应的类别标签labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))# 步骤2: 重组训练集和验证集# 将原始训练集按照指定比例分为训练集和验证集,并保存到对应目录# data_dir - str, 数据集根目录路径# labels - dict{str: str}, 文件名到标签的映射字典# valid_ratio - float, 验证集比例# reorg_train_valid(...) - 函数调用,重组训练集和验证集reorg_train_valid(data_dir, labels, valid_ratio)# 步骤3: 重组测试集# 将测试集图像整理到组织化的目录结构中,便于后续处理# data_dir - str, 数据集根目录路径# reorg_test(...) - 函数调用,重组测试集reorg_test(data_dir)
我们设定批量大小 batch_size 为32,验证集比例 valid_ratio 为0.1(即10%的训练数据用作验证)。
import os
import shutil
import collections
import math# batch_size - int, 训练和评估时的批量大小
batch_size = 32 # 设置验证集比例
# valid_ratio - float, 验证集在原始训练集中的比例,取值范围[0, 1]
# 值为0.1表示将10%的原始训练数据划分为验证集
valid_ratio = 0.1# 重组CIFAR-10数据集
# data_dir - str, CIFAR-10数据集的根目录路径
# valid_ratio - float, 验证集比例
# reorg_cifar10_data(...) - 函数调用,执行数据集重组操作
# 该函数会将原始CIFAR-10数据集重组为训练集、验证集和测试集三部分
# 重组后的数据结构为:
# - train_valid_test/train/: 训练集,按类别组织
# - train_valid_test/valid/: 验证集,按类别组织
# - train_valid_test/test/unknown/: 测试集,所有测试图像
# - train_valid_test/train_valid/: 原始训练集(包含验证部分),按类别组织
reorg_cifar10_data(data_dir, valid_ratio)
执行完毕后,data_dir 目录下会生成一个新的 train_valid_test 文件夹,其结构如下:
kaggle_cifar10_tiny/
├── trainLabels.csv
├── train/ (原始训练图像)
├── test/ (原始测试图像)
└── train_valid_test/├── train/│ ├── airplane/│ ├── automobile/│ └── ... (其他8个类别)├── valid/│ ├── airplane/│ ├── automobile/│ └── ... (其他8个类别)├── train_valid/ (原始训练图像,按类别组织)│ ├── airplane/│ ├── automobile/│ └── ... (其他8个类别)└── test/└── unknown/ (所有测试图像)
2. 图像增广
图像增广(Data Augmentation)是一种通过对训练图像进行一系列随机变换来生成新样本的技术。它可以有效增加训练数据的多样性,减少模型过拟合,提高模型的泛化能力。
2.1 训练集图像变换
对于训练集,我们应用以下变换:
- Resize (40x40): 将图像调整到 40x40 像素。
- RandomResizedCrop (32x32, scale=(0.64, 1.0), ratio=(1.0, 1.0)): 随机裁剪一个面积为原图 64% 到 100% 的正方形区域,并将其缩放到 32x32 像素。这有助于模型学习到图像的不同部分。
- RandomHorizontalFlip: 以 50% 的概率水平翻转图像。
- ToTensor: 将 PIL 图像转换为 PyTorch 张量,并将像素值从 [0, 255] 归一化到 [0.0, 1.0]。
- Normalize: 使用 CIFAR-10 数据集的均值和标准差对图像进行标准化。这有助于加速模型收敛。
import torch
import torchvision
import torchvision.transforms as transforms# 定义训练数据的图像变换流水线
# transform_train - torchvision.transforms.Compose对象, 包含多个按顺序应用的图像变换操作
transform_train = torchvision.transforms.Compose([# 步骤1: 调整图像大小# 将输入图像(任意大小)调整为40×40像素的正方形# 输入: 任意大小的PIL图像# 输出: 40×40像素的PIL图像torchvision.transforms.Resize(40),# 步骤2: 随机裁剪并调整大小# 随机裁剪一个面积为原始图像面积0.64~1倍(约为原图的80%~100%)的正方形区域,# 然后将该区域调整为32×32像素的图像# scale参数: (0.64, 1.0) - tuple(float, float), 表示裁剪区域面积占原图面积的比例范围# ratio参数: (1.0, 1.0) - tuple(float, float), 表示裁剪区域的宽高比范围,此处固定为1.0表示裁剪正方形# 输入: 40×40像素的PIL图像# 输出: 32×32像素的PIL图像torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),ratio=(1.0, 1.0)),# 步骤3: 随机水平翻转# 以0.5的概率水平翻转图像,增加数据多样性# 输入: 32×32像素的PIL图像# 输出: 32×32像素的PIL图像,可能已水平翻转torchvision.transforms.RandomHorizontalFlip(),# 步骤4: 转换为张量# 将PIL图像转换为形状为[C, H, W]的张量,并将像素值范围从[0, 255]缩放到[0.0, 1.0]# 输入: 32×32像素的PIL图像# 输出: torch.Tensor, 形状为[3, 32, 32],值范围为[0.0, 1.0]torchvision.transforms.ToTensor(),# 步骤5: 标准化# 对每个通道应用标准化处理:(x - mean) / std相关文章:
)
从代码学习深度学习 - 实战 Kaggle 比赛:图像分类 (CIFAR-10 PyTorch版)
文章目录 前言1. 读取并整理数据集1.1 读取标签文件1.2 划分训练集和验证集1.3 整理测试集1.4 执行数据整理2. 图像增广2.1 训练集图像变换2.2 测试集(和验证集)图像变换3. 读取数据集3.1 创建 Dataset 对象3.2 创建 DataLoader 对象4. 定义模型4.1 获取 ResNet-18 模型4.2 损…...

【数据结构】二分查找5.12
Basic 需求:在有序数组A内,查找值target 如果找到返回索引 如果找不到返回-1 算法描述: 前提:给定一个内含n个元素的有序数组A(升序),一个待查找值 设置两个索引:i0;jn-1; 如果…...

深入探索向量数据库:构建智能应用的新基础
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型辅助生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认…...

Swagger go中文版本手册
Swaggo(github.com/swaggo/swag)的注解语法是基于 OpenAPI 2.0 (以前称为 Swagger 2.0) 规范的,并添加了一些自己的约定。 主要官方文档: swaggo/swag GitHub 仓库: 这是最权威的来源。 链接: https://github.com/swaggo/swag重点关注: README.md: 包含了基本的安装、使用…...

Cloudera CDP 7.1.3 主机异常关机导致元数据丢失,node不能与CM通信
问题描述 plaintext ERROR Could not load post-deployment data from /var/run/cloudera-scm-agent/process/ccdeploy_hadoop-conf_etchadoopconf.cloudera.yarn_-8903374259073700469 IOError: [Errno 2] No such file or directory: /var/run/cloudera-scm-agent/proce…...

Redis特性与应用
1、分布式缓存与redis 2、redis数据结构和客户端集成 3、缓存读写模式与数据一致性 本地缓存:Hash Map、Ehcache、Caffeine、Google Guava 分布式缓存:Memcached、redis、Hazelcast、Apache ignite redis:基于键值对内存数据库,支…...
嵌入式调试新宠!J-Scope:免费+实时数据可视化,让MCU调试效率飙升!
📌 痛点直击:调试还在用“断点打印”? 嵌入式开发中,你是否也经历过这些崩溃瞬间? 想实时观察变量变化,代码里插满printf,结果拖垮系统性能? 断点调试打断程序运行,时序…...
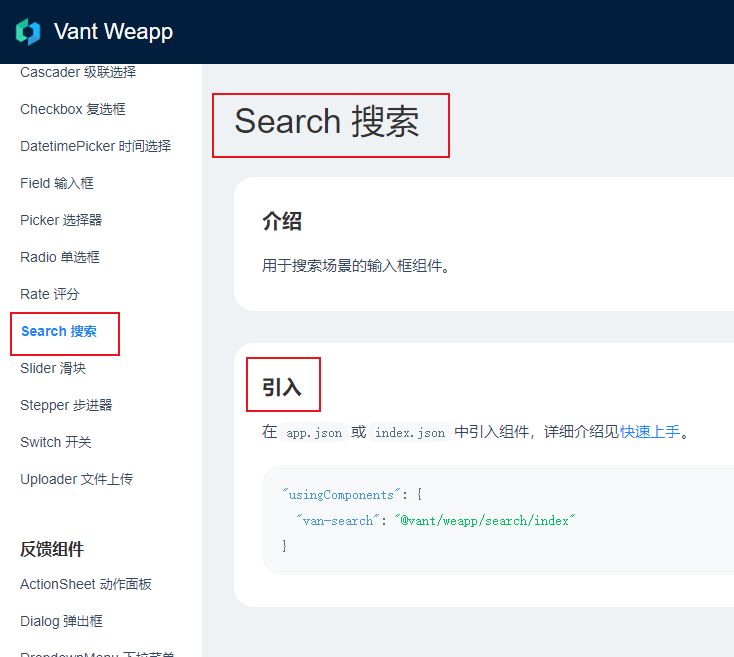
微信小程序学习之搜索框
1、第一步,我们在index.json中引入vant中的搜索框控件: {"usingComponents": {"van-search": "vant/weapp/search/index"} } 2、第二步,直接在index.wxml中添加布局: <view class"index…...

Altium Designer AD如何输出PIN带网络名的PDF装配图
Altium Designer AD如何输出PIN带网络名的PDF装配图 文描述在Altium Designer版本中设置焊盘网络名时遇到的问题,网络名大小不一致,部分PAD的网络名称未显示,可能涉及字符大小设置和版本差异。 参考 1.AD导出PCB装配图 https://blog.csd…...
VMware虚拟机 安装 CentOS 7
原文链接: VMware虚拟机 安装 CentOS 7 安装准备 软件: VMware Workstation Pro 17.6.3 镜像: CentOS-7.0-1406-x86_64-DVD.iso 我打包好放这了,VMware 和 CentOS7 ,下载即可。 关于VMware Workstation Pro 17.6.3,傻瓜式安装即可。 CentO…...

关于高并发GIS数据处理的一点经验分享
1、背景介绍 笔者过去几年在参与某个大型央企的项目开发过程中,遇到了十分棘手的难题。其与我们平常接触的项目性质完全不同。在一般的项目中,客户一般只要求我们能够通过桌面软件对原始数据进行加工处理,将各类地理信息数据加工处理成地图/场景和工作空间,然后再将工作空…...
Python训练打卡Day22
复习日: 1.标准化数据(聚类前通常需要标准化) scaler StandardScaler() X_scaled scaler.fit_transform(X) StandardScaler() :这部分代码调用了 StandardScaler 类的构造函数。在Python中,当你在类名后面加上括号…...

Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise论文阅读
冷扩散:无需噪声的任意图像变换反转 摘要 标准扩散模型通常涉及两个核心步骤:图像降质 (添加高斯噪声)和图像恢复 (去噪操作)。本文发现,扩散模型的生成能力并不强烈依赖于噪声的选择…...

2025认证杯数学建模第二阶段C题:化工厂生产流程的预测和控制,思路+模型+代码
2025认证杯数学建模第二阶段思路模型代码,详细内容见文末名片 一、探秘化工世界:问题背景大揭秘 在 2025 年 “认证杯”数学中国数学建模网络挑战赛第二阶段 C 题中,我们一头扎进了神秘又复杂的化工厂生产流程预测与控制领域。想象一下&…...

物联网驱动的共享充电站系统:智能充电的实现原理与技术解析!
随着新能源汽车的快速普及,共享充电站系统作为其核心基础设施,正通过物联网技术的深度赋能,实现从“传统充电”到“智能充电”的跨越式升级。本文将从系统架构、核心技术、优化策略及实际案例等角度,解析物联网如何驱动共享充电站…...
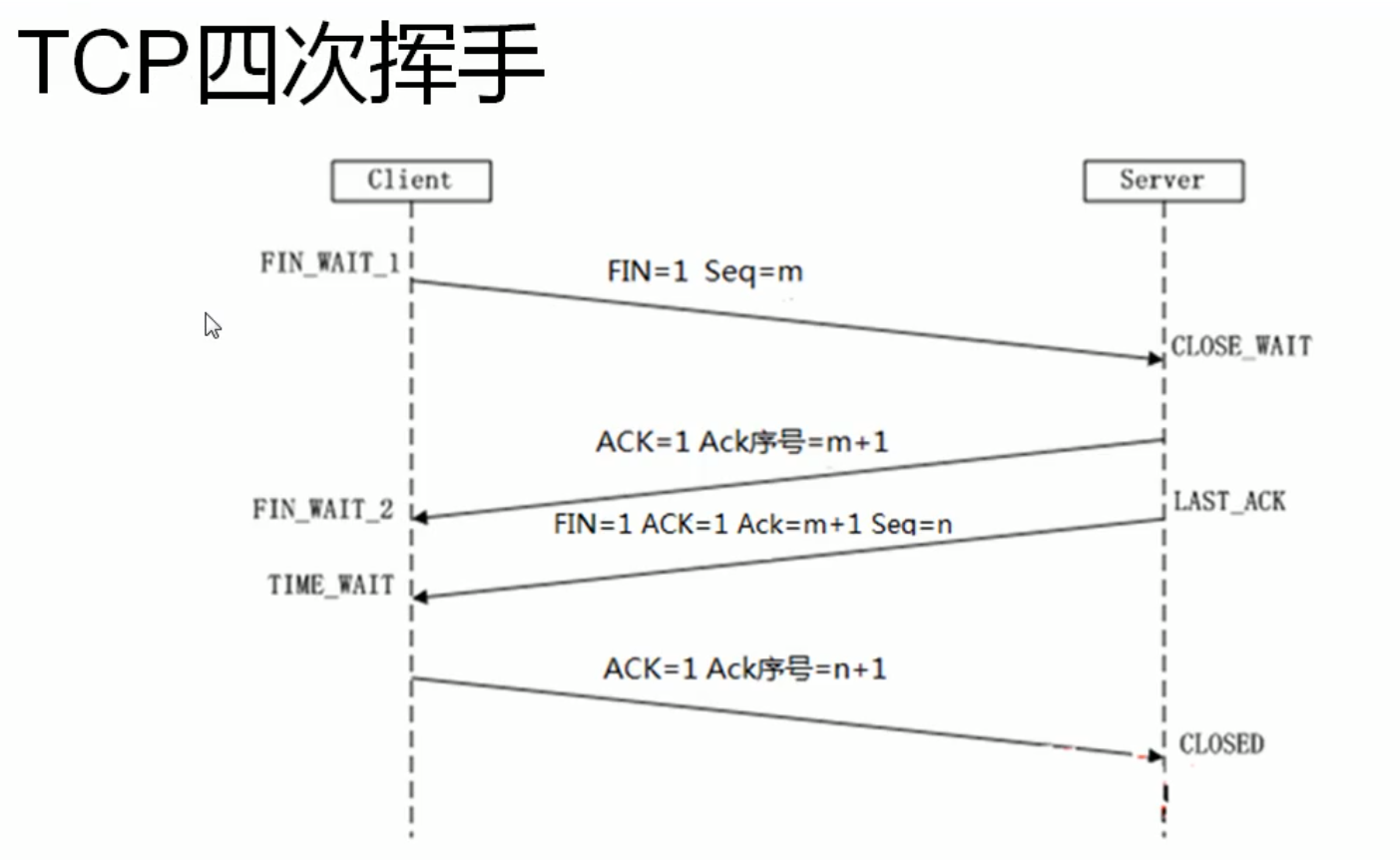
嵌软面试每日一阅----通信协议篇(二)之TCP
一. TCP和UDP的区别 可靠性 TCP:✅ 可靠传输(三次握手 重传机制) UDP:❌ 不可靠(可能丢包) 连接方式 TCP:面向连接(需建立/断开连接) UDP:无连接࿰…...
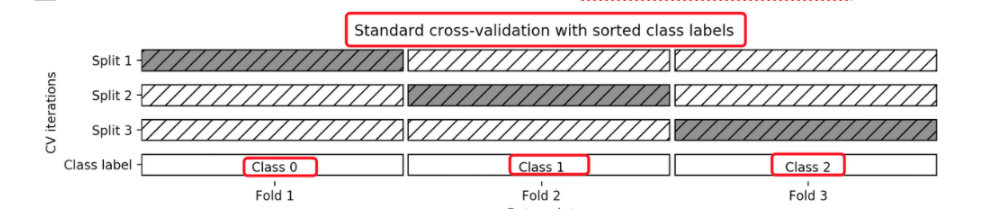
机器学习 --- 模型选择与调优
机器学习 — 模型选择与调优 文章目录 机器学习 --- 模型选择与调优一,交叉验证1.1 保留交叉验证HoldOut1.2 K-折交叉验证(K-fold)1.3 分层k-折交叉验证Stratified k-fold 二,超参数搜索三,鸢尾花数据集示例四,现实世界数据集示例…...
《Python星球日记》 第58天:Transformer 与 BERT
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、引言一、Transformer 架构简介1. 自注意力机制(Self-Attention)工作原理2. 多头注意力与位置编码多头注意力机制位置编码二、BERT 的结构…...

2900. 最长相邻不相等子序列 I
2900. 最长相邻不相等子序列 I class Solution:def getLongestSubsequence(self, words: List[str], groups: List[int]) -> List[str]:n len(groups) # 获取 groups 列表的长度ans [] # 初始化一个空列表,用于存储结果for i, g in enumerate(groups): # 遍…...
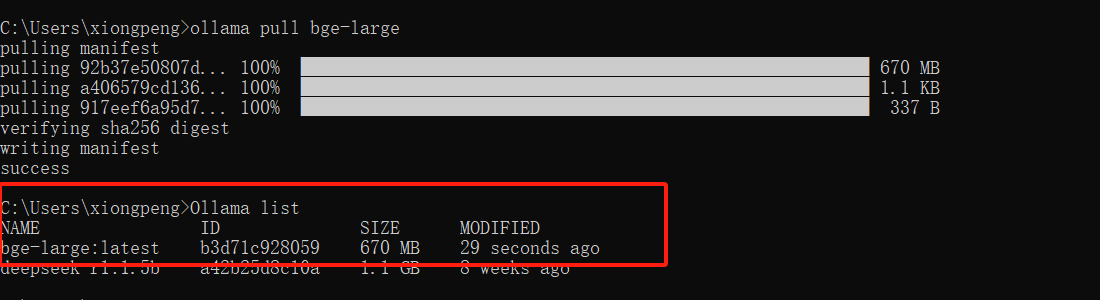
AGI大模型(15):向量检索之调用ollama向量数据库
这里介绍将向量模型下载到本地,这里使用ollama,现在本地安装ollama,这里就不过多结束了。直接从下载开始。 1 下载模型 首先搜索模型,这里使用bge-large模型,你可以根据自己的需要修改。 点击进入,复制命令到命令行工具中执行。 安装后查看: 2 代码实现 先下载ollama…...

Python网络请求利器:urllib库深度解析
一、urllib库概述 urllib是Python内置的HTTP请求库,无需额外安装即可使用。它由四个核心模块构成: urllib.request:发起HTTP请求的核心模块urllib.error:处理请求异常(如404、超时等)…...

什么是Agentic AI(代理型人工智能)?
什么是Agentic AI(代理型人工智能)? 一、概述 Agentic AI(代理型人工智能)是一类具备自主决策、目标导向性与持续行动能力的人工智能系统。与传统AI系统依赖外部输入和显式命令不同,Agentic AI在设定目标…...
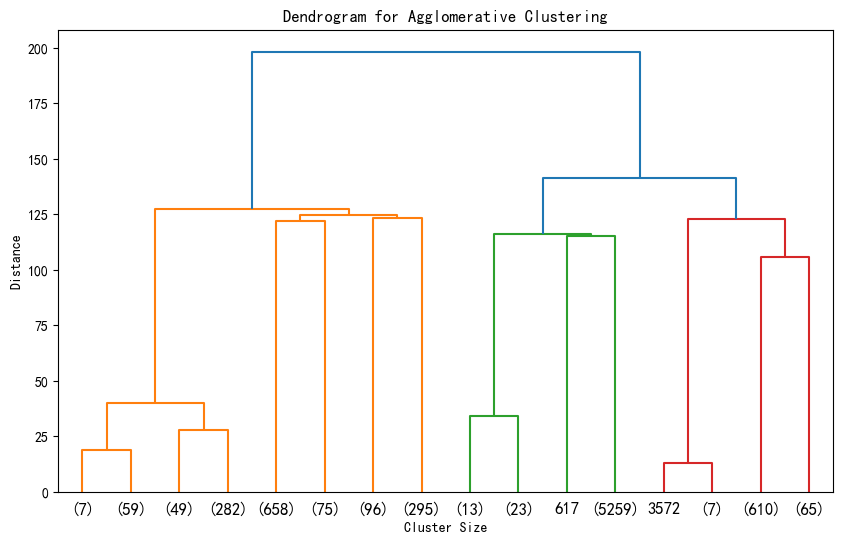
day 17 无监督学习之聚类算法
一、聚类流程 1. 利用聚类发现数据模式 无监督算法中的聚类,目的就是将数据点划分成不同的组或 “簇”,使得同一簇内的数据点相似度较高,而不同簇的数据点相似度较低,从而发现数据中隐藏的模式。 2. 对聚类后的类别特征进行可视…...

《Python星球日记》 第68天:BERT 与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、BERT模型基础1. 什么是BERT?2. BERT 的结构3.预训练和微调对比二、BERT 的预训练任务1. 掩码语言模型 (MLM)2. 下一句预测 (NSP)三、微调 …...
)
Spring 集成 SM4(国密对称加密)
Spring 集成 SM4(国密对称加密)算法 主要用于保护敏感数据,如身份证、手机号、密码等。 下面是完整集成步骤(含工具类 使用示例),采用 Java 实现(可用于 Spring Boot)。 一、依赖引…...
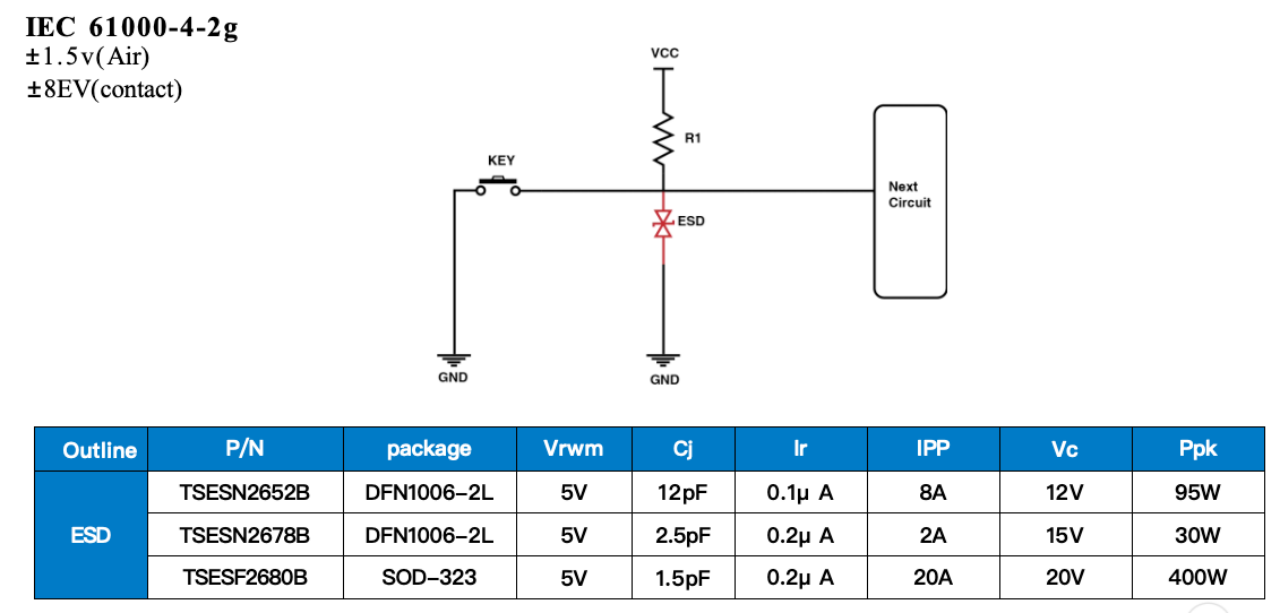
时源芯微| KY键盘接口静电浪涌防护方案
KY键盘接口静电浪涌防护方案通过集成ESD保护元件、电阻和连接键,形成了一道有效的防护屏障。当键盘接口受到静电放电或其他浪涌冲击时,该方案能够迅速将过电压和过电流引导至地,从而保护后续电路免受损害。 ESD保护元件是方案中的核心部分&a…...

CodeBuddy编程新范式
不会写?不想写? 腾讯推出的CodeBuddy彻底解放双手。 示例 以下是我对CodeBuddy的一个小体验。 我只用一行文字对CodeBuddy说明了一下我的需求,剩下的全部就交给了CodeBuddy,我需要做的就是验收结果即可。 1.首先CodeBuddy会对任…...

ArcGIS+InVEST+RUSLE:水土流失模拟与流域管理的高效解决方案;水土保持专题地图制作
在全球生态与环境面临严峻挑战的当下,水土流失问题已然成为制约可持续发展的重要因素之一。水土流失不仅影响土地资源的可持续利用,还对生态环境、农业生产以及区域经济发展带来深远影响。因此,科学、精准地模拟与评估水土流失状况࿰…...
小刚说C语言刷题—1088求两个数M和N的最大公约数
1.题目描述 求两个正整数 M 和 N 的最大公约数(M,N都在长整型范围内) .输入 输入一行,包括两个正整数。 输出 输出只有一行,包括1个正整数。 样例 输入 45 60 输出 15 2.参考代码(C语言版) #include <stdio.h> …...

【LLIE专题】基于码本先验与生成式归一化流的低光照图像增强新方法
GLARE: Low Light Image Enhancement via Generative Latent Feature based Codebook Retrieval(2024,ECCV) 专题介绍一、研究背景二、GLARE方法阶段一:正常光照代码本学习(Normal-Light Codebook Learning)…...