Java 使用 PDFBox 提取 PDF 文本并统计关键词出现次数(附Demo)
目录
- 前言
- 1. 基本知识
- 2. 在线URL
- 2.1 英文
- 2.2 混合
- 3. 实战
前言
爬虫神器,无代码爬取,就来:bright.cn
Java基本知识:
- java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)
- 【Java项目】实战CRUD的功能整理(持续更新)
需要爬虫相关的PDF,并统计对应PDF里头的词频,其中某个功能需要如下知识点
1. 基本知识
Apache PDFBox 是一个开源的 Java PDF 操作库,支持:
-
读取 PDF 文件内容(包括文字、图片、元数据)
-
创建和修改 PDF 文档
-
提取文本内容用于搜索、分析等操作
Maven相关的依赖:
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.29</version>
</dependency>
需下载 在进行统计:
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.File;
import java.io.IOException;public class PDFWordCounter {public static void main(String[] args) {String pdfPath = "sample.pdf"; // 替换为你的 PDF 文件路径String keyword = "Java"; // 要统计的词语try {// 加载 PDF 文档PDDocument document = PDDocument.load(new File(pdfPath));// 使用 PDFTextStripper 提取文本PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);document.close(); // 记得关闭文档资源// 转小写处理,方便忽略大小写String lowerText = text.toLowerCase();String lowerKeyword = keyword.toLowerCase();// 调用词频统计函数int count = countOccurrences(lowerText, lowerKeyword);System.out.println("词语 \"" + keyword + "\" 出现次数: " + count);} catch (IOException e) {e.printStackTrace();}}// 使用 indexOf 遍历匹配词语出现次数private static int countOccurrences(String text, String word) {int count = 0;int index = 0;while ((index = text.indexOf(word, index)) != -1) {count++;index += word.length();}return count;}
}
上述的Demo详细分析下核心知识:
-
PDDocument.load(File)
用于加载 PDF 文件到内存中
PDFBox 使用 PDDocument 表示整个 PDF 对象,使用完后必须调用 close() 释放资源 -
PDFTextStripper
PDFBox 中用于提取文字的核心类,会尽可能“以阅读顺序”提取文本,适用于纯文字 PDF 文件。对于图像型扫描件则无效(需 OCR) -
大小写不敏感统计
实际应用中搜索关键词通常需要忽略大小写,因此我们先统一将文本和关键词转换为小写 -
indexOf 实现词频统计
这是最基础也最直观的统计方法,效率较高,但不够精确
如果需要更精确(只统计完整单词),可以使用正则:
Pattern pattern = Pattern.compile("\\b" + Pattern.quote(word) + "\\b", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(text);
int count = 0;
while (matcher.find()) {count++;
}
2. 在线URL
2.1 英文
此处的Demo需要注意一个点:
| 注意点 | 说明 |
|---|---|
| PDF 文件是否公开访问 | 不能访问受密码或登录保护的 PDF |
| 文件大小 | 不建议下载和分析过大文件,可能导致内存问题 |
| 中文 PDF | 若是扫描图片形式的中文 PDF,则 PDFBox 无法直接提取文本(需 OCR) |
| 编码问题 | 若中文显示为乱码,可能是 PDF 没有内嵌字体 |
🔧 思路:
-
通过 URL.openStream() 获取在线 PDF 的输入流
-
使用 PDFBox 的 PDDocument.load(InputStream) 读取 PDF
-
用 PDFTextStripper 提取文本
-
用字符串方法或正则统计关键词频率
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.InputStream;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class OnlinePDFKeywordCounter {public static void main(String[] args) {String pdfUrl = "https://www.example.com/sample.pdf"; // 你的在线 PDF 链接String keyword = "Java"; // 需要统计的关键词try (InputStream inputStream = new URL(pdfUrl).openStream();PDDocument document = PDDocument.load(inputStream)) {PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);// 使用正则匹配单词边界(忽略大小写)Pattern pattern = Pattern.compile("\\b" + Pattern.quote(keyword) + "\\b", Pattern.CASE_INSENSITIVE);Matcher matcher = pattern.matcher(text);int count = 0;while (matcher.find()) {count++;}System.out.println("词语 \"" + keyword + "\" 出现在在线 PDF 中的次数为: " + count);} catch (Exception e) {System.err.println("处理 PDF 时出错: " + e.getMessage());e.printStackTrace();}}
}
2.2 混合
| 方法 | 适用场景 | 是否支持中文 |
|---|---|---|
indexOf | 中英文都适用 | ✅ |
Pattern + \\b | 仅限英文单词匹配 | ❌ 中文不支持 |
正则表达式 \\b...\\b(表示“单词边界”)并不适用于中文
统计在想的URL PDF的词频:
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.InputStream;
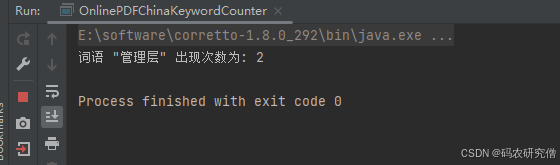
import java.net.URL;public class OnlinePDFKeywordCounter {public static void main(String[] args) {String pdfUrl = "https://www.xxxx.pdf";String keyword = "管理层"; // 要统计的中文关键词try (InputStream inputStream = new URL(pdfUrl).openStream();PDDocument document = PDDocument.load(inputStream)) {PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);// 直接用 indexOf 不区分大小写(对于中文没必要转小写)int count = countOccurrences(text, keyword);System.out.println("词语 \"" + keyword + "\" 出现次数为: " + count);} catch (Exception e) {System.err.println("处理 PDF 时出错: " + e.getMessage());e.printStackTrace();}}// 简单统计子串出现次数(适用于中文)private static int countOccurrences(String text, String keyword) {int count = 0;int index = 0;while ((index = text.indexOf(keyword, index)) != -1) {count++;index += keyword.length();}return count;}
}
截图如下:
3. 实战
如果词频比较多,可以使用List
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;import java.io.InputStream;
import java.net.URL;
import java.util.Arrays;
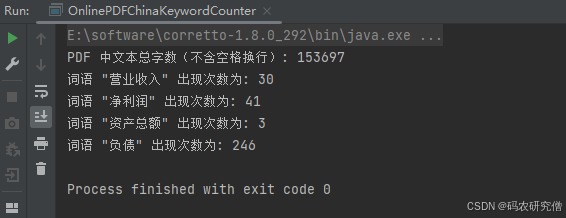
import java.util.List;public class OnlinePDFChinaKeywordCounter {public static void main(String[] args) {String pdfUrl = "https://www.pdf";// 多个中文关键词List<String> keywords = Arrays.asList("营业收入", "净利润", "资产总额", "负债");try (InputStream inputStream = new URL(pdfUrl).openStream();PDDocument document = PDDocument.load(inputStream)) {PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);// 统计 PDF 中的总文字长度(不含空格和换行)int totalCharacters = text.replaceAll("\\s+", "").length();System.out.println("PDF 中文本总字数(不含空格换行): " + totalCharacters);for (String keyword : keywords) {int count = countOccurrences(text, keyword);System.out.println("词语 \"" + keyword + "\" 出现次数为: " + count);}} catch (Exception e) {System.err.println("处理 PDF 时出错: " + e.getMessage());e.printStackTrace();}}// 统计某个关键词出现次数private static int countOccurrences(String text, String keyword) {int count = 0;int index = 0;while ((index = text.indexOf(keyword, index)) != -1) {count++;index += keyword.length();}return count;}
}
截图如下:
相关文章:
Java 使用 PDFBox 提取 PDF 文本并统计关键词出现次数(附Demo)
目录 前言1. 基本知识2. 在线URL2.1 英文2.2 混合 3. 实战 前言 爬虫神器,无代码爬取,就来:bright.cn Java基本知识: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目】实战CRUD…...
将 Element UI 表格元素导出为 Excel 文件(处理了多级表头和固定列导出的问题)
import { saveAs } from file-saver import XLSX from xlsx /*** 将 Element UI 表格元素导出为 Excel 文件* param {HTMLElement} el - 要导出的 Element UI 表格的 DOM 元素* param {string} filename - 导出的 Excel 文件的文件名(不包含扩展名)*/ ex…...

Android Development Roadmap
🔧 Android Development Roadmap (Practical First → Theory Later) Here’s a lean, real-world roadmap tailored to the mindset — build-first, theory-when-needed: 🟢 Stage 1: Core Setup & Workflow (Done ✅) ✅ Install Android Studio…...
【Linux网络】 HTTP cookie与session
HTTP cookie与session 引入HTTP Cookie 定义 HTTP Cookie(也称为Web Cookie、浏览器Cookie或简称Cookie)是服务器发送到用户浏览器并保存在浏览器上的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带并发送到服务器上。通常&…...
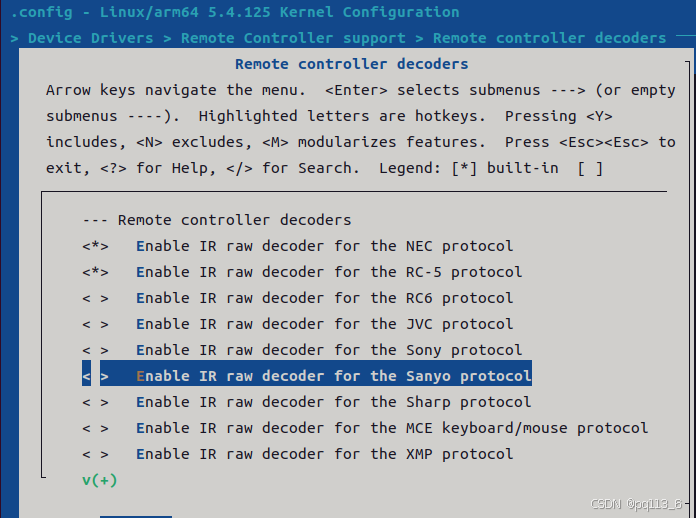
OrangePi Zero 3学习笔记(Android篇)11 - IR遥控器
目录 1. 查询IR信息 1.1.1 sunxi-ir-uinput 1.1.2 sunxi-ir 2. 调试键值 3. 匹配遥控器 4. Power键的特殊处理 5. 验证 ir的接口在13pin接口上,需要使用到扩展板。 1. 查询IR信息 在shell的界面输入命令: dumpsys input 分析返回信息…...

uniapp实现在线pdf预览以及下载
uniapp实现在线pdf预览以及下载 在线预览 遇到的问题 后端返回一个url地址,我需要将在在页面中渲染出来。因为在浏览器栏上我输入url地址就可以直接预览pdf文件,因此直接的想法是通过web-view组件直接渲染。有什么问题呢?在h5端能够正常渲…...

【蓝桥杯省赛真题49】python偶数 第十五届蓝桥杯青少组Python编程省赛真题解析
python偶数 第十五届蓝桥杯青少组python比赛省赛真题详细解析 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...

突发,苹果发布下一代 CarPlay Ultra
汽车的平均换代周期一般都超过5年,对于老旧燃油车而言,苹果的 Carplay 是黑暗中的明灯,是延续使用寿命的利器。 因为你可能不需要冰箱彩电大沙发,但一定需要大屏车载导航、倒车影像、车载听歌。如果原车不具备这个功能࿰…...

鸿蒙OSUniApp开发富文本编辑器组件#三方框架 #Uniapp
使用UniApp开发富文本编辑器组件 富文本编辑在各类应用中非常常见,无论是内容创作平台还是社交软件,都需要提供良好的富文本编辑体验。本文记录了我使用UniApp开发一个跨平台富文本编辑器组件的过程,希望对有类似需求的开发者有所启发。 背景…...

Axure设计的“广东省网络信息化大数据平台”数据可视化大屏
在数据驱动决策的时代,数据可视化大屏成为了展示数据、洞察趋势的重要工具。今天,让我们一同深入了解由Axure设计的“广东省网络信息化大数据平台”数据可视化大屏,看看它如何通过精心的布局和丰富的图表类型,将复杂的数据以直观易…...

2025认证杯数学建模第二阶段C题完整论文(代码齐全)化工厂生产流程的预测和控制
2025认证杯数学建模第二阶段C题完整论文(代码齐全)化工厂生产流程的预测和控制,详细信息见文末名片 第二阶段问题 1 分析 在第二阶段问题 1 中,由于在真实反应流程中输入反应物的量改变后,输出产物会有一定延时&#…...
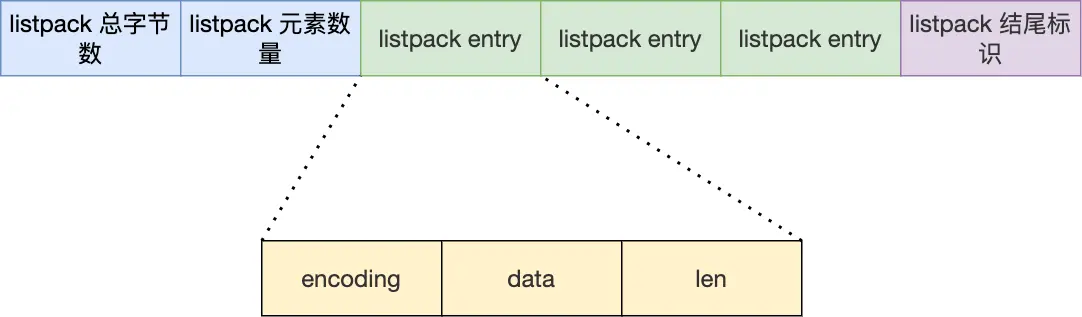
Redis——底层数据结构
SDS(simple dynamic string): 优点: O1时间获取长度(char *需要ON)快速计算剩余空间(alloc-len),拼接时根据所需空间自动扩容,避免缓存区溢出(ch…...

ChatGPT 能“记住上文”的原因
原因如下 你把对话历史传给了它 每次调用 OpenAI 接口时,都会把之前的对话作为参数传入(messages 列表),模型“看见”了之前你说了什么。 它没有长期记忆 它不会自动记住你是谁或你说过什么,除非你手动保存历史并再次…...

大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案
大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案 大疆无人机是低空行业无人机最具性价比的产品,尤其是大疆机场3的推出,以及持续自身产品升级迭代,包括司空2、大疆智图以及大疆智运等专业软件和…...

医学影像系统性能优化与调试技术:深度剖析与实践指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

day 25
*被遗忘的一集 程序:二进制文件,文件存储在磁盘中,例如/usr/bin/目录下 进程:进程是已启动的可执行程序的运行实例。 *进程和程序并不是一一对应的关系,相同的程序运行在不同的数据集上就是不同的进程 *进程还具有并…...
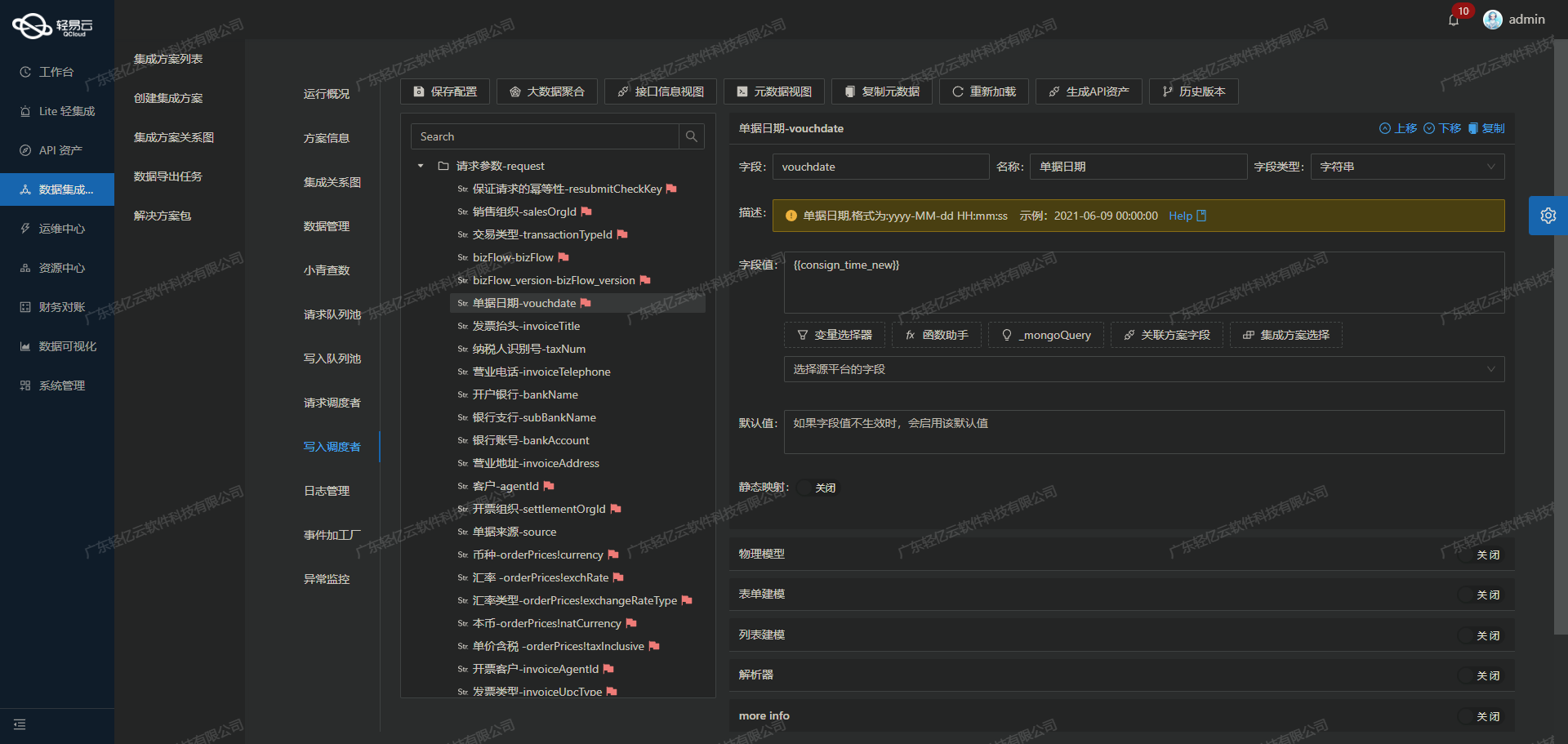
吉客云数据集成到金蝶云星空的最佳实践
吉客云数据集成到金蝶云星空的技术案例分享 在本次技术案例中,我们将探讨如何通过仓库方案-I0132,将吉客云的数据高效集成到金蝶云星空。此方案旨在解决企业在数据对接过程中遇到的多种技术挑战,包括数据吞吐量、实时监控、异常处理和数据格…...

【Spark】-- DAG 和宽窄依赖的核心
目录 Spark DAG 和宽窄依赖的核心 一、什么是 DAG? 示例:WordCount 程序的 DAG 二、宽依赖与窄依赖 1. 窄依赖 2. 宽依赖 三、DAG 与宽窄依赖的性能优化 1. 减少 Shuffle 操作 2. 合理划分 Stage 3. 使用缓存机制 四、实际案例分析:同行车判断 五、总结 Spark D…...

原生的 XMLHttpRequest 和基于 jQuery 的 $.ajax 方法的异同之处以及使用场景
近期参与一个项目的开发,发现项目中的ajax请求有两种不同的写法,查询了下两种写法的异同之处以及使用场景。 下面将从以下两段简单代码进行异同之处的分析及使用场景的介绍: // 写法一: var xhr new XMLHttpRequest(); xhr.open…...

快速选择算法:优化大数据中的 Top-K 问题
在处理海量数据时,经常会遇到这样的需求:找出数据中最大的前 K 个数,而不必对整个数据集进行排序。这种场景下,快速选择算法(Quickselect)就成了一个非常高效的解决方案。本文将通过一个 C 实现的快速选择算…...

使用Frp搭建内网穿透,外网也可以访问本地电脑。
一、准备 1、服务器:需要一台外网可以访问的服务器,不在乎配置,宽带好就行。我用的是linux服务器。(一般买一个1核1g的云服务器就行),因为配置高的服务器贵,所以这是个择中办法。 2、客户端&a…...

【RabbitMQ】消息丢失问题排查与解决
RabbitMQ 消息丢失是一个常见的问题,可能发生在消息的生产、传输、消费或 Broker 端等多个环节。消息丢失的常见原因及对应的解决方案: 一、消息丢失的常见原因 1. 生产端(Producer)原因 (1) 消息未持久化 原因:生产…...

电子电路:被动电子元件都有哪些?
在电子电路中,被动元件(Passive Components)是指不需要外部电源即可工作且不具备信号放大或能量控制能力的元件。它们主要通过消耗、存储或传递能量来调节电路的电流、电压、频率等特性。以下是常见的被动元件及其核心作用: 一、基础被动元件 1. 电阻(Resistor) 功能:限…...
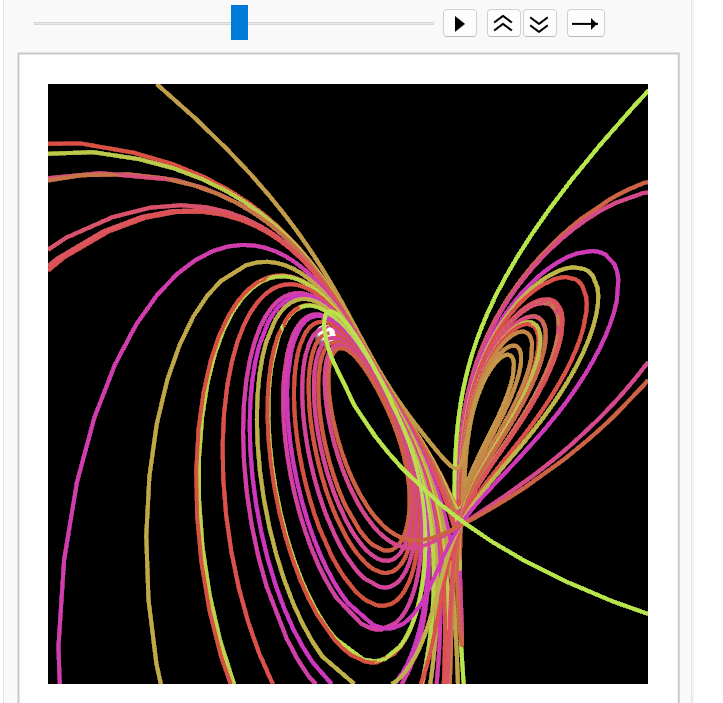
使用Mathematica制作Lorenz吸引子的轨道追踪视频
Lorenz奇异吸引子是混沌理论中最早被发现和研究的吸引子之一,它由Edward Lorenz在1963年研究确定性非周期流时提出。Lorenz吸引子以其独特的"蝴蝶"形状而闻名,是混沌系统和非线性动力学的经典例子。 L NDSolveValue[{x[t] -3 (x[t] - y[t]),…...

深入解析VPN技术原理:安全网络的护航者
在当今信息化迅速发展的时代,虚拟私人网络(VPN)技术成为了我们在互联网时代保护隐私和数据安全的重要工具。VPN通过为用户与网络之间建立一条加密的安全通道,确保了通讯的私密性与完整性。本文将深入解析VPN的技术原理、工作机制以…...
:前端框架性能优化深度解析)
JavaScript性能优化实战(10):前端框架性能优化深度解析
引言 React、Vue、Angular等框架虽然提供了强大的抽象和开发效率,但不恰当的使用方式会导致严重的性能问题,针对这些问题,本文将深入探讨前端框架性能优化的核心技术和最佳实践。 React性能优化核心技术 React通过虚拟DOM和高效的渲染机制提供了出色的性能,但当应用规模…...
 VS (LINQ) 性能比拼 ——c#)
(for 循环) VS (LINQ) 性能比拼 ——c#
在大多数情况下,for 循环的原始性能会优于 LINQ,尤其是在处理简单遍历、数据筛选或属性提取等场景时。这是由两者的实现机制和抽象层次决定的。以下是具体分析: 一、for 循环与 LINQ 的性能差异原因 1. 抽象层次与执行机制 for 循环&#…...

《Spring Boot 4.0新特性深度解析》
Spring Boot 4.0的发布标志着Java生态向云原生与开发效能革命的全面迈进。作为企业级应用开发的事实标准框架,此次升级在运行时性能、云原生支持、开发者体验及生态兼容性四大维度实现突破性创新。本文深度解析其核心技术特性,涵盖GraalVM原生镜像支持、…...
的可能原因有哪些?如何从数据或训练层面缓解?)
【大模型面试每日一题】Day 20:大模型出现“幻觉”(Hallucination)的可能原因有哪些?如何从数据或训练层面缓解?
【大模型面试每日一题】Day 20:大模型出现“幻觉”(Hallucination)的可能原因有哪些?如何从数据或训练层面缓解? 📌 题目重现 🌟🌟 面试官:大模型出现“幻觉”…...

简单图像自适应亮度对比度调整
一、背景介绍 继续在刷对比度调整相关算法,偶然间发现了这个简单的亮度/对比度自适应调整算法,做个简单笔记记录。也许后面用得到。 二、自适应亮度调整 1、基本原理 方法来自论文:Adaptive Local Tone Mapping Based on Retinex for High Dynamic Ran…...