ACM模式用Scanner和System.out超时的解决方案和原理
Hi~!这里是奋斗的明志,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~
🌱🌱个人主页:奋斗的明志
🌱🌱所属专栏:笔试强训
📚本系列文章为个人学习笔记,在这里撰写成文一为巩固知识,二为展示我的学习过程及理解。文笔、排版拙劣,望见谅。

笔试强训
- 一、ACM模式下(Java)
- 1、为什么 Scanner 在输入的时候会慢
- 2、为什么 System.out 在输出的时候会慢
- 二、利用自定义快读模版(Java)
- 三、Java StringTokenizer 类使用方法
- 1、案例一
- 2、案例二
- 四、BufferedReader
- 1、为什么要用while循环
- 2、快速写
一、ACM模式下(Java)
- 在ACM模式环境下,输入和输出的时候会先将输入输出的东西放在一个文件里面,这个文件可以称为IO设备

1、为什么 Scanner 在输入的时候会慢
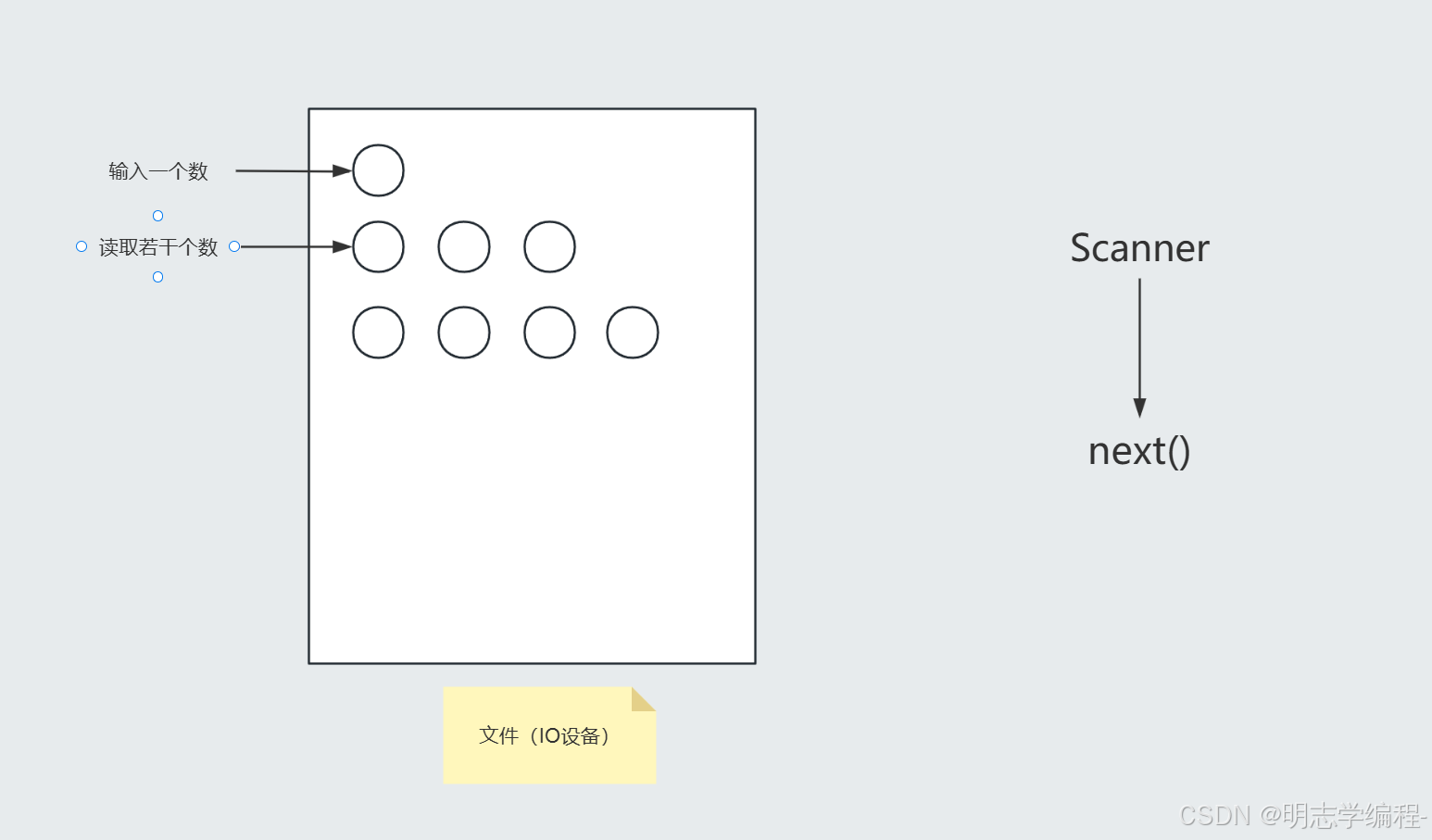
new 一个 Scanner ,在 Scanner 里面调用 next 的时候,程序会直接访问 IO 设备。在调用一个 next() 的时候,只会在 IO 设备中拿出一个数,再将这个数返回程序
调用一个 next() 就会访问一次 IO 设备,程序访问 IO 设备的速度特别慢。所以当输入的数据量很大的时候,就会多次访问这个 IO 设备,所以就会超时。
2、为什么 System.out 在输出的时候会慢
和 Scanner 读取数据一样。当输出数据的时候,也是将数据一个一个拿到 IO 设备中。由于程序访问 IO 设备的速度特别慢,所以只要数据量稍微多一些,就会超时
二、利用自定义快读模版(Java)
Java 在处理 IO 的时候,有两套标准:
字节流(System.in)
字符流(带 Reader 或者 Writer)
import java.util.*;
import java.io.*;public class Main
{public static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));public static Read in = new Read();public static void main(String[] args) throws IOException{// 写代码out.close();}
}class Read // 自定义快速读入
{// 字符串分割器StringTokenizer st = new StringTokenizer("");// 缓冲读取器BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));// 核心方法:获取下一个输入片段String next() throws IOException {while(!st.hasMoreTokens()){st = new StringTokenizer(bf.readLine());}return st.nextToken();}String nextLine() throws IOException {return bf.readLine();}int nextInt() throws IOException {return Integer.parseInt(next());}long nextLong() throws IOException {return Long.parseLong(next());}double nextDouble() throws IOException {return Double.parseDouble(next());}
}
三、Java StringTokenizer 类使用方法
Java StringTokenizer 属于 java.util 包,用于分隔字符串。
StringTokenizer 构造方法:
- StringTokenizer(String str) :构造一个用来解析 str 的 StringTokenizer 对象。java 默认的分隔符是空格(“”)、制表符(\t)、换行符(\n)、回车符(\r)。
- StringTokenizer(String str, String delim) :构造一个用来解析 str 的 StringTokenizer 对象,并提供一个指定的分隔符。
- StringTokenizer(String str, String delim, boolean returnDelims) :构造一个用来解析 str 的 StringTokenizer 对象,并提供一个指定的分隔符,同时,指定是否返回分隔符。
StringTokenizer 常用方法:
- int countTokens():返回nextToken方法被调用的次数。
- boolean hasMoreTokens():返回是否还有分隔符。
- boolean hasMoreElements():判断枚举 (Enumeration) 对象中是否还有数据。
- String nextToken():返回从当前位置到下一个分隔符的字符串。
- Object nextElement():返回枚举 (Enumeration) 对象的下一个元素。
- String nextToken(String delim):与 nextToken 类似,以指定的分隔符返回结果。
1、案例一
import java.util.*;public class Main
{ public static void main(String[] args){ String str = "runoob,google,taobao,facebook,zhihu";// 以 , 号为分隔符来分隔字符串StringTokenizer st=new StringTokenizer(str,",");while(st.hasMoreTokens()) { System.out.println(st.nextToken());}}
}输出结果为:
runoob
google
taobao
facebook
zhihu
2、案例二
import java.util.*;public class Main
{public static void main(String args[]){System.out.println("使用第一种构造函数:");StringTokenizer st1 = new StringTokenizer("Hello Runoob How are you", " ");while (st1.hasMoreTokens())System.out.println(st1.nextToken());System.out.println("使用第二种构造函数:");StringTokenizer st2 = new StringTokenizer("JAVA : Code : String", " :");while (st2.hasMoreTokens())System.out.println(st2.nextToken());System.out.println("使用第三种构造函数:");StringTokenizer st3 = new StringTokenizer("JAVA : Code : String", " :", true);while (st3.hasMoreTokens())System.out.println(st3.nextToken());}
}使用第一种构造函数:
Hello
Runoob
How
are
you
使用第二种构造函数:
JAVA
Code
String
使用第三种构造函数:
JAVA:Code:String


四、BufferedReader
它是一个带内存缓冲区的字符流。将要读取数据的时候,先将 IO 设备里面的数据一次性放到这个"内存缓冲区中"。然后 BufferedReader 再调用 next() 的时候,就是直接在内存缓冲区里面拿数据的
这对比 Scanner 调用 next 之后,一次一次地重复在 IO 设备中读取数据来说,BufferedReader 在调用 next 的时候,只需要读取一次内存缓冲区,就能读取到所有数据。
直接从内存中拿数据,肯定是比访问 IO 设备要快得多的
1、为什么要用while循环
因为有一些输入输出的题目,输入的数据不止只有一行,当把第一行的数据一个一个裁完之后,你是要读取下一行数据的。所以需要一个 while 循环判断,当后面没有数据了,就重新再读入一行,然后再返回新读入的一行的字符串
BufferedReader 相较于 System.in 快,就是因为他带了一个缓冲区。先把文件里面的数据刷新到缓冲区里面,然后在缓冲区里面拿一行一行的数据。随后通过 StringTokenizer 将读取的一行一行数据(bf.readLine())一个个地进行裁剪工作。当后面还有的行时候,就一个一个的裁;当后面没有行的时候,就再重新读一行,一个一个地裁
2、快速写
new BufferedWriter(new OutputStreamWriter(System.in))
这里是把字符流转换为字节流
此处的 BufferedReader 是在输出的时候,不直接将数据从 IO 设备输出到程序,而是先将数据输出到内存缓冲区中,然后程序在内存缓冲区中直接读取数据(与输入原理一致)
PrintWriter 其实 BufferedWriter 已经满足我们的需求了,为什么还要套一层 PrintWriter 呢?
因为 BufferWriter 的输出方式不好写,而 PrintWriter 的输出方式和 System.out 是完全一样的(使用方式完全一样)

相关文章:
ACM模式用Scanner和System.out超时的解决方案和原理
Hi~!这里是奋斗的明志,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 🌱🌱个人主页:奋斗的明志 🌱🌱所属专栏:笔试强训 📚本系列文章为个人学…...
Java注解详解:从入门到实战应用篇
1. 引言 Java注解(Annotation)是JDK 5.0引入的一种元数据机制,用于为代码提供附加信息。它广泛应用于框架开发、代码生成、编译检查等领域。本文将从基础到实战,全面解析Java注解的核心概念和使用场景。 2. 注解基础概念 2.1 什…...

QML 属性动画、行为动画与预定义动画
目录 引言相关阅读本文使用的动画属性工程结构示例解析示例1:属性动画应用示例2:行为动画实现示例3:预定义动画 总结工程下载 引言 QML动画系统为界面元素提供了流畅的过渡效果。本文通过三个示例,结合属性动画(PropertyAnimatio…...
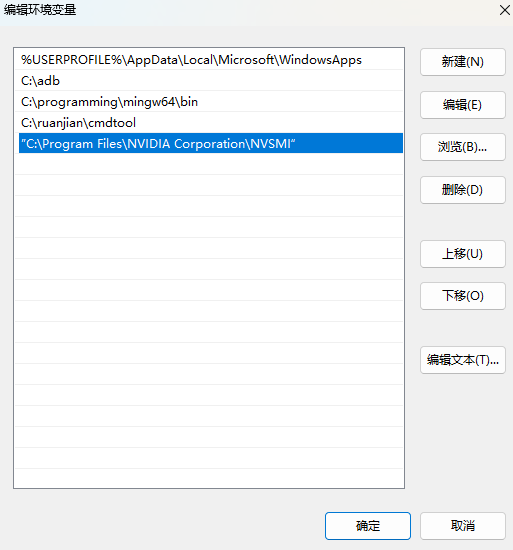
window nvidia-smi命令 Failed to initialize NVML: Unknown Error
如果驱动目录下的可以执行,那可能版本原因 "C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi"复制"C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe"替换 C:\Windows\System32\nvidia-smi.exe 或者 把C:\Windows\System3…...
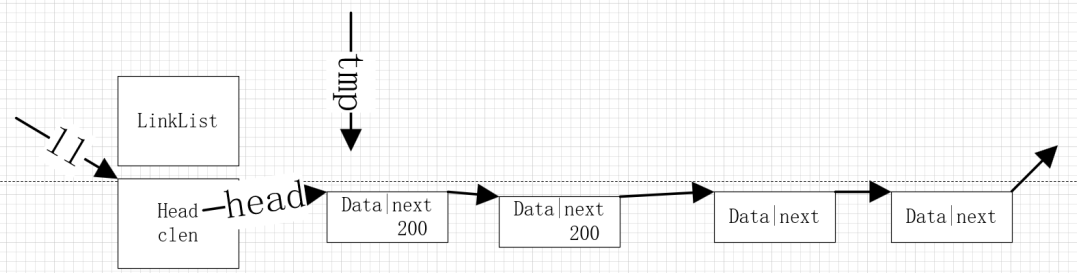
自学嵌入式 day19-数据结构 链表
二、线性表的链式存储 1.特点: (1)线性表链式存储结构的特点是一组任意的存储单位存储线性表的数据元素,存储单元可以是连续的,也可以不连续。可以被存储在任意内存未被占用的位置上。 (2)所以…...
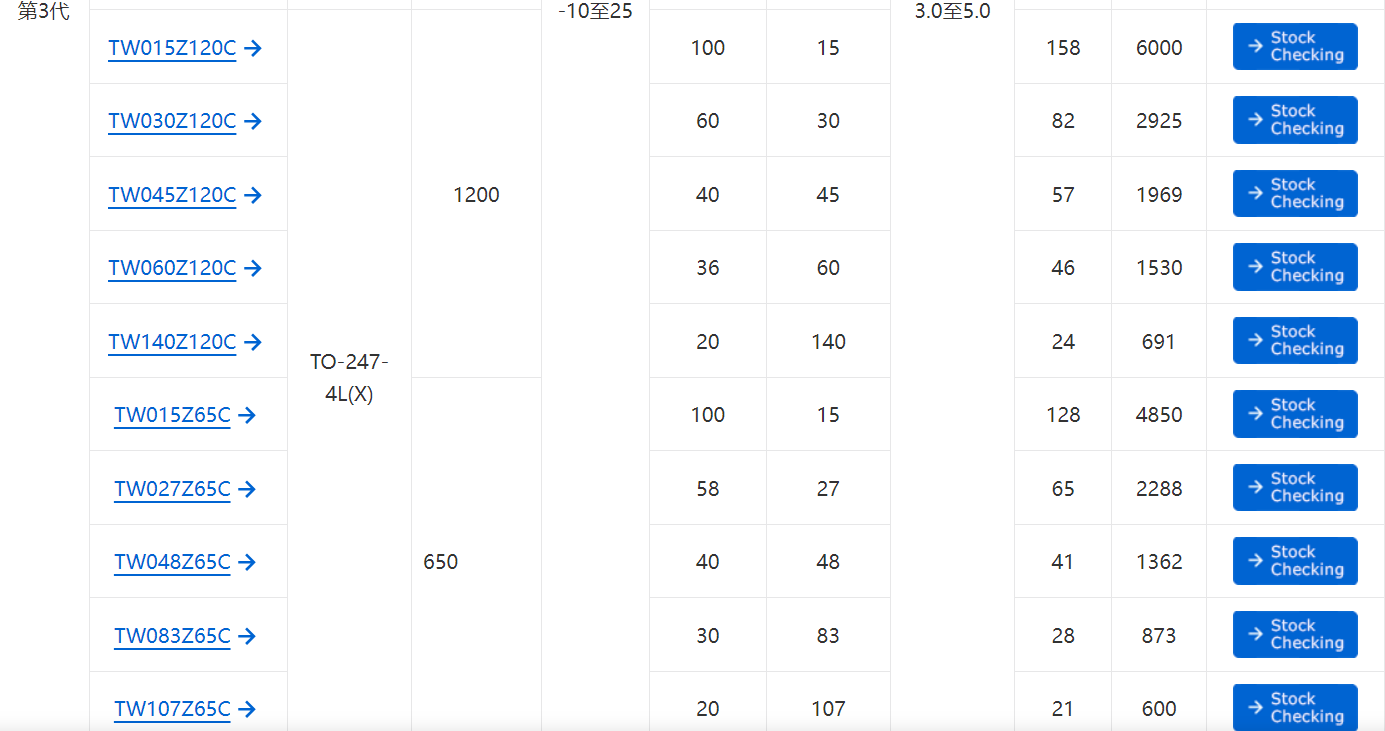
东芝第3代SiC MOSFET助于降低应用中电源损耗
功率器件是管理和降低各种电子设备电能功耗以及实现碳中和社会的重要元器件。由于与比硅材料相比,碳化硅具有更高的电压和更低的损耗,因此碳化硅(SiC)被广泛视为下一代功率器件的材料。虽然碳化硅功率器件目前主要用于列车逆变器&…...

Vue 2.0学习
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言&…...
详解)
Mendix 中的XPath 令牌(XPath Tokens)详解
在 Mendix 中,XPath 令牌(XPath Tokens) 是一种特殊的动态参数化查询技术,允许你在 XPath 表达式中使用变量或上下文相关的值,从而实现更灵活的查询逻辑。 1. 什么是 XPath 令牌? XPath 令牌是 Mendix 提…...

Spring Batch学习,和Spring Cloud Stream区别
Spring Batch学习,和Spring Cloud Stream区别 1. 使用Spring Initializr创建项目2. 使用步骤构建作业(Chunk 模式)🧩 场景说明🧰 1. 示例目录结构📄 2. 创建输入文件(users.csv)&…...

【技术原理】Linux 文件时间属性详解:Access、Modify、Change 的区别与联系
在 Linux 系统中,每个文件都有三个核心时间属性:Access Time (atime)、Modify Time (mtime) 和 Change Time (ctime)。它们分别记录文件不同维度的变更信息,以下是具体区别与联系: 一、定义与触发条件 时间属性定义触发条件示例A…...

k8s之LoadBalancer Service 解析
Kubernetes LoadBalancer Service 解析:IP与端口详解 服务类型与IP解析 Service 是 Kubernetes 中的资源类型,用来将一组 Pod 的应用作为网络服务公开。每个 Pod 都有自己的 IP,但是这个 IP 的生命周期与 Pod 生命周期一致,也就…...

Vue3项目使用ElDrawer后select方法不生效
Vue3 项目中 ElDrawer 内 ElSelect 下拉框 z-index 失效问题分析与解决方案 问题描述问题分析解决方案结论 问题描述 在 Vue3 项目中使用 Element Plus 的 ElDrawer 组件时,当在抽屉内部使用 ElSelect 组件,发现下拉选择框(dropdownÿ…...
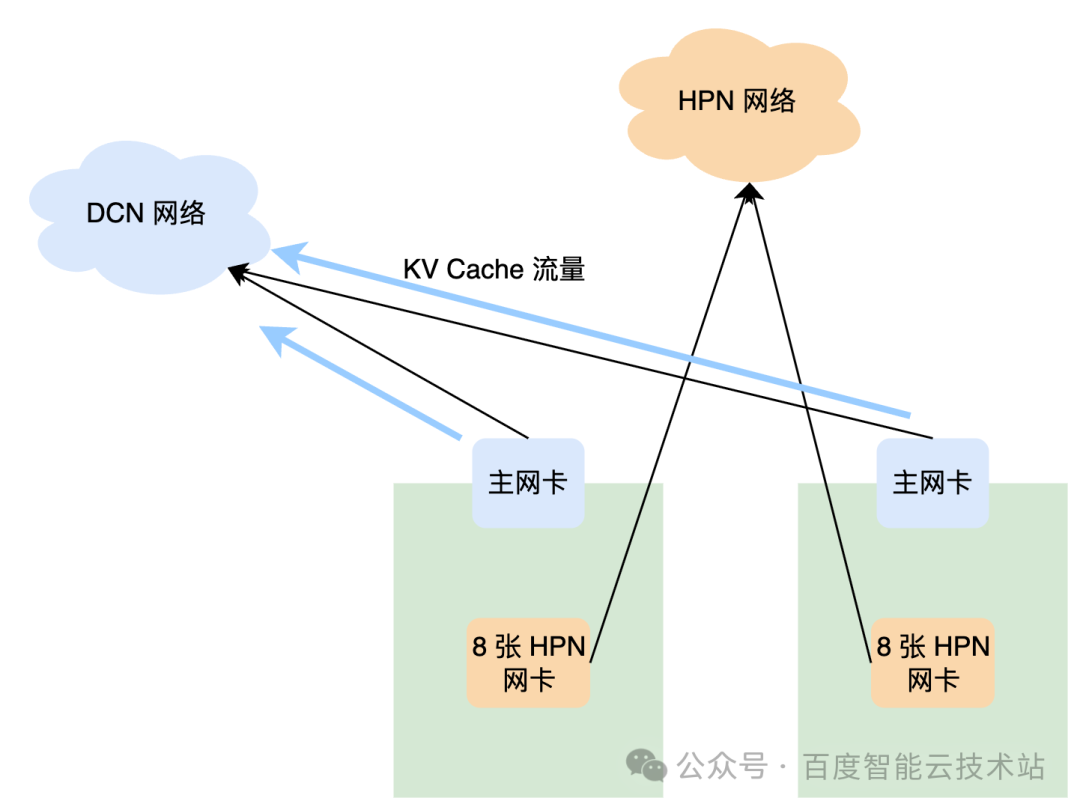
PD 分离推理的加速大招,百度智能云网络基础设施和通信组件的优化实践
为了适应 PD 分离式推理部署架构,百度智能云从物理网络层面的「4us 端到端低时延」HPN 集群建设,到网络流量层面的设备配置和管理,再到通信组件和算子层面的优化,显著提升了上层推理服务的整体性能。 百度智能云在大规模 PD 分离…...
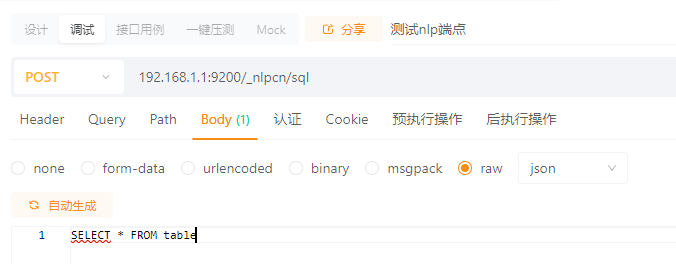
官方 Elasticsearch SQL NLPChina Elasticsearch SQL
官方的可以在kibana 控制台上进行查询: POST /_sql { “query”: “SELECT client_ip, status FROM logs-2024-05 WHERE status 500” } NLPChina Elasticsearch SQL就无法以在kibana 控制台上进行查询,但是可以使用postman接口进行查询:...
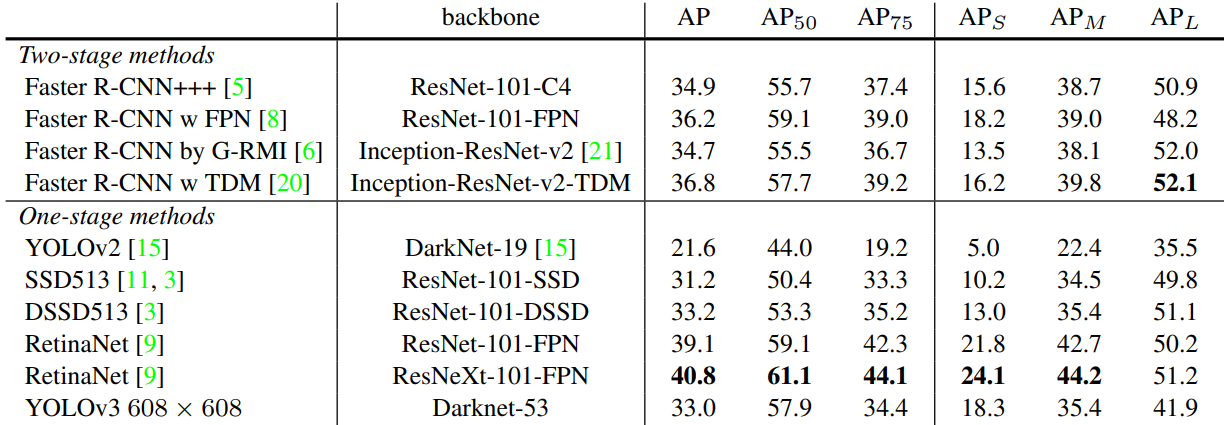
5月16日复盘-目标检测开端
5月16日复盘 一、图像处理之目标检测 1. 目标检测认知 Object Detection,是指在给定的图像或视频中检测出目标物体在图像中的位置和大小,并进行分类或识别等相关任务。 目标检测将目标的分割和识别合二为一。 What、Where 2. 使用场景 目标检测用于…...

读取toml, 合并,生成新文件
依次读取三个TOML文件并合并,后续文件覆盖之前的值,最终将结果写入新文件 import toml def deep_update(base_dict, update_dict): """ 递归合并字典,后续字典的值覆盖前者[6] """ for key, …...

mathematics-2024《Graph Convolutional Network for Image Restoration: A Survey》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...
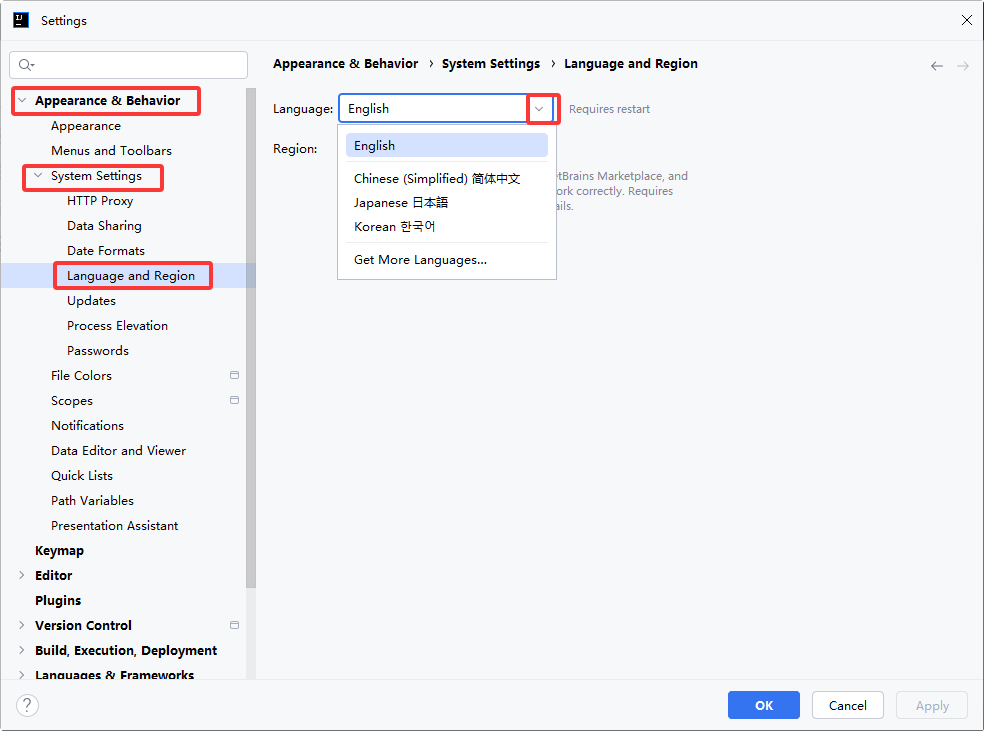
IDEA怎么汉化idea中文改回英文版
第一步:点击左上角的File,然后选择Setting 第二步:Setting页面选择 Appearance & Behavior,然后展开System Settings,然后选择 Language and Region,进行修改 我操作的是2024年的版本 File->Settings -> Ap…...

Android minSdk从21升级24后SO库异常
问题 minSdk从21调整到24后: java.nio.file.NoSuchFileException: /data/app/~~Z9s2NfuDdclOUwUBLKnk0A/com.rs.unity- Bg31QvFwF4qsCwv2XCqT-w/split_config.arm64_v8a.apkjava.nio.file.NoSuchFileException: /data/app/~~Z9s2NfuDdclOUwUBLKnk0A/com.rs.unity-…...
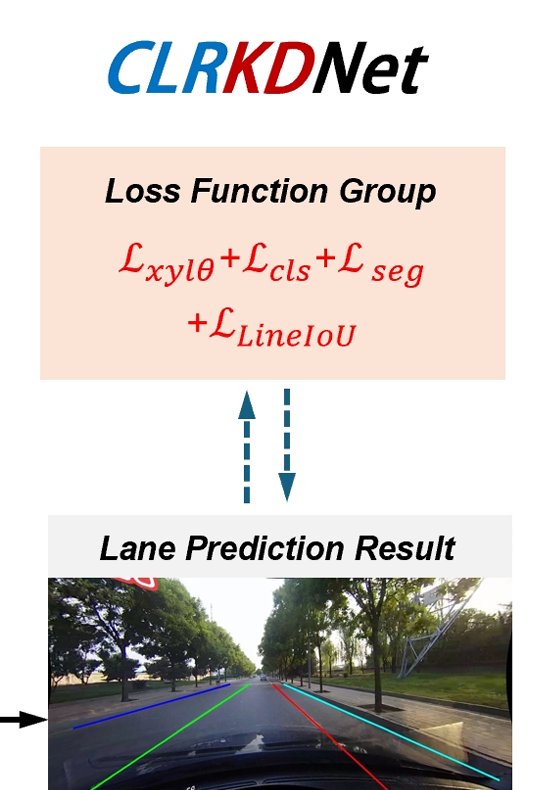
车道线检测----CLRKDNet
今天的最后一篇 车道线检测系列结束 CLRKDNet:通过知识蒸馏加速车道检测 摘要:道路车道是智能车辆视觉感知系统的重要组成部分,在安全导航中发挥着关键作用。在车道检测任务中,平衡精度与实时性能至关重要,但现有方法…...
从技术视角解构 Solana Meme 币生态
在高吞吐、高并发的 Solana 网络上,一类轻量化、高热度的代币形式正在爆发式增长——Meme Token(迷因代币)。尽管起源于社群文化,但其技术实现并非“玩笑”,而是一整套构建于 Solana Runtime 与 Token Extensions 之上…...

智能接处警系统:以秒级联动响应重塑应急处置效能
随着我国能源、化工、航空等关键行业的快速发展,传统消防管理模式已难以满足高效应急响应的需求。国家能源局、应急管理部、民航总局均出台专项规定,对消防站建设提出更高要求,在此背景下,智能接处警系统正是应对这些挑战的核…...

OpenCV直方图与直方图均衡化
一、图像直方图基础 1. 什么是图像直方图? 图像直方图是图像处理中最基本且重要的统计工具之一,它用图形化的方式表示图像中像素强度的分布情况。对于数字图像,直方图描述了每个可能的像素强度值(0-255)在图像中出现…...

7-15 计算圆周率
π131352!3573!⋯357⋯(2n1)n!⋯ 输入格式: 输入在一行中给出小于1的阈值。 输出格式: 在一行中输出满足阈值条件的近似圆周率,输出到小数点后6位。 输入样例: 0.01输出样例: 3.132157 我的代码 #i…...

Mosaic数据增强技术
Mosaic 数据增强技术是一种在计算机视觉领域广泛应用的数据增强方法。下面是Mosaic 数据增强技术原理的详细介绍 一、原理 Mosaic 数据增强是将多张图像(通常是 4 张)按照一定的规则拼接在一起,形成一张新的图像。在拼接过程中,会…...

GpuGeek 网络加速:破解 AI 开发中的 “最后一公里” 瓶颈
摘要: 网络延迟在AI开发中常被忽视,却严重影响效率。GpuGeek通过技术创新,提供学术资源访问和跨国数据交互的加速服务,助力开发者突破瓶颈。 目录 一、引言:当算力不再稀缺,网络瓶颈如何破局? …...

Sigmoid与Softmax:从二分类到多分类的深度解析
Sigmoid与Softmax:从二分类到多分类的深度解析 联系 函数性质:二者都是非线性函数 ,也都是指数归一化函数,可将输入值映射为0到1之间的实数 ,都能把输出转化成概率分布的形式,在神经网络中常作为激活函数使用。Softmax是Sigmoid的推广:从功能角度看,Softmax函数可视为…...

容器编排利器-k8s入门指南
Kubernetes(K8s)入门指南:容器编排利器 什么是 Kubernetes? Kubernetes(常简称为K8s)是一个开源的容器编排平台,由 Google 开源并交由云原生计算基金会(CNCF)管理。它可以帮助我们自动化部署、扩展和管理容器化应用程序。 为什么需要 Kubernetes? 在微服务架构盛行的今…...
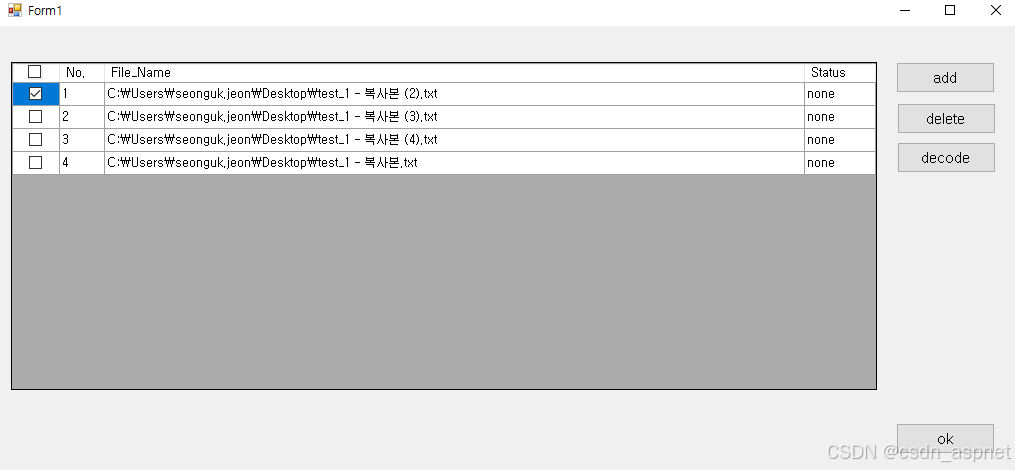
C# DataGridView 选中所有复选框
问题描述 在程序中尝试选中所有复选框,但出现错误。如果单击顶部的完整选中/释放复选框,同时选中包含复选框的列,则选定区域不会改变。该如何解决? 上面的图片是点击完整版本之后的。 下面是本文的测试代码,函数 dat…...

C#学习第23天:面向对象设计模式
什么是设计模式? 定义:设计模式是软件开发中反复出现的特定问题的解决方案。它们提供了问题的抽象描述和解决方案。目的:通过提供成熟的解决方案,设计模式可以加快开发速度并提高代码质量。 常见的设计模式 设计模式通常分为三大…...