[强化学习的数学原理—赵世钰老师]学习笔记02-贝尔曼方程
本文章为西湖大学赵世钰老师《强化学习数学原理》中文版第2章 贝尔曼方程的学习笔记,在书中内容的基础上增加了自己的一些理解内容和相关补充内容。
2.1 启发示例1:为什么回报很重要?
核心概念: 状态值,作为一个评价策略好坏的指标
核心工具: 贝尔曼方程,描述了所有状态值之间的关系。
通过求解贝尔曼方程,得到状态值,进而可以评价一个策略的好坏。
回顾: 回报可以评价一个策略的好坏。
通过如图2.1所示三个在状态 s 1 s_1 s1策略不同,其他状态策略相同的例子来说明回报的重要性,并分析三个不同策略的好坏。

直接观察结果:
- 左侧策略,从状态 s 1 s_1 s1出发不会进入禁止区域,回报最大,策略最好。
- 中间策略,从状态 s 1 s_1 s1出发一定会进入禁止区域,回报最小,策略最坏。
- 右侧策略,从状态 s 1 s_1 s1出发有0.5的概率进入禁止区域,回报一般,策略不好也不坏。
数学计算结果:
- 左侧策略,轨迹为 s 1 → s 3 → s 4 → s 4 ⋯ s_1\rightarrow s_3\rightarrow s_4\rightarrow s_4 \cdots s1→s3→s4→s4⋯,计算对应折扣回报为
r e t u r n 1 = 0 + γ 1 + γ 2 1 + ⋯ = γ ( 1 + γ + γ 2 + ⋯ ) = γ 1 − γ (1) \begin{align}\mathrm{return}_{1}&=0+\gamma1+\gamma^21+\cdots\\ &=\gamma(1+\gamma+\gamma^2+\cdots)\\&=\frac{\gamma}{1-\gamma}\end{align}\tag{1} return1=0+γ1+γ21+⋯=γ(1+γ+γ2+⋯)=1−γγ(1) - 中间策略,轨迹为 s 1 → s 2 → s 4 → s 4 ⋯ s_1\rightarrow s_2\rightarrow s_4\rightarrow s_4 \cdots s1→s2→s4→s4⋯,计算对应折扣回报为
r e t u r n 2 = − 1 + γ 1 + γ 2 1 + ⋯ = − 1 + γ ( 1 + γ + γ 2 + ⋯ ) = − 1 + γ 1 − γ (2) \begin{align}\mathrm{return}_{2}&=-1+\gamma1+\gamma^21+\cdots\\ &=-1+\gamma(1+\gamma+\gamma^2+\cdots)\\&=-1+\frac{\gamma}{1-\gamma}\end{align}\tag{2} return2=−1+γ1+γ21+⋯=−1+γ(1+γ+γ2+⋯)=−1+1−γγ(2) - 右侧策略,得到两条轨迹,分别为 s 1 → s 2 → s 4 → s 4 ⋯ s_1\rightarrow s_2\rightarrow s_4\rightarrow s_4 \cdots s1→s2→s4→s4⋯ 和 s 1 → s 3 → s 4 → s 4 ⋯ s_1\rightarrow s_3\rightarrow s_4\rightarrow s_4 \cdots s1→s3→s4→s4⋯。两条轨迹各有0.5概率发生,其对应的折扣回报分别为 r e t u r n 1 \mathrm{return}_{1} return1和 r e t u r n 2 \mathrm{return}_{2} return2,则平均回报计算为
r e t u r n 3 = 0.5 ( γ 1 − γ ) + 0.5 ( − 1 + γ 1 − γ ) = − 0.5 + γ 1 − γ (3) \begin{align}\mathrm{return}_{3}&=0.5(\frac{\gamma}{1-\gamma})+0.5(-1+\frac{\gamma}{1-\gamma})\\ &=-0.5+\frac{\gamma}{1-\gamma}\end{align}\tag{3} return3=0.5(1−γγ)+0.5(−1+1−γγ)=−0.5+1−γγ(3)
结论:根据式(1),(2)和(3)的计算结果可知
r e t u r n 1 > r e t u r n 3 > r e t u r n 2 (4) \begin{align}\mathrm{return}_{1}>\mathrm{return}_{3}>\mathrm{return}_{2}\end{align}\tag{4} return1>return3>return2(4)
数学计算折扣回报得到的结果和直接观察得到的结果是一致的。
注:例子得出的结论:回报可以评价一个策略的好坏。但是需要注意的是,回报的定义针对的是一条轨迹,但是 r e t u r n 3 \mathrm{return}_{3} return3为两条轨迹折扣回报的平均值,这其实就是后续要介绍的状态值。
2.2 启发示例2:如何计算回报?
- 定义法:回报定义为沿轨迹收集的所有奖励的折扣总和。如图2.2所示,忽略禁止区域和目标区域,给出一个简单的例子来计算回报。

定义 v i v_{i} vi为从状态 s i s_{i} si出发得到的回报, i = 1 , 2 , 3 , 4 i=1,2,3,4 i=1,2,3,4,则对应状态出发得到的折扣回报为
v 1 = r 1 + γ r 2 + γ 2 r 3 + γ 3 r 4 + ⋯ v 2 = r 2 + γ r 3 + γ 2 r 4 + γ 3 r 1 + ⋯ v 3 = r 3 + γ r 4 + γ 2 r 1 + γ 3 r 2 + ⋯ v 4 = r 4 + γ r 1 + γ 2 r 2 + γ 3 r 3 + ⋯ (5) \begin{align}v_{1}&=r_1+\gamma r_2+\gamma^2 r_3+\gamma^3 r_4+\cdots\\ v_{2}&=r_2+\gamma r_3+\gamma^2 r_4+\gamma^3 r_1+\cdots\\ v_{3}&=r_3+\gamma r_4+\gamma^2 r_1+\gamma^3 r_2+\cdots\\ v_{4}&=r_4+\gamma r_1+\gamma^2 r_2+\gamma^3 r_3+\cdots\end{align}\tag{5} v1v2v3v4=r1+γr2+γ2r3+γ3r4+⋯=r2+γr3+γ2r4+γ3r1+⋯=r3+γr4+γ2r1+γ3r2+⋯=r4+γr1+γ2r2+γ3r3+⋯(5)
- 自举法(bootstrapping):观察式(5)中针对每个状态出发获得回报的计算结果,可以改写为
v 1 = r 1 + γ ( r 2 + γ r 3 + γ 2 r 4 + ⋯ ) = r 1 + γ v 2 v 2 = r 2 + γ ( r 3 + γ r 4 + γ 2 r 1 + ⋯ ) = r 2 + γ v 3 v 3 = r 3 + γ ( r 4 + γ r 1 + γ 2 r 2 + ⋯ ) = r 3 + γ v 4 v 4 = r 4 + γ ( r 1 + γ r 2 + γ 2 r 3 + ⋯ ) = r 4 + γ v 1 (6) \begin{align}v_{1}&=r_1+\gamma(r_2+\gamma r_3+\gamma^2 r_4+\cdots)=r_1+\gamma v_{2}\\ v_{2}&=r_2+\gamma(r_3+\gamma r_4+\gamma^2 r_1+\cdots)=r_2+\gamma v_{3}\\ v_{3}&=r_3+\gamma(r_4+\gamma r_1+\gamma^2 r_2+\cdots)=r_3+\gamma v_{4}\\ v_{4}&=r_4+\gamma(r_1+\gamma r_2+\gamma^2 r_3+\cdots)=r_4+\gamma v_{1}\end{align}\tag{6} v1v2v3v4=r1+γ(r2+γr3+γ2r4+⋯)=r1+γv2=r2+γ(r3+γr4+γ2r1+⋯)=r2+γv3=r3+γ(r4+γr1+γ2r2+⋯)=r3+γv4=r4+γ(r1+γr2+γ2r3+⋯)=r4+γv1(6)式(6)的矩阵-向量形式的线性方程为
[ v 1 v 2 v 3 v 4 ] ⏟ v ∈ R 4 = [ r 1 r 2 r 3 r 4 ] + [ γ v 2 γ v 3 γ v 4 γ v 5 ] = [ r 1 r 2 r 3 r 4 ] ⏟ r ∈ R 4 + [ 0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 0 ] ⏟ P ∈ R 4 × 4 [ v 1 v 2 v 3 v 4 ] ⏟ v ∈ R 4 (7) \begin{align}\underbrace{ \begin{bmatrix} v_{1}\\ v_{2}\\ v_{3}\\ v_{4} \end{bmatrix}}_{v\in\mathbb{R}^{4}}= \begin{bmatrix} r_{1}\\ r_{2}\\ r_{3}\\ r_{4} \end{bmatrix}+ \begin{bmatrix} \gamma v_{2}\\ \gamma v_{3}\\ \gamma v_{4}\\ \gamma v_{5} \end{bmatrix}=\underbrace{ \begin{bmatrix} r_{1}\\ r_{2}\\ r_{3}\\ r_{4} \end{bmatrix}}_{r\in\mathbb{R}^{4}}+\underbrace{ \begin{bmatrix} 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 1 & 0 & 0 & 0 \end{bmatrix}}_{P\in\mathbb{R}^{4\times 4}} \underbrace{ \begin{bmatrix} v_{1}\\ v_{2}\\ v_{3}\\ v_{4} \end{bmatrix}}_{v\in\mathbb{R}^{4}} \end{align}\tag{7} v∈R4 v1v2v3v4 = r1r2r3r4 + γv2γv3γv4γv5 =r∈R4 r1r2r3r4 +P∈R4×4 0001100001000010 v∈R4 v1v2v3v4 (7)式(7)的简化形式为
v = r + P v v=r+Pv v=r+Pv总结:由式(5)可知,从不同状态出发的回报值式彼此依赖的,即, v 1 v_{1} v1依赖于 v 2 v_{2} v2, v 2 v_{2} v2依赖于 v 3 v_{3} v3, v 3 v_{3} v3依赖于 v 4 v_{4} v4, v 4 v_{4} v4又依赖于 v 1 v_{1} v1。这也反映了自举的思想,即, v 1 v_{1} v1, v 2 v_{2} v2, v 3 v_{3} v3, v 4 v_{4} v4,可以从其自身 v 2 v_{2} v2, v 3 v_{3} v3, v 4 v_{4} v4, v 1 v_{1} v1得到。
从数学的角度,由式(6)给出的矩阵-向量形式的线性方程为可以很好的理解自举。同时通过线性代数的知识可以很容易得到方程的解为
v = ( I − γ P ) − 1 r v=(I-\gamma P)^{-1}r v=(I−γP)−1r这里, I ∈ R 4 × 4 I\in\mathbb{R}^{4\times 4} I∈R4×4为单位矩阵,且 ( I − γ P ) (I-\gamma P) (I−γP)一定是可逆的,这在后续的学习中将会被证明。、
注:方程(6)即为图2所示例子对应的贝尔曼方程,方程(7)即为这个贝尔曼方程的矩阵-向量形式。
贝尔曼方程的核心思想:从一个状态出发获得的回报依赖于从其他状态出发时获得的回报。
2.3 状态值
注:严格定义下,回报只能用来评价一个确定策略的好坏,对于一般化的随机情况(从一个状态出发得到不同策略和回报的可能性),用回报来评价这种策略的好坏是不适用的。这时候就要引入状态值的概念。
首先给出一个一般化的过程,即,在任意时刻( t = 0 , 1 , 2 , … t=0,1,2,\dots t=0,1,2,…)智能体处于任意状态 S t S_{t} St按照某一策略 π \pi π执行动作 A t A_{t} At,并下一时刻转移到状态 S t + 1 S_{t+1} St+1且获得即时奖励 R t + 1 R_{t+1} Rt+1的过程
S t → A t S t + 1 , R t + 1 (8) S_{t}\rightarrow^{A_{t}}S_{t+1},R_{t+1}\tag{8} St→AtSt+1,Rt+1(8)其中, S t , S t + 1 ∈ S S_{t},S_{t+1}\in\mathcal{S} St,St+1∈S, A t ∈ A ( S t ) A_{t}\in\mathcal{A(S_{t})} At∈A(St), R t + 1 ∈ R ( S t , A t ) R_{t+1}\in\mathcal{R}(S_{t},A_{t}) Rt+1∈R(St,At)。
注: S t S_{t} St, S t + 1 S_{t+1} St+1, A t A_{t} At和 R t + 1 R_{t+1} Rt+1都为随机变量(random variables)。
由式(8)可以得到从 t t t时刻开始的一条包含一系列“状态-动作-奖励”的轨迹
S t → A t S t + 1 , R t + 1 → A t + 1 S t + 2 , R t + 2 → A t + 2 S t + 3 , R t + 3 , … S_{t}\rightarrow^{A_{t}}S_{t+1},R_{t+1}\rightarrow^{A_{t+1}}S_{t+2},R_{t+2}\rightarrow^{A_{t+2}}S_{t+3},R_{t+3},\dots St→AtSt+1,Rt+1→At+1St+2,Rt+2→At+2St+3,Rt+3,…
沿着轨迹计算得到的折扣回报为
G t ≐ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … , γ ∈ ( 0 , 1 ) G_{t}\doteq R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\dots,\;\gamma\in(0,1) Gt≐Rt+1+γRt+2+γ2Rt+3+…,γ∈(0,1)
G t G_{t} Gt由 R t + 1 R_{t+1} Rt+1, R t + 2 R_{t+2} Rt+2, … \dots …这些随机变量的组合得到,同样也为随机变量。
计算随机变量 G t G_{t} Gt的数学期望(expectation/expected value)为
v π ( s ) ≐ E [ G t ∣ S t = s ] v_{\pi}(s)\doteq\mathbb{E}[G_{t}|S_{t}=s] vπ(s)≐E[Gt∣St=s]
这里 v π ( s ) v_{\pi}(s) vπ(s)被定义为状态值函数(state-value function),又简称为状态值或状态价值(state value)。
注:关于状态值的说明。
- 状态值 v π ( s ) v_{\pi}(s) vπ(s)的值依赖于状态 s s s,不同状态下的状态值一般是不同的。状态值的本质是求随机变量 G t G_{t} Gt在条件 S t = s S_{t}=s St=s下的条件期望。
- 状态值 v π ( s ) v_{\pi}(s) vπ(s)的值依赖于策略 π \pi π,不同策略下的状态值一般是不同的。不同的策略会产生不同的轨迹,进而影响状态值。
- 状态值 v π ( s ) v_{\pi}(s) vπ(s)的值不依赖于时间 t t t。所考虑的系统模型是平稳的,不会随时间变化。
“状态值”和“回报”的关系如图2.3所示

总结:状态值所描述的情况比回报描述的情况更一般化,可以处理不确定性和随机性的情况。
状态值可以更一般化的来评价策略,能产生更高状态值的策略更好。
2.4 贝尔曼方程
贝尔曼方程(Bellman equation)描述了所有状态值之间的关系。
贝尔曼方程的推导过程如下:
- 改写 G t G_{t} Gt。
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … = R t + 1 + γ ( R t + 2 + γ R t + 3 + … ) = R t + 1 + γ G t + 1 \begin{align*}G_{t}&= R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\dots\\ &=R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\dots)\\ &=R_{t+1}+\gamma G_{t+1}\end{align*} Gt=Rt+1+γRt+2+γ2Rt+3+…=Rt+1+γ(Rt+2+γRt+3+…)=Rt+1+γGt+1 - 基于步骤1中建立的 G t G_{t} Gt和 G t + 1 G_{t+1} Gt+1之间的关系,状态值 v π ( s ) v_{\pi}(s) vπ(s)可以改写为
v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + E [ γ G t + 1 ∣ S t = s ] (9) \begin{align}v_{\pi}(s)&=\mathbb{E}[G_{t}|S_{t}=s]\\ &=\mathbb{E}[R_{t+1}+\gamma G_{t+1}|S_{t}=s]\\ &=\mathbb{E}[R_{t+1}|S_{t}=s]+\mathbb{E}[\gamma G_{t+1}|S_{t}=s]\end{align}\tag{9} vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+E[γGt+1∣St=s](9) - 分析式(9)中的两个数学期望项
- 即时奖励期望值 E [ R t + 1 ∣ S t = s ] \mathbb{E}[R_{t+1}|S_{t}=s] E[Rt+1∣St=s]
这一项可以通过全期望(total expectation) 的性质来进行改写,首先给出改写结果,然后给出具体的推导过程
E [ R t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r (10) \begin{align} \mathbb{E}[R_{t+1}|S_{t}=s]&=\sum_{a\in\mathcal{A}}\pi(a|s)\mathbb{E}[R_{t+1}|S_{t}=s,A_{t}=a]\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r \end{align}\tag{10} E[Rt+1∣St=s]=a∈A∑π(a∣s)E[Rt+1∣St=s,At=a]=a∈A∑π(a∣s)r∈R∑p(r∣s,a)r(10)
式(10)的推导过程如下:
首先基于链式规则(chain rule) 和条件概率公式可以得到
p ( a , b ) = p ( a ∣ b ) p ( b ) p ( a , b , c ) = p ( a ∣ b , c ) p ( b , c ) = p ( a ∣ b , c ) p ( b ∣ c ) p ( c ) \begin{align*}p(a,b)&=p(a|b)p(b)\\ p(a,b,c)&=p(a|b,c)p(b,c)\\&=p(a|b,c)p(b|c)p(c)\end{align*} p(a,b)p(a,b,c)=p(a∣b)p(b)=p(a∣b,c)p(b,c)=p(a∣b,c)p(b∣c)p(c)
由于 p ( a , b , c ) = p ( a , b ∣ c ) p ( c ) p(a,b,c)=p(a,b|c)p(c) p(a,b,c)=p(a,b∣c)p(c),所以 p ( a , b , c ) / p ( c ) = p ( a , b ∣ c ) = p ( a ∣ b , c ) p ( b ∣ c ) p(a,b,c)/p(c)=p(a,b|c)=p(a|b,c)p(b|c) p(a,b,c)/p(c)=p(a,b∣c)=p(a∣b,c)p(b∣c)
然后可以进一步推导出以下关系
p ( x ∣ a ) = ∑ b p ( x , b ∣ a ) = ∑ b p ( x ∣ b , a ) p ( b ∣ a ) p(x|a)=\sum_{b}p(x,b|a)=\sum_{b}p(x|b,a)p(b|a) p(x∣a)=b∑p(x,b∣a)=b∑p(x∣b,a)p(b∣a)
其次给出期望(expectation) 和条件期望(conditional expectation) 的定义,并基于此推导出全期望公式(formula of total expectation)。
(1)期望(expectation):随机变量 X X X取值 x x x的概率为 p ( x ) p(x) p(x), X X X的期望值定义为 E [ X ] = ∑ x x p ( x ) \mathbb{E}[X]=\sum_{x}xp(x) E[X]=x∑xp(x)
(2)条件期望(conditional expectation):
E [ X ∣ A = a ] = ∑ x x p ( x ∣ a ) \mathbb{E}[X|A=a]=\sum_{x}xp(x|a) E[X∣A=a]=x∑xp(x∣a)
(3)全期望公式(formula of total expectation):
E [ X ] = ∑ a E [ X ∣ A = a ] p ( a ) \mathbb{E}[X]=\sum_{a}\mathbb{E}[X|A=a]p(a) E[X]=a∑E[X∣A=a]p(a)
全期望公式的证明如下: ∑ a E [ X ∣ A = a ] p ( a ) = ∑ a ∑ x x p ( x ∣ a ) p ( a ) → 由条件期望定义得到 = ∑ x [ ∑ a p ( x ∣ a ) p ( a ) ] x = ∑ x p ( x ) x → 由全概率公式定义得到 = E [ X ] → 由期望值定义得到 \begin{align*}\sum_{a}\mathbb{E}[X|A=a]p(a)&=\sum_{a}\sum_{x}xp(x|a)p(a)\;\rightarrow 由条件期望定义得到\\ &=\sum_{x}\bigg[\sum_{a}p(x|a)p(a)\bigg]x\\ &=\sum_{x}p(x)x\;\rightarrow 由全概率公式定义得到\\ &=\mathbb{E}[X]\;\rightarrow 由期望值定义得到\end{align*} a∑E[X∣A=a]p(a)=a∑x∑xp(x∣a)p(a)→由条件期望定义得到=x∑[a∑p(x∣a)p(a)]x=x∑p(x)x→由全概率公式定义得到=E[X]→由期望值定义得到
然后,给出条件期望的另一种数学表示形式
E [ X ∣ A = a ] = ∑ b E [ X ∣ A = a , B = b ] p ( b ∣ a ) \mathbb{E}[X|A=a]=\sum_{b}\mathbb{E}[X|A=a,B=b]p(b|a) E[X∣A=a]=b∑E[X∣A=a,B=b]p(b∣a)
证明如下: ∑ b E [ X ∣ A = a , B = b ] p ( b ∣ a ) = ∑ b [ ∑ x x p ( x ∣ a , b ) ] p ( b ∣ a ) → 由条件期望定义得到 = ∑ b ∑ x [ p ( x ∣ a , b ) p ( b ∣ a ) x = ∑ x [ ∑ b p ( x ∣ a , b ) p ( b ∣ a ) ] x = ∑ x ∑ b p ( x , b ∣ a ) x → 由链式规则的推广得到 = ∑ x p ( x ∣ a ) x = E [ X ∣ A = a ] → 由期望值定义得到 \begin{align*}\sum_{b}\mathbb{E}[X|A=a,B=b]p(b|a)&=\sum_{b }\bigg[\sum_{x}xp(x|a,b)\bigg]p(b|a)\;\rightarrow 由条件期望定义得到\\ &=\sum_{b}\sum_{x}[p(x|a,b)p(b|a)x\\ &=\sum_{x}\bigg[\sum_{b}p(x|a,b)p(b|a)\bigg]x\\ &=\sum_{x}\sum_{b}p(x,b|a)x\;\rightarrow 由链式规则的推广得到\\ &=\sum_{x}p(x|a)x\\ &=\mathbb{E}[X|A=a]\;\rightarrow 由期望值定义得到\end{align*} b∑E[X∣A=a,B=b]p(b∣a)=b∑[x∑xp(x∣a,b)]p(b∣a)→由条件期望定义得到=b∑x∑[p(x∣a,b)p(b∣a)x=x∑[b∑p(x∣a,b)p(b∣a)]x=x∑b∑p(x,b∣a)x→由链式规则的推广得到=x∑p(x∣a)x=E[X∣A=a]→由期望值定义得到
因此,利用上述等式,我们可以得到即时奖励期望值 E [ R t + 1 ∣ S t = s ] \mathbb{E}[R_{t+1}|S_{t}=s] E[Rt+1∣St=s]的改写结果式(10),即 E [ R t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r \begin{align*} \mathbb{E}[R_{t+1}|S_{t}=s]&=\sum_{a\in\mathcal{A}}\pi(a|s)\mathbb{E}[R_{t+1}|S_{t}=s,A_{t}=a]\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r \end{align*} E[Rt+1∣St=s]=a∈A∑π(a∣s)E[Rt+1∣St=s,At=a]=a∈A∑π(a∣s)r∈R∑p(r∣s,a)r推导结束。
- 未来奖励期望值 E [ G t + 1 ∣ S t = s ] \mathbb{E}[G_{t+1}|S_{t}=s] E[Gt+1∣St=s]
这一项可以基于马尔可夫性质改写为如下形式
E [ G t + 1 ∣ S t = s ] = ∑ s ′ ∈ S E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ∣ p ( s ′ ∣ s ) ] = ∑ s ′ ∈ S E [ G t + 1 ∣ S t + 1 = s ′ ∣ p ( s ′ ∣ s ) ] → 由马尔可夫性质得到 = ∑ s ′ ∈ S v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ ∈ S v π ( s ′ ) ∑ a ∈ A p ( s ′ ∣ s , a ) π ( a ∣ s ) → 由链式规则的推广得到 (11) \begin{align}\mathbb{E}[G_{t+1}|S_{t}=s]&=\sum_{s'\in\mathcal{S}}\mathbb{E}[G_{t+1}|S_{t}=s,S_{t+1}=s'|p(s'|s)]\\&=\sum_{s'\in\mathcal{S}}\mathbb{E}[G_{t+1}|S_{t+1}=s'|p(s'|s)]\;\rightarrow 由马尔可夫性质得到\\ &=\sum_{s'\in\mathcal{S}}v_{\pi}(s')p(s'|s)\\ &=\sum_{s'\in\mathcal{S}}v_{\pi}(s')\sum_{a\in\mathcal{A}}p(s'|s,a)\pi(a|s)\;\rightarrow 由链式规则的推广得到\end{align}\tag{11} E[Gt+1∣St=s]=s′∈S∑E[Gt+1∣St=s,St+1=s′∣p(s′∣s)]=s′∈S∑E[Gt+1∣St+1=s′∣p(s′∣s)]→由马尔可夫性质得到=s′∈S∑vπ(s′)p(s′∣s)=s′∈S∑vπ(s′)a∈A∑p(s′∣s,a)π(a∣s)→由链式规则的推广得到(11)
马尔可夫性质: E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] = E [ G t + 1 ∣ S t = s ] \mathbb{E}[G_{t+1}|S_{t}=s,S_{t+1}=s']=\mathbb{E}[G_{t+1}|S_{t}=s] E[Gt+1∣St=s,St+1=s′]=E[Gt+1∣St=s],即未来的奖励仅依赖于当前状态,与先前的状态无关,即无记忆性。
将式(10)和式(11)带入式(9),即可得到贝尔曼方程
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S v π ( s ′ ) ∑ a ∈ A p ( s ′ ∣ s , a ) π ( a ∣ s ) = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] , s ∈ S (12) \begin{align}v_{\pi}(s)&=\mathbb{E}[R_{t+1}|S_{t}=s]+\gamma\mathbb{E}[G_{t+1}|S_{t}=s]\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}v_{\pi}(s')\sum_{a\in\mathcal{A}}p(s'|s,a)\pi(a|s)\\&=\sum_{a\in\mathcal{A}}\pi(a|s)\bigg[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s')\bigg]\;,s\in\mathcal{S}\end{align}\tag{12} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=a∈A∑π(a∣s)r∈R∑p(r∣s,a)r+γs′∈S∑vπ(s′)a∈A∑p(s′∣s,a)π(a∣s)=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′)],s∈S(12)
贝尔曼方程的解释说明:
- v π ( s ) v_{\pi}(s) vπ(s)和 v π ( s ′ ) v_{\pi}(s') vπ(s′)都是需要计算的状态值,是未知量。
- π ( a ∣ s ) \pi(a|s) π(a∣s)是一个给定的策略,是已知量。
- p ( r ∣ s , a ) p(r|s,a) p(r∣s,a)和 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)代表系统模型,可以是已知的也可以是未知的。
贝尔曼方程的常见等价形式:
- 等价形式1的表达式如下所示
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] v_{\pi}(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}}p(s',r|s,a)[r+\gamma v_{\pi}(s')] vπ(s)=a∈A∑π(a∣s)s′∈S∑r∈R∑p(s′,r∣s,a)[r+γvπ(s′)]
推导过程如下
首先给出两个与状态 s s s, s ′ s' s′,动作 a a a和奖励 r r r有关的全概率公式 p ( s ′ ∣ s , a ) = ∑ r ∈ R p ( s ′ , r ∣ s , a ) p ( r ∣ , s , a ) = ∑ s ′ ∈ S p ( s ′ , r ∣ s , a ) \begin{align*}p(s'|s,a)&=\sum_{r\in\mathcal{R}}p(s',r|s,a)\\ p(r|,s,a)&=\sum_{s'\in\mathcal{S}}p(s',r|s,a)\end{align*} p(s′∣s,a)p(r∣,s,a)=r∈R∑p(s′,r∣s,a)=s′∈S∑p(s′,r∣s,a)将上述两个全概率公式代入(12),可以得到 v π ( s ) = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] = ∑ a ∈ A π ( a ∣ s ) [ ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) r + ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) v π ( s ′ ) ] = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] \begin{align*}v_{\pi}(s)&=\sum_{a\in\mathcal{A}}\pi(a|s)\bigg[\sum_{r\in\mathcal{R}}p(r|s,a)r+\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s')\bigg]\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\bigg[\sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}}p(s',r|s,a)r+\sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}}p(s',r|s,a)v_{\pi}(s')\bigg]\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}}p(s',r|s,a)[r+\gamma v_{\pi}(s')]\end{align*} vπ(s)=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+s′∈S∑p(s′∣s,a)vπ(s′)]=a∈A∑π(a∣s)[s′∈S∑r∈R∑p(s′,r∣s,a)r+s′∈S∑r∈R∑p(s′,r∣s,a)vπ(s′)]=a∈A∑π(a∣s)s′∈S∑r∈R∑p(s′,r∣s,a)[r+γvπ(s′)]推导结束。
- 等价形式2为贝尔曼期望方程(bellman expectation equation):
v π ( s ) = E [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] , s ∈ S v_{\pi}(s)=\mathbb{E}[R_{t+1}+\gamma v_{\pi}(S_{t+1})|S_{t}=s],\;s\in\mathcal{S} vπ(s)=E[Rt+1+γvπ(St+1)∣St=s],s∈S
推导过程如下
由式(11)可知
E [ G t + 1 ∣ S t = s ] = ∑ s ′ ∈ S v π ( s ′ ) ∑ a ∈ A p ( s ′ ∣ s , a ) π ( a ∣ s ) = E [ v π ( S t + 1 ) ∣ S t = s ] \begin{align*}\mathbb{E}[G_{t+1}|S_{t}=s]&=\sum_{s'\in\mathcal{S}}v_{\pi}(s')\sum_{a\in\mathcal{A}}p(s'|s,a)\pi(a|s)\\&=\mathbb{E}[v_{\pi}(S_{t+1})|S_{t}=s]\end{align*} E[Gt+1∣St=s]=s′∈S∑vπ(s′)a∈A∑p(s′∣s,a)π(a∣s)=E[vπ(St+1)∣St=s] 将上述等式带入式(9)即可得到贝尔曼期望方程。
- 等价形式3的表达式如下所示
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S p ( s ′ ∣ s , a ) [ r ( s ′ ) + γ v π ( s ′ ) ] v_{\pi}(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}p(s'|s,a)[r(s')+\gamma v_{\pi}(s')] vπ(s)=a∈A∑π(a∣s)s′∈S∑p(s′∣s,a)[r(s′)+γvπ(s′)]
推导过程如下
在一些特殊问题中,奖励 r r r可能仅依赖于下一个状态 s ′ s' s′,这时候奖励可以表示为 r ( s ′ ) r(s') r(s′)。这时候以下等式成立
p ( r ( s ′ ) ∣ s , a ) = p ( s ′ ∣ s , a ) ∑ r ∈ R p ( r ∣ s , a ) r = ∑ s ′ ∈ S p ( r ( s ′ ) ∣ s , a ) r ( s ′ ) \begin{align*}p(r(s')|s,a)&=p(s'|s,a)\\\sum_{r\in\mathcal{R}}p(r|s,a)r&=\sum_{s'\in\mathcal{S}}p(r(s')|s,a)r(s')\end{align*} p(r(s′)∣s,a)r∈R∑p(r∣s,a)r=p(s′∣s,a)=s′∈S∑p(r(s′)∣s,a)r(s′)将上述等式带入式(12)可得到等价形式3。
2.5 示例
2.6 矩阵-向量形式
2.7 求解状态值
2.7.1 方法1:解析解
2.7.2 方法2:数值解
2.7.3 示例
2.8 动作值
2.8.1 示例
2.8.2 基于动作值的贝尔曼方程
相关文章:
[强化学习的数学原理—赵世钰老师]学习笔记02-贝尔曼方程
本人为强化学习小白,为了在后续科研的过程中能够较好的结合强化学习来做相关研究,特意买了西湖大学赵世钰老师撰写的《强化学习数学原理》中文版这本书,并结合赵老师的讲解视频来学习和更深刻的理解强化学习相关概念,知识和算法技…...

使用Spring Boot与Spring Security构建安全的RESTful API
使用Spring Boot与Spring Security构建安全的RESTful API 引言 在现代Web应用开发中,安全性是不可忽视的重要环节。Spring Boot和Spring Security作为Java生态中的主流框架,为开发者提供了强大的工具来构建安全的RESTful API。本文将详细介绍如何结合S…...

深入理解构造函数,析构函数
目录 1.引言 2.构造函数 1.概念 2.特性 3.析构函数 1.概念 2.特性 1.引言 如果一个类中什么都没有,叫作空类. class A {}; 那么我们这个类中真的是什么都没有吗?其实不是,如果我们类当中上面都不写.编译器会生成6个默认的成员函数。 默认成员函数:用户没有显…...
Day 16
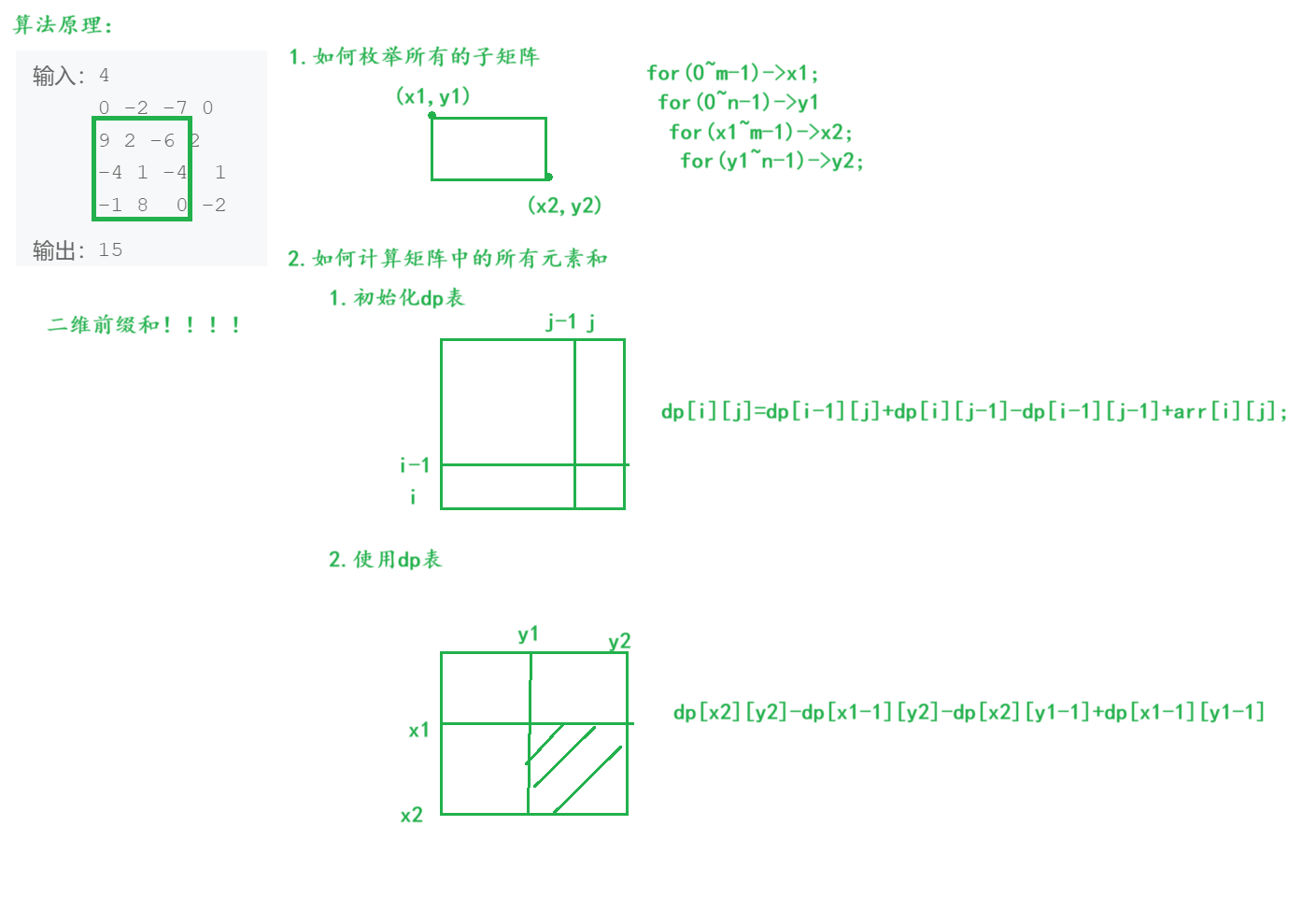
目录 1.JZ79 判断是不是平衡二叉树1.1 解析1.2 代码 2.DP10 最大子矩阵2.1 解析2.2 代码 1.JZ79 判断是不是平衡二叉树 JZ79 判断是不是平衡二叉树 dfs 1.1 解析 1.2 代码 /*** struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* TreeNode(in…...

摄影构图小节
1、三分构图法 三分构图法即将画面横竖各分为三份,即九宫格形式。 将画面用两条竖线和两条横线分割,就如同是书写中文的【井】字。这样就可以得到4个交叉点,然后再将需要表现的重点放置在4个交叉点中的一个附近即可。 拍摄自然风光时…...
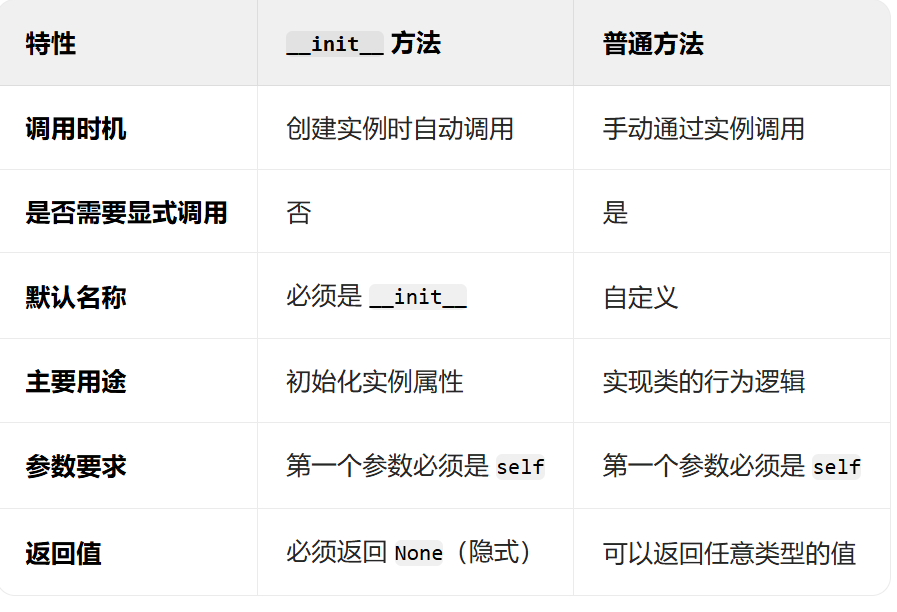
DAY 28 类的定义和方法
知识点回顾: 类的定义pass占位语句类的初始化方法类的普通方法类的继承:属性的继承、方法的继承 比如def、class这些定义的关键词后,必须有一个有占据缩进位置的代码块。 还有下面这些依赖缩进的语句,都可以用pass语句来占位 x 1…...
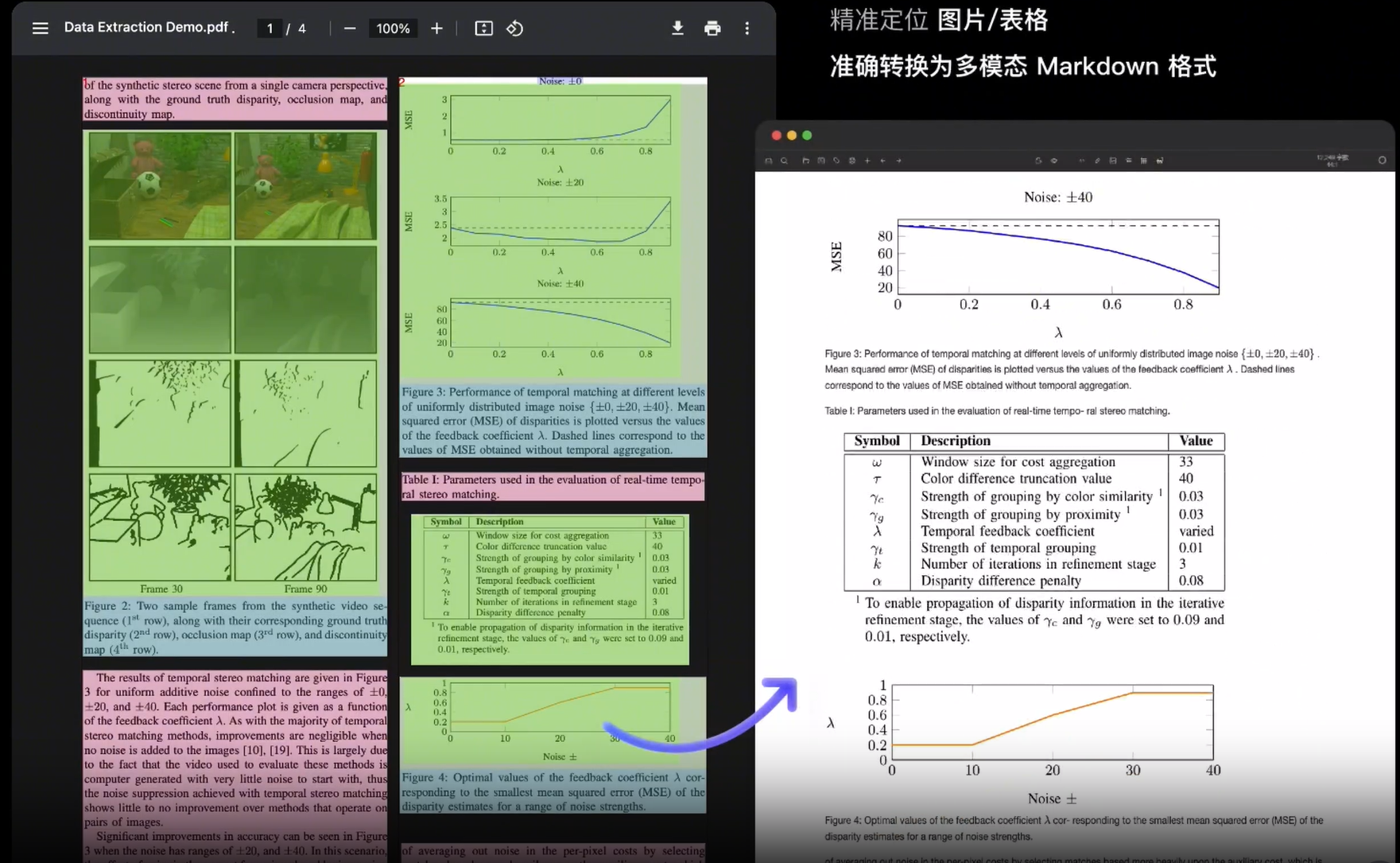
RAG数据处理:PDF/HTML
RAG而言用户输入的数据通常是各种各样文档,本文主要采用langchain实现PDF/HTML文档的处理方法 PDF文档解析 PDF文档很常见格式,但内部结构常常较复杂: 复杂的版式布局多样的元素(段落、表格、公式、图片等)文本流无…...

机器学习 day04
文章目录 前言一、线性回归的基本概念二、损失函数三、最小二乘法 前言 通过今天的学习,我掌握了机器学习中的线性回归的相关基本概念,包括损失函数的概念,最小二乘法的理论与算法实现。 一、线性回归的基本概念 要理解什么是线性回归&…...

蓝牙耳机什么牌子好?倍思值得冲不?
最近总被问“蓝牙耳机什么牌子好”,作为踩过无数坑的资深耳机党,必须安利刚入手的倍思M2s Pro主动降噪蓝牙耳机!降噪、音质、颜值全都在线,性价比直接拉满。 -52dB降噪,通勤摸鱼神器 第一次开降噪就被惊到!…...

机器学习-人与机器生数据的区分模型测试-数据处理 - 续
这里继续 机器学习-人与机器生数据的区分模型测试-数据处理1的内容 查看数据 中1的情况 #查看数据1的分布情况 one_ratio_list [] for col in data.columns:if col city or col target or col city2: # 跳过第一列continueelse:one_ratio data[col].mean() # 计算1值占…...
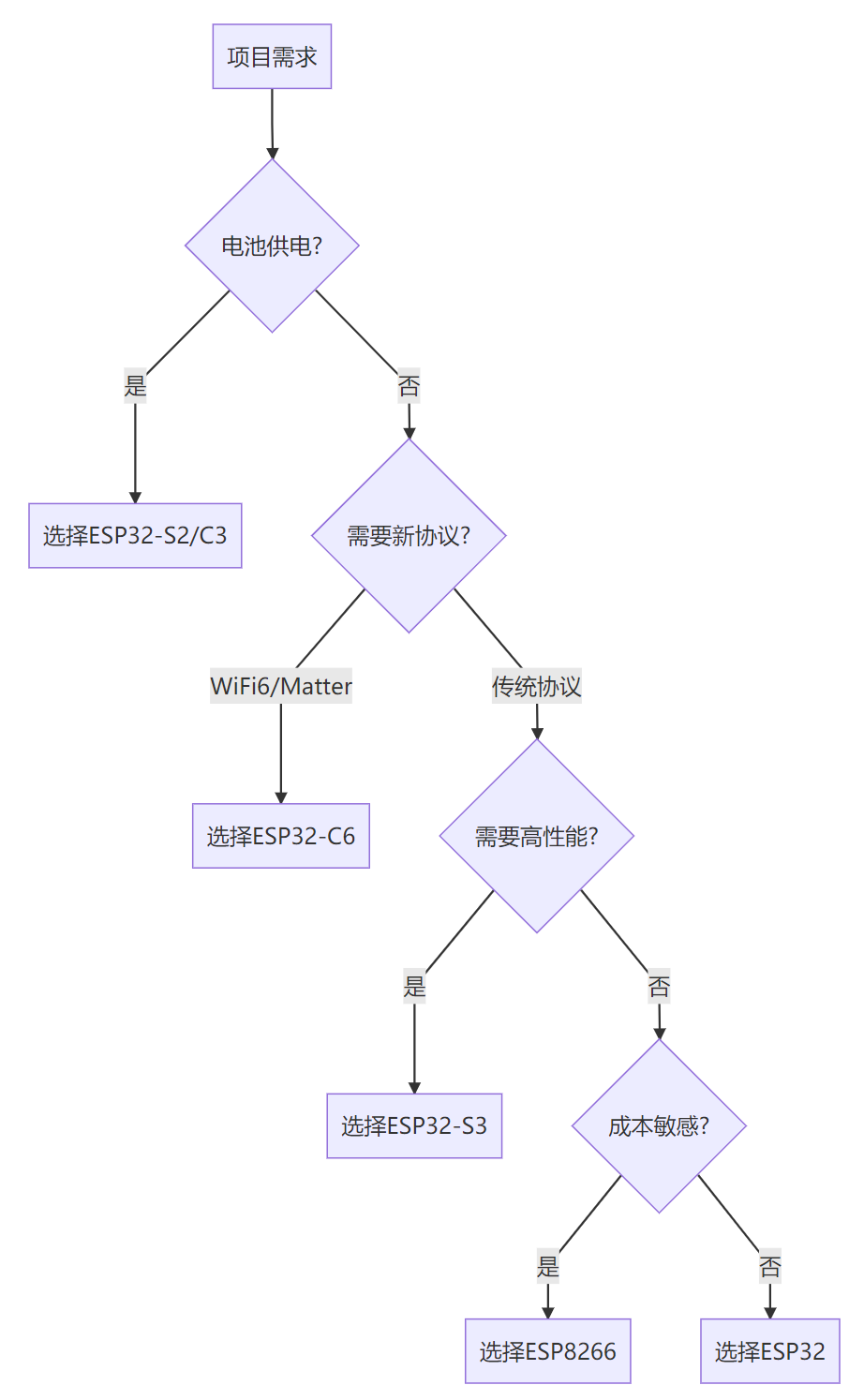
ESP系列单片机选择指南:结合实际场景的最优选择方案
前言 在物联网(IoT)快速发展的今天,ESP系列单片机凭借其优异的无线连接能力和丰富的功能特性,已成为智能家居、智慧农业、工业自动化等领域的首选方案。本文将深入分析各款ESP芯片的特点,结合典型应用场景,帮助开发者做出最优选择…...

特斯拉虚拟电厂:能源互联网时代的分布式革命
在双碳目标与能源转型的双重驱动下,特斯拉虚拟电厂(Virtual Power Plant, VPP)通过数字孪生技术与能源系统的深度融合,重构了传统电力系统的运行范式。本文从系统架构、工程实践、技术挑战三个维度,深度解析这一颠覆性…...
openjdk17 c++源码垃圾回收之安全点结束,唤醒线程)
jvm安全点(三)openjdk17 c++源码垃圾回收之安全点结束,唤醒线程
1. VMThread::inner_execute() - 触发安全点 cpp 复制 void VMThread::inner_execute(VM_Operation* op) { if (op->evaluate_at_safepoint()) { SafepointSynchronize::begin(); // 进入安全点,阻塞所有线程 // ...执行GC等操作... SafepointSynchronize::…...

Python OOP核心技巧:如何正确选择实例方法、类方法和静态方法
Python方法类型全解析:实例方法、类方法与静态方法的使用场景 一、三种方法的基本区别二、访问能力对比表三、何时使用实例方法使用实例方法的核心场景:具体应用场景:1. 操作实例属性2. 对象间交互3. 实现特定实例的行为 四、何时使用类方法使…...
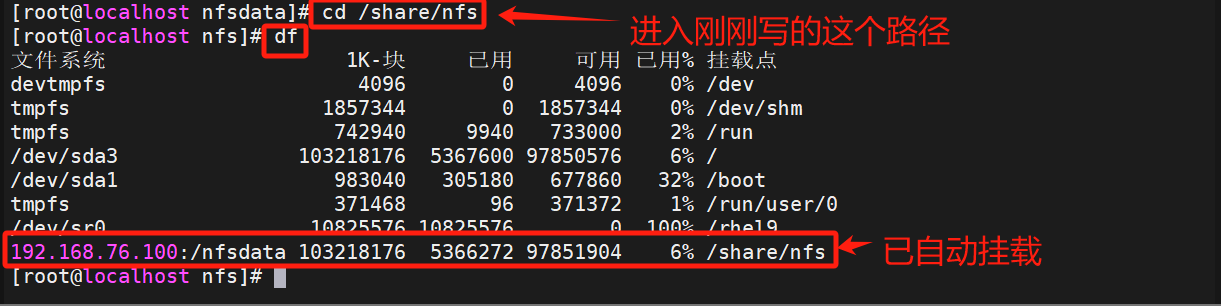
【Linux笔记】nfs网络文件系统与autofs(nfsdata、autofs、autofs.conf、auto.master)
一、nfs概念 NFS(Network File System,网络文件系统) 是一种由 Sun Microsystems 于1984年开发的分布式文件系统协议,允许用户通过网络访问远程计算机上的文件,就像访问本地文件一样。它广泛应用于 Unix/Linux 系统&a…...
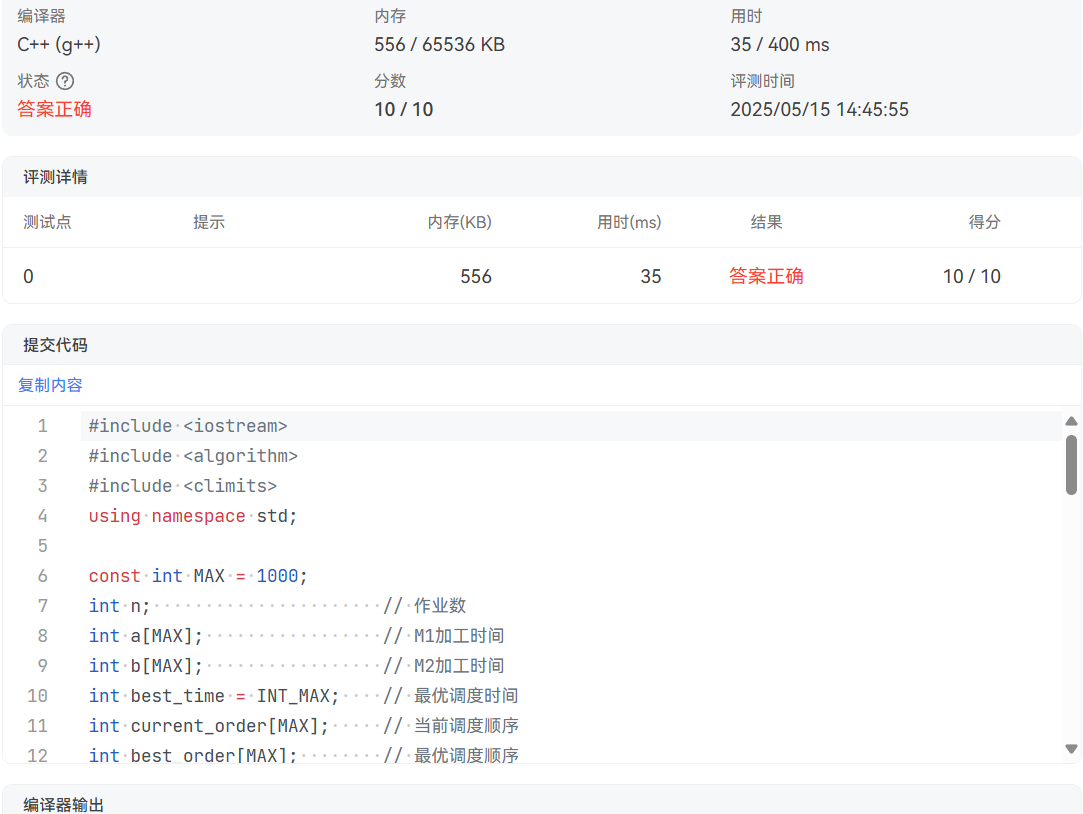
博客打卡-求解流水线调度
题目如下: 有n个作业(编号为1~n)要在由两台机器M1和M2组成的流水线上完成加工。每个作业加工的顺序都是先在M1上加工,然后在M2上加工。M1和M2加工作业i所需的时间分别为ai和bi(1≤i≤n)。 流水…...

基于React的高德地图api教程006:两点之间距离测量
文章目录 6、距离测量6.1 两点之间距离测量6.1.1 两点距离测量按钮6.1.2 点击地图添加点6.1.3 测量两点之间距离并画线6.2 测量过程显示两点之间预览线6.3 绘制完毕6.4 显示清除按钮6.5 代码下载6.06、距离测量 6.1 两点之间距离测量 6.1.1 两点距离测量按钮 实现代码: re…...

数据库blog1_信息(数据)的处理与效率提升
🌿信息的处理 🍂实际中离不开信息处理 ● 解决问题的建模 任何对问题的处理都可以看作数据的输入、处理、输出。 eg.一个项目中,用户点击信息由前端接收传递到后端处理后返回结果eg.面对一个问题,我们在搜集信息后做出处理与分析…...
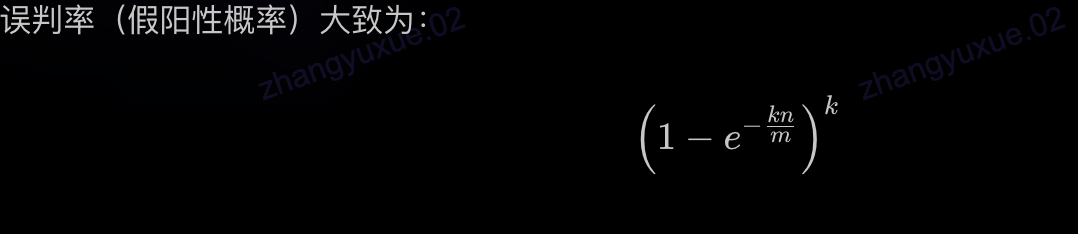
布隆过滤器介绍及其在大数据场景的应用
目录 布隆过滤器(Bloom Filter)介绍一、布隆过滤器的基本原理插入元素过程:查询元素过程: 二、布隆过滤器的特点三、误判率计算四、举例说明五、总结 Python版的简单布隆过滤器实现示例一、简单布隆过滤器Python示例二、布隆过滤器…...

Ansys 计算刚柔耦合矩阵系数
Ansys 计算刚柔耦合系数矩阵 文章目录 Ansys 计算刚柔耦合系数矩阵卫星的刚柔耦合动力学模型采用 ANSYS 的 APDL 语言的计算方法系统转动惯量的求解方法参考文献 卫星的刚柔耦合动力学模型 柔性航天器的刚柔耦合动力学模型可以表示为 m v ˙ B t r a n η F J ω ˙ ω J…...
)
微服务八股(自用)
微服务 SpringCloud 注册中心:Eureka 负载均衡:Ribbon 远程调用:Feign 服务熔断:Hystrix 网关:Gateway/Zuul Alibaba 配置中心:Nacos 负载均衡:Ribbon 服务调用:Feign 服务…...

指定elf文件dwarf 版本以及查看dwarf版本号
背景: 在实际项目开发过程中,为了让低版本的CANape 工具识别elf 文件,需要在编译elf文件时,指定dwarf的版本。 使用方法: 需要再CMakeLists.txt中指定dwarf 版本 add_compile_options(-g -gdwarf-2) #-gdwarf-4 验…...
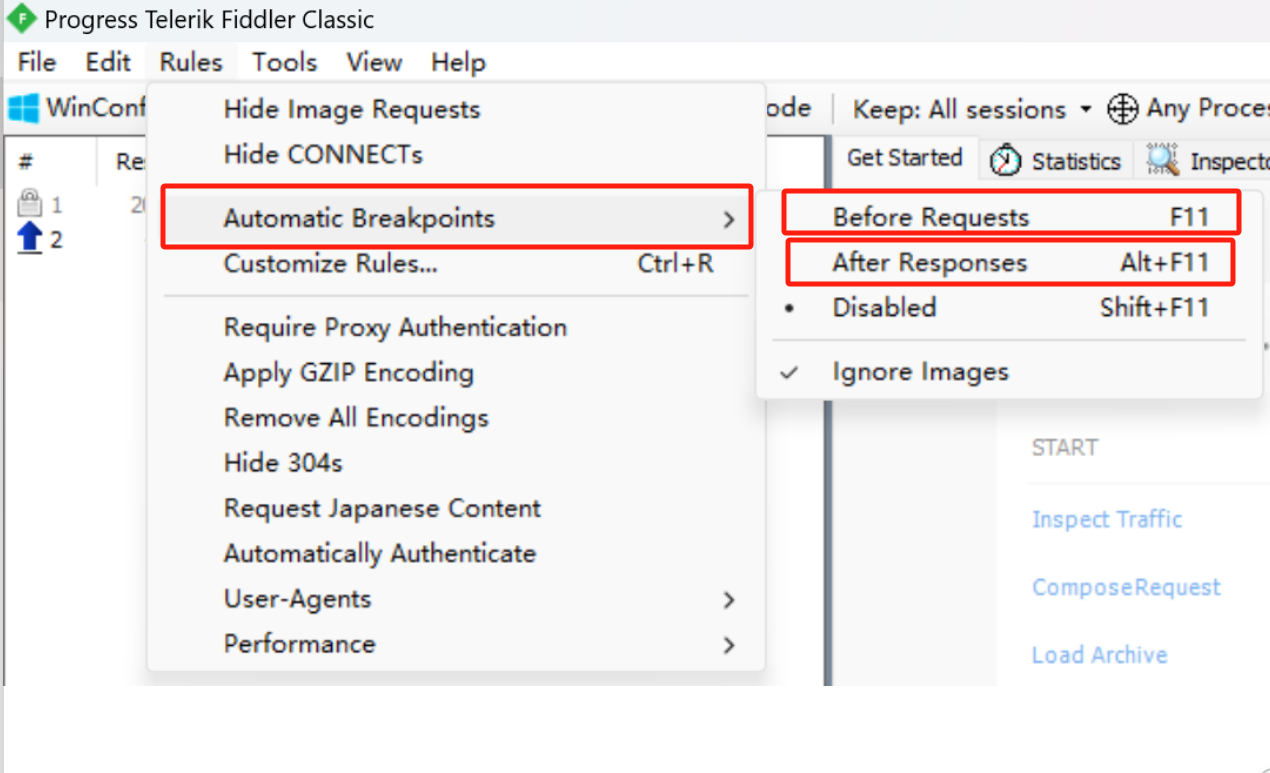
Fidder基本操作
1.抓取https请求 Fidder默认不能抓取https请求,我们必须通过相应的设置才能抓取https请求 1.选择tools下的option 2.选择https选项,并且勾选下面的选项 3.点击Actions导出信任证书到桌面(expert root certificate to desktop) 4.在浏览器中添加对应的证…...
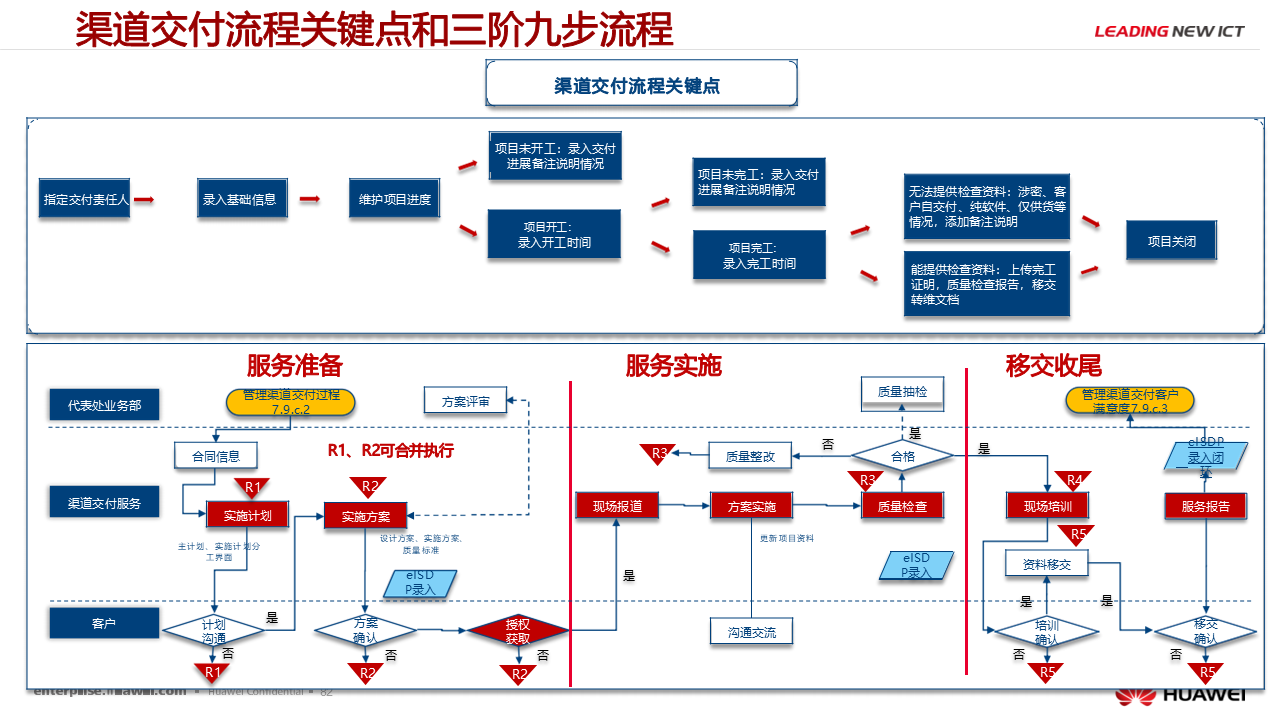
项目管理进阶:精读 78页华为项目管理高级培训教材【附全文阅读】
本文概述了华为项目管理(高级)课程的学习目标及学习方法。学习该课程后,学员应能: 1. **深刻理解项目管理**:掌握项目管理的基本概念与方法,构建项目管理思维框架。 2. **应用IBEST理念**:结合I…...
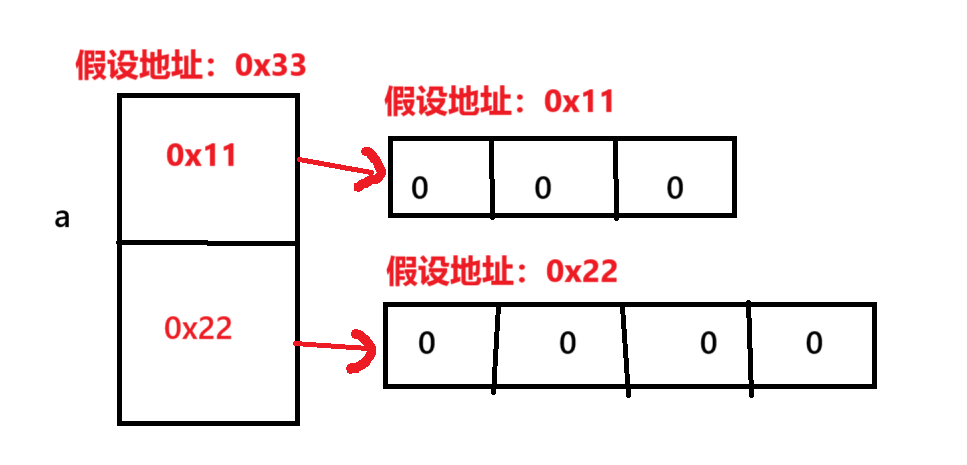
[Java] 方法和数组
目录 1. 方法 1.2 什么是方法 1.2 方法的定义 1.3 方法的调用 1.4 方法的重载 1.5 递归 2. 一维数组 2.1 什么是数组 2.2 数组的创建 2.3 数组的初始化 2.4 遍历数组 2.5 引用数据类型 2.6 关于null 2.7 数组转字符串 2.8 数组元素的查找 2.9 数组的排序 2.10…...

微软家各种copilot的AI产品:Github copilot、Microsoft copilot
背景 大家可能听到很多copilot,比如 Github Copilot,Microsoft Copilot、Microsoft 365 Copilot,有什么区别 Github Copilot:有网页版、有插件(idea、vscode等的插件),都是面向于程序员的。Mi…...
)
KL散度 (Kullback-Leibler Divergence)
KL散度,也称为相对熵 (Relative Entropy),是信息论中一个核心概念,用于衡量两个概率分布之间的差异。给定两个概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x)(对于离散随机变量)或 p ( x ) p(x) p(x) 和 q ( x …...

深入解析:java.sql.SQLException: No operations allowed after statement closed 报错
在 Java 应用程序开发过程中,尤其是涉及数据库交互时,开发者常常会遇到各种各样的异常。其中,java.sql.SQLException: No operations allowed after statement closed是一个较为常见且容易令人困惑的错误。本文将深入剖析这一报错,…...

DAY 23 训练
DAY 23 训练 DAY23 机器学习管道 pipeline基础概念转换器(Transformer)估计器(Estimator) 管道(Pipeline)代码演示没有 pipeline 的代码pipeline 的代码教学导入库和数据加载分离特征和标签,划分…...

wordcount程序
### 在 IntelliJ IDEA 中编写和运行 Spark WordCount 程序 要使用 IntelliJ IDEA 编写并运行 Spark 的 WordCount 程序,需按照以下流程逐步完成环境配置、代码编写以及任务提交。 --- #### 1. **安装与配置 IntelliJ IDEA** 确保已正确安装 IntelliJ IDEA&#x…...