LLaMA-Factory:环境准备
一、硬件和系统
- 操作系统: Ubuntu 24.04.2 LTS(64位)
- GPU: NVIDIA RTX 4090 笔记本 GPU,16GB显存
- CPU: 建议高性能多核 CPU(如 Intel i7/i9 或 AMD Ryzen 7/9)以支持数据预处理,我的是32核。
- RAM: 至少 32GB,推荐 64GB 以支持大型模型加载和数据处理,我的是64GB内存。
- 存储: NVMe SSD(至少 500GB 可用空间),用于存储模型权重、数据集和缓存文件,我的SSD2TB。
- 网络: 稳定的科学的网络连接,用于下载依赖和模型
注意: RTX 4090 笔记本 GPU 的 16GB VRAM 限制了可运行的模型大小。建议使用 4-bit 或 8-bit 量化模型(如 LLaMA 3.1 8B 或 13B)以适应 VRAM 限制。
二、安装NVIDIA驱动和CUDA
RTX 4090 需要最新的 NVIDIA 驱动和 CUDA 工具包以支持 GPU 加速。安装前检查机器配置,要适配自己的机器配置才行。
1、检查GPU识别
lspci | grep -i nvidia
# 输出应显示类似 "NVIDIA Corporation Device" 的信息。
# 如果没有输出,可能需要检查硬件连接或 BIOS 设置。
01:00.0 VGA compatible controller: NVIDIA Corporation GN21-X11 (rev a1)
01:00.1 Audio device: NVIDIA Corporation Device 22bb (rev a1)
2、检查推荐的驱动
ubuntu-drivers devices## 输出内容找到类似 "driver : nvidia-driver-575 - third-party non-free recommended" 的信息
vendor : NVIDIA Corporation
model : GN21-X11
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-575 - third-party non-free recommended
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-570-server-open - distro non-free
输出会显示推荐的驱动版本(如 nvidia-driver-575)。注意recommended信息。
3、安装推荐的驱动
sudo apt install nvidia-driver-575 -y
4、重启系统后验证驱动安装
sudo reboot
nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.20 Driver Version: 570.133.20 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
输出应显示 RTX 4090 的信息和驱动版本(如 550.XX)。
⚠️注意:安装推荐的驱动时自动安装的是CUDA运行时环境(包含基础库和头文件),但不会包含完整的CUDA Toolkit开发工具链(如nvcc编译器)。如需完整开发环境仍需单独安装。
nvidia-smi # 确认驱动版本和CUDA兼容性
ls /usr/local # 查看已安装的CUDA版本目录
假如我的驱动版本和CUDA版本分别是:Driver Version: 570.133.20 CUDA Version: 12.8 ,再查看已安装的CUDA版本目录,假如根据我的目录结构(已存在cuda-12.9),安装CUDA 12.8时需注意以下关键点:
1. 版本共存机制
- CUDA支持多版本共存,不同版本会安装到独立目录(如
/usr/local/cuda-12.8和/usr/local/cuda-12.9) - 默认符号链接
/usr/local/cuda会指向最后安装的版本,可通过ls -l /usr/local/cuda查看当前激活版本
2.安装CUDA12.8
# 添加NVIDIA官方仓库(Ubuntu 24.04)
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update# 安装指定版本
sudo apt install cuda-12-8
3.切换版本
# 修改符号链接指向目标版本
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-12.8 /usr/local/cuda# 更新环境变量
echo 'export PATH=/usr/local/cuda-12.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
4.冲突排查
- 驱动兼容性:CUDA 12.8要求驱动版本≥570.41.03,你的驱动570.133.20已满足
- 路径冲突:若安装失败,检查
/usr/local/cuda-12.8是否已存在,可手动删除旧目录 - 工具链验证:安装后运行
nvcc --version和nvidia-smi确认版本对应关系
⚠️注意
- 同时只能有一个CUDA版本通过
/usr/local/cuda符号链接激活,但编译时可显式指定路径(如I/usr/local/cuda-12.9/include) - 深度学习框架(如PyTorch)通常依赖特定CUDA版本,需匹配其要求
- 如果需要可以使用
update-alternatives管理多版本,自己查一下使用方法。 - 另外根据我的驱动版本(570.133.20)和当前环境,NVIDIA驱动570.133.20同时支持CUDA 12.8和12.923,安装CUDA 12.9无需升级驱动。
- 若项目明确要求CUDA 12.8,需保持当前版本
- 若需Blackwell GPU(如RTX 5090)或最新特性,推荐CUDA 12.94
- 灵活一些,再查看
/usr/local/cuda-12.8发现已经安装好了,我就不切换cuda版本了。
至此,GPU驱动和CUDA工具包都安装完成了。
三、安装Python和依赖
LLaMA-Factory 基于 Python,需要安装适当的 Python 版本和依赖。
1、安装python
Ubuntu 24.04 默认包含 Python 3.12。确认版本:
python3 --version
⚠️注意:如果需要特定版本(如 3.10),可以自行安装。另外最好使用虚拟环境,用venv、uv或者conda都可以,避免以来冲突,可以自行检索搭建。
2、安装PyTorch
为 RTX 4090 安装支持 CUDA 的 PyTorch:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu123
验证 PyTorch 是否识别 GPU:
记得切换环境,比如我用的conda,切换到指定环境conda activate llama_factory
python -c "import torch; print(torch.cuda.is_available())"
输出应为 True。
至此python环境准备完毕。这与平常python环境安装无异,很简单。
四、安装LLaMA-Factory
LLaMA-Factory 是一个用于高效微调 LLaMA 模型的框架。
⚠️注意:要科学上网
1、克隆LLaMA-Factory仓库,或者其他办法,把源码弄过来,进入LLaMA-Factory目录。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
2、安装依赖
安装LLama-Factory所需依赖,⚠️注意切换到虚拟环境,后续就不再提示了。
pip install -r requirements.txt
-
注意: 如果遇到依赖冲突,可尝试升级 pip:
pip install --upgrade pip
3、安装额外工具
为支持量化(如 4-bit 或 8-bit)和高效推理,安装以下工具:
pip install bitsandbytes
pip install transformers>=4.41.0
pip install accelerate
至此LLaMA-Factory框架应该已经安装完成,它提供了直观的web界面,可以通过llamafactory-cli webui 启动访问。接下来就是《准备模型和数据集》。
相关文章:
LLaMA-Factory:环境准备
一、硬件和系统 操作系统: Ubuntu 24.04.2 LTS(64位)GPU: NVIDIA RTX 4090 笔记本 GPU,16GB显存CPU: 建议高性能多核 CPU(如 Intel i7/i9 或 AMD Ryzen 7/9)以支持数据预处理,我的是32核。RAM: 至少 32GB&…...
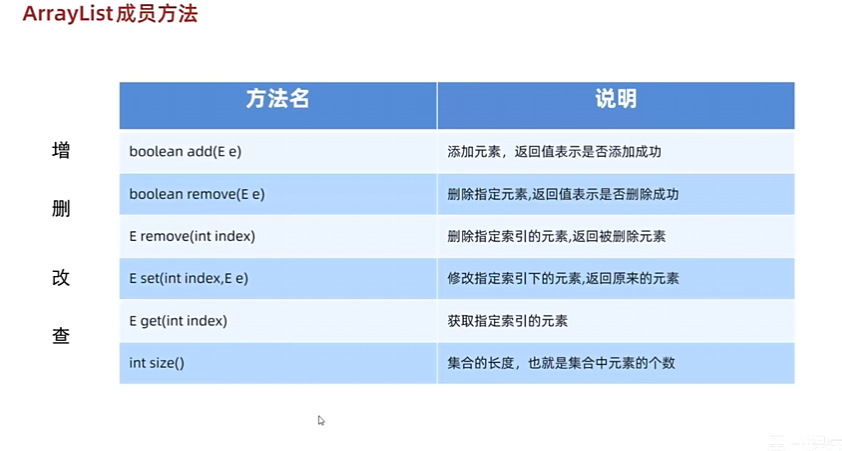
ArrayList-集合使用
自动扩容,集合的长度可以变化,而数组长度不变,集合更加灵活。 集合只能存引用数据类型,不能直接存基本数据类型,除非包装 ArrayList会拿[]展示数据...
一分钟用 MCP 上线一个 贪吃蛇 小游戏(CodeBuddy版)
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 你好,我是悟空。 背景 上篇我们用 MCP 上线了一个 2048 小游戏,这次我们继续做一个 …...
:全面解读 PyTorch 的 `torch.cumprod`——累积乘积详解与实战示例)
pytorch小记(二十二):全面解读 PyTorch 的 `torch.cumprod`——累积乘积详解与实战示例
pytorch小记(二十二):全面解读 PyTorch 的 torch.cumprod——累积乘积详解与实战示例 一、函数签名与参数说明二、基础用法1. 一维张量累积乘积2. 二维张量按行/按列累积 三、dtype 参数:避免整数溢出与提升精度四、典…...
TTS:F5-TTS 带有 ConvNeXt V2 的扩散变换器
1,项目简介 F5-TTS 于英文生成领域表现卓越,发音标准程度在本次评测软件中独占鳌头。再者,官方预设的多角色生成模式独具匠心,能够配置多个角色,一次性为多角色、多情绪生成对话式语音,别出心裁。 最低配置…...
基本概念)
强化学习笔记(一)基本概念
文章目录 1. 强化学习 (Reinforcement Learning, RL) 概述1.1 与监督学习 (Supervised Learning, SL) 的对比监督学习的特点:强化学习的特点: 2. 核心概念与术语2.1 策略 (Policy, π)2.2 价值函数 (Value Function)2.3 模型 (Model)2.4 回报 (Return, G)2.5 其他重要术语 3. 标…...

大型语言模型中的QKV与多头注意力机制解析
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
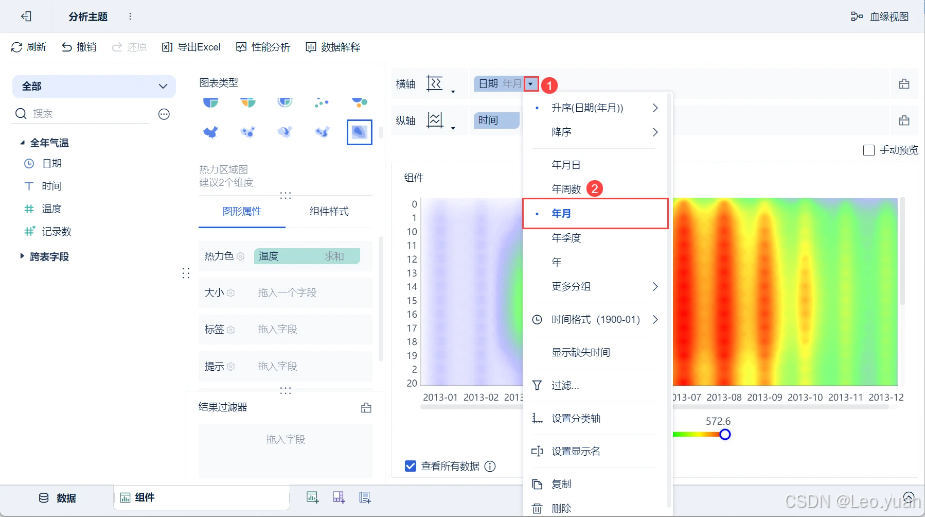
基于地图的数据可视化:解锁地理数据的真正价值
目录 一、基于地图的数据可视化概述 (一)定义与内涵 (二)重要性与意义 二、基于地图的数据可视化的实现方式 (一)数据收集与整理 (二)选择合适的可视化工具 (三&a…...

利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析
利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析 漫谈图像去雾化的挑战 在计算机视觉领域,图像复原一直是研究热点。其中,图像去雾化技术尤其具有实际应用价值。然而,复杂的气象条件和多种因素干扰使得这…...
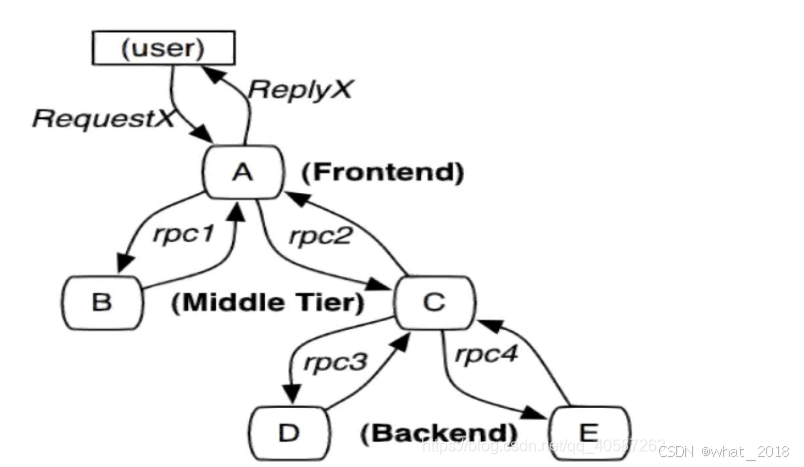
分布式链路跟踪
目录 链路追踪简介 基本概念 基于代理(Agent)的链路跟踪 基于 SDK 的链路跟踪 基于日志的链路跟踪 SkyWalking Sleuth ZipKin 链路追踪简介 分布式链路追踪是一种监控和分析分布式系统中请求流动的方法。它能够记录和分析一个请求在系统中经历的每…...
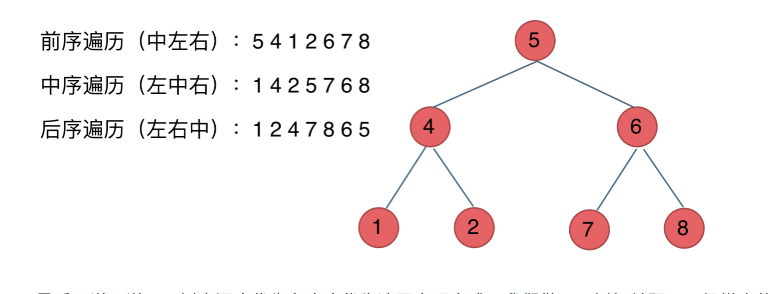
刷leetcodehot100返航版--二叉树
二叉树理论基础 二叉树的种类 满二叉树和完全二叉树,二叉树搜索树 满二叉树 如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 节点个数2^n-1【n为树的深度】 完全二叉树 在完全二叉树…...

chmod 777含义:
1.chmod 777 的含义及其在文件权限中的作用 chmod 777 是一种用于修改 Unix 和 Linux 系统中文件或目录权限的命令。它赋予指定文件或目录的所有用户(文件所有者、所属组成员以及其他用户)完全的访问权限,即 读取 (Read)、写入 (Write) 和 执…...
:混合检索之混合搜索)
AGI大模型(21):混合检索之混合搜索
为了执行混合搜索,我们结合了 BM25 和密集检索的结果。每种方法的分数均经过标准化和加权以获得最佳总体结果 1 代码 先编写 BM25搜索的代码,再编写密集检索的代码,最后进行混合。 from rank_bm25 import BM25Okapi from nltk.tokenize import word_tokenize import jieb…...

双重差分模型学习笔记4(理论)
【DID最全总结】90分钟带你速通双重差分!_哔哩哔哩_bilibili 目录 总结:双重差分法(DID)在社会科学中的应用:理论、发展与前沿分析 一、DID的基本原理与核心思想 二、经典DID:标准模型与应用案例 三、…...

Mysql 8.0.32 union all 创建视图后中文模糊查询失效
记录问题,最近在使用union all聚合了三张表的数据,创建视图作为查询主表,发现字段值为中文的筛选无法生效.......... sql示例: CREATE OR REPLACE VIEW test_view AS SELECTid,name,location_address AS address,type,"1" AS data_type,COALESCE ( update_time, cr…...
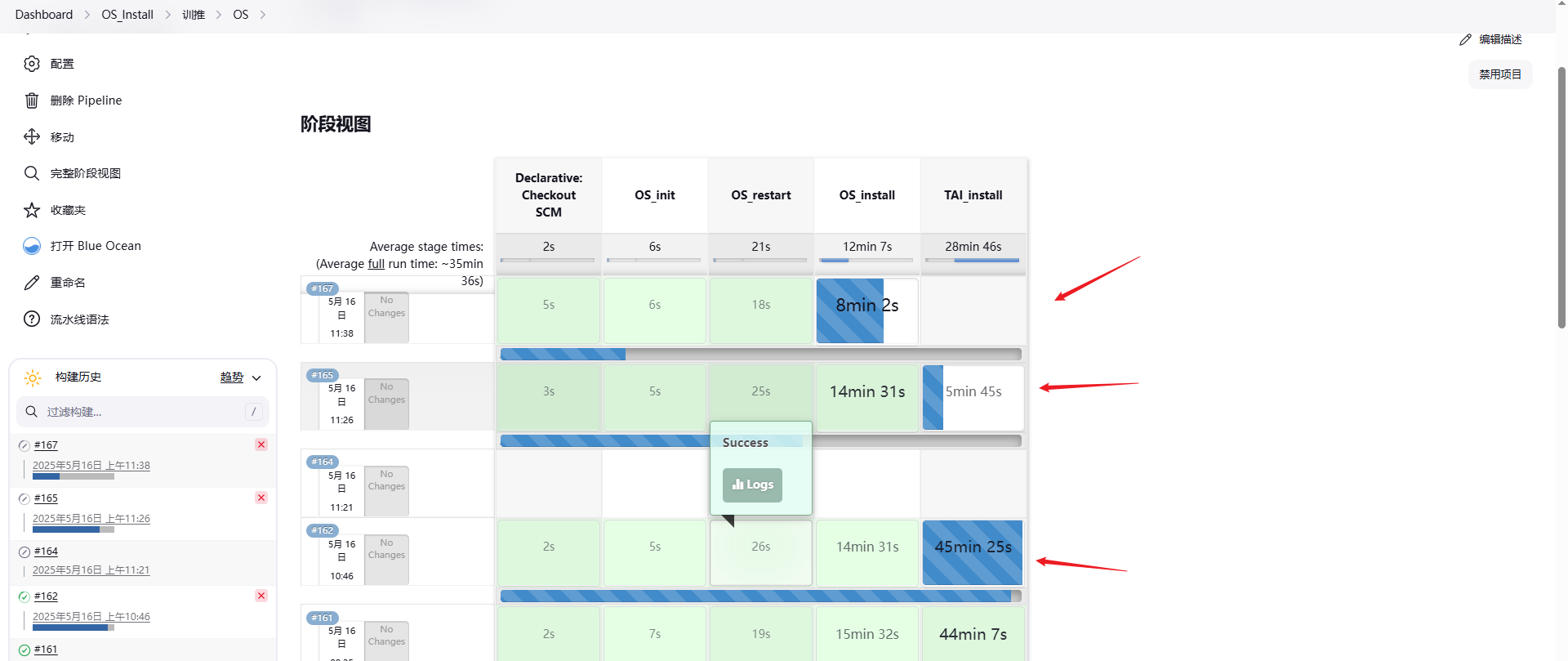
Jenkins 执行器(Executor)如何调整限制?
目录 现象原因解决 现象 Jenkins 构建时,提示如下: 此刻的心情正如上图中的小老头,火冒三丈,但是不要急,因为每一次错误,都是系统中某个环节在说‘我撑不住了’。 原因 其实是上图的提示表示 Jenkins 当…...

Android 中 权限分类及申请方式
在 Android 中,权限被分为几个不同的类别,每个类别有不同的申请和管理方式。 一、 普通权限(Normal Permissions) 普通权限通常不会对用户隐私或设备安全造成太大风险。这些权限在应用安装时自动授予,无需用户在运行时手动授权。 android.permission.INTERNETandroid.pe…...
编程错题集系列(一)
编程错题集系列(一) 人生海海,山山而川。 谨以此系列作为自己一路的见证。本期重点:明明已经安装相关库,但在PyCharm中无法调用 最大的概率是未配置合适的解释器,也就是你的书放在B房间,你在A…...
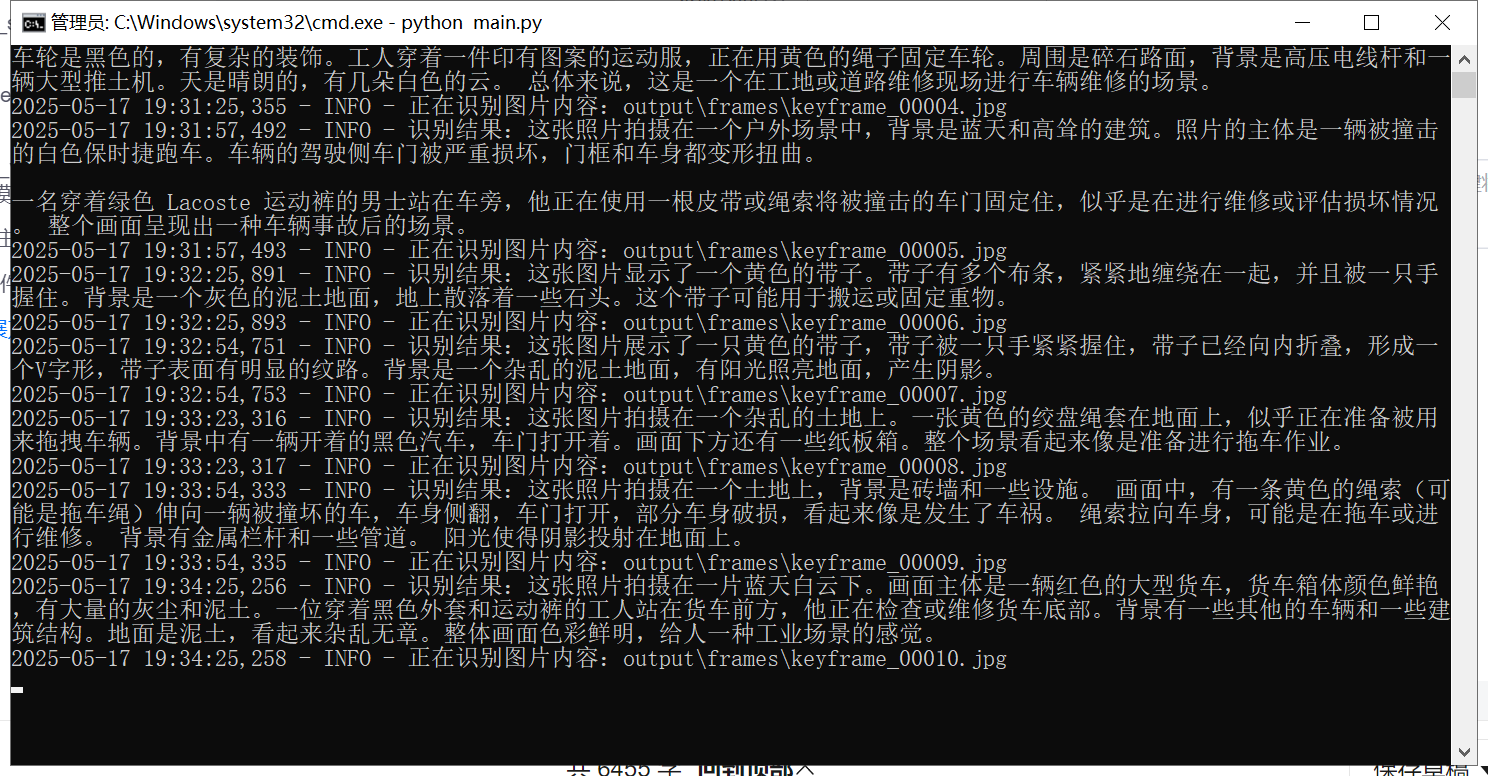
【原创】基于视觉大模型gemma-3-4b实现短视频自动识别内容并生成解说文案
📦 一、整体功能定位 这是一个用于从原始视频自动生成短视频解说内容的自动化工具,包含: 视频抽帧(可基于画面变化提取关键帧) 多模态图像识别(每帧图片理解) 文案生成(大模型生成…...
Spark(32)SparkSQL操作Mysql
(一)准备mysql环境 我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。 以下是具体步骤: 使用finalshell连接hadoop001.查看是否已安装MySQL。命令是: rpm -qa|grep ma…...
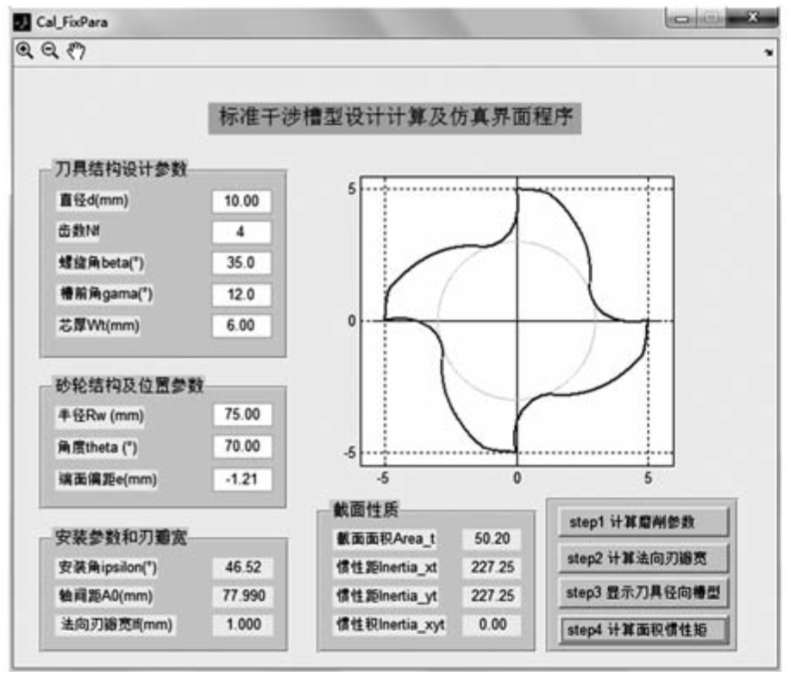
基于 Python 的界面程序复现:标准干涉槽型设计计算及仿真
基于 Python 的界面程序复现:标准干涉槽型设计计算及仿真 在工业设计与制造领域,刀具的设计与优化是提高生产效率和产品质量的关键环节之一。本文将介绍如何使用 Python 复现一个用于标准干涉槽型设计计算及仿真的界面程序,旨在帮助工程师和…...
c++成员函数返回类对象引用和直接返回类对象的区别
c成员函数返回类对象引用和直接返回类对象的区别 成员函数直接返回类对象(返回临时对象,对象拷贝) #include <iostream> class MyInt { public:int value;//构造函数explicit MyInt(int v0) : value(v){}//加法操作,返回对象副本&…...
:混合检索之rank_bm25库来实现词法搜索)
AGI大模型(20):混合检索之rank_bm25库来实现词法搜索
1 混合检索简介 混合搜索结合了两种检索信息的方法 词法搜索 (BM25) :这种传统方法根据精确的关键字匹配来检索文档。例如,如果您搜索“cat on the mat”,它将找到包含这些确切单词的文档。 基于嵌入的搜索(密集检索) :这种较新的方法通过比较文档的语义来检索文档。查…...
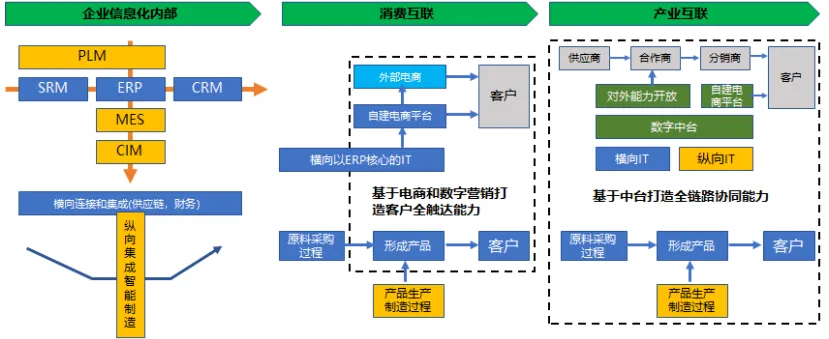
数字化转型- 数字化转型路线和推进
数字化转型三个阶段 百度百科给出的企业的数字化转型包括信息化、数字化、数智化三个阶段 信息化是将企业在生产经营过程中产生的业务信息进行记录、储存和管理,通过电子终端呈现,便于信息的传播与沟通。数字化通过打通各个系统的互联互通,…...

字体样式集合
根据您提供的字体样式列表,以下是分类整理后的完整字体样式名称(不含数量统计): 基础样式 • Regular • Normal • Plain • Medium • Bold • Black • Light • Thin • Heavy • Ultra • Extra • Semi • Hai…...

IP68防水Type-C连接器实测:水下1米浸泡72小时的生存挑战
IP68防水Type-C连接器正成为户外设备、水下仪器和高端消费电子的核心组件。其宣称的“1米水深防护”是否真能抵御长时间浸泡?我们通过极限实测,将三款主流品牌IP68防水Type-C连接器沉入1米盐水(模拟海水浓度)中持续72小时…...
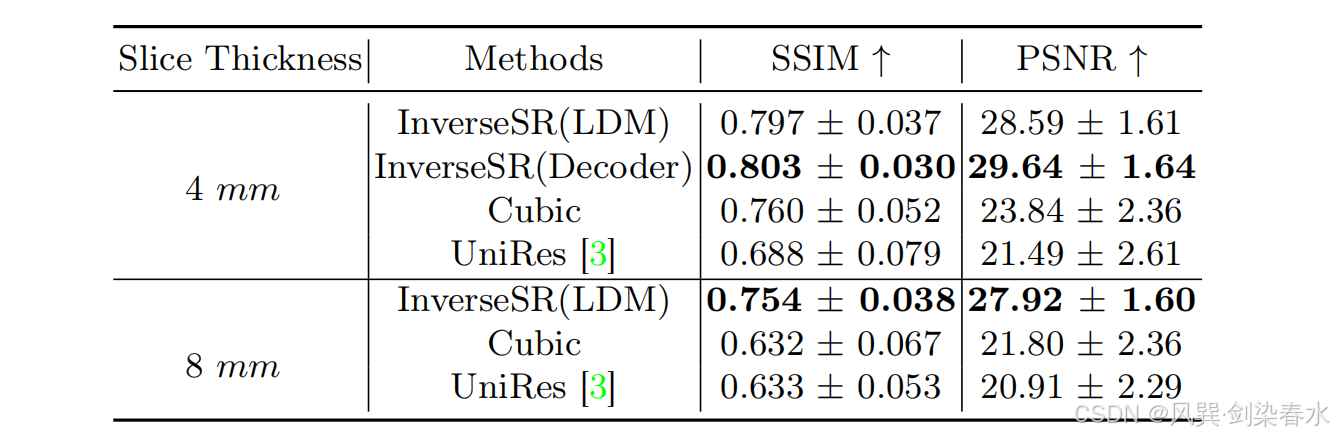
【技术追踪】InverseSR:使用潜在扩散模型进行三维脑部 MRI 超分辨率重建(MICCAI-2023)
LDM 实现三维超分辨率~ 论文:InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model 代码:https://github.com/BioMedAI-UCSC/InverseSR 0、摘要 从研究级医疗机构获得的高分辨率(HR)MRI 扫描能够提供关于成像…...
-变量)
React学习(二)-变量
也是很无聊,竟然写这玩意,毕竟不是学术研究,普通工作没那么多概念性东西,会用就行╮(╯▽╰)╭ 在React中,变量是用于存储和管理数据的基本单位。根据其用途和生命周期,React中的变量可以分为以下几类: 1. 状态变量(State) 用途:用于存储组件的内部状态,状态变化会触…...

list重点接口及模拟实现
list功能介绍 c中list是使用双向链表实现的一个容器,这个容器可以实现。插入,删除等的操作。与vector相比,vector适合尾插和尾删(vector的实现是使用了动态数组的方式。在进行头删和头插的时候后面的数据会进行挪动,时…...
基础知识④)
【自然语言处理与大模型】大模型(LLM)基础知识④
(1)微调主要用来干什么? 微调目前最主要用在定制模型的自我认知和改变模型对话风格。模型能力的适配与强化只是辅助。 定制模型的自我认知:通过微调可以调整模型对自我身份、角色功能的重新认知,使其回答更加符合自定义…...