python打卡DAY22
##注入所需库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import random
import numpy as np
import time
import shap
# from sklearn.svm import SVC #支持向量机分类器
# # from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
# # from sklearn.linear_model import LogisticRegression #逻辑回归分类器
# import xgboost as xgb #XGBoost分类器
# import lightgbm as lgb #LightGBM分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
# # from catboost import CatBoostClassifier #CatBoost分类器
# # from sklearn.tree import DecisionTreeClassifier #决策树分类器
# # from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯分类器
# from skopt import BayesSearchCV
# from skopt.space import Integer
# from deap import base, creator, tools, algorithms
# from sklearn.model_selection import StratifiedKFold, cross_validate # 引入分层 K 折和交叉验证工具
# from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
from sklearn.metrics import make_scorer#定义函数
# import warnings #用于忽略警告信息
# warnings.filterwarnings("ignore") # 忽略所有警告信息
#聚类
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
#3D可视化
from mpl_toolkits.mplot3d import Axes3D
#设置中文字体&负号正确显示
plt.rcParams['font.sans-serif']=['STHeiti']
plt.rcParams['axes.unicode_minus']=True
plt.rcParams['figure.dpi']=100
#读取数据
data=pd.read_csv(r'data.csv')
#数据填补
for i in data.columns:
if data[i].dtype!='object':
if data[i].isnull().sum()>0:
data[i].fillna(data[i].mean(),inplace=True)
else:
if data[i].isnull().sum()>0:
data[i].fillna(data[i].mode()[0],inplace=True)
mapping={'10+ years':0,
'9 years':1,
'8 years':2,
'7 years':3,
'6 years':4,
'5 years':5,
'4 years':6,
'3 years':7,
'2 years':8,
'1 year':9,
'< 1 year':10}
data['Years in current job']=data['Years in current job'].map(mapping)
dummies_list=[]
data2=pd.read_csv(r'data.csv')
data=pd.get_dummies(data=data,drop_first=True)
for i in data.columns:
if i not in data2.columns:
dummies_list.append(i)
for i in dummies_list:
data[i]=data[i].astype(int)
print(f'{data.info()}')
#划分数据集
from sklearn.model_selection import train_test_split
x=data.drop(columns=['Credit Default','Id'],axis=1)
y=data['Credit Default']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=42)
#smote
from imblearn.over_sampling import SMOTE
smote=SMOTE(random_state=42)
x_train_smote,y_train_smote=smote.fit_resample(x_train,y_train)
#标准化数据,将自变量标准化,聚类就是从自变量中聚合新的自变量,与因变量无关
scaler=StandardScaler()
x_scaled=scaler.fit_transform(x)
# #KMeans++
# k_range=range(2,5)
# inertia_value=[]
# silhouette_scores=[]
# ch_scores=[]
# db_scores=[]
# start_time=time.time()
# for k in k_range:
# kmeans=KMeans(n_clusters=k,random_state=42)
# kmeans_label=kmeans.fit_predict(x_scaled)#提供了每个数据点所属的簇的信息,用于区分不同簇的数据点
# inertia_value.append(kmeans.inertia_)
# silhouette=silhouette_score(x_scaled,kmeans_label)
# silhouette_scores.append(silhouette)
# ch=calinski_harabasz_score(x_scaled,kmeans_label)
# ch_scores.append(ch)
# db=davies_bouldin_score(x_scaled,kmeans_label)
# db_scores.append(db)
# # print(f'k={k}\n 惯性:{kmeans.inertia_:.2f}\n轮廓系数:{silhouette:.3f}\n CH系数:{ch:.2f}\n DB{db:.3f}')
# end_time=time.time()
# print(f'聚类分析耗时:{end_time-start_time:.4f}')
# #绘制评估指标图
# plt.figure(figsize=(12,6))
# #肘部法则图
# plt.subplot(2,2,1)
# plt.plot(k_range,inertia_value,marker='o')
# plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('惯性')
# plt.grid(True)
# #轮廓系数图
# plt.subplot(2,2,2)
# plt.plot(k_range,silhouette_scores,marker='o',color='orange')
# plt.title('轮廓系数确定最优聚类数 k(越大越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('轮廓系数')
# plt.grid(True)
# #CH指数图
# plt.subplot(2,2,3)
# plt.plot(k_range,ch_scores,marker='o',color='red')
# plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('CH 指数')
# plt.grid(True)
# #DB指数图
# plt.subplot(2,2,4)
# plt.plot(k_range,db_scores,marker='o',color='yellow')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('DB 指数')
# plt.grid(True)
# plt.tight_layout()
# plt.show()
#选择K值进行聚类
selected_k=3
kmeans=KMeans(n_clusters=selected_k,random_state=42)
kmeans_label=kmeans.fit_predict(x_scaled)
x['KMeans_Cluster']=kmeans_label
##PCA降维
pca=PCA(n_components=3)
x_pca=pca.fit_transform(x_scaled)
# # ##聚类可视化
# # plt.figure(figsize=(6,5))
# # sns.scatterplot(
# # x=x_pca[:,0],
# # y=x_pca[:,1],
# # hue=kmeans_label,
# # palette='viridis'
# # )
# # plt.title(f'KMean Clustering with k={selected_k} (PCA Visualization)')
# # plt.xlabel('PCA Component 1')
# # plt.ylabel('PCA Component 2')
# # plt.show()
# # #3D可视化
# pca=PCA(n_components=3)
# import plotly.express as px
# import plotly.graph_objects as go
# # 准备数据
# df_pca = pd.DataFrame(x_pca, columns=['PC1', 'PC2', 'PC3'])
# df_pca['Cluster'] = kmeans_label
# # 创建3D散点图
# fig = px.scatter_3d(df_pca, x='PC1', y='PC2', z='PC3', color='Cluster',
# color_continuous_scale=px.colors.sequential.Viridis,
# title=f'KMeans Clustering with k={selected_k} (PCA 3D Visualization)')
# # 调整图形
# fig.update_layout(scene=dict(xaxis_title='PCA Component 1',
# yaxis_title='PCA Component 2',
# zaxis_title='PCA Component 3'),
# width=1200, height=1000)
# # 显示图形
# fig.show()
# ##打印KMeans聚类前几行
# print(f'KMeans Cluster labels(k={selected_k}added to x):')
# print(x[['KMeans_Cluster']].value_counts())
start_time=time.time()
x1=x.drop('KMeans_Cluster',axis=1)
y1=x['KMeans_Cluster']
rf1_model=RandomForestClassifier(random_state=42,class_weight='balanced')
rf1_model.fit(x1,y1)
explainer=shap.TreeExplainer(rf1_model)
shap_values=explainer.shap_values(x1)
print(shap_values.shape)
end_time=time.time()
print(f'SHAP分析耗时:{end_time-start_time:.4f}')
# # --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
# print("--- 1. SHAP 特征重要性条形图 ---")
# shap.summary_plot(shap_values[:,:,0],x1,plot_type='bar',show=False)
# plt.title('shap feature importance (bar plot)')
# plt.tight_layout()
# plt.show()
selected_features=['Purpose_debt consolidation','Home Ownership_Home Mortgage','Purpose_home improvements','Purpose_other']
# for feature in selected_features:
# unique_count=x[feature].nunique()
# print(f'{feature}的唯一值数量:{unique_count}')
# if unique_count<10:
# print(f'{feature}可能是离散型变量')
# else:
# print(f'{feature}可能是连续性变量')
# fig,axes=plt.subplots(2,2,figsize=(10,8))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# axes[i].hist(x[feature],bins=10)
# axes[i].set_title(f'histogram of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('frequency')
# plt.tight_layout()
# plt.show()
print(x[['KMeans_Cluster']].value_counts())
x_cluster0=x[x['KMeans_Cluster']==0]
x_cluster1=x[x['KMeans_Cluster']==1]
x_cluster2=x[x['KMeans_Cluster']==2]
x_cluster3=x[x['KMeans_Cluster']==3]
# #簇0
# fig,axes=plt.subplots(2,2,figsize=(6,4))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# sns.countplot(x=x_cluster0[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# plt.tight_layout()
# plt.show()
# #簇1
# fig,axes=plt.subplots(2,2,figsize=(6,4))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# sns.countplot(x=x_cluster1[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# plt.tight_layout()
# plt.show()
# #簇2
# fig,axes=plt.subplots(2,2,figsize=(6,4))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# sns.countplot(x=x_cluster2[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# plt.tight_layout()
# plt.show()
print("--- 递归特征消除 (RFE) ---")
from sklearn.feature_selection import RFE
base_model=RandomForestClassifier(random_state=42,class_weight='balanced')
rfe=RFE(base_model,n_features_to_select=3)
rfe.fit(x_train_smote,y_train_smote)
x_train_rfe=rfe.transform(x_train_smote)
x_test_rfe=rfe.transform(x_test)
selected_features_rfe=x_train.columns[rfe.support_]
print(f"RFE筛选后保留的特征数量: {len(selected_features_rfe)}")
print(f"保留的特征: {selected_features_rfe}")
# #3D可视化
import plotly.express as px
import plotly.graph_objects as go
x_selected=x[selected_features_rfe]
df_viz=pd.DataFrame(x_selected)
df_viz['cluster']=x['KMeans_Cluster']
fig=px.scatter_3d(
df_viz,
x=selected_features_rfe[0],
y=selected_features_rfe[1],
z=selected_features_rfe[2],
color='cluster',
color_continuous_scale=px.colors.sequential.Viridis,
title='RFE特征选择的3D可视化'
)
fig.update_layout(
scene=dict(
xaxis_title=selected_features_rfe[0],
yaxis_title=selected_features_rfe[1],
zaxis_title=selected_features_rfe[2]
),
width=1200,
height=1000
)
fig.show()
#训练随机森林模型
rf_model_rfe=RandomForestClassifier(random_state=42,class_weight='balanced')
rf_model_rfe.fit(x_train_rfe,y_train)
rf_pred_rfe=rf_model_rfe.predict(x_test_rfe)
print("\nRFE筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_rfe))
print("RFE筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_rfe))
相关文章:

python打卡DAY22
##注入所需库 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import random import numpy as np import time import shap # from sklearn.svm import SVC #支持向量机分类器 # # from sklearn.neighbors import KNeighborsClassifier …...
【教程】Docker更换存储位置
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 背景说明 更换教程 1. 停止 Docker 服务 2. 创建新的存储目录 3. 编辑 Docker 配置文件 4. 迁移已有数据到新位置 5. 启动 Docker 服务 6…...

鸿蒙Next API17学习新特性之组件可见区域变化事件新增支持设置事件的回调参数,限制它的执行间隔
概述 鸿蒙开发文档更新的非常快,对应我们开发者的学习能力也要求非常高,今天这篇文章给大家分享一下鸿蒙API17中更新的新特性学习。 鸿蒙 Next 的组件可见区域变化事件在最新的 API Version 17 中得到了增强,新增了支持设置事件的回调参数的…...

AI大模型从0到1记录学习 mysql day23
第 1 章 MySQL概述 1.1 基本概念 1.1.1 数据库是什么? 数据库(DB:Database):存储数据的地方。 1.1.2 为什么要用数据库? 应用程序产生的数据是在内存中的,如果程序退出或者是断电了,…...

spring -MVC-02
SpringMVC-11 - 响应 在 SpringMVC 中,响应是服务器对客户端请求的反馈,它可以以多种形式呈现,包括视图名称、ModelAndView 对象、JSON 数据以及重定向等。以下是对 SpringMVC 中不同响应类型的详细介绍: 1. 视图名称 通过返回…...
深入解析 React 的 useEffect:从入门到实战
文章目录 前言一、为什么需要 useEffect?核心作用: 二、useEffect 的基础用法1. 基本语法2. 依赖项数组的作用 三、依赖项数组演示1. 空数组 []:2.无依赖项(空)3.有依赖项 四、清理副作用函数实战案例演示1. 清除定时器…...

通过Ollama读取模型
通过Ollama读取模型 前言一、查看本地Ollama上有哪些模型二、调用bge-m3模型1、调用模型2、使用bge-m3进行相似度比较 三、调用大模型 前言 手动下载和加载大模型通常需要复杂的环境配置,而使用Ollama可以避免这一问题。本文将介绍如何调用Ollama上的模型。 一、查…...

C#控制流
🧩 一、控制流概述 C# 中的控制流语句用于根据条件或循环执行代码块。它们是程序逻辑的核心部分。 ✅ 二、1. if、else if、else int score 85;if (score > 90) {Console.WriteLine("优秀"); } else if (score > 60) {Console.WriteLine("及…...

永久免费,特殊版本!
随着大家审美的不断提升,无论是社交平台的日常分享还是特定场景的图像展示,人们对图像质量的要求都日益严苛。为了呈现更完美的视觉效果,许多小伙伴都会对原始图像进行精细化的后期处理,其中复杂背景抠图、光影调整、色彩校正等专…...
Canva 推出自有应用生成器以与 Bolt 和 Lovable 竞争
AI 目前是一个巨大的市场,每个人都想从中分一杯羹。 即使是 Canva,这个以拖放图形设计而闻名的流行设计平台,也在其 Canva Create 2025 活动中发布了自己版本的代码生成器,加入了 AI 竞赛。 但为什么一个以设计为先的平台会提供代码生成工具呢? 乍看之下,这似乎有些不…...
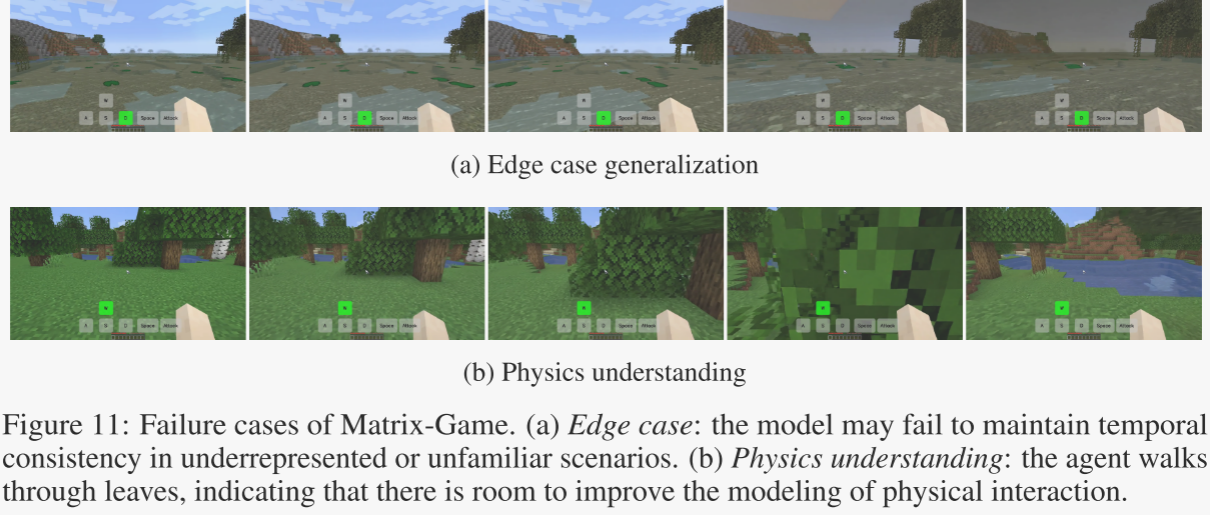
Matrix-Game:键鼠实时控制、实时生成的游戏生成模型(论文代码详细解读)
1.简介 本文介绍了一种名为Matrix-Game的交互式世界基础模型,专门用于可控的游戏世界生成。 Matrix-Game通过一个两阶段的训练流程来实现:首先进行大规模无标签预训练以理解环境,然后进行动作标记训练以生成交互式视频。为此,研…...

MySQL 5.7在CentOS 7.9系统下的安装(下)——给MySQL设置密码
新下载下来的MySQL,由于没有root密码,(1)所以如果我们希望登陆mysql,得给mysql的root账户设置密码,或者另一方面来说,(2)未来如果你忘记root密码了,也能通过这…...
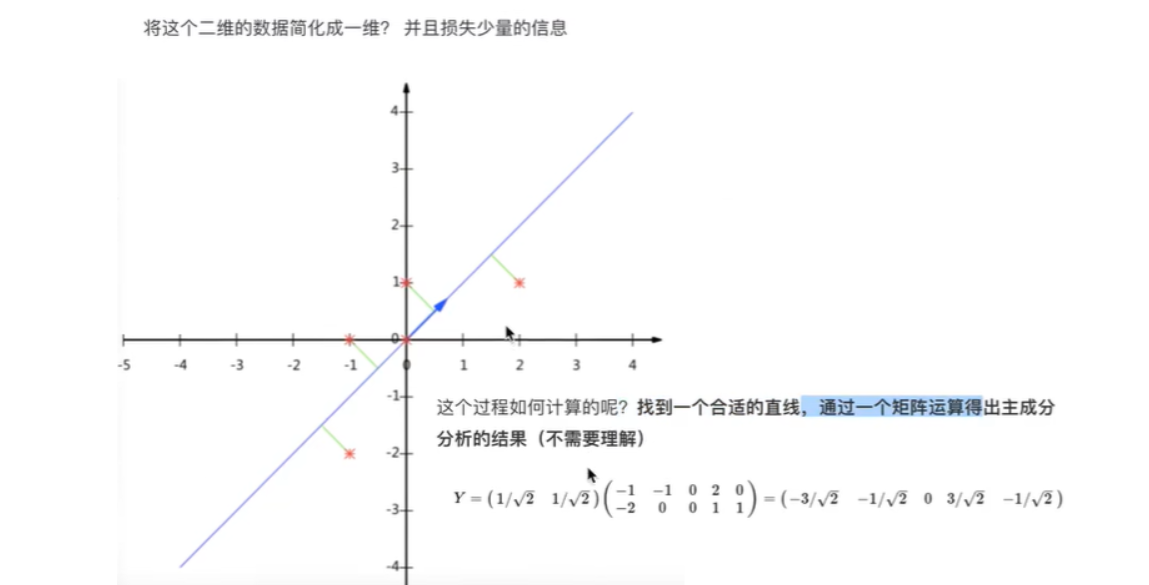
机器学习笔记2
5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取 (1) 算法 词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性 逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度 (2) API sklearn.feature_extraction.text.TfidfVector…...

AgentCPM-GUI,清华联合面壁智能开源的端侧GUI智能体模型
AgentCPM-GUI是什么 AgentCPM-GUI 是由清华大学与面壁智能团队联合开发的一款开源端侧图形用户界面(GUI)代理,专为中文应用进行优化。基于 MiniCPM-V 模型(80 亿参数),该系统能够接收智能手机的屏幕截图&a…...

Go语言实现链式调用
在 Go 语言中实现链式调用(Method Chaining),可以通过让每个方法返回对象本身(或对象的指针)来实现。这样每次方法调用后可以继续调用其他方法。 示例:实现字符串的链式操作 假设你想对一个字符串连续执行…...
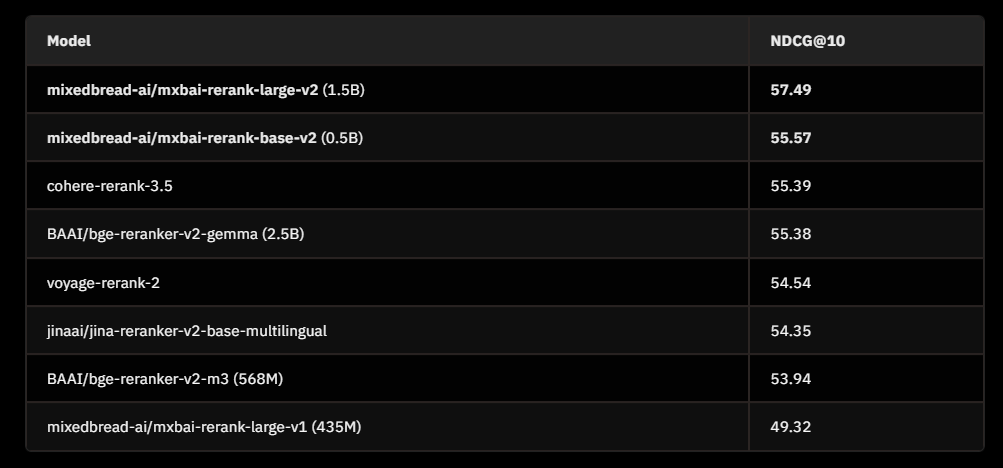
重排序模型解读 mxbai-rerank-base-v2 强大的重排序模型
mxbai-rerank-base-v2 强大的重排序模型 模型介绍benchmark综合评价安装 模型介绍 mxbai-rerank-base-v2 是 Mixedbread 提供的一个强大的重排序模型,旨在提高搜索相关性。该模型支持多语言,特别是在英语和中文方面表现出色。它还支持代码和 SQL 排序&a…...
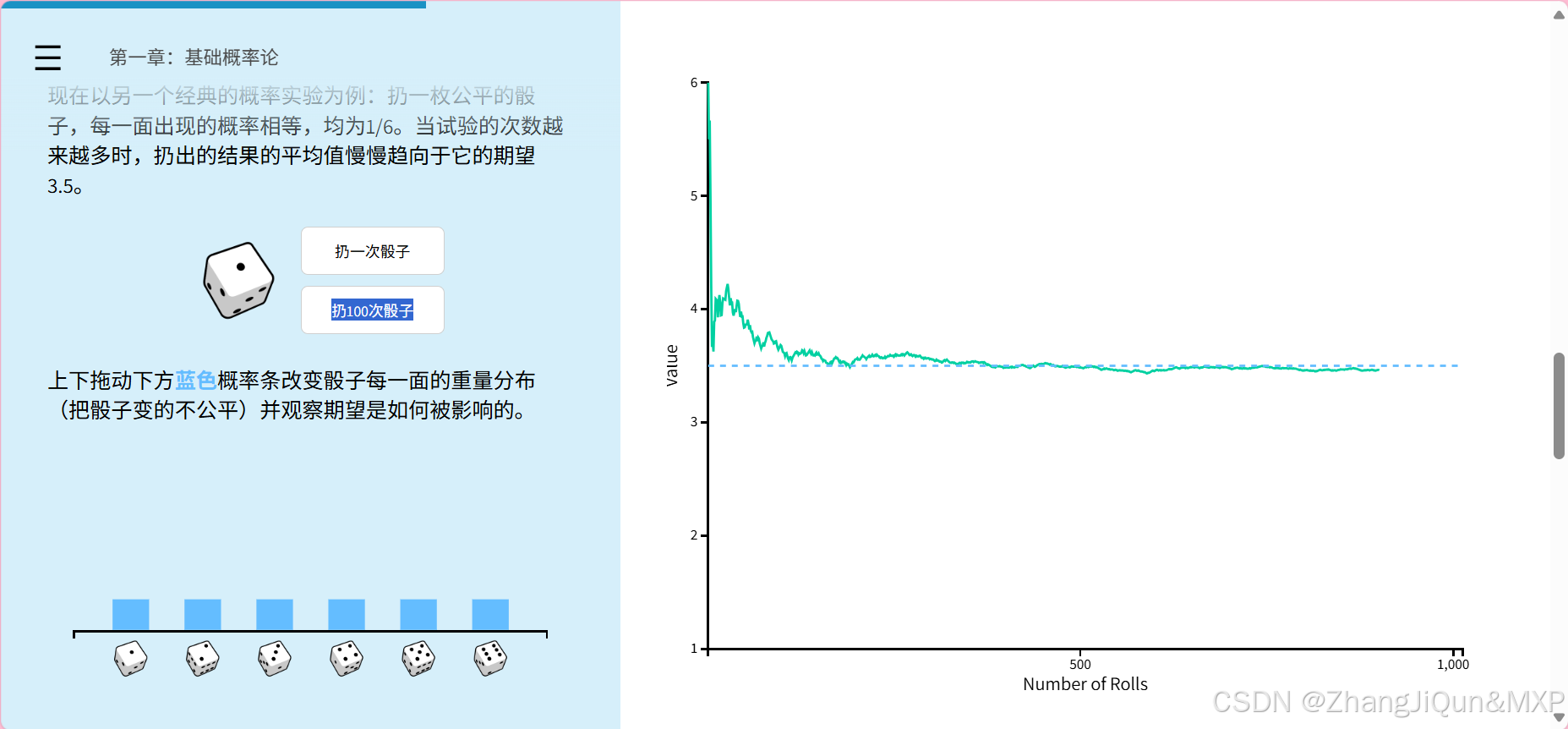
期望是什么:(无数次的均值,结合概率)21/6=3.5
https://seeing-theory.brown.edu/basic-probability/cn.html 期望是什么:(无数次的均值,结合概率)21/6=3.5 一、期望(数学概念) 在概率论和统计学中,**期望(Expectation)**是一个核心概念,用于描述随机变量的长期平均取值,反映随机变量取值的集中趋势。 (一…...
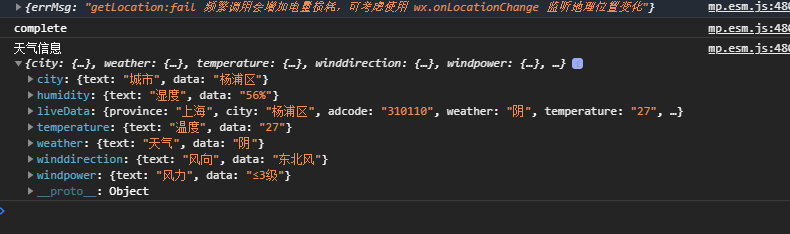
uniapp-vue3项目中引入高德地图的天气展示
前言: uniapp-vue3项目中引入高德地图的天气展示 效果: 操作步骤: 1、页面上用定义我们的 当前天气信息:<view></view> 2、引入我们的map文件 <script setup>import amapFile from ../../libs/amap-wx.js …...

容器化-k8s-介绍及下载安装教程
一、K8s 概念 官网地址: https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/ 1、含义 Kubernetes 是一个开源的容器编排引擎,用于自动化部署、扩展和管理容器化应用程序。它可以将多个容器组合成一个逻辑单元,实现对容器的集中管理和调度,从而简化复杂应用的部…...

lc42接雨水
1.原题 42. 接雨水 - 力扣(LeetCode) 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 2.题目解析 这一题是经常被考到的一道算法题,其中最简单最好用的方法就是双指…...
通义千问-langchain使用构建(三)
目录 序言docker 部署xinference1WSL环境docker安装2拉取镜像运行容器3使用的界面 本地跑chatchat1rag踩坑2使用的界面2.1配置个前置条件然后对话2.2rag对话 结论 序言 在前两天的基础上,将xinference调整为wsl环境,docker部署。 然后langchain chatcha…...

uniapp自动构建pages.json的vite插件
对于 uniapp 来说,配置 pages.json 无疑是最繁琐的事情,具有以下缺点: 冗长,页面很多时 pages 内容会很长难找,有时候因为内容很长,导致页面配置比较难找,而且看起来比较凌乱json弊端ÿ…...

系统漏洞扫描服务:维护网络安全的关键与服务原理?
系统漏洞扫描服务是维护网络安全的关键措施,能够迅速发现系统中的潜在风险,有效预防可能的风险和损失。面对网络攻击手段的日益复杂化,这一服务的重要性日益显著。 服务原理 系统漏洞扫描服务犹如一名恪尽职守的安全守护者。它运用各类扫描…...

nlf loss 学习笔记
目录 数据集: 3d 投影到2d 继续求loss reconstruct_absolute 1. 功能概述 2. 参数详解 3. 两种重建模式对比 数据集: agora3 | 5264/5264 [00:00<00:00, 143146.78it/s] behave 37736/37736 [00:00<00:00, 76669.67it/s] mads 32649/3264…...
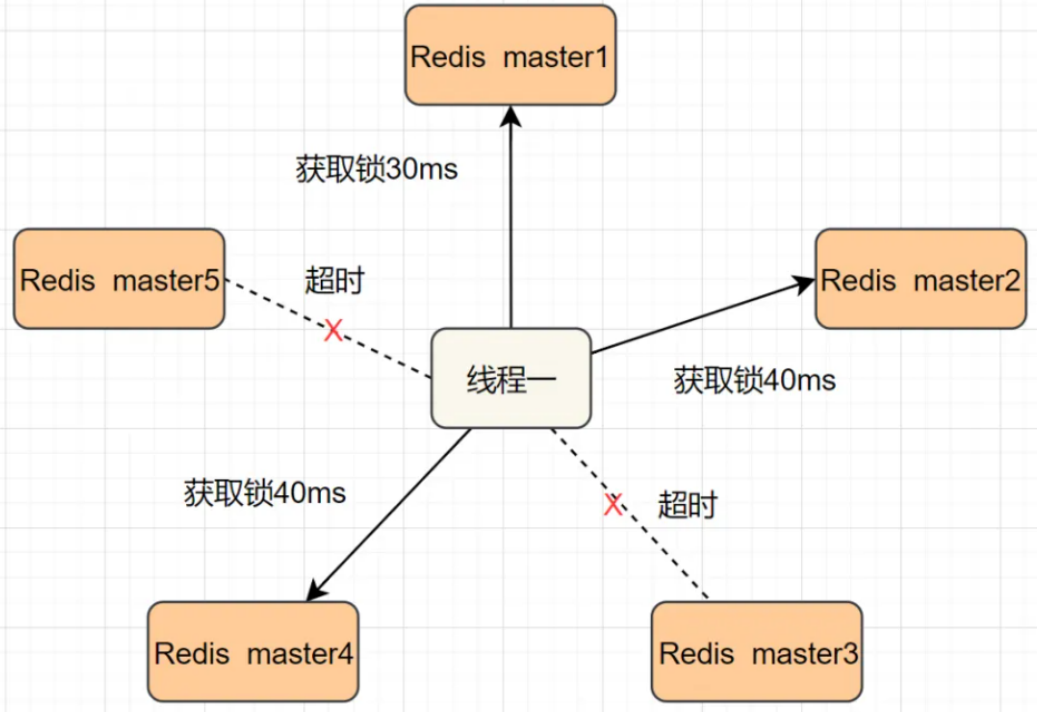
【Redis】零碎知识点(易忘 / 易错)总结回顾
一、Redis 是一种基于键值对(key-value)的 NoSQL 数据库 二、Redis 会将所有数据都存放在内存中,所以它的读写性能非常惊人 Redis 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障时…...
基于three.js 全景图片或视频开源库Photo Sphere Viewer
Photo Sphere Viewer 是一个基于 JavaScript 的开源库,专门用于在网页上展示 360 全景图片或视频。它提供了丰富的交互功能,允许用户通过鼠标、触摸屏或陀螺仪来浏览全景内容,适用于旅游、房地产、虚拟现实、教育等多个领域。 主要特点 多种…...

LangPDF: Empowering Your PDFs with Intelligent Language Processing
LangPDF: Empowering Your PDFs with Intelligent Language Processing Unlock Global Communication: AI-Powered PDF Translation and Beyond In an interconnected world, seamless multilingual document management is not just an advantage—it’s a necessity. LangP…...

OpenVLA (2) 机器人环境和环境数据
文章目录 [TOC](文章目录) 前言1 BridgeData V21.1 概述1.2 硬件环境 2 数据集2.1 场景与结构2.2 数据结构2.2.1 images02.2.2 obs_dict.pkl2.2.3 policy_out.pkl 3 close question3.1 英伟达环境3.2 LIBERO 环境更适合仿真3.3 4090 运行问题 前言 按照笔者之前的行业经验, 数…...
代码复现5——VLMaps
项目地址 1 Setup # 拉取VLMaps仓库,成功运行后会在主目录生成文件夹vlmapsgit clone https://github.com/vlmaps/vlmaps.git#通过 conda 创建虚拟环境conda create -n vlmaps python=3.8 -yconda activate vlmaps #激活环境cd vlmaps # 切换到项目文件下bash install.ba…...
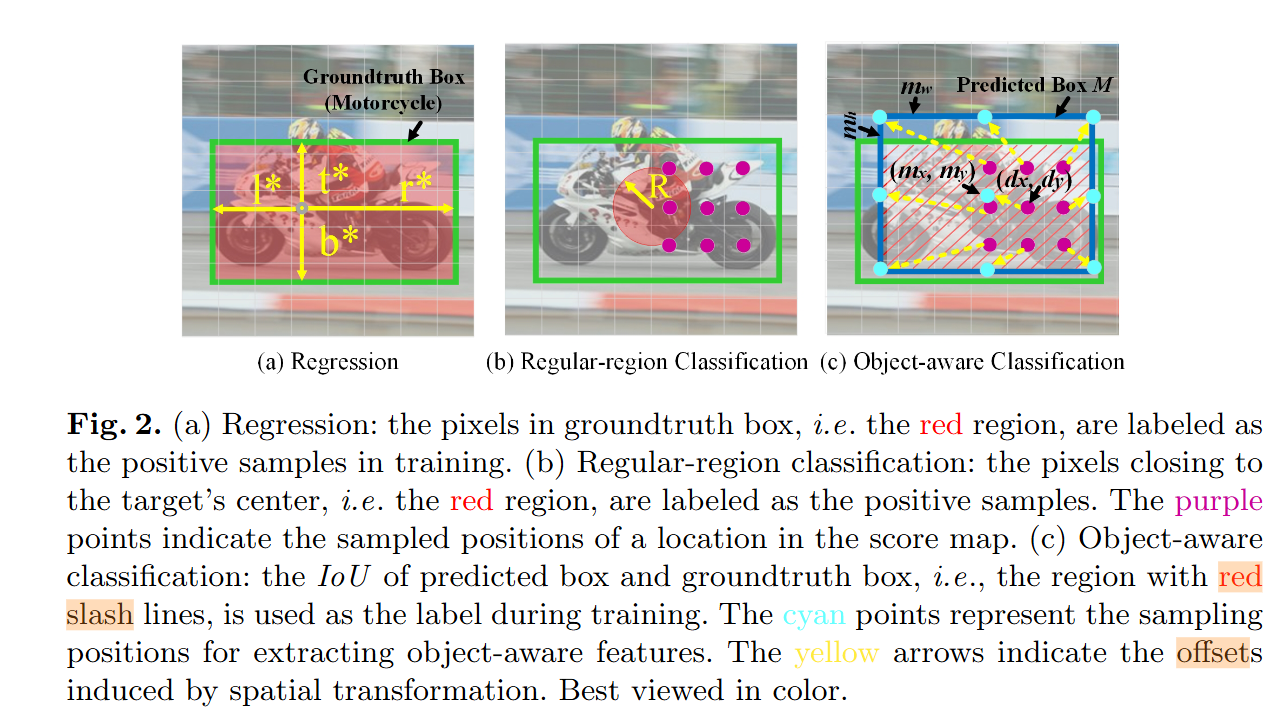
Ocean: Object-aware Anchor-free Tracking
领域:Object tracking It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame 问题/现象: Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet…...