机器学习笔记2
5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
(1) 算法
词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性
逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度

(2) API
sklearn.feature_extraction.text.TfidfVectorizer()
构造函数关键字参数stop_words,表示词特征黑名单
fit_transform函数的返回值为稀疏矩阵
(3) 示例
代码与CountVectorizer的示例基本相同,仅仅把CountVectorizer改为TfidfVectorizer即可
示例中data是一个字符串list, list中的第一个元素就代表一篇文章.
import jieba
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
def cut_words(text):return " ".join(list(jieba.cut(text)))
data = ["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]
data_new = [cut_words(v) for v in data]
transfer = TfidfVectorizer(stop_words=['期间', '做出',"重大贡献"])
data_final = transfer.fit_transform(data_new)
pd.DataFrame(data_final.toarray(), columns=transfer.get_feature_names_out())
from sklearn.feature_extraction.text import CountVectorizer
transfer = CountVectorizer(stop_words=['期间', '做出',"重大贡献"])
data_final = transfer.fit_transform(data_new)
pd.DataFrame(data_final.toarray(), columns=transfer.get_feature_names_out()) 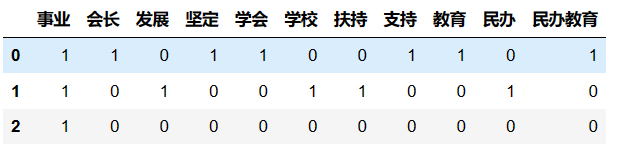
补充:在sklearn库中 TF-IDF算法做了一些细节的优化
词频 (TF)
词频是指一个词在文档中出现的频率。通常有两种计算方法:
-
原始词频:一个词在文档中出现的次数除以文档中总的词数。
-
平滑后的词频:为了防止高频词主导向量空间,有时会对词频进行平滑处理,例如使用
1 + log(TF)。 -
在 TfidfVectorizer 中,TF 默认是:直接使用一个词在文档中出现的次数也就是CountVectorizer的结果
逆文档频率 (IDF)
逆文档频率衡量一个词的普遍重要性。如果一个词在许多文档中都出现,那么它的重要性就会降低。
IDF 的计算公式是:
在 TfidfVectorizer 中,IDF 的默认计算公式是:
在 TfidfVectorizer 中还会进行归一化处理(采用的L2归一化)
L2归一化
x_1归一化后的数据=
x可以选择是行或者列的数据
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.preprocessing import normalize
from sklearn.preprocessing import StandardScaler
import jieba
import pandas as pd
import numpy as np
def my_cut(text):return " ".join(jieba.cut(text))
data=["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]
data=[my_cut(i) for i in data]
print(data)
# print("词频",CountVectorizer().fit_transform(data).toarray())
transfer=TfidfVectorizer()
res=transfer.fit_transform(data)
print(pd.DataFrame(res.toarray(),columns=transfer.get_feature_names_out()))
# 手动实现tfidf向量(跟上面的api实现出一样的效果)
def tfidf(data):# 计算词频count = CountVectorizer().fit_transform(data).toarray()print("count",count)print(np.sum(count != 0, axis=0))# 计算IDF,并采用平滑处理idf = np.log((len(data) + 1) / (1 + np.sum(count != 0, axis=0))) + 1# 计算TF-IDFtf_idf = count * idf# L2标准化tf_idf_normalized = normalize(tf_idf, norm='l2', axis=1)#axis=0是列 axis=1是行return tf_idf,tf_idf_normalized
tf_idf,tf_idf_normalized=tfidf(data)
print(pd.DataFrame(tf_idf,columns=transfer.get_feature_names_out()))
print(pd.DataFrame(tf_idf_normalized,columns=transfer.get_feature_names_out()))6 无量纲化-预处理
无量纲,即没有单位的数据
无量纲化包括"归一化"和"标准化", 为什么要进行无量纲化呢?
这是一个男士的数据表:
| 编号id | 身高 h | 收入 s | 体重 w |
|---|---|---|---|
| 1 | 1.75(米) | 15000(元) | 120(斤) |
| 2 | 1.5(米) | 16000(元) | 140(斤) |
| 3 | 1.6(米) | 20000(元) | 100(斤) |
假设算法中需要求它们之间的欧式距离, 这里以编号1和编号2为示例:
从计算上来看, 发现身高对计算结果没有什么影响, 基本主要由收入来决定了,但是现实生活中,身高是比较重要的判断标准. 所以需要无量纲化.
(1) MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
<1>归一化公式:
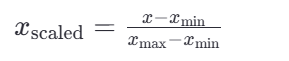
这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
比如 [-1, 1]的公式为:
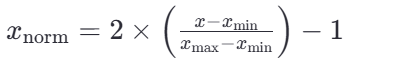
手算过程:
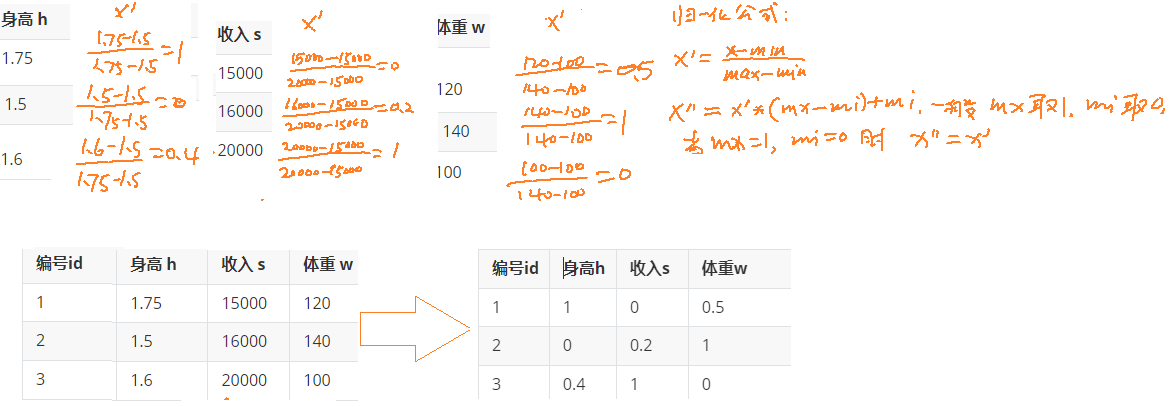
<2>归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range=(0,1) 归一化后的值域,可以自己设定
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
<3>归一化示例
示例1:原始数据类型为list
from sklearn.preprocessing import MinMaxScaler
data=[[12,22,4],[22,23,1],[11,23,9]]
#feature_range=(0, 1)表示归一化后的值域,可以自己设定
transfer = MinMaxScaler(feature_range=(0, 1))
#data_new的类型为<class 'numpy.ndarray'>
data_new = transfer.fit_transform(data)
print(data_new)输出: [[0.09090909 0. 0.375 ][1. 1. 0. ][0. 1. 1. ]]
示例2:原始数据类型为DataFrame
from sklearn.preprocessing import MinMaxScaler
import pandas as pd;
data=[[12,22,4],[22,23,1],[11,23,9]]
data = pd.DataFrame(data=data, index=["一","二","三"], columns=["一列","二列","三列"])
transfer = MinMaxScaler(feature_range=(0, 1))
data_new = transfer.fit_transform(data)
print(data_new)示例3:原始数据类型为 ndarray
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import MinMaxScaler
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=False)
data = transfer.fit_transform(data) #data类型为ndarray
print(data)
transfer = MinMaxScaler(feature_range=(0, 1))
data = transfer.fit_transform(data)
print(data)<4>缺点
最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化
(2)normalize归一化
API
from sklearn.preprocessing import normalize
normalize(data, norm='l2', axis=1)
#data是要归一化的数据
#norm是使用那种归一化:"l1" "l2" "max
#axis=0是列 axis=1是行<1> L1归一化
绝对值相加作为分母,特征值作为分子
<2> L2归一化
平方相加作为分母,特征值作为分子
<3> max归一化
max作为分母,特征值作为分子
(3)StandardScaler 标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
<1>标准化公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算:
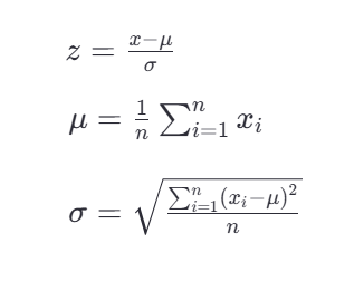
其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的 标准差
<2> 标准化 API
sklearn.preprocessing.StandardScale
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
from sklearn.preprocessing import StandardScaler
#不能加参数feature_range=(0, 1)
transfer = StandardScaler()
data_new = transfer.fit_transform(data) #data_new的类型为ndarray<3>标准化示例
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
# 1、获取数据
df_data = pd.read_csv("src/dating.txt")
print(type(df_data)) #<class 'pandas.core.frame.DataFrame'>
print(df_data.shape) #(1000, 4)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
new_data = transfer.fit_transform(df_data) #把DateFrame数据进行归一化
print("DateFrame数据被归一化后:\n", new_data[0:5])
nd_data = df_data.values #把DateFrame转为ndarray
new_data = transfer.fit_transform(nd_data) #把ndarray数据进行归一化
print("ndarray数据被归一化后:\n", new_data[0:5])
nd_data = df_data.values.tolist() #把DateFrame转为list
new_data = transfer.fit_transform(nd_data) #把ndarray数据进行归一化
print("list数据被归一化后:\n", new_data[0:5])输出: <class 'pandas.core.frame.DataFrame'> (1000, 4) DateFrame数据被归一化后:[[ 0.33193158 0.41660188 0.24523407 1.24115502][-0.87247784 0.13992897 1.69385734 0.01834219][-0.34554872 -1.20667094 -0.05422437 -1.20447063][ 1.89102937 1.55309196 -0.81110001 -1.20447063][ 0.2145527 -1.15293589 -1.40400471 -1.20447063]] ndarray数据被归一化后:[[ 0.33193158 0.41660188 0.24523407 1.24115502][-0.87247784 0.13992897 1.69385734 0.01834219][-0.34554872 -1.20667094 -0.05422437 -1.20447063][ 1.89102937 1.55309196 -0.81110001 -1.20447063][ 0.2145527 -1.15293589 -1.40400471 -1.20447063]] list数据被归一化后:[[ 0.33193158 0.41660188 0.24523407 1.24115502][-0.87247784 0.13992897 1.69385734 0.01834219][-0.34554872 -1.20667094 -0.05422437 -1.20447063][ 1.89102937 1.55309196 -0.81110001 -1.20447063][ 0.2145527 -1.15293589 -1.40400471 -1.20447063]]
自己实现标准化来测试
#数据
data=np.array([[5],[20],[40],[80],[100]])
#API实现标准化
data_news=scaler.fit_transform(data)
print("API实现:\n",data_news)
#标准化自己实现
mu=np.mean(data)
sum=0
for i in data:sum+=((i[0]-mu)**2)
d=np.sqrt(sum/(len(data)))
print("自己实现:\n",(data[3]-mu)/d)<4> 注意点
在数据预处理中,特别是使用如StandardScaler这样的数据转换器时,fit、fit_transform和transform这三个方法的使用是至关重要的,它们各自有不同的作用:
-
fit:
-
这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。这些统计信息随后会被用于数据的标准化。 -
你应当仅在训练集上使用
fit方法。
-
-
fit_transform:
-
这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。 -
它同样应当仅在训练集上使用,它会计算训练集的统计信息并立即应用到该训练集上。
-
-
transform:
-
这个方法使用已经通过
fit方法计算出的统计信息来转换数据。 -
它可以应用于任何数据集,包括训练集、验证集或测试集,但是应用时使用的统计信息必须来自于训练集。
-
当你在预处理数据时,首先需要在训练集X_train上使用fit_transform,这样做可以一次性完成统计信息的计算和数据的标准化。这是因为我们需要确保模型是基于训练数据的统计信息进行学习的,而不是整个数据集的统计信息。
一旦scaler对象在X_train上被fit,它就已经知道了如何将数据标准化。这时,对于测试集X_test,我们只需要使用transform方法,因为我们不希望在测试集上重新计算任何统计信息,也不希望测试集的信息影响到训练过程。如果我们对X_test也使用fit_transform,测试集的信息就可能会影响到训练过程。
7 特征降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
-
特征选择
-
从原始特征集中挑选出最相关的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
-
1 .特征选择
(a) VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
-
方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
-
计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
-
设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
-
过滤特征:移除所有方差低于设定阈值的特征
-
-
创建对象,准备把方差为等于小于2的去掉,threshold的缺省值为2.0 sklearn.feature_selection.VarianceThreshold(threshold=2.0) 把x中低方差特征去掉, x的类型可以是DataFrame、ndarray和list VananceThreshold.fit_transform(x) fit_transform函数的返回值为ndarray
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
def variance_demo():# 1、获取数据,data是一个DataFrame,可以是读取的csv文件data=pd.DataFrame([[10,1],[11,3],[11,1],[11,5],[11,9],[11,3],[11,2],[11,6]])print("data:\n", data) # 2、实例化一个转换器类transfer = VarianceThreshold(threshold=1)#0.1阈值# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n",data_new)return None
variance_demo()(b) 根据相关系数的特征选择
<1>理论
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
-
如果第一个变量增加,第二个变量也有很大的概率会增加。
-
同样,如果第一个变量减少,第二个变量也很可能会减少。
正相关性并不意味着一个变量的变化直接引起了另一个变量的变化,它仅仅指出了两个变量之间存在的一种统计上的关联性。这种关联性可以是因果关系,也可以是由第三个未观察到的变量引起的,或者是纯属巧合。
在数学上,正相关性通常用正值的相关系数来表示,这个值介于0和1之间。当相关系数等于1时,表示两个变量之间存在完美的正相关关系,即一个变量的值可以完全由另一个变量的值预测。
举个例子,假设我们观察到在一定范围内,一个人的身高与其体重呈正相关,这意味着在一般情况下,身高较高的人体重也会较重。但这并不意味着身高直接导致体重增加,而是可能由于营养、遗传、生活方式等因素共同作用的结果。
负相关性(Negative Correlation)与正相关性刚好相反,但是也说明相关,比如运动频率和BMI体重指数程负相关
不相关指两者的相关性很小,一个变量变化不会引起另外的变量变化,只是没有线性关系. 比如饭量和智商
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是 [−1,1],其中:
-
表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。
-
表示完全负相关,即随着一个变量的增加,另一个变量线性减少。
-
表示两个变量之间不存在线性关系。
相关系数$\rho$的绝对值为0-1之间,绝对值越大,表示越相关,当两特征完全相关时,两特征的值表示的向量是
在同一条直线上,当两特征的相关系数绝对值很小时,两特征值表示的向量接近在同一条直线上。当相关系值为负数时,表示负相关
<2>皮尔逊相关系数:pearsonr相关系数计算公式, 该公式出自于概率论
对于两组数据 𝑋={𝑥1,𝑥2,...,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,...,𝑦𝑛},皮尔逊相关系数可以用以下公式计算:
和
分别是𝑋和𝑌的平均值
|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关
<3>api:
scipy.stats.personr(x, y) 计算两特征之间的相关性
返回对象有两个属性:
statistic皮尔逊相关系数[-1,1]
pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关
<4>示例:
from scipy.stats import pearsonr
def association_demo():# 1、获取数据data = pd.read_csv("src/factor_returns.csv")data = data.iloc[:, 1:-2]# 计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print(r1.statistic) #-0.0043893227799362555 相关性, 负数表示负相关,正数表示正相关print(r1.pvalue) #0.8327205496590723 相关性,越小越相关r2 = pearsonr(data['revenue'], data['total_expense'])print(r2) #PearsonRResult(statistic=0.9958450413136111, pvalue=0.0)return None
association_demo()开发中一般不使用求相关系数的方法,一般使用主成分分析,因为主成分分样过程中就包括了求相关系数了。
2.主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
(a) 原理
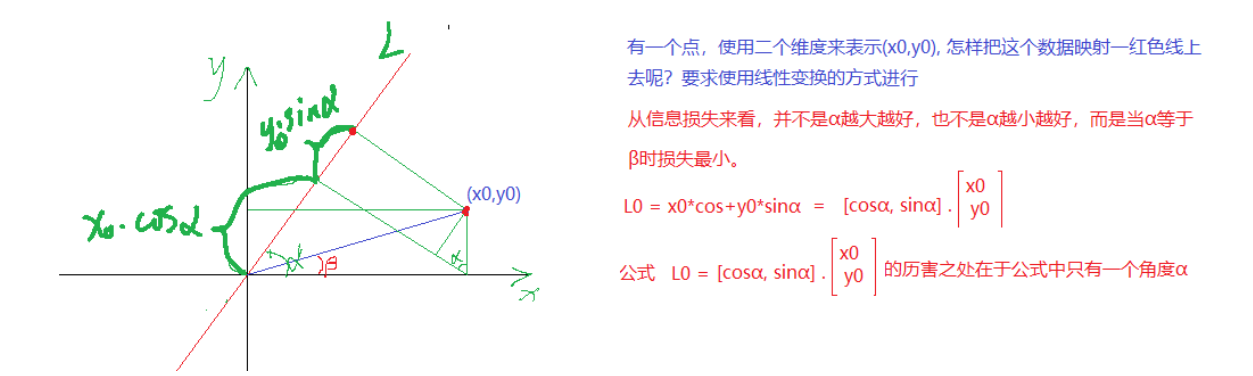
投影到L的大小为
投影到L的大小为
使用表示一个点, 表明该点有两个特征, 而映射到L上有一个特征就可以表示这个点了。这就达到了降维的功能 。
投影到L上的值就是降维后保留的信息,投影到与L垂直的轴上的值就是丢失的信息。保留信息/原始信息=信息保留的比例
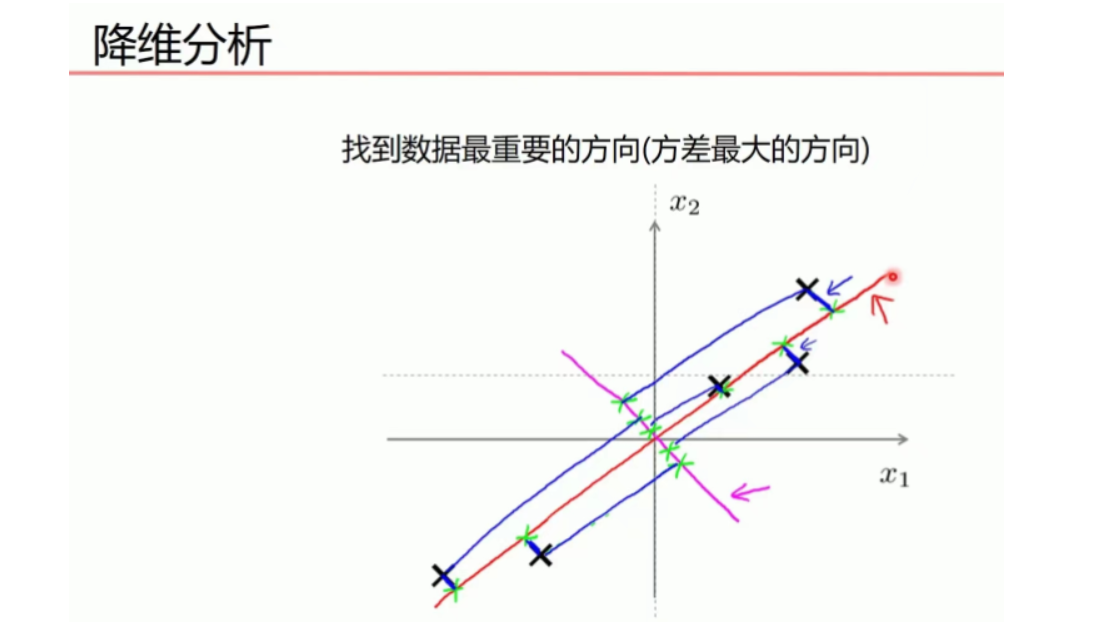
下图中红线上点与点的距离是最大的,所以在红色线上点的方差最大,粉红线上的刚好相反.
所以红色线上点来表示之前点的信息损失是最小的。
(b) 步骤
-
得到矩阵
-
用矩阵P对原始数据进行线性变换,得到新的数据矩阵Z,每一列就是一个主成分, 如下图就是把10维降成了2维,得到了两个主成分
-
-
根据主成分的方差等,确定最终保留的主成分个数, 方差大的要留下。一个特征的多个样本的值如果都相同,则方差为0, 则说明该特征值不能区别样本,所以该特征没有用。
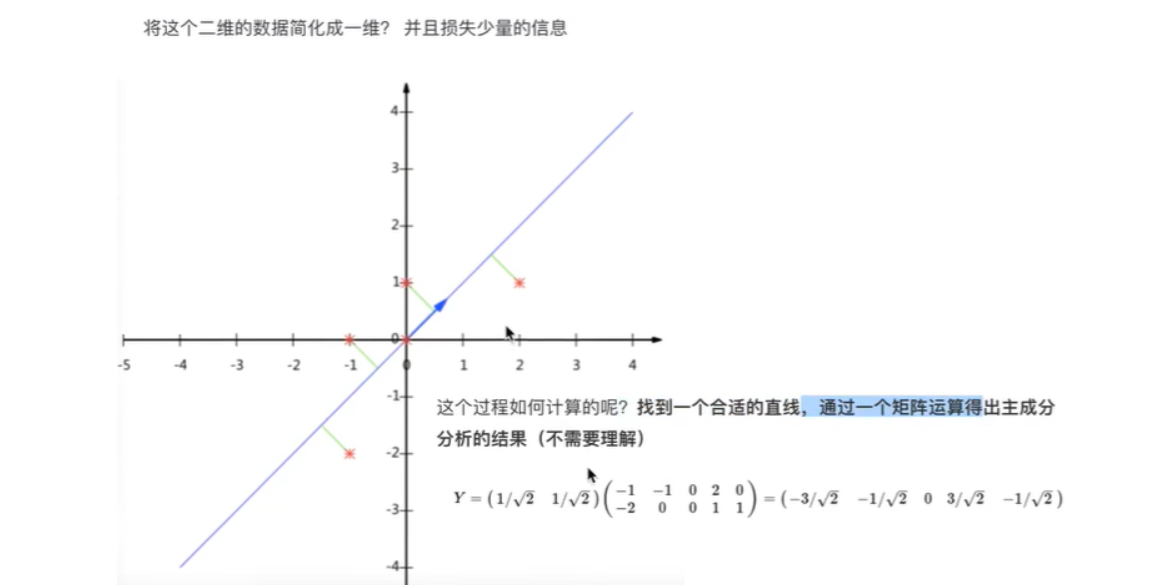
比如下图的二维数据要降为一维数据,图形法是把所在数据在二维坐标中以点的形式标出,然后给出一条直线,让所有点垂直映射到直线上,该直线有很多,只有点到线的距离之和最小的线才能让之前信息损失最小。
这样之前所有的二维表示的点就全部变成一条直线上的点,从二维降成了一维。
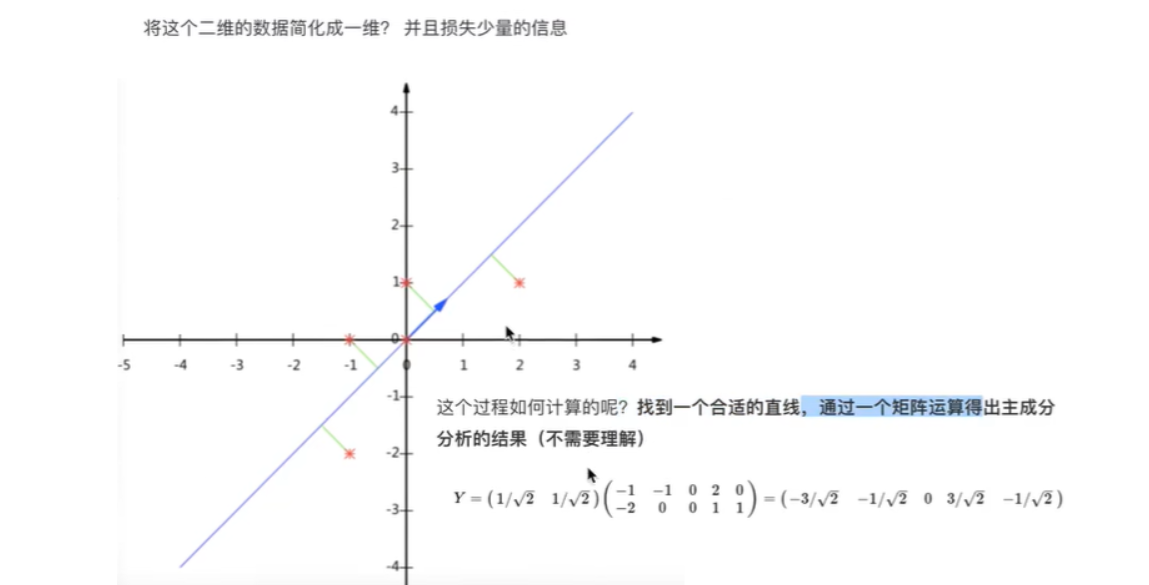
上图是一个从二维降到一维的示例:的原始数据为
| 特征1-X1 | 特征2-X2 |
|---|---|
| -1 | -2 |
| -1 | 0 |
| 0 | 0 |
| 2 | 1 |
| 0 | 1 |
降维后新的数据为
| 特征3-X0 |
|---|
| -3/√2 |
| -1/√2 |
| 0 |
| 3/√2 |
| -1/√2 |
3.api
-
from sklearn.decomposition import PCA
-
PCA(n_components=None)
-
主成分分析
-
n_components:
-
实参为小数时:表示降维后保留百分之多少的信息
-
实参为整数时:表示减少到多少特征
-
-
(3)示例-n_components为小数
from sklearn.decomposition import PCA
def pca_demo():data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、实例化一个转换器类, 降维后还要保留原始数据0.95%的信息, 最后的结果中发现由4个特征降维成2个特征了transfer = PCA(n_components=0.95)# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None
pca_demo()输出: data_new:[[-3.13587302e-16 3.82970843e+00][-5.74456265e+00 -1.91485422e+00][ 5.74456265e+00 -1.91485422e+00]]
(4)示例-n_components为整数
from sklearn.decomposition import PCA
def pca_demo():data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、实例化一个转换器类, 降维到只有3个特征transfer = PCA(n_components=3)# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None
pca_demo()输出: data_new:[[-3.13587302e-16 3.82970843e+00 4.59544715e-16][-5.74456265e+00 -1.91485422e+00 4.59544715e-16][ 5.74456265e+00 -1.91485422e+00 4.59544715e-16]]
相关文章:
机器学习笔记2
5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取 (1) 算法 词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性 逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度 (2) API sklearn.feature_extraction.text.TfidfVector…...

AgentCPM-GUI,清华联合面壁智能开源的端侧GUI智能体模型
AgentCPM-GUI是什么 AgentCPM-GUI 是由清华大学与面壁智能团队联合开发的一款开源端侧图形用户界面(GUI)代理,专为中文应用进行优化。基于 MiniCPM-V 模型(80 亿参数),该系统能够接收智能手机的屏幕截图&a…...

Go语言实现链式调用
在 Go 语言中实现链式调用(Method Chaining),可以通过让每个方法返回对象本身(或对象的指针)来实现。这样每次方法调用后可以继续调用其他方法。 示例:实现字符串的链式操作 假设你想对一个字符串连续执行…...
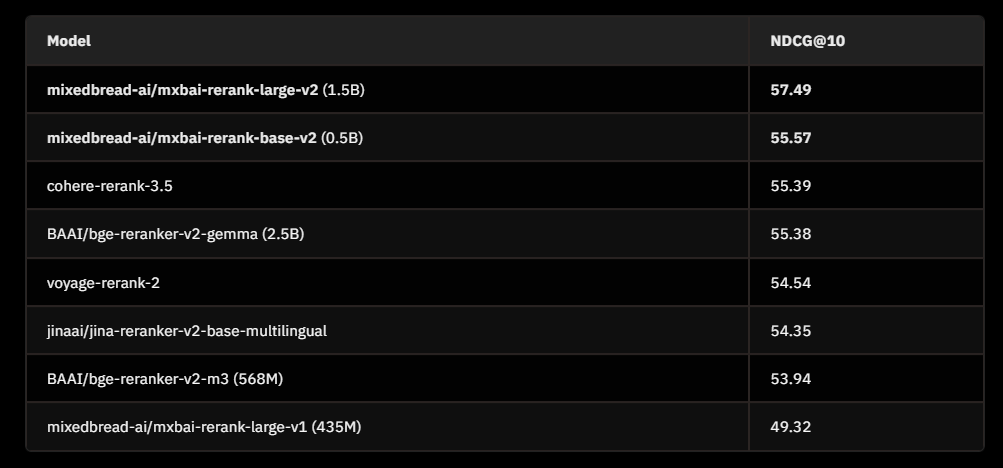
重排序模型解读 mxbai-rerank-base-v2 强大的重排序模型
mxbai-rerank-base-v2 强大的重排序模型 模型介绍benchmark综合评价安装 模型介绍 mxbai-rerank-base-v2 是 Mixedbread 提供的一个强大的重排序模型,旨在提高搜索相关性。该模型支持多语言,特别是在英语和中文方面表现出色。它还支持代码和 SQL 排序&a…...
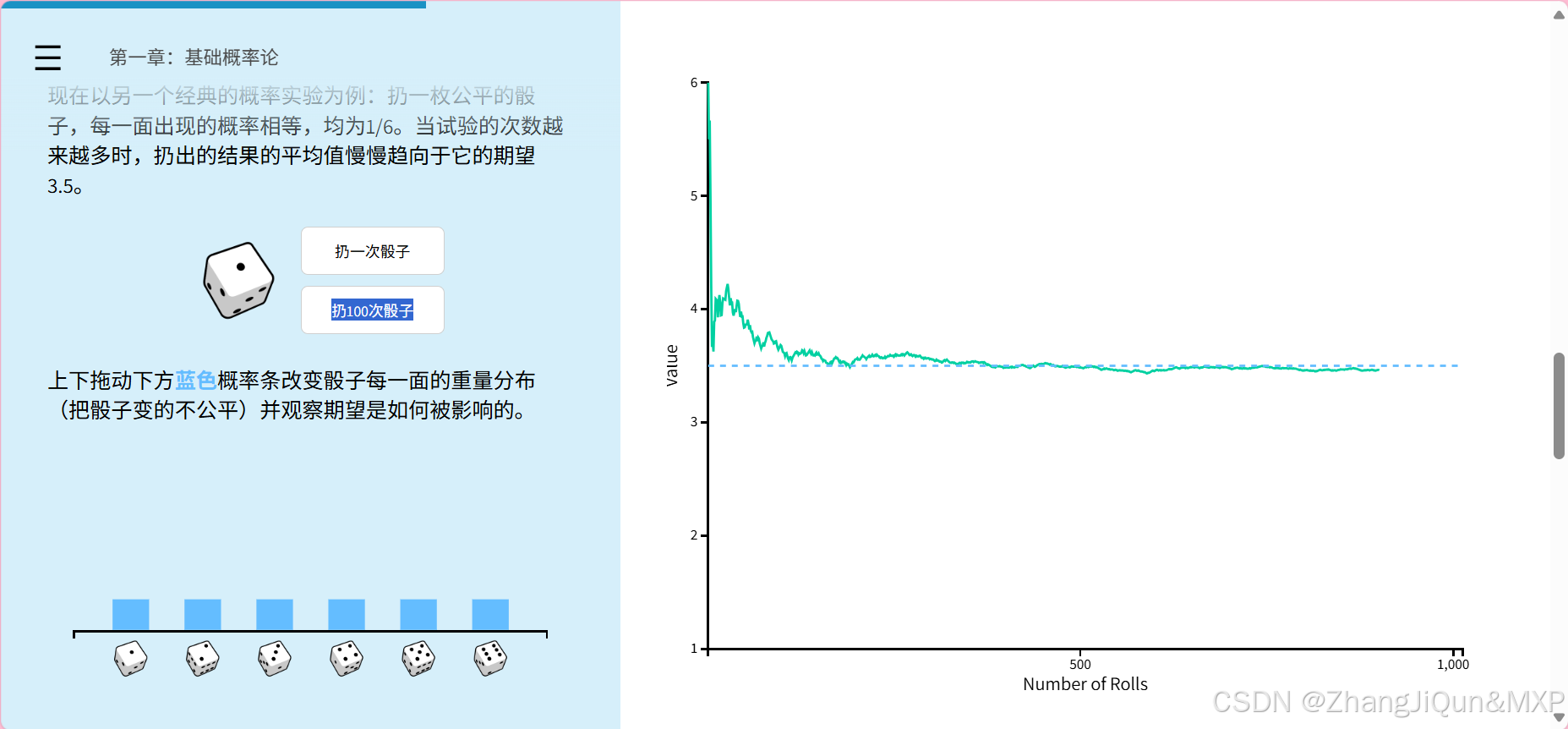
期望是什么:(无数次的均值,结合概率)21/6=3.5
https://seeing-theory.brown.edu/basic-probability/cn.html 期望是什么:(无数次的均值,结合概率)21/6=3.5 一、期望(数学概念) 在概率论和统计学中,**期望(Expectation)**是一个核心概念,用于描述随机变量的长期平均取值,反映随机变量取值的集中趋势。 (一…...
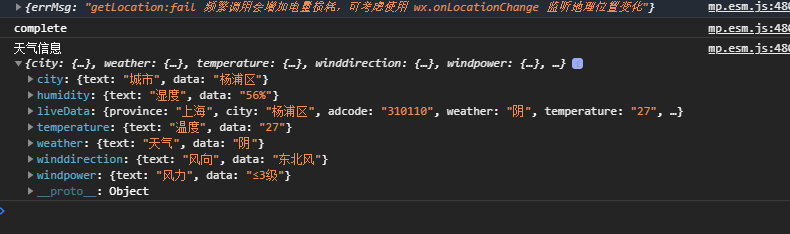
uniapp-vue3项目中引入高德地图的天气展示
前言: uniapp-vue3项目中引入高德地图的天气展示 效果: 操作步骤: 1、页面上用定义我们的 当前天气信息:<view></view> 2、引入我们的map文件 <script setup>import amapFile from ../../libs/amap-wx.js …...

容器化-k8s-介绍及下载安装教程
一、K8s 概念 官网地址: https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/ 1、含义 Kubernetes 是一个开源的容器编排引擎,用于自动化部署、扩展和管理容器化应用程序。它可以将多个容器组合成一个逻辑单元,实现对容器的集中管理和调度,从而简化复杂应用的部…...

lc42接雨水
1.原题 42. 接雨水 - 力扣(LeetCode) 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 2.题目解析 这一题是经常被考到的一道算法题,其中最简单最好用的方法就是双指…...
通义千问-langchain使用构建(三)
目录 序言docker 部署xinference1WSL环境docker安装2拉取镜像运行容器3使用的界面 本地跑chatchat1rag踩坑2使用的界面2.1配置个前置条件然后对话2.2rag对话 结论 序言 在前两天的基础上,将xinference调整为wsl环境,docker部署。 然后langchain chatcha…...

uniapp自动构建pages.json的vite插件
对于 uniapp 来说,配置 pages.json 无疑是最繁琐的事情,具有以下缺点: 冗长,页面很多时 pages 内容会很长难找,有时候因为内容很长,导致页面配置比较难找,而且看起来比较凌乱json弊端ÿ…...

系统漏洞扫描服务:维护网络安全的关键与服务原理?
系统漏洞扫描服务是维护网络安全的关键措施,能够迅速发现系统中的潜在风险,有效预防可能的风险和损失。面对网络攻击手段的日益复杂化,这一服务的重要性日益显著。 服务原理 系统漏洞扫描服务犹如一名恪尽职守的安全守护者。它运用各类扫描…...

nlf loss 学习笔记
目录 数据集: 3d 投影到2d 继续求loss reconstruct_absolute 1. 功能概述 2. 参数详解 3. 两种重建模式对比 数据集: agora3 | 5264/5264 [00:00<00:00, 143146.78it/s] behave 37736/37736 [00:00<00:00, 76669.67it/s] mads 32649/3264…...
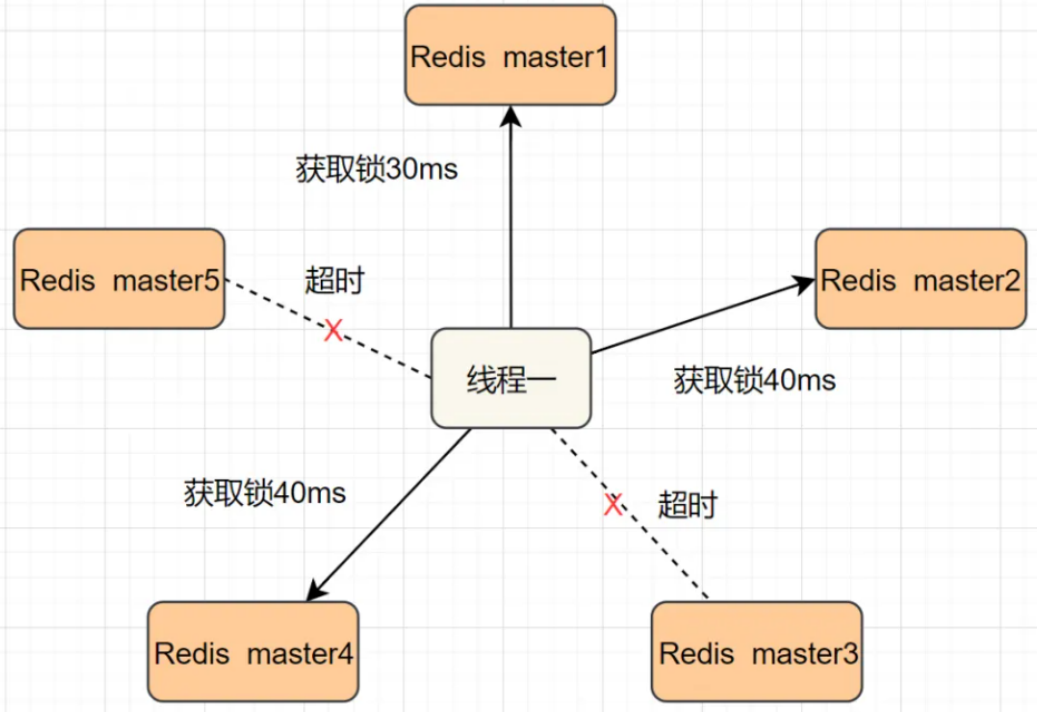
【Redis】零碎知识点(易忘 / 易错)总结回顾
一、Redis 是一种基于键值对(key-value)的 NoSQL 数据库 二、Redis 会将所有数据都存放在内存中,所以它的读写性能非常惊人 Redis 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障时…...
基于three.js 全景图片或视频开源库Photo Sphere Viewer
Photo Sphere Viewer 是一个基于 JavaScript 的开源库,专门用于在网页上展示 360 全景图片或视频。它提供了丰富的交互功能,允许用户通过鼠标、触摸屏或陀螺仪来浏览全景内容,适用于旅游、房地产、虚拟现实、教育等多个领域。 主要特点 多种…...

LangPDF: Empowering Your PDFs with Intelligent Language Processing
LangPDF: Empowering Your PDFs with Intelligent Language Processing Unlock Global Communication: AI-Powered PDF Translation and Beyond In an interconnected world, seamless multilingual document management is not just an advantage—it’s a necessity. LangP…...

OpenVLA (2) 机器人环境和环境数据
文章目录 [TOC](文章目录) 前言1 BridgeData V21.1 概述1.2 硬件环境 2 数据集2.1 场景与结构2.2 数据结构2.2.1 images02.2.2 obs_dict.pkl2.2.3 policy_out.pkl 3 close question3.1 英伟达环境3.2 LIBERO 环境更适合仿真3.3 4090 运行问题 前言 按照笔者之前的行业经验, 数…...
代码复现5——VLMaps
项目地址 1 Setup # 拉取VLMaps仓库,成功运行后会在主目录生成文件夹vlmapsgit clone https://github.com/vlmaps/vlmaps.git#通过 conda 创建虚拟环境conda create -n vlmaps python=3.8 -yconda activate vlmaps #激活环境cd vlmaps # 切换到项目文件下bash install.ba…...
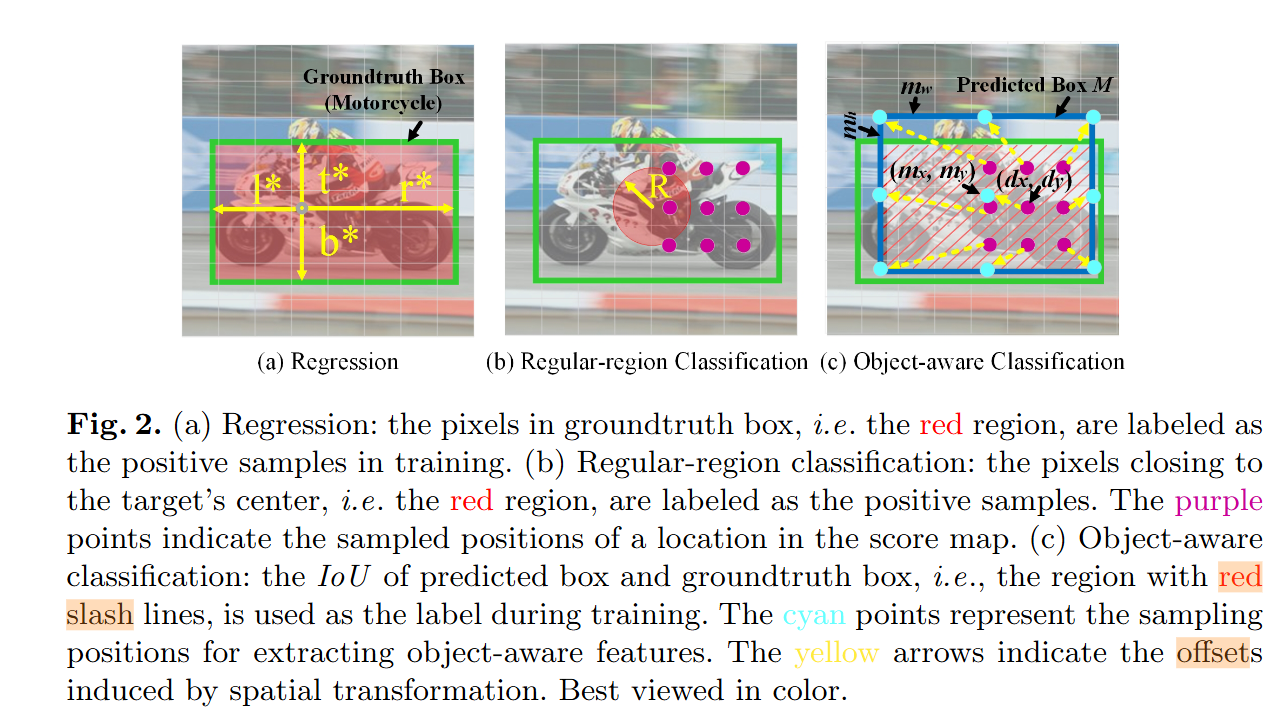
Ocean: Object-aware Anchor-free Tracking
领域:Object tracking It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame 问题/现象: Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet…...

计算机网络(1)——概述
1.计算机网络基本概念 1.1 什么是计算机网络 计算机网络的产生背景 在计算机网络出现之前,计算机之间都是相互独立的,每台计算机只能访问自身存储的数据,无法与其他计算机进行数据交换和资源共享。这种独立的计算机系统存在诸多局限性&#…...

刘家祎双剧收官见证蜕变,诠释多面人生
近期,两部风格迥异的剧集迎来收官时刻,而青年演员刘家祎在《我家的医生》与《无尽的尽头》中的精彩演绎,无疑成为观众热议的焦点。从温暖治愈的医疗日常到冷峻深刻的少年救赎,他以极具张力的表演,展现出令人惊叹的可塑…...
Axure制作可视化大屏动态滚动列表教程
在可视化大屏设计中,动态滚动列表是一种常见且实用的展示方式,能够有效地展示大量信息。本文将详细介绍如何使用Axure制作一个动态滚动的列表展示模块。 一、准备工作 打开Axure软件:确保你已经安装并打开了Axure RP软件。创建新项目&#x…...
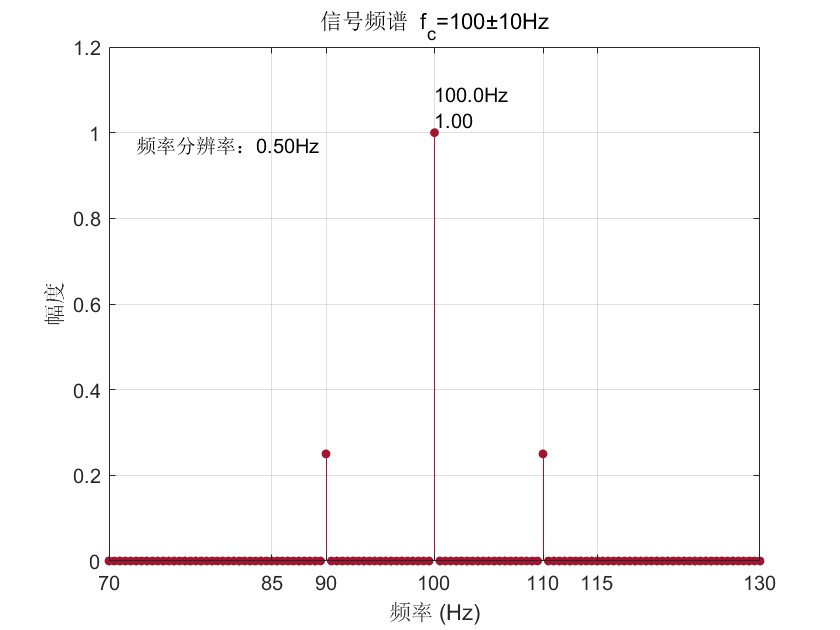
MATLAB实现振幅调制(AM调制信号)
AM调制是通信专业非常重要的一个知识点。今天我们使用MATLAB编程实现AM调制。 我们实现输入一个载波信号的频率与调制信号的频率后,再输入调幅度,得到已调信号的波形与包络信号的波形,再使用FFT算法分析出已调信号的频谱图。 源代码&#x…...
)
LLM-Based Agent综述及其框架学习(五)
文章目录 摘要Abstract1. 引言2. 文本输出3. 工具的使用3.1 理解工具3.2 学会使用工具3.3 制作自给自足的工具3.4 工具可以扩展LLM-Based Agent的行动空间3.5 总结 4. 具身动作5. 学习智能体框架5.1 CrewAI学习进度5.2 LangGraph学习进度5.3 MCP学习进度 参考总结 摘要 本文围绕…...

6.1.1图的基本概念
基本概念 图: 顶点集边集 顶点集:所有顶点的集合,不能为空(因为图是顶点集和边集组成,其中一个顶点集不能为空,则图肯定不为空) 边集:所有边的集合,边是由顶点集中的2…...
Linux面试题集合(6)
创建多级目录或者同级目录 mkdir -p 文件名/文件名/文件名 mkdir -p 文件名 文件名 文件名 Linux创建一个文件 touch 文件名 DOS命令创建文件 echo 内容>文件名(创建一个有内容的文件) echo >文件名(创建一个没有内容的文件)…...

时间筛掉了不够坚定的东西
2025年5月17日,16~25℃,还好 待办: 《高等数学1》重修考试 《高等数学2》备课 《物理[2]》备课 《高等数学2》取消考试资格学生名单 《物理[2]》取消考试资格名单 职称申报材料 2024年税务申报 5月24日、25日监考报名 遇见:敲了一…...

Python集合运算:从基础到进阶全解析
Python基础:集合运算进阶 文章目录 Python基础:集合运算进阶一、知识点详解1.1 集合运算(运算符 vs 方法)1.2 集合运算符优先级1.3 集合关系判断方法1.4 方法对比 二、说明示例2.1 权限管理系统2.2 数据去重与差异分析2.3 数学运算…...
openjdk17 c++源码垃圾回收安全点信号函数处理线程阻塞)
jvm安全点(二)openjdk17 c++源码垃圾回收安全点信号函数处理线程阻塞
1. 信号处理与桩代码(Stub) 当线程访问安全点轮询页(Polling Page)时: 触发 SIGSEGV 信号:访问只读的轮询页会引发 SIGSEGV 异常。信号处理函数:pd_hotspot_signal_handl…...
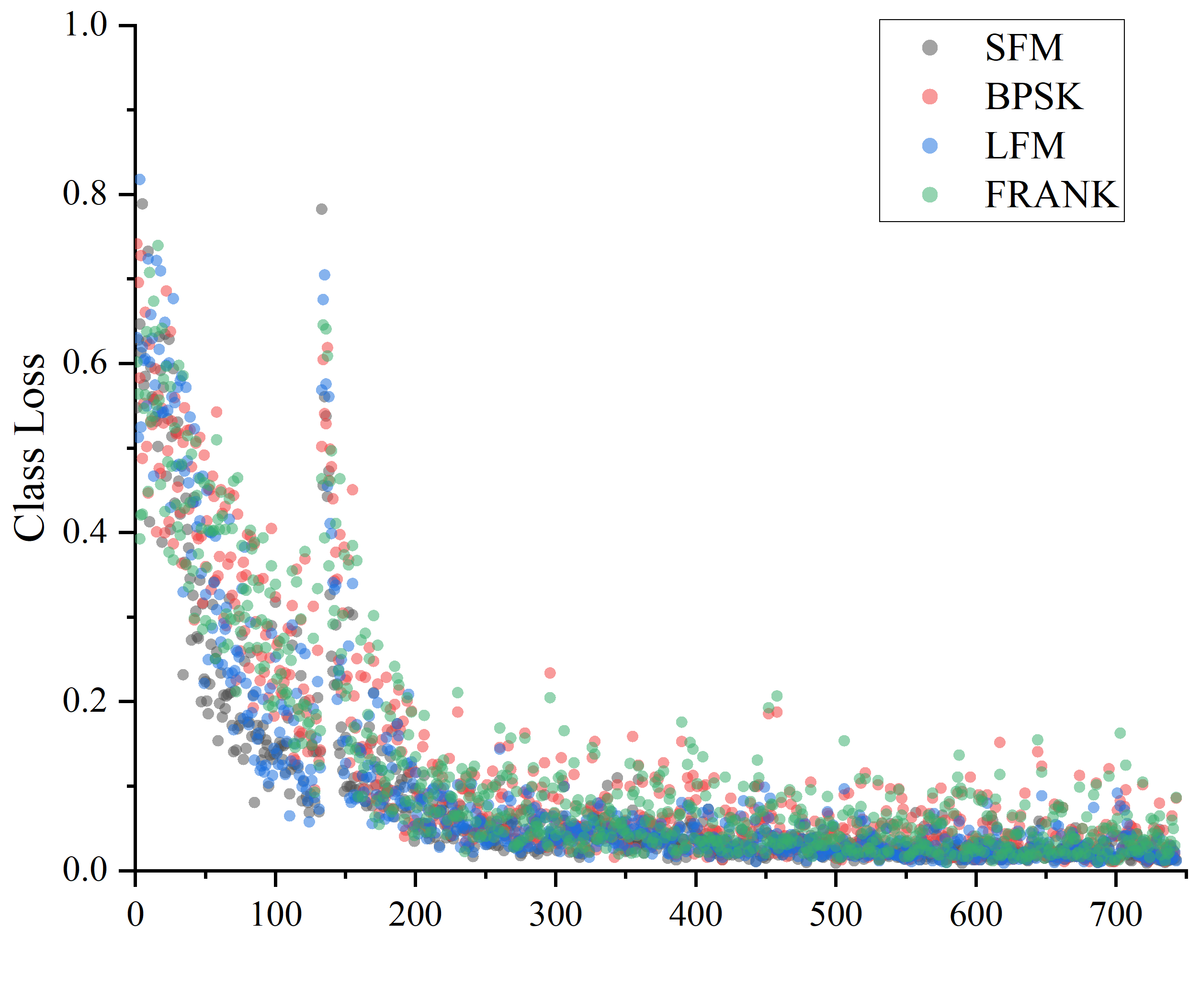
YOLOv7训练时4个类别只出2个类别
正常是4个类别: 但是YOLOv7训练完后预测总是只有两个类别: 而且都是LFM和SFM 我一开始检查了下特征图大小,如果输入是640*640的话,三个尺度特征图是80*80,40*40,20*20;如果输入是416*416的话,三个尺度特征…...
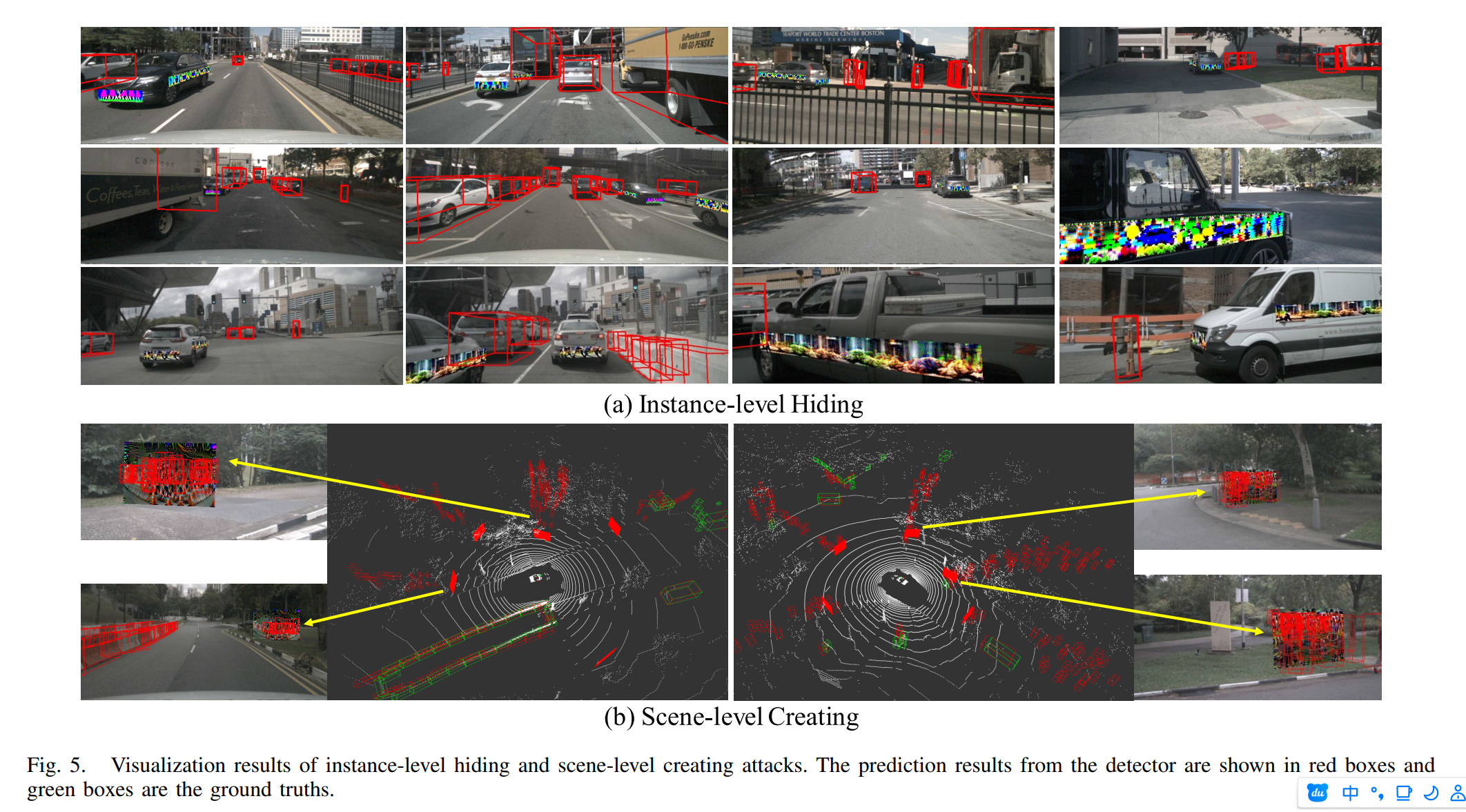
【论文阅读】针对BEV感知的攻击
Understanding the Robustness of 3D Object Detection with Bird’s-Eye-View Representations in Autonomous Driving 这篇文章是发表在CVPR上的一篇文章,针对基于BEV的目标检测算法进行了两类可靠性分析,即恶劣自然条件以及敌对攻击。同时也提出了一…...