生成对抗网络(Generative Adversarial Networks ,GAN)
生成对抗网络是深度学习领域最具革命性的生成模型之一。
一 GAN框架
1.1组成
构造生成器(G)与判别器(D)进行动态对抗,实现数据的无监督生成。
G(造假者):接收噪声 ,生成数据
。
D(鉴定家):接收真实数据 和生成数据
,输出概率
或
1.2核心原理
对抗目标:
该公式为极大极小博弈,D和G互为对手,在动态博弈中驱动模型逐步提升性能。
其中:
第一项(真实性强化) 的目标为:
让判别器 D 将真实数据 x 识别为“真”(即让 ),最大化这一项可使D对真实数据的判断置信度更高。
第二项(生成性对抗):的目标为:
生成器G希望生成的假数据被判别器D判为“真”(即让
)从而最小化
,判别器D则希望判假数据为“假”(即让
),从而最大化
。
生成器和判别器在此项上存在直接对抗。
数学原理:
(1)最优判别器理论
固定生成器G时,最大化 得到最优判别器
。
其中, 是生成数据的分布。当生成数据完美匹配真实分布时
,判别器无法区分真假(输出
)。
推导一下:
(1)
转换为积分形式,设真实数据分布为 ,生成数据分布为
,则(1)可以改写为:
(2)
逐点最大化,对于每个样本 x,单独最大化以下函数:
(3)
求导并解方程:
(4)
求得:
(5)
(2) 目标化简:JS散度(Jensen-Shannon Divergence)
将最优判别器 代入原目标函数,可得:
最小化目标即等价于最小化 与
的JS散度。
JS散度特性:对称、非负,衡量两个分布的相似性。
1.3训练过程解释
每个训练步骤包含两阶段:
(1)判别器更新(固定G,最大化 ):
通过梯度上升优化D的参数,提升判别能力。
(2)生成器更新(固定D,最小化 ):
实际训练中常用 代替以增强梯度稳定性。
训练中出现的问题:
(1)JS散度饱和导致梯度消失
(2)参数空间的非凸优化(存在无数个局部极值,优化算法极易陷入次优解,而非全局最优解)使训练难以收敛
二 经典GAN架构
DCGAN(GAN+卷积)
| 特性 | 原始GAN | DCGAN |
|---|---|---|
| 网络结构 | 全连接层(MLPs) | 卷积生成器 + 卷积判别器 |
| 稳定性 | 容易梯度爆炸/消失,难以收敛 | 通过BN和特定激活函数稳定训练 |
| 生成图像分辨率 | 低分辨率(如32x32) | 支持64x64及以上分辨率的清晰图像生成 |
| 图像质量 | 轮廓模糊,缺乏细节 | 细粒度纹理(如毛发、砖纹) |
| 计算效率 | 参数量大,训练速度慢 | 卷积结构参数共享,效率提升 |
(1)生成器架构(反卷积)
class Generator(nn.Module):def __init__(self, noise_dim=100, output_channels=3):super().__init__()self.main = nn.Sequential(# 输入:100维噪声,输出:1024x4x4nn.ConvTranspose2d(noisel_dim, 512, 4, 1, 0, bias=False),nn.BatchNorm2d(512),nn.ReLU(True),# 上采样至8x8nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),nn.BatchNorm2d(256),nn.ReLU(True),# 输出层:3通道RGB图像nn.ConvTranspose2d(64, output_channels, 4, 2, 1, bias=False),nn.Tanh() # 将输出压缩到[-1,1])
(2) 判别器架构(卷积)
class Discriminator(nn.Module):def __init__(self, input_channels=3):super().__init__()self.main = nn.Sequential(# 输入:3x64x64nn.Conv2d(input_channels, 64, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# 下采样至32x32nn.Conv2d(64, 128, 4, 2, 1, bias=False),nn.BatchNorm2d(128),nn.LeakyReLU(0.2, inplace=True),# 输出层:二分类概率nn.Conv2d(512, 1, 4, 1, 0, bias=False),nn.Sigmoid())
(3)双重优化问题
保持生成器和判别器动态平衡的核心机制。
for epoch in range(num_epochs):# 更新判别器optimizer_D.zero_grad()real_loss = adversarial_loss(D(real_imgs), valid)fake_loss = adversarial_loss(D(gen_imgs.detach()), fake)d_loss = (real_loss + fake_loss) / 2d_loss.backward()optimizer_D.step()# 更新生成器optimizer_G.zero_grad()g_loss = adversarial_loss(D(gen_imgs), valid) # 欺诈判别器g_loss.backward()optimizer_G.step()
三 应用场景
图像合成引擎(语义图到照片)、医学影像增强、语音与音频合成。
GAN作为生成式AI的基石模型,其核心价值不仅在于数据生成能力,更在于构建了一种全新的深度学习范式——通过对抗博弈驱动模型持续进化。
四 一个完整DCGAN代码示例
MNIST数据集
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 参数设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 128
image_size = 64
num_epochs = 50
latent_dim = 100
lr = 0.0002
beta1 = 0.5# 数据准备
transform = transforms.Compose([transforms.Resize(image_size),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,)) # MNIST是单通道
])dataset = datasets.MNIST(root="./data", train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)# 可视化辅助函数
def show_images(images):plt.figure(figsize=(8,8))images = images.permute(1,2,0).cpu().numpy()plt.imshow((images * 0.5) + 0.5) # 反归一化plt.axis('off')plt.show()# 权重初始化
def weights_init(m):classname = m.__class__.__name__if classname.find('Conv') != -1:nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find('BatchNorm') != -1:nn.init.normal_(m.weight.data, 1.0, 0.02)nn.init.constant_(m.bias.data, 0)# 生成器定义
class Generator(nn.Module):def __init__(self, latent_dim):super(Generator, self).__init__()self.main = nn.Sequential(# 输入:latent_dim x 1 x 1nn.ConvTranspose2d(latent_dim, 512, 4, 1, 0, bias=False),nn.BatchNorm2d(512),nn.ReLU(True),# 输出:512 x 4 x 4nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),nn.BatchNorm2d(256),nn.ReLU(True),# 输出:256 x 8 x 8nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),nn.BatchNorm2d(128),nn.ReLU(True),# 输出:128 x 16x16nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),nn.BatchNorm2d(64),nn.ReLU(True),# 输出:64 x 32x32nn.ConvTranspose2d(64, 1, 4, 2, 1, bias=False),nn.Tanh() # 输出范围[-1,1]# 最终输出:1 x 64x64)def forward(self, input):return self.main(input)# 判别器定义
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.main = nn.Sequential(# 输入:1 x 64x64nn.Conv2d(1, 64, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# 输出:64 x32x32nn.Conv2d(64, 128, 4, 2, 1, bias=False),nn.BatchNorm2d(128),nn.LeakyReLU(0.2, inplace=True),# 输出:128x16x16nn.Conv2d(128, 256, 4, 2, 1, bias=False),nn.BatchNorm2d(256),nn.LeakyReLU(0.2, inplace=True),# 输出:256x8x8nn.Conv2d(256, 512, 4, 2, 1, bias=False),nn.BatchNorm2d(512),nn.LeakyReLU(0.2, inplace=True),# 输出:512x4x4nn.Conv2d(512, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):return self.main(input).view(-1, 1).squeeze(1)# 初始化模型
generator = Generator(latent_dim).to(device)
discriminator = Discriminator().to(device)# 应用权重初始化
generator.apply(weights_init)
discriminator.apply(weights_init)# 损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999))# 训练过程可视化准备
fixed_noise = torch.randn(64, latent_dim, 1, 1, device=device)# 训练循环
for epoch in range(num_epochs):for i, (real_images, _) in enumerate(dataloader):# 准备数据real_images = real_images.to(device)batch_size = real_images.size(0)# 真实标签和虚假标签real_labels = torch.full((batch_size,), 0.9, device=device) # label smoothingfake_labels = torch.full((batch_size,), 0.0, device=device)# ========== 训练判别器 ==========optimizer_D.zero_grad()# 真实图片的判别结果outputs_real = discriminator(real_images)loss_real = criterion(outputs_real, real_labels)# 生成假图片noise = torch.randn(batch_size, latent_dim, 1, 1, device=device)fake_images = generator(noise)# 假图片的判别结果outputs_fake = discriminator(fake_images.detach())loss_fake = criterion(outputs_fake, fake_labels)# 合并损失并反向传播loss_D = loss_real + loss_fakeloss_D.backward()optimizer_D.step()# ========== 训练生成器 ==========optimizer_G.zero_grad()# 更新生成器时的判别结果outputs = discriminator(fake_images)loss_G = criterion(outputs, real_labels) # 欺骗判别器# 反向传播loss_G.backward()optimizer_G.step()# 打印训练状态if i % 100 == 0:print(f"[Epoch {epoch}/{num_epochs}] [Batch {i}/{len(dataloader)}] "f"Loss_D: {loss_D.item():.4f} Loss_G: {loss_G.item():.4f}")# 每个epoch结束时保存生成结果with torch.no_grad():test_images = generator(fixed_noise)grid = torchvision.utils.make_grid(test_images, nrow=8, normalize=True)show_images(grid)# 保存模型检查点if (epoch+1) % 5 == 0:torch.save(generator.state_dict(), f'generator_epoch_{epoch+1}.pth')torch.save(discriminator.state_dict(), f'discriminator_epoch_{epoch+1}.pth')print("训练完成!")
相关文章:
生成对抗网络(Generative Adversarial Networks ,GAN)
生成对抗网络是深度学习领域最具革命性的生成模型之一。 一 GAN框架 1.1组成 构造生成器(G)与判别器(D)进行动态对抗,实现数据的无监督生成。 G(造假者):接收噪声 ,…...

六、磁盘划分与磁盘配额
目录 1、磁盘划分1.1、什么是磁盘1.2、机械硬盘的结构与关键概念1.3、思考:为什么新买一个1T硬盘,使用时发现可使用容量低于1T1.4、Linux中inode和block1.5、查看超级快信息1.6、磁盘分区与挂载1.6.1、分区工具fdisk与格式化1.6.2、分区工具gdisk与格式化1.7、查看磁盘使用情…...

在WSL中的Ubuntu发行版上安装Anaconda、CUDA、CUDNN和TensorRT
在Windows 11的WSL(Windows Subsystem for Linux)环境中安装Anaconda、CUDA、CUDNN和TensorRT的详细步骤整理: 本文是用cuda12.4与CuDNN 8.9.7 和 TensorRT 9.1.0 及以上对应 一、前言(准备) 确保电脑上有NVIDIA GPU…...

小刚说C语言刷题—1230蝴蝶结
1.题目描述 请输出 n 行的蝴蝶结的形状,n 一定是一个奇数! 输入 一个整数 n ,代表图形的行数! 输出 n 行的图形。 样例 输入 9 输出 ***** **** *** ** * ** *** **** ***** 2.参考代码(C语言版)…...

代码随想录算法训练营第60期第三十九天打卡
大家好,我们今天继续讲解我们的动态规划章节,昨天我们讲到了动态规划章节的背包问题,昨天讲解的主要是0-1背包问题,那么今天我们可能就会涉及到完全背包问题,昨天的题目有一道叫做分割等和子集,今天应该会有…...
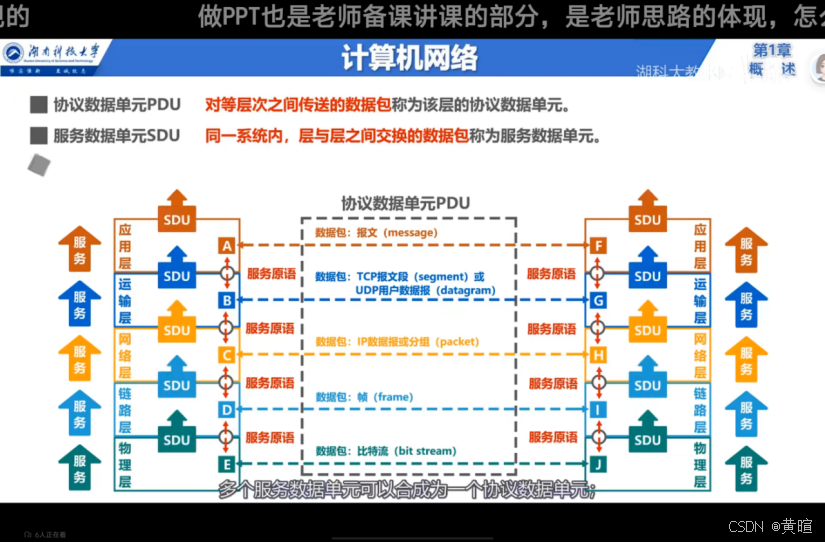
计算机网络体系结构深度解析:从理论到实践的全面梳理
计算机网络体系结构深度解析:从理论到实践的全面梳理 本系列博客源自作者在大二期末复习计算机网络时所记录笔记,看的视频资料是B站湖科大教书匠的计算机网络微课堂,祝愿大家期末都能考一个好成绩! 一、常见计算机网络体系结构 …...

Qwen2.5-VL模型sft微调和使用vllm部署
本文的server.py和req.py代码参见:https://github.com/zysNLP/quickllm 配套课程《AIGC大模型理论与工业落地实战》;Deepseek相关课程更新中 1. 安装相关docker镜像:nvcr.io/nvidia/pytorch:25.02-py3 docker pull nvcr.io/nvidia/pytorch:…...

python打卡DAY22
##注入所需库 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import random import numpy as np import time import shap # from sklearn.svm import SVC #支持向量机分类器 # # from sklearn.neighbors import KNeighborsClassifier …...
【教程】Docker更换存储位置
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 背景说明 更换教程 1. 停止 Docker 服务 2. 创建新的存储目录 3. 编辑 Docker 配置文件 4. 迁移已有数据到新位置 5. 启动 Docker 服务 6…...

鸿蒙Next API17学习新特性之组件可见区域变化事件新增支持设置事件的回调参数,限制它的执行间隔
概述 鸿蒙开发文档更新的非常快,对应我们开发者的学习能力也要求非常高,今天这篇文章给大家分享一下鸿蒙API17中更新的新特性学习。 鸿蒙 Next 的组件可见区域变化事件在最新的 API Version 17 中得到了增强,新增了支持设置事件的回调参数的…...

AI大模型从0到1记录学习 mysql day23
第 1 章 MySQL概述 1.1 基本概念 1.1.1 数据库是什么? 数据库(DB:Database):存储数据的地方。 1.1.2 为什么要用数据库? 应用程序产生的数据是在内存中的,如果程序退出或者是断电了,…...

spring -MVC-02
SpringMVC-11 - 响应 在 SpringMVC 中,响应是服务器对客户端请求的反馈,它可以以多种形式呈现,包括视图名称、ModelAndView 对象、JSON 数据以及重定向等。以下是对 SpringMVC 中不同响应类型的详细介绍: 1. 视图名称 通过返回…...
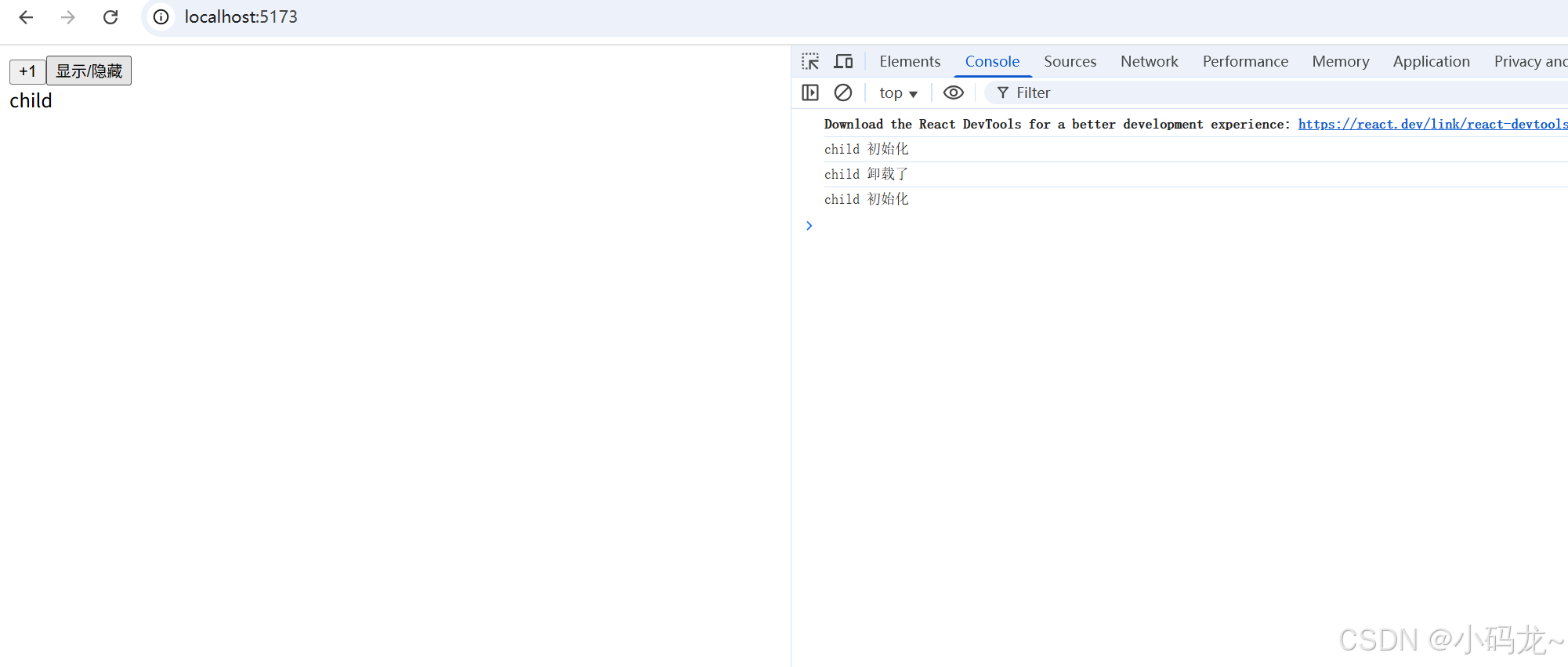
深入解析 React 的 useEffect:从入门到实战
文章目录 前言一、为什么需要 useEffect?核心作用: 二、useEffect 的基础用法1. 基本语法2. 依赖项数组的作用 三、依赖项数组演示1. 空数组 []:2.无依赖项(空)3.有依赖项 四、清理副作用函数实战案例演示1. 清除定时器…...

通过Ollama读取模型
通过Ollama读取模型 前言一、查看本地Ollama上有哪些模型二、调用bge-m3模型1、调用模型2、使用bge-m3进行相似度比较 三、调用大模型 前言 手动下载和加载大模型通常需要复杂的环境配置,而使用Ollama可以避免这一问题。本文将介绍如何调用Ollama上的模型。 一、查…...

C#控制流
🧩 一、控制流概述 C# 中的控制流语句用于根据条件或循环执行代码块。它们是程序逻辑的核心部分。 ✅ 二、1. if、else if、else int score 85;if (score > 90) {Console.WriteLine("优秀"); } else if (score > 60) {Console.WriteLine("及…...

永久免费,特殊版本!
随着大家审美的不断提升,无论是社交平台的日常分享还是特定场景的图像展示,人们对图像质量的要求都日益严苛。为了呈现更完美的视觉效果,许多小伙伴都会对原始图像进行精细化的后期处理,其中复杂背景抠图、光影调整、色彩校正等专…...
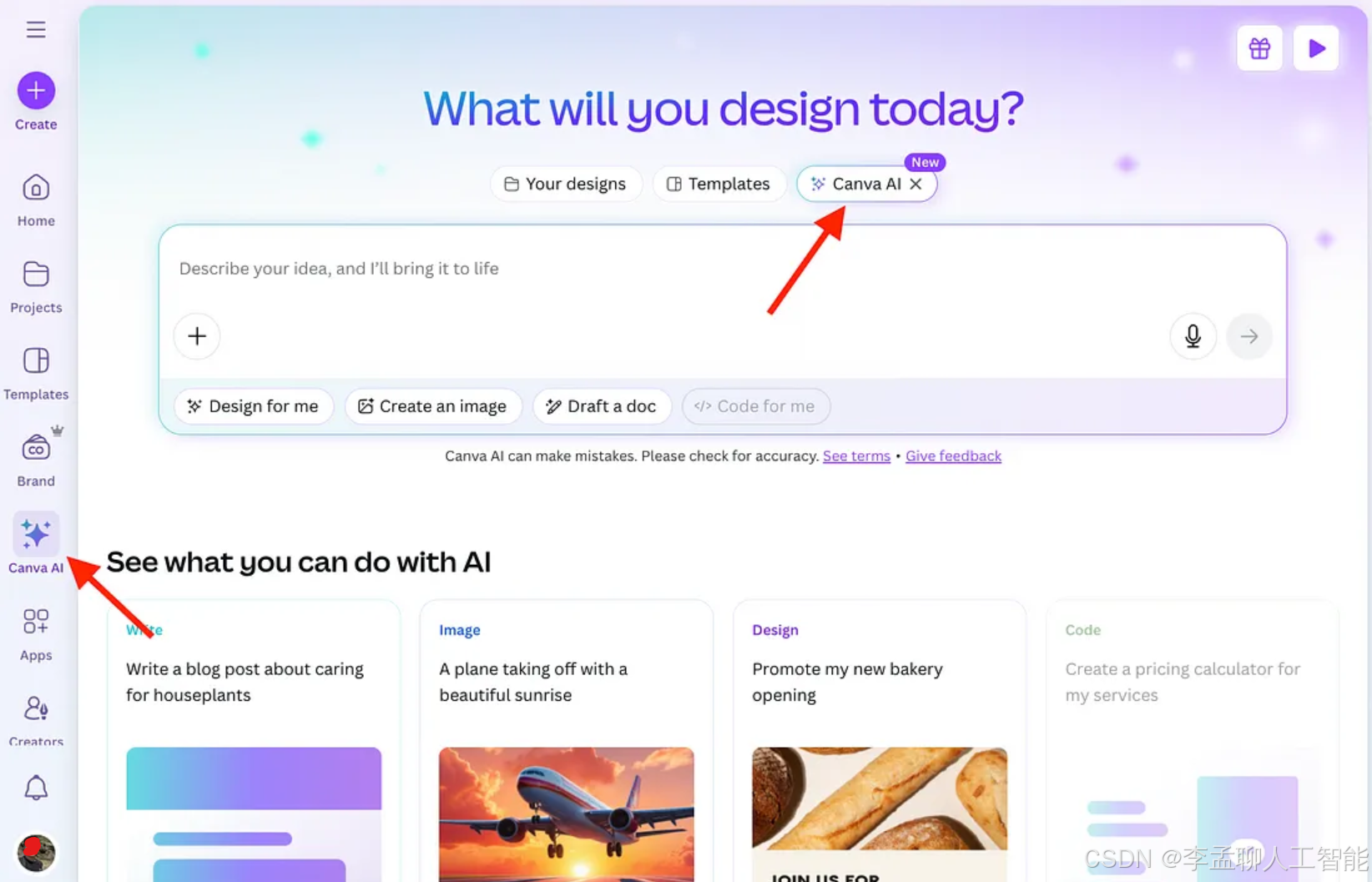
Canva 推出自有应用生成器以与 Bolt 和 Lovable 竞争
AI 目前是一个巨大的市场,每个人都想从中分一杯羹。 即使是 Canva,这个以拖放图形设计而闻名的流行设计平台,也在其 Canva Create 2025 活动中发布了自己版本的代码生成器,加入了 AI 竞赛。 但为什么一个以设计为先的平台会提供代码生成工具呢? 乍看之下,这似乎有些不…...
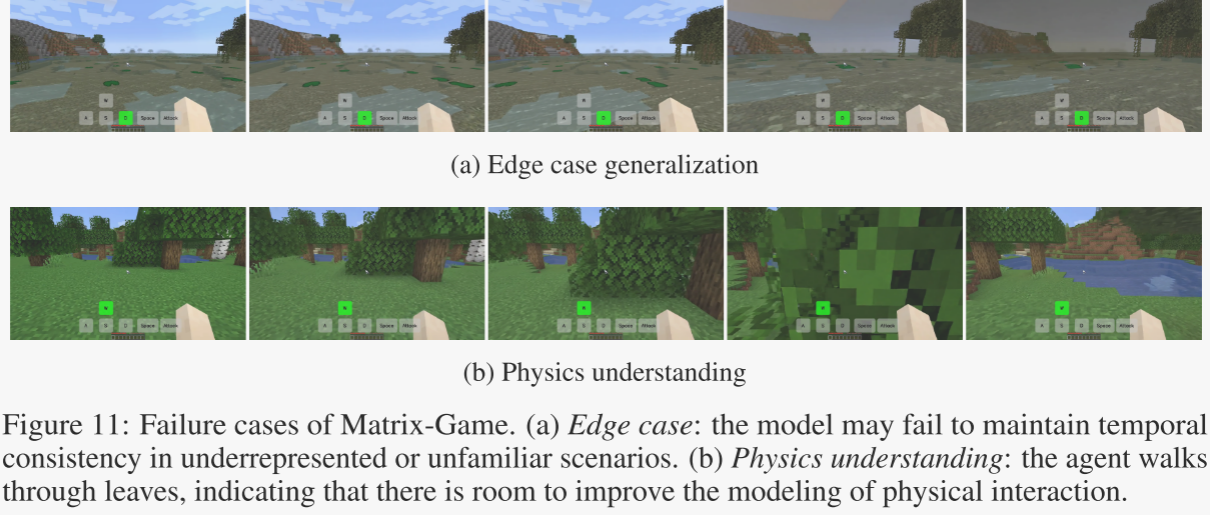
Matrix-Game:键鼠实时控制、实时生成的游戏生成模型(论文代码详细解读)
1.简介 本文介绍了一种名为Matrix-Game的交互式世界基础模型,专门用于可控的游戏世界生成。 Matrix-Game通过一个两阶段的训练流程来实现:首先进行大规模无标签预训练以理解环境,然后进行动作标记训练以生成交互式视频。为此,研…...

MySQL 5.7在CentOS 7.9系统下的安装(下)——给MySQL设置密码
新下载下来的MySQL,由于没有root密码,(1)所以如果我们希望登陆mysql,得给mysql的root账户设置密码,或者另一方面来说,(2)未来如果你忘记root密码了,也能通过这…...
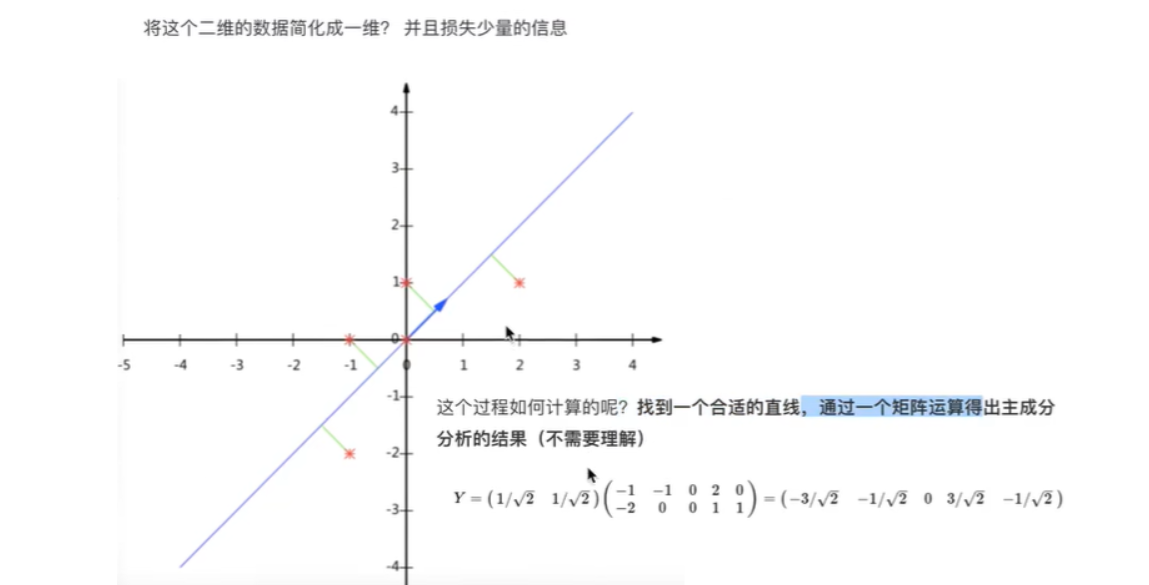
机器学习笔记2
5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取 (1) 算法 词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性 逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度 (2) API sklearn.feature_extraction.text.TfidfVector…...

AgentCPM-GUI,清华联合面壁智能开源的端侧GUI智能体模型
AgentCPM-GUI是什么 AgentCPM-GUI 是由清华大学与面壁智能团队联合开发的一款开源端侧图形用户界面(GUI)代理,专为中文应用进行优化。基于 MiniCPM-V 模型(80 亿参数),该系统能够接收智能手机的屏幕截图&a…...

Go语言实现链式调用
在 Go 语言中实现链式调用(Method Chaining),可以通过让每个方法返回对象本身(或对象的指针)来实现。这样每次方法调用后可以继续调用其他方法。 示例:实现字符串的链式操作 假设你想对一个字符串连续执行…...
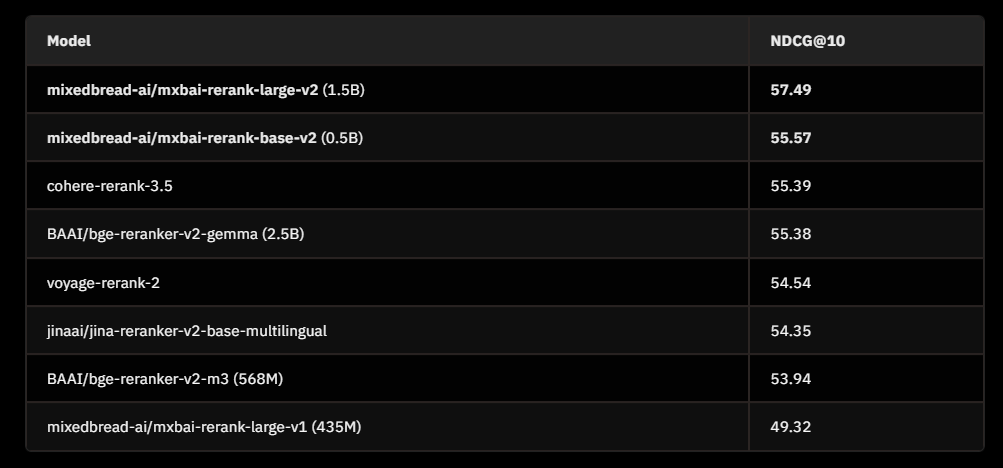
重排序模型解读 mxbai-rerank-base-v2 强大的重排序模型
mxbai-rerank-base-v2 强大的重排序模型 模型介绍benchmark综合评价安装 模型介绍 mxbai-rerank-base-v2 是 Mixedbread 提供的一个强大的重排序模型,旨在提高搜索相关性。该模型支持多语言,特别是在英语和中文方面表现出色。它还支持代码和 SQL 排序&a…...
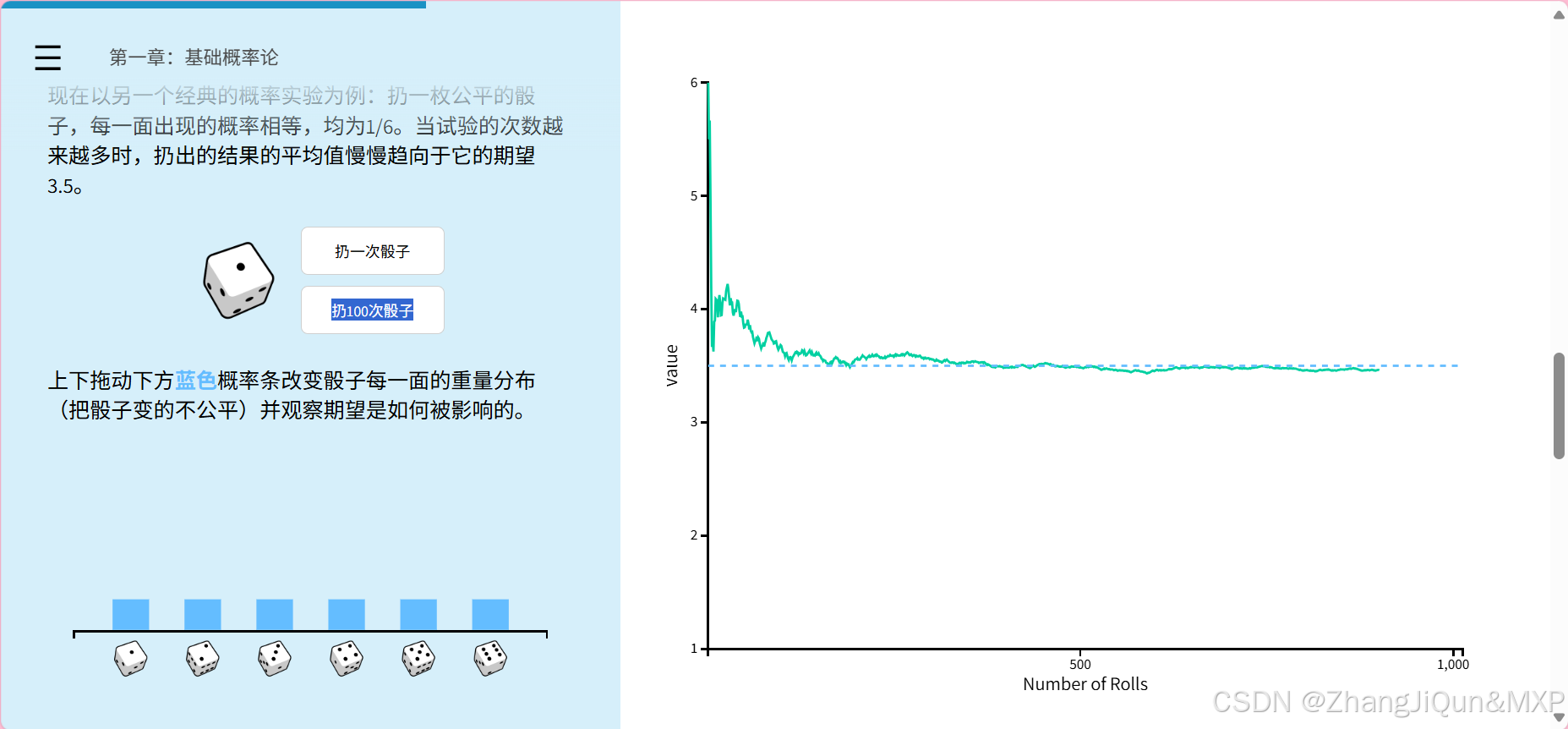
期望是什么:(无数次的均值,结合概率)21/6=3.5
https://seeing-theory.brown.edu/basic-probability/cn.html 期望是什么:(无数次的均值,结合概率)21/6=3.5 一、期望(数学概念) 在概率论和统计学中,**期望(Expectation)**是一个核心概念,用于描述随机变量的长期平均取值,反映随机变量取值的集中趋势。 (一…...
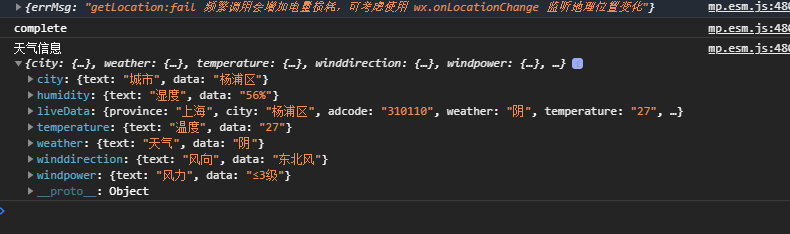
uniapp-vue3项目中引入高德地图的天气展示
前言: uniapp-vue3项目中引入高德地图的天气展示 效果: 操作步骤: 1、页面上用定义我们的 当前天气信息:<view></view> 2、引入我们的map文件 <script setup>import amapFile from ../../libs/amap-wx.js …...

容器化-k8s-介绍及下载安装教程
一、K8s 概念 官网地址: https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/ 1、含义 Kubernetes 是一个开源的容器编排引擎,用于自动化部署、扩展和管理容器化应用程序。它可以将多个容器组合成一个逻辑单元,实现对容器的集中管理和调度,从而简化复杂应用的部…...

lc42接雨水
1.原题 42. 接雨水 - 力扣(LeetCode) 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 2.题目解析 这一题是经常被考到的一道算法题,其中最简单最好用的方法就是双指…...
通义千问-langchain使用构建(三)
目录 序言docker 部署xinference1WSL环境docker安装2拉取镜像运行容器3使用的界面 本地跑chatchat1rag踩坑2使用的界面2.1配置个前置条件然后对话2.2rag对话 结论 序言 在前两天的基础上,将xinference调整为wsl环境,docker部署。 然后langchain chatcha…...

uniapp自动构建pages.json的vite插件
对于 uniapp 来说,配置 pages.json 无疑是最繁琐的事情,具有以下缺点: 冗长,页面很多时 pages 内容会很长难找,有时候因为内容很长,导致页面配置比较难找,而且看起来比较凌乱json弊端ÿ…...

系统漏洞扫描服务:维护网络安全的关键与服务原理?
系统漏洞扫描服务是维护网络安全的关键措施,能够迅速发现系统中的潜在风险,有效预防可能的风险和损失。面对网络攻击手段的日益复杂化,这一服务的重要性日益显著。 服务原理 系统漏洞扫描服务犹如一名恪尽职守的安全守护者。它运用各类扫描…...