从40秒到11毫秒:TiDB环境下一次SQL深潜优化实战
作者: meathill 原文来源: https://tidb.net/blog/edb6061b
在数据库应用中,慢SQL是常见的性能瓶颈。本文将详细记录一次针对TiDB Cloud v7.5.2环境中复杂评论查询的SQL优化过程,如何通过分析执行计划、添加索引、改写SQL(使用 EXISTS 、 UNION )等手段,将一个40多秒的查询逐步优化到11毫秒,希望能为读者提供有价值的实战参考。
不知道什么时候,TiDB Cloud 升级到 v7.5.2,于是我们的评论应用 RU 消耗开始起飞,达到以往月份的 3 倍左右。没办法,只好拖着病榻之躯来 Debug。还好 Gemini 2.5 Pro 给力,很快我就完成了这次优化,记录在这篇博客里。另外,这篇博客也是 Gemini 2.5 Pro 帮我写的,AI 之力,恐怖如斯 😱😱。
下文中的“我们”,是 Gemini 的自称。“用户”就是博主我。恐怖如斯,恐怖如斯。
一、问题的初现:一个耗时40秒的评论计数查询
故事的起点,是一个在TiDB Cloud v7.5.2版本上运行缓慢的SQL查询。其目的是统计符合特定条件的评论( ac_comment 表)及其子评论的总数。原始SQL如下:
-- SQL查询一:原始计数查询
WITH `cte` AS (SELECT `id`FROM `ac_comment`WHERE `post_id` = ? -- 参数绑定AND STATUS = ? -- 参数绑定AND `ancestor_id` = ? -- 参数绑定 (例如0,代表根评论)AND `deleted_at` IS NULL -- 注意原始为 IS ?,但逻辑上应为 IS NULL
)
SELECTcount('x') AS `num` -- 注意:count('x') 非标准,但功能类似 count(*)
FROM `ac_comment`
WHERE `id` IN (SELECT * FROM `cte`) -- 匹配CTE中的评论OR (`ancestor_id` IN (SELECT * FROM `cte`) -- 匹配父评论在CTE中的评论AND STATUS = ? -- 参数绑定AND `deleted_at` IS NULL -- 参数绑定);
这个查询的逻辑是:
- 通过一个公共表表达式(CTE)
cte筛选出特定帖子 (post_id) 下的“根评论”(假设ancestor_id = 0代表根评论,且状态正常、未删除)。 - 主查询统计两部分评论的总数:
- 本身ID就在
cte结果集中的评论(即根评论本身)。 - 其父评论ID (
ancestor_id) 在cte结果集中,并且自身状态正常、未删除的评论(即这些根评论的直接子评论)。
- 本身ID就在
初次拿到这个查询的执行计划( EXPLAIN ANALYZE ),我们发现其耗时高达 40.5秒 。执行计划的核心问题点暴露无遗:
| id | estRows | actRows | task | access object | execution info | operator info |
|---|---|---|---|---|---|---|
| HashAgg_33 | 1.00 | 1 | root | time:40.5s, loops:2 | funcs:count("x")->Column#33 | |
| └─Selection_35 | 28510.72 | 15053 | root | time:40.5s, loops:16 | or(Column#30, and(Column#32, ...)) | |
| └─HashJoin_36 | 35638.40 | 42854 | root | time:40.5s, loops:44, probe:{max:40.5s,...} | CARTESIAN left outer semi join , other cond:... | |
| ├─... | ... | ... | ... | |||
| └─TableFullScan_39 | 44548.00 | 44548 | cop[tikv] | table:ac_comment |
- 罪魁祸首:
CARTESIAN left outer semi join:执行计划中出现了刺眼的“CARTESIAN”字样。这意味着在处理IN (SELECT * FROM cte)时,优化器未能找到有效的连接键或索引来进行关联,而是退化到了类似笛卡尔积的低效操作。这通常是性能杀手。 -
TableFullScan:对ac_comment表进行了全表扫描,当表数据量大时,这无疑是雪上加霜。
初步诊断:查询结构中的 IN (CTE) 与 OR 条件的组合,使得优化器难以生成高效的执行计划。
二、初次尝试:索引的力量能拯救一切吗?
面对慢SQL,我们的第一反应通常是检查索引。合理的索引是数据库高性能的基石。针对上述查询,我们推荐了以下索引:
- CTE优化索引 :针对CTE的
WHERE条件,创建复合索引(post_id, status, ancestor_id, deleted_at, id),期望能覆盖CTE的查询。 - 主查询优化索引 :
-
id列:通常是主键,自带索引。 -
ancestor_id相关条件:为(ancestor_id, status, deleted_at)创建复合索引,以加速OR条件的第二部分。
-
用户反馈,索引添加后,"目测还是有 slow sql 产生"。我们再次获取了执行计划:
| id | estRows | actRows | task | access object | execution info | operator info |
|---|---|---|---|---|---|---|
| HashAgg_20 | 1.00 | 1 | root | time:36.9s, loops:2 | funcs:count("x")->Column#33 | |
| └─Selection_22 | 28520.96 | 15055 | root | time:36.9s, loops:16 | or(Column#30, and(Column#32, ...)) | |
| └─HashJoin_23 | 35651.20 | 42874 | root | time:36.9s, loops:44, probe:{max:36.9s,...} | CARTESIAN left outer semi join , other cond:... | |
| └─... | ... | ... | ... | |||
| └─IndexReader_31 | 44564.00 | 44563 | root | index:IndexFullScan_30 (ac_comment_ancestor_count_index) |
耗时从 40.5秒 降至 36.9秒 ,略有改善,但远未达到预期。仔细分析计划,发现:
-
CARTESIAN连接依然存在 :核心问题未解决。 - 索引误用 :在处理
id IN (CTE)这部分逻辑时,优化器竟然选择对一个为ancestor_id设计的索引 (ac_comment_ancestor_count_index) 进行了全扫描 (IndexFullScan_30),而非使用id列的主键索引。
结论 :对于这个查询,仅添加索引不足以根治问题。查询本身的结构对TiDB优化器造成了困扰,使其无法有效利用索引并选择了低效的执行路径。
三、转换思路:用 EXISTS 改写SQL结构
既然索引效果不彰,我们需要从SQL结构本身入手。 IN (subquery) 在某些情况下确实容易引发性能问题,一个常见的优化思路是将其改写为 EXISTS 。 EXISTS 通常能更明确地向优化器表达半连接(semi-join)的意图。
我们将计数查询改写如下:
-- SQL查询一:EXISTS改写版本 (计数)
WITH CTE AS (SELECT idFROM ac_commentWHERE post_id=? AND status=1 AND ancestor_id=0 AND deleted_at IS NULL
)
SELECT COUNT(*) AS num -- 改为 COUNT(*)
FROM ac_comment AS main_ac
WHEREEXISTS (SELECT 1 FROM CTE WHERE CTE.id = main_ac.id)OR (EXISTS (SELECT 1 FROM CTE WHERE CTE.id = main_ac.ancestor_id)AND main_ac.status = 1AND main_ac.deleted_at IS NULL);
再次查看执行计划,惊喜出现了!
| id | estRows | actRows | task | access object | execution info | operator info |
|---|---|---|---|---|---|---|
| HashAgg_22 | 1.00 | 1 | root | time:498ms, loops:2 | funcs:count("x")->Column#35 | |
| └─Selection_24 | 28520.96 | 15055 | root | time:497.4ms, loops:16 | or(Column#31, and(Column#34, ...)) | |
| └─HashJoin_25 | 35651.20 | 42874 | root | time:492.2ms, loops:44, probe:{max:497.1ms,...} | left outer semi join , equal:[eq(example.ac_comment.ancestor_id, example.ac_comment.id)] | |
| ├─CTEFullScan_35 | 7452.00 | 7506 | root | CTE:cte | time:275.5ms | data:CTE_0 |
| └─... | ||||||
| └─HashJoin_27 | 44564.00 | 44563 | root | time:469ms, loops:47, probe:{max:482.1ms,...} | left outer semi join , equal:[eq(example.ac_comment.id, example.ac_comment.id)] | |
| ├─CTEFullScan_34 | 7452.00 | 7506 | root | CTE:cte | time:263.6ms | data:CTE_0 |
| └─IndexReader_33 | 44564.00 | 44563 | root | time:263.6ms | index:IndexFullScan_32 (ac_comment_ancestor_count_index) |
执行时间从 36.9秒 骤降至 498毫秒 !提升约74倍。关键变化:
-
CARTESIAN连接消失了 !取而代之的是left outer semi join。优化器正确理解了半连接的语义,执行效率大大提升。 - CTE本身执行仍然很快(
actRows: 7506,构建哈希表约270ms)。 - 美中不足 :在处理
EXISTS (CTE.id = main_ac.id)时,Probe端(IndexReader_33)依然是对为ancestor_id设计的索引进行了全扫描。理想情况下,应使用main_ac.id的主键索引。但由于semi join的效率以及CTE结果集的大小(7506行),这个问题的影响已不像笛卡尔积时那么致命。
结论 : EXISTS 改写是本次优化的一个重要转折点,它成功引导优化器避开了最低效的执行路径。
四、新的挑战:分页查询的优化
在解决了计数查询的性能问题后,用户提出了一个新的、结构类似的查询,但这次是获取实际数据并带有分页逻辑:
-- SQL查询二:原始分页查询
WITH CTE AS (SELECT idFROM ac_commentWHERE post_id=${post_id}AND status=1AND ancestor_id=0AND deleted_at IS NULLORDER BY id DESCLIMIT ${start}, 21 -- 分页,取出21条
)
SELECT * -- 获取所有列
FROM ac_comment
WHERE id IN (SELECT * FROM CTE)OR (ancestor_id IN (SELECT * FROM CTE)AND status=1AND deleted_at IS NULL);
该查询的目的是获取某篇文章下“根评论”的一个分页结果(21条),以及这些根评论的直接子评论。
我们沿用之前的成功经验,将其用 EXISTS 改写:
-- SQL查询二:EXISTS改写版本 (分页)
WITH CTE AS (SELECT id FROM ac_commentWHERE post_id=${post_id} AND status=1 AND ancestor_id=0 AND deleted_at IS NULLORDER BY id DESC LIMIT ${start}, 21
)
SELECT main_ac.*
FROM ac_comment AS main_ac
WHEREEXISTS (SELECT 1 FROM CTE WHERE CTE.id = main_ac.id)OR (EXISTS (SELECT 1 FROM CTE WHERE CTE.id = main_ac.ancestor_id)AND main_ac.status = 1 AND main_ac.deleted_at IS NULL);
执行计划显示,耗时为 1.01秒 ,最终返回42行。
| id | estRows | actRows | task | access object | execution info | operator info |
|---|---|---|---|---|---|---|
| Projection_43 | 28521.60 | 42 | root | time:1.01s, loops:2 | ... | |
| └─Selection_44 | 28521.60 | 42 | root | time:1.01s, loops:2 | or(Column#31, and(Column#34, ...)) | |
| └─HashJoin_45 | 35652.00 | 42874 | root | time:1.01s, loops:44, build:{total:2.5ms,...} | left outer semi join , equal:[eq(main_ac.ancestor_id, CTE.id)] | |
| ├─CTEFullScan_51 | 21.00 | 21 | root | CTE:cte | time:2.44ms | data:CTE_0 |
| └─Selection_46 | 35652.00 | 42874 | root | time:1.01s, loops:43 | or(Column#31, and(eq(main_ac.status,1),...)) | |
| └─HashJoin_47 | 44565.00 | 44565 | root | time:930ms, loops:46, build:{total:2.33ms,...} | left outer semi join , equal:[eq(main_ac.id, CTE.id)] | |
| ├─CTEFullScan_50 | 21.00 | 21 | root | CTE:cte | time:2.3ms | data:CTE_0 |
| └─TableReader_49 | 44565.00 | 44565 | root | time:917.6ms, cop_task:{max:917ms,...} | data:TableFullScan_48 | |
| └─TableFullScan_48 | 44565.00 | 44565 | cop[tikv] | table:main_ac | tikv_task:{time:130ms,...} | |
| CTE_0 | 21.00 | 21 | root | time:2.44ms | Non-Recursive CTE |
分析结果:
- 依然没有
CARTESIAN连接 :优化器正确使用了semi join。 - CTE执行极快 :由于
LIMIT 21,CTE部分仅耗时2.4ms左右,返回21行。 - 瓶颈转移 :查询的主要耗时(约
917ms)在于HashJoin_47的Probe端——TableReader_49,它对main_ac表(即ac_comment)执行了 全表扫描 (TableFullScan_48) 。 尽管CTE只有21行,优化器在处理OR条件,特别是EXISTS (CTE.id = main_ac.id)时,仍然选择全表扫描main_ac。这可能是因为它需要评估OR的另一半,或者SELECT *的成本考量。
虽然1.01秒相比最初已经好太多,但全表扫描的存在暗示着仍有优化空间。
五、终极一击: UNION 改写带来的极致性能
OR 条件有时确实会给优化器带来困扰,使其难以对 OR 的各个分支独立采用最优访问路径。一种更彻底的优化策略是将 OR 条件拆分为多个独立的查询,然后用 UNION (或 UNION ALL )合并结果。
我们对分页查询进行了如下 UNION 改写:
-- SQL查询二:UNION改写版本 (分页)
WITH CTE AS (SELECT idFROM ac_commentWHERE post_id=${post_id} AND status=1 AND ancestor_id=0 AND deleted_at IS NULLORDER BY id DESC LIMIT ${start}, 21
)
-- Part 1: 匹配根评论 (id IN CTE)
SELECT main_ac.*
FROM ac_comment AS main_ac
JOIN CTE ON main_ac.id = CTE.id -- 使用INNER JOIN,因为EXISTS隐含了匹配UNION -- UNION会自动去重,确保与OR逻辑一致-- Part 2: 匹配子评论 (ancestor_id IN CTE AND status=1 AND deleted_at IS NULL)
SELECT main_ac.*
FROM ac_comment AS main_ac
JOIN CTE ON main_ac.ancestor_id = CTE.id -- 使用INNER JOIN
WHERE main_ac.status = 1 AND main_ac.deleted_at IS NULL;
这次改写带来了惊人的效果,执行计划显示耗时仅为 11.4毫秒 !
| id | estRows | actRows | task | access object | execution info | operator info |
|---|---|---|---|---|---|---|
| HashAgg_53 | 46.14 | 42 | root | time:11.4ms, loops:6 | group by:all_columns..., funcs:firstrow(...) | |
| └─Union_54 | 46.14 | 42 | root | time:7.4ms, loops:3 | ||
| ├─Projection_55 | 13.44 | 21 | root | time:6.76ms, loops:2 | ... | |
| │ └─IndexHashJoin_63 | 13.44 | 21 | root | time:6.59ms, loops:2 | inner join, inner:TableReader_58, outer key:main_ac.id, inner key:CTE.id | |
| │ ├─...CTE... | 16.80 | 21 | root | CTE:cte | time:2.8ms | data:CTE_0 |
| │ └─TableReader_58 | 13.44 | 21 | root | time:2.88ms | data: TableRangeScan_57 (range decided by main_ac.id) | |
| └─Projection_72 | 32.70 | 21 | root | time:4.99ms, loops:2 | ... | |
| └─IndexHashJoin_80 | 32.70 | 21 | root | time:4.97ms, loops:2 | inner join, inner: IndexLookUp_77 , outer key:CTE.id, inner key:main_ac.ancestor_id |
关键变化:
- 全表扫描彻底消失 :
-
UNION的第一个分支(匹配根评论):IndexHashJoin_63的Probe端显示TableRangeScan_57,其range: decided by [example.ac_comment.id]。这意味着它利用main_ac.id上的索引(主键)对CTE返回的21个ID进行了高效的 点查 。 -
UNION的第二个分支(匹配子评论):IndexHashJoin_80的Probe端显示IndexLookUp_77。这意味着它利用了main_ac.ancestor_id和status、deleted_at上的复合索引来查找匹配的子评论,然后回表获取数据。
-
-
HashAgg_53:顶部的HashAgg操作是UNION(等同于UNION DISTINCT)为了去除重复行而执行的。由于总共最多处理42行,这个开销极小。
通过 UNION 将复杂的 OR 逻辑分解为两个独立的、更简单的查询,使得TiDB优化器能够为每个子查询都选择最优的、基于索引的访问路径,从而达到了极致的性能。
六、优化总结与启示
这次从40多秒到11毫秒的优化之旅,充满了抽丝剥茧的分析和柳暗花明的尝试,带给我们几点深刻的启示:
-
EXPLAIN ANALYZE是你的导航仪 :没有它,我们就像在黑暗中航行。它是诊断慢SQL、理解优化器行为、验证优化效果不可或缺的工具。务必学会阅读和理解它的输出。 - 索引是基础,但并非万能 :合理的索引是高性能的起点。但如此案例所示,当SQL查询结构本身对优化器不友好时,仅靠索引可能无法解决根本问题。
- 警惕
IN (subquery)的陷阱 :尤其当子查询返回较多行或与OR等复杂条件结合时,IN子查询有时会被优化器错误处理。考虑使用EXISTS或JOIN作为更稳健的替代方案。 -
OR条件有时是优化的“硬骨头” :复杂的OR条件可能让优化器难以抉择,导致选择次优的全局计划(如全表扫描)。通过UNION或UNION ALL将OR的各个分支拆解,让每个分支独立优化,往往能奇效。 - 迭代优化,不断试错 :SQL优化往往不是一蹴而就的。它需要我们根据执行计划的反馈,不断调整索引策略、改写SQL,是一个分析、假设、验证、再分析的迭代过程。
- 理解业务逻辑与数据特性 :例如,CTE中
LIMIT 21使得CTE结果集极小,这对后续的JOIN策略有很大影响。了解数据分布和业务场景有助于做出更合理的优化判断。
七、结语
SQL优化是一门技术,更是一门艺术。它要求我们不仅要理解SQL的语法,更要洞察数据库优化器的工作原理。通过这次实战,我们不仅解决了一个棘手的性能问题,更重要的是深化了对TiDB查询优化机制的理解。希望这个案例能为你未来的SQL优化工作带来一些启发和帮助。记住,每一个慢查询背后,都可能隐藏着一次学习和提升的绝佳机会。
总之,希望大家所有收获,如果大家对 SQL、Web 全栈开发、AI 使用、Gemini 有任何问题或意见,欢迎留言讨论。
相关文章:

从40秒到11毫秒:TiDB环境下一次SQL深潜优化实战
作者: meathill 原文来源: https://tidb.net/blog/edb6061b 在数据库应用中,慢SQL是常见的性能瓶颈。本文将详细记录一次针对TiDB Cloud v7.5.2环境中复杂评论查询的SQL优化过程,如何通过分析执行计划、添加索引、改写SQL&…...
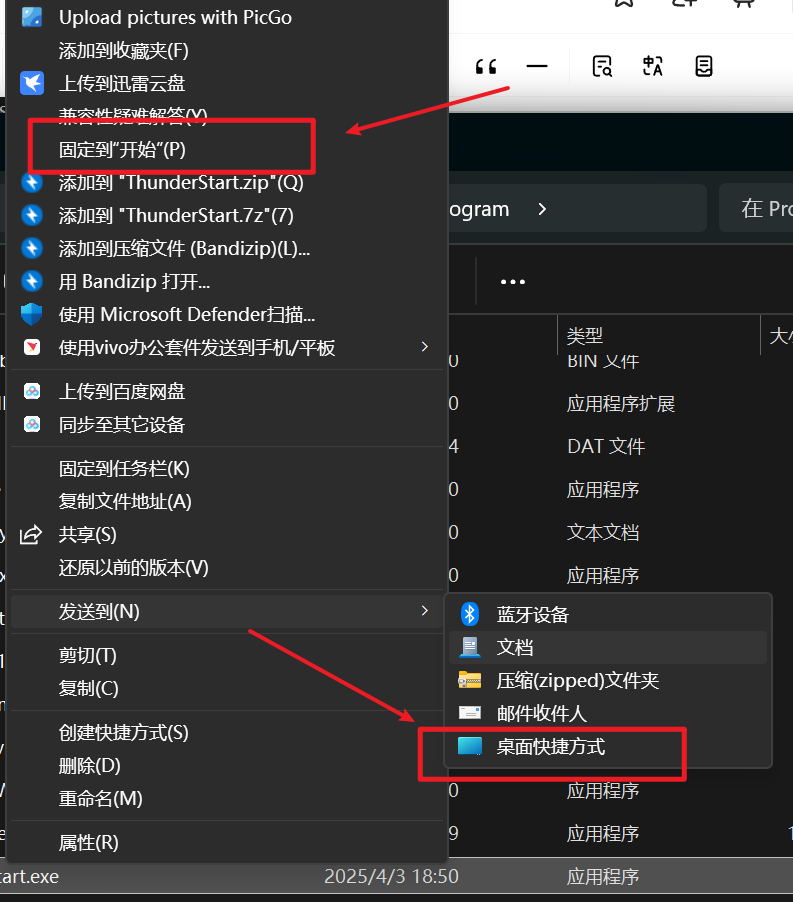
Win 11开始菜单图标变成白色怎么办?
在使用windows 11的过程中,有时候开始菜单的某些程序图标变成白色的文件形式,但是程序可以正常打开,这个如何解决呢? 这通常是由于快捷方式出了问题,下面跟着操作步骤来解决吧。 1、右键有问题的软件,打开…...
入门OpenTelemetry——应用自动埋点
埋点 什么是埋点 埋点,本质就是在你的应用程序里,在重要位置插入采集代码,比如: 收集请求开始和结束的时间收集数据库查询时间收集函数调用链路信息收集异常信息 这些埋点数据(Trace、Metrics、Logs)被…...
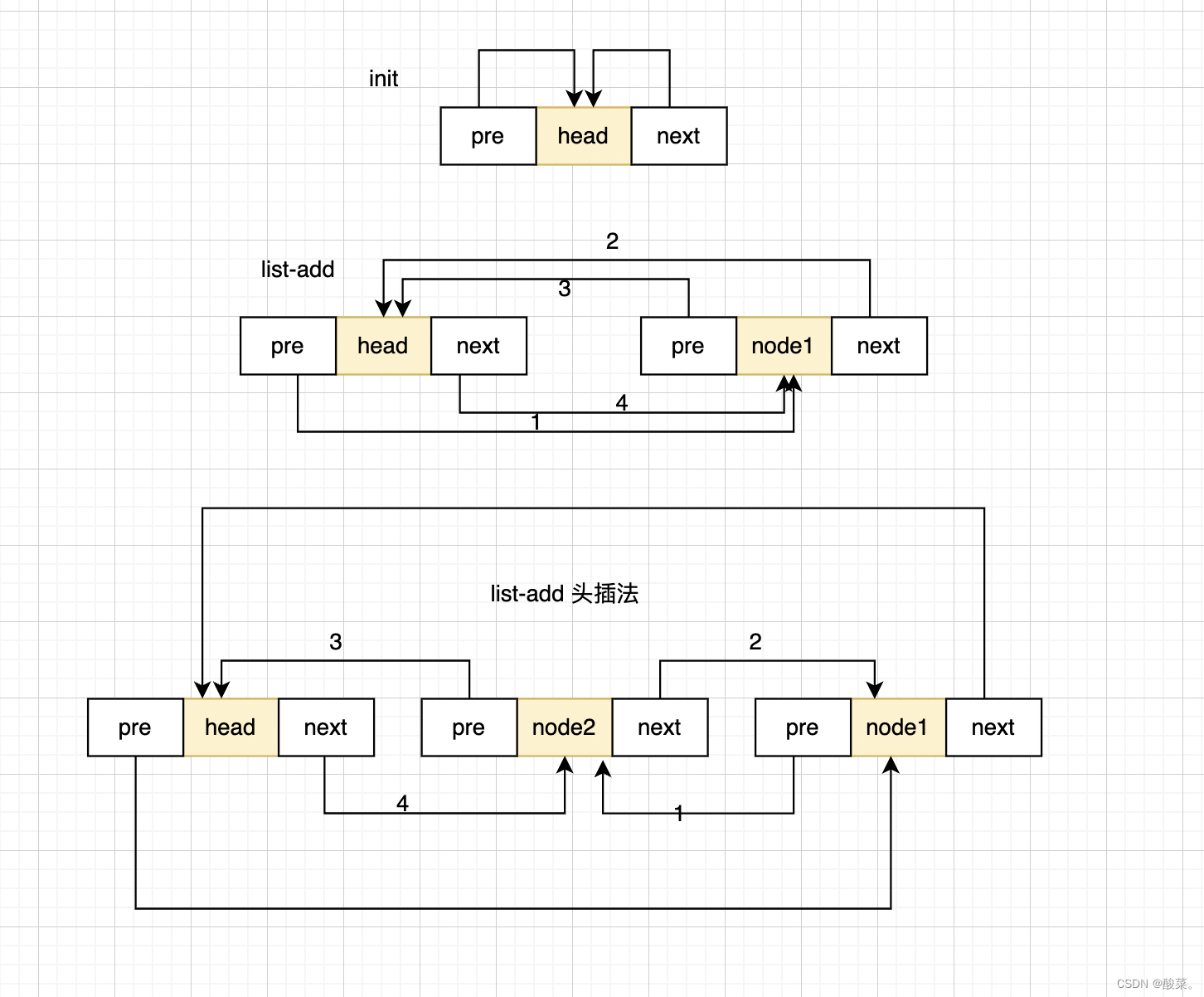
C语言链表的操作
初学 初学C语言时,对于链表节点的定义一般是这样的: typedef struct node {int data;struct node *next; } Node; 向链表中添加节点: void addNode(Node **head, int data) {Node *newNode (Node*)malloc(sizeof(Node));newNode->dat…...

芯片生态链深度解析(二):基础设备篇——人类精密制造的“巅峰对决”
【开篇:设备——芯片工业的“剑与盾”】 当ASML的EUV光刻机以每秒5万次激光脉冲在硅片上雕刻出0.13nm精度的电路(相当于在月球表面精准定位一枚二维码),当国产28nm光刻机在华虹产线实现“从0到1”的突破,这场精密制造…...
C语言指针深入详解(二):const修饰指针、野指针、assert断言、指针的使用和传址调用
目录 一、const修饰指针 (一)const修饰变量 (二)const 修饰指针变量 二、野指针 (一)野指针成因 1、指针未初始化 2、指针越界访问 3、指针指向的空间释放 (二)如何规避野指…...

【unity游戏开发——编辑器扩展】使用EditorGUI的EditorGUILayout绘制工具类在自定义编辑器窗口绘制各种UI控件
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言常用的EditorGUILayout控件专栏推荐完结 前言 EditorG…...
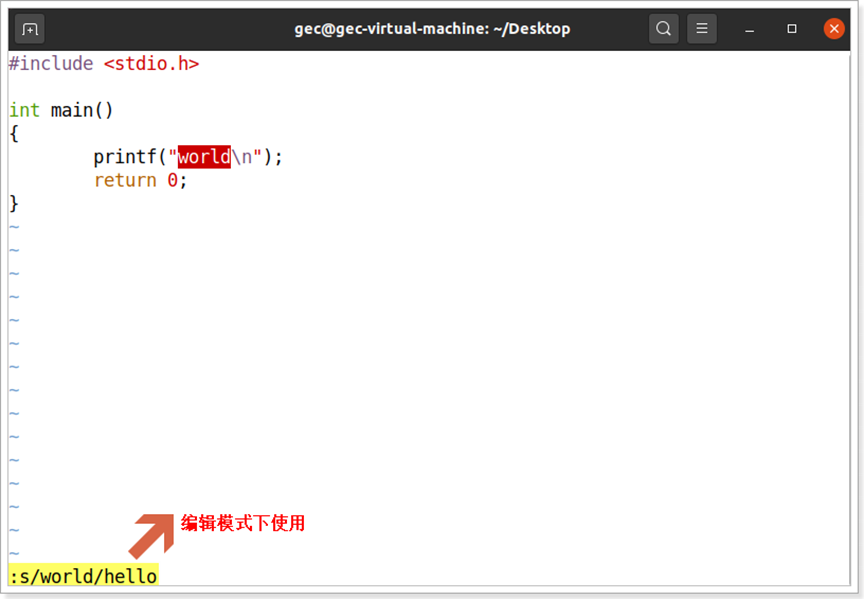
Linux基础第三天
系统时间 date命令,date中文具有日期的含义,利用该命令可以查看或者修改Linux系统日期和时间。 基本格式如下: gecubuntu:~$ date gecubuntu:~$ date -s 日期时间 // -s选项可以设置日期和时间 文件权限 chmod命令,是英文…...
MoodDrop:打造一款温柔的心情打卡单页应用
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 起心动念:我想做一款温柔的情绪应用 「今天的你,心情如何?」 有时候&#x…...

接口——类比摄像
最近迷上了买相机,大疆Pocket、Insta Go3、大疆Mini3、佳能50D、vivo徕卡人像大师(狗头),在买配件的时候,发现1/4螺口简直是神中之神,这个万能接口让我想到计算机设计中的接口,遂有此篇—— 接…...

【上位机——WPF】布局控件
布局控件 常用布局控件Panel基类Grid(网格)UniformGrid(均匀分布)StackPanel(堆积面板)WrapPanel(换行面板)DockerPanel(停靠面板)Canvas(画布布局)Border(边框)GridSplitter(分割窗口)常用布局控件 Grid:网格,根据自定义行和列来设置控件的布局StackPanel:栈式面板,包含的…...

深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用
深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用 引言 在现代分布式系统中,消息队列是实现异步通信和解耦的重要组件。Apache Kafka作为一种高性能、分布式的消息系统,被广泛应用于大数据和实时数据处理场景。本文将详细介绍如何在…...

二十、案例特训专题3【系统设计篇】web架构设计
一、前言 二、内容提要 三、单机到应用与数据分离 四、集群与负载均衡 五、集群与有状态无状态服务 六、ORM 七、数据库读写分离 八、数据库缓存Memcache与Redis 九、Redis数据分片 哈希分片如果新增分片会很麻烦,需要把之前数据取出来再哈希除模 一致性哈希分片是…...
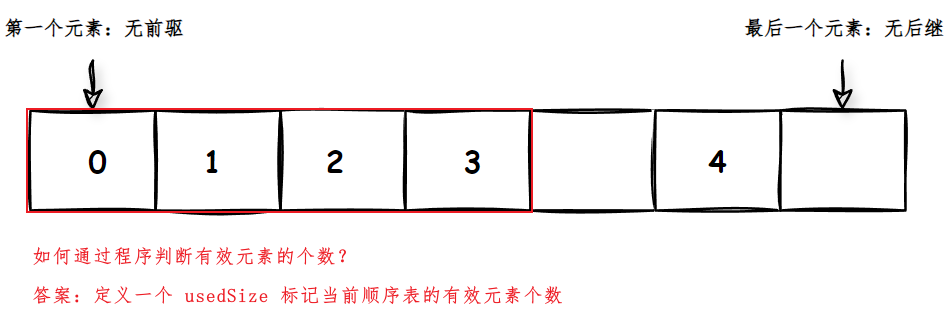
【数据结构与算法】ArrayList 与顺序表的实现
目录 一、List 接口 1.1 List 接口的简单介绍 1.1 常用方法 二、顺序表 2.1 线性表的介绍 2.2 顺序表的介绍 2.3 顺序表的实现 2.3.1 前置条件:自定义异常 2.3.2 顺序表的初始化 2.3.2 顺序表的实现 三、ArrayList 实现类 3.1 ArrayList 的两种使用方式 3.2 Array…...
)
处理金融数据,特别是股票指数数据,以计算和分析RSRS(相对强度指数)
Python脚本,用于处理金融数据,特别是股票指数数据,以计算和分析RSRS(相对强度指数)指标。以下是代码的逐部分解释: 1. **导入库**: - `pandas`:用于数据处理和CSV文件操作。 - `numpy`:用于数值计算。 - `ElasticNet`:来自`sklearn.linear_model`,用于线性…...

【图像处理基石】OpenCV中都有哪些图像增强的工具?
OpenCV 图像增强工具系统性介绍 OpenCV 提供了丰富的图像增强工具,主要分为以下几类: 亮度与对比度调整 线性变换(亮度/对比度调整)直方图均衡化自适应直方图均衡化(CLAHE) 滤波与平滑 高斯滤波中值滤波双…...
WPS PPT设置默认文本框
被一个模板折磨了好久,每次输入文本框都是很丑的24号粗体还有行标,非常恶心,我甚至不知道如何描述自己的问题,非常憋屈,后来终于知道怎么修改文本框了。这种软件操作问题甚至不知道如何描述问题本身,非常烦…...

PostGIS实现矢量数据转栅格数据【ST_AsRaster】
ST_AsRaster函数应用详解:将矢量数据转换为栅格数据 [文章目录] 一、函数概述 二、函数参数与分组说明 三、核心特性与注意事项 四、示例代码 五、应用场景 六、版本依赖 七、总结 一、函数概述 ST_AsRaster是PostGIS中用于将几何对象(如点、线…...
FAST-DDS源码分析PDP(一)
准备开一个FAST-DDS源码分析系列,源码版本FAST-DDS 1.1.0版本。 FAST-DDS这种网络中间件是非常复杂的,所以前期先去分析每个类的作用是什么,然后在结合RTPS DOC,FAST-DDS DEMO,以及FAST-DDS的doc去串起来逻辑。 Builtin Discovery…...
python打卡day29@浙大疏锦行
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...
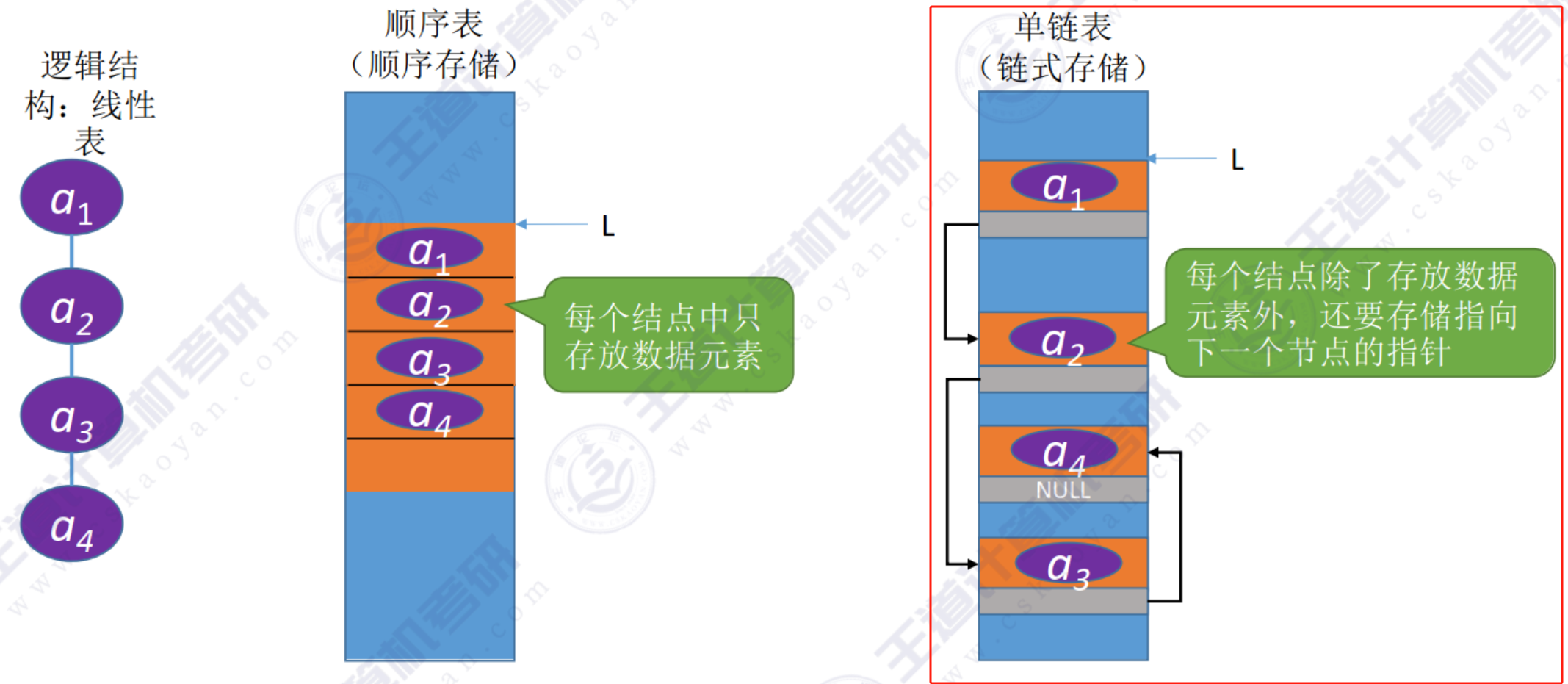
【数据结构】2-3-1单链表的定义
数据结构知识点合集 知识点 单链表存储结构 优点:不要求大片连续空间,改变容量方便;缺点:不可随机存取,要耗费一定空间存放指针 /*单链表节点定义*/ typedef struct LNode{ElemType data;struct LNode *next; }LNo…...

贝塞尔曲线原理
文章目录 一、 低阶贝塞尔曲线1.一阶贝塞尔曲线2. 二阶贝塞尔曲线3. 三阶贝塞尔曲线 一、 低阶贝塞尔曲线 1.一阶贝塞尔曲线 如下图所示, P 0 P_0 P0, P 1 P_1 P1 是平面中的两点,则 B ( t ) B ( t ) B(t) 代表平面中的一段线段。…...
3D个人简历网站 4.小岛
1.模型素材 在Sketchfab上下载狐狸岛模型,然后转换为素材资源asset,嫌麻烦直接在网盘链接下载素材, Fox’s islandshttps://sketchfab.com/3d-models/foxs-islands-163b68e09fcc47618450150be7785907https://gltf.pmnd.rs/ 素材夸克网盘&a…...
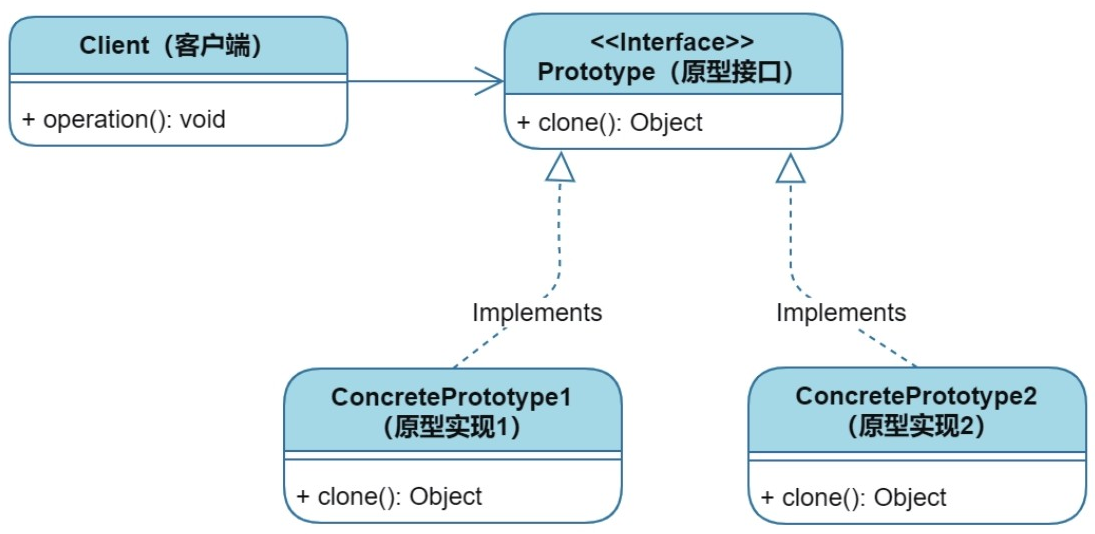
创建型:原型模式
目录 1、核心思想 2、实现方式 2.1 基本结构 2.2 代码示例(Java) 3、适用场景 4、new与clone实际场景建议 1、核心思想 目的:通过复制(克隆)现有对象来创建新对象,而不是通过new关键字实例化。对于那…...

浅谈“量子计算应用:从基础原理到行业破局”
量子计算应用:从基础原理到行业破局 引言:量子计算为何成为科技革命新引擎? 量子计算利用量子力学原理(叠加态、纠缠态、量子干涉)突破经典计算的极限,在特定领域可实现指数级加速。根据中研普华预测,2025年全球量子计算市场规模将突破80亿美元,2035年可达8117亿美元。…...

Java面试攻略:从Spring Boot到微服务架构的深入探讨
Java面试攻略:从Spring Boot到微服务架构的深入探讨 场景设定 在一家知名互联网大厂的会议室里,资深面试官王老师正在对一位求职者谢飞机进行技术面试。谢飞机是一位幽默风趣的程序员,他的回答有时让人捧腹大笑。 第一轮:核心技…...

关于文件分片的介绍和应用
文件分片,顾名思义,就是将一个大文件分割成多个小的文件块(chunk)。每个文件块都是原始文件的一部分,并可以通过特定的方式将这些小文件块重新组装成原始文件。 1. 基本原理: 文件分片从底层来看,主要是对…...
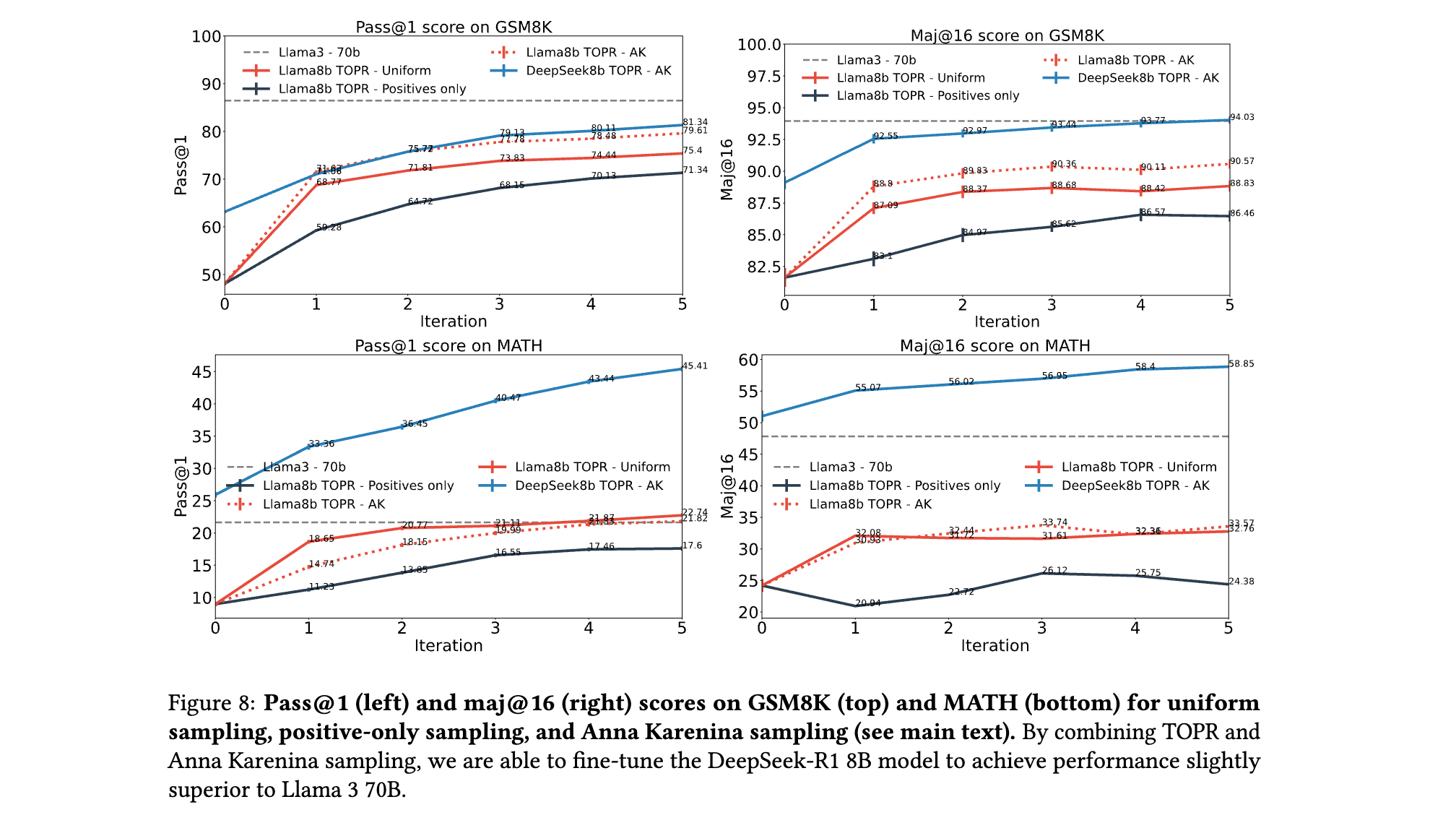
Tapered Off-Policy REINFORCE_ 如何为LLM实现稳定高效的策略优化?
Tapered Off-Policy REINFORCE: 如何为LLM实现稳定高效的策略优化? 在大语言模型(LLM)的微调领域,强化学习(RL)正成为提升复杂任务性能的核心方法。本文聚焦于一篇突破性论文,其提出的Tapered …...

使用lvm进行磁盘分区
使用lvm进行磁盘分区 目的: 使用/dev/vdb创建一个5g的逻辑卷挂载到/mnt/lvmtest 前提: /dev/vdb是一块干净的空磁盘,数据会被清空!!! 1. 创建物理卷(PV): pvcreate /dev/sdb2. 验证…...

[Java实战]Spring Boot整合Elasticsearch(二十六)
[Java实战]Spring Boot整合Elasticsearch(二十六) 摘要:本文通过完整的实战演示,详细讲解如何在Spring Boot项目中整合Elasticsearch,实现数据的存储、检索和复杂查询功能。包含版本适配方案、Spring Data Elasticsea…...