【图像生成大模型】Step-Video-T2V:下一代文本到视频生成技术
Step-Video-T2V:下一代文本到视频生成技术
- 引言
- Step-Video-T2V 项目概述
- 核心技术
- 1. 视频变分自编码器(Video-VAE)
- 2. 3D 全注意力扩散 Transformer(DiT w/ 3D Full Attention)
- 3. 视频直接偏好优化(Video-DPO)
- 项目运行方式与执行步骤
- 1. 环境准备
- 2. 安装依赖
- 3. 模型下载
- 4. 推理脚本
- 多 GPU 并行部署
- 单 GPU 推理和量化
- 5. 最佳实践推理设置
- 6. 性能基准
- 执行报错与问题解决
- 1. 显存不足
- 2. 环境依赖问题
- 3. 模型下载问题
- 相关论文与研究
- 1. 扩散模型(Diffusion Models)
- 2. Transformer 架构
- 3. 3D 变分自编码器(3D VAE)
- 4. 直接偏好优化(Direct Preference Optimization, DPO)
- 总结
引言
随着人工智能技术的飞速发展,文本到视频生成(Text-to-Video, T2V)技术逐渐成为研究和应用的热点领域。这种技术能够根据文本描述生成相应的视频内容,具有广泛的应用前景,如视频创作、广告制作、教育娱乐等。Step-Video-T2V 是一个由 Stepfun-AI 团队开发的先进文本到视频生成模型,它以其卓越的性能和高效的实现方式,为这一领域带来了新的突破。
Step-Video-T2V 项目概述
Step-Video-T2V 是一个具有 300 亿参数的先进文本到视频生成模型,能够生成长达 204 帧的视频。为了提高训练和推理效率,Step-Video-T2V 提出了一种深度压缩的视频变分自编码器(Video-VAE),实现了 16x16 空间和 8x 时间压缩比。此外,Step-Video-T2V 还采用了直接偏好优化(Direct Preference Optimization, DPO)技术,进一步提升了生成视频的视觉质量。
核心技术
1. 视频变分自编码器(Video-VAE)
Step-Video-T2V 的 Video-VAE 是一种深度压缩的变分自编码器,能够实现 16x16 空间和 8x 时间压缩比,同时保持卓越的视频重建质量。这种压缩不仅加速了训练和推理过程,还与扩散过程对压缩表示的偏好相一致。
2. 3D 全注意力扩散 Transformer(DiT w/ 3D Full Attention)
Step-Video-T2V 基于扩散 Transformer(DiT)架构,包含 48 层,每层有 48 个注意力头,每个头的维度为 128。AdaLN-Single 用于引入时间步条件,QK-Norm 机制确保训练的稳定性,3D RoPE 在处理不同长度和分辨率的视频序列中发挥关键作用。
3. 视频直接偏好优化(Video-DPO)
Step-Video-T2V 通过直接偏好优化(DPO)技术进一步提升生成视频的视觉质量。DPO 利用人类偏好数据对模型进行微调,确保生成内容更符合人类期望。
项目运行方式与执行步骤
1. 环境准备
在开始运行 Step-Video-T2V 之前,需要确保你的开发环境已经准备好。以下是推荐的环境配置:
- 操作系统:推荐使用 Linux,Windows 用户可能需要额外配置 WSL 或虚拟机。
- Python 版本:建议使用 Python 3.10 或更高版本。
- CUDA 和 GPU:确保你的系统安装了 CUDA,并且 GPU 驱动程序是最新的。推荐使用具有 80GB 内存的 GPU 以获得更好的生成质量。
2. 安装依赖
首先,需要克隆项目仓库并安装依赖项:
git clone https://github.com/stepfun-ai/Step-Video-T2V.git
cd Step-Video-T2V
创建并激活 Conda 环境:
conda create -n stepvideo python=3.10
conda activate stepvideo
安装项目依赖:
pip install -e .
pip install flash-attn --no-build-isolation ## flash-attn 是可选的
3. 模型下载
Step-Video-T2V 提供了多种模型版本,可以通过 Hugging Face 或 ModelScope 下载。例如,下载 Step-Video-T2V 模型:
# Hugging Face
huggingface-cli download stepfun-ai/Step-Video-T2V --local-dir ./Step-Video-T2V# ModelScope
modelscope-cli download stepfun-ai/Step-Video-T2V --local_dir ./Step-Video-T2V
4. 推理脚本
多 GPU 并行部署
Step-Video-T2V 采用了文本编码器、VAE 解码和 DiT 的解耦策略,以优化 DiT 对 GPU 资源的利用。因此,需要一个专用 GPU 来处理文本编码器的嵌入和 VAE 解码的 API 服务。
python api/call_remote_server.py --model_dir where_you_download_dir & ## 假设你有超过 4 个 GPU 可用。此命令将返回文本编码器 API 和 VAE API 的 URL。请在以下命令中使用返回的 URL。parallel=4 # 或 parallel=8
url='127.0.0.1'
model_dir=where_you_download_dirtp_degree=2
ulysses_degree=2# 确保 tp_degree x ulysses_degree = parallel
torchrun --nproc_per_node $parallel run_parallel.py --model_dir $model_dir --vae_url $url --caption_url $url --ulysses_degree $ulysses_degree --tensor_parallel_degree $tp_degree --prompt "一名宇航员在月球上发现一块石碑,上面印有‘stepfun’字样,闪闪发光" --infer_steps 50 --cfg_scale 9.0 --time_shift 13.0
单 GPU 推理和量化
对于单 GPU 推理,ModelScope 的 DiffSynth-Studio 项目提供了单 GPU 推理和量化支持,可以显著减少所需的显存。具体信息请参考其示例。
5. 最佳实践推理设置
Step-Video-T2V 在推理设置中表现出色,能够生成高保真和动态的视频。然而,实验表明,推理超参数的变化对视频保真度和动态性的权衡有显著影响。为了获得最佳结果,推荐以下最佳实践推理参数:
| 模型 | infer_steps | cfg_scale | time_shift | num_frames |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo (推理步数蒸馏) | 10-15 | 5.0 | 17.0 | 204 |
6. 性能基准
Step-Video-T2V 发布了一个新的基准测试 Step-Video-T2V-Eval,包含 128 个来自真实用户的中文提示,涵盖 11 个不同类别:体育、美食、风景、动物、节日、组合概念、超现实、人物、3D 动画、电影摄影和风格。
执行报错与问题解决
在运行 Step-Video-T2V 项目时,可能会遇到一些常见的问题。以下是一些常见问题及其解决方法:
1. 显存不足
如果在运行时遇到显存不足的错误,可以尝试以下方法:
- 使用量化技术:通过量化技术减少模型的显存占用。
- 降低分辨率:降低生成视频的分辨率,例如从 768x768 降低到 544x992。
- 减少推理步数:通过调整
infer_steps参数来减少推理步数。
2. 环境依赖问题
如果在安装依赖时遇到问题,可以尝试以下方法:
- 更新 pip 和 setuptools:确保 pip 和 setuptools 是最新版本。
- 手动安装依赖:对于某些依赖项,可以尝试手动安装,例如
torch和transformers。
3. 模型下载问题
如果在下载模型时遇到问题,可以尝试以下方法:
- 检查网络连接:确保你的网络连接正常,能够访问 Hugging Face 或 ModelScope。
- 手动下载模型:如果自动下载失败,可以手动下载模型文件并放置到指定目录。
相关论文与研究
Step-Video-T2V 的开发基于多项前沿研究,其中一些关键的论文和技术包括:
1. 扩散模型(Diffusion Models)
扩散模型是一种基于噪声扩散和去噪过程的生成模型。其核心思想是通过逐步添加噪声将数据分布转换为先验分布,然后通过去噪过程恢复原始数据分布。Step-Video-T2V 使用了扩散模型的框架,结合了 Flow Matching 技术,显著提高了生成视频的质量。
2. Transformer 架构
Step-Video-T2V 的模型架构基于 Transformer,这种架构在自然语言处理和计算机视觉领域都取得了巨大成功。Transformer 的自注意力机制能够有效地捕捉长距离依赖关系,使其在视频生成任务中表现出色。
3. 3D 变分自编码器(3D VAE)
Step-Video-T2V 的 Video-VAE 是一种深度压缩的变分自编码器,专门用于视频生成。它通过结合多种策略,显著提高了时空压缩效率,并保留了时间信息。
4. 直接偏好优化(Direct Preference Optimization, DPO)
DPO 是一种基于人类偏好数据的优化技术,通过微调模型以生成更符合人类期望的内容。Step-Video-T2V 在最终阶段应用了 DPO 技术,进一步提升了生成视频的视觉质量。
总结
Step-Video-T2V 项目以其卓越的性能、高效的实现方式和开源性,为文本到视频生成领域提供了一个强大的工具。通过本文的详细介绍,读者可以全面了解 Step-Video-T2V 的技术架构,并掌握如何在实际项目中应用这一模型。无论是研究人员还是开发者,都可以从 Step-Video-T2V 中受益,推动视频生成技术的发展和应用。
未来,随着技术的不断进步,Step-Video-T2V 有望在更多领域发挥更大的作用,为人类创造更加丰富多彩的视觉内容。
相关文章:
【图像生成大模型】Step-Video-T2V:下一代文本到视频生成技术
Step-Video-T2V:下一代文本到视频生成技术 引言Step-Video-T2V 项目概述核心技术1. 视频变分自编码器(Video-VAE)2. 3D 全注意力扩散 Transformer(DiT w/ 3D Full Attention)3. 视频直接偏好优化(Video-DPO…...

C语言中的指针:从基础到进阶实战
指针是C语言中最具特色且功能强大的特性之一。它们不仅是内存管理的核心工具,还能帮助程序员实现复杂的数据结构和高效算法。本文将从指针的基础知识入手,逐步深入探讨其高级应用,结合实际示例,助你掌握指针的精髓。 一、指针的基…...

深度学习推理引擎---ONNX Runtime
一、基础概念 1. 什么是ONNX Runtime? 定位:由微软开发的跨平台推理引擎,专为优化ONNX(Open Neural Network Exchange)模型的推理性能设计。目标:提供高效、可扩展的推理能力,支持从云到边缘的…...

JAVA Spring MVC+Mybatis Spring MVC的工作流程*,多表连查
目录 注解总结 将传送到客户端的数据转成json数据 **描述一下Spring MVC的工作流程** 1。属性赋值 BeanUtils.copyProperties(addUserDTO,user); 添加依赖: spring web、mybatis framework、mysql driver Controller和ResponseBody优化 直接改成RestControl…...

ctr查看镜像
# 拉取镜像到 k8s.io 命名空间 sudo nerdctl --namespace k8s.io pull nginx:1.23.4 # 验证镜像是否已下载 sudo nerdctl --namespace k8s.io images 下载镜像到k8s.io名称空间下 nerdctl --namespace k8s.io pull zookeeper:3.6.2 sudo ctr image pull --namespace k8s.io …...
VueUse/Core:提升Vue开发效率的实用工具库
文章目录 引言什么是VueUse/Core?为什么选择VueUse/Core?核心功能详解1. 状态管理2. 元素操作3. 实用工具函数4. 浏览器API封装5. 传感器相关 实战示例:构建一个拖拽上传组件性能优化技巧与原生实现对比常见问题解答总结 引言 在现代前端开发…...

数字格式化库 accounting.js的使用说明
accounting.js 是一个用于格式化数字、货币和金额的轻量级库,特别适合财务和会计应用。以下是其详细使用说明: 安装与引入 通过 npm 安装: bash 复制 下载 npm install accounting 引入: javascript 复制 下载 const accounting …...

Docker 网络
目录 前言 1. Docker 网络模式 2. 默认 bridge 网络详解 (1)特点 (2)操作示例 3. host 网络模式 (1)特点 (2)操作示例 4. overlay…...
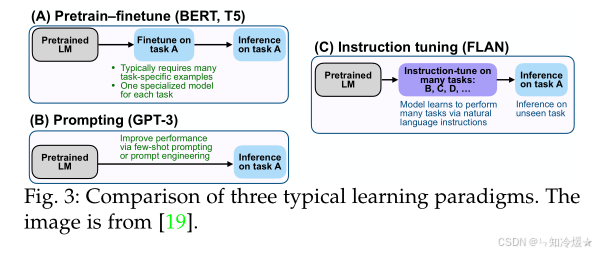
【论文阅读】A Survey on Multimodal Large Language Models
目录 前言一、 背景与核心概念1-1、多模态大语言模型(MLLMs)的定义 二、MLLMs的架构设计2-1、三大核心模块2-2、架构优化趋势 三、训练策略与数据3-1、 三阶段训练流程 四、 评估方法4-1、 闭集评估(Closed-set)4-2、开集评估&…...
增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化)
基于多头自注意力机制(MHSA)增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化
深度学习在计算机视觉领域的快速发展推动了目标检测算法的持续进步。作为实时检测框架的典型代表,YOLO系列凭借其高效性与准确性备受关注。本文提出一种基于多头自注意力机制(Multi-Head Self-Attention, MHSA)增强的YOLOv11主干网络结构,旨在提升模型在复杂场景下的目标特征…...
vue3 elementplus tabs切换实现
Tabs 标签页 | Element Plus <template><!-- editableTabsValue 是当前tab 的 name --><el-tabsv-model"editableTabsValue"type"border-card"editableedit"handleTabsEdit"><!-- 这个是标签面板 面板数据 遍历 editableT…...

关于机器学习的实际案例
以下是一些机器学习的实际案例: 营销与销售领域 - 推荐引擎:亚马逊、网飞等网站根据用户的品味、浏览历史和购物车历史进行推荐。 - 个性化营销:营销人员使用机器学习联系将产品留在购物车或退出网站的用户,根据客户兴趣定制营销…...
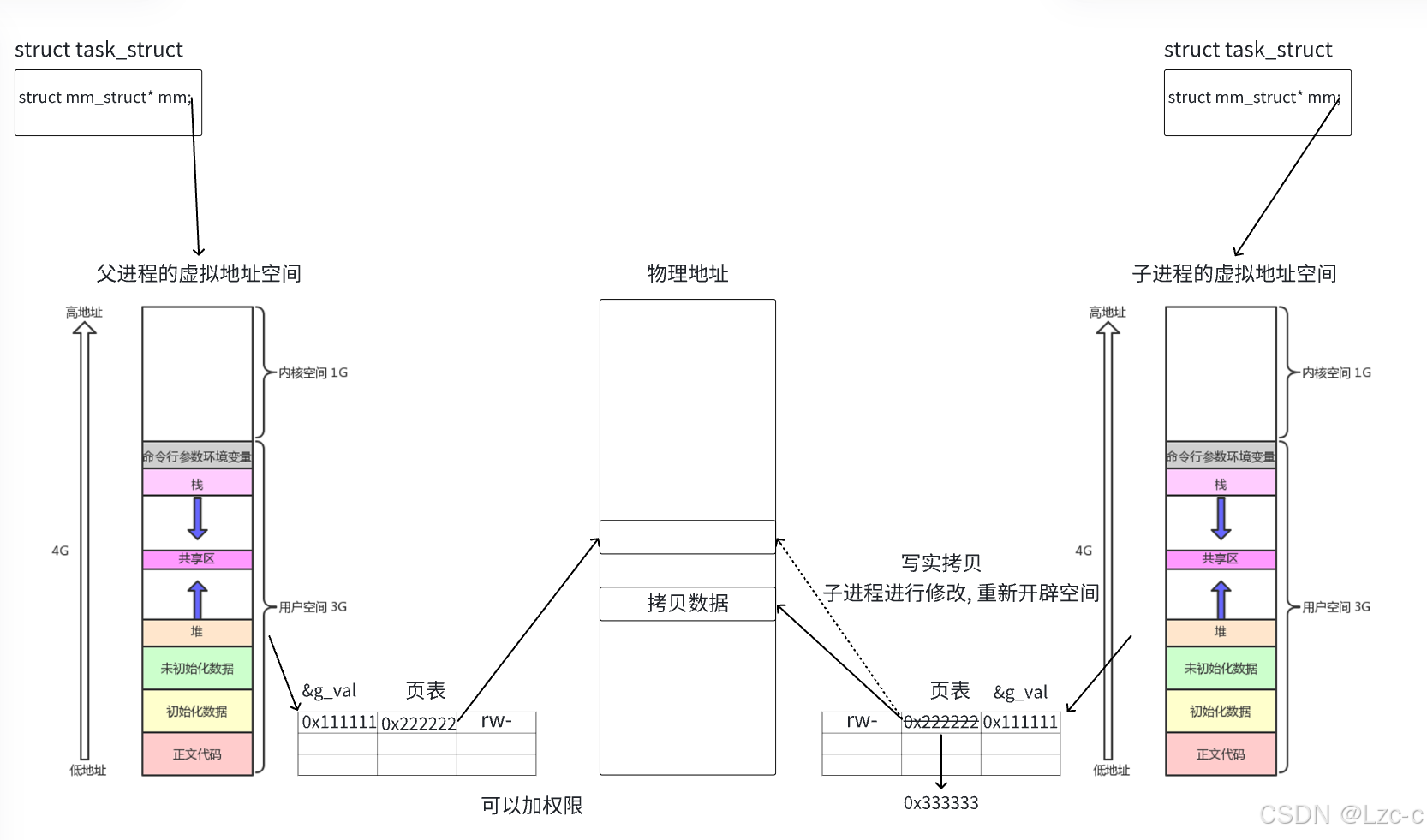
Linux的进程概念
目录 1、冯诺依曼体系结构 2、操作系统(Operating System) 2.1 基本概念 编辑 2.2 目的 3、Linux的进程 3.1 基本概念 3.1.1 PCB 3.1.2 struct task_struct 3.1.3 进程的定义 3.2 基本操作 3.2.1 查看进程 3.2.2 初识fork 3.3 进程状态 3.3.1 操作系统的进程状…...

C++ map容器: 插入操作
1. map插入操作基础 map是C STL中的关联容器,存储键值对(key-value pairs)。插入元素时有四种主要方式,各有特点: 1.1 头文件与声明 #include <map> using namespace std;map<int, string> mapStu; // 键为int,值…...

基于STC89C52的红外遥控的电子密码锁设计与实现
一、引言 电子密码锁作为一种安全便捷的门禁系统,广泛应用于家庭、办公室等场景。结合红外遥控功能,可实现远程控制开锁,提升使用灵活性。本文基于 STC89C52 单片机,设计一种兼具密码输入和红外遥控的电子密码锁系统,详细阐述硬件选型、电路连接及软件实现方案。 二、硬…...

Docker配置容器开机自启或服务重启后自启
要将一个 Docker 容器设置为开机自启,你可以使用 docker update 命令或配置 Docker 服务来实现。以下是两种常见的方法: 方法 1:使用 docker update 设置容器自动重启 使用 docker update 设置容器为开机自启 你可以使用以下命令,…...
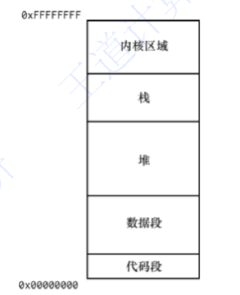
计算机单个进程内存布局的基本结构
这张图片展示了一个计算机内存布局的基本结构,从低地址(0x00000000)到高地址(0xFFFFFFFF)依次分布着不同的内存区域。 代码段 这是程序代码在内存中的存储区域。它包含了一系列的指令,这些指令是计算机执行…...

我的电赛(简易的波形发生器大一暑假回顾)
DDS算法:当时是用了一款AD9833芯片搭配外接电路实现了一个波形发生,配合stm32f103芯片实现一个幅度、频率、显示的功能; 在这个过程中,也学会了一些控制算法;就比如DDS算法,当时做了一些了解,可…...

AI工程 新技术追踪 探讨
文章目录 一、核心差异维度对比二、GitHub对AI工程师的独特价值三、需要警惕的陷阱四、推荐追踪策略五、与传统开发的平衡建议 以下内容整理来自 deepseek 作为AI工程师,追踪GitHub开源项目 对技术成长和职业发展的影响 比传统应用开发工程师 更为显著,…...
算法题(149):矩阵消除游戏
审题: 本题需要我们找到消除矩阵行与列后可以获得的最大权值 思路: 方法一:贪心二进制枚举 这里的矩阵消除时,行与列的消除会互相影响,所以如果我们先统计所有行和列的总和,然后选择消除最大的那一行/列&am…...

在 Vue 中插入 B 站视频
前言 在 Vue 项目中,有时我们需要嵌入 B 站视频来丰富页面内容,为用户提供更直观的信息展示。本文将详细介绍在 Vue 中插入 B 站视频的多种方法。 使用<iframe>标签直接嵌入,<iframe>标签是一种简单直接的方式,可将 B 站视频嵌…...
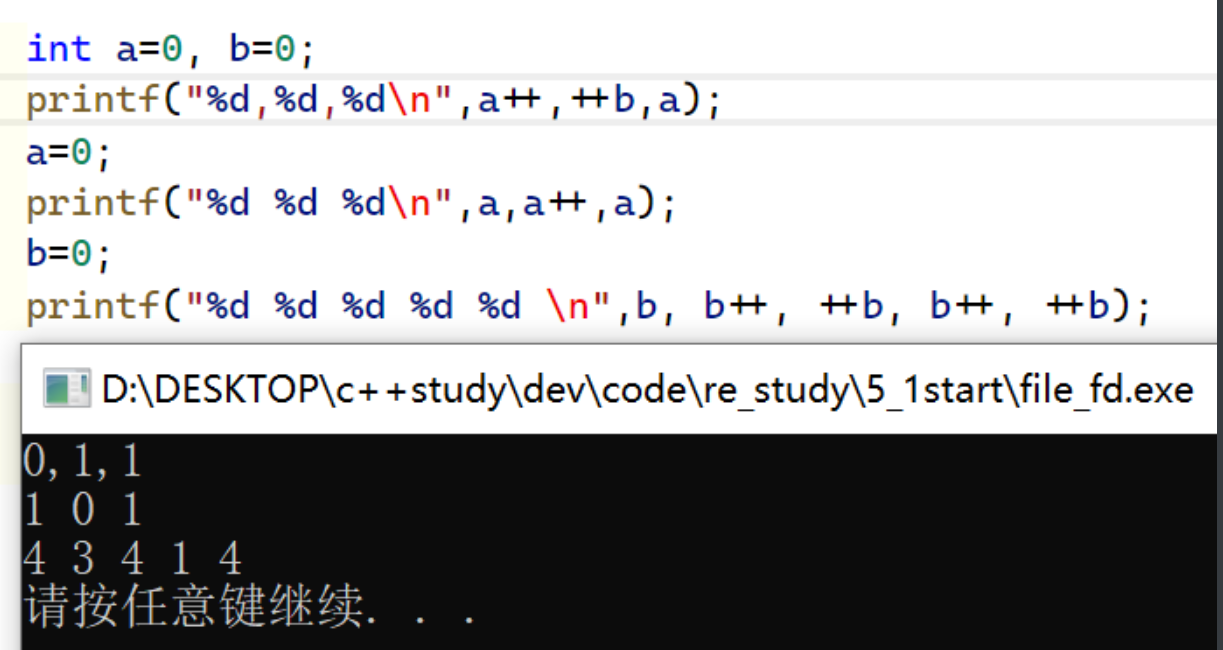
printf函数参数与入栈顺序
01. printf()的核心功能 作用:将 格式化数据 输出到 标准输出(stdout),支持多种数据类型和格式控制。 int printf(const char *format, ...);参数: format:格式字符串,字符串或%开头格式符...:…...

仿生眼机器人(人脸跟踪版)系列之一
文章不介绍具体参数,有需求可去网上搜索。 特别声明:不论年龄,不看学历。既然你对这个领域的东西感兴趣,就应该不断培养自己提出问题、思考问题、探索答案的能力。 提出问题:提出问题时,应说明是哪款产品&a…...

08、底层注解-@Configuration详解
# Configuration 注解详解 08、底层注解-Configuration详解 Configuration 是 Spring 框架中用于定义配置类的核心注解,它允许开发者以 Java 代码的形式替代传统的 XML 配置,声明和管理 Bean。 ## 一、基本作用 ### 1. 标识配置类 使用 Configuration…...
Go语言语法---输入控制
文章目录 1. fmt包读取输入1.1. 读取单个值1.2. 读取多个值 2. 格式化输入控制 在Go语言中,控制输入主要涉及从标准输入(键盘)或文件等来源读取数据。以下是几种常见的输入控制方法: 1. fmt包读取输入 fmt包中的Scan和Scanln函数都可以读取输入…...

蓝桥杯单片机按键进阶
蓝桥杯单片机按键进阶 ——基于柳离风老师模板及按键进阶教程 文章目录 蓝桥杯单片机按键进阶1、按键测试-按下生效2、按键进阶-松手生效3、按键进阶-按键禁用(未完待续) 1、按键测试-按下生效 key.c #include "key.h"/*** brief 独立按键…...

CSS- 4.3 绝对定位(position: absolute)学校官网导航栏实例
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...

Flink 作业提交流程
Apache Flink 的 作业提交流程(Job Submission Process) 是指从用户编写完 Flink 应用程序,到最终在 Flink 集群上运行并执行任务的整个过程。它涉及多个组件之间的交互,包括客户端、JobManager、TaskManager 和 ResourceManager。…...

拓展运算符
拓展运算符(Spread Operator)是ES6中引入的新特性,以下是关于它的一些知识点总结: 语法 拓展运算符的语法是三个点(...),它可以将数组或对象展开成多个元素或属性。 数组中的应用 • 数组展…...
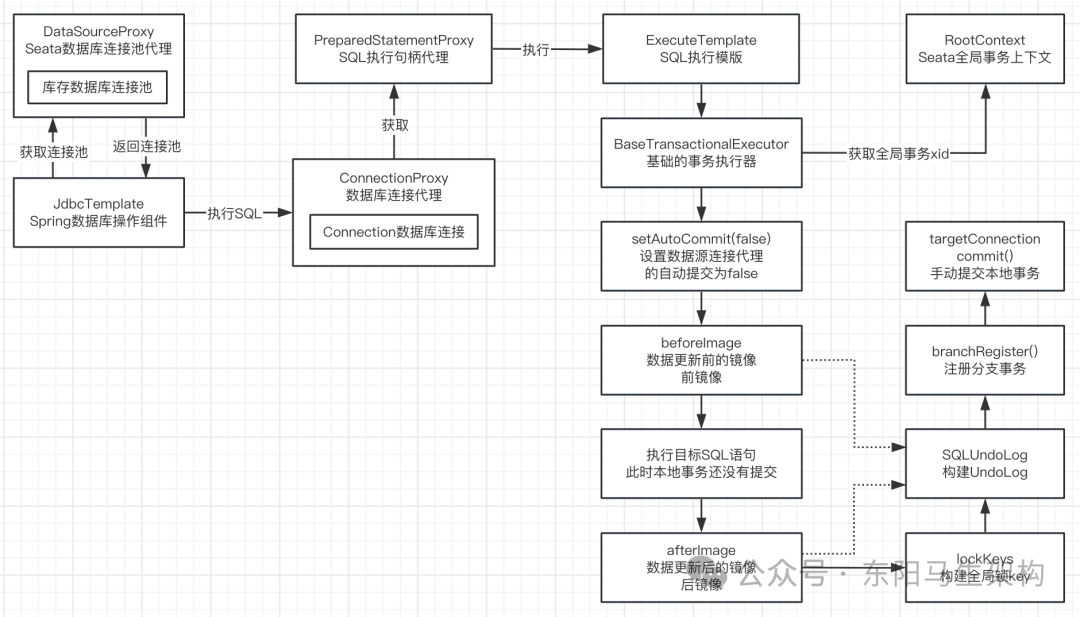
Seata源码—6.Seata AT模式的数据源代理一
大纲 1.Seata的Resource资源接口源码 2.Seata数据源连接池代理的实现源码 3.Client向Server发起注册RM的源码 4.Client向Server注册RM时的交互源码 5.数据源连接代理与SQL句柄代理的初始化源码 6.Seata基于SQL句柄代理执行SQL的源码 7.执行SQL语句前取消自动提交事务的源…...