将嵌入映射到 Elasticsearch 字段类型:semantic_text、dense_vector、sparse_vector
作者: Andre Luiz

讨论如何以及何时使用 semantic_text、dense_vector 或 sparse_vector,以及它们与嵌入生成的关系。
通过这个自定进度的 Search AI 实践学习亲自体验向量搜索。你可以开始免费云试用,或者在本地机器上尝试 Elastic。
多年来,使用嵌入来提升信息检索的相关性和准确性已经显著增长。像 Elasticsearch 这样的工具已经发展出支持这种类型数据的专用字段类型,比如密集向量、稀疏向量和语义文本。然而,为了获得良好的效果,关键在于理解如何正确地将嵌入映射到 Elasticsearch 可用的字段类型:semantic_text、dense_vector 和 sparse_vector。
本文将讨论这些字段类型、各自的适用时机,以及它们在索引和查询过程中与嵌入生成和使用策略之间的关系。
密集向量类型
在 Elasticsearch 中,dense_vector 字段类型用于存储密集向量,这些向量是文本的数值表示,其中几乎所有维度都是相关的。这些向量由语言模型生成,如 OpenAI、Cohere 和 Hugging Face,旨在捕捉文本的整体语义含义,即使它与其他文档没有共享相同的词语。
在 Elasticsearch 中,密集向量的维度上限为 4096,具体取决于所使用的模型。例如,all-MiniLM-L6-v2 模型生成 384 维向量,而 OpenAI 的 text-embedding-ada-002 生成 1536 维向量。
当需要更大的控制权时,例如使用预生成的向量、应用自定义相似度函数或与外部模型集成,dense_vector 字段通常被作为存储这类嵌入的默认类型。
何时以及为何使用 dense_vector 类型?
密集向量非常适合用于捕捉句子、段落或完整文档之间的语义相似性。当目标是比较文本的整体含义,即使它们不共享相同词语时,它们也表现得非常好。
当你已经有一个外部嵌入生成流程,使用如 OpenAI、Cohere 或 Hugging Face 等模型,并且只想手动存储和查询这些向量时,dense_vector 字段是理想选择。这种字段类型高度兼容嵌入模型,并在生成和查询上提供完全的灵活性,让你可以控制向量的生成、索引以及搜索中的使用方式。
此外,它支持多种语义搜索形式,如 KNN 或 script_score 查询,适用于需要调整排序逻辑的场景。这些能力使 dense_vector 成为 RAG(检索增强生成)、推荐系统以及基于相似度的个性化搜索等应用的理想选择。
最后,该字段允许你自定义相关性逻辑,可使用如 cosineSimilarity、dotProduct 或 l2norm 等函数,根据你使用场景的需求来调整排序。
对于那些需要灵活性、自定义能力和与高级用例兼容性的用户来说,密集向量仍然是最佳选择。
如何对 dense_vector 类型使用查询?
对定义为 dense_vector 的字段进行搜索时,使用的是 k-nearest neighbor 查询(KNN 查询)。该查询用于查找与查询向量最接近的文档。以下是一个将 KNN 查询应用于 dense_vector 字段的示例:
{"knn": {"field": "my_dense_vector","k": 10,"num_candidates": 50,"query_vector": [/* vector generated by model */]}
}除了使用 Knn 查询外,如果需要自定义文档评分,也可以使用 script_score 查询,将其与如 cosineSimilarity、dotProduct 或 l2norm 等向量比较函数结合,以更可控的方式计算相关性。请看示例:
{
"script_score": {"query": { "match_all": {} },"script": {"source": "cosineSimilarity(params.query_vector,
'my_dense_vector') + 1.0","params": {"query_vector": [/* vector */]}}}
}如果你想深入了解,我推荐阅读文章《How to set up vector search in Elasticsearch》。
稀疏向量类型
sparse_vector 字段类型用于存储稀疏向量,这种向量的大多数值为零,只有少数词语具有显著权重。这种向量常见于基于词项的模型,如 SPLADE 或 ELSER(Elastic Learned Sparse EncodeR)。
何时以及为何使用稀疏向量类型?
稀疏向量非常适合在需要词汇层面更精确搜索,同时不牺牲语义智能的情况下使用。它们将文本表示为 token/value 对,仅突出最相关的词语及其权重,提供了清晰性、控制力和效率。
这种字段类型在基于词项生成向量时特别有用,比如 ELSER 或 SPLADE 模型,根据词元在文本中的相对重要性为每个词元分配不同权重。
当你想控制查询中特定词语的影响时,稀疏向量类型允许你手动调整词语的权重,以优化结果排序。
主要优势包括搜索的透明性,因为可以清楚理解为什么某个文档被认为相关;存储效率,因为只保存非零值的词元,而密集向量则保存所有维度。
此外,稀疏向量是混合搜索策略的理想补充,甚至可以与密集向量结合,将词汇精度与语义理解融合。
如何对稀疏向量类型使用查询?
sparse_vector 查询允许你基于词元/值格式的查询向量搜索文档。下面是查询示例:
{"query": {"sparse_vector": {"field": "field_sparse","query_vector": {"token1": 0.5,"token2": 0.3,"token3": 0.2}}}
}如果你更喜欢使用训练好的模型,可以使用推理端点,它会自动将查询文本转换为稀疏向量:
{"query": {"sparse_vector": {"field": "field_sparse","inference_id": "the inference ID to produce the token/weights","query": "search text"}}
}要进一步了解这个主题,我建议阅读《Understanding sparse vector embeddings with trained ML models》。
语义文本类型 - semantic_text
semantic_text 字段类型是 Elasticsearch 中使用语义搜索最简单、最直接的方式。它通过推理端点自动处理嵌入生成,既在索引时也在查询时完成。这意味着你不必担心手动生成或存储向量。
何时以及为何使用 semantic_text?
semantic_text 字段是采用 Elasticsearch 语义搜索最简单直接的方式。它适合那些想以最少技术投入开始,并且不想手动处理向量的用户。该字段自动化了嵌入生成和向量搜索映射等步骤,使设置更快、更方便。
当你重视简洁和抽象时,应考虑使用 semantic_text,它消除了手动配置映射、嵌入生成和数据接收流程的复杂性。只需选择推理模型,剩下的由 Elasticsearch 处理。
主要优势包括自动嵌入生成(在索引和查询时进行),以及预配置支持所选推理模型的现成映射。
此外,该字段原生支持长文本自动拆分(文本分块),允许将大段文本分成更小的片段,每个片段都有自己的嵌入,提升搜索精度。这极大提高了生产力,特别适合希望快速交付价值且不想处理语义搜索底层工程的团队。
不过,虽然 semantic_text 提供速度和简洁,但也有一定限制。它支持市场标准模型,只要它们作为 Elasticsearch 中的推理端点可用。但不支持像 dense_vector 字段那样使用外部生成的嵌入。
如果你需要更多控制嵌入生成方式、想使用自己的嵌入,或者需要结合多个字段进行高级策略,dense_vector 和 sparse_vector 字段则提供了适合更定制或领域专用场景的灵活性。
如何对 semantic_text 类型使用查询
在 semantic_text 出现之前,查询要根据嵌入类型(密集或稀疏)使用不同的查询。稀疏字段用 sparse_vector 查询,密集字段用 KNN 查询。
使用 semantic_text 类型时,搜索通过 semantic 查询进行,它自动生成查询向量,并与已索引文档的嵌入进行比较。semantic_text 类型允许你定义一个推理端点来嵌入查询,如果没有指定,则会使用索引时相同的端点来处理查询。
{"query": {"semantic": {"field": "semantic_text_field","query": "search text"}}
}要了解更多,我建议阅读文章《Elasticsearch:使用 semantic_text 简化语义搜索》。
总结
在选择如何在 Elasticsearch 中映射嵌入时,理解你想如何生成向量以及需要多少控制权是非常重要的。如果你追求简单,semantic_text 字段支持自动且可扩展的语义搜索,适合很多初始用例。当需要更多控制、微调性能或与自定义模型集成时,dense_vector 和 sparse_vector 字段提供所需的灵活性。
理想的字段类型取决于你的用例、可用基础设施以及机器学习堆栈的成熟度。最重要的是,Elastic 提供了构建现代且高度适应性搜索系统的工具。
原文:Elasticsearch new semantic_text mapping: Simplifying semantic search - Elasticsearch Labs
相关文章:
将嵌入映射到 Elasticsearch 字段类型:semantic_text、dense_vector、sparse_vector
作者: Andre Luiz 讨论如何以及何时使用 semantic_text、dense_vector 或 sparse_vector,以及它们与嵌入生成的关系。 通过这个自定进度的 Search AI 实践学习亲自体验向量搜索。你可以开始免费云试用,或者在本地机器上尝试 Elastic。 多年来…...
(Go语言版))
【LeetCode 热题100】17:电话号码的字母组合(详细解析)(Go语言版)
☎️ LeetCode 17. 电话号码的字母组合(回溯 DFS 详解) 📌 题目描述 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按任意顺序返回。 数字到字母的映射如下(与电话按键相同)…...
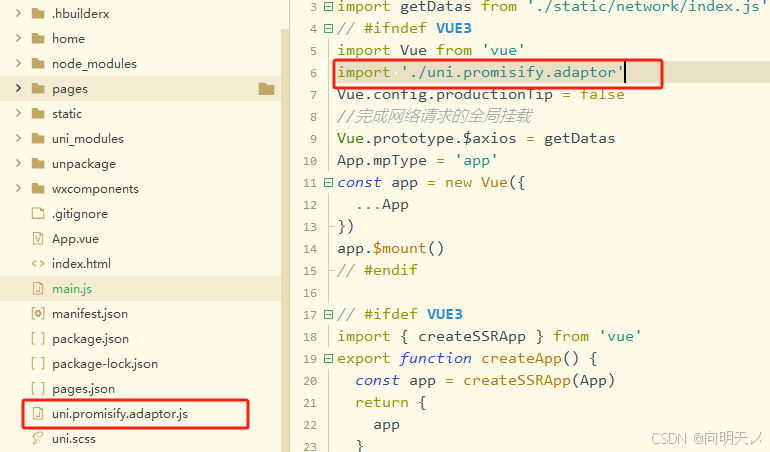
解决uni-app开发中的“TypeError: Cannot read property ‘0‘ of undefined“问题
问题背景 在使用uni-app开发小程序或App时,你可能会遇到这样一个错误: TypeError: Cannot read property 0 of undefinedat uni.promisify.adaptor.js:7这个错误看起来很唬人,但它实际上与uni-app框架中的Promise适配器有关。今天,我们将深…...

翻译:20250518
翻译题 文章目录 翻译题一带一路中国结 一带一路 The “One Belt and One Road” Initiative aims to achieve win-win and shared development. China remains unchanged in its commitment to foster partnerships. China pursues an independent foreign policy of peace, …...

西门子1200/1500博图(TIA Portal)寻址方式详解
西门子博图(TIA Portal)是西门子公司推出的自动化工程软件平台,广泛应用于工业自动化领域。在编写PLC程序时,寻址方式是一个非常重要的概念,它决定了如何访问和操作PLC中的数据和资源。本文将详细介绍西门子博图中的寻…...

《Python星球日记》 第78天:CV 基础与图像处理
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、计算机视觉(CV)简介1. 什么是计算机视觉?2. 计算机视觉的应用场景3. 图像的基本属性a》像素(Pixel)b》通道(Channel)c》分辨率(Res…...

踩坑:uiautomatorviewer.bat 打不开
错误信息 运行 sdk\tools\bin\uiautomatorviewer.bat 报错 -Djava.ext.dirs..\lib\x86_64;..\lib is not supported. Use -classpath instead. Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit. 原因 java版…...

Atcoder Beginner Contest 406
比赛链接:ABC406 A - Not Acceptable 将小时转换成分钟直接进行判断。 时间复杂度: O ( 1 ) O(1) O(1)。 #include <bits/stdc.h> using namespace std;int main() {ios::sync_with_stdio(false); cin.tie(nullptr); cout.tie(nullptr);int a,…...
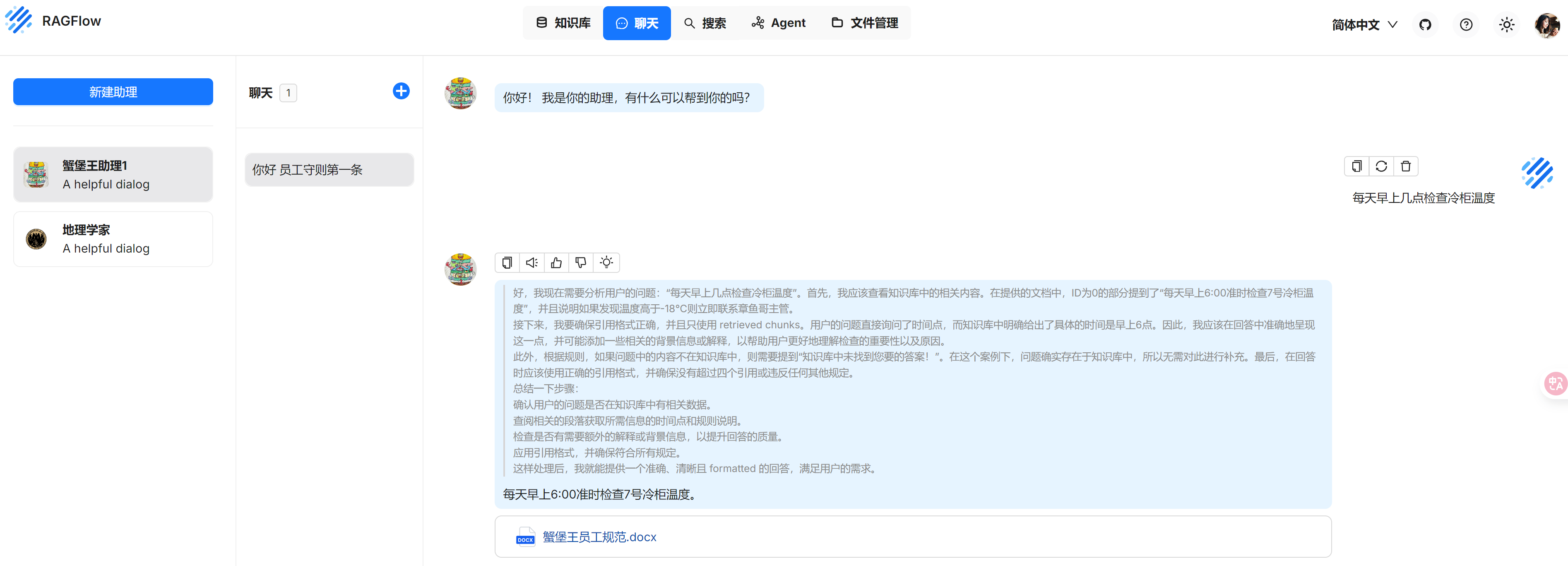
记录一次win11本地部署deepseek的过程
20250518 win11 docker安装部署 ollama安装 ragflow部署 deepseek部署 文章目录 1 部署Ollama下载安装ollama配置环境变量通过ollama下载模型deepseek-r1:7b 2 部署docker2.1 官网下载amd版本安装2.2 配置wsl2.3 Docker配置:位置代理镜像源 3 部署RAGFlow更换ragfl…...
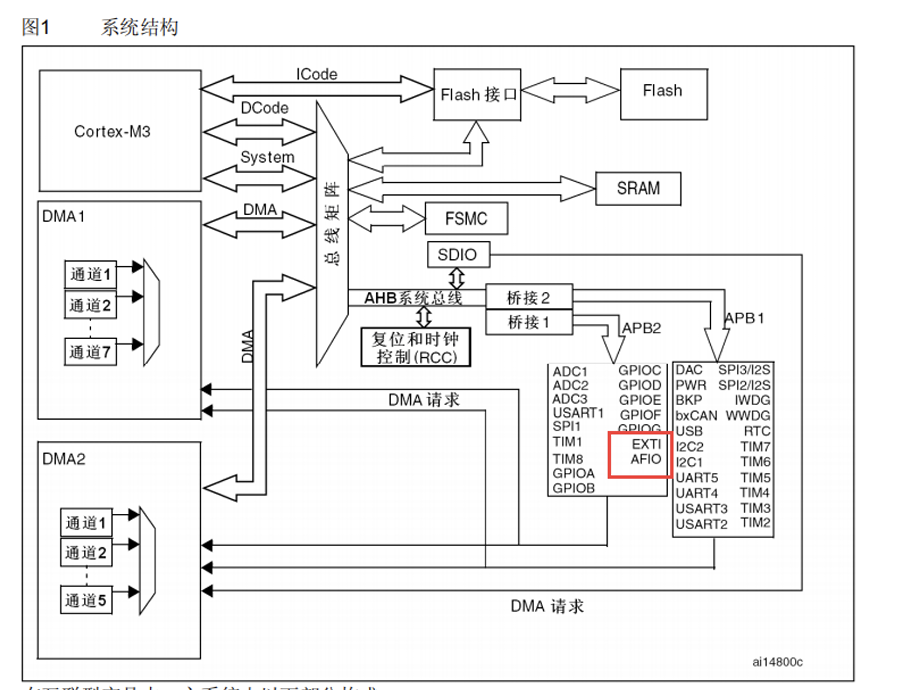
嵌入式STM32学习——外部中断EXTI与NVIC的基础练习⭐
按键控制LED灯 按键控制LED的开发流程: 第一步:使能功能复用时钟 第二布,配置复用寄存器 第三步,配置中断屏蔽寄存器 固件库按键控制LED灯 外部中断EXTI结构体:typedef struct{uint32_t EXTI_Line; …...

进程状态并详解S和D状态
#define TASK_RUNNING 0x0000 // 运行或就绪(在运行队列) #define TASK_INTERRUPTIBLE 0x0001 // 可中断睡眠(S状态) #define TASK_UNINTERRUPTIBLE 0x0002 // 不可中断睡眠(D状态) #define __TASK_STOP…...

数据获取_Python
1 导入数据 (1) 文件系统 ①表格形式的数据:CSV/Excel import pandas as pd# 读取 CSV 文件 data pd.read_csv(sales_data.csv)# 读取excel data2 pd.read_excel(file.xlsx, sheet_nameSheet2, skiprows5, nrows100) ②JSON # 使用 pandas 库 import pandas as pddata pd…...
<前端小白> 前端网页知识点总结
HTML 标签 1. 标题标签 h1到h6 2. 段落标签 p 3. 换行 br 水平线 hr 4. 加粗 strong 倾斜 em 下划线 ins 删除 del 5. 图像标签 img src-图像的位置 alt- 图片加载失败显示的文字 替换文本 title--- 鼠标放到图片上显示的文字 提示…...
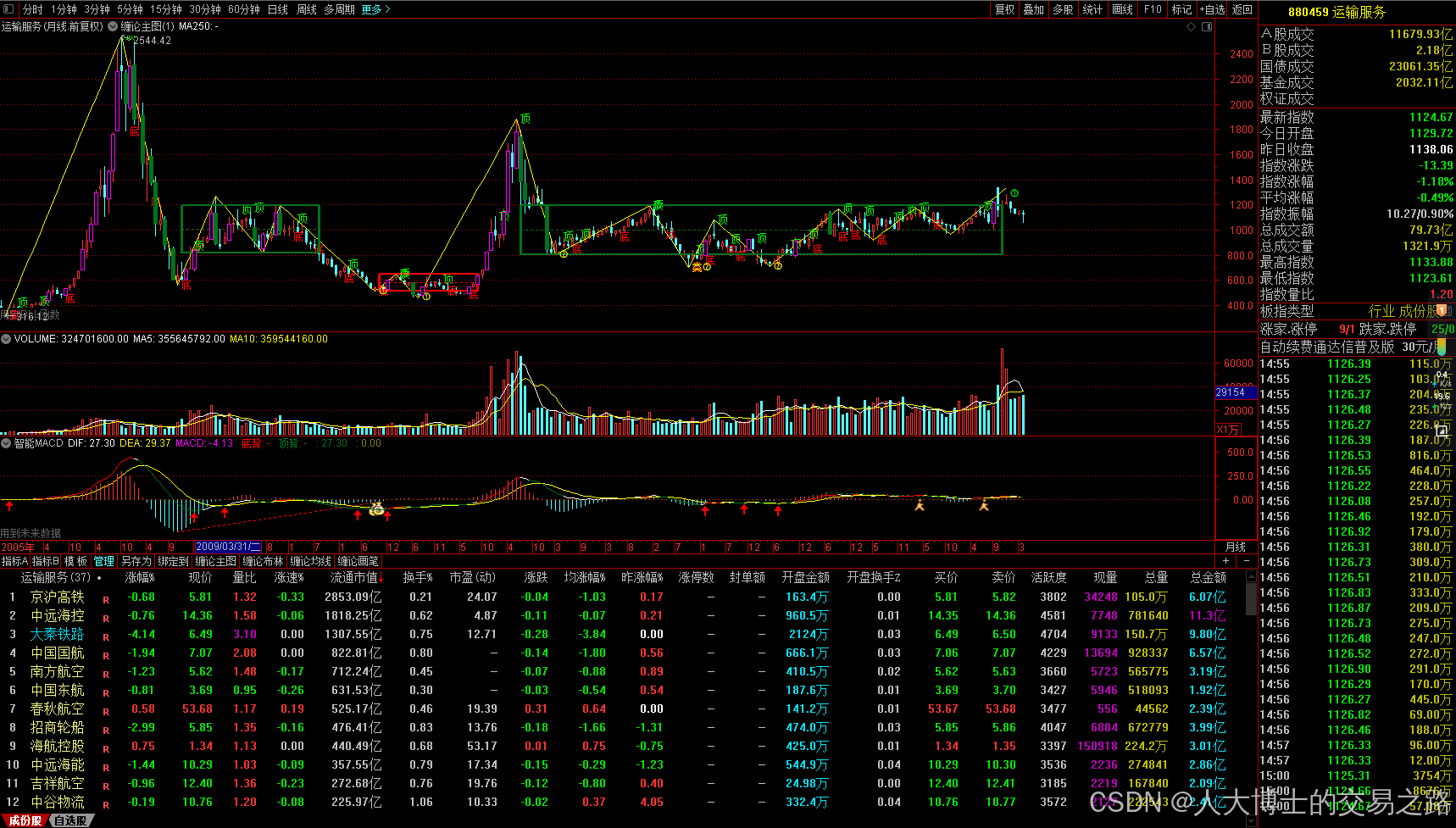
历史数据分析——宁波海运
运输服务 运输服务板块简介: 运输服务板块主要是为货物与人员流动提供核心服务的企业的集合,涵盖铁路、公路、航空、海运、物流等细分领域。该板块具有强周期属性,与经济复苏、政策调控、供需关系密切关联,尤其是海运领域。有不少国内股市的铁路、公路等相关的上市公司同…...
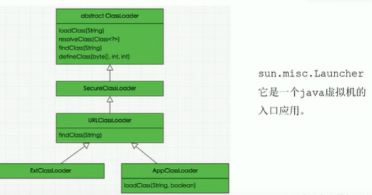
小结:jvm 类加载过程
类加载过程 是Java虚拟机(JVM)将字节码文件(.class文件)加载到内存中,并转换为运行时数据结构的过程。这个过程可以分为多个步骤,每个步骤都有其特定的任务和目的。根据你提供的信息,以下是类加…...

OpenCv高阶(八)——摄像头调用、摄像头OCR
文章目录 前言一、摄像头调用通用方法1、导入必要的库2、创建摄像头接口 二、摄像头OCR1.引入库2、定义函数(1)定义显示opencv显示函数(2)保持宽高比的缩放函数(3)坐标点排序函数(4)…...

Java开发经验——阿里巴巴编码规范实践解析3
摘要 本文深入解析了阿里巴巴编码规范中关于错误码的制定与管理原则,强调错误码应便于快速溯源和沟通标准化,避免过于复杂。介绍了错误码的命名与设计示例,推荐采用模块前缀、错误类型码和业务编号的结构。同时,探讨了项目错误信…...
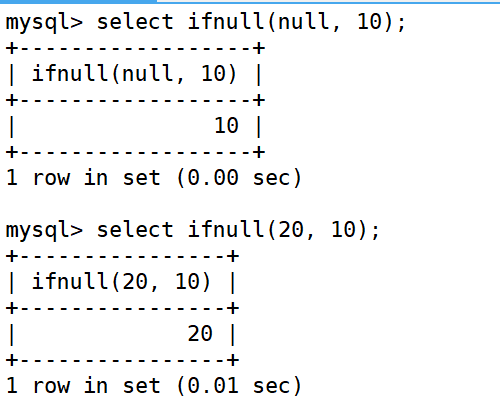
MySQL——6、内置函数
内置函数 1、日期函数2、字符串函数3、数学函数4、其他函数 1、日期函数 1.1、获取当前日期: 1.2、获取当前时间: 1.3、获取当前时间戳: 1.4、获取当前日期时间: 1.5、提取出日期: 1.6、给日期添加天数或时间…...
)
MySQL如何查看某个表所占空间大小?(表空间大小查看方法)
文章目录 一、使用SQL查询查看表空间1.1 查询所有表的大小(包括数据和索引)1.2 查询特定数据库的表大小1.3 查询单个表的详细空间信息 二、使用命令行工具查看表空间2.1 使用mysql客户端查询2.2 查看物理文件大小(适用于MyISAM/InnoDB&#x…...

软件架构之-论软件系统架构评估以及应用
论软件系统架构评估以及应用 摘要正文 摘要 2023年2月,本人所在集团公司承接了长三角地区某省渔船图纸电子化审查系统项目开发,该项目旨在为长三角地区渔船建造设计院,以及渔船图纸审查机构提供一个便捷化的服务平台。在此项目中,…...
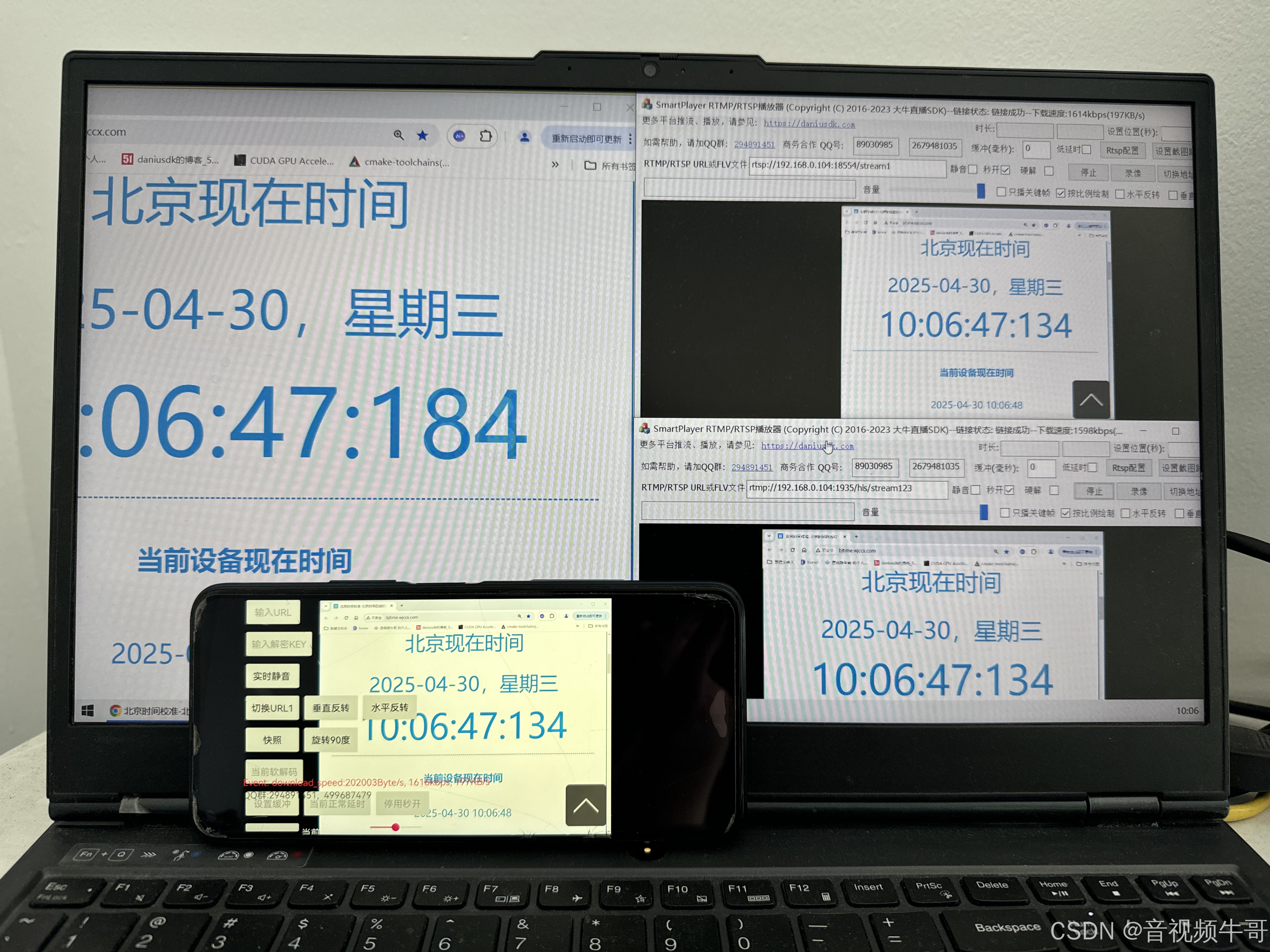
低延迟与高性能的技术优势解析:SmartPlayer VS VLC Media Player
在实时视频流的应用中,RTSP(Real-Time Streaming Protocol)播放器扮演着至关重要的角色,尤其是在视频监控、远程医疗、直播等高实时性需求的场景中。随着行业需求的不断升级,对播放器的低延迟、稳定性、兼容性等方面的…...
:深入理解 PyTorch 的 `torch.randint()` 与 `.long()` 转换)
pytorch小记(十九):深入理解 PyTorch 的 `torch.randint()` 与 `.long()` 转换
pytorch小记(十九):深入理解 PyTorch 的 torch.randint 与 .long 转换 一、torch.randint() 基本概念示例:生成一个二维随机整型张量 二、为什么需要调用 .long()三、典型场景示例1. 随机索引采样2. 伪标签生成3. 直接在 GPU 上生…...

深入解析Spring Boot与微服务架构:从入门到实践
深入解析Spring Boot与微服务架构:从入门到实践 引言 Spring Boot作为Java生态中最受欢迎的框架之一,以其简洁的配置和强大的功能赢得了开发者的青睐。本文将带领大家从Spring Boot的基础知识入手,逐步深入到微服务架构的实践,帮…...

【交互 / 差分约束】
题目 代码 #include <bits/stdc.h> using namespace std; using ll long long;const int N 10510; const int M 200 * 500 10; int h[N], ne[M], e[M], w[M], idx; ll d[N]; int n, m; bool st[N]; int cnt[N];void add(int a, int b, int c) {w[idx] c, e[idx] b…...
宝塔面板部署前后端项目SpringBoot+Vue2
这篇博客主要用来记录宝塔部署前端后端项目的过程。因为宝塔部署有点麻烦,至少在我看来挺麻烦的。我还是喜欢原始的ssh连接服务器进行操作。但是公司有项目用到了宝塔,没办法啊,只能摸索记录一下。 我们需要提前准备好后端项目的jar包和前端项…...

现代生活健康养生新视角
在科技飞速发展的今天,我们的生活方式发生巨大转变,健康养生也需要新视角。从光线、声音等生活细节入手,能为健康管理开辟新路径。 光线与健康密切相关。早晨接触自然光线,可调节生物钟,提升血清素水平,…...

鸿蒙Next API17新特性学习之如何使用新增鼠标轴事件
今天咱们接着学习鸿蒙开发文档API17版本的新特性——对鼠标轴事件的支持。这对于需要精细交互的应用来说是一个非常有用的特性,例如地图滚动、文档浏览等场景。本文将详细介绍在鸿蒙 Next 中如何使用新增的鼠标轴事件。 开发步骤 环境准备 在开始开发之前&#x…...

多模态大语言模型arxiv论文略读(八十一)
What is the Visual Cognition Gap between Humans and Multimodal LLMs? ➡️ 论文标题:What is the Visual Cognition Gap between Humans and Multimodal LLMs? ➡️ 论文作者:Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai …...
3.4/Q2,Charls最新文章解读
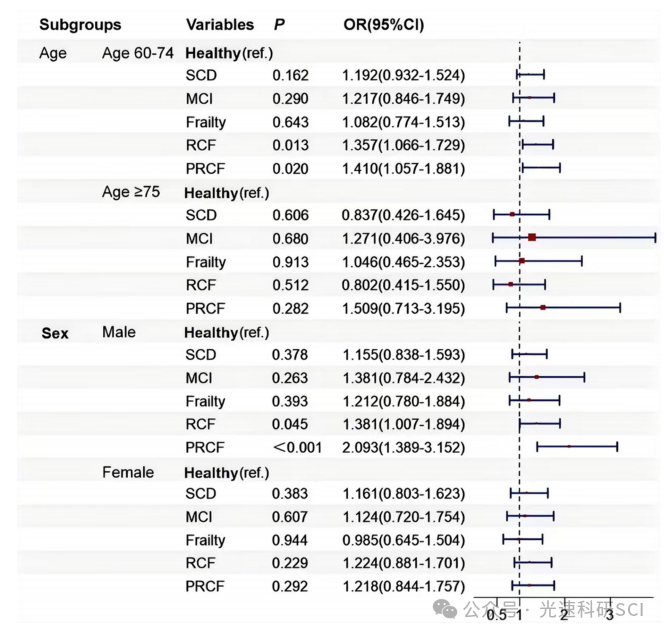
文章题目:Associations between reversible and potentially reversible cognitive frailty and falls in community-dwelling older adults in China: a longitudinal study DOI:10.1186/s12877-025-05872-2 中文标题:中国社区老年人可逆性和…...
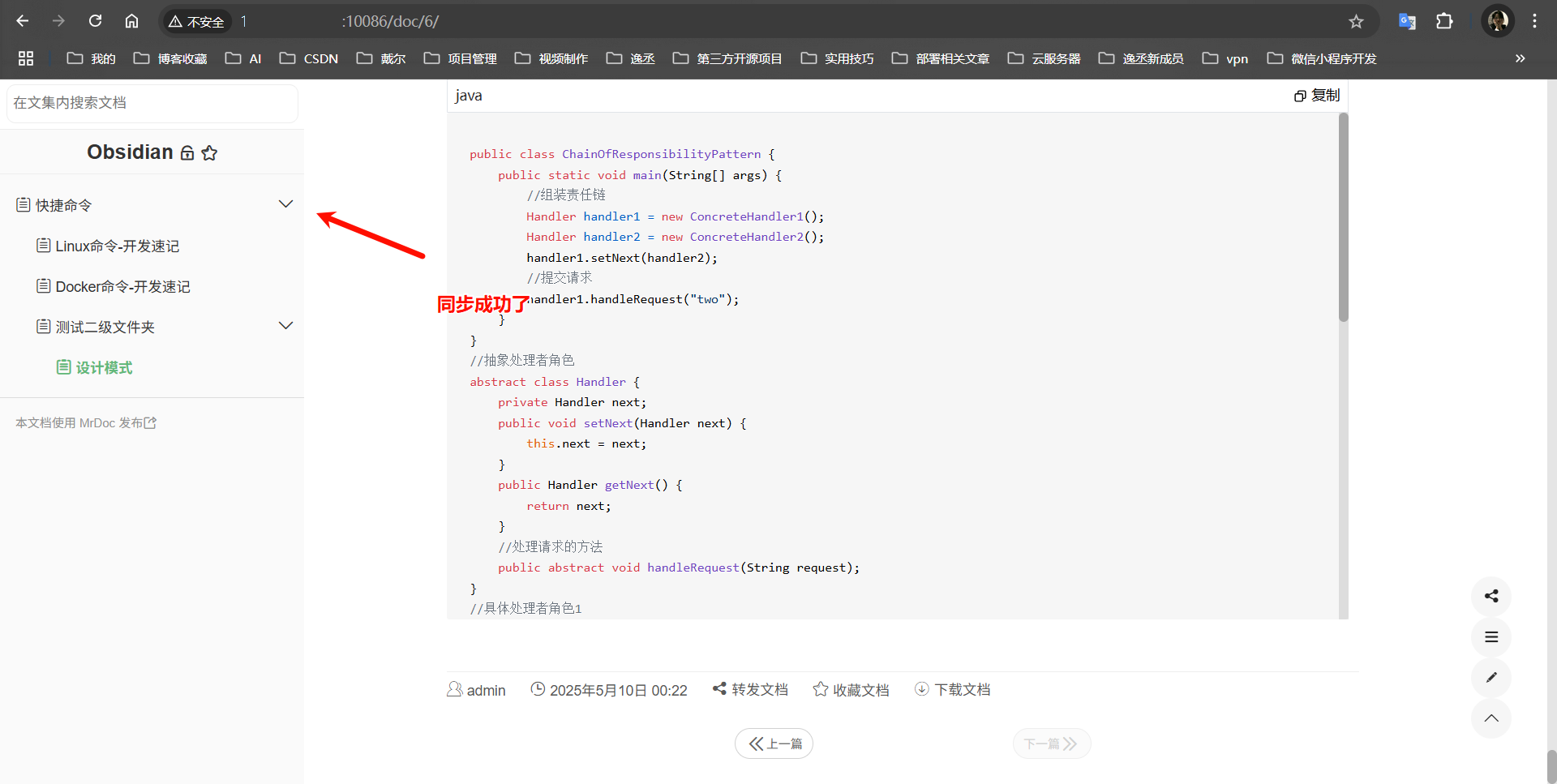
通过觅思文档项目实现Obsidian文章浏览器在线访问
觅思文档项目开源地址 觅思文档项目开源地址:https://gitee.com/zmister/MrDoc 觅思文档部署步骤概览 服务器拉取代码: git clone https://gitee.com/zmister/mrdoc-install.git && cd mrdoc-install && chmod x docker-install.sh &a…...