深入解析JVM字节码解释器执行流程(OpenJDK 17源码实现)
一、核心流程概述
JVM解释器的核心任务是将Java字节码逐条翻译为本地机器指令并执行。其执行流程可分为以下关键阶段:
-
方法调用入口构建:生成栈帧、处理参数、同步锁等。
-
字节码分派(Dispatch):根据字节码跳转到对应处理逻辑。
-
操作数栈与局部变量管理:维护方法执行上下文。
-
方法返回与栈帧销毁:处理返回值、恢复调用者栈帧。
以下结合OpenJDK 17源码详细分析各环节实现。
二、方法调用入口构建
1. generate_call_stub:调用桩(Call Stub)生成
这是从本地代码(如JNI)调用Java方法的核心入口,负责设置调用环境:
address generate_call_stub(address& return_address) {// 保存调用者寄存器状态(rbx, r12-r15等)__ enter();__ subptr(rsp, -rsp_after_call_off * wordSize);// 处理参数传递(Windows与Linux差异)__ movptr(parameters, c_rarg5); // 参数指针__ movptr(entry_point, c_rarg4); // 方法入口地址// 保存线程上下文到栈帧__ movptr(rbx_save, rbx);__ movptr(r12_save, r12);// ... 其他寄存器保存// 加载线程对象并检查异常__ movptr(r15_thread, thread);__ reinit_heapbase(); // 重置堆基址// 压入参数到栈(通过循环逐个压入)Label loop;__ movptr(c_rarg2, parameters);__ movl(c_rarg1, c_rarg3); // 参数计数器__ BIND(loop);__ movptr(rax, Address(c_rarg2, 0));__ push(rax); // 参数入栈__ jcc(Assembler::notZero, loop);// 调用Java方法(entry_point为方法入口)__ call(c_rarg1); // c_rarg1=entry_pointreturn_address = __ pc();// 处理返回值(根据类型存储到指定地址)__ movptr(c_rarg0, result);Label is_long, is_float, exit;__ cmpl(c_rarg1, T_OBJECT);__ jcc(Assembler::equal, is_long);// ... 其他类型处理
关键点:
-
寄存器保存与恢复:通过
movptr保存调用者寄存器,调用结束后恢复。 -
参数传递:根据ABI规范处理不同平台(如Windows使用
rcx, rdx, r8, r9传递前4参数)。 -
异常检查:通过
cmpptr验证线程是否有未处理异常。
三、字节码分派机制
1. 分发表(Dispatch Table)
每个字节码对应一个处理函数地址,按栈顶状态(TosState)分类:
void InterpreterMacroAssembler::dispatch_base(TosState state, address* table) {// 验证栈帧完整性(调试模式)if (VerifyActivationFrameSize) { /* ... */ }// 安全点轮询:检查是否需要进入安全点if (generate_poll) {testb(Address(r15_thread, JavaThread::polling_word_offset()), poll_bit());jccb(Assembler::zero, no_safepoint);lea(rscratch1, ExternalAddress(safepoint_table));}// 跳转到分发表项lea(rscratch1, ExternalAddress(table));jmp(Address(rscratch1, rbx, Address::times_8)); // rbx=字节码值
}
分发表结构:
// 每个TosState对应一个分发表
address* Interpreter::dispatch_table(TosState state) {switch(state) {case vtos: return _active_table[vtos];case itos: return _active_table[itos];// ... 其他状态}
}
2. dispatch_next:逐条分派字节码
void InterpreterMacroAssembler::dispatch_next(TosState state, int step) {load_unsigned_byte(rbx, Address(_bcp_register, step)); // 加载下一字节码increment(_bcp_register, step); // 移动字节码指针dispatch_base(state, Interpreter::dispatch_table(state)); // 分派
}
核心逻辑:
-
加载字节码:从
_bcp_register(字节码指针)读取下一条指令。 -
指针前进:
increment调整指针位置。 -
分派跳转:通过
dispatch_base跳转到对应处理函数。
四、方法调用与虚方法分派
1. invokevirtual实现
void TemplateTable::invokevirtual(int byte_no) {prepare_invoke(byte_no, rbx, noreg, rcx, rdx); // 准备调用参数invokevirtual_helper(rbx, rcx, rdx); // 实际分派逻辑
}void invokevirtual_helper(Register index, Register recv, Register flags) {// 检查是否为final方法__ testl(rax, (1 << ConstantPoolCacheEntry::is_vfinal_shift));__ jcc(Assembler::zero, notFinal);// Final方法直接调用(无虚表查找)__ jump_from_interpreted(method, rax);__ bind(notFinal);// 虚方法查找:通过接收者klass查找vtable__ load_klass(rax, recv); // 加载接收者类__ lookup_virtual_method(rax, index, method);// 查找虚方法__ jump_from_interpreted(method, rdx); // 跳转执行
}
虚方法查找逻辑:
void MacroAssembler::lookup_virtual_method(Register klass, Register index, Register method) {// 计算vtable条目地址Address vtable_entry_addr(klass, index, Address::times_ptr, base + vtableEntry::method_offset_in_bytes());movptr(method, vtable_entry_addr); // 加载Method*
}
2. 同步方法处理
在方法入口处理同步锁:
address TemplateInterpreterGenerator::generate_normal_entry(bool synchronized) {if (synchronized) {lock_method(); // 生成monitorenter指令}// ... 后续执行逻辑
}void lock_method() {__ movptr(rax, Address(rbx, Method::const_offset()));__ movl(rax, Address(rax, ConstMethod::access_flags_offset()));__ testl(rax, JVM_ACC_SYNCHRONIZED);__ jcc(Assembler::zero, done);// 生成锁获取代码(monitorenter)
}
五、栈帧构建与上下文管理
1. 栈帧初始化
在generate_normal_entry中构建解释器栈帧:
// 分配局部变量空间 __ load_unsigned_short(rdx, size_of_locals); __ subl(rdx, rcx); // 计算额外局部变量数 Label loop; __ bind(loop); __ push((int)NULL_WORD); // 初始化局部变量为NULL __ decrementl(rdx); __ jcc(Assembler::greater, loop);// 构建固定帧头(包含返回地址、方法指针等) generate_fixed_frame(false);
固定帧结构:
| Return Address | | Method* | | Constant Pool | | Local Variables | | Operand Stack | | Monitor Block |
2. 调试支持(新增的自定义逻辑)
在方法入口插入调试信息打印(用户自定义代码):
// 保存寄存器状态 __ push(rax); __ push(rcx); // ... 保存其他寄存器// 调用调试函数打印方法名 __ movptr(rdi, rbx); // Method*作为参数 __ call(CAST_FROM_FN_PTR(address, print_debug_info));// 恢复寄存器 __ pop(r15); __ pop(r11); // ... 恢复其他寄存器
作用:通过os::write系统调用输出调试信息(如打印"yym"标识),便于跟踪方法调用链。
六、性能优化与安全机制
1. 调用计数器与JIT编译
Label invocation_counter_overflow; generate_counter_incr(&invocation_counter_overflow); // 递增计数器// 计数器溢出触发编译 __ bind(invocation_counter_overflow); generate_counter_overflow(continue_after_compile);
逻辑:当方法调用次数超过阈值,调用InterpreterRuntime::frequency_counter_overflow触发JIT编译。
2. 安全点轮询
在分派前插入安全点检查:
testb(Address(r15_thread, JavaThread::polling_word_offset()), poll_bit()); jccb(Assembler::zero, no_safepoint); lea(rscratch1, ExternalAddress(safepoint_table)); // 跳转到安全点处理
作用:确保在GC或Deoptimization时,线程能及时响应。
七、总结
OpenJDK解释器的执行流程通过高度优化的汇编代码实现,核心特点包括:
-
高效分派:通过分发表实现字节码快速跳转。
-
栈帧精细管理:严格处理局部变量、操作数栈和监视器锁。
-
与JIT协作:通过调用计数器触发编译优化。
-
安全机制:集成安全点、异常检查等关键功能。
新增的调试代码(如"yym"打印)展示了如何在解释器关键路径插入定制逻辑,为开发者提供灵活的调试能力。
##源码
address generate_call_stub(address& return_address) {assert((int)frame::entry_frame_after_call_words == -(int)rsp_after_call_off + 1 &&(int)frame::entry_frame_call_wrapper_offset == (int)call_wrapper_off,"adjust this code");StubCodeMark mark(this, "StubRoutines", "call_stub");address start = __ pc();// same as in generate_catch_exception()!const Address rsp_after_call(rbp, rsp_after_call_off * wordSize);const Address call_wrapper (rbp, call_wrapper_off * wordSize);const Address result (rbp, result_off * wordSize);const Address result_type (rbp, result_type_off * wordSize);const Address method (rbp, method_off * wordSize);const Address entry_point (rbp, entry_point_off * wordSize);const Address parameters (rbp, parameters_off * wordSize);const Address parameter_size(rbp, parameter_size_off * wordSize);// same as in generate_catch_exception()!const Address thread (rbp, thread_off * wordSize);const Address r15_save(rbp, r15_off * wordSize);const Address r14_save(rbp, r14_off * wordSize);const Address r13_save(rbp, r13_off * wordSize);const Address r12_save(rbp, r12_off * wordSize);const Address rbx_save(rbp, rbx_off * wordSize);// stub code__ enter();__ subptr(rsp, -rsp_after_call_off * wordSize);// save register parameters
#ifndef _WIN64__ movptr(parameters, c_rarg5); // parameters__ movptr(entry_point, c_rarg4); // entry_point
#endif__ movptr(method, c_rarg3); // method__ movl(result_type, c_rarg2); // result type__ movptr(result, c_rarg1); // result__ movptr(call_wrapper, c_rarg0); // call wrapper// save regs belonging to calling function__ movptr(rbx_save, rbx);__ movptr(r12_save, r12);__ movptr(r13_save, r13);__ movptr(r14_save, r14);__ movptr(r15_save, r15);#ifdef _WIN64int last_reg = 15;if (UseAVX > 2) {last_reg = 31;}if (VM_Version::supports_evex()) {for (int i = xmm_save_first; i <= last_reg; i++) {__ vextractf32x4(xmm_save(i), as_XMMRegister(i), 0);}} else {for (int i = xmm_save_first; i <= last_reg; i++) {__ movdqu(xmm_save(i), as_XMMRegister(i));}}const Address rdi_save(rbp, rdi_off * wordSize);const Address rsi_save(rbp, rsi_off * wordSize);__ movptr(rsi_save, rsi);__ movptr(rdi_save, rdi);
#elseconst Address mxcsr_save(rbp, mxcsr_off * wordSize);{Label skip_ldmx;__ stmxcsr(mxcsr_save);__ movl(rax, mxcsr_save);__ andl(rax, MXCSR_MASK); // Only check control and mask bitsExternalAddress mxcsr_std(StubRoutines::x86::addr_mxcsr_std());__ cmp32(rax, mxcsr_std);__ jcc(Assembler::equal, skip_ldmx);__ ldmxcsr(mxcsr_std);__ bind(skip_ldmx);}
#endif// Load up thread register__ movptr(r15_thread, thread);__ reinit_heapbase();#ifdef ASSERT// make sure we have no pending exceptions{Label L;__ cmpptr(Address(r15_thread, Thread::pending_exception_offset()), (int32_t)NULL_WORD);__ jcc(Assembler::equal, L);__ stop("StubRoutines::call_stub: entered with pending exception");__ bind(L);}
#endif// pass parameters if anyBLOCK_COMMENT("pass parameters if any");Label parameters_done;__ movl(c_rarg3, parameter_size);__ testl(c_rarg3, c_rarg3);__ jcc(Assembler::zero, parameters_done);Label loop;__ movptr(c_rarg2, parameters); // parameter pointer__ movl(c_rarg1, c_rarg3); // parameter counter is in c_rarg1__ BIND(loop);__ movptr(rax, Address(c_rarg2, 0));// get parameter__ addptr(c_rarg2, wordSize); // advance to next parameter__ decrementl(c_rarg1); // decrement counter__ push(rax); // pass parameter__ jcc(Assembler::notZero, loop);// call Java function__ BIND(parameters_done);__ movptr(rbx, method); // get Method*//yym-gaizao// #ifdef DEBUG_PRINT_METHOD_NAME// 打印 "yym" 字符串{__ push(rax); // 保存寄存器__ push(rdi);__ push(rsi);__ push(rdx);__ movl(rax, 1); // syscall number for sys_write (1)__ movl(rdi, 1); // fd = stdout (1)__ lea(rsi, ExternalAddress((address)"yym\n")); // 字符串地址__ movl(rdx, 4); // length = 4 ("yym\n")__ call(RuntimeAddress(CAST_FROM_FN_PTR(address, os::write))); // 调用系统调用__ pop(rdx); // 恢复寄存器__ pop(rsi);__ pop(rdi);__ pop(rax);}// #endif__ movptr(c_rarg1, entry_point); // get entry_point__ mov(r13, rsp); // set sender spBLOCK_COMMENT("call Java function");__ call(c_rarg1);BLOCK_COMMENT("call_stub_return_address:");return_address = __ pc();// store result depending on type (everything that is not// T_OBJECT, T_LONG, T_FLOAT or T_DOUBLE is treated as T_INT)__ movptr(c_rarg0, result);Label is_long, is_float, is_double, exit;__ movl(c_rarg1, result_type);__ cmpl(c_rarg1, T_OBJECT);__ jcc(Assembler::equal, is_long);__ cmpl(c_rarg1, T_LONG);__ jcc(Assembler::equal, is_long);__ cmpl(c_rarg1, T_FLOAT);__ jcc(Assembler::equal, is_float);__ cmpl(c_rarg1, T_DOUBLE);__ jcc(Assembler::equal, is_double);// handle T_INT case__ movl(Address(c_rarg0, 0), rax);__ BIND(exit);// pop parameters__ lea(rsp, rsp_after_call);#ifdef ASSERT// verify that threads correspond{Label L1, L2, L3;__ cmpptr(r15_thread, thread);__ jcc(Assembler::equal, L1);__ stop("StubRoutines::call_stub: r15_thread is corrupted");__ bind(L1);__ get_thread(rbx);__ cmpptr(r15_thread, thread);__ jcc(Assembler::equal, L2);__ stop("StubRoutines::call_stub: r15_thread is modified by call");__ bind(L2);__ cmpptr(r15_thread, rbx);__ jcc(Assembler::equal, L3);__ stop("StubRoutines::call_stub: threads must correspond");__ bind(L3);}
#endif// restore regs belonging to calling function
#ifdef _WIN64// emit the restores for xmm regsif (VM_Version::supports_evex()) {for (int i = xmm_save_first; i <= last_reg; i++) {__ vinsertf32x4(as_XMMRegister(i), as_XMMRegister(i), xmm_save(i), 0);}} else {for (int i = xmm_save_first; i <= last_reg; i++) {__ movdqu(as_XMMRegister(i), xmm_save(i));}}
#endif__ movptr(r15, r15_save);__ movptr(r14, r14_save);__ movptr(r13, r13_save);__ movptr(r12, r12_save);__ movptr(rbx, rbx_save);#ifdef _WIN64__ movptr(rdi, rdi_save);__ movptr(rsi, rsi_save);
#else__ ldmxcsr(mxcsr_save);
#endif// restore rsp__ addptr(rsp, -rsp_after_call_off * wordSize);// return__ vzeroupper();__ pop(rbp);__ ret(0);// handle return types different from T_INT__ BIND(is_long);__ movq(Address(c_rarg0, 0), rax);__ jmp(exit);__ BIND(is_float);__ movflt(Address(c_rarg0, 0), xmm0);__ jmp(exit);__ BIND(is_double);__ movdbl(Address(c_rarg0, 0), xmm0);__ jmp(exit);return start;}void TemplateTable::invokevirtual_helper(Register index,Register recv,Register flags) {// Uses temporary registers rax, rdxassert_different_registers(index, recv, rax, rdx);assert(index == rbx, "");assert(recv == rcx, "");// Test for an invoke of a final methodLabel notFinal;__ movl(rax, flags);__ andl(rax, (1 << ConstantPoolCacheEntry::is_vfinal_shift));__ jcc(Assembler::zero, notFinal);const Register method = index; // method must be rbxassert(method == rbx,"Method* must be rbx for interpreter calling convention");// do the call - the index is actually the method to call// that is, f2 is a vtable index if !is_vfinal, else f2 is a Method*// It's final, need a null check here!__ null_check(recv);// profile this call__ profile_final_call(rax);__ profile_arguments_type(rax, method, rbcp, true);__ jump_from_interpreted(method, rax);__ bind(notFinal);// get receiver klass__ null_check(recv, oopDesc::klass_offset_in_bytes());Register tmp_load_klass = LP64_ONLY(rscratch1) NOT_LP64(noreg);__ load_klass(rax, recv, tmp_load_klass);// profile this call__ profile_virtual_call(rax, rlocals, rdx);// get target Method* & entry point__ lookup_virtual_method(rax, index, method);__ profile_arguments_type(rdx, method, rbcp, true);__ jump_from_interpreted(method, rdx);
}// virtual method calling
void MacroAssembler::lookup_virtual_method(Register recv_klass,RegisterOrConstant vtable_index,Register method_result) {const int base = in_bytes(Klass::vtable_start_offset());assert(vtableEntry::size() * wordSize == wordSize, "else adjust the scaling in the code below");Address vtable_entry_addr(recv_klass,vtable_index, Address::times_ptr,base + vtableEntry::method_offset_in_bytes());movptr(method_result, vtable_entry_addr);
}// Jump to from_interpreted entry of a call unless single stepping is possible
// in this thread in which case we must call the i2i entry
void InterpreterMacroAssembler::jump_from_interpreted(Register method, Register temp) {prepare_to_jump_from_interpreted();if (JvmtiExport::can_post_interpreter_events()) {Label run_compiled_code;// JVMTI events, such as single-stepping, are implemented partly by avoiding running// compiled code in threads for which the event is enabled. Check here for// interp_only_mode if these events CAN be enabled.// interp_only is an int, on little endian it is sufficient to test the byte only// Is a cmpl faster?LP64_ONLY(temp = r15_thread;)NOT_LP64(get_thread(temp);)cmpb(Address(temp, JavaThread::interp_only_mode_offset()), 0);jccb(Assembler::zero, run_compiled_code);jmp(Address(method, Method::interpreter_entry_offset()));bind(run_compiled_code);}jmp(Address(method, Method::from_interpreted_offset()));
}void TemplateTable::invokevirtual(int byte_no) {transition(vtos, vtos);assert(byte_no == f2_byte, "use this argument");prepare_invoke(byte_no,rbx, // method or vtable indexnoreg, // unused itable indexrcx, rdx); // recv, flags// rbx: index// rcx: receiver// rdx: flagsinvokevirtual_helper(rbx, rcx, rdx);
}void TemplateTable::prepare_invoke(int byte_no,Register method, // linked method (or i-klass)Register index, // itable index, MethodType, etc.Register recv, // if caller wants to see itRegister flags // if caller wants to test it) {// determine flagsconst Bytecodes::Code code = bytecode();const bool is_invokeinterface = code == Bytecodes::_invokeinterface;const bool is_invokedynamic = code == Bytecodes::_invokedynamic;const bool is_invokehandle = code == Bytecodes::_invokehandle;const bool is_invokevirtual = code == Bytecodes::_invokevirtual;const bool is_invokespecial = code == Bytecodes::_invokespecial;const bool load_receiver = (recv != noreg);const bool save_flags = (flags != noreg);assert(load_receiver == (code != Bytecodes::_invokestatic && code != Bytecodes::_invokedynamic), "");assert(save_flags == (is_invokeinterface || is_invokevirtual), "need flags for vfinal");assert(flags == noreg || flags == rdx, "");assert(recv == noreg || recv == rcx, "");// setup registers & access constant pool cacheif (recv == noreg) recv = rcx;if (flags == noreg) flags = rdx;assert_different_registers(method, index, recv, flags);// save 'interpreter return address'__ save_bcp();load_invoke_cp_cache_entry(byte_no, method, index, flags, is_invokevirtual, false, is_invokedynamic);// maybe push appendix to arguments (just before return address)if (is_invokedynamic || is_invokehandle) {Label L_no_push;__ testl(flags, (1 << ConstantPoolCacheEntry::has_appendix_shift));__ jcc(Assembler::zero, L_no_push);// Push the appendix as a trailing parameter.// This must be done before we get the receiver,// since the parameter_size includes it.__ push(rbx);__ mov(rbx, index);__ load_resolved_reference_at_index(index, rbx);__ pop(rbx);__ push(index); // push appendix (MethodType, CallSite, etc.)__ bind(L_no_push);}void TemplateTable::resolve_cache_and_index(int byte_no,Register cache,Register index,size_t index_size) {const Register temp = rbx;assert_different_registers(cache, index, temp);Label L_clinit_barrier_slow;Label resolved;Bytecodes::Code code = bytecode();switch (code) {case Bytecodes::_nofast_getfield: code = Bytecodes::_getfield; break;case Bytecodes::_nofast_putfield: code = Bytecodes::_putfield; break;default: break;}assert(byte_no == f1_byte || byte_no == f2_byte, "byte_no out of range");__ get_cache_and_index_and_bytecode_at_bcp(cache, index, temp, byte_no, 1, index_size);__ cmpl(temp, code); // have we resolved this bytecode?__ jcc(Assembler::equal, resolved);// resolve first time through// Class initialization barrier slow path lands here as well.__ bind(L_clinit_barrier_slow);// std::cout << "@@@@yym%%%%" << "method begin" << "----begin" << std::endl;address entry = CAST_FROM_FN_PTR(address, InterpreterRuntime::resolve_from_cache);__ movl(temp, code);__ call_VM(noreg, entry, temp);// std::cout << "@@@@yym%%%%" << "method end" << "----end" << std::endl;// Update registers with resolved info__ get_cache_and_index_at_bcp(cache, index, 1, index_size);__ bind(resolved);// Class initialization barrier for static methodsif (VM_Version::supports_fast_class_init_checks() && bytecode() == Bytecodes::_invokestatic) {const Register method = temp;const Register klass = temp;const Register thread = LP64_ONLY(r15_thread) NOT_LP64(noreg);assert(thread != noreg, "x86_32 not supported");__ load_resolved_method_at_index(byte_no, method, cache, index);__ load_method_holder(klass, method);__ clinit_barrier(klass, thread, NULL /*L_fast_path*/, &L_clinit_barrier_slow);}
}void TemplateTable::load_invoke_cp_cache_entry(int byte_no,Register method,Register itable_index,Register flags,bool is_invokevirtual,bool is_invokevfinal, /*unused*/bool is_invokedynamic) {// setup registersconst Register cache = rcx;const Register index = rdx;assert_different_registers(method, flags);assert_different_registers(method, cache, index);assert_different_registers(itable_index, flags);assert_different_registers(itable_index, cache, index);// determine constant pool cache field offsetsassert(is_invokevirtual == (byte_no == f2_byte), "is_invokevirtual flag redundant");const int flags_offset = in_bytes(ConstantPoolCache::base_offset() +ConstantPoolCacheEntry::flags_offset());// access constant pool cache fieldsconst int index_offset = in_bytes(ConstantPoolCache::base_offset() +ConstantPoolCacheEntry::f2_offset());size_t index_size = (is_invokedynamic ? sizeof(u4) : sizeof(u2));resolve_cache_and_index(byte_no, cache, index, index_size);__ load_resolved_method_at_index(byte_no, method, cache, index);if (itable_index != noreg) {// pick up itable or appendix index from f2 also:__ movptr(itable_index, Address(cache, index, Address::times_ptr, index_offset));}__ movl(flags, Address(cache, index, Address::times_ptr, flags_offset));
}void TemplateTable::prepare_invoke(int byte_no,Register method, // linked method (or i-klass)Register index, // itable index, MethodType, etc.Register recv, // if caller wants to see itRegister flags // if caller wants to test it) {// determine flagsconst Bytecodes::Code code = bytecode();const bool is_invokeinterface = code == Bytecodes::_invokeinterface;const bool is_invokedynamic = code == Bytecodes::_invokedynamic;const bool is_invokehandle = code == Bytecodes::_invokehandle;const bool is_invokevirtual = code == Bytecodes::_invokevirtual;const bool is_invokespecial = code == Bytecodes::_invokespecial;const bool load_receiver = (recv != noreg);const bool save_flags = (flags != noreg);assert(load_receiver == (code != Bytecodes::_invokestatic && code != Bytecodes::_invokedynamic), "");assert(save_flags == (is_invokeinterface || is_invokevirtual), "need flags for vfinal");assert(flags == noreg || flags == rdx, "");assert(recv == noreg || recv == rcx, "");// setup registers & access constant pool cacheif (recv == noreg) recv = rcx;if (flags == noreg) flags = rdx;assert_different_registers(method, index, recv, flags);// save 'interpreter return address'__ save_bcp();load_invoke_cp_cache_entry(byte_no, method, index, flags, is_invokevirtual, false, is_invokedynamic);// maybe push appendix to arguments (just before return address)if (is_invokedynamic || is_invokehandle) {Label L_no_push;__ testl(flags, (1 << ConstantPoolCacheEntry::has_appendix_shift));__ jcc(Assembler::zero, L_no_push);// Push the appendix as a trailing parameter.// This must be done before we get the receiver,// since the parameter_size includes it.__ push(rbx);__ mov(rbx, index);__ load_resolved_reference_at_index(index, rbx);__ pop(rbx);__ push(index); // push appendix (MethodType, CallSite, etc.)__ bind(L_no_push);}// load receiver if needed (after appendix is pushed so parameter size is correct)// Note: no return address pushed yetif (load_receiver) {__ movl(recv, flags);__ andl(recv, ConstantPoolCacheEntry::parameter_size_mask);const int no_return_pc_pushed_yet = -1; // argument slot correction before we push return addressconst int receiver_is_at_end = -1; // back off one slot to get receiverAddress recv_addr = __ argument_address(recv, no_return_pc_pushed_yet + receiver_is_at_end);__ movptr(recv, recv_addr);__ verify_oop(recv);}if (save_flags) {__ movl(rbcp, flags);}// compute return type__ shrl(flags, ConstantPoolCacheEntry::tos_state_shift);// Make sure we don't need to mask flags after the above shiftConstantPoolCacheEntry::verify_tos_state_shift();// load return address{const address table_addr = (address) Interpreter::invoke_return_entry_table_for(code);ExternalAddress table(table_addr);LP64_ONLY(__ lea(rscratch1, table));LP64_ONLY(__ movptr(flags, Address(rscratch1, flags, Address::times_ptr)));NOT_LP64(__ movptr(flags, ArrayAddress(table, Address(noreg, flags, Address::times_ptr))));}// push return address__ push(flags);// Restore flags value from the constant pool cache, and restore rsi// for later null checks. r13 is the bytecode pointerif (save_flags) {__ movl(flags, rbcp);__ restore_bcp();}
}//
// Generic interpreted method entry to (asm) interpreter
//
address TemplateInterpreterGenerator::generate_normal_entry(bool synchronized) {// determine code generation flagsbool inc_counter = UseCompiler || CountCompiledCalls || LogTouchedMethods;// ebx: Method*// rbcp: sender spaddress entry_point = __ pc();const Address constMethod(rbx, Method::const_offset());const Address access_flags(rbx, Method::access_flags_offset());const Address size_of_parameters(rdx,ConstMethod::size_of_parameters_offset());const Address size_of_locals(rdx, ConstMethod::size_of_locals_offset());// get parameter size (always needed)__ movptr(rdx, constMethod);__ load_unsigned_short(rcx, size_of_parameters);// rbx: Method*// rcx: size of parameters// rbcp: sender_sp (could differ from sp+wordSize if we were called via c2i )__ load_unsigned_short(rdx, size_of_locals); // get size of locals in words__ subl(rdx, rcx); // rdx = no. of additional locals// YYY
// __ incrementl(rdx);
// __ andl(rdx, -2);// see if we've got enough room on the stack for locals plus overhead.generate_stack_overflow_check();//yym-gaizao// #ifdef DEBUG_PRINT_METHOD_NAME// ---yym--- 打印代码移动到堆栈检查之后{// 保存寄存器状态__ push(rax);__ push(rcx);__ push(rdx);__ push(rdi);__ push(rsi);__ push(r8);__ push(r9);__ push(r10);__ push(r11);NOT_LP64(__ get_thread(r15_thread));__ push(r15);// 准备调用参数__ movptr(rdi, rbx); // Method* 作为第一个参数__ lea(rsi, Address(rsp, 14*wordSize)); // 原始rsp地址__ mov(r8, rcx); // 参数大小__ mov(r9, rdx); // 本地变量大小// 调用调试信息输出函数__ call(RuntimeAddress(CAST_FROM_FN_PTR(address, ::TemplateInterpreterGenerator::print_debug_info)));// 恢复寄存器__ pop(r15);NOT_LP64(__ restore_thread(r15_thread));__ pop(r11);__ pop(r10);__ pop(r9);__ pop(r8);__ pop(rsi);__ pop(rdi);__ pop(rdx);__ pop(rcx);__ pop(rax);}// #endif// get return address__ pop(rax);// compute beginning of parameters__ lea(rlocals, Address(rsp, rcx, Interpreter::stackElementScale(), -wordSize));// rdx - # of additional locals// allocate space for locals// explicitly initialize locals{Label exit, loop;__ testl(rdx, rdx);__ jcc(Assembler::lessEqual, exit); // do nothing if rdx <= 0__ bind(loop);__ push((int) NULL_WORD); // initialize local variables__ decrementl(rdx); // until everything initialized__ jcc(Assembler::greater, loop);__ bind(exit);}// initialize fixed part of activation framegenerate_fixed_frame(false);// make sure method is not native & not abstract
#ifdef ASSERT__ movl(rax, access_flags);{Label L;__ testl(rax, JVM_ACC_NATIVE);__ jcc(Assembler::zero, L);__ stop("tried to execute native method as non-native");__ bind(L);}{Label L;__ testl(rax, JVM_ACC_ABSTRACT);__ jcc(Assembler::zero, L);__ stop("tried to execute abstract method in interpreter");__ bind(L);}
#endif// Since at this point in the method invocation the exception// handler would try to exit the monitor of synchronized methods// which hasn't been entered yet, we set the thread local variable// _do_not_unlock_if_synchronized to true. The remove_activation// will check this flag.const Register thread = NOT_LP64(rax) LP64_ONLY(r15_thread);NOT_LP64(__ get_thread(thread));const Address do_not_unlock_if_synchronized(thread,in_bytes(JavaThread::do_not_unlock_if_synchronized_offset()));__ movbool(do_not_unlock_if_synchronized, true);__ profile_parameters_type(rax, rcx, rdx);// increment invocation count & check for overflowLabel invocation_counter_overflow;if (inc_counter) {generate_counter_incr(&invocation_counter_overflow);}Label continue_after_compile;__ bind(continue_after_compile);// check for synchronized interpreted methodsbang_stack_shadow_pages(false);// reset the _do_not_unlock_if_synchronized flagNOT_LP64(__ get_thread(thread));__ movbool(do_not_unlock_if_synchronized, false);// check for synchronized methods// Must happen AFTER invocation_counter check and stack overflow check,// so method is not locked if overflows.if (synchronized) {// Allocate monitor and lock methodlock_method();} else {// no synchronization necessary
#ifdef ASSERT{Label L;__ movl(rax, access_flags);__ testl(rax, JVM_ACC_SYNCHRONIZED);__ jcc(Assembler::zero, L);__ stop("method needs synchronization");__ bind(L);}
#endif}// start execution
#ifdef ASSERT{Label L;const Address monitor_block_top (rbp,frame::interpreter_frame_monitor_block_top_offset * wordSize);__ movptr(rax, monitor_block_top);__ cmpptr(rax, rsp);__ jcc(Assembler::equal, L);__ stop("broken stack frame setup in interpreter");__ bind(L);}
#endif// jvmti support__ notify_method_entry();__ dispatch_next(vtos);// invocation counter overflowif (inc_counter) {// Handle overflow of counter and compile method__ bind(invocation_counter_overflow);generate_counter_overflow(continue_after_compile);}return entry_point;
}void InterpreterMacroAssembler::dispatch_next(TosState state, int step, bool generate_poll) {// load next bytecode (load before advancing _bcp_register to prevent AGI)load_unsigned_byte(rbx, Address(_bcp_register, step));// advance _bcp_registerincrement(_bcp_register, step);dispatch_base(state, Interpreter::dispatch_table(state), true, generate_poll);
}void InterpreterMacroAssembler::dispatch_base(TosState state,address* table,bool verifyoop,bool generate_poll) {verify_FPU(1, state);if (VerifyActivationFrameSize) {Label L;mov(rcx, rbp);subptr(rcx, rsp);int32_t min_frame_size =(frame::link_offset - frame::interpreter_frame_initial_sp_offset) *wordSize;cmpptr(rcx, (int32_t)min_frame_size);jcc(Assembler::greaterEqual, L);stop("broken stack frame");bind(L);}if (verifyoop) {interp_verify_oop(rax, state);}address* const safepoint_table = Interpreter::safept_table(state);
#ifdef _LP64Label no_safepoint, dispatch;if (table != safepoint_table && generate_poll) {NOT_PRODUCT(block_comment("Thread-local Safepoint poll"));testb(Address(r15_thread, JavaThread::polling_word_offset()), SafepointMechanism::poll_bit());jccb(Assembler::zero, no_safepoint);lea(rscratch1, ExternalAddress((address)safepoint_table));jmpb(dispatch);}bind(no_safepoint);lea(rscratch1, ExternalAddress((address)table));bind(dispatch);jmp(Address(rscratch1, rbx, Address::times_8));#elseAddress index(noreg, rbx, Address::times_ptr);if (table != safepoint_table && generate_poll) {NOT_PRODUCT(block_comment("Thread-local Safepoint poll"));Label no_safepoint;const Register thread = rcx;get_thread(thread);testb(Address(thread, JavaThread::polling_word_offset()), SafepointMechanism::poll_bit());jccb(Assembler::zero, no_safepoint);ArrayAddress dispatch_addr(ExternalAddress((address)safepoint_table), index);jump(dispatch_addr);bind(no_safepoint);}{ArrayAddress dispatch_addr(ExternalAddress((address)table), index);jump(dispatch_addr);}
#endif // _LP64
}相关文章:
)
深入解析JVM字节码解释器执行流程(OpenJDK 17源码实现)
一、核心流程概述 JVM解释器的核心任务是将Java字节码逐条翻译为本地机器指令并执行。其执行流程可分为以下关键阶段: 方法调用入口构建:生成栈帧、处理参数、同步锁等。 字节码分派(Dispatch):根据字节码跳转到对应…...
分别用 语言模型雏形N-Gram 和 文本表示BoW词袋 来实现文本情绪分类
语言模型的雏形 N-Gram 和简单文本表示 Bag-of-Words 语言表示模型简介 (1) Bag-of-Words (BoW) 是什么? *定义:将文本表示为词频向量,忽略词序和语法,仅记录每个词的出现次数。 **示例: 句子1:I love …...
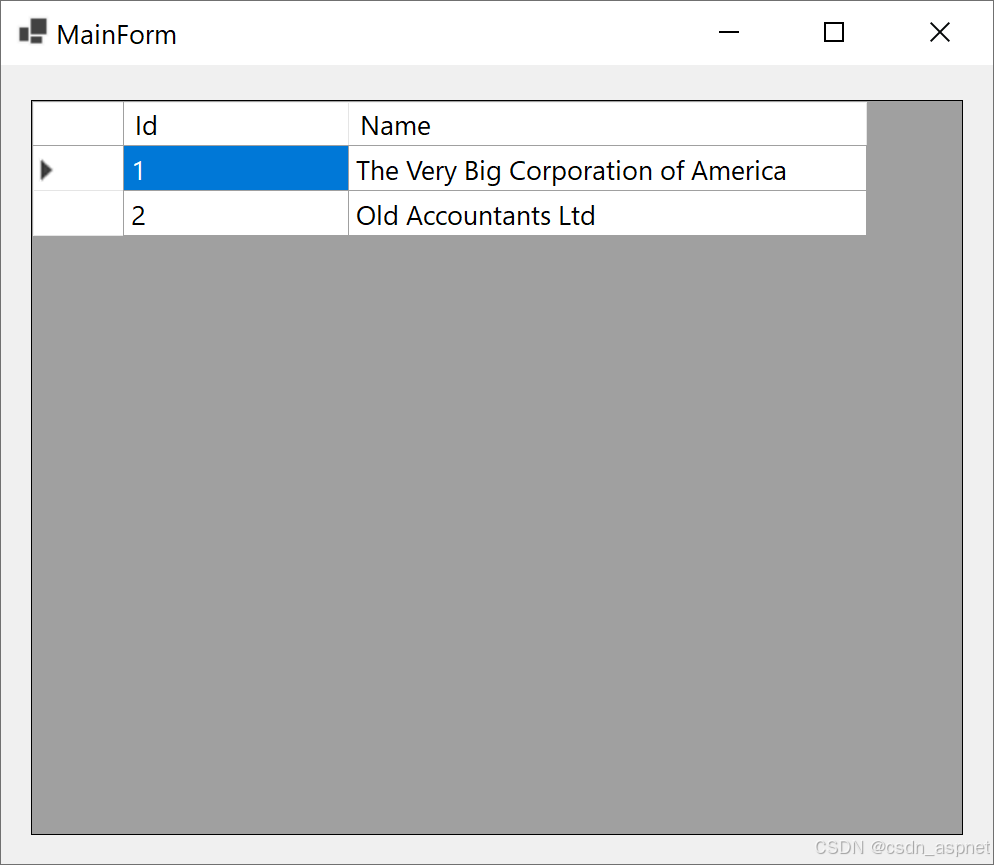
C#.NET 或 VB.NET Windows 窗体中的 DataGridView – 技巧、窍门和常见问题
DataGridView 控件是一个 Windows 窗体控件,它允许您自定义和编辑表格数据。它提供了许多属性、方法和事件来自定义其外观和行为。在本文中,我们将讨论一些常见问题及其解决方案。这些问题来自各种来源,包括一些新闻组、MSDN 网站以及一些由我…...
PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录 音频处理技术及应用音频处理技术音视频摘要技术音频识别及应用 梅尔频率倒谱系数音频特征尔频率倒谱系数简介及参数提取过程音频处理快速傅里叶变换(FFT)能量谱处理离散余弦转换 练习案例:音频建模加载音频数据源波形变换的类型绘制波形频谱图波形Mu-Law 编…...

SHAP分析图的含义
1. 训练集预测结果对比图 表征含义: 展示模型在训练集上的预测值(红色曲线)与真实值(灰色曲线)的对比。通过曲线重合度可直观判断模型的拟合效果。标题中显示的RMSE(均方根误差)量化了预测值与…...
VSTO(C#)Excel开发进阶2:操作图片 改变大小 滚动到可视区
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 入…...

多用途商务,电子产品发布,科技架构,智能手表交互等发布PPT模版20套一组分享
产品发布类PPT模版20套一组:产品发布PPT模版https://pan.quark.cn/s/25c8517b0be3 第一套PPT模版是一个总结用的PPT封面,背景浅灰色,有绿色叶片和花朵装饰,深绿色标题,多个适用场景和占位符。突出其清新自然的设计和商…...

Java正则表达式:从基础到高级应用全解析
Java正则表达式应用与知识点详解 一、正则表达式基础概念 正则表达式(Regular Expression)是通过特定语法规则描述字符串模式的工具,常用于: 数据格式验证文本搜索与替换字符串分割模式匹配提取 Java通过java.util.regex包提供支持,核心类…...
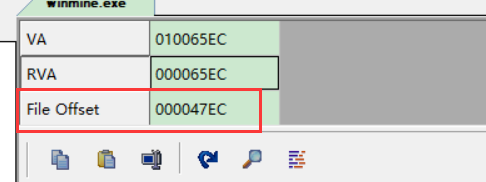
WindowsPE文件格式入门11.资源表
https://www.bpsend.net/thread-411-1-1.html 资源表 资源的管理方式采用windows资源管理器目录的管理方式,一般有三层目录。根目录 结构体IMAGE_RESOURCE_DIRECTORY:描述名称资源和ID资源各自的数量,不描述文件。资源本质都是二进制数据&…...
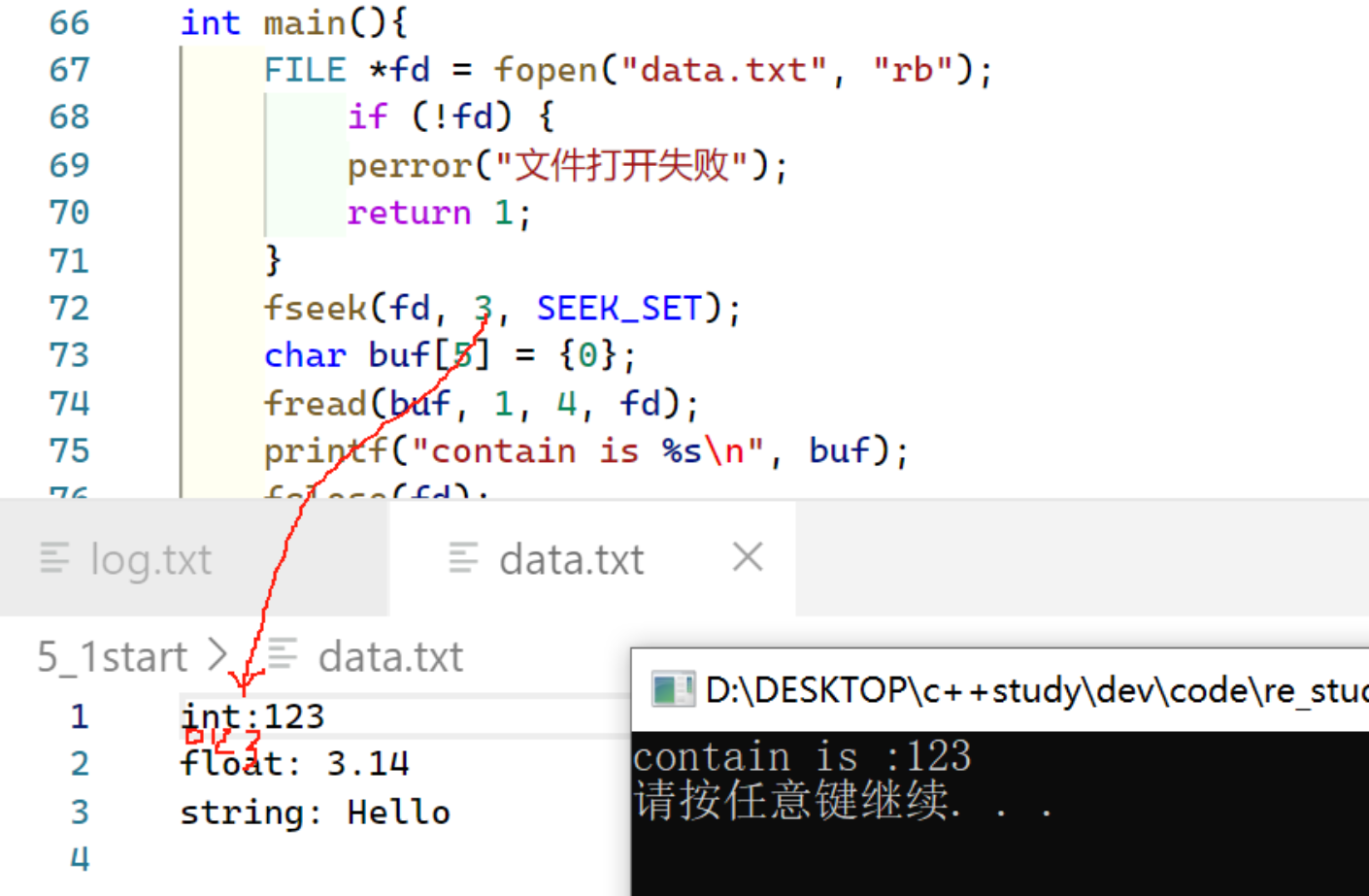
C语言标准I/O与Linux系统调用的文件操作
01. 标准库函数与系统调用对比 系统调用标准I/O库open/read/write/closefopen/fread/fwrite/fclose文件描述符(fd)文件指针(FILE*)无缓冲,直接系统调用自动缓冲管理每次操作触发系统调用减少系统调用次数<fcntl.h> <unistd.h><stdio.h> 系统调用…...

【MYSQL】笔记
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 在ubuntu中,改配置文件: sudo nano /etc/mysql/mysql.conf.d/mysq…...
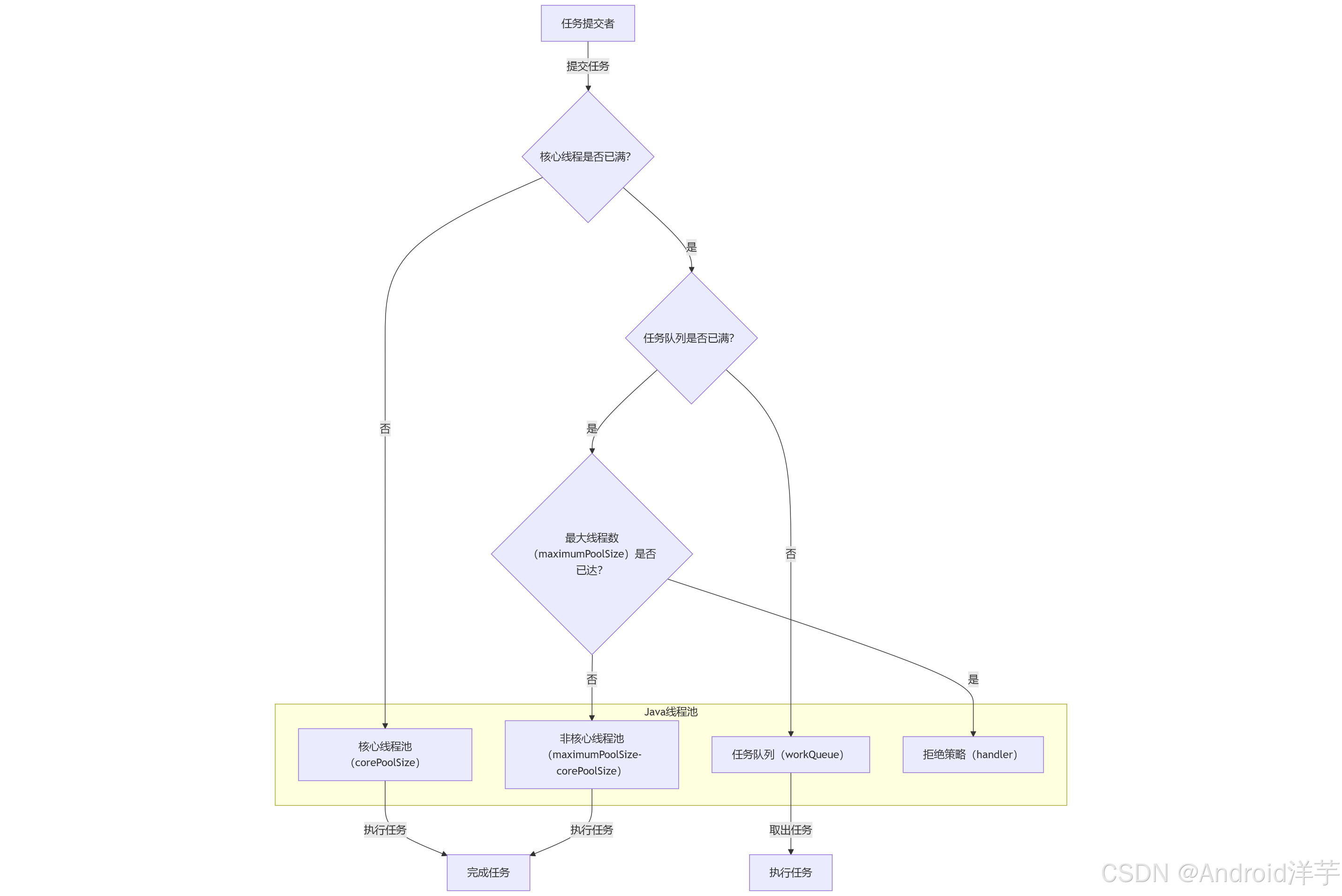
线程池核心线程永续机制:从源码到实战的深度解析
简介 源管理的基石,其核心线程为何不会超时销毁一直是开发者关注的焦点。核心线程的永续机制不仅确保了系统的稳定响应,还避免了频繁创建和销毁线程带来的性能损耗。本文将从源码层面深入剖析线程池核心线程的存活原理,同时结合企业级实战案例,展示如何正确配置和管理线程…...
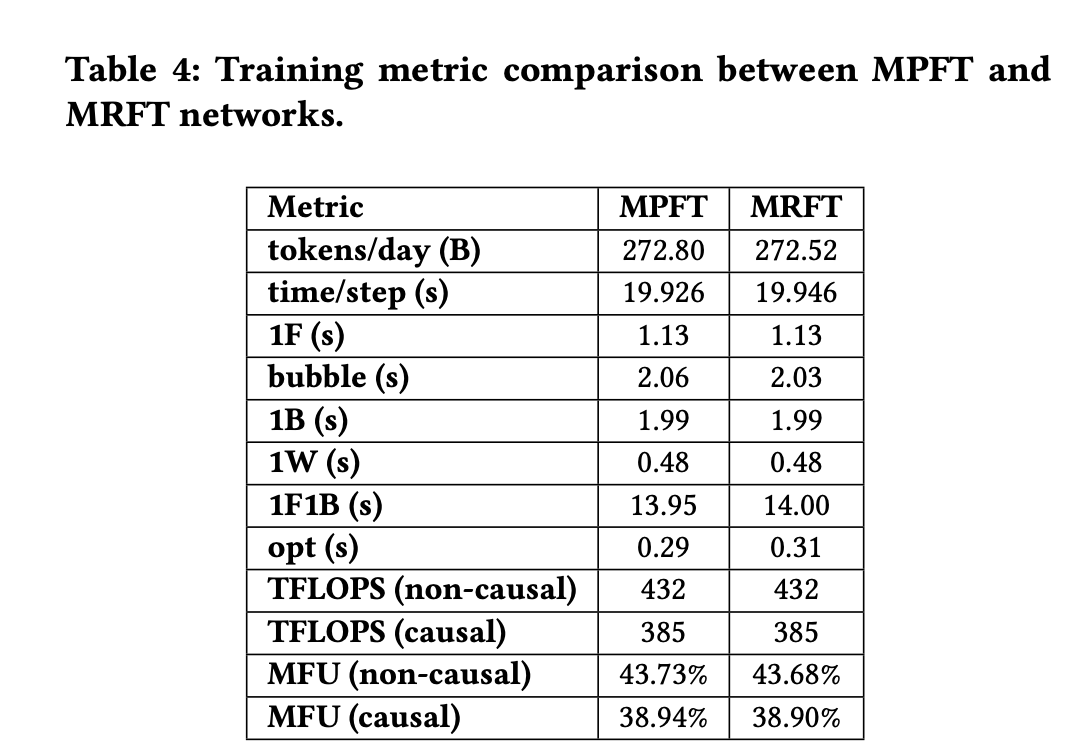
DS新论文解读(2)
上一章忘了说论文名字了,是上图这个名字 我们继续,上一章阅读地址: dsv3新论文解读(1) 这论文剩下部分值得说的我觉得主要就是他们Infra通信的设计 先看一个图 这个是一个标准的h800 8卡with 8cx7 nic的图…...
html文件cdn一键下载并替换
业务场景: AI生成的html文件,通常会使用多个cdn资源、手动替换or下载太过麻烦、如下py程序为此而生,指定html目录自动下载并替换~ import os import requests from bs4 import BeautifulSoup from urllib.parse import urlparse import has…...

react路由中Suspense的介绍
好的,我们来详细解释一下这个 AppRouter 组件的代码。 这个组件是一个在现代 React 应用中非常常见的模式,特别是在使用 React Router v6 进行路由管理和结合代码分割(Code Splitting)来优化性能时。 JavaScript const AppRout…...
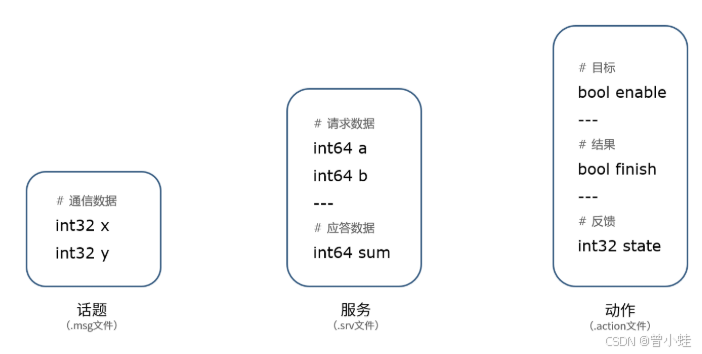
【ROS2】 核心概念6——通信接口语法(Interfaces)
古月21讲/2.6_通信接口 官方文档:Interfaces — ROS 2 Documentation: Humble documentation 官方接口代码实战:https://docs.ros.org/en/humble/Tutorials/Beginner-Client-Libraries/Single-Package-Define-And-Use-Interface.html ROS 2使用简化的描…...

matlab官方免费下载安装超详细教程2025最新matlab安装教程(MATLAB R2024b)
文章目录 准备工作MATLAB R2024b 安装包获取详细安装步骤1. 文件准备2. 启动安装程序3. 配置安装选项4. 选择许可证文件5. 设置安装位置6. 选择组件7. 开始安装8. 完成辅助设置 常见问题解决启动失败问题 结语 准备工作 本教程将帮助你快速掌握MATLAB R2024b的安装技巧&#x…...
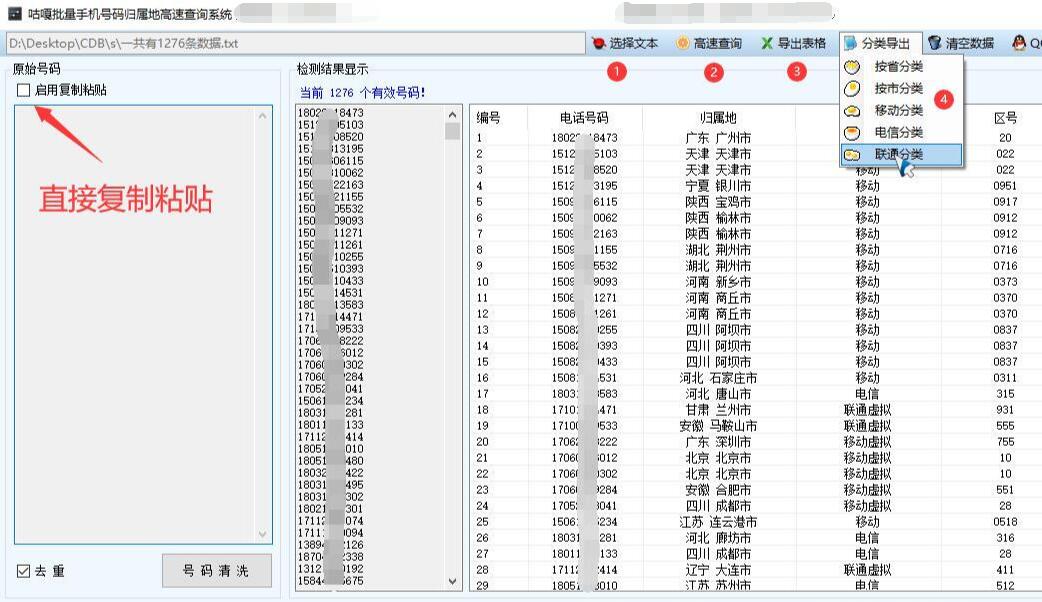
【运营商查询】批量手机号码归属地和手机运营商高速查询分类,按省份城市,按运营商移动联通电信快速分类导出Excel表格,基于WPF的实现方案
WPF手机号码归属地批量查询与分类导出方案 应用场景 市场营销:企业根据手机号码归属地进行精准营销,按城市或省份分类制定针对性推广策略客户管理:快速对客户手机号码进行归属地分类,便于后续客户关系管理数…...
ctf 基础
一、软件安装和基本的网站: 网安招聘网站 xss跨站脚本攻击 逆向:可以理解为游戏里的外挂 pwn最难的题目 密码学: 1、编码:base64 2、加密:凯撒 3、摘要:MD5、SHA1、SHA2 调查取证:杂项&am…...

掌握HTML文件上传:从基础到高级技巧
HTML中input标签的上传文件功能详解 一、基础概念 1. 文件上传的基本原理 在Web开发中,文件上传是指将本地计算机中的文件(如图片、文档、视频等)传输到服务器的过程。HTML中的<input type"file">标签是实现这一功能的基础…...

UE5无法编译问题解决
1. vs编译 2. 删除三个文件夹 参考...
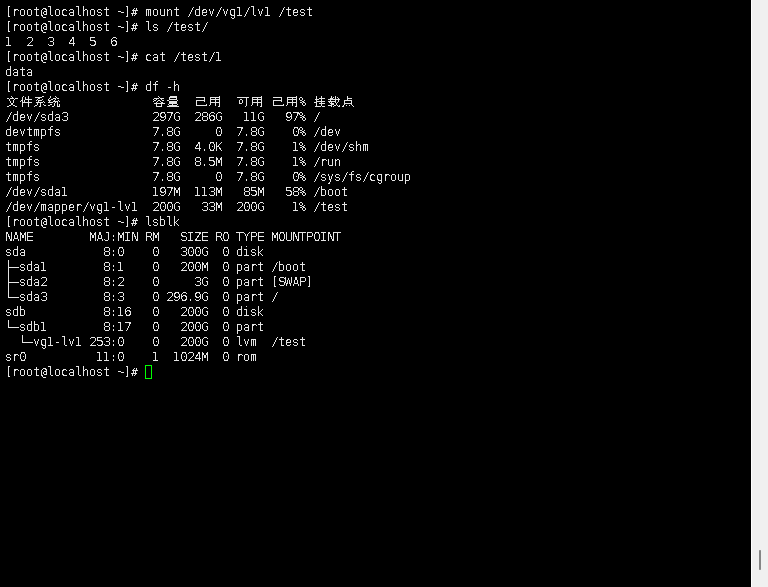
CentOS7原有磁盘扩容实战记录(LVM非LVM)【针对GPT分区】
一、环境 二、命令及含义 fdisk fdisk是一个较老的分区表创建和管理工具,主要支持MBR(Master Boot Record)格式的分区表。MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。fdisk通过命令行界面进行操…...

机器学习07-归一化与标准化
归一化与标准化 一、基本概念 归一化(Normalization) 定义:将数据缩放到一个固定的区间,通常是[0,1]或[-1,1],以消除不同特征之间的量纲影响和数值范围差异。公式:对于数据 ( x ),归一化后的值…...
AI agent与lang chain的学习笔记 (1)
文章目录 智能体的4大要素一些上手的例子与思考。创建简单的AI agent.从本地读取文件,然后让AI智能体总结。 也可以自己定义一些工具 来完成一些特定的任务。我们可以使用智能体总结一个视频。用户可以随意问关于视频的问题。 智能体的4大要素 AI 智能体有以下几个…...

优化 Spring Boot 应用启动性能的实践指南
1. 引言 Spring Boot 以其“开箱即用”的特性深受开发者喜爱,但随着项目复杂度的增加,应用的启动时间也可能会变得较长。对于云原生、Serverless 等场景而言,快速启动是一个非常关键的指标。 2. 分析启动过程 2.1 启动阶段概述 Spring Boot 的启动流程主要包括以下几个阶…...
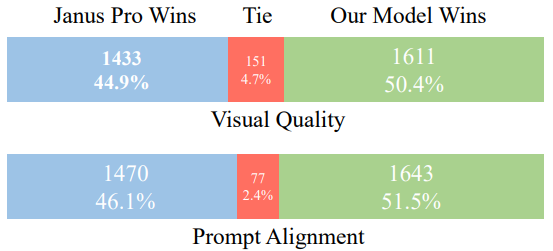
谢赛宁团队提出 BLIP3-o:融合自回归与扩散模型的统一多模态架构,开创CLIP特征驱动的图像理解与生成新范式
BLIP3-o 是一个统一的多模态模型,它将自回归模型的推理和指令遵循优势与扩散模型的生成能力相结合。与之前扩散 VAE 特征或原始像素的研究不同,BLIP3-o 扩散了语义丰富的CLIP 图像特征,从而为图像理解和生成构建了强大而高效的架构。 此外还…...
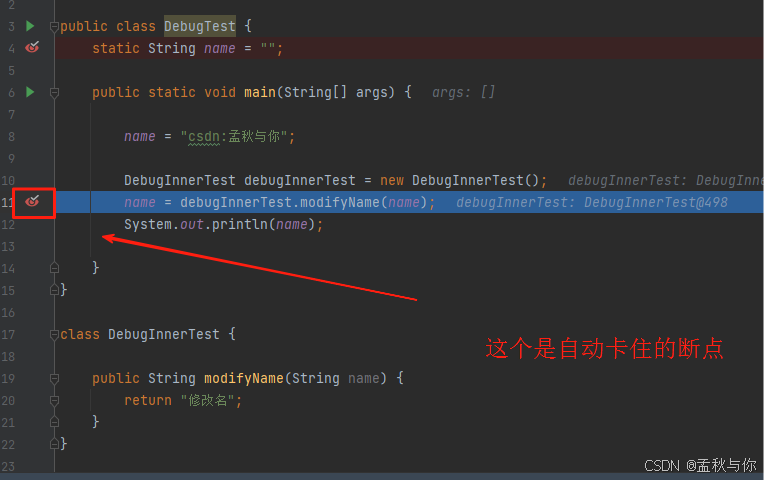
【idea】调试篇 idea调试技巧合集
前言:之前博主写过一篇idea技巧合集的文章,由于技巧过于多了,文章很庞大,所以特地将调试相关的技巧单独成章, 调试和我们日常开发是息息相关的,用好调试可以事半功倍 文章目录 1. idea调试异步线程2. idea调试stream流…...
二叉树深搜:在算法森林中寻找路径
专栏:算法的魔法世界 个人主页:手握风云 目录 一、搜索算法 二、回溯算法 三、例题讲解 3.1. 计算布尔二叉树的值 3.2. 求根节点到叶节点数字之和 3.3. 二叉树剪枝 3.4. 验证二叉搜索树 3.5. 二叉搜索树中第 K 小的元素 3.6. 二叉树的所有路径 …...

golang 安装gin包、创建路由基本总结
文章目录 一、安装gin包和热加载包二、路由简单场景总结 一、安装gin包和热加载包 首先终端新建一个main.go然后go mod init ‘项目名称’执行以下命令 安装gin包 go get -u github.com/gin-gonic/gin终端安装热加载包 go get github.com/pilu/fresh终端输入fresh 运行 &…...
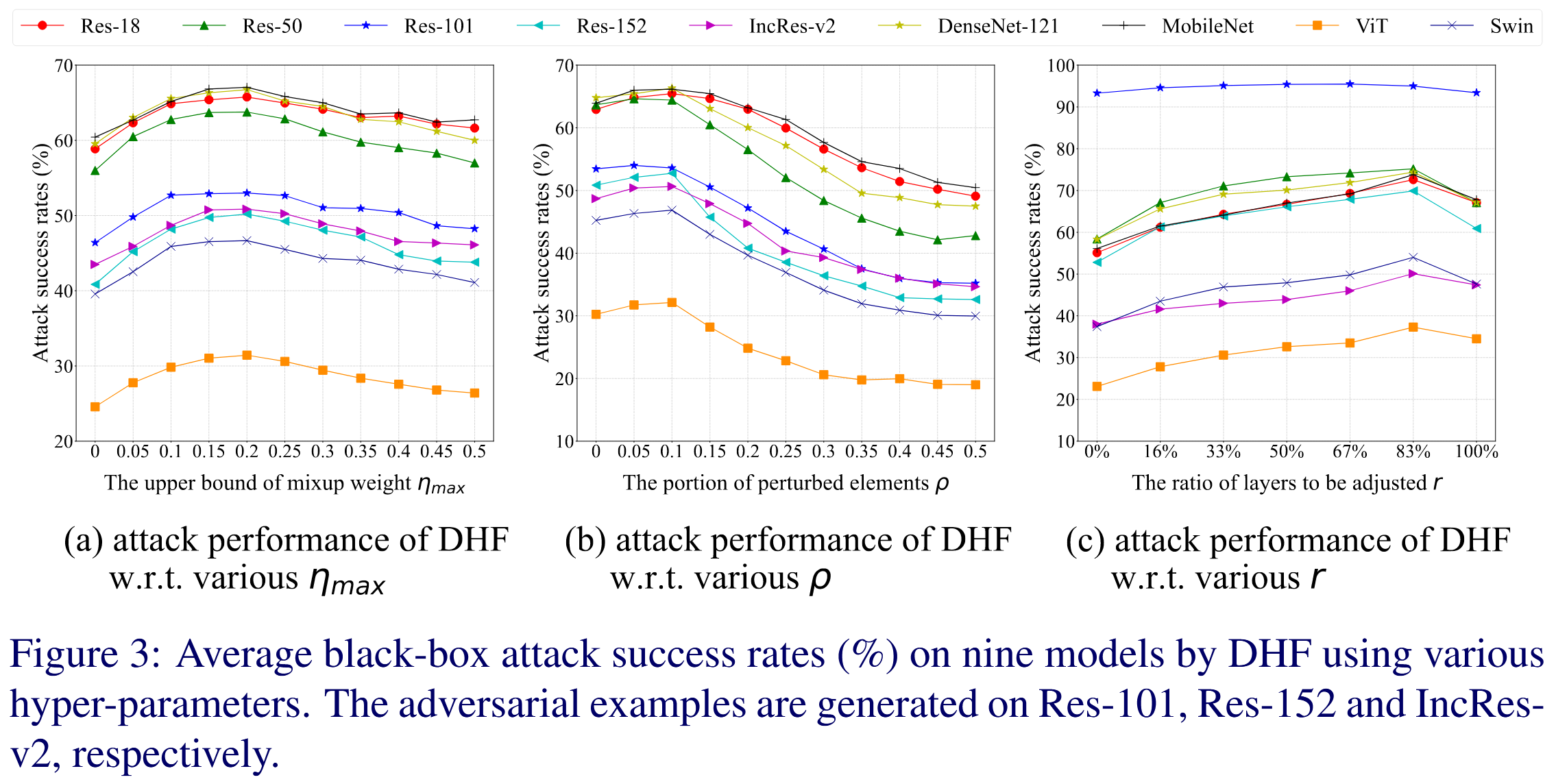
BMVC2023 | 多样化高层特征以提升对抗迁移性
Diversifying the High-level Features for better Adversarial Transferability 摘要-Abstract引言-Introduction相关工作-Related Work方法-Methodology实验-Experiments结论-Conclusion 论文链接 GitHub链接 本文 “Diversifying the High-level Features for better Adve…...