从零开始实现大语言模型(十五):并行计算与分布式机器学习
1. 前言
并行计算与分布式机器学习是一种使用多机多卡加速大规模深度神经网络训练过程,以减少训练时间的方法。在工业界的训练大语言模型实践中,通常会使用并行计算与分布式机器学习方法来减少训练大语言模型所需的钟表时间。
本文介绍PyTorch中的一种将训练数据划分为多个子集,并使用多台计算服务器上的多个GPU并行处理这些数据子集的同步式并行计算与分布式机器学习策略Distributed Data Parallel(DDP),并实现分布式预训练大语言模型函数ddp_hyper_pretrain_model。
2. Distributed Data Parallel
Distributed Data Parallel是一种适用于多机多卡环境的同步式并行计算与分布式机器学习策略,每轮迭代必须等待所有训练进程全部计算完成才能开启下一轮迭代训练流程。使用DDP训练深度神经网络模型,总共会启动world_size个训练进程,每个训练进程都会维护一份模型参数副本。在每轮迭代训练流程中,DDP会将一个batch的训练样本拆分成world_size个交集为空集的minibatch,每个训练进程独立处理一个minibatch的训练样本,其中world_size是多台计算服务器上的GPU总数。如下图所示,假设训练环境中总共有2块GPU,则DDP总共会创建两个训练进程,其中第一个训练进程会使用第一块GPU,第二个训练进程会使用第二块GPU。在每轮迭代训练流程中,其会将一个batch的训练样本拆分成两个交集为空集minibatch,每个训练进程分别独立地处理一个minibatch的训练样本。

在每轮迭代训练流程中,每个训练进程会同时并行地将一个minibatch的训练样本输入深度神经网络模型。前向传播可以计算得到深度神经网络模型输出的logits向量,后向传播流程首先使用损失函数计算神经网络模型的预测输出与训练样本标签之间的损失loss,再通过后向传播算法计算神经网络参数梯度。DDP在所有训练进程均计算得到神经网络参数梯度之后,会使用Ring All-Reduce算法在所有训练进程之间同步神经网络参数梯度,使每个训练进程均具有所有训练进程的神经网络参数梯度信息。最后每个训练进程会同时并行地使用梯度下降算法更新神经网络参数。

DDP不仅适用于多机多卡环境,同样适用于单机多卡环境。如果忽略不同设备之间的同步及通信时间开销,使用DDP策略利用 n n n张GPU卡训练深度神经网络模型,几乎可以将神经网络模型的训练时间缩短为原来的 1 n \frac{1}{n} n1。
3. 实现分布式预训练函数
使用PyTorch中的并行计算与分布式机器学习策略DDP预训练大语言模型GPTModel,需要使用torch.multiprocessing模块中的spawn函数,torch.distributed模块中的init_process_group与destroy_process_group函数,torch.utils.data.distributed模块中的DistributedSampler类,以及torch.nn.parallel模块中的DistributedDataParallel类,共同组成一个并行计算与分布式机器学习系统。
torch.multiprocessing模块中的spawn函数用于在每台训练服务器上启动多个训练进程。torch.distributed模块中的init_process_group函数用于初始化并行计算与分布式机器学习环境,配置所有训练进程之间的通讯和同步方式,destroy_process_group函数会在分布式训练完成后销毁各个训练进程,并释放系统资源。torch.utils.data.distributed模块中的DistributedSampler类可以将一个batch的训练样本拆分成world_size个交集为空集的minibatch,确保每个训练进程处理的各个minibatch的训练样本完全不同。
如下面的代码所示,可以定义一个初始化并行计算与分布式机器学习环境的函数ddp_setup,分别使用os.environ["MASTER_ADDR"]和os.environ["MASTER_PORT"]指定整个并行计算与分布式机器学习系统中主节点的通信IP地址和端口。使用init_process_group初始化分布式训练环境,配置多个GPU之间的通信的backend为"nccl"(NVIDIA Collective Communication Library),指定当前训练进程的序号rank以及整个并行计算与分布式机器学习系统中的训练进程总数world_size。最后使用torch.cuda.set_device函数设置当前训练进程使用的GPU设备:
import os
import mathimport torch
import tiktoken
from torch.utils.data import DataLoader
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP # noqa
from torch.distributed import init_process_group, destroy_process_groupdef ddp_setup(rank, world_size, master_addr, master_port):os.environ["MASTER_ADDR"] = master_addros.environ["MASTER_PORT"] = master_portinit_process_group(backend="nccl", rank=rank, world_size=world_size)torch.cuda.set_device(rank)
在Windows系统中需要将backend指定为"gloo"。
实现分布式预训练大语言模型函数ddp_hyper_pretrain_model,可以修改前文从零开始实现大语言模型(十四):高阶训练技巧中实现的高阶预训练函数hyper_pretrain_model,在训练开始前,首先使用ddp_setup函数初始化当前训练进程中的并行计算环境,并使用model.to(rank)将模型参数转移到当前训练进程使用的GPU。创建torch.nn.parallel模块中的DistributedDataParallel类对象,使各个训练进程均计算得到神经网络参数梯度之后,可以同步大语言模型model的参数梯度。在训练迭代流程结束后,使用destroy_process_group函数销毁当前训练进程,并释放系统资源。具体代码如下所示:
# from [从零开始实现大语言模型(十二):文本生成策略] import generate_text
# from [从零开始实现大语言模型(十三):预训练大语言模型GPTModel] import calc_loss_batch, calc_loss_loaderdef ddp_hyper_pretrain_model(rank, world_size, master_addr, master_port, learning_rate, weight_decay,model, train_loader, num_epochs, eval_freq, eval_iter, tokenizer, start_context,save_freq, checkpoint_dir, warmup_steps=10, initial_lr=3e-05, min_lr=1e-6, max_norm=1.0,checkpoint=None, val_loader=None
):ddp_setup(rank, world_size, master_addr, master_port)model.to(rank)optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)if rank == 0:if not os.path.exists(checkpoint_dir):os.makedirs(checkpoint_dir, exist_ok=True)if checkpoint is not None:model_checkpoint_path = os.path.join(checkpoint_dir, f"model_{checkpoint:06d}.pth")optimizer_checkpoint_path = os.path.join(checkpoint_dir, f"optimizer_{checkpoint:06d}.pth")model.load_state_dict(torch.load(model_checkpoint_path))optimizer.load_state_dict(torch.load(optimizer_checkpoint_path))else:checkpoint = -1model = DDP(model, device_ids=[rank])train_losses, val_losses, track_tokens_seen, track_lrs = [], [], [], []tokens_seen, global_step = 0, -1peak_lr = optimizer.param_groups[0]["lr"]total_training_steps = len(train_loader) * num_epochslr_increment = (peak_lr - initial_lr) / warmup_stepsfor epoch in range(num_epochs):model.train()for i, (input_batch, target_batch) in enumerate(train_loader):if global_step % eval_freq == 0:model.train()optimizer.zero_grad()global_step += 1if global_step < warmup_steps:lr = initial_lr + global_step * lr_incrementelse:progress = (global_step - warmup_steps) / (total_training_steps - warmup_steps)lr = min_lr + (peak_lr - min_lr) * 0.5 * (1 + math.cos(math.pi * progress))for param_group in optimizer.param_groups:param_group["lr"] = lrtrack_lrs.append(lr)loss = calc_loss_batch(input_batch, target_batch, model, rank)loss.backward()if global_step > warmup_steps:torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=max_norm)optimizer.step()tokens_seen += input_batch.numel()print(f"[GPU{rank}] Epoch {epoch + 1} (Batch {i:06d}): Train loss {loss.item():.3f}")checkpoint, train_loss, val_loss = val_and_save(model, optimizer, train_loader, val_loader, epoch, global_step, eval_freq,eval_iter, start_context, tokenizer, save_freq, checkpoint_dir, checkpoint, rank)if train_loss is not None:train_losses.append(train_loss)val_losses.append(val_loss)track_tokens_seen.append(tokens_seen)checkpoint, _, _ = val_and_save(model, optimizer, train_loader, val_loader, epoch, global_step, 1,eval_iter, start_context, tokenizer, 1, checkpoint_dir, checkpoint, rank)print(f"[GPU{rank}] Epoch {epoch + 1} finished, checkpoint: {checkpoint:06d}")destroy_process_group()return train_losses, val_losses, track_tokens_seen, track_lrsdef val_and_save(model, optimizer, train_loader, val_loader, epoch, global_step, eval_freq,eval_iter, start_context, tokenizer, save_freq, checkpoint_dir, checkpoint, device
):train_loss, val_loss = None, Noneif global_step % eval_freq == 0:if val_loader is not None:train_loss = calc_loss_loader(train_loader, model, device, eval_iter)val_loss = calc_loss_loader(val_loader, model, device, eval_iter)print(f"Epoch {epoch + 1} (Step {global_step:06d}): Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")generated_sample_text = generate_text(model, start_context, max_new_tokens=50, tokenizer=tokenizer,context_size=model.pos_emb.weight.shape[0], top_k=1, compact_format=True)print(f"Generated Sample Text: {generated_sample_text}")print("=====================================================================")if device == 0:if global_step % save_freq == 0:checkpoint += 1model_checkpoint_path = os.path.join(checkpoint_dir, f"model_{checkpoint:06d}.pth")optimizer_checkpoint_path = os.path.join(checkpoint_dir, f"optimizer_{checkpoint:06d}.pth")torch.save(model.state_dict(), model_checkpoint_path)torch.save(optimizer.state_dict(), optimizer_checkpoint_path)return checkpoint, train_loss, val_loss
使用从零开始实现大语言模型(二):文本数据处理中构建的Dataset创建训练集train_dataset及验证集val_dataset,并通过PyTorch内置的torch.utils.data.DataLoader类创建训练集及验证集对应的DataLoader,并指定train_loader的sampler为DistributedSampler(train_dataset),使多个训练进程可以从train_loader中分别获取相应minibatch的训练样本。实例化大语言模型gpt2_small,并使用torch.multiprocessing模块中的spawn函数启动训练进程。具体代码如下所示:
# from [从零开始实现大语言模型(七):多头注意力机制] import MultiHeadAttention
# from [从零开始实现大语言模型(八):Layer Normalization] import LayerNorm
# from [从零开始实现大语言模型(九):前馈神经网络与GELU激活函数] import GELU, FeedForward
# from [从零开始实现大语言模型(十一):构建大语言模型GPTModel] import TransformerBlock, GPTModel
# from [从零开始实现大语言模型(二):文本数据处理] import LLMDatasetif __name__ == "__main__":print("PyTorch version:", torch.__version__)print("CUDA available:", torch.cuda.is_available())print("Number of GPUs available:", torch.cuda.device_count())torch.manual_seed(123)world_size = 4master_addr = "192.168.0.1"master_port = "16801"train_data_path = "train_data"val_data_path = "val_data"vocabulary = "gpt2"special_token_id = 50256context_len = 1024stride = 1024batch_size = 2train_dataset = LLMDataset(train_data_path, vocabulary, special_token_id, context_len, stride)val_dataset = LLMDataset(val_data_path, vocabulary, special_token_id, context_len, stride)train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False, drop_last=True,pin_memory=True, sampler=DistributedSampler(train_dataset))val_loader = DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=False, drop_last=False)embedding_dim = 768num_layers = 12num_heads = 12context_len = 1024vocabulary_size = 50257dropout = 0.1qkv_bias = Falsegpt2_small = GPTModel(embedding_dim=embedding_dim,num_layers=num_layers,num_heads=num_heads,context_len=context_len,vocabulary_size=vocabulary_size,dropout=dropout,qkv_bias=qkv_bias)learning_rate = 0.0006weight_decay = 0.1num_epochs = 10eval_freq = 5eval_iter = 1tokenizer = tiktoken.encoding_for_model(vocabulary)start_context = "萧炎,斗之力,三段"save_freq = 5checkpoint_dir = "checkpoint"warmup_steps = 10initial_lr = 3e-05min_lr = 1e-6max_norm = 1.0checkpoint = Nonemp.spawn(ddp_hyper_pretrain_model,args=(world_size, master_addr, master_port, learning_rate, weight_decay,gpt2_small, train_loader, num_epochs, eval_freq, eval_iter, tokenizer, start_context,save_freq, checkpoint_dir, warmup_steps, initial_lr, min_lr, max_norm,checkpoint, val_loader),nprocs=torch.cuda.device_count())
将上述代码保存为Python脚本文件ddp_train.py,在多台训练服务器分别使用如下命令启动训练进程:
python ddp_train.py
上述并行计算与分布式机器学习策略DDP代码不能在Jupyter Notebook这样的交互式环境中运行。使用DDP策略训练深度神经网络模型,会启动多个训练进程,每个训练进程都会创建一个Python解释器实例。
如果不想使用一个计算服务器上的全部GPU,可以在启动训练进程的shell命令上通过
CUDA_VISIBLE_DEVICES参数设置可用的GPU设备。假设某台训练服务器上共有4块GPU设备,但是只能使用其中两块GPU训练深度神经网络模型,可以使用如下命令启动训练进程:CUDA_VISIBLE_DEVICES=0,2 python ddp_train.py
4. 结束语
并行计算与分布式机器学习中的计算非常简单,复杂的地方在于怎样通信。并行计算与分布式机器学习领域的通信算法可以分为两大类:同步算法及异步算法。本文原计划详细介绍并行计算与分布式机器学习领域的同步及异步通信算法原理,并解释DDP策略在所有训练进程之间同步神经网络参数梯度的Ring All-Reduce算法,但是后面发现内容实在是太多了,一篇文章根本讲不完。
《从零开始实现大语言模型》系列专栏全部完成之后,我应该会写几篇博客详细并行计算与分布式机器学习领域的通信算法原理,感兴趣的读者可以关注我的个人博客。
相关文章:
从零开始实现大语言模型(十五):并行计算与分布式机器学习
1. 前言 并行计算与分布式机器学习是一种使用多机多卡加速大规模深度神经网络训练过程,以减少训练时间的方法。在工业界的训练大语言模型实践中,通常会使用并行计算与分布式机器学习方法来减少训练大语言模型所需的钟表时间。 本文介绍PyTorch中的一种…...
OpenCV进阶操作:指纹验证、识别
文章目录 前言一、指纹验证1、什么是指纹验证2、流程步骤 二、使用步骤(案例)三、指纹识别(案例)1、这是我们要识别的指纹库2、这是待识别的指纹图3、代码4、结果 总结 前言 指纹识别作为生物识别领域的核心技术之一,…...
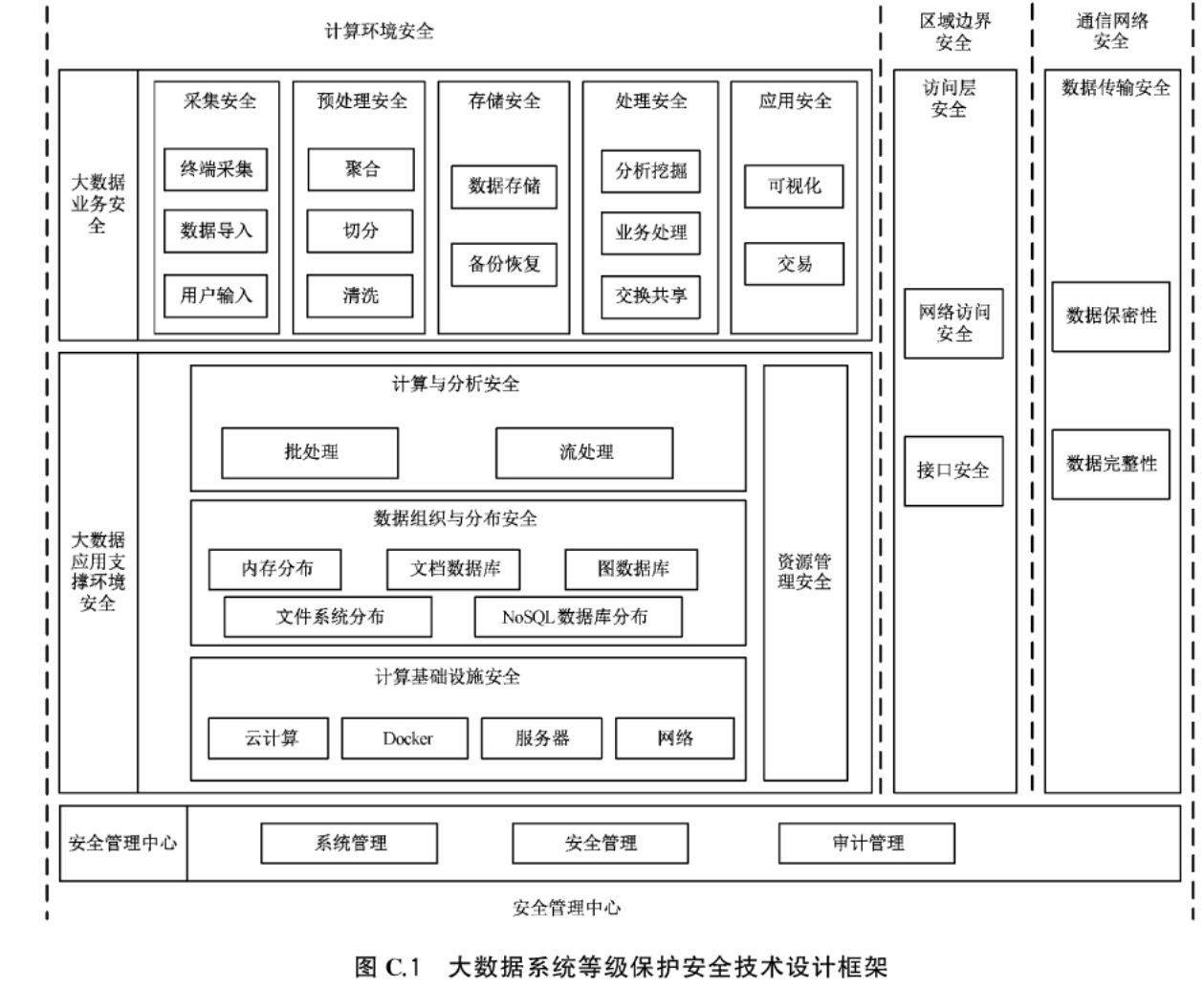
网络安全-等级保护(等保) 2-5 GB/T 25070—2019《信息安全技术 网络安全等级保护安全设计技术要求》-2019-05-10发布【现行】
################################################################################ GB/T 22239-2019 《信息安全技术 网络安全等级保护基础要求》包含安全物理环境、安全通信网络、安全区域边界、安全计算环境、安全管理中心、安全管理制度、安全管理机构、安全管理人员、安…...
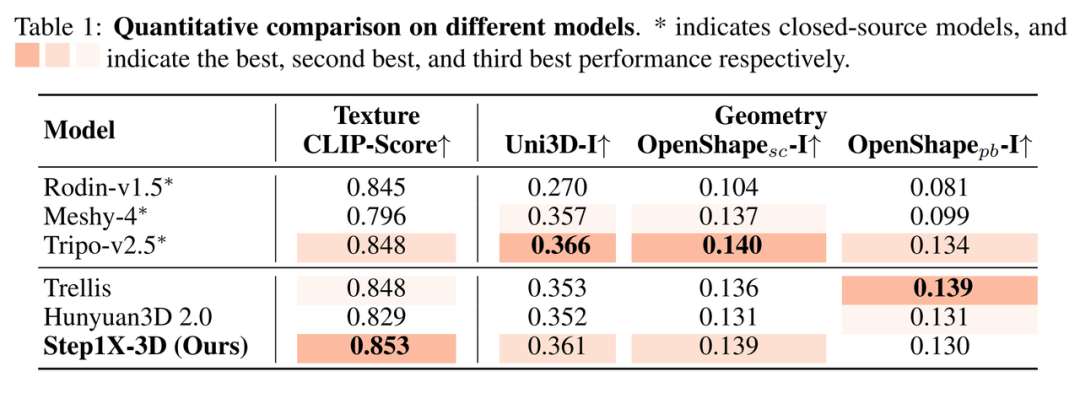
3D生成新突破:阶跃星辰Step1X-3D开源,可控性大幅提升
Step1X-3D 是由 StepFun 联合 LightIllusions 推出的新一代 高精度、高可控性 3D资产生成框架。基于严格的 数据清洗与标准化流程,我们从 500万 3D资产 中筛选出 200万高质量数据,构建了 标准化的几何与纹理属性数据集,为3D生成提供更可靠的训…...
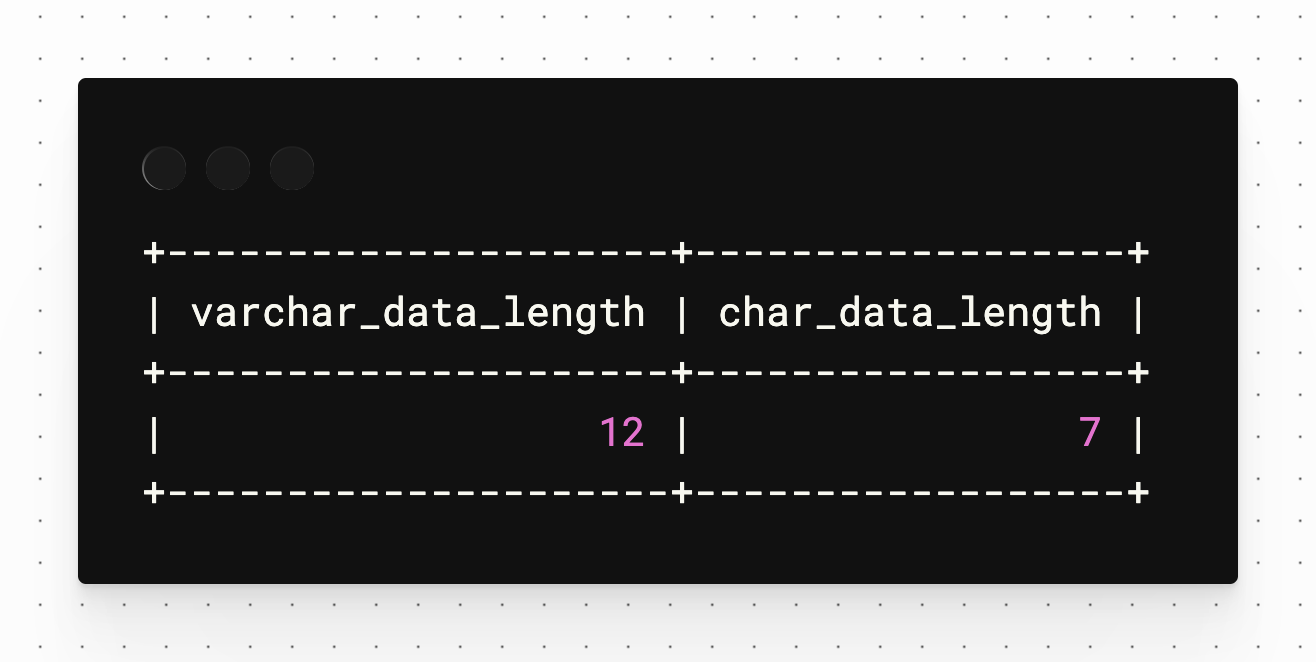
MySQL数据类型之VARCHAR和CHAR使用详解
在设计数据库字段时,字符串类型算是最常见的数据类型之一了,这篇文章带大家深入探讨一下MySQL数据库中VARCHAR和CHAR数据类型的基本特性,以及它们之间的区别。 VARCHAR类型 VARCHAR(Variable Character,可变长度字符…...

数字人 LAM 部署笔记
目录 windos踩坑 GitHub - aigc3d/LAM: [SIGGRAPH 2025] LAM: Large Avatar Model for One-shot Animatable Gaussian Head windos踩坑 nvidia-smi环境 cuda 11.8conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit conda create --name cuda11.8 -y pyth…...
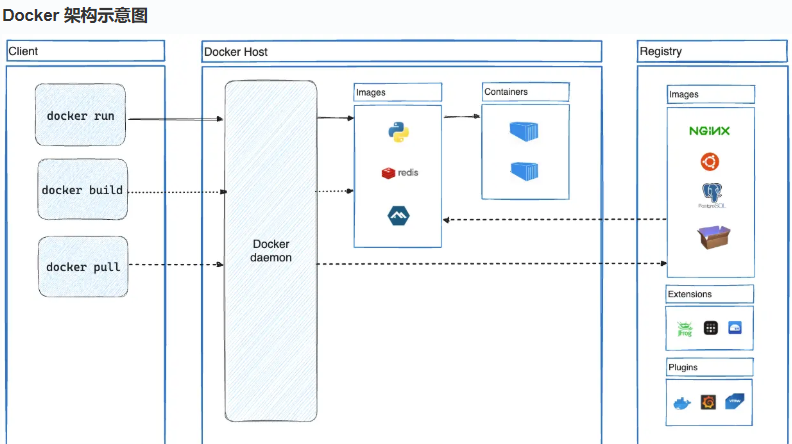
《Docker 入门与进阶:架构剖析、隔离原理及安装实操》
1 docker 简介 1.1 Docker 的优点 Docker 是一款开放平台,用于应用程序的开发、交付与运行,能将应用和基础架构分离,实现软件快速交付 ,还能以统一方式管理应用和基础架构,缩短代码从编写到上线的时间。其核心优势如…...
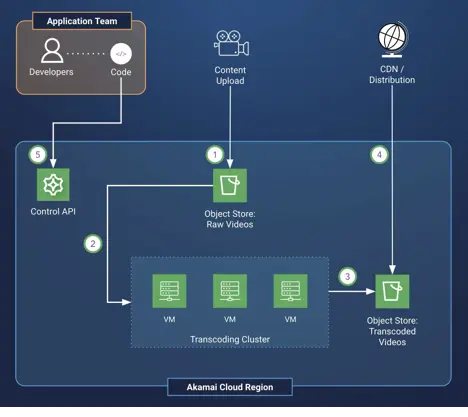
基于Akamai云计算平台的OTT媒体点播转码解决方案
点播视频(VOD)流媒体服务依赖于视频流的转码来高效分发内容。在转码工作流程中,视频被转换为适合观看设备、网络条件和性能限制的格式。视频转码是计算密集型过程,因此最大化可用硬件上可转码的视频流数量是首要考虑因素。不同基础…...
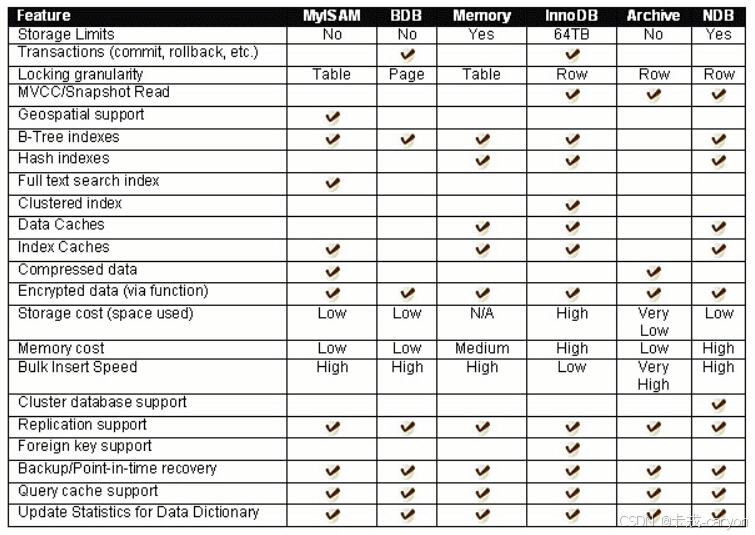
【MySQL】02.数据库基础
1. 数据库的引入 之前存储数据用文件就可以了,为什么还要弄个数据库? 文件存储存在安全性问题,文件不利于数据查询和管理,文件不利于存储海量数据,文件在程序中控制不方便。而为了解决上述问题,专家们设计出更加利于…...

选错方向太致命,华为HCIE数通和云计算到底怎么选?
现在搞HCIE的兄弟越来越多了,但“数通和云计算,到底考哪个?”这问题,依旧让不少人头疼。 一个是华为认证的老牌王牌专业——HCIE数通,稳、系统、岗位多; 一个是新趋势方向,贴合云原生、数字化…...
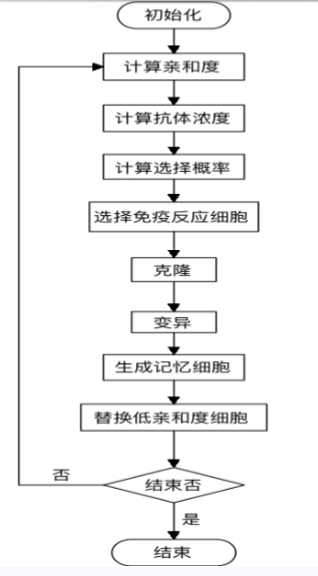
经典启发算法【早期/启发式/HC爬山/SA模拟退火/TS禁忌搜/IA免疫 思想流程举例全】
文章目录 一、早期算法二、启发式算法三、爬山法HC3.1 基本思路3.2 伪代码 四、模拟退火SA4.1 算法思想4.2 基本流程4.3 再究原理4.3.1 Metropolis准则4.3.2 再理解 4.4 小Tips4.5 应用举例4.5.1 背包问题:分析:求解: 4.5.2 TSP问题ÿ…...
IntraWeb 16.0.2 + Bootstrap 4 居中布局实战(附源码+效果图)
前言 最近在优化一个 IntraWeb 16.0.2 项目时,发现默认布局方式不够灵活,尤其是在不同屏幕尺寸下对齐效果不佳。于是,我决定引入 Bootstrap 4 来实现 完美居中布局,并成功落地!今天就把完整的 源代码 实际效果图 分享…...

Spring 框架中适配器模式的五大典型应用场景
Spring 框架中适配器模式的应用场景 在 Spring 框架中,适配器模式(Adapter Pattern)被广泛应用于将不同组件的接口转化为统一接口,从而实现组件间的无缝协作。以下是几个典型的应用场景: 1. HandlerAdapter - MVC 请…...
【Java ee初阶】jvm(3)
一、双亲委派机制(类加载机制中,最经常考到的问题) 类加载的第一个环节中,根据类的全限定类名(包名类名)找到对应的.class文件的过程。 JVM中进行类加载的操作,需要以来内部的模块“类加载器”…...

C 语言多维数组:定义、初始化与访问的深度解析
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在 C 语言中,我们已经熟悉了一维数组(存储线性数据)和二维数组(存储表格或矩阵数据)。但现实世界的数据结构往往更加复杂,例如表示空间中的点、图像数据、物理模拟的网格等。这时,就需要用到多维数…...
、ES2023(ES14)版本对比,及使用建议---ES6就够用(个人觉得))
浅入ES5、ES6(ES2015)、ES2023(ES14)版本对比,及使用建议---ES6就够用(个人觉得)
JavaScript(ECMAScript)的发展经历了多个版本,每个版本都引入了新特性和改进。以下仅是对三个常用版本(ES5、ES6(ES2015) 和 ES2023)的基本对比及使用建议: 目前常见项目中还是用ES6…...

23种设计模式考试趋势分析之——适配器(Adapter)设计模式——求三连
文章目录 一、考点分值占比与趋势分析二、真题考点深入挖掘三、"wwwh"简述四、真题演练与解析五、极简备考笔记 适配器模式核心要点六、考点记忆顺口溜七、多角度解答 一、考点分值占比与趋势分析 由于知识库提供的真题年份信息不完整,我们仅能对现有数据…...

Python 翻译词典小程序
一、概述 本工具是基于Python开发的智能翻译系统,采用有道词典进行翻译,并具有本地词典缓存以及单词本功能。 版本号:v1.0 (2025-05-15) 二、核心功能说明 1. 基础翻译功能 即时翻译:输入英文单词自动获取中文释义 词性识别&…...

【Linux笔记】——线程互斥与互斥锁的封装
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】——Linux线程封装 🔖流水不争,争的是滔滔不息 一、线程互斥的概念二、互…...
Android屏幕采集编码打包推送RTMP技术详解:从开发到优化与应用
在现代移动应用中,屏幕采集已成为一个广泛使用的功能,尤其是在实时直播、视频会议、远程教育、游戏录制等场景中,屏幕采集技术的需求不断增长。Android 平台为开发者提供了 MediaProjection API,这使得屏幕录制和采集变得更加简单…...
【深度学习】残差网络(ResNet)
如果按照李沐老师书上来,学完 VGG 后还有 NiN 和 GoogLeNet 要学,但是这两个我之前听都没听过,而且我看到我导师有发过 ResNet 相关的论文,就想跳过它们直接看后面的内容。 现在看来这不算是不踏实,因为李沐老师说如果…...
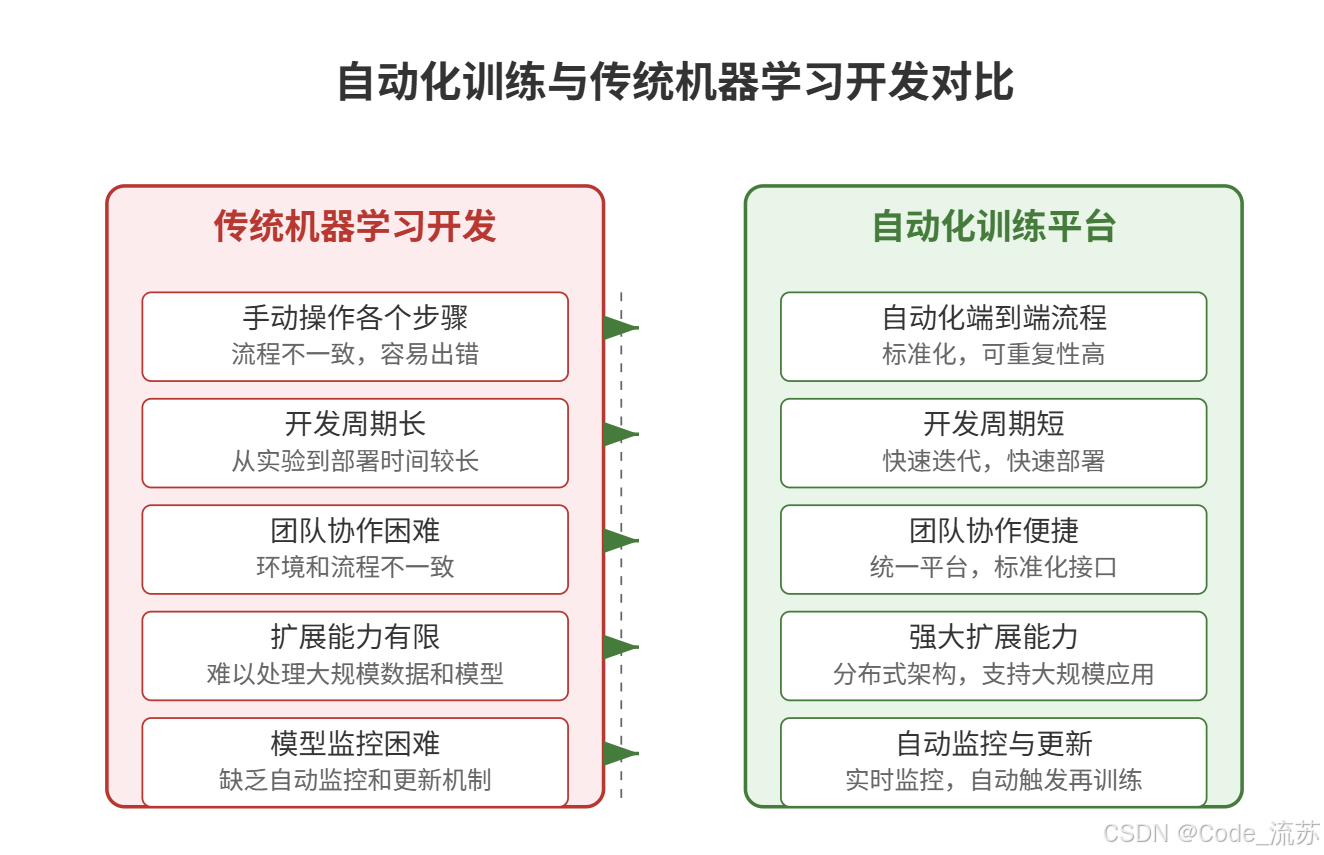
《Python星球日记》 第94天:走近自动化训练平台
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、自动化训练平台简介1. Kubeflow Pipelines2. TensorFlow Extended (TFX) 二…...
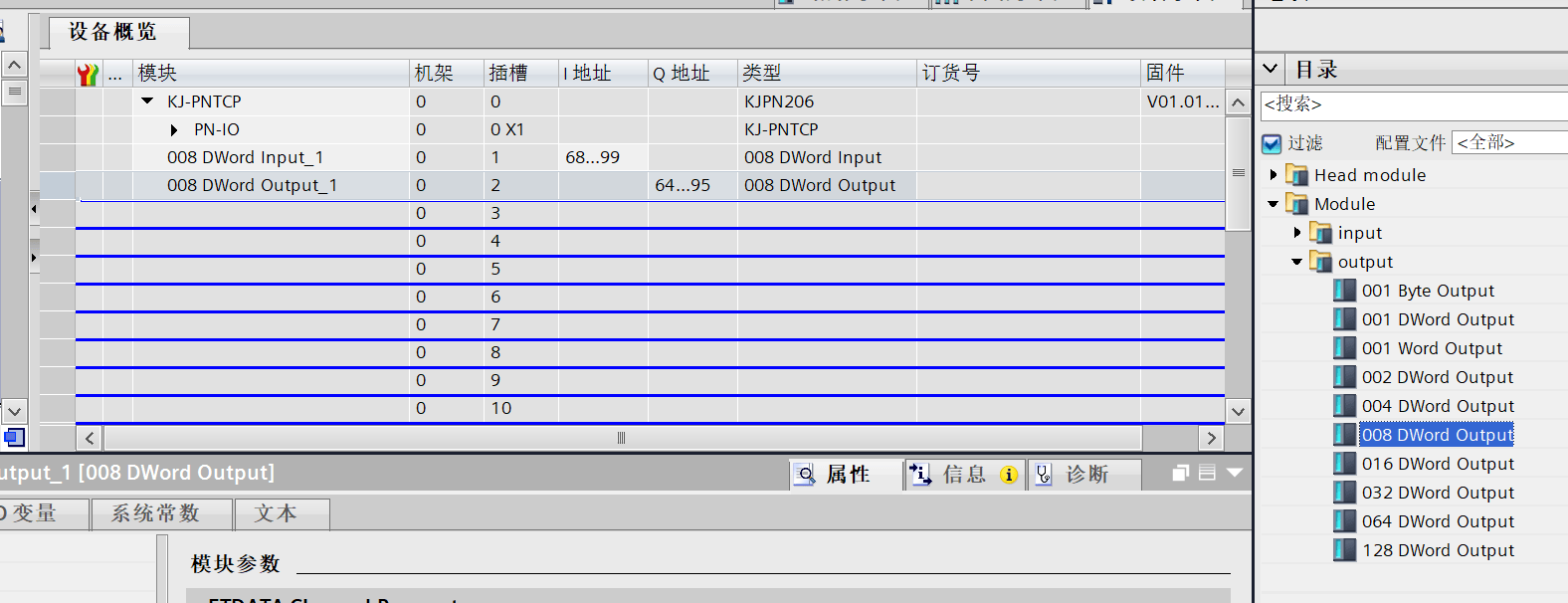
S7 200 smart连接Profinet转ModbusTCP网关与西门子1200PLC配置案例
控制要求:使用MODBUSTCP通信进行两台PLC之间的数据交换,由于改造现场不能改动程序,只留出了对应的IQ地址。于是客户决定使用网关进行通讯把数据传到plc。 1、读取服务器端40001~40005地址中的数据,放入到VW200~VW208中࿱…...

React中巧妙使用异步组件Suspense优化页面性能。
文章目录 前言一、为什么需要异步组件?1. 性能瓶颈分析2. 异步组件的价值 二、核心实现方式1. React.lazy Suspense(官方推荐)2. 路由级代码分割(React Router v6) 总结 前言 在 React 应用中,随着功能复…...

学习笔记:黑马程序员JavaWeb开发教程(2025.4.7)
12.9 登录校验-Filter-入门 /*代表所有,WebFilter(urlPatterns “/*”)代表拦截所有请求 Filter是JavaWeb三大组件,不是SpringBoot提供的,要在SpringBoot里面使用JavaWeb,则需要加上ServletComponentScan注…...

11 web 自动化之 DDT 数据驱动详解
文章目录 一、DDT 数据驱动介绍二、实战 一、DDT 数据驱动介绍 数据驱动: 现在主流的设计模式之一(以数据驱动测试) 结合 unittest 框架如何实现数据驱动? ddt 模块实现 数据驱动的意义: 通过不同的数据对同一脚本实现…...

OpenCV-python灰度变化和直方图修正类型
实验1 实验内容 该段代码旨在读取名为"test.png"的图像,并将其转换为灰度图像。使用加权平均值法将原始图像的RGB值转换为灰度值。 代码注释 image cv.imread("test.png")h np.shape(image)[0] w np.shape(image)[1] gray_img np.zeros…...

从 Excel 到 Data.olllo:数据分析师的提效之路
背景:Excel 的能力边界 对许多数据分析师而言,Excel 是入门数据处理的第一工具。然而,随着业务数据量的增长,Excel 的一些固有限制逐渐显现: 操作容易出错,难以审计; 打开或操作百万行数据时&…...

图像定制大一统?字节提出DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,有效解决多泛化性冲突。
字节提出了一个统一的图像定制框架DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,不仅在广泛的图像定制场景中取得了高质量的结果,而且在适应多条件场景方面也表现出很强的灵活性。现在已经可以支持消费级 GPU(16G…...
Nginx 动静分离在 ZKmall 开源商城静态资源管理中的深度优化
在 B2C 电商高并发场景下,静态资源(图片、CSS、JavaScript 等)的高效管理直接影响页面加载速度与用户体验。ZKmall开源商城通过对 Nginx 动静分离技术的深度优化,将静态资源响应速度提升 65%,带宽成本降低 40%…...