TTS:VITS-fast-fine-tuning 快速微调 VITS
1,项目概述
VITS是一种语音合成的方法,是一个完全端到端的TTS 模型,它使用预先训练好的语音编码器将文本转化为语音,并且是直接从文本到语音波形的转换,无需额外的中间步骤或特征提取。
VITS的工作流程为:首先,系统接收输入的文本,然后通过一系列复杂的算法将其转换为发音规则。然后,这些规则被送入一个预先训练好的语音编码器,该编码器负责生成语音信号的特征表示。最后,这些特征会被输入到语音合成模型中,模型根据这个生成最终的语音。
它的优点在于能够生成与真实人声相媲美的高质量语音,但是缺点就是训练需要大量的训练语料来训练语音合成模型,同时也需要较复杂的训练流程。
所以, VITS-fast-fine-tuning 就是在 VITS 的基础上开发的一站式多角色模型微调工具,它通过微调预训练的 VITS 模型,使用户在不到 1 小时的时间内完成对预训练模型的微调,然后生成好的训练模型,就可以用指定的音色进行语音合成和声音克隆了。
【项目地址】https://github.com/Plachtaa/VITS-fast-fine-tuning
【数据格式】https://github.com/Plachtaa/VITS-fast-fine-tuning/blob/main/DATA_EN.MD
2,本地部署
确保您已经安装了Python==3.8、CMake 和 C/C++ 编译器、ffmpeg;
pip install -r requirements.txt;# 安装处理视频数据所需的库 pip install imageio==2.4.1 pip install moviepyBuild monotonic align (necessary for training)
cd monotonic_align mkdir monotonic_align python setup.py build_ext --inplace cd ..下载训练辅助数据:
mkdir pretrained_models # download data for fine-tuning wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/sampled_audio4ft_v2.zip unzip sampled_audio4ft_v2.zip # create necessary directories mkdir video_data mkdir raw_audio mkdir denoised_audio mkdir custom_character_voice mkdir segmented_character_voice下载任意一个预训练模型,可用选项有:
CJE: Trilingual (Chinese, Japanese, English) wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/D_trilingual.pth -O ./pretrained_models/D_0.pth wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/G_trilingual.pth -O ./pretrained_models/G_0.pth wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/configs/uma_trilingual.json -O ./configs/finetune_speaker.jsonCJ: Dualigual (Chinese, Japanese) wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/D_0-p.pth -O ./pretrained_models/D_0.pth wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/G_0-p.pth -O ./pretrained_models/G_0.pth wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/config.json -O ./configs/finetune_speaker.jsonC: Chinese only wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/D_0.pth -O ./pretrained_models/D_0.pth wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/G_0.pth -O ./pretrained_models/G_0.pth wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/config.json -O ./configs/finetune_speaker.json自定义数据放在 custom_character_voice:
custom_character_voice- XiJun-XiJun_1.wav-XiJun_2.wav
3,本地训练
【语音识别】借助 whisper-lager 语音识别,有哪些数据执行哪个!!!:
python scripts/video2audio.py python scripts/denoise_audio.py python scripts/long_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size large python scripts/short_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size large # 有辅助训练数据执行,记得修改目录 python scripts/resample.py【报错】Given groups=1, weight of size [1280, 128, 3], expected input[1, 80, 3000]
【解决】short_audio_transcribe line 24
mel = whisper.log_mel_spectrogram(audio).to(model.device) 👇 mel = whisper.log_mel_spectrogram(audio, n_mels=128).to(model.device)【数据整理】python preprocess_v2.py --add_auxiliary_data True --languages "{PRETRAINED_MODEL}"
【正式训练】python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs "{Maximum_epochs}" --drop_speaker_embed True
- epoch 建议100以上
- 关闭一些日志会很好
import warnings warnings.simplefilter(action='ignore', category=FutureWarning) logging.getLogger('numba').setLevel(logging.WARNING) warnings.filterwarnings("ignore",message="stft with return_complex=False is deprecated" )【报错】Could not find module libtorio_ffmpeg6.pyd' (or one of its dependencies).
【解决】finetune_speaker_v2.py 最开始添加:
from torchaudio._extension.utils import _init_dll_path _init_dll_path()【报错】RuntimeError: use_libuv was requested but PyTorch was build without libuv support
【解决】finetune_speaker_v2 main() 添加:
os.environ['USE_LIBUV'] = '0'【报错】size mismatch for enc_p.emb.weight: copying a param with shape torch.Size([50, 192]) from checkpoint, the shape in current model is torch.Size([78, 192]).
【解决1】可能下载的预训练模型与配置文件搞串了,可能的多次下载导致。
【解决2】修改 untils.py 下的配置:
parser.add_argument('-c', '--config', type=str, default="./configs/modified_finetune_speaker.json", help='JSON file for configuration') 👇 parser.add_argument('-c', '--config', type=str, default="D:\\PyCharmWorkSpace\\TTS\\VITS-fast-fine-tuning\\configs\\finetune_speaker.json", help='JSON file for configuration')【报错】mel() takes 0 positional arguments but 5 were given
【解决】pip install librosa==0.8.0
4,推理效果
VITS:4张 V100 显卡训练一周,连话都说不清楚。
VITS-fast-fine:1张 4070 训练20分钟(200 epoch),效果还不错。
【注意】使用微调后的 config.json,主要在 VC_inference.py 中配置。
python VC_inference.py【报错】__init__() got an unexpected keyword argument 'source'
【解决】修改 VC_inference.py
record_audio = gr.Audio(label="record your voice", source="microphone") upload_audio = gr.Audio(label="or upload audio here", source="upload") 👇 record_audio = gr.Audio(label="record your voice") upload_audio = gr.Audio(label="or upload audio here")
相关文章:

TTS:VITS-fast-fine-tuning 快速微调 VITS
1,项目概述 VITS是一种语音合成的方法,是一个完全端到端的TTS 模型,它使用预先训练好的语音编码器将文本转化为语音,并且是直接从文本到语音波形的转换,无需额外的中间步骤或特征提取。 VITS的工作流程为:…...

从虚拟仿真到行业实训再到具身智能--华清远见嵌入式物联网人工智能全链路教学方案
2025年5月23-25日,第63届中国高等教育博览会(高博会)将在长春中铁东北亚国际博览中心举办。作为国内高等教育领域规模大、影响力广的综合性展会,高博会始终聚焦教育科技前沿,吸引全国高校管理者、一线教师、教育科技企…...
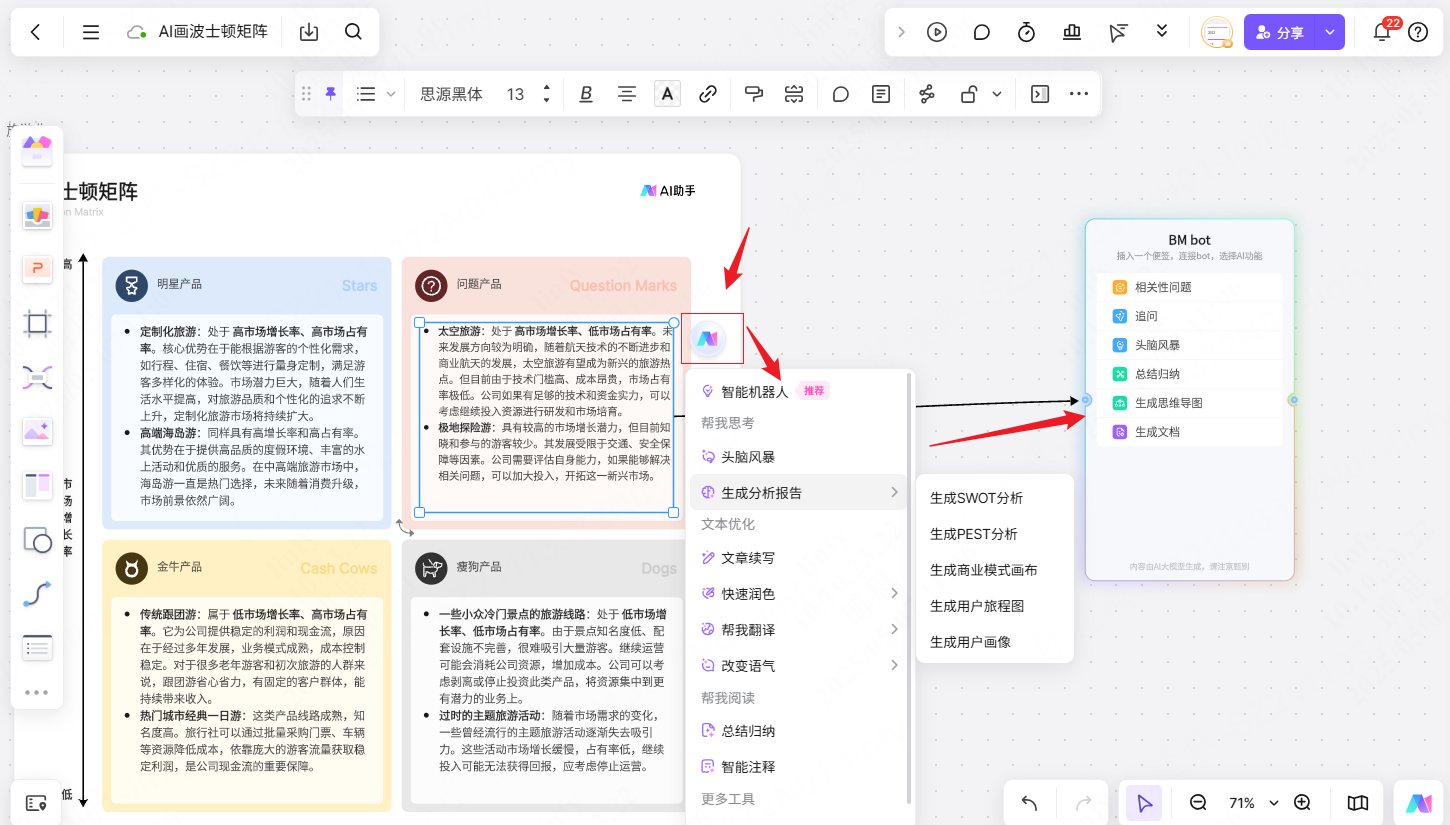
告别手动绘图!2分钟用 AI 生成波士顿矩阵
波士顿矩阵作为经典工具,始终是企业定位产品组合、制定竞争策略的核心方法论。然而,传统手动绘制矩阵的方式,往往面临数据处理繁琐、图表调整耗时、团队协作低效等痛点。 随着AI技术的发展,这一现状正在被彻底改变。boardmix博思白…...

GraphPad Prism工作表的管理
《2025新书现货 GraphPad Prism图表可视化与统计数据分析(视频教学版)雍杨 康巧昆 清华大学出版社教材书籍 9787302686460 GraphPadPrism图表可视化 无规格》【摘要 书评 试读】- 京东图书 GraphPad Prism统计数据分析_夏天又到了的博客-CSDN博客 工作…...
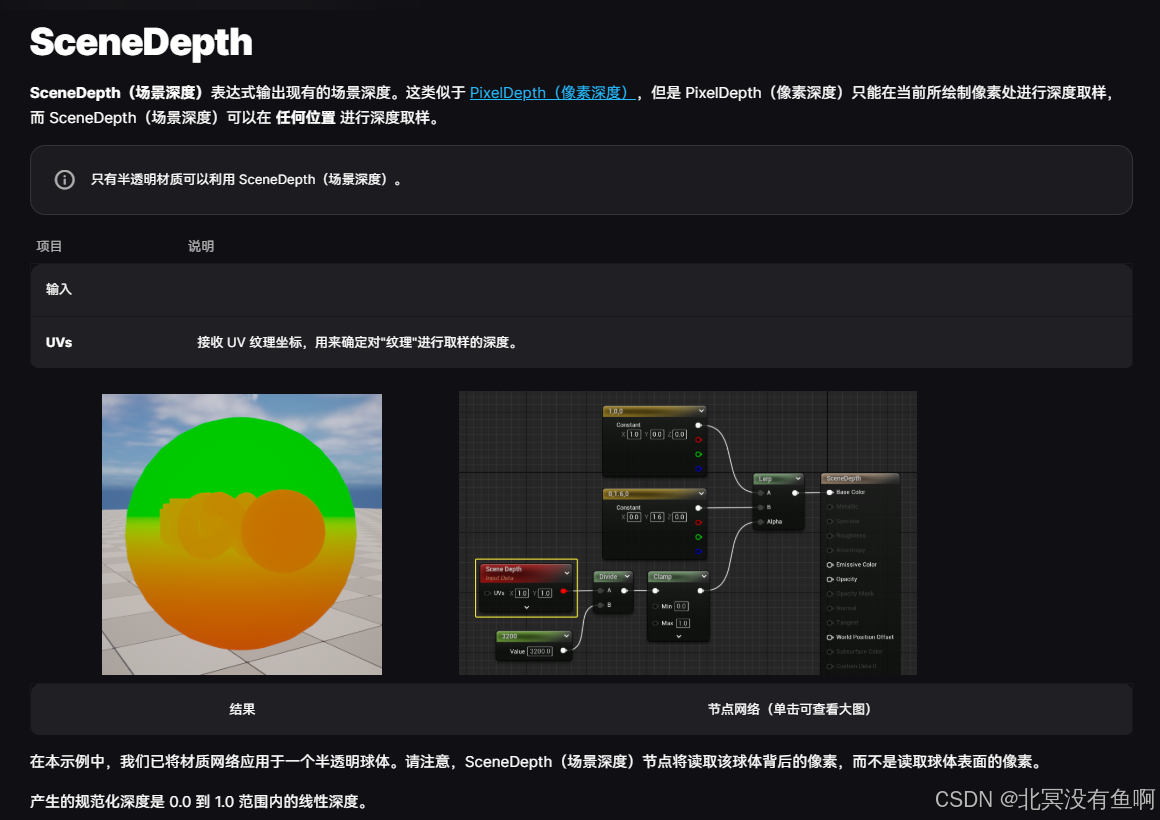
UE 材质几个输出向量节点
PixelNormalWS...

【modelscope/huggingface 通过colab将huggingface 模型/数据集/空间转移到 modelscope并下载】
1. 准备 注册一个modelscope账号(国内的)拿到对应的访问令牌SDK/API令牌注册一个google账号, 登录colab 2. 开始干! 打开一个ipynb 安装依赖包 !pip install -qqq modelscope huggingface-hub -U选择安装git lfs !curl -s https://packag…...
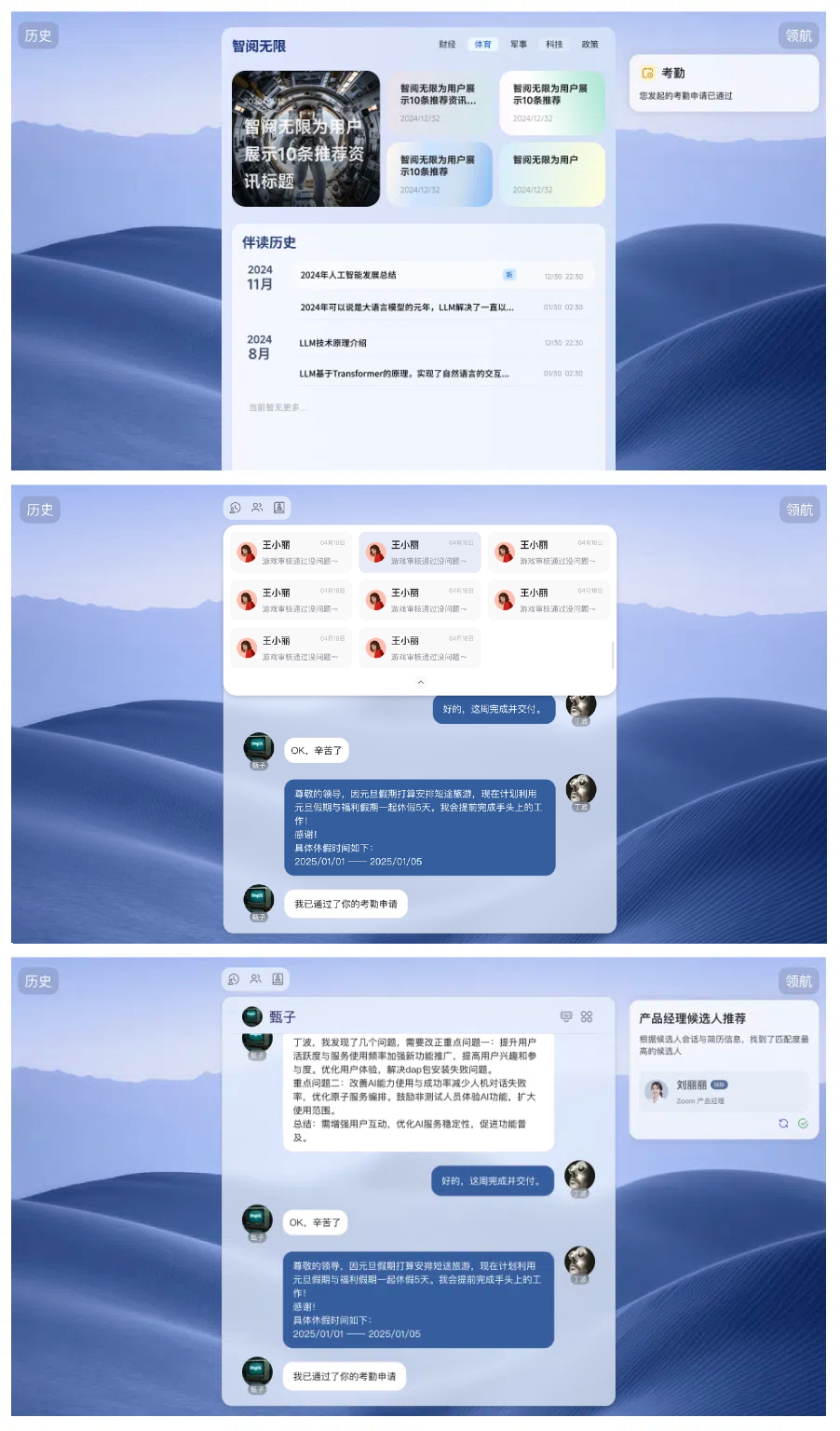
告别静态UI!Guineration用AI打造用户专属动态界面
摘 要 作为智能原生操作系统 DingOS 的核心技术之一,Guineration 生成式 UI 体系深刻践行了 DingOS“服务定义软件”的核心理念。DingOS 以“一切皆服务、服务按需而取、按用付费”为设计宗旨,致力于通过智能原生能力与粒子服务架构,实现资源…...

第六届电子通讯与人工智能国际学术会议(ICECAI 2025)
在数字化浪潮中,电子通讯与人工智能的融合正悄然重塑世界的运行逻辑。技术基础的共生关系是这场变革的核心——电子通讯如同“信息高速公路”,通过5G等高速传输技术,将海量数据实时输送至AI系统,使其能够像人类神经系统般快速响应…...

【C/C++】C++并发编程:std::async与std::thread深度对比
文章目录 C并发编程:std::async与std::thread深度对比1 核心设计目的以及区别2 详细对比分析3 代码对比示例4 适用场景建议5 总结 C并发编程:std::async与std::thread深度对比 在 C 中,std::async 和 std::thread 都是用于并发编程的工具&am…...

每日算法刷题Day11 5.20:leetcode不定长滑动窗口求最长/最大6道题,结束不定长滑动窗口求最长/最大,用时1h20min
6. 1695.删除子数组的最大得分(中等) 1695. 删除子数组的最大得分 - 力扣(LeetCode) 思想 1.给你一个正整数数组 nums ,请你从中删除一个含有 若干不同元素 的子数组**。**删除子数组的 得分 就是子数组各元素之 和 。 返回 只删除一个 子…...
)
STL中的Vector(顺序表)
vector容器的基本用法: template<class T> class vector { T* _a; size_t size; size_t capacity; } 尾插和遍历: vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3);//遍历 for(int i0;i<v.size();i) {cout<<…...

iOS Runtime与RunLoop的对比和使用
Runtime 机制 核心概念 Objective-C 的动态特性:Objective-C 是一门动态语言,很多工作都是在运行时而非编译时决定的消息传递机制:方法调用实际上是发送消息 objc_msgSend(receiver, selector, ...)方法决议机制:动态方法解析、…...
解决vscode在任务栏显示白色图标
长久不用,不知道怎么着就显示成白色图标,虽然不影响使用,但是看起来不爽 问了豆包,给了个解决方法: 1、打开隐藏文件, 由于图标缓存文件是隐藏文件,首先点击资源管理器中的 “查看” 菜单&am…...

架构思维:构建高并发扣减服务_分布式无主架构
文章目录 Pre无主架构的任务简单实现分布式无主架构 设计和实现扣减中的返还什么是扣减的返还返还实现原则原则一:扣减完成才能返还原则二:一次扣减可以多次返还原则三:返还的总数量要小于等于原始扣减的数量原则四:返还要保证幂等…...

Vue 3 官方 Hooks 的用法与实现原理
Vue 3 引入了 Composition API,使得生命周期钩子(hooks)在函数式风格中更清晰地表达。本篇文章将从官方 hooks 的使用、实现原理以及自定义 hooks 的结构化思路出发,全面理解 Vue 3 的 hooks 系统。 📘 1. Vue 3 官方生…...

Vue3 打印表格、Element Plus 打印、前端打印、表格导出打印、打印插件封装、JavaScript 打印、打印预览
🚀 Vue3 高级表格打印工具封装(支持预览、分页、样式美化) 现已更新至npm # npm npm install vue-table-print# yarn yarn add vue-table-print# pnpm pnpm add vue-table-printgithunb地址: https://github.com/zhoulongshao/vue-table-print/blob/main/README.MD关键词…...

湖北理元理律师事务所:专业债务优化如何助力负债者重获生活掌控权
在当前经济环境下,个人债务问题日益凸显。湖北理元理律师事务所通过其专业的债务优化服务,为负债群体提供了一条合法合规的解决路径。本文将客观分析专业债务规划的实际价值,不涉及任何营销内容。 一、债务优化的核心价值 科学评估…...

RAGFlow知识检索原理解析:混合检索架构与工程实践
一、核心架构设计 RAGFlow构建了四阶段处理流水线,其检索系统采用双路召回+重排序的混合架构: S c o r e f i n a l = α ⋅ B M...

5月22总结
P1024 [NOIP 2001 提高组] 一元三次方程求解 题目描述 有形如:$ a x^3 b x^2 c x d 0 $ 这样的一个一元三次方程。给出该方程中各项的系数($ a,b,c,d $ 均为实数),并约定该方程存在三个不同实根(根的范围在 $ -1…...

Java设计模式之桥接模式:从入门到精通
1. 桥接模式概述 1.1 定义与核心思想 桥接模式(Bridge Pattern)是一种结构型设计模式,它将抽象部分与实现部分分离,使它们可以独立变化。这种模式通过提供桥梁结构(Bridge)将抽象和实现解耦。 专业定义:桥接模式将抽象部分与它的实现部分分离,使它们都可以独立地变化…...
uni-app学习笔记九-vue3 v-for指令
v-for 指令基于一个数组来渲染一个列表。v-for 指令的值需要使用 item in items 形式的特殊语法,其中 items 是源数据的数组,而 item 是迭代项的别名: <template><view v-for"(item,index) in 10" :key"index"…...

MAC电脑中右键后复制和拷贝的区别
在Mac电脑中,右键菜单中的“复制”和“拷贝”操作在功能上有所不同: 复制 功能:在选定的位置创建一个与原始文件相同的副本。快捷键:CommandD用于在当前位置快速复制文件,CommandC用于将内容复制到剪贴板。效果&…...

Regmap子系统之六轴传感器驱动-编写icm20607.c驱动
(一)在驱动中要操作很多芯片相关的寄存器,所以需要先新建一个icm20607.h的头文件,用来定义相关寄存器值。 #ifndef ICM20607_H #define ICM20607_H /*************************************************************** 文件名 : i…...

常见高危端口解析:网络安全中的“危险入口”
目录 1. 经典高危端口列表 2. 典型漏洞案例:445端口与永恒之蓝 攻击原理 防御方案 Linux命令 2. 防护策略建议 三、扩展思考:从端口到攻防体系 结语 1. 经典高危端口列表 端口号 协议/服务 风险场景 21 FTP 明文传输凭据、弱密码爆破、匿名…...
华为2025年校招笔试手撕真题教程(二)
一、题目 大湾区某城市地铁线路非常密集,乘客很难一眼看出选择哪条线路乘坐比较合适,为了解决这个问题,地铁公司希望你开发一个程序帮助乘客挑选合适的乘坐线路,使得乘坐时间最短,地铁公司可以提供的数据是各相邻站点…...

征程 6 J6E/M linear 双int16量化支持替代方案
1.背景简介 当发现使用 plugin 精度 debug 工具定位到是某个 linear 敏感时,示例如下: op_name sensitive_type op_type L1 quant_dty…...
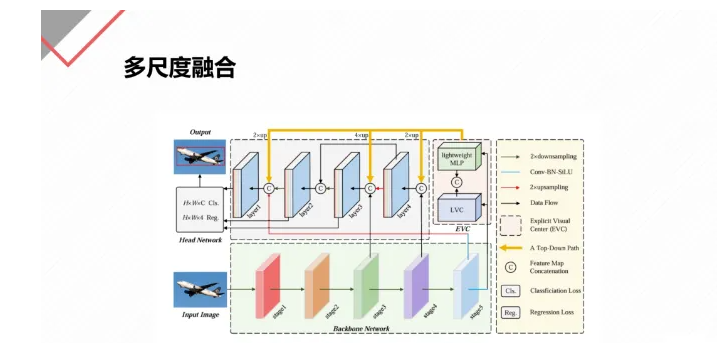
深度学习模块缝合拼接方法套路+即插即用模块分享
前言 在深度学习中,模型的设计往往不是从头开始,而是通过组合不同的模块来构建。这种“模块缝合”技术,就像搭积木一样,把不同的功能模块拼在一起,形成一个强大的模型。今天,我们就来聊聊四种常见的模块缝…...

改写视频生产流程!快手SketchVideo开源:通过线稿精准控制动态分镜的AI视频生成方案
Sketch Video 的核心特点 Sketch Video 通过手绘生成动画的形式,将复杂的信息以简洁、有趣的方式展现出来。其核心特点包括: 超强吸引力 Sketch Video 的手绘风格赋予了视频一种质朴而真实的质感,与常见的精致特效视频形成鲜明对比。这种独…...

Graphics——基于.NET 的 CAD 图形预览技术研究与实现——CAD c#二次开发
一、Graphics 类的本质与作用 Graphics 是 .NET 框架中 System.Drawing 命名空间下的核心类,用于在二维画布(如 Bitmap 图像)上绘制图形、文本或图像。它相当于 “绘图工具”,提供了一系列方法(如 DrawLine、FillElli…...

ElasticSearch 8.x 快速上手并了解核心概念
目录 核心概念概念总结 常见操作索引的常见操作常见的数据类型指定索引库字段类型mapping查看索引库的字段类型最高频使用的数据类型 核心概念 在新版Elasticsearch中,文档document就是一行记录(json),而这些记录存在于索引库(index)中, 索引名称必须是…...