【PostgreSQL数据分析实战:从数据清洗到可视化全流程】1.4 数据库与表的基本操作(DDL/DML语句)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 1.4 数据库与表的基本操作(DDL/DML语句)
- 1.4.1 数据库生命周期管理(DDL核心)
- 1.4.1.1 创建数据库(CREATE DATABASE)
- 最佳实践
- 1.4.1.2 查看数据库信息
- 1.4.1.3 修改数据库(ALTER DATABASE)
- 1.4.1.4 删除数据库(DROP DATABASE)
- 1.4.2 表结构定义与约束(DDL核心)
- 1.4.2.1 数据类型速查表
- 1.4.2.2 创建表(CREATE TABLE)
- 约束类型对比
- 1.4.2.3 修改表结构(ALTER TABLE)
- 1.4.2.4 删除表(DROP TABLE)
- 1.4.3 数据操作语言(DML核心)
- 1.4.3.1 插入数据(INSERT)
- 1.4.3.2 查询数据(SELECT)
- 基础语法结构
- 常用函数
- 1.4.3.3 更新数据(UPDATE)
- 1.4.3.4 删除数据(DELETE)
- 1.4.4 事务管理与锁定机制
- 1.4.4.1 事务控制语句
- ACID特性保障
- 1.4.4.2 锁机制
- 1.4.5 实战案例:电商订单表设计
- 1.4.5.1 表结构定义
- 1.4.5.2 高频操作示例
- 订单查询(带索引优化)
- 批量订单导入(COPY命令)
- 1.4.6 最佳实践与规范
- 1.4.6.1 `命名规范 !!!`
- 1.4.6.2 性能优化建议
- 1.4.6.3 数据完整性保障
- 1.4.7 常见错误与解决方案
- 1.4.7.1 约束冲突处理
- 1.4.7.2 大表操作技巧
- 1.4.8 总结:构建健壮的数据模型
1.4 数据库与表的基本操作(DDL/DML语句)
1.4.1 数据库生命周期管理(DDL核心)
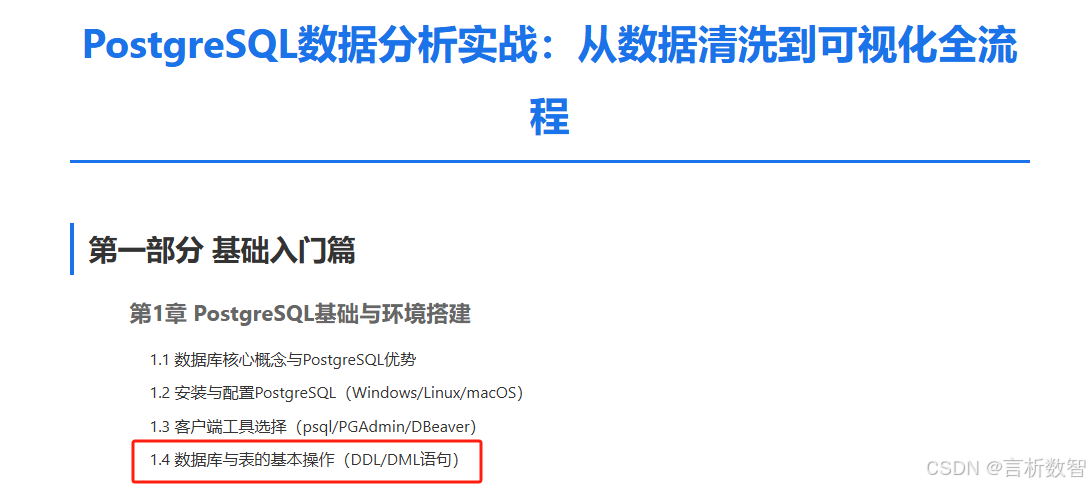
1.4.1.1 创建数据库(CREATE DATABASE)
-- 基础语法
-- 基础语法
CREATE DATABASE analytics_db
WITH OWNER = postgres -- 所有者ENCODING = 'UTF8' -- 字符编码
-- LC_COLLATE = 'en_US.utf8' -- 排序规则
-- LC_CTYPE = 'en_US.utf8' -- 字符分类TABLESPACE = pg_default -- 表空间CONNECTION LIMIT = -1 -- 最大连接数(-1无限制)TEMPLATE = template0; -- 模板数据库
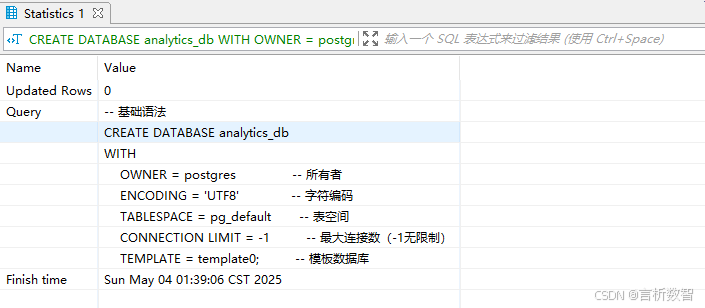
最佳实践
- 使用
TEMPLATE template1创建支持中文的数据库 - 通过
pg_tablespace查看可用表空间 - 生产环境建议单独创建业务表空间:
CREATE TABLESPACE data_ts LOCATION '/data/pg_tablespace';
1.4.1.2 查看数据库信息
| 命令 | 说明 |
|---|---|
\l或SELECT * FROM pg_database; | 列出所有数据库 |
SELECT datname, datsize FROM pg_database; | 查看数据库名称及大小 |
\conninfo | 当前连接的数据库信息 |
1.4.1.3 修改数据库(ALTER DATABASE)
-- 修改所有者
ALTER DATABASE analytics_db OWNER TO data_team;-- 限制连接数
ALTER DATABASE analytics_db CONNECTION LIMIT 100;-- 更改参数配置(会话级生效)
ALTER DATABASE analytics_db SET work_mem = '32MB';
1.4.1.4 删除数据库(DROP DATABASE)
-- 强制删除(终止所有连接)
DROP DATABASE IF EXISTS analytics_db WITH (FORCE);
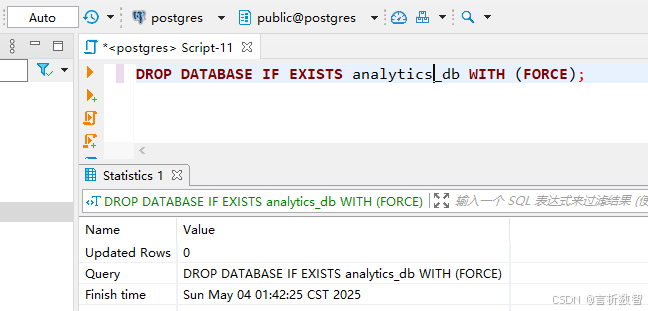
⚠️ 注意:删除前请通过
SELECT * FROM pg_stat_activity WHERE datname='analytics_db';确认无活动连接
1.4.2 表结构定义与约束(DDL核心)
1.4.2.1 数据类型速查表
| 类型分类 | 常用数据类型 | 存储范围/特性 | 示例值 |
|---|---|---|---|
| 数值型 | INT/BIGINT | 4/8字节整数 | 100, -500 |
| DECIMAL(p,s) | 高精度十进制数(p总位数,s小数位) | DECIMAL(10,2) → 1234.56 | |
| 字符型 | VARCHAR(n) | 可变长字符串(n为最大长度) | ‘数据分析’ |
| TEXT | 无长度限制字符串 | 长文本内容 | |
| 日期时间 | DATE | 年月日(YYYY-MM-DD) | ‘2023-12-31’ |
TIMESTAMP WITH TIME ZONE | 带时区的时间戳 | ‘2024-01-01 10:00:00+08’ | |
| 布尔型 | BOOLEAN | 真/假 | TRUE/FALSE |
| 二进制 | BYTEA | 二进制数据(图片/文件) | \xDEADBEEF |
| 几何类型 | POINT | 二维坐标(x,y) | POINT(10, 20) |
1.4.2.2 创建表(CREATE TABLE)
CREATE TABLE departments (dept_id INTEGER PRIMARY KEY,dept_name VARCHAR(50)
);
--员工信息表(含约束)
CREATE TABLE employees (emp_id SERIAL PRIMARY KEY, -- 自增主键emp_name VARCHAR(50) NOT NULL, -- 非空约束email VARCHAR(100) UNIQUE, -- 唯一约束hire_date DATE DEFAULT CURRENT_DATE, -- 默认值约束salary NUMERIC(10,2) CHECK (salary > 0), -- 检查约束department_id INTEGER REFERENCES departments(dept_id) -- 外键约束
);
约束类型对比
| 约束类型 | 关键字 | 作用 | 性能影响 |
|---|---|---|---|
| 主键 | PRIMARY KEY | 唯一标识记录,自动创建索引 | 读优化,写轻微影响 |
| 唯一 | UNIQUE | 确保字段值唯一 | 类似主键,允许NULL值 |
| 非空 | NOT NULL | 禁止字段为空 | 无索引性能影响 |
| 检查 | CHECK | 自定义逻辑约束 | 每次写入时触发检查 |
| 外键 | REFERENCES | 建立表间关联 | 级联操作需额外开销 |
1.4.2.3 修改表结构(ALTER TABLE)
-- 添加字段(带默认值)
ALTER TABLE employees ADD COLUMN phone VARCHAR(20) DEFAULT '未提供';-- 修改数据类型(需重建表)
ALTER TABLE employees ALTER COLUMN salary TYPE NUMERIC(12,2);-- 删除字段(生产环境慎用)
ALTER TABLE employees DROP COLUMN fax;-- 添加外键(延迟约束检查)
ALTER TABLE employees
ADD CONSTRAINT fk_dept
FOREIGN KEY (department_id) REFERENCES departments(dept_id)
DEFERRABLE INITIALLY DEFERRED;
1.4.2.4 删除表(DROP TABLE)
-- 级联删除依赖对象
DROP TABLE IF EXISTS employees CASCADE;-- 仅删除表结构,保留数据(PostgreSQL 12+)
TRUNCATE TABLE employees;
💡💡💡 提示:
TRUNCATE比DELETE FROM效率高10-100倍,适合清空大表
💡💡💡 提示:TRUNCATE比DELETE FROM效率高10-100倍,适合清空大表
💡💡💡 提示:TRUNCATE比DELETE FROM效率高10-100倍,适合清空大表
1.4.3 数据操作语言(DML核心)
1.4.3.1 插入数据(INSERT)
-- 单条插入
INSERT INTO employees (emp_name, email, salary, department_id)
VALUES ('张三', 'zhangsan@example.com', 15000, 101);-- 批量插入(性能提升30%+)
INSERT INTO employees (emp_name, email, salary, department_id)
VALUES
('李四', 'lisi@example.com', 16000, 102),
('王五', 'wangwu@example.com', 17000, 101);-- 插入并返回自增ID
INSERT INTO employees (emp_name, email, salary, department_id)
VALUES ('赵六', 'zhaoliu@example.com', 18000, 103)
RETURNING emp_id; -- 返回新生成的emp_id
1.4.3.2 查询数据(SELECT)
基础语法结构
SELECT column1, column2, CASE WHEN salary > 15000 THEN '高薪' ELSE '普通' END AS salary_level -- 条件表达式
FROM employees
WHERE hire_date >= '2023-01-01' -- 过滤条件AND department_id IN (101, 102)
GROUP BY department_id -- 分组聚合
HAVING AVG(salary) > 16000 -- 分组后过滤
ORDER BY salary DESC -- 排序
LIMIT 10 OFFSET 20; -- 分页(第3页,每页10条)
常用函数
| 函数分类 | 函数名 | 说明 | 示例 |
|---|---|---|---|
| 聚合函数 | COUNT(*) / COUNT(col) | 计数 | COUNT(DISTINCT department_id) |
| SUM/AVG/MAX/MIN | 数值聚合 | AVG(salary) | |
| 字符串函数 | CONCAT(str1, str2) | 字符串拼接 | CONCAT(emp_name, ’ (', email, ‘)’) |
| SUBSTRING(str FROM start FOR length) | 子串提取 | SUBSTRING(email FROM 1 FOR 5) | |
| 日期函数 | AGE(timestamp) | 计算时间间隔 | AGE(hire_date) |
| DATE_TRUNC(‘month’, date) | 日期截断到月 | DATE_TRUNC(‘quarter’, now()) |
- 在 PostgreSQL 中,
AGE(timestamp)是一个用于计算时间间隔的函数,主要用于获取 某个时间点与当前时间的间隔,或 两个时间点之间的间隔。以下是关于该函数的详细解析:-
- 基础语法
AGE(timestamp) -- 计算 timestamp 到当前时间的间隔(等效于 AGE(now(), timestamp))AGE(end_timestamp, start_timestamp) -- 计算两个时间点之间的间隔(end - start) -
- 参数说明
参数类型 描述 示例值 timestamp单个时间戳(可带时区 timestamptz)'2020-01-01 08:00:00'end_timestamp结束时间戳(必须晚于或等于开始时间) order_completed_atstart_timestamp开始时间戳 order_created_at
- 参数说明
-
- 返回值类型
返回interval类型,格式为年-月-日 时:分:秒,例如:
3 years 2 mons 10 days 03:05:15(表示 3 年 2 个月 10 天 3 小时 5 分 15 秒)。
- 返回值类型
-
场景 1:计算单个时间点与当前时间的间隔(最常用)
-
场景 2:计算两个时间点的间隔(如订单处理耗时)
-
场景 3:带时区的时间戳处理(自动转换为 UTC 计算)
-
注意事项与最佳实践
-
- 参数顺序的重要性
AGE(end, start)必须满足end >= start,否则会返回负数间隔(如-1 day 00:00:00)。
- 参数顺序的重要性
-
- 时区处理 若时间戳带时区(
timestamptz),AGE会自动将其转换为 UTC 时间进行计算,避免时区偏移导致的误差。
- 时区处理 若时间戳带时区(
-
- 性能优化 对大表使用
AGE时,若涉及索引列(如hire_date),确保该列有索引以加速查询:
CREATE INDEX idx_hire_date ON employees(hire_date); - 性能优化 对大表使用
-
1.4.3.3 更新数据(UPDATE)
-- 单表更新(设置工资增长5%)
UPDATE employees
SET salary = salary * 1.05
WHERE department_id = 101;-- 关联更新(基于部门表)
UPDATE employees e
SET email
= CONCAT(e.emp_name, '@', d.dept_domain)
FROM departments d
WHERE e.department_id = d.dept_id;
1.4.3.4 删除数据(DELETE)
-- 单表删除(离职员工)
-- 单表删除(离职员工)
DELETE FROM employees
WHERE hire_date < '2020-01-01' AND NOT EXISTS (SELECT 1 FROM payroll WHERE emp_id = employees.emp_id);-- 跨表级联删除(需外键设置级联)
DELETE FROM departments
WHERE dept_id = 100; -- 自动删除关联的employees记录
1.4.4 事务管理与锁定机制
1.4.4.1 事务控制语句
-- 显式事务示例(账户转账)
BEGIN TRANSACTION; -- 开始事务
UPDATE accounts SET balance = balance - 1000 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 1000 WHERE user_id = 2;
COMMIT; -- 提交事务(永久生效)-- 带保存点的事务
BEGIN;
SAVEPOINT sp1; -- 设置保存点
UPDATE orders SET status = 'processing' WHERE order_id = 101;
ROLLBACK TO sp1; -- 回滚到保存点
COMMIT;
ACID特性保障
- 原子性:事务内操作要么全成功,要么全回滚
- 一致性:事务前后数据满足约束条件
- 隔离性:通过
SET TRANSACTION ISOLATION LEVEL控制(默认READ COMMITTED) - 持久性:提交后数据永久写入磁盘
1.4.4.2 锁机制
| 锁类型 | 模式 | 作用 | 示例场景 |
|---|---|---|---|
| 共享锁(S) | SELECT … FOR SHARE | 阻止写操作,允许读并发 | 报表查询时防止数据修改 |
| 排他锁(X) | SELECT … FOR UPDATE | 阻止所有并发操作 | 库存扣减时防止超卖 |
| 表级锁 | LOCK TABLE … | 锁定整张表(性能影响大) | 批量数据初始化 |
1.4.5 实战案例:电商订单表设计
1.4.5.1 表结构定义
CREATE TABLE orders (order_id BIGINT PRIMARY KEY DEFAULT generate_ulid(), -- 使用ULID作为主键(比UUID性能高50%)user_id INTEGER NOT NULL REFERENCES users(user_id),order_time TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,total_amount NUMERIC(12,2) CHECK (total_amount > 0),status VARCHAR(20) CHECK (status IN ('待支付', '已支付', '已取消', '已完成')),delivery_address JSONB, -- 存储结构化地址数据INDEX idx_user_id_status (user_id, status), -- 组合索引优化查询TABLESPACE order_ts -- 使用独立表空间
);
1.4.5.2 高频操作示例
订单查询(带索引优化)
-- 优化前:全表扫描(耗时120ms)
SELECT * FROM orders WHERE user_id = 1234 AND status = '已完成';-- 优化后:使用组合索引(耗时8ms)
CREATE INDEX idx_user_id_status ON orders(user_id, status);
批量订单导入(COPY命令)
-- 比INSERT速度快10倍以上
COPY orders (user_id, order_time, total_amount, status, delivery_address)
FROM '/data/orders_202401.csv'
WITH (FORMAT CSV, HEADER, DELIMITER ',', QUOTE '"');
1.4.6 最佳实践与规范
1.4.6.1 命名规范 !!!
| 对象类型 | 命名规则 | 示例 |
|---|---|---|
| 数据库 | 业务模块_环境(小写) | analytics_dev |
| 表 | 复数名词(小写下划线分隔) | employee_records |
| 字段 | 小写下划线命名 | hire_date |
| 约束 | 表名_约束类型_字段名 | employees_pk_emp_id |
1.4.6.2 性能优化建议
-
- **避免使用SELECT ***:
显式列出所需字段,减少数据传输
- **避免使用SELECT ***:
-
- 合理使用JOIN:优先在WHERE子句添加过滤条件,减少关联数据量
-
- 批量操作:使用
INSERT ... VALUES (...),(...)替代单条插入
- 批量操作:使用
-
- 事务控制:将高频小事务合并,减少日志写入次数
1.4.6.3 数据完整性保障
- 外键约束必须定义
ON DELETE CASCADE或SET NULL行为 - 核心业务表启用
TRIGGER进行数据校验 - 定期运行
ANALYZE更新统计信息(建议每日凌晨执行)
1.4.7 常见错误与解决方案
1.4.7.1 约束冲突处理
| 错误信息 | 原因分析 | 解决方案 |
|---|---|---|
| 唯一约束冲突 | 插入重复数据 | 使用INSERT ... ON CONFLICT UPDATE |
| 外键约束失败 | 父表无对应记录 | 先插入父表数据,或设置DEFERRABLE约束 |
| 检查约束违反 | 数据不符合自定义规则 | 添加数据清洗步骤,或修改CHECK条件 |
1.4.7.2 大表操作技巧
-- 在线重命名大表(PostgreSQL 11+)
ALTER TABLE large_table RENAME TO new_large_table;-- 分批次删除数据(避免锁表)
-- 开始一个无限循环,用于分批次删除数据,避免一次性删除大量数据导致锁表和性能问题
WHILE TRUE LOOP-- 从 old_data 表中删除创建时间早于 '2023-01-01' 的数据,每次最多删除 10000 条记录DELETE FROM old_data WHERE create_time < '2023-01-01' LIMIT 10000;-- 检查上一条 DELETE 语句是否删除了任何记录-- 如果没有删除任何记录(即 NOT FOUND 条件为真),则说明已经没有符合条件的数据需要删除IF NOT FOUND THEN-- 当没有符合条件的数据可删除时,退出当前的循环EXIT;END IF;-- 提交当前事务,将已删除的数据永久保存到数据库中-- 分批次提交事务可以减少锁的持有时间,提高并发性能COMMIT;
-- 结束循环
END LOOP;
1.4.8 总结:构建健壮的数据模型
- 通过掌握DDL与DML的核心语法,我们能够:
-
- 设计符合业务需求的数据表结构(合理使用约束与索引)
-
- 高效操作数据(批量处理、事务控制、性能优化)
-
- 保障数据完整性与一致性(ACID特性、外键约束)
-
该文章讲解了PostgreSQL的DDL/DML操作。
后续章节将深入讲解数据清洗技巧(使用CTE、窗口函数)、复杂查询优化(执行计划分析)以及与数据分析工具的集成方法。
建议在实践中遵循"先设计ER图,再编写建表语句"的流程,逐步积累数据库设计经验。
CTE 即公共表表达式(Common Table Expressions),它是在 SQL 中定义的临时命名结果集,这些结果集只在当前查询的执行期间存在。- CTE 的基本语法如下:
WITH cte_name (column1, column2, ...) AS (-- CTE 的查询语句SELECT column1, column2, ...FROM table_nameWHERE condition ) -- 主查询,使用 CTE SELECT * FROM cte_name; - 其中,WITH 关键字用于引入 CTE,cte_name 是 CTE 的名称,括号内可指定列名,AS 后面的括号中是 CTE 的查询语句,最后是使用该 CTE 的主查询。
- 使用注意事项
- CTE 的作用域: CTE 只在当前查询中有效,
查询执行完毕后,CTE 占用的资源会被释放。 - 性能问题:虽然 CTE 在某些情况下可以提高性能,但在处理大量数据或复杂递归时,可能会导致性能下降。需要根据具体情况进行性能测试和优化。
- 递归终止条件:在使用递归 CTE 时,必须确保递归有终止条件,否则会导致无限递归,使数据库陷入死循环。
- CTE 的作用域: CTE 只在当前查询中有效,
- CTE 的基本语法如下:
相关文章:
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】1.4 数据库与表的基本操作(DDL/DML语句)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 1.4 数据库与表的基本操作(DDL/DML语句)1.4.1 数据库生命周期管理(DDL核心)1.4.1.1 创建数据库(CREATE DATABASE&…...

CUDA加速的线性代数求解器库cuSOLVER
cuSOLVER是NVIDIA提供的GPU加速线性代数库,专注于稠密和稀疏矩阵的高级线性代数运算。它建立在cuBLAS和cuSPARSE之上,提供了更高级的线性代数功能。 cuSOLVER主要功能 1. 稠密矩阵运算 矩阵分解: LU分解 (gesvd) QR分解 (geqrf) Cholesky分解 (potrf…...

Oracle 物理存储与逻辑管理
1. 表空间(Tablespace) 定义: 表空间是Oracle中最高级别的逻辑存储容器,由一个或多个物理数据文件(Datafile)组成。所有数据库对象(如表、索引)的逻辑存储均属于某个表空间。 类型与…...
)
vscode优化使用体验篇(快捷键)
本文章持续更新中 最新更新时间为2025-5-18 1、方法查看方法 1.1当前标签跳到新标签页查看方法实现 按住ctrl 鼠标左键点击方法。 1.2使用分屏查看方法实现(左右分屏) 按住ctrl alt 鼠标左键点击方法。...

如何在电脑上登录多个抖音账号?多开不同IP技巧分解
随着短视频的爆发式增长,抖音已经成为许多人生活和工作的必备平台。不论是个人内容创作者、品牌商家,还是营销人员,都可能需要管理多个抖音账号。如何在电脑上同时登录多个抖音账号,提升工作效率,避免频繁切换账号的麻…...
【东枫科技】usrp rfnoc 开发环境搭建
作者 太原市东枫电子科技有限公司 ,代理销售 USRP,Nvidia,等产品与技术支持,培训服务。 环境 Ubuntu 20.04 依赖包 sudo apt-get updatesudo apt-get install autoconf automake build-essential ccache cmake cpufrequtils …...

【JAVA资料,C#资料,人工智能资料,Python资料】全网最全编程学习文档合集,从入门到全栈,保姆级整理!
文章目录 前言一、编程学习前的准备1.1 明确学习目标1.2 评估自身基础 二、编程语言的选择2.1 热门编程语言介绍2.2 如何根据目标选择语言 三、编程基础学习3.1 变量与数据类型3.2 控制结构3.3 函数 四、面向对象编程(OOP)4.1 OOP…...

[IMX] 05.串口 - UART
目录 1.通信格式 2.电平标准 3.IMX UART 模块 4.时钟寄存器 - CCM_CSCDR1 5.控制寄存器 5.1.UART_UCR1 5.2.UART_UCR2 5.3.UART_UCR3 6.状态寄存器 6.1.UART_USR1 6.2.UART_USR2 7.FIFO 控制寄存器 - UART_UFCR 8.波特率寄存器 8.1.分母 - UART_UBIR 8.2.分子 -…...

使用Tkinter写一个发送kafka消息的工具
文章目录 背景工具界面展示功能代码讲解运行环境创建GUI程序搭建前端样式编写功能实现代码 背景 公司是做AR实景产品的,近几年无人机特别的火,一来公司比较关注低空经济这个新型领域,二来很多政企、事业单位都采购了无人机用于日常工作。那么…...
MongoDB 与 EF Core 深度整合实战:打造结构清晰的 Web API 应用
题纲 MongoDB 字符串连接 URIC# 连接字符串实例 实现一个电影信息查询 demo创建项目创建实体实现 DbContext 上下文仓储实现服务实现控制器实现服务注册快照注入数据库连接配置1. 注册配置类2. 注入 IOptionsSnapshot<MongoDbSettings>3. 配置文件 appsettings.json 示例…...

JAVA|后端编码规范
目录 零、引言 一、基础 二、集合 三、并发 四、日志 五、安全 零、引言 规范等级: 【强制】:强制遵守,来源于线上历史故障,将通过工具进行检查。【推荐】:推荐遵守,来源于日常代码审查、开发人员反馈…...
重写B站(网页、后端、小程序)
1. 网页端 1.1 框架 Vue ElementUI axios 1.2 框架搭建步骤 搭建Vue 1.3 配置文件 main.js import {createApp} from vue import ElementUi from element-plus import element-plus/dist/index.css; import axios from "axios"; import router from…...

文档债务拖累交付速度?5大优化策略文档自动化
开发者在追求开发速度的过程中,往往会忽视文档的编写,如省略设计文档、代码注释或API文档等。这种做法往往导致在后期调试阶段需要花费三倍以上的时间来理解代码逻辑,进而形成所谓的文档债务,严重拖累交付速度并造成资源浪费。而积…...
【数据结构与算法】LeetCode 每日三题
如果你已经对数据结构与算法略知一二,现在正在复习数据结构与算法的一些重点知识 ------------------------------------------------------------------------------------------------------------------------- 关注我🌈,每天更新总结文章…...
基于深度学习的电力负荷预测研究
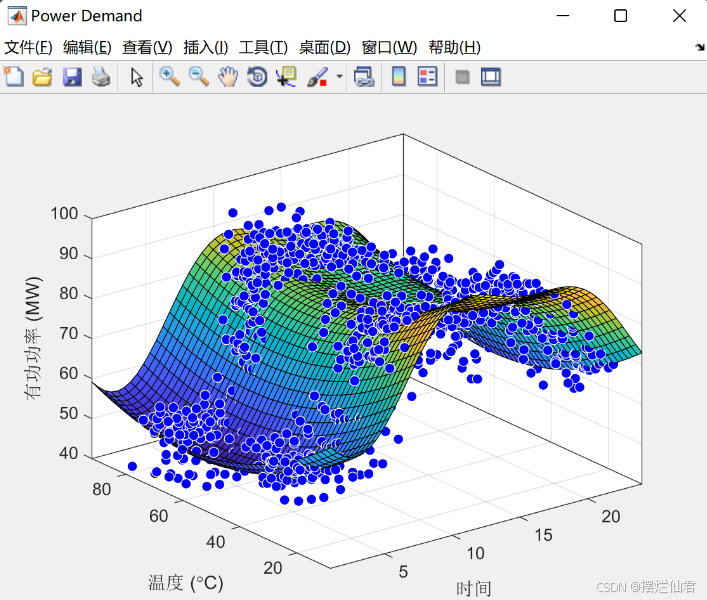
一、深度学习模型框架 在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,…...

篇章十 消息持久化(二)
目录 1.消息持久化-创建MessageFileManger类 1.1 创建一个类 1.2 创建关于路径的方法 1.3 定义内部类 1.4 实现消息统计文件读写 1.5 实现创建消息目录和文件 1.6 实现删除消息目录和文件 1.7 实现消息序列化 1. 消息序列化的一些概念: 2. 方案选择…...

【IDEA】删除/替换文件中所有包含某个字符串的行
目录 前言 正则表达式 示例 使用方法 前言 在日常开发中,频繁地删除无用代码或清理空行是不可避免的操作。许多开发者希望找到一种高效的方式,避免手动选中代码再删除的繁琐过程。 使用正则表达式是处理字符串的一个非常有效的方法。 正则表达式 …...
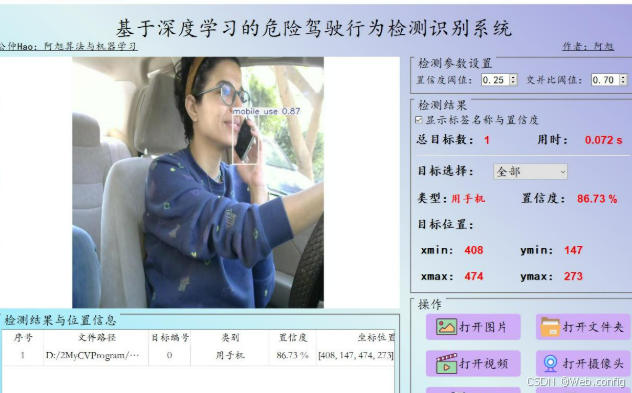
基于深度学习的不良驾驶行为为识别检测
一.研究目的 随着全球汽车保有量持续增长,交通安全问题日益严峻,由不良驾驶行为(如疲劳驾驶、接打电话、急加速/急刹车等)引发的交通事故频发,不仅威胁生命财产安全,还加剧交通拥堵与环境污染。传统识别方…...

FD+Mysql的Insert时的字段赋值乱码问题
方法一 FDQuery4.SQL.Text : INSERT INTO 信息表 (中心, 分组) values(:中心,:分组); FDQuery4.Params[0].DataType : ftWideString; //必须加这个数据类型的定义,否则会有乱码 FDQuery4.Params[1].DataType : ftWideString; //ftstring就不行,必须是…...
第十周作业
一、CSRF 1、DVWA-High等级 2、使用Burp生成CSRF利用POC并实现攻击 二、SSRF:file_get_content实验,要求获取ssrf.php的源码 三、RCE 1、 ThinkPHP 2、 Weblogic 3、Shiro...

Python操作PDF书签详解 - 添加、修改、提取和删除
目录 简介 使用工具 Python 向 PDF 添加书签 添加书签 添加嵌套书签 Python 修改 PDF 书签 Python 展开或折叠 PDF 书签 Python 提取 PDF 书签 Python 删除 PDF 书签 简介 PDF 书签是 PDF 文件中的导航工具,通常包含一个标题和一个跳转位置(如…...

One-shot和Zero-shot的区别以及使用场景
Zero-shot是模型在没有任务相关训练数据的情况下进行预测,依赖预训练知识。 One-shot则是提供一个示例,帮助模型理解任务。两者的核心区别在于是否提供示例,以及模型如何利用这些信息。 在机器学习和自然语言处理中,Zero-Shot 和…...

微软 Build 2025:开启 AI 智能体时代的产业革命
在 2025 年 5 月 19 日的微软 Build 开发者大会上,萨提亚・纳德拉以 "我们已进入 AI 智能体时代" 的宣言,正式拉开了人工智能发展的新纪元。这场汇聚了奥特曼、黄仁勋、马斯克三位科技领袖的盛会,不仅发布了 50 余项创新产品&#…...
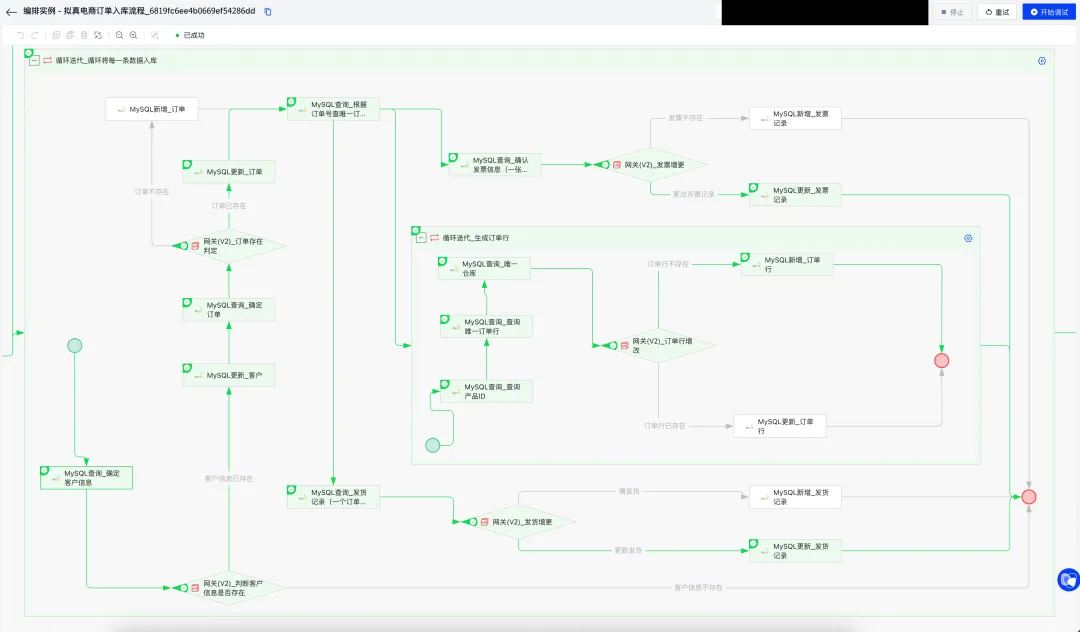
集星獭 | 重塑集成体验:新版编排重构仿真电商订单数据入库
概要介绍 新版服务编排以可视化模式驱动电商订单入库流程升级,实现订单、客户、库存、发票、发货等环节的自动化处理。流程中通过循环节点、判断逻辑与数据查询的编排,完成了低代码构建业务逻辑,极大提升订单处理效率与业务响应速度。 背景…...

多模态大语言模型arxiv论文略读(八十八)
MammothModa: Multi-Modal Large Language Model ➡️ 论文标题:MammothModa: Multi-Modal Large Language Model ➡️ 论文作者:Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang ➡️ 研究机构: ByteDance, Beijing, China ➡️ 问题背景…...

创建Workforce
创建你的Workforce 3.3.1 简单实践 1. 创建 Workforce 实例 想要使用 Workforce,首先需要创建一个 Workforce 实例。下面是最简单的示例: from camel.agents import ChatAgent from camel.models import ModelFactory from camel.types import Model…...

Cribl 中 Parser 扮演着重要的角色 + 例子
先看文档: Parser | Cribl Docs Parser The Parser Function can be used to extract fields out of events or reserialize (rewrite) events with a subset of fields. Reserialization will preserve the format of the events. For example, if an event contains comma…...

WebSocket 从入门到进阶实战
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受. 聊天系统是WebSocket的最佳实践,以下是使用WebSocket技术实现的一个聊天系统的关键代码,可以通过这些关键代码ÿ…...

CSS:vertical-align用法以及布局小案例(较难)
文章目录 一、vertical-align说明二、布局案例 一、vertical-align说明 上面的文字介绍,估计大家也看不懂 二、布局案例...

Linux 正则表达式 扩展正则表达式 gawk
什么是正则表达式 正则表达式是我们所定义的模式模板(pattern template),Linux工具用它来过滤文本。Linux工具(比如sed编辑器或gawk程序)能够在处理数据时,使用正则表达式对数据进行模式匹配。如果数据匹配…...