ElasticSearch各种查询语法示例
1. 每种查询语法的区别与优缺点
Query DSL
- 区别: JSON 格式的结构化查询,功能强大,支持复杂查询逻辑,适用于 Elasticsearch 的核心查询场景。
- 优点: 灵活,功能全面,支持全文搜索、精确匹配、聚合等;可组合多种查询类型。
- 缺点: 语法复杂,学习曲线较陡;JSON 格式对新手不友好。
SQL Query
- 区别: 使用标准 SQL 语法,适合熟悉关系型数据库的用户。
- 优点: 语法简单,易于上手;与传统 SQL 数据库兼容性高,适合快速查询。
- 缺点: 功能受限,无法完全发挥 Elasticsearch 的全文搜索和复杂查询能力。
EQL (Event Query Language)
- 区别: 专注于时间序列和事件数据,适合分析日志、事件流等场景。
- 优点: 针对事件序列分析优化,支持时间相关查询;语法直观。
- 缺点: 应用场景较窄,仅限事件数据;功能不如 Query DSL 全面。
Painless Scripting
- 区别: 基于脚本的查询,允许自定义逻辑,操作字段值或复杂条件。
- 优点: 高度灵活,可实现复杂计算或过滤逻辑。
- 缺点: 性能开销大,脚本错误可能导致查询失败;调试困难。
Kibana Console Query
- 区别: 通过 Kibana 的 REST API 风格执行查询,结合 HTTP 方法操作 Elasticsearch。
- 优点: 直观,适合调试和快速测试;与 Query DSL 无缝集成。
- 缺点: 依赖 Kibana 界面,手动输入 JSON 查询效率较低。
2. 带解释的查询示例
Query DSL
a. Match Query
{"query": {"match": {"name": "apple phone"}}
}
- 解释: 全文搜索
name字段中包含 “apple” 或 “phone” 的文档。使用分词器匹配,适合模糊搜索。 - 场景: 搜索产品名称包含 “apple phone” 的商品。
b. Match with Fuzziness
{"query": {"match": {"name": {"query": "apple phone","fuzziness": "AUTO"}}}
}
- 解释: 允许模糊匹配,容忍拼写错误(如 “aple” 匹配 “apple”)。
fuzziness: AUTO自动调整容错范围。 - 场景: 用户输入可能有误时,增强搜索容错。
c. Term Query
{"query": {"term": {"category": "electronics"}}
}
- 解释: 精确匹配
category字段为 “electronics” 的文档,不分词。 - 场景: 查找特定类别的产品,如电子产品。
d. Terms Query
{"query": {"terms": {"category": ["electronics", "accessories"]}}
}
- 解释: 匹配
category字段为 “electronics” 或 “accessories” 的文档。 - 场景: 筛选多个特定类别的产品。
e. Range Query
{"query": {"range": {"price": {"gte": 100,"lte": 500}}}
}
- 解释: 查找
price字段在 100 到 500 之间的文档。 - 场景: 筛选价格区间内的产品。
f. Bool Query
{"query": {"bool": {"must": [{ "match": { "name": "phone" } },{ "range": { "price": { "lte": 1000 } } }],"filter": [{ "term": { "category": "electronics" } }]}}
}
- 解释: 组合查询,
must要求name包含 “phone” 且price≤ 1000,filter要求category为 “electronics”。filter不影响评分,性能更高。 - 场景: 复杂条件筛选,如电子产品中价格低于 1000 的手机。
g. Exists Query
{"query": {"exists": {"field": "description"}}
}
- 解释: 返回具有非空
description字段的文档。 - 场景: 筛选有描述信息的产品。
h. Wildcard Query
{"query": {"wildcard": {"name": "app*"}}
}
- 解释: 匹配
name字段以 “app” 开头的文档,*表示任意字符。 - 场景: 搜索以 “app” 开头的产品名称。
i. Nested Query
{"query": {"nested": {"path": "comments","query": {"match": { "comments.text": "good" }}}}
}
- 解释: 查询嵌套字段
comments中text包含 “good” 的文档。处理嵌套对象关系。 - 场景: 搜索包含正面评论的产品。
SQL Query
a. Basic SELECT
SELECT name, price FROM products WHERE price > 100
- 解释: 返回
price大于 100 的文档,仅显示name和price字段。 - 场景: 快速查看高价产品的基本信息。
b. With Conditions
SELECT * FROM products WHERE category = 'electronics' AND price BETWEEN 200 AND 500
- 解释: 筛选
category为 “electronics” 且price在 200-500 之间的所有字段。 - 场景: 查找特定类别和价格范围的产品。
c. Aggregation
SELECT category, AVG(price) FROM products GROUP BY category
- 解释: 按
category分组,计算每组的平均price。 - 场景: 分析各产品类别的平均价格。
EQL
a. Sequence Query
{"query": "sequence [event where event_type == 'login'] [event where event_type == 'logout' by user_id]"
}
- 解释: 查找按
user_id关联的连续事件,先login后logout。 - 场景: 分析用户登录和登出行为序列。
b. Simple Event Query
{"query": "event where event_type == 'error' and severity > 3"
}
- 解释: 查找
event_type为 “error” 且severity大于 3 的事件。 - 场景: 筛选高严重性错误日志。
Painless Scripting
a. Field Calculation
{"query": {"script_score": {"query": { "match_all": {} },"script": {"source": "doc['price'].value * 0.9"}}}
}
- 解释: 对所有文档的
price字段值乘以 0.9,影响搜索评分。 - 场景: 动态调整价格用于排序(如折扣计算)。
b. Filter with Script
{"query": {"bool": {"filter": {"script": {"script": {"source": "doc['price'].value > params.min_price","params": { "min_price": 100 }}}}}}
}
- 解释: 过滤
price大于 100 的文档,使用参数化脚本。 - 场景: 动态设置价格过滤条件。
Kibana Console Query
a. Simple GET
GET products/_search
{"query": {"match": {"name": "phone"}}
}
- 解释: 通过 REST API 搜索
name包含 “phone” 的文档。 - 场景: 在 Kibana 控制台快速测试查询。
b. Aggregation
GET products/_search
{"aggs": {"by_category": {"terms": { "field": "category" }}}
}
- 解释: 按
category字段分组,统计每个类别的文档数。 - 场景: 分析产品类别分布。
注意
- 每个查询语法针对不同场景:Query DSL 适合复杂查询,SQL 适合快速上手,EQL 适合事件分析,Painless 适合自定义逻辑,Kibana 适合调试。
- 示例基于通用字段,实际使用需调整字段名和索引。
- 更多细节参考:https://www.elastic.co/docs/reference/query-languages/
相关文章:

ElasticSearch各种查询语法示例
1. 每种查询语法的区别与优缺点 Query DSL 区别: JSON 格式的结构化查询,功能强大,支持复杂查询逻辑,适用于 Elasticsearch 的核心查询场景。优点: 灵活,功能全面,支持全文搜索、精确匹配、聚合等;可组合…...

CUDA的设备,流处理器(Streams),核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念 CUDA的设备,流处理器,核&…...

PyTorch的dataloader制作自定义数据集
PyTorch的dataloader是用于读取训练数据的工具,它可以自动将数据分割成小batch,并在训练过程中进行数据预处理。以下是制作PyTorch的dataloader的简单步骤: 导入必要的库 import torch from torch.utils.data import DataLoader, Dataset定…...
LeetCode 1340. 跳跃游戏 V(困难)
题目描述 给你一个整数数组 arr 和一个整数 d 。每一步你可以从下标 i 跳到: i x ,其中 i x < arr.length 且 0 < x < d 。i - x ,其中 i - x > 0 且 0 < x < d 。 除此以外,你从下标 i 跳到下标 j 需要满…...
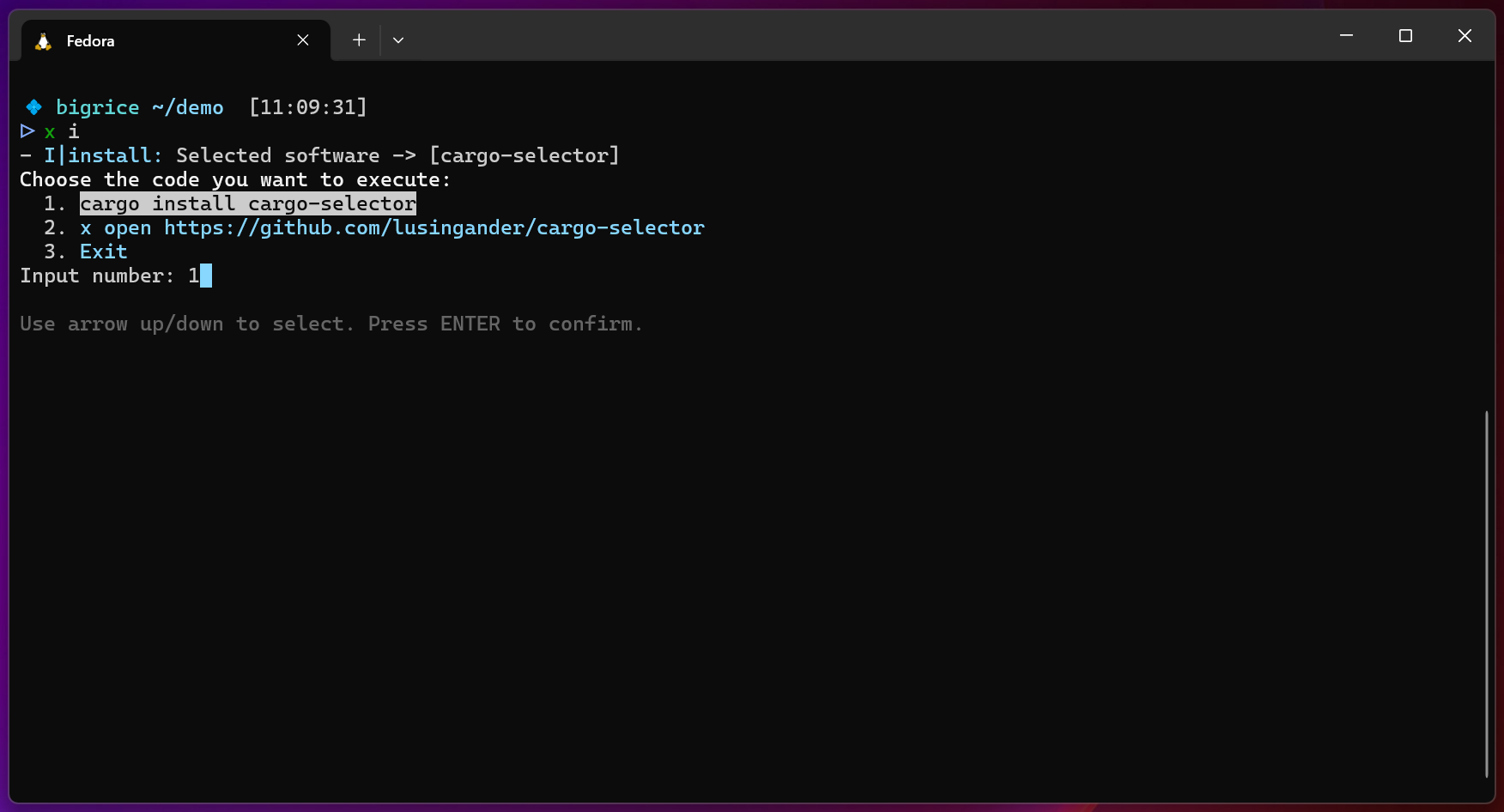
x-cmd install | cargo-selector:优雅管理 Rust 项目二进制与示例,开发体验升级
目录 功能亮点安装优势特点适用场景总结 还在为 Rust 项目中众多的二进制文件和示例而烦恼吗?cargo-selector 让你告别繁琐的命令行,轻松选择并运行目标程序! 功能亮点 交互式选择: 在终端中以交互方式浏览你的二进制文件和示例&…...

数据库设计文档撰写攻略
数据库设计文档撰写攻略 一、数据库设计文档的核心价值二、数据库设计文档的核心框架与内容详解2.1 文档基础信息2.2 需求分析与设计原则2.2.1 业务需求概述2.2.2 设计原则 2.3 数据模型设计2.3.1 概念模型(ER 图)2.3.2 逻辑模型(表结构设计&…...
Python数据存储实战:基于pymongo的MongoDB开发深度指南)
Python爬虫(10)Python数据存储实战:基于pymongo的MongoDB开发深度指南
目录 一、为什么需要文档型数据库?1.1 数据存储的范式变革1.2 pymongo的核心优势 二、pymongo核心操作全解析2.1 环境准备2.2 数据库连接与CRUD操作2.3 聚合管道实战2.4 分批次插入百万级数据(进阶)2.5 分批次插入百万级数据(进阶…...

大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战摘要引言一、轻量化技术…...

从逻辑视角学习信息论:概念框架与实践指南
文章目录 一、信息论的逻辑基础与哲学内涵1.1 信息的逻辑本质:区分与差异1.2 逆范围原理与信息内容 二、信息论与逻辑学的概念交汇2.1 熵作为逻辑不确定性的度量2.2 互信息与逻辑依赖2.3 信道容量的逻辑极限 三、信息论的核心原理与逻辑基础3.1 最大熵原理的逻辑正当…...

springboot配置mysql druid连接池,以及连接池参数解释
文章目录 前置配置方式参数解释 前置 springboot 项目javamysqldruid 连接池 配置方式 在 springboot 的 application.yml 中配置基本方式 # Druid 配置(Spring Boot YAML 格式) spring:datasource:url: jdbc:mysql://localhost:3306/testdb?useSSL…...

Spring Boot集成Resilience4j实现微服务容错机制
在Spring Boot中集成Resilience4j实现微服务容错 引言 在微服务架构中,服务之间的调用不可避免,但由于网络延迟、服务不可用等问题,调用失败的情况时有发生。为了提高系统的稳定性和可用性,我们需要引入容错机制。Resilience4j是…...
 本地hadoop虚拟机系统设置)
(一) 本地hadoop虚拟机系统设置
1.配置固定IP地址(每一台都配置) 开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131 # 修改主机名 hostnamectl set-hostname node1# 修改IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR"…...

TDengine 运维—容量规划
概述 若计划使用 TDengine 搭建一个时序数据平台,须提前对计算资源、存储资源和网络资源进行详细规划,以确保满足业务场景的需求。通常 TDengine 会运行多个进程,包括 taosd、taosadapter、taoskeeper、taos-explorer 和 taosx。 在这些进程…...

【MySQL成神之路】MySQL索引相关介绍
1 相关理论介绍 一、索引基础概念 二、索引类型 1. 按数据结构分类 2. 按功能分类 三、索引数据结构原理 B树索引特点: 哈希索引特点: 四、索引使用原则 1. 创建索引原则 2. 避免索引失效情况 五、索引优化策略 六、索引维护与管理 七、特殊…...

PPP 拨号失败:ATD*99***1# ... failed
从日志来看,主要有两类问题: 一、led_indicator_stop 报 invalid p_handle E (5750) led_indicator: …/led_indicator.c:461 (led_indicator_stop):invalid p_handle原因分析 led_indicator_stop() 的参数 p_handle (即之前 led_indicator…...

PostgreSQL跨数据库表字段值复制实战经验分
场景需求 在实际工作中,我们经常需要将一个PostgreSQL数据库中的表字段值复制到另一个数据库中。最近我在处理两个ERP系统数据库(A库和B库)之间的数据同步时,就遇到了这样的需求:需要将B库中sale_order表的合同信息&a…...
【计网】五六章习题测试
目录 1. (单选题, 3 分)某个网络所分配到的地址块为172.16.0.0/29,能接收目的地址为172.16.0.7的IP分组的最大主机数是( )。 2. (单选题, 3 分)若将某个“/19”的CIDR地址块划分为7个子块,则可能的最小子块中的可分配IP地址数量…...
汇川EasyPLC MODBUS-RTU通信配置和编程实现
累积流量计算(MODBUS RTU通信数据处理)数据处理相关内容。 累积流量计算(MODBUS RTU通信数据处理)_流量积算仪modbus rtu通讯-CSDN博客文章浏览阅读219次。1、常用通信数据处理MODBUS通信系列之数据处理_modbus模拟的数据变化后会在原来的基础上累加是为什么-CSDN博客MODBUS通…...

从 CANopen到 PROFINET:网关助力物流中心实现复杂的自动化升级
使用 CANopen PLC 扩展改造物流中心的传送带 倍讯科技profinet转CANopen网关BX-601-EIP将新的 PROFINET PLC 系统与旧的基于 CANopen 的传送带连接起来,简化了物流中心的自动化升级。 新建还是升级?这些问题通常出现在复杂的内部物流设施中,…...
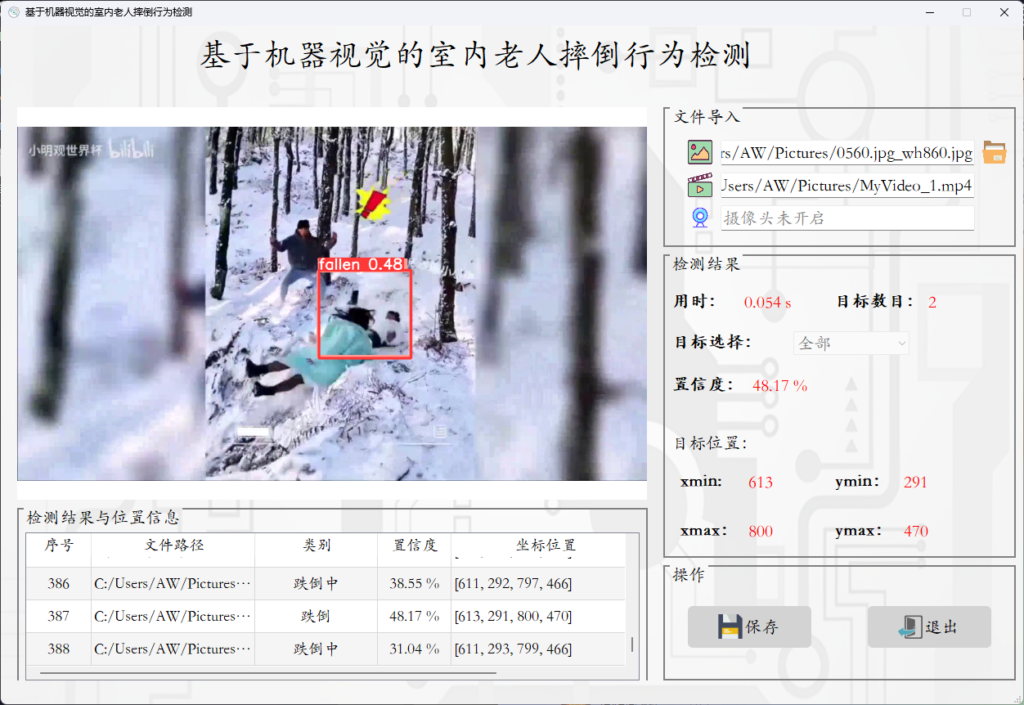
基于Yolov8+PyQT的老人摔倒识别系统源码
概述 基于Yolov8PyQT的老人摔倒识别系统,该系统通过深度学习算法实时检测人体姿态,精准识别站立、摔倒中等3种状态,为家庭或养老机构提供及时预警功能。 主要内容 完整可运行代码 项目采用Yolov8目标检测框架结合PyQT5开发…...
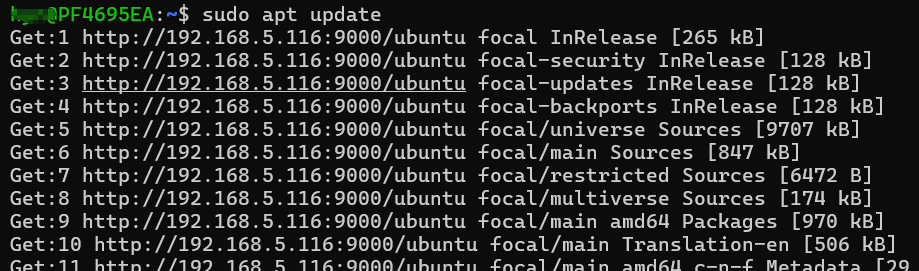
wsl2 不能联网
wsl2 安装后用 wifi 共享是能联网,问题出在公司网络限制 wsl2 IP 访问网络,但是主机可以上网。 解决办法,在主机用 nginx 设置代理,可能需要开端口权限 server {listen 9000;server_name localhost;location /ubuntu/ {#…...

双击重复请求的方法
1、限制点击次数 2、vue中 可以自定义一个属性指令 preventReClick.js中定义: import Vue from vue Vue.directive(preventReClick, {inserted: (el, binding) > {el.addEventListener(click, () > {if (!el.disabled) {el.disabled truesetTimeout(() >…...
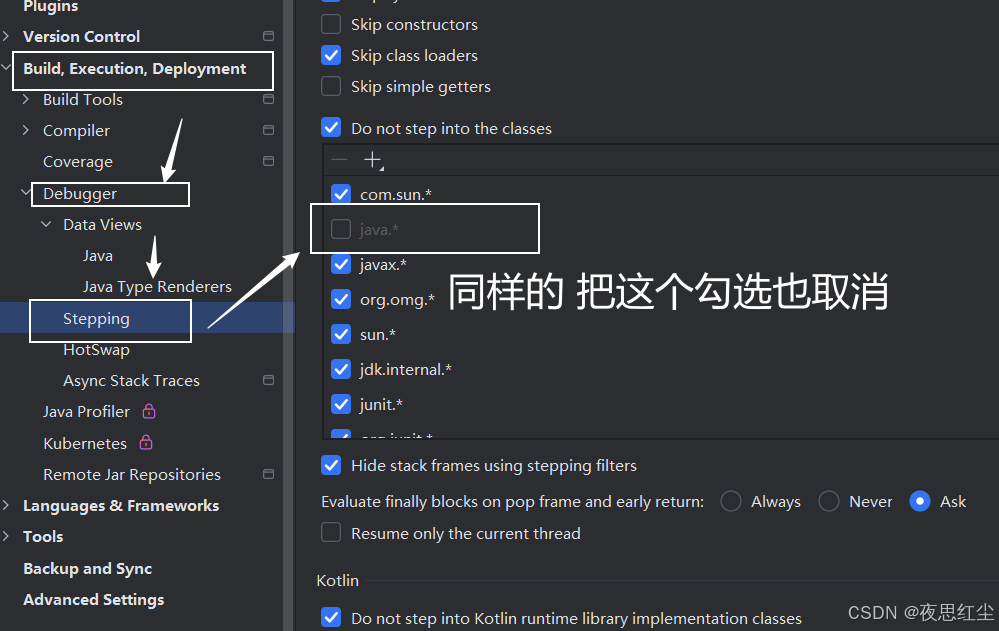
Java[IDEA]里的debug
目录 前言 Debug 使用Debug 总结 前言 这里我说一下就是 java IDEA 工具里的debug工具 里的一个小问题 就是 当我们使用debug去查看内部文档 查看不到 是为什么 Debug 所谓 debug 工具 他就是用来调试程序的 当我们写代码 报错 出错时 我们就可以使用这个工具 因此这个工具…...

一条SQL语句的旅程:解析、优化与执行全过程研究
1、引言 在现代信息系统中,数据库是核心组件之一。SQL(结构化查询语言)作为与数据库交互的主要方式,其执行效率直接影响到整个系统的性能表现。虽然开发者常常只需编写一行简单的 SQL,但数据库内部却经历了一个复杂而精密的过程来完成这条 SQL 的处理。 本文将以一个完整…...

动态规划经典三题_完全平方数
279. 完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而…...
)
LVGL(lv_textarea文本框控件)
文章目录 一、lv_textarea 是什么?二、基本用法1. 创建 lv_textarea 对象2. 设置提示文字(占位符)3. 设置最大长度4. 设置密码模式(显示为\*号)5. 获取和设置内容6. 配合虚拟键盘使用(常用于触摸屏…...

蓝桥杯国14 互质
问题描述 请计算在 [1,2023的2023次幂] 范围内有多少个整数与 2023 互质。由于结果可能很大,你只需要输出对 1097 取模之后的结果。 答案提交 这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个…...

DAO模式
1. 持久化 简单来说,就是把代码的处理结果转换成需要的格式进行储存。 2. JDBC的封装 3. DAO模式 4. Properties类与Properties配置文件 添加 读取 5. 使用实体类传递数据 6. 总结 附录: BaseDao指南 BaseDao指南-CSDN博客...
ECharts图表工厂,完整代码+思路逻辑
Echart工厂支持柱状图(bar)折线图(line)散点图(scatter)饼图(pie)雷达图(radar)极坐标柱状图(polarBar)和极坐标折线图(po…...

Logback 在 Spring Boot 中的详细配置
1. Logback 配置文件 Spring Boot 默认会加载 classpath 下的 logback-spring.xml(推荐)或 logback.xml 作为 Logback 的配置文件。 推荐使用 logback-spring.xml,因为 Spring Boot 提供了扩展支持(例如基于 Profile 的配置&am…...