Go语言爬虫系列教程(三)HTML解析技术
第3课:HTML解析技术
在上一章中,我们使用正则表达式提取网页内容,但这种方法有局限性。对于复杂的HTML结构,我们需要使用专门的HTML解析库。下面将介绍如何在Go中解析HTML。
1. HTML DOM树结构介绍
1.1 什么是DOM
DOM(Document Object Model)是HTML文档的树形结构表示。每个HTML元素都是一个节点,节点之间存在父子关系。
1.2 DOM树的基本组成
DOM树由多种类型的节点组成:
- 元素节点:对应HTML标签,如
<div>、<p>等 - 文本节点:包含文本内容
- 属性节点:元素的属性,如
class="container" - 注释节点:HTML注释
<!-- 注释 -->
1.3 节点关系
DOM树中的节点具有以下关系:
- 父子关系:包含其他元素的节点是父节点,被包含的是子节点
- 兄弟关系:共享同一父节点的节点互为兄弟节点
- 祖先和后代关系:间接的父子关系
1.4 DOM树示例
以下是一个简单HTML文档及其DOM树结构:
<!DOCTYPE html>
<html>
<head><title>示例页面</title>
</head>
<body><div class="container"><h1>标题</h1><p>这是<a href="https://example.com">一个</a>段落。</p></div>
</body>
</html>
其树状结构可以表示为:
html
├── head
│ └── title
│ └── "示例页面"
└── body└── div.container├── h1│ └── "标题"└── p├── "这是"├── a[href="https://example.com"]│ └── "一个"└── "段落。"
1.5 HTML解析的重要性
理解DOM树结构对于HTML解析至关重要,因为它是我们进行网页数据提取的基础。
- 从网页中提取结构化数据
- 查找特定的元素和属性
- 分析网页结构
- 数据清洗和处理
2. Go中的HTML解析库:goquery
2.1 goquery简介
goquery是Go语言的一个强大HTML解析库,灵感来自jQuery。它基于Go标准库中的net/html包,并提供了类似jQuery的链式API,使HTML文档的遍历和操作变得简单。
2.2 安装goquery
使用以下命令安装goquery:
go get github.com/PuerkitoBio/goquery
2.3 创建文档
在使用goquery之前,首先需要创建一个文档对象。这相当于将HTML转换成可以用代码操作的结构。
从字符串创建文档
package mainimport ("fmt""github.com/PuerkitoBio/goquery""strings"
)func main() {html := `<html><body><div class="content"><h1>标题</h1><p>这是段落</p></div></body></html>`// 将HTML字符串转换为可读取的对象reader := strings.NewReader(html)doc, err := goquery.NewDocumentFromReader(reader)if err != nil {fmt.Println("加载HTML出错:", err)return}// 现在我们有了一个doc对象,可以用它来查找元素title := doc.Find("h1").Text()content := doc.Find("p").Text()fmt.Println("标题:", title)fmt.Println("内容:", content)
}得到的结果:
标题: 标题
内容: 这是段落
NewDocumentFromReader()从字符串创建一个新的文档, 返回了一个*Document和error。Document代表一个将要被操作的HTML文档。
Find() 主要是用来查找元素, Find("h1") 即代表获取html中h1标签的元素,包括它的子元素。如果有多个h1标签,默认获取的是最后一个。
Text() 获取元素的纯文本内容
从网络加载文档
如果你还记得上一章的内容,我们使用 https://quotes.toscrape.com/ 作为演示,使用正则表达式获取了引言和作者,现在我们使用goquery代替
package mainimport ("fmt""github.com/PuerkitoBio/goquery""net/http"
)func main() {// 发送HTTP请求获取网页resp, err := http.Get("https://quotes.toscrape.com/")if err != nil {fmt.Println("请求网页失败:", err)return}defer resp.Body.Close() // 记得关闭连接// 检查HTTP状态码if resp.StatusCode != 200 {fmt.Printf("状态码不对: %d %s\n", resp.StatusCode, resp.Status)return}// 从响应创建文档doc, err := goquery.NewDocumentFromReader(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}// 使用文档quote := doc.Find(".text").Text()author := doc.Find(".author").Text()fmt.Println("引言:", quote)fmt.Println("作者:", author)
}.text 和.author 都是类选择器,代表class="quote"和class="author" 类名前加.表示类
2.4 CSS选择器
CSS选择器是一种用于选择HTML元素的语法。在goquery中,我们可以使用CSS选择器来定位需要的元素。上面的例子中,我们使用了元素选择器(h1和p)和类选择器(.text和.author) ,goquery跟jquery一样都支持很多选择器,以下是常用的CSS选择器:
- 元素选择器
选择指定标签的所有元素,例如:p 选择所有段落元素
doc.Find("p") //相当于查找 <p></p>的元素
- 类选择器
选择有指定class的所有元素 ,例如:.quote选择所有class为"quote"的元素,id选择器以.开头,紧跟着元素class的值。
doc.Find(".quote") //相当于查找 class="quote"的元素
- ID选择器
选择有指定id的元素, 例如:#author选择id为"author"的元素 ,id选择器以#开头,紧跟着元素id的值。
doc.Find("#author") //相当于查找 id="author"的元素
- 后代选择器
选择某元素后代中的元素 ,例如:.quote .text选择class为"quote"的元素中的class为"text"的元素
doc.Find(".quote .text") //相当于查找 class="quote text" 元素
- 属性选择器
选择具有特定属性的元素,一个HTML元素都有自己的属性以及属性值,所以我们也可以通过属性和值筛选元素。
例如:a[href="https://example.com"] 选择href属性值为"https://example.com" 的链接,这个使用的是完全相等的匹配方式,属性选择器还要很多匹配方式。
| 选择器 | 说明 |
|---|---|
| Find(“div[my]“) | 筛选含有my属性的div元素 |
| Find(“div[my=zh]“) | 筛选my属性为zh的div元素 |
| Find(“div[my!=zh]“) | 筛选my属性不等于zh的div元素 |
| Find(“div[my¦=zh]“) | 筛选my属性为zh或者zh-开头的div元素 |
| Find(“div[my*=zh]“) | 筛选my属性包含zh这个字符串的div元素 |
| Find(“div[my~=zh]“) | 筛选my属性包含zh这个单词的div元素,单词以空格分开的 |
| Find(“div[my$=zh]“) | 筛选my属性以zh结尾的div元素,区分大小写 |
| Find(“div[my^=zh]“) | 筛选my属性以zh开头的div元素,区分大小写 |
- 子元素选择器
选择某元素的直接子元素, 例如:.quote > .text选择class为"quote"的元素的直接子元素中class为"text"的元素 , 子元素选择是使用父>子代表父子关系
doc.Find(".quote >.text") //相当于查找 class="quote"元素下的class="text" 元素
- 相邻选择器
如果要筛选的元素没有规律,但是该元素的上一个元素有规律,我们就可以使用这种下一个相邻选择器来进行选择,例如:p[my=a]+p筛选出p标签属性my的值为a的相邻p标签。使用+号表示相邻。
doc.Find("p[my=a]+p")
- 兄弟选择器
有时候我们需要筛选同一父元素下,所有同级元素,可以使用兄弟选择器,例如:p[my=a]~p,筛选出p标签属性my的值为a的兄弟p标签。使用~号表示兄弟。
doc.Find("p[my=a]~p")
2.5 过滤器(伪类选择器)
有时候我们选择出来的结果,并不是我们心目中的最优结果,我们希望对其进行过滤。
- :contains 过滤器 - 按文本内容筛选
筛选出包含指定文本的元素,就像在页面上按Ctrl+F搜索特定文字,:contains可以找出所有包含这个文字的元素。
// 筛选出包含"文章:"文本的段落
doc.Find("p:contains(文章:)")- :has 过滤器:
选择至少有一个符合selector的后代元素的element。
// :has查找包含<a>标签的段落(不关心文本内容)doc.Find("p:has(a)")
- :empty 过滤器:
用于选择没有子元素且没有文本内容的元素
// 查找没有任何内容的元素(既没有文本也没有子元素)doc.Find(":empty")// 通常用于查找空div或空容器
doc.Find("div:empty")- :first-child 与 :first-of-type 过滤器 - 获取首个元素
:first-child:选择作为父元素第一个子元素的元素,就像"班里第一排第一位学生":first-of-type:选择作为父元素中同类型的第一个元素,就像"班里所有姓张的学生,找到其中座位最前面的一个"
// 查找所有作为第一个子元素的p标签
doc.Find("p:first-child")// 查找所有在父元素中作为第一个p类型的标签
doc.Find("p:first-of-type")
- :last-child 与 :last-of-type 过滤器 - 获取最后元素
:last-child:选择作为父元素最后一个子元素的元素,就像"班里最后一排最后一位学生":last-of-type:选择作为父元素中同类型的最后一个元素,就像"班里所有姓张的学生,找到其中座位最后面的一个"
// 查找所有作为最后一个子元素的li标签
doc.Find("li:last-child")// 查找所有在父元素中作为最后一个p类型的标签
doc.Find("p:last-of-type")
- :nth-child(n) 过滤器和:nth-of-type(n) - 按位置选择元素
选择作为父元素的第n个子元素的元素(n从1开始),就像"请第3排的学生起立",无论他们是什么性别或姓名。
// 查找所有父元素下的第2个子元素
doc.Find(":nth-child(2)")// 查找所有父元素下的第2个li元素
doc.Find("li:nth-child(2)")- :nth-last-child(n) 与 :nth-last-of-type(n) 过滤器 - 从末尾开始计数
:nth-last-child(n):从最后一个开始倒数,选择第n个子元素:nth-last-of-type(n):从同类型的最后一个开始倒数,选择第n个元素
// 查找倒数第2个子元素
doc.Find(":nth-last-child(2)")// 查找倒数第2个li元素doc.Find("li:nth-last-child(2)")// 查找每个父元素下倒数第1个p标签
doc.Find("p:nth-last-of-type(1)") // 等同于p:last-of-type
- :only-child 与 :only-of-type 过滤器 - 唯一子元素
:only-child:选择作为父元素唯一子元素的元素:only-of-type:选择在父元素中是唯一类型的元素
// 查找作为唯一子元素的段落
doc.Find("p:only-child")// 查找在其父元素中是唯一p类型的段落
doc.Find("p:only-of-type")
2.5 goquery常用方法介绍
Find方法 - 查找所有匹配元素
Find方法是最基础也是最常用的方法,它可以查找符合CSS选择器的所有元素。
// 查找所有段落
paragraphs := doc.Find("p")// 获取找到的元素数量
count := paragraphs.Length()
fmt.Printf("找到了%d个段落\n", count)// 获取第一个段落的文本
firstParagraph := paragraphs.First().Text()
fmt.Printf("第一个段落内容: %s\n", firstParagraph)
Length()告诉我们找到了多少个元素First()取出第一个找到的元素
Text方法 - 获取文本内容
// 获取h1标签的文本
title := doc.Find("h1").Text()
fmt.Println("标题文本:", title)
// 输出: 标题文本: 欢迎来到我的网站Text()方法提取元素内的所有文本,包括子元素的文本- 它会自动去除HTML标签,只保留纯文本
- 它会合并所有文本节点,中间可能有空格
Html方法 - 获取HTML内容
// 获取元素的HTML
contentHtml, err := doc.Find(".content").Html()
if err == nil {fmt.Println("内容区HTML:")fmt.Println(contentHtml)// 输出会包含所有HTML标签和内容
}Html()方法获取元素的完整HTML代码,包括所有标签- 如果你需要保留原始格式,比如需要分析HTML结构,这很有用
Attr方法 - 获取属性
// 获取链接的href属性
doc.Find("a").Each(func(i int, s *goquery.Selection) {// Attr返回两个值:属性值和是否存在该属性href, exists := s.Attr("href")if exists {fmt.Printf("链接 #%d 指向: %s\n", i+1, href)// 获取链接文本text := s.Text()fmt.Printf("链接文本: %s\n", text)}
})
s.Attr("href")尝试获取元素的href属性- 它返回两个值:属性的值和一个布尔值表示属性是否存在
exists告诉我们属性是否存在,防止我们使用不存在的属性
Each方法 - 遍历所有元素
刚刚我们获取quotes的例子中,我们想要获取到页面所有的.text 和.author 元素,Each是一个不二的选择,简单的修改下代码:
// 从响应创建文档doc, err := goquery.NewDocumentFromReader(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}// 使用文档doc.Find(`.quote`).Each(func(i int, s *goquery.Selection) {quote := s.Find(".text").Text()author := s.Find(".author").Text()fmt.Printf("第%d个: \n", i)fmt.Println("引言:", quote)fmt.Println("作者:", author)fmt.Println()})Each方法就像是一个循环,会依次处理每个找到的元素,- 函数
func(i int, s *goquery.Selection)中:i是当前处理的是第几个元素(从0开始计数)s就是当前正在处理的元素, 示例代码中s代表.quote及下面的子元素
筛选元素方法
筛选元素的方法有很多个,我一起介绍
items := doc.Find("li")// 获取第一个元素
first := items.First()
fmt.Println("第一个菜单项:", first.Text())// 获取最后一个元素
last := items.Last()
fmt.Println("最后一个菜单项:", last.Text())// 获取特定索引的元素(从0开始)
second := items.Eq(1) // 第二个元素
fmt.Println("第二个菜单项:", second.Text())// 过滤有特定类的元素
selected := items.Filter(".selected")
fmt.Println("选中的菜单项:", selected.Text())// 排除特定元素
notSelected := items.Not(".selected")
fmt.Printf("未选中的菜单项有%d个\n", notSelected.Length())First():拿出第一个元素Last():拿出最后一个元素Eq(1):拿出索引为1的元素(实际上是第2个,因为索引从0开始)Filter(".selected"):只保留有class="selected"的元素Not(".selected"):排除有class="selected"的元素,只留下其他的
2.6 完整实例
package mainimport ("fmt""github.com/PuerkitoBio/goquery""strings"
)func main() {// 一个包含各种元素的HTML示例html := `<!DOCTYPE html><html><head><title>我的图书列表</title></head><body><div id="header"><h1>我收藏的图书</h1><p>这是我最喜欢的一些书籍</p></div><div class="book-list"><div class="book"><h2 class="title">Go语言编程</h2><p class="author">作者: 张三</p><p class="year">出版年份: 2022</p><p class="description">这是一本关于<b>Go语言</b>的入门书籍</p><span class="rating">评分: 4.5/5</span><a href="https://example.com/go-book" class="link">查看详情</a></div><div class="book"><h2 class="title">Python数据分析</h2><p class="author">作者: 李四</p><p class="year">出版年份: 2021</p><p class="description">这本书讲解了Python在<b>数据分析</b>中的应用</p><span class="rating">评分: 4.8/5</span><a href="https://example.com/python-book" class="link">查看详情</a></div><div class="book"><h2 class="title">JavaScript高级编程</h2><p class="author">作者: 王五</p><p class="year">出版年份: 2023</p><p class="description">深入讲解<b>JavaScript</b>的高级特性</p><span class="rating">评分: 4.2/5</span><a href="https://example.com/js-book" class="link">查看详情</a></div><div class="book"><h2 class="title">Python入门</h2><p class="author"></p><p class="year">出版年份: 2023</p><p class="description">深入讲解<b>Python</b>的高级特性</p><span class="rating">评分: 4.3/5</span><a href="https://example.com/js-book" class="link">查看详情</a></div></div><div id="footer"><p>更新时间: 2025年3月15日</p></div></body></html>`// 创建goquery文档reader := strings.NewReader(html)doc, err := goquery.NewDocumentFromReader(reader)if err != nil {fmt.Println("解析HTML失败:", err)return}// 1. 提取页面标题fmt.Println("=== 页面信息 ===")pageTitle := doc.Find("title").Text()headerTitle := doc.Find("#header h1").Text()fmt.Printf("页面标题: %s\n", pageTitle)fmt.Printf("主标题: %s\n", headerTitle)// 2. 提取所有图书信息fmt.Println("\n=== 图书列表 ===")doc.Find(".book").Each(func(i int, book *goquery.Selection) {// 提取图书标题title := book.Find(".title").Text()// 提取作者(使用替代方法)authorElem := book.Find(".author")author := authorElem.Text()// 清理"作者: "前缀author = strings.TrimPrefix(author, "作者: ")// 提取评分(使用属性选择器)ratingText := book.Find(".rating").Text()// 使用strings包处理字符串rating := strings.TrimPrefix(ratingText, "评分: ")// 提取链接URL和文本linkElem := book.Find(".link")linkText := linkElem.Text()linkHref, _ := linkElem.Attr("href")// 输出图书信息fmt.Printf("图书 #%d:\n", i+1)fmt.Printf(" 标题: %s\n", title)fmt.Printf(" 作者: %s\n", author)fmt.Printf(" 评分: %s\n", rating)fmt.Printf(" 链接: %s (%s)\n", linkText, linkHref)// 检查描述中是否有强调内容desc := book.Find(".description")boldText := desc.Find("b").Text()if boldText != "" {fmt.Printf(" 重点内容: %s\n", boldText)}fmt.Println() // 添加空行分隔不同图书})// 3. 统计信息fmt.Println("=== 统计信息 ===")bookCount := doc.Find(".book").Length()fmt.Printf("图书总数: %d本\n", bookCount)// 统计高评分(>4.5)的书籍highRatedBooks := 0doc.Find(".book").Each(func(i int, s *goquery.Selection) {ratingText := s.Find(".rating").Text()// 提取评分数字ratingStr := strings.TrimPrefix(ratingText, "评分: ")ratingStr = strings.TrimSuffix(ratingStr, "/5")// 简单转换为浮点数进行比较var rating float64fmt.Sscanf(ratingStr, "%f", &rating)if rating > 4.5 {highRatedBooks++}})fmt.Printf("高评分图书(>4.5): %d本\n", highRatedBooks)// 获取页脚信息footerText := doc.Find("#footer").Text()fmt.Printf("页脚信息: %s\n", strings.TrimSpace(footerText))fmt.Println("=== 分隔符 ===")// 4. 查找并修改元素 ,查找作者为空的元素,填充作者doc.Find(".author:empty").SetHtml(`老六`)//查找.book ,第四个元素newSelection := doc.Find(".book").Eq(3)title := newSelection.Find(".title").Text()// 提取作者(使用替代方法)authorElem := newSelection.Find(".author")author := authorElem.Text()// 清理"作者: "前缀author = strings.TrimPrefix(author, "作者: ")// 提取评分(使用属性选择器)ratingText := newSelection.Find(".rating").Text()// 使用strings包处理字符串rating := strings.TrimPrefix(ratingText, "评分: ")// 提取链接URL和文本linkElem := newSelection.Find(".link")linkText := linkElem.Text()linkHref, _ := linkElem.Attr("href")// 输出图书信息fmt.Printf(" 标题: %s\n", title)fmt.Printf(" 作者: %s\n", author)fmt.Printf(" 评分: %s\n", rating)fmt.Printf(" 链接: %s (%s)\n", linkText, linkHref)
}3. XPath查询
XPath(XML Path Language)是一种用于在XML/HTML文档中定位节点的查询语言。尽管goquery主要使用CSS选择器,但在某些场景下,XPath可能更为强大或直观。
3.1XPath语法基础
基本路径表达式
/- 从根节点选择//- 从当前节点选择文档中符合条件的所有节点.- 选择当前节点..- 选择当前节点的父节点@- 选择属性
XPath高级功能
- 谓语(筛选条件)
//li[1]- 选择第一个li元素//li[last()]- 选择最后一个li元素//div[count(p) > 2]- 选择包含超过2个段落的div元素
- 轴(指定节点关系方向)
//h1/following-sibling::p- 选择h1后的所有兄弟段落//li/ancestor::div- 选择li的所有div祖先元素//a/parent::div- 选择a的父元素中的div
- 函数
string(//h1)- 获取第一个h1元素的文本contains(//p, '文本')- 检查段落是否包含"文本"count(//li)- 计算li元素的数量
实例演示
| XPath表达式 | 描述 |
|---|---|
/html/body/div | 选择html下的body元素下的所有div元素 |
//div | 选择文档中的所有div元素 |
//div[@class="header"] | 选择所有class为header的div元素 |
//a/@href | 选择所有a元素的href属性值 |
//div[contains(@class, "item")] | 选择class属性包含"item"的所有div元素 |
3.2 在Go中使用XPath
要在Go中使用XPath,可以使用github.com/antchfx/htmlquery库:
go get github.com/antchfx/htmlquery
3.3 简单示例
package mainimport ("fmt""log""strings""github.com/antchfx/htmlquery""golang.org/x/net/html"
)func xpathExamples() {htmlStr := `<books><book id="1" category="fiction"><title>Go编程</title><author>作者1</author><price>59.90</price></book><book id="2" category="technical"><title>数据结构</title><author>作者2</author><price>79.90</price></book><book id="3" category="fiction"><title>算法导论</title><author>作者3</author><price>99.90</price></book></books>`doc, err := html.Parse(strings.NewReader(htmlStr))if err != nil {log.Fatal(err)}// 1. 基本路径表达式fmt.Println("=== 基本XPath ===")// 选择所有书的标题titles := htmlquery.Find(doc, "//title")for _, title := range titles {fmt.Printf("Title: %s\n", htmlquery.InnerText(title))}// 2. 属性选择fmt.Println("\n=== 属性选择 ===")// 选择category为fiction的书fictionBooks := htmlquery.Find(doc, "//book[@category='fiction']/title")for _, book := range fictionBooks {fmt.Printf("Fiction book: %s\n", htmlquery.InnerText(book))}// 3. 位置选择fmt.Println("\n=== 位置选择 ===")// 选择第一本书firstBook := htmlquery.FindOne(doc, "//book[1]/title")if firstBook != nil {fmt.Printf("First book: %s\n", htmlquery.InnerText(firstBook))}// 选择最后一本书lastBook := htmlquery.FindOne(doc, "//book[last()]/title")if lastBook != nil {fmt.Printf("Last book: %s\n", htmlquery.InnerText(lastBook))}// 4. 条件表达式fmt.Println("\n=== 条件表达式 ===")// 价格大于60的书expensiveBooks := htmlquery.Find(doc, "//book[price>60]/title")for _, book := range expensiveBooks {fmt.Printf("Expensive book: %s\n", htmlquery.InnerText(book))}// 5. 轴运算fmt.Println("\n=== 轴运算 ===")// 选择作者为"作者2"的书的下一个兄弟节点nextBook := htmlquery.FindOne(doc, "//author[text()='作者2']/parent::book/following-sibling::book[1]/title")if nextBook != nil {fmt.Printf("Next book after 作者2's book: %s\n", htmlquery.InnerText(nextBook))}
}
4.CSS选择器与XPath比较
| CSS选择器 | 等效XPath | 描述 |
|---|---|---|
div | //div | 选择所有div元素 |
div.content | //div[@class='content'] | 选择class为content的div元素 |
#header | //*[@id='header'] | 选择id为header的元素 |
div > p | //div/p | 选择div的直接子元素p |
div p | //div//p | 选择div的所有后代p元素 |
a[href] | //a[@href] | 选择有href属性的所有a元素 |
| 使用CSS选择器的场景: |
- 熟悉前端开发,更习惯CSS语法
- 需要简洁的选择表达式
- 使用goquery库
使用XPath的场景:
- 需要更复杂的查询能力(如祖先/后代选择)
- 需要访问元素的函数(如count()、position())
- 需要基于文本内容筛选元素
- 使用htmlquery库
相关文章:
HTML解析技术)
Go语言爬虫系列教程(三)HTML解析技术
第3课:HTML解析技术 在上一章中,我们使用正则表达式提取网页内容,但这种方法有局限性。对于复杂的HTML结构,我们需要使用专门的HTML解析库。下面将介绍如何在Go中解析HTML。 1. HTML DOM树结构介绍 1.1 什么是DOM DOM…...
【三维重建】【3DGS系列】【深度学习】3DGS的理论基础知识之如何形成高斯椭球
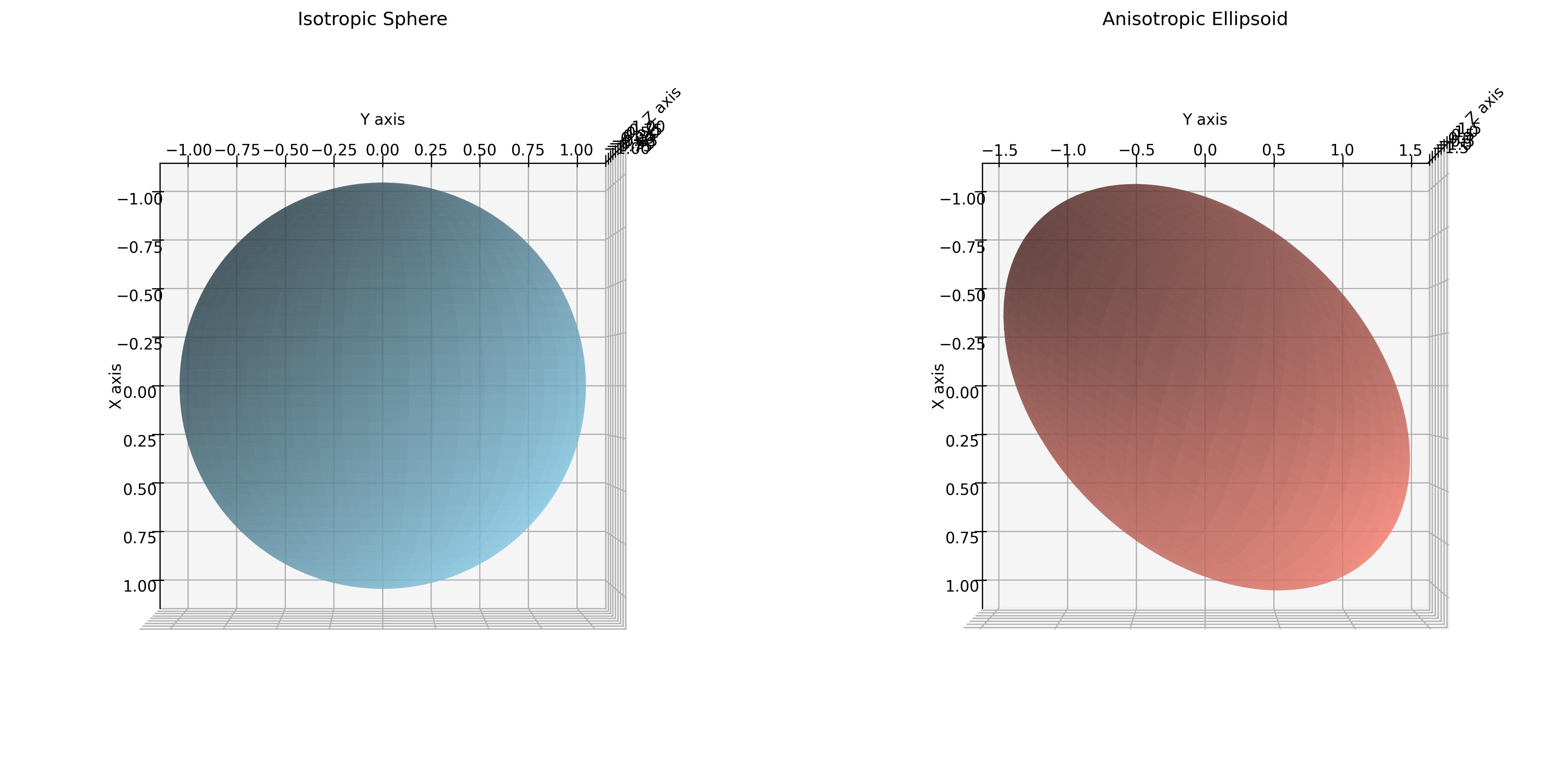
【三维重建】【3DGS系列】【深度学习】3DGS的理论基础知识之如何形成高斯椭球 文章目录 【三维重建】【3DGS系列】【深度学习】3DGS的理论基础知识之如何形成高斯椭球前言高斯函数一维高斯多维高斯 椭球基本定义一般二次形式 3D高斯椭球3D高斯与椭球的关系各向同性(Isotropic)和…...

“夹子音”的发声原理和潜在风险
关于“夹子音”的发声原理和潜在风险,以下从科学角度和声乐实践出发,为你详细解析: 一、什么是夹子音? 夹子音是近年来网络流行的非专业术语,指通过刻意挤压喉部、改变共鸣腔形态发出的 尖细、嗲气、幼态化 的声音。常…...

思科硬件笔试面试题型解析
本专栏预计更新60期左右。当前第13期 这个系列通过在各类网上搜索大厂公开的笔试和面试题目,然后构造相关的知识点矩阵,让大家对核心的知识点有更深的认识,这个过程虽然耗时费力,但大厂的很多题目(包括模拟题)确实非常巧妙,很有代表性。由于官方没有发布过这样的题库,所…...
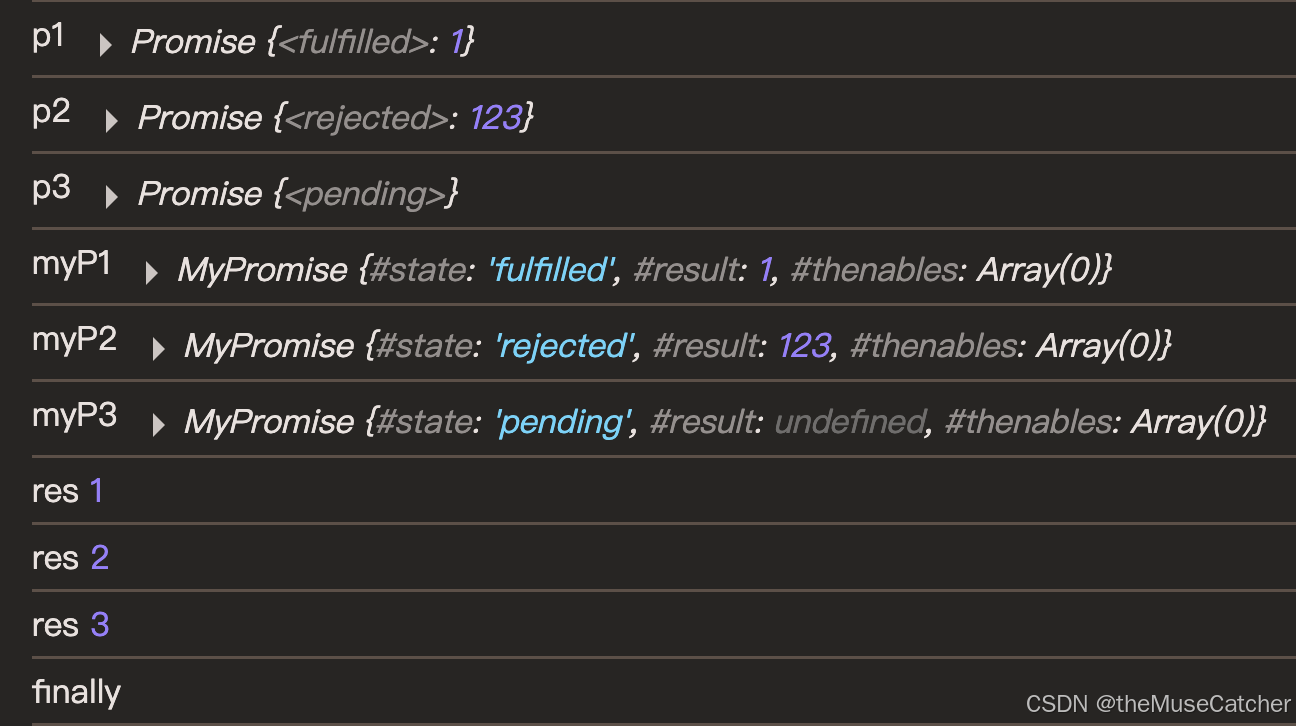
手写ES6 Promise() 相关函数
手写 Promise() 相关函数: Promise()、then()、catch()、finally() // 定义三种状态常量 const PENDING pending const FULFILLED fulfilled const REJECTED rejectedclass MyPromise {/*定义状态和结果两个私有属性:1.使用 # 语法(ES2022 官方私有字…...

Windows 平台 TCP 通信开发指南
开篇介绍 在 Windows 平台进行 TCP 通信开发,是网络编程中的常见需求。本文将详细讲解在 Windows 平台下,如何利用 Winsock API 实现高效的 TCP 客户端与服务端通信。 使用示例 必须引入的头文件 #include <windows.h> #pragma comment(lib,&q…...

【NLP 76、Faiss 向量数据库】
压抑与痛苦,那些辗转反侧的夜,终会让我们更加强大 —— 25.5.20 Faiss(Facebook AI Similarity Search)是由 Facebook AI 团队开发的一个开源库,用于高效相似性搜索的库,特别适用于大规模向…...

软件名称:系统日志监听工具 v1.0
软件功能:一款基于 PyQt5 开发的 Windows 系统日志监听工具,适用于系统运维、网络管理、故障排查等场景,具备以下核心功能: 支持监听系统三大日志源:应用程序 / 系统 / 安全日志实时抓取新日志事件,自动滚…...
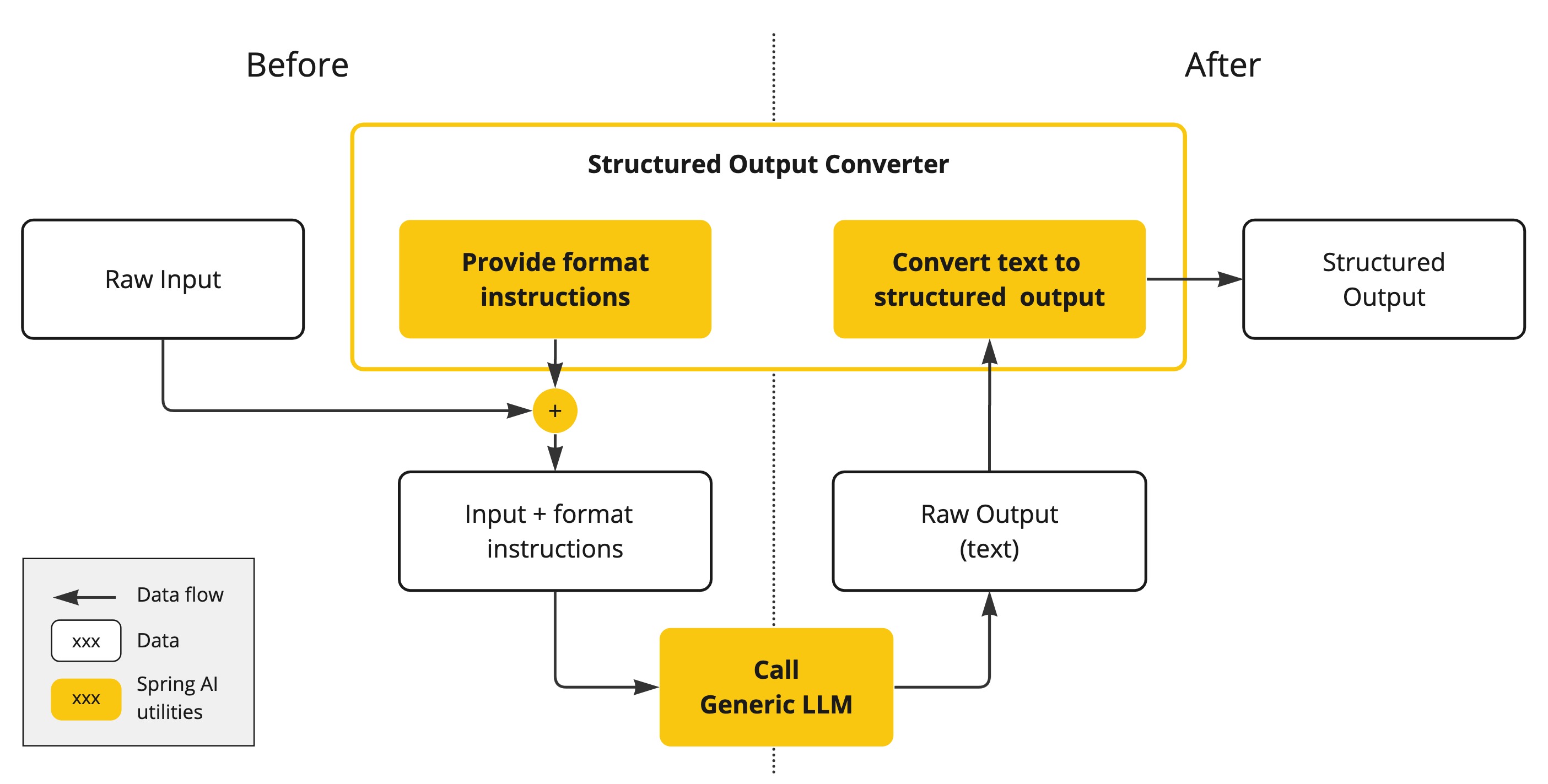
Spring AI 之结构化输出转换器
截至 2024 年 2 月 5 日,旧的 OutputParser、BeanOutputParser、ListOutputParser 和 MapOutputParser 类已被弃用,取而代之的是新的 StructuredOutputConverter、BeanOutputConverter、ListOutputConverter 和 MapOutputConverter 实现类。后者可直接替换前者,并提供相同的…...

Java虚拟机面试题:内存管理(上)
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

进程间通信I·匿名管道
目录 进程间通信(IPC) 含义 目的 分类 匿名管道 原理 创建过程 特性 四大情况 close问题 代码练习 简单通信 进程池 小知识 进程间通信(IPC) 含义 就是让不同的进程能看到同一份资源,实现数据交流。 …...
Ubuntu Linux系统的基本命令详情
1.Ubuntu Linux是以桌面应用为主的Linux发行版操作系统 2.Ubuntu的用户使用 在登录系统一般使用在安装系统时建立的普通用户登录,如果要使用超级用户权限 #sudo ---执行命令 sudo passwd ---修改用户密码 su - root ---切换超级用户 系统的不同,命令也不…...

大数据治理:理论、实践与未来展望(二)
书接上文 文章目录 七、大数据治理的未来发展趋势(一)智能化与自动化(二)数据隐私与安全的强化(三)数据治理的云化(四)数据治理的跨行业合作(五)数据治理的生…...
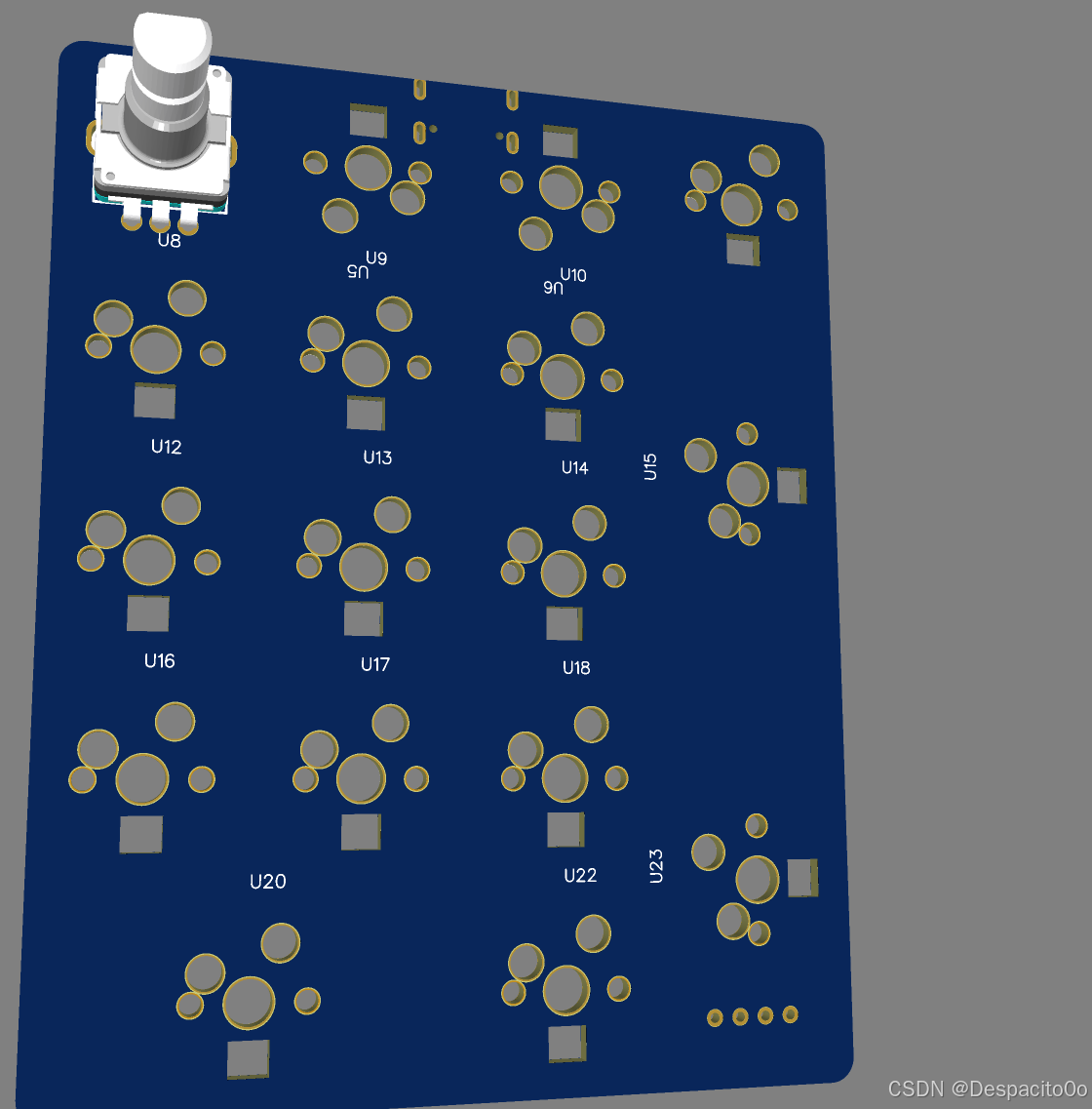
PCB布局设计
PCB布局设计 一、原理图到PCB转换前的准备工作 在将原理图转换为PCB之前,我们需要进行一系列准备工作,确保设计的正确性和完整性。这一步骤至关重要,可以避免后续PCB设计中出现不必要的错误。 // 原理图转PCB前必要检查步骤 // 1. 仔细检查…...

【49. 字母异位词分组】
Leetcode算法练习 笔记记录 49. 字母异位词分组 49. 字母异位词分组 public List<List<String>> groupAnagrams(String[] strs) {Map<String, List<String>> map new HashMap<>();for (int i 0; i < strs.length; i) {//排序就是相同字符了…...

用 AI 让学习更懂你:如何打造自动化个性化学习系统?
用 AI 让学习更懂你:如何打造自动化个性化学习系统? 在这个信息爆炸的时代,传统的学习方式已经难以满足个体化需求。过去,我们依赖固定的教学课程,所有学生按照统一进度进行学习,但每个人的学习节奏、兴趣点和理解方式都不尽相同。而人工智能(AI)正在彻底改变这一局面…...
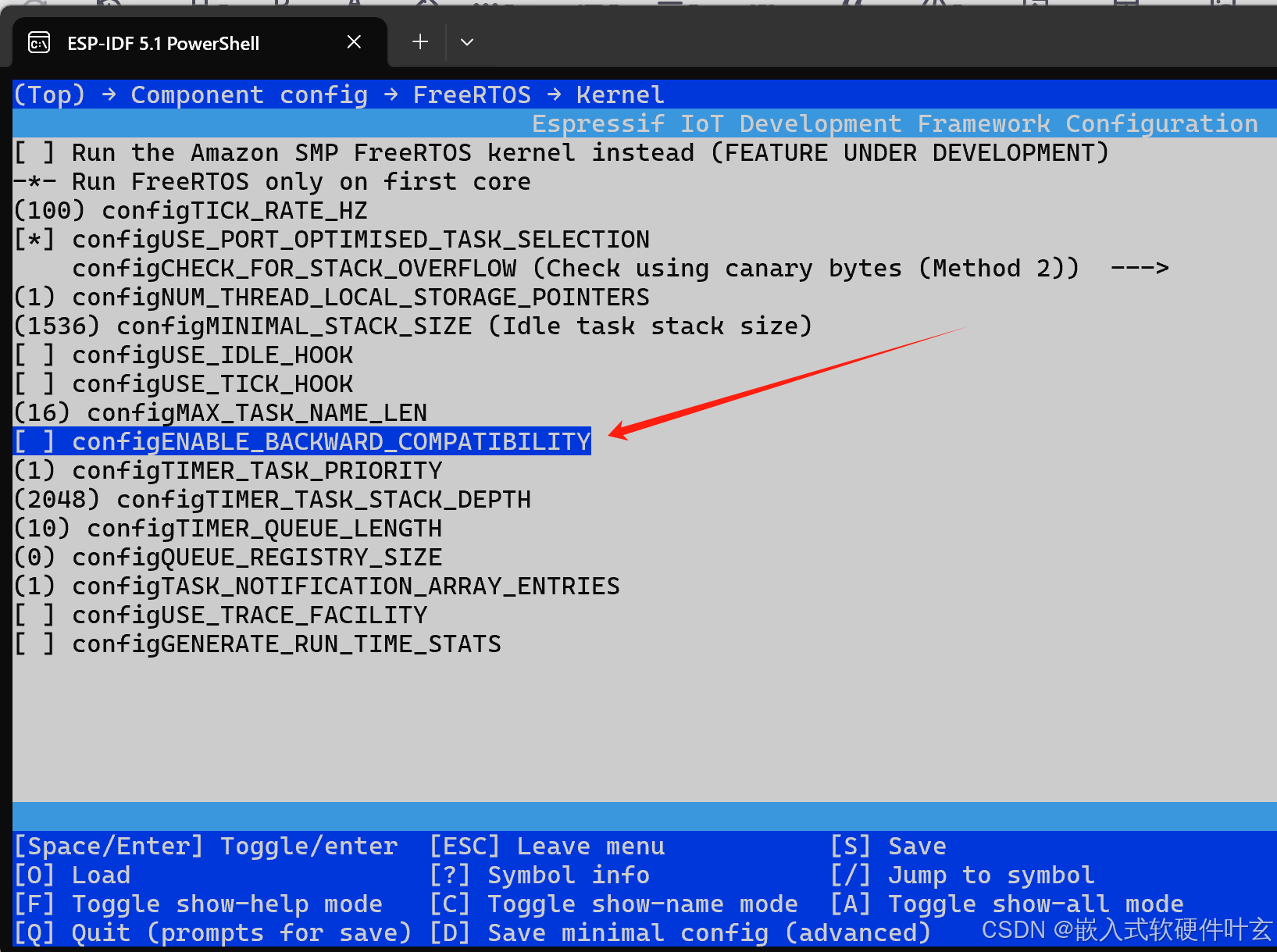
esp32+IDF V5.1.1版本编译freertos报错
error: portTICK_RATE_MS undeclared (first use in this function); did you mean portTICK_PERIOD_MS 解决方法: 使用命令 idf.py menuconfig 打开配置界面配置freeRtos 使能configENABLE_BACKWARD_COMPATIBLITY...

嵌入式软件-如何做好一份技术文档?
嵌入式软件-如何做好一份技术文档? 文章目录 嵌入式软件-如何做好一份技术文档?一.技术文档的核心价值与挑战二.文档体系的结构化设计三.精准表达嵌入式特有概念四. **像管理代码一样管理文档**,代码与文档的协同维护五.质量评估与持续改进5.…...

笔记本6GB本地可跑的图生视频项目(FramePack)
文章目录 (一)简介(二)本地执行(2.1)下载(2.2)更新(2.3)运行(2.4)生成 (三)注意(3.1)效…...

SpringMVC实战:动态时钟
引言 在现代 Web 开发中,选择一个合适的框架对于项目的成功至关重要。Spring MVC 作为 Spring 框架的核心模块之一,以其清晰的架构、强大的功能和高度的可配置性,成为了 Java Web 开发领域的主流选择。本文将通过一个“动态时钟”的实战项目…...

vscode include总是报错
VSCode 的 C/C 扩展可以通过配置 c_cpp_properties.json 来使用 compile_commands.json 文件中的编译信息,包括 include path、编译选项等。这样可以确保 VSCode 的 IntelliSense 与实际编译环境保持一致。 方法一:直接指定 compile_commands.json 路径…...

哈希表的实现(上)
前言 在C98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将…...
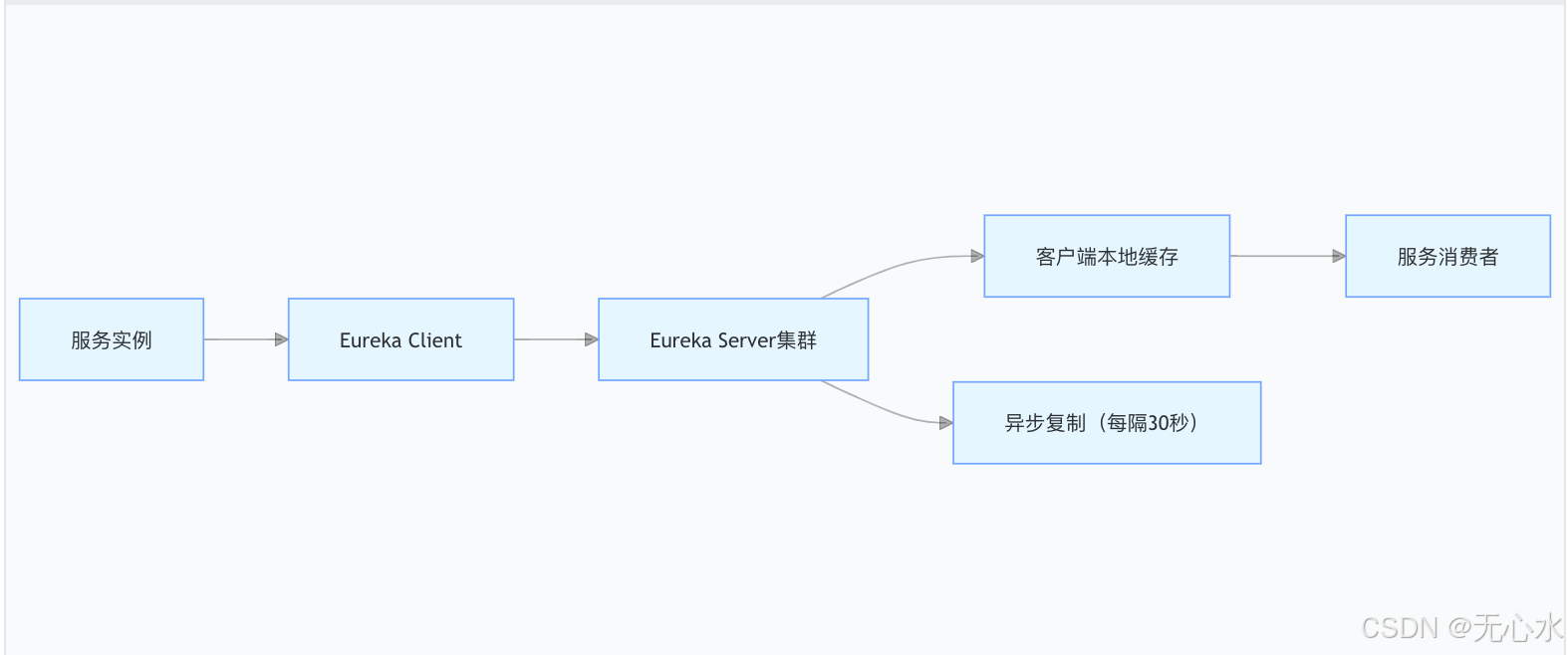
【Java高阶面经:微服务篇】1.微服务架构核心:服务注册与发现之AP vs CP选型全攻略
一、CAP理论在服务注册与发现中的落地实践 1.1 CAP三要素的技术权衡 要素AP模型实现CP模型实现一致性最终一致性(Eureka通过异步复制实现)强一致性(ZooKeeper通过ZAB协议保证)可用性服务节点可独立响应(支持分区存活)分区期间无法保证写操作(需多数节点可用)分区容错性…...
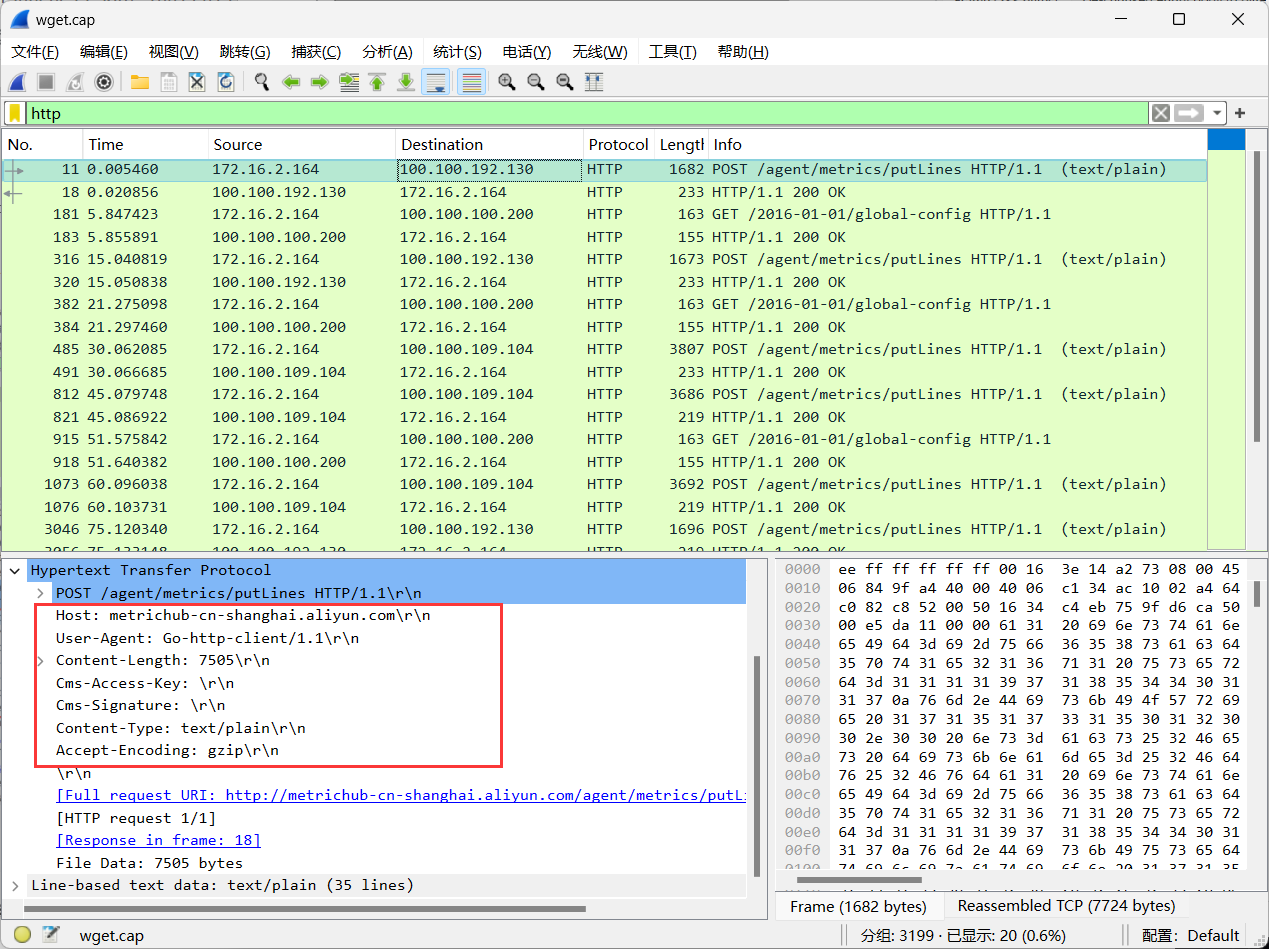
实验7 HTTP协议分析与测量
实验7 HTTP协议分析与测量 1、实验目的 了解HTTP协议及其报文结构 了解HTTP操作过程:TCP三次握手、请求和响应交互 掌握基于tcpdump和wireshark软件进行HTTP数据包抓取和分析技术 2、实验环境 硬件要求:阿里云云主机ECS 一台。 软件要求࿱…...
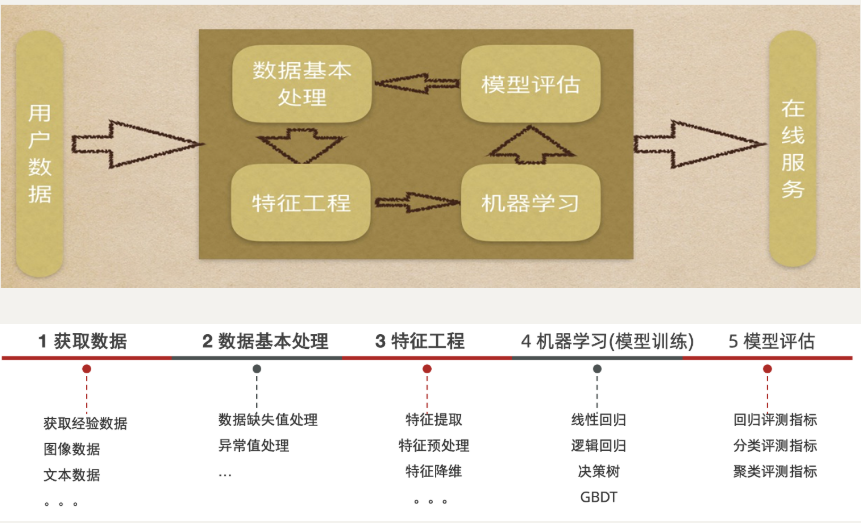
python:机器学习概述
本文目录: 一、人工智能三大概念二、学习方式三、人工智能发展史**1950-1970****1980-2000****2010-2017****2017-至今** 四、机器学习三要素五、常见术语六、数据集的划分七、常见算法分类八、机器学习的建模流程九、特征工程特征工程包括**五大步**:特…...

【一. Java基础:注释、变量与数据类型详解】
1. Java 基础概念 1.1 注释 注释:对代码的解释和说明文字 java的三种注释: 单行注释:两个斜杠 // 后面跟着你的注释内容 //哈哈多行注释:以 /* 开头,以 */ 结尾,中间可以写很多行 /*哈哈哈哈哈哈…...

得力DE-620K针式打印机打印速度不能调节维修一例
基本参数: 产品类型 票据针式打印机(平推式) 打印方式 串行点阵击打式 打印宽度 85列 打印针数 24针 可靠性 4亿次/针 色带性能 1000万字符纠错 复写能力 7份(1份原件+6份拷贝) 缓冲区 128KB 接口类型 …...

SAP在金属行业的数字化转型:无锡哲讯科技的智能解决方案
金属行业面临的发展挑战 金属行业作为制造业的基础支柱,涵盖钢铁、有色金属、金属制品等多个细分领域。当前行业正面临原材料价格波动、能耗双控政策、市场竞争加剧等多重压力。数字化转型已成为金属企业提升生产效率、优化供应链、实现绿色可持续发展的必由之路。…...

安装openresty使用nginx+lua,openresty使用jwt解密
yum install -y epel-release yum update yum search openresty # 查看是否有可用包 yum install -y openresty启动systemctl start openresty验证服务状态systemctl status openresty设置开机自启systemctl enable openrestysystemctl stop openresty # 停止服务 system…...

java基础(继承)
什么是继承 继承好处 提高代码的复用性 继承注意事项 权限修饰符 单继承、Object类 冲突: 方法重写 扩展: 其实我们不想看地址,地址看来没用,我们是用来看对象有没有问题 重写toString: 比如这个如果返回的是地址值,…...