stream数据流
核心知识点:数据流(Stream Data Flow)
1. 通俗易懂的解释
想象一下你正在用花园里的水管浇花。水管里的水不是一次性全部倒出来的,而是持续不断地从水龙头流出,经过水管,最终从喷头喷洒到花上。在这个过程中,水是“数据”,水管是“数据流”,水龙头是“数据源”,喷头是“数据消费者”。
“数据流”在计算机领域就是这个概念:数据不是一次性全部处理完或传输完,而是像水流一样,以连续的、渐进的方式产生、传输和消费。它强调的是数据的流动性和顺序性。当数据量非常大,或者数据是实时产生时,这种方式就非常有效。
现实例子:
-
在线视频播放: 当你在 Bilibili 或 YouTube 观看视频时,视频文件通常非常大。你的设备不是等到整个视频文件下载完才开始播放,而是边下载边播放。视频数据就是以数据流的形式从服务器传输到你的设备,然后播放器实时解码并显示画面。
-
网络电台/直播: 音乐或直播内容是实时产生的,它通过数据流的方式从主播端持续传输到观众端,观众可以即时收听或观看。
-
日志文件写入: 应用程序在运行过程中会不断产生日志信息。这些日志信息不是等到程序结束才一次性写入文件,而是随着事件的发生,一条一条地写入日志文件。
2. 抽象理解
共性 (Abstract Understanding):
数据流(Stream Data Flow)是一种数据处理范式,其核心抽象是将数据视为一个连续的、无边界的序列,而不是一个有限的、静态的集合。它强调数据的渐进式处理,即在数据完全可用之前就开始处理,并且能够处理无限量的数据。这种范式与传统的批处理(Batch Processing)形成对比,批处理通常要求所有数据都已收集完毕后才开始处理。
数据流的共性在于:
-
连续性/渐进性: 数据以小块或事件的形式连续到达,并被实时或近实时处理。
-
顺序性: 数据通常按照产生的时间顺序进行处理。
-
无边界性: 数据流可以被认为是无限的,没有明确的结束点(除非被显式终止)。
-
低延迟: 目标是最小化数据从产生到被处理之间的时间延迟。
-
资源效率: 不需要将所有数据加载到内存中,从而节省内存资源,尤其适用于大数据场景。
潜在问题 (Potential Issues):
-
状态管理复杂性: 在处理连续数据流时,如果需要维护跨多个数据点的状态(例如,计算滑动平均、检测序列模式),状态管理会变得复杂,需要考虑如何存储、更新和恢复状态。
-
乱序与重复数据: 在分布式系统或网络传输中,数据包可能乱序到达、丢失或重复。数据流处理系统需要机制来处理这些情况,例如事件时间戳、去重逻辑。
-
容错与可靠性: 数据流通常是实时或近实时的,任何处理节点的故障都可能导致数据丢失或处理中断。确保数据不丢失、处理结果准确且系统高可用是一个挑战。
-
背压(Backpressure)问题: 如果数据源产生数据的速度快于消费者处理数据的速度,可能会导致系统过载、内存溢出或数据丢失。
-
调试和测试困难: 由于数据是动态流动的,且可能涉及复杂的分布式组件,调试和重现特定问题可能比批处理系统更困难。
解决方案 (Solutions):
-
状态管理复杂性:
-
解决方案: 使用专门的状态管理框架(如 Apache Flink, Apache Kafka Streams 的有状态操作),它们提供内置的状态存储、检查点(Checkpointing)和恢复机制。
-
解决方案: 采用微批处理(Micro-batching)策略,将连续流数据在短时间内聚集成小批次进行处理,简化状态管理。
-
-
乱序与重复数据:
-
解决方案: 引入事件时间(Event Time)和水位线(Watermark)机制来处理乱序数据,允许系统等待一定时间以接收迟到的数据。
-
解决方案: 使用去重算法(如基于消息 ID 或业务键)来识别和丢弃重复数据。
-
解决方案: 采用幂等性(Idempotency)设计,确保重复处理相同数据不会产生副作用。
-
-
容错与可靠性:
-
解决方案: 采用分布式消息队列(如 Apache Kafka, RabbitMQ)作为数据缓冲区,确保数据持久化和高可用。
-
解决方案: 使用检查点(Checkpointing)或快照(Snapshotting)机制定期保存处理状态,以便在故障后从最近的检查点恢复。
-
解决方案: 采用冗余部署和自动故障转移机制。
-
-
背压(Backpressure)问题:
-
解决方案: 实现流量控制机制。例如,在生产者端限制发送速率,或在消费者端通过反馈机制通知生产者减速。
-
解决方案: 引入缓冲区(Buffer)或队列,但要注意缓冲区溢出的风险。
-
解决方案: 弹性伸缩,根据数据量动态调整处理能力。
-
-
调试和测试困难:
-
解决方案: 完善的日志记录和监控系统,提供数据流的实时可见性。
-
解决方案: 开发模拟数据流的工具,以便在受控环境中进行测试和重现问题。
-
解决方案: 采用单元测试和集成测试,对数据流处理逻辑的各个阶段进行验证。
-
3. 实现的原理
数据流的实现原理主要围绕着生产者-消费者模型和管道(Pipeline)概念展开。数据从一个源头产生,经过一系列的处理阶段,最终被一个或多个目的地消费。
-
数据源 (Source / Producer):
-
负责产生数据。数据源可以是传感器、日志文件、数据库变更日志、消息队列、网络连接等。
-
数据通常以事件(Event)的形式发出,每个事件包含一个数据单元和可选的元数据(如时间戳)。
-
原理: 持续地读取或生成数据,并将其推送到数据流中。
-
-
数据传输/通道 (Channel / Queue / Stream):
-
连接数据源和数据处理组件,以及不同处理组件之间。
-
通常是消息队列(如 Kafka, RabbitMQ)、管道(Pipe)、套接字(Socket)等。
-
原理: 提供一个可靠、有序(或至少是可排序)的数据传输机制,通常带有缓冲能力,以应对生产者和消费者速度不匹配的情况。
-
-
数据处理单元 (Processor / Operator / Consumer):
-
从数据流中读取数据,执行业务逻辑,然后将处理结果输出到另一个数据流或最终目的地。
-
处理可以是简单的转换(如格式转换)、过滤、聚合、分析等。
-
原理:
-
拉取(Pull)模式: 消费者主动从通道中拉取数据。
-
推送(Push)模式: 生产者或上游处理单元将数据推送到下游。
-
流式计算引擎: 复杂的流处理通常依赖于专门的流计算框架(如 Apache Flink, Apache Spark Streaming, Apache Storm),它们提供了高层次的 API 来定义数据转换和聚合操作,并处理底层的分布式、容错和状态管理。
-
-
-
数据目的地 (Sink / Consumer):
-
数据流的终点,负责将处理后的数据存储到数据库、文件系统、发送到其他系统或显示给用户。
-
原理: 接收处理后的数据,并将其持久化或展示。
-
整个数据流系统通过将数据处理任务分解为一系列相互连接的、独立的功能单元来实现。每个单元只关注其输入和输出,数据像流水线一样在这些单元之间流动。
4. 实现代码 (示例)
由于数据流处理通常涉及并发、网络通信和分布式系统,一个完整的、生产级别的示例会非常复杂。这里提供一个高度简化的 Python 概念性示例,模拟一个简单的生产者-消费者数据流,使用队列作为数据通道。
import time
import random
import queue
import threading# --- 1. 数据源 (Producer) ---
class DataSource:def __init__(self, output_queue, name="Sensor"):self.output_queue = output_queueself.name = nameself._running = Falsedef run(self):self._running = Trueprint(f"[{self.name}] 数据源启动...")counter = 0while self._running:temperature = round(random.uniform(20.0, 30.0), 2)event = {"timestamp": time.time(),"sensor_id": self.name,"reading_id": counter,"temperature": temperature}try:self.output_queue.put(event, timeout=1) # 放入队列,带超时print(f"[{self.name}] 生成并发送数据: {event['temperature']}°C")except queue.Full:print(f"[{self.name}] 队列已满,无法发送数据。")time.sleep(random.uniform(0.1, 0.5)) # 模拟数据生成间隔counter += 1def stop(self):self._running = Falseprint(f"[{self.name}] 数据源停止。")# --- 2. 数据处理单元 (Processor) ---
class DataProcessor:def __init__(self, input_queue, output_queue, name="Processor"):self.input_queue = input_queueself.output_queue = output_queueself.name = nameself._running = Falseself.processed_count = 0def run(self):self._running = Trueprint(f"[{self.name}] 数据处理器启动...")while self._running:try:event = self.input_queue.get(timeout=1) # 从队列获取数据,带超时self.processed_count += 1# 模拟数据处理:过滤掉温度低于 22 度的事件if event["temperature"] >= 22.0:processed_event = {"timestamp": event["timestamp"],"sensor_id": event["sensor_id"],"reading_id": event["reading_id"],"filtered_temperature": event["temperature"]}try:self.output_queue.put(processed_event, timeout=1)print(f"[{self.name}] 处理并转发数据: {processed_event['filtered_temperature']}°C")except queue.Full:print(f"[{self.name}] 输出队列已满,无法转发数据。")else:print(f"[{self.name}] 过滤掉低温度数据: {event['temperature']}°C")self.input_queue.task_done() # 标记任务完成except queue.Empty:# print(f"[{self.name}] 输入队列为空,等待数据...")pass # 队列为空时继续循环等待except Exception as e:print(f"[{self.name}] 处理数据时发生错误: {e}")self.input_queue.task_done() # 即使出错也标记完成,避免阻塞def stop(self):self._running = Falseprint(f"[{self.name}] 数据处理器停止。总处理数据量: {self.processed_count}")# --- 3. 数据目的地 (Consumer/Sink) ---
class DataConsumer:def __init__(self, input_queue, name="Logger"):self.input_queue = input_queueself.name = nameself._running = Falseself.consumed_count = 0def run(self):self._running = Trueprint(f"[{self.name}] 数据消费者启动...")while self._running:try:event = self.input_queue.get(timeout=1)self.consumed_count += 1print(f"[{self.name}] 消费数据: {event}")# 模拟数据存储或展示self.input_queue.task_done()except queue.Empty:# print(f"[{self.name}] 输入队列为空,等待数据...")passexcept Exception as e:print(f"[{self.name}] 消费数据时发生错误: {e}")self.input_queue.task_done()def stop(self):self._running = Falseprint(f"[{self.name}] 数据消费者停止。总消费数据量: {self.consumed_count}")# --- 主程序:构建数据流管道 ---
if __name__ == "__main__":# 创建队列作为数据通道queue_source_to_processor = queue.Queue(maxsize=10) # 模拟有界队列,可能出现背压queue_processor_to_consumer = queue.Queue(maxsize=10)# 实例化组件sensor = DataSource(output_queue=queue_source_to_processor, name="TempSensor")filter_processor = DataProcessor(input_queue=queue_source_to_processor,output_queue=queue_processor_to_consumer,name="TempFilter")logger = DataConsumer(input_queue=queue_processor_to_consumer, name="DataLogger")# 创建并启动线程sensor_thread = threading.Thread(target=sensor.run)processor_thread = threading.Thread(target=filter_processor.run)consumer_thread = threading.Thread(target=logger.run)sensor_thread.start()processor_thread.start()consumer_thread.start()# 运行一段时间后停止try:print("\n数据流运行中,按 Ctrl+C 停止...")time.sleep(10) # 运行 10 秒except KeyboardInterrupt:print("\n检测到停止指令...")finally:# 停止所有组件sensor.stop()filter_processor.stop()logger.stop()# 等待线程结束sensor_thread.join()processor_thread.join()consumer_thread.join()# 确保所有队列任务都已处理完毕 (可选,对于演示足够)# queue_source_to_processor.join()# queue_processor_to_consumer.join()print("\n所有数据流组件已停止。")print(f"最终队列1大小: {queue_source_to_processor.qsize()}")print(f"最终队列2大小: {queue_processor_to_consumer.qsize()}")代码解释:
-
DataSource(生产者): 模拟一个传感器,周期性地生成带有随机温度的事件数据,并将其放入output_queue。 -
DataProcessor(处理单元): 从input_queue获取数据,执行一个简单的过滤逻辑(只转发温度 >= 22.0 的数据),然后将处理后的数据放入output_queue。 -
DataConsumer(消费者/目的地): 从input_queue获取最终处理后的数据,并模拟将其打印到控制台(实际应用中可能是写入数据库或文件)。 -
queue.Queue(数据通道): Python 的queue模块用于实现线程安全的队列,这里作为数据流中的缓冲区,连接不同的处理阶段。maxsize参数模拟了队列的容量限制,当队列满时,put操作会阻塞或抛出异常,这可以用来观察背压现象。 -
threading.Thread: 每个组件都在单独的线程中运行,模拟了数据流处理中常见的并发执行。 -
get(timeout=1)和put(timeout=1): 带超时的队列操作,避免线程在队列为空或满时无限期阻塞,使演示更健壮。 -
input_queue.task_done(): 配合input_queue.join()可以等待队列中所有任务被处理完毕,但在这个简化示例中,我们主要通过time.sleep控制运行时间。
这个示例展示了数据如何从源头连续产生,经过一个处理阶段,最终被消费,体现了数据流的基本概念和管道式处理的结构。
5. 实际应用和场景
数据流处理在现代 IT 架构中扮演着越来越重要的角色,特别是在需要实时或近实时响应的场景:
-
大数据实时分析:
-
场景: 监控网站点击流、社交媒体数据、物联网传感器数据、金融交易数据等,进行实时欺诈检测、个性化推荐、异常行为识别。
-
应用: Apache Flink, Apache Spark Streaming, Apache Kafka Streams 等流处理框架。
-
-
物联网 (IoT) 数据处理:
-
场景: 从大量传感器(如智能家居、工业设备、车载传感器)收集实时数据,进行设备状态监控、预测性维护、环境监测。
-
应用: 数据通过 MQTT 等协议传输,然后进入流处理平台。
-
-
日志和事件监控:
-
场景: 实时收集应用程序、服务器、网络设备的日志和事件,进行故障诊断、安全审计、性能分析。
-
应用: ELK Stack (Elasticsearch, Logstash, Kibana) 与 Kafka 结合,或 Splunk。
-
-
金融交易系统:
-
场景: 实时处理股票交易、外汇交易等数据,进行高频交易、风险管理、市场趋势分析。
-
应用: 需要极低延迟和高吞吐量的定制化流处理系统。
-
-
推荐系统:
-
场景: 根据用户实时行为(浏览、点击、购买)动态更新推荐列表,提供个性化体验。
-
应用: 结合流处理和机器学习模型。
-
-
在线游戏:
-
场景: 实时处理玩家操作、游戏状态更新,进行作弊检测、匹配系统优化、游戏内事件触发。
-
-
网络安全:
-
场景: 实时分析网络流量、安全日志,检测入侵行为、DDoS 攻击、恶意软件传播。
-
6. 知识的迁移
数据流(Stream Data Flow)所体现的“连续处理”、“管道化”和“事件驱动”思想,是计算机科学和系统设计中非常重要的通用模式,可以迁移到许多其他领域:
-
Unix/Linux 管道 (Pipes):
-
迁移: Unix 哲学中的管道(
|)是数据流思想的经典体现。ls | grep "txt" | wc -l命令链将前一个命令的输出作为后一个命令的输入,数据像水流一样从一个程序流向另一个程序,每个程序只做一小部分处理。 -
类比: 每个命令是一个“处理单元”,
|是“数据通道”。
-
-
响应式编程 (Reactive Programming):
-
迁移: 响应式编程框架(如 RxJava, RxJS, Reactor)将事件和数据视为“流”,并提供丰富的操作符来组合、转换和过滤这些流。它强调对数据变化的“响应”而非主动“拉取”。
-
类比: 观察者模式、事件总线是其基础,数据流是核心概念。
-
-
函数式编程中的惰性求值 (Lazy Evaluation):
-
迁移: 在函数式编程中,惰性求值意味着表达式直到其值真正需要时才被计算。这与数据流的“渐进式处理”类似,数据只有在被消费者请求时才可能被生成或处理。
-
类比: 潜在的无限列表或序列可以被视为数据流,只有当需要时才计算下一个元素。
-
-
编译器/解释器设计:
-
迁移: 编译器通常采用多阶段设计:词法分析器(生成 Token 流)、语法分析器(生成抽象语法树)、语义分析器、代码生成器等。数据(源代码)在这些阶段之间以流的形式传递。
-
类比: 每个阶段是一个“处理单元”,中间表示是“数据流”。
-
-
图形渲染管线 (Graphics Pipeline):
-
迁移: 现代 GPU 的图形渲染管线是一个典型的并行数据流系统。顶点数据、纹理数据等从应用程序输入,经过顶点着色器、几何着色器、光栅化、片段着色器等多个阶段,最终输出到屏幕。每个阶段都对数据进行特定处理。
-
类比: 每个着色器阶段是一个“处理单元”,数据在 GPU 内部以流的形式高效流动。
-
-
供应链管理与物流:
-
迁移: 货物从生产到交付给客户的过程可以视为一个物理数据流。每个环节(生产、仓储、运输、分拣)都是一个处理节点,数据(货物)在这些节点之间流动,目标是优化流程、减少库存和提高效率。
-
类比: 货物是“数据”,运输路线是“数据通道”。
-
这些例子都说明了将复杂问题分解为一系列顺序处理的阶段,并让数据在这些阶段之间连续流动的思想,是解决高吞吐量、低延迟和大规模数据处理问题的强大范式。理解数据流的原理,能够帮助我们在设计各种系统时,更好地利用这种思想来构建更高效、更具响应性和可扩展性的解决方案。
相关文章:

stream数据流
核心知识点:数据流(Stream Data Flow) 1. 通俗易懂的解释 想象一下你正在用花园里的水管浇花。水管里的水不是一次性全部倒出来的,而是持续不断地从水龙头流出,经过水管,最终从喷头喷洒到花上。在这个过程…...
读取文件和探测内部网络)
利用 XML 外部实体注入(XXE)读取文件和探测内部网络
利用 XML 外部实体注入(XXE)读取文件和探测内部网络 引言 XML 外部实体注入(XXE)是一种常见的安全漏洞,攻击者可以通过这种漏洞读取服务器上的文件或探测内部网络。本文将通过一个实际的 Python 代码示例,…...
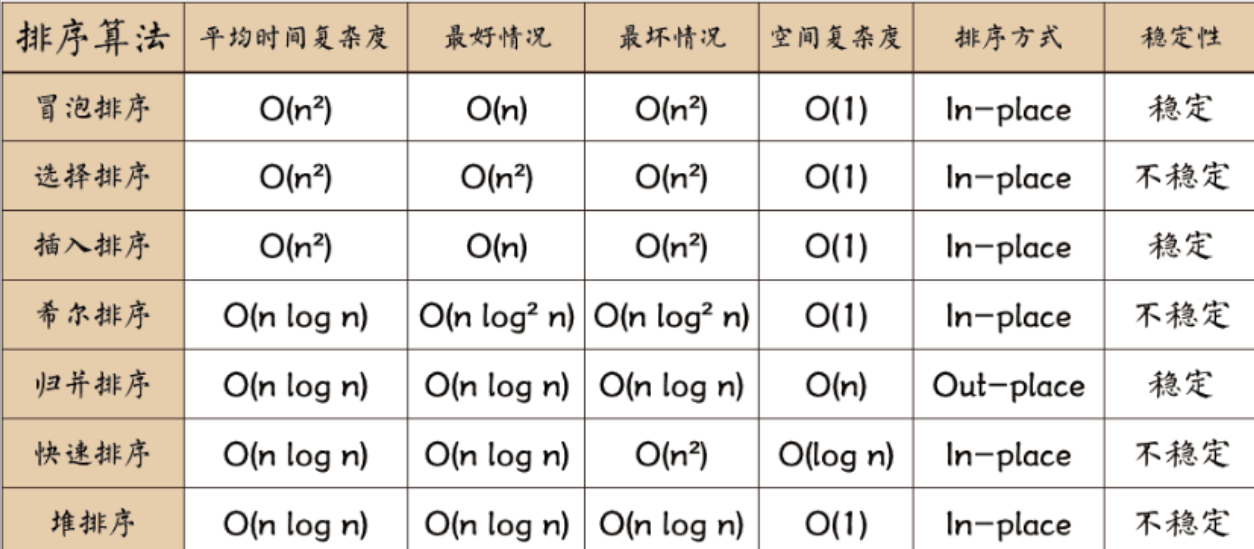
软件设计师“排序算法”真题考点分析——求三连
一、考点分值占比与趋势分析 综合知识题分值统计表 年份考题数量总分值分值占比考察重点2018222.67%时间复杂度/稳定性判断2019334.00%算法特性对比分析2020222.67%空间复杂度要求2021111.33%算法稳定性判断2022334.00%综合特性应用2023222.67%时间复杂度计算2024222.67%分治…...
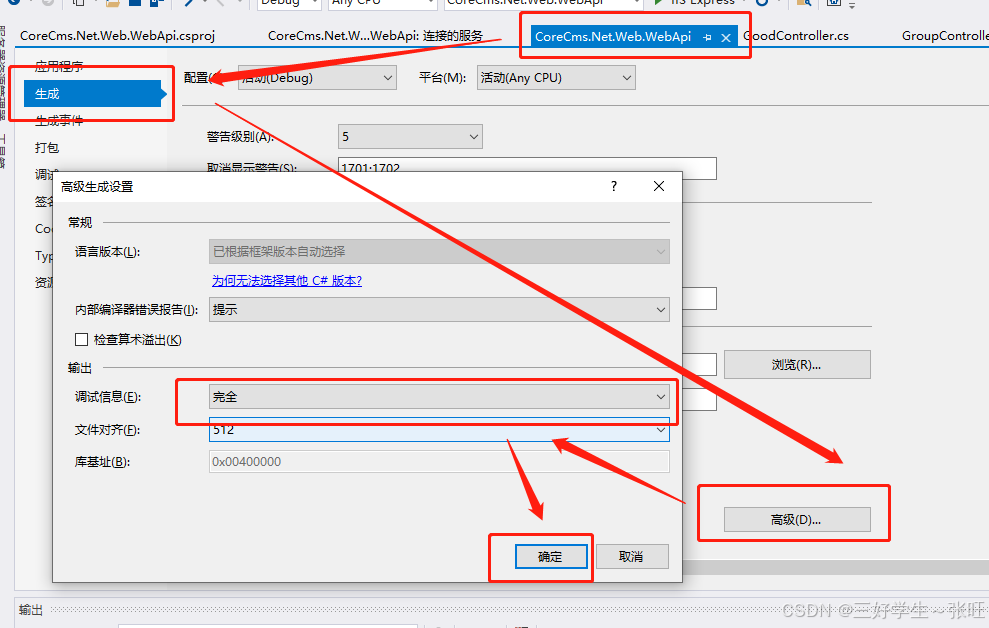
Visual Studio 2019/2022:当前不会命中断点,还没有为该文档加载任何符号。
1、打开调试的模块窗口,该窗口一定要在调试状态下才会显示。 vs2019打开调试的模块窗口 2、Visual Studio 2019提示未使用调试信息生成二进制文件 未使用调试信息生成二进制文件 3、然后到debug目录下看下确实未生成CoreCms.Net.Web.WebApi.pdb文件。 那下面的…...
vue--ofd/pdf预览实现
背景 实现预览ofd/pdf超链接功能 业务实现 pdf的预览 实现方式: 直接使用 <iframe :src"${url}#navpanes0&toolbar0" /> 实现pdf的预览。 navpanes0 隐藏侧边栏toolbar0 隐藏顶部工具栏 使用pdf.js,代码先行: <tem…...
Python 爬虫之requests 模块的应用
requests 是用 python 语言编写的一个开源的HTTP库,可以通过 requests 库编写 python 代码发送网络请求,其简单易用,是编写爬虫程序时必知必会的一个模块。 requests 模块的作用 发送网络请求,获取响应数据。 中文文档…...
【MySQL】CRUD
CRUD 简介 CRUD是对数据库中的记录进行基本的增删改查操作 Create(创建)Retrieve(读取)Update(更新)Delete(删除) 一、新增(Create) 语法: I…...

Spring Boot微服务架构(三):Spring Initializr创建CRM项目
使用Spring Initializr创建CRM项目 一、创建项目前的准备 访问Spring Initializr网站: 打开浏览器访问 https://start.spring.io/或者直接使用IDE(如IntelliJ IDEA或Eclipse)内置的Spring Initializr功能 项目基本信息配置: Proj…...
【笔记】PyCharm 中创建Poetry解释器
#工作记录 在使用 PyCharm 进行 Python 项目开发时,为项目配置合适的 Python 解释器至关重要。Poetry 作为一款强大的依赖管理和打包工具,能帮助我们更便捷地管理项目的依赖项与虚拟环境。下面将详细记录在 PyCharm 中创建 Poetry 解释器的步骤。 前提条…...

SDL2常用函数SDL事件处理:SDL_Event|SDL_PollEvent
SDL_Event SDL_Event是个联合体,是SDL中所有事件处理的核心。 SDL_Event是SDL中使用的所有事件结构的并集。 只要知道了那个事件类型对应SDL_Event结构的那个成员,使用它是一个简单的事情。 下表罗列了所有SDL_Event的所有成员和对应类型。 Uint32typ…...

RAID技术全解析:从基础到实战应用指南
一、RAID核心概念与级别对比 1. RAID的核心目标 数据冗余:通过镜像或校验机制防止数据丢失。 性能提升:利用条带化技术实现并行读写。 存储扩展:聚合多块磁盘容量,突破单盘限制。 2. 常见RAID级别对比 RAID级别最小磁盘数容…...

word通配符表
目录 一、word查找栏代码&通配符一览表二、word替换栏代码&通配符一览表三、参考文献 一、word查找栏代码&通配符一览表 序号清除使用通配符复选框勾选使用通配符复选框特殊字符代码特殊字符代码or通配符1任意单个字符^?一个任意字符?2任意数字^#任意数字&#…...

python中的numpy(数组)
(0)numpy介绍 NumPy是Python中用于科学计算的基础库,提供高效的多维数组对象ndarray,支持向量化运算,能大幅提高数值计算效率。它集成了大量数学函数(如线性代数、傅里叶变换等),可…...

C++ 正则表达式简介
1. 正则表达式简介 正则表达式(Regular Expression,简称Regex)是一种用于匹配和处理文本的强大工具。它通过特定的符号组合形成匹配规则,常用于表单验证、文本搜索与替换、数据清洗等场景。 C11标准引入了 <regex> 头文件…...

iOS知识复习
block原理 OC block 是个结构体,内部有个一个结构体成员 专门保存 捕捉对象 Swift闭包 是个函数,捕获了全局上下文的常量或者变量 修改数组存储的内容,不需要加_block,修改数组对象本身时需要 weak原理 Weak 哈希表 (散列表&a…...
rce命令执行原理及靶场实战(详细)
2. 原理 在根源上应用系统从设计上要给用户提供一个指定的远程命令操作的接口。漏洞主要出现在常见的路由器、防火墙、入侵检测等设备的web管理界面上。在管理界面提供了一个ping服务。提交后,系统对该IP进行ping,并且返回结果。如果后台服务器并没有对…...
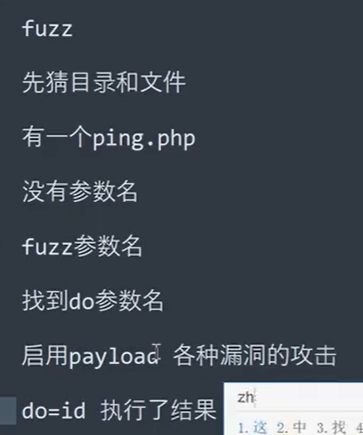
Fuzz 模糊测试篇JS 算法口令隐藏参数盲 Payload未知文件目录
1 、 Fuzz 是一种基于黑盒的自动化软件模糊测试技术 , 简单的说一种懒惰且暴力的技术融合了常见 的以及精心构建的数据文本进行网站、软件安全性测试。 2 、 Fuzz 的核心思想 : 口令 Fuzz( 弱口令 ) 目录 Fuzz( 漏洞点 ) 参数 Fuzz( 利用参数 ) PayloadFuzz(Bypass)…...

展示了一个三轴(X, Y, Z)坐标系!
等轴测投影”(isometric projection)风格的手绘风格三维图,即三条坐标轴(x₁, x₂, x₃)看起来彼此垂直、等角分布(通常是 120 夹角),它是常见于教材和数学书籍的 “假三维”表示法。…...
【b站计算机拓荒者】【2025】微信小程序开发教程 - chapter1 初识小程序 - 3项目目录结构4快速上手
3 项目目录结构 3.1 项目目录结构 3.1.1 目录介绍 # 1 项目主配置文件,在项目根路径下,控制整个项目的-app.js # 小程序入口文件,小程序启动,会执行此js-app.json # 小程序全局配置文件,配置小程序导航栏颜色等信息…...
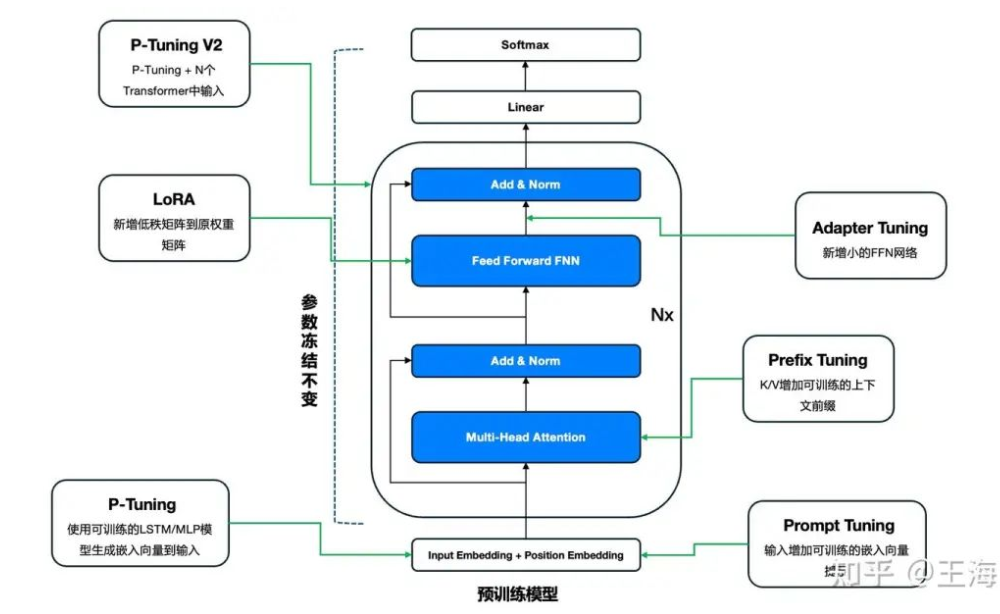
LLM Tuning
Lora-Tuning 什么是Lora微调? LoRA(Low-Rank Adaptation) 是一种参数高效微调方法(PEFT, Parameter-Efficient Fine-Tuning),它通过引入低秩矩阵到预训练模型的权重变换中,实现无需大规模修改…...
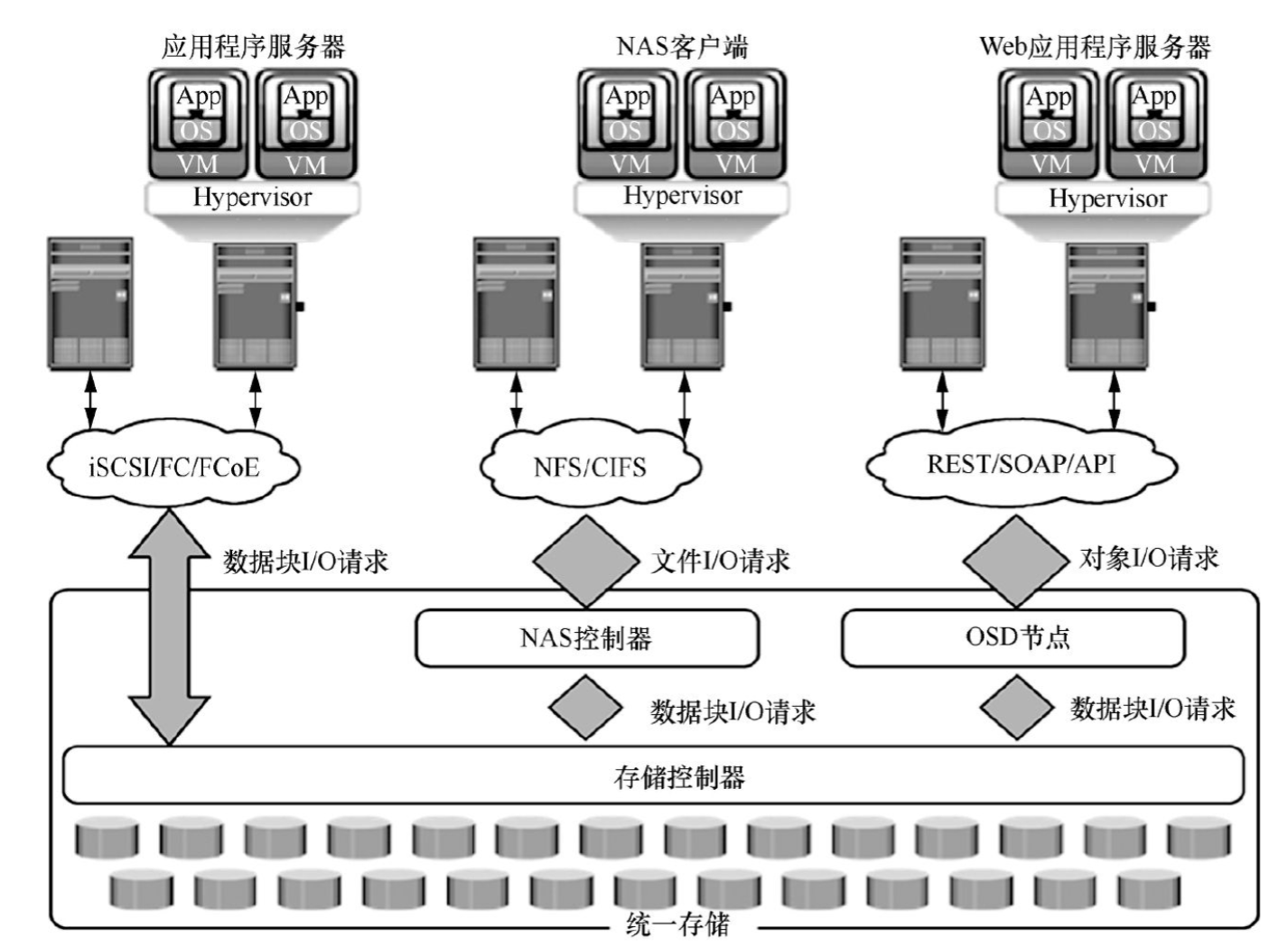
云计算与大数据进阶 | 28、存储系统如何突破容量天花板?可扩展架构的核心技术与实践—— 分布式、弹性扩展、高可用的底层逻辑(下)
在上篇中,我们围绕存储系统可扩展架构详细探讨了基础技术原理与典型实践。然而,在实际应用场景中,存储系统面临的挑战远不止于此。随着数据规模呈指数级增长,业务需求日益复杂多变,存储系统还需不断优化升级࿰…...
)
SQL每日一练(3)
前言: 难得看到了套好题,没考我,呜呜,今日第三更! 原始表(ai生成) 1. 销售表(sales) 用途:记录每笔销售的产品 ID 及金额。 product_id(产品 …...

Axure高级交互设计:中继器嵌套动态面板实现超强体验感台账
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:中继器嵌套动态面板 主要内容:中继器内部嵌套动态面板,实现可移动式台账,增强数据表现…...

水利数据采集MCU水资源的智能守护者
水利数据采集仪MCU,堪称水资源的智能守护者,其重要性不言而喻。在水利工程建设和水资源管理领域,MCU数据采集仪扮演着不可或缺的角色。它通过高精度的传感器和先进的微控制器技术,实时监测和采集水流量、水位、水质等关键数据&…...

函数式编程思想详解
函数式编程思想详解 1. 核心概念 不可变数据 (Immutable Data) 数据一旦创建,不可修改。任何操作均生成新数据,而非修改原数据。 优点:避免副作用,提升并发安全,简化调试。 Java实现:使用final字段、不可变…...

SAP全面转向AI战略,S/4HANA悄然隐身
在2025年SAP Sapphire大会上,SAP首席执行官Christian Klein提出了一个雄心勃勃的愿景:让人工智能(AI)无处不在,推动企业数字化转型。SAP的AI战略核心是将AI深度融入其业务应用生态,包括推出全新版本的AI助手…...
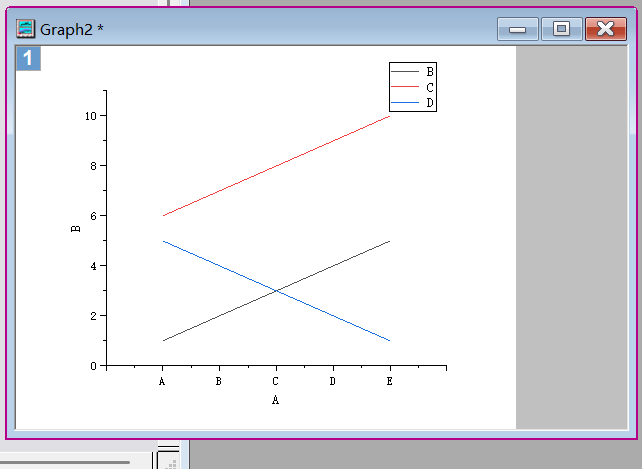
origin绘图之【如何将横坐标/x设置为文字、字母形式】
在使用 Origin 进行科研绘图或数据可视化的过程中,我们常常会遇到这样一种需求:希望将横坐标(X轴)由默认的数字形式,改为字母(如 A、B、C……)或中文文字(如 一、二、三………...

工业智能网关建立烤漆设备故障预警及远程诊断系统
一、项目背景 烤漆房是汽车、机械、家具等工业领域广泛应用的设备,主要用于产品的表面涂装。传统的烤漆房控制柜采用本地控制方式,操作人员需在现场进行参数设置和设备控制,且存在设备智能化程度低、数据孤岛、设备维护成本高以及依靠传统人…...
生成的视频无法在浏览器展)
cv2.VideoWriter_fourcc(*‘mp4v‘)生成的视频无法在浏览器展
看这个博主的博客,跟我碰到的问题的一致,都是使用AVC1写视频时报编码器不存在的异常,手动编译opencv-python或者使用conda install -c conda-forge opencv安装依赖即可。 博主博客:Python OpenCV生成视频无法浏览器播放问题说明及…...

MySQL 8.0 OCP 1Z0-908 161-170题
Q161.Examine this command, which executes successfully: cluster.addInstance ( ‘:’,{recoveryMethod: ‘clone’ 1}) Which three statements are true? (Choose three.) A)The account used to perform this recovery needs the BACKUP_ ADMIN privilege. B)A target i…...