多场景游戏AI新突破!Divide-Fuse-Conquer如何激发大模型“顿悟时刻“?
多场景游戏AI新突破!Divide-Fuse-Conquer如何激发大模型"顿悟时刻"?
大语言模型在强化学习中偶现的"顿悟时刻"引人关注,但多场景游戏中训练不稳定、泛化能力差等问题亟待解决。Divide-Fuse-Conquer方法,通过分组训练、参数融合等策略,在18款TextArena游戏中实现与Claude3.5相当的性能,为多场景强化学习提供新思路。
论文标题
Divide-Fuse-Conquer: Eliciting “Aha Moments” in Multi-Scenario Games
来源
arXiv:2505.16401v1 [cs.LG] + https://arxiv.org/abs/2505.16401
文章核心
研究背景
近年来,大语言模型(LLMs)在强化学习(RL)中展现出令人瞩目的推理能力,在数学、编程、视觉等领域通过简单的基于结果的奖励,就能触发类似人类“顿悟时刻”的能力突破。
尽管RL在单场景任务中成效显著,但在多场景游戏领域却面临严峻挑战。游戏场景中,规则、交互模式和环境复杂度的多样性,导致策略常出现“此长彼消”的泛化困境——在某一场景表现优异,却难以迁移至其他场景。而简单合并多场景进行训练,还会引发训练不稳定、性能不佳等问题,这使得多场景游戏成为检验RL与LLMs结合成效的关键领域,也亟需新的方法来突破现有瓶颈。
研究问题
1. 训练不稳定性:多场景游戏中任务分布异质性强,直接应用强化学习易导致训练崩溃,如DeepSeek-R1在场景增多时性能显著下降。
2. 泛化能力不足:简单合并多场景训练时,模型在某一场景表现良好,却难以迁移到其他场景,出现"顾此失彼"的情况。
3. 效率与性能矛盾:统一训练所有场景时,模型可能优先学习简单任务,忽视复杂任务,导致整体优化效率低下且最终性能不佳。
主要贡献
1. 提出Divide-Fuse-Conquer框架:通过启发式分组、参数融合和渐进式训练,系统性解决多场景强化学习中的训练不稳定和泛化问题,这与传统单一训练或简单合并训练的方式有本质区别。
2. 创新技术组合提升训练质量:集成格式奖励塑造、半负采样、混合优先级采样等技术,从稳定性、效率和性能三方面优化训练过程,如半负采样通过过滤一半负样本防止梯度主导,就像在嘈杂环境中过滤掉部分干扰信号。
3. 多场景游戏验证与性能突破:在18款TextArena游戏中,使用Qwen2.5-32B-Align模型训练后,与Claude3.5对战取得7胜4平7负的成绩,证明该框架能有效激发大模型在多场景游戏中的"顿悟时刻"。
方法论精要
框架设计:Divide-Fuse-Conquer的三级递进策略
分组(Divide):根据游戏规则(如固定/随机初始状态)和难度(基础模型胜率是否为零),将18款TextArena游戏划分为4个组。例如,ConnectFour-v0等固定初始状态且基础模型可获胜的游戏归为一组,而LiarsDice-v0等随机初始状态且初始胜率为零的游戏归为另一组,如同将复杂任务按类型和难度分类拆解。
融合(Fuse):采用参数平均策略融合各组最优策略。具体而言,第 k k k组策略参数 θ ( π k ) \theta^{(\pi_k)} θ(πk)与前 k − 1 k-1 k−1组合并后的参数 θ ( π ( k − 1 ) ) ) \theta^{(\pi{(k-1)})}) θ(π(k−1)))按 θ ( π ( k ) ) = 1 2 ( θ π ( k − 1 ) + θ π k ) \theta^{(\pi{(k)})} = \frac{1}{2}(\theta^{\pi{(k-1)}} + \theta^{\pi_k}) θ(π(k))=21(θπ(k−1)+θπk)融合,使新模型继承跨组知识,类似将不同领域的专家经验整合为“全能选手”。
征服(Conquer):通过GRPO算法对融合模型持续训练,结合多维度优化技术,逐步提升跨场景泛化能力。


核心技术:多维度训练优化组合
奖励机制重构:
格式奖励 ( R format ) (R_{\text{format}}) (Rformat):对无效动作(如格式错误)施加-2惩罚,确保模型输出合规,如同考试中规范答题格式。
环境奖励 ( R env ) (R_{\text{env}}) (Renv):按游戏结果赋予1(胜)、0(平)、-1(负),直接反馈游戏胜负。
仓促动作惩罚 ( R step ) (R_{\text{step}}) (Rstep):在获胜场景中,根据轨迹步数 n T n_T nT缩放奖励(如TowerOfHanoi中高效解法获更高分),引导模型避免短视决策。

样本与探索优化:
半负采样(Half-Negative Sampling):随机丢弃50%负样本,防止负梯度主导训练,类似在嘈杂数据中过滤干扰。
混合优先级采样(MPS):动态分配采样权重,优先训练中低胜率游戏,如学生重点攻克薄弱科目。
ϵ \epsilon ϵ-greedy扰动与随机种子:以概率 ϵ \epsilon ϵ随机选择动作,并随机初始化环境种子,增强探索多样性,避免陷入局部最优。
实验验证:多场景与基线对比设计
数据集:TextArena平台18款游戏,包括4款单玩家(如TowerOfHanoi-v0)和14款双玩家(如Poker-v0、ConnectFour-v0),覆盖规则简单到复杂的场景。
基线方法:
- Naive-MSRL:直接多场景RL训练;
- Naive-SSRL:单场景RL训练;
- Claude3.5:先进大模型基线。
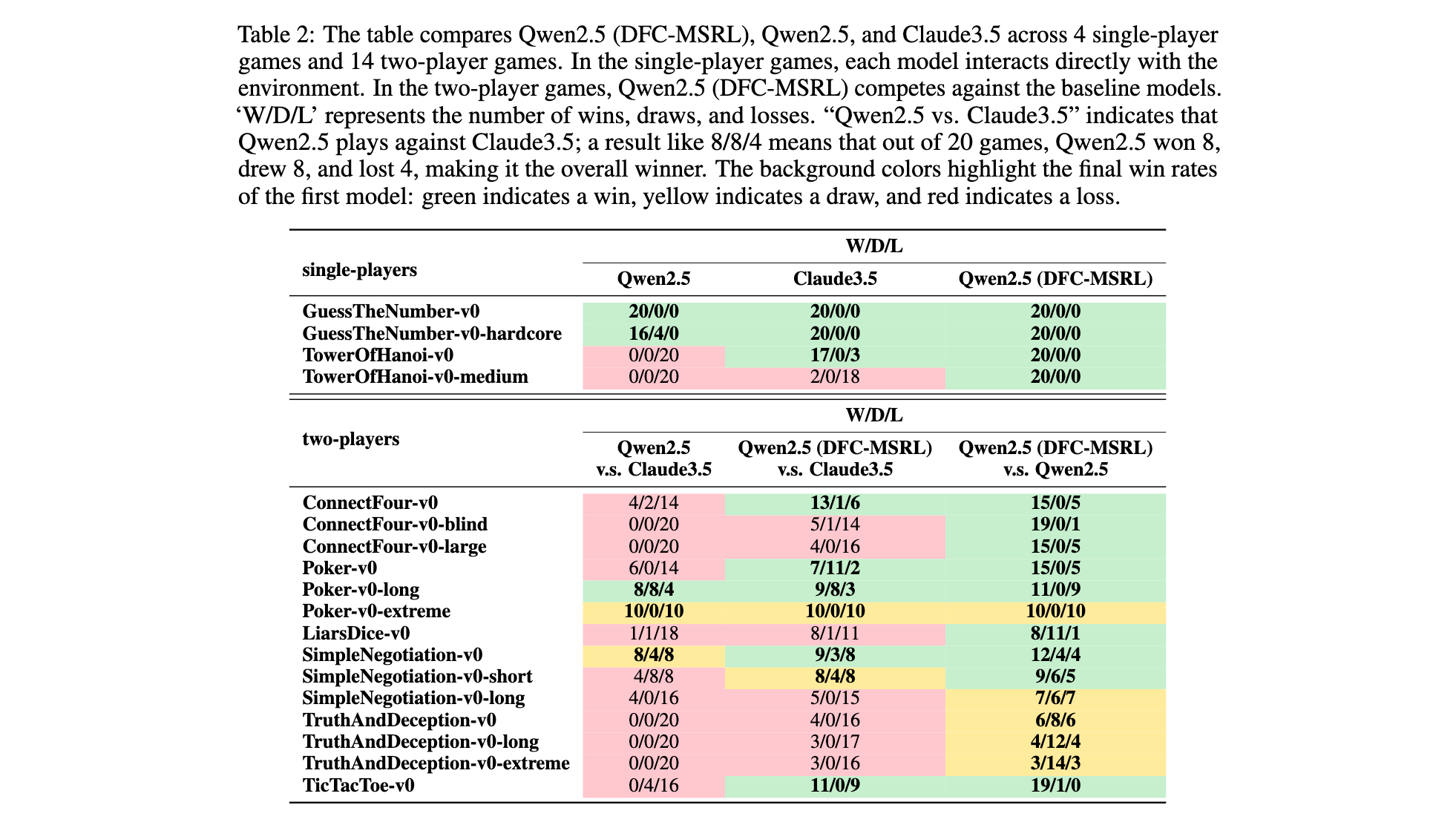
实施细节:使用64张A100 GPU,batch size=1,学习率2e-6,训练100轮,每轮通过自玩收集轨迹数据,结合GRPO算法更新策略,最终以胜率(W/D/L)评估跨场景性能。
实验洞察
跨场景性能突破:Qwen2.5与Claude3.5的对战表现
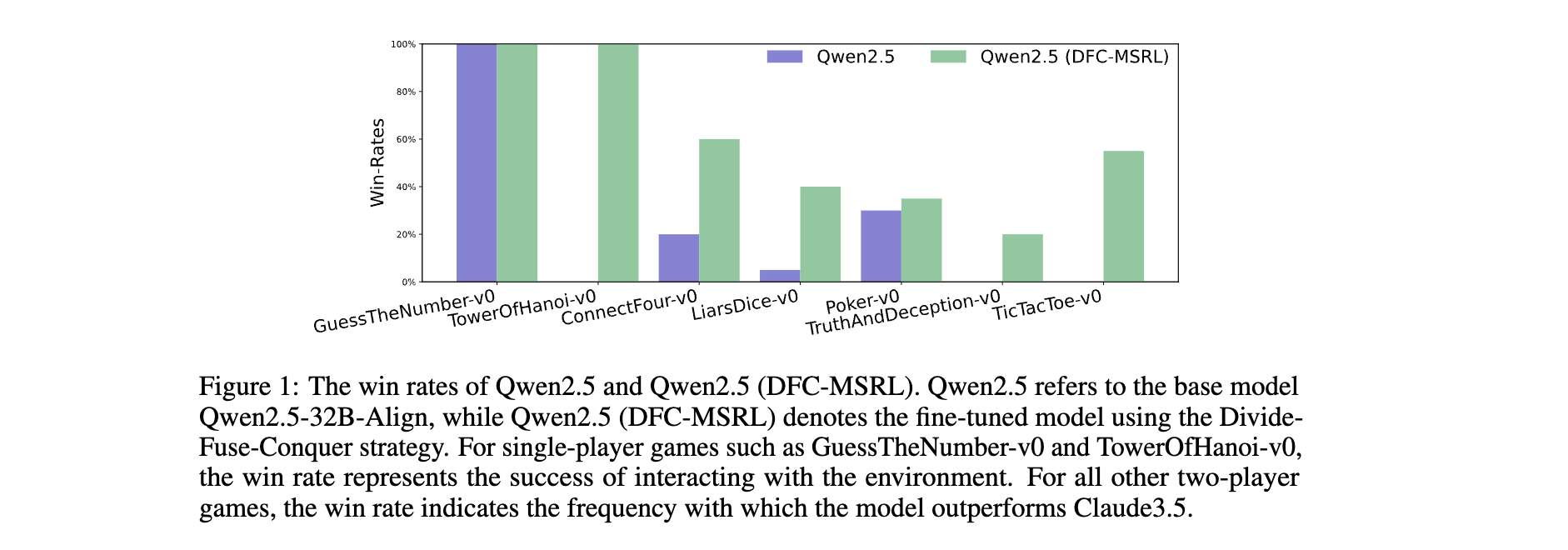
在18款TextArena游戏中,采用Divide-Fuse-Conquer(DFC-MSRL)训练的Qwen2.5-32B-Align模型展现出显著提升:
- 单玩家游戏全胜突破:在TowerOfHanoi-v0-medium等场景中,模型从基础版本的0胜率提升至100%胜率,如3层汉诺塔问题中,通过策略优化实现7步内完成移动(传统解法最优步数)。
- 双玩家游戏竞争力:与Claude3.5对战时,取得7胜4平7负的战绩。其中在ConnectFour-v0中以13胜1平6负显著超越基础模型(4胜2平14负);在Poker-v0中以7胜11平2负实现平局率提升,证明在策略博弈中具备动态决策能力。
效率验证:训练收敛速度与资源优化
- 对比单/多场景训练:DFC-MSRL在ConnectFour-v0中仅用10轮迭代就达到65%胜率,而Naive-MSRL需30轮才收敛至40%,训练效率提升约3倍。这得益于分组训练减少了跨场景干扰,类似分阶段攻克知识点的学习模式。
- 采样策略的效率优势:混合优先级采样(MPS)使TowerOfHanoi-v0-medium的有效训练样本增加40%,模型在20轮内即稳定至100%胜率,而均匀采样基线需40轮,验证了“优先攻克薄弱场景”策略的高效性。
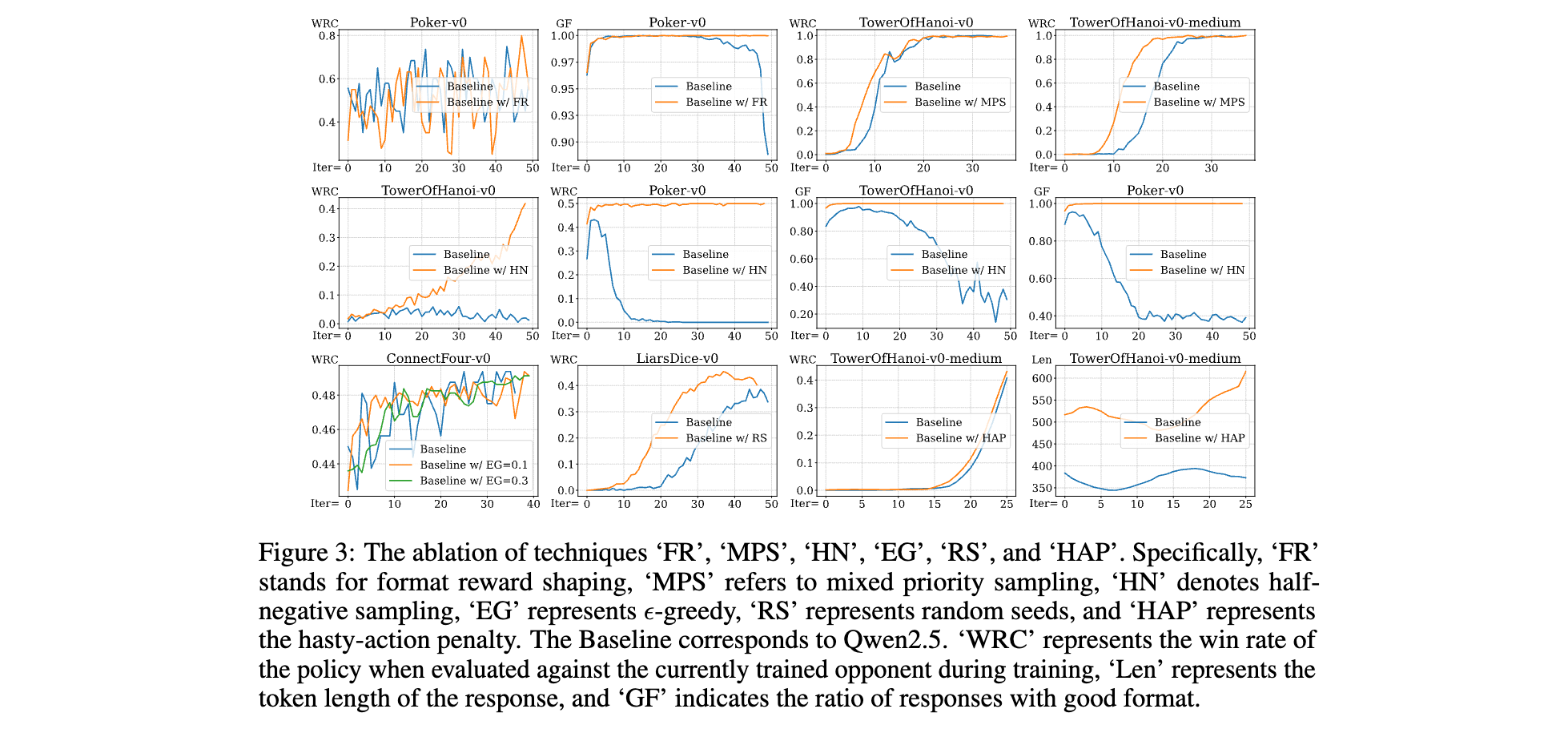
消融研究:核心技术的有效性拆解
稳定性优化技术
- 格式奖励塑造(FR):在Poker-v0中,FR使模型输出有效动作比例(GF)始终维持1.0,而无FR的基线模型在10轮后GF骤降至0.6,出现大量格式错误(如未按“[Action]”格式输出),证明格式约束是训练基石。
- 半负采样(HN):在TowerOfHanoi-v0中,HN将训练初期的胜率波动从±30%降至±5%,避免负样本主导导致的策略崩溃,如同在学习中过滤掉过多错误示例的干扰。
探索与采样技术
- ε-greedy扰动(EG):在ConnectFour-v0中,EG=0.3时模型从持续输给Claude3.5(0胜20负)转变为可获胜(5胜1平14负),证明随机探索能帮助模型发现“四子连线”的关键策略,而纯贪心策略易陷入固定思维。
- 随机种子初始化(RS):在LiarsDice-v0中,RS使模型面对不同初始骰子分布时胜率提升25%,从基线的40%升至65%,验证了多样化初始状态对策略泛化的重要性。
奖励机制优化
- 仓促动作惩罚(HAP):在TowerOfHanoi-v0-medium中,HAP使模型平均决策步数从12步降至8步(接近最优解),轨迹长度减少33%,表明惩罚机制有效抑制了“盲目试错”行为,引导模型追求高效策略。
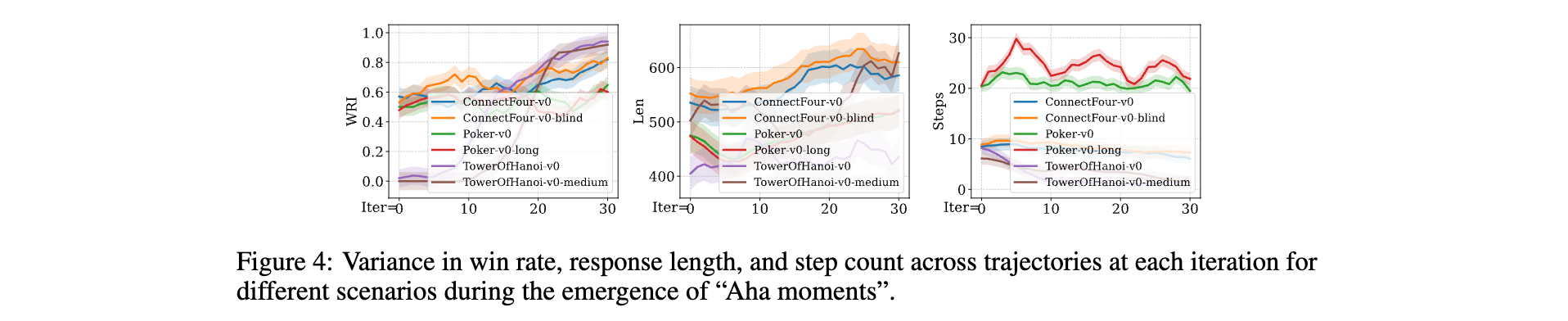
Aha Moment
在TextArena游戏中应用GRPO训练时,模型偶现“Aha moments”。表现为胜率显著提升,如ConnectFour-v0从4胜到13胜;响应更深入,token长度增30%;结合惩罚后执行步数减25%,如TowerOfHanoi-v0-medium达最优解,体现从试错到策略推理的突破。

相关文章:
多场景游戏AI新突破!Divide-Fuse-Conquer如何激发大模型“顿悟时刻“?
多场景游戏AI新突破!Divide-Fuse-Conquer如何激发大模型"顿悟时刻"? 大语言模型在强化学习中偶现的"顿悟时刻"引人关注,但多场景游戏中训练不稳定、泛化能力差等问题亟待解决。Divide-Fuse-Conquer方法,通过…...

Java 函数式接口(Functional Interface)
一、理论说明 1. 函数式接口的定义 Java 函数式接口是一种特殊的接口,它只包含一个抽象方法(Single Abstract Method, SAM),但可以包含多个默认方法或静态方法。函数式接口是 Java 8 引入 Lambda 表达式的基础,通过函…...
分布式锁总结
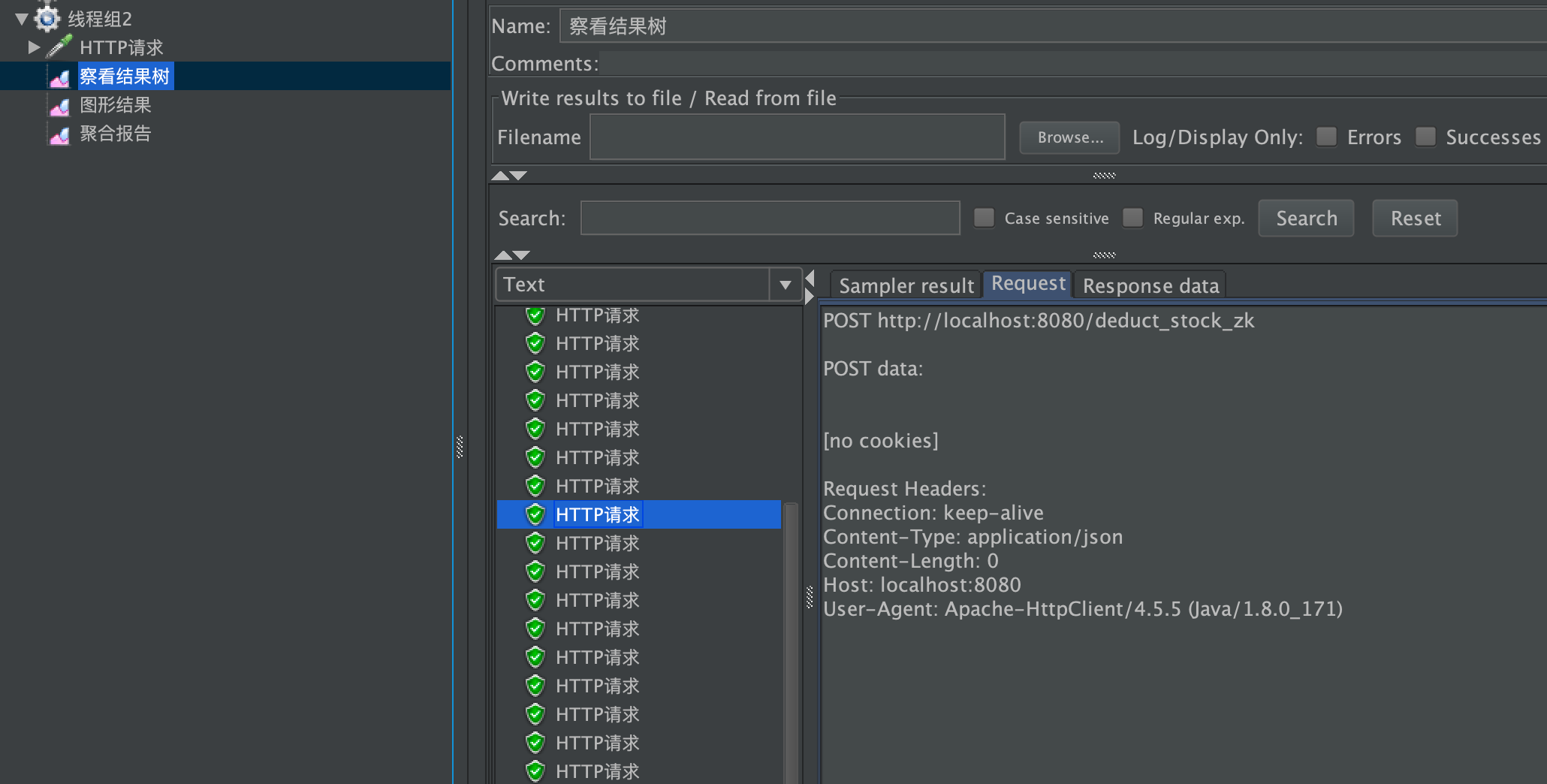
文章目录 分布式锁什么是分布式锁?分布式锁的实现方式基于数据库(mysql)实现基于缓存(redis)多实例并发访问问题演示项目代码(使用redis)配置nginx.confjmeter压测复现问题并发是1,即不产生并发问题并发30测试,产生并发问题(虽然单实例是synchronized&am…...
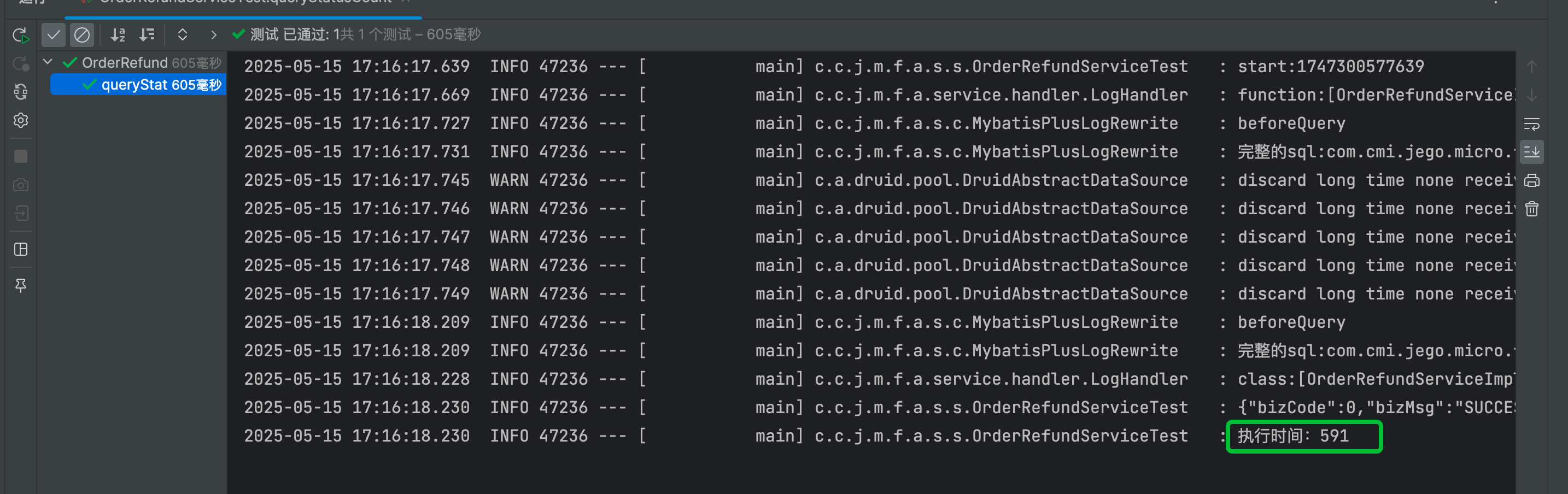
使用MybatisPlus实现sql日志打印优化
背景: 在排查无忧行后台服务日志时,一个请求可能会包含多个执行的sql,经常会遇到SQL语句与对应参数不连续显示,或者参数较多需要逐个匹配的情况。这种情况下,如果需要还原完整SQL语句就会比较耗时。因此,我…...

springboot中redis的事务的研究
redis的事务类似于队列操作,执行过程分为三步: 开启事务入队操作执行事务 使用到的几个命令如下: 命令说明multi开启一个事务exec事务提交discard事务回滚watch监听key(s):当监听一个key(s)时,如果在本次事务提交之…...

为什么我输入对了密码,还是不能用 su 切换到 root?
“为什么我输入对了密码,还是不能用 su 切换到 root?” 其实这背后可能不是“密码错了”,而是系统不允许你用 su 切 root,即使密码对了。 👇 以下是最常见的几个真正原因: ❌ 1. Root 用户没有设置密码&…...
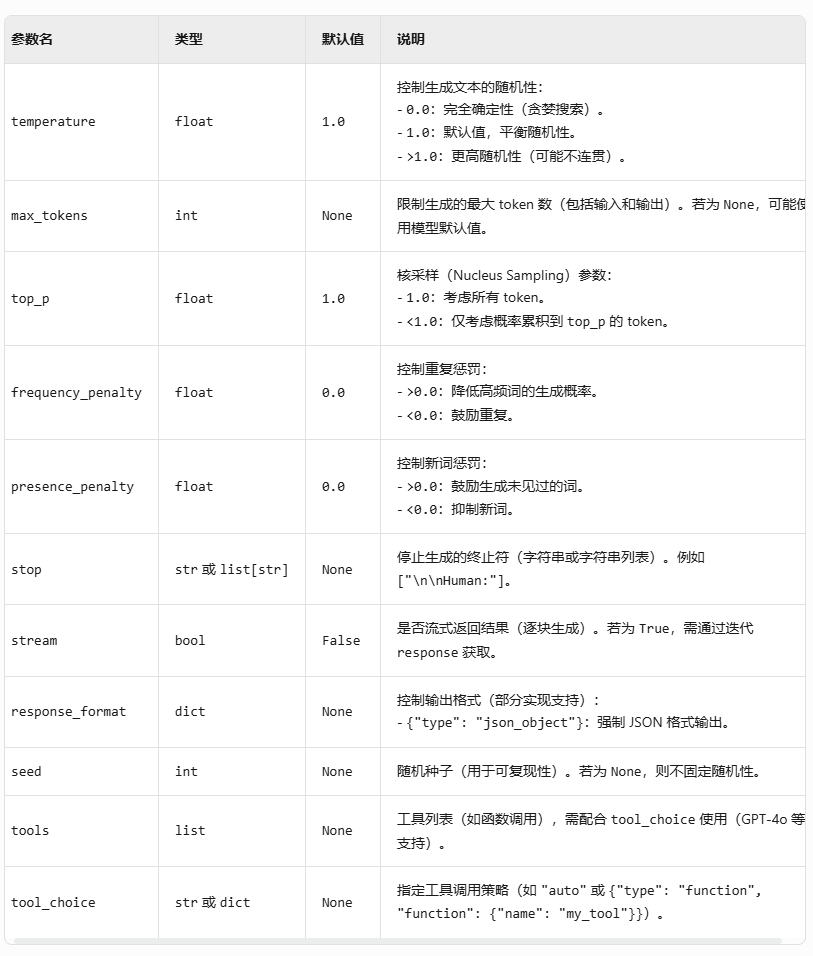
client.chat.completions.create方法参数详解
response client.chat.completions.create(model"gpt-3.5-turbo", # 必需参数messages[], # 必需参数temperature1.0, # 可选参数max_tokensNone, # 可选参数top_p1.0, # 可选参数frequency_penalty0.0, # 可选参数presenc…...

量子计算与云计算的融合:技术前沿与应用前景
目录 引言 量子计算基础 量子计算的基本原理 量子计算的优势与挑战 量子计算的发展阶段 云计算基础 云计算的基本概念 云计算的应用领域 云计算面临的挑战 量子计算与云计算的结合 量子云计算的概念与架构 量子云计算的服务模式 量子云计算的优势 量子云计算的发展…...

《企业级日志该怎么打?Java日志规范、分层设计与埋点实践》
大家好呀!👋 今天我们要聊一个Java开发中超级重要但又经常被忽视的话题——日志系统!📝 不管你是刚入门的小白,还是工作多年的老司机,日志都是我们每天都要打交道的"好朋友"。那么,如…...

python模块管理环境变量
概要 在 Python 应用中,为了将配置信息与代码分离、增强安全性并支持多环境(开发、测试、生产)运行,使用专门的模块来管理环境变量是最佳实践。常见工具包括: 标准库 os.environ:直接读取操作系统环境变量…...

【泛微系统】后端开发Action常用方法
后端开发Action常用方法 代码实例经验分享:代码实例 经验分享: 本文分享了后端开发中处理工作流Action的常用方法,主要包含以下内容:1) 获取工作流基础信息,如流程ID、节点ID、表单ID等;2) 操作请求信息,包括请求紧急程度、操作类型、用户信息等;3) 表单数据处理,展示…...

【算法】力扣体系分类
第一章 算法基础题型 1.1 排序算法题 1.1.1 冒泡排序相关题 冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,…...

sql:如何查询一个数据表字段:Scrp 数据不为空?
在SQL中,要查询一个数据表中的字段 Scrp 不为空的记录,可以使用 IS NOT NULL 条件。以下是一个基本的SQL查询示例: SELECT * FROM your_table_name WHERE Scrp IS NOT NULL;在这个查询中,your_table_name 应该替换为你的实际数据…...

深入浅出人工智能:机器学习、深度学习、强化学习原理详解与对比!
各位朋友,大家好!今天咱们聊聊人工智能领域里最火的“三剑客”:机器学习 (Machine Learning)、深度学习 (Deep Learning) 和 强化学习 (Reinforcement Learning)。 听起来是不是有点高大上? 别怕,我保证把它们讲得明明…...
)
索引下探(Index Condition Pushdown,简称ICP)
索引下探(Index Condition Pushdown,简称ICP)是一种数据库查询优化技术,常见于MySQL等关系型数据库中。 1. 核心概念 作用:将原本在服务器层执行的WHERE条件判断尽可能下推到存储引擎层执行。减少回表查询次数支持部…...
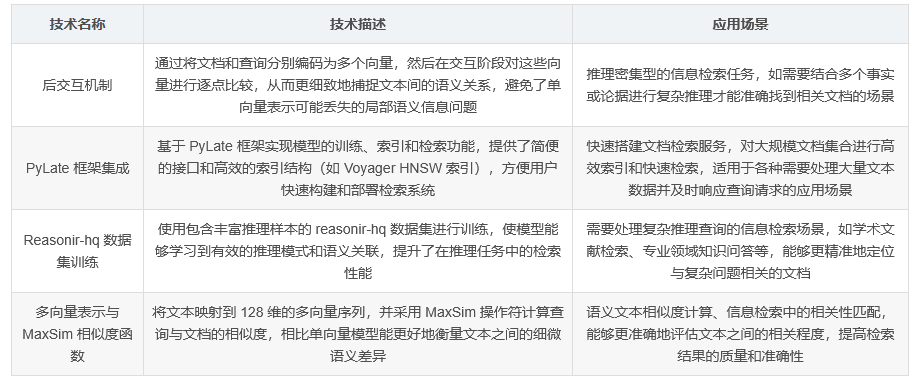
基于 ColBERT 框架的后交互 (late interaction) 模型速递:Reason-ModernColBERT
一、Reason-ModernColBERT 模型概述 Reason-ModernColBERT 是一种基于 ColBERT 框架的后交互 (late interaction) 模型,专为信息检索任务中的推理密集型场景设计。该模型在 reasonir-hq 数据集上进行训练,于 BRIGHT 基准测试中取得了极具竞争力的性能表…...
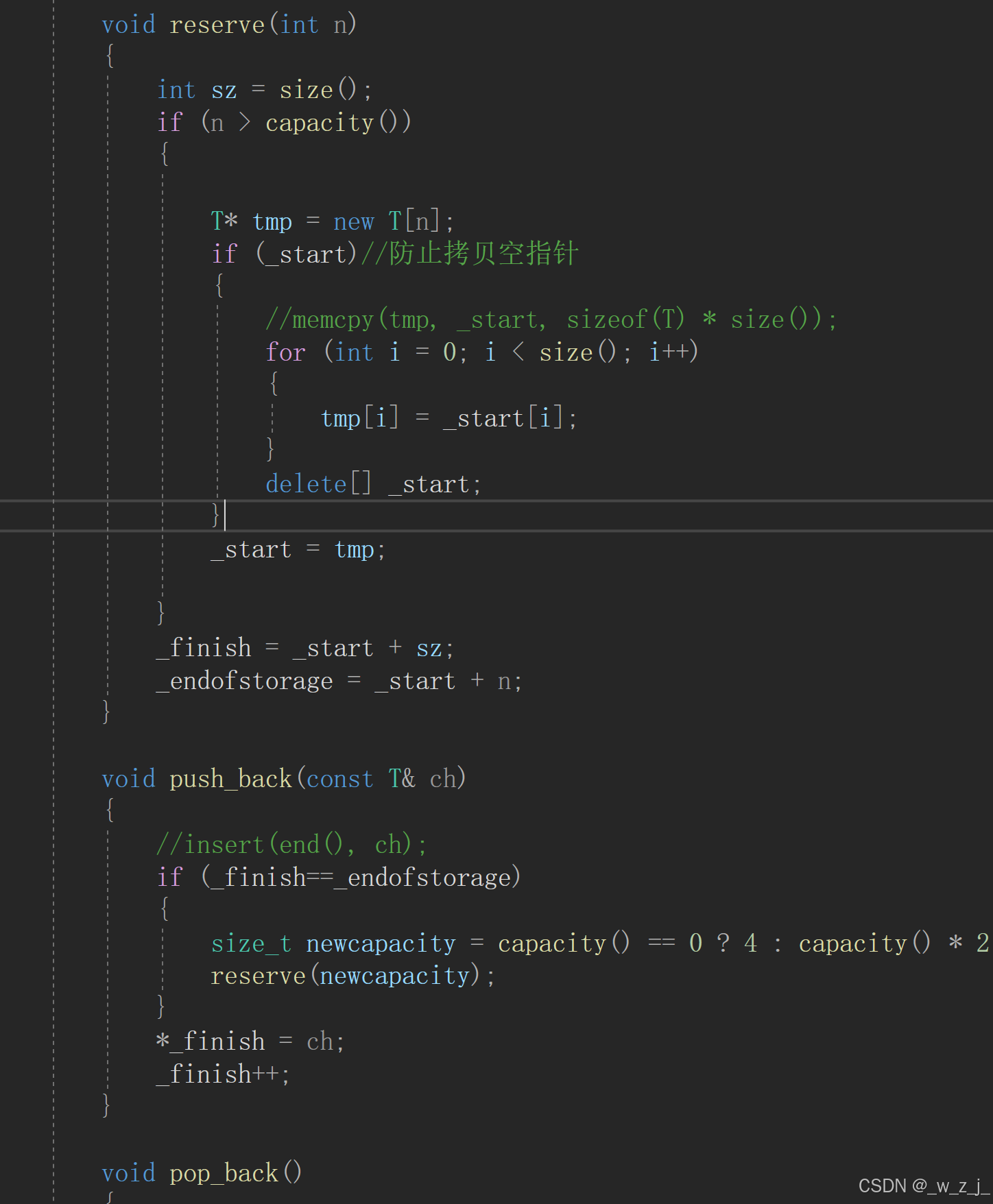
vector中reserve导致的析构函数问题
接上一节vector实现,解决杨辉三角问题时,我在最后调试的时候,发现return vv时,调用析构函数,到第四步时才析构含有14641的vector。我设置了一个全局变量i来记录。 初始为35: 当为39时,也就是第…...
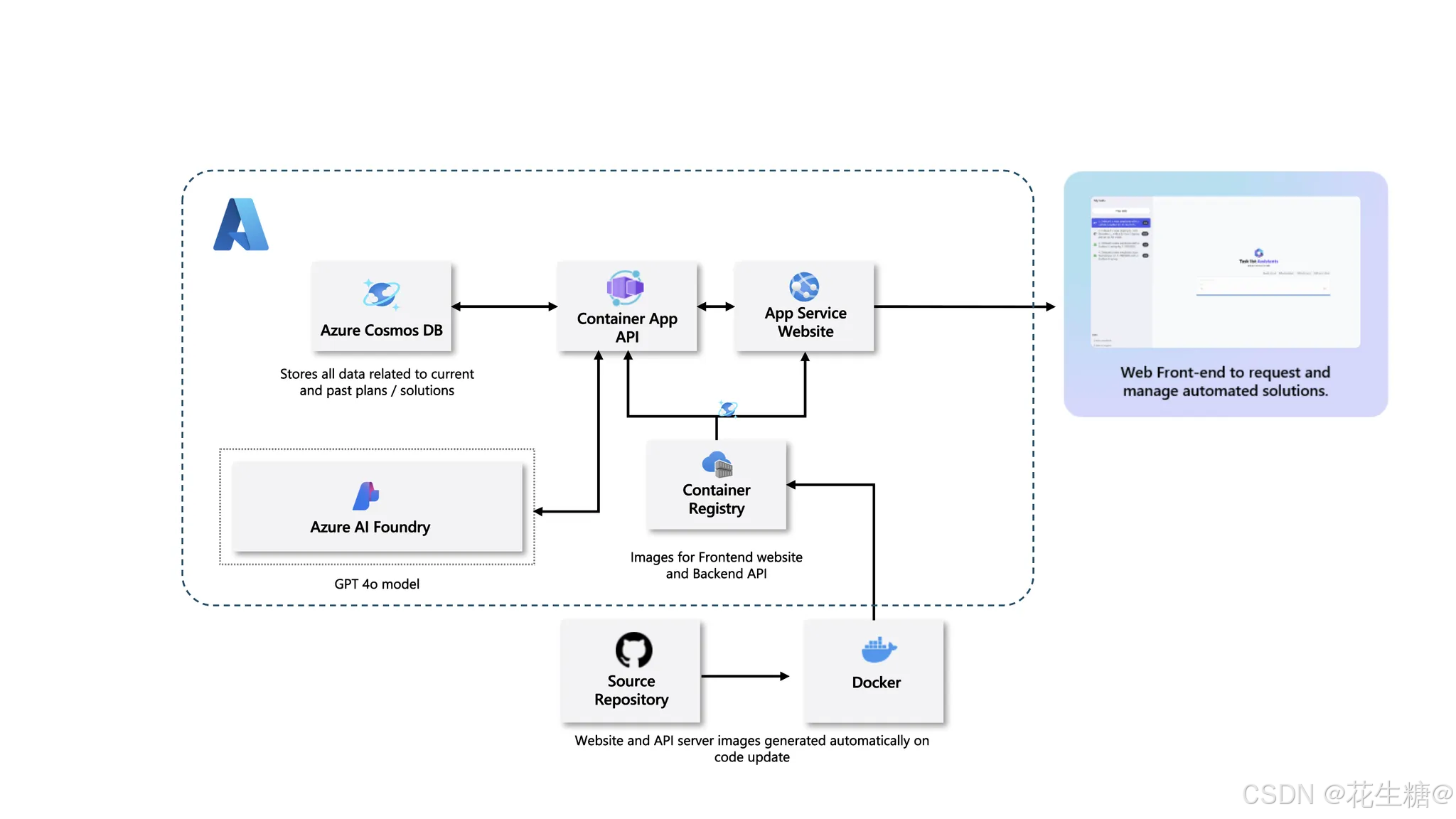
微软开源多智能体自定义自动化工作流系统:构建企业级AI驱动的智能引擎
微软近期推出了一款开源解决方案加速器——Multi-Agent Custom Automation Engine Solution Accelerator,这是一个基于AI多智能体协作的自动化工作流系统。该系统通过指挥多个智能体(Agent)协同完成复杂任务,显著提升企业在数据处理、业务流程管理等场景中的效率与准确性。…...

关于vector、queue、list哪边是front、哪边是back,增加、删除元素操作
容器的 front、back 及操作方向 1.1vector(动态数组) 结构:连续内存块,支持快速随机访问。 操作方向: front:第一个元素(索引 0)。 back:最后一个元素(索引…...

KubeVela入门到精通-K8S多集群交付
目录 1、介绍 2、部署 3、部署UI界面 4、御载 5、Velaux概念 6、OAM应用模型介绍 7、应用部署计划 8、系统架构 9、基础环境配置 9.1 创建项目 9.2 创建集群 9.3 创建交付目标 9.4 创建环境 9.5、创建服务测试 9.6、服务操作 10、插件、项目、权限管理 10.1 插…...

RocketMq的消息类型及代码案例
RocketMQ 提供了多种消息类型,以满足不同业务场景对 顺序性、事务性、时效性 的要求。其核心设计思想是通过解耦 “消息传递模式” 与 “业务逻辑”,实现高性能、高可靠的分布式通信。 一、主要类型包括 普通消息(基础类型)顺序…...

Eigen 直线拟合/曲线拟合/圆拟合/椭圆拟合
一、直线拟合 使用Eigen库进行直线拟合是数据分析和科学计算中的常见任务,主要通过最小二乘法实现。以下是关键实现方法和示例: 核心原理最小二乘法通过最小化点到直线距离的平方和来求解最优直线参数间接平差法是最小二乘法的具体实现形式,适用于直线拟合场景通过构建误差…...

安卓无障碍脚本开发全教程
文章目录 第一部分:无障碍服务基础1.1 无障碍服务概述核心功能: 1.2 基本原理与架构1.3 开发环境配置所需工具:关键依赖: 第二部分:创建基础无障碍服务2.1 服务声明配置2.2 服务配置文件关键属性说明: 2.3 …...

svn迁移到git保留记录和Python字符串格式化 f-string的进化历程
svn迁移到git保留记录 and Python字符串格式化(二): f-string的进化历程 在将项目从SVN迁移到Git时,保留完整的版本历史记录非常重要。下面是详细的步骤和工具,可以帮助你完成这一过程: 安装Git和SVN工具 首先&#…...
SOC-ESP32S3部分:10-GPIO中断按键中断实现
飞书文档https://x509p6c8to.feishu.cn/wiki/W4Wlw45P2izk5PkfXEaceMAunKg 学习了GPIO输入和输出功能后,参考示例工程,我们再来看看GPIO中断,IO中断的配置分为三步 配置中断触发类型安装中断服务注册中断回调函数 ESP32-S3的所有通用GPIO…...

【神经网络与深度学习】扩散模型之原理解释
引言: 在人工智能的生成领域,扩散模型(Diffusion Model)是一项极具突破性的技术。它不仅能够生成高质量的图像,还可以应用于音频、3D建模等领域。扩散模型的核心思想来源于物理扩散现象,其工作方式类似于从…...
跳跃与重复问题的解析:成因、机制及解决方案)
语音合成之十六 语音合成(TTS)跳跃与重复问题的解析:成因、机制及解决方案
语音合成(TTS)跳跃与重复问题的解析:成因、机制及解决方案 引言TTS中跳跃与重复问题的根本原因注意力机制的失效文本到语音的对齐挑战自回归(AR)TTS模型的固有挑战时长建模的重要性输入数据特征的影响 构建鲁棒性&…...

战略-2.1 -战略分析(PEST/五力模型/成功关键因素)
战略分析路径,先宏观(PEST)、再产业(产品生命周期、五力模型、成功关键因素)、再竞争对手分析、最后企业内部分析。 本文介绍:PEST、产品生命周期、五力模型、成功关键因素、产业内的战略群组 一、宏观环境…...
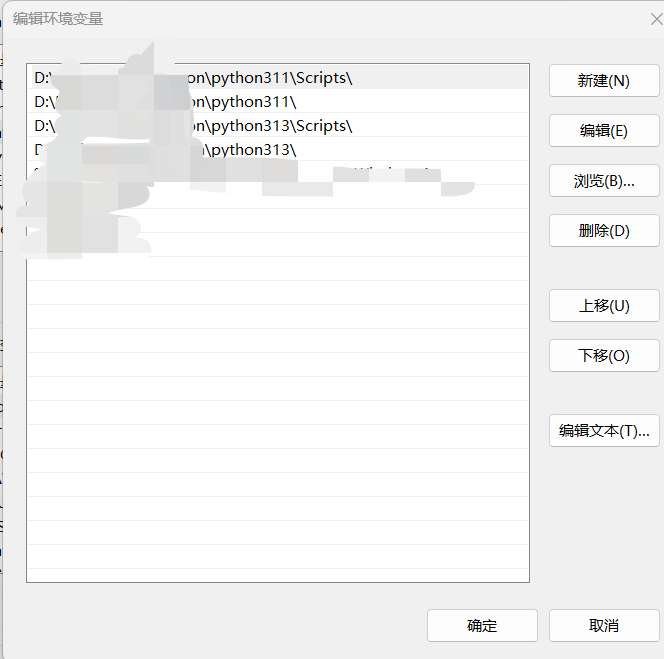
python第三方库安装错位
问题所在 今天在安装我的django库时,我的库安装到了python3.13版本。我本意是想安装到python3.11版本的。我的pycharm右下角也设置了python3.11 但是太可恶了,我在pycharm的项目终端执行安装命令的时候还是给我安装到了python3.13的位置。 解决方法 我…...
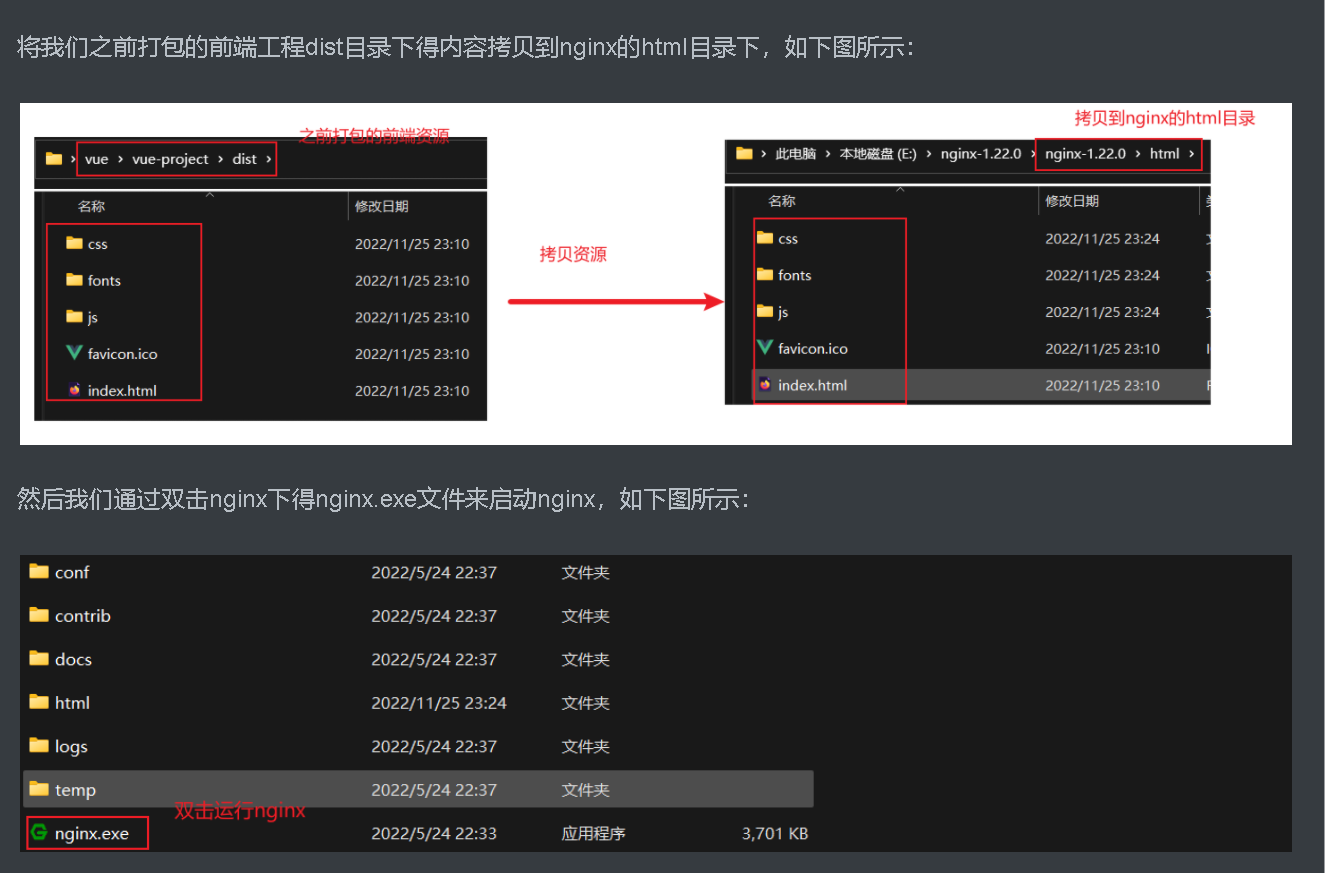
如何把vue项目部署在nginx上
1:在vscode中把vue项目打包会出现dist文件夹 按照图示内容即可把vue项目部署在nginx上...