python打卡day34
知识点回归:
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
判断 CPU 的好坏需要综合考虑硬件参数、性能表现、适用场景:
- 看架构代际,新一代架构通常优化指令集、缓存设计和能效比。如Intel 第 13 代 i5-13600K 比第 12 代 i5-12600K 多核性能提升约 15%
- 看制程工艺,制程越小,晶体管密度越高,能效比越好,如AMD Ryzen 7000 系列(5nm)比 Ryzen 5000 系列(7nm)能效比提升约 30%
- 看核心数:性能核负责高负载任务(如游戏、视频剪辑),单核性能强。能效核负责多任务后台处理(如下载、杀毒),功耗低。如游戏 / 办公:4-8 核足够,内容创作 / 编程:12 核以上更优
- 看线程数目
- 看频率,高频适合单线程任务(如游戏、Office),低频多核适合多线程任务(如 3D 渲染)
- 支持的指令集和扩展能力
如何衡量GPU的性能好坏?
1.通过“代”
前两位数字代表“代”: 40xx (第40代), 30xx (第30代), 20xx (第20代)。“代”通常指的是其底层的架构 (Architecture)。每一代新架构的发布,通常会带来工艺制程的进步和其他改进。也就是新一代架构的目标是在能效比和绝对性能上超越前一代同型号的产品
2.通过级别
后面的数字代表“级别”:
- xx90: 通常是该代的消费级旗舰或次旗舰,性能最强,显存最大 (如 RTX 4090, RTX 3090)
- xx80: 高端型号,性能强劲,显存较多 (如 RTX 4080, RTX 3080)
- xx70: 中高端,甜点级,性能和价格平衡较好 (如 RTX 4070, RTX 3070)
- xx60: 主流中端,性价比较高,适合入门或预算有限 (如 RTX 4060, RTX 3060)
- xx50: 入门级,深度学习能力有限
3.通过后缀
Ti 通常是同型号的增强版,性能介于原型号和更高一级型号之间 (如 RTX 4070 Ti 强于 RTX 4070,小于4080)
4.通过显存容量 VRAM (最重要!!)
他是GPU 自身的独立高速内存,用于存储模型参数、激活值、输入数据批次等。单位通常是 GB(例如 8GB, 12GB, 24GB, 48GB)。如果显存不足,可能无法加载模型,或者被迫使用很小的批量大小,从而影响训练速度和效果
1、GPU训练
要让模型在 GPU 上训练,主要是将模型和数据迁移到 GPU 设备上。在 PyTorch 里,.to(device) 方法的作用是把张量或者模型转移到指定的计算设备(像 CPU 或者 GPU)上:
- 对于张量(Tensor):调用 .to(device) 之后,会返回一个在新设备上的新张量
- 对于模型(nn.Module):调用 .to(device) 会直接对模型进行修改,让其所有参数和缓冲区都移到新设备上
在进行计算时,所有输入张量和模型必须处于同一个设备,要是它们不在同一设备上,就会引发运行时错误。并非所有 PyTorch 对象都有 .to(device) 方法,只有继承自 torch.nn.Module 的模型以及 torch.Tensor 对象才有此方法
我这里用的kaggle的云服务器(算力平台真的很推荐,环境啥的都配置好了,猛猛用就行),迁移到GPU时先看看CUDA,再设置一下设备
import torch# ----------- cell 1 ------------
# 检查CUDA是否可用
if torch.cuda.is_available():print("CUDA可用!")# 获取可用的CUDA设备数量device_count = torch.cuda.device_count()print(f"可用的CUDA设备数量: {device_count}")# 获取当前使用的CUDA设备索引current_device = torch.cuda.current_device()print(f"当前使用的CUDA设备索引: {current_device}")# 获取当前CUDA设备的名称device_name = torch.cuda.get_device_name(current_device)print(f"当前CUDA设备的名称: {device_name}")# 获取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")# 查看cuDNN版本(如果可用)print("cuDNN版本:", torch.backends.cudnn.version())else:print("CUDA不可用。")# ------------ cell 2 ------------
# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")代码改动很小,就是张量和模型实例化的时候改一改
# 转换为张量
x_train = torch.FloatTensor(x_train).to(device)
x_test = torch.FloatTensor(x_test).to(device)
y_train = torch.LongTensor(y_train).to(device)
y_test = torch.LongTensor(y_test).to(device)# 实例化网络
model = MLP().to(device)CPU和GPU都用kaggle的跑,CPU训练用时0.3726秒,GPU训练用时0.7579秒,照理说GPU会更快对吧。但对于非常小的数据集和简单的模型,CPU通常会比GPU更快,本质是因为GPU在计算的时候,相较于cpu多了3个时间上的开销:
- 数据传输开销 (CPU 内存 <-> GPU 显存),对于少量数据和非常快速的计算任务,这个传输时间可能比 GPU 通过并行计算节省下来的时间还要长
- 核心启动开销 (GPU 核心启动时间),GPU执行的每个操作都涉及到在GPU上启动一个“核心”(kernel),如果核心内的实际计算量非常小(本项目的小型网络和鸢尾花数据),这个启动开销在总时间中的占比就会比较大
- 性能浪费:计算量和数据批次,这个数据量太少,GPU的很多计算单元都没有被用到,即使用了全批次也没有用到的全部计算单元
所以综上所述,GPU适合大型数据集,大型模型,复杂繁琐的并行计算操作
2、__call__方法
在 Python 中,__call__ 方法是一个特殊的魔术方法(双下划线方法),如果一个类定义了 __call__ 方法,它的实例可以通过 实例名() 的方式调用,就像调用函数一样,这种特性使得对象可以表现得像函数,同时保留对象的内部状态
举个例子,之前训练时要选定损失函数,nn.CrossEntropyLoss() 是一个类,criterion 是它的实例,criterion(output, y_train) 实际上是 criterion.__call__(output, y_train),这个__call__方法内部会计算交叉熵损失,并返回结果
criterion = nn.CrossEntropyLoss() # 实例化损失函数
loss = criterion(output, y_train) # 像函数一样调用说白了,PyTorch 的损失函数、模型层(如 nn.Linear)等模块都通过__call__方法来实现相应的功能,它们内部可能保存了参数和状态,每次调用时利用这些状态进行计算,所以用的时候一定要记住实例化(加括号),忘了好多次总会出莫名其妙的错误
判断到底是函数还是类的实例化,可以看官方文档决定,但是看看命名也是好方法:
-
类名:通常首字母大写(如
CrossEntropyLoss, torch.FloatTensor) -
函数名:全小写(如
sum,add)
@浙大疏锦行
相关文章:

python打卡day34
GPU训练及类的call方法 知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作…...

华为OD机试真题—— 流水线(2025B卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
【数据架构01】数据技术架构篇
✅ 9张高质量数据架构图:大数据平台功能架构、数据全生命周期管理图、AI技术融合架构等; 🚀无论你是数据架构师、治理专家,还是数字化转型负责人,这份资料库都能为你提供体系化参考,高效解决“架构设计难、…...

【安全攻防与漏洞】HTTPS中的常见攻击与防御
HTTPS 中常见攻击与防御策略涵盖中间人攻击(MITM)、SSL剥离、重放攻击等,帮助构建安全的 HTTPS 通信环境: 一、中间人攻击(MITM) 攻击原理 场景:攻击者通过伪造证书或劫持网络流量,…...

esp32cmini SK6812 2个方式
1 #include <SPI.h> // ESP32-C系列的SPI引脚 #define MOSI_PIN 7 // ESP32-C3/C6的SPI MOSI引脚 #define NUM_LEDS 30 // LED灯带实际LED数量 - 确保与实际数量匹配! #define SPI_CLOCK 10000000 // SPI时钟频率 // 颜色结构体 st…...

【数据集】30 m地表温度LST数据集
目录 数据概述🔧研究目标与意义🧠 算法核心组成1. 地表比辐射率(LSE)估算2. 大气校正(Atmospheric Correction)LST反演流程图📊 精度验证与评估结果参考《Generating the 30-m land surface temperature product over continental China and USA from Landsat 5/7/8 …...

【CATIA的二次开发07】草图编辑器对象结构及应用
【CATIA的二次开发07】草图编辑器对象结构及应用 草图编辑器(SketchEditor)是用于创建和编辑2D草图的核心对象。其对象结构遵循CATIA的层级关系,以下是详细说明及代码示例: 一、核心对象结构图 Application │ └─ Documents│└─ Document (.CATPart)│└─ Part│└─…...

IT | 词汇科普手册Ⅱ
目录 1.报文(Message) 2.Token(令牌) Token vs. Cookie Token vs. Key "碰一碰"支付 3.NFC 4.Nginx 5.JSON 6.前置机 前置机vs.Nginx反向代理 以PDA、WMS举例前置机场景 7.RabbitMQ 核心功能 1.报文(Message) 报文(Message)是系统或组件之…...
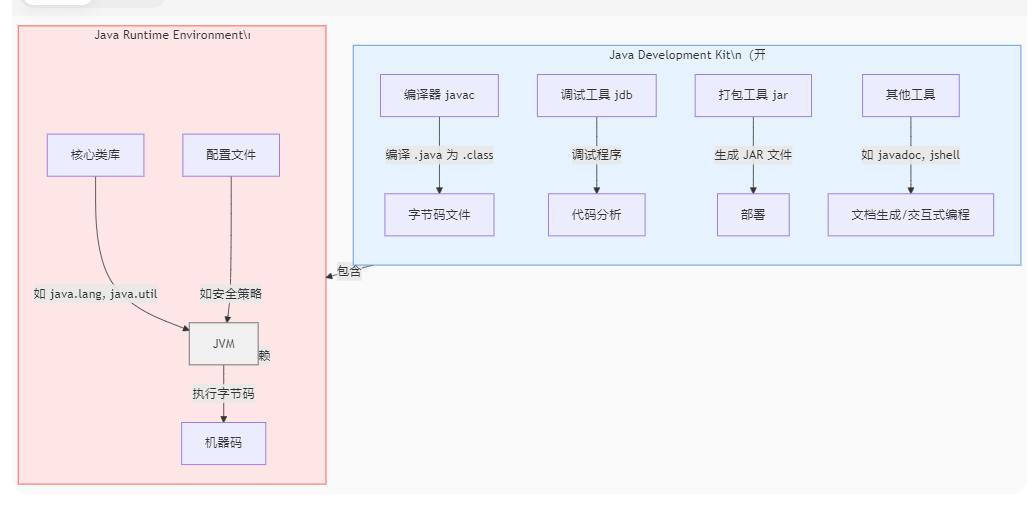
【 java 基础问题 第一篇 】
目录 1.概念 1.1.java的特定有哪些? 1.2.java有哪些优势哪些劣势? 1.3.java为什么可以跨平台? 1.4JVM,JDK,JRE它们有什么区别? 1.5.编译型语言与解释型语言的区别? 2.数据类型 2.1.long与int类型可以互转吗&…...
)
以前端的角度理解 Kubernetes(K8s)
作为一名前端开发者,我们每天都在与 React、Vue、Webpack 等工具打交道,而 Kubernetes(K8s)听起来更像是后端或运维的“专属领域”。但实际上,K8s 的核心思想和前端开发中的某些模式高度相似。那么咱们用熟悉的类比帮助…...
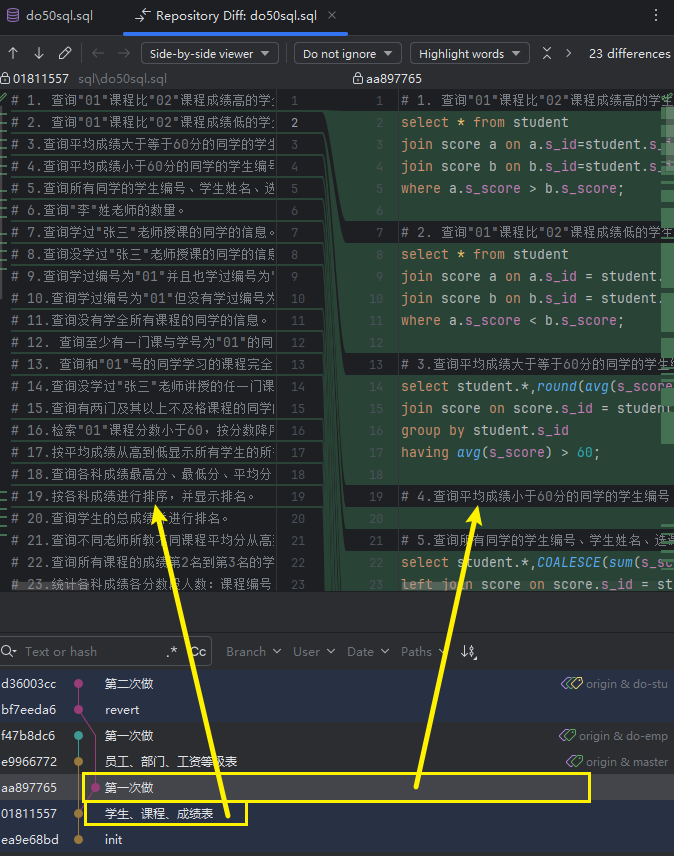
自用git记录
像重复做自己在网上找的练习题,这种类型的git仓库管理,一般会用到以下命令: git revert a1b2c3 很复杂的git历史变成简单git历史 能用git rebase -i HEAD~5^这种命令解决,就最好(IDEA还带GUI,很方便&…...

pyhton基础【2】基本语法
一. 注释 单行注释 以#开头,#右边的所有的内容当做说明,起辅助说明作用 # 我是一个单行注释 print(Hello) 多行注释 """ 在三引号中的注释被称之为多行注释 可以写很多行的功能说明 """ 二. 交互模式 终端输入代码…...

python数据结构-列表详解
Python中的列表(List)是一种序列类型的数据结构,它支持元素的动态添加和删除,可以容纳任意类型的数据,包括数字、字符串、甚至是其他列表或其他复杂数据结构。列表因其灵活性和广泛的应用场景,成为Python中最常用的数据结构之一。…...
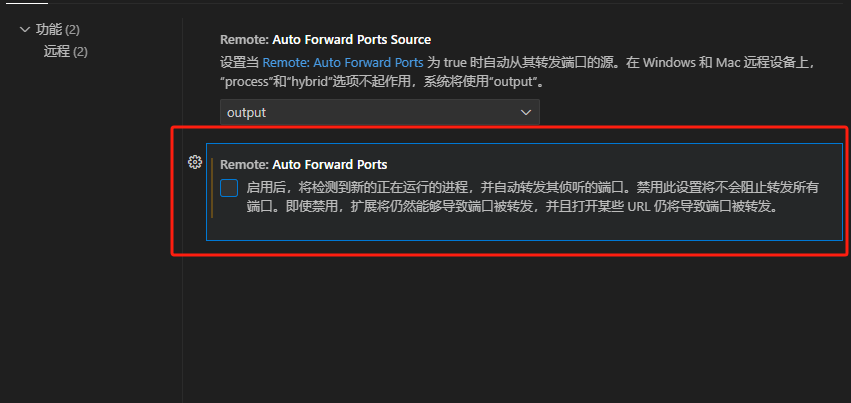
本地环境下 前端突然端口占用问题 针对vscode
1.问题背景 本地运行前端代码,虚拟机中使用nginx反向代理。两者都使用vscode进行开发。后端使用vscode远程连接。在前端发起一次接口请求后,后端会产生新的监听端口,出现如下图的提示情况。随后前端刷新,甚至无法正常显示界面。 …...

flutter 项目调试、flutter run --debug调试模式 devtools界面说明
Flutter DevTools 网页界面说明 1. 顶部导航栏 Inspector:查看和调试 Widget 树,实时定位 UI 问题。Performance-- 性能分析面板,查看帧率、CPU 和 GPU 使用情况,识别卡顿和性能瓶颈。Memory-- 内存使用和对象分配分析ÿ…...
中查看设备的 IP 地址)
在局域网(LAN)中查看设备的 IP 地址
在局域网(LAN)中查看设备的 IP 地址,可以使用以下几种方法: 方法 1:使用 ipconfig(Windows) 1. 打开 CMD: 按 Win R,输入 cmd,回车。 2. 输入命令&#…...

Axure 基本用法学习笔记
一、元件操作基础 1. 可见性控制 隐藏/显示:可以设置元件的可见性,使元件在特定条件下隐藏或可见 应用场景:创建动态交互效果,如点击按钮显示隐藏内容 2. 层级管理 层级概念:元件有上下层关系,上层元件…...

使用 Hyperlane 实现 WebSocket广播
使用 Hyperlane 实现 WebSocket广播 hyperlane 框架原生支持 WebSocket 协议,开发者无需关心协议升级过程,即可通过统一接口处理 WebSocket 请求。本文将介绍如何使用 hyperlane 实现服务端的单点发送与广播发送功能,以及如何配套实现一个简…...
)
SQL每日一题(5)
前言:五更!五更琉璃!不对!是,五更佩可! 原始数据: new_hires reasonother_column1other_column2校园招聘信息 11社会招聘信息 22内部推荐信息 33猎头推荐信息 44校园招聘信息 55社会招聘信息…...

git提交通用规范
提交类型 类型说明feat新增功能或特性fix修复Bugdocs文档更新(README、CHANGELOG、注释等)style代码样式调整(空格、分号、格式等,不改变逻辑)refactor代码重构(既非新增功能,也非修复Bug的代码…...
C++ - 仿 RabbitMQ 实现消息队列(3)(详解使用muduo库)
C - 仿 RabbitMQ 实现消息队列(3)(详解使用muduo库) muduo库的基层原理核心概念总结:通俗例子:餐厅模型优势体现典型场景 muduo库中的主要类EventloopMuduo 的 EventLoop 核心解析1. 核心机制:事…...
docker部署XTdrone
目录 一、前置准备 二、依赖安装 三、ros安装 四、gazebo安装 五、mavros安装 六、PX4的配置 七、Xtdrone源码下载 八、xtdrone与gazebo(实际上应该是第四步之后做这件事) 九、键盘控制 参考链接:仿真平台基础配置 语雀 一、前置准…...
图解 | 大模型智能体LLM Agents
文章目录 正文1. 存储 Memory1.1 短期记忆 Short-Term Memory1.1.1 模型的上下文窗口1.1.2 对话历史1.1.3 总结对话历史 1.2 长期记忆Long-term Memory 2. 工具Tools2.1 工具的类型2.2 function calling2.3 Toolformer2.3.1 大模型调研工具的过程2.3.2 生成工具调用数据集 2.4 …...

Lambda表达式的方法引用详解
Lambda表达式的方法引用详解 1. 方法引用的概念与作用 定义:方法引用(Method Reference)是Lambda表达式的一种简化写法,允许直接通过方法名引用已有的方法。核心目的:减少冗余代码,提升可读性,尤其在Lambda仅调用一个现有方法时。语法符号:双冒号 ::。2. 方法引用的四种…...
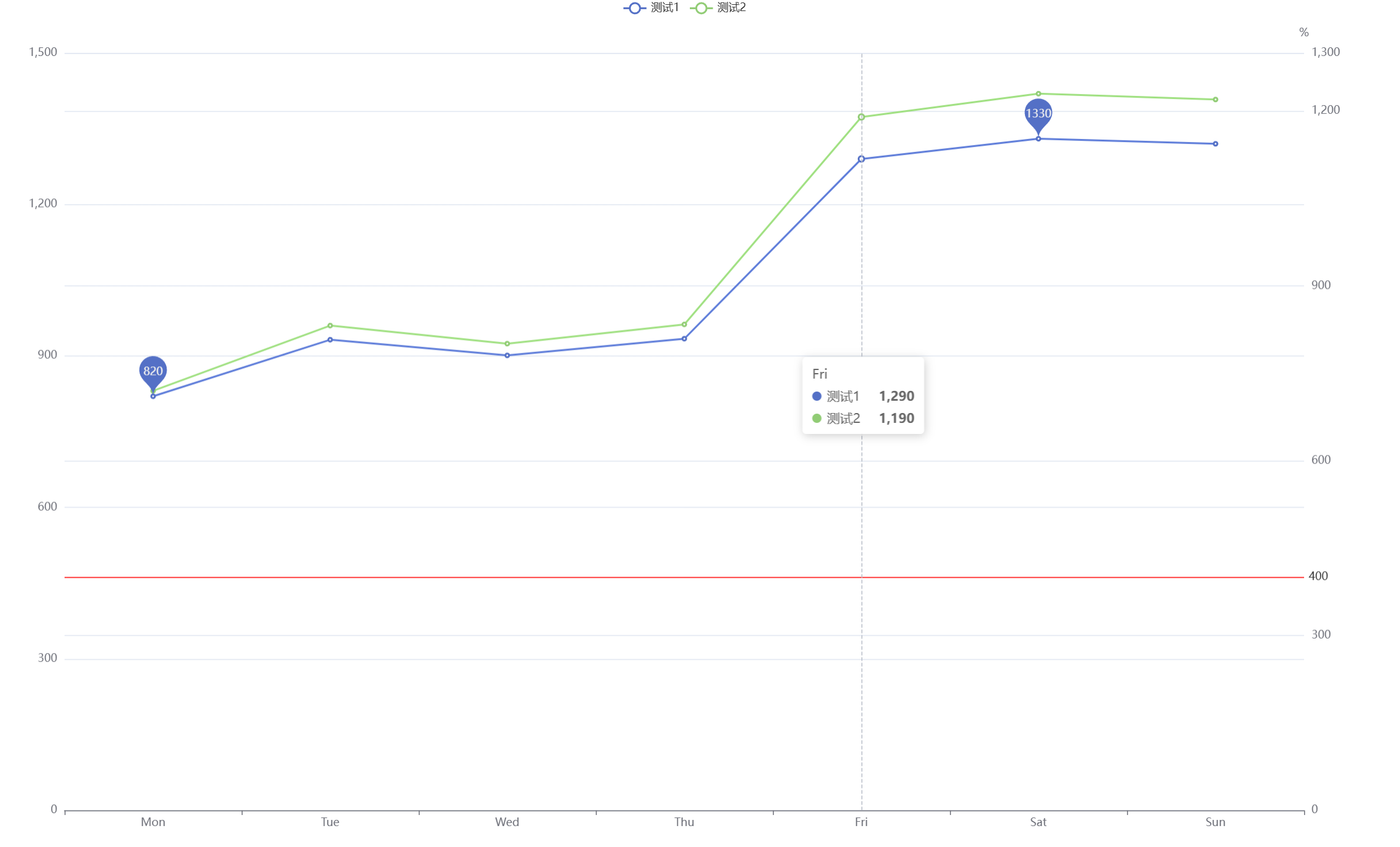
echarts设置标线和最大值最小值
echarts设置标线和最大值最小值 基本ECharts图表初始化配置 设置动态的y轴范围(min/max值) 通过markPoint标记最大值和最小值点 使用markLine添加水平参考线 配置双y轴图表 自定义标记点和线的样式(颜色、符号等) 响应式调整图表大…...

gcc编译构建流程
0. 项目结构 /home/pi/test/ ├── src/ │ ├── add/ │ │ ├── add.cpp │ │ ├── add.h │ └── log/ │ ├── log.cpp │ ├── log.h │ ├── data.h ├── main.cppmain.cpp代码 // main.cpp #include "log.h&quo…...

Maven 中央仓库操作指南
Maven 中央仓库操作指南 登录注册 在 Maven Central 登录(注册)账号。 添加命名空间 注册 通过右上角用户菜单跳转到命名空间管理页面: 注册命名空间: 填入你拥有的域名并注册: 刚提交的命名空间状态是Unverified…...

BUUCTF——RCE ME
BUUCTF——RCE ME 进入靶场 <?php error_reporting(0); if(isset($_GET[code])){$code$_GET[code];if(strlen($code)>40){die("This is too Long.");}if(preg_match("/[A-Za-z0-9]/",$code)){die("NO.");}eval($code); } else{highlight…...

clickhouse-1-特性及docker化安装
clickhouse-1-特性及docker化安装 1.核心特性1.1.列式存储与高效压缩1.2.向量化执行引擎1.3.分布式架构与高可用性1.4.多样化的表引擎1.5.实时处理能力2.安装2.1 拉取镜像2.2 创建容器3.连接4.使用4.1.创建数据库5.其他5.1 primary key5.2 ENG…...

Docker核心笔记
一、概述 1、架构 Docker容器基于镜像运行,容器共享宿主机的内核,不会加载额外内核,通过Namespaces(环境隔离)和Cgroups(资源控制)实现隔离,Cgroups会限容器使用资源并控制优先级和统计数据。隔离后的容器仅包含应用所需的用户态依赖 2、安装 安装先卸载再安装,使用的yum…...