2021年认证杯SPSSPRO杯数学建模A题(第二阶段)医学图像的配准全过程文档及程序
2021年认证杯SPSSPRO杯数学建模
A题 医学图像的配准
原题再现:
图像的配准是图像处理领域中的一个典型问题和技术难点,其目的在于比较或融合同一对象在不同条件下获取的图像。例如为了更好地综合多种信息来辨识不同组织或病变,医生可能使用多种仪器对患者的同一部位进行成像。在综合多幅图像时,首先需要将它们严格对齐,使得图上同一个坐标的位置对应的是真实对象的同一个点,这个过程称之为配准。现在的许多医学成像技术,包括 CT、MRI、PET 等,最终生成的是人体的断层影像。在这里,我们主要关心的是断层成像的配准问题。
我们考虑对一个患者的腹部进行断层成像。由于人体组织是柔软的,所以即使使用同一台成像设备,两次成像的结果也并不完全一致。最终输出时还会对图像进行自动放缩,所以输出图片的大小也并不完全相同。想要精确配准,需要将其中一次的成像结果进行某种仿射变换(或非线性变换),以尽可能地匹配另一次的结果(或将两次结果都映射到同一个标准模板中)。求得合适的变换就是图像配准的核心任务。
第二阶段问题:多模态的配准是指对来自不同设备的图像进行配准,例如对CT和MRI图像进行配准。有的组织或病变部位在单一的成像技术下与周边组织的区分不明显,所以我们可以对多种成像技术得到的图片进行融合处理,让每个像素点的成像结果表现为一个多维向量(每个分量都是一种成像技术的成像结果),这样可以更好地识别组织或病变的细节。多模态的配准则是图像融合的第一步。
现在我们有对患者同一身体部位(同一时间)的CT、MRI和PET成像结果。但在图像融合处理时遇到了两个问题:首先,每一种成像技术对不同组织的区分能力是不同的,例如有些不同的组织在CT下看起来区别不大,但在MRI下区分却十分明显;另外一些组织在MRI下区别不大,但在CT下区分却十分明显。所以对不同的成像设备而言,即使是同一个位置的成像结果,也并非完全相似,这给配准带来了难度。第二,在进行断层成像时,虽然对每个设备而言,我们能够确切地知道每个断层的位置,但不同设备扫描的断层位置并不完全相同。请你设计一个有效的方法,对这样的成像结果进行图像的融合。
整体求解过程概述(摘要)
一种基于多模态医学图像的图像融合方法可以显著提高融合图像的质量。一种有效的图像融合技术通过保留从源图像中收集到的所有可行的和显著的信息而不引入任何缺陷或不必要的扭曲来产生输出图像。
大多数深度学习方法采用所谓的单流高到低、低到高的网络结构,能够获得满意的整体配准结果。然而,一些严重变形的局部区域的精确定位,这是精确定位手术目标的关键,却经常被忽视。因此,这些方法对一些难以对齐的区域不敏感,例如畸形肝叶的图像配准融合。针对这一问题,我们提出一种新的无监督配准网络,即全分辨率残差配准网络(F3RNet),用于严重变形器官的变形配准。该方法以残差学习的方式结合了两个并行处理流。一个流利用全分辨率信息,促进准确的体素级注册。另一个流学习深度多尺度残差表示以获得鲁棒特征识别与提取。此外,我们还使用了提升小波变换,混合融合等方法对图像特征进行精确分类。最后对三维卷积进行因式分解,得到图像配准与融合结果。我们选用了腹部和肺部的CT-MRI数据集对所提方法进行验证,实验结果表明所提方法可以获取更高质量的配准融合图像,同时又能显著提高配准融合效率。
为了验证我们提出方法的有效性,我们选用自备的医学CT图像和MRI图像数据集进行了评估,本文配准模型在肺部图像与脑部图像的配准值有一定程度的提升。从模型的运行的结果可以看出,当AUC值为0.883时,得到Dice稀疏为0.575,准确率为0.884,灵敏度为0.647,特异性为0.929,F1得分为0.640。模型中还进行了病变程度与匹配程度的相关性分析,在保证快捷的同时方便简洁地解决了问题,具有一定的推广意义。
问题分析:
考虑到在进行疾病诊断时,不同的医学图像在进行疾病诊断时所发挥的作用时不同的,为更全面的了解病人的病情,往往需要多种医学图像提供不同的信息,通过这些信息的综合分析,能够为临床诊断治疗提供全面的信息。深度学习的发展为多模态医学配准和图像融合提供了新的思路,利用深度学习的模型寻找待配准图像对像素点间的空间对应关系,使固定图像与浮动图像的像素点在空间解剖结构上对齐,根据对齐关系进行利用融合特性对这些提取的特征进行融合,能够更清晰的反应病变的情况。该方案的具体解决措施如下:
首先,提出一种全分辨率残差配准网络用于配准不同医学图像中的相关特征,通过设计全分辨率和多尺度残差块这两个并行的网络,全分辨率网络在密集网络表现较好,能够通过常规残差块提取不同医学图像中的低阶特征。多尺度残差块利用连续池化和卷积操作来增加识别范围,善于捕捉高级特征,从而提高识别性能。这两个并行网络能够全面提取不同医学图像的特征,不会因为医学图像分辨率不同导致特征提取不全面的情况。
其次,在提取完全特征的基础上,使用小波变换融合和混合图像融合相结合的方法进行医学图像的融合。小波变换融合利用小波变换对源参考的医学图像进行分解,利用定量度量度量技术的性能,并比较技术的效率,以找到合适的融合规则。再使用混合图像融合技术可以从有噪声、失真的图像中提取原始图像特征,从而获得改进和增强的图像质量。
模型假设:
在数学建模的过程中,为了使模型简单明确,简化运算过程,在不影响模型意义与计算精度的前提下,建立了如下假设:
(1)假设同一组的医学图像来自于同一位患者。
(2)假设用来采集每一张医学图像的设备都能正常采集医学图像。
(3)假设采集到的医学图像没有人为修改与损坏,并且能够直接使用。
(4)假设同一组诊断图像为患者同一部位的医学图像。
(5)假设患者在两次成像之间身体没有发生其他部分的病变,或者存在导致成像偏差的身体异状。
(6)假设每台计算机辅助医疗系统的参数设定与配置都保持一致。
论文缩略图:

程序代码:
from typing import Union, Optional, List, Tuple, Text, BinaryIO
import pathlib
import torch
import math
import warnings
import numpy as np
from PIL import Image, ImageDraw, ImageFont, ImageColor
__all__=["make_grid","save_image", "draw_bounding_boxes", "draw_segmentation_masks"]
def make_grid(tensor: Union[torch.Tensor, List[torch.Tensor]],nrow: int = 8,padding: int = 2,normalize: bool = False,value_range: Optional[Tuple[int, int]] = None,scale_each: bool = False,pad_value: int = 0,**kwargs
) -> torch.Tensor:if not (torch.is_tensor(tensor) or(isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):raise TypeError(f'tensor or list of tensors expected, got {type(tensor)}')if "range" in kwargs.keys():warning = "range will be deprecated, please use value_range instead."warnings.warn(warning)value_range = kwargs["range"]# if list of tensors, convert to a 4D mini-batch Tensorif isinstance(tensor, list):tensor = torch.stack(tensor, dim=0)if tensor.dim() == 2: # single image H x Wtensor = tensor.unsqueeze(0)if tensor.dim() == 3: # single imageif tensor.size(0) == 1: # if single-channel, convert to 3-channeltensor = torch.cat((tensor, tensor, tensor), 0)tensor = tensor.unsqueeze(0)if tensor.dim() == 4 and tensor.size(1) == 1: # single-channel imagestensor = torch.cat((tensor, tensor, tensor), 1)if normalize is True:tensor = tensor.clone() # avoid modifying tensor in-placeif value_range is not None:assert isinstance(value_range, tuple), \"value_range has to be a tuple (min, max) if specified. min and max are numbers"def norm_ip(img, low, high):img.clamp_(min=low, max=high)img.sub_(low).div_(max(high - low, 1e-5))def norm_range(t, value_range):if value_range is not None:norm_ip(t, value_range[0], value_range[1])else:norm_ip(t, float(t.min()), float(t.max()))if scale_each is True:for t in tensor: # loop over mini-batch dimensionnorm_range(t, value_range)else:norm_range(tensor, value_range)if tensor.size(0) == 1:return tensor.squeeze(0)# make the mini-batch of images into a gridnmaps = tensor.size(0)xmaps = min(nrow, nmaps)ymaps = int(math.ceil(float(nmaps) / xmaps))height, width = int(tensor.size(2) + padding), int(tensor.size(3) + padding)num_channels = tensor.size(1)grid = tensor.new_full((num_channels, height * ymaps + padding, width * xmaps + padding), pad_value)k = 0for y in range(ymaps):for x in range(xmaps):if k >= nmaps:break# Tensor.copy_() is a valid method but seems to be missing from the stubs# https://pytorch.org/docs/stable/tensors.html#torch.Tensor.copy_grid.narrow(1, y * height + padding, height - padding).narrow( # type: ignore[attr-defined]2, x * width + padding, width - padding).copy_(tensor[k])k = k + 1return grid
@torch.no_grad()
def save_image(tensor: Union[torch.Tensor, List[torch.Tensor]],fp: Union[Text, pathlib.Path, BinaryIO],format: Optional[str] = None,**kwargs
) -> None:grid = make_grid(tensor, **kwargs)# Add 0.5 after unnormalizing to [0, 255] to round to nearest integerndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()im = Image.fromarray(ndarr)im.save(fp, format=format)
def draw_bounding_boxes(image: torch.Tensor,boxes: torch.Tensor,labels: Optional[List[str]] = None,colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,fill: Optional[bool] = False,width: int = 1,font: Optional[str] = None,font_size: int = 10
) -> torch.Tensor:if not isinstance(image, torch.Tensor):raise TypeError(f"Tensor expected, got {type(image)}")elif image.dtype != torch.uint8:raise ValueError(f"Tensor uint8 expected, got {image.dtype}")elif image.dim() != 3:raise ValueError("Pass individual images, not batches")ndarr = image.permute(1, 2, 0).numpy()img_to_draw = Image.fromarray(ndarr)img_boxes = boxes.to(torch.int64).tolist()if fill:draw = ImageDraw.Draw(img_to_draw, "RGBA")else:draw = ImageDraw.Draw(img_to_draw)txt_font = ImageFont.load_default() if font is None else ImageFont.truetype(font=font, size=font_size)for i, bbox in enumerate(img_boxes):if colors is None:color = Noneelse:color = colors[i]if fill:if color is None:fill_color = (255, 255, 255, 100)elif isinstance(color, str):# This will automatically raise Error if rgb cannot be parsed.fill_color = ImageColor.getrgb(color) + (100,)elif isinstance(color, tuple):fill_color = color + (100,)draw.rectangle(bbox, width=width, outline=color, fill=fill_color)else:draw.rectangle(bbox, width=width, outline=color)if labels is not None:draw.text((bbox[0], bbox[1]), labels[i], fill=color, font=txt_font)return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1).to(dtype=torch.uint8)
def draw_segmentation_masks(image: torch.Tensor,masks: torch.Tensor,alpha: float = 0.2,colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,
) -> torch.Tensor:if not isinstance(image, torch.Tensor):raise TypeError(f"Tensor expected, got {type(image)}")elif image.dtype != torch.uint8:raise ValueError(f"Tensor uint8 expected, got {image.dtype}")elif image.dim() != 3:raise ValueError("Pass individual images, not batches")elif image.size()[0] != 3:raise ValueError("Pass an RGB image. Other Image formats are not supported")num_masks = masks.size()[0]masks = masks.argmax(0)if colors is None:palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])colors_t = torch.as_tensor([i for i in range(num_masks)])[:, None] * palettecolor_arr = (colors_t % 255).numpy().astype("uint8")else:color_list = []for color in colors:if isinstance(color, str):# This will automatically raise Error if rgb cannot be parsed.fill_color = ImageColor.getrgb(color)color_list.append(fill_color)elif isinstance(color, tuple):color_list.append(color)color_arr = np.array(color_list).astype("uint8")_, h, w = image.size()img_to_draw = Image.fromarray(masks.byte().cpu().numpy()).resize((w, h))img_to_draw.putpalette(color_arr)img_to_draw = torch.from_numpy(np.array(img_to_draw.convert('RGB')))img_to_draw = img_to_draw.permute((2, 0, 1))return (image.float() * alpha + img_to_draw.float() * (1.0 - alpha)).to(dtype=torch.uint8)
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2021年认证杯SPSSPRO杯数学建模A题(第二阶段)医学图像的配准全过程文档及程序
2021年认证杯SPSSPRO杯数学建模 A题 医学图像的配准 原题再现: 图像的配准是图像处理领域中的一个典型问题和技术难点,其目的在于比较或融合同一对象在不同条件下获取的图像。例如为了更好地综合多种信息来辨识不同组织或病变,医生可能使用…...
CV中常用Backbone-3:Clip/SAM原理以及代码操作
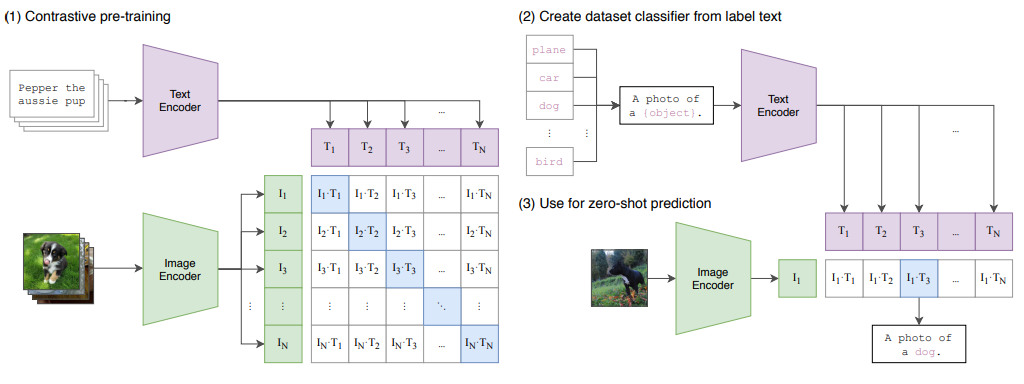
前面已经介绍了简单的视觉编码器,这里主要介绍多模态中使用比较多的两种backbone:1、Clip;2、SAM。对于这两个backbone简单介绍基本原理,主要是讨论使用这个backbone。 1、CV中常用Backbone-2:ConvNeXt模型详解 2、CV中…...
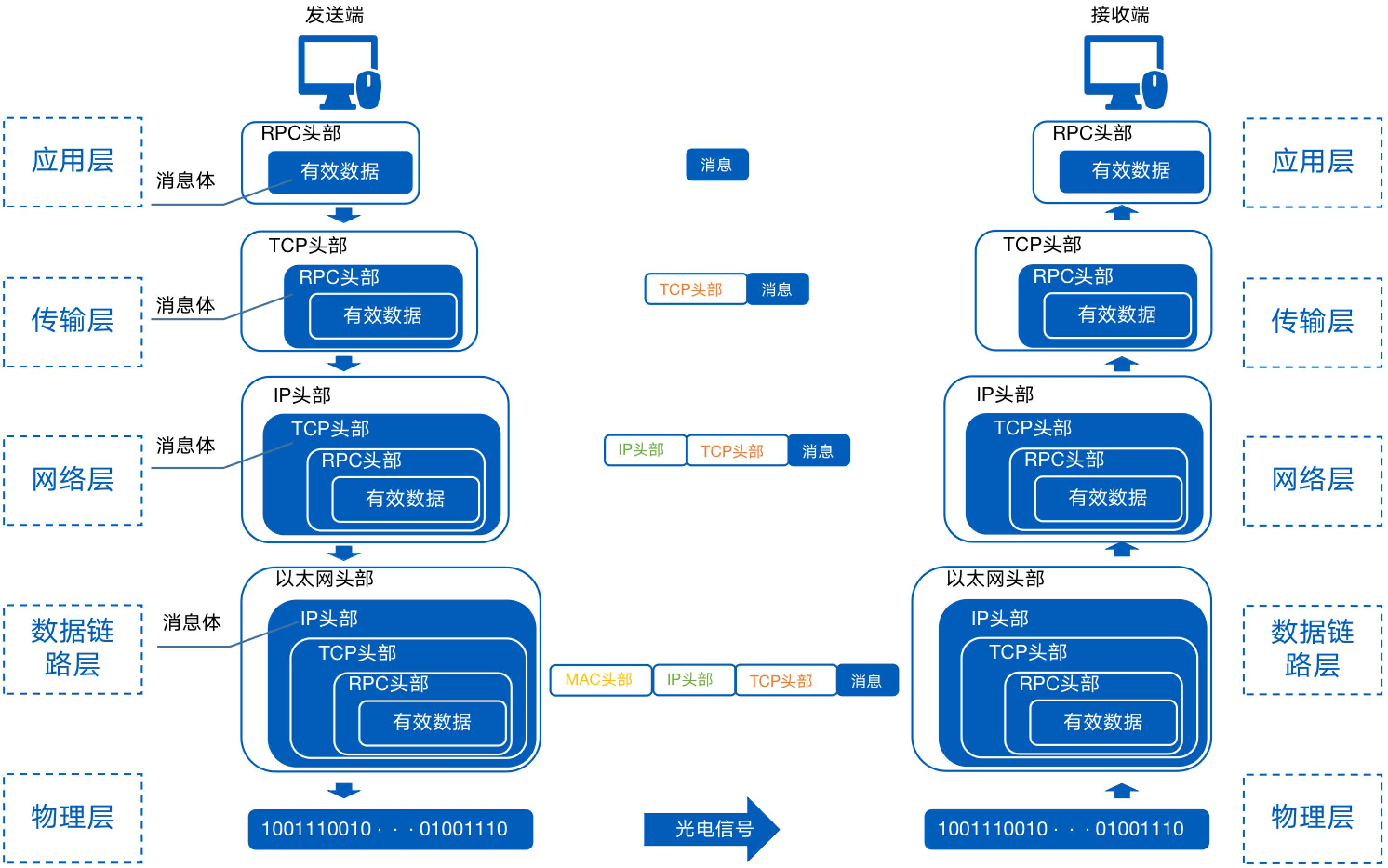
RPC 协议详解、案例分析与应用场景
一、RPC 协议原理详解 RPC 协议的核心目标是让开发者像调用本地函数一样调用远程服务,其实现过程涉及多个关键组件与流程。 (一)核心组件 客户端(Client):发起远程过程调用的一方,它并不关心调…...
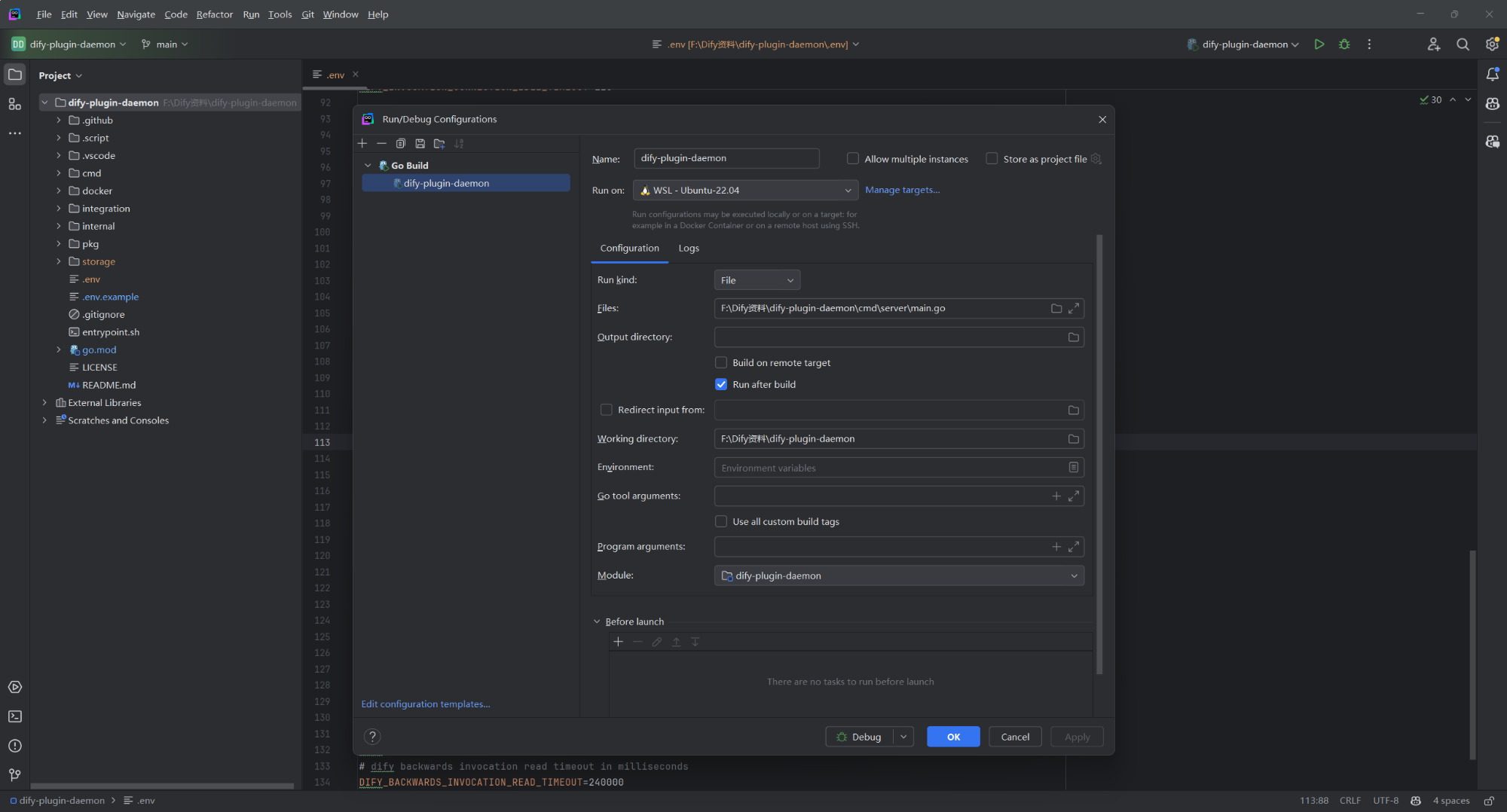
dify-plugin-daemon的.env配置文件
源码位置:dify-plugin-daemon\.env 本文使用dify-plugin-daemon v0.1.0版本,主要总结了dify-plugin-daemon\.env配置文件。为了本地调试方便,采用本地运行时环境WSL2Ubuntu22.04方式运行dify-plugin-daemon服务。 一.服务器基本配置 服务器…...

【Python】开发工具uv
文章目录 1. uv install1.1 下载安装脚本来安装1.2 使用pipx安装uv1.3 补充 2. 考虑在离线系统上安装uv2.1 下载并上传安装包2.2 用户级安装uv(~/.local/bin/)2.3 补充 3. uv 管理Python解释器4. uv 管理依赖5. uv运行代码5.1 uv不在项目下执行脚本5.2 u…...

《技术择时,价值择股》速读笔记
文章目录 书籍信息概览技术择时价值择股投资策略投资心态 书籍信息 书名:《技术择时,价值择股:A股投资实战笔记》 作者:二十八画生 概览 技术择时 三种简单方法,教你买在起涨点 趋势行情中的“买点”判断ÿ…...

Python可视化设计原则
在数据驱动的时代,可视化不仅是结果的呈现方式,更是数据故事的核心载体。Python凭借其丰富的生态库(Matplotlib/Seaborn/Plotly等),已成为数据可视化领域的主力工具。但工具只是起点,真正让图表产生价值的&…...

SAP重塑云ERP应用套件
在2025年Sapphire大会上,SAP正式发布了其云ERP产品的重塑计划,推出全新“Business Suite”应用套件,并对供应链相关应用进行AI增强升级。这一变革旨在简化新客户进入SAP生态系统的流程,同时为现有客户提供更加统一、智能和高效的业…...

2025.5.25总结
今天早上刷了会手机,然后下午去刷了一道科目一,限时训练3.5h。遗憾的是,这周只刷了一道题,并没有达成每周两道的目标。 其次,一天下来跟平时的节假日一样,有些小压抑。我也察觉到了自己的情绪。烦心事无非…...
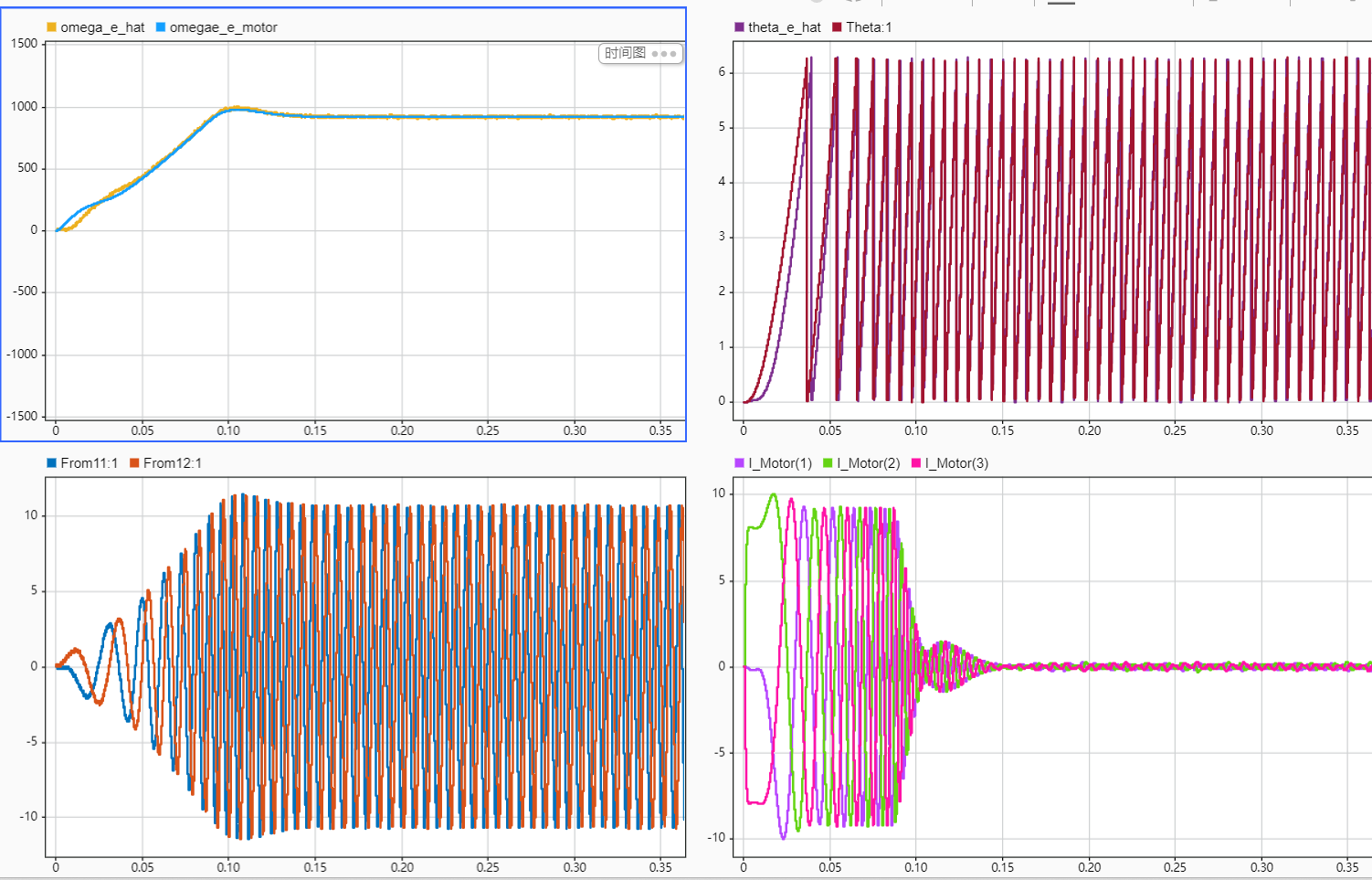
(九)PMSM驱动控制学习---无感控制之高阶滑膜观测器
在之前的文章中,我们介绍了永磁同步电机无感控制中的滑模观测器,但是同时我们也认识到了他的缺点:因符号函数带来的高频切换分量,使用低通滤波器引发相位延迟;在本篇文章,我们将会介绍高阶滑模观测器的无感…...

6个跨境电商独立站平台
1. WP最主题(WPZUI) 官网:http://www.wpzui.com 简介: WP最主题专注于专业WordPress主题开发定制,致力于为用户提供高质量、高性能的WordPress主题。其主题设计注重用户体验和SEO优化,适用于多种网站类型,包括企业站…...

电子电路:电学都有哪些核心概念?
电子是基本粒子,带负电荷。电荷是物质的一种属性,电子带有负电荷,而质子带有正电荷。电荷的单位是库仑。 电流呢,应该是指电荷的流动,单位是安培,也就是库仑每秒。所以电流其实就是电荷在导体中的移动形成的。比如,当电子在导线中流动时,就形成了电流。不过要注意,传…...

SQL进阶之旅 Day 2:基础查询优化技巧
【SQL进阶之旅 Day 2】基础查询优化技巧 开篇:为什么需要基础查询优化? 在SQL学习的旅程中,掌握基础查询优化是迈向专业数据库开发的关键一步。随着数据量的爆炸式增长,简单的SELECT语句已经无法满足现代应用对性能的要求。今天…...

时序数据库 TDengine × Superset:一键构建你的可视化分析系统
如果你正在用 TDengine 管理时序数据,写 SQL 查询没问题,但一到展示环节就犯难——图表太基础,交互不够,甚至连团队都看不懂你辛苦分析的数据成果?别担心,今天要介绍的这个组合,正是为你量身打造…...

一键化部署
好的,我明白了。你希望脚本变得更简洁,主要负责: 代码克隆:从 GitHub 克隆你的后端和前端项目,并在克隆前确保目标目录为空。文件复制:将你预先准备好的 Dockerfile (后端和前端各一个)、前端的 nginx.con…...

Win 系统 conda 如何配置镜像源
通过命令添加镜像源(推荐) 以 清华源 为例,依次执行以下命令: # 添加主镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main # 添加免费开源镜像源 conda config --add channels http…...

Devicenet主转Profinet网关助力改造焊接机器人系统智能升级
某汽车零部件焊接车间原有6台焊接机器人(采用Devicenet协议)需与新增的西门子S7-1200 PLC(Profinet协议)组网。若更换所有机器人控制器或上位机系统,成本过高且停产周期长。 《解决方案》 工程师选择稳联技术转换网关…...

《STL--list的使用及其底层实现》
引言: 上次我们学习了容器vector的使用及其底层实现,今天我们再来学习一个容器list, 这里的list可以参考我们之前实现的单链表,但是这里的list是双向循环带头链表,下面我们就开始list的学习了。 一:list的…...
)
whisper相关的开源项目 (asr)
基于 Whisper(OpenAI 的开源语音识别模型)的开源项目有很多,涵盖了不同应用场景和优化方向。以下是一些值得关注的项目: 1. 核心工具 & 增强版 Whisper OpenAI Whisper 由 OpenAI 开源的通用语音识别模型,支持多语…...
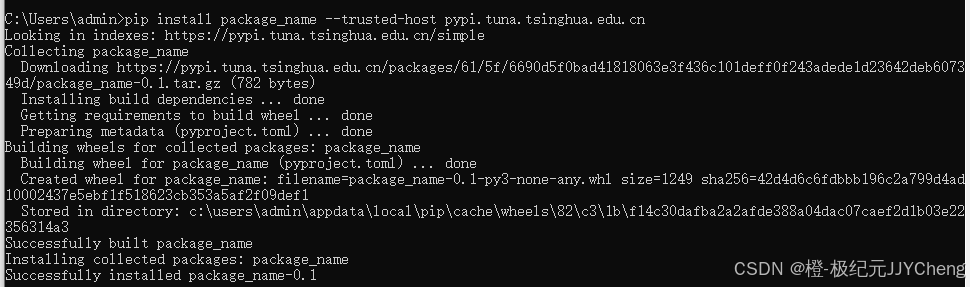
python的pip怎么配置的国内镜像
以下是配置pip国内镜像源的详细方法: 常用国内镜像源列表 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple阿里云:https://mirrors.aliyun.com/pypi/simple中科大:https://pypi.mirrors.ustc.edu.cn/simple华为云࿱…...
PCB 通孔是电容性的,但不一定是电容器
哼?……这是什么意思?…… 多年来,流行的观点是 PCB 通孔本质上是电容性的,因此可以用集总电容器进行建模。虽然当信号的上升时间大于或等于过孔不连续性延迟的 3 倍时,这可能是正确的,但我将向您展示为什…...

领域驱动设计与COLA框架:从理论到实践的落地之路
目录 引言 DDD核心概念 什么是领域驱动设计 DDD的核心概念 1. 统一语言(Ubiquitous Language) 2. 限界上下文(Bounded Context) 3. 实体(Entity)与值对象(Value Object) 4. 聚…...
公有云AWS基础架构与核心服务:从概念到实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 (初学者技术专栏) 一、基础概念 定义:AWS(Amazon Web Services)是亚马逊提供的云计算服务&a…...

Python60日基础学习打卡D35
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matplotlib.pyplot as plt# 设置GPU设…...

Python经典算法实战
在编程的世界里,算法是解决问题的灵魂,而Python以其简洁优雅的语法成为实现算法的理想语言。无论你是初学者还是有一定经验的开发者,《Python经典算法实战》都能带你深入算法的殿堂,从理论到实践,一步步构建起扎实的编…...

spring+tomcat 用户每次发请求,tomcat 站在线程的角度是如何处理用户请求的,spinrg的bean 是共享的吗
对于 springtomcat 用户每次发请求,tomcat 站在线程的角度是如何处理的 比如 bio nio apr 等情况 tomcat 配置文件中 maxThreads 的数量是相对于谁来说的? 以及 spring Controller 中的全局变量:各种bean 对于线程来说是共享的吗? 一、Tomca…...
目标检测 RT-DETR(2023)详细解读
文章目录 主干网络:Encoder:不确定性最小Query选择Decoder网络: 将DETR扩展到实时场景,提高了模型的检测速度。网络架构分为三部分组成:主干网络、混合编码器、带有辅助预测头的变换器编码器。具体来说,先利…...

微信小程序 隐私协议弹窗授权
开发微信小程序的第一步往往是隐私协议授权,尤其是在涉及用户隐私数据时,必须确保用户明确知晓并同意相关隐私政策。我们才可以开发后续的小程序内容。友友们在按照文档开发时可能会遇到一些问题,我把所有的授权方法和可能遇到的问题都整理出…...

题目 3325: 蓝桥杯2025年第十六届省赛真题-2025 图形
题目 3325: 蓝桥杯2025年第十六届省赛真题-2025 图形 时间限制: 2s 内存限制: 192MB 提交: 494 解决: 206 题目描述 小蓝要画一个 2025 图形。图形的形状为一个 h w 的矩形,其中 h 表示图形的高,w 表示图形的宽。当 h 5,w 10 时,图形如下所…...
金众诚业财一体化解决方案如何提升项目盈利能力?
在工程项目管理领域,复杂的全生命周期管理、成本控制的精准性以及业务与财务的高效协同,是决定项目盈利能力的核心要素。随着数字化转型的深入,传统的项目管理方式已难以满足企业对效率、透明度和盈利能力的需求。基于金蝶云星空平台打造的金…...