大模型知识
##############################################################
一、vllm大模型测试参数和原理
tempreature top_p top_k
##############################################################
tempreature top_p top_k
作用:总体是控制模型的发散程度、多样性、确定性,不同参数设置匹配不同的场景
1. Temperature(温度)
作用:控制生成文本的随机性和多样性。
原理:
在 softmax 计算概率分布时,调整 logits(模型输出的原始分数)的缩放比例。
公式:softmax(logits / temperature)。
影响:
temperature > 1:放大低概率选项,输出更随机、多样(可能包含更多错误或创造性内容)。
temperature < 1:缩小低概率选项,输出更确定、保守(倾向于高概率的常见词)。
temperature = 0:完全确定性,总是选择概率最高的词(但实际实现中通常设为接近 0 的小值)。
适用场景:
需要创造性(如诗歌、故事生成)时提高温度。
需要准确性和一致性(如问答、代码生成)时降低温度。
2. Top-k(顶部 k 采样)
作用:限制每一步只从概率最高的 k 个候选词中采样。
原理:
对概率分布进行排序,保留前 k 个最可能的词,重新归一化它们的概率后采样。
影响:
k 值大:候选词多,输出多样性高(可能包含不相关词)。
k 值小:候选词少,输出更保守(但可能重复或单调)。
k = 1:退化为贪心搜索(等同 temperature=0)。
缺点:
固定 k 可能在某些上下文保留不合理的词(如概率分布平坦时,低概率词也可能进入候选)。
3. Top-p(核采样,Nucleus Sampling)
作用:动态地从累积概率超过 p 的最小候选词集合中采样。
原理:
对概率分布排序,累加概率直到超过阈值 p,仅从这部分词中采样。
例如 p=0.9 时,选择最小数量的词使得它们的总概率 ≥ 90%。
影响:
p 值大(如 0.9):候选词多,多样性高。
p 值小(如 0.3):候选词少,输出更确定。
p → 0:退化为贪心搜索。
优势:
自适应候选词数量,适合概率分布不均匀的场景(避免固定 k 的缺陷)。
4. 参数间的交互
优先级:top_p 和 top_k 通常联合使用(如 top_k=40, top_p=0.9),但若同时设置,top_p 会覆盖 top_k 的条件。
与温度的关系:
temperature 在 top_p/top_k 之前生效,先调整概率分布的形状,再应用采样策略。
例如:高温 + 低 top_p 可能导致更多样但低质量的输出。
5. 典型配置示例
场景 推荐参数 说明
代码生成/事实问答 temperature=0.2, top_p=0.1 确定性高,减少错误
创意文本/对话生成 temperature=0.7, top_p=0.9 平衡多样性和合理性
极端创造性任务 temperature=1.0, top_k=50 高风险高多样性
6. 其他相关参数
Repetition Penalty:抑制重复词(如 repetition_penalty=1.2)。
Beam Search:完全确定性生成时使用(与采样参数互斥)。
##############################################################
二、vllm大模型推理原理
##############################################################
vLLM(Very Large Language Model) 是一个针对大语言模型(LLM)推理优化的高效推理框架,由加州大学伯克利分校团队开发。其核心目标是 提升大模型推理的吞吐量和降低延迟,同时支持灵活的采样策略(如 Top-k、Top-p)和长上下文处理。以下是其核心原理和关键技术的详细解析:
1. 核心设计目标
高吞吐量:支持同时处理大量请求(如数百个并发用户)。
低延迟:快速生成响应,减少用户等待时间。
内存高效:优化显存使用,支持更大的模型或更长的上下文。
灵活性:兼容多种采样参数(Temperature、Top-p、Top-k)和模型架构(如 GPT、LLaMA)。
2. 关键技术原理
(1)PagedAttention(分页注意力机制)
问题背景:
传统注意力机制在处理长序列时,需要将全部 KV Cache(键值缓存)存储在连续显存中,导致显存碎片化和浪费。
例如,不同请求的序列长度差异大时,显存分配效率低。
解决方案:
将 KV Cache 分页管理,类似操作系统的虚拟内存分页:
每个序列的 KV Cache 被划分为固定大小的“块”(如 16 个 token 一块)。
显存按需分配块,不同序列的块可以非连续存储。
优势:
显著减少显存浪费,支持更长的上下文(如 100K tokens)。
提升并发请求的吞吐量(显存利用率更高)。
(2)Continuous Batching(连续批处理)
问题背景:
传统批处理(Static Batching)需等待所有请求完成后才能处理下一批,导致 GPU 空闲。
生成式模型的请求完成时间不一致(如短回答 vs 长文生成)。
解决方案:
动态插入新请求到运行中的批次:
当一个请求生成完一个 token 后,若批次中有空闲槽位,立即插入新请求。
称为 Iteration-level Scheduling(迭代级调度)。
优势:
GPU 利用率接近 100%,吞吐量提升 2-4 倍。
用户感知的延迟更低(无需等待整批完成)。
(3)内存优化
KV Cache 共享:
对于同一提示词(prompt)的多个请求,共享其 KV Cache,减少重复计算。
Zero-copy 技术:
主机(CPU)和设备(GPU)间数据传输优化,减少内存拷贝开销。
(4)高效采样支持
原生支持 Temperature、Top-k、Top-p 等采样策略,无需额外计算开销。
通过并行化采样步骤,减少生成延迟。
3. 推理流程(Step-by-Step)
以生成式推理(如 GPT)为例:
输入处理:
用户输入提示词(prompt),转换为 token 序列。
模型编码 token 并生成初始 KV Cache。
分页存储:
PagedAttention 将 KV Cache 分块存储到显存中。
迭代生成:
每次迭代生成一个 token,动态更新批次(Continuous Batching)。
根据采样参数(如 Top-p)选择下一个 token。
输出返回:
当生成结束符(EOS)或达到最大长度时,返回结果并释放显存。
4. 性能对比
技术指标 vLLM 传统推理框架(如 HF Transformers)
吞吐量 高(支持数百并发) 低(受限于静态批处理)
显存效率 高(PagedAttention 减少浪费) 低(KV Cache 需连续存储)
长上下文支持 支持 100K+ tokens 通常限制在 4K-32K tokens
采样灵活性 原生支持 Top-k/Top-p 需手动实现,可能引入延迟
5. 适用场景
高并发服务:如聊天机器人、API 服务。
长文本生成:如文档摘要、代码生成。
研究实验:快速测试不同采样参数的影响。
6. 代码示例(使用 vLLM)
python
from vllm import LLM, SamplingParams
# 初始化模型和采样参数
llm = LLM(model="meta-llama/Llama-2-7b-chat-hf")
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=100)
# 批量推理
prompts = ["Explain AI in one sentence.", "Write a poem about winter."]
outputs = llm.generate(prompts, sampling_params)
for out in outputs:
print(f"Prompt: {out.prompt}, Generated: {out.outputs[0].text}")
7. 与同类框架对比
框架 核心优势 局限性
vLLM 高吞吐、PagedAttention 主要支持自回归模型(如 GPT)
TGI (HuggingFace) 支持多模态模型 长上下文显存效率较低
DeepSpeed-Inference 分布式推理优化 配置复杂
8. 未来方向
多模态扩展:支持视觉-语言联合推理。
更细粒度调度:优化混合长短请求的场景。
量化集成:结合 4-bit 量化进一步降低显存占用。
总结来说,vLLM 通过 PagedAttention 和 Continuous Batching 两大核心技术,解决了大模型推理中的显存效率和吞吐量瓶颈,成为目前生产环境部署 LLM 的首选框架之一。
##############################################################
二、多卡并行推理的并行方式的基本原理
##############################################################
多卡并行推理的并行方式的基本原理
TP并行 Tensor Parallelism,张量并行
PP并行 流水线并行(Pipeline Parallelism)
EP并行 Expert Parallelism,专家并行
deepseek PD分离
1、1. 数据并行(Data Parallelism)
原理:
将输入数据(批次)拆分到不同GPU,每张卡独立计算完整模型的推理结果,最后同步结果。
每张GPU存储完整的模型副本。
工作流程:
主GPU将批次数据均分到各GPU(如批次大小=16,4卡时每卡分到4条数据)。
各GPU并行计算前向传播。
收集所有GPU的输出结果(如通过 all_gather 操作)。
优势:
实现简单,适合高吞吐场景(如批量处理大量短文本)。
缺点:
每卡需存储完整模型,显存占用高,无法支持超大规模模型。
适用场景:
模型能单卡放下,但需要提高批量推理效率。
2. 模型并行(Model Parallelism)
(1)张量并行(Tensor Parallelism)
原理:
将模型单层的权重矩阵拆分到不同GPU,每张卡只计算部分结果,通过通信拼接完整输出。
例如:线性层
Y
=
X
W
Y=XW 中,将权重矩阵
W
W 按列拆分,每卡计算部分乘积。
关键技术:
Megatron-LM 风格拆分:对矩阵乘法的行或列拆分,配合 all-reduce 通信。
通信开销:每层需同步中间结果(如通过NCCL)。
示例:
在4卡上拆分FFN层的权重矩阵:
python
# 原始权重 W (hidden_dim, 4*hidden_dim)
# 拆分到4卡,每卡存储 W_part (hidden_dim, hidden_dim)
Y = torch.cat([X @ W_part_i for W_part_i in W_parts], dim=-1) # 需要通信
优势:
支持单层参数量超过单卡显存的模型。
缺点:
通信频繁,延迟敏感。
(2)层间并行(Layer-wise Parallelism)
原理:
将模型的不同层分配到不同GPU(如GPU0处理1-10层,GPU1处理11-20层)。
缺点:
设备空闲率高(如GPU0需等待GPU1完成前一层的计算),较少单独使用。
3. 流水线并行(Pipeline Parallelism)
原理:
将模型按层分组,每组层放到不同GPU,数据像流水线一样依次流过各设备。
通过微批次(Micro-batching)隐藏通信延迟。
工作流程:
将输入数据分成多个微批次(如批次=8,微批次=2)。
GPU0处理微批次1的第1组层后,将激活值发送给GPU1,同时开始处理微批次2的第1组层。
各GPU交替计算和通信,形成流水线。
优势:
支持超长模型(如千亿参数模型)。
缺点:
需要平衡各阶段计算负载,否则效率下降(气泡问题)。
优化技术:
梯度累积:多个微批次后再反向传播,减少气泡。
1F1B调度(One-Forward-One-Backward):优化设备利用率。
4. 混合并行策略
实际部署中常组合多种并行方式:
案例1:GPT-3 175B 的推理:
张量并行:每层的矩阵计算拆分到8卡。
流水线并行:将模型按层分组,分配到多组设备(如8组,每组8卡)。
数据并行:对流水线并行的每组设备复制多份(如64卡=8组×8卡)。
案例2:vLLM 的多卡推理:
数据并行:处理不同请求的批次。
张量并行:单个大请求的模型计算拆分。
5. 通信机制
关键操作:
all-reduce:聚合各卡的梯度或输出(数据并行)。
all-gather:拼接拆分后的张量(张量并行)。
point-to-point:流水线并行的层间数据传输。
通信库:
NCCL(NVIDIA):优化多GPU通信,支持高速PCIe/NVLink。
RPC(PyTorch):用于跨节点通信。
6. 显存优化技术
KV Cache 分区:
在张量并行中,将注意力机制的KV Cache拆分到多卡,减少单卡显存压力。
Zero-Inference:
类似Zero-Redundancy Optimizer(ZeRO)的技术,优化显存占用。
#################################################################
三、PD 分离的基本思想
#################################################################
1. PD 分离的基本思想
参数解耦:将模型的参数划分为多个相对独立的子集,每个子集负责不同的功能或任务,避免参数之间的过度耦合。
典型场景:
多任务学习:不同任务共享部分参数(如特征提取层),但保留任务专属参数(如分类头)。
模块化设计:模型的不同模块(如注意力头、专家层)参数独立优化。
动态推理:根据输入动态激活部分参数(如MoE模型中的专家选择)。
2. DeepSeek 中 PD 分离的可能应用
(1)专家模型(MoE)中的参数解耦
背景:DeepSeek 可能采用混合专家(MoE)架构,其中不同专家(Expert)对应不同的参数子集。
PD 分离:
每个专家的参数完全独立,通过门控(Gating)机制动态激活。
例如:输入 token A 由专家1处理,token B 由专家2处理,两者参数无共享。
优势:
显存高效:仅激活部分参数,适合超大规模模型。
专业化:不同专家可学习不同领域的特征。
(2)多阶段训练的参数隔离
预训练 vs 微调解耦:
预训练阶段:冻结核心参数(如底层Transformer层),仅微调特定头部参数。
例如:DeepSeek-R1 模型可能解耦通用知识和领域适配参数。
优势:
避免灾难性遗忘,提升微调效率。
(3)硬件感知的参数分布
显存与计算分离:
高频访问参数(如注意力头的KV Cache)放在高速显存,低频参数(如部分FFN层)放在低速存储。
类似 DeepSpeed-ZeRO 的分级参数管理。
3. PD 分离的技术实现
(1)参数分组与优化器配置
在优化器(如AdamW)中为不同参数组设置独立的学习率或权重衰减:
python
# 示例:PyTorch 中的参数分组
group1 = {'params': model.shared_parameters(), 'lr': 1e-5} # 共享参数
group2 = {'params': model.task_specific_parameters(), 'lr': 1e-4} # 任务专属参数
optimizer = torch.optim.AdamW([group1, group2])
(2)动态参数激活
基于输入选择性地加载部分参数(如MoE的门控机制):
python
def forward(self, x):
gate_scores = self.gating_network(x) # 计算门控分数
expert_idx = torch.argmax(gate_scores, dim=-1) # 选择专家
y = self.experts[expert_idx](x) # 仅激活被选专家的参数
return y
(3)梯度隔离
通过停止梯度(detach)或掩码阻止某些参数的更新:
python
frozen_params = model.embedding.weight
frozen_params.requires_grad = False # 冻结嵌入层参数
4. PD 分离的优势
训练效率:减少冗余计算和显存占用。
模型可解释性:不同参数组对应明确的功能模块。
灵活部署:可单独更新或替换部分参数(如领域适配时仅微调头部)。
5. 与其他技术的对比
技术 PD 分离 传统耦合参数
参数更新粒度 细粒度(分组/模块化) 全局统一更新
显存占用 动态降低(仅激活部分参数) 固定
适用场景 MoE、多任务、大规模模型 小型单一任务模型
6. 潜在挑战
路由偏差:在MoE中,门控机制可能偏向某些专家,导致负载不均衡。
通信开销:分布式训练中,参数解耦可能增加同步复杂度(如All-to-All通信)。
收敛性:需谨慎设计参数组的优化策略,避免训练不稳定。
总结来说,DeepSeek 中的 PD 分离 可能指通过参数解耦实现更高效的模型设计或训练策略,尤其在 MoE 架构或多任务学习中表现突出。具体实现需结合模型架构和任务需求,核心目标是平衡参数共享与专业化,以提升性能和可扩展性。
#################################################################
大模型推理主要过程
比如prefill和decode阶段都做了什么
#################################################################
在大模型(如GPT、LLaMA等)的推理过程中,生成文本通常分为两个核心阶段:Prefill(预填充)阶段 和Decode(解码)阶段。两者的分工和计算模式差异显著,直接影响推理性能和资源占用。以下是它们的详细流程和关键技术:
1. Prefill 阶段(预填充)
作用:
处理输入的提示词(Prompt),生成初始的 KV Cache(键值缓存),为后续解码阶段做准备。
关键步骤:
输入处理:
将用户输入的文本(如 "Explain AI in one sentence.")通过分词器(Tokenizer)转换为 Token ID 序列。
添加特殊Token(如 <BOS>、<EOS>)并截断/填充至固定长度(如有必要)。
计算初始隐藏状态:
Token ID 序列通过模型的 Embedding 层 转换为向量表示(形状:[seq_len, hidden_dim])。
经过所有Transformer层的 前向传播,生成每个Token的隐藏状态。
生成 KV Cache:
在Transformer的 自注意力层 中,计算每个Token的 Key(K) 和 Value(V) 矩阵。
将K、V缓存到显存中(形状:[num_layers, seq_len, num_heads, head_dim]),供后续解码复用。
输出首个Token的概率分布:
对最后一个Token的隐藏状态应用 LM Head(语言模型头),得到词汇表上的概率分布。
根据采样策略(如Top-p、Temperature)选择首个生成的Token(如 "Artificial")。
计算特点:
计算密集型:需要处理整个输入序列(可能很长),所有Token并行计算。
显存占用高:KV Cache的大小与输入序列长度成正比(长Prompt需优化显存管理,如PagedAttention)。
2. Decode 阶段(解码)
作用:
基于Prefill阶段的KV Cache,逐个Token生成输出序列,直到达到停止条件(如最大长度或EOS Token)。
关键步骤:
输入当前Token:
将上一步生成的Token(如 "Artificial")作为新一轮的输入(形状:[1])。
通过Embedding层转换为向量(形状:[1, hidden_dim])。
增量计算:
仅计算 当前Token的隐藏状态(无需重新处理历史Token)。
在注意力层中:
计算当前Token的 新Key/Value,并追加到KV Cache中(序列长度+1)。
使用完整的KV Cache(包括Prefill和之前生成的Token)计算注意力权重。
生成下一个Token:
对当前Token的隐藏状态应用LM Head,得到概率分布。
采样下一个Token(如 "intelligence")。
循环生成:
重复步骤1-3,直到生成停止符或达到 max_tokens。
计算特点:
内存带宽受限:每次迭代仅处理1个Token,计算量小,但需频繁读写KV Cache。
延迟敏感:生成速度直接影响用户体验(通常追求低延迟)。
3. 两阶段对比
特性 Prefill 阶段 Decode 阶段
输入长度 整个Prompt序列(可能很长) 单个Token(逐步增长)
计算模式 全序列并行计算 增量计算(自回归)
主要瓶颈 计算能力(FLOPs) 内存带宽(KV Cache访问)
显存占用 高(存储完整Prompt的KV Cache) 逐步增加(每步+1 Token的Cache)
优化重点 长序列压缩、显存管理 KV Cache读写效率、采样加速
4. 关键技术优化
(1)Prefill 阶段优化
Flash Attention:加速长序列注意力计算,减少显存访问。
PagedAttention(vLLM):将KV Cache分块存储,支持超长Prompt。
Prompt 压缩:移除重复或无效Token(如ChatML模板中的固定指令)。
(2)Decode 阶段优化
KV Cache 复用:共享不同请求的相同Prompt的Cache。
连续批处理(Continuous Batching):动态插入新请求到运行中的批次,提高GPU利用率。
投机解码(Speculative Decoding):用小模型预测多个Token,大模型仅验证。
5. 示例流程(代码逻辑)
python
# 伪代码:基于Transformer的推理流程
def generate(prompt, max_tokens=100):
# Prefill 阶段
input_ids = tokenizer.encode(prompt) # 编码输入
kvs = [] # KV Cache初始化
hidden_states = model.embed(input_ids)
for layer in model.layers:
hidden_states, k, v = layer(hidden_states, use_cache=True)
kvs.append((k, v)) # 缓存KV
next_token = sample(hidden_states[-1]) # 采样首个Token
# Decode 阶段
output = [next_token]
for _ in range(max_tokens - 1):
hidden_states = model.embed(next_token)
for i, layer in enumerate(model.layers):
hidden_states, k, v = layer(hidden_states, past_kv=kvs[i])
kvs[i] = (torch.cat([kvs[i][0], k]), torch.cat([kvs[i][1], v])) # 更新Cache
next_token = sample(hidden_states[-1])
output.append(next_token)
if next_token == EOS: break
return tokenizer.decode(output)
6. 性能影响指标
Prefill 延迟:与Prompt长度成正比(优化方向:算法优化、显存管理)。
Decode 吞吐量:与批次大小、KV Cache效率相关(优化方向:连续批处理、内存带宽优化)。
显存占用:由KV Cache主导(优化方向:量化、共享Cache)。
总结来说,Prefill 阶段是“准备期”,负责处理输入并初始化KV Cache;Decode 阶段是“生成期”,以自回归方式逐步产生输出。两者的优化策略差异显著,共同决定了推理效率和用户体验。生产环境中(如vLLM、TGI等框架)会针对这两阶段分别进行极致优化。
#################################################################
三、自己测试内容的理解
讲清楚测试的内容为什么这么测
怎么测试更加有效,为什么更有效
相关文章:

大模型知识
############################################################## 一、vllm大模型测试参数和原理 tempreature top_p top_k ############################################################## tempreature top_p top_k 作用:总体是控制模型的发散程度、多样…...

C/C++ 结构体:. 与 -> 的区别与用法及其STM32中的使用
目录 引言 一、深入理解 C/C 结构体:. 与 -> 的区别与用法 1. .(点运算符)详解2. ->(箭头运算符)详解3. . 与 -> 的等价与转换4. 常见错误与调试技巧5. C 特性与运算符重载6. 实战案例:链表与智能…...

docker中使用openresty
1.为什么要使用openresty 我这边是因为要使用1Panel,第一个最大的原因,就是图方便,比较可以一键安装。但以前一直都是直接安装nginx。所以需要一个过度。 2.如何查看openResty使用了nginx哪个版本 /usr/local/openresty/nginx/sbin/nginx …...

Jetpack Compose 中更新应用语言
在 Jetpack Compose 应用中更新语言需要结合传统的 Android 语言配置方法和 Compose 的重组机制。以下是完整的实现方案: 1. 创建语言管理类 object LocaleManager {private var currentLocale: Locale Locale.getDefault()fun setLocale(context: Context, local…...
Java 中的 super 关键字
个人总结: 1.子类构造方法中没有显式使用super,Java 也会默认调用父类的无参构造方法 2.当父类中没有无参构造方法,只有有参构造方法时,子类构造方法就必须显式地使用super来调用父类的有参构造方法。 3.如果父类没有定义任何构造…...

CMake基础:CMakeLists.txt 文件结构和语法
目录 1.CMakeLists.txt基本结构 2.核心语法规则 3.关键命令详解 4.常用预定义变量 5.变量和缓存 6.变量作用域与传递 7.注意事项 1.CMakeLists.txt基本结构 CMakeLists.txt 是 CMake 构建系统的核心配置文件,采用命令式语法组织项目结构和编译流程。主要用于…...
PCM音频数据的编解码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

WebView2 Win7下部分机器触屏失效的问题
这个问题官方给了解决的方案,相关地址,只需要在项目中运行这个代码即可 public static void DisableWPFTabletSupport(){TabletDeviceCollection devices Tablet.TabletDevices;if (devices.Count > 0){Type inputManagerType typeof(InputManager)…...

Ubuntu 通过指令远程命令行配置WiFi连接
前提设备已经安装了无线网卡。 1、先通过命令行 ssh 登录机器。 2、搜索wifi设备,指令如下: sudo nmcli device wifi 3、输入需要联接的 wifi 名称和对应的wifi密码,指令如下: sudo nmcli device wifi connect wifi名称 passw…...

线程池优雅关闭的哲学
引言 关于并发的哲学,本文将着重强调那些关于线程池优雅关闭的一些技巧,希望对你有所启发。 强制关闭线程池的弊端 对于池化的线程池,如果采用强制关闭的方式将线程池直接关闭,就可能存在上下文消息消息,无法的很好…...

11.8 LangGraph生产级AI Agent开发:从节点定义到高并发架构的终极指南
使用 LangGraph 构建生产级 AI Agent:LangGraph 节点与边的实现 关键词:LangGraph 节点定义, 条件边实现, 状态管理, 多会话控制, 生产级 Agent 架构 1. LangGraph 核心设计解析 LangGraph 通过图结构抽象复杂 AI 工作流,其核心要素构成如下表所示: 组件作用描述代码对应…...

8天Python从入门到精通【itheima】-41~44
目录 41节-while循环的嵌套应用 1.学习目标 2.while循环的伪代码和生活情境中的应用 3.图片应用的代码案例 4.代码实例【Patrick自己亲手写的】: 5.whlie嵌套循环的注意点 6.小节总结 42节-while循环的嵌套案例-九九乘法表 1.补充知识-print的不换行 2.补充…...
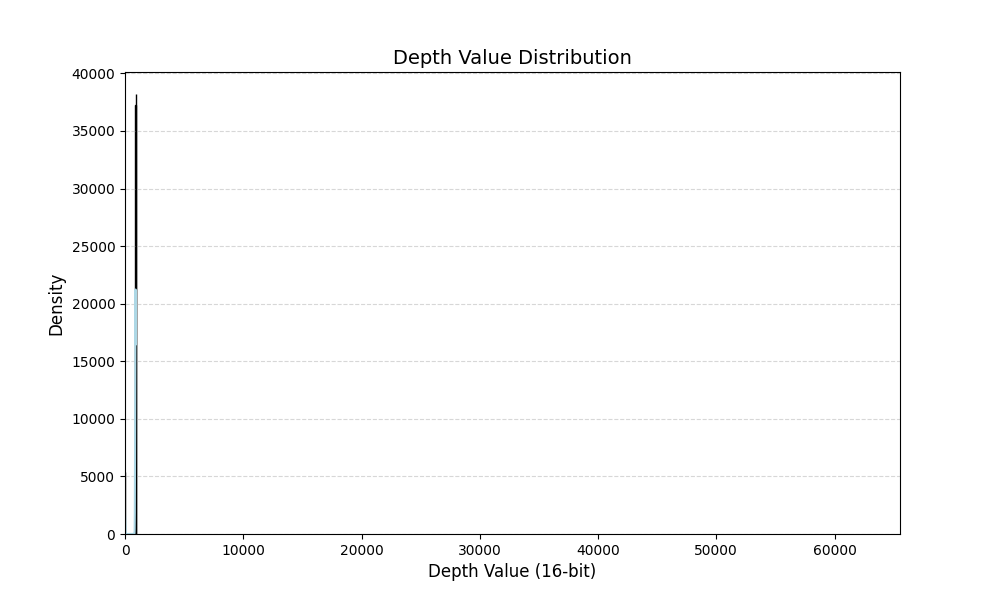
深度图数据增强方案-随机增加ROI区域的深度
主要思想:随机增加ROI区域的深度,模拟物体处在不同位置的形态。 首先打印一张深度图中的深度信息分布: import cv2 import matplotlib.pyplot as plt import numpy as np import seaborn as sns def plot_grayscale_histogram(image_path)…...

[Java恶补day6] 15. 三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&a…...

Django模板及表单
什么是Django模板 Django模板是一种用于生成动态内容的文件,它使用Django模板语言(Django Template Language,简称DTL)来描述和渲染HTML页面。模板允许开发人员将动态数据与静态HTML结构分离,以实现更灵活和可维护的W…...
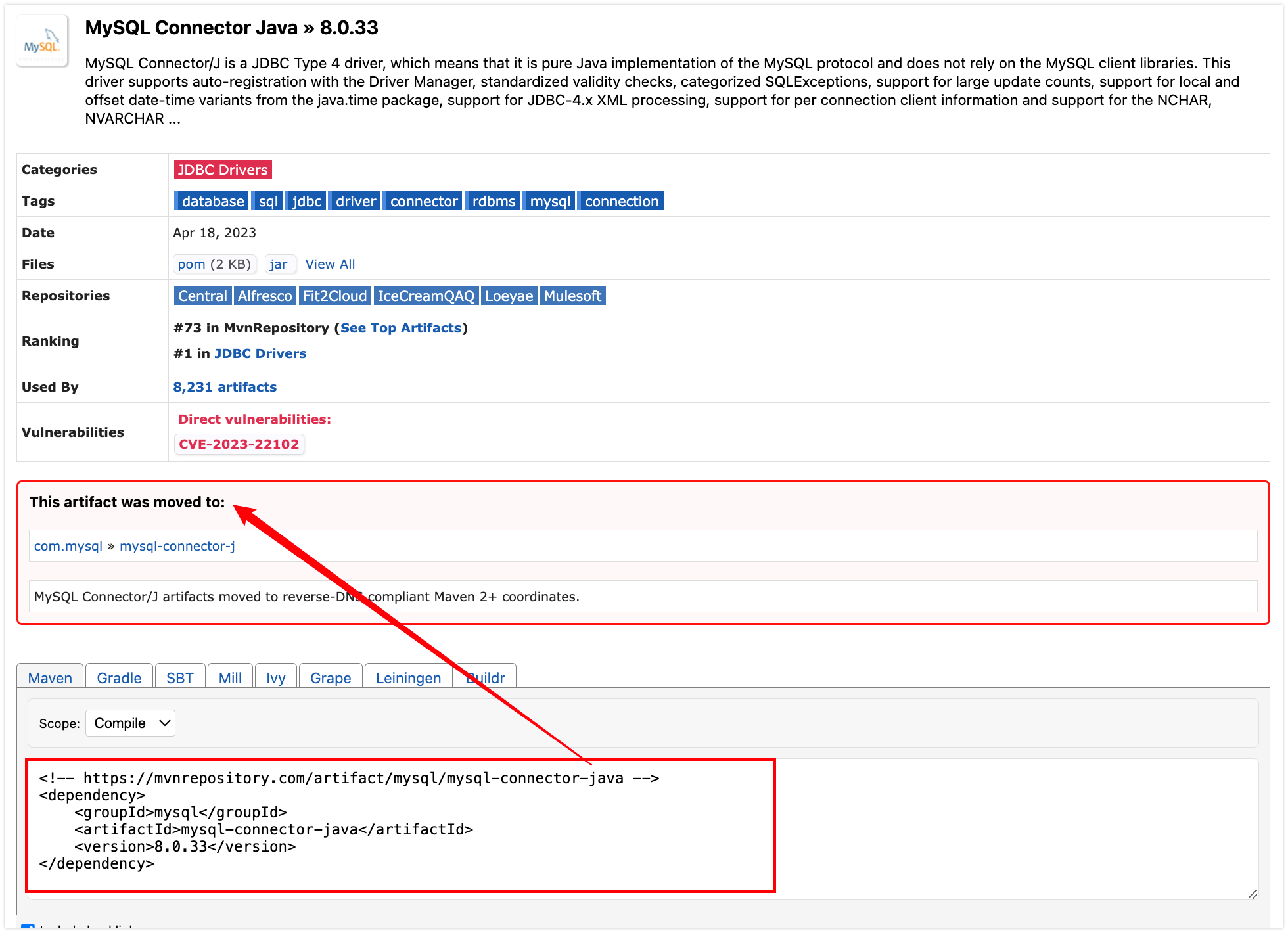
两个mysql的maven依赖要用哪个?
背景 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency>和 <dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId> &l…...
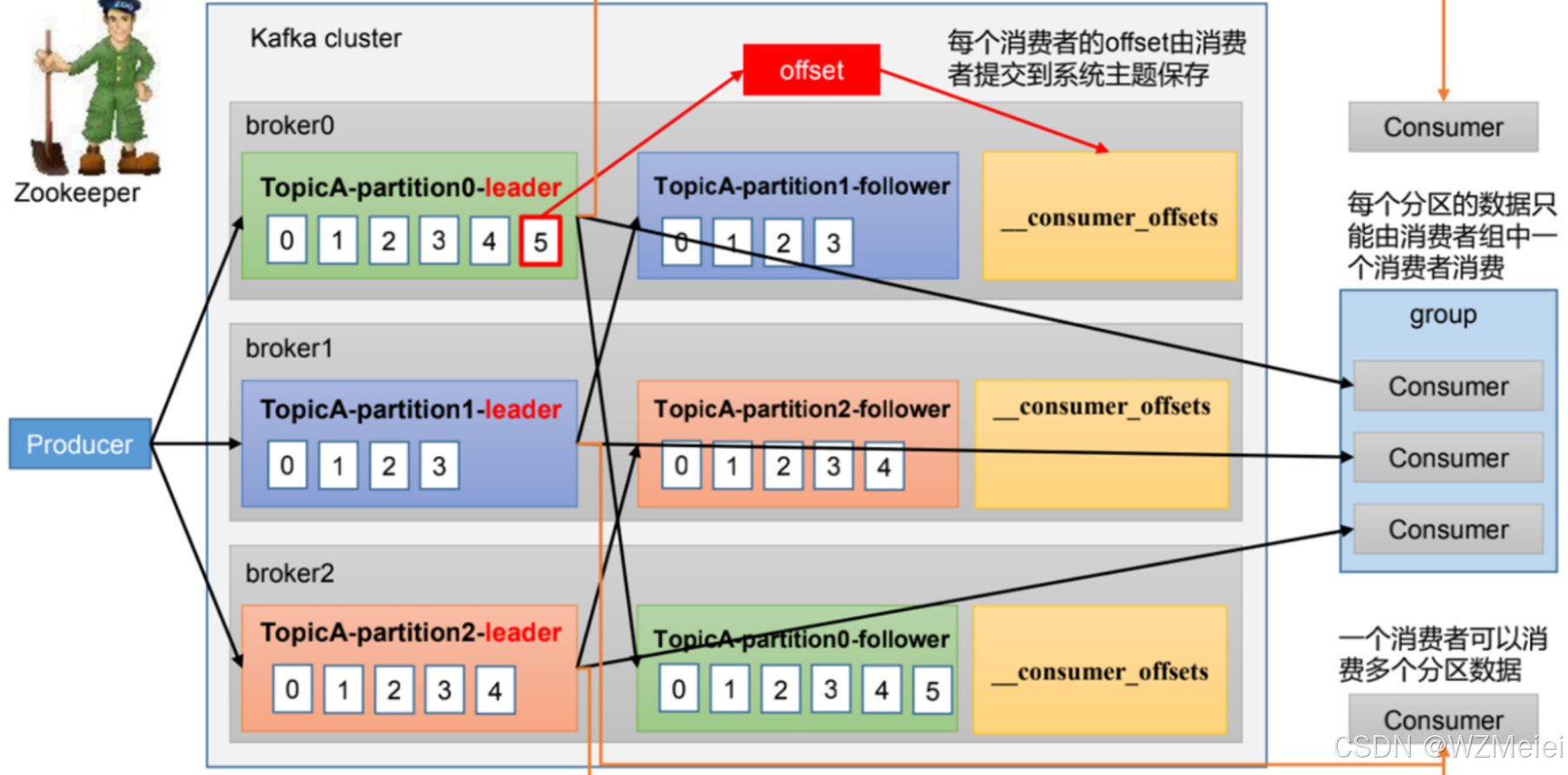
Kafka Consumer工作流程
Kafka Consumer工作流程图 1、启动与加入组 消费者启动后,会向 Kafka 集群中的某个 Broker 发送请求,请求加入特定消费者组。这个 Broker 中的消费者协调器(Consumer Coordinator)负责管理消费者组相关事宜。 2、组内分区分配&am…...
大腾智能 PDM 系统:全生命周期管理重塑制造企业数字化转型路径
在当今激烈的市场竞争中,产品迭代速度与质量已成为企业生存与发展的核心命脉。面对客户需求多元化、供应链协同复杂化、研发成本管控精细化等挑战,企业亟需一套能够贯穿产品全生命周期的数字化解决方案。 大腾智能PDM系统通过构建覆盖设计、研发、生产、…...

GATT 服务的核心函数bt_gatt_discover的介绍
目录 概述 1 GATT 基本概念 1.1 GATT 的介绍 1.2 GATT 的角色 1.3 核心组件 1.4 客户端操作 2 bt_gatt_discover函数的功能和应用 2.1 函数介绍 2.1 发现类型(Discover Type) 3 典型使用流程 3.1 服务发现示例 3.2 级联发现模式 3.3 按UUID过…...
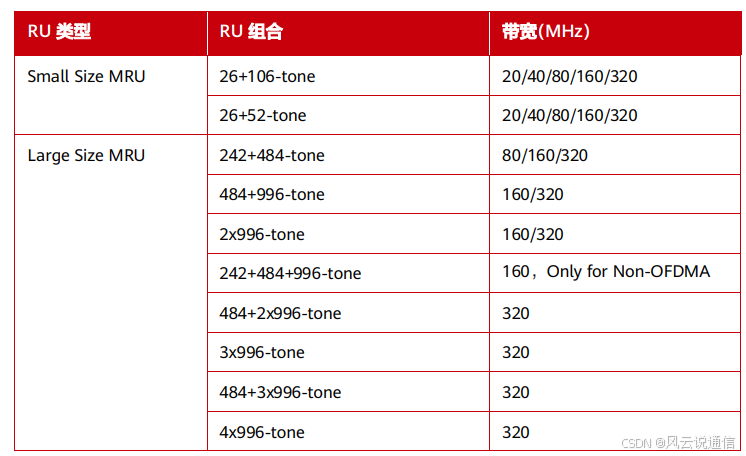
【短距离通信】【WiFi】WiFi7关键技术之4096-QAM、MRU
目录 3. 4096-QAM 3.1 4096-QAM 3.2 QAM 的阶数越高越好吗? 4. MRU 4.1 OFDMA 和 RU 4.2 MRU 资源分配 3. 4096-QAM 摘要 本章主要介绍了Wi-Fi 7引入的4096-QAM对数据传输速率的提升。 3.1 4096-QAM 对速率的提升 Wi-Fi 标准一直致力于提升数据传输速率&a…...

C 语言学习笔记
文章目录 程序设计入门 --- C 语言第一周 程序设计与 C 语言1 计算机与编程语言:计算机怎么做事情的,编程语言是什么📒 1.1 计算机的普遍应用 —— 离了它,现代人可能不会“活”了**🌐 科学计算:计算机的“最强大脑”时刻****📊 数据处理:现代社会的“数字管家”***…...

【MySQL成神之路】MySQL函数总结
以下是MySQL函数的全面总结,包含概念说明和代码示例: 一、MySQL函数分类 1. 字符串函数 -- CONCAT:连接字符串 SELECT CONCAT(Hello, , World); -- 输出 Hello World -- SUBSTRING:截取子串 SELECT SUBSTRING(MySQL, 2, 3…...
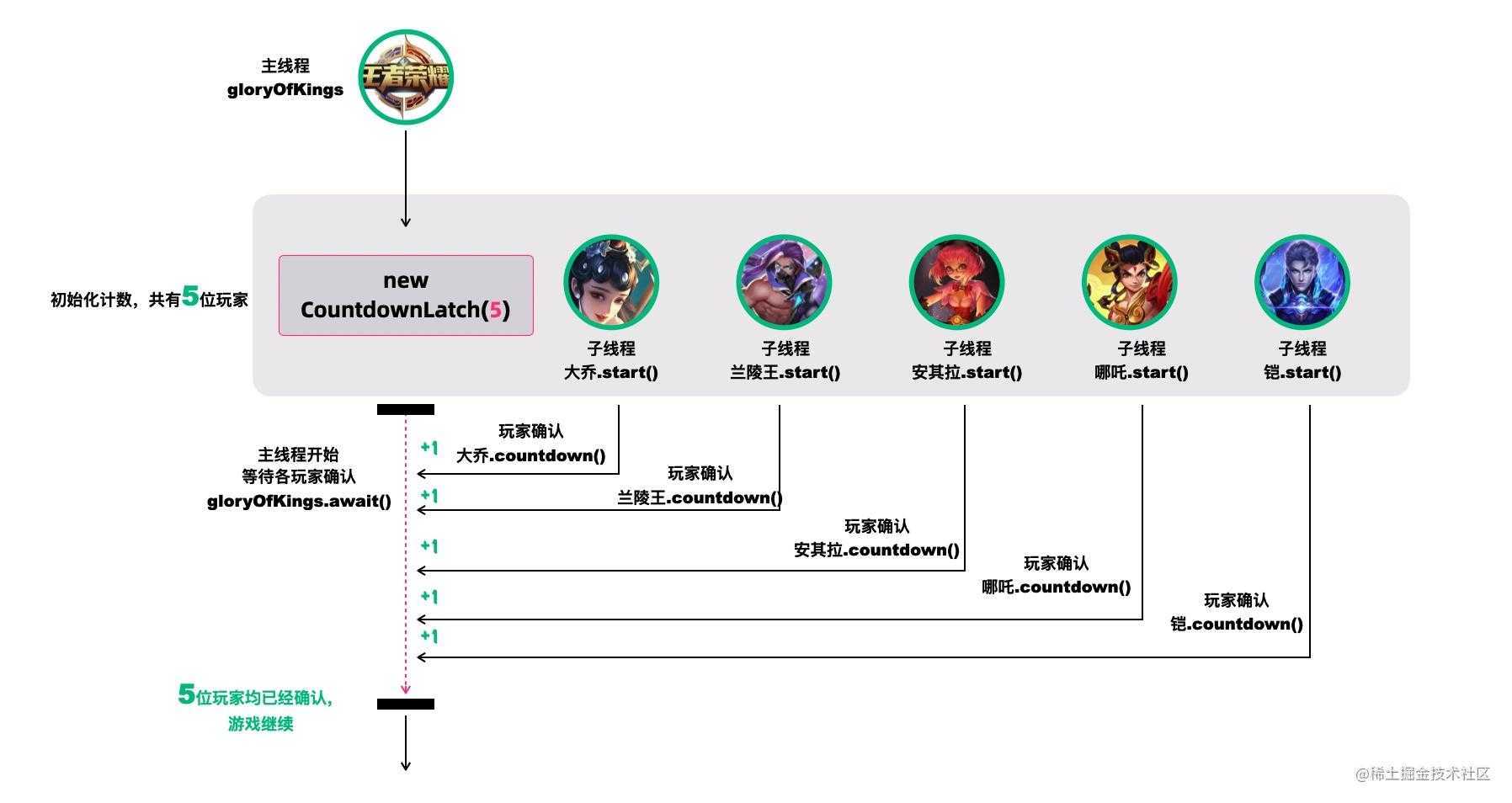
线程池实战——数据库连接池
引言 作者在前面写了很多并发编程知识深度探索系列文章,反馈得知友友们收获颇丰,同时我也了解到友友们也有了对知识如何应用感到很模糊的问题。所以作者就打算写一个实战系列文章,让友友们切身感受一下怎么应用知识。话不多说,开…...

修改 vue-pdf 源码升级 pdfjs-dist 包, 以解决部分 pdf 文件显示花屏问题
文章目录 背景: 客户反馈有部分文件预览花屏 最终解决方案: 自己 fork vue-pdf 仓库, 修改 pdfjs-dist 版本, 升级到 3.3.122 (我是 vue2 项目 node 10 环境)修改源码中引用地址带有 pdfjs-dist/es5/ 的地方, 去掉 es5 , 另外如果还有报错自己搜一下 pdfjs-dist/ , 看看引用…...
基于moonshot模型的Dify大语言模型应用开发核心场景
基于moonshot模型的Dify大语言模型应用开发核心场景学习总结 一、Dify环境部署 1.Docker环境部署 这里使用vagrant部署,下载vagrant之后,vagrant up登陆,vagrant ssh,在vagrant 中使用 vagrant centos/7 init 快速创建虚拟机 安装…...

华为OD机试真题——字符串序列判定(2025B卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
中,无法直接使用 continue 或 break 语句的解决办法)
在Java的list.forEach(即 Stream API 的 forEach 方法)中,无法直接使用 continue 或 break 语句的解决办法
说明 在 Java 的 list.forEach(即 Stream API 的 forEach 方法)中,无法直接使用 continue 或 break 语句,因为它是一个终结操作(Terminal Operation),依赖于 Lambda 表达式或方法引用。 有些时…...

Java面向对象高级学习笔记
面向对象高级 -类变量 类变量-提出问题 提出问题的主要目的就是让大家思考解决之道,从而引出我要讲的知识点 说:有一群小孩在玩堆雪人,不时有新的小孩加入,请问如何知道现在共有多少人在玩?,编写程序解决。 类变量快速入门 思考: 如果,设计一个int co…...

LLM之Agent:Mem0的简介、安装和使用方法、案例应用之详细攻略
LLM之Agent:Mem0的简介、安装和使用方法、案例应用之详细攻略 目录 Mem0的简介 1、Mem0的特点 2、性能: Mem0的安装及使用方法 1、安装 2、基本用法(基本用法) Mem0的案例应用 Mem0的简介 Mem0(发音为“mem-ze…...
工商总局可视化模版-Echarts的纯HTML源码
概述 基于ECharts的工商总局数据可视化HTML模版,帮助开发者快速搭建专业级工商广告数据展示平台。这款模版设计规范,功能完善,适合各类工商监管场景使用。 主要内容 本套模版采用现代化设计风格,主要包含以下核心功能模块&…...