11|省下钱买显卡,如何利用开源模型节约成本?
不知道课程上到这里,你账户里免费的5美元的额度还剩下多少了?如果你尝试着完成我给的几个数据集里的思考题,相信这个额度应该是不太够用的。而ChatCompletion的接口,又需要传入大量的上下文信息,实际消耗的Token数量其实比我们感觉的要多。
而且,除了费用之外,还有一个问题是数据安全。因为每个国家的数据监管要求不同,并不是所有的数据,都适合通过OpenAI的API来处理的。所以,从这两个角度出发,我们需要一个OpenAI以外的解决方案。那对于没有足够技术储备的中小型公司来说,最可行的一个思路就是利用好开源的大语言模型。
在Colab里使用GPU
因为这一讲我们要使用一些开源模型,但不是所有人的电脑里都有一个强劲的NVidia GPU的。所以,我建议你通过Colab来运行对应的Notebook,并且注意,要把对应的运行环境设置成GPU。
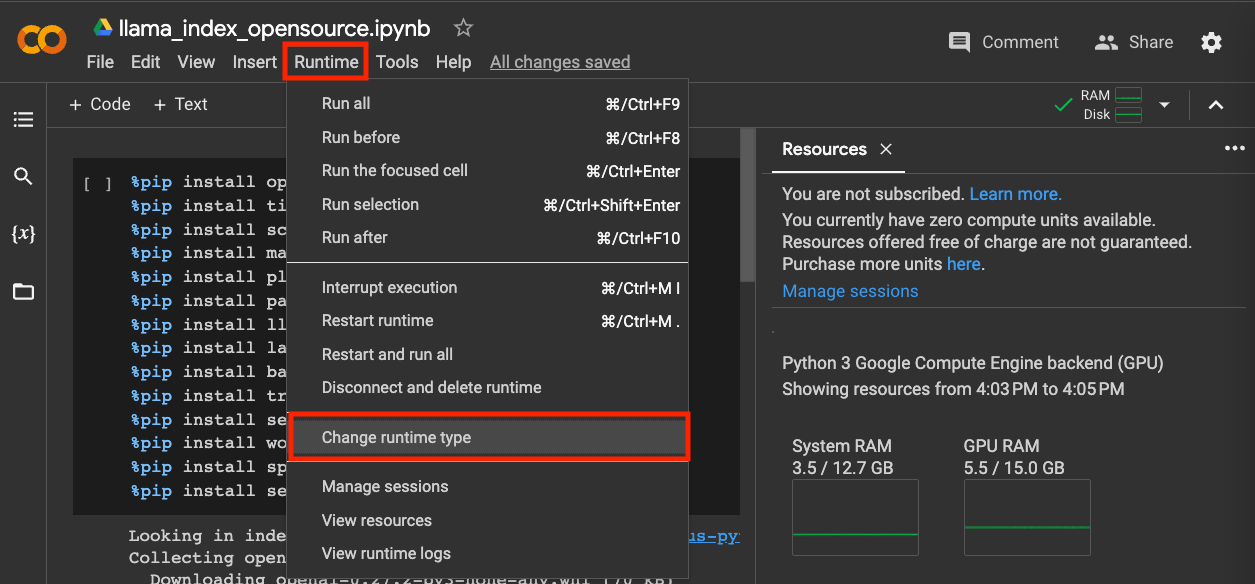
- 你先选择菜单栏里的Runtime,然后点击Change runtime type。
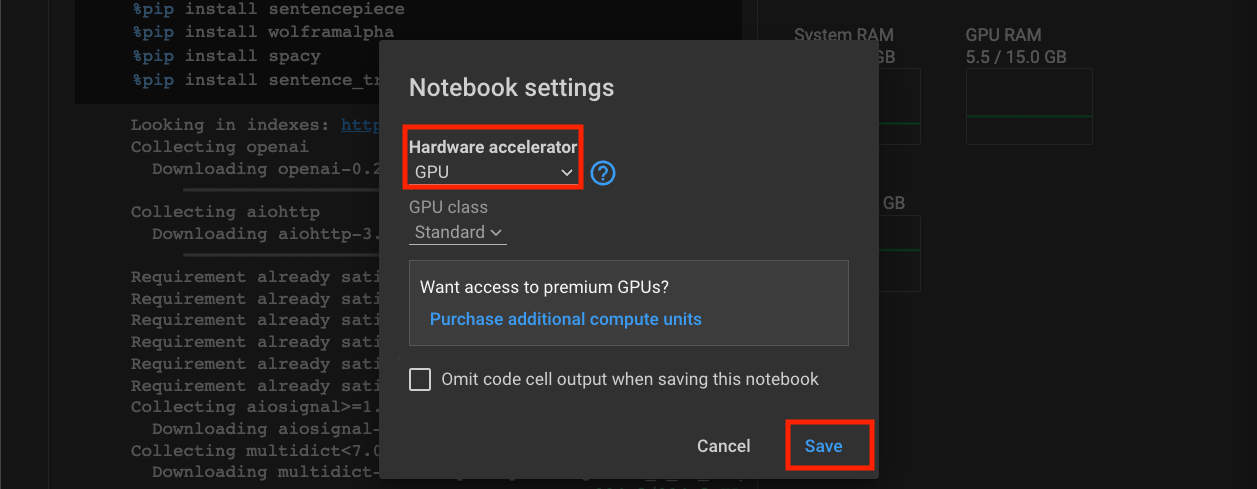
- 然后在弹出的对话框里,把Hardware accelerator换成GPU,然后点击Save就可以了。
只要用得不是太多,Colab的GPU是可以免费使用的。
HuggingfaceEmbedding,你的开源伙伴
其实我们之前在 第 4 讲 对比零样本分类效果的时候,就已经使用过Google开源的模型T5了。那个模型的效果,虽然比OpenAI的API还是要差一些,但是其实90%的准确率也还算不错了。那么联想一下,上一讲我们使用的llama-index向量搜索部分,是不是可以用开源模型的Embedding给替换掉呢?
当然是可以的,llama-index支持你自己直接定义一个定制化的Embedding,对应的代码我放在了下面。
conda install -c conda-forge sentence-transformers注:我们需要先安装一下sentence-transformers这个库。
import openai, os
import faiss
from llama_index import SimpleDirectoryReader, LangchainEmbedding, GPTFaissIndex, ServiceContext
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from llama_index.node_parser import SimpleNodeParseropenai.api_key = ""text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=100, chunk_overlap=20)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./data/faq/').load_data()
nodes = parser.get_nodes_from_documents(documents)embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2"
))
service_context = ServiceContext.from_defaults(embed_model=embed_model)dimension = 768
faiss_index = faiss.IndexFlatIP(dimension)
index = GPTFaissIndex(nodes=nodes,faiss_index=faiss_index, service_context=service_context)输出结果:
INFO:sentence_transformers.SentenceTransformer:Load pretrained SentenceTransformer: sentence-transformers/paraphrase-multilingual-mpnet-base-v2
INFO:sentence_transformers.SentenceTransformer:Use pytorch device: cpu
WARNING:root:Created a chunk of size 130, which is longer than the specified 100
……
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total embedding token usage: 3198 tokens在这个例子里面,我们使用了一个面向电商的FAQ的纯文本文件作为输入。里面是一系列预设好的FAQ问答对。为了确保我们没有使用OpenAI的API,我们先把openai.api_key给设成了一个空字符串。然后,我们定义了一个embeded_model,这个embeded_model里面,我们包装的是一个HuggingFaceEmbeddings的类。
因为HuggingFace为基于transformers的模型定义了一个标准,所以大部分模型你只需要传入一个模型名称,HuggingFacebEmbedding这个类就会下载模型、加载模型,并通过模型来计算你输入的文本的Embedding。使用HuggingFace的好处是,你可以通过一套代码使用所有的transfomers类型的模型。
sentence-transformers 是目前效果最好的语义搜索类的模型,它在BERT的基础上采用了对比学习的方式,来区分文本语义的相似度,它包括了一系列的预训练模型。我们在这里,选用的是 sentence-transformers下面的 paraphrase-multilingual-mpnet-base-v2 模型。顾名思义,这个是一个支持多语言(multilingual)并且能把语句和段落(paraphrase)变成向量的一个模型。因为我们给的示例都是中文,所以选取了这个模型。你可以根据你要解决的实际问题,来选取一个适合自己的模型。
我们还是使用Faiss这个库来作为我们的向量索引库,所以需要指定一下向量的维度,paraphrase-multilingual-mpnet-base-v2 这个模型的维度是768,所以我们就把维度定义成768维。
相应的对文档的切分,我们使用的是CharacterTextSplitter,并且在参数上我们做了一些调整。
首先,我们把“\n\n”这样两个连续的换行符作为一段段文本的分隔符,因为我们的FAQ数据里,每一个问答对都有一个空行隔开,正好是连续两个换行。
然后,我们把chunk_size设置得比较小,只有100。这是因为我们所使用的开源模型是个小模型,这样我们才能在单机加载起来。它能够支持的输入长度有限,只有128个Token,超出的部分会进行截断处理。如果我们不设置chunk_size,llama-index会自动合并多个chunk变成一个段落。
其次,我们还增加了一个小小的参数,叫做chunk_overlap。这个参数代表我们自动合并小的文本片段的时候,可以接受多大程度的重叠。它的默认值是200,超过了单段文档的chunk_size,所以我们这里要把它设小一点,不然程序会报错。
我们可以在对应的verbose日志里看到,这里的Embedding使用了3198个Token,不过这些Token都是我们通过sentence_transformers类型的开源模型计算的,不需要花钱。你的成本就节约下来了。
在创建完整个索引之后,我们就可以拿一些常见的电商类型的FAQ问题试一试。
问题1:
from llama_index import QueryModeopenai.api_key = os.environ.get("OPENAI_API_KEY")response = index.query("请问你们海南能发货吗?",mode=QueryMode.EMBEDDING,verbose=True,
)
print(response)输出结果:
> Got node text: Q: 支持哪些省份配送?
A: 我们支持全国大部分省份的配送,包括北京、上海、天津、重庆、河北、山西、辽宁、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏和新疆...INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 341 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 24 tokens是的,我们支持海南省的配送。问题2:
response = index.query("你们用哪些快递公司送货?",mode=QueryMode.EMBEDDING,verbose=True,
)
print(response)输出结果:
> Got node text: Q: 提供哪些快递公司的服务?
A: 我们与顺丰速运、圆通速递、申通快递、韵达快递、中通快递、百世快递等多家知名快递公司合作。...
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 281 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 27 tokens我们与顺丰速运、圆通速递、申通快递、韵达快递、中通快递、百世快递等多家知名快递公司合作,用他们的服务送货。问题3:
response = index.query("你们的退货政策是怎么样的?",mode=QueryMode.EMBEDDING,verbose=True,
)
print(response)输出结果:
> Got node text: Q: 退货政策是什么?
A: 自收到商品之日起7天内,如产品未使用、包装完好,您可以申请退货。某些特殊商品可能不支持退货,请在购买前查看商品详情页面的退货政策。...
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 393 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 27 tokens我们的退货政策是自收到商品之日起7天内,如产品未使用、包装完好,您可以申请退货。某些特殊商品可能不支持退货,请在购买前查看商品详情页面的退货政策。我们在问问题的时候,指定了query的mode是Embedding。通过三个常用的问题,我们可以看到,AI都给出了正确的回答,效果还是不错的。
使用ChatGLM提供对话效果
通过上面的代码,我们已经把生成Embedding以及利用Embedding的相似度进行搜索搞定了。但是,我们在实际问答的过程中,使用的还是OpenAI的Completion API。那么这一部分我们有没有办法也替换掉呢?
同样的,我们寻求开源模型的帮助。在这里,我们就不妨来试一下来自清华大学的ChatGLM语言模型,看看中文的开源语言模型,是不是也有基本的知识理解和推理能力。
首先我们还是要安装一些依赖包,因为icetk我没有找到Conda的源,所以我们这里通过pip来安装,但是在Conda的包管理器里一样能够看到。
pip install icetk
pip install cpm_kernels然后,我们还是先通过transformers来加载模型。 ChatGLM 最大的一个模型有1300亿个参数。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
model = model.eval()输出结果:
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
No compiled kernel found.
Compiling kernels : /root/.cache/huggingface/modules/transformers_modules/THUDM/chatglm-6b-int4/dac03c3ac833dab2845a569a9b7f6ac4e8c5dc9b/quantization_kernels.c
Compiling gcc -O3 -fPIC -std=c99 /root/.cache/huggingface/modules/transformers_modules/THUDM/chatglm-6b-int4/dac03c3ac833dab2845a569a9b7f6ac4e8c5dc9b/quantization_kernels.c -shared -o /root/.cache/huggingface/modules/transformers_modules/THUDM/chatglm-6b-int4/dac03c3ac833dab2845a569a9b7f6ac4e8c5dc9b/quantization_kernels.so
Kernels compiled : /root/.cache/huggingface/modules/transformers_modules/THUDM/chatglm-6b-int4/dac03c3ac833dab2845a569a9b7f6ac4e8c5dc9b/quantization_kernels.so
Load kernel : /root/.cache/huggingface/modules/transformers_modules/THUDM/chatglm-6b-int4/dac03c3ac833dab2845a569a9b7f6ac4e8c5dc9b/quantization_kernels.so
Using quantization cache
Applying quantization to glm layers但是这么大的模型,无论是你自己的电脑,还是Colab提供的GPU和TPU显然都放不了。所以我们只能选用一个裁剪后的60亿个参数的版本,并且我们还必须用int-4量化的方式,而不是用float16的浮点数。所以,这里我们的模型名字就叫做 chatglm-6b-int4,也就是 6B的参数量,通过int-4量化。然后,在这里,我们希望通过GPU进行模型的计算,所以加载模型的时候调用了.cuda()。
这里加载模型的时候,我们还设置了一个 trust_remote_code = true 的参数,这是因为ChatGLM的模型不是一个Huggingface官方发布的模型,而是由用户贡献的,所以需要你显式确认你信任这个模型的代码,它不会造成恶意的破坏。我们反正是在Colab里面运行这个代码,所以倒是不用太担心。
如果你想要用CPU运行,可以把模型加载的代码换成下面这样。
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()不过,我不建议你这么做。你没有GPU的话,还是直接使用Colab的GPU就好了。因为CPU在运行对话的时候非常慢。
在拿到模型之后我们就可以尝试着通过这个模型来进行问答了。
问题1:
question = """
自收到商品之日起7天内,如产品未使用、包装完好,您可以申请退货。某些特殊商品可能不支持退货,请在购买前查看商品详情页面的退货政策。根据以上信息,请回答下面的问题:Q: 你们的退货政策是怎么样的?
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)输出结果:
我们的退货政策是在产品未使用、包装完好的情况下,自收到商品之日起7天内可以退货。请注意,某些特殊商品可能不支持退货,在购买前请查看商品详情页面的退货政策,以了解具体情况。可以看到,ChatGLM的回答,的确是按照我们提示语里面有的上下文给出的。我们可以试着去掉提供的FAQ的内容,看看它的回答是怎样的。
问题2:
question = """
Q: 你们的退货政策是怎么样的?
A:
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)输出结果:
我们公司的政策是,如果您在购买后的7天内发现我们的产品不符合您的期望,可以申请退货。退货条件如下:
1. 符合退货政策要求的产品;
2. 未使用或损坏的产品;
3. 符合退货地点的要求,即退货地址与购买地址相同;
4. 符合退货流程的要求,即您需要提供有效的退货单并完成退货流程。
如果符合上述退货政策要求,我们将尽快处理您的退货申请,并为您退款。请注意,如果您已经使用了我们的产品,或者产品有损坏或变质等情况,我们将无法为您提供退货服务。可以看到,在没有合适的上下文信息的时候,它编造出了一些原本没有的要求,比如“退货地址与购买地址相同”。
我们再来看一个例子,看看它能不能拥有简单的推理能力。我们的上下文里只说了可以送到海南,没有说是否支持三亚这个城市,看看这个时候AI能不能回答对这个问题。
问题3:
question = """
我们支持全国大部分省份的配送,包括北京、上海、天津、重庆、河北、山西、辽宁、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏和新疆.根据以上信息,请回答下面的问题:Q: 你们能配送到三亚吗?
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)输出结果:
是的,我们支持全国大部分省份的配送,包括三亚市。可以看到,ChatGLM知道是可以配送到三亚的。不过万一是巧合呢?我们再看看在上下文里面,去掉了东三省,然后问问它能不能送到哈尔滨。
问题4:
question = """
我们支持全国大部分省份的配送,包括北京、上海、天津、重庆、河北、山西、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏和新疆.但是不能配送到东三省根据以上信息,请回答下面的问题:Q: 你们能配送到哈尔滨吗?
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)回答:
很抱歉,我们目前不能配送到哈尔滨。结果也是正确的,这个时候,ChatGLM会回答我们是送不到哈尔滨的。既然ChatGLM能够正确回答这个问题,那我们的FAQ问答就可以用ChatGLM来搞定了。
将ChatGLM封装成LLM
不过上面的代码里面,我们用的还是原始的ChatGLM的模型代码,还不能直接通过query来访问llama-index直接得到答案。要做到这一点倒也不难,我们把它封装成一个LLM类,让我们的index使用这个指定的大语言模型就好了。对应的 llama-index 的文档,你也可以自己去看一下。
import openai, os
import faiss
from llama_index import SimpleDirectoryReader, LangchainEmbedding, GPTFaissIndex, ServiceContext
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from llama_index.node_parser import SimpleNodeParserfrom langchain.llms.base import LLM
from llama_index import LLMPredictor
from typing import Optional, List, Mapping, Anyclass CustomLLM(LLM):def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:response, history = model.chat(tokenizer, prompt, history=[])return response@propertydef _identifying_params(self) -> Mapping[str, Any]:return {"name_of_model": "chatglm-6b-int4"}@propertydef _llm_type(self) -> str:return "custom"我们把这个CustomLLM对象,传入index的构造函数里,重新运行一下我们的问题,看看效果是怎样的。
from langchain.text_splitter import SpacyTextSplitterllm_predictor = LLMPredictor(llm=CustomLLM())text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=100, chunk_overlap=20)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./drive/MyDrive/colab_data/faq/').load_data()
nodes = parser.get_nodes_from_documents(documents)embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2"
))
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm_predictor=llm_predictor)dimension = 768
faiss_index = faiss.IndexFlatIP(dimension)
index = GPTFaissIndex(nodes=nodes, faiss_index=faiss_index, service_context=service_context)from llama_index import QuestionAnswerPrompt
from llama_index import QueryModeQA_PROMPT_TMPL = ("{context_str}""\n\n""根据以上信息,请回答下面的问题:\n""Q: {query_str}\n")
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)response = index.query("请问你们海南能发货吗?",mode=QueryMode.EMBEDDING,text_qa_template=QA_PROMPT,verbose=True,
)
print(response)输出结果:
> Got node text: Q: 支持哪些省份配送?
A: 我们支持全国大部分省份的配送,包括北京、上海、天津、重庆、河北、山西、辽宁、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏和新疆...海南能发货。可以看到,这样处理之后,我们就可以直接使用ChatGLM的模型,来进行我们的FAQ的问答了。
现在,我们有了一个通过paraphrase-multilingual-mpnet-base-v2模型来计算Embeddding并进行语义搜索,然后通过chatglm-6b-int4的模型来进行问答的解决方案了。而且这两个模型,可以跑在一块家用级别的显卡上。是不是很厉害?
开源模型的不足之处
看起来,我们这个本机就能运行的小模型似乎已经完成了。数据安全,又不用担心花费。但显然,事情没有那么简单。因为刚才我们处理的电商FAQ问题比较简单,我们再拿一个稍微复杂一点的问题来看看效果。
text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 128, chunk_overlap=32)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./drive/MyDrive/colab_data/zhaohuaxishi/').load_data()
nodes = parser.get_nodes_from_documents(documents)embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2"
))
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm_predictor=llm_predictor)dimension = 768
faiss_index = faiss.IndexFlatIP(dimension)
index = GPTFaissIndex(nodes=nodes, faiss_index=faiss_index, service_context=service_context)输出结果:
INFO:sentence_transformers.SentenceTransformer:Load pretrained SentenceTransformer: sentence-transformers/paraphrase-multilingual-mpnet-base-v2
INFO:sentence_transformers.SentenceTransformer:Use pytorch device: cpu
……
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total embedding token usage: 91882 tokens这一次,我们输入索引起来的数据,是鲁迅先生整套《朝花夕拾》的散文集。选用这个是因为对应作品的版权已经过了保护期。我们来看看,在这套文集的内容里面,使用我们上面的纯开源方案,效果会是怎样的。
对应的模型和索引加载的代码基本一致,只有一个小小的区别,就是在文本分割的时候,我们用了上一讲介绍过的SpacyTextSplitter,因为这里都是散文的内容,而不是确定好格式的QA对。所以通过SpacyTextSplitter来分句,并在允许的时候合并小的片段是有意义的。
然后,我们试着问一下上一讲我们问过的问题,看看效果怎么样。
问题1:
# query will use the same embed_model
from llama_index import QueryMode
from llama_index import QuestionAnswerPromptopenai.api_key = os.environ.get("OPENAI_API_KEY")QA_PROMPT_TMPL = ("下面的内容来自鲁迅先生的散文集《朝花夕拾》,很多内容是以第一人称写的 \n""---------------------\n""{context_str}""\n---------------------\n""根据这些信息,请回答问题: {query_str}\n""如果您不知道的话,请回答不知道\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)response = index.query("鲁迅先生在日本学习医学的老师是谁?",mode=QueryMode.EMBEDDING,similarity_top_k = 1,text_qa_template=QA_PROMPT,verbose=True,
)
print(response)输出结果:
> Got node text: 一将书放在讲台上,便用了缓慢而很有顿挫的声调,向学生介绍自己道:——“我就是叫作藤野严九郎的……。”后面有几个人笑起来了。
他接着便讲述解剖学在日本发达的历史,那些大大小小的书,便是从最初到现今关于这一门学问的著作。...鲁迅先生在日本学习医学的老师是藤野严九郎。问题2:
response = index.query("鲁迅先生是在日本的哪个城市学习医学的?",mode=QueryMode.EMBEDDING,similarity_top_k = 1,text_qa_template=QA_PROMPT,verbose=True,
)
print(response)输出结果:
> Got node text: 有时我常常想:他的对于我的热心的希望,不倦的教诲,小而言之,是为中国,就是希望中国有新的医学;大而言之,是为学术,就是希望新的医学传到中国去。...根据这些信息,无法得出鲁迅先生是在日本的哪个城市学习医学的答案。可以看到,有些问题在这个模式下,定位到的文本片段是正确的。但是有些问题,虽然定位的还算是一个相关的片段,但是的确无法得出答案。
在这个过程中,我们可以观察到这样一个问题: 那就是单机的开源小模型能够承载的文本输入的长度问题。在我们使用OpenAI的gpt-3.5-turbo模型的时候,我们最长支持4096个Token,也就是一个文本片段可以放上上千字在里面。但是我们这里单机用的paraphrase-multilingual-mpnet-base-v2模型,只能支持128个Token的输入,虽然对应的Tokenizer不一样,但是就算一个字一个Token,也就100个字而已。这使得我们检索出来的内容的上下文太少了,很多时候没有足够的信息,让语言模型去回答。
当然,这个问题并不是无法弥补的。我们可以通过把更大规模的模型,部署到云端来解决。这个内容,我们课程的第三部分专门有一讲会讲解。
不过,有一个更难解决的问题,就是模型的推理能力问题。比如,我们可以再试试 第 1 讲 里给商品总结英文名称和卖点的例子。
question = """Consideration proudct : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具1. Compose human readale product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.Output the result in json format with three properties called title, selling_points and price_range"""
response, history = model.chat(tokenizer, question, history=[])
print(response)输出结果:
1. title: 充气玩具青蛙夜市地摊卖
2. selling_points:- 工厂现货:保证产品质量- PVC充气:环保耐用- 夜市地摊:方便销售- 热卖:最受欢迎产品- 儿童水上玩具:适合各种年龄段儿童
3. price_range: (in USD)- low: $1.99- high: $5.99可以看到,虽然这个结果不算太离谱,多少和问题还是有些关系的。但是无论是翻译成英文,还是使用JSON返回,模型都没有做到。给到的卖点也没有任何“推理出来”的性质,都是简单地对标题的重复描述。即使你部署一个更大版本的模型到云端,也好不到哪里去。
这也是ChatGPT让人震撼的原因,的确目前它的效果还是要远远超出任何一个竞争对手和开源项目的。
小结
好了,最后我们来回顾一下。这一讲里,我们一起尝试用开源模型来代替ChatGPT。我们通过sentence_transfomers类型的模型,生成了文本分片的Embedding,并且基于这个Embedding来进行语义检索。我们通过 ChatGLM 这个开源模型,实现了基于上下文提示语的问答。在简单的电商QA这样的场景里,效果也还是不错的。即使我们使用的都是单机小模型,它也能正确回答出来。这些方法,也能节约我们的成本。不用把钱都交给OpenAI,可以攒着买显卡来训练自己的模型。
但是,当我们需要解决更加复杂的问题时,比如需要更长的上下文信息,或者需要模型本身更强的推理能力的时候,这样的小模型就远远不够用了。更长的上下文信息检索,我们还能够通过在云端部署更大规模的模型,解决部分问题。但是模型的推理能力,目前的确没有好的解决方案。
所以不得不佩服,OpenAI的在AGI这个目标上耕耘多年后震惊世人的效果。
🔥运维干货分享
- 软考高级系统架构设计师备考学习资料
- 软考中级数据库系统工程师学习资料
- 软考高级网络规划设计师备考学习资料
- Kubernetes CKA认证学习资料分享
- AI大模型学习资料合集
- 免费文档翻译工具(支持word、pdf、ppt、excel)
- PuTTY中文版安装包
- MobaXterm中文版安装包
- pinginfoview网络诊断工具中文版
- Xshell、Xsftp、Xmanager中文版安装包
- Typora简单易用的Markdown编辑器
- Window进程监控工具,能自动重启进程和卡死检测
- Spring 源码学习资料分享
- 毕业设计高质量毕业答辩 PPT 模板分享
- IT行业工程师面试简历模板分享
相关文章:
11|省下钱买显卡,如何利用开源模型节约成本?
不知道课程上到这里,你账户里免费的5美元的额度还剩下多少了?如果你尝试着完成我给的几个数据集里的思考题,相信这个额度应该是不太够用的。而ChatCompletion的接口,又需要传入大量的上下文信息,实际消耗的Token数量其…...

GDB调试工具详解
GDB调试工具详解 一、基本概念 调试信息 编译时需添加 -g 选项(如 gcc -g -o program program.c),生成包含变量名、函数名、行号等调试信息的可执行文件。断点(Breakpoint) 程序执行到指定位置(函数、行号…...

机器学习圣经PRML作者Bishop20年后新作中文版出版!
机器学习圣经PRML作者Bishop20年后新书《深度学习:基础与概念》出版。作者克里斯托弗M. 毕晓普(Christopher M. Bishop)微软公司技术研究员、微软研究 院 科学智 能 中 心(Microsoft Research AI4Science)负责人。剑桥…...

Armadillo C++ 线性代数库介绍与使用
文章目录 Armadillo C 线性代数库介绍与使用主要特点安装Linux (Ubuntu/Debian)macOS (使用 Homebrew)Windows (使用 vcpkg) 基本使用包含头文件矩阵创建与初始化基本运算矩阵分解统计运算保存和加载数据 性能优化建议示例程序与 MATLAB 语法对比 使用Armadillo函数库的稀疏矩阵…...
吴恩达机器学习笔记:逻辑回归3
3.判定边界 现在说下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。 在逻辑回归中,我们预测: 当ℎθ (x) > 0.5时,预测 y 1。 当ℎθ (x) < 0.5时,预测 y 0 。 根据…...

大模型知识
############################################################## 一、vllm大模型测试参数和原理 tempreature top_p top_k ############################################################## tempreature top_p top_k 作用:总体是控制模型的发散程度、多样…...

C/C++ 结构体:. 与 -> 的区别与用法及其STM32中的使用
目录 引言 一、深入理解 C/C 结构体:. 与 -> 的区别与用法 1. .(点运算符)详解2. ->(箭头运算符)详解3. . 与 -> 的等价与转换4. 常见错误与调试技巧5. C 特性与运算符重载6. 实战案例:链表与智能…...

docker中使用openresty
1.为什么要使用openresty 我这边是因为要使用1Panel,第一个最大的原因,就是图方便,比较可以一键安装。但以前一直都是直接安装nginx。所以需要一个过度。 2.如何查看openResty使用了nginx哪个版本 /usr/local/openresty/nginx/sbin/nginx …...

Jetpack Compose 中更新应用语言
在 Jetpack Compose 应用中更新语言需要结合传统的 Android 语言配置方法和 Compose 的重组机制。以下是完整的实现方案: 1. 创建语言管理类 object LocaleManager {private var currentLocale: Locale Locale.getDefault()fun setLocale(context: Context, local…...
Java 中的 super 关键字
个人总结: 1.子类构造方法中没有显式使用super,Java 也会默认调用父类的无参构造方法 2.当父类中没有无参构造方法,只有有参构造方法时,子类构造方法就必须显式地使用super来调用父类的有参构造方法。 3.如果父类没有定义任何构造…...

CMake基础:CMakeLists.txt 文件结构和语法
目录 1.CMakeLists.txt基本结构 2.核心语法规则 3.关键命令详解 4.常用预定义变量 5.变量和缓存 6.变量作用域与传递 7.注意事项 1.CMakeLists.txt基本结构 CMakeLists.txt 是 CMake 构建系统的核心配置文件,采用命令式语法组织项目结构和编译流程。主要用于…...
PCM音频数据的编解码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

WebView2 Win7下部分机器触屏失效的问题
这个问题官方给了解决的方案,相关地址,只需要在项目中运行这个代码即可 public static void DisableWPFTabletSupport(){TabletDeviceCollection devices Tablet.TabletDevices;if (devices.Count > 0){Type inputManagerType typeof(InputManager)…...

Ubuntu 通过指令远程命令行配置WiFi连接
前提设备已经安装了无线网卡。 1、先通过命令行 ssh 登录机器。 2、搜索wifi设备,指令如下: sudo nmcli device wifi 3、输入需要联接的 wifi 名称和对应的wifi密码,指令如下: sudo nmcli device wifi connect wifi名称 passw…...

线程池优雅关闭的哲学
引言 关于并发的哲学,本文将着重强调那些关于线程池优雅关闭的一些技巧,希望对你有所启发。 强制关闭线程池的弊端 对于池化的线程池,如果采用强制关闭的方式将线程池直接关闭,就可能存在上下文消息消息,无法的很好…...

11.8 LangGraph生产级AI Agent开发:从节点定义到高并发架构的终极指南
使用 LangGraph 构建生产级 AI Agent:LangGraph 节点与边的实现 关键词:LangGraph 节点定义, 条件边实现, 状态管理, 多会话控制, 生产级 Agent 架构 1. LangGraph 核心设计解析 LangGraph 通过图结构抽象复杂 AI 工作流,其核心要素构成如下表所示: 组件作用描述代码对应…...

8天Python从入门到精通【itheima】-41~44
目录 41节-while循环的嵌套应用 1.学习目标 2.while循环的伪代码和生活情境中的应用 3.图片应用的代码案例 4.代码实例【Patrick自己亲手写的】: 5.whlie嵌套循环的注意点 6.小节总结 42节-while循环的嵌套案例-九九乘法表 1.补充知识-print的不换行 2.补充…...
深度图数据增强方案-随机增加ROI区域的深度
主要思想:随机增加ROI区域的深度,模拟物体处在不同位置的形态。 首先打印一张深度图中的深度信息分布: import cv2 import matplotlib.pyplot as plt import numpy as np import seaborn as sns def plot_grayscale_histogram(image_path)…...

[Java恶补day6] 15. 三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&a…...

Django模板及表单
什么是Django模板 Django模板是一种用于生成动态内容的文件,它使用Django模板语言(Django Template Language,简称DTL)来描述和渲染HTML页面。模板允许开发人员将动态数据与静态HTML结构分离,以实现更灵活和可维护的W…...
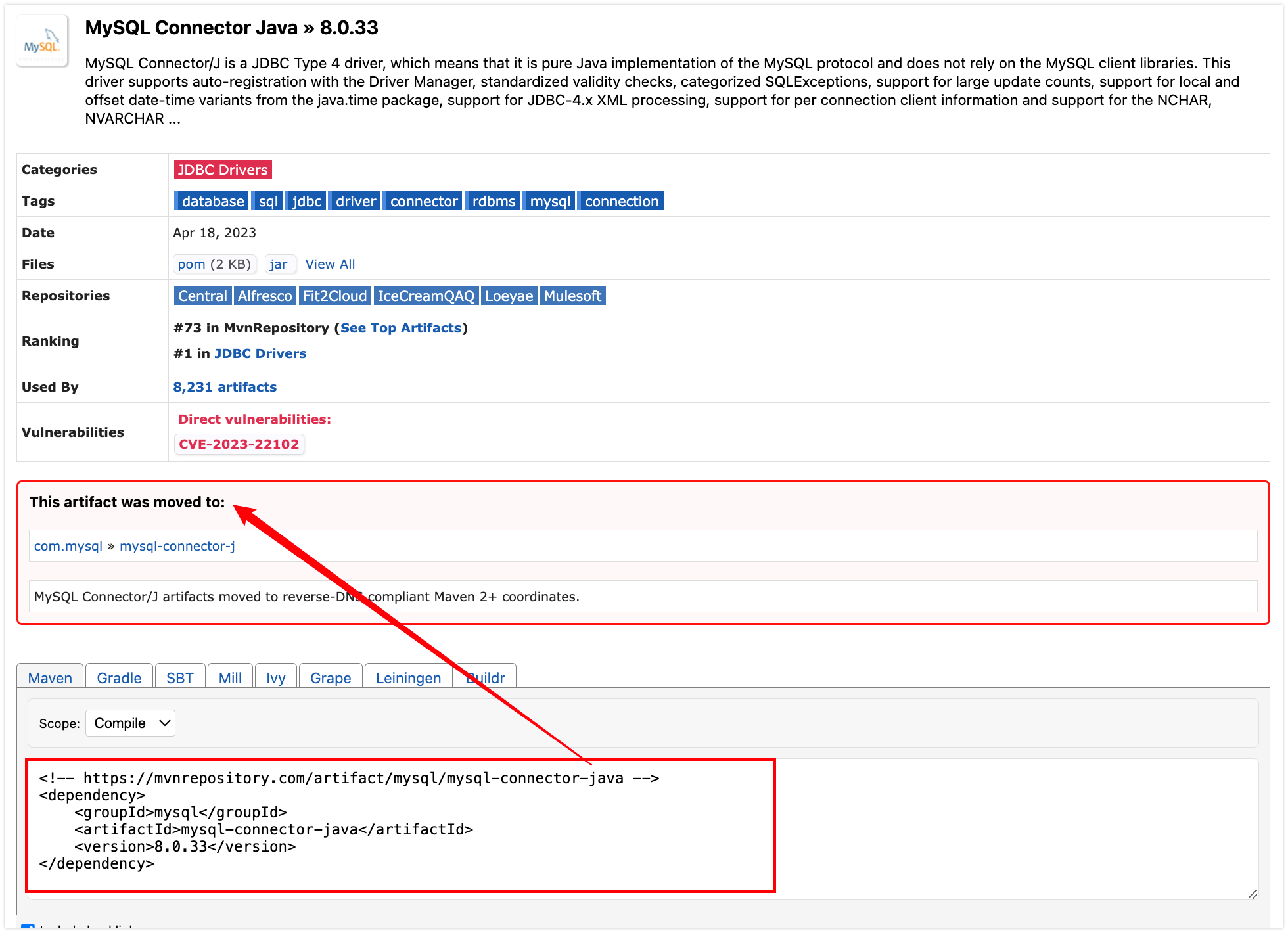
两个mysql的maven依赖要用哪个?
背景 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency>和 <dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId> &l…...
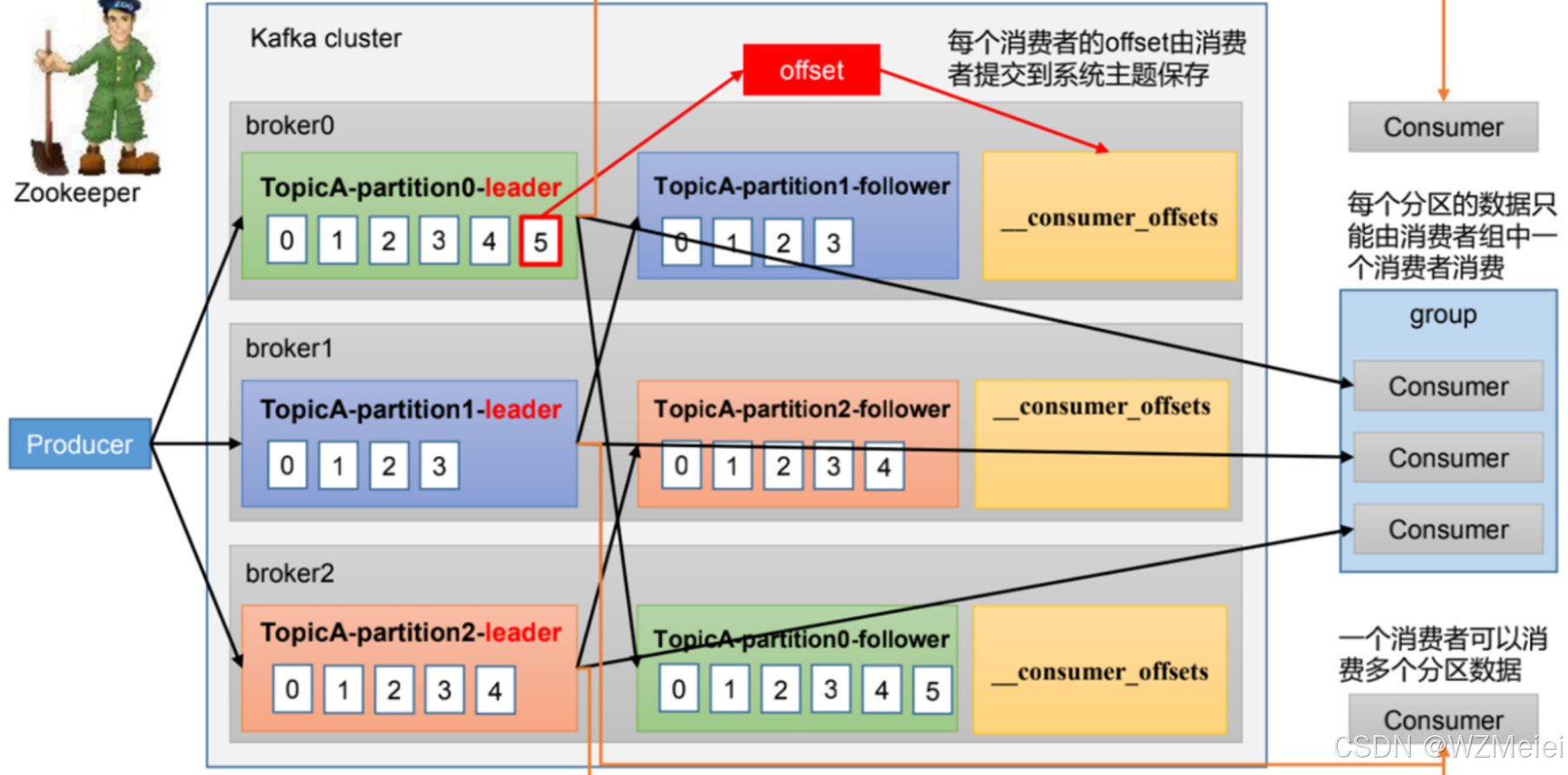
Kafka Consumer工作流程
Kafka Consumer工作流程图 1、启动与加入组 消费者启动后,会向 Kafka 集群中的某个 Broker 发送请求,请求加入特定消费者组。这个 Broker 中的消费者协调器(Consumer Coordinator)负责管理消费者组相关事宜。 2、组内分区分配&am…...
大腾智能 PDM 系统:全生命周期管理重塑制造企业数字化转型路径
在当今激烈的市场竞争中,产品迭代速度与质量已成为企业生存与发展的核心命脉。面对客户需求多元化、供应链协同复杂化、研发成本管控精细化等挑战,企业亟需一套能够贯穿产品全生命周期的数字化解决方案。 大腾智能PDM系统通过构建覆盖设计、研发、生产、…...

GATT 服务的核心函数bt_gatt_discover的介绍
目录 概述 1 GATT 基本概念 1.1 GATT 的介绍 1.2 GATT 的角色 1.3 核心组件 1.4 客户端操作 2 bt_gatt_discover函数的功能和应用 2.1 函数介绍 2.1 发现类型(Discover Type) 3 典型使用流程 3.1 服务发现示例 3.2 级联发现模式 3.3 按UUID过…...
【短距离通信】【WiFi】WiFi7关键技术之4096-QAM、MRU
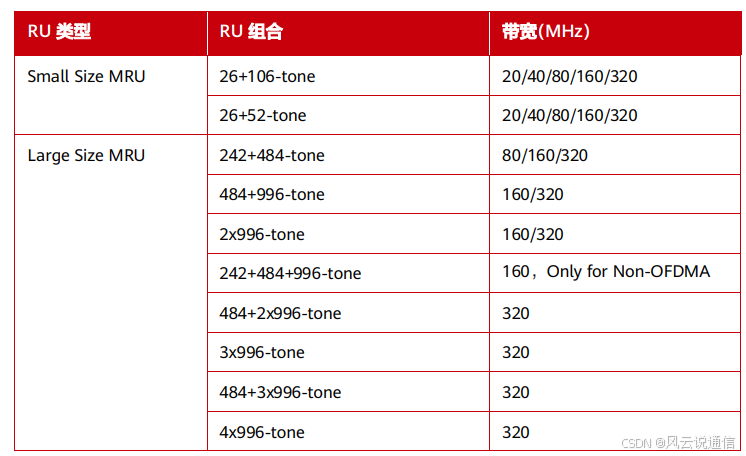
目录 3. 4096-QAM 3.1 4096-QAM 3.2 QAM 的阶数越高越好吗? 4. MRU 4.1 OFDMA 和 RU 4.2 MRU 资源分配 3. 4096-QAM 摘要 本章主要介绍了Wi-Fi 7引入的4096-QAM对数据传输速率的提升。 3.1 4096-QAM 对速率的提升 Wi-Fi 标准一直致力于提升数据传输速率&a…...

C 语言学习笔记
文章目录 程序设计入门 --- C 语言第一周 程序设计与 C 语言1 计算机与编程语言:计算机怎么做事情的,编程语言是什么📒 1.1 计算机的普遍应用 —— 离了它,现代人可能不会“活”了**🌐 科学计算:计算机的“最强大脑”时刻****📊 数据处理:现代社会的“数字管家”***…...

【MySQL成神之路】MySQL函数总结
以下是MySQL函数的全面总结,包含概念说明和代码示例: 一、MySQL函数分类 1. 字符串函数 -- CONCAT:连接字符串 SELECT CONCAT(Hello, , World); -- 输出 Hello World -- SUBSTRING:截取子串 SELECT SUBSTRING(MySQL, 2, 3…...
线程池实战——数据库连接池
引言 作者在前面写了很多并发编程知识深度探索系列文章,反馈得知友友们收获颇丰,同时我也了解到友友们也有了对知识如何应用感到很模糊的问题。所以作者就打算写一个实战系列文章,让友友们切身感受一下怎么应用知识。话不多说,开…...

修改 vue-pdf 源码升级 pdfjs-dist 包, 以解决部分 pdf 文件显示花屏问题
文章目录 背景: 客户反馈有部分文件预览花屏 最终解决方案: 自己 fork vue-pdf 仓库, 修改 pdfjs-dist 版本, 升级到 3.3.122 (我是 vue2 项目 node 10 环境)修改源码中引用地址带有 pdfjs-dist/es5/ 的地方, 去掉 es5 , 另外如果还有报错自己搜一下 pdfjs-dist/ , 看看引用…...
基于moonshot模型的Dify大语言模型应用开发核心场景
基于moonshot模型的Dify大语言模型应用开发核心场景学习总结 一、Dify环境部署 1.Docker环境部署 这里使用vagrant部署,下载vagrant之后,vagrant up登陆,vagrant ssh,在vagrant 中使用 vagrant centos/7 init 快速创建虚拟机 安装…...