LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
导读:Qwen3是Qwen系列最新的大型语言模型,它通过集成思考和非思考模式、引入思考调度机制、扩展多语言支持以及采用强到弱的知识等创新技术,在性能、效率和多语言能力方面都取得了显着提升。实验结果表明,Qwen3在各种基准测试中都表现出色,尤其是在代码生成、数学推理和Agent等任务领域,证明了其作为一种强大而灵活的开源LLM的潜力。
>> 背景痛点
●一直追求实现通用人工智能(AGI)或人工超智能(ASI)。几乎所有大型基础模型(如GPT-4o、Claude 3.7、Gemini 2.5、DeepSeek-V3、Llama-4、Qwen2.5)在实现这一目标上取得了显着进展。
●这些模型通过在海量数据集上训练,将有效的人类知识和能力提炼到模型参数中。然而,大多数最先进的模型仍然是开源的,开源社区的发展正在急剧缩小开源模型和闭源模型之间的性能差距。
● 现有的模型通常需要在聊天优化模型和专门的推理模型之间切换,效率较低。
>> 具体的解决方案:提出了Qwen3,Qwen模型系列的最新版本,旨在提高性能、效率和多语言能力。
● Qwen3包含一系列大型模型(LLM),参数规模从0.6到2350亿不等,包括密集模型和混合专家(MoE架构)。
● 核心创新的是思考模式(用于复杂的多步骤推理)和非思考模式(用于快速的、后续驱动的响应)集成到一个统一的框架中。
● 引入了“思考预算”,允许用户在推理过程中自适应地分配计算资源,从而根据复杂度平衡延迟机制和性能。
● 通过利用模型模型的知识,显着减少构建小规模模型所需的计算资源,同时确保其具有高度可比性的性能。
● 显着扩展了多语言支持,从29种语言和方言增加到119种,通过改进的跨旗舰语言全球理解和生成能力增强了可访问性。
>> 核心思路步骤
●预训练阶段:
●●数据准备:使用Qwen2.5-VL提取PDF文档中的文本,并使用Qwen2.5、Qwen2.5-Math、Qwen2.5-Coder等模型生成合成数据。
●多阶段训练:
●●第一阶段(通用阶段):在超过30万亿的代币上进行训练,学习语言和通用世界知识。
●●第二阶段(推理思维阶段):增加STEM、训练编码、推理和合成数据的比例,提高推理能力。
●●第三阶段(长上下文阶段):收集高质量的长上下文语料库,将上下文长度从4,096个32,768个tokens。
●后期阶段:
● Long-CoT Cold Start:构建包含数学、代码、逻辑推理和通用STEM问题的综合数据集,用于长-CoT的“冷启动”阶段。
●推理RL:采用GRPO等强化学习方法,优化模型参数,提高推理能力。
●思维模式融合:将“非思考”能力集成到“思考”模型中,设计聊天模板,使用户可以动态切换模型的思考过程。
●通用强化学习:建立覆盖20多个不同任务的奖励系统,全面提升模型在指令遵循、格式遵循、偏好在线营销和代理能力等方面的能力。
●由强到弱的蒸馏:通过离线策略和策略的知识转移,从大型模型中提炼到轻量级模型的知识转移,提高小规模模型的性能和推理能力。
>> 优势
●统一的思维模式:在不同模型之间切换,可以在不同模型之间切换,可以在思维模式和非思维模式之间快速动态地切换。
●可控的计算资源:通过“思考调度机制”,用户可以根据任务复杂度自适应地分配计算资源。
●强大的多语言能力:支持119种语言和方言,增强了全球可访问性。
●小规模模型构建:通过知识,可以以最少的计算资源构建具有性能的小规模模型。
●卓越的性能:在代码生成、数学推理和Agent任务等多种基准测试中取得了最先进的结果,与更大的MoE模型和母体模型相比具有竞争力。
>> 总结和观点
● Qwen3-235B-A22B在大多数任务中承担其他开源模型,参数较少。
● Qwen3 MoE模型可以用1/5的激活参数实现与Qwen3密集模型相似的性能。
● Qwen3密集模型在STEM、编码和推理基准测试中的性能甚至超过了参数规模更大的Qwen2.5模型。 ● 增加思考布局可以持续提高模型在各种
任务中的性能。
在线策略增长比强化学习能力以更少的GPU时间实现更好的性能。
● 思考模式融合和通用强化学习可以提高模型的通用能力和稳定性。
目录
《Qwen3 Technical Report》翻译与解读
Abstract
1、Introduction
Conclusion
《Qwen3 Technical Report》翻译与解读
| 地址 | 论文地址:[2505.09388] Qwen3 Technical Report |
| 时间 | 2025年5月14日 |
| 作者 | Qwen Team |
Abstract
| In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0. | 在本研究中,我们推出了 Qwen3,这是 Qwen 模型系列的最新版本。Qwen3 包含一系列大型语言模型(LLM),旨在提升性能、效率和多语言能力。Qwen3 系列涵盖了密集型和专家混合(MoE)架构的模型,参数规模从 0.6 亿到 2350 亿不等。Qwen3 的一项关键创新在于将思考模式(用于复杂、多步骤推理)和非思考模式(用于快速、基于上下文的响应)整合到一个统一框架中。这消除了在诸如聊天优化模型(例如 GPT-4o)和专用推理模型(例如 QwQ-32B)之间切换的需要,并能够根据用户查询或聊天模板动态切换模式。同时,Qwen3 引入了思考预算机制,允许用户在推理过程中自适应地分配计算资源,从而根据任务复杂度平衡延迟和性能。此外,通过利用旗舰模型的知识,我们显著减少了构建较小规模模型所需的计算资源,同时确保其具有高度竞争力的性能。实证评估表明,Qwen3 在包括代码生成、数学推理、代理任务等在内的各种基准测试中均取得了最先进的成果,与更大的 MoE 模型和专有模型相比也毫不逊色。与前一代 Qwen2.5 相比,Qwen3 扩大了多语言支持,从 29 种语言和方言增加到 119 种,通过改进跨语言理解和生成能力,增强了全球可访问性。为了促进可重复性以及社区驱动的研究和开发,所有 Qwen3 模型均在 Apache 2.0 许可下公开可用。 |
1、Introduction
| The pursuit of artificial general intelligence (AGI) or artificial super intelligence (ASI) has long been a goal for humanity. Recent advancements in large foundation models, e.g., GPT-4o (OpenAI, 2024), Claude 3.7 (Anthropic, 2025), Gemini 2.5 (DeepMind, 2025), DeepSeek-V3 (Liu et al., 2024a), Llama-4 (Meta-AI, 2025), and Qwen2.5 (Yang et al., 2024b), have demonstrated significant progress toward this objective. These models are trained on vast datasets spanning trillions of tokens across diverse domains and tasks, effectively distilling human knowledge and capabilities into their parameters. Furthermore, recent developments in reasoning models, optimized through reinforcement learning, highlight the potential for foundation models to enhance inference-time scaling and achieve higher levels of intelligence, e.g., o3 (OpenAI, 2025), DeepSeek-R1 (Guo et al., 2025). While most state-of-the-art models remain proprietary, the rapid growth of open-source communities has substantially reduced the performance gap between open-weight and closed-source models. Notably, an increasing number of top-tier models (Meta-AI, 2025; Liu et al., 2024a; Guo et al., 2025; Yang et al., 2024b) are now being released as open-source, fostering broader research and innovation in artificial intelligence. In this work, we introduce Qwen3, the latest series in our foundation model family, Qwen. Qwen3 is a collection of open-weight large language models (LLMs) that achieve state-of-the-art performance across a wide variety of tasks and domains. We release both dense and Mixture-of-Experts (MoE) models, with the number of parameters ranging from 0.6 billion to 235 billion, to meet the needs of different downstream applications. Notably, the flagship model, Qwen3-235B-A22B, is an MoE model with a total of 235 billion parameters and 22 billion activated ones per token. This design ensures both high performance and efficient inference. | 1. 引言 长期以来,追求通用人工智能(AGI)或超级人工智能(ASI)一直是人类的目标。近期,大型基础模型(如 OpenAI 于 2024 年发布的 GPT-4、Anthropic 于 2025 年发布的 Claude 3.7、DeepMind 于 2025 年发布的 Gemini 2.5、Liu 等人于 2024 年发布的 DeepSeek-V3、Meta-AI 于 2025 年发布的 Llama-4 以及 Yang 等人于 2024 年发布的 Qwen2.5)取得了显著进展,朝着这一目标迈进。这些模型在涵盖数万亿标记的广泛领域和任务的海量数据集上进行训练,有效地将人类的知识和能力融入其参数之中。此外,通过强化学习优化的推理模型的最新发展,突显了基础模型在推理时间扩展方面提升性能以及实现更高智能水平的潜力,例如 OpenAI 于 2025 年发布的 o3 和 Guo 等人于 2025 年发布的 DeepSeek-R1。尽管大多数最先进的模型仍为专有,但开源社区的迅速发展已大幅缩小了开源模型与闭源模型之间的性能差距。值得注意的是,越来越多的顶级模型(如 Meta-AI 于 2025 年发布的、Liu 等人于 2024 年发布的、Guo 等人于 2025 年发布的)杨等人(2024 年 b)正在将相关成果以开源形式发布,这促进了人工智能领域更广泛的研究与创新。 在本研究中,我们推出了 Qwen 系列的最新成员——Qwen3。Qwen3 是一系列开放权重的大语言模型(LLM),在众多任务和领域中均达到了最先进的性能水平。我们发布了密集型和专家混合型(MoE)模型,参数数量从 6 亿到 2350 亿不等,以满足不同下游应用的需求。值得一提的是,旗舰模型 Qwen3-235B-A22B 是一个 MoE 模型,总参数量达 2350 亿,每标记激活参数量为 220 亿。这种设计既保证了高性能,又实现了高效推理。 |
| Qwen3 introduces several key advancements to enhance its functionality and usability. First, it integrates two distinct operating modes, thinking mode and non-thinking mode, into a single model. This allows users to switch between these modes without alternating between different models, e.g., switching from Qwen2.5 to QwQ (Qwen Team, 2024). This flexibility ensures that developers and users can adapt the model’s behavior to suit specific tasks efficiently. Additionally, Qwen3 incorporates thinking budgets, pro-viding users with fine-grained control over the level of reasoning effort applied by the model during task execution. This capability is crucial to the optimization of computational resources and performance, tai-loring the model’s thinking behavior to meet varying complexity in real-world applications. Furthermore, Qwen3 has been pre-trained on 36 trillion tokens covering up to 119 languages and dialects, effectively enhancing its multilingual capabilities. This broadened language support amplifies its potential for deployment in global use cases and international applications. These advancements together establish Qwen3 as a cutting-edge open-source large language model family, capable of effectively addressing complex tasks across various domains and languages. The pre-training process for Qwen3 utilizes a large-scale dataset consisting of approximately 36 trillion tokens, curated to ensure linguistic and domain diversity. To efficiently expand the training data, we employ a multi-modal approach: Qwen2.5-VL (Bai et al., 2025) is finetuned to extract text from extensive PDF documents. We also generate synthetic data using domain-specific models: Qwen2.5-Math (Yang et al., 2024c) for mathematical content and Qwen2.5-Coder (Hui et al., 2024) for code-related data. The pre-training process follows a three-stage strategy. In the first stage, the model is trained on about 30 trillion tokens to build a strong foundation of general knowledge. In the second stage, it is further trained on knowledge-intensive data to enhance reasoning abilities in areas like science, technology, engineering, and mathematics (STEM) and coding. Finally, in the third stage, the model is trained on long-context data to increase its maximum context length from 4,096 to 32,768 tokens. | Qwen3 引入了多项关键改进,以增强其功能性和易用性。首先,它将两种不同的运行模式——思考模式和非思考模式整合到了一个模型中。这使得用户能够在不切换不同模型的情况下(例如从 Qwen2.5 切换到 QwQ,Qwen 团队,2024 年)在这些模式之间进行切换。这种灵活性确保了开发人员和用户能够高效地调整模型的行为以适应特定任务。此外,Qwen3 还引入了思考预算,让用户能够精细控制模型在任务执行过程中所投入的推理努力程度。这一能力对于优化计算资源和性能至关重要,能够根据实际应用中的复杂程度调整模型的思考行为。此外,Qwen3 还在涵盖多达 119 种语言和方言的约 36 万亿个标记的数据集上进行了预训练,极大地增强了其多语言能力。这种广泛的语言支持扩大了其在全球用例和国际应用中的部署潜力。这些进步共同使 Qwen3 成为一个前沿的开源大型语言模型系列,能够有效应对各种领域和语言中的复杂任务。 Qwen3 的预训练过程使用了一个大规模的数据集,包含约 36 万亿个标记,经过精心整理以确保语言和领域的多样性。为了高效地扩充训练数据,我们采用了一种多模态方法:对 Qwen2.5-VL(Bai 等人,2025 年)进行微调,以从大量的 PDF 文档中提取文本。我们还使用特定领域的模型生成合成数据:Qwen2.5-Math(Yang 等人,2024 年 c)用于数学内容,Qwen2.5-Coder(Hui 等人,2024 年)用于代码相关数据。预训练过程遵循三阶段策略。在第一阶段,模型在约 30 万亿个标记上进行训练,以构建扎实的通用知识基础。在第二阶段,模型进一步在知识密集型数据上进行训练,以增强在科学、技术、工程和数学(STEM)以及编码等领域的推理能力。最后,在第三阶段,模型在长上下文数据上进行训练,将其最大上下文长度从 4096 个标记增加到 32768 个标记。 |
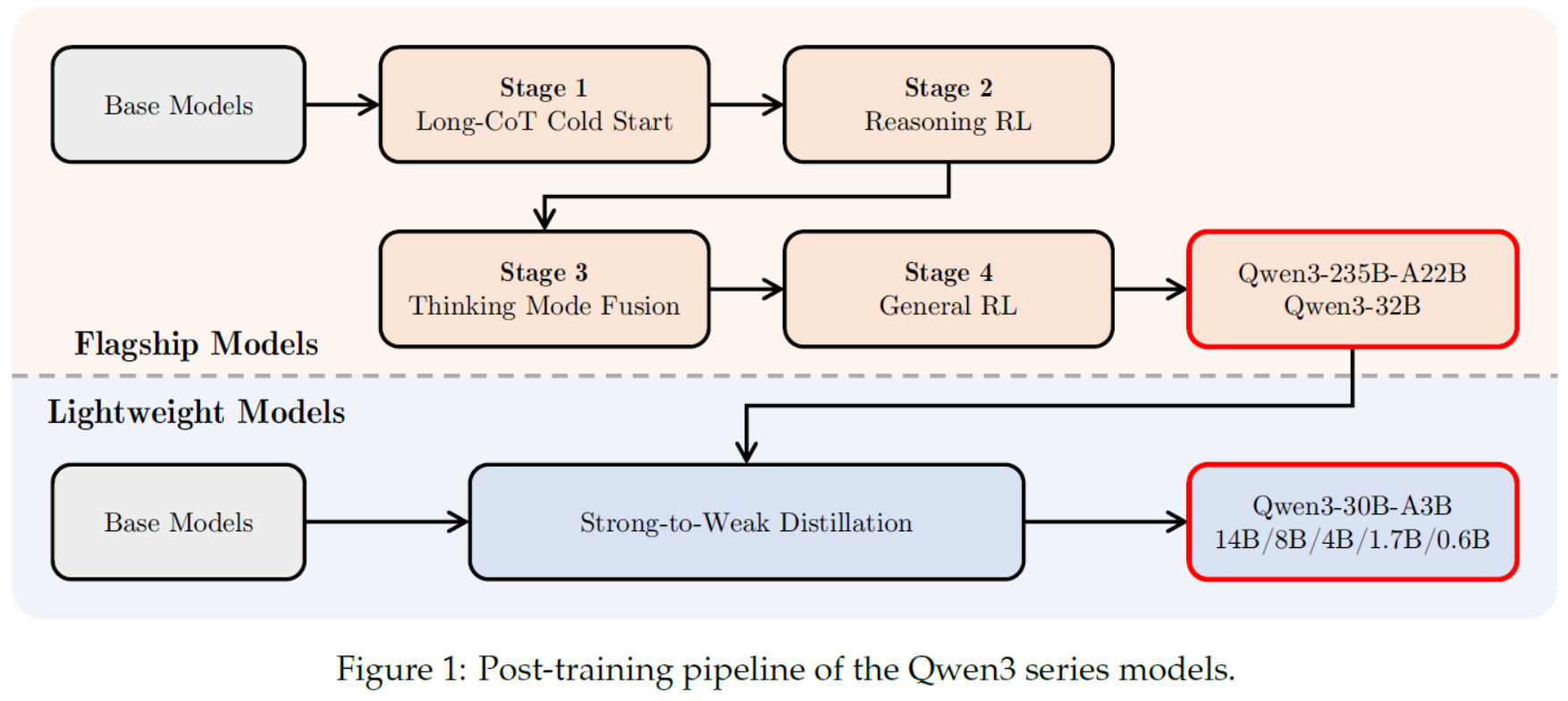
| To better align foundation models with human preferences and downstream applications, we employ a multi-stage post-training approach that empowers both thinking (reasoning) and non-thinking modes. In the first two stages, we focus on developing strong reasoning abilities through long chain-of-thought (CoT) cold-start finetuning and reinforcement learning focusing on mathematics and coding tasks. In the final two stages, we combine data with and without reasoning paths into a unified dataset for further fine-tuning, enabling the model to handle both types of input effectively, and we then apply general-domain reinforcement learning to improve performance across a wide range of downstream tasks. For smaller models, we use strong-to-weak distillation, leveraging both off-policy and on-policy knowledge transfer from larger models to enhance their capabilities. Distillation from advanced teacher models significantly outperforms reinforcement learning in performance and training efficiency. We evaluate both pre-trained and post-trained versions of our models across a comprehensive set of benchmarks spanning multiple tasks and domains. Experimental results show that our base pre-trained models achieve state-of-the-art performance. The post-trained models, whether in thinking or non-thinking mode, perform competitively against leading proprietary models and large mixture-of-experts (MoE) models such as o1, o3-mini, and DeepSeek-V3. Notably, our models excel in coding, mathematics, and agent-related tasks. For example, the flagship model Qwen3-235B-A22B achieves 85.7 on AIME’24 and 81.5 on AIME’25 (AIME, 2025), 70.7 on LiveCodeBench v5 (Jain et al., 2024), 2,056 on CodeForces, and 70.8 on BFCL v3 (Yan et al., 2024). In addition, other models in the Qwen3 series also show strong performance relative to their size. Furthermore, we observe that increasing the thinking budget for thinking tokens leads to a consistent improvement in the model’s performance across various tasks. In the following sections, we describe the design of the model architecture, provide details on its training procedures, present the experimental results of pre-trained and post-trained models, and finally, conclude this technical report by summarizing the key findings and outlining potential directions for future research. | 为了使基础模型更好地与人类偏好和下游应用相契合,我们采用了一种多阶段的后期训练方法,这种方法既支持推理模式也支持非推理模式。在前两个阶段,我们通过长链思维(CoT)冷启动微调和专注于数学和编程任务的强化学习来培养强大的推理能力。在最后两个阶段,我们将有推理路径和无推理路径的数据合并到一个统一的数据集中进行进一步微调,使模型能够有效地处理这两种类型的输入,然后应用通用领域的强化学习来提高其在广泛下游任务中的表现。对于较小的模型,我们采用强到弱的知识蒸馏,利用来自较大模型的离策略和在策略知识转移来增强其能力。来自先进教师模型的知识蒸馏在性能和训练效率方面显著优于强化学习。 我们对模型的预训练版本和后期训练版本进行了全面评估,涵盖了多个任务和领域的基准测试。实验结果表明,我们的基础预训练模型达到了最先进的性能。无论是思考模式还是非思考模式下的后训练模型,在与领先的专有模型和大型专家混合模型(如 o1、o3-mini 和 DeepSeek-V3)的竞争中都表现出色。值得注意的是,我们的模型在编程、数学和代理相关任务中表现出色。例如,旗舰模型 Qwen3-235B-A22B 在 AIME'24 中得分 85.7,在 AIME'25(AIME,2025)中得分 81.5,在 LiveCodeBench v5(Jain 等人,2024)中得分 70.7,在 CodeForces 中得分 2056,在 BFCL v3(Yan 等人,2024)中得分 70.8。此外,Qwen3 系列中的其他模型相对于其规模也表现出色。另外,我们观察到增加思考标记的思考预算会持续提升模型在各种任务中的性能。 在接下来的部分中,我们将描述模型架构的设计,提供其训练过程的详细信息,展示预训练和后训练模型的实验结果,并在最后总结本技术报告的关键发现,概述未来研究的潜在方向。 |
Table 1: Model architecture of Qwen3 dense models.
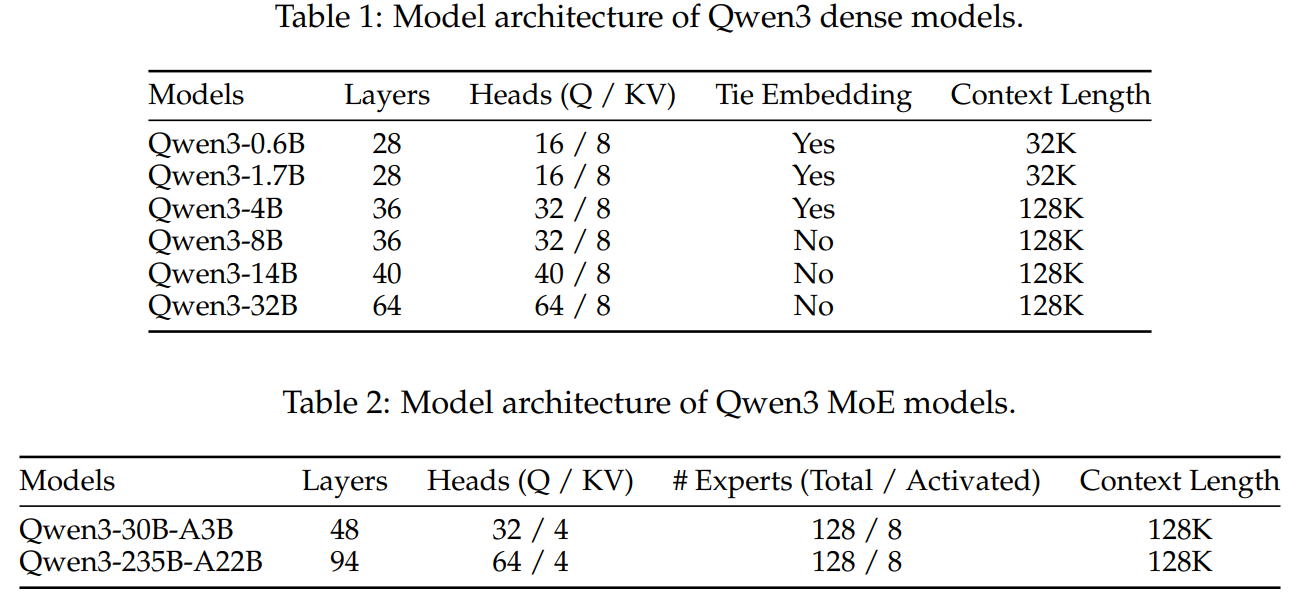
Figure 1: Post-training pipeline of the Qwen3 series models.
Conclusion
| In this technical report, we introduce Qwen3, the latest version of the Qwen series. Qwen3 features both thinking mode and non-thinking mode, allowing users to dynamically manage the number of tokens used for complex thinking tasks. The model was pre-trained on an extensive dataset containing 36 trillion tokens, enabling it to understand and generate text in 119 languages and dialects. Through a series of comprehensive evaluations, Qwen3 has shown strong performance across a range of standard benchmarks for both pre-trained and post-trained models, including tasks related to code generation, mathematics, reasoning, and agents. In the near future, our research will focus on several key areas. We will continue to scale up pretraining by using data that is both higher in quality and more diverse in content. At the same time, we will work on improving model architecture and training methods for the purposes of effective compression, scaling to extremely long contexts, etc. In addition, we plan to increase computational resources for reinforcement learning, with a particular emphasis on agent-based RL systems that learn from environmental feedback. This will allow us to build agents capable of tackling complex tasks that require inference time scaling. | 在这份技术报告中,我们介绍了 Qwen 系列的最新版本 Qwen3。Qwen3 具备思考模式和非思考模式,用户能够动态管理用于复杂思考任务的标记数量。该模型在包含 36 万亿标记的大型数据集上进行了预训练,能够理解和生成 119 种语言和方言的文本。通过一系列全面的评估,Qwen3 在预训练和后训练模型的标准基准测试中均表现出色,包括代码生成、数学、推理和代理相关的任务。 在不久的将来,我们的研究将集中在几个关键领域。我们将继续通过使用质量更高、内容更丰富的数据来扩大预训练规模。同时,我们将致力于改进模型架构和训练方法,以实现有效的压缩、扩展到极长的上下文等目标。此外,我们计划增加用于强化学习的计算资源,特别侧重于从环境反馈中学习的基于代理的强化学习系统。这将使我们能够构建出能够应对需要推理时间扩展的复杂任务的智能体。 |
相关文章:
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读 导读:Qwen3是Qwen系列最新的大型语言模型,它通过集成思考和非思考模式、引入思考调度机制、扩展多语言支持以及采用强到弱的知识等创新技术,在性能、效率和多语言能力方面都取得…...

springboot3 configuration
1 多数据库配置 github: https://github.com/baomidou/dynamic-datasource 使用DS()注解来切换数据库 详情介绍:https://www.kancloud.cn/tracy5546/dynamic-datasource/2264611 注意:DS 可以注解在方法上或类上,同时存在就近原则 方法上注…...
从工程实践角度分析H.264与H.265的技术差异
作为音视频从业者,我们时刻关注着视频编解码技术的最新发展。RTMP推流、轻量级RTSP服务、RTMP播放、RTSP播放等模块是大牛直播SDK的核心功能,在这些模块的实现过程中,H.264和H.265两种视频编码格式的应用实践差异是我们技术团队不断深入思考的…...
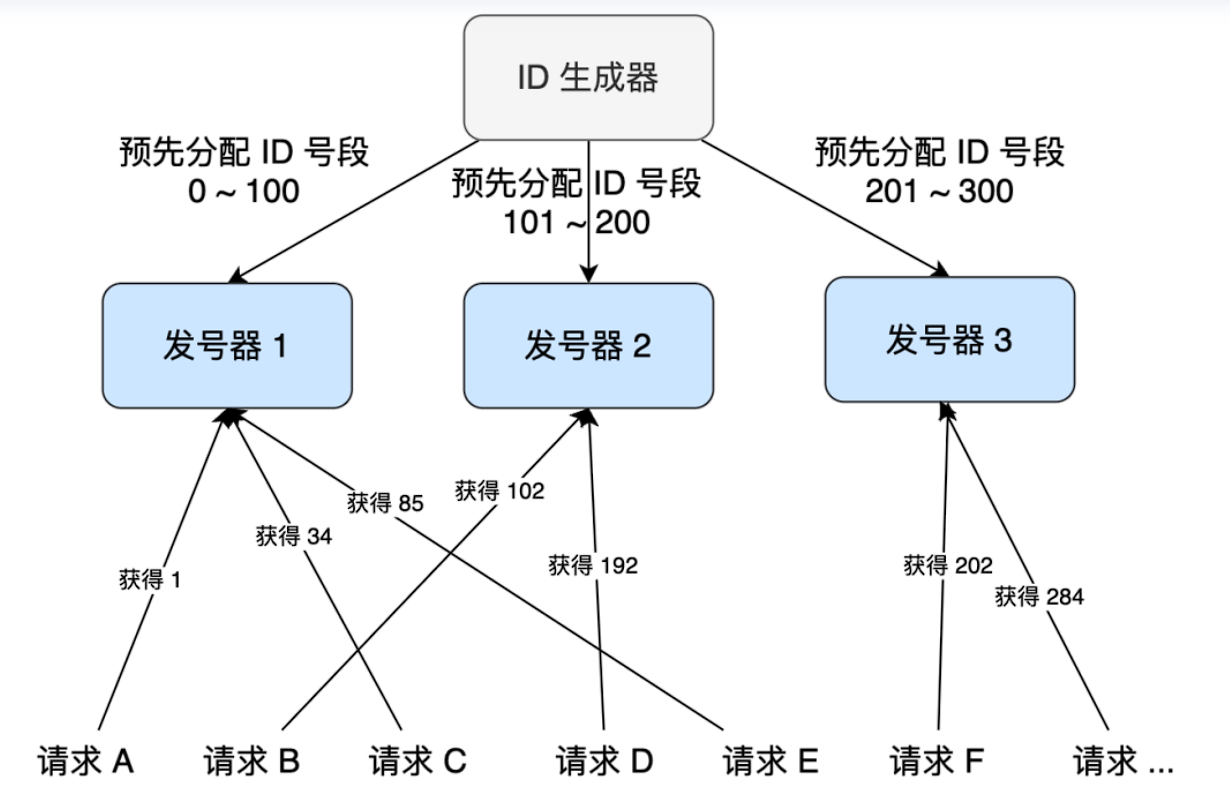
如何设计一个高性能的短链设计
1.什么是短链 短链接(Short URL) 是通过算法将长 URL 压缩成简短字符串的技术方案。例如将 https://flowus.cn/veal/share/3306b991-e1e3-4c92-9105-95abf086ae4e 缩短为 https://sourl.cn/aY95qu,用户点击短链时会自动重定向到原始长链接。其…...
提升工作效率的可视化笔记应用程序
StickyNotes桌面便签软件介绍 StickyNotes是一款极为简洁的桌面便签应用程序,让您能够快速记录想法、待办事项或其他重要信息。这款工具操作极其直观,只需输入文字内容,选择合适的字体大小和颜色,然后点击添加按钮即可创建个性化…...
11|省下钱买显卡,如何利用开源模型节约成本?
不知道课程上到这里,你账户里免费的5美元的额度还剩下多少了?如果你尝试着完成我给的几个数据集里的思考题,相信这个额度应该是不太够用的。而ChatCompletion的接口,又需要传入大量的上下文信息,实际消耗的Token数量其…...

GDB调试工具详解
GDB调试工具详解 一、基本概念 调试信息 编译时需添加 -g 选项(如 gcc -g -o program program.c),生成包含变量名、函数名、行号等调试信息的可执行文件。断点(Breakpoint) 程序执行到指定位置(函数、行号…...

机器学习圣经PRML作者Bishop20年后新作中文版出版!
机器学习圣经PRML作者Bishop20年后新书《深度学习:基础与概念》出版。作者克里斯托弗M. 毕晓普(Christopher M. Bishop)微软公司技术研究员、微软研究 院 科学智 能 中 心(Microsoft Research AI4Science)负责人。剑桥…...

Armadillo C++ 线性代数库介绍与使用
文章目录 Armadillo C 线性代数库介绍与使用主要特点安装Linux (Ubuntu/Debian)macOS (使用 Homebrew)Windows (使用 vcpkg) 基本使用包含头文件矩阵创建与初始化基本运算矩阵分解统计运算保存和加载数据 性能优化建议示例程序与 MATLAB 语法对比 使用Armadillo函数库的稀疏矩阵…...
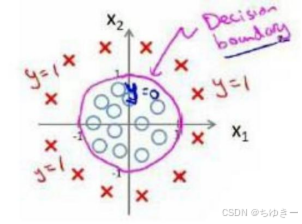
吴恩达机器学习笔记:逻辑回归3
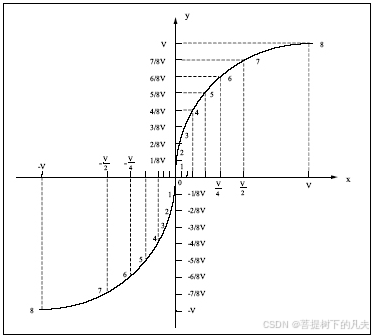
3.判定边界 现在说下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。 在逻辑回归中,我们预测: 当ℎθ (x) > 0.5时,预测 y 1。 当ℎθ (x) < 0.5时,预测 y 0 。 根据…...

大模型知识
############################################################## 一、vllm大模型测试参数和原理 tempreature top_p top_k ############################################################## tempreature top_p top_k 作用:总体是控制模型的发散程度、多样…...

C/C++ 结构体:. 与 -> 的区别与用法及其STM32中的使用
目录 引言 一、深入理解 C/C 结构体:. 与 -> 的区别与用法 1. .(点运算符)详解2. ->(箭头运算符)详解3. . 与 -> 的等价与转换4. 常见错误与调试技巧5. C 特性与运算符重载6. 实战案例:链表与智能…...

docker中使用openresty
1.为什么要使用openresty 我这边是因为要使用1Panel,第一个最大的原因,就是图方便,比较可以一键安装。但以前一直都是直接安装nginx。所以需要一个过度。 2.如何查看openResty使用了nginx哪个版本 /usr/local/openresty/nginx/sbin/nginx …...

Jetpack Compose 中更新应用语言
在 Jetpack Compose 应用中更新语言需要结合传统的 Android 语言配置方法和 Compose 的重组机制。以下是完整的实现方案: 1. 创建语言管理类 object LocaleManager {private var currentLocale: Locale Locale.getDefault()fun setLocale(context: Context, local…...
Java 中的 super 关键字
个人总结: 1.子类构造方法中没有显式使用super,Java 也会默认调用父类的无参构造方法 2.当父类中没有无参构造方法,只有有参构造方法时,子类构造方法就必须显式地使用super来调用父类的有参构造方法。 3.如果父类没有定义任何构造…...

CMake基础:CMakeLists.txt 文件结构和语法
目录 1.CMakeLists.txt基本结构 2.核心语法规则 3.关键命令详解 4.常用预定义变量 5.变量和缓存 6.变量作用域与传递 7.注意事项 1.CMakeLists.txt基本结构 CMakeLists.txt 是 CMake 构建系统的核心配置文件,采用命令式语法组织项目结构和编译流程。主要用于…...
PCM音频数据的编解码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

WebView2 Win7下部分机器触屏失效的问题
这个问题官方给了解决的方案,相关地址,只需要在项目中运行这个代码即可 public static void DisableWPFTabletSupport(){TabletDeviceCollection devices Tablet.TabletDevices;if (devices.Count > 0){Type inputManagerType typeof(InputManager)…...

Ubuntu 通过指令远程命令行配置WiFi连接
前提设备已经安装了无线网卡。 1、先通过命令行 ssh 登录机器。 2、搜索wifi设备,指令如下: sudo nmcli device wifi 3、输入需要联接的 wifi 名称和对应的wifi密码,指令如下: sudo nmcli device wifi connect wifi名称 passw…...

线程池优雅关闭的哲学
引言 关于并发的哲学,本文将着重强调那些关于线程池优雅关闭的一些技巧,希望对你有所启发。 强制关闭线程池的弊端 对于池化的线程池,如果采用强制关闭的方式将线程池直接关闭,就可能存在上下文消息消息,无法的很好…...

11.8 LangGraph生产级AI Agent开发:从节点定义到高并发架构的终极指南
使用 LangGraph 构建生产级 AI Agent:LangGraph 节点与边的实现 关键词:LangGraph 节点定义, 条件边实现, 状态管理, 多会话控制, 生产级 Agent 架构 1. LangGraph 核心设计解析 LangGraph 通过图结构抽象复杂 AI 工作流,其核心要素构成如下表所示: 组件作用描述代码对应…...

8天Python从入门到精通【itheima】-41~44
目录 41节-while循环的嵌套应用 1.学习目标 2.while循环的伪代码和生活情境中的应用 3.图片应用的代码案例 4.代码实例【Patrick自己亲手写的】: 5.whlie嵌套循环的注意点 6.小节总结 42节-while循环的嵌套案例-九九乘法表 1.补充知识-print的不换行 2.补充…...
深度图数据增强方案-随机增加ROI区域的深度
主要思想:随机增加ROI区域的深度,模拟物体处在不同位置的形态。 首先打印一张深度图中的深度信息分布: import cv2 import matplotlib.pyplot as plt import numpy as np import seaborn as sns def plot_grayscale_histogram(image_path)…...

[Java恶补day6] 15. 三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&a…...

Django模板及表单
什么是Django模板 Django模板是一种用于生成动态内容的文件,它使用Django模板语言(Django Template Language,简称DTL)来描述和渲染HTML页面。模板允许开发人员将动态数据与静态HTML结构分离,以实现更灵活和可维护的W…...
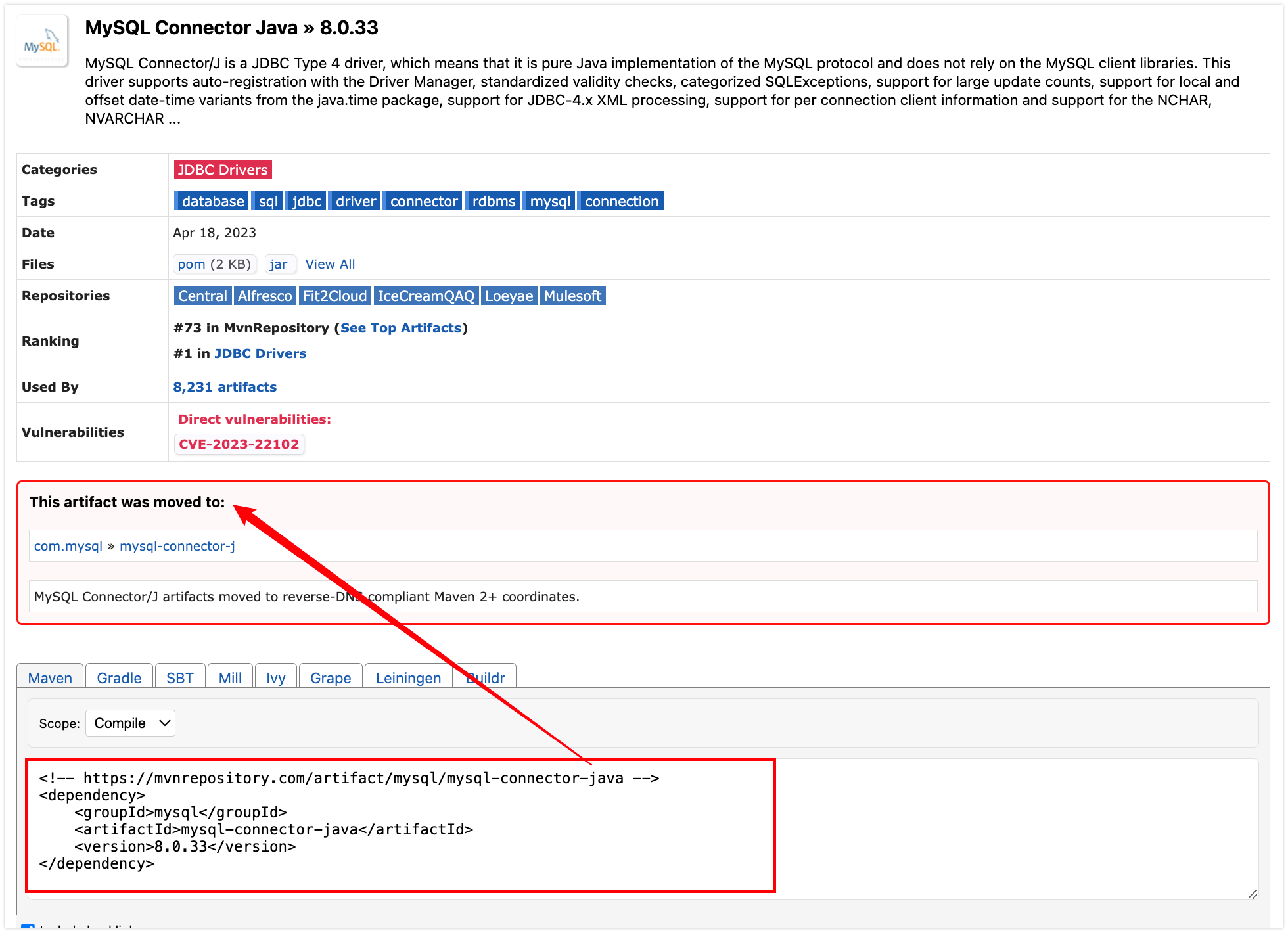
两个mysql的maven依赖要用哪个?
背景 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency>和 <dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId> &l…...
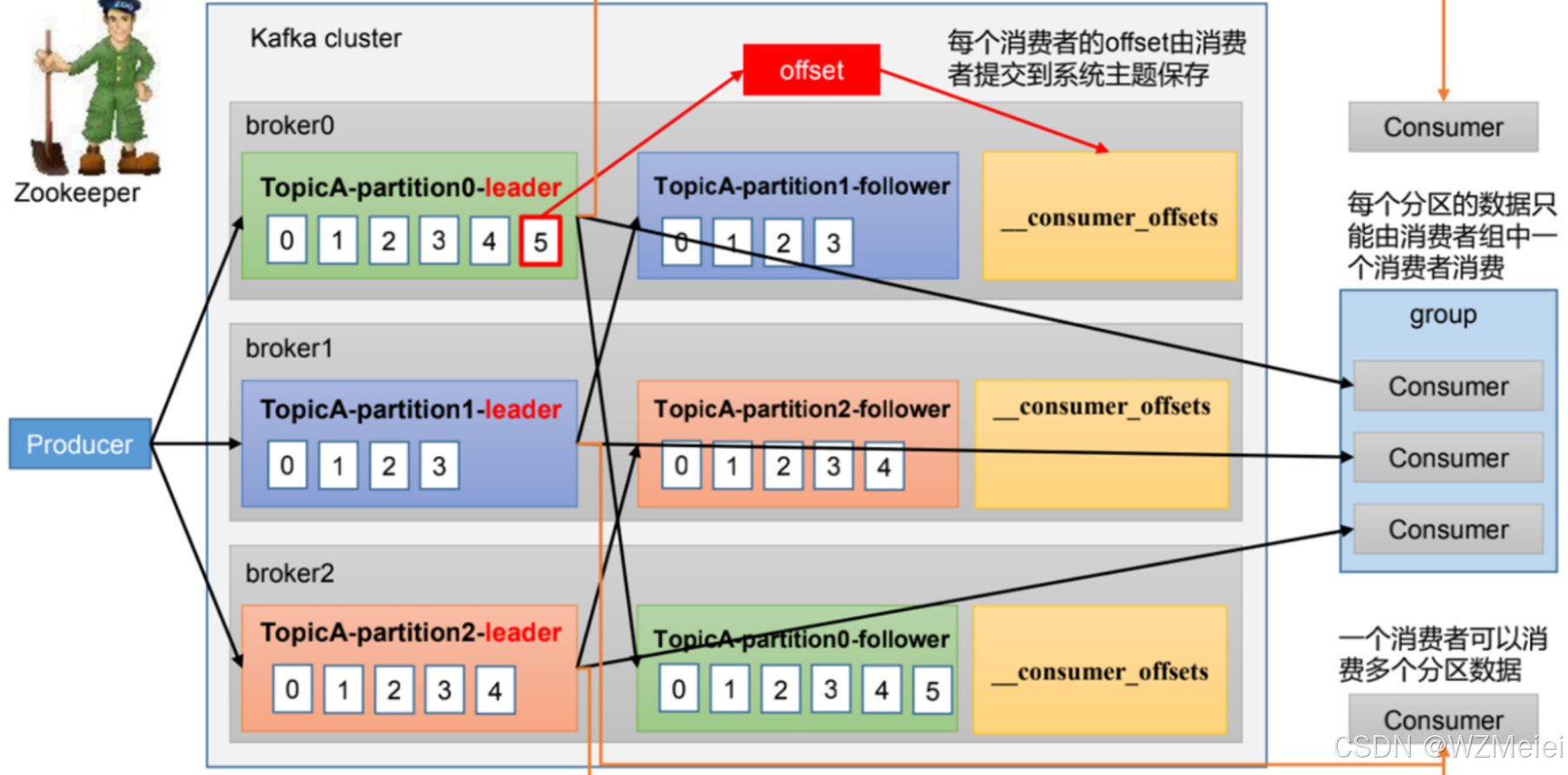
Kafka Consumer工作流程
Kafka Consumer工作流程图 1、启动与加入组 消费者启动后,会向 Kafka 集群中的某个 Broker 发送请求,请求加入特定消费者组。这个 Broker 中的消费者协调器(Consumer Coordinator)负责管理消费者组相关事宜。 2、组内分区分配&am…...
大腾智能 PDM 系统:全生命周期管理重塑制造企业数字化转型路径
在当今激烈的市场竞争中,产品迭代速度与质量已成为企业生存与发展的核心命脉。面对客户需求多元化、供应链协同复杂化、研发成本管控精细化等挑战,企业亟需一套能够贯穿产品全生命周期的数字化解决方案。 大腾智能PDM系统通过构建覆盖设计、研发、生产、…...

GATT 服务的核心函数bt_gatt_discover的介绍
目录 概述 1 GATT 基本概念 1.1 GATT 的介绍 1.2 GATT 的角色 1.3 核心组件 1.4 客户端操作 2 bt_gatt_discover函数的功能和应用 2.1 函数介绍 2.1 发现类型(Discover Type) 3 典型使用流程 3.1 服务发现示例 3.2 级联发现模式 3.3 按UUID过…...
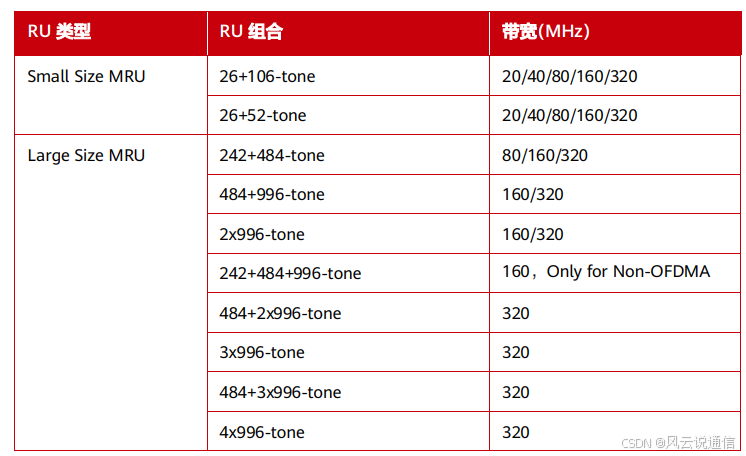
【短距离通信】【WiFi】WiFi7关键技术之4096-QAM、MRU
目录 3. 4096-QAM 3.1 4096-QAM 3.2 QAM 的阶数越高越好吗? 4. MRU 4.1 OFDMA 和 RU 4.2 MRU 资源分配 3. 4096-QAM 摘要 本章主要介绍了Wi-Fi 7引入的4096-QAM对数据传输速率的提升。 3.1 4096-QAM 对速率的提升 Wi-Fi 标准一直致力于提升数据传输速率&a…...