人工智能数学基础实验(一):智能推荐系统实战
一、实验目的
本次实验旨在通过构建用户相似度矩阵和实现个性化推荐,帮助我们直观理解推荐系统的核心原理及其背后的数学基础。具体目标如下:
- 运用 Python 计算用户间的评分相似度,掌握余弦相似度等数学工具在衡量用户偏好中的应用,将抽象的向量空间关系转化为可量化的相似性指标。
- 模拟真实推荐场景,学习基于相似用户群体挖掘潜在兴趣的方法,体会协同过滤算法 “物以类聚,人以群分” 的核心思想。
- 将数学中的矩阵运算、相似度度量等知识与实际编程相结合,培养数据分析和算法实现能力,深化对 “相似性” 这一人工智能核心概念的理解,为后续学习更复杂的推荐模型奠定实践基础。
二、实验要求
(一)用户相似度矩阵构建
- 输入:6 位用户对 6 本书的 5 分制评分矩阵(含未评分项)。
- 要求:基于余弦相似度(仅计算共同评分项)生成 6×6 的用户相似度矩阵,输出结果并分析合理性。
(二)个性化书籍推荐
- 输入:目标用户(如用户 A)及其相似度矩阵。
- 要求:选取最相似的 2 位用户,提取他们阅读过但目标用户未读的书籍,通过加权评分预测(相似度 × 评分)生成推荐列表。
(三)实验报告
附代码、相似度矩阵截图及推荐结果,分析推荐逻辑的合理性。
三、实验原理
本实验基于协同过滤推荐算法,核心思想是通过用户历史行为(评分)挖掘相似用户群体,利用群体偏好预测目标用户的兴趣,分为以下两阶段:
(一)用户相似度计算
采用余弦相似度衡量用户兴趣相似性。将用户评分向量化,仅提取共同评分项(剔除未读的 0 值),通过公式计算向量夹角余弦值,公式为:
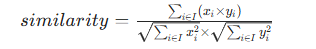
其中,I 为 A、B 共同评分的书籍索引集,避免未读书籍干扰相似度。
(二)兴趣预测与推荐
选取相似度最高的用户作为邻居,对其阅读过而目标用户未读的书籍,按加权评分(邻居评分 × 相似度)排序,归一化后生成推荐列表。例如,用户 A 未读《spark》,若相似用户 B、C 对其评分分别为 4、5,相似度分别为 0.95、0.89,则预测评分为:
0.95+0.894×0.95+5×0.89≈4.4
四、实验步骤
(一)数据准备
定义 6 位用户(A-F)对 6 本书(线性代数、大学物理、spark、人工智能、IB、Python)的评分数据,用列表存储,示例如下:
A_list = [4, 3, 0, 0, 5, 0] # 用户A的评分(未读为0)
B_list = [5, 0, 4, 0, 4, 0](二)余弦相似度计算
- 定义向量内积函数:计算两个向量对应元素的乘积之和。
def Multiplication(x, y):sum = 0if len(x) == len(y):for i in range(len(y)):sum += x[i] * y[i]return sum- 定义向量模计算函数:计算向量的长度(各元素平方和的平方根)。
def Length(x):sum = 0for i in range(len(x)):sum += x[i] ** 2length = sqrt(sum)return length- 遍历所有用户对计算相似度:通过嵌套循环计算任意两个用户的余弦相似度,保留两位小数,存储为 6×6 的相似度矩阵。
data_similiar = []
similiar_list = []
for i in range(len(data_original)):for j in range(len(data_original)):similiar = Multiplication(data_list[i], data_list[j]) / Length(data_list[i]) / Length(data_list[j])similiar = round(similiar, 2)similiar_list.append(similiar)
data_similiar = np.array(data_similiar).reshape(6, 6)(三)生成推荐列表
- 相似度排序:对每个用户的相似度矩阵行进行降序排序,获取最相似的 2 位用户(排除自身)。
- 加权评分计算:对相似用户阅读过但目标用户未读的书籍,计算加权评分(相似度 × 评分之和 / 相似度之和)。
- 过滤与排序:排除目标用户已读书籍和评分为 0 的书籍,按评分降序生成推荐列表。
def recommend_books(target_index, top_n=2):similar_users = sorted_similiar[target_index][1:top_n+1]for sim, user in similar_users:user_index = human_list.index(user)user_score = data_list[user_index][book_index]if user_score > 0:total_score += user_score * simtotal_sim += sim# 过滤已读书籍并排序完整源代码:
#人人推荐选书import numpy as np
from math import *
#1.原始数据,A~F,书籍:线性代数,大学物理,spark,人工智能,IB,Python
#用列表存放原始数据,列表元素分别对应A~F对六本书籍的喜爱程度
human_list=['A','B','C','D','E','F']
Book_list=['线性代数','大学物理','spark','人工智能','IB','Python']
A_list=[4,3,0,0,5,0]
B_list=[5,0,4,0,4,0]
C_list=[4,0,5,3,4,0]
D_list=[0,3,0,0,0,5]
E_list=[0,4,0,0,0,4]
F_list=[0,0,2,4,0,5]data_original=np.matrix([A_list,B_list,C_list,D_list,E_list,F_list])
print('原始数据:')
print(data_original)
data_list=[A_list,B_list,C_list,D_list,E_list,F_list]#2.进行相似度计算,cos<x,y>=x*y/|x|*|y|
#2.1定义向量内积函数
def Multiplication(x,y):sum=0if len(x)==len(y):for i in range(len(y)):sum +=x[i]*y[i]return sum#2.2定义计算向量模函数
def Length(x):sum=0for i in range(len(x)):sum +=x[i]**2length=sqrt(sum)return length#数据相似度,cos<A,B>...
data_similiar=[]
similiar_list=[]
for i in range(len(data_original)):for j in range(len(data_original)):#计算相似度similiar=Multiplication(data_list[i],data_list[j])/Length(data_list[i])/Length(data_list[j])#相似度保留小数点后两位similiar=round(similiar,2)#相似度列表按一行一行加到加工数据列表里similiar_list.append(similiar)
#相似度数据总列表
data_similiar.append(similiar_list)
data_similiar=np.array(data_similiar).reshape(6,6)
print('相似度数据:')
print(data_similiar)#3.计算评分并排序推荐书籍
#3.1对每一行的相似度进行降序排序
sorted_similiar = []
for i, row in enumerate(data_similiar):# 将相似度值与人的编号(索引)配对paired_row = list(zip(row, human_list))# 按相似度值降序排序sorted_row = sorted(paired_row, key=lambda x: x[0], reverse=True)# 将相似度值转换为普通浮点数(去掉 np.float64)sorted_row = [(float(sim), person) for sim, person in sorted_row]sorted_similiar.append(sorted_row)# 输出排序后的结果
print("\n排序后的相似度矩阵:")
for i, row in enumerate(sorted_similiar):print(f"{human_list[i]} 的相似度排序: {row}")#3.2评分(推荐书籍指数)
def recommend_books(target_index, top_n=2):target = human_list[target_index]print(f"\n为目标用户 {target} 推荐书籍:")# 获取与目标用户最相似的 top_n 个人(不包括自己)similar_users = sorted_similiar[target_index][1:top_n + 1] # 跳过自己print(f"与 {target} 最相似的用户: {similar_users}")# 初始化书籍评分和相似度总和book_scores = {book: 0.0 for book in Book_list}book_sim_sum = {book: 0.0 for book in Book_list}# 遍历相似用户,逐本书计算for book_index, book_name in enumerate(Book_list):total_score = 0.0total_sim = 0.0# 检查每个相似用户是否喜欢这本书for sim, user in similar_users:user_index = human_list.index(user)user_score = data_list[user_index][book_index]if user_score > 0:total_score += user_score * simtotal_sim += sim# 计算加权评分if total_sim > 0:book_scores[book_name] = total_score / total_simelse:book_scores[book_name] = 0.0# 过滤掉目标用户已经喜欢的书籍target_liked_books = [Book_list[i] for i, score in enumerate(data_list[target_index]) if score > 0]for book in target_liked_books:book_scores.pop(book, None)# 过滤掉评分为 0 的书籍book_scores = {book: score for book, score in book_scores.items() if score > 0}# 对书籍评分进行降序排序sorted_books = sorted(book_scores.items(), key=lambda x: x[1], reverse=True)# 输出推荐结果if sorted_books:for book, score in sorted_books:print(f"推荐书籍: {book}, 评分为: {score:.2f}")else:print("没有合适的推荐书籍。")#3.3输出推荐书籍
#全部输出A-F
#for i in range(len(human_list)):#recommend_books(i)#输入指定输出
i=input("为用户推荐书籍:")
index=human_list.index(i)
recommend_books(index)五、实验结果
(一)相似度矩阵
原始数据:
[[4 3 0 0 5 0][5 0 4 0 4 0][4 0 5 3 4 0][0 3 0 0 0 5][0 4 0 0 0 4][0 0 2 4 0 5]]相似度数据:
[[1.00 0.75 0.63 0.22 0.30 0.00][0.75 1.00 0.91 0.00 0.00 0.16][0.63 0.91 1.00 0.00 0.00 0.40][0.22 0.00 0.00 1.00 0.97 0.64][0.30 0.00 0.00 0.97 1.00 0.53][0.00 0.16 0.40 0.64 0.53 1.00]]
(二)推荐结果示例(以用户 A 为例)
- 最相似用户:B(0.75)、C(0.63)。
- 推荐书籍:
- spark:加权评分 4.46(B 评分 4×0.75 + C 评分 5×0.63 = 6.45,6.45/(0.75+0.63)≈4.46)。
- 人工智能:加权评分 3.00(仅 C 评分 3×0.63 = 1.89,1.89/0.63=3.00)。




(三)结果分析
程序通过余弦相似度准确计算了用户间的兴趣相似性,并基于相似用户的评分生成了合理的推荐列表。例如,用户 A 与 B、C 的阅读偏好相似,系统推荐的 spark 和人工智能均为 A 未读但相似用户高分评价的书籍,验证了协同过滤算法的有效性。
六、总结
本次实验将数学理论(余弦相似度、矩阵运算)与 Python 编程结合,成功实现了基于用户协同过滤的智能推荐系统。通过实践,我们深入理解了推荐系统的核心逻辑,掌握了从数据处理到算法实现的完整流程,为后续学习深度学习推荐模型打下了基础。
相关文章:
人工智能数学基础实验(一):智能推荐系统实战
一、实验目的 本次实验旨在通过构建用户相似度矩阵和实现个性化推荐,帮助我们直观理解推荐系统的核心原理及其背后的数学基础。具体目标如下: 运用 Python 计算用户间的评分相似度,掌握余弦相似度等数学工具在衡量用户偏好中的应用ÿ…...
uni-app学习笔记十二-vue3中组件传值(对象传值)
一.单对象传值 父组件定义对象的值 <template><view><UserInfo :obj"userinfo"></UserInfo></view> </template><script setup>import {ref} from "vue"const userinfo ref({name:"蛛儿",avatar:&…...

Vue.js教学第十四章:Vuex模块化,打造高效大型应用状态管理
Vuex(二):深入剖析 Vuex 模块化与高级应用 在大型 Vue 应用开发中,随着应用功能的不断扩展和复杂度的增加,状态管理的难度也随之上升。Vuex 作为 Vue.js 的官方状态管理库,提供了模块化功能,使得我们可以将状态管理逻辑拆分成多个模块,从而提高 Vuex 的可维护性和可读…...
)
Ubuntu/Linux 服务器上调整系统时间(日期和时间)
在 Ubuntu/Linux 服务器上调整系统时间(日期和时间)可以通过以下命令实现,具体分为 手动设置 和 自动同步(NTP)两种方式: 1. 查看当前系统时间 date或查看详细时区信息: timedatectl2. 手动设…...
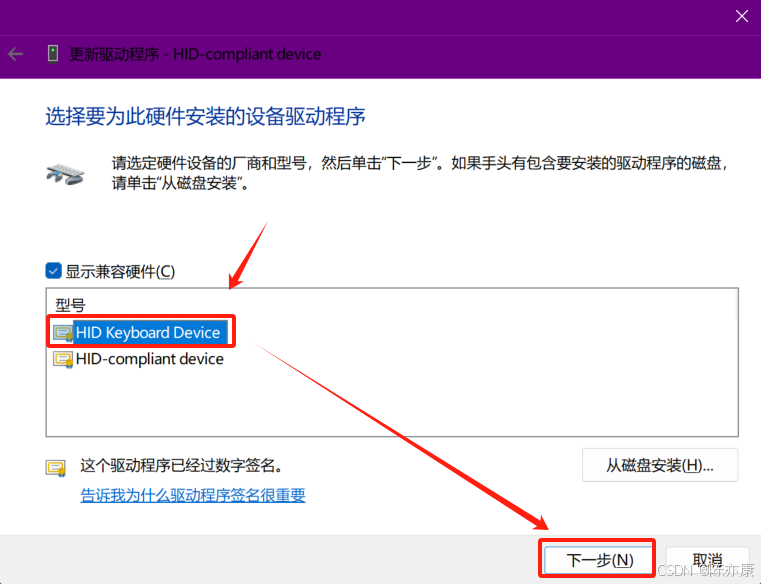
win11 禁用/恢复 内置笔记本键盘(保证管用)
文章目录 禁用启用 禁用 1)按下 win x,点击 设备管理器 2)拔掉所有笔记本外设(一定要都拔掉,不然后面禁用设备会混淆),然后右键点击 键盘 > HID Keyboard Device 2)点击 更新…...

精度不够?光纤激光尺0.2ppm误差解锁微米级制造
当“精度焦虑”成为制造业的隐形门槛: 在半导体光刻中,1nm偏差可能导致整片晶圆报废; 在精密机床加工中,热变形让传统测量工具“失灵”…… “高精度、高稳定、抗干扰”——工业超精密制造的三大痛点,如何破局…...
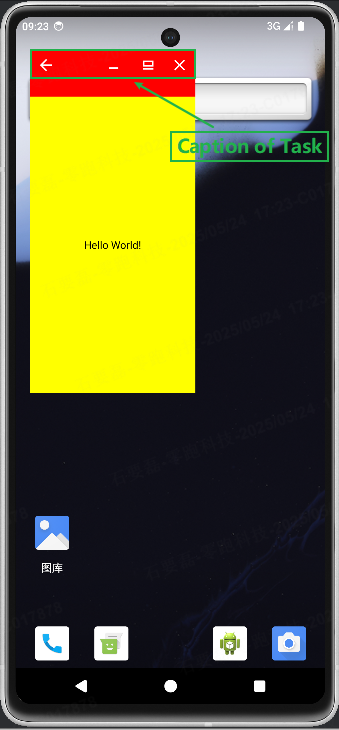
Android 16系统源码_自由窗口(一)触发自由窗口模式
前言 从 Android 7.0 开始,Google 推出了一个名为“多窗口模式”的新功能,允许在设备屏幕上同时显示多个应用,多窗口模式允许多个应用同时共享同一屏幕,多窗口模式(Multi Window Supports)目前支持以下三种…...

sqli-labs第十八关——POST-UA注入
一:判断注入类型 先在用户名和密码框尝试判断,发现都得不到需要的回显 所以查看源码 可以发现username和password的输入后端都做了检查,没法直接注入 所以我们尝试uagent注入 UA注入: 没有url解码处理只识别原始空格ÿ…...

流式优先架构:彻底改变实时数据处理
近年来,随着现代组织的数据环境日趋复杂且高速流动,传统数据库系统已难以满足实时分析、物联网应用以及即时决策的需求。围绕批处理和静态数据模型设计的 RDBMS(关系型数据库管理系统)在架构层面缺乏实时处理能力,而流…...

WebSockets 在实时通信中的应用与优化
WebSockets 在实时通信中的应用与优化 1. 引言 在现代互联网应用中,实时通信 已成为许多场景的核心需求,如在线聊天、直播互动、在线游戏、实时数据推送等。而传统的 HTTP 轮询或长轮询方式往往伴随着 高延迟、资源浪费 等问题,使得开发者在…...

零基础教程:用 Docker + pgloader 将 MySQL 数据库迁移到 PostgreSQL
在日常开发中,可能会遇到从 MySQL 迁移到 PostgreSQL 的需求。你也许是: 正在准备从传统架构转向云原生;想使用 PostgreSQL 更强的事务与 JSON 支持;想统一团队数据库技术栈;纯粹为了尝试学习不同的数据库系统。别担心,无需手动写导出脚本,无需配置复杂工具,只需借助 D…...

mac上安装 Rust 开发环境
1.你可以按照提示在终端中执行以下命令(安全、官方支持): curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh然后按提示继续安装即可。 注意:安装过程中建议选择默认配置(按 1 即可)。 如果遇…...

解决RedisTemplate的json反序列泛型丢失问题
背景 在使用redisTemplate操作redis时我们针对对象的序列化通常将序列化成json存储到redis。一般如下配置 Bean ConditionalOnMissingBean public RedisTemplate<?, ?> redisTemplate(RedisConnectionFactory redisConnectionFactory, ObjectProvider<RedisT…...

【Elasticsearch】创建别名的几种方式
在 Elasticsearch 中,有以下几种创建索引别名的方式: 1. 在创建索引时指定别名 在创建索引时,可以直接在索引定义中指定别名。这种方式可以在索引创建的同时完成别名的绑定,避免后续的额外操作。 示例: json PUT /te…...

【JAVA】中文我该怎么排序?
📘 Java 中文排序教学文档(基于 Collator) 🧠 目录 概述Java 中字符串排序的默认行为为什么需要 Collator使用 Collator 进行中文排序升序 vs 降序排序自定义对象字段排序多字段排序示例总结对比表附录:完整代码示例 …...
《C 语言字符串操作从入门到实战(下篇):strncpy/strncat/strstr 等函数原理与实现》
目录 七. strncpy函数的使用与模拟实现 7.1 strncpy函数理解 7.2 strncpy函数使用示例 7.3 strncpy函数模拟实现 八. strncat函数的使用与模拟实现 8.1 strncat函数理解 8.2 strncat函数使用示例 8.3 strncat函数模拟实现 九. strncmp函数的使用 9.1 strncmp函数理…...

百度飞桨PaddleOCR 3.0开源发布 OCR精度跃升13%
百度飞桨 PaddleOCR 3.0 开源发布 2025 年 5 月 20 日,百度飞桨团队正式发布了 PaddleOCR 3.0 版本,并将其开源。这一新版本在文字识别精度、多语种支持、手写体识别以及高精度文档解析等方面取得了显著进展,进一步提升了 PaddleOCR 在 OCR …...
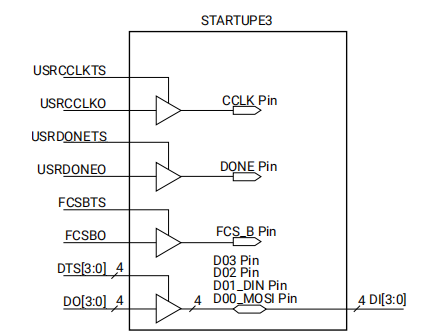
Xilinx 7Series\UltraScale 在线升级FLASH STARTUPE2和STARTUPE3使用
一、FPGA 在线升级 FPGA 在线升级FLASH时,一般是通过逻辑生成SPI接口操作FLASH,当然也可以通过其他SOC经FPGA操作FLASH,那么FPGA就要实现在启动后对FLASH的控制。 对于7Series FPGA,只有CCLK是专用引脚,SPI接口均为普…...
数字孪生驱动的离散制造智能升级:架构设计与工程实践
针对离散制造行业多品种、小批量的生产特性,本文提出一种基于数字孪生的智能制造解决方案。以某国家级智能制造试点示范项目为载体,构建"云-边-端"协同的数字孪生系统,实现设备综合效率(OEE)提升28.7%、订单…...
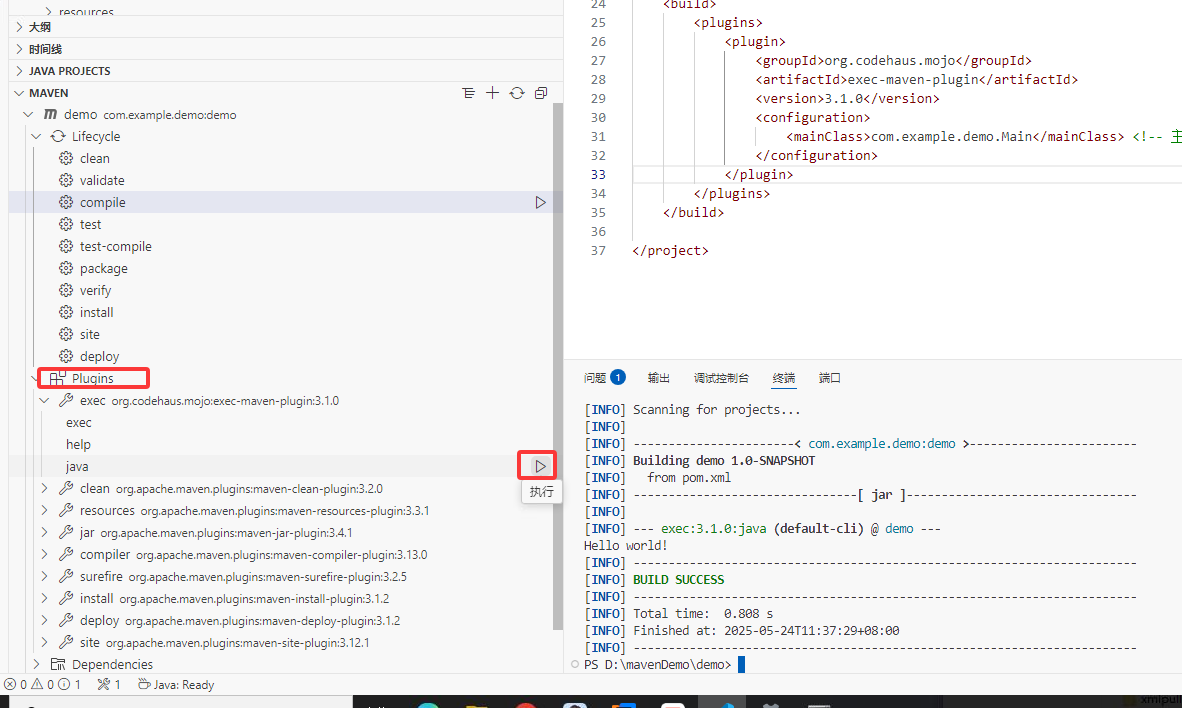
9.4在 VS Code 中配置 Maven
在 VS Code 中配置 Maven 需要完成 Maven 环境安装 一、安装 Maven(如果未安装) 下载 Maven 访问 Apache Maven 官网,下载最新版本的 Maven(如apache-maven-3.9.9-bin.zip)。 解压文件 将下载的 ZIP 文件解压到本地目…...

mmaction2——tools文件夹下
build_rawframes.py 用法示例 python tools/data/build_rawframes.py data/videos data/frames --task rgb --level 2 --ext mp4 --use-opencv --num-worker 8总结: 只需要 RGB 帧,推荐 --use-opencv,简单高效,无需额外依赖。 …...
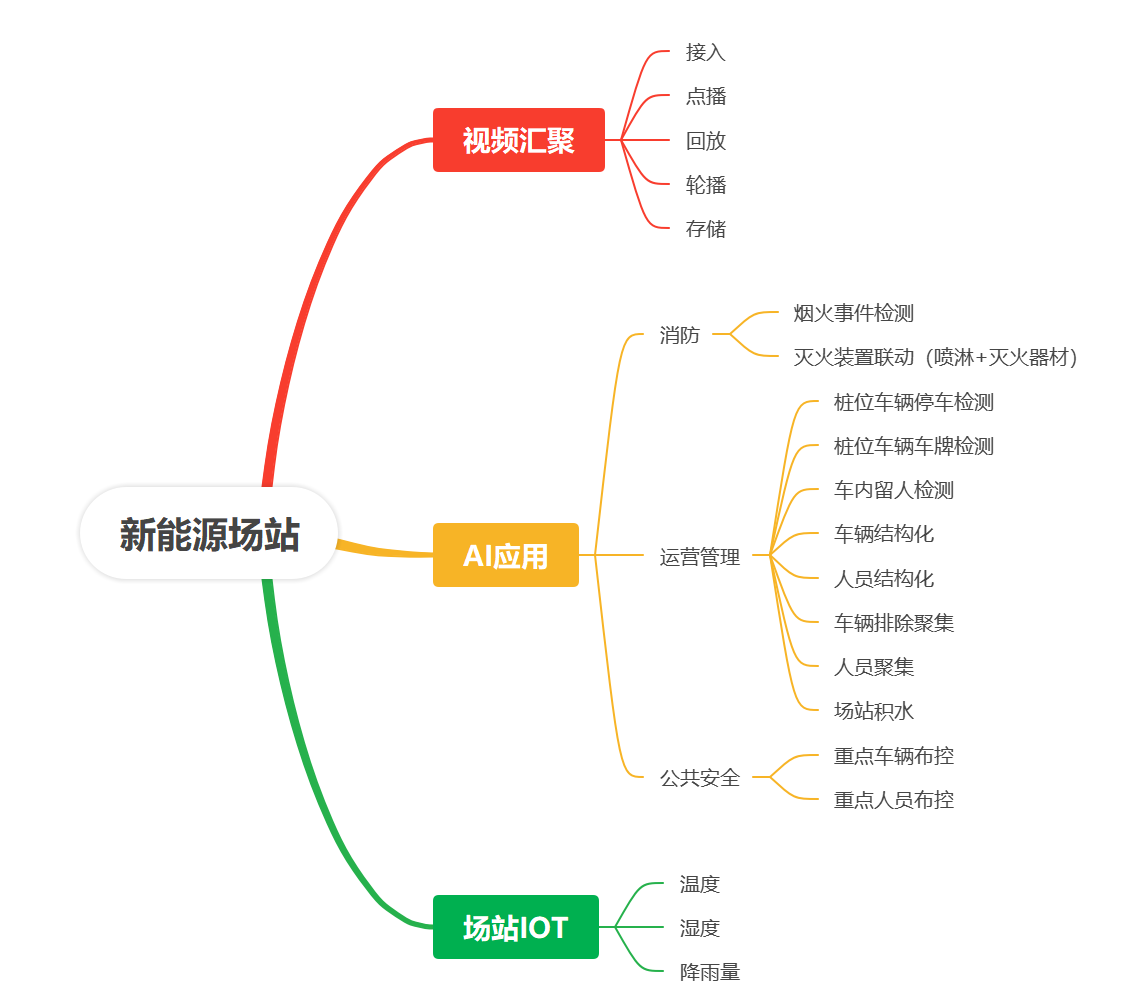
新能源汽车充电桩资源如何利用资源高效配置?
新能源汽车充电桩资源的高效配置是实现绿色交通转型的关键环节。随着新能源汽车保有量的快速增长,充电基础设施的供需矛盾日益凸显。如何优化充电桩资源布局、提升使用效率、平衡不同场景需求,成为当前亟待解决的问题。以下是几点关于充电桩资源高效配置…...

python 程序实现了毫米波大规模MIMO系统中的信道估计对比实验
python 程序实现了毫米波大规模MIMO系统中的信道估计对比实验 import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from tensorflow.keras.models import Sequential, Model from tensorflow.keras.layers...

NTFS0x90属性和0xa0属性和0xb0属性的一一对应关系是index_entry中的index_node中VCN和runlist和bitmap
第一部分: 0: kd> dt _FILE_RECORD_SEGMENT_HEADER 0xc1241400 Ntfs!_FILE_RECORD_SEGMENT_HEADER 0x000 MultiSectorHeader : _MULTI_SECTOR_HEADER 0x008 Lsn : _LARGE_INTEGER 0x80e74aa 0x010 SequenceNumber : 5 0x012 Referen…...

PDF 编辑批量拆分合并OCR 识别
各位办公小能手们!你们有没有过被PDF文件折磨得死去活来的经历?反正我是有,每次要编辑PDF,那叫一个费劲啊!不过呢,今天我要给大家介绍一款神器——WPS PDF to Word,有了它,PDF编辑那…...
LeetCode --- 450周赛
题目列表 3550. 数位和等于下标的最小下标 3551. 数位和排序需要的最小交换次数 3552. 网格传送门旅游 3553. 包含给定路径的最小带权子树 II 一、数位和等于下标的最小下标 直接模拟计算数位和即可,代码如下 // C class Solution { public:int smallestIndex(ve…...
SpringBoot中消息转换器的选择
SpringBoot返回xml-CSDN博客 是返回JSON 还是XML 是由内容协商机制确认的,SpringBoot为了开发便利性,如果我没有该消息转换器,默认就返回了JSON,如果需要XML那么,引入 <dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>…...
前端初学者入门指南:HTML5与CSS3核心知识详解)
(初级)前端初学者入门指南:HTML5与CSS3核心知识详解
对于前端初学者来说,掌握HTML5和CSS3的基础知识是构建现代化网页的第一步。本文将围绕语义化标签、多媒体嵌入、盒模型、Flexbox布局和Grid布局五大核心知识点展开,通过代码示例和详细解析帮助大家快速上手。 一、HTML5:从结构到交互的革新 …...

基于点标注的弱监督目标检测方法研究
摘要 在计算机视觉领域,目标检测需要大量精准标注数据,但人工标注成本高昂。弱监督目标检测通过低成本标注训练模型,成为近年研究热点。本文提出一种基于点标注的弱监督目标检测算法,仅需在图像中物体中心点标注,即可高…...

【RichTextEditor】 【分析2】RichTextEditor设置文字内容背景色
【RichTextEditor】 【分析2】RichTextEditor设置文字内容背景色 都说AI Coder的Cursor很牛,也付费用了, 但这个背景色,搞了一天也没改过来。 最后,让它分析该控件的层次结构及文本内容显示的位置。 然后,搞定&#…...