【MPC控制 - 从ACC到自动驾驶】3 MPC控制器设计原理与参数配置:打造ACC的“最强大脑”
【MPC控制 - 从ACC到自动驾驶】MPC控制器设计原理与参数配置:打造ACC的“最强大脑”
在Day 1,我们认识了ACC自适应巡航和MPC这位“深谋远虑的棋手”。Day 2,我们一起给汽车“画像”,建立了它的纵向动力学模型,并把它翻译成了计算机能懂的离散语言。可以说,我们已经为MPC准备好了“沙盘”和“棋子”。
那么今天,Day 3,我们将进入激动人心的核心环节:MPC控制器设计原理与参数配置。我们要揭开MPC大脑内部的秘密,看看它是如何思考,如何做决策,以及我们如何“调教”它,让它成为一个优秀的“智能驾驶员”。准备好了吗?这部分内容是MPC的灵魂所在,打起精神,我们发车!
想象一下,你现在已经有了一张精确的地图(车辆模型),并且知道每条路怎么走(模型方程)。现在,你想从A点到B点(控制目标,比如保持安全车距),你该如何规划路线呢?你可能会考虑:
- 哪条路最短?(效率)
- 哪条路最平坦?(舒适性)
- 路上有没有限速?(约束)
- 是不是只规划下一步,还是多看几步?(预测)
MPC做决策的过程,和这个非常相似。它会在一个“有限的未来”里,不断地进行“规划-执行-再规划”。今天,我们就来一步步解构这个“规划”过程。
MPC的核心运作三部曲:预测、优化、执行
我们昨天提到,MPC像个棋手。它的每一步行动,都遵循着一个固定的套路:
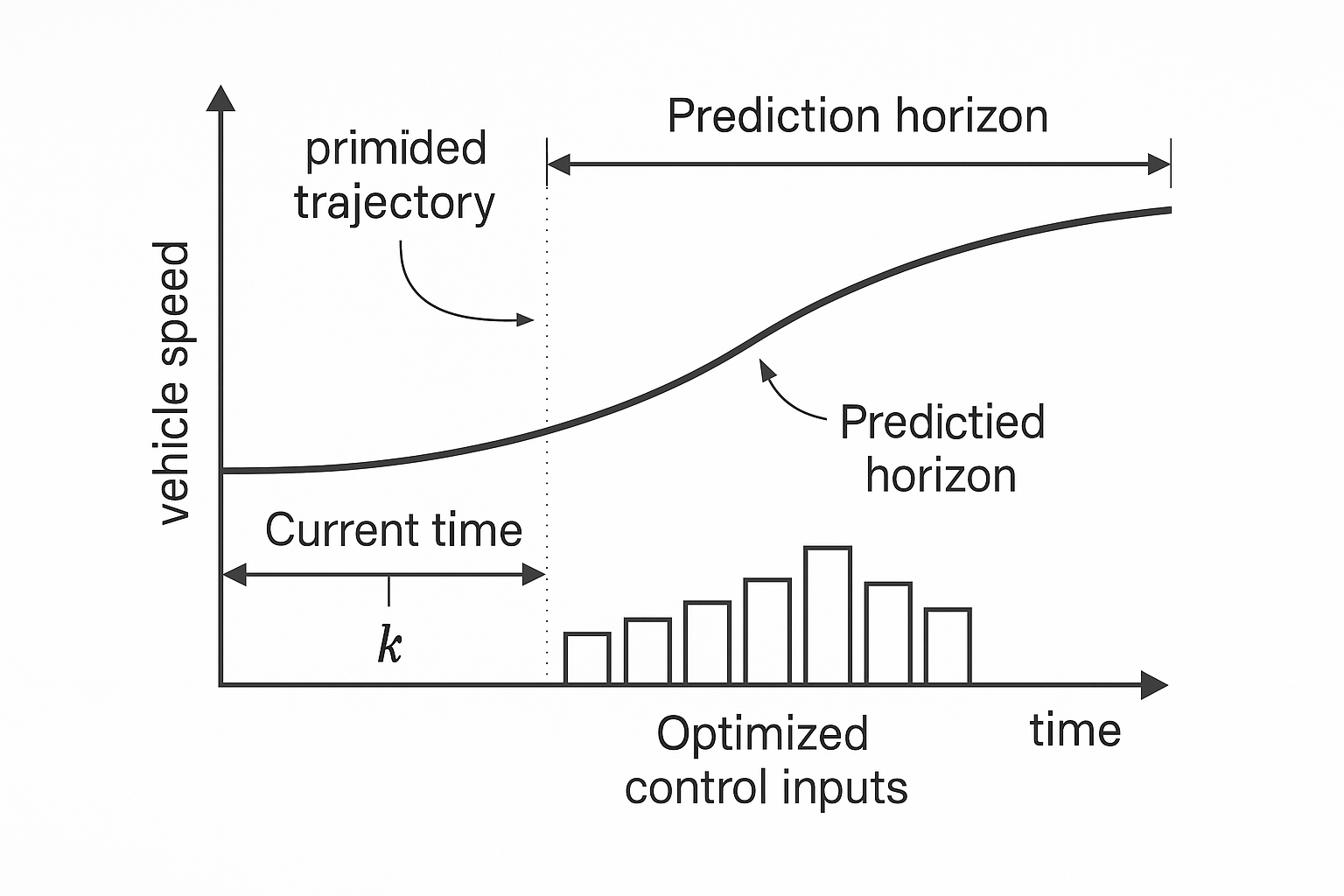
- 预测未来 (Prediction): 基于我们Day 2建立的离散车辆模型 x ( k + 1 ) = A d x ( k ) + B d u ( k ) + B w d w ( k ) \mathbf{x}(k+1) = \mathbf{A}_d\mathbf{x}(k) + \mathbf{B}_d u(k) + \mathbf{B}_{wd} w(k) x(k+1)=Adx(k)+Bdu(k)+Bwdw(k),MPC会展望未来的一小段时间(称为预测时域 N p N_p Np)。它会尝试不同的控制输入序列 u ( k ) , u ( k + 1 ) , … , u ( k + N c − 1 ) u(k), u(k+1), \dots, u(k+N_c-1) u(k),u(k+1),…,u(k+Nc−1) (其中 N c N_c Nc 是控制时域, N c ≤ N p N_c \le N_p Nc≤Np),并预测在这些控制作用下,车辆未来的状态(如速度 v e g o v_{ego} vego、相对距离 d r e l d_{rel} drel)会如何演变。
- 预测时域 N p N_p Np (Prediction Horizon): 指MPC向前看多少步。比如 N p = 20 N_p=20 Np=20, T s = 0.1 T_s=0.1 Ts=0.1秒,就代表MPC会预测未来2秒钟车辆的轨迹。
- 控制时域 N c N_c Nc (Control Horizon): 指MPC在一个优化周期内,实际计算并优化的未来控制输入的数量。通常 N c ≤ N p N_c \le N_p Nc≤Np。在 N c N_c Nc 步之后,控制输入通常被假定为保持不变或按某种规律延续。
-
优化决策 (Optimization): 在预测出的众多未来可能性中,哪一个是“最好”的呢?这就需要一个“评价标准”,在MPC中,这个标准就是代价函数 (Cost Function,或称目标函数 Objective Function)。MPC会努力寻找一个控制序列,使得这个代价函数的值最小。同时,它还要确保所有的控制行为都符合实际的物理限制和安全要求,这些就是约束条件 (Constraints)。这个寻找最优解的过程,本质上是在求解一个带约束的优化问题。
-
滚动执行 (Receding Horizon Execution): 优化完成后,MPC会得到一串“最优”的未来控制指令 u ∗ ( k ∣ k ) , u ∗ ( k + 1 ∣ k ) , … , u ∗ ( k + N c − 1 ∣ k ) u^*(k|k), u^*(k+1|k), \dots, u^*(k+N_c-1|k) u∗(k∣k),u∗(k+1∣k),…,u∗(k+Nc−1∣k)。但它并不会把这些指令全部执行。而是只执行第一个控制指令 u ∗ ( k ∣ k ) u^*(k|k) u∗(k∣k)。然后,在下一个控制时刻 k + 1 k+1 k+1 到来时,系统会获得新的测量值(车辆实际的状态),然后MPC会重复上述的预测和优化过程,重新计算下一串最优控制指令,并再次只执行第一个。这个过程不断“滚动”向前,因此也称为滚动时域控制 (Receding Horizon Control, RHC)。
这个“预测-优化-执行第一个-再重复”的循环,就是MPC工作的核心机制。它赋予了MPC强大的适应性和鲁棒性。
代价函数:MPC的“导航地图”与“评价标准”
代价函数 J J J 是MPC的灵魂,它告诉MPC什么是“好”的控制,什么是“坏”的控制。设计一个好的代价函数,是MPC成功的关键。
对于ACC系统,我们期望达到的控制目标可以概括为:
- 准确性 (Accuracy):
- 车速跟踪: 当没有前车或前车很远时,本车速度 v e g o v_{ego} vego 应尽可能接近驾驶员设定的期望速度 v s e t v_{set} vset。
- 距离保持: 当有前车时,本车与前车的相对距离 d r e l d_{rel} drel 应尽可能接近计算出的安全距离 d s a f e d_{safe} dsafe (回顾Day 1, d s a f e = d 0 + T h w ⋅ v e g o d_{safe} = d_0 + T_{hw} \cdot v_{ego} dsafe=d0+Thw⋅vego)。
- 舒适性 (Comfort):
- 避免过大的加速度或减速度,即控制输入 u ( k ) = a e g o ( k ) u(k) = a_{ego}(k) u(k)=aego(k) 不宜过大。
- 避免加速度的剧烈变化(即过大的“冲击度”或“Jerk”),即 u ( k ) − u ( k − 1 ) u(k) - u(k-1) u(k)−u(k−1) 不宜过大。
- 经济性 (Economy) (可选):
- 尽量减少不必要的加速和减速,以节省燃油或电能。这通常与舒适性目标部分重合。
MPC通常采用二次型代价函数 (Quadratic Cost Function),因为它形式简单,易于求解(尤其是当系统模型是线性的,约束也是线性的情况下,优化问题会变成一个凸的二次规划QP问题,有高效的解法)。
一个典型的MPC代价函数可以写成如下形式:
J = ∑ i = 1 N p ∥ y p r e d ( k + i ∣ k ) − y r e f ( k + i ∣ k ) ∥ Q 2 + ∑ j = 0 N c − 1 ∥ Δ u ( k + j ∣ k ) ∥ R 2 + ∑ j = 0 N c − 1 ∥ u ( k + j ∣ k ) ∥ S 2 J = \sum_{i=1}^{N_p} \left\| \mathbf{y}_{pred}(k+i|k) - \mathbf{y}_{ref}(k+i|k) \right\|_{\mathbf{Q}}^2 + \sum_{j=0}^{N_c-1} \left\| \Delta u(k+j|k) \right\|_{\mathbf{R}}^2 + \sum_{j=0}^{N_c-1} \left\| u(k+j|k) \right\|_{\mathbf{S}}^2 J=∑i=1Np∥ypred(k+i∣k)−yref(k+i∣k)∥Q2+∑j=0Nc−1∥Δu(k+j∣k)∥R2+∑j=0Nc−1∥u(k+j∣k)∥S2
是不是看起来有点吓人?别慌,我们把它拆开来看:
- k k k: 当前的离散时间步。
- i i i: 在预测时域 N p N_p Np 内的未来时间步索引,从1到 N p N_p Np。
- j j j: 在控制时域 N c N_c Nc 内的未来控制步索引,从0到 N c − 1 N_c-1 Nc−1。
- y p r e d ( k + i ∣ k ) \mathbf{y}_{pred}(k+i|k) ypred(k+i∣k): 在当前时刻 k k k 预测的未来第 k + i k+i k+i 时刻的系统输出。对于ACC,它可能包含预测的相对距离 d r e l ( k + i ∣ k ) d_{rel}(k+i|k) drel(k+i∣k) 和本车速度 v e g o ( k + i ∣ k ) v_{ego}(k+i|k) vego(k+i∣k)。
- y r e f ( k + i ∣ k ) \mathbf{y}_{ref}(k+i|k) yref(k+i∣k): 我们期望系统在未来第 k + i k+i k+i 时刻达到的参考输出值。
- 在速度控制模式下,参考速度是 v s e t v_{set} vset,参考距离可以设为一个很大的值或者其权重为0。
- 在距离控制模式下,参考距离是 d s a f e ( k + i ∣ k ) d_{safe}(k+i|k) dsafe(k+i∣k)(注意 d s a f e d_{safe} dsafe 可能也依赖于预测的本车速度 v e g o ( k + i ∣ k ) v_{ego}(k+i|k) vego(k+i∣k),这会使问题更复杂,有时会用当前时刻计算的 d s a f e d_{safe} dsafe 作为未来一段时间的参考,或进行迭代逼近),参考速度可以是前车速度 v l e a d ( k + i ∣ k ) v_{lead}(k+i|k) vlead(k+i∣k) 或 v s e t v_{set} vset(取较小者)。
- u ( k + j ∣ k ) u(k+j|k) u(k+j∣k): 在当前时刻 k k k 优化的未来第 k + j k+j k+j 时刻的控制输入(即本车期望加速度 a e g o ( k + j ∣ k ) a_{ego}(k+j|k) aego(k+j∣k))。
- Δ u ( k + j ∣ k ) \Delta u(k+j|k) Δu(k+j∣k): 控制输入的增量,即 u ( k + j ∣ k ) − u ( k + j − 1 ∣ k ) u(k+j|k) - u(k+j-1|k) u(k+j∣k)−u(k+j−1∣k)。它代表了加速度的变化率(与Jerk相关)。我们通常希望这个增量小一些,以保证舒适性。
- ∥ v ∥ M 2 \left\| \mathbf{v} \right\|_{\mathbf{M}}^2 ∥v∥M2: 这是一个带权重的二次型范数,表示 v T M v \mathbf{v}^T \mathbf{M} \mathbf{v} vTMv。 M \mathbf{M} M 是一个半正定的权重矩阵。
- Q \mathbf{Q} Q: 状态/输出权重矩阵。它衡量我们对跟踪误差的重视程度。 Q \mathbf{Q} Q 中对应某个输出(如 d r e l d_{rel} drel)的对角线元素越大,MPC就会越努力地减小该输出的跟踪误差。
- R \mathbf{R} R: 控制增量权重矩阵。它衡量我们对控制输入变化剧烈程度的惩罚。 R \mathbf{R} R 的元素越大,MPC计算出的控制输入变化就越平缓(即加速度变化越小,越舒适)。
- S \mathbf{S} S: 控制量权重矩阵 (可选,有时包含在R中或不显式列出)。它衡量我们对控制输入大小本身的惩罚。 S \mathbf{S} S 越大,MPC倾向于使用更小的控制输入(更节能,但不一定能快速响应)。
代价函数的通俗理解:
J = ( 未来一段时间内,预测输出与期望输出的差距有多大? ) + ( 未来的控制指令变化是不是太剧烈了? ) + ( 未来的控制指令本身是不是太大了? ) J = (\text{未来一段时间内,预测输出与期望输出的差距有多大?}) + (\text{未来的控制指令变化是不是太剧烈了?}) + (\text{未来的控制指令本身是不是太大了?}) J=(未来一段时间内,预测输出与期望输出的差距有多大?)+(未来的控制指令变化是不是太剧烈了?)+(未来的控制指令本身是不是太大了?)
MPC的目标就是找到一串未来的控制指令 u ( k ∣ k ) , … , u ( k + N c − 1 ∣ k ) u(k|k), \dots, u(k+N_c-1|k) u(k∣k),…,u(k+Nc−1∣k),使得这个总的“代价” J J J 最小。
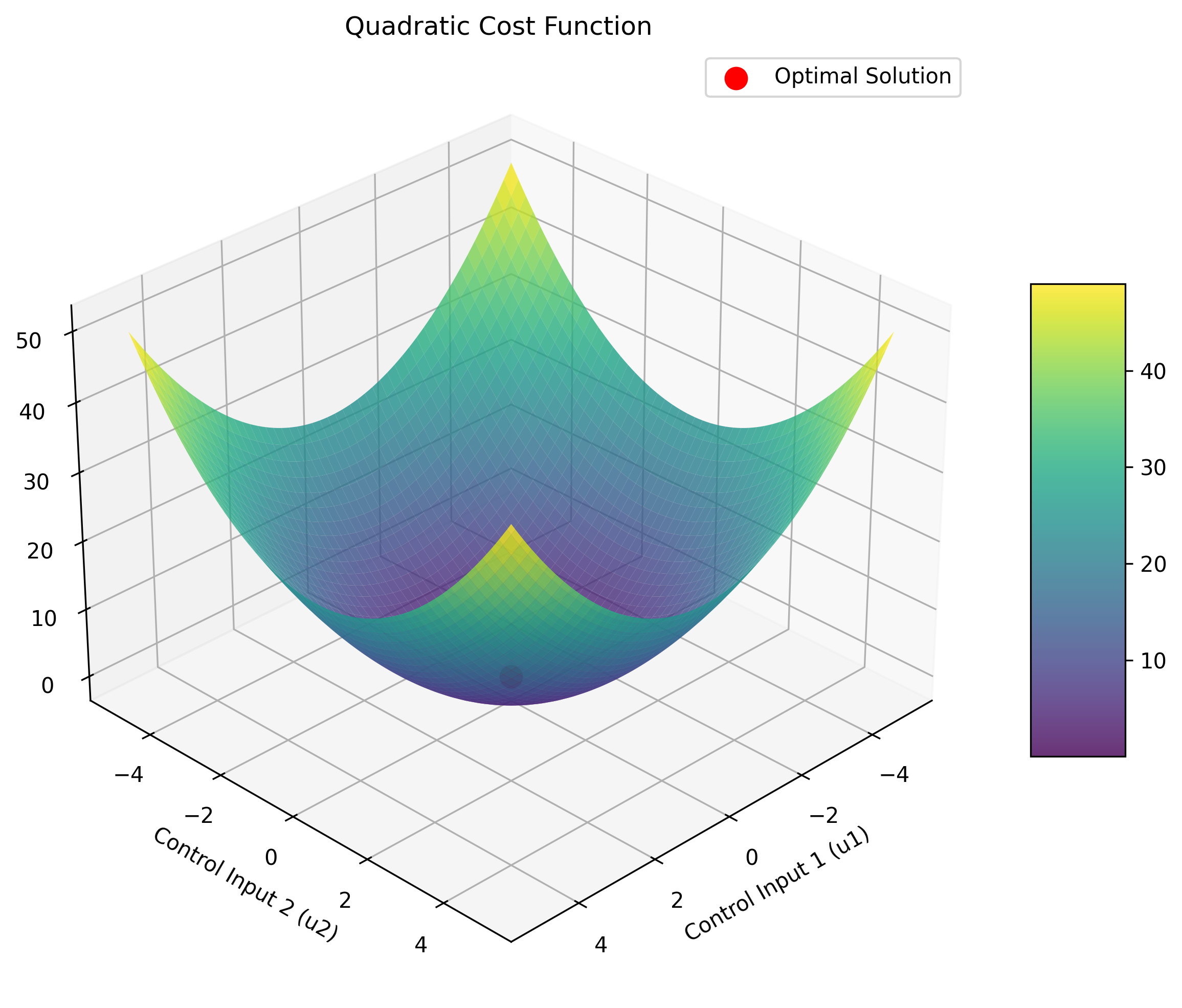
权重矩阵 Q \mathbf{Q} Q 和 R \mathbf{R} R 的奥秘——调校的艺术
Q \mathbf{Q} Q 和 R \mathbf{R} R (以及 S \mathbf{S} S)是我们与MPC沟通的“语言”。通过调整这些权重,我们可以告诉MPC我们更看重什么:
- 增大 Q \mathbf{Q} Q 中对应 d r e l d_{rel} drel 误差的权重: MPC会更积极地保持安全距离,即使这意味着加速度变化可能大一些。
- 增大 Q \mathbf{Q} Q 中对应 v e g o v_{ego} vego 误差的权重: MPC会更努力地跟踪设定速度。
- 增大 R \mathbf{R} R 的权重: MPC会倾向于输出更平滑、变化更小的加速度指令,驾驶体验更舒适,但可能响应速度会慢一些。
- 增大 S \mathbf{S} S 的权重: MPC会尽量使用较小的加速度值,可能更节能,但跟踪性能可能会下降。
这些权重的选取是一个权衡 (Trade-off) 的过程,也是MPC参数调优中最核心、最具挑战性的部分之一。通常需要通过大量的仿真和实车测试,反复迭代,才能找到一组在不同工况下都表现良好的权重。这很像给音响调均衡器,不同的参数组合会带来不同的“听感”(驾驶体验)。
约束条件:MPC的“行为准则”
现实世界中,汽车的性能不是无限的,道路交通也有规则。MPC的一大优势就是能够直接、显式地处理这些约束条件 (Constraints)。
对于ACC系统,常见的约束有:
-
控制输入约束 (Input Constraints):
- 加速度限制: 车辆的发动机/电机提供的驱动加速度和刹车系统提供的制动加速度都是有限的。
a m i n ≤ u ( k + j ∣ k ) ≤ a m a x a_{min} \le u(k+j|k) \le a_{max} amin≤u(k+j∣k)≤amax
例如, a m i n a_{min} amin 可能是 -5 m/s² (最大刹车), a m a x a_{max} amax 可能是 2 m/s² (舒适的加速上限)。 - 加速度变化率限制 (Slew Rate / Jerk Constraints): 为了舒适性,加速度的变化不宜过快。
Δ u m i n ≤ u ( k + j ∣ k ) − u ( k + j − 1 ∣ k ) ≤ Δ u m a x \Delta u_{min} \le u(k+j|k) - u(k+j-1|k) \le \Delta u_{max} Δumin≤u(k+j∣k)−u(k+j−1∣k)≤Δumax
例如,一个采样周期内加速度变化不超过 0.5 m/s³。
- 加速度限制: 车辆的发动机/电机提供的驱动加速度和刹车系统提供的制动加速度都是有限的。
-
状态/输出约束 (State/Output Constraints):
- 速度限制: 本车速度不能超过道路限速,也不能低于某个最低速度(如果有的话),并且不能超过驾驶员设定的 v s e t v_{set} vset。
v e g o _ m i n ≤ v e g o ( k + i ∣ k ) ≤ v e g o _ m a x v_{ego\_min} \le v_{ego}(k+i|k) \le v_{ego\_max} vego_min≤vego(k+i∣k)≤vego_max - 最小安全距离: 即使在优化过程中,预测的相对距离 d r e l d_{rel} drel 也不能小于某个绝对的最小安全距离 d a b s _ m i n d_{abs\_min} dabs_min(这比通过代价函数去“软”逼近 d s a f e d_{safe} dsafe 更严格)。
d r e l ( k + i ∣ k ) ≥ d a b s _ m i n d_{rel}(k+i|k) \ge d_{abs\_min} drel(k+i∣k)≥dabs_min
这通常是一个硬约束 (Hard Constraint),必须严格遵守。 - 有些输出约束也可以是软约束 (Soft Constraint),即允许在一定程度上违反,但在代价函数中给予巨大的惩罚。这可以增加优化问题的求解鲁棒性,避免因为过于严格的约束导致找不到可行解。
- 速度限制: 本车速度不能超过道路限速,也不能低于某个最低速度(如果有的话),并且不能超过驾驶员设定的 v s e t v_{set} vset。
MPC在求解优化问题时,会确保找到的控制序列 u ∗ ( k ∣ k ) , … , u ∗ ( k + N c − 1 ∣ k ) u^*(k|k), \dots, u^*(k+N_c-1|k) u∗(k∣k),…,u∗(k+Nc−1∣k) 所产生的预测状态和输出都满足这些约束条件。这就好比给MPC划定了一个“安全操作区域”,它只能在这个区域内寻找最优解。
优化求解:寻找代价最小的控制序列
有了代价函数 J J J 和一系列约束条件,MPC的下一步工作就是求解这个带约束的优化问题:
Minimize J ( U ) J(U) J(U)
Subject to:
- System Dynamics: x ( k + i + 1 ∣ k ) = A d x ( k + i ∣ k ) + B d u ( k + i ∣ k ) + B w d w ( k + i ∣ k ) \mathbf{x}(k+i+1|k) = \mathbf{A}_d\mathbf{x}(k+i|k) + \mathbf{B}_d u(k+i|k) + \mathbf{B}_{wd} w(k+i|k) x(k+i+1∣k)=Adx(k+i∣k)+Bdu(k+i∣k)+Bwdw(k+i∣k) (for i = 0 … N p − 1 i=0 \dots N_p-1 i=0…Np−1)
- Input Constraints: a m i n ≤ u ( k + j ∣ k ) ≤ a m a x a_{min} \le u(k+j|k) \le a_{max} amin≤u(k+j∣k)≤amax (for j = 0 … N c − 1 j=0 \dots N_c-1 j=0…Nc−1)
- Input Rate Constraints: Δ u m i n ≤ Δ u ( k + j ∣ k ) ≤ Δ u m a x \Delta u_{min} \le \Delta u(k+j|k) \le \Delta u_{max} Δumin≤Δu(k+j∣k)≤Δumax (for j = 0 … N c − 1 j=0 \dots N_c-1 j=0…Nc−1)
- State/Output Constraints: e.g., v e g o _ m i n ≤ v e g o ( k + i ∣ k ) ≤ v e g o _ m a x v_{ego\_min} \le v_{ego}(k+i|k) \le v_{ego\_max} vego_min≤vego(k+i∣k)≤vego_max (for i = 1 … N p i=1 \dots N_p i=1…Np)
… (and other constraints)
其中 U = [ u ( k ∣ k ) T , u ( k + 1 ∣ k ) T , … , u ( k + N c − 1 ∣ k ) T ] T U = [u(k|k)^T, u(k+1|k)^T, \dots, u(k+N_c-1|k)^T]^T U=[u(k∣k)T,u(k+1∣k)T,…,u(k+Nc−1∣k)T]T 是待优化的控制序列。
如果系统模型是线性的(我们Day 2建立的模型就是),代价函数是二次的,约束条件是线性的(我们上面列举的都是),那么这个优化问题就是一个二次规划 (Quadratic Programming, QP) 问题。QP问题是一类研究得比较成熟的优化问题,有很多现成的、高效的QP求解器 (QP Solvers) 可以使用,例如 OSQP, qpOASES, MOSEK, Gurobi 等。这些求解器能够在毫秒级的时间内给出QP问题的解,满足车载实时性的要求。
求解器会输出一个最优的控制序列 U ∗ U^* U∗,也就是 u ∗ ( k ∣ k ) , u ∗ ( k + 1 ∣ k ) , … , u ∗ ( k + N c − 1 ∣ k ) u^*(k|k), u^*(k+1|k), \dots, u^*(k+N_c-1|k) u∗(k∣k),u∗(k+1∣k),…,u∗(k+Nc−1∣k)。
滚动时域控制:不断向前看,稳健应对变化
正如前面提到的,MPC并不会把计算出来的整个 N c N_c Nc 步的控制序列都用掉。它只采纳序列中的第一个控制动作 u ∗ ( k ∣ k ) u^*(k|k) u∗(k∣k) (即 a e g o ( k ) a_{ego}(k) aego(k)),并将其施加到车辆上。
然后,在下一个采样时刻 k + 1 k+1 k+1:
- 系统通过传感器测量得到新的实际状态 x ( k + 1 ) \mathbf{x}(k+1) x(k+1) (比如新的 v e g o v_{ego} vego, d r e l d_{rel} drel, v l e a d v_{lead} vlead)。
- 预测时域和控制时域都向前“滚动”一个时间步。
- MPC以新的状态 x ( k + 1 ) \mathbf{x}(k+1) x(k+1) 为起点,重新进行预测、代价函数评估和约束检查,再次求解QP优化问题,得到新的最优控制序列 u ∗ ( k + 1 ∣ k + 1 ) , … , u ∗ ( k + N c ∣ k + 1 ) u^*(k+1|k+1), \dots, u^*(k+N_c|k+1) u∗(k+1∣k+1),…,u∗(k+Nc∣k+1)。
- 再次只应用第一个控制动作 u ∗ ( k + 1 ∣ k + 1 ) u^*(k+1|k+1) u∗(k+1∣k+1)。
- 如此循环往复。
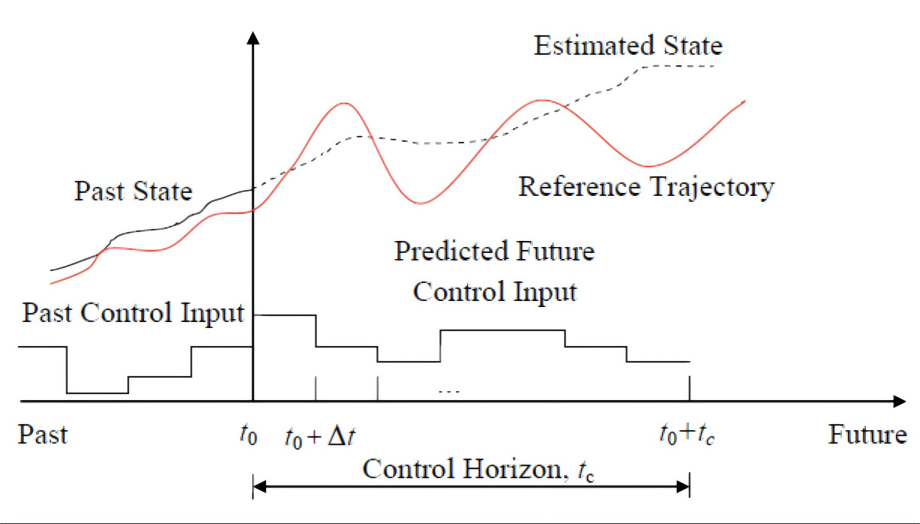
为什么采用滚动时域策略?
- 处理扰动: 真实世界充满不确定性。前车可能突然加速减速( w ( k ) w(k) w(k) 的变化),路面可能突然变化,我们的模型也可能不是100%精确。通过在每个时刻都根据最新的测量值重新优化,MPC能够及时地对这些扰动和模型误差做出反应,保持控制的鲁棒性。
- 反馈校正: 它本质上是一种闭环反馈控制。虽然MPC在“开环”地预测未来,但由于不断地用实际测量值来校正预测的起点,使得整个系统是闭环稳定的。
- 计算可行性: 如果我们试图一次性优化一个非常非常长的未来控制序列,计算量会大到无法接受。滚动时域将大问题分解为一系列在有限时域内求解的小问题。
MPC参数配置:调校出最佳性能的关键“旋钮”
一个MPC控制器的性能,很大程度上取决于其参数的选择和调校。这些参数就像汽车上的各种调节旋钮,需要精心设置,才能让ACC系统运行得既安全又舒适。
主要的参数包括:
-
采样时间 T s T_s Ts (Sampling Time):
- 影响: 我们在Day 2已经讨论过。它决定了MPC的反应速度和计算频率。
- 选择: 对于ACC,通常在 0.05 s ∼ 0.2 s 0.05s \sim 0.2s 0.05s∼0.2s (50ms ~ 200ms) 之间。需要平衡车辆动态响应、传感器刷新率和车载处理器的计算能力。
-
预测时域 N p N_p Np (Prediction Horizon):
- 影响:
- 优点: 较长的 N p N_p Np 能让MPC“看得更远”,更好地预见未来的情况,从而做出更平滑、更具前瞻性的控制决策。例如,如果能预见到前方较远处有一个慢车,就可以提前、缓慢地开始减速。
- 缺点: 极大地增加QP问题的规模和计算复杂度(变量数量和约束数量都随 N p N_p Np 增长)。而且,对模型精度的要求也更高,因为远期预测的误差会累积放大。
- 选择: 通常需要覆盖被控对象的主要动态响应时间,或者说,足够长到能看到一个控制动作的显著效果。对于ACC,几秒钟的预测时域(例如 N p ⋅ T s = 2 ∼ 5 N_p \cdot T_s = 2 \sim 5 Np⋅Ts=2∼5 秒)是比较常见的。
- 影响:
-
控制时域 N c N_c Nc (Control Horizon):
- 影响:
- N c N_c Nc 是实际优化的控制输入变量的个数。通常 N c ≤ N p N_c \le N_p Nc≤Np。在 N c N_c Nc 之后的控制输入,通常假定为 u ( k + N c − 1 ∣ k ) u(k+N_c-1|k) u(k+Nc−1∣k) 或某个固定值。
- 优点: 较小的 N c N_c Nc (比如1到5) 可以显著减少优化变量的数量,从而大大降低计算时间,同时仍然能获得不错的控制性能。
- 缺点: 如果 N c N_c Nc 太小,可能会限制控制器的灵活性,使其难以应对一些需要复杂控制序列的情况。
- 选择: 很多情况下, N c N_c Nc 会远小于 N p N_p Np。甚至 N c = 1 N_c=1 Nc=1 也是可行的,但可能会使控制动作有些“短视”。 N c N_c Nc 的选择也是一个权衡计算量和控制性能的过程。
- 影响:
-
权重矩阵 Q \mathbf{Q} Q (State/Output Weights) 和 R \mathbf{R} R (Control Input Weights):
- 影响: 正如前面详细讨论的,它们决定了MPC在不同控制目标(如跟踪精度、舒适性、经济性)之间的平衡。
- Q \mathbf{Q} Q 矩阵: 通常是对角矩阵。对角线上的元素 q i i q_{ii} qii 越大,表示对应的第 i i i 个状态/输出的跟踪误差越不被容忍。
- 例如,在ACC中, Q = diag ( q v _ e g o , q d _ r e l , q v _ l e a d ) \mathbf{Q} = \text{diag}(q_{v\_ego}, q_{d\_rel}, q_{v\_lead}) Q=diag(qv_ego,qd_rel,qv_lead) (如果这三个都是状态变量,并且都需要被加权)。如果 q d _ r e l q_{d\_rel} qd_rel 远大于 q v _ e g o q_{v\_ego} qv_ego,则MPC会优先保证安全距离,即使速度跟踪稍差。
- R \mathbf{R} R 矩阵: 通常也是对角矩阵(如果控制输入是向量的话,ACC中 u u u 通常是标量 a e g o a_{ego} aego,所以R是标量)。 r j j r_{jj} rjj 越大,表示对应的第 j j j 个控制输入的增量(或本身)的惩罚越大,控制会越平缓。
- 选择与调校:
- Bryson法则 (Bryson’s Rule) 作为起点: 一种经验性的方法是将权重设置为允许的最大误差(或控制量)的平方的倒数。例如,如果速度误差允许在 ± 2 m/s \pm 2 \text{ m/s} ±2 m/s,则 q v _ e g o ≈ 1 / ( 2 2 ) = 0.25 q_{v\_ego} \approx 1/(2^2) = 0.25 qv_ego≈1/(22)=0.25。如果加速度变化允许在 ± 0.5 m/s 2 / sample \pm 0.5 \text{ m/s}^2/\text{sample} ±0.5 m/s2/sample,则 r Δ a ≈ 1 / ( 0.5 2 ) = 4 r_{\Delta a} \approx 1/(0.5^2) = 4 rΔa≈1/(0.52)=4。但这只是一个非常粗略的起点。
- 归一化: 将不同物理量的误差归一化到相似的数值范围,再进行加权,可能更容易调整。
- 迭代试凑: 大量的仿真测试是必不可少的。从一组初始值开始,观察系统的响应(超调、响应速度、平稳性、约束满足情况),然后逐步调整 Q \mathbf{Q} Q 和 R \mathbf{R} R 的相对大小,直到获得满意的性能。这是一个经验和技巧积累的过程。
- 先调 Q \mathbf{Q} Q,再调 R \mathbf{R} R。或者先固定 R \mathbf{R} R 为一个较小的值(比如1),然后调整 Q \mathbf{Q} Q 来满足主要的跟踪性能,最后再调整 R \mathbf{R} R 来改善平顺性。
-
约束的边界值:
- a m i n , a m a x , Δ u m i n , Δ u m a x , v e g o _ m i n , v e g o _ m a x , d a b s _ m i n a_{min}, a_{max}, \Delta u_{min}, \Delta u_{max}, v_{ego\_min}, v_{ego\_max}, d_{abs\_min} amin,amax,Δumin,Δumax,vego_min,vego_max,dabs_min 等。
- 影响: 直接决定了MPC的操作空间。
- 选择:
- a m i n , a m a x a_{min}, a_{max} amin,amax 通常由车辆的物理性能决定(如最大驱动力、最大制动力),并考虑一定的安全裕量和舒适性。例如,虽然车能做到-9m/s²的急刹,但ACC一般不会用到这么大的值,可能会限制在-3m/s² 到 -5m/s²。
- Δ u \Delta u Δu 的限制主要为了舒适性。
- 速度限制由法规、设定速度和安全考虑决定。
- d a b s _ m i n d_{abs\_min} dabs_min 是绝对的红线,比如一个车身的长度。
参数调校的一般流程:
- 明确控制目标和性能指标: 你希望ACC系统达到什么样的响应速度?多大的超调可以接受?舒适性要求如何?
- 根据经验或规则选择初始参数: T s , N p , N c T_s, N_p, N_c Ts,Np,Nc 可以根据系统动态和计算能力初步选定。 Q , R \mathbf{Q}, \mathbf{R} Q,R 可以用Bryson法则或简单的单位矩阵开始。约束根据物理限制设定。
- 仿真测试: 在各种典型工况下(如跟车、切入、前车急刹、畅通路段巡航)进行仿真。
- 分析结果,调整参数:
- 如果响应太慢:尝试减小 R \mathbf{R} R,或增大 Q \mathbf{Q} Q 中对应误差项的权重,或适当增大 N c N_c Nc。
- 如果超调太大或震荡:尝试增大 R \mathbf{R} R,或减小 Q \mathbf{Q} Q,或检查 N p N_p Np 是否足够长。
- 如果控制输入变化太剧烈(不舒服):增大 R \mathbf{R} R (惩罚 Δ u \Delta u Δu)。
- 如果频繁触碰约束:检查约束设置是否合理,或者模型是否准确。
- 如果计算时间太长:减小 N p N_p Np 或 N c N_c Nc,或增大 T s T_s Ts (但这会牺牲性能)。
- 迭代: 重复步骤3和4,直到获得满意的综合性能。
- 实车测试与微调: 仿真毕竟是理想化的,最终参数还需要在实车上进行验证和细致调整。
这是一个充满挑战但也非常有趣的过程,就像一位调音师在精心雕琢一件乐器,使其发出最美妙的声音。
ACC控制模式切换与MPC的配合
还记得Day 1我们讲的ACC的两种主要工作模式吗?速度控制和距离控制。MPC如何适应这两种模式呢?答案是调整代价函数中的参考值 y r e f \mathbf{y}_{ref} yref 和权重 Q \mathbf{Q} Q。
-
速度控制模式 (无前车或前车远/快):
- 目标: v e g o → v s e t v_{ego} \to v_{set} vego→vset。
- y r e f \mathbf{y}_{ref} yref 中的速度参考设为 v s e t v_{set} vset。
- y r e f \mathbf{y}_{ref} yref 中的距离参考可以设为一个非常大且无关的值,或者 Q \mathbf{Q} Q 矩阵中与距离误差对应的权重设为0或一个很小的值。
- 此时,代价函数主要惩罚 ( v e g o − v s e t ) 2 (v_{ego} - v_{set})^2 (vego−vset)2。
-
距离控制模式 (有前车且需要跟驰):
- 目标: d r e l → d s a f e d_{rel} \to d_{safe} drel→dsafe,同时 v e g o ≈ v l e a d v_{ego} \approx v_{lead} vego≈vlead (但不超过 v s e t v_{set} vset)。
- y r e f \mathbf{y}_{ref} yref 中的距离参考设为 d s a f e ( k + i ∣ k ) = d 0 + T h w ⋅ v e g o ( k + i ∣ k ) d_{safe}(k+i|k) = d_0 + T_{hw} \cdot v_{ego}(k+i|k) dsafe(k+i∣k)=d0+Thw⋅vego(k+i∣k) (或其近似值)。
- y r e f \mathbf{y}_{ref} yref 中的速度参考可以设为预测的前车速度 v l e a d ( k + i ∣ k ) v_{lead}(k+i|k) vlead(k+i∣k),或者 m i n ( v l e a d ( k + i ∣ k ) , v s e t ) min(v_{lead}(k+i|k), v_{set}) min(vlead(k+i∣k),vset)。
- 此时, Q \mathbf{Q} Q 矩阵中与距离误差 d r e l d_{rel} drel 和速度误差 v e g o v_{ego} vego 相关的权重都会比较大,MPC会努力同时满足这两个目标。
通过在每个控制周期根据当前是否有有效跟车对象,动态地调整MPC代价函数中的参考信号和权重,就可以实现ACC在不同模式下的平滑切换和精确控制。
今日总结与明日展望
今天,我们深入探索了MPC控制器设计的三大核心要素:代价函数、约束条件和优化求解,以及关键的滚动时域控制策略。我们还详细讨论了MPC中最重要的参数——预测时域 N p N_p Np、控制时域 N c N_c Nc、采样时间 T s T_s Ts 以及权重矩阵 Q \mathbf{Q} Q 和 R \mathbf{R} R——它们是如何影响控制器性能,以及如何进行初步的配置和调校。
可以说,我们已经掌握了设计一个MPC控制器的基本蓝图。我们知道它如何设定目标(代价函数),如何遵守规则(约束),如何做出决策(优化求解),以及如何不断适应变化(滚动时域)。
这个“大脑”已经初具雏形,但它是否真的好用,还需要实践的检验。在明天的博客中,我们将进入MPC的仿真与参数精调环节。我们会看到如何将今天设计的MPC控制器在一个模拟环境中运行起来,观察它的实际表现,并通过系统的方法来优化那些关键的参数,让我们的ACC系统真正达到“聪明又稳重”的境界。
习题
1. 简答题:请用你自己的话解释MPC中的“预测时域 ( N p N_p Np)”和“控制时域 ( N c N_c Nc)”分别是什么含义?为什么通常 N c ≤ N p N_c \le N_p Nc≤Np?
2. 判断题:在MPC的代价函数 J = ∑ ∥ y p r e d − y r e f ∥ Q 2 + ∑ ∥ Δ u ∥ R 2 J = \sum \|\mathbf{y}_{pred} - \mathbf{y}_{ref}\|_{\mathbf{Q}}^2 + \sum \|\Delta u\|_{\mathbf{R}}^2 J=∑∥ypred−yref∥Q2+∑∥Δu∥R2 中,如果我希望车辆的加速度变化更平缓,驾驶感觉更舒适,我应该增大权重矩阵 Q \mathbf{Q} Q 还是 R \mathbf{R} R?
3. 选择题:以下哪项不是模型预测控制(MPC)能够直接处理的约束类型?
A. 控制输入的大小限制 (如最大加速度)
B. 控制输入的变化率限制 (如最大Jerk)
C. 系统状态的限制 (如最大车速)
D. 未建模的外部随机扰动的大小
4. 思考题:假设你在为一个ACC系统调试MPC参数。你发现车辆在跟车时,与前车的距离总是比设定的安全距离 d s a f e d_{safe} dsafe 要小一点,而且减速时有点突兀。你会考虑调整哪些MPC参数,以及如何调整?请说明理由。
答案:
-
答案:
- 预测时域 ( N p N_p Np): 指MPC在做当前决策时,会向前预测未来多少个时间步长的系统行为。它代表了MPC“看得有多远”。例如,如果采样时间是0.1秒, N p = 20 N_p=20 Np=20,那么MPC会预测未来2秒内系统的状态。
- 控制时域 ( N c N_c Nc): 指MPC在一个优化周期内,实际计算并优化的未来控制输入的数量。它代表了MPC一次“规划多少步控制动作”。
- 为什么通常 N c ≤ N p N_c \le N_p Nc≤Np:
- 计算量: 优化变量的数量直接由 N c N_c Nc 决定。较小的 N c N_c Nc 可以显著减少优化问题的复杂度,加快求解速度。如果 N c = N p N_c = N_p Nc=Np,则优化变量会很多。
- 性能与鲁棒性: 实践表明,很多情况下,不需要对整个预测时域内的所有控制输入都进行精细优化。只优化前面少数几步的控制输入(即较小的 N c N_c Nc),然后在 N c N_c Nc 之后假设控制输入保持不变或按简单规律延续,往往也能获得很好的控制效果,并且对模型不确定性的鲁棒性可能更好。因为远期的控制决策对当前影响较小,且依赖于更不可靠的远期预测。
- 滚动时域特性: 由于MPC采用滚动时域策略,只执行第一个控制输入,然后在下一时刻重新优化,所以并不强求一次性计算出非常长期的精确控制序列。
-
答案:增大权重矩阵 R \mathbf{R} R。
R \mathbf{R} R 是用来惩罚控制输入增量 Δ u \Delta u Δu (即加速度的变化) 的。增大 R \mathbf{R} R 会使得MPC在优化时更倾向于选择那些加速度变化较小的控制序列,从而使驾驶感觉更平顺、更舒适。 Q \mathbf{Q} Q 是惩罚状态/输出跟踪误差的。 -
答案:D. 未建模的外部随机扰动的大小
MPC通过其滚动时域和反馈校正机制,能够对未建模扰动产生一定的鲁棒性(即在扰动发生后进行补偿),但它不能直接将“未建模的随机扰动的大小”作为优化问题中的一个显式约束来处理,因为这些扰动本质上是不可预测或难以精确量化的。A, B, C 都是MPC可以显式处理的常见约束类型。 -
答案:
-
问题1:距离总是比 d s a f e d_{safe} dsafe 小一点(稳态误差或跟踪不准):
- 可能原因与调整:
- Q \mathbf{Q} Q 中对应 d r e l d_{rel} drel 误差的权重 ( q d _ r e l q_{d\_rel} qd_rel) 可能偏小: 这使得MPC对距离误差的容忍度较高。可以尝试增大 q d _ r e l q_{d\_rel} qd_rel,让MPC更重视减小距离跟踪误差。
- 模型不准确: 如果车辆模型(特别是与阻力相关的部分)与实际情况偏差较大,可能导致稳态误差。需要回顾和改进Day 2的模型。
- d s a f e d_{safe} dsafe 的计算或参考设置: 确保 d s a f e d_{safe} dsafe 的计算是准确的,并且在代价函数中正确地作为 d r e l d_{rel} drel 的参考。如果 d s a f e d_{safe} dsafe 本身依赖于 v e g o v_{ego} vego,需要确认这个依赖关系在参考值设定中是否得到妥善处理。
- 积分作用缺失(如果适用): 某些MPC实现中,为了消除稳态误差,可能会引入增量式控制或者在状态中加入积分项。如果当前MPC结构没有这类机制,可能会存在静差。
- 可能原因与调整:
-
问题2:减速时有点突兀(舒适性差):
- 可能原因与调整:
- R \mathbf{R} R 中对应控制增量 Δ u \Delta u Δu 的权重 ( r Δ u r_{\Delta u} rΔu) 可能偏小: 这使得MPC允许较大的加速度变化。可以尝试增大 r Δ u r_{\Delta u} rΔu,以惩罚剧烈的加速度变化,使减速过程更平缓。
- 控制输入变化率约束 ( Δ u m a x \Delta u_{max} Δumax) 设置过大: 检查约束 Δ u m i n ≤ u ( k + j ∣ k ) − u ( k + j − 1 ∣ k ) ≤ Δ u m a x \Delta u_{min} \le u(k+j|k) - u(k+j-1|k) \le \Delta u_{max} Δumin≤u(k+j∣k)−u(k+j−1∣k)≤Δumax 是否设置得过于宽松。可以尝试减小 Δ u m a x \Delta u_{max} Δumax 的绝对值(对于减速,是负的 Δ u \Delta u Δu)。
- 预测时域 N p N_p Np 可能偏短: 如果 N p N_p Np 太短,MPC可能“看得不够远”,导致在需要减速时反应比较“急促”。可以尝试适当增大 N p N_p Np,让MPC有更长的规划窗口。
- Q \mathbf{Q} Q 中 q d _ r e l q_{d\_rel} qd_rel 权重过大,而 R \mathbf{R} R 权重过小: 过于强调距离跟踪的精确性,可能会牺牲舒适性。需要在两者之间找到平衡。
- 可能原因与调整:
调整策略的先后顺序建议:
- 首先尝试调整权重 Q \mathbf{Q} Q 和 R \mathbf{R} R。比如,先稍微增大 q d _ r e l q_{d\_rel} qd_rel 看看能否改善距离跟踪,然后增大 r Δ u r_{\Delta u} rΔu 看看能否让减速平缓。这两个是影响性能最直接的参数。
- 如果调整权重效果不佳,再考虑检查和调整约束值,或者审视 N p N_p Np 是否合适。
- 最后,如果问题依然存在,可能需要回到模型层面,检查模型精度。
在调整时,最好一次只改一个或一类参数,观察效果,避免多个参数同时大幅度修改导致难以判断是哪个参数起了作用。
-
相关文章:
【MPC控制 - 从ACC到自动驾驶】3 MPC控制器设计原理与参数配置:打造ACC的“最强大脑”
【MPC控制 - 从ACC到自动驾驶】MPC控制器设计原理与参数配置:打造ACC的“最强大脑” 在Day 1,我们认识了ACC自适应巡航和MPC这位“深谋远虑的棋手”。Day 2,我们一起给汽车“画像”,建立了它的纵向动力学模型,并把它翻…...
Unity3D仿星露谷物语开发52之菜单页面
1、目标 创建菜单页面,可通过Esc键开启或关闭。 当把鼠标悬停在上面时它会高亮,然后当点击按钮时标签页会被选择。 2、 创建PauseMenuCanvas (1)创建Canvas 在Hierarchy -> PersistentScene -> UI下创建新的Cavans命名为…...

待定事项之存储数据
#### 部署云服务器  ### 部署云服务器完整步骤 1. **连接到云服务器** bash ssh root<服务器IP> 2. **创建项目目录结构** bash mkdir -p /var/www/three/study/待办事项 3. **克隆项目仓库** bash cd /var/www…...

电脑装的数据越多,会不会越重
在这个数字化飞速发展的时代,有一个看似荒诞却又引人深思的问题:电脑装的数据越多,会不会越重? 先来说说大家的普遍认知,我们通常认为数据只是一些虚拟的代码和信息,存放在电脑的硬盘或其他存储设备中&…...

君正Ingenic webRTC P2P库libyangpeerconnection7编程指南
概述 libyangpeerconnection7是一个实现P2P媒体传输/数据通道的一个轻量级的webRTC库,基于metaRTC7.0的传输模块构建,支持H264/H265视频编码,通过 P2P 连接为用户提供高效、低延迟的音视频和数据通信。 君正版libyangpeerconnection7可适用…...
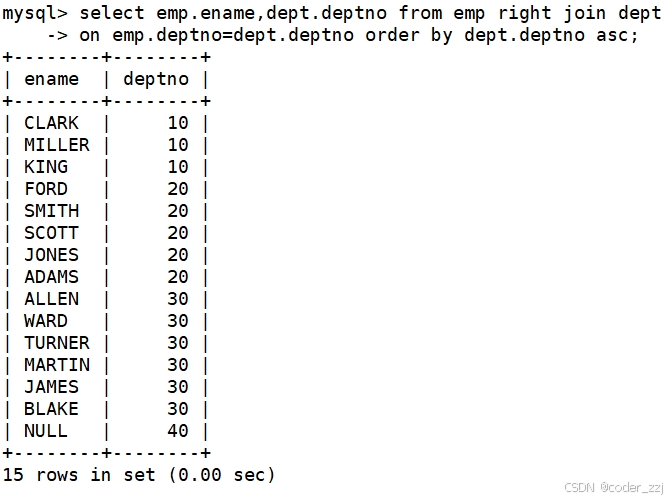
MySQL——复合查询表的内外连
目录 复合查询 回顾基本查询 多表查询 自连接 子查询 where 字句中使用子查询 单行子查询 多行子查询 多列子查询 from 字句中使用子查询 合并查询 实战OJ 查找所有员工入职时候的薪水情况 获取所有非manager的员工emp_no 获取所有员工当前的manager 表的内外…...

小米玄戒O1架构深度解析(一):十核异构设计与缓存层次详解
前言 这两天,小米的全新SOC玄戒O1横空出世,引发了科技数码圈的一次小地震,那么小米的这颗所谓的自研SOC,内部究竟有着什么不为人知的秘密呢?我们一起一探究竟。 目录 前言1 架构总览1.1 基本构成1.2 SLC缺席的原因探…...
)
Numba模块的用法(高性能计算)
文章目录 介绍核心装饰器与基础用法@jit(nopython=True):最常用的编译装饰器@njit的简写编译时指定类型签名并行加速(parallel=True)@cuda.jit: GPU 编程(CUDA)向量化函数(@vectorize)性能优化技巧调试与常见问题调试模式常见错误适用场景与局限性实例:加速蒙特卡洛模拟…...

Kafka自定义分区策略实战避坑指南
文章目录 概要代码示例小结 概要 kafka生产者发送消息默认根据总分区数和设置的key计算哈希取余数,key不变就默认存放在一个分区,没有key则随机数分区,明显默认的是最不好用的,那kafka也提供了一个轮询分区策略,我自己…...

PyTorch中cdist和sum函数使用示例详解
以下是PyTorch中cdist与sum函数的联合使用详解: 1. cdist函数解析 功能:计算两个张量间的成对距离矩阵 输入格式: X1:形状为(B, P, M)的张量X2:形状为(B, R, M)的张量p:距离类型(默认2表示欧式距离)输出:形状为(B, P, R)的距离矩阵,其中元素 d i j d_{ij} dij表示…...

[免费]微信小程序宠物医院管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序宠物医院管理系统(uni-appSpringBoot后端Vue管理端),分享下哈。 项目视频演示 【免费】微信小程序宠物医院管理系统(uni-appSpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibi…...

centos7.9使用docker-compose安装kafka
docker-compose配置文件 services:zookeeper:image: confluentinc/cp-zookeeper:7.0.1hostname: zookeepercontainer_name: zookeeperports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000kafka:image: confluentinc/cp-kafka:7.0…...
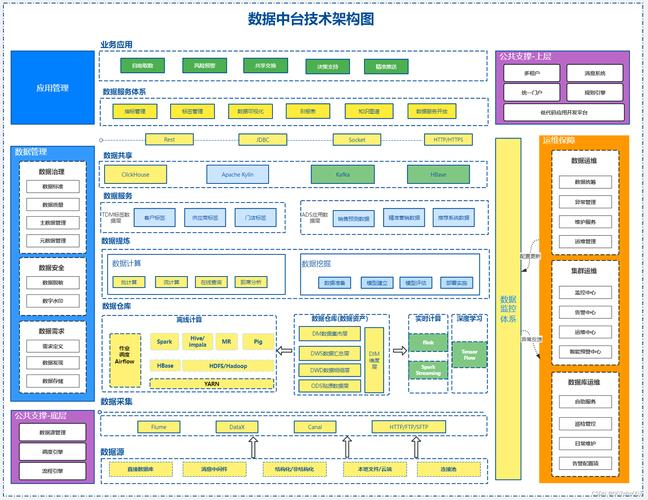
ETL 工具与数据中台的关系与区别
ETL 工具和数据中台作为数据处理领域的关键概念,虽然存在一定的关联,但二者有着明显的区别。本文将深入剖析 ETL 工具与数据中台之不同。 一、ETL 工具概述 ETL 是数据仓库技术中的核心技术之一,其全称为 Extract(抽取ÿ…...
SQLMesh Typed Macros:让SQL宏更强大、更安全、更易维护
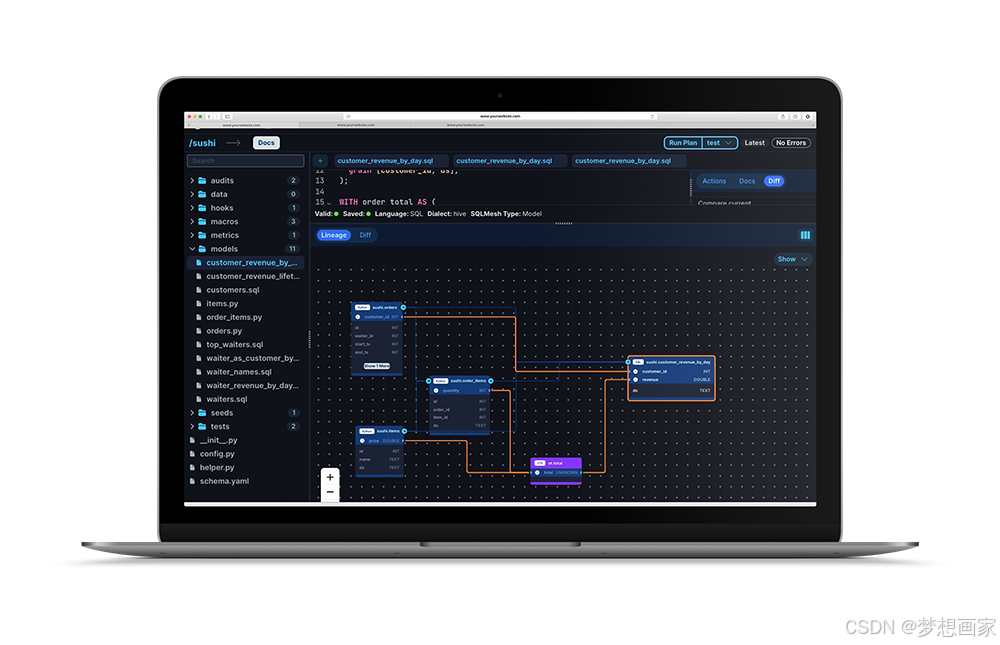
在SQL开发中,宏(Macros)是一种强大的工具,可以封装重复逻辑,提高代码复用性。然而,传统的SQL宏往往缺乏类型安全,容易导致运行时错误,且难以维护。SQLMesh 引入了 Typed Macros&…...
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法 flyfish 名字 Ulysses “Ulysses” 和 “奥德修斯(Odysseus)” 指的是同一人物,“Ulysses” 是 “Odysseus” 的拉丁化版本 《尤利西斯》(詹姆…...
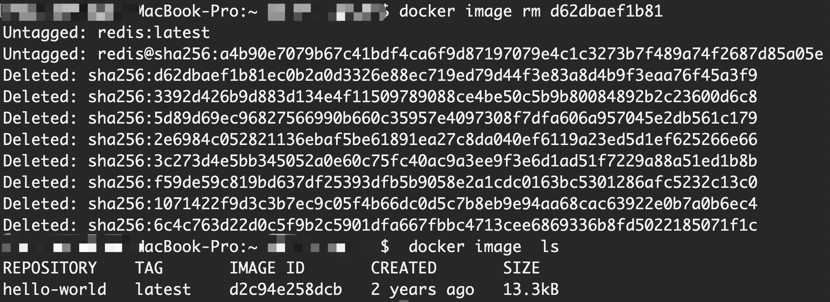
Docker 使用镜像[SpringBoot之Docker实战系列] - 第537篇
历史文章(文章累计530) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 《…...

解锁MCP:AI大模型的万能工具箱
摘要:MCP(Model Context Protocol,模型上下文协议)是由Anthropic开源发布的一项技术,旨在作为AI大模型与外部数据和工具之间沟通的“通用语言”。它通过标准化协议,让大模型能够自动调用外部工具完成任务&a…...
Error in beforeDestroy hook: “Error: [ElementForm]unpected width “
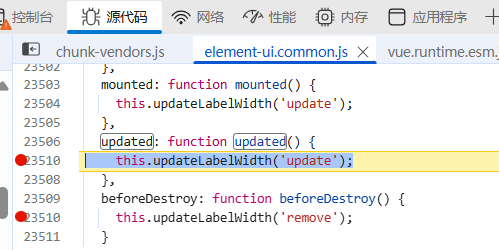
使用 element 的 form 时候报错: vue.runtime.esm.js:3065 Error: [ElementForm]unpected width at VueComponent.getLabelWidthIndex (element-ui.common.js:23268:1) at VueComponent.deregisterLabelWidth (element-ui.common.js:23281:1) at Vue…...

vscode包含工程文件路径
在 VSCode 中配置 includePath 以自动识别并包含上层目录及其所有子文件夹,需结合通配符和相对/绝对路径实现。以下是具体操作步骤及原理说明: 1. 使用通配符 ** 递归包含所有子目录 在 c_cpp_properties.json 的 includePath 中,${workspac…...
私有知识库 Coco AI 实战(七):摄入本地 PDF 文件
是否有些本地文件要检索?没问题。我们先对 PDF 类的文件进行处理,其他的文件往后稍。 Coco Server Token 创建一个 token 备用。 PDF_Reader 直接写个 python 程序解析 PDF 内容,上传到 Coco Server 就行了。还记得以前都是直接写入 Coco …...

GitLab 18.0 正式发布,15.0 将不再受技术支持,须升级【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

NtfsLookupAttributeByName函数分析之和Scb->AttributeName的关系
第一部分: VOID FindFirstIndexEntry ( IN PIRP_CONTEXT IrpContext, IN PSCB Scb, IN PVOID Value, IN OUT PINDEX_CONTEXT IndexContext ) { 。。。。。。 // // Lookup the attribute record from the Scb. // if (!NtfsLookupAt…...

STM32H7系列USART驱动区别解析 stm32h7xx_hal_usart.c与stm32h7xx_ll_usart.c的区别?
在STM32H7系列中,stm32h7xx_hal_usart.c和stm32h7xx_ll_usart.c是ST提供的两种不同层次的USART驱动程序,主要区别在于设计理念、抽象层次和使用场景: 1. HAL库(Hardware Abstraction Layer) 文件:stm32h7x…...

网络原理 | TCP与UDP协议的区别以及回显服务器的实现
目录 TCP与UDP协议的区别 基于 UDP 协议实现回显服务器 UDP Socket 编程常用 Api UDP 服务器 UDP 客户端 基于 TCP 协议实现回显服务器 TCP Socket 编程常用 Api TCP 服务器 TCP 客户端 TCP 服务端常见的 bug 客户端发送数据后,没有响应 服务器仅支持…...

IP动态伪装开关
IP动态伪装开关 在OpenWrt系统中,IP动态伪装(IP Masquerading)是一种网络地址转换(NAT)技术,用于在私有网络和公共网络之间转换IP地址。它通常用于允许多个设备共享单个公共IP地址访问互联网。以下是关于O…...
【Unity3D】将自动生成的脚本包含到C#工程文件中
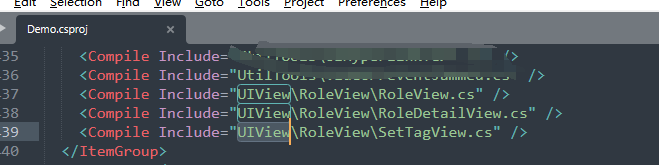
我们知道,在用C#开发中,通过vs编辑器新建的脚本,会自动包含到vs工程中,而通过外部创建,比如复制别的工程或代码创建的C#脚本不会包含到vs工程。 在我们的日常开发中,通常会自动创建C#脚本,特别…...

解决leetcode第3509题.最大化交错和为K的子序列乘积
3509.最大化交错和为K的子序列乘积 难度:困难 问题描述: 给你一个整数数组nums和两个整数k与limit,你的任务是找到一个非空的子序列,满足以下条件: 它的交错和等于k。 在乘积不超过limit的前提下,最大…...
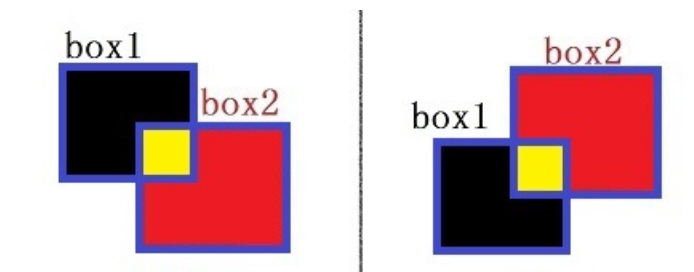
【Python 深度学习】1D~3D iou计算
一维iou 二维 import numpy as npdef iou_1d(set_a, set_b):# 获得集合A和B的边界 x1, x2 set_ay1, y2 set_b# 计算交集的上下界low max(x1,y1)high - min(x2, y2)# 计算交集if high - low < 0:inter 0else:inter high - low# 计算并集union (x2 -x1) (y2 - y1) - in…...
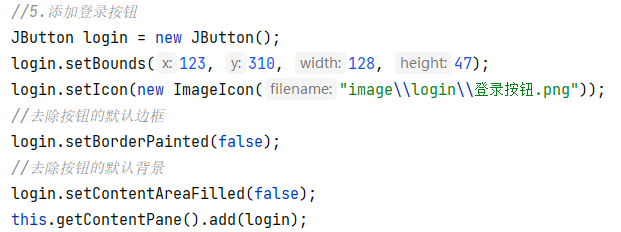
java23
1.美化界面 添加背景图片 所以我们添加背景图片要放在后面添加 添加图片边框 绝对路径: 相对(模块)路径: 第一个是绝对路径,第二个是相对路径,但是斜杠的方向不对 总结: 2.图片移动 先实现KeyListener接口…...

嵌入式工程师常用软件
1、 Git Git 是公司常用的版本管理工具,人人都要会。在线的 git 教程可以参考菜鸟教程: https://www.runoob.com/git/git-tutorial.html 电子书教程请在搜索栏搜索: git Git 教程很多,常用的命令如下,这些命令可…...