python打卡day38
知识点回顾:
- Dataset类的__getitem__和__len__方法(本质是python的特殊方法)
- Dataloader类
- minist手写数据集的了解
作业:了解下cifar数据集,尝试获取其中一张图片
在遇到大规模数据集时,显存常常无法一次性存储所有数据,所以需要使用分批训练的方法。为此,PyTorch提供了DataLoader类,该类可以自动将数据集切分为多个批次batch,并支持多线程加载数据。此外,还存在Dataset类,该类可以定义数据集的读取方式和预处理方式,均继承自torch.utils.data
- DataLoader类:决定数据如何加载(批量大小batch_size和是否打乱数据顺序shuffle=True/False)
- Dataset类:告诉程序去哪里找数据,如何读取单个样本,以及如何预处理(数据路径和预处理transform)
torch.utils.data.Dataset是一个抽象基类,所有数据集都需要继承Dataset并定义两个核心方法:
- __len__():返回数据集的样本总数
- __getitem__(idx):根据索引idx返回对应样本的数据和标签
__getitem__和__len__ 是类的特殊方法(也叫魔术方法 ),它们不是像普通函数那样直接使用,而是需要在自定义类中进行定义,来赋予类特定的行为,举个例子:
class MyList:def __init__(self):self.data = [10, 20, 30, 40, 50]def __getitem__(self, idx):return self.data[idx]def __len__(self):return len(self.data) # 创建类的实例
my_list_obj = MyList()
# 此时可以使用索引访问元素,这会自动调用__getitem__方法
print(my_list_obj[2]) # 输出:30
# 使用len()函数获取元素数量,这会自动调用__len__方法
print(len(my_list_obj)) # 输出:5DataLoader类就更好理解了,使用DataLoader类的正确流程是先通过Dataset类定义数据的读取方式和预处理,再通过DataLoader设定批次大小等参数进行加载,以一个自定义数据集举个例子
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self, data_path, transform=None):self.data = [...] # 加载数据列表(如文件路径列表)self.transform = transform # 预处理操作def __len__(self):return len(self.data)def __getitem__(self, idx):# 读取单个样本(如从文件路径加载图像)sample = self.load_sample(self.data[idx]) if self.transform is not None:sample = self.transform(sample) # 应用预处理return sample, label # 返回样本和标签# 先创建Dataset实例
dataset = MyDataset(data_path="./data", transform=my_transform) # 假设前面定义了预处理操作transform# 再创建DataLoader实例
dataloader = DataLoader(dataset,batch_size=32, # 批次大小shuffle=True, # 打乱数据顺序num_workers=4 # 使用4个线程加载数据
)为了引入这些概念,我们现在接触一个新的而且非常经典的数据集:MNIST手写数字数据集。该数据集包含60000张训练图片和10000张测试图片,每张图片大小为28*28像素,共包含10个类别。因为每个数据的维度比较小,所以既可以视为结构化数据,用机器学习、MLP训练,也可以视为图像数据,用卷积神经网络训练
1、用到的库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt# 设置随机种子,确保结果可复现
torch.manual_seed(42)torchvision
├── datasets # 视觉数据集(如 MNIST、CIFAR)
├── transforms # 视觉数据预处理(如裁剪、翻转、归一化)
├── models # 预训练模型(如 ResNet、YOLO)
├── utils # 视觉工具函数(如目标检测后处理)
└── io # 图像/视频 IO 操作
2、定义预处理操作transform
这里用 torchvision 的 transforms 模块,提供了一系列常用的图像预处理操作
# 数据预处理,该写法非常类似于管道pipeline
# 先归一化,再标准化
transform = transforms.Compose([ # compose用于将多个数据预处理操作按顺序组合成一个整体,参数是一个列表,每个操作是一个元素transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # 标准化,MNIST数据集的均值和标准差,这个值很出名,所以直接使用# 参数格式是元组 (mean_channel1, mean_channel2, ...),由于MNIST是单通道(灰度图),这里只有一个值
])3、创建dataset实例
torchvision 的 datasets 模块已经预定义了许多常见的数据集,实例化一个数据类就是创建dataset对象了
# 加载MNIST数据集,如果没有会自动下载,pytorch的思路是,数据在加载阶段就预处理结束
# 训练集
train_dataset = datasets.MNIST(root='./data', # 数据存储路径train=True,download=True, # 如果目录下数据不存在则自动下载transform=transform # 应用预处理
)# 测试集
test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)3、创建dataloader实例
# 创建数据加载器
train_loader = DataLoader(train_dataset,batch_size=64, # 每个批次64张图片,一般是2的幂次方,这与GPU的计算效率有关shuffle=True # 随机打乱数据
)test_loader = DataLoader(test_dataset,batch_size=1000 # 每个批次1000张图片# shuffle=False # 测试时不需要打乱数据
)过程就是定义预处理transform ➡ 实例化一个数据集类(创建dataset实例)➡ 创建数据加载器(创建dataloader实例)➡ 后续操作
作业:了解下cifar数据集,尝试获取其中一张图片
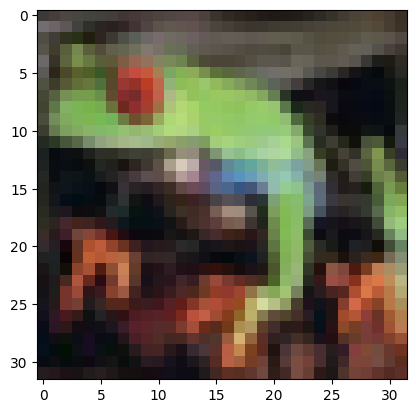
cifar-10的图片就是32*32的彩色图,那就存在RGB三个通道上不同的灰度图,分别标准化和反标准化
import matplotlib.pyplot as plt
import numpy as np
import torch
from torchvision import datasets, transforms# 设置中文字体
plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei']
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# 定义CIFAR-10的均值和标准差
cifar_mean = (0.4914, 0.4822, 0.4465)
cifar_std = (0.2470, 0.2435, 0.2616)# 定义预处理操作
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(cifar_mean, cifar_std)
])# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)# CIFAR-10的类别标签
classes = ('飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车')# 随机选择一个样本
index = np.random.randint(0, len(train_dataset))
image, label = train_dataset[index]# 反标准化操作 (针对3通道图像)
image = image.clone() # 避免修改原始数据
for i in range(3): # 对RGB三个通道分别反标准化image[i] = image[i] * cifar_std[i] + cifar_mean[i]# 转换为numpy并调整维度 (PyTorch: [C,H,W] → Matplotlib: [H,W,C])
image = np.transpose(image.numpy(), (1, 2, 0))# 显示图像
plt.figure(figsize=(5, 5))
plt.imshow(image)
plt.title(f'随机抽取的样本 - 标签: {classes[label]}')
plt.axis('off')
plt.show()
最后输出图片很模糊,可能因为数据集本身分辨率就不高,plot参数设置了但是中文还是没显示出来,很奇怪搞不懂
@浙大疏锦行
相关文章:
python打卡day38
Dataset和DataLoader 知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 在遇到大规模数据集时,…...

vLLM 核心技术 PagedAttention 原理详解
本文是 vLLM 系列文章的第二篇,介绍 vLLM 核心技术 PagedAttention 的设计理念与实现机制。 vLLM PagedAttention 论文精读视频可以在这里观看:https://www.bilibili.com/video/BV1GWjjzfE1b 往期文章: vLLM 快速部署指南 1 引言…...

rpm安装jenkins-2.452
rpm安装jenkins-2.452 一、下载和安装 1、Jenkins下载 版本2.452可用windows下载: https://mirrors.jenkins-ci.org/redhat-stable/jenkins-2.452.4-1.1.noarch.rpm 其他版本 wget https://pkg.jenkins.io/redhat-stable/jenkins-2.440.3-1.1.noarch.rpm 2、jenkins安装 $r…...
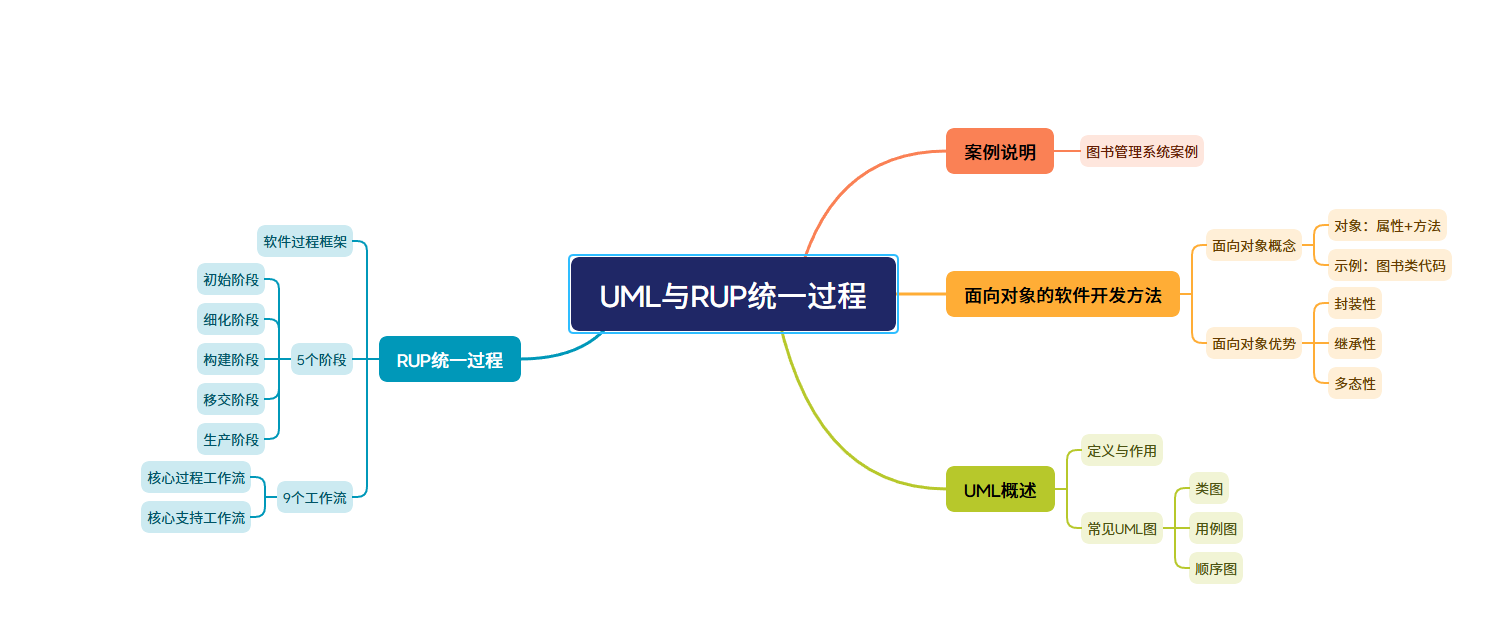
《软件工程》第 2 章 -UML 与 RUP 统一过程
在软件工程领域,UML(统一建模语言)与 RUP(统一过程)是进行面向对象软件开发的重要工具和方法。接下来,我们将深入探讨第 2 章的内容,通过案例和代码,帮助大家理解和掌握相关知识。 …...
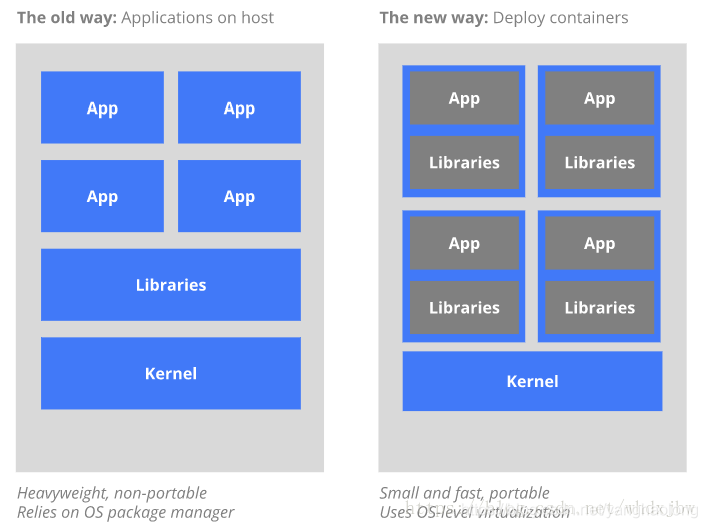
(转)Docker与K8S的区别
1 定义角度 Docker是一种开放源码的应用容器引擎,允许开发人员将其应用和依赖包打包成可移植的容器/镜像中;然后,发布到任何流行的 Linux 或 Windows 机器上,也能实现虚拟化。该容器完全使用沙箱机制,彼此之间没有任何…...

服务器数据迁移
写在前面:为满足业务需求,我们采购了一台新的高性能服务器,现在想把旧服务器中的用户文件以及conda环境等迁移到新服务器中去。为了保证迁移过程尽可能不出错,并且迁移后新的服务器可以直接使用,以下方案提供一个稳健、…...

VB.NET与SQL连接问题解决方案
1.基本连接步骤 使用SqlConnection、SqlCommand和SqlDataReader进行基础操作: vb.net Imports System.Data.SqlClient Public Sub ConnectToDatabase() Dim connectionString As String "ServermyServerAddress;DatabasemyDataBase;Integrated Security…...

商用密码 vs 普通密码:安全加密的核心区别
商用密码 vs 普通密码:安全加密的核心区别 一. 引言:密码的世界二. 什么是普通密码?三. 什么是商用密码?四. 普通密码 vs 商用密码:核心区别五. 选择合适的密码方案六. 结语 前言 肝文不易,点个免费的赞和…...
MYSQL中的分库分表及产生的分布式问题
分库分表是分布式数据库架构中常用的优化手段,用于解决单库单表数据量过大、性能瓶颈等问题。其核心思想是将数据分散到多个数据库(分库)或多个表(分表)中,以提升系统的吞吐量、查询性能和可扩展性。 一&am…...

拥塞控制算法cubic 和bbr
1. 背景 CUBIC 和 BBR 是两种用于网络流量控制的拥塞控制算法,广泛应用于传输中,本质上是用于提升网络速度、稳定性和效率的方案。CUBIC 和 BBR 在本质思想、设计目标和工作方式上存在很大的差异,以下是两者的详细对比。 1.1 CUBIC 提出者…...

投影机三色光源和单色光源实拍对比:一场视觉体验的终极较量
一、光源技术:从 “单色模拟” 到 “三色原生” 的进化 (一)单色光源:白光的 “色彩魔术” 单色光源投影机采用单一白光作为基础光源,通过LCD上出现色彩呈现颜色。这种技术路线的优势在于成本可控,早期被广…...
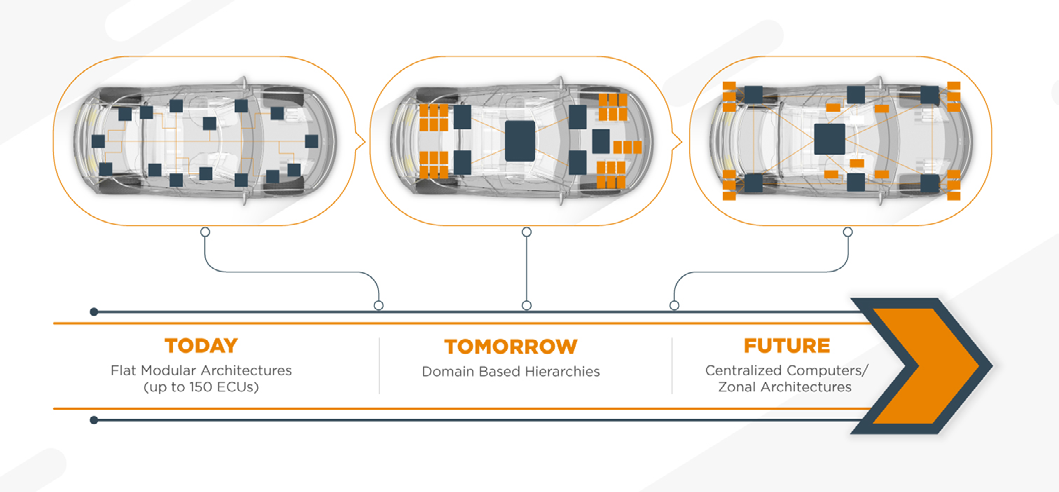
电子电气架构 --- 下一代汽车电子电气架构中的连接性
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...
笔记)
解析极限编程-拥抱变化(第2版)笔记
思维导图(转载) https://www.cnblogs.com/OneFri/p/17055449.html 极限编程(XP)是以人为核心、响应变化、持续交付价值的软件开发方法论 1.核心思想与价值观 XP 建立在 5 个核心价值观 之上: 价值观含义说明沟通团…...
手写Tomcat(一)
一、Tomcat简介 Tomcat 服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。 1.1 Tomcat基本架构 Servlet接口文件中定义的方法有以下…...

【机器学习基础】机器学习入门核心算法:支持向量机(SVM)
机器学习入门核心算法:支持向量机(SVM) 一、算法逻辑1.1 基本概念1.2 核心思想线性可分情况 二、算法原理与数学推导2.1 原始优化问题2.2 拉格朗日对偶2.3 对偶问题2.4 核函数技巧2.5 软间隔与松弛变量 三、模型评估3.1 评估指标3.2 交叉验证…...
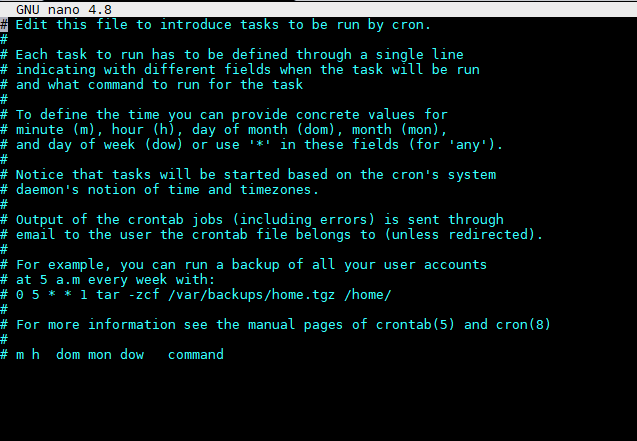
定时清理流媒体服务器录像自动化bash脚本
定时清理流媒体服务器保存录像文件夹 首先创建一个文件,解除读写权限 touch rm_videos.sh chmod 777 rm_videos.sh将内容复制进去,将对应文件夹等需要修改的内容,根据自己的实际需求进行修改 #!/bin/bash# 设置目标目录(修改为你的实际路…...

Logi鼠标切换桌面失效
Mac上习惯了滑屏切换桌面,所以Logi鼠标也定制了切换桌面的动作,有一天发现这个动作失效了,且只有切换桌面的动作失效。 发现Logi Options出现了这个提示,如图所示(具体原因未知,已配置不自动更新版本&…...

Go语言之匿名字段与组合 -《Go语言实战指南》
Go 没有传统的面向对象继承机制,但它通过“匿名字段(embedding)”实现了类似继承的组合方式,使得一个类型可以“继承”另一个类型的字段和方法。 一、什么是匿名字段 匿名字段就是在结构体中嵌套一个类型而不显式命名字段名。该字…...

Linux 进阶命令篇
一、Linux 系统软件安装命令 (一)Ubuntu 系统(基于 Debian) apt :是 Ubuntu 系统中常用的包管理工具,可以自动处理软件依赖关系。 安装命令格式 :sudo apt install 软件名 示例 :…...
)
OpenCV CUDA模块图像处理------颜色空间处理之拜耳模式去马赛克函数demosaicing()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于在 GPU 上执行拜耳图像(Bayer Pattern)的去马赛克操作(Demosaicing),将单通…...

2025年全国青少年信息素养大赛复赛C++集训(15):因子问题(题目及解析)
2025年全国青少年信息素养大赛复赛C集训(15):因子问题(题目及解析) 题目描述 任给两个正整数N、M,求一个最小的正整数a,使得a和(M-a)都是N的因子。 时间限制:10000 内存限制&…...

如何通过仿真软件优化丝杆升降机设计
通过仿真软件优化丝杆升降机设计可从多维度入手,以下为具体方法和分析: 一、基于有限元分析的结构优化 材料优化:通过ANSYS等软件建立三维模型,施加实际工况载荷(如轴向力、径向力、扭矩),计算…...
Vue3进阶教程:1.初次了解vue
1.初次了解vue vue文件目录和各个文件在这里不做介绍 此课程对针对有点vue基础的同学,或者看过我上部分vue的教程 与之前我的Vue教程不同的是,写法和内容有区别 真正的了解Vue3 1.创建vue组件 1.npm create vuelatest 2.取名 3.TS要选上 4.其他先不选 5…...

WordPress免费网站模板下载
大背景图免费wordpress建站模板 这个wordpress模板设计以简约和专业为主题,旨在为用户提供清晰、直观的浏览体验。以下是对其风格、布局和设计理念的详细介绍: 风格 简约现代:整体设计采用简约风格,使用了大量的白色和灰色调&am…...

【深度学习新浪潮】以图搜地点是如何实现的?(含大模型方案)
1. 以图搜地点的实现方式有哪些? 扫描手机照片中的截图并识别出位置信息,主要有以下几种实现方式: 通过照片元数据获取: 原理:现代智能手机拍摄的照片通常会包含Exif(Exchangeable Image File)元数据。Exif中除了有像素信息之外,还包含了光圈、快门、白平衡、ISO、焦距…...
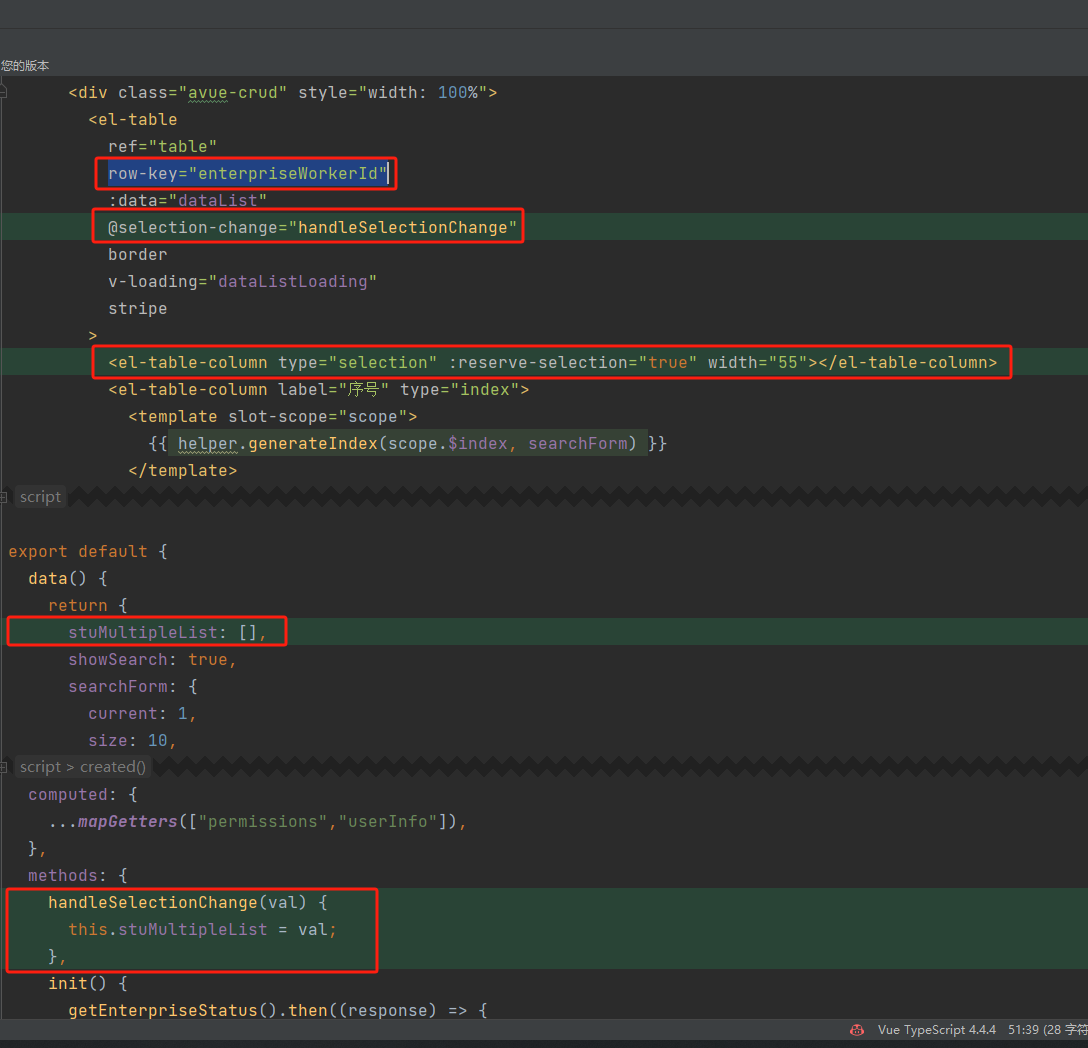
element的el-table翻页选中功能
el-table翻页选中功能 row-key"enterpriseWorkerId" selection-change"handleSelectionChange"<el-table-column type"selection" :reserve-selection"true" width"55"></el-table-column>stuMultipleList: []…...
Python打卡训练营学习记录Day38
知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torch.nn as nn import torch.opt…...
deepseek开源资料汇总
参考:DeepSeek“开源周”收官,连续五天到底都发布了什么? 目录 一、首日开源-FlashMLA 二、Day2 DeepEP 三、Day3 DeepGEMM 四、Day4 DualPipe & EPLB 五、Day5 3FS & Smallpond 总结 一、首日开源-FlashMLA 多头部潜在注意力机制&#x…...

CollUtil详解
CollUtil 是 Hutool 工具库中的一个工具类,专门用于操作集合(Collection)。它提供了许多静态方法,可以简化对集合的常见操作,例如判断集合是否为空、合并集合、过滤集合等。 以下是关于 CollUtil 的详细介绍和常用方法…...

Elasticsearch的运维
Elasticsearch 运维工作详解:从基础保障到性能优化 Elasticsearch(简称 ES)作为分布式搜索和分析引擎,其运维工作需要兼顾集群稳定性、性能效率及数据安全。以下从核心运维模块展开说明,结合实践场景提供可落地的方案…...