C++(初阶)(二十)——封装实现set和map
二十,封装实现set和map
- 二十,封装实现set和map
- 1,参数类型
- 2,比较方式
- 3,迭代器
- 3.1,普通迭代器
- 3.2,const迭代器
- 3.3,set_map的迭代器实现
- 4,插入和查找
- 5,特别的:map支持[]
- 6,完整代码
1,参数类型
本篇介绍模拟实现set和map的方法,由于set和map的底层是红黑树,所以需要先实现红黑树,此处的重点是封装上层的set和map。
感兴趣的可以看一下红黑树的实现:
链接: https://blog.csdn.net/2401_88328558/article/details/148177722?fromshare=blogdetail&sharetype=blogdetail&sharerId=148177722&sharerefer=PC&sharesource=2401_88328558&sharefrom=from_link
在之前实现的红黑树中,我们默认参数类型是pair<K, V>也就是k_value结构,而要实现泛型,就不知道参数到底是K还是pair<K, V>,所以我们将数据类型写作T。
template<class T>
struct RBTreeNode
{// 这⾥更新控制平衡也要加⼊parent指针T _data;RBTreeNode<T>* _left;RBTreeNode<T>* _right;RBTreeNode<T>* _parent;Colour _col;RBTreeNode(const T& data): _data(data), _left(nullptr), _right(nullptr), _parent(nullptr), _col(BLACK){}
};
2,比较方式
此时就出现了一个很明显的问题:在insert操作时,对数据的大小比较就失去了原本的意义。我们并不知道参数T到底是K还是pair<K, V>,因为pair<K, V>在比较大小时,默认⽀持的是key和value⼀起参与⽐较。
例如:
//我们之前比较大小的方式如下:
if (cur->_kv.first < kv.first)
{parent = cur;cur = cur->_right;
}
else if (cur->_kv.first > kv.first)
{parent = cur;cur = cur->_left;
}
显然此时的比较方式在参数T是K时,并不正确。那么如何改造?
在map和set层分别实现⼀个MapKeyOfT和SetKeyOfT的仿函数传给RBTree的KeyOfT,然后RBTree中通过KeyOfT仿函数取出T类型对象中的key,再进行比较。
部分参考代码:
//set
template<class K>
class set
{struct SetKeyOfT{const K& operator()(const K& key){return key;}};
private:// 第一个模板参数带const,保证key不能被修改RBTree<K, const K, SetKeyOfT> _t;
};//map
template<class K, class V>
class map
{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};
private://pair<>可以修改,其中的K不能修改,使用const修饰RBTree<K, pair<const K, V>, MapKeyOfT> _t;
};//红黑树
//实例化出对象kot
KeyOfT kot;//比较
if (kot(cur->_data) < kot(data))
{parent = cur;cur = cur->_right;
}
else if (kot(data) < kot(cur->_data))
{parent = cur;cur = cur->_left;
}
3,迭代器
3.1,普通迭代器
其中实现的难点就是:operator++和operator–
3.1.1,首先要知道++的本质是移动到下一个顺序位置。举一个简单的例子:
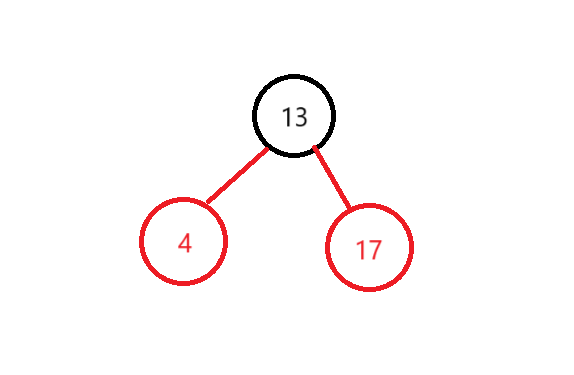
此时有一棵如图所示的红黑树,当前结点为4这个结点,那经过++后,所得到的就是13结点的位置,再次++得到17,再次++就走到null。
经过扩展分析得到结论:++的核心是不看全局只看局部。如果右子树不为空,找到右子树中序遍历的第一个结点。
3.1.2,如果右子树为空,那么可以分析到父亲结点也已经访问完成,原因是:我们访问的顺序是中序遍历(左根右)。此时需要找到祖先结点,先向上更新结点,结束特征是孩子结点是父亲结点左子树的那个位置,此时的父亲结点就是我们需要找到的祖先结点。但是如果parent为空,当前树遍历结束,将空作为end()。
3.1.3,控制end()位置的方式:找到孩子结点是父亲结点左子树的那个位置,如果不是,那么更新结点位置,最后如果更新到root(根)结点,那么就走到了空结点,将空结点作为end()结点
3.1.4,关于–是和++非常类似的,核心是访问顺序是右根左。
那是否是可以it=end(),对迭代器–遍历呢?
1),是可以的,但是实现时end()结点为空了,可以改为哨兵位(红色),也就是需要进行++操作,但是如果进行旋转,会增加维护哨兵位的成本。
2),不改变end(),依旧为空,其实只需要找到最右结点即可,因为我们的目标就是找到整棵树的末尾结点,但是我们此时是没有根结点进行遍历的,所以需要先定义根结点之后传过来即可。
普通迭代器参考代码:
template<class T, class Ref, class Ptr>
struct RBTreeIterator
{typedef RBTreeNode<T> Node;typedef RBTreeIterator<T, Ref, Ptr> Self;RBTreeIterator(Node* node, Node* root):_node(node), _root(root){}Node* _node;//--end()需要Node* _root;Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){//++就是走到下一个位置if (_node == nullptr){//如果是空树,直接返回即可;}else if (_node->_right){//2,如果右子树不为空//那么需要的就是右子树中序遍历的第一个结点(最左结点)Node* minleft = _node->_right;while (minleft->_left){minleft = minleft->_left;}_node = minleft;}else{//3,右子树为空//那么下一个结点就是当前结点的祖先,是孩子结点是父亲左结点的那个祖先//比如:18->25->28->30,如果cur=28,那么我们要找到的祖先结点就是30// 18// 30// 25// 28Node* cur = _node;Node* parent = cur->_parent;//但是注意特殊情况:cur就是根结点,并且没有右子树while (parent && cur == parent->_right){cur = parent;parent = cur->_parent;}//此时parent就是我们要找的祖先_node = parent;}return *this;}Self& operator--(){//++就是走到上一个位置,逻辑和++相反if (_node == nullptr){//1,如果_node为空//等价于--end(),也就是返回最右结点Node* maxright = _root;while (maxright && maxright->_right){maxright = maxright->_right;}_node = maxright;}else if (_node->_left){//2,左子树不为空//中序左子树最右结点Node* left_maxright = _node->_left;while (left_maxright->_right){left_maxright = left_maxright->_right;}_node = left_maxright;}else{//3,左子树为空//找到孩子是父亲右孩子的那个祖先(父亲),如果_node是25,需要找到18// 18// 30// 25Node* cur = _node;Node* parent = cur->_parent;while (parent && cur == parent->_left){cur = parent;parent = parent->_parent;}_node = parent;}return *this;}bool operator==(const Self& s) const{return _node == s._node;}bool operator!=(const Self& s) const{return _node != s._node;}
};template<class K, class T, class KeyOfT>
class RBTree
{typedef RBTreeNode<T> Node;
public:typedef RBTreeIterator<T, T&, T*> Iterator;Iterator Begin(){//begin()就是最左结点Node* minleft = _root;while (minleft->_left){minleft = minleft->_left;}return Iterator(minleft, _root);}Iterator End(){//end()就是最右结点的下一个结点,即空结点return Iterator(nullptr, _root);}
};
3.2,const迭代器
逻辑与普通迭代器没有区别,主要限制K不能修改,加const修饰即可。
template<class K, class T, class KeyOfT>
class RBTree
{typedef RBTreeNode<T> Node;
public:typedef RBTreeIterator<T, const T&, const T*> ConstIterator;ConstIterator Begin() const{//begin()就是最左结点Node* minleft = _root;while (minleft->_left){minleft = minleft->_left;}return ConstIterator(minleft, _root);}ConstIterator End() const{//end()就是最右结点的下一个结点,即空结点return ConstIterator(nullptr, _root);}
};
3.3,set_map的迭代器实现
//set
template<class K>
class set
{
public:typedef typename RBTree<K, const K, SetKeyOfT>::Iterator iterator;typedef typename RBTree<K, const K, SetKeyOfT>::ConstIterator const_iterator;iterator begin(){return _t.Begin();}iterator end(){return _t.End();}const_iterator begin() const{return _t.Begin();}const_iterator end() const{return _t.End();}
};//map
template<class K, class V>
class map
{
public:typedef typename RBTree<K, pair<const K, V>, MapKeyOfT>::Iterator iterator;typedef typename RBTree<K, pair<const K, V>, MapKeyOfT>::ConstIterator const_iterator;iterator begin(){return _t.Begin();}iterator end(){return _t.End();}const_iterator begin() const{return _t.Begin();}const_iterator end() const{return _t.End();}
};
4,插入和查找
依旧是对底层红黑树修改后,在set和map套一层壳。
//set
pair<iterator, bool> insert(const K& key)
{return _t.Insert(key);
}iterator find(const K& key)
{return _t.Find(key);
}//map
pair<iterator, bool> insert(const pair<K, V>& kv)
{return _t.Insert(kv);
}iterator find(const K& key)
{return _t.Find(key);
}
5,特别的:map支持[]
map要⽀持[]主要需要修改insert返回值⽀持,修改RBtree中的insert返回值为
pair<Iterator, bool> Insert(const T& data)
实例:
//return { Iterator(cur, _root), false };
//return { Iterator(newnode, _root), true };
//对于map需要重载[]
V& operator[](const K& key)
{pair<iterator, bool> ret = _t.Insert({ key, V() });iterator it = ret.first;return it->second;
}
6,完整代码
my_set_my_map
相关文章:
C++(初阶)(二十)——封装实现set和map
二十,封装实现set和map 二十,封装实现set和map1,参数类型2,比较方式3,迭代器3.1,普通迭代器3.2,const迭代器3.3,set_map的迭代器实现 4,插入和查找5,特别的&a…...
【MySQL】06.内置函数
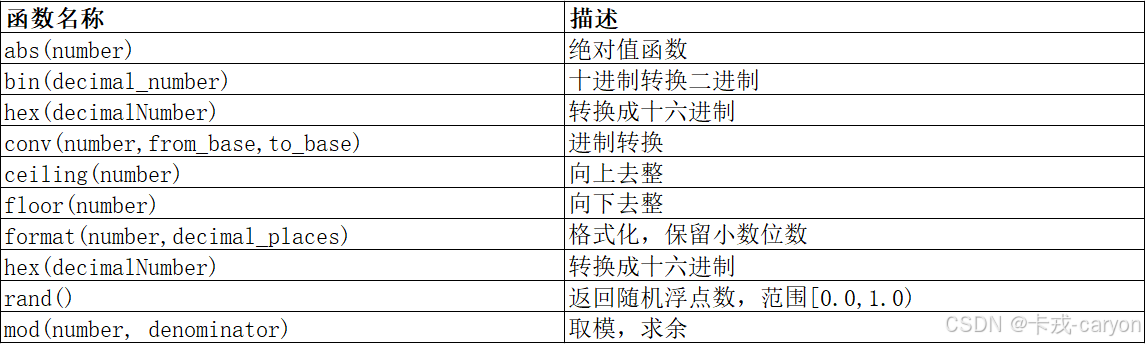
1. 聚合函数 -- 统计表中的人数 -- 使用 * 做统计,不受 NULL 影响 mysql> select count(*) 人数 from exam_result; -------- | 人数 | -------- | 5 | -------- 1 row in set (0.01 sec)-- 使用表达式做统计 mysql> select count(name) 人数 from ex…...
企业微信内部网页开发流程笔记
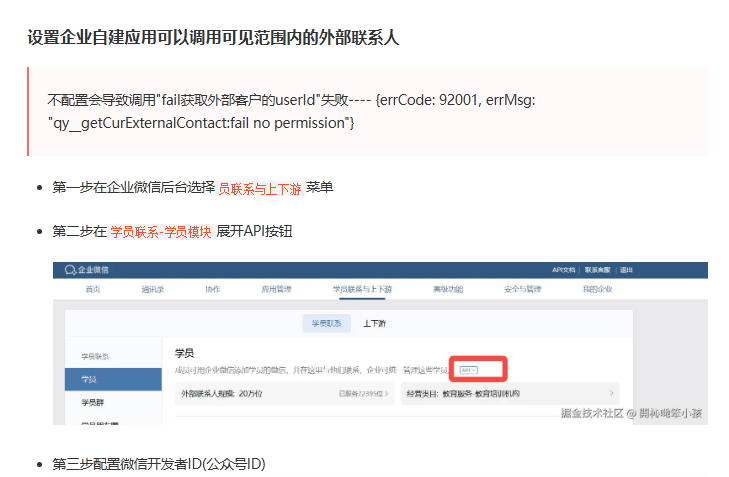
背景 基于ai实现企微侧边栏和工作台快速问答小助,需要h5开发,因为流程不清楚摸索半天,所以记录一下 一、网页授权登录 1. 配置步骤 1.1 设置可信域名 登录企业微信管理后台 进入"应用管理" > 选择开发的具体应用 > “网…...

智慧在线判题OJ系统项目总体,包含功能开发思路,内部中间件,已经部分知识点
目录 回顾一下xml文件怎么写 哪个地方使用了哪个技术 MyBatis-Plus-oj的表结构设计, 管理员登录功能 Swagger Apifox编辑 BCrypt 日志框架引入(slf4jlogback) nacos Swagger无法被所有微服务获取到修改的原因 身份认证三种方式: JWT(Json Web Json,一…...

【MySQL】2-MySQL索引P2-执行计划
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 有很多很多不足的地方,欢迎评论交流,感谢您的阅读和评论😄。 目录 EXPLAINexplain output 执行计划输出解释重点typ…...
云电脑显卡性能终极对决:ToDesk云电脑/顺网云/海马云,谁才是4K游戏之王?
一、引言 1.1 云电脑的算力革命 云电脑与传统PC的算力供给差异 传统PC的算力构建依赖用户一次性配置本地硬件,特别是CPU与显卡(GPU)。而在高性能计算和游戏图形渲染等任务中,GPU的能力往往成为决定体验上限的核心因素。随着游戏分…...

11 接口自动化-框架封装之统一请求封装和接口关联封装
文章目录 一、框架封装1、统一请求封装和路径处理2、接口关联封装 二、简单封装代码实现config.yml - 放入一些配置数据yaml_util.py - 处理 yaml 数据requests_util.py - 将请求封装在同一个方法中test_tag.py - 测试用例执行conftest.py - 会话之前清除数据 一、框架封装 1、…...

influxdb时序数据库
以下概念及操作均来自influxdb2 官方文档 InfluxDB2 is the platform purpose-built to collect, store, process and visualize time series data. Time series data is a sequence of data points indexed in time order. Data points typically consist of successive meas…...
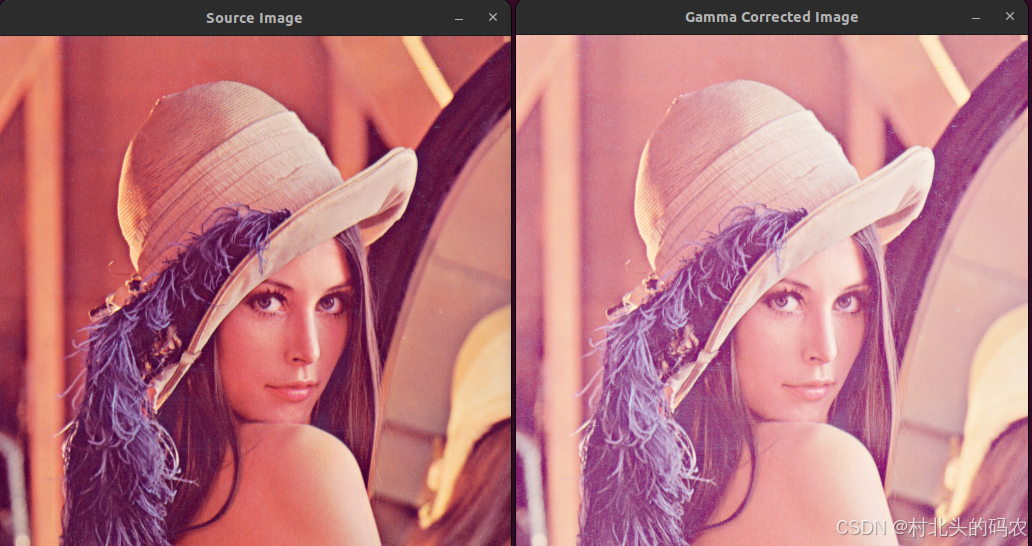
OpenCV CUDA模块图像处理------颜色空间处理之用于执行伽马校正(Gamma Correction)函数gammaCorrection()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::gammaCorrection 是 OpenCV 的 CUDA 模块中用于执行伽马校正(Gamma Correction)的一个函数。伽马校正通常用于…...

机器学习10-随机森林
随机森林学习笔记 一、随机森林简介 随机森林(Random Forest)是一种集成学习算法,基于决策树构建模型。它通过组合多个决策树的结果来提高模型的准确性和稳定性。随机森林的核心思想是利用“集成”的方式,将多个弱学习器组合成一…...
商品条形码查询接口如何用C#进行调用?
一、什么是商品条码查询接口? 1974年6月26日,美国俄亥俄州的一家超市首次使用商品条码完成结算,标志着商品条码正式进入商业应用领域。这项技术通过自动识别和数据采集,极大提升了零售行业的作业效率,减少了人工录入错…...

编译pg_duckdb步骤
1. 要求cmake的版本要高于3.17,可以通过下载最新的cmake的程序,然后设置.bash_profile的PATH环境变量,将最新的cmake的bin目录放到PATH环境变量的最前面 2. g的版本要支持c17标准,否则会报 error ‘invoke_result in namespace ‘…...

多模态大语言模型arxiv论文略读(九十一)
FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs ➡️ 论文标题:FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs ➡️ 论文作者:Haodong C…...

攻防世界 - MISCall
下载得到一个没有后缀的文件,把文件放到kali里面用file命令查看 发现是bzip2文件 解压 变成了.out文件 查看发现了一个压缩包 将其解压 发现存在.git目录和一个flag.txt,flag.txt是假的 恢复git隐藏文件 查看发现是将flag.txt中内容读取出来然后进行s…...
)
数据结构测试模拟题(2)
1、选择排序(输出过程) #include <iostream> using namespace std;int main() {int a[11]; // 用a[1]到a[10]来存储输入// 读取10个整数for(int i 1; i < 10; i) {cin >> a[i];}// 选择排序过程(只需9轮)for(int…...
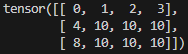
在PyTorch中,对于一个张量,如何快速为多个元素赋值相同的值
我们以“a torch.arange(12).reshape((3, -1))”为例,a里面现在是: 如果我们想让a的右下角的2行3列的元素都为10的话,可以如何快速实现呢? 我们可以用到索引和切片技术,执行如下的指令即可达到目标: a[1…...

苍穹外卖--Redis
1.Redis入门 1.1Redis简介 Redis是一个基于内存的key-value结果数据库 基于内存存储,读写性能高 适合存储热点数据(热点商品、资讯、新闻) 企业应用广泛 Redis的Windows版属于绿色软件,直接解压即可使用,解压后目录结构如下:…...

C++ 条件变量虚假唤醒问题的解决
在 C 中,std::condition_variable 的 wait 和 wait_for 方法除了可以传入一个锁(std::unique_lock),还可以传入一个谓词函数(函数或可调用对象)。这个谓词的作用是让条件变量在特定的条件满足时才退出等待。…...
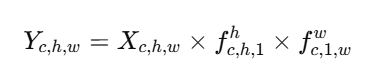
深度学习————注意力机制模块
关于注意力机制我自己的一点理解:建立各个维度数据之间的关系,就是对已经处理为特征图的数据,将其他影响因素去除(比如通道注意力,就将空间部分的影响因素消除或者减到极小)再对特征图进行以此特征提取 以此…...

openssl 使用生成key pem
好的,以下是完整的步骤,帮助你在 Windows 系统中使用 OpenSSL 生成私钥(key)和 PEM 文件。假设你的 openssl.cnf 配置文件位于桌面。 步骤 1:打开命令提示符 按 Win R 键,打开“运行”对话框。输入 cmd&…...

python:基础爬虫、搭建简易网站
一、基础爬虫代码: # 导包 import requests # 从指定网址爬取数据 response requests.get("http://192.168.34.57:8080") print(response) # 获取数据 print(response.text)二、使用FastAPI快速搭建网站: # TODO FastAPI 是一个现代化、快速…...
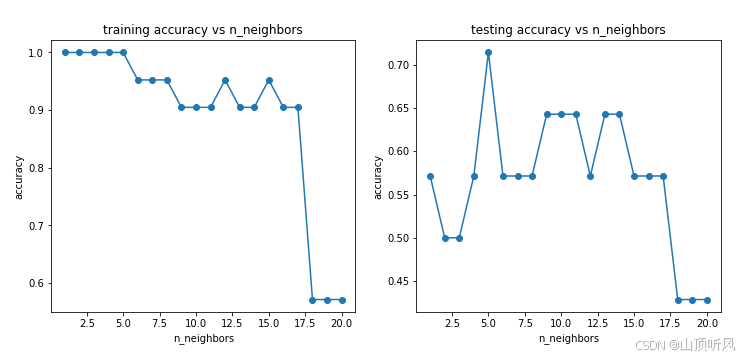
好坏质检分类实战(异常数据检测、降维、KNN模型分类、混淆矩阵进行模型评估)
任务 好坏质检分类实战 task: 1、基于 data_class_raw.csv 数据,根据高斯分布概率密度函数,寻找异常点并剔除 2、基于 data_class_processed.csv 数据,进行 PCA 处理,确定重要数据维度及成分 3、完成数据分离,数据分离…...

链表:数据结构的灵动舞者
在数据结构的舞台之上,链表以它灵动的身姿演绎着数据的精彩故事。与顺序表的规整有序不同,链表展现出了别样的灵活性与独特魅力。今天,就让我们一同走进链表的世界,去领略它的定义、结构、操作,对比它与顺序表的优缺点…...
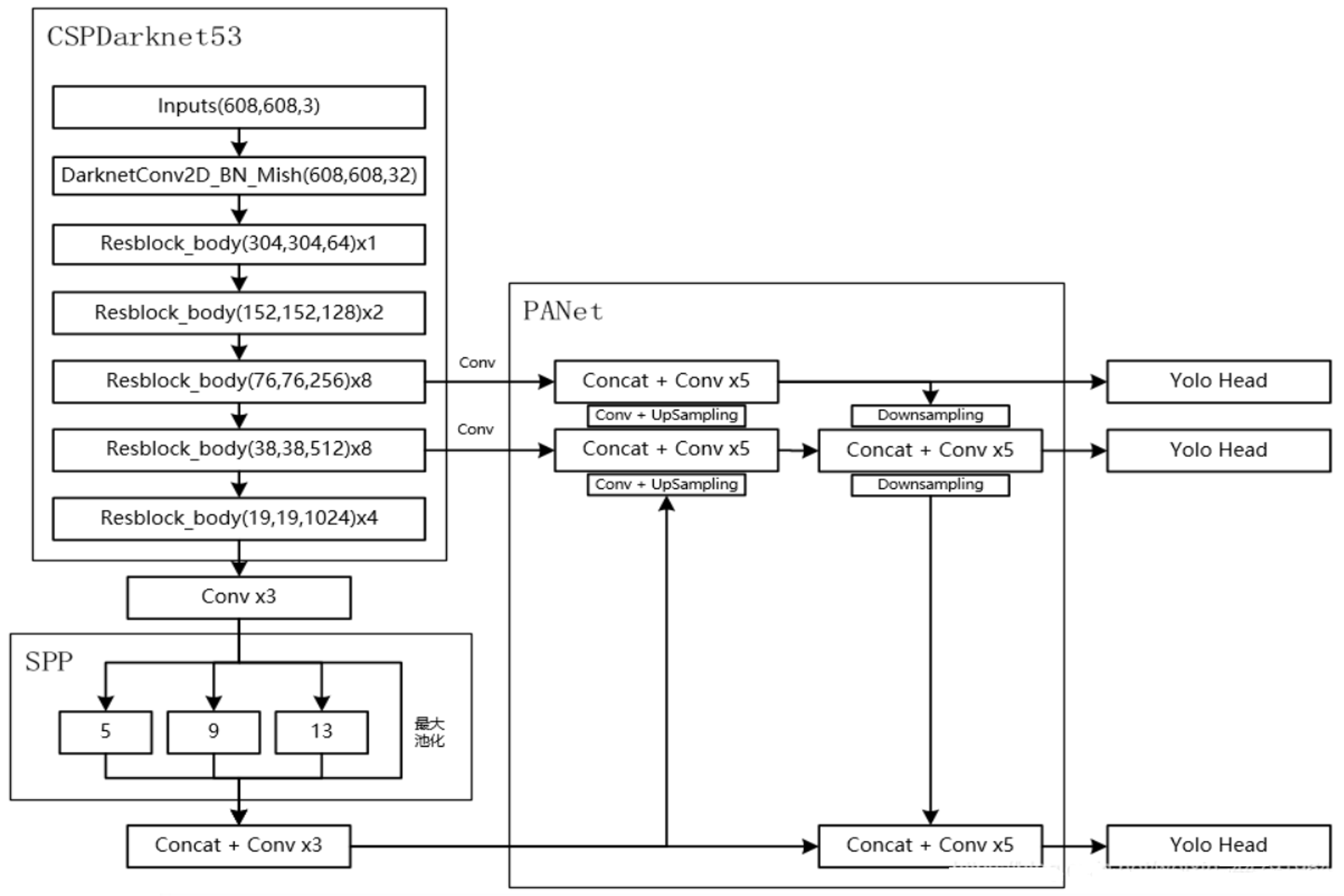
YOLOv4:目标检测的新标杆
引言 YOLO(You Only Look Once)系列作为目标检测领域的经典算法,以其高效的检测速度和良好的准确率闻名。2020年推出的YOLOv4在保持YOLO系列高速检测特点的同时,通过引入多项创新技术,将检测性能提升到了新高度。本文将详细介绍YOLOv4的核心…...
)
PyTorch 2.1新特性:TorchDynamo如何实现30%训练加速(原理+自定义编译器开发)
一、PyTorch 2.1动态编译架构演进 PyTorch 2.1的发布标志着深度学习框架进入动态编译新纪元。其核心创新点TorchDynamo通过字节码即时重写技术,将Python动态性与静态图优化完美结合。相较于传统JIT方案,TorchDynamo实现了零侵入式加速——开发者只需添加…...
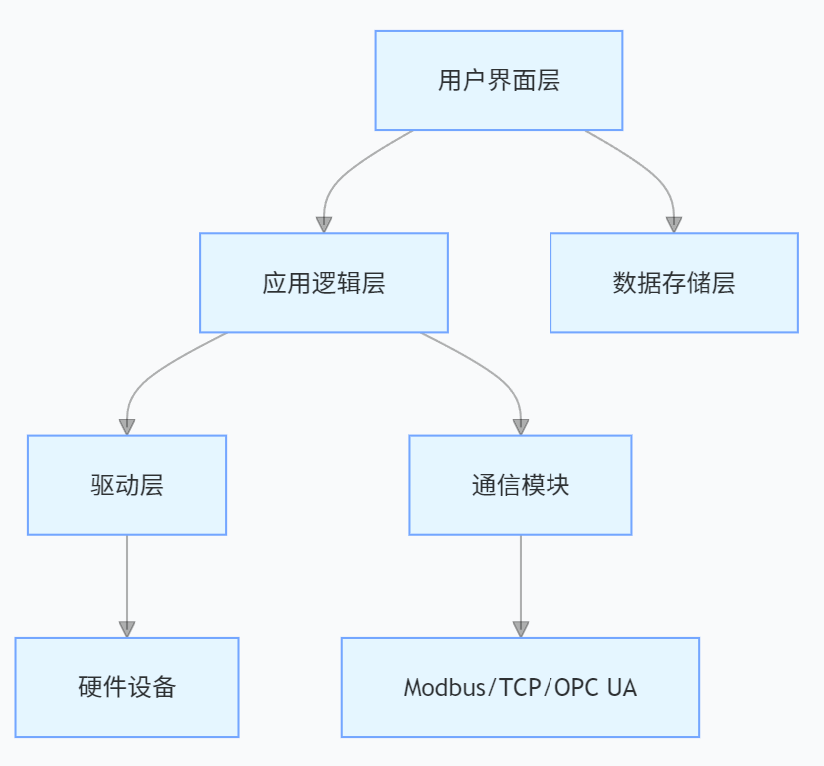
LabVIEW通用测控平台设计
基于 LabVIEW 图形化编程环境,设计了一套适用于工业自动化、科研测试领域的通用测控平台。通过整合研华、NI等品牌硬件,实现多类型数据采集、实时控制及可视化管理。平台采用模块化架构,支持硬件灵活扩展,解决了传统测控系统开发周…...

【机器学习基础】机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN)
机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN) 一、算法逻辑1.1 基本概念1.2 关键要素距离度量K值选择 二、算法原理与数学推导2.1 分类任务2.2 回归任务2.3 时间复杂度分析 三、模型评估3.1 评估指标3.2 交叉验证调参 四、应用…...
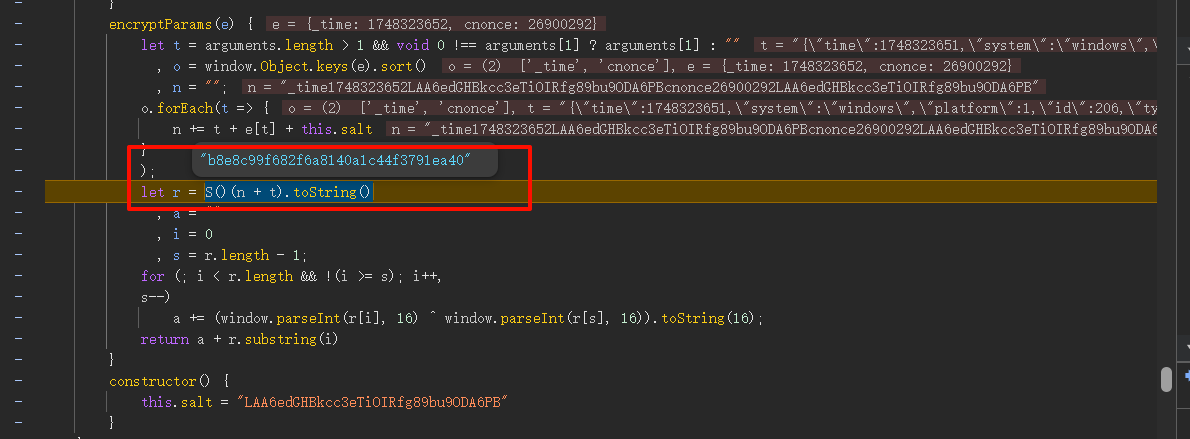
FastMoss 国际电商Tiktok数据分析 JS 逆向 | MD5加密
1.目标 目标网址:https://www.fastmoss.com/zh/e-commerce/saleslist 切换周榜出现目标请求 只有请求头fm-sign签名加密 2.逆向分析 直接搜fm-sign 可以看到 i["fm-sign"] A 进入encryptParams方法 里面有个S()方法加密,是MD5加密 3.代…...

Redis分布式缓存核心架构全解析:持久化、高可用与分片实战
一、持久化机制:数据安全双引擎 1.1 RDB与AOF的架构设计 Redis通过RDB(快照持久化)和AOF(日志持久化)两大机制实现数据持久化。 • RDB架构:采用COW(写时复制)技术,主进程…...
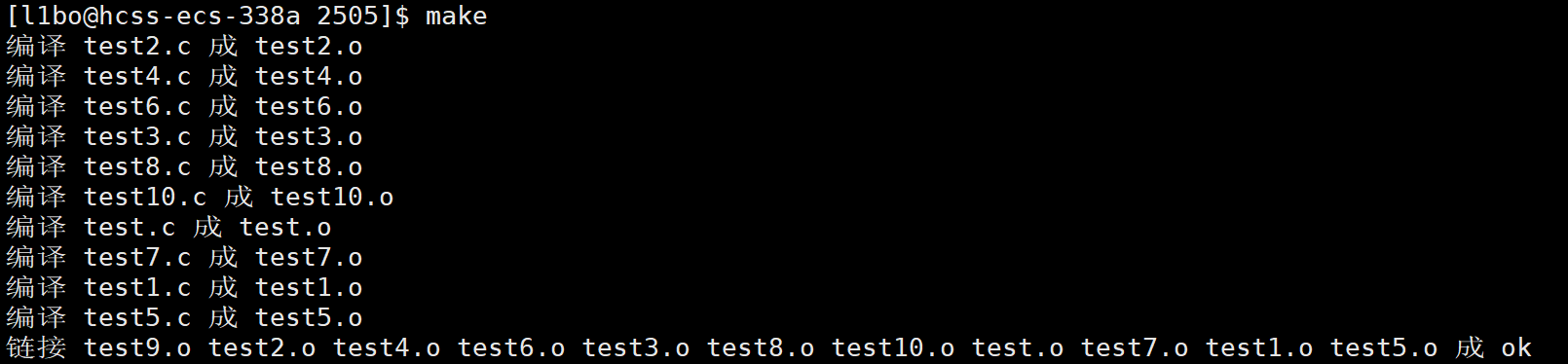
【Linux】基础开发工具(下)
文章目录 一、自动化构建工具1. 什么是 make 和 Makefile?2. 如何自动化构建可执行程序?3. Makefile 的核心思想4. 如何清理可执行文件?5. make 的工作原理5.1 make 的执行顺序5.2 为什么 make 要检查文件是否更新?5.2.1 避免重复…...