Java开发经验——阿里巴巴编码规范实践解析4
摘要
本文主要介绍了阿里巴巴编码规范中关于日志处理的相关实践解析。强调了使用日志框架(如 SLF4J、JCL)而非直接使用日志系统(如 Log4j、Logback)的 API 的重要性,包括解耦日志实现、统一日志调用方式等好处。同时,还涉及了日志文件的保存规范、扩展日志的命名方式、日志输出时字符串拼接的占位符方式、日志级别的开关判断以及避免重复打印日志等多方面的内容,旨在提升日志系统的可维护性、性能和合规性。

1. 【强制】应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架(SLF4J、JCL—Jakarta Commons Logging)中的 API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
说明:日志框架(SLF4J、JCL--Jakarta Commons Logging)的使用方式(推荐使用 SLF4J)
使用 SLF4J:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Test.class);使用 JCL:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
private static final Log log = LogFactory.getLog(Test.class);这是面向接口编程思想在日志系统中的体现,使用**门面模式(Facade Pattern)**的日志框架如 SLF4J,可以将日志 API 与具体实现解耦。主要好处包括:
1.1. ✅ 解耦日志实现
- 直接使用
Log4j或Logback,代码就“绑死”在某个实现上。 - 如果以后想从 Log4j 切换为 Logback,需要大规模修改代码。
- 使用 SLF4J 接口编程,只需要更换依赖包即可,无需改业务代码。
1.2. ✅ 日志调用方式统一
- 所有类都用统一的 API,比如
LoggerFactory.getLogger(...)。 - 日志格式、等级统一,便于维护和查错。
1.3. ❌ 错误示例(直接使用 Log4j)
import org.apache.log4j.Logger;public class UserService {private static final Logger logger = Logger.getLogger(UserService.class);public void createUser() {logger.info("创建用户...");}
}如果以后换用 Logback,就得改成用 ch.qos.logback 的类,改动大。
1.4. ✅ 正确示例(使用 SLF4J)
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class UserService {private static final Logger logger = LoggerFactory.getLogger(UserService.class);public void createUser() {logger.info("创建用户...");}
}🔧 此时你在 pom.xml 中引入:
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId>
</dependency>
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId>
</dependency>将来你想换成 Log4j 也很简单,只需换 Log4j 的绑定依赖即可,无需改业务代码。
2. 【强制】日志文件至少保存 15 天,因为有些异常具备以“周”为频次发生的特点。对于当天日志,以“应用名.log”来保存,保存在/{统一目录}/{应用名}/logs/目录下,过往日志格式为:{logname}.log.{保存日期},日期格式:yyyy-MM-dd
2.1. 日志保留周期要求
“日志文件至少保存 15 天”
- 有些问题并非每天都发生,而是按周循环出现(如每周一的定时任务、周末批处理等);
- 如果日志只保留几天,可能无法回溯历史问题;
- 因此,强制日志保留至少 15 天,以便问题排查。
2.2. 当前日志文件
- 命名规则:
应用名.log - 存储路径:
/{统一目录}/{应用名}/logs/
例如:
/data/apps/user-service/logs/user-service.log2.3. 历史日志文件
- 命名规则:
{logname}.log.{保存日期} - 日期格式:
yyyy-MM-dd
例如:
/data/apps/user-service/logs/user-service.log.2025-05-27
/data/apps/user-service/logs/user-service.log.2025-05-262.4. Logback 配置(以 Spring Boot 工程为例)
以下是一个使用 SLF4J + Logback,满足该规范的配置片段:
2.4.1. logback-spring.xml
<configuration><!-- 定义日志目录和应用名 --><property name="LOG_HOME" value="/data/apps/user-service/logs" /><property name="APP_NAME" value="user-service" /><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 当前日志文件 --><file>${LOG_HOME}/${APP_NAME}.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 过往日志文件命名 --><fileNamePattern>${LOG_HOME}/${APP_NAME}.log.%d{yyyy-MM-dd}</fileNamePattern><!-- 保留历史日志天数 --><maxHistory>15</maxHistory></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern></encoder></appender><root level="INFO"><appender-ref ref="FILE"/></root></configuration>3. 【强制】根据国家法律,网络运行状态、网络安全事件、个人敏感信息操作等相关记录,留存的日志不少于六个月,并且进行网络多机备份。
3.1. 合规性要求(《网络安全法》第21条等)
国家法律要求对“网络运行、网络安全事件、用户操作敏感数据”等日志至少留存6个月。
必须记录以下行为,并保留:
- 网络运行状态(服务启停、接口调用、异常状态)
- 网络安全事件(攻击、入侵、漏洞、越权访问)
- 个人敏感信息操作(查看、导出、修改用户敏感数据等)
⚠️ 否则将面临罚款、吊销许可证等法律责任。
3.2. 留存时间:不少于6个月
- 日志存储不能只保留15天或一个月,而要长期归档保存6个月以上。
3.3. 多机备份要求(防单点失败)
所谓“网络多机备份”,是指:
- 日志不仅保存在本机,还应同步到另一台机器或远程日志服务器;
- 防止机器损坏或系统故障导致日志丢失。
3.4. 如何实现这项规范?(示例方案)
方案一:本地持久 + 多机远程备份(推荐)
本地日志配置保留 180 天(Logback)
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_HOME}/${APP_NAME}.log.%d{yyyy-MM-dd}</fileNamePattern><maxHistory>180</maxHistory> <!-- 保留180天 -->
</rollingPolicy>使用 rsync / scp / 日志采集工具进行多机备份
- 定期同步本地日志到远程备份机(如每小时同步一次):
rsync -az /data/apps/user-service/logs/ logserver:/backup/user-service/或使用 ELK/EFK 等集中采集日志:
- Filebeat + Elasticsearch + Kibana
- Flume + HDFS
- Kafka + Logstash
方案二:Spring Boot + ELK 日志采集方案
- 使用 Filebeat 收集本地日志
- 发往 Logstash → Elasticsearch
- 设置 Elasticsearch 索引生命周期(ILM)策略,保留180天日志
- Kibana 可视化查询、安全审计
| 要求项 | 解释 | 实现方式 |
| 保留日志时间 ≥6个月 | 符合国家《网络安全法》《等级保护2.0》要求 | 日志文件保留180天或存入长期归档系统(如HDFS、ES) |
| 多机备份 | 避免日志因故障丢失 | rsync/rsyslog/Filebeat → 日志服务器 |
| 记录重点内容 | 网络运行、异常事件、敏感信息操作 | 通过埋点/日志拦截记录操作 |
4. 【强制】应用中的扩展日志(如打点、临时监控、访问日志等) 命名方式:appName_logType_logName.log。logType:日志类型,如 stats / monitor / access 等;logName:日志描述。这种命名的好处:通过文件名就可知道日志文件属于什么应用,什么类型,什么目的,也有利于归类查找。
说明:推荐对日志进行分类,将错误日志和业务日志分开放,便于开发人员查看,也便于通过日志对系统进行及时监控。
正例:mppserver 应用中单独监控时区转换异常,如:mppserver_monitor_timeZoneConvert.log
扩展日志必须使用统一规范的命名格式,以提高可读性、可分类性与可运维性。
4.1. 如何理解这条规则?
在实际开发中,我们的系统往往输出多种不同目的的日志,比如:
| 类型 | 示例内容 |
| 访问日志 | 用户访问接口的信息 |
| 监控日志 | 系统关键指标、性能监控等 |
| 打点日志 | 埋点数据、用户行为路径 |
| 业务操作日志 | 某个业务流程的处理记录 |
| 错误日志 | 异常堆栈、错误信息 |
这些日志如果都输出到一个文件中,就会:
- 不便查找
- 不利于自动监控
- 日志量爆炸,影响性能
解决办法:分类输出日志,并采用统一命名规范
命名规则:
appName_logType_logName.log| 部分 | 说明 | 示例 |
| appName | 应用名 |
|
| logType | 日志类型(如 access / stats / monitor) |
|
| logName | 日志内容描述(模块或业务名称) |
|
好处:
- 文件名一看就知道日志内容,方便开发 & 运维;
- 日志文件容易归类,便于定向排查、自动告警等;
- 可以设置不同的日志滚动策略与等级。
正例示例分析
mppserver_monitor_timeZoneConvert.log含义如下:
| 部分 | 含义 |
| mppserver | 应用名 |
| monitor | 日志类型:监控日志 |
| timeZoneConvert | 日志主题:时区转换相关 |
这个日志就可能记录了:
[INFO] 2025-05-27 10:00:01 时区转换失败,源=GMT+8,目标=UTC+1,用户ID=1234.2. 日志分类输出示例(以 Logback 为例)
logback-spring.xml 示例配置:
<property name="LOG_PATH" value="/data/apps/mppserver/logs"/><!-- 监控日志 -->
<appender name="MONITOR_TIMEZONE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_PATH}/mppserver_monitor_timeZoneConvert.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_PATH}/mppserver_monitor_timeZoneConvert.log.%d{yyyy-MM-dd}</fileNamePattern><maxHistory>15</maxHistory></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level - %msg%n</pattern></encoder>
</appender><!-- 访问日志 -->
<appender name="ACCESS_LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_PATH}/mppserver_access_gateway.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_PATH}/mppserver_access_gateway.log.%d{yyyy-MM-dd}</fileNamePattern><maxHistory>15</maxHistory></rollingPolicy><encoder><pattern>%msg%n</pattern></encoder>
</appender><!-- 日志分类写入 -->
<logger name="com.example.monitor.TimeZoneService" level="INFO" additivity="false"><appender-ref ref="MONITOR_TIMEZONE"/>
</logger><logger name="com.example.gateway.AccessLogger" level="INFO" additivity="false"><appender-ref ref="ACCESS_LOG"/>
</logger>5. 【强制】在日志输出时,字符串变量之间的拼接使用占位符的方式。
说明:因为 String 字符串的拼接会使用 StringBuilder 的 append() 方式,有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。
正例:logger.debug("Processing trade with id : {} and symbol : {}", id, symbol);
5.1. ✳️ 避免不必要的字符串拼接开销
假设我们使用拼接方式:
logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);即使当前日志级别是 INFO,不会真正输出这条 DEBUG 日志,但拼接操作仍会执行:
String s = "Processing trade with id: " + id + " and symbol: " + symbol;
// 实际生成一个新的 String 对象,性能浪费这在高并发或大量日志打印场景下性能损耗非常明显。
5.2. ✳️ 占位符方式性能更优
SLF4J / Log4j 等日志门面在内部做了优化,只有当对应日志级别开启时才会替换 {}:
logger.debug("Processing trade with id: {} and symbol: {}", id, symbol);- 如果
DEBUG级别关闭,连字符串拼接都不会做; - 性能更优,垃圾更少(无多余 StringBuilder 创建);
5.3. ✅ 正确与错误用法对比
| ❌ 错误用法 | ✅ 正确用法 |
|
|
|
|
|
|
5.4. ✅ SLF4J 占位符说明
logger.info("User {} logged in from IP {}", username, ip);{}是占位符,不需要写成{0},{1};- 变量顺序一一对应;
- 也可以传数组或异常对象:
logger.error("Request failed: {}", e.getMessage(), e); // 可打印异常栈5.5. ✅ 附加示例:错误与业务日志对比
String orderId = "ORD123";
String product = "Camera";
BigDecimal price = new BigDecimal("1999.00");// ❌ 错误方式(始终拼接)
logger.debug("Creating order: " + orderId + ", product=" + product + ", price=" + price);// ✅ 推荐方式
logger.debug("Creating order: {}, product={}, price={}", orderId, product, price);6. 【强制】对于 trace / debug / info 级别的日志输出,必须进行日志级别的开关判断:
说明:虽然在 debug(参数) 的方法体内第一行代码 isDisabled(Level.DEBUG_INT) 为真时(Slf4j 的常见实现 Log4j 和Logback) , 就直接 return, 但是参数可能会进行字符串拼接运算。 此外, 如果 debug(getName()) 这种参数内有getName() 方法调用,无谓浪费方法调用的开销。
正例:
// 如果判断为真,那么可以输出 trace 和 debug 级别的日志
if (logger.isDebugEnabled()) {
logger.debug("Current ID is: {} and name is: {}", id, getName());
}6.1. 为什么要加 logger.isDebugEnabled() 判断?
防止不必要的函数调用和拼接操作,即使我们使用了占位符 {},但传参中包含方法调用或对象构造时,这些操作仍然会执行:
6.2. ❌ 示例(不加判断):
logger.debug("Current ID is: {} and name is: {}", id, getName());- 即使
DEBUG日志关闭了, getName()这个函数还是会执行,可能造成性能浪费或副作用!
6.3. ✅ 示例(加判断):
if (logger.isDebugEnabled()) {logger.debug("Current ID is: {} and name is: {}", id, getName());
}- 如果日志级别关闭,整个代码块不会执行
- 避免无谓函数调用,提高性能
6.4. 有些方法计算成本高或可能抛异常
举个例子:
logger.debug("Big JSON result: {}", toJSONString(largeObject));toJSONString()比较耗时;- 如果 DEBUG 没开启,这个方法白执行了;
- 有可能还抛异常,影响主流程!
这时候最好加判断:if (logger.isDebugEnabled())
6.5. 正确写法示例
if (logger.isDebugEnabled()) {logger.debug("Current ID is: {} and name is: {}", id, getName());
}如果 getName() 是一个代价比较高的方法,或者日志中拼接了庞大的对象(如 Map、JSON),建议使用这种写法。
6.6. 其他级别也适用
| 日志级别 | 判断方法 | 适用场景 |
|
|
| 最低级别,性能敏感 |
|
|
| 开发调试时大量使用 |
|
| 一般不加判断(轻量) | 可省略 |
|
| 通常不加判断 | 可省略 |
|
| 不需要判断 | 永远输出 |
7. 【强制】避免重复打印日志,浪费磁盘空间,务必在日志配置文件中设置 additivity=false
正例:<logger name="com.taobao.dubbo.config" additivity="false">
7.1. 如何理解 additivity=false?
7.1.1. 📌 additivity 是什么?
在日志系统(如 Logback、Log4j)中,logger 是有层级结构的,例如:
com└── taobao└── dubbo└── config- 每个层级的 logger 默认 会把日志向上传递 到父 logger(这叫 "additivity")。
- 如果不禁止传递(即
additivity=true,默认值),那么日志可能被父 logger 重复处理并输出。
7.1.2. ❌ 问题示例:重复日志打印
你配置了两个 logger:
<logger name="com.taobao.dubbo.config"><appender-ref ref="A1"/>
</logger><root><appender-ref ref="A2"/>
</root>如果 additivity=true(默认):
com.taobao.dubbo.config的日志:
-
- 会被
A1打一次 - 然后“冒泡”到 root,被
A2再打一次 ❌
- 会被
7.1.3. 🔁 结果:日志被打印两遍,占用两倍磁盘空间!
7.2. ✅ 正确做法:设置 additivity="false"
<logger name="com.taobao.dubbo.config" additivity="false"><level value="INFO"/><appender-ref ref="A1"/>
</logger>这样:
- 日志只输出一次到
A1; - 不会再上传给父 logger(如 root);
- ✅ 减少重复、避免浪费磁盘。
7.3. 实际示例(Logback)完整配置片段
<configuration><appender name="DUBBO_LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>/app/logs/dubbo.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>/app/logs/dubbo.log.%d{yyyy-MM-dd}</fileNamePattern><maxHistory>15</maxHistory></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern></encoder></appender><!-- 👇 防止日志向上传递、重复输出 --><logger name="com.taobao.dubbo.config" level="INFO" additivity="false"><appender-ref ref="DUBBO_LOG"/></logger><!-- 根日志,输出系统其他日志 --><root level="INFO"><appender-ref ref="CONSOLE"/></root>
</configuration>| 项目 | 内容 |
| 🔧 设置项 |
|
| 📌 功能说明 | 防止日志上传父 logger,重复打印 |
| 🚫 如果不加 | 日志可能被打印多次,占磁盘、扰乱分析 |
| ✅ 推荐写法 | 任何定义了 appender 的子 logger,都应显式设置 |
8. 优秀的Spring项目中日志分类应该是怎么样?Logback配置文件应该是怎么样设计?
在一个良好结构化的 Java Spring项目 中,日志分类和 Logback配置应当遵循可读性、可维护性、按模块分类、可定位问题、环境适配几个核心原则。
8.1. ✅ 日志分类建议(按职责和层级)
通常可以按照以下分类方式命名 logger,并做等级管理:
| 类别/层 | 包路径示例 | log level 建议 | 说明 |
| Controller 层 |
| INFO/WARN | 记录接口访问、参数、响应耗时等 |
| Service 层 |
| INFO/DEBUG | 业务核心逻辑,建议包含调用链信息 |
| DAO 层 |
| DEBUG | 数据库操作,调试使用 |
| 异常处理层 |
| ERROR | 异常堆栈、关键异常处理 |
| 第三方调用层 |
| INFO/ERROR | 外部服务接口日志 |
| 定时任务 |
| INFO/DEBUG | 定时调度相关日志 |
| 通用工具类 |
| WARN/DEBUG | 工具类、通用组件 |
| 框架组件日志 |
| WARN | Spring 框架日志 |
| 数据源、MyBatis |
| WARN/INFO | 数据源和持久层日志 |
8.2. ✅ Logback 配置文件标准示例(logback-spring.xml)
这是一个功能齐全、分模块控制、环境切换灵活的样板:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="30 seconds"><property name="LOG_HOME" value="${LOG_HOME:-logs}"/><property name="APP_NAME" value="${spring.application.name:-app}"/><property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n"/><property name="LOG_LEVEL" value="INFO"/><!-- 控制台输出 --><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${LOG_PATTERN}</pattern></encoder></appender><!-- 按天滚动的文件输出 --><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_HOME}/${APP_NAME}.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_HOME}/${APP_NAME}.%d{yyyy-MM-dd}.log</fileNamePattern><maxHistory>15</maxHistory></rollingPolicy><encoder><pattern>${LOG_PATTERN}</pattern></encoder></appender><!-- 异步日志,提升性能 --><appender name="ASYNC_FILE" class="ch.qos.logback.classic.AsyncAppender"><queueSize>1024</queueSize><discardingThreshold>0</discardingThreshold><neverBlock>true</neverBlock><appender-ref ref="FILE"/></appender><!-- Spring、MyBatis、SQL 等默认组件日志 --><logger name="org.springframework" level="WARN"additivity="false"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></logger><logger name="org.mybatis" level="WARN" additivity="false"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></logger><logger name="com.zaxxer.hikari" level="WARN" additivity="false"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></logger><!-- 控制层日志,只记录 INFO 及以上,输出到 CONSOLE 和 ASYNC_FILE --><logger name="com.example.project.controller" level="INFO" additivity="false"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></logger><!-- 服务层日志,记录 DEBUG 及以上,输出到 CONSOLE 和 ASYNC_FILE --><logger name="com.example.project.service" level="DEBUG" additivity="false"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></logger><!-- 持久层日志,记录 DEBUG 及以上,输出到 ASYNC_FILE --><logger name="com.example.project.repository" level="DEBUG" additivity="false"><appender-ref ref="ASYNC_FILE"/></logger><!-- 错误处理模块日志,只记录 ERROR,输出到 CONSOLE 和 ASYNC_FILE --><logger name="com.example.project.error" level="ERROR" additivity="false"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></logger><!-- 定时任务模块日志,记录 INFO 及以上 --><logger name="com.example.project.job" level="INFO" additivity="false"><appender-ref ref="ASYNC_FILE"/></logger><!-- 系统集成、三方接口模块日志 --><logger name="com.example.project.integration" level="INFO" additivity="false"><appender-ref ref="ASYNC_FILE"/></logger><!-- 根日志配置 --><root level="${LOG_LEVEL}"><appender-ref ref="CONSOLE"/><appender-ref ref="ASYNC_FILE"/></root>
</configuration>8.3. ✅ 附加建议
8.3.1. 按环境区分日志配置(Spring Profiles)
<springProfile name="dev"><logger name="com.example.project" level="DEBUG"/>
</springProfile><springProfile name="prod"><logger name="com.example.project" level="INFO"/>
</springProfile>8.3.2. 使用 MDC 实现链路追踪(如 traceId)
在 filter 中设置:
MDC.put("traceId", UUID.randomUUID().toString());在 logback pattern 中使用:
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level [%X{traceId}] %logger - %msg%n</pattern>8.4. ✅ 总结
| 优秀实践 | 说明 |
| 按模块分 logger | 易于查找、屏蔽某一类日志 |
| 使用 AsyncAppender | 避免 I/O 阻塞,性能更好 |
| 使用 MDC + traceId | 日志链路追踪 |
| 环境敏感日志级别 | 开发 debug,生产 info |
| 保留最近 N 天日志 | 利于问题追溯 |
| 不要用 | 统一日志管理 |
9. 【强制】生产环境禁止使用 System.out 或 System.err 输出或使用 e.printStackTrace() 打印异常堆栈。
说明:标准日志输出与标准错误输出文件每次 Jboss 重启时才滚动,如果大量输出送往这两个文件,容易造成文件大小超过操作系统大小限制。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class ExampleService {private static final Logger logger = LoggerFactory.getLogger(ExampleService.class);public void doSomething() {try {// 业务逻辑...} catch (Exception e) {// ❌ 错误做法:e.printStackTrace();// System.out.println("出现异常:" + e.getMessage());// ✅ 推荐做法:logger.error("业务处理失败", e);}}
}使用 logger.error("xxx", e) 输出异常,有以下优势:
- 自动打印完整堆栈;
- 日志等级明确(ERROR);
- 包含上下文信息;
- 可配置输出到不同文件或集中式日志系统(如 ELK、Loki);
- 避免信息泄露(通过脱敏配置);
- 支持异步写入提高性能
10. 【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字throws 往上抛出。
正例:logger.error("inputParams: {} and errorMessage: {}", 各类参数或者对象 toString(), e.getMessage(), e);
这是一个非常重要的日志输出规范要求,旨在保证出现异常时,日志中不仅有错误堆栈信息(异常是什么),还包括上下文信息(发生异常时系统在做什么),以便于问题排查和复现。理解说明:“案发现场” + “异常堆栈” = 有价值的异常日志,两类信息:
| 信息类型 | 说明 | 目的 |
| 案发现场信息 | 方法入参、操作用户、请求来源、处理上下文等 | 定位是哪个请求或数据导致的 |
| 异常堆栈信息 |
| 定位代码具体出错位置 |
10.1. 正例解读
logger.error("inputParams: {} and errorMessage: {}", request.toString(), e.getMessage(), e);这行日志做到了:
- {} 第一个参数:打印
request的内容(案发现场)。 - {} 第二个参数:打印异常提示信息(便于快速识别异常类型)。
- 最后的
e:打印完整异常堆栈。
日志最终可能打印成:
ERROR com.example.UserService - inputParams: UserRequest{id=1, name='张三'} and errorMessage: java.lang.NullPointerException: xx
java.lang.NullPointerException
at com.example.UserService.getUser(UserService.java:45)
at ...10.2. ✅ 示例:推荐做法
public void handleRequest(UserRequest request) {try {// 业务处理} catch (Exception e) {logger.error("处理请求失败,请求参数: {}, 异常原因: {}", request, e.getMessage(), e);throw new BusinessException("用户处理失败", e); // 或者继续往上抛}
}10.3. ❌ 反例:不包含上下文
catch (Exception e) {logger.error("出错了", e); // 缺少关键参数信息
}无法知道是哪一个请求、哪个参数导致错误,排查困难。
10.4. ✅ 再进阶:统一异常处理(推荐)
如果你用 Spring Boot,可以统一用 @ControllerAdvice 把这些信息收集起来打日志:
@RestControllerAdvice
public class GlobalExceptionHandler {private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);@ExceptionHandler(Exception.class)public ResponseEntity<String> handleException(HttpServletRequest request, Exception e) {logger.error("请求地址: {}, 请求参数: {}, 异常信息: {}", request.getRequestURI(),request.getQueryString(), e.getMessage(), e);return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("系统异常");}
}11. 【强制】日志打印时禁止直接用 JSON 工具将对象转换成 String。
说明: 如果对象里某些 get 方法被覆写, 存在抛出异常的情况,则可能会因为打印日志而影响正常业务流程的执行。正例:打印日志时仅打印出业务相关属性值或者调用其对象的 toString() 方法。这是一个非常重要的日志打印规范,防止因为“日志打印本身”而引发系统异常。
规范理解:不要直接使用 JSON 工具(如 ObjectMapper, Gson, FastJson)将对象序列化为字符串用于日志打印。
11.1. 原因:
- 有些对象的
getXxx()方法被重写,里面可能抛异常(例如懒加载未初始化、连接已关闭等); - JSON 工具在序列化时会自动调用所有 getter,如果其中某个抛异常,会打断日志打印,甚至影响主业务流程。
11.2. ❌ 反例(违背规范)
// 错误做法:直接用 JSON 工具打印整个对象
logger.info("用户信息: {}", objectMapper.writeValueAsString(user));潜在风险:
- 如果
user.getAccountBalance()内部操作数据库连接,而连接已关闭,日志打印时会报错; - 程序可能在日志阶段抛异常,导致主流程中断。
11.3. ✅ 正例(推荐做法)
- 调用对象的
toString()(前提是实现良好) - 只打印业务关键字段
// 推荐方式 1:对象已有良好的 toString 实现
logger.info("用户信息: {}", user.toString());// 推荐方式 2:只打印关键属性
logger.info("用户信息: id={}, name={}", user.getId(), user.getName());12. 不建议使用 JSON.toJSONString(obj) 等类似方法直接打印日志
12.1. 为什么 JSON.toJSONString() 不推荐用于日志打印?
因会调用对象的所有 getter 方法
JSON.toJSONString(user)这会自动遍历对象属性并执行 getXxx() 方法,而这些方法中:
- 可能含有业务逻辑;
- 可能访问数据库(如懒加载字段);
- 有些重写的 getter 甚至会抛异常;
结果就是:🔥 日志打印行为影响业务执行流程,甚至导致程序异常。
12.2. 推荐做法
12.2.1. ✅ 方案 1:只打印关键字段
logger.info("userId={}, userName={}", user.getId(), user.getName());12.2.2. ✅ 方案 2:使用toString(),前提是你确认安全
logger.info("user info: {}", user.toString());⚠️ 注意:不要在 toString() 里调用会抛异常的方法。
12.3. ❓举个反例
logger.info("用户信息:{}", JSON.toJSONString(user)); // ❌ 可能触发懒加载/空指针异常如果 user.getBalance() 是懒加载字段,没初始化,打印时就会抛 LazyInitializationException,程序可能因此挂掉。
13. 【推荐】为了保护用户隐私,日志文件中的用户敏感信息需要进行脱敏处理。
不要在日志中输出敏感信息:姓名、身份证号、手机号、银行卡号、地址、登录密码、验证码等。这些数据如果未脱敏就出现在日志中,一旦日志泄露就会导致用户隐私泄露、触发法律风险。
13.1. 推荐做法:敏感信息日志中要脱敏处理
| 信息类型 | 脱敏规则示例 |
| 手机号 | 136****1234 |
| 身份证号 | 110***********1234 |
| 姓名 | 王** |
| 银行卡号 | 6227********3456 |
13.2. 正例代码示例
User user = getUser();// 脱敏处理
String maskedPhone = DesensitizationUtil.maskPhone(user.getPhone());
String maskedIdCard = DesensitizationUtil.maskIdCard(user.getIdCard());logger.info("用户信息 - userId: {}, phone: {}, idCard: {}", user.getId(), maskedPhone, maskedIdCard);推荐在日志中使用 userId、orderId、uuid 等非敏感的唯一标识进行问题定位。
13.3. ❌ 反例代码(绝对禁止)
logger.info("用户信息 - 姓名: {}, 身份证: {}, 手机号: {}", user.getName(), user.getIdCard(), user.getPhone());
// 泄露完整敏感信息,严重违规13.4. ✅ 推荐脱敏工具类 DesensitizationUtil
public class DesensitizationUtil {public static String maskPhone(String phone) {if (phone == null || phone.length() != 11) return phone;return phone.substring(0, 3) + "****" + phone.substring(7);}public static String maskIdCard(String idCard) {if (idCard == null || idCard.length() < 8) return idCard;return idCard.substring(0, 3) + "***********" + idCard.substring(idCard.length() - 4);}public static String maskName(String name) {if (name == null || name.length() < 2) return "*";return name.charAt(0) + "*".repeat(name.length() - 1);}
}13.5. ✅ 日志中推荐使用哪些字段定位问题?
userId/accountIdorderIduuidtransactionIdrequestId(可作为链路跟踪标识)
这些字段 既不包含用户隐私,又能唯一定位问题。
博文参考
相关文章:
Java开发经验——阿里巴巴编码规范实践解析4
摘要 本文主要介绍了阿里巴巴编码规范中关于日志处理的相关实践解析。强调了使用日志框架(如 SLF4J、JCL)而非直接使用日志系统(如 Log4j、Logback)的 API 的重要性,包括解耦日志实现、统一日志调用方式等好处。同时&…...
HTML应用指南:利用GET请求获取全国捞王锅物料理门店位置信息
随着新零售业态的快速发展,门店位置信息的获取变得越来越重要。作为知名中式餐饮品牌之一,捞王锅物料理自2009年创立以来,始终致力于为消费者提供高品质的锅物料理与贴心的服务体验。经过多年的发展,捞王在全国范围内不断拓展门店…...
算法日记32:埃式筛、gcd和lcm、快速幂、乘法逆元
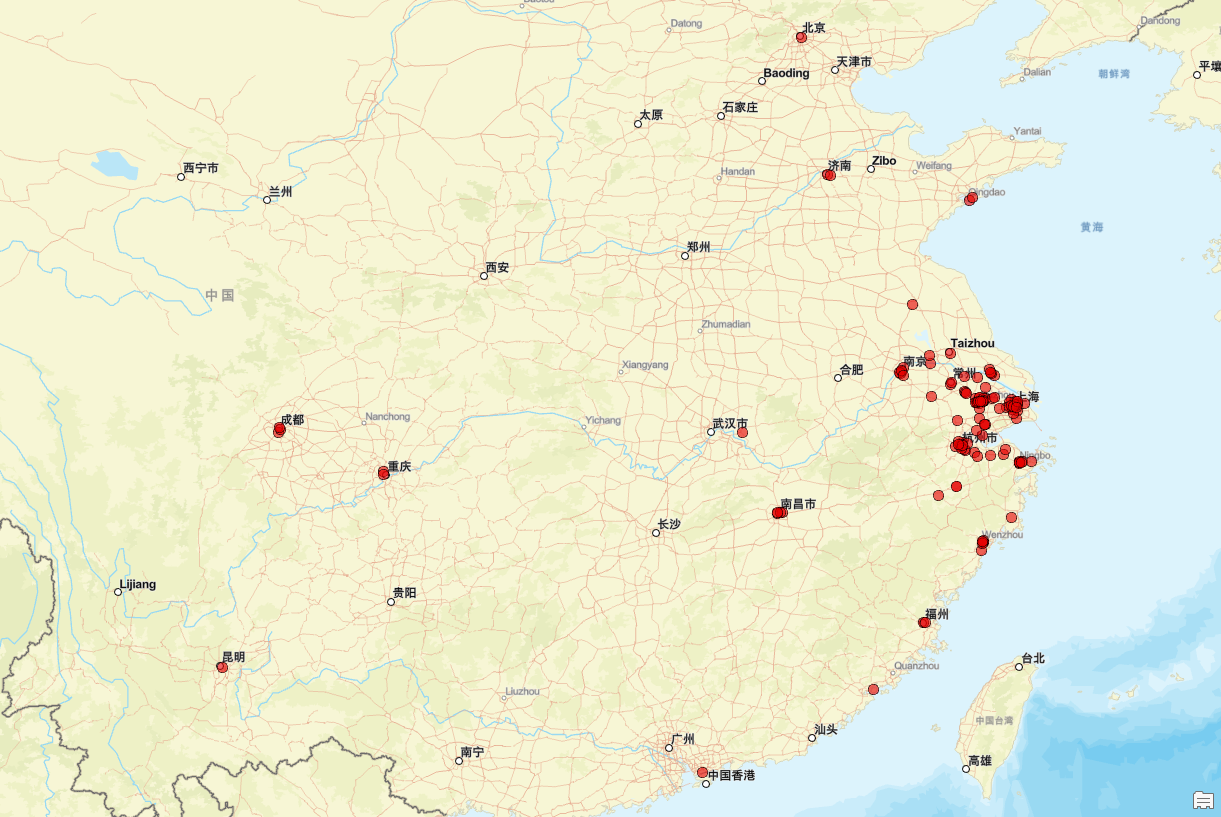
一、埃式筛(计算质数) 1.1、概念 1.1.1、在传统的计算质数中,我们采用单点判断,即判断(2~sqrt(n))是否存在不合法元素,若存在则判否,否则判是 1.1.2、假设,此时我们需要求1~1000的所有质数&am…...

黑马点评-分布式锁Lua脚本
文章目录 分布式锁Redis setnxredis锁误删Lua脚本 分布式锁 当我们的项目服务器不只是一台(单体),而是部署在多态服务器上(集群/分布式),同样会出现线程安全问题。不同服务器内部有不同的JVM,每…...

P7-大规模语言模型分布式训练与微调框架调研文档
1. 引言 随着大语言模型(LLMs)在自然语言处理(NLP)、对话系统、文本生成等领域的广泛应用,分布式训练和高效微调技术成为提升模型性能和部署效率的关键。分布式训练框架如 Megatron-LM 和 DeepSpeed 针对超大规模模型…...
机械师安装ubantu双系统:三、GPT分区安装Ubantu
目录 一、查看磁盘格式 二、安装ubantu 参考链接: GPT分区安装Ubuntu_哔哩哔哩_bilibili 一、查看磁盘格式 右击左边灰色区域,点击属性 二、安装ubantu 插入磁盘,重启系统,狂按F7(具体我也忘了)&#…...

ORM++ 封装实战指南:安全高效的 C++ MySQL 数据库操作
ORM 封装实战指南:安全高效的 C MySQL 数据库操作 一、环境准备 1.1 依赖安装 # Ubuntu/Debian sudo apt-get install libmysqlclient-dev # CentOS sudo yum install mysql-devel# 编译时链接库 (-I 指定头文件路径 -L 指定库路径) g main.cpp -stdc17 -I/usr/i…...

kafka学习笔记(三、消费者Consumer使用教程——从指定位置消费)
1.简介 Kafka的poll()方法消费无法精准的掌握其消费的起始位置,auto.offset.reset参数也只能在比较粗粒度的指定消费方式。更细粒度的消费方式kafka提供了seek()方法可以指定位移消费允许消费者从特定位置(如固定偏移量、时间戳或分区首尾)开…...

【后端高阶面经:架构篇】46、分布式架构:如何应对高并发的用户请求
一、架构设计原则:构建可扩展的系统基石 在分布式系统中,高并发场景对架构设计提出了极高要求。 分层解耦与模块化是应对复杂业务的核心策略,通过将系统划分为客户端、CDN/边缘节点、API网关、微服务集群、缓存层和数据库层等多个层次,实现各模块的独立演进与维护。 1.1 …...

网络编程学习笔记——TCP网络编程
文章目录 1、socket()函数2、bind()函数3、listen()4、accept()5、connect()6、send()/write()7、recv()/read()8、套接字的关闭9、TCP循环服务器模型10、TCP多线程服务器11、TCP多进程并发服务器 网络编程常用函数 socket() 创建套接字bind() 绑定本机地址和端口connect() …...
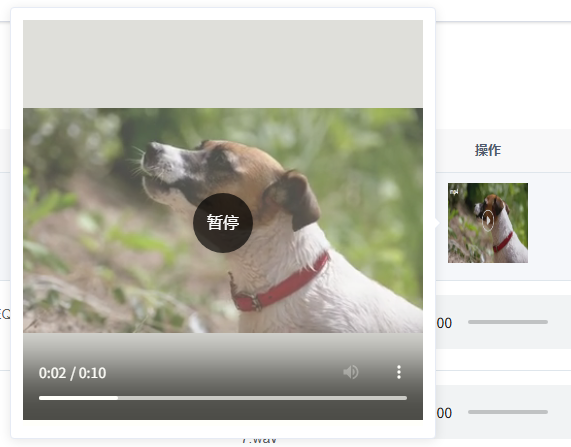
Vue+element-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频(一)
Vueelement-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频 前言整体代码预览图具体分析基础结构主要标签作用videoel-popover 前言 如标题,需要实现这样的业务 此处文章所实现的,是静态视频资源。 注…...
day13 leetcode-hot100-22(链表1)
160. 相交链表 - 力扣(LeetCode) 1.哈希集合HashSet 思路 (1)将A链的所有数据存储到HashSet中。 (2)遍历B链,找到是否在A中存在。 具体代码 /*** Definition for singly-linked list.* pu…...

【Oracle】DQL语言
个人主页:Guiat 归属专栏:Oracle 文章目录 1. DQL概述1.1 什么是DQL?1.2 DQL的核心功能 2. SELECT语句基础2.1 基本语法结构2.2 最简单的查询2.3 DISTINCT去重 3. WHERE条件筛选3.1 基本条件运算符3.2 逻辑运算符组合3.3 高级条件筛选 4. 排序…...
HUAWEI华为MateBook D 14 2021款i5,i7集显非触屏(NBD-WXX9,NbD-WFH9)原装出厂Win10系统
适用型号:NbD-WFH9、NbD-WFE9A、NbD-WDH9B、NbD-WFE9、 链接:https://pan.baidu.com/s/1qTCbaQQa8xqLR-4Ooe3ytg?pwdvr7t 提取码:vr7t 华为原厂WIN系统自带所有驱动、出厂主题壁纸、系统属性联机支持标志、系统属性专属LOGO标志、Office…...
【STIP】安全Transformer推理协议
Secure Transformer Inference Protocol 论文地址:https://arxiv.org/abs/2312.00025 摘要 模型参数和用户数据的安全性对于基于 Transformer 的服务(例如 ChatGPT)至关重要。虽然最近在安全两方协议方面取得的进步成功地解决了服务 Transf…...
leetcode hot100刷题日记——27.对称二叉树
方法一:递归法 class Solution { public:bool check(TreeNode *left,TreeNode *right){//左子树和右子树的节点同时是空的是对称的if(leftnullptr&&rightnullptr){return true;}if(leftnullptr||rightnullptr){return false;}//检查左右子树的值相不相等&a…...

高考加油(Python+HTML)
前言 询问DeepSeek根据自己所学到的知识来生成多个可执行的代码,为高考学子加油。最开始生成的都会有点小问题,还是需要自己调试一遍,下面就是完整的代码,当然了最后几天也不会有多少人看,都在专心的备考。 Python励…...

贪心算法应用:Ford-Fulkerson最大流问题详解
Java中的贪心算法应用:Ford-Fulkerson最大流问题详解 1. 最大流问题概述 最大流问题(Maximum Flow Problem)是图论中的一个经典问题,旨在找到一个从源节点(source)到汇节点(sink)的最大流量。Ford-Fulkerson方法是解决最大流问题的经典算法之一,它属于贪心算法的范畴…...
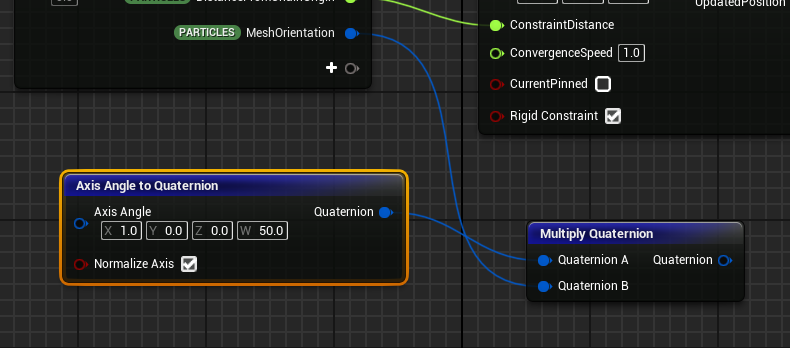
UE5 Niagara 如何让四元数进行旋转
Axis Angle中,X,Y,Z分别为旋转的轴向,W为旋转的角度,在这里旋转角度不需要除以2,因为里面已经除了,再将计算好的四元数与要进行旋转的四元数进行相乘,结果就是按照原来的角度绕着某一轴向旋转了某一角度...

从“黑箱”到透明化:MES如何重构生产执行全流程?
引言 在传统制造企业中,生产执行环节常面临“计划混乱、进度难控、异常频发、数据滞后”的困境。人工派工效率低下、物料错配频发、质量追溯困难等问题,直接导致交付延期、成本攀升、客户流失。深蓝易网MES系统以全流程数字化管理为核心,通过…...

探索Linux互斥:线程安全与资源共享
个人主页:chian-ocean 文章专栏-Linux 前言: 互斥是并发编程中避免竞争条件和保护共享资源的核心技术。通过使用锁或信号量等机制,能够确保多线程或多进程环境下对共享资源的安全访问,避免数据不一致、死锁等问题。 竞争条件 竞…...
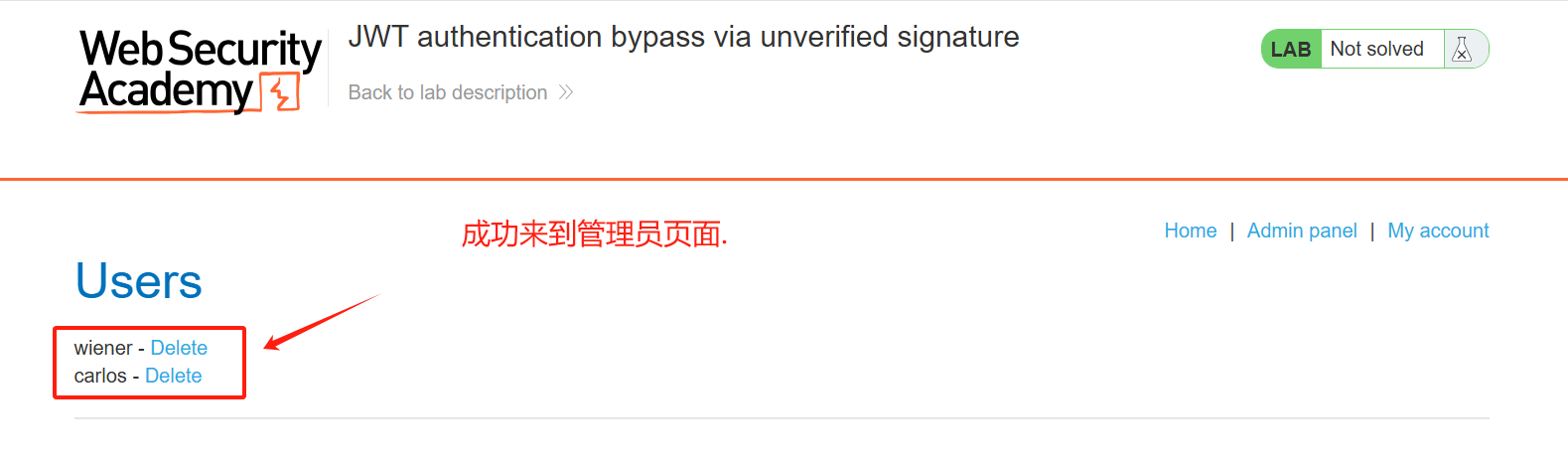
JWT安全:假密钥.【签名随便写实现越权绕过.】
JWT安全:假密钥【签名随便写实现越权绕过.】 JSON Web 令牌 (JWT)是一种在系统之间发送加密签名 JSON 数据的标准化格式。理论上,它们可以包含任何类型的数据,但最常用于在身份验证、会话处理和访问控制机制中发送有关用户的信息(“声明”)。…...
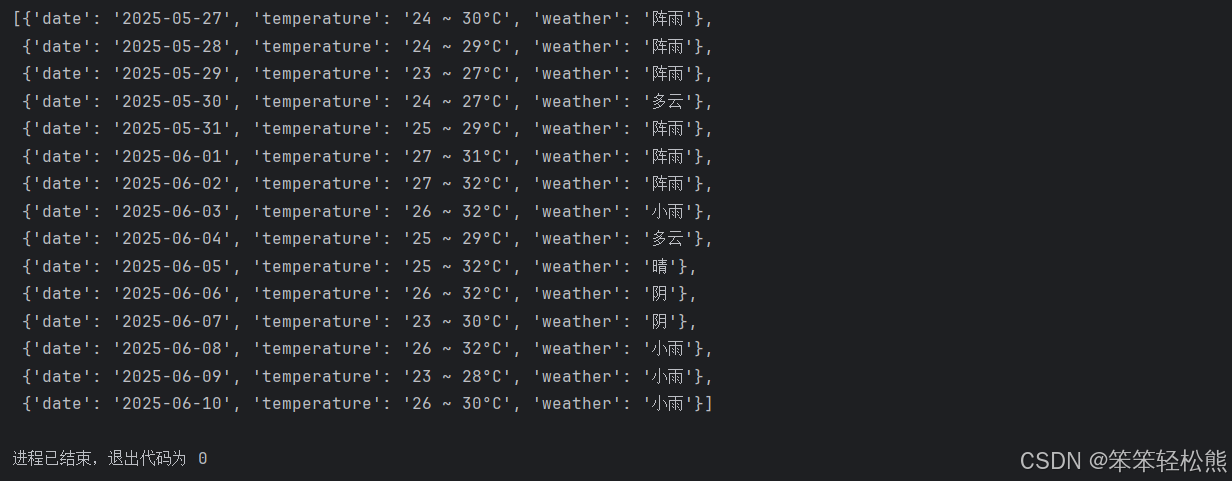
Python爬虫实战:抓取百度15天天气预报数据
🌐 编程基础第一期《9-30》–使用python中的第三方模块requests,和三个内置模块(re、json、pprint),实现百度地图的近15天天气信息抓取 记得安装 pip install requests📑 项目介绍 网络爬虫是Python最受欢迎的应用场景之一&…...
RV1126 + FFPEG多路码流项目
代码主体思路: 一.VI,VENC,RGA模块初始化 1.先创建一个自定义公共结构体,用于方便管理各个模块 rkmedia_config_public.h //文件名字#ifndef _RV1126_PUBLIC_H #define _RV1126_PUBLIC_H#include <assert.h> #include <fcntl.h> #include …...
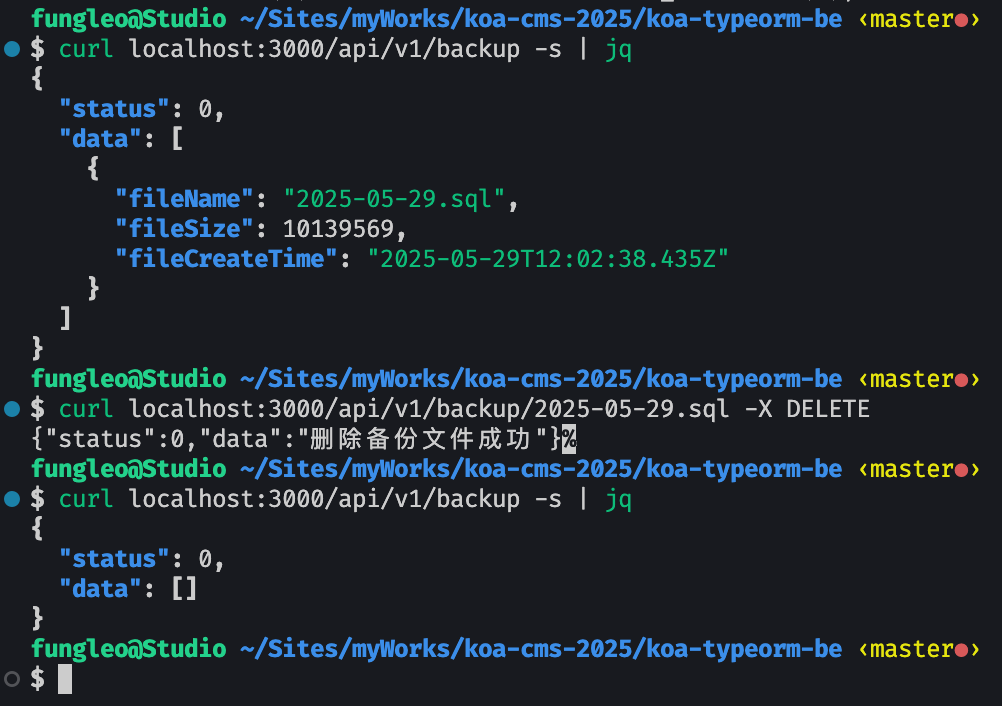
NodeJS 基于 Koa, 开发一个读取文件,并返回给客户端文件下载,以及读取文件形成列表和文件删除的代码演示
前言 在上一篇文章 《Nodejs 实现 Mysql 数据库的全量备份的代码演示》 中,我们演示了如何将用户的 Mysql 数据库进行备份的代码。但是,这个备份,只是备份在了服务器上了。 而我们用户的真实需求,是需要将备份文件下载到本地进行…...
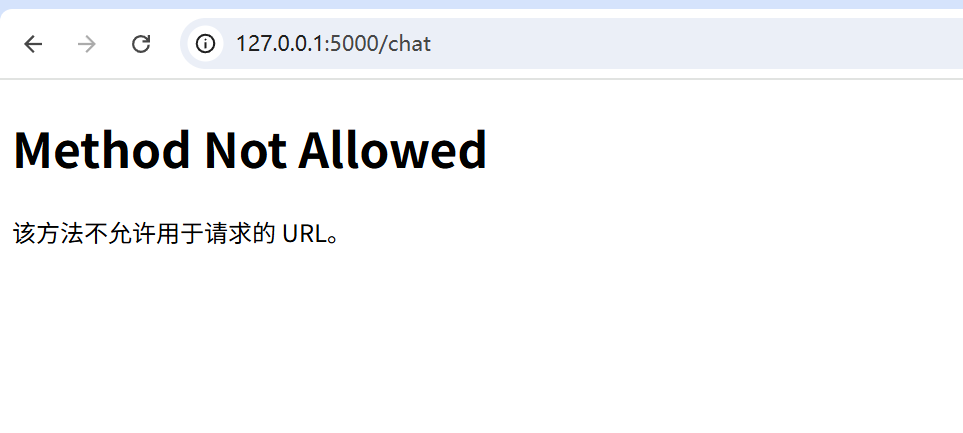
为什么在我的Flask里面有两个路由,但是在网页里有一个却不能正确访问到智能体
1. /zhoushibo 能访问,/chat 直接浏览器访问报 Method Not Allowed 原因: /zhoushibo 路由是你用 app.route(/zhoushibo) 定义的,返回的是一个HTML网页,浏览器访问没问题。 /chat 路由你用的是 app.route(/chat, methods[POST])…...

哈工大计算机系统2024大作业——Hello的程序人生
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 人工智能 学 号 2022112040 班 级 2203601 学 生 郄东昕 指 导 教 师 吴锐 计算机科学与技术学院…...

2025年软件测试面试八股文(含答案+文档)
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 Part1 1、你的测试职业发展是什么? 测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师…...

【仿生系统】qwen的仿生机器人解决方案
收到完整需求后,我将从系统架构设计、算法实现路径、训练方法三个维度为您构建完整的仿生机器人解决方案。以下是分阶段实施方案: 一、核心系统架构设计(模块化可进化架构) 1. 多模态感知引擎 - 视觉子系统:YOLOv8SAM…...

Flutter3.22适配运行鸿蒙系统问题记录
Flutter3.22适配运行鸿蒙系统问题记录 一:适配条件适配过程问题记录(1)环境配置问题(2)Concurrent modification during iteration: Instance(length:2) of_GrowableList 报错(3)三方插件寻找替…...