时序模型介绍
一.整体介绍
1.单变量 vs 多变量时序数据
单变量就是只根据时间预测,多变量还要考虑用户
2.为什么不能用机器学习预测:
a.时间不是影响标签的关键因素
b.时间与标签之间的联系过于弱/过于复杂,因此时序模型依赖于时间与时间的相关性来进行预测,但普通机器学习模型并不会考虑样本之间的相关性。
c.机器学习模型无法处理“没见过的特征值”,但时序预测中时间特征永远是未曾在历史数据中出现过的、未来的日期
3.如何预测:
多步预测:如下图所示,我们将测试集上的时间分割为5段,假设t是当前的时间,我们先使用训练好的模型预测出t+d时间段的结果,将该结果加入训练集、构成全新的训练数据。即是说,我们将预测的值作为真实值加入到训练集中再对下一个单位时间进行预测,这样累加可以让训练数据的时间点与测试数据的时间点尽量接近。

缺点:多步预测中可能会导致误差累加
需要注意的是,多步预测、单步预测都只适用于时间线的预测、而不适用于时间点的预测(即大部分时候不适用于多变量时间序列数据)。多变量时间序列数据在样本上可以被打乱,因此只要保证同一对象在训练集和测试集中的时间差,即可使用普通机器学习方式进行训练和预测。
4.时序模型不太实用交叉验证
传统时序模型大多是统计学模型/数学模型,这些模型在建模前需要经过层层检验以满足各种各样的先决条件,因此当这些先决条件被满足时,模型在理论上已经拥有一定的泛化能力,因此在学术界持有一派观点:统计学模型/数学模型不需要交叉验证。
如果想做:
单变量时序数据有自己独特的交叉验证方式,一般称之为时序交叉验证:先把训练集按日期顺序排序后分割,在每次验证完之后将验证时使用的样本加入训练集。如下图
图!!!!!!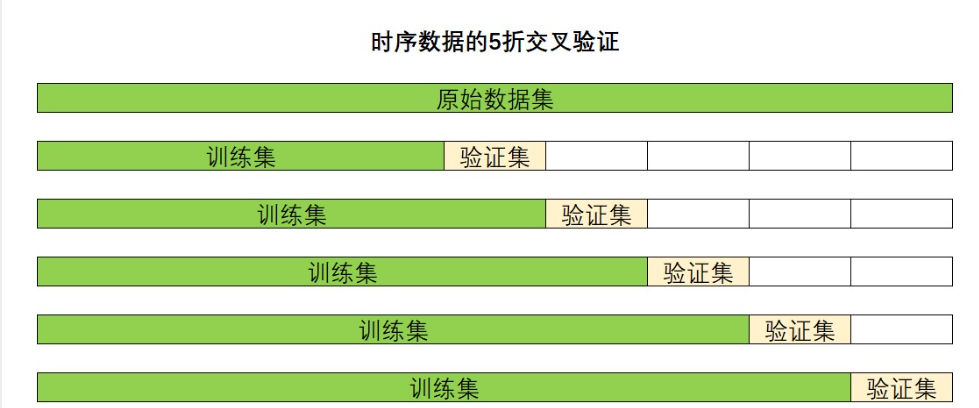
多变量时序数据由于没有“不能打乱样本顺序”的铁则,因此使用普通的交叉验证也没问题。
5.时间序列模型:
a.时序预测:我们使用规则+统计学模型来完成这类预测,但只要遵守“过去预测未来”的铁律,我们也可以使用机器学习模型+多步预测等方式完成Forecasting。
b.时序有监督学习(重点):在多变量时间序列上,基于时间或时间相关的数据,完成回归或分类任务。
它对样本与样本之间的时间顺序、相关等都没有要求、反而更关注特征之间的关系,因此这类任务要求:
数据中必须存在除时间之外的其他特征,且特征越多越好
如果有必要,可以完成“去时序化”处理,将时序数据彻底变为一般机器学习数据
我们使用规则+机器学习模型来完成这类预测。
二.当代时间序列算法群
派系1:ARIMA
四种方法:
AR:自回归模型(AutoRegressive),是最典型的、最基础的统计学时序模型之一,其基本思想就是根据历史行为预测未来行为的模型。AR模型非常关注时间序列中的值与它之前和之后的值之间是否存在某种相关性,AR模型依赖于这种相关性运行。
MA:移动平均模型(Moving Average Model),同样是非常经典的统计学模型之一,使用不同于自回归模型的思路构建、也能够得到很好的效果。相比起关注过去和未来的联系,MA模型更在意每个时间点上的数值受到了外界偶然因素多大的影响。
ARIMA(最重要,综合了前两种):自回归移动平均模型(ARIMA,Autoregressive Integrated Moving Average),是名声最大、使用最广泛时间序列预测方法之一。它结合了AR模型与MA模型的思想,即关系过去对未来的影响,也关心每个时间点上的数值受到外界偶然因素的影响,因此可以应对相对复杂的时间序列数据。
SARIMA:季节性自回归综合移动平均(SARIMA),这个模型扩展了ARIMA模型、在原本模型的基础上允许ARIMA学习季节性模式,在按月、按季节或按年度呈现某种规律的数据上总是有很好的表现。
派系2:指数平滑
针对数据在较长一段时间内的趋势性和季节性,因此指数平滑尤其擅长处理带有系统性趋势或季节性成分的数据。
派系3:Prophet
Prophet即没有使用ARIMA一族、也没有使用指数平滑的方法,而是使用Additive Model(加法模型)作为核心完成时序预测。
加法模型是一类与机器学习模型思路高度类似、但遵守时序预测规则的模型,它能够支持非线性的时间序列趋势、同时还能够与年、周、月、季节等周期性的效应相匹配,因此非常适合用于受强烈季节性影响的时间序列。
在Facebook开发过程中,Prophet被设计成能够处理节假日效应、能够处理缺失值、能够处理异常值、甚至能够使用加法模型对非时序数据进行预测的“全能型时间序列库”。可以说,Prophet是目前为止完成度较高的时间序列库之一。
派系4:树模型及其他高阶机器学习模型:
只要对数据进行“去时序化”处理,或遵循“过去预测未来”的铁则,我们就可以使用机器学习中任何高阶有监督模型来对时间序列进行预测,例如XGBoost,LightGBM,CatBoost,DeepForest等等。(能够使用机器学习模型的前提下,我们可能不会优先选择时序模型,因为时序模型在建模过程中需要避开的陷阱实在是太多了。)
派系5:深度学习
RNN:循环神经网络,本质是全连接网络、但考虑了过去的信息,输出不仅取决于当前输入,还取决于之前的信息,因此可以被用于时间序列预测。循环神经网络的输出由之前的信息和此时的输入共同决定,是深度学习领域最基础的时序模型。
LSTM:长短期记忆网络(Long Short-Term Memory Net)是循环神经网络的变体,除了继承循环神经网络同时纳入历史和当前信息的能力之外,LSTM还可以学习序列中项目之间的顺序依赖性和时间滞后性,这意味着LSTM可以处理不连续的时间,因此它非常适合基于时间序列数据进行分类、处理和预测。LSTM的开发是为了解决在训练传统RNN时可能遇到的梯度消失问题,而对断裂的时间段相对不敏感是LSTM在众多算法中优于RNN、隐马尔可夫模型和其他序列学习方法的优势。
GRU:门控循环单元结构(Gated Recurrent Unit)是LSTM网络的一种变体,结构更加简单、参数更少、训练速度更快、训练效果更好,能够解决RNN网络中的长依赖问题也能够降低过拟合风险。在大多数时候,GRU表现出的结果与LSTM类似,但它的整体模型比LSTM更轻量。
前沿模型:
DeepAR:由Amazon提出的一种针对大量相关时间序列统一建模的预测算法,该算法使用循环神经网络 (RNN) 结合自回归(AR)来预测标量时间序列,在大量时间序列上训练自回归递归网络模型,并通过预测目标在序列每个时间步上取值的概率分布来完成预测任务。
CNN:卷积神经网络。卷积神经网络是著名的图像、视频处理的基础网络,但近年来CNN用于时序数据的研究也越发成熟。通常来说,CNN比较少被用于单变量时序数据,更多是被用于多变量时序数据上的时序有监督分类。
N-BEATS:N-BEATS 是一种定制的深度学习算法,它基于后向和前向残差链接进行单变量时间序列点预测。
Temporal Fusion Transformer(Google):时序融合transformer,一种新颖的基于注意力的架构,它结合了高性能多水平预测和对时间动态的可解释洞察力。
三:具体算法介绍
1.ARIMA
AR自回归模型
两个假设:
不同时间点的标签值之间强相关(highly-correlated),位于时间点t的标签值一定强烈地受到t之前的标签值的影响。在数学上,这意味着两个时间点的标签值之间的相关系数会较大。
根据时间的基本属性,两个时间点之间相隔越远,相互之间的影响越弱(例如,昨天是否下雨对今天是否下雨的影响很大,但三个月前的某天是否下雨,对明天是否下雨的影响就相对较小)
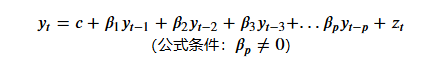
需要注意的是,该公式中包含两个常数项: 𝑐 和 𝑧𝑡。其中,𝑐是线性方程中惯例存在的常数项(可以为0),而 𝑧𝑡则代表当前时间点下无法被捕捉到的某些影响,也就是白噪音(White Noise)。
很明显,自回归模型的公式与多元线性回归相同,因此我们对自回归模型的建模几乎等同于对多元线性回归的建模。但稍有区别的是,多元线性回归中每个自变量都是一列数据,要求解的标签也是一列数据,但在自回归模型中每个自变量y都是一个样本的数值,要求解的标签y也是一个样本的数值。
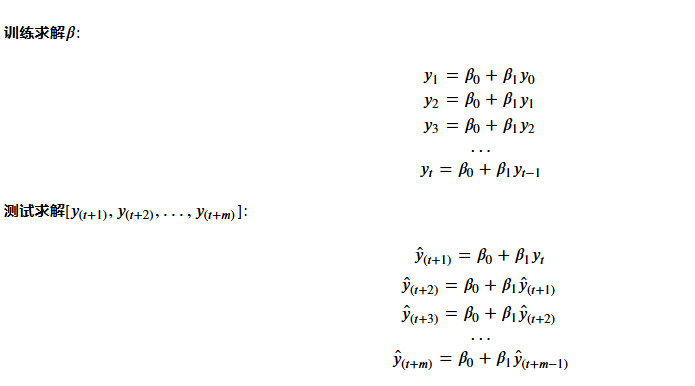
要用参数估计,根据t个方程来估计
问题:
1.p如何确定?
如果模型是AR(p),则需要保证要预测的第一个日期前面至少有p天的历史记录。可以通过ACF和PACF参数确定
2.MA模型:
思想是:大部分时候时间序列应当是相对稳定的。在稳定的基础上,每个时间点上的标签值受过去一段时间内、不可预料的各种偶然事件影响而波动。
该模型假设:
时间序列的(长期)趋势与时间序列的(短期)波动受不同因素的影响。
不同时间点的标签值之间是关联的,但各种偶然事件在不同时间点上产生的影响之间却是相互独立的。

即均值+历史偶然事件的加和
在理想条件下,MA模型规定 𝜖 应当服从均值为0、标准差为1的正态分布,但在实际计算时,MA模型规定 𝜖等同于模型的预测值𝑦^ 𝑡与真实标签 𝑦𝑡之间的差值(Residuals),即:𝜖𝑡=𝑦𝑡−𝑦^ 𝑡
由于偶然事件是无法被预料的、偶然事件带来的影响也是无法被预估的,因此MA模型使用预测标签与真实标签之间的差异就来代表“无法被预料、无法被估计、无法被模型捕捉的偶然事件的影响”。
训练与预测:
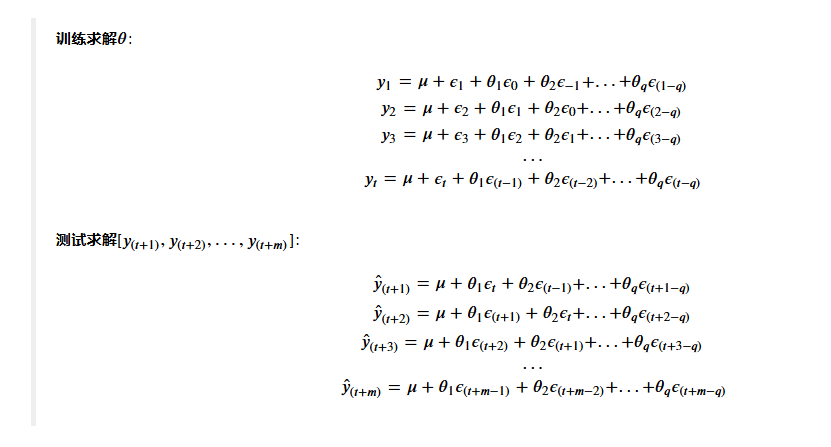
a.q是多少:一般都设置为[1,5]之内的正整数。
我们可以使用自相关系数ACF(Auto-correlation function)、偏相关系数PACF(Partial Auto-Correlation Function)或者相关的假设检验来帮助我们确定p、q等超参数的值,其中PACF用于确定AR模型的p值,ACF用于确定MA模型的q值,假设检验则可以同时用于两种模型。
b.{ 𝜖1,𝜖2,𝜖3,...,𝜖𝑞 }分别是多少?{ 𝜇,𝜃1,𝜃2,...,𝜃𝑞 }分别是多少?
方法:使用带迭代过程的参数估计办法(如最小二乘、梯度下降等)对这些参数进行求解。先假设一组初始参数值(一般为随机数),并在迭代过程中逐渐修正这些参数。因此我们可以假设最初的 𝜇和 𝜃1是任意随机数。
9.ARIMA模型=MA+AR
a.公式:
![]()
以上模型被称之为ARIMA(p,d,q)模型,其中p和q的含义与原始MA、AR模型中完全一致,且p和q可以被设置为不同的数值,而d是ARIMA模型需要的差分的阶数
b.差分:未来时间点标签值减去过去时间点标签值
比如:

差分的阶数:二阶差分是两次一阶差分
差分的值滞后:往后移动几格
差分的作用:消除时间序列中的季节性、周期性、节假日等影响。
推导可得:
𝑦″ =(𝑦𝑡−𝑦𝑡−1)−(𝑦𝑡−1−𝑦𝑡−2)=(1−𝐵)^2𝑦𝑡
在该公式中的 𝑑也正是ARIMA模型中的超参数 𝑑,𝐵𝑦𝑡=𝑦𝑡−1,B也称为滞后运算
在实际使用中,我们经常将多步差分和高阶差分混用,最典型的就是在ARIMA模型建模之前:一般我们会先使用多步差分令数据满足ARIMA模型的基础建模条件,再在ARIMA模型中使用低阶的差分帮助模型更好地建模。例如,先对数据进行12步差分(相隔12步的值相减)、再在模型中进行1阶差分,这样可以令数据变得平稳的同时、又提取出数据中的周期性,极大地提升模型对数据的拟合精度。多步差分和高阶差分可以混用。
误区:只要数据具有趋势性/周期性,我们就可以利用差分运算将其消除
差分运算的确可以被应用到大部分有趋势性、周期性的时间序列数据上,但它不能解决所有时序数据的问题。首先,不是所有时序模型都要求数据是无趋势性、无周期性的状态,即便模型要求了,当差分运算不管用时,我们也可以使用其他方式消除数据的周期性和趋势性。
比如如果数据存在季节性,我们可以从每个观测值中减去当季所有观测点的均值,如果数据是月度数据,我们则可以让每月的观测值减去当月的均值,以此类推。如果数据随时间波动,形成类似于三角函数的波动,那我们可以让每个观测点除以周围的波动率,以消除峰值。总之,我们需要具体情况具体分析,同时积累时序数据处理的经验。
c.ARIMA对数据的基本要求:输入ARIMA的时间序列数据必须是平稳的(stationary)数据。
平稳定义:在一段时间序列中,无论时间如何变化,该序列的标签值的统计特性,
如均值、方差、协方差等属性都保持不变,那这段时间序列就是平稳的。这样过去才能预测未来。
怎么验证平稳:
绘制折线图/对时序数据进行统计并绘制直方图/做统计检验
流程:用ADF单位根检验来完成平稳性的判断——如果不平稳,则用差分运算消除数据中的趋势(如果不行就用取对数,减均值等方法)——输入ARIMA模型
ARIMA思考:ARIMA模型的假设与当代机器学习的假设一致:即时间并不是真正影响时序模型标签值的因子。这为我们后续在单变量和多变量时间序列上进行去时序化提供了一定的理论基础。
d.ACF与PACF:
自相关系数ACF衡量当前时间点上的观测值与任意历史时间点的观测值之间的相关性大小(不关心是以什么方式相关),而偏自相关系数PACF衡量当前时间点上的观测值与任意历史时间点的观测值之间的直接相关性的大小。
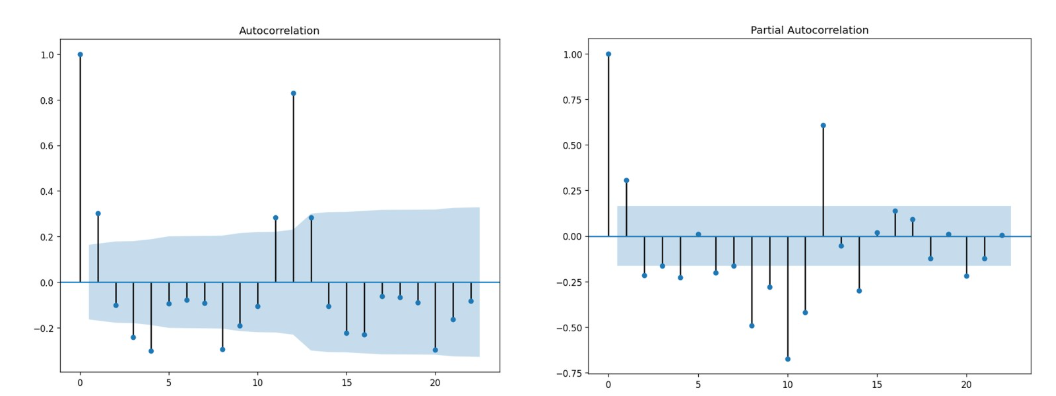
ACF图和PACF图的横坐标相同,都是不同的滞后程度,而纵坐标是当前滞后程度下序列的ACF和PACF值。
蓝色区域:当ACF/PACF值在蓝色区域之外时,我们就认为当前滞后程度下的ACF/PACF是统计上显著的值,即这个滞后程度下的序列之间的相关性很大程度上是信任的、不是巧合。
三种趋势:拖尾(图像呈现按规律衰减、自相关性呈现逐渐减弱的状态)、截尾和既不拖尾也不截尾。
如何计算:ACF可以是任何能够衡量两个变量/两个序列之间相关性的相关系数,最为常见的是直接使用皮尔逊相关系数。
e.用ACF、PACF进行超参数p、q、d的确定
对ARIMA模型来说,确定p和q的值有两层含义:
1)确定要使用的具体模型是AR,MA还是ARIMA?(即,p和q中任意一个值为0吗?)
2)如果是AR模型,p的值是多少?如果是MA模型,q的值是多少?如果是ARIMA模型,p和q分别是多少?
分类:
当ACF图像呈现拖尾、且PACF图像呈现截尾状态时,当前时间序列适用AR模型,且PACF截尾的滞后阶数就是超参数p的理想值
当PACF图像呈现拖尾、且ACF图像呈现截尾状态时,当前时间序列适用MA模型,且ACF截尾的滞后阶数就是超参数q的理想值(如下图所示,q=1)。
当ACF图像和PACF图像都呈现不呈现拖尾状态时,无论图像是否截尾,时间序列都适用于ARIMA模型,且此时ACF和PACF图像无法帮助我们确定p和q的具体值,但能确认p和q一定都不为0。
方法:当确定使用AR模型时,我们用PACF决定p值。当确定使用MA模型时,我们用ACF决定q值。当确定使用ARIMA模型时,ACF和PACF是失效的,并无作用。
当确定要使用ARIMA模型时,傻瓜式尝试确定p和q值。
d:从0 1 2 3 中选择方差最小、差分后数据噪音程度较低的阶数,尽量避免过差分。我们也可以对进行差分后的数据绘制ACF图像,如果滞后为1时ACF为负数,那大概率说明此时的高阶差分会导致过差分。
几个问题:
1.是否会出现ACF和PACF都拖尾、不截尾的情况?
几乎不会出现,如果是这样的情况,可以尝试先保证时间序列平稳后再绘制ACF和PACF。
2.如果ACF或PACF拖尾,但另一个指标不截尾(比如,没有任何滞后对应的值显著),无法选择p或q的值怎么办?
同样的,尝试令序列平稳后再绘制ACF和PACF。如果依然出现相同的情况,考虑使用[1,3]之间的正整数进行尝试。如果尝试失败,则考虑直接升级为ARIMA模型。
3.如果ACF或PACF中出现多个显著的值,如何选择截断处?
这种情况下往往选择第一个截断处作为p或q的值,当然你也可以尝试其他显著的点,但一般来说都是第一个截断处效果最好。
f.时序模型的评估指标
常用赤池信息准则(Akaike Information Criterion,AIC)、贝叶斯信息准则(Bayesian Information Criterion,BIC)、汉南-奎因信息准则(Hannan–Quinn information criterion,HQIC)等
其中最常用的AIC:
𝐴𝐼𝐶=−2𝑙𝑛(𝐿)+2𝑘
𝐿可以被认为是当前模型的积极性评估指标(即模型越好、该评估指标越高),大部分情况下我们使用的是统计学模型的极大似然估计结果(MLE,Maximum Likelihood Estimation),𝑘
则代表该模型中需要被估计的参数量,而𝑙𝑛的底数为自然底数𝑒。AIC越小越好
其他指标:BIC与AIC非常相似,它对模型参数量的惩罚高于AIC,因此BIC也是越低越好,经常和AIC一起组合使用。HQIC平时使用不多,但同样作为越低越好的指标,当模型的AIC和BIC高度相似时,我们可能会对比HQIC的值来评估模型。
注意:BIC与AIC非常相似,它对模型参数量的惩罚高于AIC,因此BIC也是越低越好,经常和AIC一起组合使用。HQIC平时使用不多,但同样作为越低越好的指标,当模型的AIC和BIC高度相似时,我们可能会对比HQIC的值来评估模型。
四.多变量时序模型:
1.多变量时间序列要做变形,如图:
图!!!!!!!!!!!!!!!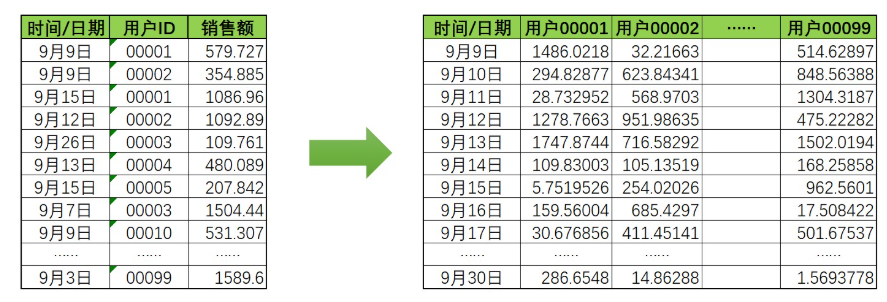
在多变量时间序列中,一个时间点下会需要求解多个值。并且,不同变量之间的值应该是会互相影响的,否则没有必要强行组成多变量时序数据,但单变量时序模型只能处理一个变量和自己历史数据的关系,却不能处理变量与变量之间的联系。
多变量时序模型的预测思路:所有变量的历史数据共同影响一个变量的未来。
解决思路:拓展ARIMA系列模型的假设,直接跨变量建立当前时间点上的值与所有历史时间点上的值的关联。
如下图所示,ARIMA模型假设一个变量的未来是由该变量的历史决定的,而我们可以将该假设拓展至所有变量:一个变量的未来是由该变量自己和所有其他变量的历史共同决定的。只要我们求解出未来的值和多个变量上的历史值之间的系数,就可以拟合变量与自身关系的同时、也拟合出变量之间的关系。大部分统计学模型使用了这样的思路。
2.VAR与VARMA
分别是在AR模型和ARIMA基础上把变量改为向量组得到
二.机器学习中的时序模型:用pmdarima实现
pmd自动化建模:仅考虑AIC最小的模型,不考虑其它稳定性等因素
# 自动化建模,只支持SARIMAX混合模型,不支持VARMAX系列模型
arima = pm.auto_arima(train, trace=True, #训练数据,是否打印训练过程?
error_action='ignore', suppress_warnings=True, #无视警告和错误
maxiter=5, #允许的最大迭代次数
seasonal=True, m=12 #是否使用季节性因子?如果使用的话,多步预测的步数是多少?
)
存在的问题:它会遍历所有pqd找到最佳模型,但这个结果往往无法满足统计学上的各类检验要求
同时我们也很容易发现,由于数据集分割的缘故,autoarima选择出的最佳模型可能无法被复现
交叉验证:
因为时间序列数据必须遵守“过去预测未来”、“训练中时间顺序不能打乱”等基本原则,因此传统机器学习中的k折交叉验证肯定无法使用。
在时间序列的世界中,有以下两种常见的交叉验证方式:滚动交叉验证(RollingForecastCV)和滑窗交叉验证(SlidingWindowForecastCV),当我们提到“时序交叉验证”时,一般特指滚动交叉验证。我们具体来看一下两种交叉验证的操作:
1.滚动交叉验证(RollingForecastCV)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
results = cross_validate(reg,Xtrain,Ytrain,cv=cv)
图!!!!!!!!!!!!!!!!
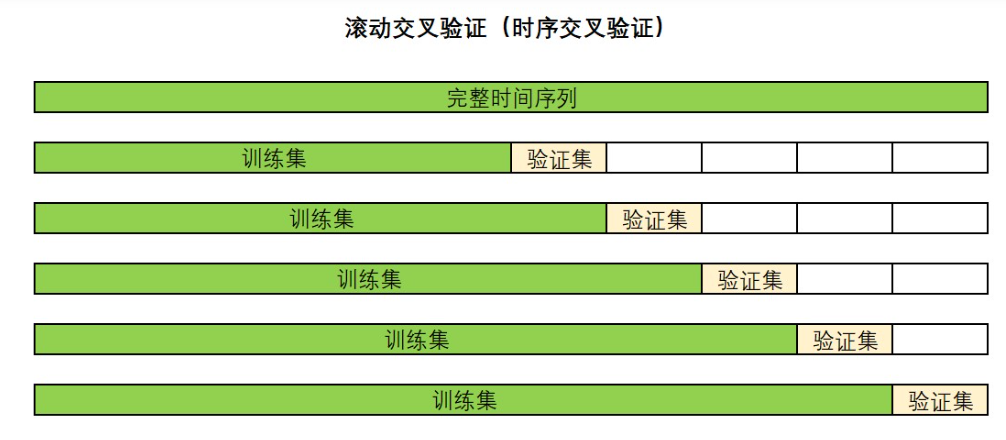 注意:普通K折交叉验证是由折数来控制的,但时序交叉验证其实是以单个样本为单位的。一般来说,时序交叉验证的验证集可以是多个时间点,也可以为单个时间点。
注意:普通K折交叉验证是由折数来控制的,但时序交叉验证其实是以单个样本为单位的。一般来说,时序交叉验证的验证集可以是多个时间点,也可以为单个时间点。
pmdarima.model_selection.RollingForecastCV(h=1, step=1, initial=None)
其中参数:
h:验证集中的样本数量,可以输入[1, n_samples]的整数。
step:训练集中每次增加的样本数量,必须为大于等于1的正整数。
initial:第一次交叉验证时的训练集样本量,如果不填写则按1/3处理。
注意:验证集不一定要完全放入训练集
存在的问题:前几次训练分数较差,不清楚到底是模型泛化能力不行导致的过拟合还是训练数据不够导致的欠拟合
因此希望让训练集和验证集样本大小都保持不变:滑窗交叉验证
2.滑窗交叉验证
pmdarima.model_selection.SlidingWindowForecastCV(h=1, step=1, window_size=None)

h:验证集中的样本数量,可以输入[1, n_samples]的整数。
step:每次向未来滑窗的样本数量,必须为大于等于1的正整数。
window_size:滑窗的尺寸大小,如果填写None则按照样本量整除5得到的数来决定。
#使用pm自带的数据集进行尝试
cv = model_selection.SlidingWindowForecastCV(h=1, step=1, window_size = 10)
cv_generator = cv.split(data)
next(cv_generator) #首次进行交叉验证时的数据分割状况
next(cv_generator) #第二次进行交叉验证时的数据分割状况
时序交叉验证不会返回训练集上的分数,同时pmdarima的预测功能predict中也不接受对过去进行预测。通常来说我们判断过拟合的标准是训练集上的结果远远好于测试集,但时序交叉验证却不返回训练集分数,因此时间序列数据无法通过对比训练集和测试集结果来判断是否过拟合。通常来说,验证集上的分数最佳的模型过拟合风险往往最小,因为当一个模型学习能够足够强、且既不过拟合又不欠拟合的时候,模型的训练集和验证集分数应该是高度接近的,所以验证集分数越好,验证集的分数就越可能更接近训练集上的分数。
相关文章:
时序模型介绍
一.整体介绍 1.单变量 vs 多变量时序数据 单变量就是只根据时间预测,多变量还要考虑用户 2.为什么不能用机器学习预测: a.时间不是影响标签的关键因素 b.时间与标签之间的联系过于弱/过于复杂,因此时序模型依赖于时间与时间的相关性来进行预…...

Java面试实战:从Spring到大数据的全栈挑战
Java面试实战:从Spring到大数据的全栈挑战 在某家知名互联网大厂,严肃的面试官正在面试一位名叫谢飞机的程序员。谢飞机以其搞笑的回答和对Java技术栈的独特见解而闻名。 第一轮:Spring与微服务的探索 面试官:“请你谈谈Spring…...

解决idea与springboot版本问题
遇到以下问题: 1、springboot3.2.0与jdk1.8 提示这个包org.springframework.web.bind.annotation不存在,但是pom已经引入了spring-boot-starter-web 2、Error:Cannot determine path to tools.jar library for 17 (D:/jdk17) 3、Error:(3, 28) java: …...
【第4章 图像与视频】4.4 离屏 canvas
文章目录 前言为什么要使用 offscreenCanvas为什么要使用 OffscreenCanvas如何使用 OffscreenCanvas第一种使用方式第二种使用方式 计算时长超过多长时间适合用Web Worker 前言 在 Canvas 开发中,我们经常需要处理复杂的图形和动画,这些操作可能会影响页…...

[AXI]如何验证AXI5原子操作
如何验证 AXI5 原子操作 摘要:在 UVM (Universal Verification Methodology) 验证环境中,验证 AXI5 协议的原子操作 (Atomic Operations) 是一项重要的任务,特别是在验证支持高并发和数据一致性的 SoC (System on Chip) 设计时。AXI5 引入了原…...
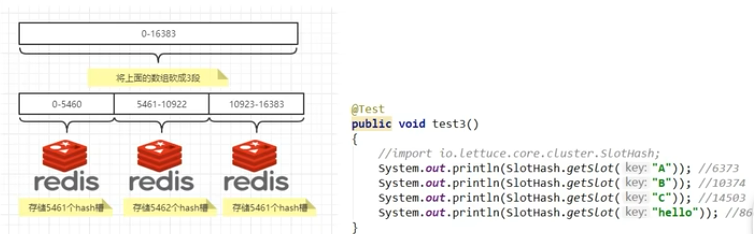
尚硅谷redis7 74-85 redis集群分片之集群是什么
74 redis集群分片之集群是什么 如果主机宕机,那么写操作就被暂时中断,后面就要由哨兵进行投票和选举。那么一瞬间若有大量的数据修改,由于写操作中断就会导致数据流失。 由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行…...

Android获取设备信息
使用java: List<TableMessage> dataListnew ArrayList<TableMessage>();//获取设备信息Hashtable<String,String> ht MyDeviceInfo.getDeviceAllInfo2(LoginActivity.this);for (Map.Entry<String, String> entry : ht.entrySet()) {String key entry…...

WPF的基础控件:布局控件(StackPanel DockPanel)
布局控件(StackPanel & DockPanel) 1 StackPanel的Orientation属性2 DockPanel的LastChildFill3 嵌套布局示例4 性能优化建议5 常见问题排查 在WPF开发中,布局控件是构建用户界面的基石。StackPanel和DockPanel作为两种最基础的布局容器&…...

apache的commons-pool2原理与使用详解
Apache Commons Pool2 是一个高效的对象池化框架,通过复用昂贵资源(如数据库连接、线程、网络连接)优化系统性能。 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击…...
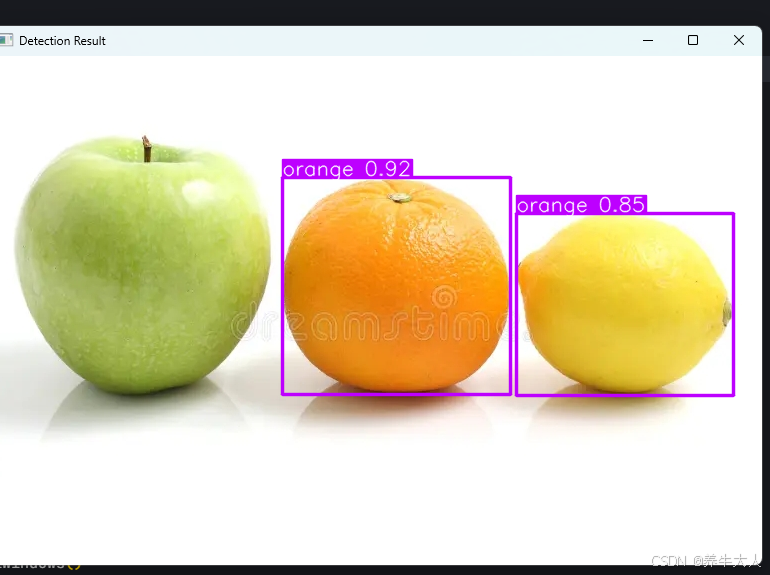
打印Yolo预训练模型的所有类别及对应的id
有时候我们可能只需要用yolo模型检测个别类别,并显示,这就需要知道id,以下代码可打印出 from ultralytics import YOLO# 加载模型 model YOLO(yolo11x.pt)# 打印所有类别名称及其对应的ID print(model.names) {0: person, 1: bicycle, 2: c…...
)
语法糖介绍(C++ Python)
语法糖(Syntactic Sugar)是编程语言中为了提升代码可读性和简洁性而设计的语法结构。它不改变语言的功能,但能让代码更易写和理解。以下是 C 和 Python 中常见的语法糖示例: C 中的常见语法糖 范围 for 循环(Range-bas…...

事务详解及面试常考知识点整理
事务详解及面试常考知识点整理 1. 什么是事务? **事务(Transaction)**是将多条 SQL 语句打包执行的操作单元,具有“一气呵成”的特性。就好比你要完成“把大象放进冰箱”这件事,一共分三步: 打开冰箱门把…...

设计模式26——解释器模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 解释器模式(Interp…...

在MDK中自动部署LVGL,在stm32f407ZGT6移植LVGL-8.3,运行demo,显示label
在MDK中自动部署LVGL,在stm32f407ZGT6移植LVGL-8.3 一、硬件平台二、实现功能三、移植步骤1、下载LVGL-8.42、MDK中安装LVGL-8.43、配置RTE4、配置头文件 lv_conf_cmsis.h5、配置lv_port_disp_template 四、添加心跳相关文件1、在STM32CubeMX中配置TIM7的参数2、使能…...
ArcGIS 与 HEC-RAS 协同:流域水文分析与洪水模拟全流程
技术点目录 洪水淹没危险性评价方法及技术介绍基于ArcGIS的水文分析基于HecRAS淹没模拟的洪水危险性评价洪水风险评价综合案例分析应用了解更多 —————————————————————————————————————————————————— 前言综述 洪水危险性及…...

树莓派设置静态ip 永久有效 我的需要设置三个 一个摄像头的 两个设备的
通过 systemd-networkd 配置 此方法适用于较新的Raspberry Pi OS版本,支持同时绑定多个IP地址到同一网卡,且配置清晰稳定。 1.禁用DHCP客户端对eth0的管理:编辑/etc/dhcpcd.conf文件,添加以下内容以忽略eth0接口的自动分配 sudo nano /etc…...

多模态大语言模型arxiv论文略读(九十九)
PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects ➡️ 论文标题:PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects ➡️ 论文作者:Junyi Li, Junfeng Wu, Weizhi Zhao, Song Bai, Xiang Bai ➡️ 研究机构…...
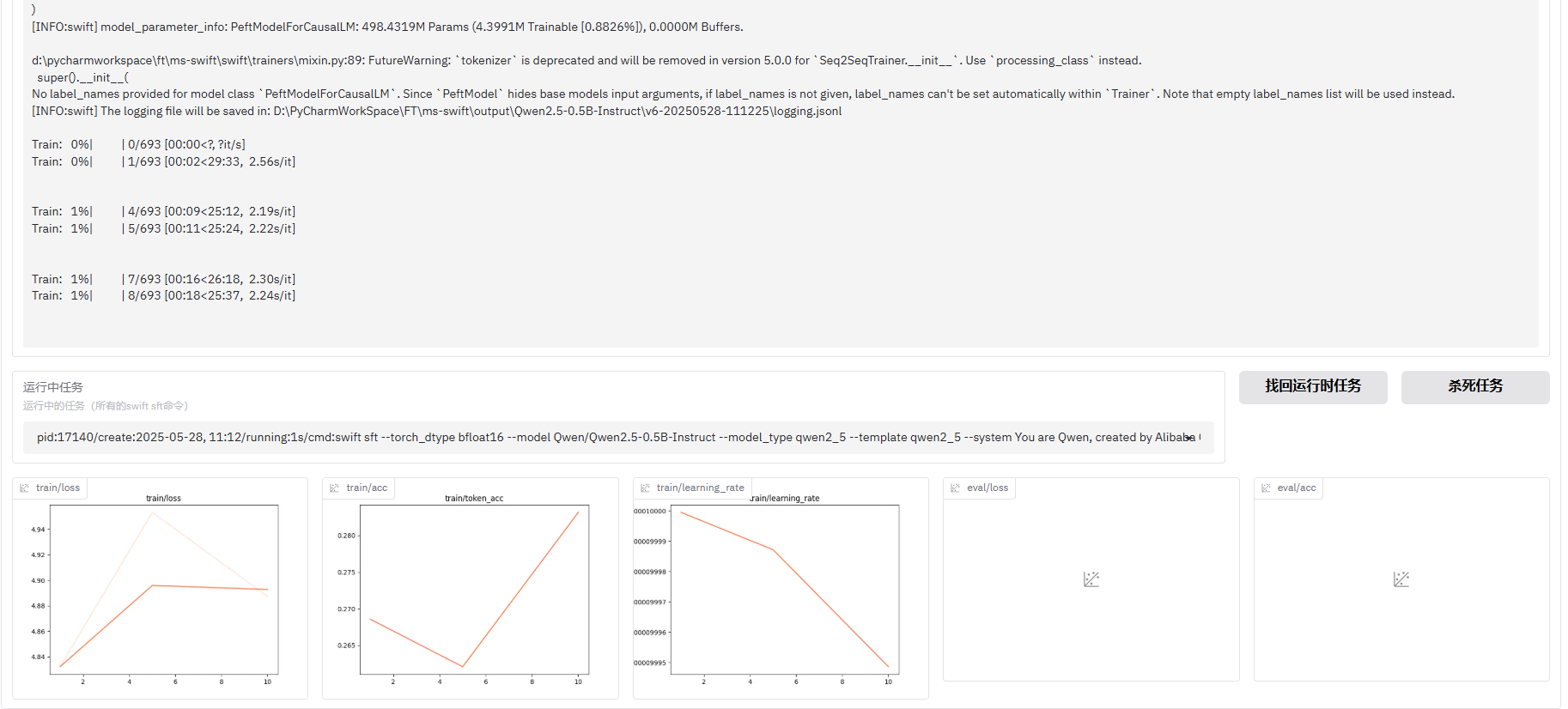
Fine-tuning:微调技术,训练方式,LLaMA-Factory,ms-swift
1,微调技术 特征Full-tuningFreeze-tuningLoRAQLoRA训练参数量全部少量极少极少显存需求高低很低最低模型性能最佳中等较好接近 LoRA模型修改方式无变化局部冻结插入模块量化插入模块多任务共享不便较便非常适合非常适合适合超大模型微调❌✅✅✅(最优&…...

vscode连接的linux服务器,上传项目至github
问题 已将项目整个文件夹拷贝到克隆下来的文件夹中,并添加了所有文件,并修改了commit -m,使用git push -u origin main提交的时候会出现vscode请求登录github,确定之后需要等待很久,也无果 原因 由于 远程服务器无法…...
XCTF-web-mfw
发现了git 使用GitHack下载一下源文件,找到了php源代码 <?phpif (isset($_GET[page])) {$page $_GET[page]; } else {$page "home"; }$file "templates/" . $page . ".php";// I heard .. is dangerous! assert("strpos…...

indel_snp_ssr_primer
indel标记使用 1.得到vcf文件 2.提取指定区域vcf文件并压缩构建索引 bcftools view -r <CHROM>:<START>-<END> input.vcf -o output.vcf bgzip -c all.filtered.indel.vcf > all.filtered.indel.vcf.gz tabix -p vcf all.filtered.indel.vcf.gz3.准备参…...

图论核心:深度搜索DFS 与广度搜索BFS
一、深度优先搜索(DFS):一条路走到黑的探索哲学 1. 算法核心思想 DFS(Depth-First Search)遵循 “深度优先” 原则,从起始节点出发,尽可能深入地访问每个分支,直到无法继续时回溯&a…...

Java 调用 HTTP 和 HTTPS 的方式详解
文章目录 1. HTTP 和 HTTPS 基础知识1.1 什么是 HTTP/HTTPS?1.2 HTTP 请求与响应结构1.3 常见的 HTTP 方法1.4 常见的 HTTP 状态码 2. Java 原生 HTTP 客户端2.1 使用 URLConnection 和 HttpURLConnection2.1.1 基本 GET 请求2.1.2 基本 POST 请求2.1.3 处理 HTTPS …...

Redis--基础知识点--28--慢查询相关
1 慢查询的原因 1.1 非命令数据相关原因 1.1.1 网络延迟 原因:客户端与 Redis 服务器之间的网络延迟可能导致客户端感知到的响应时间变长。 解决方案:优化网络环境 排查: 1.1.2 CPU 竞争 原因:Redis 是单线程的,…...

目标检测:YOLO 模型详解
目录 一、YOLO(You Only Look Once)模型讲解 YOLOv1 YOLOv2 (YOLO9000) YOLOv3 YOLOv4 YOLOv5 YOLOv6 YOLOv7 YOLOv8 YOLOv9 YOLOv10 YOLOv11 YOLOv12 其他变体:PP-YOLO 二、YOLO 模型的 Backbone:Focus 结构 三、…...

HDFS存储原理与MapReduce计算模型
HDFS存储原理 1. 架构设计 主从架构:包含一个NameNode(主节点)和多个DataNode(从节点)。 NameNode:管理元数据(文件目录结构、文件块映射、块位置信息),不存储实际数据…...

电机控制选 STM32 还是 DSP?技术选型背后的现实博弈
现在搞电机控制,圈里人都门儿清 —— 主流方案早就被 STM32 这些 Cortex-M 单片机给拿捏了。可要是撞上系统里的老甲方,技术认知还停留在诺基亚砸核桃的年代,非揪着 DSP 不放,咱也只能赔笑脸:“您老说的对,…...
.NET 开源工业视觉系统 OpenIVS 快速搭建自动化检测平台
前言 随着工业4.0和智能制造的发展,工业视觉在质检、定位、识别等场景中发挥着越来越重要的作用。然而,开发一个完整的工业视觉系统往往需要集成相机控制、图像采集、图像处理、AI推理、PLC通信等多个模块,这对开发人员提出了较高的技术要求…...

从0到1掌握Kotlin高阶函数:开启Android开发新境界!
简介 在当今的Android开发领域,Kotlin已成为开发者们的首选编程语言。其高阶函数特性更是为代码的编写带来了极大的灵活性和简洁性。本文将深入探讨Kotlin中的高阶函数,从基础概念到实际应用,结合详细的代码示例和mermaid图表,为你呈现一个全面且深入的学习指南。无论你是…...

【OSS】 前端如何直接上传到OSS 上返回https链接,如果做到OSS图片资源加密访问
使用阿里云OSS(对象存储服务)进行前端直接上传并返回HTTPS链接,同时实现图片资源的加密访问,可以通过以下步骤实现: 前端直接上传到OSS并返回HTTPS链接 设置OSS Bucket: 确保你的OSS Bucket已创建…...