Fine-tuning:微调技术,训练方式,LLaMA-Factory,ms-swift
1,微调技术
| 特征 | Full-tuning | Freeze-tuning | LoRA | QLoRA |
|---|---|---|---|---|
| 训练参数量 | 全部 | 少量 | 极少 | 极少 |
| 显存需求 | 高 | 低 | 很低 | 最低 |
| 模型性能 | 最佳 | 中等 | 较好 | 接近 LoRA |
| 模型修改方式 | 无变化 | 局部冻结 | 插入模块 | 量化+插入模块 |
| 多任务共享 | 不便 | 较便 | 非常适合 | 非常适合 |
| 适合超大模型微调 | ❌ | ✅ | ✅ | ✅(最优) |
1.1,Full-tuning
Full-tuning(全参数微调):对模型的全部参数进行微调。训练过程中,所有层的权重都会被更新。
加载预训练模型;
所有参数设为可训练;
使用下游任务的数据继续训练整个模型。
📈 优点:
最大化模型性能;
可适配大幅度任务转变;
简单直接,无结构变化。
📉 缺点:
资源消耗大:内存和显存使用高;
训练时间长;
在多任务场景下缺乏参数复用;
不适合频繁变更的小任务定制(每次都得保存整套参数)。
✅ 适用场景:
对模型效果要求极高;
拥有大量训练资源;
任务和原始预训练任务差别较大。
1.2,Freeze-tuning
Freeze-tuning(冻结微调):冻结预训练模型的部分或全部参数,仅微调某些新增模块(如分类头)或少数层。
加载预训练模型;
冻结大部分参数(如 Transformer encoder);
仅微调一小部分,如最后几层或添加的下游任务层。
📈 优点:
节省计算资源;
防止过拟合;
训练速度快;
对原始模型破坏小。
📉 缺点:
性能提升有限;
表达能力受限,难以适配大跨度任务;
调参难度大(决定哪些层冻结、哪些不冻结)。
✅ 适用场景:
轻量级部署;
任务与预训练相似;
快速原型验证。
1.3,LoRA
LoRA(Low-Rank Adaptation):使用低秩矩阵插入到原始模型权重的更新路径中,只训练这些额外的低秩参数,而不更新原始参数。
- 不修改原始权重矩阵
,而在其前后插入两个较小的可训练矩阵
,构造为:
其中:
- 进训练
📈 优点:
极大减少可训练参数数量(可减少至原来的 0.1%~1%);
内存占用显著降低;
适合多任务共享大模型,仅保存不同任务的低秩参数。
📉 缺点:
微调能力有限;
可能无法达到 Full-tuning 的最优精度;
在某些任务上收敛较慢。
✅ 适用场景:
多任务微调(如一个大模型服务多个业务);
边缘设备或存储受限场景;
希望在多个微调版本之间快速切换。
1.4,QLoRA
QLoRA(Quantized LoRA):在 LoRA 的基础上,将原始模型进行 量化(Quantization)(通常是 4-bit 量化),结合 LoRA 插件模块进行微调。
使用 4-bit 量化将大模型压缩到极小显存占用;
原始权重被量化,但仍然保持冻结状态;
LoRA 模块保持 float32/float16 精度进行训练;
利用量化感知训练技术减少精度损失。
📈 优点:
显存占用极低(单卡 24GB GPU 可微调 65B 模型);
准确率接近 LoRA;
支持 CPU/GPU 微调;
无需对全模型解冻,训练负担极小。
📉 缺点:
量化带来一定的数值不稳定性;
性能略逊于全精度微调;
对部署系统需支持混合精度和量化运算。
✅ 适用场景:
极端显存受限的环境;
想在消费级设备(如笔记本、消费级 GPU)微调大模型;
用于实验、原型开发和模型压缩部署。
2,训练方式
| 阶段 | 是否涉及标签 | 是否使用人类偏好 | 是否使用强化学习 | 典型方法/目标 |
|---|---|---|---|---|
| Pre-Training | ❌ | ❌ | ❌ | 学习语言通用能力 |
| Supervised Fine-Tuning | ✅ | ❌ | ❌ | 执行指令、完成任务 |
| Reward Modeling | ✅(对比标签) | ✅ | ❌ | 构造奖励函数 |
| PPO | ❌ | ✅ | ✅ | 提升人类偏好表现 |
| DPO | ✅(对比标签) | ✅ | ❌(间接) | 更高效的人类偏好训练 |
| KTO | ✅(对比标签) | ✅ | ❌ | 用 KL 优化拟合偏好分布 |
| ORPO | ✅ | ✅ | ❌ | 离线优化,有效融合监督与偏好学习 |
| SimPO | ✅ | ✅ | ❌ | 极简偏好优化方式 |
2.1,Pre-Training
Pre-Training(预训练):预训练是整个语言模型生命周期的第一阶段,其目标是让模型掌握语言的基本结构、语义关系和常识知识。
使用大规模无标签语料(如网页、图书、维基百科等);
模型通常采用自监督学习目标,如:
Masked Language Modeling(BERT 系列):预测被遮盖的词;
Causal Language Modeling(GPT 系列):预测下一个词。
目标:学习词法、句法、语义、语言结构等通用能力,为下游任务打下基础。
特点:
数据量最大;
训练时间最长;
不依赖人工标注。
2.2,Supervised Fine-Tuning
Supervised Fine-Tuning(有监督微调):在预训练模型基础上,使用有标签的数据集对模型进行微调,使其适配特定任务,如问答、摘要、分类等。
⚙️ 方法:
数据来源于人工标注或规则生成;
常用损失函数为 Cross-Entropy;
多用于 Instruct 模型训练(例如指令跟随数据,如 "请翻译以下句子")。
目标:让模型“听得懂”任务指令,具备基础的任务执行能力。
特点:
通常比预训练快;
微调数据越高质量,模型行为越稳定;
是 RLHF 流程的第一步。
2.3,Reward Modeling
Reward Modeling(奖励建模):Reward Modeling 是强化学习前的关键步骤,用于训练一个奖励模型(Reward Model, RM),模拟人类偏好。
输入:模型输出的多个候选答案;
标签:由人类评审者对答案进行排序或打分;
模型学习:预测哪个答案更好(即更符合人类偏好)。
目标:用一个可训练的模型替代人工打分,供后续强化学习优化使用。
特点:
训练的是一个新模型,不是语言模型本体;
训练数据来源于人类偏好对比;
是 RLHF(强化学习人类反馈)流程的桥梁环节。
2.4,PPO Training
PPO Training(Proximal Policy Optimization):PPO 是一种常见的强化学习算法,广泛用于 LLM 微调中的 RLHF 阶段,使模型生成更符合人类期望的响应。
使用奖励模型作为环境;
模型作为策略网络,尝试生成更高分的回答;
引入“剪切项”防止训练不稳定。
目标:在不显著破坏原模型的语言能力前提下,优化生成结果的人类偏好分数。
特点:
引入强化学习思想;
训练复杂、稳定性要求高;
是 ChatGPT 等对齐性模型的重要步骤。
2.5,DPO Training
DPO Training(Direct Preference Optimization):DPO 是一种无需训练奖励模型的新方法,直接优化模型使其偏向于人类更喜欢的回答,是对 RLHF 的简化。
直接用人类偏好对比(好 vs 差)训练语言模型;
不需要额外的 Reward Model;
目标函数基于“人类偏好答案比非偏好答案概率高”。
目标:简化 RLHF 流程,提高训练效率和稳定性。
特点:
更容易实现;
效果接近 PPO;
越来越受研究社区关注。
2.6,KTO Training
KTO Training(Kullback-Leibler Preference Optimization):KTO 是一种在 DPO 基础上发展的方法,通过 KL 散度更精确地拟合人类偏好分布,进一步提升模型对齐性。
构建基于 KL 散度的目标函数;
训练使模型生成的分布更接近于偏好更高的样本。
目标:在对齐能力和训练效率之间取得更好的平衡。
特点:
相较 DPO 提供更细粒度的控制;
数学上更严谨;
适用于人类偏好数据不充分的情况。
2.7,ORPO Training
ORPO Training(Offline RL with Preference Optimization):ORPO 是一种使用离线数据进行偏好优化的方法,融合了监督学习和偏好强化学习的优势。
不依赖交互式环境;
利用已存在的偏好标注对模型进行偏好学习;
通常和行为克隆(Behavior Cloning)结合使用。
目标:避免在线 RL 的不稳定性,使用偏好数据离线优化生成行为。
特点:
更易部署;
更稳定;
适合偏好数据多但不能实时交互的场景。
2.8,SimPO Training
SimPO Training(Simplified Preference Optimization) :SimPO 是一种对 DPO 的进一步精简版,采用更简单的结构实现相近的偏好优化效果。
利用简单的正负样本对比训练;
可看作是 DPO 的轻量变种。
目标:以极简实现替代复杂 RL 训练流程,适用于低资源环境。
特点:
非常轻量;
效果仍然优于纯监督微调;
实现快速、适配性强。
3,LLaMA-Factory
参考:
3步轻松微调Qwen3,本地电脑就能搞,这个方案可以封神了!【喂饭级教程】
12 大模型学习——LLaMA-Factory微调_llama factory-CSDN博客
3.1,项目安装
依赖安装:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]" --no-build-isolation必需项 至少 推荐 python 3.9 3.10 torch 2.0.0 2.6.0 torchvision 0.15.0 0.21.0 transformers 4.45.0 4.50.0 datasets 2.16.0 3.2.0 accelerate 0.34.0 1.2.1 peft 0.14.0 0.15.1 trl 0.8.6 0.9.6Gradio 启动:
llamafactory-cli webui
模型名称:
- Base 版本(如 Qwen3-1.7B-Base)
- 基础预训练模型
- 没有经过指令微调
- 适合继续搞预训练或从头开始指令微调
- 通常情况下输出质量不如 Instruct 版本
- Instruct 版本(如 Qwen3-1.7B-Instruct)
- 经过指令微调的模型
- 更适合直接对话和指令遵循
- 已经具备基本的对话能力
- 更适合用来进一步微调
微调方法:lora
检查点路径:在长时间训练大模型的时候会经常用,主要作用是把训练过程中的阶段性结果进行保存,这里是设置指定的保存地址的。这样如果训练过程意外中断,可以从检查点开始继续训练,不用从头再开始训练。若不设置,则默认保存在 LLaMA-Factory 的 /saves文件中
微调前可以加载模型 进入chat模型,看模型能否正常加载。
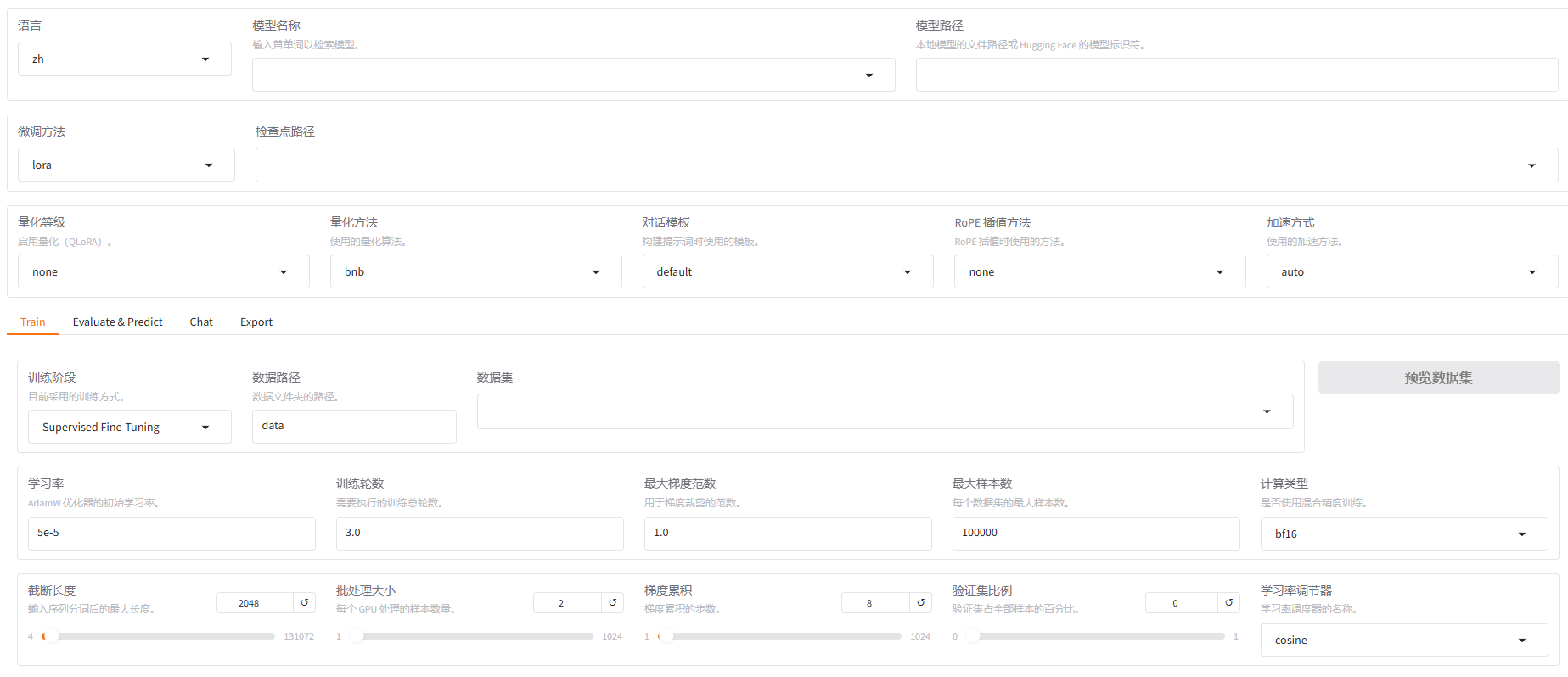
3.2,量化
【量化等级】用于指定是否对模型权重进行量化以减少内存使用:
- none:不启用量化,使用原始全精度模型(如 FP16 或 BF16)。
- 8:8比特量化(int8),在大多数场景下能提供不错的精度与性能平衡。
- 4:4比特量化(int4),更大幅度地压缩模型大小,适合资源受限设备,精度会有所下降。
👉 QLoRA(Quantized LoRA)结合了量化和LoRA(低秩适配)技术,常用于在消费级显卡上进行大模型微调。
【量化方法】用于指定具体的量化实现库或算法:
- bnb:BitsAndBytes(Meta 的实现),支持 int8 和 int4,兼容 HuggingFace。
- hqq:HQQ(High Quality Quantization),一种高保真度的量化方法,强调量化后精度保持。
- eetq:EETQ(Efficient and Effective Transformer Quantization),侧重性能与部署效率。
【对话模板】用于指定对话格式模板,影响 prompt 格式化,适配不同训练数据结构。
【RoPE 插值方法】用于扩展模型上下文长度:
- none:不启用插值,只使用默认的 RoPE。
- linear:线性插值法,广泛用于上下文扩展(如从 2K 扩展到 8K、32K)。
- yam:Yarn-Aware Method,Yarn 插值的衍生方法。
- llama3:LLaMA3 模型使用的插值方案,已被验证性能优秀。
- dynatic:动态调整的插值方案(Dynamic RoPE Interpolation),提升长上下文效果。
【加速方法】
- auto:自动选择最优的加速方法。
- flashattn2:FlashAttention v2,显著提高 Transformer 中注意力模块的速度和效率。
- unsloth:用于极高效训练,尤其配合 LoRA 等技术,适用于 consumer GPU。
- liger_kernel:专为 NVIDIA GPU 优化的 kernel 级推理加速,速度极快。

3.3,数据集
llama-factory目前只支持两种格式的数据集:Alpaca格式和Sharegpt格式
Alpaca 格式(单单轮指令跟随任务):每条数据是一个 JSON 对象。
{"instruction": "请写一篇关于气候变化的短文。","input": "","output": "气候变化是指由于自然因素和人类活动导致的气候系统的长期变化..." }ShareGPT 格式(多轮对话训练):通常是一个列表,每条数据是一个对话(dialogue),每个对话是多轮消息的列表。
[{"conversations": [{"from": "human","value": "你好,你是谁?"},{"from": "gpt","value": "你好!我是由OpenAI训练的大语言模型,很高兴为你服务。"},{"from": "human","value": "你能告诉我关于机器学习的基础知识吗?"},{"from": "gpt","value": "当然可以!机器学习是人工智能的一个子领域,主要研究如何让计算机通过数据自动学习和改进..."}]} ]【甄嬛数据集】魔搭社区
modelscope download --dataset kmno4zx/huanhuan-chat
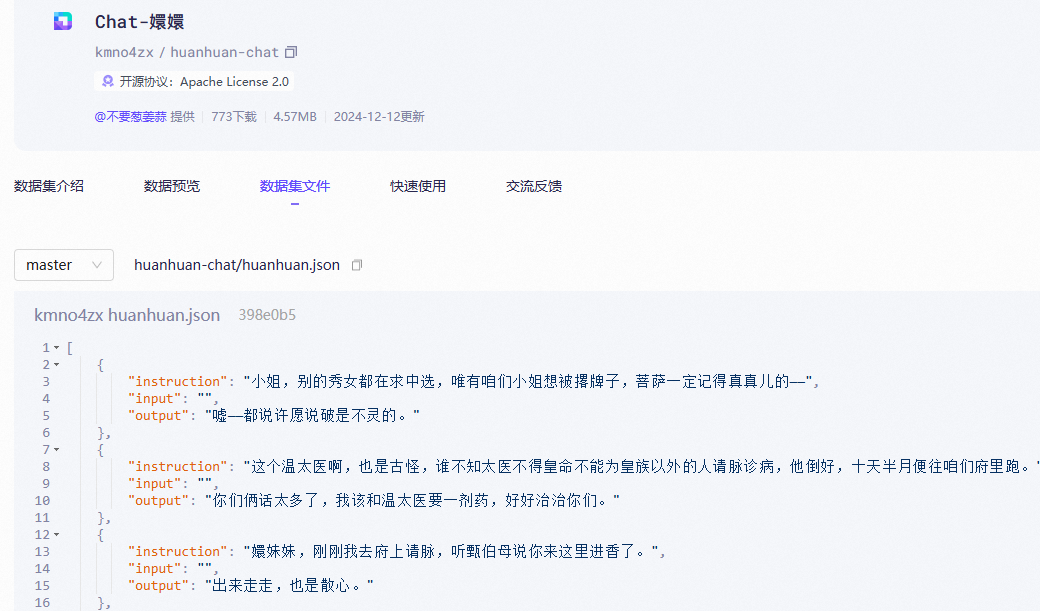
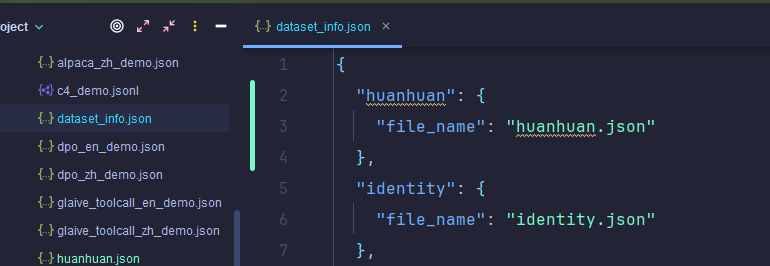
【适配 LLaMA】
- 将下载的数据集放在项目根目录的data文件夹下:
- 修改:dataset_info.json
- 保存之后,webui那边会实时更新,不需要重启


3.4,训练
学习率:可以不用修改
训练轮数:可以选择1轮,会快一些(如果后面发现效果不理想,可以多训练几轮),我这里最终选择了3轮,因为我发现仅1轮效果不佳。
最大梯度范数:防止梯度爆炸的一种技术,称为 梯度裁剪(Gradient Clipping)。
最大样本数:根据数据集大小和训练需求设置。主要是防止数据量过大导致的内存溢出问题
计算类型:
- fp16:GPU 推理、训练等,NVIDIA 的 Tensor Core 使用该格式(混合精度训练)。节省内存带宽,能更快训练神经网络(尤其是 CNN)。
- bf16:精度虽然比 fp16 更低,但动态范围更大,不易梯度爆炸/消失,更适合在 大模型训练 中替代 fp32。
截断长度:由于我们的数据集都是一些短问答,可以把截断长度设置小一点,为1024(默认是2048)
批处理大小:每个 GPU 处理的样本数量。
梯度累计:设置为4
验证集比例:验证集占全部样本的百分比。
学习率调节器:学习率调度器的名称。

日志间隔:多久输出日志信息
保存问题:多久保存权重,这里不是按轮次保存
预热步数:是学习率预热采用的步数,通常设置范围在2-8之间,这里配置4。

lora秩越大(可以看作学习的广度),学习的东西越多,微调之后的效果可能会越好,但是也不是越大越好。太大的话容易造成过拟合(书呆子,照本宣科,不知变通)。
lora缩放系数(可以看作学习强度),越大效果可能会越好,对于一些用于复杂场景的数据集可以设置更大一些,简单场景的数据集可以稍微小一点。
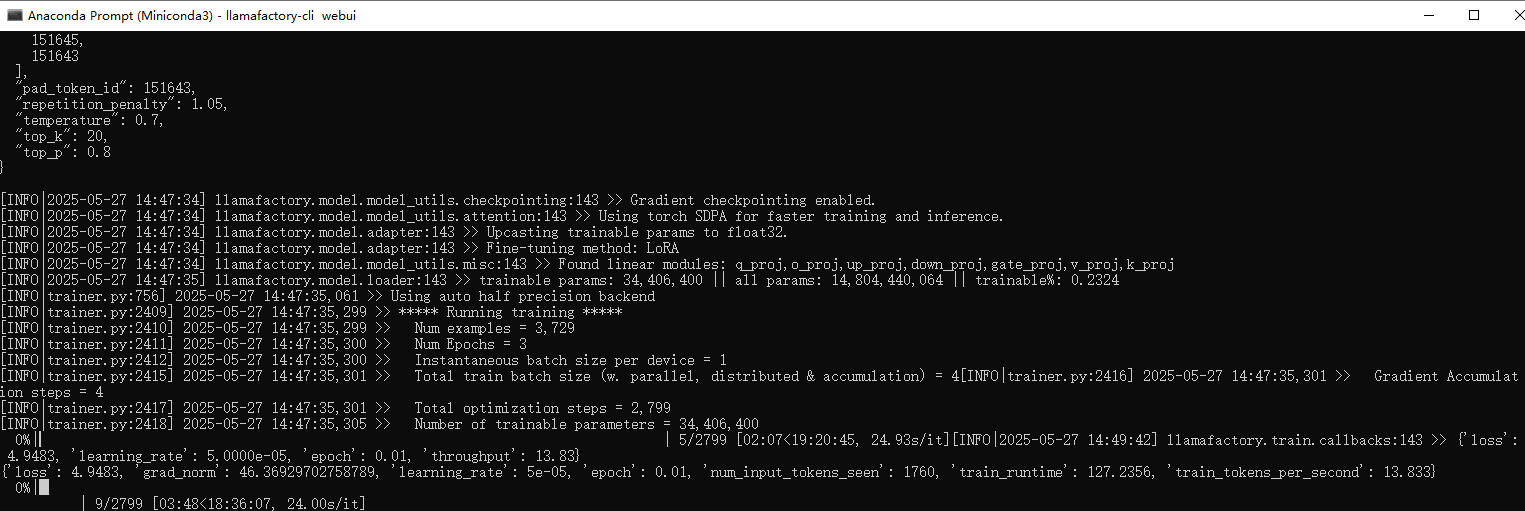
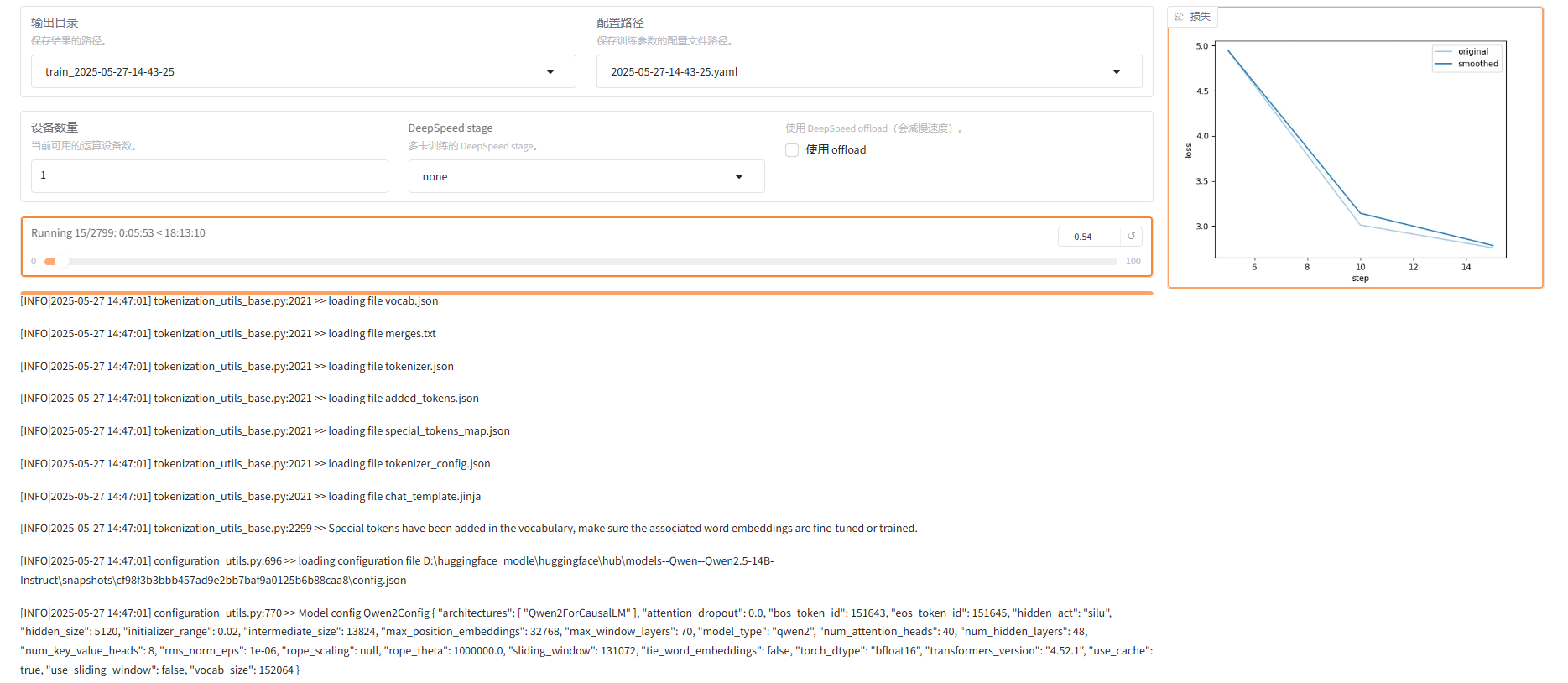
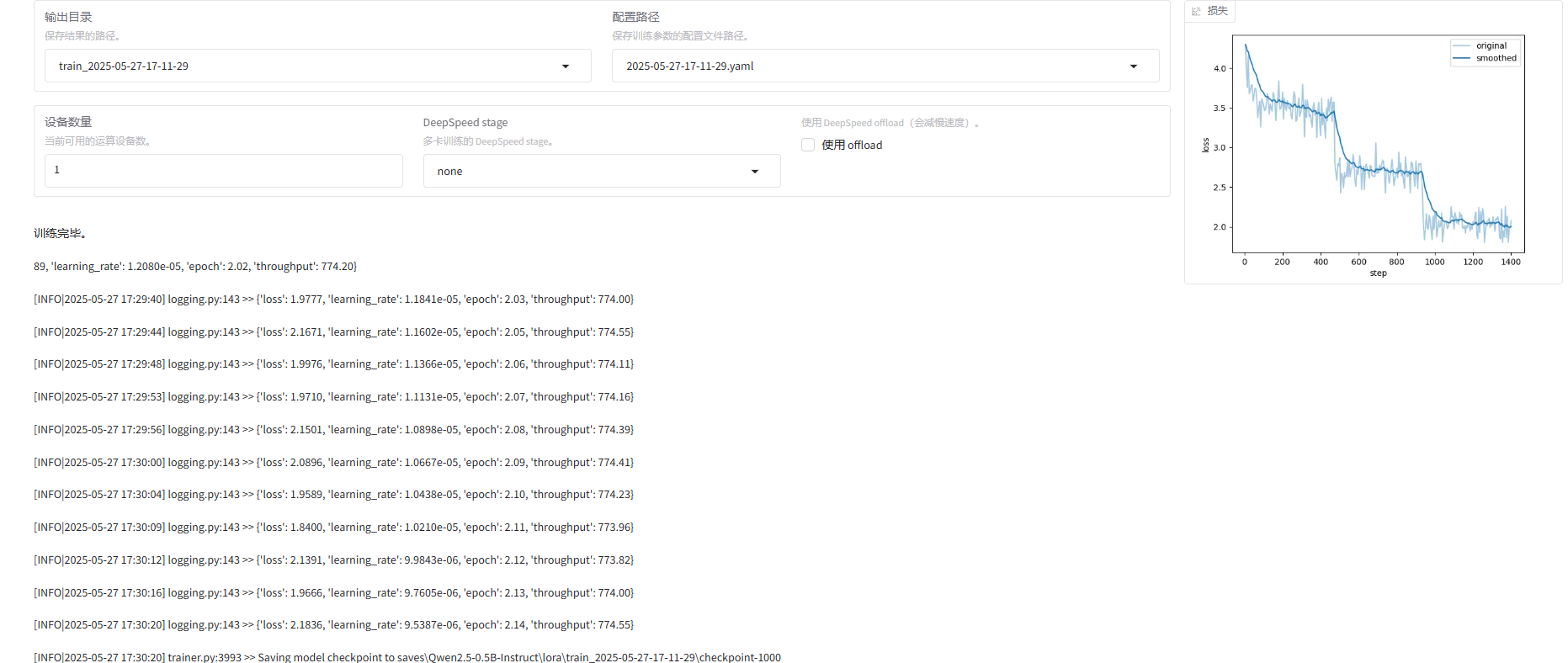
一轮接近24小时,在个人设备考虑微调小参数模型,这里14B的耗时实在是太久了。
训练结束:
如果想重新微调,记得改一下下面两个值


3.5,测试
微调成功后,在检查点路径这里,下拉可以选择刚刚微调好的模型:
把窗口切换到chat,点击加载模型:


【模型导出】切换到export,填写导出目录 /app/output/qwen2-0.5b-huanhuan
D:\app\output\qwen2-0.5b-huanhuanfrom modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "D:\\app\\output\\qwen2-0.5b-huanhuan"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "你好啊,请问你是谁" messages = [{"role": "system", "content": "你是甄嬛"},{"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512 ) generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response) ====================== 我是甄嬛,家父是大理寺少卿甄远道。
4,ms-swift
4.1,项目安装
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .swift web-ui【报错】ValueError: Cannot parse cmd line: cmd:D:\Miniconda3\envs\LLaMA\python.exe
【解决】关闭后重启就可以,具体原因未知。
【报错】ImportError: FlashAttention2 has been toggled on, but it cannot be used due to the following error: the package flash_attn seems to be not installed. Please refer to the documentation of https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2 to install Flash Attention 2.
【解决】下载 windows 版本 https://github.com/kingbri1/flash-attention/releases
4.2,参数介绍
【数据集】
【报错】All the data files must have the same columns, but at some point there are 3 new columns ({'input', 'output', 'instruction'}) and 1 missing columns ({'default'}).
【解决】ms-swift 跟 LLaMA 不同,数据需要直接指定到文件!
D:\modelscope_cache\datasets\kmno4zx\huanhuan-chat\huanhuan.json

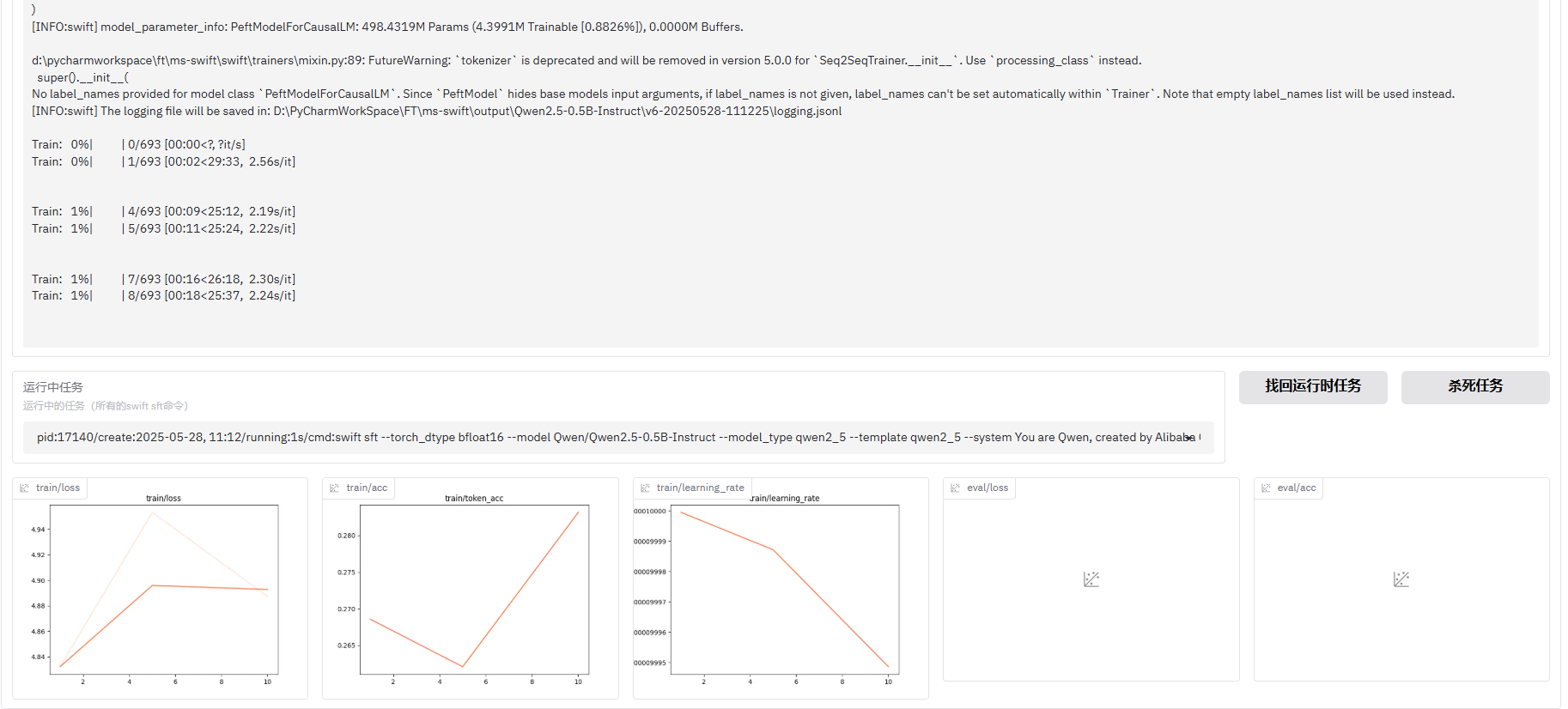
4.3,训练
相关文章:
Fine-tuning:微调技术,训练方式,LLaMA-Factory,ms-swift
1,微调技术 特征Full-tuningFreeze-tuningLoRAQLoRA训练参数量全部少量极少极少显存需求高低很低最低模型性能最佳中等较好接近 LoRA模型修改方式无变化局部冻结插入模块量化插入模块多任务共享不便较便非常适合非常适合适合超大模型微调❌✅✅✅(最优&…...

vscode连接的linux服务器,上传项目至github
问题 已将项目整个文件夹拷贝到克隆下来的文件夹中,并添加了所有文件,并修改了commit -m,使用git push -u origin main提交的时候会出现vscode请求登录github,确定之后需要等待很久,也无果 原因 由于 远程服务器无法…...
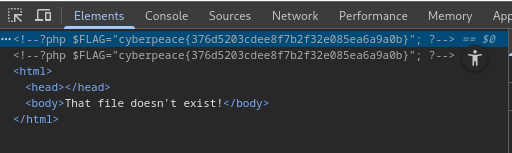
XCTF-web-mfw
发现了git 使用GitHack下载一下源文件,找到了php源代码 <?phpif (isset($_GET[page])) {$page $_GET[page]; } else {$page "home"; }$file "templates/" . $page . ".php";// I heard .. is dangerous! assert("strpos…...

indel_snp_ssr_primer
indel标记使用 1.得到vcf文件 2.提取指定区域vcf文件并压缩构建索引 bcftools view -r <CHROM>:<START>-<END> input.vcf -o output.vcf bgzip -c all.filtered.indel.vcf > all.filtered.indel.vcf.gz tabix -p vcf all.filtered.indel.vcf.gz3.准备参…...

图论核心:深度搜索DFS 与广度搜索BFS
一、深度优先搜索(DFS):一条路走到黑的探索哲学 1. 算法核心思想 DFS(Depth-First Search)遵循 “深度优先” 原则,从起始节点出发,尽可能深入地访问每个分支,直到无法继续时回溯&a…...

Java 调用 HTTP 和 HTTPS 的方式详解
文章目录 1. HTTP 和 HTTPS 基础知识1.1 什么是 HTTP/HTTPS?1.2 HTTP 请求与响应结构1.3 常见的 HTTP 方法1.4 常见的 HTTP 状态码 2. Java 原生 HTTP 客户端2.1 使用 URLConnection 和 HttpURLConnection2.1.1 基本 GET 请求2.1.2 基本 POST 请求2.1.3 处理 HTTPS …...

Redis--基础知识点--28--慢查询相关
1 慢查询的原因 1.1 非命令数据相关原因 1.1.1 网络延迟 原因:客户端与 Redis 服务器之间的网络延迟可能导致客户端感知到的响应时间变长。 解决方案:优化网络环境 排查: 1.1.2 CPU 竞争 原因:Redis 是单线程的,…...

目标检测:YOLO 模型详解
目录 一、YOLO(You Only Look Once)模型讲解 YOLOv1 YOLOv2 (YOLO9000) YOLOv3 YOLOv4 YOLOv5 YOLOv6 YOLOv7 YOLOv8 YOLOv9 YOLOv10 YOLOv11 YOLOv12 其他变体:PP-YOLO 二、YOLO 模型的 Backbone:Focus 结构 三、…...

HDFS存储原理与MapReduce计算模型
HDFS存储原理 1. 架构设计 主从架构:包含一个NameNode(主节点)和多个DataNode(从节点)。 NameNode:管理元数据(文件目录结构、文件块映射、块位置信息),不存储实际数据…...

电机控制选 STM32 还是 DSP?技术选型背后的现实博弈
现在搞电机控制,圈里人都门儿清 —— 主流方案早就被 STM32 这些 Cortex-M 单片机给拿捏了。可要是撞上系统里的老甲方,技术认知还停留在诺基亚砸核桃的年代,非揪着 DSP 不放,咱也只能赔笑脸:“您老说的对,…...
.NET 开源工业视觉系统 OpenIVS 快速搭建自动化检测平台
前言 随着工业4.0和智能制造的发展,工业视觉在质检、定位、识别等场景中发挥着越来越重要的作用。然而,开发一个完整的工业视觉系统往往需要集成相机控制、图像采集、图像处理、AI推理、PLC通信等多个模块,这对开发人员提出了较高的技术要求…...

从0到1掌握Kotlin高阶函数:开启Android开发新境界!
简介 在当今的Android开发领域,Kotlin已成为开发者们的首选编程语言。其高阶函数特性更是为代码的编写带来了极大的灵活性和简洁性。本文将深入探讨Kotlin中的高阶函数,从基础概念到实际应用,结合详细的代码示例和mermaid图表,为你呈现一个全面且深入的学习指南。无论你是…...

【OSS】 前端如何直接上传到OSS 上返回https链接,如果做到OSS图片资源加密访问
使用阿里云OSS(对象存储服务)进行前端直接上传并返回HTTPS链接,同时实现图片资源的加密访问,可以通过以下步骤实现: 前端直接上传到OSS并返回HTTPS链接 设置OSS Bucket: 确保你的OSS Bucket已创建…...
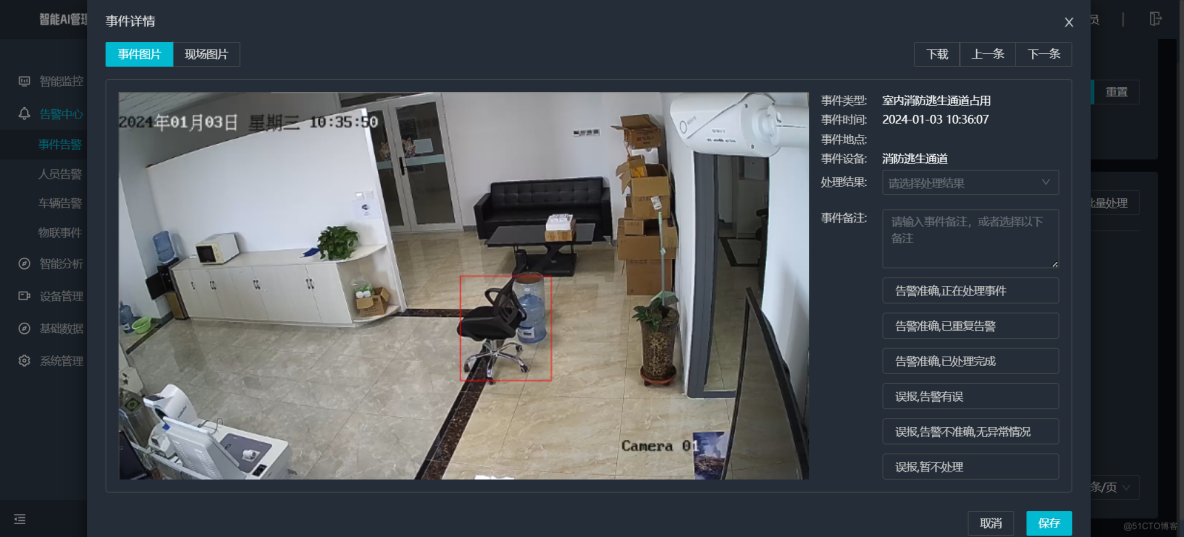
AI智能分析网关V4室内消防逃生通道占用检测算法打造住宅/商业/工业园区等场景应用方案
一、方案背景 火灾严重威胁生命财产安全,消防逃生通道畅通是人员疏散的关键。但现实中通道被占用、堵塞现象频发,传统人工巡查监管效率低、不及时。AI智能分析网关V4结合消防逃生通道占用算法,以强大的图像识别和数据分析能力,…...

商城前端监控体系搭建:基于 Sentry + Lighthouse + ELK 的全链路监控实践
在电商行业,用户体验直接关乎转化率和用户留存。一个页面加载延迟1秒可能导致7%的订单流失,一次未捕获的前端错误可能引发用户信任危机。如何构建一套高效的前端监控体系,实现错误实时追踪、性能深度优化与数据可视化分析?本文将揭…...

Kotlin 中的数据类型有隐式转换吗?为什么?
在 Kotlin 中,基本数据类型没有隐式转换。主要出于安全性和明确性的考虑。 1 Kotlin 的显式类型转换规则 Kotlin 要求开发者显式调用转换函数进行类型转换, 例如: val a: Int 10 val b: Long a.toLong() // 必须显式调用 toLong() // 错…...

基于 HTTP 的邮件认证深入解读 ngx_mail_auth_http_module
一、模块启用与示例配置 mail {server {listen 143; # IMAPprotocol imap;auth_http http://auth.local/auth;# 可选:传递客户端证书给认证服务auth_http_pass_client_cert on;auth_http_timeout 5s;auth_http_header X-Auth-Key "shared_se…...
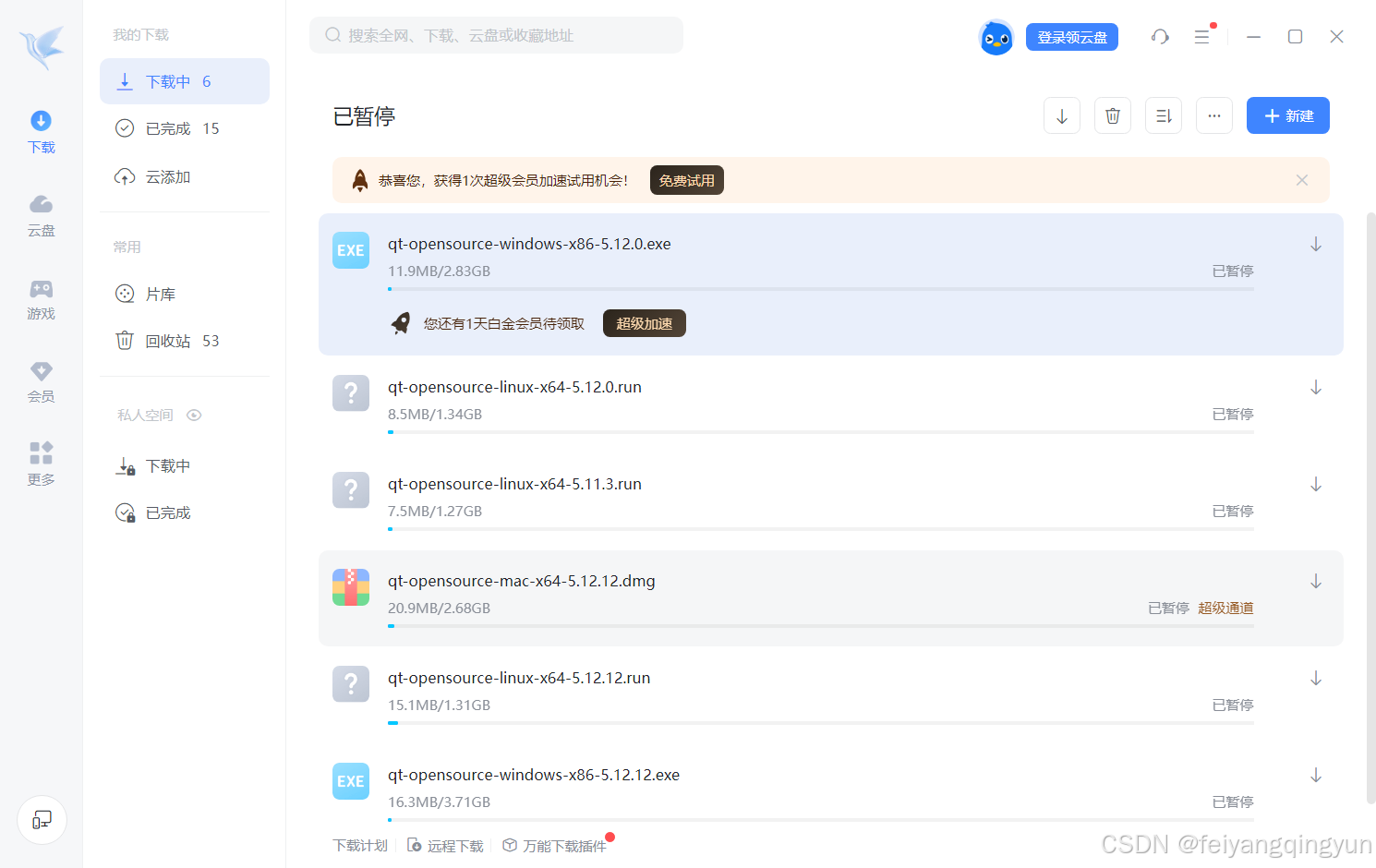
关于无法下载Qt离线安装包的说明
不知道出于什么原因考虑,Qt官方目前不提供离线的安装包下载,意味着网上各种文章提供的各种下载地址都失效了,会提示Download from your IP address is not allowed,当然目前可以在线安装,但是据说只提供了从5.15开始的…...

Java开发经验——阿里巴巴编码规范实践解析4
摘要 本文主要介绍了阿里巴巴编码规范中关于日志处理的相关实践解析。强调了使用日志框架(如 SLF4J、JCL)而非直接使用日志系统(如 Log4j、Logback)的 API 的重要性,包括解耦日志实现、统一日志调用方式等好处。同时&…...
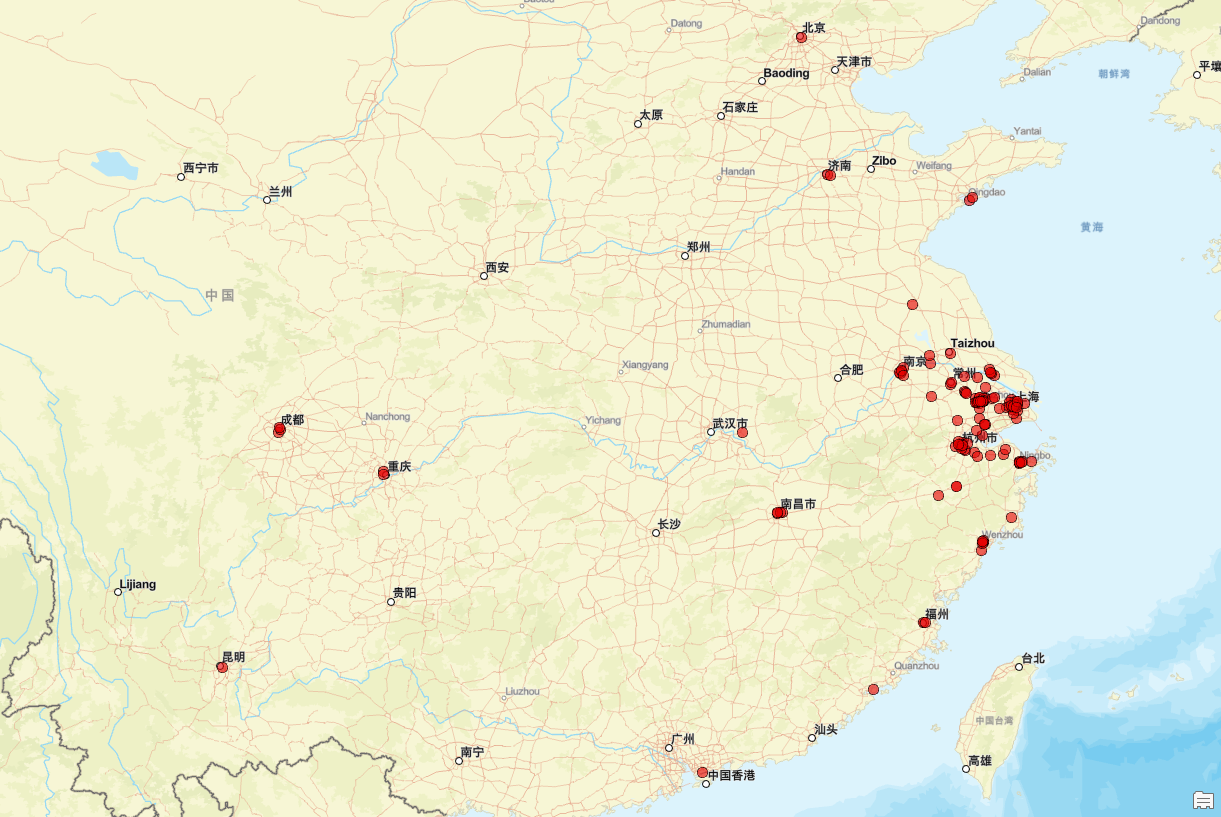
HTML应用指南:利用GET请求获取全国捞王锅物料理门店位置信息
随着新零售业态的快速发展,门店位置信息的获取变得越来越重要。作为知名中式餐饮品牌之一,捞王锅物料理自2009年创立以来,始终致力于为消费者提供高品质的锅物料理与贴心的服务体验。经过多年的发展,捞王在全国范围内不断拓展门店…...
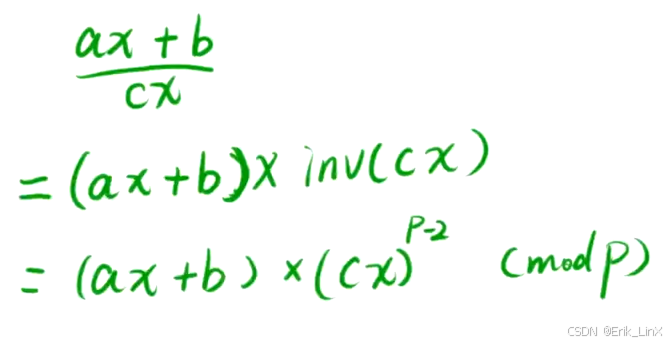
算法日记32:埃式筛、gcd和lcm、快速幂、乘法逆元
一、埃式筛(计算质数) 1.1、概念 1.1.1、在传统的计算质数中,我们采用单点判断,即判断(2~sqrt(n))是否存在不合法元素,若存在则判否,否则判是 1.1.2、假设,此时我们需要求1~1000的所有质数&am…...

黑马点评-分布式锁Lua脚本
文章目录 分布式锁Redis setnxredis锁误删Lua脚本 分布式锁 当我们的项目服务器不只是一台(单体),而是部署在多态服务器上(集群/分布式),同样会出现线程安全问题。不同服务器内部有不同的JVM,每…...

P7-大规模语言模型分布式训练与微调框架调研文档
1. 引言 随着大语言模型(LLMs)在自然语言处理(NLP)、对话系统、文本生成等领域的广泛应用,分布式训练和高效微调技术成为提升模型性能和部署效率的关键。分布式训练框架如 Megatron-LM 和 DeepSpeed 针对超大规模模型…...
机械师安装ubantu双系统:三、GPT分区安装Ubantu
目录 一、查看磁盘格式 二、安装ubantu 参考链接: GPT分区安装Ubuntu_哔哩哔哩_bilibili 一、查看磁盘格式 右击左边灰色区域,点击属性 二、安装ubantu 插入磁盘,重启系统,狂按F7(具体我也忘了)&#…...

ORM++ 封装实战指南:安全高效的 C++ MySQL 数据库操作
ORM 封装实战指南:安全高效的 C MySQL 数据库操作 一、环境准备 1.1 依赖安装 # Ubuntu/Debian sudo apt-get install libmysqlclient-dev # CentOS sudo yum install mysql-devel# 编译时链接库 (-I 指定头文件路径 -L 指定库路径) g main.cpp -stdc17 -I/usr/i…...

kafka学习笔记(三、消费者Consumer使用教程——从指定位置消费)
1.简介 Kafka的poll()方法消费无法精准的掌握其消费的起始位置,auto.offset.reset参数也只能在比较粗粒度的指定消费方式。更细粒度的消费方式kafka提供了seek()方法可以指定位移消费允许消费者从特定位置(如固定偏移量、时间戳或分区首尾)开…...

【后端高阶面经:架构篇】46、分布式架构:如何应对高并发的用户请求
一、架构设计原则:构建可扩展的系统基石 在分布式系统中,高并发场景对架构设计提出了极高要求。 分层解耦与模块化是应对复杂业务的核心策略,通过将系统划分为客户端、CDN/边缘节点、API网关、微服务集群、缓存层和数据库层等多个层次,实现各模块的独立演进与维护。 1.1 …...

网络编程学习笔记——TCP网络编程
文章目录 1、socket()函数2、bind()函数3、listen()4、accept()5、connect()6、send()/write()7、recv()/read()8、套接字的关闭9、TCP循环服务器模型10、TCP多线程服务器11、TCP多进程并发服务器 网络编程常用函数 socket() 创建套接字bind() 绑定本机地址和端口connect() …...
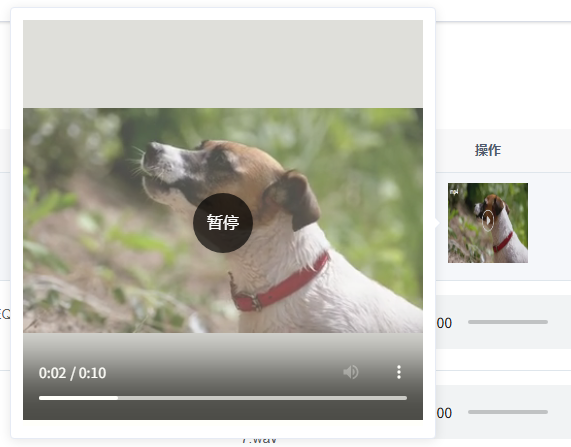
Vue+element-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频(一)
Vueelement-ui,实现表格渲染缩略图,鼠标悬浮缩略图放大,点击缩略图播放视频 前言整体代码预览图具体分析基础结构主要标签作用videoel-popover 前言 如标题,需要实现这样的业务 此处文章所实现的,是静态视频资源。 注…...
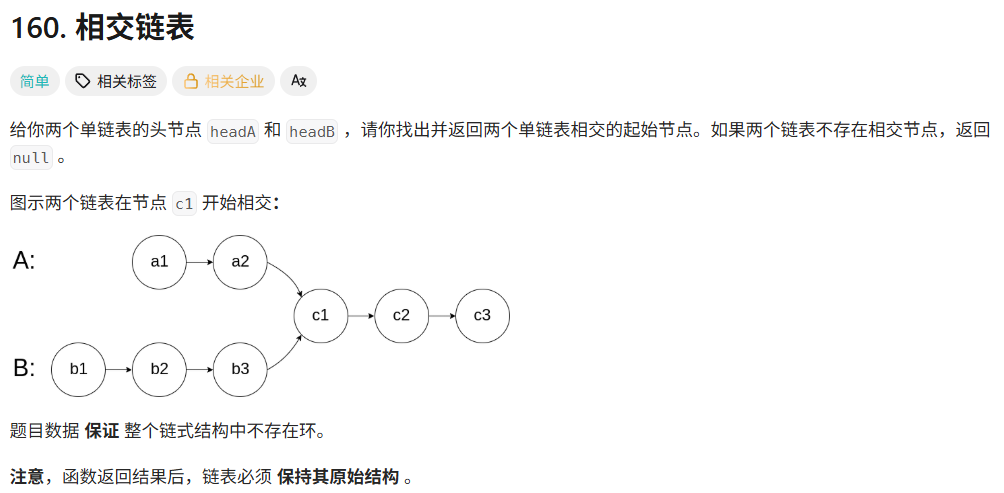
day13 leetcode-hot100-22(链表1)
160. 相交链表 - 力扣(LeetCode) 1.哈希集合HashSet 思路 (1)将A链的所有数据存储到HashSet中。 (2)遍历B链,找到是否在A中存在。 具体代码 /*** Definition for singly-linked list.* pu…...