使用 Redis 作为向量数据库
一、什么是向量数据库?
-
向量(Vector):在机器学习和 AI 中,向量是由一系列数字组成的序列,用于数值化地描述数据的特征或语义。文本、图像、音频等非结构化数据可以通过模型转换成固定长度的向量。
-
向量数据库:专门存储、索引和检索向量的数据库系统。可以基于向量之间的距离度量(如余弦相似度、欧氏距离等)进行高效的近邻搜索(Nearest Neighbor Search),从而实现“语义搜索”或“相似度搜索”。
-
与传统搜索的区别:
- 传统搜索依赖于关键词精确匹配,无法识别同义词、上下文或语义抽象。
- 向量搜索通过将数据空间映射到高维向量空间,使语义相近的内容在向量空间中距离更近,从而返回更符合用户意图的结果。
二、准备工作
本文示例使用 Python 客户端库 RedisVL,以及常见的 Python 生态组件:
# 建议在虚拟环境中安装
pip install redis pandas sentence-transformers tabulate redisvl
说明
redis:官方 Python 客户端。pandas:用于结果展示。sentence-transformers:生成文本向量。tabulate:渲染 Markdown 表格。redisvl:Redis 向量搜索专用扩展(可选,本文使用原生 redis.commands.search API)。
三、连接 Redis
如果你使用本地 Redis:
import redisclient = redis.Redis(host="localhost", port=6379, decode_responses=True)
如果使用 Redis Cloud,则将 host、port、password 替换为云端实例参数:
client = redis.Redis(host="redis-16379.c283.us-east-1-4.ec2.cloud.redislabs.com",port=16379,password="your_password_here",decode_responses=True,
)
四、准备示例数据集
本文使用开源的 bikes 数据集,每条记录包含如下字段:
{"model": "Jigger","brand": "Velorim","price": 270,"type": "Kids bikes","specs": {"material": "aluminium","weight": "10"},"description": "Small and powerful, the Jigger is the best ride for the smallest of tikes! ..."
}
1. 拉取数据
import requestsURL = ("https://raw.githubusercontent.com/""bsbodden/redis_vss_getting_started""/main/data/bikes.json")
response = requests.get(URL, timeout=10)
bikes = response.json()
2. 存储到 Redis(JSON 文档)
pipeline = client.pipeline()
for i, bike in enumerate(bikes, start=1):key = f"bikes:{i:03}"pipeline.json().set(key, "$", bike)
pipeline.execute()
你可以这样读取某个字段:
client.json().get("bikes:010", "$.model")
# => ['Summit']
五、生成并存储向量嵌入
1. 选择文本嵌入模型
from sentence_transformers import SentenceTransformerembedder = SentenceTransformer('msmarco-distilbert-base-v4')
2. 批量获取描述并生成向量
import numpy as np# 获取所有 key
keys = sorted(client.keys("bikes:*"))# 批量读取 description
descs = client.json().mget(keys, "$.description")
# 扁平化列表
descriptions = [item for sublist in descs for item in sublist]# 生成嵌入并转换为 float32 列表
embeddings = embedder.encode(descriptions).astype(np.float32).tolist()
VECTOR_DIM = len(embeddings[0]) # 768
3. 插入向量字段
pipeline = client.pipeline()
for key, vec in zip(keys, embeddings):pipeline.json().set(key, "$.description_embeddings", vec)
pipeline.execute()
此时,每条记录都多了一个 $.description_embeddings 数组字段。
六、创建检索索引
为了同时支持基于字段和基于向量的搜索,需要创建一个 Redis Search 索引:
# 在 Redis CLI 环境中执行
FT.CREATE idx:bikes_vss ON JSONPREFIX 1 bikes:SCHEMA$.model TEXT WEIGHT 1.0 NOSTEM$.brand TEXT WEIGHT 1.0 NOSTEM$.price NUMERIC$.type TAG SEPARATOR ","$.description TEXT WEIGHT 1.0$.description_embeddings AS vector VECTOR FLAT \TYPE FLOAT32 DIM 768 DISTANCE_METRIC COSINE
FLAT:扁平索引;也可使用HNSW(图索引)以提高速度与扩展性。TYPE FLOAT32:32 位浮点。DIM 768:向量维度。DISTANCE_METRIC COSINE:余弦相似度。
创建完成后,通过 FT.INFO idx:bikes_vss 可以查看索引状态,确认文档是否全部就绪。
七、执行向量搜索
1. 嵌入查询文本
queries = ["Bike for small kids","Best Mountain bikes for kids","Cheap Mountain bike for kids",# ... 共 11 条
]
encoded_queries = embedder.encode(queries)
注意:必须使用与文档相同的模型和参数,否则语义相似度会大打折扣。
2. 构造 KNN 查询模板
from redis.commands.search.query import Queryknn_query = (Query("(*)=>[KNN 3 @vector $qvector AS score]").sort_by("score").return_fields("score", "id", "brand", "model", "description").dialect(2)
)
(*):不过滤,检索全集。KNN 3:返回最相近的 3 个向量。@vector $qvector:向量字段名与占位符。dialect(2):必要参数以支持向量查询语法。
3. 执行查询并展示
import pandas as pddef run_search(queries, encoded_qs):rows = []for q, vec in zip(queries, encoded_qs):docs = client.ft("idx:bikes_vss") \.search(knn_query, {"qvector": np.array(vec, dtype=np.float32).tobytes()}) \.docsfor doc in docs:rows.append({"query": q,"score": round(1 - float(doc.score), 2),"id": doc.id,"brand": doc.brand,"model": doc.model,"desc": doc.description[:100] + "..."})df = pd.DataFrame(rows)return df.sort_values(["query","score"], ascending=[True,False])table = run_search(queries, encoded_queries)
print(table.to_markdown(index=False))
| query | score | id | brand | model | desc |
|---|---|---|---|---|---|
| Best Mountain bikes for kids | 0.54 | bikes:003 | Nord | Chook air 5 | The Chook Air 5 gives kids aged six years and … |
| … | … | … | … | … | … |
八、总结与后续
Redis 强大的模块化生态(如 RedisJSON、RediSearch)让其成为轻量级、易上手的向量数据库方案。想深入了解更多:
- 向量索引参数:扁平 VS HNSW、距离度量、并行构建等。
- 多模态数据:结合 RedisAI,直接在 Redis 中进行模型推理。
- 扩展语言客户端:C#、JavaScript、Java、Go 等,满足多种开发场景。
欢迎访问 Redis University 和 Redis AI 资源库 以获得更多学习资料。
相关文章:

使用 Redis 作为向量数据库
一、什么是向量数据库? 向量(Vector):在机器学习和 AI 中,向量是由一系列数字组成的序列,用于数值化地描述数据的特征或语义。文本、图像、音频等非结构化数据可以通过模型转换成固定长度的向量。 向量数据…...
Matlab实现LSTM-SVM时间序列预测,作者:机器学习之心
Matlab实现LSTM-SVM时间序列预测,作者:机器学习之心 目录 Matlab实现LSTM-SVM时间序列预测,作者:机器学习之心效果一览基本介绍程序设计参考资料 效果一览 基本介绍 该代码实现了一个结合LSTM和SVM的混合模型,用于时间…...

美国服务器文件系统的基本功能和命令
文件系统的核心功能是实现数据的存储与组织。美国服务器支持多种文件系统类型(如EXT4、NTFS、ZFS等),每种文件系统通过树状目录结构管理文件和文件夹,并为每个文件分配唯一标识符(如Inode或NTFS索引)。以下是具体操作步骤: 创建文件系统 使…...

开源软件协议大白话分类指南
开源软件协议分类对比表 协议类型代表协议核心规则允许/禁止操作适合场景宽松型MIT、Apache 2.0允许免费使用、修改、商用,可闭源,但需保留原作者版权声明。✅ 闭源商用 ⚠️ 必须署名快速开发商用软件(如APP、网站)强开源型GPL…...

JAVA 集合的进阶 泛型的继承和通配符
1 泛型通配符 可以对传递的类型进行限定 1.1 格式 ? 表示不确定的类型 ?extends E: 表示可以传递 E 或者 E 所有的子类类型 ?super E: 表示可以传递 E 或者 E 所有的父类类…...

机器学习与深度学习05-决策树01
目录 前文回顾1.决策树的基本原理2.构建决策树的划分准则3.决策树中如何避免过拟合4.决策树的剪枝操作 前文回顾 上一篇文章链接:地址 1.决策树的基本原理 决策树(Decision Tree)是一种用于分类和回归问题的机器学习模型。它是一个树状结构…...

下一代液晶显示底层技术与九天画芯的技术突围
一、液晶产业:撑起数字经济的显示脊梁 (一)全球显示市场的核心支柱 作为电子信息产业的战略基石,液晶显示(LCD)占据全球平板显示市场超 60% 的份额,2022 年全球市场规模达 782.41 亿元…...
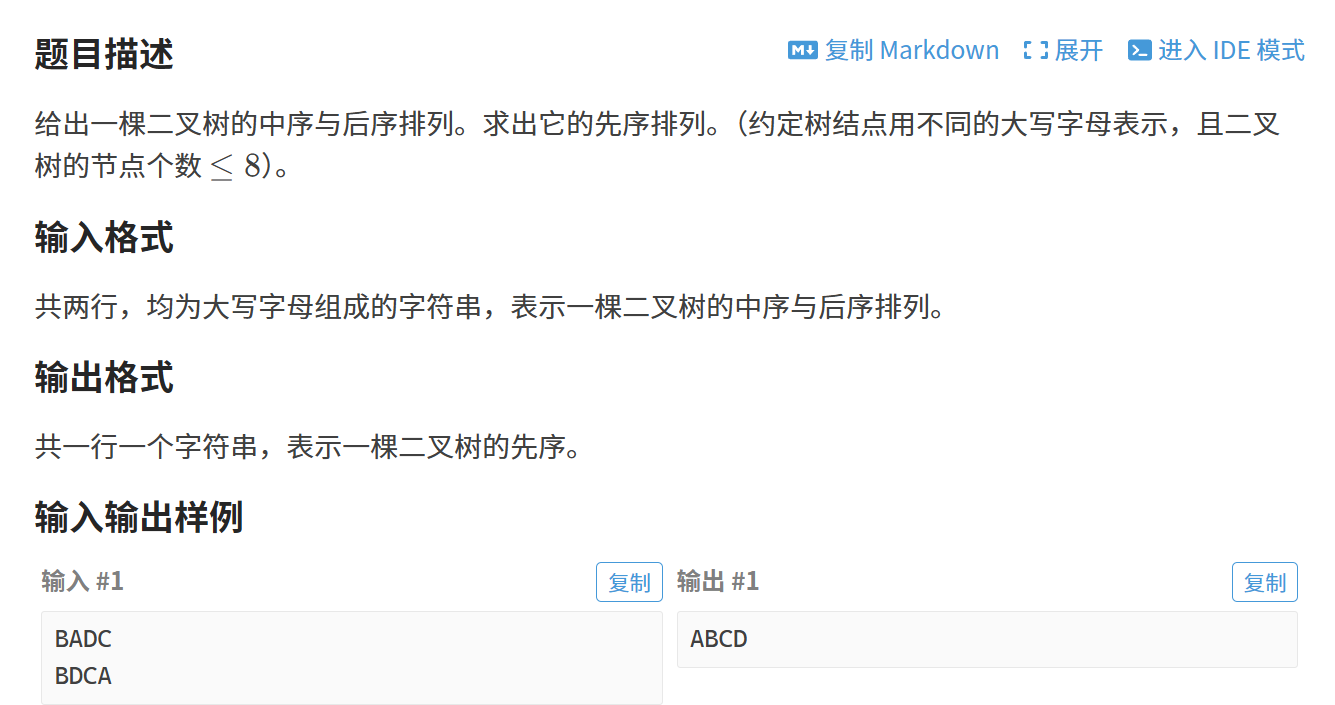
[NOIP 2001 普及组] 求先序排列 Java
import java.util.*;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);String infixOrder sc.nextLine(); // 中序String postOrder sc.nextLine(); // 后序sc.close();System.out.println(preOrder(infixOrder, postOrder))…...
Rockey Linux 安装ffmpeg
1.环境准备 Rockey linux 9.2 ffmpeg 静态资源包 这个是我自己的: https://download.csdn.net/download/liudongyang123/90920340https://download.csdn.net/download/liudongyang123/90920340 这个是官网的 Releases BtbN/FFmpeg-Builds GitHub 以上两个资…...
STM32 Modbus RTU从机开发实战:核心实现与五大调试陷阱解析
知识点1【CRC校验】 CRC校验生成网址 CRC(循环冗余校验)在线计算_ip33.com 知识点2【代码演示】 代码书写思路 代码演示 main.c #include "stm32f10x.h" #include "stm32f10x_conf.h" #include "rs485.h"int main(voi…...
Python----目标检测(《Fast R-CNN》和Fast R-CNN)
一、《Fast R-CNN》 1.1、基本信息 作者:Ross Girshick 机构:Microsoft Research 发表时间:2015年 论文链接:arXiv:1504.08083 代码开源:GitHub仓库(MIT License) 1.2、主要内容 Fast R…...

iEKF的二维应用实例
如果熟悉 EKF 与卡尔曼的推导的话,iEKF 就比较容易理解,关于卡尔曼滤波的推导以及EKF,可以参考以前的文章: 卡尔曼滤波原理:https://blog.csdn.net/a_xiaoning/article/details/130564473?spm1001.2014.3001.5502 E…...

机器学习中的线性回归:从理论到实践的深度解析
一、引言 线性回归(Linear Regression)是机器学习和统计学中最基础且应用广泛的模型之一,用于预测连续型目标变量。它通过建立输入特征与输出变量之间的线性关系,实现对未知数据的预测。无论是预测房价、股票走势,还是…...
【通关文件操作(下)】--文件的顺序读写(续),sprintf和sscanf函数,文件的随机读写,文件缓冲区,更新文件
目录 四.文件的顺序读写(续) 4.8--fwrite函数 4.9--fread函数 五.sprintf函数和sscanf函数 5.1--函数对比 5.2--sprintf函数 5.3--sscanf函数 六.文件的随机读写 6.1--fseek函数 6.2--ftell函数 6.3--rewind函数 七.文件缓冲区 7.1--fflush函数 八.更新文件 &…...

mysql的Memory引擎的深入了解
目录 1、Memory引擎介绍 2、Memory内存结构 3、内存表的锁 4、持久化 5、优缺点 6、应用 前言 Memory 存储引擎 是 MySQL 中一种高性能但非持久化的存储方案,适合临时数据存储和缓存场景。其核心优势在于极快的读写速度,需注意数据丢失风险和内存占…...

尚硅谷-尚庭公寓部署文档
文章目录 整合版部署文档部署架构图1. 项目目录结构增加注释的 Dockerfile 配置(1) 后端服务1 Dockerfile (backend/service1/Dockerfile)(2) 后端服务2 Dockerfile (backend/service2/Dockerfile) Dockerfile 配置说明重要注意事项3. Nginx 配置(1) 主配置文件 (nginx/nginx.c…...

使用函数证明给定的三个数是否能构成三角形
问题描述 给定三条边,请你判断一下能不能组成一个三角形。 输入数据第一行包含一个数M,接下有M行,每行一个实例,包含三个正数A,B,C。其中A,B,C <1000; 对于每个测试实例,如果三条边长A,B,C能组成三角形的话&#x…...

【数据结构】——二叉树堆(下)
一、堆中两个重要的算法 我们前面学习了树的概念和结构,还要树的一种特殊树--二叉树,然后我们学习了堆,知道了堆分为大堆和小堆,接下来我们就使用堆来进行一个排序。 在学习我们的堆排序前,我们先详细学习一下我们堆…...
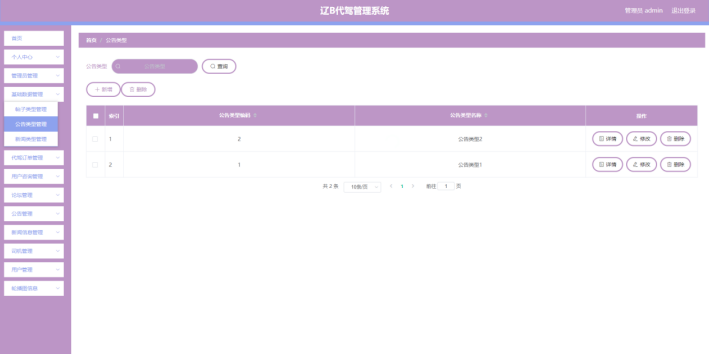
t009-线上代驾管理系统
项目演示地址 摘 要 使用旧方法对线上代驾管理系统的信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运用在线上代驾管理系统的管理上面可以解决许多信息管理上面的难题,比如处理数据时间很长,数据存在错误不能及时纠正等问题…...
目标检测预测框置信度(Confidence Score)计算方式
预测框的置信度(Confidence Score)是目标检测模型输出的一个关键部分,它衡量了模型对一个预测框中包含特定类别对象的确定程度。 不同的目标检测模型(如Faster R-CNN、SSD、YOLO、DETR等)在计算置信度时有其特有的机制…...
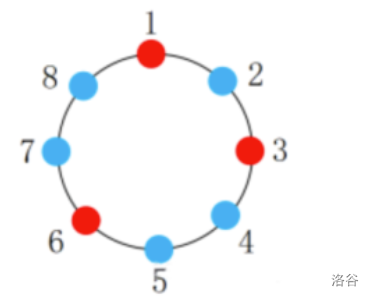
【题解-洛谷】B4295 [蓝桥杯青少年组国赛 2022] 报数游戏
题目:B4295 [蓝桥杯青少年组国赛 2022] 报数游戏 题目描述 某班级男生人数为 X X X 人,女生人数为 Y Y Y 人,现全班同学围成一个圆圈,并按照顺时针方向为每名同学编号(从 1 1 1 到 X Y XY XY)。现给…...

Bootstrap项目 - 个人作品与成就展示网站
文章目录 前言一、项目整体概述1. 项目功能介绍1.1 导航栏1.2 首页模块1.3 关于我模块1.4 技能模块1.5 作品模块1.6 成就模块1.7 博客模块1.8 联系我模块 2. 技术选型说明 二、项目成果展示1. PC端展示1.1 首页1.2 关于我1.3 技能1.4 作品1.5 成就1.6 博客1.7 联系我 2. 移动端…...

新能源汽车霍尔线束介绍
新能源汽车作为传统燃油车的重要替代方案,其核心驱动系统依赖于高效、精准的电子控制技术。在这一体系中,霍尔线束作为关键传感器组件,承担着电机转速、位置信号的实时采集与传输任务,其性能直接影响整车动力输出的稳定性和能量利…...

2023网络应用专业-Python程序设计复习题目
2023技校网络应用专业-Python程序设计复习题目 须知: 个人信息要填写正确,在线答题时间不限,可以反复作答,次数不限,最后取最高分。 第一部分:单选题 1. 在Python交互模式下,输入下面代码: >>> “{0:.2f}”.format(12345.6789) 回车后显示的结果为: [单选…...

Termux可用中间人网络测试工具Xerosploit
Termux可用中间人网络测试工具Xerosploit。 Xerosploit 是一款基于 MITM 的本地网络渗透测试工具包。 食用方法: git clone https://github.com/LionSec/xerosploit cd xerosploit sudo python3 install.py 运行: sudo xerosploit 使用备注࿱…...

气镇阀是什么?
01、阀门介绍: 油封机械真空泵的压缩室上开一小孔,并装上调节阀,当打开阀并调节入气量,转子转到某一位置,空气就通过此孔掺入压缩室以降低压缩比,从而使大部分蒸汽不致凝结而和掺入的气体一起被排除泵外起此…...
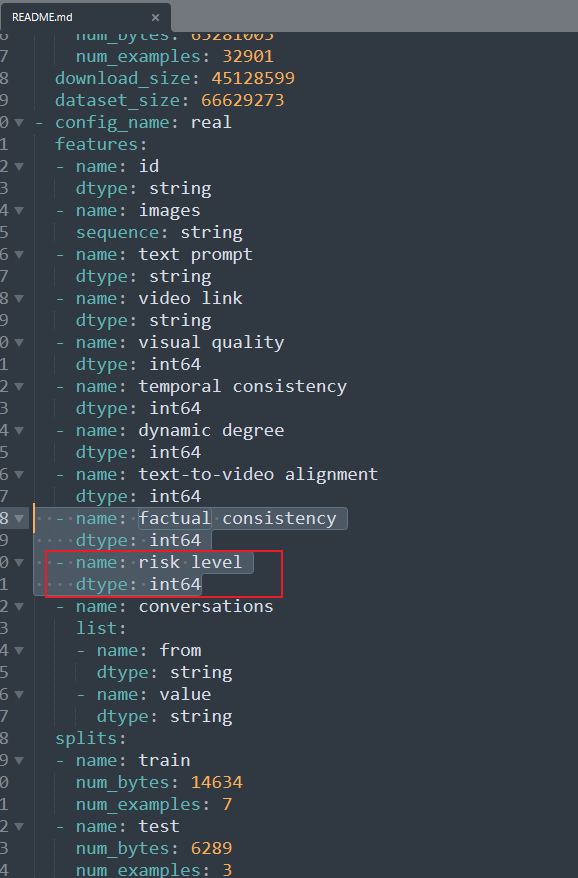
SmolVLM2: The Smollest Video Model Ever(七)
编写测试代码与评价指标 现在的数据集里面只涉及tool的分类和手术phase的分类,所以编写的评价指标还是那些通用的,但是: predicted_labels:[The current surgical phase is CalotTriangleDissection, Grasper, Hook tool exists., The curre…...
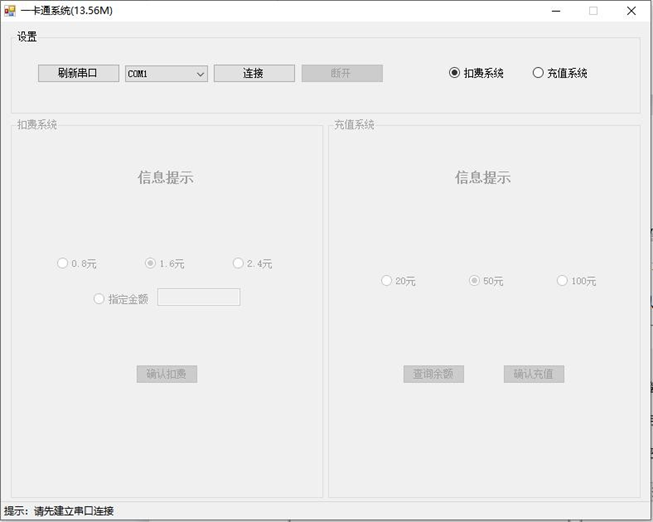
RFID综合项目实训 | 基于C#的一卡通管理系统
目录 基于C#的一卡通管理系统 【实验目的】 【实验设备】 【实验内容】 【实验步骤】 实验准备 第一部分 界面布局设计 第二部分 添加串口通讯函数及高频标签操作功能函数(部分代码) 第五部分 实验运行效果 基于C#的一卡通管理系统 【实验目的】 熟悉 …...
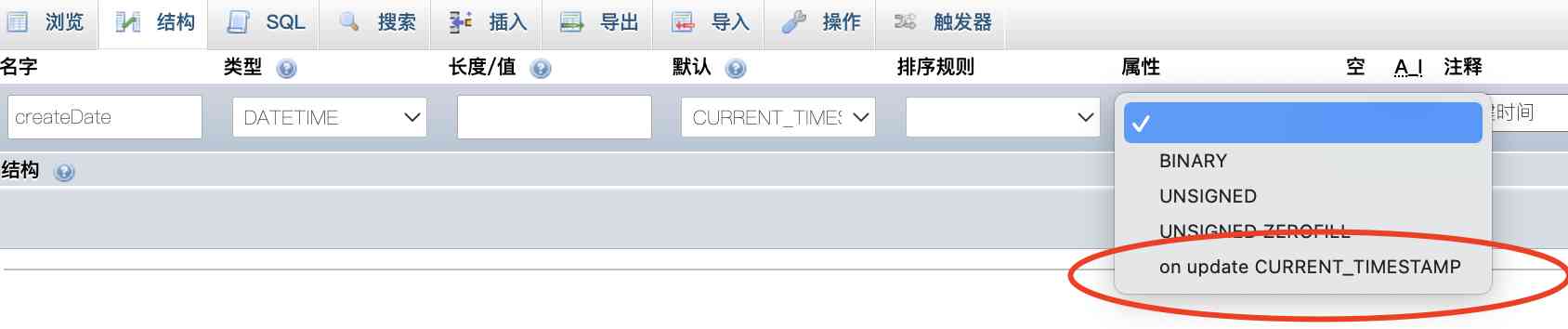
mysql如何设置update时间字段自动更新?
之前在给网站做表设计的时候时间字段都是用的datetime类型,初始值都是设置的CURRENT_TIMESTAMP。 由于给文章表设计的有创建时间和更新时间两个字段,但是更新时间字段需要在更新文章后再次更新,当时由于不了解mysql还可以设置自动更新时间戳…...

数据库备份与恢复专业指南
数据库备份与恢复专业指南 一、备份与恢复核心概念 关键结论:数据库备份是数据安全的最后防线,恢复能力才是真正的备份有效性检验标准。 AI大模型专栏:https://duoke360.com/tutorial/path/ai-lm 1.1 备份类型 物理备份:直接复制数据库文件(如MySQL的.ibd文件、Oracle的.d…...