2、PyTorch基础教程:从张量到神经网络训练
1、PyTorch基础
PyTorch 是一个开源的深度学习框架,以其灵活性和动态计算图而广受欢迎。
PyTorch 主要有以下几个基础概念:张量(Tensor)、自动求导(Autograd)、神经网络模块(nn.Module)、优化器(optim)等。
- 张量(Tensor):PyTorch 的核心数据结构,支持多维数组,并可以在 CPU 或 GPU 上进行加速计算。
- 自动求导(Autograd):PyTorch 提供了自动求导功能,可以轻松计算模型的梯度,便于进行反向传播和优化。
- 神经网络(nn.Module):PyTorch 提供了简单且强大的 API 来构建神经网络模型,可以方便地进行前向传播和模型定义。
- 优化器(Optimizers):使用优化器(如 Adam、SGD 等)来更新模型的参数,使得损失最小化。
- 设备(Device):可以将模型和张量移动到 GPU 上以加速计算。
2、张量(Tensor):深度学习的基础数据结构
核心概念:张量是多维数组的泛化形式:
0 维张量:标量(单个数字)
1 维张量:向量
2 维张量:矩阵
更高维度:处理图像、视频等复杂数据
import torch# ========= 创建张量 =========
# 创建全零张量 (2行3列)
zeros_tensor = torch.zeros(2, 3)
print("全零张量:\n", zeros_tensor)# 创建全一张量 (3行2列)
ones_tensor = torch.ones(3, 2)
print("\n全一张量:\n", ones_tensor)# 创建随机张量 (正态分布)
rand_tensor = torch.randn(2, 2)
print("\n随机张量:\n", rand_tensor)# 从Python列表创建
list_tensor = torch.tensor([[1, 2], [3, 4]])
print("\n列表转换张量:\n", list_tensor)# 从NumPy数组创建
import numpy as np
numpy_array = np.array([[5, 6], [7, 8]])
numpy_tensor = torch.from_numpy(numpy_array)
print("\nNumPy转换张量:\n", numpy_tensor)# ========= 张量运算 =========
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])# 张量加法
print("\n加法结果:\n", a + b)# 张量乘法(逐元素)
print("\n逐元素乘法:\n", a * b)# 矩阵乘法
print("\n矩阵乘法:\n", torch.matmul(a, b))# 改变形状 (2x2 -> 4x1)
reshaped = a.view(4, 1)
print("\n重塑形状:\n", reshaped)# ========= 张量属性 =========
print("\n张量形状:", a.shape) # 输出: torch.Size([2, 2])
print("数据类型:", a.dtype) # 输出: torch.int64
print("存储设备:", a.device) # 输出: cpu关键属性:
shape:维度结构(如 (3, 224, 224) 表示3通道224x224图像)
dtype:数据类型(float32, int64等)
device:存储位置(CPU/GPU)
3、自动求导(Autograd):深度学习的引擎
在 PyTorch 中,自动求导(Autograd)是其核心功能之一,它允许自动计算梯度,这对于训练神经网络至关重要。
Tensor 的
requires_grad属性
当设置为
True时,PyTorch 会跟踪在该张量上的所有操作。例如:
x = torch.tensor([1.0], requires_grad=True)计算图(Computation Graph)
PyTorch 动态构建一个计算图,记录张量之间的操作。
反向传播时根据这个图计算梯度。
backward()方法
调用此方法自动计算梯度,结果存储在
.grad属性中。例如:
loss.backward()梯度累积
梯度默认会累积(累加到
.grad中),每次反向传播前需手动清零。
# ========= 基础梯度计算 =========
# 创建需要梯度的张量
x = torch.tensor(2.0, requires_grad=True)# 定义计算过程
y = x ** 3 + 2 * x + 1 # y = x³ + 2x + 1# 反向传播计算梯度
y.backward()# 查看x的梯度 (dy/dx = 3x² + 2)
print("x的梯度:", x.grad) # 输出: tensor(14.) 因为 3*(2)^2 + 2 = 14# ========= 复杂计算图 =========
a = torch.tensor([1.0, 2.0], requires_grad=True)
b = torch.tensor([3.0, 4.0], requires_grad=True)c = a * b # 逐元素乘法
d = c.sum() # 求和d.backward() # 反向传播print("\na的梯度:", a.grad) # 输出: tensor([3., 4.])
print("b的梯度:", b.grad) # 输出: tensor([1., 2.])# ========= 梯度控制 =========
# 临时禁用梯度计算(推理时使用)
# with限定了torch.no_grad()的作用范围,确保只在该代码块内禁用梯度计算,离开代码块后自动恢复。
with torch.no_grad():e = a * 10print("\n禁用梯度时的操作:", e.requires_grad) # 输出: False# 永久禁用梯度
a.requires_grad_(False) # 原地修改张量的requires_grad属性
print("禁用梯度后的a:", a.requires_grad) # 输出: False梯度计算过程:
前向传播:构建计算图
反向传播:从输出开始,应用链式法则计算梯度
梯度存储:结果存储在张量的
.grad属性中
4、神经网络模块(nn.Module):模型构建核心
核心组件:
nn.Linear:全连接层(y = xWᵀ + b)
nn.Conv2d:卷积层(图像处理)
nn.ReLU:激活函数(引入非线性)
nn.Sequential:层容器(简化模型构建)
import torch
import torch.nn as nn# ========= 定义神经网络模型 =========
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()# 定义网络层self.flatten = nn.Flatten() # 展平输入 (例如将28x28图像->784维向量)self.linear1 = nn.Linear(784, 128) # 全连接层 (输入784维,输出128维)self.relu = nn.ReLU() # 激活函数self.linear2 = nn.Linear(128, 10) # 输出层 (10个类别)def forward(self, x):# 定义前向传播路径x = self.flatten(x)x = self.linear1(x)x = self.relu(x)x = self.linear2(x)return x# 实例化模型
model = NeuralNetwork()
print("模型结构:\n", model)# 模拟输入 (批量大小64, 通道1, 28x28图像)
input_data = torch.randn(64, 1, 28, 28)
output = model(input_data)
print("\n输出形状:", output.shape) # 输出: torch.Size([64, 10])关键方法:
__init__():定义网络层
forward():指定数据流动路径继承
nn.Module自动获得参数管理功能
5、优化器与损失函数:训练的动力系统
优化器原理:通过梯度下降算法更新参数:
参数 = 参数 - 学习率 × 梯度
PyTorch 提供多种改进算法(SGD, Adam, RMSProp等)
import torch
import torch.nn as nn
from torch.optim import Adam# ========= 模型定义 =========
# 定义一个简单的神经网络模型
# 在PyTorch中,模型参数的requires_grad属性默认是True
class SimpleModel(nn.Module):def __init__(self, input_size=10, hidden_size=5, num_classes=5):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size) # 输入层到隐藏层self.relu = nn.ReLU() # 激活函数,实例化 ReLUself.fc2 = nn.Linear(hidden_size, num_classes) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# ========= 初始化组件 =========
model = SimpleModel(input_size=10, num_classes=5) # 创建模型实例
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = Adam(model.parameters(), lr=0.001) # Adam优化器# ========= 模拟数据 =========
# 生成3个样本,每个样本有10个特征
inputs = torch.randn(3, 10) # 输入数据 (batch_size=3, input_size=10)
# 生成3个样本的真实标签 (类别索引)
labels = torch.tensor([1, 0, 4]) # 每个样本的真实类别# ========= 训练循环 =========
epochs = 100 # 训练轮数for epoch in range(epochs):# 前向传播 (Forward Pass)predictions = model(inputs) # 模型计算预测结果# 计算损失 (Compute Loss)loss = loss_fn(predictions, labels) # 比较预测值和真实标签# 反向传播前清零梯度 (Zero Gradients)optimizer.zero_grad() # 清除上一轮计算的梯度,避免累积# 反向传播 (Backward Pass)loss.backward() # 自动计算所有参数的梯度# 更新参数 (Update Parameters)optimizer.step() # 根据梯度更新模型权重# 打印训练进度if (epoch+1) % 10 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')# ========= 输出最终结果 =========
print("\n训练完成!")
print(f"最终损失值: {loss.item():.4f}")常用损失函数:
nn.MSELoss():回归问题(均方误差)
nn.CrossEntropyLoss():分类问题
nn.BCELoss():二分类问题
6、GPU加速:深度学习的关键性能
import torch
import torch.nn as nn
import torch.nn.functional as F
import time# ========= 神经网络模型定义 =========
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()# 卷积层 (输入通道=1, 输出通道=32, 卷积核=3x3)self.conv1 = nn.Conv2d(1, 32, 3, 1)# 卷积层 (输入通道=32, 输出通道=64, 卷积核=3x3)self.conv2 = nn.Conv2d(32, 64, 3, 1)# 丢弃层 (防止过拟合)self.dropout = nn.Dropout(0.25)# 计算全连接层的输入尺寸 # 经过两次卷积和池化后的特征图尺寸self.fc_input_size = self.calculate_fc_input_size()# 全连接层self.fc1 = nn.Linear(self.fc_input_size, 128)# 输出层 (输入特征=128, 输出类别=10)self.fc2 = nn.Linear(128, 10)def calculate_fc_input_size(self):"""计算卷积层输出后的特征向量尺寸"""# 创建模拟输入 (1通道, 28x28图像)x = torch.randn(1, 1, 28, 28)# 第一层卷积 + ReLU激活 + 最大池化x = F.relu(self.conv1(x)) # 使用F,relu函数不需要实例化x = F.max_pool2d(x, 2)# 第二层卷积 + ReLU激活 + 最大池化x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)# 返回展平后的特征数量return x.numel()def forward(self, x):# 第一层卷积 + ReLU激活 + 最大池化x = self.conv1(x)x = F.relu(x)x = F.max_pool2d(x, 2)# 第二层卷积 + ReLU激活 + 最大池化x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)# 展平多维张量 (保持批量维度)x = x.view(x.size(0), -1) # 使用view而不是flatten以兼容旧版本PyTorch# 全连接层 + ReLU激活x = self.fc1(x)x = F.relu(x)# 随机丢弃部分神经元x = self.dropout(x)# 输出层x = self.fc2(x)return x# ========= 设备设置 =========
# 检测可用设备:优先使用CUDA(GPU),否则使用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")# ========= 模型初始化 =========
model = NeuralNetwork().to(device) # 将模型移至指定设备
print(f"模型已移至 {device}")# ========= 损失函数定义 =========
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数(多分类任务)# ========= 模拟数据生成 =========
# 创建随机输入数据 (batch_size=64, 通道=1, 高度=28, 宽度=28)
data = torch.randn(64, 1, 28, 28).to(device)
# 创建随机标签 (64个0-9的整数)
labels = torch.randint(0, 10, (64,)).to(device) # (64,)是torch.randint的size参数,是一个单元素元组print(f"数据形状: {data.shape}, 设备: {data.device}")
print(f"标签形状: {labels.shape}, 设备: {labels.device}")# ========= GPU加速验证 =========
# 预热GPU(首次运行可能有额外开销)
_ = model(data)start_time = time.time()# 前向传播
output = model(data)
# 计算损失
loss = loss_fn(output, labels)
# 反向传播(计算梯度)
loss.backward()# 计算耗时
gpu_time = time.time() - start_time
print(f"GPU计算时间: {gpu_time:.6f}秒")# ========= 梯度信息输出 =========
print("\n梯度示例:")
print(f"conv1.weight.grad 形状: {model.conv1.weight.grad.shape if model.conv1.weight.grad is not None else '无梯度'}")
if model.fc2.bias.grad is not None:print(f"fc2.bias.grad 前5个值: {model.fc2.bias.grad[:5]}")# ========= CPU对比测试 =========
if device == "cuda":print("\n========= CPU对比测试 =========")# 将模型和数据移至CPUcpu_model = NeuralNetwork().to('cpu')cpu_data = data.cpu()cpu_labels = labels.cpu()# 预热(避免第一次运行的开销)_ = cpu_model(cpu_data)# CPU计时start_time = time.time()cpu_output = cpu_model(cpu_data)cpu_loss = loss_fn(cpu_output, cpu_labels)cpu_loss.backward()cpu_time = time.time() - start_timeprint(f"CPU计算时间: {cpu_time:.6f}秒")print(f"加速比: {cpu_time/gpu_time:.2f}x")最佳实践:
使用
.to(device)统一模型和数据位置避免 CPU-GPU 间不必要的数据传输
使用
torch.cuda.empty_cache()清理GPU内存
7、完整训练流程示例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# ========= 1. 准备数据 =========
# 模拟数据集 (1000个样本, 10个特征)
X = torch.randn(1000, 10)
y = (X.sum(dim=1) > 0).float() # 二分类标签# 创建数据集和数据加载器
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# ========= 2. 定义模型 =========
class Classifier(nn.Module):def __init__(self):super().__init__()self.layer1 = nn.Linear(10, 5)self.relu = nn.ReLU()self.output = nn.Linear(5, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.relu(self.layer1(x))x = self.sigmoid(self.output(x))return xmodel = Classifier()# ========= 3. 设置损失函数和优化器 =========
criterion = nn.BCELoss() # 二分类交叉熵
optimizer = optim.Adam(model.parameters(), lr=0.01)# ========= 4. 训练循环 =========
num_epochs = 10for epoch in range(num_epochs):total_loss = 0for batch_X, batch_y in dataloader:# 前向传播predictions = model(batch_X).squeeze()# 计算损失loss = criterion(predictions, batch_y)total_loss += loss.item()# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 打印每个epoch的平均损失avg_loss = total_loss / len(dataloader)print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")# ========= 5. 模型验证 =========
with torch.no_grad():test_data = torch.randn(5, 10)predictions = model(test_data)print("\n测试预测:", predictions.squeeze().numpy())标准训练流程:
数据准备 → 2. 模型定义 → 3. 损失/优化器设置
训练循环:
前向传播
损失计算
梯度清零
反向传播
参数更新
模型评估
8、关键概念总结
| 概念 | 作用 | 典型组件 |
|---|---|---|
| 张量(Tensor) | 基础数据结构 | torch.Tensor, .shape, .dtype |
| 自动求导(Autograd) | 自动梯度计算 | requires_grad, .backward(), .grad |
| 神经网络(nn.Module) | 模型构建 | nn.Linear, nn.Conv2d, forward() |
| 优化器(Optimizer) | 参数优化 | torch.optim.Adam, .step(), .zero_grad() |
| 损失函数(Loss) | 性能评估 | nn.MSELoss, nn.CrossEntropyLoss |
| 数据加载(DataLoader) | 数据管理 | Dataset, DataLoader, 批处理 |
| 设备管理(Device) | GPU加速 | .to(device), torch.cuda.is_available() |
PyTorch 的动态计算图设计使其特别适合研究和原型开发。掌握这些基础概念后,可以进一步学习:
卷积神经网络(CNN)处理图像数据
循环神经网络(RNN)处理序列数据
迁移学习利用预训练模型
模型部署和生产化
相关文章:

2、PyTorch基础教程:从张量到神经网络训练
1、PyTorch基础 PyTorch 是一个开源的深度学习框架,以其灵活性和动态计算图而广受欢迎。 PyTorch 主要有以下几个基础概念:张量(Tensor)、自动求导(Autograd)、神经网络模块(nn.Module…...

《数据结构初阶》【番外篇:快速排序的前世今生】
【番外篇:快速排序的前世今生】目录 前言:---------------起源---------------一、诞生:二、突破:三、核心: ---------------发展---------------1. 早期版本:简单但不稳定1960 年:初始版本 2. …...
【笔记】基于 MSYS2(MINGW64)的 Poetry 虚拟环境创建指南
#工作记录 基于 MSYS2(MINGW64)的 Poetry 虚拟环境创建指南 一、背景说明 在基于 MSYS2(MINGW64)的环境中,使用 Poetry 创建虚拟环境是一种高效且灵活的方式来管理 Python 项目依赖。本指南将详细介绍如何在 PyChar…...
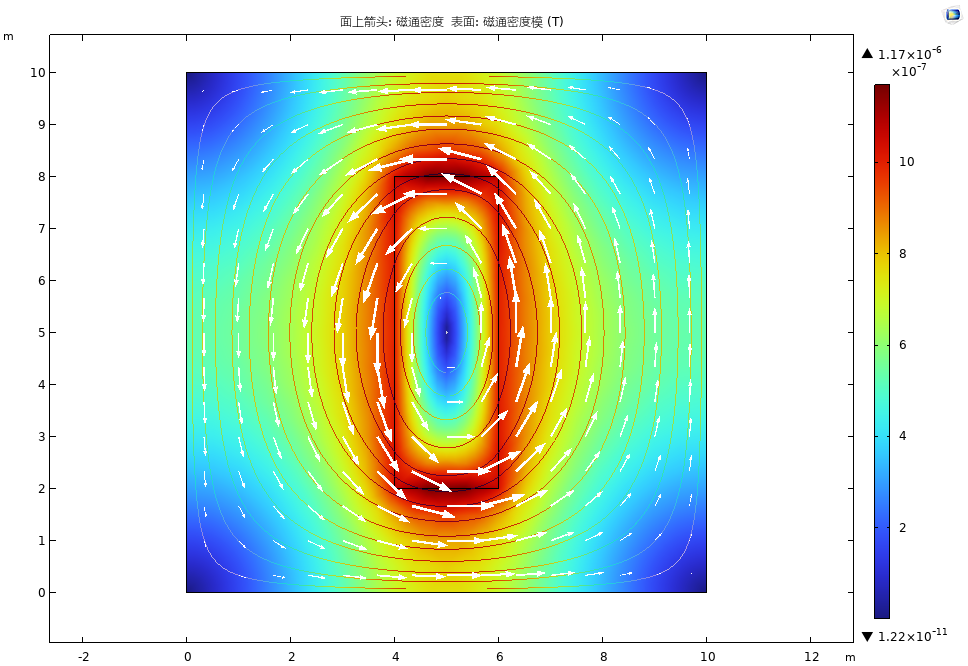
PINNs案例——二维磁场计算
基于物理信息的神经网络是一种解决偏微分方程计算问题的全新方法… 有关PINN基础详见:PINNs案例——中心热源温度场预测问题的torch代码 今日分享代码案例:二维带电流源磁场计算 该案例参考学习论文:[1]张宇娇,孙宏达࿰…...

Hive SQL 中 BY 系列关键字全解析:从排序、分发到分组的核心用法
一、排序与分发相关 BY 关键字 1. ORDER BY:全局统一排序 作用:对查询结果进行全局排序,确保最终结果集完全有序(仅允许单个 Reducer 处理数据)。 语法: SELECT * FROM table_name ORDER BY column1 [A…...

数据类型检测有哪些方式?
typeof 其中数组 对象 null都会判断为Object,其他正确 typeof 2 // number typeof true //bolean typeof str //string typeof [] //Object typeof function (){} // function typeof {} //object typeof undefined //undefined typeof null // nullinstanceof 判断…...
算法打开13天
41.前 K 个高频元素 (力扣347题) 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。 示例 1: 输入: nums [1,1,1,2,2,3], k 2 输出: [1,2]示例 2: 输入: nums [1], k 1 输出: …...

Freeqwq 世界首个免费无限制 分布式 AI 算力平台 https://qwq.aigpu.cn/
官网:Free QWQ - 免费分布式 AI 算力平台 基于来自全国各地 50 台家用电脑的 3090、4080、4090 显卡分布式算力,我们为开发者提供完全免费、无限制的 QwQ 32B 大语言模型 API。无需注册,无需充值,立即获取 API Key 开始使用。 …...
广告拦截器:全方位拦截,畅享无广告体验
在数字时代,广告无处不在。无论是浏览网页、使用社交媒体,还是观看视频,广告的频繁弹出常常打断我们的体验,让人不胜其烦。更令人担忧的是,一些广告可能包含恶意软件,威胁我们的设备安全和个人隐私。AdGuar…...

.net Avalonia应用程序生命周期
.NET Avalonia 应用程序生命周期全解析 在 .NET 开发领域,Avalonia 作为一个跨平台的 UI 框架,为开发者提供了强大的功能和灵活性。了解 Avalonia 应用程序的生命周期,对于构建高效、稳定的应用至关重要。本文将深入探讨 Avalonia 应用程序生…...

主数据编码体系全景解析:从基础到高级的编码策略全指南
在数字化转型的浪潮中,主数据管理(MDM)已成为企业数字化转型的基石。而主数据编码作为MDM的核心环节,其设计质量直接关系到数据管理的效率、系统的可扩展性以及业务决策的准确性。本文将系统性地探讨主数据编码的七大核心策略&…...

Selenium操作指南(全)
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 大家好,今天带大家一起系统的学习下模拟浏览器运行库Selenium,它是一个用于Web自动化测试及爬虫应用的重要工具。 Selenium测试直接运行在…...

Go语言中的数据类型转换
Go 语言中只有强制类型转换,没有隐式类型转换。 1. 数值类型之间的相互转换 1.1. 整型和整型之间的转换 package main import "fmt"func main() {var a int8 20var b int16 40fmt.Println(int16(a) b)// 60 }1.2. 浮点型和浮点型之间的转换 packag…...

35、请求处理-【源码分析】-自定义参数绑定原理
35、请求处理-【源码分析】-自定义参数绑定原理 自定义参数绑定原理主要涉及Spring Boot如何将HTTP请求中的参数自动绑定到控制器方法的自定义对象参数上。以下是详细的解析: ### 1. 参数解析器的选择 - **HandlerMethodArgumentResolverComposite**: - …...

智绅科技——科技赋能健康养老,构建智慧晚年新生态
当老龄化浪潮与数字技术深度碰撞,智绅科技以 “科技赋能健康,智慧守护晚年” 为核心理念,锚定数字健康与养老服务赛道,通过人工智能、物联网、大数据等技术集成,为亚健康群体与中老年人群构建 “监测 - 预防 - 辅助 - …...
STM32通过KEIL pack包轻松移植LVGL,并学会使用GUI guider
先展示最终实现的功能效果如下: 1.目的与意义 之前在学习STM32移植LVGL图形库的时候,搜到的很多教程都是在官网下载LVGL的文件包,然后一个个文件包含进去,还要添加路径,还要给文件改名字,最后才能修改程序…...

day43 python Grad-CAM
目录 一、为什么需要 Grad-CAM? 二、Grad-CAM 的原理 三、Grad-CAM 的实现 1. 模块钩子(Module Hooks) 2. Grad-CAM 的实现代码 四、学习总结 在深度学习领域,神经网络模型常常被视为“黑盒”,因为其复杂的内部结…...

在 Ubuntu 上挂载其他硬盘的步骤
一、查看当前磁盘信息 打开终端,执行: lsblk 这个命令会列出所有的块设备(包括硬盘和分区)。比如输出可能如下: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 1.8T 0 disk └─sda1 8:1 0 …...

SQL的查询优化
1. 查询优化器 1.1. SQL语句执行需要经历的环节 解析阶段:语法分析和语义检查,确保语句正确;优化阶段:通过优化器生成查询计划;执行阶段:由执行器根据查询计划实际执行操作。 1.2. 查询优化器 查询优化器…...
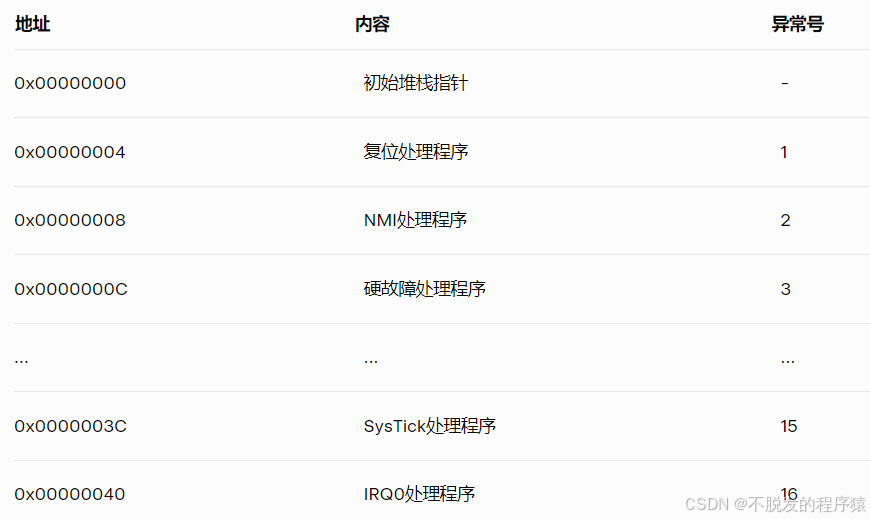
MCU如何从向量表到中断服务
目录 1、中断向量表 2、编写中断服务例程 中断处理的核心是中断向量表(IVT),它是一个存储中断服务例程(ISR)地址的内存结构。当中断发生时,MCU通过IVT找到对应的ISR地址并跳转执行。本文将深入探讨MCU&am…...

物联网基础概念
入行物联网两年半,想写点东西记录踩过的坑,能让自己反省的同时,也希望能帮到其他小伙伴。 本人仍是小白,请看客朋友谨慎参考。另,本人主要从事智慧用电和智慧医疗行业,其他行业不一定有参考性。 以下所有内…...

Linux线程同步实战:多线程程序的同步与调度
个人主页:chian-ocean 文章专栏-Linux Linux线程同步实战:多线程程序的同步与调度 个人主页:chian-ocean文章专栏-Linux 前言:为什么要实现线程同步线程饥饿(Thread Starvation)示例:抢票问题 …...
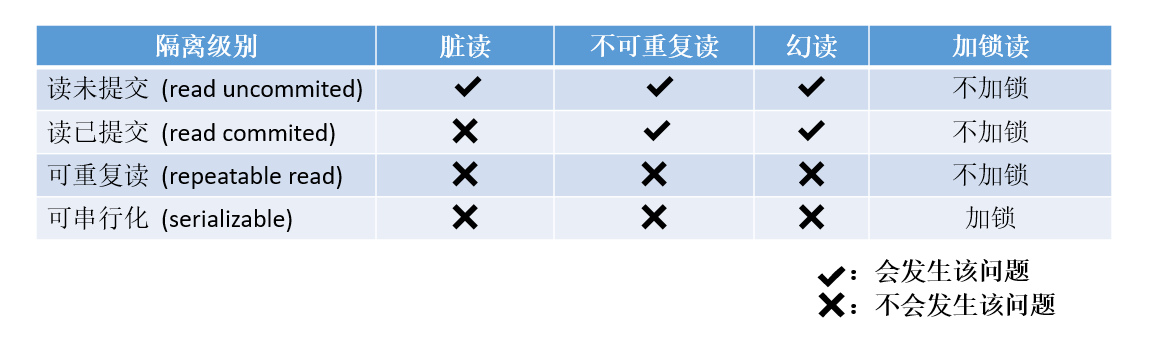
【MySQL】事务及隔离性
目录 一、什么是事务 (一)概念 (二)事务的四大属性 (三)事务的作用 (四)事务的提交方式 二、事务的启动、回滚与提交 (一)事务的启动、回滚与提交 &am…...

Leetcode 3566. Partition Array into Two Equal Product Subsets
Leetcode 3566. Partition Array into Two Equal Product Subsets 1. 解题思路2. 代码实现 题目链接:3566. Partition Array into Two Equal Product Subsets 1. 解题思路 这一题我的实现还是比较暴力的,首先显而易见的,若要满足题目要求&…...
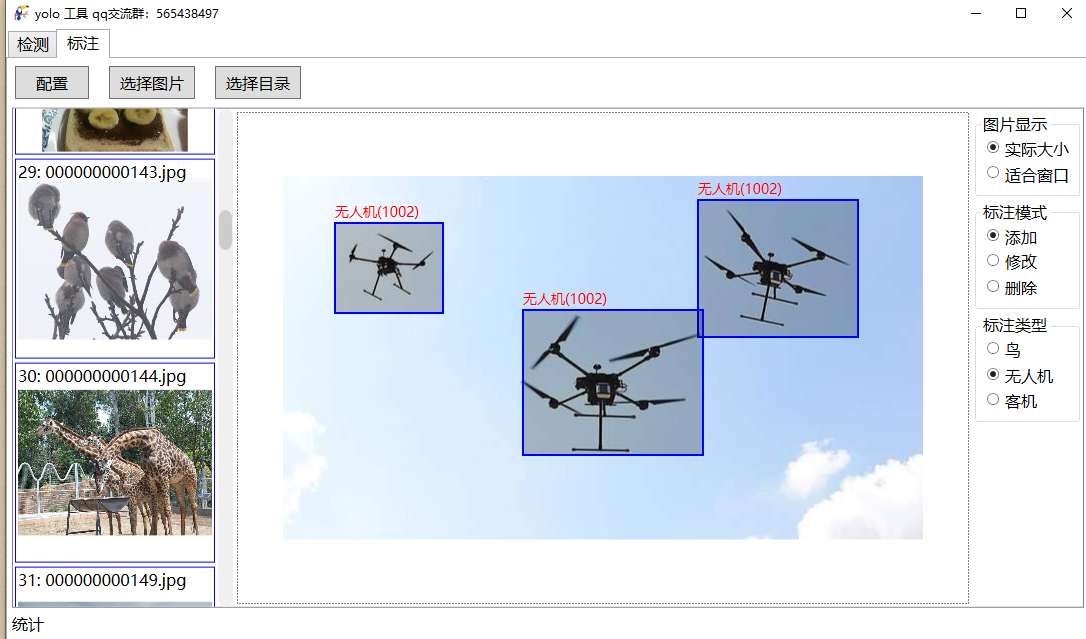
yolo目标检测助手:具有模型预测、图像标注功能
在人工智能浪潮席卷各行各业的今天,计算机视觉模型(如 YOLO)已成为目标检测领域的标杆。然而,模型的强大能力需要直观的界面和便捷的工具才能充分发挥其演示、验证与迭代优化的价值。为此,我开发了一款基于 WPF 的桌面…...

传统数据表设计与Prompt驱动设计的范式对比:以NBA投篮数据表为例
引言:数据表设计方法的演进 在数据库设计领域,传统的数据表设计方法与新兴的Prompt驱动设计方法代表了两种截然不同的思维方式。本文将以NBA赛季投篮数据表(shots)的设计为例,深入探讨这两种方法的差异、优劣及适用场景。随着AI技术在数据领…...

2022 RoboCom 世界机器人开发者大赛(睿抗 caip) -高职组(国赛)解题报告 | 科学家
前言 题解 2022 RoboCom 世界机器人开发者大赛(睿抗 caip) -高职组(国赛)。 最后一题还考验能力,需要找到合适的剪枝。 RC-v1 智能管家 分值: 20分 签到题,map的简单实用 #include <bits/stdc.h>using namespace std;int…...

WIN11 Docker Desktop 安装问题解决
windows version 打开windows 命令行,执行 ver显示 Microsoft Windows [版本 10.0.26100.4061]安装docker desktop 后,启动出问题,可以按下面步骤解决 安装 virtual machine plateform 开始 —》 控制面板 ----》程序 ----》启动或关闭w…...

网站服务器出现异常的原因是什么?
网站时企业和个人用户进行提供信息和服务的重要平台,随着时间的推移,网站服务器出现异常情况也是常见的问题之一,这可能会导致网站无法正常访问或者是运行缓慢,会严重影响到用户的体验感,本文就来介绍一下网站服务器出…...

Python实例题:Python3实现图片转彩色字符
目录 Python实例题 题目 代码实现 实现原理 图像预处理: 灰度值计算: 字符映射: 彩色输出: 关键代码解析 1. 字符映射和灰度计算 2. 图像模式输出 3. 命令行参数处理 使用说明 基本用法(终端输出&#x…...