BLIP-2
目录
摘要
Abstract
BLIP-2
模型框架
预训练策略
模型优势
应用场景
实验
代码
总结
摘要
BLIP-2 是一种基于冻结的图像编码器和大型语言模型的高效视觉语言预训练模型,由 Salesforce 研究团队提出。它在 BLIP 的基础上进一步优化,通过轻量级的查询 Transformer桥接图像和文本模态,解决了先前模型在参数效率和多模态对齐方面的不足。BLIP-2 在少样本学习和零样本生成任务中表现出色,例如:在 zero-shot VQAv2 任务上比 Flamingo 提升了 8.7% 的性能,同时可训练参数减少了 54 倍。其高效的计算性能和轻量级设计使其在图像描述生成、视觉问答和图像到文本检索等任务上展现出强大的能力,为多模态人工智能的发展提供了新的方向。
Abstract
BLIP-2 is an efficient vision-language pre-training model based on frozen image encoders and large language models, proposed by the Salesforce research team. Building on the foundation of BLIP, it further optimizes the model by using a lightweight Query Transformer to bridge the image and text modalities, addressing the limitations of previous models in terms of parameter efficiency and multimodal alignment. BLIP-2 performs exceptionally well in few-shot learning and zero-shot generation tasks. For example, it achieves an 8.7% improvement in performance on the zero-shot VQAv2 task compared to Flamingo, while reducing the number of trainable parameters by 54 times. Its high computational efficiency and lightweight design enable it to demonstrate strong capabilities in tasks such as image captioning, visual question answering, and image-to-text retrieval, providing a new direction for the development of multimodal artificial intelligence.
BLIP-2
项目地址:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
模型框架
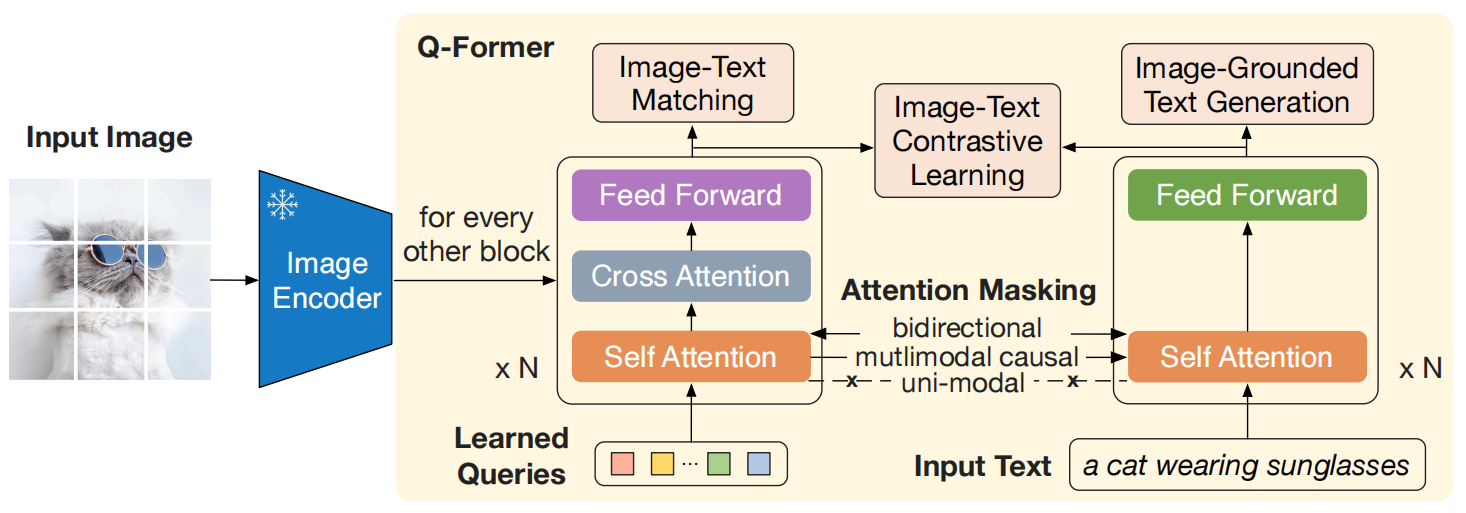
BLIP-2的核心架构包括三个主要部分:
冻结的图像编码器:通常使用类似CLIP的视觉模型(如ViT),其权重在训练过程中保持不变。
轻量级的查询Transformer:这是BLIP-2的核心模块,用于桥接图像编码器和语言模型之间的模态差距。Q-Former包含两个子模块:
- 图像Transformer:用于从冻结的图像编码器中提取视觉特征;
- 文本Transformer:作为文本编码器和解码器,用于生成文本。
冻结的大型语言模型:如Flan-T5或LLaMA,其权重在训练过程中也保持不变。
预训练策略
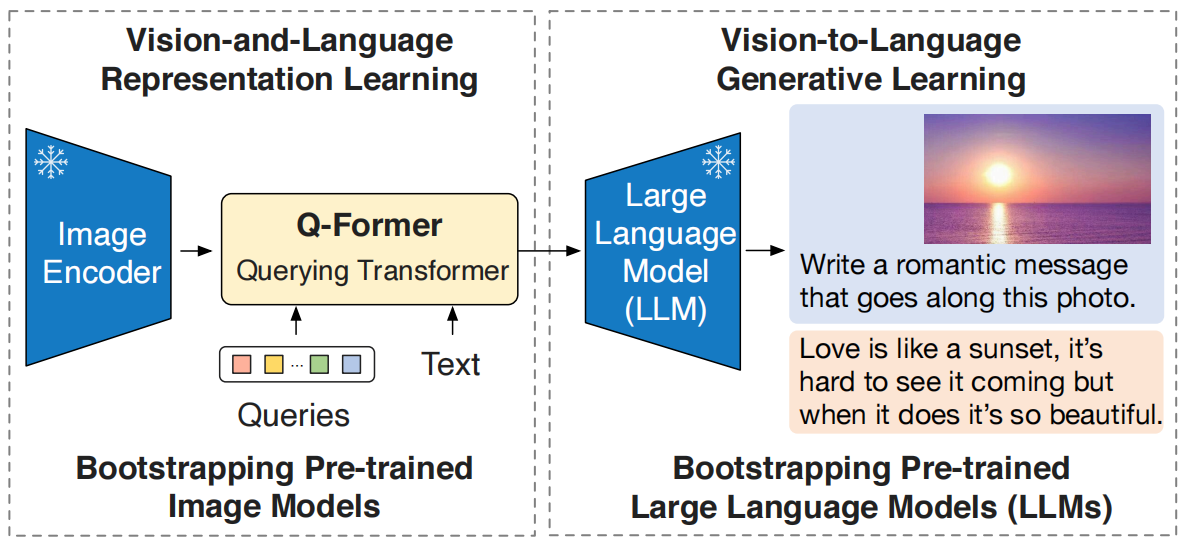
BLIP-2采用两阶段预训练策略:
第一阶段:视觉语言表示学习:
- 使用冻结的图像编码器,通过图像-文本对比学习(ITC)、图像-文本匹配(ITM)和图像引导的文本生成(ITG)任务,学习视觉与语言的对齐;
- ITC任务通过对比图像和文本嵌入来对齐模态;
- ITM任务通过二分类任务判断图像和文本是否匹配。 ITG任务通过生成文本任务来学习图像特征。
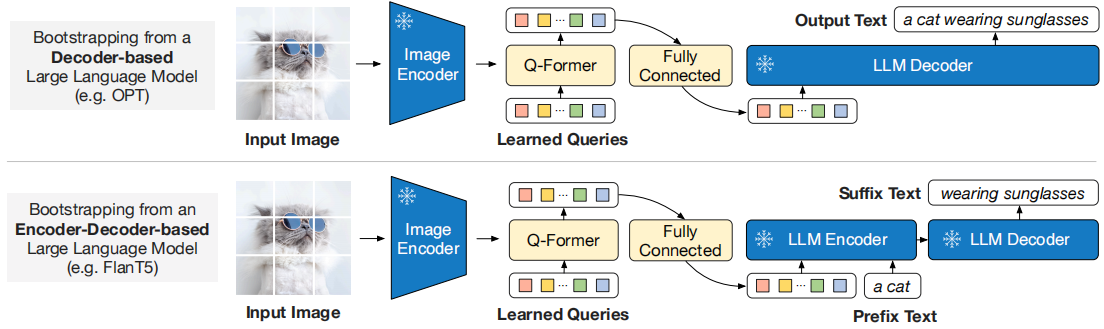
第二阶段:视觉到语言的生成学习:
- 将Q-Former提取的视觉特征传递给冻结的LLM,通过语言建模损失进行预训练;
- 对于解码器型LLM,使用语言建模损失进行训练;
- 对于编码器-解码器型LLM,使用前缀语言建模损失进行训练。
模型优势
高效利用预训练模型:通过冻结图像编码器和LLM,显著减少了可训练参数的数量。例如,BLIP-2在zero-shot VQAv2任务上比Flamingo模型提升了8.7%的性能,但可训练参数减少了54倍。
强大的少样本学习能力:即使在训练参数较少的情况下,BLIP-2也能在多种视觉语言任务上达到最先进的性能。
计算效率高:由于使用了冻结的模型和轻量级的Q-Former,BLIP-2的计算效率更高,更易于部署和使用。
零样本图像到文本生成能力:BLIP-2能够根据自然语言指令生成与图像相关的文本。
应用场景
图像描述生成:能够根据图像生成准确的描述文本;
视觉问答:能够根据图像和问题生成答案;
图像到文本检索:能够根据图像检索相关的文本内容。
实验
零镜头能力:
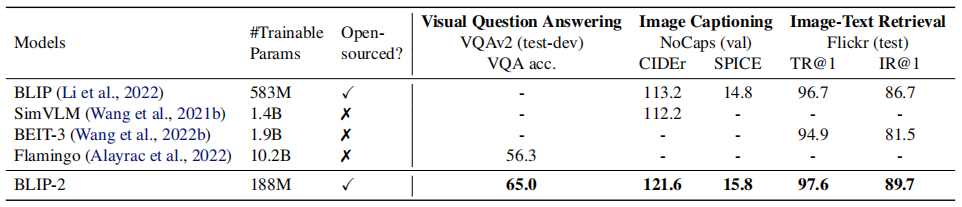
零镜头视觉问答:
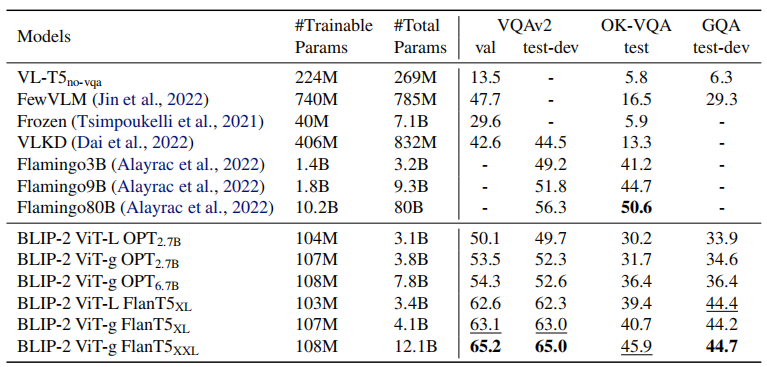
图像文本检索:
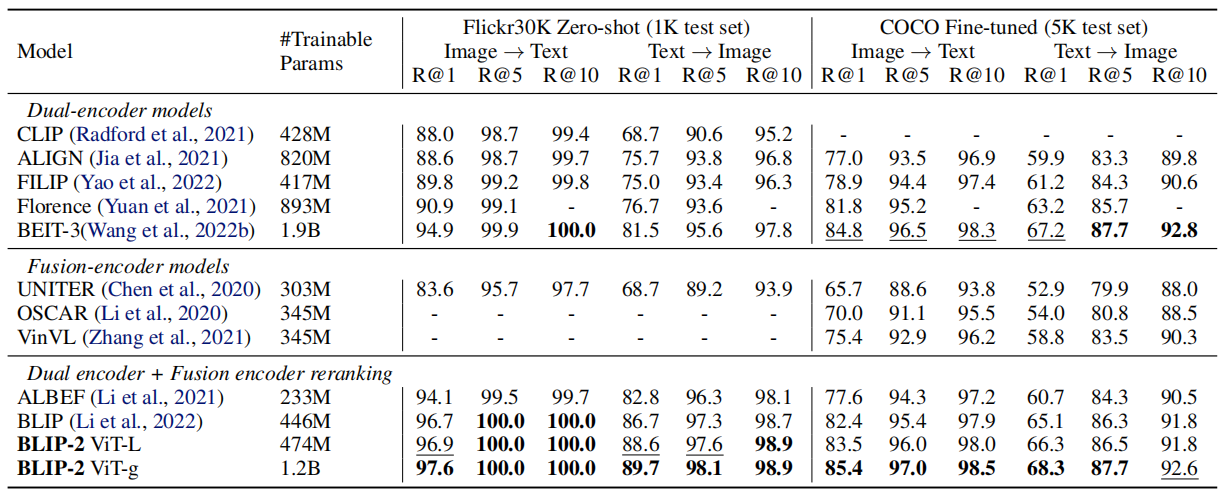
代码
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
import torch
import pandas as pd
from lavis.models import load_model_and_preprocess
from transformers import Blip2Processor, Blip2ForConditionalGeneration
from PIL import Image
import requestsdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# loads BLIP caption base model, with finetuned checkpoints on MSCOCO captioning dataset.
# this also loads the associated image processors
processor = Blip2Processor.from_pretrained("blip2-opt-2.7b/")
model = Blip2ForConditionalGeneration.from_pretrained("blip2-opt-2.7b/", torch_dtype=torch.float16
)
model.to(device)
# preprocess the image
# vis_processors stores image transforms for "train" and "eval" (validation / testing / inference)
raw_image = Image.open("https://storage.googleapis.com/sfr-vision-language-research/LAVIS/assets/merlion.png").convert("RGB")image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
# generate caption
res = model.generate({"image": image})print(res)
# ['a large fountain spewing water into the air']输入图像1:

输入图像2:

输出:

1、a person is holding a cup in their hand.
2、a man is cleaning a car with a pressure gun.
总结
BLIP-2 是一种创新的视觉语言预训练模型,通过结合冻结的图像编码器和大型语言模型,并引入轻量级查询Transformer桥接视觉与文本模态,有效解决了先前模型在参数效率和多模态对齐方面的不足。在少样本学习和零样本生成任务中,BLIP-2 表现卓越,例如在 zero-shot VQAv2 任务上性能比 Flamingo 提升了 8.7%,同时可训练参数减少了 54 倍。其高效的设计和强大的性能使其在图像描述生成、视觉问答和图像到文本检索等任务中展现出巨大优势,为多模态人工智能的发展提供了新的高效路径。
相关文章:
BLIP-2
目录 摘要 Abstract BLIP-2 模型框架 预训练策略 模型优势 应用场景 实验 代码 总结 摘要 BLIP-2 是一种基于冻结的图像编码器和大型语言模型的高效视觉语言预训练模型,由 Salesforce 研究团队提出。它在 BLIP 的基础上进一步优化,通过轻量级…...

【Go-6】数据结构与集合
6. 数据结构与集合 数据结构是编程中用于组织和存储数据的方式,直接影响程序的效率和性能。Go语言提供了多种内置的数据结构,如数组、切片、Map和结构体,支持不同类型的数据管理和操作。本章将详细介绍Go语言中的主要数据结构与集合…...

支持向量机(SVM)例题
对于图中所示的线性可分的20个样本数据,利用支持向量机进行预测分类,有三个支持向量 A ( 0 , 2 ) A\left(0, 2\right) A(0,2)、 B ( 2 , 0 ) B\left(2, 0\right) B(2,0) 和 C ( − 1 , − 1 ) C\left(-1, -1\right) C(−1,−1)。 求支持向量机分类器的线…...
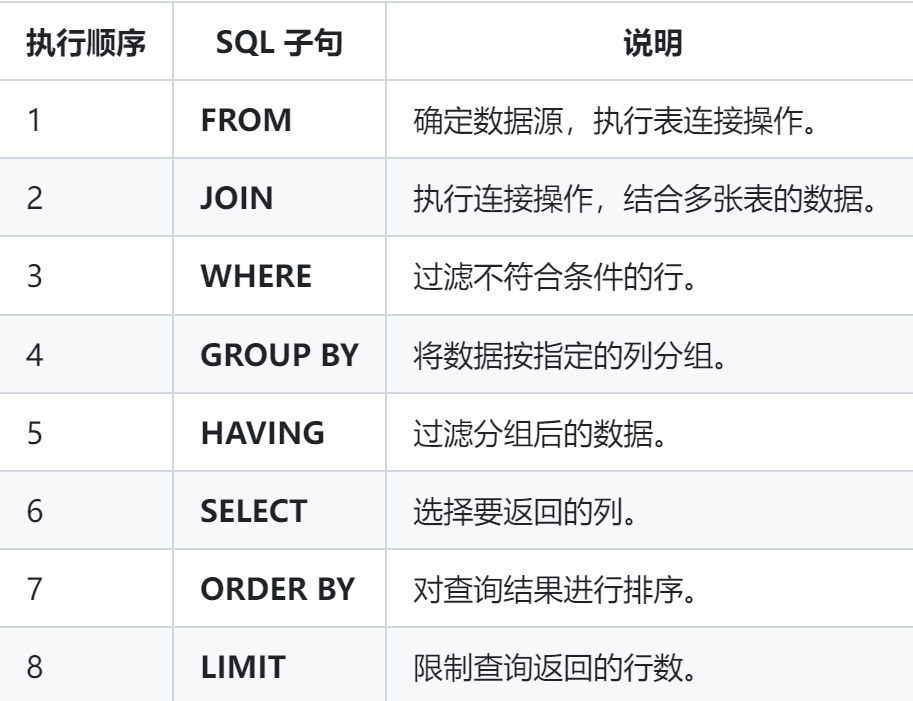
SQL中各个子句的执行顺序
select、from、 join、where、order by、group by、having、limit 解释 1) FROM (确定数据源) 查询的执行首先从FROM子句开始,确定数据的来源(表、视图、连接等)。 2) JOIN (如果有JOIN操作) 在FROM子句之后,SQL引擎会执行连接操作(JOIN),…...

PHP下实现RSA的加密,解密,加签和验签
前言: RSA下加密,解密,加签和验签是四种不同的操作,有时候会搞错,记录一下。 1.公钥加密,私钥解密 发送方通过公钥将原数据加密成一个sign参数,相当于就是信息的载体,接收方能通过si…...
本地部署消息代理软件 RabbitMQ 并实现外部访问( Windows 版本 )
RabbitMQ 是由 Erlang 语言开发的 消息中间件,是一种应用程序之间的通信方法。支持多种编程和语言和协议发展,用于实现分布式系统的可靠消息传递和异步通信等方面。 本文将详细介绍如何在 Windows 系统本地部署 RabbitMQ 并结合路由侠实现外网访问本…...
)
每日c/c++题 备战蓝桥杯(P2240 【深基12.例1】部分背包问题)
P2240 【深基12.例1】部分背包问题 - 详解与代码实现 一、题目概述 阿里巴巴要在承重为 T 的背包中装走尽可能多价值的金币,共有 N 堆金币,每堆金币有总重量和总价值。金币可分割,且分割后单位价格不变。目标是求出能装走的最大价值。 二、…...

Java异步编程:CompletionStage接口详解
CompletionStage 接口分析 接口能力概述 CompletionStage 是 Java 8 引入的接口,用于表示异步计算的一个阶段,它提供了强大的异步编程能力: 链式异步操作:允许将一个异步操作的结果传递给下一个操作组合操作&a…...

Java后端接受前端数据的几种方法
在前后端分离的开发模式中,前端(Vue)与后端(Java)的数据交互有多种格式,下面详细介绍几种常见的格式以及后端对应的接收方式。 一、JSON 格式 前端传输 在 Vue 里,可借助 axios 把数据以 JSO…...

Oracle OCP认证的技术定位怎么样?
一、引言:Oracle OCP认证的技术定位 Oracle Certified Professional(OCP)认证是数据库领域含金量最高的国际认证之一,其核心价值在于培养具备企业级数据库全生命周期管理能力的专业人才。随着数字化转型加速,OCP认证…...

powershell7.5@.net环境@pwsh7.5在部分windows10系统下的运行问题
文章目录 powershell7.5及更高版本和.net 9解决方案 powershell7.5及更高版本和.net 9 相对较新的.Net 9版本在老一些的windows10系统上(比如内核版本号:10.0.19044.1288以及之前的),由于默认启用了CET,导致编译运行失败,需要自己在项目中添加关闭CET的配置语句才能够顺利编译…...
基于微信小程序的垃圾分类系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

CSS3 渐变、阴影和遮罩的使用
全文目录: 开篇语**前言****1. CSS3 渐变 (Gradient)****1.1 线性渐变 (linear-gradient)****1.2 径向渐变 (radial-gradient)** **2. CSS3 阴影 (Shadow)****2.1 盒子阴影 (box-shadow)****2.2 文本阴影 (text-shadow)** **3. CSS3 遮罩 (Mask)****3.1 基本遮罩 (m…...

Spring Boot 全局配置文件优先级
好的,Spring Boot的全局配置文件优先级是一个非常重要的概念,它决定了在不同位置的同名配置属性以哪个为准。 Spring Boot 全局配置文件优先级核心知识点 📌 文件格式优先级: 在同一目录下,如果同时存在 application.properties 和…...
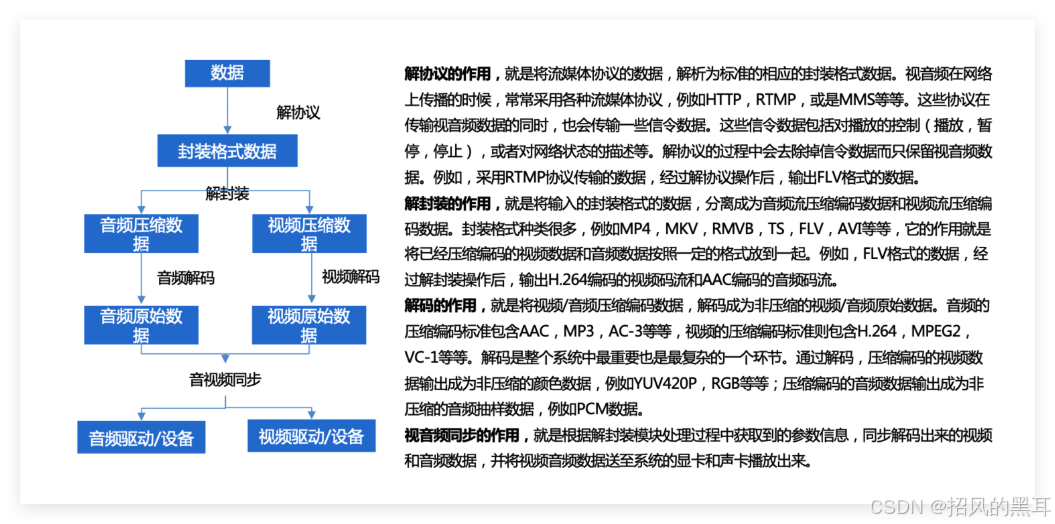
流媒体基础解析:视频清晰度的关键因素
在视频处理的过程中,编码解码及码率是影响视频清晰度的关键因素。今天,我们将深入探讨这些概念,并解析它们如何共同作用于视频质量。 编码解码概述 编码,简单来说,就是压缩。视频编码的目的是将原始视频数据压缩成较…...

grid网格布局
使用flex布局的痛点 如果使用justify-content: space-between;让子元素两端对齐,自动分配中间间距,假设一行4个,如果每一行都是4的倍数那没任何问题,但如果最后一行是2、3个的时候就会出现下面的状况: /* flex布局 两…...

C#数字金额转中文大写金额:代码解析
C#数字金额转中文大写金额:代码解析 在金融相关的业务场景中,我们常常需要将数字金额转换为中文大写金额,以避免金额被篡改,增加金额的准确性和安全性。本文将深入解析一段 C# 代码,这段代码通过巧妙的设计࿰…...
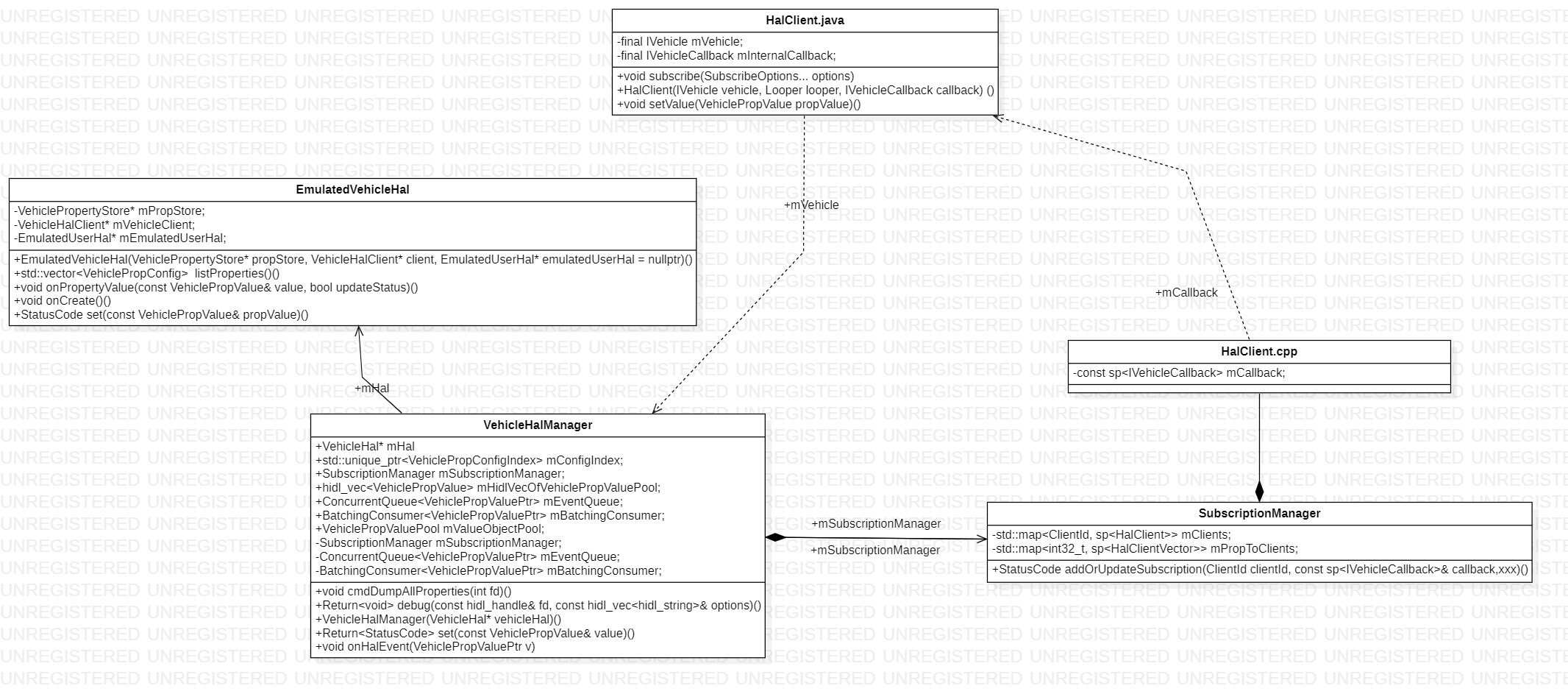
Vehicle HAL(2)--Vehicle HAL 的启动
目录 1. VehicleService-main 函数分析 2. 构建EmulatedVehicleHal 2.1 EmulatedVehicleHal::EmulatedVehicleHal(xxx) 2.2 EmulatedVehicleHal::initStaticConfig() 2.3 EmulatedVehicleHal::onPropertyValue() 3. 构建VehicleEmulator 4. 构建VehicleHalManager (1)初…...

JS中的函数防抖和节流:提升性能的关键技术
在JavaScript开发中,函数防抖和节流是两种常用的优化技术,用于处理那些可能会被频繁触发的事件,如resize、scroll、mousemove等。本文将详细介绍函数防抖和节流的概念、实现方法以及它们之间的区别。 一、什么是函数防抖和节流? …...

Android Compose开发架构选择指南:单Activity vs 多Activity
简介 掌握Jetpack Compose的Activity架构选择,是构建高性能、易维护Android应用的关键一步。在2025年的Android开发领域,随着Jetpack Compose的成熟和Android系统对多窗口模式的支持,开发者面临架构选择时需要更加全面地考虑各种因素。本文将深入探讨单Activity架构和多Act…...

【Netty系列】Reactor 模式 1
目录 一、Reactor 模式的核心思想 二、Netty 中的 Reactor 模式实现 1. 服务端代码示例 2. 处理请求的 Handler 三、运行流程解析(结合 Reactor 模式) 四、关键点说明 五、与传统模型的对比 六、总结 Reactor 模式是 Netty 高性能的核心设计思想…...

vue3 el-input type=“textarea“ 字体样式 及高度设置
在Vue 3中,如果你使用的是Element Plus库中的<el-input>组件作为文本域(type"textarea"),你可以通过几种方式来设置字体样式和高度。 1. 直接在<el-input>组件上使用style属性 你可以直接在<el-input&…...

并发解析hea,转为pdf格式
由于每次解析一个heap需要时间有点久,就写了一个自动解析程pdf的一个脚本。 down_lib.sh是需要自己写的哦,主要是用于下载自己所需程序的库,用于解析heap。 #!/bin/bash# 优化版通用解析脚本(并发加速):批…...
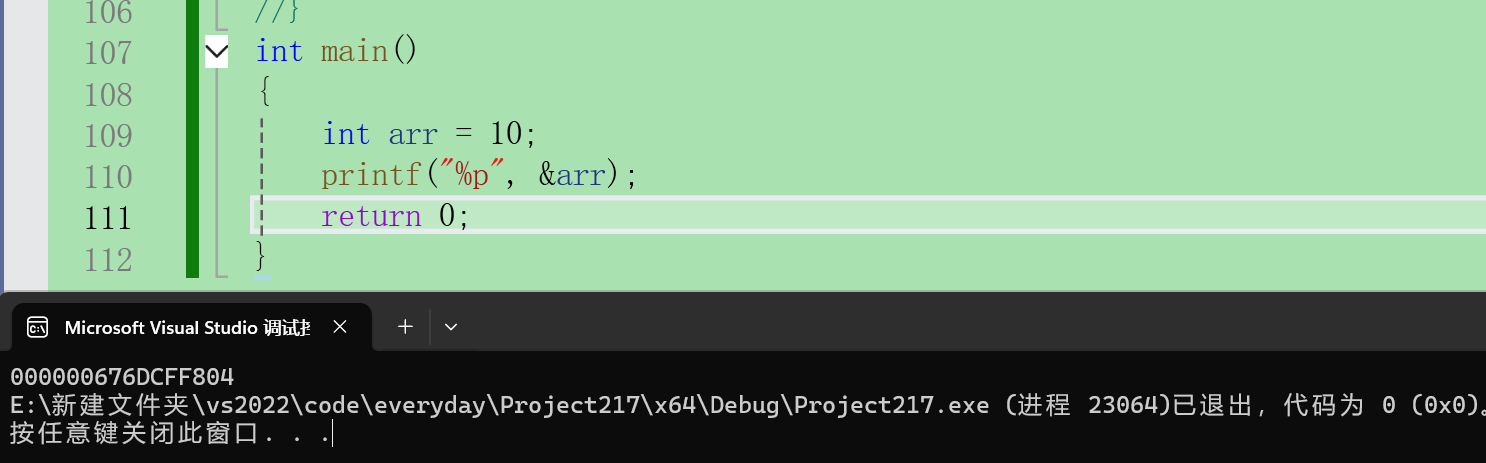
【C语言】详解 指针
前言: 在学习指针前,通过比喻的方法,让大家知道指针的作用。 想象一下,你在一栋巨大的图书馆里找一本书。如果没有书架编号和目录,这几乎是不可能完成的任务。 在 C 语言中,指针就像是图书馆的索引系统&…...

RabbitMQ仲裁队列高可用架构解析
#作者:闫乾苓 文章目录 概述工作原理1.节点之间的交互2.消息复制3.共识机制4.选举领导者5.消息持久化6.自动故障转移 集群环境节点管理仲裁队列增加集群节点重新平衡仲裁队列leader所在节点仲裁队列减少集群节点 副本管理add_member 在给定节点上添加仲裁队列成员&…...

刚出炉热乎的。UniApp X 封装 uni.request
HBuilder X v4.66 当前最新版本 由于 uniapp x 使用的是自己包装的 ts 语言 uts。目前语言还没有稳定下来,各种不支持 ts 各种报错各种不兼容问题。我一个个问题调通的,代码如下: 封装方法 // my-app/utils/request.uts const UNI_APP_BASE…...

Apache Kafka 实现原理深度解析:生产、存储与消费全流程
Apache Kafka 实现原理深度解析:生产、存储与消费全流程 引言 Apache Kafka 作为分布式流处理平台的核心,其高吞吐、低延迟、持久化存储的设计使其成为现代数据管道的事实标准。本文将从消息生产、持久化存储、消息消费三个阶段拆解 Kafka 的核心实现原…...
Python 训练营打卡 Day 41
简单CNN 一、数据预处理 在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富…...
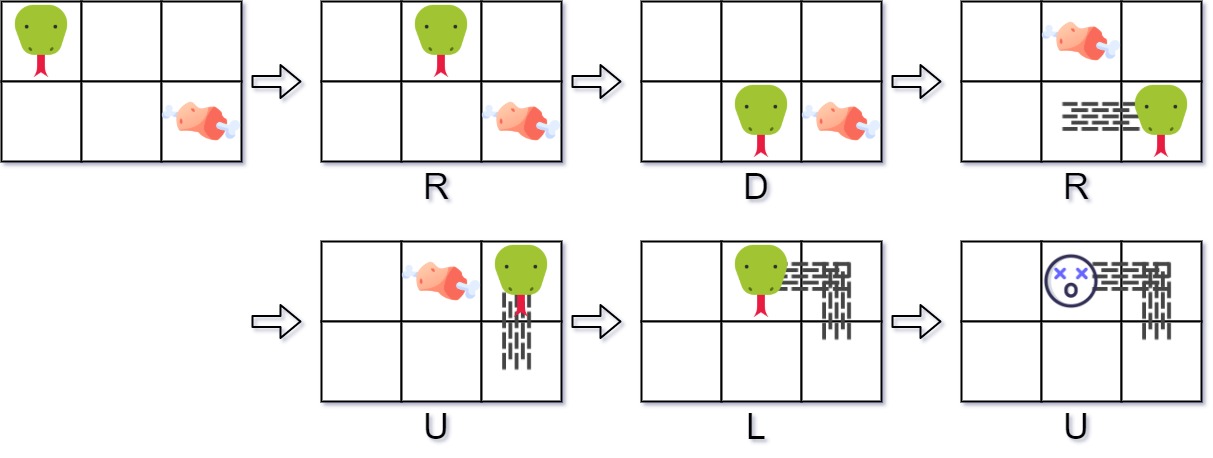
leetcode付费题 353. 贪吃蛇游戏解题思路
贪吃蛇游戏试玩:https://patorjk.com/games/snake/ 问题描述 设计一个贪吃蛇游戏,要求实现以下功能: 初始化游戏:给定网格宽度、高度和食物位置序列移动操作:根据指令(上、下、左、右)移动蛇头规则: 蛇头碰到边界或自身身体时游戏结束(返回-1)吃到食物时蛇身长度增加…...

CCPC dongbei 2025 I
题目链接:https://codeforces.com/gym/105924 题目背景: 给定一个二分图,左图编号 1 ~ n,右图 n 1 ~ 2n,左图的每个城市都会与右图的某个城市犯冲(每个城市都只与一个城市犯冲),除…...