python常用库-pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))
文章目录
- python常用库pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))
- 背景
- 什么是JSONL(JSON Lines)
- 通过pandas读取和保存JSONL文件
- pandas读取和保存JSONL文件
- Hugging Face的datasets库
- Hugging Face的datasets库 和 pandas 我应该用哪个
- 参考
python常用库pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))
背景
在当今的数据交换领域,各种格式层出不穷,其中 Comma Separated Values(CSV)格式作为一种常见的数据交换格式,被广泛用于表示具有相同字段列表的记录集。而 JavaScript Object Notation(JSON)则已成为事实上的数据交换格式标准,取代了曾在 21 世纪初备受瞩目的 XML。JSON 不仅具有自我描述性,而且易于人类阅读。
在处理和分析大型数据集时,JSON Lines 格式成为了一种受欢迎的选择。
与传统的 JSON 格式相比,JSON Lines 不需要一次性加载整个文件,而是可以逐行读取和处理数据。这种特性使得 JSON Lines 非常适用于处理大型数据集,无需担心内存限制或性能问题。
每一行表示一个单独的条目这一特点使得 JSON Lines 格式化的文件具有可流式处理的特性。您可以根据需要读取任意多行来获取相同数量的记录。在网络爬虫等需要处理大量数据的场景中,JSON Lines 格式无疑是一种非常实用的选择。
JSONL(JSON Lines)在大模型时代,通常用于保存模型训练的数据集。
什么是JSONL(JSON Lines)
官网:https://jsonlines.org/
JSON Lines 特点
- 采用 UTF-8 编码;
- 每行必须是一个有效的 JSON 对象;
- 在每个 JSON 对象,采用 \n 或 \r\n 作为行分隔符;
建议约定:
- JSON Lines文件通常使用文件扩展名
.jsonl保存 - 建议使用像 gzip 或 bzip2 这样的流压缩器以节省空间,生成 .jsonl.gz 或 .jsonl.bz2 文件
- MIME 类型可以是 application/jsonl,但这 还没有被标准化
- 文本编辑程序将文本文件的第一行称为“第1行”。JSON Lines文件中的第一个值也应称为“第1个值”
通过pandas读取和保存JSONL文件
微调任何人工智能模型的第一步是准备训练数据集。
很多时候,我们需要把一些我们常见的格式,如csv等,转换为更适合训练 AI 模型的 JSONL(JSON Lines)格式。
目前大模型很多的数据格式都是jsonl和json的,通常我们使用json的文件相对较多,对于jsonl的处理,我们其中每一行都是一个独立的JSON对象。这种格式非常适合于那些需要逐行读取和写入数据的场景,比如日志文件处理。Pandas是一个强大的Python数据分析库,它提供了读取和保存JSONL文件的功能,使得处理这种格式的数据变得简单快捷。
pandas读取和保存JSONL文件
在使用Python的数据处理库pandas时,可以轻松地读取和写入JSONL格式的文件。
当处理大型JSONL文件时,我们可能不希望一次性将所有数据加载到内存中。Pandas的read_json方法支持分块读取:
chunk_size = 1000 # 每次读取1000行
chunks = pd.read_json('large_data.jsonl', lines=True, chunksize=chunk_size)for chunk in chunks:print(chunk)# 可以在这里对每个块进行处理
Hugging Face的datasets库
官方地址:https://huggingface.co/docs/datasets/index
Hugging Face中的datasets库为数据处理提供了强大且灵活的工具,能够帮助开发者和研究人员更高效地处理各种类型的数据集。通过其丰富的特性和广泛的社区支持,datasets库已成为机器学习项目中不可或缺的重要工具之一。
Hugging Face是用来处理数据集的一个python库。当微调一个模型时候,需要在以下三个方面使用该库,如下。
- 从Huggingface Hub上下载和缓冲数据集(也可以本地哟!)
- 使用Dataset.map()预处理数据
- 加载和计算指标
现在上GB的数据集是非常常见的,例如训练BERT和GPT2的数据集。加载如此之大的数据集对内存大要求很高。预训练GPT2的数据集包含8百万个文档和40GB的文本。如果你有尝试加载过这些数据,就会知道这有多么的麻烦!
Datasets针对大数据加载的痛点做了很多工作,在加载数据上使用内存映射的方法,使得加载数据不再受内存大小的限制,只要磁盘空间够大,就能够快速加载大数据文件。
只需要在load_dataset()函数中指定加载数据的类型(csv或tsv表格数据、text文本数据、json或json lines格式数据已经pandas保存的pickle文件)以及设置参数data_files来指定一个或多个文件即可。
Hugging Face的datasets库 和 pandas 我应该用哪个
Hugging Face的datasets库
- 专用性:datasets库专为处理和加载各类自然语言处理(NLP)任务的数据集而设计,支持从Hugging Face Hub直接下载和加载多个公共数据集,比如GLUE、SQuAD、IMDB等1。
- 高效性:该库使用内存映射(memory mapping)和缓存机制,能够高效处理大规模数据集,并支持GPU加速5。
- 便捷性:通过简单的一行代码即可加载数据集,具备多线程处理能力,适合需要快速迭代的深度学习项目^6。
- 灵活性:可以方便地进行数据集的处理和变换(例如过滤、切分、映射)1。
- 与Transformers兼容:适合与Hugging Face的Transformers库结合使用,便于直接应用于模型训练和验证3。
Pandas
- 多功能性:Pandas是一个通用的数据处理库,不仅限于NLP领域,适合处理各种数据格式(如CSV、Excel、JSON等),非常适合一般的数据分析任务。
- 灵活的数据操作:Pandas提供了丰富的数据操作功能(如数据清洗、变换、合并、重塑等),在结构化数据的处理上非常强大2。
- 更广的应用场景:如果你的数据分析不仅限于NLP,比如数据可视化、数据科学等场景,Pandas则是更合适的选择。
- 学习曲线:对于新的数据科学家来说,Pandas的学习曲线相对较平缓,因为它的应用场景更广泛且有丰富的学习资源。
总结:
如果你的项目更多地涉及到深度学习和模型训练,建议优先使用datasets库;如果涉及到多样化的数据处理和分析任务,则Pandas更为合适。
参考
【大模型-驯化】成功搞懂大模型的jsonl数据格式处理和写入,通过pandas读取和保存JSONL文件
https://blog.csdn.net/lov1993/article/details/142494045
Hugging Face教程 - 5、huggingface的datasets库使用
参考URL: https://zhuanlan.zhihu.com/p/564816807
相关文章:
))
python常用库-pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))
文章目录 python常用库pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))背景什么是JSONL(JSON Lines)通过pandas读取和保存JSONL文件pandas读取和保存JSONL文件 Hugging Face的datasets库Hugg…...

高端装备制造企业如何选择适配的项目管理系统提升项目执行效率?附选型案例
高端装备制造项目通常涉及多专业协同、长周期交付和高风险管控,因此系统需具备全生命周期管理能力。例如,北京奥博思公司出品的 PowerProject 项目管理系统就是一款非常适合制造企业使用的项目管理软件系统。 国内某大型半导体装备制造企业与奥博思软件达…...

【Dv3Admin】工具权限配置文件解析
接口级权限控制是后台系统安全防护的核心手段。基于用户角色、请求路径与方法进行细粒度授权,可以有效隔离不同用户的数据访问范围,防止越权操作,保障系统整体稳定性。 本文解析 dvadmin/utils/permission.py 模块,重点关注其在匿…...
AI炼丹日志-22 - MCP 自动操作 Figma+Cursor 自动设计原型
MCP 基本介绍 官方地址: https://modelcontextprotocol.io/introduction “MCP 是一种开放协议,旨在标准化应用程序向大型语言模型(LLM)提供上下文的方式。可以把 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 提供了一种…...
)
Python爬虫:AutoScraper 库详细使用大全(一个智能、自动、轻量级的网络爬虫)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、AutoScraper概述1.1 AutoScraper介绍1.2 安装1.3 注意事项二、基本使用方法2.1 创建 AutoScraper 实例2.2 训练模型2.3 保存和加载模型2.4 数据提取方法2.5 自定义规则三、高级功能3.1 多规则抓取3.2 分页抓取3.3 代…...

2025.6.1总结
今天又上了一天课,假期三天,上了两天的课,明天还得刷题。利用假期时间上课学习,并没有让我感到有多充实,反而让我感到有些小压抑。 在下午的好消息分享环节,我分享了毕业工作以来的一些迷茫。我不知道自己…...
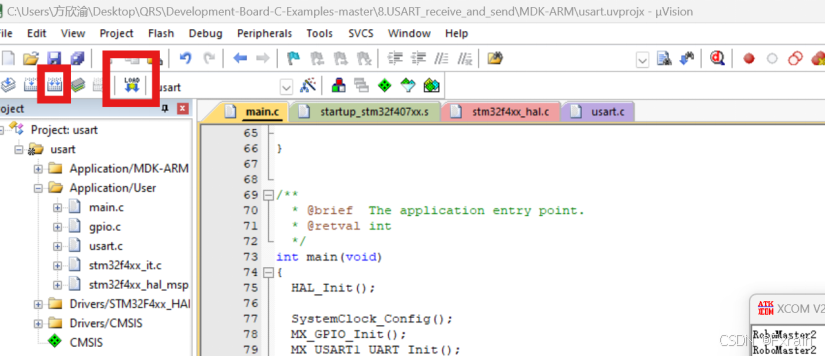
[嵌入式实验]实验四:串口打印电压及温度
一、实验目的 熟悉开发环境在开发板上读取电压和温度信息使用串口和PC通信在PC上输出当前电压和温度信息 二、实验环境 硬件:STM32开发板、CMSIS-DAP调试工具 软件:STM32CubeMX软件、ARM的IDE:Keil C51 三、实验内容 配置相关硬件设施 &…...

LVS+Keepalived 高可用
目录 一、核心概念 1. LVS(Linux Virtual Server) 2. Keepalived 二、高可用架构设计 1. 架构拓扑图 2. 工作流程 三、部署步骤(以 DR 模式为例) 1. 环境准备 2. 主 LVS 节点配置 (1)安装 Keepali…...
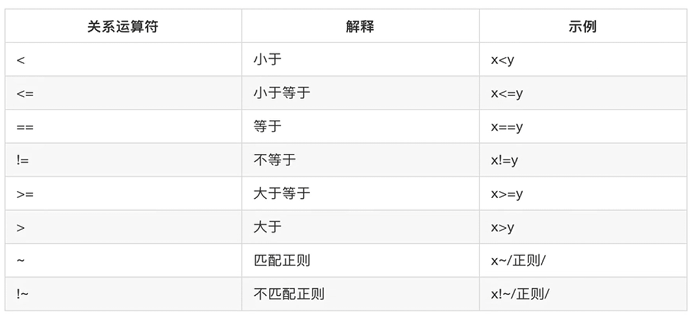
Linux正则三剑客篇
一、历史命令 history 命令 :用于输出历史上使用过的命令行数量及具体命令。通过 history 可以快速查看并回顾之前执行过的命令,方便重复操作或追溯执行过程。 !行号 :通过指定历史命令的行号来重新执行该行号对应的命令。例如,若…...

HTML5 视频播放器:从基础到进阶的实现指南
在现代Web开发中,视频播放功能是许多网站的重要组成部分。无论是在线教育平台、视频分享网站,还是企业官网,HTML5视频播放器都扮演着不可或缺的角色。本文将从基础到进阶,详细介绍如何实现一个功能完善的HTML5视频播放器ÿ…...
的实战教程)
鸿蒙HarmonyOS (React Native)的实战教程
一、环境配置 安装鸿蒙专属模板 bashCopy Code npx react-native0.72.5 init HarmonyApp --template react-native-template-harmony:ml-citation{ref"4,6" data"citationList"} 配置 ArkTS 模块路径 在 entry/src/main/ets 目录下创建原生模块&…...

函数栈帧深度解析:从寄存器操作看函数调用机制
文章目录 一、程序运行的 "舞台":内存栈区与核心寄存器二、寄存器在函数调用中的核心作用三、函数调用全流程解析:以 main 调用 func 为例阶段 1:main 函数栈帧初始化**阶段 2:参数压栈(右→左顺序&#x…...
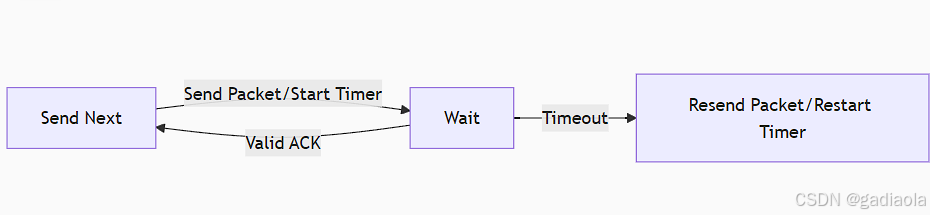
【计算机网络】第3章:传输层—可靠数据传输的原理
目录 一、PPT 二、总结 (一)可靠数据传输原理 关键机制 1. 序号机制 (Sequence Numbers) 2. 确认机制 (Acknowledgements - ACKs) 3. 重传机制 (Retransmission) 4. 校验和 (Checksum) 5. 流量控制 (Flow Control) 协议实现的核心:滑…...

rv1126b sdk移植
DDR rkbin bin/rv11/rv1126bp_ddr_v1.00.bin v1.00 板子2 reboot异常 [ 90.334976] reboot:Restarting system DDR 950804cb85 wesley.yao 25/04/02-15:54:40,fwver: v1.00In Derate1 tREFI1x SR93 PD13 R ddrconf 4 rgef0 rgcsb0 1 ERR: Read gate CS0 err error ERR …...

第6节 Node.js 回调函数
Node.js 异步编程的直接体现就是回调。 异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。 回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。 例如,我们可以一边读取文…...

OpenCV CUDA模块直方图计算------在 GPU上执行直方图均衡化(Histogram Equalization)函数equalizeHist
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::equalizeHist 用于增强图像的对比度,通过将图像的灰度直方图重新分布,使得图像整体对比度更加明显。 这在医学…...

构建系统maven
1 前言 说真的,我是真的不想看构建了,因为真的太多了。又多又乱。Maven、Gradle、Make、CMake、Meson、Ninja,Android BP。。。感觉学不完,根本学不完。。。 但是没办法最近又要用一下Maven,所以咬着牙再简单整理一下…...
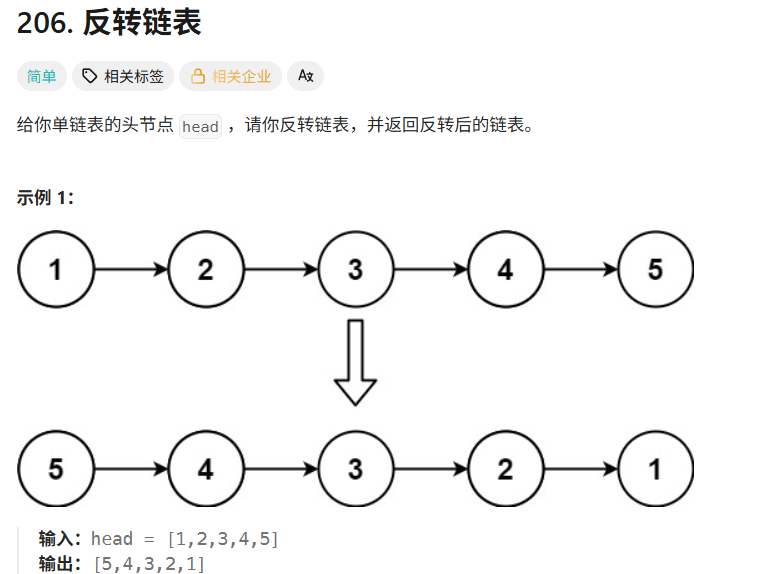
day13 leetcode-hot100-23(链表2)
206. 反转链表 - 力扣(LeetCode) 1.迭代 思路 这个题目很简单,最主要的就是了解链表的数据结构。 链表由多个节点构成,每个节点包括值与指针,其中指针指向下一个节点(单链表)。 方法就是将指…...
)
Java面试八股(Java基础,Spring,SpringBoot篇)
java基础 JDK,JRE,JVMJava语言的特点Java常见的运行时异常Java为什么要封装自增自减的隐式转换移位运算符1. 左移运算符(<<)2. 带符号右移运算符(>>)3. 无符号右移运算符(>>>) 可变…...
| 列表简介)
Python编程基础(二)| 列表简介
引言:很久没有写 Python 了,有一点生疏。这是学习《Python 编程:从入门到实践(第3版)》的课后练习记录,主要目的是快速回顾基础知识。 练习1: 姓名 将一些朋友的姓名存储在一个列表中…...
:解锁数据分类与回归的强大工具)
支持向量机(SVM):解锁数据分类与回归的强大工具
在机器学习的世界中,支持向量机(Support Vector Machine,简称 SVM)一直以其强大的分类和回归能力而备受关注。本文将深入探讨 SVM 的核心功能,以及它如何在各种实际问题中发挥作用。 一、SVM 是什么? 支持…...
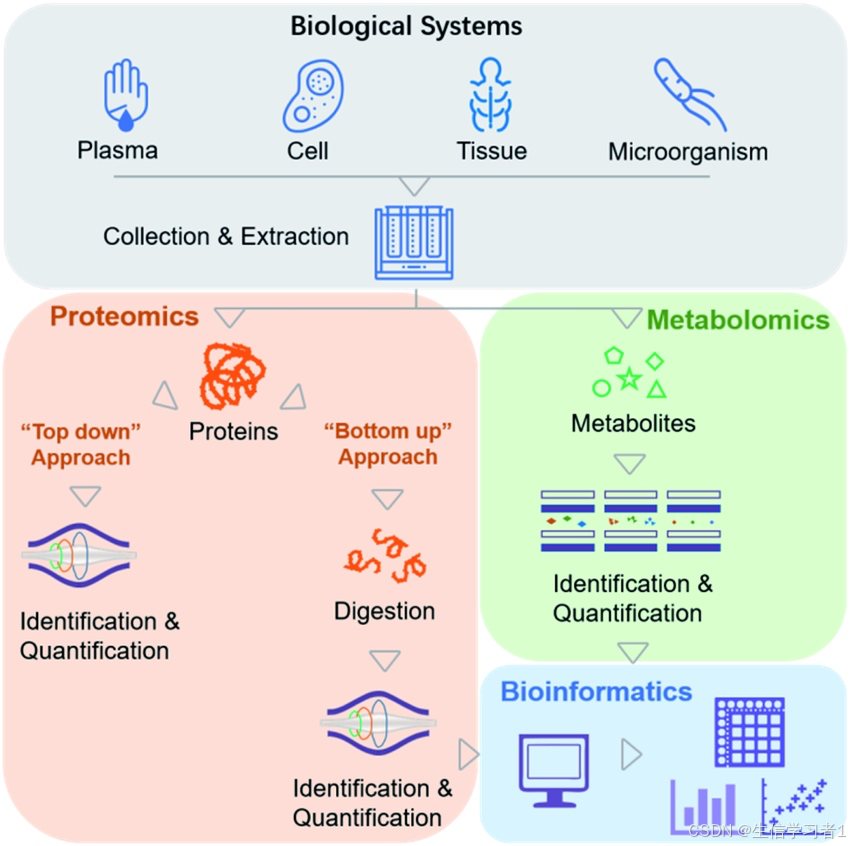
代谢组数据分析(二十五):代谢组与蛋白质组数据分析的异同
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍蛋白质组定义与基因的关系蛋白质组学(Proteomics)检测技术蛋白质的鉴定与定量分析蛋白质“鉴定”怎么做蛋白质“定量”怎么做蛋白质鉴定与定量对比应用领域代谢组定义代谢组学(M…...
002 flutter基础 初始文件讲解(1)
在学习flutter的时候,要有“万物皆widget”的思想,这样有利于你的学习,话不多说,开始今天的学习 1.创建文件 进入trae后,按住ctrlshiftP,输入Flutter:New Project,回车,…...

AI 让无人机跟踪更精准——从视觉感知到智能预测
AI 让无人机跟踪更精准——从视觉感知到智能预测 无人机跟踪技术正在经历一场前所未有的变革。曾经,我们只能依靠 GPS 或简单的视觉识别来跟踪无人机,但如今,人工智能(AI)结合深度学习和高级视觉算法,正让无人机的跟踪变得更加智能化、精准化。 尤其是在自动驾驶、安防监…...

Launcher3体系化之路
👋 欢迎来到Launcher 3 背景 车企对于桌面的排版布局好像没有手机那般复杂,但也有一定的需求。部分场景下,要考虑的上下文比手机要多一些,比如有如下的一些场景: 手车互联。HiCar,CarPlay,An…...
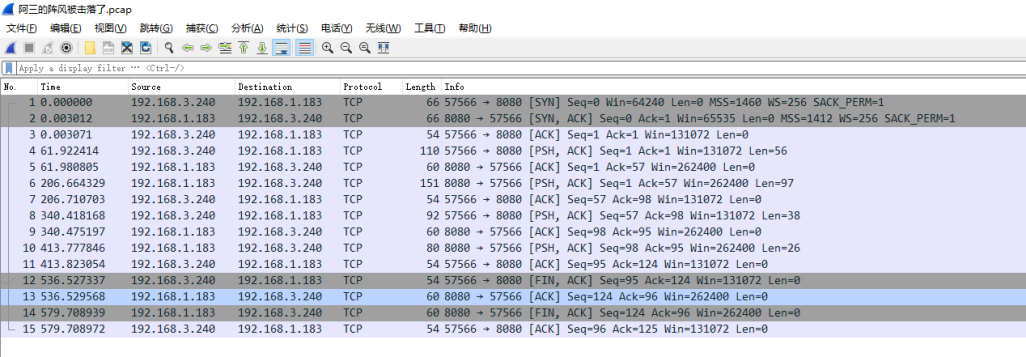
用wireshark抓了个TCP通讯的包
昨儿个整理了下怎么用wireshark抓包,链接在这里:捋捋wireshark 今天打算抓个TCP通讯的包试试,整体来说比较有收获,给大家汇报一下。 首先就是如何搞到可以用来演示TCP通讯的客户端、服务端,问了下deepseek,…...
VR/AR 显示瓶颈将破!铁电液晶技术迎来关键突破
在 VR/AR 设备逐渐走进大众生活的今天,显示效果却始终是制约其发展的一大痛点。纱窗效应、画面拖影、眩晕感…… 传统液晶技术的瓶颈让用户体验大打折扣。不过,随着铁电液晶技术的重大突破,这一局面有望得到彻底改变。 一、传统液晶技术瓶颈…...

【前端】Vue中实现pdf逐页转图片,图片再逐张提取文字
给定场景:后端无法实现pdf转文字,由前端实现“pdf先转图片再转文字”。 方法: 假设我们在< template>中有一个元素存放我们处理过的canvas集合 <div id"canvasIDpdfs" />我们给定一个按钮,编写click函数&…...

焦虑而烦躁的上午
半年了,每逢周末或者节假日都被催着去医院。 今天早上依旧,还在睡梦之中,就被喊醒“赶紧得,抢上儿童医院的票了!” 无奈,从床上爬起来,草草用过早餐之后,奔赴儿童医院!…...
Python使用
Python学习,从安装,到简单应用 前言 Python作为胶水语言在web开发,数据分析,网络爬虫等方向有着广泛的应用 一、Python入门 相关基础语法直接使用相关测试代码 Python编译器版本使用3以后,安装参考其他教程…...