美化显示GDB调试的数据结构
笔者在前面的博文记一次pdf转Word的技术经历中有使用到mupdf库,该库是使用C语言写的一个操作PDF文件的库,同时提供了Python接口,Java接口和JavaScript接口。
在使用该库时,如果想要更高的性能,使用C语言接口是不二的选择。笔者在使用mupdf库C API时,遇到一个问题:调试它时不能看到数据结构,全部是一个地址,比如mupdf中的pdf_obj对象,它的API中只有一个typedef,参见mupdf/pdf/object.h:
typedef struct pdf_obj pdf_obj;
实际的结构定义是在库的pdf-object.c文件中,库使用者并不可见。它把整数(int)、浮点数(real)、字符串(string)、名字(name)、数组(array)、字典(dictinary)、间接引用(indirect reference)都抽象成pdf_obj:
typedef enum pdf_objkind_e
{PDF_INT = 'i',PDF_REAL = 'f',PDF_STRING = 's',PDF_NAME = 'n',PDF_ARRAY = 'a',PDF_DICT = 'd',PDF_INDIRECT = 'r'
} pdf_objkind;struct pdf_obj
{short refs;unsigned char kind;unsigned char flags;
};typedef struct
{pdf_obj super;union{int64_t i;float f;} u;
} pdf_obj_num;typedef struct
{pdf_obj super;char *text; /* utf8 encoded text string */size_t len;char buf[FZ_FLEXIBLE_ARRAY];
} pdf_obj_string;typedef struct
{pdf_obj super;char n[FZ_FLEXIBLE_ARRAY];
} pdf_obj_name;typedef struct
{pdf_obj super;pdf_document *doc;int parent_num;int len;int cap;pdf_obj **items;
} pdf_obj_array;typedef struct
{pdf_obj super;pdf_document *doc;int parent_num;int len;int cap;struct keyval *items;
} pdf_obj_dict;typedef struct
{pdf_obj super;pdf_document *doc; /* Only needed for arrays, dicts and indirects */int num;int gen;
} pdf_obj_ref;
然后API中全部使用pdf_obj*来操作上述数据结构:
// 创建API
pdf_obj *pdf_new_int(fz_context *ctx, int64_t i);
pdf_obj *pdf_new_real(fz_context *ctx, float f);
pdf_obj *pdf_new_name(fz_context *ctx, const char *str);
pdf_obj *pdf_new_string(fz_context *ctx, const char *str, size_t len);
pdf_obj *pdf_new_text_string(fz_context *ctx, const char *s);
pdf_obj *pdf_new_indirect(fz_context *ctx, pdf_document *doc, int num, int gen);
pdf_obj *pdf_new_array(fz_context *ctx, pdf_document *doc, int initialcap);
pdf_obj *pdf_new_dict(fz_context *ctx, pdf_document *doc, int initialcap);// 释放内存的API
void pdf_drop_obj(fz_context *ctx, pdf_obj *obj);// 检测API
int pdf_is_null(fz_context *ctx, pdf_obj *obj);
int pdf_is_bool(fz_context *ctx, pdf_obj *obj);
int pdf_is_int(fz_context *ctx, pdf_obj *obj);
int pdf_is_real(fz_context *ctx, pdf_obj *obj);
int pdf_is_number(fz_context *ctx, pdf_obj *obj);
int pdf_is_name(fz_context *ctx, pdf_obj *obj);
int pdf_is_string(fz_context *ctx, pdf_obj *obj);
int pdf_is_array(fz_context *ctx, pdf_obj *obj);
int pdf_is_dict(fz_context *ctx, pdf_obj *obj);
int pdf_is_indirect(fz_context *ctx, pdf_obj *obj);// pdf_obj转换C标准数据类型的API
int pdf_to_bool(fz_context *ctx, pdf_obj *obj);
int pdf_to_int(fz_context *ctx, pdf_obj *obj);
int64_t pdf_to_int64(fz_context *ctx, pdf_obj *obj);
float pdf_to_real(fz_context *ctx, pdf_obj *obj);
const char *pdf_to_name(fz_context *ctx, pdf_obj *obj);
const char *pdf_to_text_string(fz_context *ctx, pdf_obj *obj);
const char *pdf_to_string(fz_context *ctx, pdf_obj *obj, size_t *sizep);
char *pdf_to_str_buf(fz_context *ctx, pdf_obj *obj);
size_t pdf_to_str_len(fz_context *ctx, pdf_obj *obj);
int pdf_to_num(fz_context *ctx, pdf_obj *obj);
int pdf_to_gen(fz_context *ctx, pdf_obj *obj);
还有很多操作pdf_obj的API,就不一一列出了。这里想要说的是API的封装非常好,只是使用者在使用库时,想要更深入地查看数据,就很不友好了。
我们在C/C++语言中,经常会自定义数据结构,但是调试时调试器都会默认的按最原始的组织方式展示它们,很不直观。只有借助调试器的美化输出才能达到目的。比如C++中的STL库,定义了很多数据结构,如果不美化调试器的输出是很难查看其数据的,只是由于STL是标准库,编译器厂商已经帮我们做了相应的美化输出工作,所以可以直观地看数据。
下面笔者借调试研究mupdf库,介绍一下如何美化显示调试器的输出。目前主流的调试器有GDB、LLDB以及MS Debugger,以GDB的使用最广泛,跨Linux、MacOS、Windows、IOS、安卓等等,LLDB作为后起之秀,使用也越来越广泛,而MS Debugger本地调试器局限于Windows,但Windows使用广泛。所以笔者打算以mupdf库为例,介绍这三个调试器的美化输出。本文先介绍GDB的美化输出(Windows下的MinGW中的GDB)。
一、加载自定义脚本
GDB在启动时,会尝试加载~/.gdbinit文件(如果有就加载)。所以我们可以把一些基本设置放在这个文件中来,比如设置反汇编的格式为intel(GDB默认的反汇编格式为att)、调用自定义的python脚本。
需要注意的是在Windows下,假定用户名为admin,如果是Windows控制台,~/.gdbinit位于C:/Users/admin/.gdbinit;如果是MinGW的终端,则位于MinGW的/home/admin/.gdbinit。
比如笔者的~/.gdbinit文件如下:
# 设置反汇编格式为intel
set disassembly-flavor intel
# 允许自动执行本地gdbinit,即允许执行项目级的`.gdbinit`
set auto-load local-gdbinit on
# 设置自动加载GDB脚本的安全路径,`/`表示所有项目,如果要指定特定项目,给出具体路径即可
set auto-load safe-path /
# 执行shell指令,Windows下执行chcp 65001修改控制台编码为UTF8
shell chcp 65001
# python脚本
python
import sys
# 添加python搜索模块的路径
sys.path.insert(0, 'C:/Users/admin/gdbscripts')
# 导入mupdf_printer模块
import mupdf_printer
end
在C:/Users/admin/gdbscripts中添加一个mupdf_printer.pdf文件,写一句:
print("MuPDF GDB pretty printers loaded.")
分别在Windows控制台以及MinGW终端执行GDB,看是否有输出:
看到输出就说明自定义的脚本加载成功了。
二、写mupdf测试代码
#include <mupdf/fitz.h>
#include <mupdf/pdf.h>// 为GDB调试器使用,不能设置为static
// 这将使得GDB可以在运行时获取mupdf的版本信息
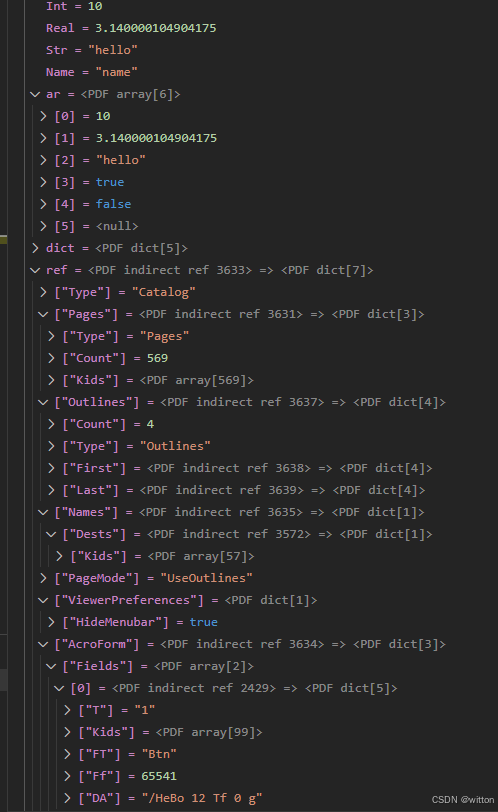
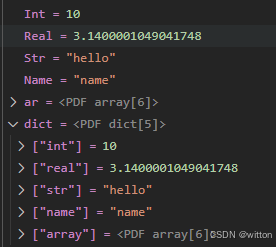
const char* mupdf_version = FZ_VERSION;int main(int argc, char* argv[]) {pdf_obj* nil = nullptr;fz_context* ctx = fz_new_context(nullptr, nullptr, FZ_STORE_UNLIMITED);pdf_document* doc = pdf_open_document(ctx, "t.pdf");pdf_obj* Int = pdf_new_int(ctx, 10);pdf_obj* Real = pdf_new_real(ctx, 3.14);pdf_obj* Str = pdf_new_text_string(ctx, "hello");pdf_obj* Name = pdf_new_name(ctx, "name");pdf_obj* ar = pdf_new_array(ctx, doc, 10);pdf_array_put(ctx, ar, 0, Int);pdf_array_put(ctx, ar, 1, Real);pdf_array_put(ctx, ar, 2, Str);pdf_array_push_bool(ctx, ar, 1);pdf_array_push_bool(ctx, ar, 0);pdf_array_push(ctx, ar, PDF_NULL);pdf_obj* dict = pdf_new_dict(ctx, doc, 10);pdf_dict_puts(ctx, dict, "int", Int);pdf_dict_puts(ctx, dict, "real", Real);pdf_dict_puts(ctx, dict, "str", Str);pdf_dict_puts(ctx, dict, "name", Name);pdf_dict_puts(ctx, dict, "array", ar);// 这里3633是笔者pdf文件中的Catalog对象pdf_obj* ref = pdf_new_indirect(ctx, doc, 3633, 0);pdf_drop_obj(ctx, Int);pdf_drop_obj(ctx, Real);pdf_drop_obj(ctx, Str);pdf_drop_obj(ctx, Name);pdf_drop_obj(ctx, ar);pdf_drop_obj(ctx, dict);pdf_drop_obj(ctx, ref);fz_drop_context(ctx);
}
目前在VSCode下使用GDB调试时显示的变量值全部是地址:
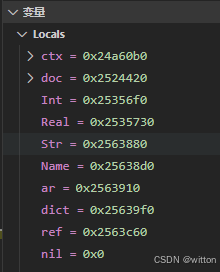
下面是笔者添加了美化显示后的效果:
三、写GDB的Python脚本
GDB的Python扩展可以参见Extending GDB using Python,我们目前只需要美化输出的API,参见Pretty Printing API,我主要使用到以下三个函数:
- pretty_printer.children (self):用于展示子节点,如果有子节点,需要实现此函数,如果没有则不写。
- pretty_printer.display_hint (self):用于提示该节点的类型,如果是字典返回
"map";如果是数组返回"array";如果是字符串,返回"string";其它情况返回None。 - pretty_printer.to_string (self):用于显示节点的值。
1. 向GDB注册pdf_obj类型
要让GDB以自定义的方式显示数据,需要先向GDB注册数据类型,这里需要注册的是pdf_obj类型。
import gdbdef pdf_obj_lookup(val):try:t = val.type.strip_typedefs()if t.code == gdb.TYPE_CODE_PTR:t = t.target()if t.name == "pdf_obj":print("<pdf_obj>")except:return Nonegdb.pretty_printers.append(pdf_obj_lookup)
print("MuPDF GDB pretty printers loaded.")
由于C语言中很多类型都是使用typedef方式定义过的,所以在解析类型时,可能需要调用strip_typedefs去掉typedef,最重要的是要去掉指针,这样方便只检测pdf_obj类型。
2. 写美化输出代码
在写美化输出的Python代码前,需要了解一下如何取值:
1. 直接使用C/C++中的字段名取字段值
如果是自己写的代码,或者使用库有调试信息,则可以直接使用字段名来取字段值,比如:
struct foo { int a, b; };
struct bar { struct foo x, y; };
则可以直接使用字段名"a"、“b”、“x”,"y"来取值:
class fooPrinter(gdb.ValuePrinter):"""Print a foo object."""def __init__(self, val):self.__val = valdef to_string(self):return ("a=<" + str(self.__val["a"]) +"> b=<" + str(self.__val["b"]) + ">")class barPrinter(gdb.ValuePrinter):"""Print a bar object."""def __init__(self, val):self.__val = valdef to_string(self):return ("x=<" + str(self.__val["x"]) +"> y=<" + str(self.__val["y"]) + ">")
2. 调用C/C++代码中的函数
如果是使用的别人编译的库,且没有调试信息,但有提供相应的API,则可以使用GDB调用API来取值。这里使用的mupdf库,在MinGW下就没有调试信息,但是提供了一系列的操作API,所以这里使用gdb.parse_and_eval来调用C/C++中的函数。需要注意的是在调用完成后需要强制转换成API对应的类型。比如,调用pdf_is_int,它的函数原型为:
int pdf_is_int(fz_context *ctx, pdf_obj *obj);
需要写成:
result = gdb.parse_and_eval(f"(int)pdf_is_int({ctx_addr}, {obj_addr}")
result中保存的就是调用的结果,如果GDB设置了set print address on,则字符串会返回地址和字符串内容:
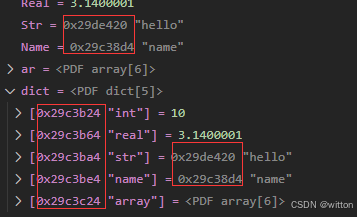
在字典显示中Key的显示会比较难看,所以需要对结果进行处理,GDB提供了string()函数去掉地址,判断到返回值是字符串,则调用result.string()去掉地址。
为了方便调用API,定义专门的函数来处理:
# 由于mupdf中的API都带有一个 fz_context* 参数,
# 为了提高性能,我们调用 fz_new_context_imp 来创建一个全局的pdf_ctx。
pdf_ctx = None# 由于fz_new_context_imp需要用到mupdf的版本号,但mupdf库并没提供这样的获取途径,
# 所以需要在C/C++代码中定义一个全局变量mupdf_version,且不能设置为静态变量
# const char* mupdf_version = FZ_VERSION;
# 然后在此写一个专门的函数来获取mupdf的版本号
def get_mupdf_version_from_symbol():try:version = gdb.parse_and_eval('(const char*)mupdf_version')return version.string()except gdb.error as e:return f"<symbol not found: {e}>"# 调用mupdf API的专用函数
# func_name是要调用的mupdf API名
# val是pdf_obj或者pdf_obj*
# retType是API的返回类型,支持int, float, str和object
# *args 是可能需要的参数,比如pdf_obj *pdf_array_get(fz_context *ctx, pdf_obj *array, int i)需要传一个索引i
def call_mupdf_api(func_name, val, retType, *args):try:# 获取地址,如果是指针,直接转成int# 如果是对象,需要取地址,再转成intif val.type.code == gdb.TYPE_CODE_PTR:addr = int(val)else:addr = int(val.address)cast = {int: "(int)",float: "(float)",str: "(const char*)",object: "(pdf_obj *)", # 转成pdf_obj指针}.get(retType, "(void)") # 根据Python传的参数,转成C/C++中的类型,默认强转为void# 如果pdf_ctx还没创建,则调用fz_new_context_imp创建global pdf_ctxif pdf_ctx is None:ver = get_mupdf_version_from_symbol()pdf_ctx = gdb.parse_and_eval(f"(fz_context*)fz_new_context_imp(0,0,0,\"{ver}\")")# 有额外参数的情况if args.__len__() > 0:args_str = ', '.join([str(arg) for arg in args])expr = f"{cast}{func_name}({pdf_ctx},{addr}, {args_str})"else: # 没额外参数的情况expr = f"{cast}{func_name}({pdf_ctx},{addr})"result = gdb.parse_and_eval(expr)# 使用全局 pdf_ctx 则此处不需要释放#gdb.parse_and_eval(f"(void)fz_drop_context({ctx})")# 根据返回类型进行处理,为了避免异常,使用cast转为C/C++中的类型if retType == int:return int(result.cast(gdb.lookup_type("int")))elif retType == float:return float(result.cast(gdb.lookup_type("float")))elif retType == str:# 去掉字符串中的地址return result.string()else:return resultexcept Exception as e:print(f"<error calling {func_name}: {e}>")return f"<error calling {func_name}: {e}>"
由于很多API的返回值都是int,为了方便,封装一下:
def call_pdf_api(func_name, val, rettype=int):return call_mupdf_api(func_name, val, rettype)def call_pdf_api_1(func_name, val, args, rettype=int):return call_mupdf_api(func_name, val, rettype, args)
3.检测pdf_obj的类型
pdf_obj可能是布尔(bool)、整数(int)、浮点数(real)、字符串(string)、名字(name)、数组(array)、字典(dictinary)、间接引用(indirect reference),在解析前,需要知道具体的类型:
def detect_pdf_obj_kind(val):try:if call_pdf_api("pdf_is_int", val):return "int"elif call_pdf_api("pdf_is_real", val):return "real"elif call_pdf_api("pdf_is_string", val):return "string"elif call_pdf_api("pdf_is_name", val):return "name"elif call_pdf_api("pdf_is_array", val):return "array"elif call_pdf_api("pdf_is_dict", val):return "dict"elif call_pdf_api("pdf_is_bool", val):return "bool"elif call_pdf_api("pdf_is_null", val):return "null"else:return "unknown"except Exception as e:print(f"<error detecting pdf_obj kind: {e}>")return "error"
4. 写各类型的美化输出
布尔(bool)、整数(int)、浮点数(real)、字符串(string)、名字(name)这些都是没有子节点的简单数据结构,所以不需要children函数:
class PDFObjIntPrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_int', self.val, int)def display_hint(self):return Noneclass PDFObjRealPrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_real', self.val, float)def display_hint(self):return Noneclass PDFObjStringPrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_text_string', self.val, str)def display_hint(self):return "string"class PDFObjNamePrinter:def __init__(self, val):self.val = valdef to_string(self):return call_pdf_api('pdf_to_name', self.val, str)def display_hint(self):return "string"class PDFObjBoolPrinter:def __init__(self, val):self.val = valdef to_string(self):ret = call_pdf_api("pdf_to_bool", self.val, int)return 'true' if ret else 'false'def display_hint(self):return Noneclass PDFObjNullPrinter:def __init__(self, val):self.val = valdef to_string(self):return "<null>"def display_hint(self):return None
而数组(array)、字典(dictinary)是需要展开子节点的数据结构,必须要有children函数,children函数需要返回的是一个Python的迭代器,迭代器中需要返回两个值,第一个值是名字name,第二个值则是显示内容;而字典是键值对,需要yield返回两次:
class PDFArrayPrinter:def __init__(self, val):self.val = valself.count = call_pdf_api("pdf_array_len", self.val)def to_string(self):return f"<PDF array[{self.count}]>"class _interator:def __init__(self, val, count):self.val = valself.count = countself.index = 0def __iter__(self):return selfdef __next__(self):if self.index >= self.count:raise StopIterationi = self.indexself.index += 1try:item = call_pdf_api_1("pdf_array_get", self.val, i, object)return f"{i}", itemexcept Exception:raise StopIterationdef children(self):return self._interator(self.val, self.count)def display_hint(self):return "array"class PDFDictPrinter:def __init__(self, val):self.val = valdef to_string(self):count = call_pdf_api("pdf_dict_len", self.val)return f"<PDF dict[{count}]>"def children(self):count = call_pdf_api("pdf_dict_len", self.val)for i in range(count):try:key = call_pdf_api_1("pdf_dict_get_key",self.val, i, object)val = call_pdf_api_1("pdf_dict_get_val",self.val, i, object)# 下面两个yield语句中,元组的第一个元素不能相同yield (f"{i}:k", key) # 返回键值对的键yield (f"{i}:v", val) # 返回键值对的值except Exception as e:print(f"PDFDictPrinter: error getting key {i} {e}")yield f"<key:{i}>", "<invalid>"def display_hint(self):return "map"
四、完整Python脚本:
import gdbpdf_ctx = Nonedef get_mupdf_version_from_symbol():try:version = gdb.parse_and_eval('(const char*)mupdf_version')return version.string()except gdb.error as e:return f"<symbol not found: {e}>"def call_mupdf_api(func_name, val, retType, *args):try:# 获取地址if val.type.code == gdb.TYPE_CODE_PTR:addr = int(val)else:addr = int(val.address)cast = {int: "(int)",float: "(float)",str: "(const char*)", # for functions returning const char*object: "(pdf_obj *)", # for pdf_obj pointers}.get(retType, "(void)")global pdf_ctxif pdf_ctx is None:ver = get_mupdf_version_from_symbol()pdf_ctx = gdb.parse_and_eval(f"(fz_context*)fz_new_context_imp(0,0,0,\"{ver}\")")if args.__len__() > 0:args_str = ', '.join([str(arg) for arg in args])expr = f"{cast}{func_name}({pdf_ctx},{addr}, {args_str})"else:expr = f"{cast}{func_name}({pdf_ctx},{addr})"result = gdb.parse_and_eval(expr)# 使用全局 pdf_ctx 则此处不需要释放#gdb.parse_and_eval(f"(void)fz_drop_context({ctx})") # Clean up contextif retType == int:return int(result.cast(gdb.lookup_type("int")))elif retType == float:return float(result.cast(gdb.lookup_type("float")))elif retType == str:return result.string()else:return resultexcept Exception as e:print(f"<error calling {func_name}: {e}>")return f"<error calling {func_name}: {e}>"def call_pdf_api(func_name, val, rettype=int):return call_mupdf_api(func_name, val, rettype)def call_pdf_api_1(func_name, val, args, rettype=int):return call_mupdf_api(func_name, val, rettype, args)def detect_pdf_obj_kind(val):try:if call_pdf_api("pdf_is_int", val):return "int"elif call_pdf_api("pdf_is_real", val):return "real"elif call_pdf_api("pdf_is_string", val):return "string"elif call_pdf_api("pdf_is_name", val):return "name"elif call_pdf_api("pdf_is_array", val):return "array"elif call_pdf_api("pdf_is_dict", val):return "dict"elif call_pdf_api("pdf_is_bool", val):return "bool"elif call_pdf_api("pdf_is_stream", val):return "stream"elif call_pdf_api("pdf_is_null", val):return "null"else:return "unknown"except Exception as e:print(f"<error detecting pdf_obj kind: {e}>")return "error"class PDFObjIntPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_int', self.val, int)}"def display_hint(self):return Noneclass PDFObjRealPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_real', self.val, float)}"def display_hint(self):return Noneclass PDFObjStringPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_text_string', self.val, str)}"def display_hint(self):return "string"class PDFObjNamePrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}{call_pdf_api('pdf_to_name', self.val, str)}"def display_hint(self):return "string"class PDFObjBoolPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):ret = call_pdf_api("pdf_to_bool", self.val, int)return f"{self.ref}{'true' if ret else 'false'}"def display_hint(self):return Noneclass PDFObjNullPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):return f"{self.ref}<null>"def display_hint(self):return Noneclass PDFArrayPrinter:def __init__(self, val, ref):self.val = valself.ref = refself.count = call_pdf_api("pdf_array_len", self.val)def to_string(self):return f"{self.ref}<PDF array[{self.count}]>"class _interator:def __init__(self, val, count):self.val = valself.count = countself.index = 0def __iter__(self):return selfdef __next__(self):if self.index >= self.count:raise StopIterationi = self.indexself.index += 1try:item = call_pdf_api_1("pdf_array_get", self.val, i, object)return f"{i}", itemexcept Exception:raise StopIterationdef children(self):return self._interator(self.val, self.count)def display_hint(self):return "array"class PDFDictPrinter:def __init__(self, val, ref):self.val = valself.ref = refdef to_string(self):count = call_pdf_api("pdf_dict_len", self.val)return f"{self.ref}<PDF dict[{count}]>"def children(self):count = call_pdf_api("pdf_dict_len", self.val)for i in range(count):try:key = call_pdf_api_1("pdf_dict_get_key",self.val, i, object)val = call_pdf_api_1("pdf_dict_get_val",self.val, i, object)# 下面两个yield语句中,元组的第一个元素不能相同yield (f"{i}:k", key) # 返回键值对的键yield (f"{i}:v", val) # 返回键值对的值except Exception as e:print(f"PDFDictPrinter: error getting key {i} {e}")yield f"<key:{i}>", "<invalid>"def display_hint(self):return "map"def pdf_obj_lookup(val):try:t = val.typeif t.code == gdb.TYPE_CODE_PTR:t = t.target()if t.name == "pdf_obj":ref = ""if call_pdf_api("pdf_is_indirect", val):ref_num = call_pdf_api("pdf_to_num", val, int)ref = f"<PDF indirect ref {ref_num}> => "kind = detect_pdf_obj_kind(val)if kind == "int":return PDFObjIntPrinter(val, ref)elif kind == "real":return PDFObjRealPrinter(val, ref)elif kind == "string":return PDFObjStringPrinter(val, ref)elif kind == "name":return PDFObjNamePrinter(val, ref)elif kind == "array":return PDFArrayPrinter(val, ref)elif kind == "dict":return PDFDictPrinter(val, ref)elif kind == "bool":return PDFObjBoolPrinter(val, ref)elif kind == "null":return PDFObjNullPrinter(val, ref)else:print(f"<unknown pdf_obj kind: {kind}>")return Noneexcept:return Nonegdb.pretty_printers.append(pdf_obj_lookup)
print("MuPDF GDB pretty printers loaded.")不知道细心的读者有没发现,目前还有一点问题就是在VSCode中数组和字典的在展开过程中,如果已经没有可展开的项了,但是还是有一个箭头在前面。有解决办法的读者也可以在评论区讨论!
笔者可能会持续改进与补充,欲知后续版本,请移步:
https://github.com/WittonBell/demo/tree/main/mupdf/gdbscripts
如果对你有帮助,欢迎点赞收藏!
相关文章:
美化显示GDB调试的数据结构
笔者在前面的博文记一次pdf转Word的技术经历中有使用到mupdf库,该库是使用C语言写的一个操作PDF文件的库,同时提供了Python接口,Java接口和JavaScript接口。 在使用该库时,如果想要更高的性能,使用C语言接口是不二的选…...

一篇学习CSS的笔记
一、简介 Cascading Style Sheets简称CSS,中文翻译为层叠样式表。当HTML被发明出来初期,不同的浏览器提供了各种各样的样式语言给用户控制网页的效果,HTML包含的显示属性并不是很多。但是随着各种使用者对HTML的需求,HTML添加了大…...

Rust 学习笔记:自定义构建和发布配置
Rust 学习笔记:自定义构建和发布配置 Rust 学习笔记:自定义构建和发布配置发布配置文件自定义 profile 的选项 Rust 学习笔记:自定义构建和发布配置 发布配置文件 在 Rust 中,发布配置文件是预定义的和可定制的概要文件…...

StarRocks x Iceberg:云原生湖仓分析技术揭秘与最佳实践
导读: 本文将深入探讨基于 StarRocks 和 Iceberg 构建的云原生湖仓分析技术,详细解析两者结合如何实现高效的查询性能优化。内容涵盖 StarRocks Lakehouse 架构、与 Iceberg 的性能协同、最佳实践应用以及未来的发展规划,为您提供全面的技术解…...

笔试笔记(运维)
(数据库,SQL) limit1 随机返回其中一个聚合函数不可以嵌套使用 【^】这个里面的数据任何形式组合都没有 sql常用语句顺序:from-->where-->group by-->having-->select-->order by-->limit 只要其中一个表存在匹…...

JVM——云原生时代JVM的演进之路
引入 在风云变幻的技术世界里,JVM(Java Virtual Machine)作为 Java 语言的基石,长久以来承载着无数开发者构建软件系统的梦想。从 20 世纪 90 年代 Java 的诞生,到如今云原生时代的大幕拉开,JVM 经历了岁月…...
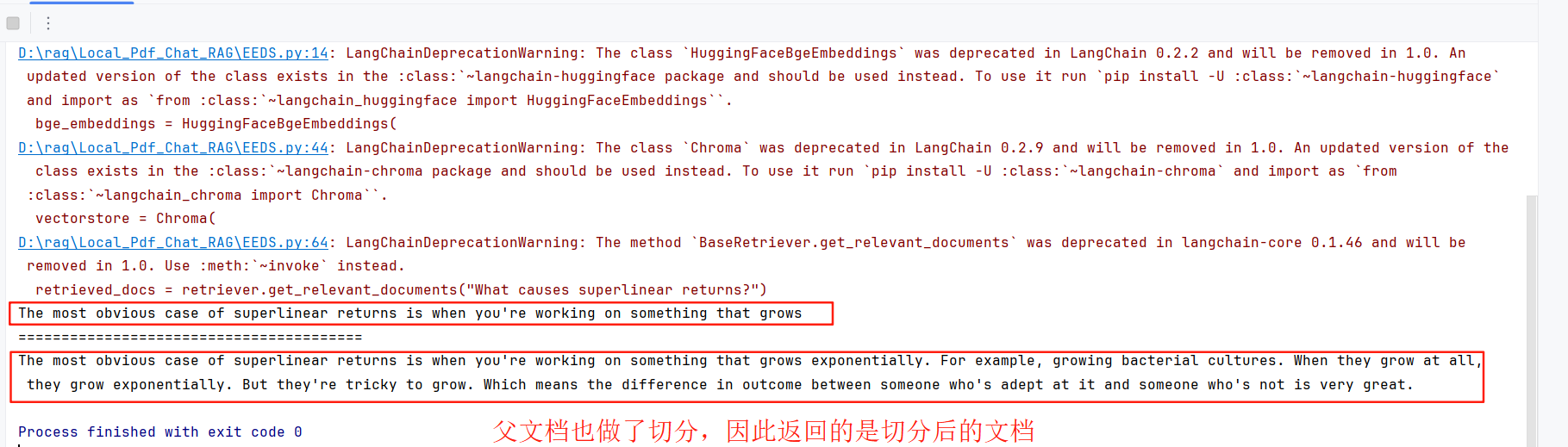
使用langchain实现五种分块策略:语义分块、父文档分块、递归分块、特殊格式、固定长度分块
文章目录 分块策略详解1. 固定长度拆分(简单粗暴)2. 递归字符拆分(智能切割)3. 特殊格式拆分(定向打击)Markdown分块 4. 语义分割(更智能切割)基于Embedding的语义分块基于模型的端到…...
【项目记录】登录认证(下)
1 过滤器 Filter 刚才通过浏览器的开发者工具,可以看到在后续的请求当中,都会在请求头中携带JWT令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT令牌。 那怎么样来统一拦截到所有的请求校验令牌的有…...

Debian上安装PostgreSQL的故障和排除
命令如下: apt install postgresql#可能是apt信息错误,报错 E: Failed to fetch http://deb.debian.org/debian/pool/main/p/postgresql-15/postgresql-client-15_15.12-0%2bdeb12u2_amd64.deb 404 Not Found [IP: 146.75.46.132 80] E: Failed to f…...
linux文件管理(补充)
1、查看文件命令 1.1 cat 用于连接文件并打印到标准输出设备上,它的主要作用是用于查看和连接文件。 用法: cat 参数 文件名 参数: -n:显示行号,会在输出的每一行前加上行号。 -b:显示行号,…...
Python训练营---Day42
DAY 42 Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 1、回调函数 回调函数(Callback Function)是一种特殊的函数,它作为参数传递给另一个函数&#…...

基于空天地一体化网络的通信系统matlab性能分析
目录 1.引言 2.算法仿真效果演示 3.数据集格式或算法参数简介 4.MATLAB核心程序 5.算法涉及理论知识概要 5.1 QPSK调制原理 5.2 空天地一体化网络信道模型 5.3 空天地一体化网络信道特性 6.参考文献 7.完整算法代码文件获得 1.引言 空天地一体化网络是一种将卫星通信…...
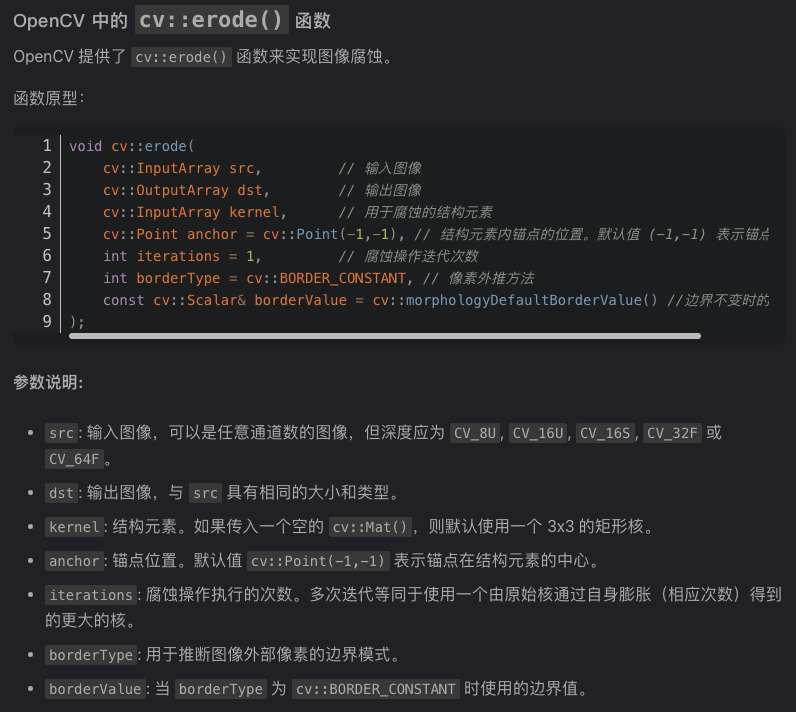
c++ opencv 形态学操作腐蚀和膨胀
https://www.jb51.net/article/247894.htm(上图图片来自这个博客) https://codec.wang/docs/opencv/basic/erode-and-dilate(上图图片参考博客) cv::Mat kernel cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3)); cv::erode(src, dst, kern…...
)
Axure组件即拖即用:横向拖动菜单(支持左右拖动选中交互)
亲爱的小伙伴,在您浏览之前,请关注一下,在此深表感谢!如有帮助请订阅专栏!免费哦! Axure横向菜单拖不动?一拖就乱?你缺的是这个"防手残"组件! 💢…...

Hadoop MapReduce:大数据处理利器
Hadoop 的 MapReduce 是一种用于处理大规模数据集的分布式计算框架,基于“分而治之”思想设计。以下从核心概念、工作流程、代码结构、优缺点和应用场景等方面详细讲解: 一、MapReduce 核心概念 核心思想: Map࿰…...

RabbitMQ-Go 性能分析
更多个人笔记见: github个人笔记仓库 gitee 个人笔记仓库 个人学习,学习过程中还会不断补充~ (后续会更新在github和 gitee上) 文章目录 对比功能没有rabbitMQ有rabbitMQwrk 测试分析 链接: 项目连接,完整…...

【c++】【数据结构】红黑树
目录 红黑树的定义红黑树的部分模拟实现颜色的向上更新旋转算法单旋算法双旋算法 红黑树与AVL树的对比 红黑树的定义 红黑树是一种自平衡的二叉搜索树,通过特定的规则维持树的平衡。红黑树在每个结点上都增加一个存储位表示结点的颜色,结点的颜色可以是…...
基于SpringBoot+Redis实现RabbitMQ幂等性设计,解决MQ重复消费问题
解决MQ重复消费问题 一、实现方案 本方案参考 「RabbitMQ消息可靠性深度解析|从零构建高可靠消息系统的实战指南」,向开源致敬! 1、业务层幂等处理: 每个消息携带一个全局唯一ID,在业务处理过程中,首先检查…...

React从基础入门到高级实战:React 生态与工具 - React 单元测试
React 单元测试 引言 在现代软件开发中,单元测试是确保代码质量和可靠性的关键环节。对于React开发者而言,单元测试不仅能帮助捕获潜在的错误,还能提升代码的可维护性和团队协作效率。随着React应用的复杂性不断增加,掌握单元测…...

使用lighttpd和开发板进行交互
文章目录 🧠 一、Lighttpd 与开发板的交互原理1. 什么是 Lighttpd?2. 与开发板交互的方式? 🧾 二、lighttpd.conf 配置文件讲解⚠️ 注意事项: 📁 三、目录结构说明💡 四、使用 C 编写 CGI 脚本…...
DRF的使用
1. DRF概述 DRF即django rest framework,是一个基于Django的Web API框架,专门用于构建RESTful API接口。DRF的核心特点包括: 序列化:通过序列化工具,DRF能够轻松地将Django模型转换为JSON格式,也可以将JS…...

2024年09月 C/C++(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:有几个PAT 字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位,第 4 位(A),第 6 位(T);第二个 PAT 是第 3 位,第 4 位(A),第 6 位(T)。 现给定字符串,问一共可以形成多少个 PAT? 时间限制:1000 内存限制:26214…...
免费且好用的PDF水印添加工具
软件介绍 琥珀扫描.zip下载链接:https://pan.quark.cn/s/3a8f432b29aa 今天要给大家推荐一款超实用的PDF添加水印工具,它能够满足用户给PDF文件添加水印的需求,而且完全免费。 这款PDF添加水印的软件有着简洁的界面,操作简便&a…...

mqtt协议连接阿里云平台
首先现在的阿里云物联网平台已经不在新购了,如下图所示: 解决办法:在咸鱼上租用一个账号,先用起来。 搭建阿里云平台,参考博客: (一)MQTT连接阿里云物联网平台(小白向&…...
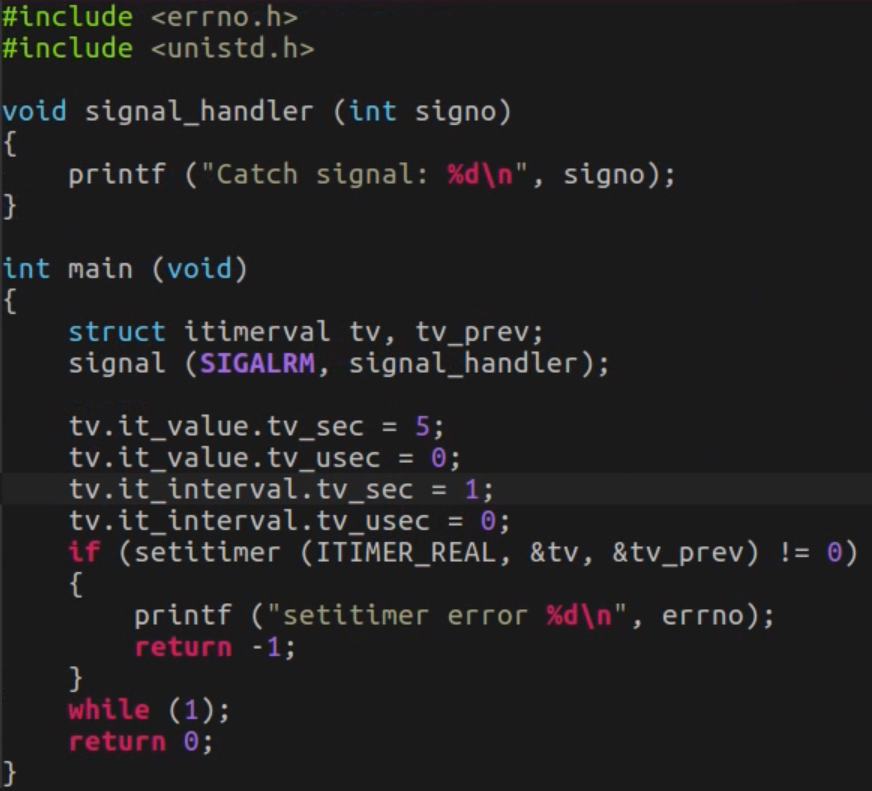
一文详谈Linux中的时间管理和定时器编程
(目录) 先说一些在计算机中需要用到时间的地方:系统日志log、OS调度(时间片、定时器)等等~~ 时间的计量 计时的方式发展:日晷、沙漏 -> 机械钟 -> 石英振荡器、晶振 -> 铯原子钟 -> 氢原子钟 计算机中的计时方式&…...

Ubuntu 安装 Miniconda 及配置国内镜像源完整指南
目录 Miniconda 安装Conda 镜像源配置Pip 镜像源配置验证配置基本使用常见问题 1. Miniconda 安装 1.1 下载安装脚本 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh1.2 执行安装 bash Miniconda3-latest-Linux-x86_64.sh按回车查看许可协议…...

性能优化 - 理论篇:常见指标及切入点
文章目录 引言一、 Java 性能优化的核心思路二、为什么要度量?三、常用性能衡量指标详解3.1 吞吐量与响应速度3.2 响应时间的具体度量:平均响应时间与百分位数3.3 并发量3.4 秒开率(页面秒开)3.5 正确性(功能可用性&am…...

青少年编程与数学 02-020 C#程序设计基础 08课题、字符和字符串
青少年编程与数学 02-020 C#程序设计基础 08课题、字符和字符串 一、字符和字符集1. 字符(Character)定义特点示例 2. 字符集(Character Set)定义特点常见字符集 小结 二、char数据类型1. 定义2. 特点3. 声明和初始化4. 转义字符示…...

【论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合】
论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合 1.摘要&&引言2.方法2.1 架构2.2 双模态特征融合(DMFF)2.2.1 跨模态特征增强(CFE)2.2.2 空间特征压缩(SFS)…...

Spring Security加密模块深度解析
Spring Security加密模块概述 Spring Security Crypto模块(简称SSCM)是Spring Security框架中专门处理密码学相关操作的组件。由于Java语言本身并未提供开箱即用的加密/解密功能及密钥生成能力,开发者在实现这些功能时往往需要引入额外依赖库。SSCM通过提供内置解决方案,有…...