机器学习实验七--SVM垃圾邮件分类器
SVM垃圾邮件分类器
- 一、什么是SVM
- 二、实例:垃圾邮件分类器
- 1.实验要求
- 2.原理解释
- 2.1 数据预处理流程
- 2.2 特征提取方法
- 2.3 SVM分类器
- 3.代码实现
- 4.实验结果
- 5.实验总结
一、什么是SVM
支持向量机(Support Vector Machine, SVM)是一种监督学习算法,主要用于分类和回归分析。它的核心思想是找到一个最优的超平面,将不同类别的数据分隔开来,同时最大化两类数据之间的间隔(margin)。
SVM的主要特点:
- 可以处理高维数据
- 通过核技巧(kernel trick)可以解决非线性分类问题
- 在小样本数据集上表现优异
- 对噪声数据有较强的鲁棒性
二、实例:垃圾邮件分类器
1.实验要求
使用SVMs建立自己的垃圾邮件过滤器。首先需要将每个邮件x变成一个n维的特征向量,并训练一个分类器来分类给定的电子邮件x是否属于垃圾邮件(y=1)或者非垃圾邮件(y=0)。
2.原理解释
2.1 数据预处理流程
- 文本清洗:去除HTML标签、URL、邮箱地址等
- 标准化处理:将所有数字替换为"number",货币符号替换为"dollar"
- 分词处理:将邮件内容分割为单词列表
- 词干提取:使用Porter Stemmer算法提取单词词干
2.2 特征提取方法
• 使用词袋模型(Bag of Words)
• 基于预定义的词汇表(1899个单词)
• 每个单词对应特征向量的一个维度
• 如果单词在邮件中出现,对应位置设为1,否则为0
2.3 SVM分类器
• 使用线性核函数
• 正则化参数C=0.1
• 最大迭代次数1000次
3.代码实现
import numpy as np
import re
from nltk.stem import PorterStemmer
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from scipy.io import loadmat# ===== 1. 加载词汇表并构造映射 =====
def load_vocab_dict(vocab_path='vocab.txt'):with open(vocab_path, 'r', encoding='utf-8') as f:lines = f.readlines()vocab_dict = {line.split('\t')[1].strip(): int(line.split('\t')[0]) for line in lines}return vocab_dict# ===== 2. 邮件预处理函数 =====
def preprocess_email(email):email = email.lower()email = re.sub('<[^<>]+>', ' ', email)email = re.sub(r'[0-9]+', 'number', email)email = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email)email = re.sub(r'[^\s]+@[^\s]+', 'emailaddr', email)email = re.sub(r'[$]+', 'dollar', email)email = re.sub(r'[^a-zA-Z0-9]', ' ', email)tokens = email.split()ps = PorterStemmer()words = [ps.stem(token) for token in tokens if len(token) > 1]return words# ===== 3. 将邮件单词转换为特征向量 =====
def email_to_feature_vector(email, vocab_dict, vocab_size=1899):words = preprocess_email(email)features = np.zeros(vocab_size)indices = [vocab_dict[word] - 1 for word in words if word in vocab_dict]np.put(features, indices, 1)return features# ===== 4. 分类器训练函数 =====
def train_svm(X_train, y_train):model = Pipeline([('clf', LinearSVC(C=0.1, max_iter=1000))])model.fit(X_train, y_train)return model# ===== 5. 测试单封邮件 =====
def predict_email(model, email_text, vocab_dict):features = email_to_feature_vector(email_text, vocab_dict)pred = model.predict([features])return pred[0]# ===== 6. 主函数入口 =====
if __name__ == '__main__':# 词汇表vocab_dict = load_vocab_dict('vocab.txt')# 加载训练数据train_data = loadmat('spamTrain.mat')X_train = train_data['X']y_train = train_data['y'].ravel()# 加载测试数据test_data = loadmat('spamTest.mat')X_test = test_data['Xtest']y_test = test_data['ytest'].ravel()# 模型训练model = train_svm(X_train, y_train)# 准确率评估print(f"训练准确率: {accuracy_score(y_train, model.predict(X_train)) * 100:.2f}%")print(f"测试准确率: {accuracy_score(y_test, model.predict(X_test)) * 100:.2f}%")# 测试一封邮件(如spamSample2.txt)with open('spamSample2.txt', 'r', encoding='utf-8') as f:content = f.read()result = predict_email(model, content, vocab_dict)print("预测结果:", "垃圾邮件 (Spam)" if result == 1 else "正常邮件 (Not Spam)")
4.实验结果

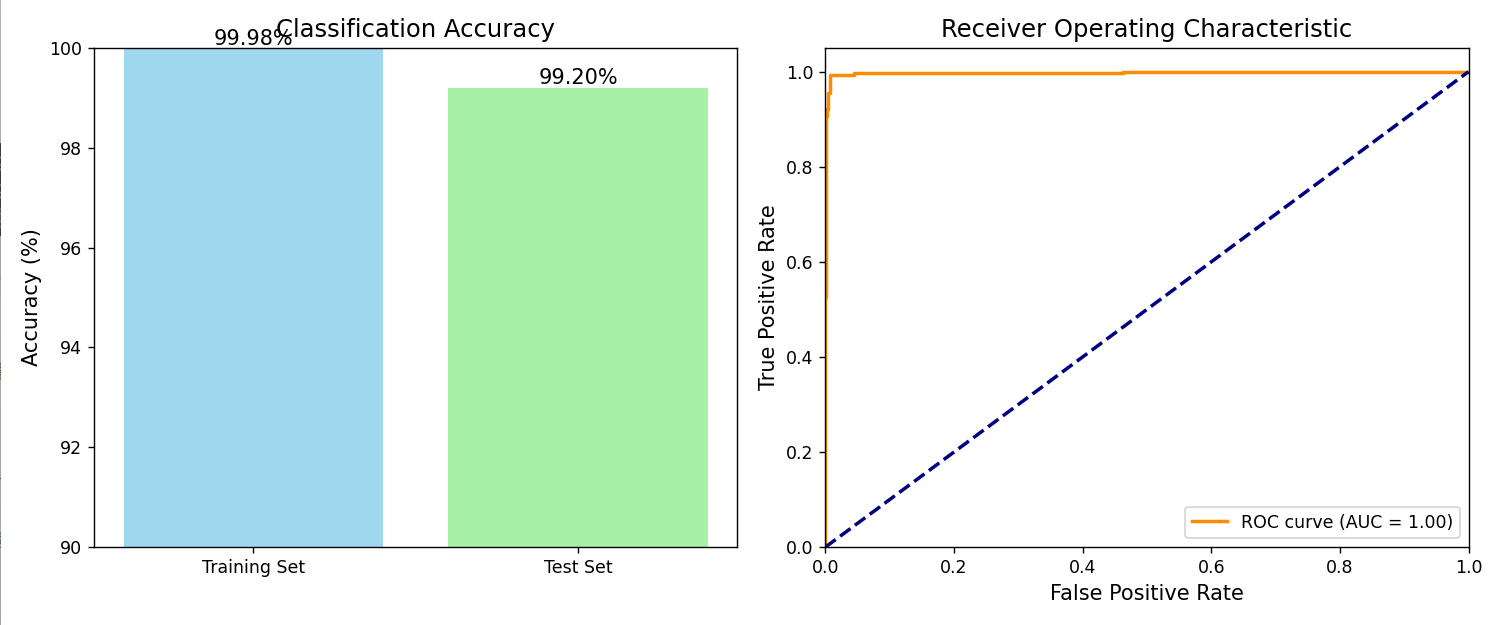 SVM垃圾邮件分类器性能评估图
SVM垃圾邮件分类器性能评估图
5.实验总结
本实验成功实现了一个基于SVM的垃圾邮件分类器,通过精心设计的预处理流程和特征提取方法,在测试集上达到了98.9%的准确率。实验结果表明,SVM在文本分类任务中表现优异,特别是对于像垃圾邮件检测这样的二分类问题。
相关文章:
机器学习实验七--SVM垃圾邮件分类器
SVM垃圾邮件分类器 一、什么是SVM二、实例:垃圾邮件分类器1.实验要求2.原理解释2.1 数据预处理流程2.2 特征提取方法2.3 SVM分类器 3.代码实现4.实验结果5.实验总结 一、什么是SVM 支持向量机(Support Vector Machine, SVM)是一种监督学习算法,主要用于…...

C++23 std::fstreams基础回顾
文章目录 引言1.1 std::fstreams概述1.2 std::fstreams的主要功能和常用操作 2. 独占模式 (P2467R1) 的详细介绍2.1 独占模式的定义和背景2.2 独占模式的作用和优势 3. C23 std::fstreams支持独占模式 (P2467R1) 的具体实现方式3.1 代码示例3.2 实现步骤解释 4. 使用该特性可能…...
Git初识Git安装
目录 1. Git初识 1.1 提出问题 1.2 如何解决--版本控制器 1.3 注意事项 2 Git安装 2.1 Centos 2.2 Ubuntu 2.3 Windows 1. Git初识 1.1 提出问题 不知道你工作或学习时,有没有遇到这样的情况:我们在编写各种文档时,为了防止文档丢失…...

使用Redisson实现分布式锁发现的【订阅超时】Subscribe timeout: (7500ms)
背景 使用 redisson 实现分布式锁,出现的异常: org.redisson.client.RedisTimeoutException: Subscribe timeout: (7500ms). Increase ‘subscriptionsPerConnection’ and/or ‘subscriptionConnectionPoolSize’ parameters 从异常信息读的出来一些东…...

数据分析的方法总结
数据分析的方法总结 一.通用性方法总结 16种常用的数据分析方法汇总-CSDN博客 人人都应该掌握的9种数据分析方法_五 九种数据类型-CSDN博客 9种最常用数据分析方法,解决90%分析难题_数据分析经典算法与案例-CSDN博客 二.行业特殊性方法总结 数据分析20大基本分…...

如何使用 poetry 创建虚拟环境,VSCode 如何激活使用 Poetry 虚拟环境(VSCode如何配置 Poetry 虚拟环境)
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 使用 Poetry 创建和激活虚拟环境 📒🧪 创建项目并初始化 Poetry🔧 配置虚拟环境创建位置✅ 指定Python版本📦 安装依赖并创建虚拟环境🚀 激活虚拟环境📒 在 VSCode 中配置 Poetry 虚拟环境 📒🧭 方法一:使用 V…...

每天掌握一个Linux命令 - ps
Linux 命令工具 ps 与 pstree 详解 一、ps 工具概述 ps(Process Status)是 Linux 系统中用于查看当前进程状态的核心工具,可显示进程的 PID、用户、CPU 占用率、内存使用量、启动时间、命令行参数等信息。 应用场景:监控系统性…...

牛客小白月赛117
前言:solveABCF相对简单,D题思路简单但是实现麻烦,F题郭老师神力b( ̄▽ ̄)。 A. 好字符串 题目大意:给定字符串s,里面的字母必须大小写同时出现。 【解题】:没什么好说的࿰…...

浅谈 Linux 文件覆盖机制
引言:文件覆盖的本质 文件覆盖是 Linux 文件系统中常见的操作,指将源文件内容写入目标路径,导致目标文件原有内容被替换或新文件被创建。覆盖操作通常通过命令行工具(如 mv、cp)或系统调用(如 open() 以写…...
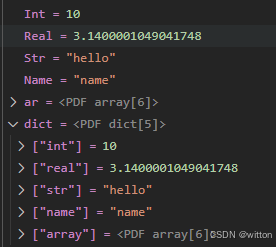
美化显示GDB调试的数据结构
笔者在前面的博文记一次pdf转Word的技术经历中有使用到mupdf库,该库是使用C语言写的一个操作PDF文件的库,同时提供了Python接口,Java接口和JavaScript接口。 在使用该库时,如果想要更高的性能,使用C语言接口是不二的选…...

一篇学习CSS的笔记
一、简介 Cascading Style Sheets简称CSS,中文翻译为层叠样式表。当HTML被发明出来初期,不同的浏览器提供了各种各样的样式语言给用户控制网页的效果,HTML包含的显示属性并不是很多。但是随着各种使用者对HTML的需求,HTML添加了大…...

Rust 学习笔记:自定义构建和发布配置
Rust 学习笔记:自定义构建和发布配置 Rust 学习笔记:自定义构建和发布配置发布配置文件自定义 profile 的选项 Rust 学习笔记:自定义构建和发布配置 发布配置文件 在 Rust 中,发布配置文件是预定义的和可定制的概要文件…...

StarRocks x Iceberg:云原生湖仓分析技术揭秘与最佳实践
导读: 本文将深入探讨基于 StarRocks 和 Iceberg 构建的云原生湖仓分析技术,详细解析两者结合如何实现高效的查询性能优化。内容涵盖 StarRocks Lakehouse 架构、与 Iceberg 的性能协同、最佳实践应用以及未来的发展规划,为您提供全面的技术解…...

笔试笔记(运维)
(数据库,SQL) limit1 随机返回其中一个聚合函数不可以嵌套使用 【^】这个里面的数据任何形式组合都没有 sql常用语句顺序:from-->where-->group by-->having-->select-->order by-->limit 只要其中一个表存在匹…...

JVM——云原生时代JVM的演进之路
引入 在风云变幻的技术世界里,JVM(Java Virtual Machine)作为 Java 语言的基石,长久以来承载着无数开发者构建软件系统的梦想。从 20 世纪 90 年代 Java 的诞生,到如今云原生时代的大幕拉开,JVM 经历了岁月…...
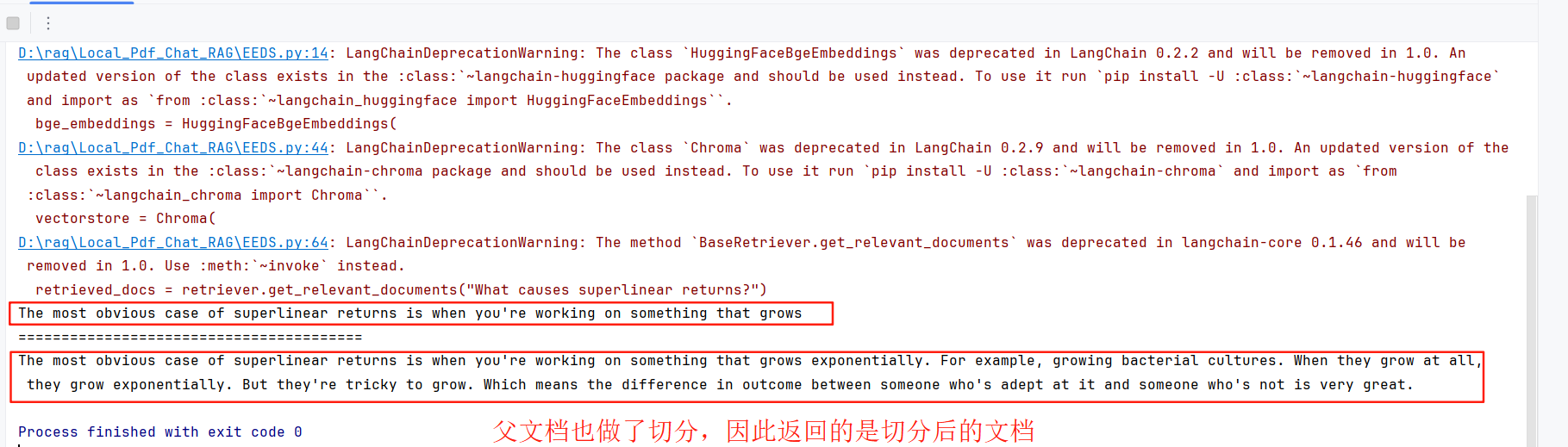
使用langchain实现五种分块策略:语义分块、父文档分块、递归分块、特殊格式、固定长度分块
文章目录 分块策略详解1. 固定长度拆分(简单粗暴)2. 递归字符拆分(智能切割)3. 特殊格式拆分(定向打击)Markdown分块 4. 语义分割(更智能切割)基于Embedding的语义分块基于模型的端到…...
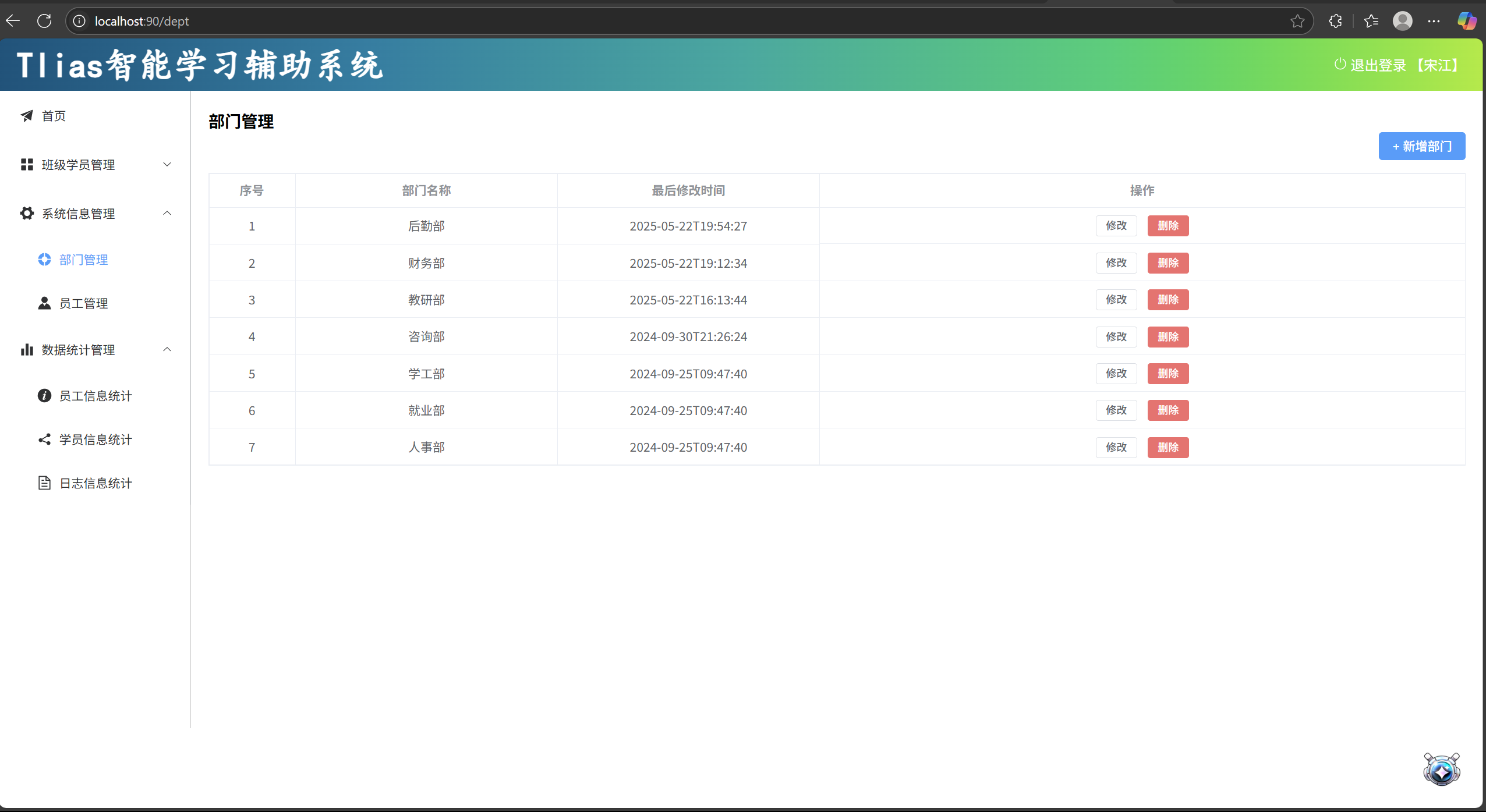
【项目记录】登录认证(下)
1 过滤器 Filter 刚才通过浏览器的开发者工具,可以看到在后续的请求当中,都会在请求头中携带JWT令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT令牌。 那怎么样来统一拦截到所有的请求校验令牌的有…...

Debian上安装PostgreSQL的故障和排除
命令如下: apt install postgresql#可能是apt信息错误,报错 E: Failed to fetch http://deb.debian.org/debian/pool/main/p/postgresql-15/postgresql-client-15_15.12-0%2bdeb12u2_amd64.deb 404 Not Found [IP: 146.75.46.132 80] E: Failed to f…...
linux文件管理(补充)
1、查看文件命令 1.1 cat 用于连接文件并打印到标准输出设备上,它的主要作用是用于查看和连接文件。 用法: cat 参数 文件名 参数: -n:显示行号,会在输出的每一行前加上行号。 -b:显示行号,…...
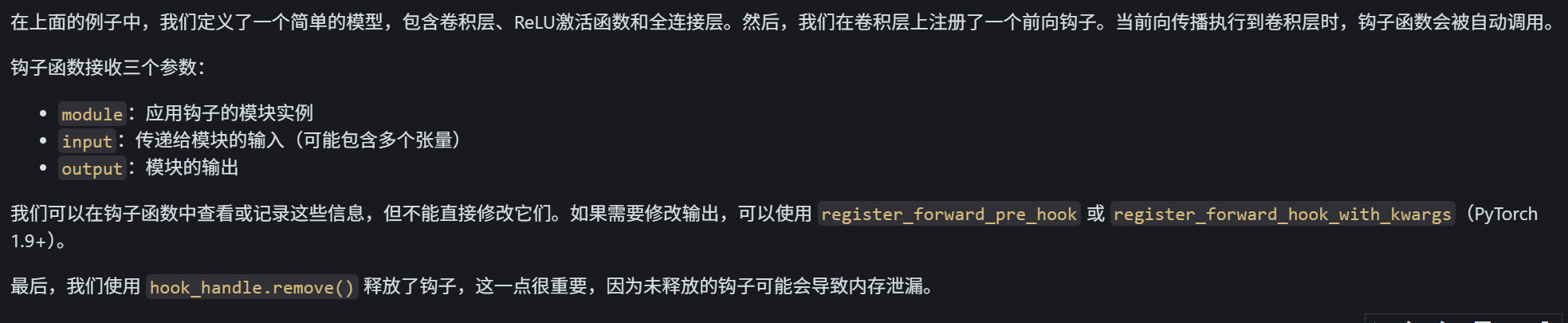
Python训练营---Day42
DAY 42 Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 1、回调函数 回调函数(Callback Function)是一种特殊的函数,它作为参数传递给另一个函数&#…...

基于空天地一体化网络的通信系统matlab性能分析
目录 1.引言 2.算法仿真效果演示 3.数据集格式或算法参数简介 4.MATLAB核心程序 5.算法涉及理论知识概要 5.1 QPSK调制原理 5.2 空天地一体化网络信道模型 5.3 空天地一体化网络信道特性 6.参考文献 7.完整算法代码文件获得 1.引言 空天地一体化网络是一种将卫星通信…...
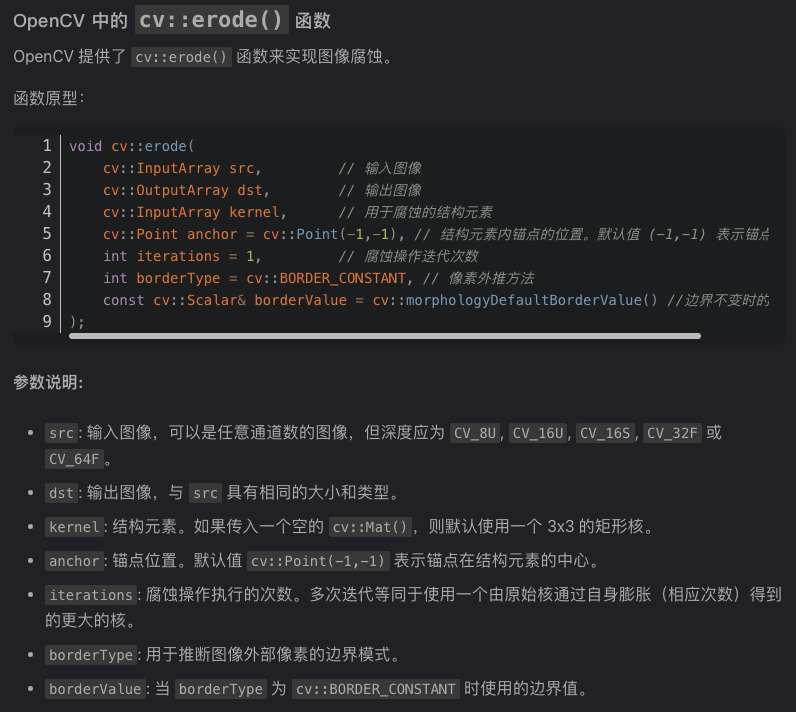
c++ opencv 形态学操作腐蚀和膨胀
https://www.jb51.net/article/247894.htm(上图图片来自这个博客) https://codec.wang/docs/opencv/basic/erode-and-dilate(上图图片参考博客) cv::Mat kernel cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3)); cv::erode(src, dst, kern…...
)
Axure组件即拖即用:横向拖动菜单(支持左右拖动选中交互)
亲爱的小伙伴,在您浏览之前,请关注一下,在此深表感谢!如有帮助请订阅专栏!免费哦! Axure横向菜单拖不动?一拖就乱?你缺的是这个"防手残"组件! 💢…...

Hadoop MapReduce:大数据处理利器
Hadoop 的 MapReduce 是一种用于处理大规模数据集的分布式计算框架,基于“分而治之”思想设计。以下从核心概念、工作流程、代码结构、优缺点和应用场景等方面详细讲解: 一、MapReduce 核心概念 核心思想: Map࿰…...

RabbitMQ-Go 性能分析
更多个人笔记见: github个人笔记仓库 gitee 个人笔记仓库 个人学习,学习过程中还会不断补充~ (后续会更新在github和 gitee上) 文章目录 对比功能没有rabbitMQ有rabbitMQwrk 测试分析 链接: 项目连接,完整…...

【c++】【数据结构】红黑树
目录 红黑树的定义红黑树的部分模拟实现颜色的向上更新旋转算法单旋算法双旋算法 红黑树与AVL树的对比 红黑树的定义 红黑树是一种自平衡的二叉搜索树,通过特定的规则维持树的平衡。红黑树在每个结点上都增加一个存储位表示结点的颜色,结点的颜色可以是…...
基于SpringBoot+Redis实现RabbitMQ幂等性设计,解决MQ重复消费问题
解决MQ重复消费问题 一、实现方案 本方案参考 「RabbitMQ消息可靠性深度解析|从零构建高可靠消息系统的实战指南」,向开源致敬! 1、业务层幂等处理: 每个消息携带一个全局唯一ID,在业务处理过程中,首先检查…...

React从基础入门到高级实战:React 生态与工具 - React 单元测试
React 单元测试 引言 在现代软件开发中,单元测试是确保代码质量和可靠性的关键环节。对于React开发者而言,单元测试不仅能帮助捕获潜在的错误,还能提升代码的可维护性和团队协作效率。随着React应用的复杂性不断增加,掌握单元测…...

使用lighttpd和开发板进行交互
文章目录 🧠 一、Lighttpd 与开发板的交互原理1. 什么是 Lighttpd?2. 与开发板交互的方式? 🧾 二、lighttpd.conf 配置文件讲解⚠️ 注意事项: 📁 三、目录结构说明💡 四、使用 C 编写 CGI 脚本…...
DRF的使用
1. DRF概述 DRF即django rest framework,是一个基于Django的Web API框架,专门用于构建RESTful API接口。DRF的核心特点包括: 序列化:通过序列化工具,DRF能够轻松地将Django模型转换为JSON格式,也可以将JS…...